
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Remote sensing image segmentation plays an important role in many industrial-grade image processing applications. However, the problem of uncertainty caused by intraclass heterogeneity and interclass blurring is prevalent in high-resolution remote sensing images. Moreover, the complexity of information in high-resolution remote sensing images leads to a large amount of background information around objects. To solve this problem, a new fuzzy convolutional neural network is proposed in this paper. This network resolves the ambiguity and uncertainty of feature information by introducing a fuzzy neighbourhood module in the deep learning network structure. In addition, it adds a multi-attention gating module to highlight small object features and separate them from the complex background information to achieve fine segmentation of high-resolution remote sensing images. Experimental results on three different segmentation datasets suggest that the proposed method has higher segmentation accuracy and better performance than other deep learning networks, especially for complicated shadow information. Code will be provided in (https://github.com/tingtingqu/code).
Introduction
Remote sensing image segmentation technology has been widely used in urban planning (Wurm et al., Citation2019), environmental protection (Song et al., Citation2018), climate change, and other fields (Salzano et al., Citation2019). However, it is still a challenging task due to the complexity of the objects in remote sensing image, such as the wide observation range, high information complexity and unstable imaging quality (X. Li et al., Citation2021).
A considerable amount of literature has been published on the remote sensing image segmentation. The conventional methods rely on the priori knowledge for manual selection of target features, and there is a gap with the actual semantic features in the process of building the corresponding segmentation model (Guo et al., Citation2018; Han & Wu, Citation2017; Yuan et al., Citation2014; Jabri et al., Citation2014). In recent years, convolutional neural networks have been extensively used in high-resolution remote sensing image segmentation due to their superior nonlinear representation capabilities (Pan et al., Citation2021), which can learn deeper and more essential features from massive sample data (Wang et al., Citation2022; Pan et al., Citation2021). From scene classification (Zhang et al., Citation2016), semantic segmentation (Bao et al., Citation2021; R. Liu et al., Citation2020), instance segmentation to panoramic segmentation (de Carvalho, de Carvalho Júnior, Silva, et al., Citation2022). Segmentation approaches vary from the patch-based methods (Zhang et al., Citation2018; Sharma et al., Citation2017) to a large variety of convolutional neural networks (Caesar et al., Citation2018; Wang et al., Citation2020; M. Liu et al., Citation2020; Ni et al., Citation2019; X. Li et al., Citation2019; Yue et al., Citation2016; Z. Zhao et al., Citation2021). M. Chen et al. (Citation2021) added dense connection blocks and residual structures to the DeepLabv3+ encoder and decoder to overcome the drawback of incomplete fusion of shallow-extracted low-level features and depth-extracted abstract features. Hua et al. (Citation2021) proposed a cascade panoramic segmentation network for high-resolution remote sensing images. This method integrates the complementary features of different stages by sharing foreground instance segmentation with background semantic segmentation. Khoshboresh-Masouleh and Shah-Hosseini (Citation2021a) proposed a building panoramic change segmentation method based on the squeeze-and-attention convolutional neural network. The proposed method provided better panoptic segmentation performance for bitemporal images. de Carvalho, de Carvalho Júnior, de Albuquerque, et al. (Citation2022) introduced all-optical segmentation of multi-spectral remote sensing data and evaluated different configurations regarding band arrangements.
Remote sensing images have the similarity among non-homogeneous targets and the diversity of homogeneous targets. The boundary of ground objects is confused and even shadow overlap, which leads to uncertainty in the remote sensing image segmentation (Zhao, Xu et al., Citation2021). shows an appropriate example (The building shadows obscure the boundaries of cars and roads, and buildings are intricately connected to low vegetation boundaries). Some methods utilize a multiscale feature fusion strategy (Abdollahi et al., Citation2020) and multiscale structure to extract feature maps with large receptive fields to recognize those challenging and complicated objects (H. Zhao et al., Citation2017; Yuan et al., Citation2020; Zheng et al., Citation2019). But these methods ignore the problem that the semantic information of objects is covered and the scale sensing receptive field of feature map does not match. Fortunately, the fuzzy learning systems (Mylonas et al., Citation2013; Sugeno & Yasukawa, Citation1993) can capture the ambiguity of human thinking from a macroscopic view, and it has the unique strength in solving uncertainty problems (Huang et al., Citation2021; Lu et al., Citation2020; Nida et al., Citation2019; Pal & Sudeep, Citation2016). Extensive researchers have attempted to apply fuzzy systems to vision tasks. Deng et al. (Citation2016) proposed a fuzzy neural network for segmentation to reduce the data noise caused by image uncertainty by fusing fuzzy features and convolutional features. Zhang et al. (Citation2017) proposed a deep belief network that uses the fuzzy c-means clustering algorithm to partition the input space and implicitly creates a deep belief network by defining a fuzzy affiliation function. Hurtik et al. (Citation2019) proposed a new image structure that reduces the error classification during pre-processing by transforming clear pixel values to fuzzy values. To this end, we propose a fuzzy neighbourhood module to learn the relationship between pixels and their neighbourhood and solve the uncertainty problem in the remote sensing image semantic segmentation.
Figure 1. Boundary pixels and shadows in remote sensing image. (a) the building shadows obscure the boundaries of cars and roads. (b) the buildings are intricately connected to low vegetation boundaries.

In addition, remote sensing images also have the characteristic of high complexity (Xu et al., Citation2021; Zhou et al., Citation2019) and different object sizes (Xiao et al., Citation2018). The attention mechanism can selectively focus on a certain part of the image, which combines information from different regions (Wei et al., Citation2021). Qi et al. (Citation2020) added an attention module to the convolutional neural network (CNN). Their network refines the nonlinear boundaries of objects in remote sensing images by using multi-scale convolution and attention mechanisms. Li, Zheng, et al. (Citation2021) proposed a dense jump-connected network with a multi-scale feature fusion attention mechanism to solve the problem of detailed and blurred edge loss during high-resolution down-sampling of remote sensing images. Sun et al. (Citation2020) proposed a boundary-aware semi-supervised semantic segmentation network, which uses a channel-weighted multi-scale feature module to balance semantic and spatial information and a boundary attention module to weight the boundary information.
Inspired by the above analysis and discussion, this paper proposes a fuzzy neighbourhood convolutional neural network for high-resolution remote sensing image segmentation. Due to the low contrast at the boundaries, such as shaded and occluded areas, the segmentation results for the boundary pixels are likely to be uncertain. We use the fuzzy neighbourhood module to eliminate unfavourable factors that affect inter-class noise and intra-class complexity, and the multi-attention gating module to acquire object features. The main contributions of this paper can be summarized as follows.
We propose a new architecture that combines fuzzy learning and convolutional neural network for high-resolution remote sensing image segmentation.
The fuzzy neighbourhood module is used to process each pixel and learn the relationship between one pixel and its neighbourhood pixels, so as to tackle the problem of the diversity of homogeneous objects and the similitude among non-homogeneous objects in remote sensing images.
A multi-attention gating module is introduced to use low-level features to provide guidance information for high-level features and to highlight small object detail information in the feature map through weighting indices.
The effectiveness of the proposed method has been demonstrated by visualizing the segmentation results and by objective indexes in a comparative experimental analysis using three benchmark remote sensing datasets.
Methodology
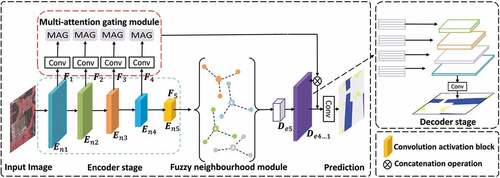
The network architecture is shown in . It is designed with an encoder-decoder structure, which is one of the most common frameworks of deep neural networks. Because some significant spatial information may be lost in the encoder, the multi-attention gating module is introduced into the down-sampling stage to fuse the detail information of low-level features with the semantic information of high-level features and thereby prevent the loss of spatial information in the low-level features. The outputs of the fuzzy neighbourhood module and the results from the multi-attention gating module are input to the decoder, and the non-local features are used as local features for information guidance to complete the final feature map prediction.
Figure 2. Network architecture.
Feature extraction structure
The symmetric network architecture can efficiently extract global and local information from feature intervals. The encoder in this network is used for multi-scale feature extraction from high-resolution remote sensing images. Because the scale information obtained from the convolution modules of different layers is not exactly the same, by feeding information at different scales to the multi-attention gating module, the connection between low-level features and high-level features achieves a refinement effect, suppressing irrelevant regions and highlighting useful features in salient regions. To solve the problem of foreground-background information imbalance, the features of the multi-attention gating module and the deconvolution module are stitched several times. The encoder and decoder are denoted by and
, respectively. The input image is first passed through five convolutional activation blocks in the encoder to generate a fine feature map
with
in the horizontal and vertical directions.
to
denote the image features at five different resolutions. The network integrates various feature maps with different scales into a unified feature map for prediction. Specifically, the output result of the convolution blocks in the final layer is obtained by (1).
where denotes the extraction process of
,
is the learning parameter,
is the output of the encoder, and
is the output of the
th encoder.
The fuzzy neighbourhood module
Compared with the method of pre-processing fuzzy data and cascading to neural networks, our fuzzy neighbourhood module can extract fuzzy features from a clear set of limited information. This can solve the problem of intraclass heterogeneity caused by complex feature information in high-resolution remote sensing images by using pixel-to-pixel fuzzy relationships. The module processes the feature map instead of the original image. This avoids the information confusion caused by the phenomena of high contrast and border shadows in the original image.
The fuzzy neighbourhood module falsifies a fuzzy neighbourhood set Z for feature points in each channel by fuzzifying the function
, where
,
denotes the height of the feature map, and
denotes its width.
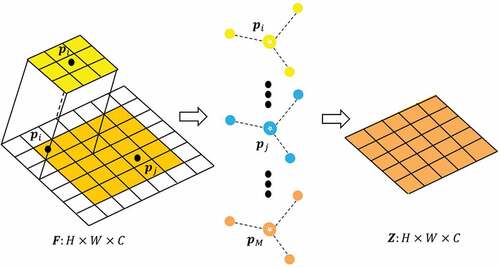
As shown in , let be the input feature map with size
, where
denotes the number of channels. For the input feature map
, we use
fuzzy functions to fuzzy transform each point in
with the help of the convolution operation. It is worth noting that
remains the same for all channels of each feature map. For each channel in a different feature map,
is different.
varies only between different input feature maps, and is related to the feature map size, not to the number of channels.
Figure 3. Fuzzy neighbourhood module.
To obtain the fuzzy set Z, the fuzzy function uses a Gaussian fuzzy function, as shown in (2).
where are the coordinates of the feature point
in channel
.
and
denote the mean difference and standard deviation, respectively.
The fuzzy degree denotes the fuzzy relationship between the feature points
and
in
, and the fuzzy value of each pixel is calculated from the fuzzy degree. For
fuzzy functions, it is necessary to recombine them through defined fuzzy logic decision rules; each Gaussian function can learn the original eigenvalue values under various distributions. The definition of fuzzy degree is as follows:
Given the feature point in a channel, a fuzzy neighbour set
is calculated for each channel according to the proposed fuzzification process. After obtaining the fuzzy neighbourhood of different classes, they are passed through a convolutional normalization module to ensure that they have the same size as the input feature map
. It is then stitched with the original feature map to obtain the final output feature map, which enters the next branch.
The multi-attention gating module
The input image is processed by the convolution module to obtain feature maps with different sizes. A shallow network acquires feature maps with higher resolution that contain more local detail, whereas a deep network contains more semantic information. Because remote sensing images suffer from an uneven distribution between foreground and background, low contrast, and large variability in size and shape, small objects in the foreground are not easily recognized. To achieve accurate semantic segmentation, the high-level semantic information should be preserved while the low-level detail information is also considered. To achieve this, we introduce a multi-attention gating module to refine different feature details. Finally, the splicing design is adopted to ensure the stability of propagation.
As shown in , assuming that is a vector from the low-level feature channel and
is a vector from the high-level feature channel, multi-attention gating is defined by (4).
Figure 4. Multi-attention gating module.
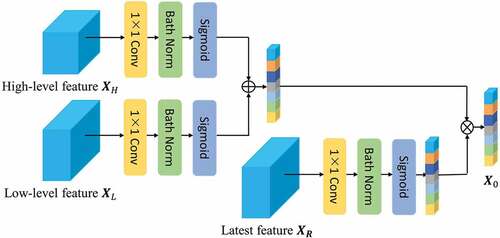
where is the output of the module,
is the corresponding function that calculates the relationship between
and
,
is the normalization factor (referred to here as the attention factor), and
is the unary function that calculates the input vector. For each element of
and
there is a corresponding
response. EquationEquation (4)
(4)
(4) is converted to a computable neural network module by (5).
where and
denote the output of the deconvolution information and the original information, respectively.
denotes the convolution block formed by the convolution, normalization, and activation layers.
denotes the activation function. The coefficients
are used to identify the foreground region containing small objects and construct the feature map response information.
The output of the multi-attention gating module is the product of the input characteristic graph and the attention coefficient . The module computes a single scalar attention value for each pixel vector. Thus, each attention learns to focus on a subset of the target structure rather than the entire background information. In this manner, it is more convenient to focus on a specific area and thereby reduce the amount of redundant computation. The multi-attention gating module trims the low-level feature information through contextual information, connects low-level features with high-level features to achieve information refinement. The overall definition of the module is as follows:
where denotes the output deconvolution information,
denotes the information after the multi-attention gating module,
denotes the convolution block formed by the convolution, normalization, and activation layers, and
denotes the splicing operation.
Experiments and analysis
In this section, we evaluate the effectiveness, superiority, and generalization ability of the proposed network. First, we describe the three datasets used and present the details of the experimental setup. Second, we report quantitative and qualitative comparison results for three datasets. Finally, we demonstrate the effectiveness of our network through ablation experiments.
Datasets and experimental setup
To validate the effectiveness of the proposed model for segmentation, we selected the China Computer Federation (CCF) dataset (Alam et al., Citation2021), the Vaihingen dataset from the ISPRS 2D Semantic Benchmark (Sherrah, Citation2016), and the IND.v2 dataset (Khoshboresh-Masouleh & Shah-Hosseini, Citation2021b).
The CCF dataset
The CCF dataset was derived from the “CCF Satellite Image AI Classification and Recognition Competition”, a high-resolution remote sensing image of a region in southern China captured in 2015. The types of features are divided into five categories: low vegetation, roads, buildings, water body, and others. Because the sizes of the original dataset images ranged from 4000 × 2000 pixels to 8000 × 8000 pixels, we sliced the sample images into slices of size 320 × 320 pixels and extended the data with remote sensing images and the corresponding labels by using OpenCV. Finally, we obtained 10, 489 slices for training and 3011 slices for testing.
The Vaihingen dataset
The Vaihingen dataset was imaged in the Vaihingen area of Stuttgart, Germany. It shows many separate buildings. The objects are divided into impervious surfaces, buildings, low vegetation, trees, clutter, and cars. This dataset includes 33 images, each with three bands, corresponding to near-infrared, red, and green wavelengths, and the ground sampling is 9 cm. In this study, we used 16 patches for training and 17 patches for testing. Finally, we used 1324 and 395 slices for training and testing, respectively.
The IND.V2 dataset
The IND.v2 dataset shows many separate buildings. The objects are divided into shadows, occluded areas, vegetation covers, complex roofs, and dense building areas. This dataset contains 294 images with a size of 1024 × 1024 pixels. This study used 256 patches for training and 38 patches for testing. We sliced the sample images into slices of size 520 × 520 pixels. Finally, we obtained 1536 slices for training and 228 slices for testing.
Implementation details
The PyTorch deep learning framework was used to conduct experiments on high-performance computing equipment with an Intel Core I7-7820× CPU and an NVIDIA GeForce GTX 1080 Ti GPU (with 23.2 GB RAM). The maximum boost frequency of this CPU is 3.6 GHz, each instruction can perform four single-precision floating-point operations, and the CPU has eight physical cores. The operating system was Linux, the compiler was PyCharm Community, and the program was written in Python 3.6. The image processing functionality was provided by open-source computer vision libraries. A commonly used stochastic gradient descent optimizer (Adam) guided the optimization. The learning rate was 0.000,1 and the base was set to 0.95. Because of the limited physical memory on our GPU card, the batch size was set to 4 during training.
The evaluation metrics used are derived from those used in (Qi et al., Citation2020): Overall Accuracy (OA), Recall, Precision, F1 Score, Mean Intersection over Union (MIoU) and Frequency Weighted Intersection over Union (FWIoU).
Comparison with existing methods
Results on the CCF dataset
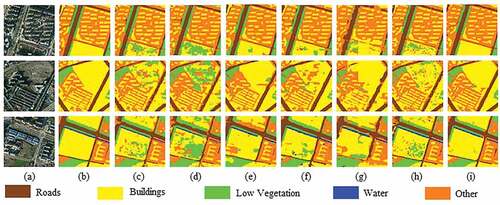
The efficiency of our network was compared with those of UNet (Ronneberger et al., Citation2015), SegNet (Badrinarayanan et al., Citation2017), FCN (Long et al., Citation2015), Deeplabv3+ (L. C. Chen et al., Citation2018), LinkNet (Chaurasia & Culurciello, Citation2017), EffuNet, Deeplabv3, MacuNet (Li, Duan, et al., Citation2021) and RSFCNN (Zhao et al., Citation2021). EffuNet is a combination of UNet and Efficient-net-B7 baseline. Example results of the proposed network on the CCF dataset are shown in . Our segmentation result is complete for low vegetation, roads, and buildings. In comparing with other methods, the segmentation results of our network have clearer boundaries and are more accurate for some segmentation details within the images. Representative detailed results for the CCF database are presented as an example in . In the first row of , our network segments images with more complete buildings and roads simultaneously. The segmentations of roads and buildings are not mixed with too much orange background information. As shown in the second row of , SegNet and UNet incorrectly classify the buildings as low vegetation. In contrast, the segmentation performed by our model is a little more accurate. As shown by the third row of , our network has the advantage of identifying disturbing factors, such as buildings affected by shadows and light. The above results prove that our network can perform robust feature extraction and high-resolution detail recovery from high-resolution remote sensing images.
Figure 5. Segmentation results on the CCF dataset. (a) Original Image. (b) Ground truth. (c) UNet. (d) SegNet. (e) Deeplabv3. (f) FCN. (g) Deeplabv3+. (h) LinkNet. (i) MacuNet. (j) EffuNet. (k) RSFCNN. (l) Ours.
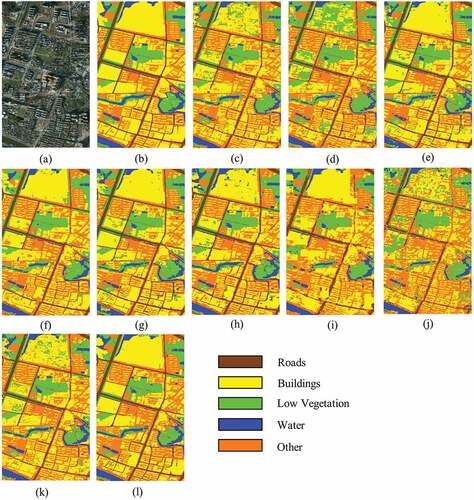
Figure 6. Visual examples of the CCF dataset. (a) Original Image. (b) Ground truth. (c) UNet. (d) SegNet. (e) FCN. (f) LinkNet. (g) MacuNet. (h) RSFCNN. (i) Ours.
shows the OA, Precision, Recall, FWIoU, MIoU, and Mean F1 of the different methods on the CCF dataset. Our method is superior to the comparison network in terms of Recall and MIoU. Among the indices, our model scores worse than LinkNet methods for Precision. Compared with RSFCNN, it achieves improvements of 3.486% in Mean F1, respectively. Compared with LinkNet, our method improves the OA and Recall by 0.846% and 3.453%, respectively. shows the detailed results for each class of the CCF dataset. It shows that our method achieves the highest F1 Score for buildings, road, and low vegetation. These results also prove the effectiveness of our network.
Table 1. Performance comparison of different methods on the CCF dataset.
Table 2. F1 score of different classes on the CCF dataset.
Results on the Vaihingen dataset
To further evaluate the effectiveness of our method, we also conducted comparative experiments on the Vaihingen dataset. The experimental results are presented in , which shows that our network achieved the best performance in Mean F1, MIoU, and Precision. The visualization results on the test set are shown in .
Figure 7. Segmentation results on the Vaihingen dataset. (a) Original Image. (b) Ground truth. (c) UNet. (d) SegNet. (e) Deeplabv3. (f) FCN. (g) Deeplabv3+. (h) LinkNet. (i) MacuNet. (j) EffuNet. (k) RSFCNN. (l) Ours.
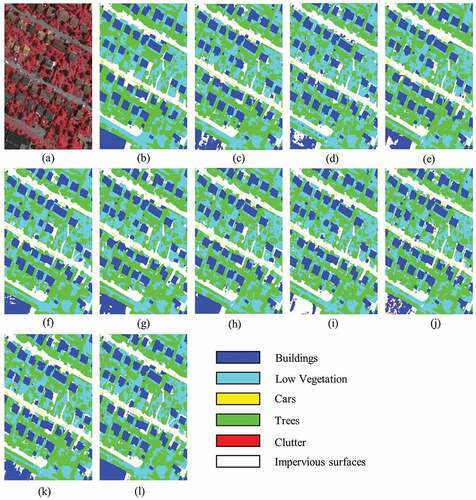
Table 3. Performance comparison of different methods on the Vaihingen dataset.
The prediction results based on this dataset show that our method achieved a good segmentation effect on the impervious surfaces in the cyan area of Vaihingen, with more explicit building boundaries and attenuated blurred mismatch caused by shadows. In addition, objects with almost the same colour were differentiated well into their categories. For example, as shown in the first row of , SegNet and UNet incorrectly classify buildings as trees because of their shadows. RSFCNN, although relatively accurate in classification, introduced too much background information in tree classification. In contrast, our network performs optimal segmentation. As shown in the third row of , our results for buildings are significantly better than those of the other networks in large areas of low vegetation and trees.
The quantitative results for the Vaihingen dataset are shown in . These results show that our model outperformed other methods with respect to Mean F1 and MIoU. The Mean F1 of our model is 1.382% greater than those of UNet. The OA of our model is 0.541% greater than that of Deeplabv3+. Our model also demonstrates significant advantages in handling small objects. For example, for the classification of buildings and cars, the F1 Score of our model is improved by 3.072% and 0.561%, respectively, compared with that of RSFCNN.
Table 4. F1 score of different classes on the Vaihingen dataset.
Results on the IND.V2 dataset
We conducted the experiments that are based on the IND.v2 dataset. We performed plenty of visualization processing on the prediction results, as shown in . Since the dataset consists of a large number of single small objects, as shown in the local prediction results of the dataset, our method has a better segmentation effect on detailed information in buildings. UNet and LinkNet correctly identify the buildings but also incorrectly identify the surrounding concrete as buildings, as shown in . FCN introduces too much background information in classification, resulting in blurred building boundaries. In contrast, our network achieves satisfactory performance on shadow regions and tricky buildings, such as the building covered by the tree in the top right of the image. Finally, lists the performance comparison for the different methods. Our method outperforms the other methods for OA, FWIoU, and MIoU. In this case, FWIoU reached 94.478%, which is at a rather advanced level. MIoU reached 85.119%, which is at least 1% points better than that for the other methods.
Figure 8. Segmentation results on the IND.V2 dataset. (a) Original Image. (b) Ground truth. (c) UNet. (d) SegNet. (e) Deeplabv3. (f) FCN. (g) Deeplabv3+. (h) LinkNet. (i) MacuNet. (j) EffuNet. (k) RSFCNN. (l) Ours.
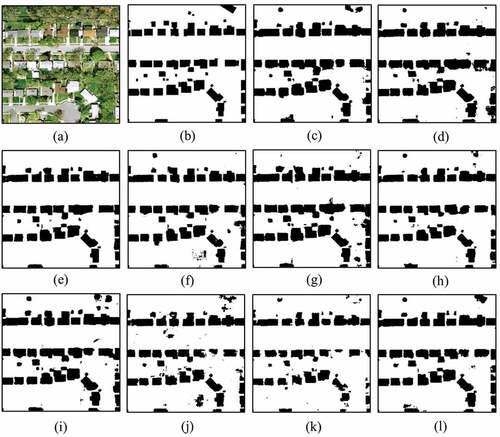
Figure 9. Visual examples of the IND.V2 dataset. (a) Original Image. (b) Ground truth. (c) UNet. (d) FCN. (e) LinkNet. (f) Ours.
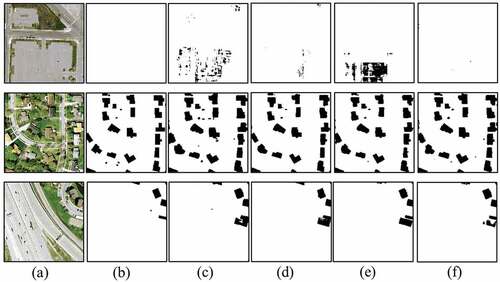
Table 5. Performance comparison of different methods on the IND.V2 dataset.
Ablation Study and optimizer
The optimization algorithm has a significant impact on the performance of the model. In this section, according to different optimization algorithms, we report full-scale ablation experiments to validate each module. Taking the Vaihingen dataset as an example, the baseline network was trained, and we then gradually added the multi-attention gating module and the fuzzy module. We conducted and reported their performance with respect to OA. M represents the multi-attention gating module, and F represents the fuzzy module.
presents the results of the ablation study on the Vaihingen dataset. The OA of our model in the ablation experiment is 84.960%, which is better than that of the benchmark model. In addition, the use of multi-attention gating blocks significantly improves the OA, compared with the benchmark model. Using the multi-attention gating module to enhance contextual information improves the OA by at least 0.934%. Moreover, adding the fuzzy module improves the OA by 1.097%. Obviously, the fuzzy neighbourhood module is more conducive to high-resolution remote sensing image segmentation. Furthermore, when the two are combined, the OA increases by 2.924%, which proves (to some extent) that both modules are required.
Table 6. Comparison between the baseline only and the baseline with the corresponding model added.
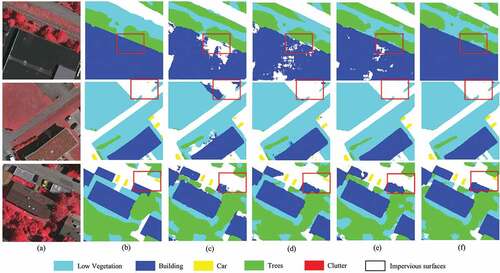
The results of the visual ablation study of the Adam optimizer on the Vaihingen dataset are presented in . In comparison with the ground truth, only the baseline is used for segmentation, the boundary between the two objects is adhered to because of shadow overlap, the edge noise was evident, and the boundary was mostly jagged. After the fuzzy neighbourhood module and multi-attention gating module are added, the mutual independence between the objects is improved, and the edge noise and region noise are reduced. The corresponding visualization results are shown in the third row of .
Figure 10. Results of the same baseline fusion test on the Vaihingen dataset with six different modules. (a) Original Image. (b) Ground truth. (c) BS. (d) BS+M. (e) BS+F. (f) Ours.
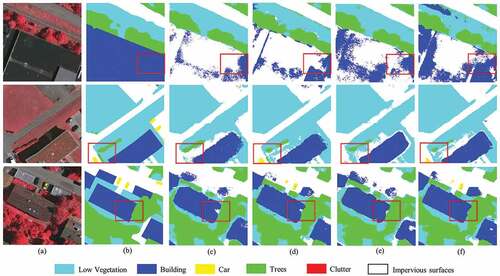
The results of the visual ablation study of the SGD optimizer on the Vaihingen dataset are presented in . The semantic information of car is easily covered by other categories. As illustrated in , when applying M to the baseline, the performance of the car has been improved. When applying F to the baseline, the performance for classification of heterogeneous object has been improved. We set two different optimization algorithms and trained the models separately to investigate the segmentation effect. We have determined that the model performs best when the Adam optimiser is used.
Figure 11. Results of the same baseline fusion test on the Vaihingen dataset with six different modules. (a) Original Image. (b) Ground truth. (c) BS. (d) BS+M. (e) BS+F. (f) Ours.
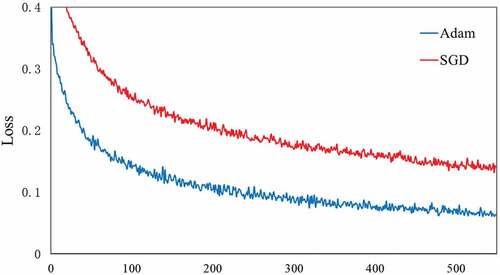
We set up two different optimisers, Adam and SGD, and train the models separately to examine the effect of the iterations. This is only effective when the loss function becomes small. illustrates the visualization of the loss value per iteration for the IND.v2 datasets. It is not difficult to see that in the initial stage of training, the loss varies greatly. However, as the number of cycles increases, the loss value changes slowly. When the number of epochs reaches 500, the loss value gradually converges. Besides, when the optimizer is SGD, the loss function decreases slowly. Therefore, we chose Adam as the optimiser when the model was trained on different datasets.
Figure 12. Loss curves for the training set with different optimizer.
Discussion
In this study, we proposed a fuzzy neighbourhood convolutional neural network that extract ground objects from high-resolution remote sensing images. The network combined multi-level feature extractor and fuzzy neighbourhood module, which is used to process uncertain information resulting from intra-class noise and the boundaries of different object. However, people may question that, for the remote sensing images with high intra-class difference and complex object boundaries, the fuzzy neighbourhood module may not be reliable. Our fuzzy neighbourhood module proceeds under a basic assumption that a pixel in the feature map is related to neighbourhood pixel
, which contains most of the corresponding feature representation. Based on this assumption, the difference of uncertain information can be minimized by considering pixel neighbourhood information in the pixel classification process. Thereby, the only question is whether this assumption holds true in the complex scenarios as aforementioned. We think the hypothesis holds. Our method was tested on three remote sensing datasets and obtained some remarkable segmentation results. Such results showed the potential of fuzzy neighbourhood module to solve the above problems.
Also, our method improved the deep-learning structure by adopting the fuzzy pattern recognition methods, which can construct fuzzy relations to express problems that is difficult to be accurately described by classical mathematical logic, and have a unique advantage in solving uncertain problems. Recent research combining convolutional neural networks and fuzzy learning (M. Liu et al., Citation2019) extends the image input by adding additional channels, which is equivalent to adding additional handcrafted features represented by fuzzy set to the crisp input. However, these handcrafted fuzzy features computed based on the crisp input may fundamentally limit their performance. These methods may lose the original deterministic information. Rather than using the methods of the fuzzy data pre-processing cascading neural network that extract features from crisp input, we deeply integrated a fuzzy neighbourhood module in network architecture level to boost the performance of our model. Our approach was able to incorporate the convolutional neural network model alongside with the fuzzy learning methods in an effective manner. That is, the original definite information is retained. At the same time, the local features of each point are captured, and the permutation of the data feeding order is kept unchanged.
A commonly used design in the convolutional neural networks is based on stacked convolutions and pooling operations, which constantly reduce the spatial size of features to enhance their semantic representations. As mentioned in feature extraction structure section, we used a five-layers deep convolutional neural network structure. Although a deeper and wider network can capture richer and more complex features, it came at the cost of losing detailed spatial information (He et al., Citation2016). After down sampling several times in the deep convolutional neural network architectures, the latter feature maps lost spatial information. A small object of size 32 × 32 pixels is clearly visible in shallower feature maps, but not in the deeper feature maps.
The early method (Y. Liu et al., Citation2021) to solve the small object semantic segmentation was to improve the segmentation performance through image multi-scale strategy. This method enlarged the input image to different sizes, and judged the prediction results of all the size images to get the final segmentation result. Other methods (G. Chen et al., Citation2019; Xiao et al., Citation2020) used pyramid pooling layers to segment objects in multiple scales. Recent studies on small object detection (Nguyen et al., Citation2020; Tong et al., Citation2020) have successfully improved the detection accuracy by mainly focusing on top-down or bottom-up feature fusion. For example, some methods used skip connections to directly add lower-level feature maps to higher-level feature maps, or concatenated features by performing pooling and deconvolution simultaneously.
ln our method, we adopted weight coefficients that can adaptively fuse shallow and deep features. For this manner, it is more convenient to focus on a specific area rather than the entire background information. The performance of the fuzzy neighbourhood neural network was based on the result information of the fuzzy neighbourhood module and the feature complement of the multi-attention gating module respectively. The addition of the multi-attention gating part helped to supplement object information clearly. Therefore, our method was a process of mutual promotion, not only had certain effects in small object segmentation, but also had certain advantages in eliminating complex boundaries and intra-class noise. Based on the resulting segmentation and the corresponding accuracies, we concluded that fuzzy neighbourhood neural network can plays an important role in remote sensing image segmentation.
At the same time, other works on small object detection (Pang et al., Citation2019; Qian et al., Citation2019) proposed to use losses to address class imbalance for small objects. These methods give us a lot of inspiration for improving the recognition of small objects and thus optimizing the overall segmentation effect. In addition, the proposed model heavily relies on large labelled datasets. However, it is time-consuming and laborious to label large-scale remote sensing images that contain various diversity, such as different sensors, data ground sampling distances, acquisition areas and so on. Transfer learning can extract common knowledge from labelled datasets to help improve the performance of the model when the object lacks labels. In the follow-up study, we are planning to further delve into fuzzy learning, modify the proposed architecture and explore other excellent ideas.
Conclusion
This paper proposes a network structure to solve the problems of shadow noise and classification in remote sensing images. The network performs processing using the fuzzy neighbourhood module to overcome the inherent uncertainty of remote sensing images, achieve better boundary delineation, and improve segmentation performance. It realizes the filtering and extraction of shallow information in remote sensing images by using the multi-attention gating module, which can effectively remove noise from the shallow feature images and compensate for the detail in the deep feature images more robustly. As verified on the CCF, Vaihingen, and INDv2 dataset, our method can relatively better identify shadow information and smaller targets and can recognize target edge boundaries, while maintaining high accuracy. In the future, we will continue to study fuzzy learning in depth and adhere to the idea of combining fuzzy learning with deep learning for remote sensing image segmentation and further optimization of our proposed method.
Acknowledgments
All authors would sincerely thank the reviewers and editors for their suggestions and opinions for improving this article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data used to support this work will be provided in the https://github.com/tingtingqu/code.
Additional information
Funding
References
- Abdollahi, A., Pradhan, B., & Alamri, A. (2020). Vnet: An end-to-end fully convolutional neural network for road extraction from high-resolution remote sensing data. IEEE Access, 8, 179424–16. https://doi.org/10.1109/ACCESS.2020.3026658
- Alam, M., Wang, J. F., Guangpei, C., Yunrong, L., & Chen, Y. (2021). Convolutional neural network for the semantic segmentation of remote sensing images. Mobile Networks and Applications, 26(1), 200–215. https://doi.org/10.1007/s11036-020-01703-3
- Badrinarayanan, V., Kendall, A., & Cipolla, R. (2017). Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(12), 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615
- Bao, Y., Liu, W., Gao, O., Lin, Z., & Hu, Q. (2021). E-unet++: A semantic segmentation method for remote sensing images. 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference, (pp. 1858–1862). Chongqing, China. https://doi.org/10.1109/IMCEC51613.2021.9482266
- Caesar, H., Uijlings, J., & Ferrari, V. (2018). Coco-stuff: Thing and stuff classes in context. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (pp. 1209–1218). Salt Lake City, Utah, United States. https://doi.org/10.48550/arXiv.1612.03716
- Chaurasia, A., & Culurciello, E. (2017). Linknet: Exploiting encoder representations for efficient semantic segmentation. Proceedings of the IEEE Visual Communications and Image Processing, Petersburg, (pp. 1–4). FL, USA. http://doi.org/10.1109/VCIP.2017.8305148
- Chen, G., Li, C., Wei, W., Jing, W., Woźniak, M., Blažauskas, T., & Damaševičius, R. (2019). Fully convolutional neural network with augmented atrous spatial pyramid pool and fully connected fusion path for high resolution remote sensing image segmentation. Applied SciencesHttp, 9(9), 1816. https://doi.org/10.3390/app9091816
- Chen, M., Wu, J., Liu, L., Zhao, W., Tian, F., Shen, Q., Zhao, B., & Du, R. (2021). Dr-net: An improved network for building extraction from high resolution remote sensing image. Remote Sensing, 13(2), 294. https://doi.org/10.3390/rs13020294
- Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F., & Adam, H. (2018). Encoder-decoder with atrous separable convolution for semantic image segmentation. Proceedings of the European Conference on Computer Vision, (pp. 801–808). Munich, Germany. https://doi.org/10.48550/arXiv.1802.02611
- de Carvalho, O. L. F., de Carvalho Júnior, O. A., de Albuquerque, A. O., Santana, N. C., Borges, D. L., Luiz, A. S., Gomes, R. A. T., & Guimarães, R. F. (2022). Multispectral panoptic segmentation: Exploring the beach setting with worldview-3 imagery. International Journal of Applied Earth Observation and Geoinformation, 112, 102910. https://doi.org/10.1016/j.jag.2022.102910
- de Carvalho, O. L. F., de Carvalho Júnior, O. A., Silva, C. R. E., de Albuquerque, A. O., Santana, N. C., Borges, D. L., Gomes, R. A. T., & Guimarães, R. F. (2022). Panoptic segmentation meets remote sensing. Remote Sensing, 14(4), 965. https://doi.org/10.3390/rs14040965
- Deng, Y., Ren, Z., Kong, Y., Bao, F., & Dai, Q. (2016). A hierarchical fused fuzzy deep neural network for data classification. IEEE Transactions on Fuzzy Systems, 25(4), 1006–1012. https://doi.org/10.1109/TFUZZ.2016.2574915
- Guo, W., Yang, W., Zhang, H. J., & Hua, G. (2018). Geospatial object detection in high resolution satellite images based on multi-scale convolutional neural network. Remote Sensing, 10(1), 131. https://doi.org/10.3390/rs10010131
- Han, B., & Wu, Y. (2017). A novel active contour model based on modified symmetric cross entropy for remote sensing river image segmentation. Pattern recognition, 67(7), 396–409. https://doi.org/10.1016/j.patcog.2017.02.022
- He, K., Zhang, X., Ren, X., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (pp. 770–778). Las Vegas, USA. http://doi.org/10.1109/CVPR.2016.90
- Huang, K., Zhang, Y., Cheng, H. D., Xing, P., & Zhang, B. (2021). Semantic segmentation of breast ultrasound image with pyramid fuzzy uncertainty reduction and direction connectedness feature. 25th International Conference on Pattern Recognition, (pp.3357–3364). Milan, Italy. https://doi.org/10.1109/ICPR48806.2021.9413082
- Hua, X., Wang, X., Rui, T., Shao, F., & Wang, D. (2021). Cascaded panoptic segmentation method for high resolution remote sensing image. Applied Soft Computing, 109, 107515. https://doi.org/10.1016/j.asoc.2021.107515
- Hurtik, P., Molek, V., & Hula, J. (2019). Data preprocessing technique for neural networks based on image represented by a fuzzy function. IEEE Transactions on Fuzzy Systems, 28(7), 1195–1204. https://doi.org/10.1109/TFUZZ.2019.2911494
- Jabri, S., Zhang, Y., & Alaeldin, S. (2014). Stereo-based building detection in very high resolution satellite imagery using IHS color system. Proceedings of the IEEE Geoscience and Remote Sensing Symposium, (pp. 2301–2304). Quebec City, Canada. https://doi.org/10.1109/IGARSS.2014.6946930
- Khoshboresh-Masouleh, M., & Shah-Hosseini, R. (2021a). Building panoptic change segmentation with the use of uncertainty estimation in squeeze-and-attention CNN and remote sensing observations. International Journal of Remote Sensing, 42(20), 7798–7820. https://doi.org/10.1080/01431161.2021.1966853
- Khoshboresh-Masouleh, M., & Shah-Hosseini, R. (2021b). A deep multi-modal learning method and a new rgb-depth data set for building roof extraction. Photogrammetric Engineering & Remote Sensing, 87(10), 759–766. https://doi.org/10.14358/PERS.21-00007R2
- Li, R., Duan, C., Zheng, S., Atkinson, P. M., & Atkinson, P. M. (2021). MACU-Net for semantic segmentation of fine-resolution remotely sensed images. IEEE Geoscience and Remote Sensing Letters, 99, 1–5. https://doi.org/10.1109/LGRS.2021.3052886
- Li, X., He, H., Li, X., Li, D., Cheng, G., Shi, J., Weng, L., Tong, Y., & Lin, Z. (2021). Pointflow: Flowing semantics through points for aerial image segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (pp. 4217–4226). Kuala Lumpur, Malaysia. http://doi.org/10.48550/arXiv.2103.06564
- Liu, M., Jiao, L., Liu, X., Li, L., Liu, F., & Yang, S. (2020). C-CNN: Contourlet convolutional neural networks. IEEE Transactions on Neural Networks and Learning Systems, 32(6), 2636–2649. https://doi.org/10.1109/TNNLS.2020.3007412
- Liu, R., Mi, L., & Chen, Z. (2020). Afnet: Adaptive fusion network for remote sensing image semantic sementation. IEEE Transactions on Geoscience and Romote Sensing, 59(9), 7871–7886. https://doi.org/10.1109/TGRS.2020.3034123
- Liu, Y., Sun, P., Wergeles, N., & Shang, Y. (2021). A survey and performance evaluation of deep learning methods for small object detection. Expert Systems with Applications, 172(6), 114602. https://doi.org/10.1016/j.eswa.2021.114602
- Liu, M., Zhou, Z., Shang, P., & Xu, D. (2019). Fuzzified image enhancement for deep learning in iris recognition. IEEE Transactions on Fuzzy Systems. PP(99) 1-1. https://doi.org/10.1109/TFUZZ.2019.2958558
- Li, X., Zhang, L., You, A., Yang, M., Yang, K., & Tong, Y. (2019). Global aggregation then local distribution in fully convolutional networks. International Conference on Machine Learning. http://doi.org/10.48550/arXiv.1909.07229
- Li, R., Zheng, S., Zhang, C., Duan, C., Su, J., Wang, L., & Atkinson, P. M. (2021). Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60, 1–13. https://doi.org/10.1109/TGRS.2021.3093977
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (pp. 3431–3440). Boston, United States. https://doi.org/10.1109/TPAMI.2016.2572683
- Lu, H., Zhang, M., Xu, X., Li, Y. J., & Shen, H. T. (2020). Deep fuzzy hashing network for efficient image retrieval. IEEE Transactions on Fuzzy Systems, 29(1), 166–176. https://doi.org/10.1109/TFUZZ.2020.2984991
- Mylonas, S. K., Stavrakoudis, D. G., & Theocharis, J. B. (2013). GeneSIS: A ga-based fuzzy segmentation algorithm for remote sensing images. Knowledge-Based Systems, 54, 86–102. https://doi.org/10.1016/j.knosys.2013.07.018
- Nguyen, N. D., Do, T., Ngo, T. D., & Le, D. (2020). An evaluation of deep learning methods for small object detection. Journal of Electrical and Computer Engineering, 2020, 1–18. https://doi.org/10.1155/2020/3189691
- Ni, Z. L., Bian, G. B., Xie, X. L., Hou, Z. G., Zhou, X. H., & Zhou, Y. J. (2019). Rasnet: Segmentation for tracking surgical instruments in surgical videos using refined attention segmentation network. 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society, (pp. 5735–5738). Berlin, Germany. https://doi.org/10.1109/EMBC.2019.8856495
- Nida, N., Irtaza, A., Javed, A., Yousaf, M. H., & Mahmood, M. T. (2019). Melanoma lesion detection and segmentation using deep region based convolutional neural network and fuzzy c-means clustering. International Journal of Medical Informatics, 124, 37–48. https://doi.org/10.1016/j.ijmedinf.2019.01.005
- Pal, K. K., & Sudeep, K. (2016). Preprocessing for image classification by convolutional neural networks. In Proceedings of the IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology, (pp. 1778–1781). Bangalore, India. https://doi.org/10.1109/RTEICT.2016.7808140
- Pang, J., Chen, K., Shi, J., Feng, H., Ouyang, W., & Lin, D. (2019). Libra r-cnn: Towards balanced learning for object detection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (pp. 821–830). Long Beach, USA. http://doi.org/10.1109/CVPR.2019.00091
- Pan, S. M., Tao, Y. L., Nie, C. C., & Chong, Y. W. (2021). Pegnet: Progressive edge guidance network for semantic segmentation of remote sensing images. IEEE Geoscience and Remote Sensing Letters, 18(4), 637–641. https://doi.org/10.1109/ACCESS.2020.3015587
- Qian, Q., Chen, L., Li, H., & Jin, R. (2019). DR loss: Improving object detection by distributional ranking. Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (pp. 12164–12172). Seattle, USA. http://doi.org/10.1109/CVPR42600.2020.01218
- Qi, X., Li, K., Liu, P., Zhou, X., & Sun, M. (2020). Deep attention and multi-scale networks for accurate remote sensing image segmentation. IEEE Access, 8, 146627–146639. https://doi.org/10.1109/ACCESS.2020.3015587/
- Ronneberger, O., Fischer, P., & Brox, T. (2015). Unet: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-assisted Intervention, (pp. 234–241). Munich, Germany. https://doi.org/10.1007/978331924574428
- Salzano, R., Salvatori, R., Valt, M., Giuliani, G., Chatenoux, B., & Ioppi, L. (2019). Automated classification of terrestrial images: The contribution to the remote sensing of snow cover. Geosciences, 9(2), 97. https://doi.org/10.3390/geosciences9020097
- Sharma, A., Liu, X., Yang, X., & Shi, D. (2017). A patch-based convolutional neural network for remote sensing image classification. Neural Networks, 95(11), 19–28. https://doi.org/10.1016/j.neunet.2017.07.017
- Sherrah, J. (2016). Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. Computer Vision and Pattern Recognition. http://doi.org/10.48550/arXiv.1606.02585
- Song, N. Q., Wang, N., Lin, W. N., & Wu, N. (2018). Using satellite remote sensing and numerical modelling for the monitoring of suspended particulate matter concentration during reclamation construction at dalian offshore airport in china. European Journal of Remote Sensing, 51(1), 878–888. https://doi.org/10.1080/22797254.2018.1498301
- Sugeno, M., & Yasukawa, T. (1993). A fuzzy-logic-based approach to qualitative modeling. IEEE Transactions on Fuzzy Systems, 1(1), 7–31. https://doi.org/10.1109/TFUZZ.1993.390281
- Sun, X., Shi, A., Huang, H., & Mayer, H. (2020). Bas4net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 13, 5398–5413. https://doi.org/10.1109/JSTARS.2020.3021098
- Tong, K., Wu, Y., & Zhou, F. (2020). Recent advances in small object detection based on deep learning: A review. Image and Vision Computing, 97(6), 103910. https://doi.org/10.1016/j.imavis.2020.103910
- Wang, H., Chen, X. Z., Zhang, T. X., Xu, Z. Y., & Li, J. Y. (2022). Cctnet: Coupled CNN and transformer network for crop segmentation of remote sensing images. Remote Sensing, 14(9), 1956. https://doi.org/10.3390/rs14091956
- Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., Liu, D., Mu, Y., Tan, M., Wang, X., Liu, W., & Xiao, B. (2020). Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10), 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686
- Wei, H., Xu, X., Ou, N., Zhang, X., & Dai, Y. (2021). Deanet: Dual encoder with attention network for semantic segmentation of remote sensing imagery. Remote Sensing, 13(19), 3900. https://doi.org/10.3390/rs13193900
- Wurm, M., Stark, T., Zhu, X. X., Weigand, M., & Taubenböck, H. (2019). Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. Isprs Journal of Photogrammetry and Remote Sensing, 150, 59–69. https://doi.org/10.1016/j.isprsjprs.2019.02.006
- Xiao, T., Liu, Y., Zhou, B., & Jiang, Y. (2018). Unified perceptual parsing for scene understanding. Proceedings of the European Conference on Computer Vision, (pp. 418–434). Munich, Germany. https://doi.org/10.1109/CVPRW53098.2021.00179
- Xiao, Y., Tian, Z., Yu, J., Zhang, Y. S., Liu, S., Du, S., & Lan, X. (2020). A review of object detection based on deep learning. Multimedia Tools and Applications, 79(33), 23729–23791. https://doi.org/10.1007/s11042-020-08976-6
- Xu, J., Zhao, T., Feng, G., Ni, M., & Ou, S. (2021). A fuzzy C-means clustering algorithm based on spatial context model for image segmentation. International Journal of Fuzzy Systems, 23(3), 816–832. https://doi.org/10.1007/s40815-020-01015-4
- Yuan, Y., Chen, X., & Wang, J. (2020). Object-contextual representations for semantic segmentation. European Conference on Computer Vision, (pp. 173–190). Springer, Cham. https://doi.org/10.48550/arXiv.1909.11065
- Yuan, J., Wang, D., & Li, R. (2014). Remote sensing image segmentation by combining spectral and texture features. IEEE Transactions on Geoscience and Remote Sensing, 52(1), 16–24. https://doi.org/10.1109/TGRS.2012.2234755
- Yue, J., Mao, S., & Li, M. (2016). A deep learning framework for hyperspectral image classification using spatial pyramid pooling. Remote Sensing Letters, 7(9), 875–884. https://doi.org/10.1080/2150704X.2016.1193793
- Zhang, F., Du, B., & Zhang, L. (2016). Scene classification via a gradient boosting random convolutional network framework. IEEE Transactions on Geoscience and Remote Sensing, 54(3), 1793–1802. https://doi.org/10.1109/TGRS.2015.2488681
- Zhang, C., Pan, X., Li, H., Gardiner, A., Sargent, I., Hare, J., & Atkinson, P. M. (2018). A hybrid mlp-cnn classifier for very fine resolution remotely sensed image classification. Isprs Journal of Photogrammetry and Remote Sensing, 140, 133–144. https://doi.org/10.1016/J.ISPRSJPRS.2017.07.014
- Zhang, X., Pan, X., & Wang, S. (2017). Fuzzy dbn with rule-based knowledge representation and high interpretability. In 12th International Conference on Intelligent Systems and Knowledge Engineering, (pp. 1–25). Nanjing, China. https://doi.org/10.1109/ISKE.2017.8258762
- Zhao, H., Shi, J., Qi, X., Wang, X., & Jia, J. (2017). Pyramid scene parsing network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (pp. 2881–2890). Hawaii, USA. http://doi.org/10.1109/CVPR.2017.660
- Zhao, Z., Vuran, M. C., Guo, F., & Scott, S. D. (2021). Deep-waveform: A learned ofdm receiver based on deep complex-valued convolutional networks. IEEE Journal on Selected Areas in Communications, 39(8), 2407–2420. https://doi.org/10.1109/JSAC.2021.3087241
- Zhao, T., Xu, J., Chen, R., & Ma, X. (2021). Remote sensing image segmentation based on the fuzzy deep convolutional neural network. International Journal of Remote Sensing, 42(16), 6264–6283. https://doi.org/10.1080/01431161.2021.1938738
- Zheng, X., Huan, L., Xiong, H., & Gong, J. (2019). Elkppnet: An edge-aware neural network with large kernel pyramid pooling for learning discriminative features in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA. https://doi.org/10.48550/arXiv.1906.11428
- Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., & Torralba, A. (2019). Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3), 302–321. https://doi.org/10.1007/s11263-018-1140-0