
Abstract
With increasing international trade and growing emphasis on security and efficiency, enhanced information and data-sharing between different stakeholders in global supply chains is required. Currently, data quality is not only problematic for traders, but also for various government agencies that are involved in border control, such as customs authorities, food and health inspection agencies, or border force. We adapt principles from the value cycle modelling in accounting, and show how these principles enabled by ICT can be extended to supply chain management to ensure quality of data reported to customs. We then describe a typical application scenario based on a real but anonymized case, to show that value cycle monitoring can be applied (feasibility), and if applied, what the expected benefits are (usefulness).
1. Introduction
Currently, data about shipments available in international supply chains often do not provide a timely and accurate description of the goods [Citation1]. For customs authorities, the low quality of data in reporting has proved to be a big problem. For instance, the explosion of the sea vessel MSC Flaminia, where authorities discovered that 605 of the data elements about the cargo in the containers were not accurate.Footnote1 Stakeholders involved have different data formats and communication channels. Redundancy and post-processing are common problems in measures of control. For example, import declarations and bills of loading about goods are often made several days after the vessels with the goods leave the port of origin. If companies in transport logistics and supply chains had perfect data quality, then customs could rely on the business controls of enterprises, and at least for fiscal matters, additional inspecting and correcting customs-related data afterwards at the port of destination should not be necessary. Data-quality issues often result from other stakeholders, further upstream in the supply chain. Under these circumstances, the so-called “push-left principle” [Citation2] could be a solution: the consequences of deviations that are found in an audit or inspection, are “pushed left”, i.e. upstream in the supply chain to the party that caused them.
In order to identify and develop new value-adding services and accounting information systems design principles for “pushing left”, sustainable cooperation and communications between different stakeholders are needed. The connections among enterprises, governmental and audit agencies in logistics and supply chains are enforced by contracts. According to contract theory, the principal-agent problem cannot be ignored [Citation3]. Moral hazard and adverse selectionFootnote2 problems are sometimes inevitable. Therefore, assurance and management over data quality is necessary, in particular for accounting information systems that are used to record such data [Citation4].
Data Quality Management (DQM) entails the establishment and deployment of roles, responsibilities, policies, and procedures concerning the acquisition, maintenance, dissemination, and disposition of data [Citation5]. We identify some specific challenges concerning for DQM in international supply chains.
Firstly, the roles and responsibilities of the different stakeholders involved need to be analysed, from the manufacturer, exporter, forwarder to the warehouse keeper, customs agent, carrier and importer. Others – for instance, terminal operators, stevedores and cargo packers – are also important. Secondly, cross-organizational boundaries are difficult to delineate. For example, customs import formalities, which are formally the responsibility of the importer, are outsourced by him to his freight forwarder or customs broker. Thirdly, the contractual relationship is often weak and difficult to manage. For example, the customs agent depends for his import declaration on data about the goods provided to him by the ocean carrier, but this carrier only has a contractual relationship with the freight forwarder of the exporter in the country of origin. Business processes and data governance processes need to be well integrated. However, contracts are often negotiated on price, not on service level. Other challenges, like the allocation of financial and human resources, require a cost–benefit analysis.
How can we ensure quality of data reported to customs considering these challenges? Business reality can generally be modelled as a value cycle: an interrelated system of flows of money and goods [Citation6]. The value cycle of a trading company for simplicity contains two types of transactions: purchasing and selling goods. The flow of money should mirror the flow of goods, but in reverse. The point of an accounting information system is to accurately and completely capture these two reverse flows using accounts information. Value-cycle models are well established in the owner-ordered audit tradition in the Netherlands that concentrates on financial reporting completeness, in addition to correctness [Citation7]. When applied to DQM, value-cycle models can prove to be beneficial and this will be illustrated in this paper.
Our goal here is to propose guidelines for designing and developing an information infrastructure and technology-based mechanism in international supply chains, for DQM. In this paper, data quality needs are assessed and evaluated within the context of organizational strategies, supply chain structure and existing business processes. They are positioned relative to existing service-oriented architectures and development capabilities. The rest of this paper is structured as follows. First, we provide a brief overview of data quality and relevant definitions, as well as the general steps of data quality assurance. In the next section, we apply the value cycle approach to data quality management in international supply chain domain. The section after that is an application scenario of a case study in the Netherlands. The paper concludes with recommendations and implications on design principles for implementing value cycle (customs) control principles in supply chains.
2. Data quality assurance and data quality management
2.1. Defining data quality
Data quality is conformance to valid requirements. In defining data quality, we must first [Citation5] determine who sets the requirements. Then, determine how the requirements are set. After that, determine the degree of conformance that is needed. Ultimately, in the international supply chain domain, it is both the business and the governmental agency that need to set data quality requirements. They are aware of the existing data quality deficiencies, as well as the possibility and costs overcoming them. Sometimes, changes in business processes will be needed to address data quality problems. These factors must enter the decision process.
Operationally, we can first define data quality in terms of data quality parameters and data quality indicators [Citation8]: a data quality indicator is a data dimension that provides objective information about the data. Source, creation time, and collection method are examples. A data quality parameter is a qualitative or subjective dimension by which a user evaluates data quality. Source credibility and timeliness are examples. The value is directly or indirectly based on underlying quality indicator values. User-defined functions may be used to map quality indicator values to quality parameter values. For example, if the source is an RFID (radio-frequency identification) database, an auditor may conclude that data credibility is high. A data quality requirement specifies the indicators required to be documented for the data, so that at query time users can retrieve data within some acceptable range of quality indicator values.
2.2. Dimensions of data quality management objectives
Under general accounting settings, data quality should improve from the following dimensions[Citation9].
| (1) | Accuracy/correctness: data should correspond to business reality and minimize errors of recording and sampling to a point of being negligible. | ||||
| (2) | Completeness: the system is appropriately inclusive and represents the complete list of eligible data units about the business and not just a fraction of the list. | ||||
| (3) | Timeliness: data are up-to-date and available on time. | ||||
| (4) | Consistency: data generated by systems are based on protocols and procedures that do not change according to users and when or how they are used. If reporting data are stored at different data repositories, they should be the same in all repositories. | ||||
For information system and IT infrastructure settings, we have more goals of DQM.
| (1) | Integrity: the system used to generate data is protected from deliberate bias or manipulation for commercial or personal reasons. | ||||
| (2) | Independency: this means that data are independently used by the stakeholders involved and are not disclosed inappropriately. | ||||
| (3) | Relevance: concerned with whether the available data shed light on the issues of most importance to users. | ||||
2.3. General processes of data quality assurance (DQA)
DQA is the process of verifying the reliability of data. Protocols and methods must be employed to ensure that data are properly collected, handled, processed, used, and maintained at all stages of the scientific data lifecycle. This is commonly referred to as “QA/QC” (quality assurance/quality control). QA focuses on building-in quality to prevent defects while QC focuses on testing for quality (e.g. detecting defects) [Citation10]. To improve data quality, it is necessary to improve the linkage among the various uses of data throughout the system and across all business processes.
| (1) | Data acquisition and identification: the first step in a data-quality redesign program is to identity the critical data areas. This involves a careful re-examination of how critical data elements are used. Normally this is manifest in two areas: (a) the basic business processes and (b) support for decision-making about management of these business processes [Citation11]. | ||||
| (2) | Data profiling and discovery: data profiling is the systematic analysis of data to gather actionable and measurable information about its quality. Information gathered from data profiling is used to assess the overall data quality and determine the direction of data-quality initiatives. Data discovery is achieved by executing data profiling and data monitoring tasks, analysing the data and determining the business rules used to manage the data. | ||||
| (3) | Data cleansing and enrichment: detecting and correcting erroneous data and data inconsistencies both within and across systems. Data cleansing can take place in both real-time as data are entered or afterwards as part of a data-cleansing initiative. Data enrichment involves enhancing existing data, by adding meta-data or changing data from industry standards and business insights to make it more useful downstream. This can also be accomplished by adding records based on data available from other applications, or third-party data providers. | ||||
3. Data quality assurance with the value cycle approach
3.1. Data quality assurance in supply chain management (SCM)
The relation between DQA and SCM is crucial. Stakeholders in supply chains depend on each other; therefore, information about agreements and the current situation must be reliable. Supply chains are generally present in enterprises across logistics, retail and other sectors. “Supply Chain Management describes the discipline of optimizing the delivery of goods, services and related information from supplier to customer” [Citation12]. Enterprise Resource Planning (ERP) systems are seen as the digital backbone for information in supply chains, especially when the supply chains are integrated over several companies or entities [Citation13]. There are other information systems as well. If they are well-connected, data monitoring and quality control in SCM can be continuous and automated throughout the whole DQA process.
In SCM, data quality can have strong effects on operations in the supply chain. Consider, for instance, the bullwhip effect. The bullwhip effect is the phenomenon of amplifying demand variability when moving up the supply chain, leading to growing inefficiencies and diminishing revenues [Citation14]. This means that if a certain piece of data in a supply chain is erroneous or uncertain – for example, the demand forecast of a certain product is far from the actual demand – then fluctuations increase rapidly along the supply chain. This effect is affected by data quality, as business processes rely on data provided by others. When data cannot be relied on, it is prudential to keep extra stock. The next link in the chain will think likewise, amplifying the effect. When no specific requirements are set for a certain data element in the supply chain, this will not only cause an overall low data quality, but also amplified variances in stock levels along the supply chain. For this reason, the bullwhip effect must be taken into account when determining the effect of DQM.
3.2. Data quality in flows of money and goods
Supply chains have a big impact on organizations and are represented by the following flows [Citation15 and Citation12]: financial flow, goods flow as primary processes and information flow as CRUD (Create, Read, Update, Delete) processes. By CRUD operations in a database, whenever the status of the goods or money in the actual flow changes, information changes as well. In this way, information flow is linked with goods flow and financial flow. CRUD processes are the four basic processes that can be performed with data in databases and describe the state of the data at a certain point in the process [Citation16, 17]. These flows can often be used for cross-verification. For establishing proper DQM in a supply chain, it is thus required to take into account the goods flow and financial flow. The process of payments depends greatly on data quality, as errors in these data can damage the relations with customers.
We look at data quality issues from an auditing perspective, because auditing has practices to deal with cross-verification, using independent sources of data. One of these practices is to model businesses as a value cycle. Figure shows an example of the value cycle for two trading companies, connected by trade documents (e.g. quittance, invoice, purchase order, etc.). We use the following notations. Activities are shown as a rectangle. Ovals are the recordings of a state of a certain value to the company, such as inventory or accounts payable. States, i.e. accounts, are related through reconciliation relationships, indicated by dashed lines, which come together in the general ledger. The direction of the arrow indicates the influence of events. Arrows generally indicate an increment, while the sign “–/–” indicates a decrement of the corresponding account. Thus, a purchase leads to an increment of the accounts payable, while the purchased goods are added to the inventory. A sale leads to an increment of the accounts receivable and a decrement of the inventory, and so on.
Figure 1. Value cycle models of two trading companies linked by trade documents [18].
The general idea of value cycle modelling is to use Reconciliation Relations to define a mathematically precise model of how the flow of money and goods should be, depending on the specific manufacturing inputs and outputs for each type of business, and use it to verify actual audit business samples [Citation7]. The mathematical models could be instantiations of the following kinds of equations.
In Figure , for all accounts S, T which are affected by an event e: (S) ← [e] → (T), e.g. (inventory) ← [sale] → (accounts receivable), we have the following transformation equations, where f is a constant (here: sales price) that depends on the business model:
As accounts are recorded in specific units of measurement (kg, tons, 22 ft container, $, mph), we also need conversion equations,
In addition, for all accounts S, we have the following preservation equations:
where for time interval [t0, t1],
3.3. Applying the value cycle model to customs reporting
We need to adjust the value cycle model in three aspects for international trade. First, add costs components related to goods transport and handling. Second, verify across interorganizational links. Third, the key approach is finding the right reconciliation relationships that govern the international trade, in particular, capturing equations related to the flow of physical goods [18].
Here is a specific example of the goods flow in a bonded warehouse. Figure illustrates that the data about goods entering a bonded warehouseFootnote3 should correspond, according to many reconciliation checks, with the data about the goods leaving the warehouse, either in transit or for import into free circulation in the EU (European Union). Checks on the goods relate to all mutations in the goods movement. Customs have delegated controls over the warehouse to the company. To make sure the warehouse management system is reliable, and no goods or documents are missing in the records, they verify this afterwards every month, on the basis of electronic data. This is called an “electronic declaration” or audit file. The “stock movement declaration” is part of the electronic declaration. The basic principle is that the total in the movement of goods must be balanced, using the following preservation equation, for any period of time:
Figure 2. Conceptual model of the goods inflow and outflow of a customs warehouse.
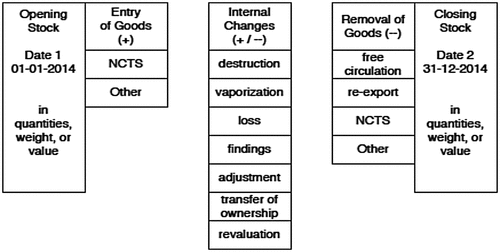
From this formula, we can derive more equations for the case of a bonded warehouse:
What makes the above equations complicated is the case when several information lines together make up one mutation. An illustration is packing goods together as a usual form of handling in a customs warehouse. Three different articles (A, B and C) are packed together into one article (D) (three-in-one box) according to the rules governing usual forms of handling. In the stock records, individual articles are registered separately from the articles packed together with different article codes. When the three articles are packed together, this has an effect on the individual stock levels. The stock of the different articles (A, B and C) reduces and the stock of the article packed together (D) increases. This therefore involves four transactions: three minus-transactions and one plus-transactions. These information lines are linked to each other by including the same mutation number of each information line in the declaration system.
4. Application scenario
4.1. Data collection
The data for this application scenario were collected from relatively open interviews with experts in trade, customs legislation, customs audit and within companies. The materials from these interviews were supplemented with public sources about customs legislations and inspection policies.
4.2. Scenario description
ABC is a Dutch company manufacturing machines for the international market. Many components that they use in manufacturing are produced abroad, both in EU and non-EU member states. Some of these parts are built into appliances and re-exported, both within and outside the EU. Other parts are re-exported directly. In the last case, no customs import duties are due. For these reasons, some warehouses at ABC operate as a Bonded Warehouse. Under this licence it is allowed to store components from foreign origins, of which payments of import or export duties have been suspended, for an indefinite period until a customs destination is known: entering into the EU (free circulation), or re-exporting outside the EU (transit). In order to obtain and keep the licence, ABC must allow regular audits and inspections from the Dutch customs. These involve IT audits of the administrative systems of the warehouse, physical security measures and occasionally inspections to find out if the inventory in the bonded warehouse corresponds to the reported goods.
We are interested in the requirements on ABC’s inventory management and information systems. The most important requirement is that customs authorities should be able to rely on ABC’s administration. It should be impossible to lose track of the stored goods (accurate and complete recording), to lose goods from the warehouse (physical security), or to assign the wrong customs destination (procedures). Errors that have a negative impact on accuracy or completeness of reporting data directly affect these key objectives. Data quality is crucial in two capacities.
| (1) | Data quality is part of the requirements that follow from the Customs Warehouse licence. It is therefore a key characteristic that must be audited regularly. Both the company and the auditors of customs develop policies and procedures for assessing reliability of the company’s record keeping. | ||||
| (2) | In the audit itself, audit evidence is produced by the party being audited and its reliability is not immediately guaranteed. Therefore, also to improve data quality for its own interest, the company must build in certain additional precautions into the business processes, procedures and information systems to ensure reliability: so-called internal controls, e.g. segregation of duties, master data management, limited reading and writing access rights, access control measures, logging and monitoring, baseline security. Many controls are implemented using IT systems, hence IT audit is necessary. These controls also need to be audited. | ||||
4.3. Problem investigation
As part of the regular audits, both customs and the internal control department of ABC have identified a number of weaknesses in the internal controls. Initial analysis has revealed that many errors can be attributed to the crucial process of “reception”, when goods are entered into the warehouse. At this point, ABC can still ensure that records of the goods match with the actual contents, on attributes like order numbers, container numbers, price, origin, goods description and barcodes. Once goods have entered into the warehouse, it is much harder to trace errors and mistakes. For this reason, ABC has temporarily implemented a number of manual checks regarding the reception of goods. These controls are meant to detect and immediately correct deviations between shipping documents, such as the purchase order, invoice, customs declaration, with the actual goods being received at the warehouse.
What complicates the issue is that the physical warehouse in fact contains goods that are not under customs supervision. Another complication is that at some of these premises, the reception process is not carried out by ABC itself, but has been outsourced to logistics service providers. So, ABC is dependent on logistics providers to carry out these checks adequately.
4.4. Solutions analysis
ABC has identified risks of overall processes, from general IT control, setting up purchase order and production order to sales. Also using controls in their ERP system and prescribing the right sequence of procedures in ERP, ABC sets up controls based on risks. The “risk matrix” is updated on a regular basis. There are more generic controls in normal manufactural and other functional parts of ERP systems.
Experts from ABC jointly with the customs made the following steps to produce so-called “risk matrix”.
| (1) | Identify for each individual movement type in the ERP system that is used in ABC whether it is customs-relevant or not; i.e. whether it might have implications for customs duties that have to be paid. Not customs-related means end of the data flow in the system, so if the goods are mistakenly categorized as customs-related, it should trigger a control response in the system. | ||||
| (2) | ABC implements for each identified customs-relevant movement type a specific internal control to mitigate the risk. | ||||
| (3) | These internal controls are built in the ERP software of ABC. Financial flows rely on logistics flows and are automatically recorded in ERP systems. The high level automation helps reduce risks. | ||||
| (4) | ABC arranges regular IT audits that these internal controls are indeed working in the ERP software. From business processes to customs processes, internal auditors and external auditors can acquire this information. | ||||
ABC obtained a licence from customs to report customs declarations on a monthly basis instead of per transaction. The monthly declarations for customs are made using the Automated Periodic Reporting (in Dutch: “Geautomatiseerde Periodieke Aangifte” (GPA)) which is generated by a special information system. The EU has a special system New Customs Transit System (NCTS) for the reporting of so-called transit goods; i.e. goods that have entered the EU via a specific country, but have not yet been formally imported, and hence, for which no import duties have been paid yet. NCTS requires a manual step to enter the transit status of goods; i.e. a person has to send a message to NCTS that certain goods have a transit status. NCTS then returns a specific Movement Reference Number (MRN), which can be used as proof that this shipment has the transit status. MRN is essential for ABC to generate an accurate GPA about the goods. This manual reporting of their transit goods is done by their freight forwarder (FF) that has arranged the transport of their goods into the Netherlands. However, because this step is done manually, it can happen that some transit goods are not reported to NCTS. To make sure that no such mistakes are made by FF, the compliance department of ABC has implemented extra internal controls to double check that for all transit goods stored in their bonded warehouse a corresponding MRN is recorded in their ERP system.
We propose a systematic approach to improve these internal controls, based on general risk management approaches (e.g. COSO ERM). First, identify deficiencies in data quality as these may indicate risks related to customs compliance. Second, find the underlying root cause of these deficiencies. In many cases, the cause will be with another party, on whose data the organization depends. Try to fix the deficiency by improving the information system, the process or even the condition in the contract with other parties. Third, evaluate the remaining compliance risks. If they are unacceptable repeat the procedure. The approach is related to the “push-left” principle [Citation2], because it aims to push any remaining control deficiencies left in the supply chain.
Process control in data processing is the underlying basis for data quality. If there is a gap in the process, this could mean goods are disappearing. Process control is on top of data quality problems, and is more about optimizing the physical goods’ movements. Start from GPA, investigate which fields are mapped and covered by standard procedures, and then scope into the customs-related “risk matrix”. The suggested process controls for DQA are as follows.
| (1) | Acquire and record data from various sources with segregation of duties. Get data from different sources with internal controls. Segregation of duties before data collection is a precondition for DQA at the data source. Despite internal controls within organizations, third parties who manage the information infrastructure must be unbiased. Value cycle monitoring, as represented in Figure , can play a crucial role in the analysis of the segregation of duties. The crucial issue is assurance of the EPD periodic customs reporting of ABC to customs, and the key auditing question from a customs point of view is how ABC can assure the accuracy of these data. The accuracy of these data is an issue, because there is a chain dependency of ABC on FF in providing relevant data, e.g. the transit status data of received goods, and it is known that due to the manual processing of the transit status of goods transported by FF to the bonded warehouse of ABC, mistakes can happen. We will now explain how the model in Figure can be applied to analyse this auditing problem. The first observation is that these transit status reports of FF can be viewed as an information service provided by FF to ABC. Actually, this information service is just one activity in a broader portfolio of information services called customs brokerage, which are typically provided by FF and customs brokers. The second observation is the chain perspective. The key assumption of the model is that data accuracy can be improved by using the countervailing interests between the different parties in a value network. In this case the value network consists of a simple chain of two parties: FF and ABC. FF has a different interest from ABC, because although FF offers the transit status report as a commercial service to ABC, it does not directly affect their own business interest if they make a mistake. However, the accuracy of these data is of direct interest for ABC, because they want to be compliant to customs, and if the EPD of ABC is not correct, ABC might be fined by customs. Therefore, ABC added extra internal controls in their ERP system to double-check whether the transit status reports that they receive from FF are accurate; the accuracy of these data improve the accuracy of the EPD that ABC sends to customs. The third observation is that from a customs auditing point of view this chain can be viewed as a typical example of segregation of duties in chain perspective, as is depicted in Figure , that enhances the accuracy of the EPD data. FF that is producing the transit status reports is checked by another party, namely ABC, for the correctness of these data. If ABC would only transfer the transit status data via their EPD to customs, then customs would not be satisfied from an auditing point of view. However, now that ABC is first double-checking the transit status data, the whole chain receives a positive audit assessment, because of the built-in segregation of duties between FF and ABC for this data validation. | ||||
| (2) | Validate data at the source against predefined data quality requirements. Evaluate those manual checks, set detailed data requirements and make them explicit in the contract with the vendor. Note that the “push-left principle” requires more responsibility from the vendor. Develop automated services for validating data records at the source company. A strategic implementation enables the rules and validation mechanisms to be shared across applications and deployed at various organizations’ information flows for continuous data inspection. These processes usually result in a variety of reporting schemes, for instance flagging, documenting and subsequent checking of suspect records. Validation checks may also involve checking for compliance against applicable standards, rules, and conventions. A key stage in data validation and cleaning is to identify the root causes of the errors detected and to focus on preventing those errors from re-occurring [Citation19]. | ||||
| (3) | Set up unified standards, data formats and communication channels in international supply chains. All data providers need to agree on a communications protocol and the data format to standardize data. For example, automated checks are performed during the sending of the GPA to customs. The format of data required for filing is a unified standard, and should be the same tracing back to the source manufacturers. The consequences of lack of IT and data interoperability across all stakeholders in a supply chain are that the process halts and the declarant is not informed. | ||||
| (4) | Build an information infrastructure to share data between stakeholders of a supply chain. Create a data pipeline with built-in controls, allowing more real-time collaborations. Transport conventions, systems and procedures in the Logistics Layer dominate the management of the supply chain. However, the data relating to the goods to be bought, sold and moved needs to be known in the Transaction Layer to ensure the order is properly met and paid for. If that information is clarified and verified at the point of consignment completion and captured in a data system running parallel to the Logistics Layer, then many of the risks associated with poor data would be reduced [Citation1]. This means for reports about goods entry into the bonded warehouse, collect data via the data pipeline from the actual packing list of the consolidator that actually “packed the box” with goods in the country of origin. For automated monitoring and sufficient built-in controls, an application platform should include much more than a traditional server operating system does. A modern cloud platform could, for instance, provide capabilities such as data synchronization, identity and entitlement management, and process orchestrationFootnote4. And it should also provide access to new technologies and ideas of enterprise computing. | ||||
| (5) | Check reconciliation relationships and build feedback systems to enhance monitoring. With the help of normative or prescriptive equations in Section 3.2 that describe the situation as it should be, deviations in the actual flows of money and goods can be identified based on actual measurements of the variables during operations. The checks could be on the net weight, number of units and money value using the equations we illustrated in Section 3.3. Re-valuation and transfer of ownership also need to be carefully checked with details. Goods movement in the bonded warehouse is the physical element that triggers payment of duties, which place responsibility for customs, but more requirements for FF and ABC. For instance, in the warehouse when goods are issued to production, FF needs to do entry in the system about goods issued to production and movements. A simple illustration is when goods part A and part B they together produce part C. FF enters SAP 261 in the system for A and B. The moment when production is ready he enters goods received 101 for C. When goods are missing or defective there could also be C, but formally those goods have to be put back into inventory. These are all done in automated system interfaces without going into the duty management system. ABC does have controls at the end by doing goods received and then the production order is closed. However, sometimes FF forgets to do one step and C remains either disappeared or put back in stock somewhere. This way inventory needs to have a record. The production order will still be closed, but the finance department of ABC will make corrections and implement other procedures afterwards, for example a fine to FF. Furthermore, create an automated feedback loop together with human capital investment. If one of the data users (either internal of external) spots a data defect, he can create a flag in the system and the defect will be automatically sent to the data source for review. | ||||
5. Conclusions
How can we get quality data with multiple standards, formats and communication channels in international supply chains? How can the value cycle approach contribute to data-quality management for customs reporting? In this paper we have tried to answer these questions by introducing an approach that builds on value cycle modelling from a chain perspective to application in international supply chains. This approach, specifically for data-quality assurance in customs reporting, is based on the segregation of duties and developing verification equations that can be used to verify data quality across the whole supply chain.
We illustrate the approach by a case scenario of a manufacturing company. It provides generic guidelines for data-quality assurance for different stakeholders and if implemented successfully would be beneficial for them. If the goods information generated by the vendor at the starting point of the supply chain is accurate and complete, those manual checks by parties at the other end of the supply chain would be unnecessary. The development of analytical detection models of faults and risks from reconciliation relationships is left for further research. Nevertheless, we believe that if information sharing could be improved this way, data quality in international supply chains could also be improved and regulatory compliance risks would be reduced, resulting in operational benefit as well.
Notes on contributors
 Yuxin Wang is a PhD candidate in the section of Information and Communication Technology at the Department of Technology, Policy and Management of Delft University of Technology in the Netherlands. She received her Bachelor’s degree from Beijing Institute of Technology in China and Master’s degree of Economics from Duke University in the USA. Her current research is a subproject of Supply Chain Control and Compliance (SAtIN) funded by the Netherlands Organization for Scientific Research (NWO). She is interested in fault detection and diagnosis in international supply chains. She also has work experience in data analysis and IT consulting in Accenture. She had been an operating manager in the USA for 2 years after being a research assistant at Duke University.
Yuxin Wang is a PhD candidate in the section of Information and Communication Technology at the Department of Technology, Policy and Management of Delft University of Technology in the Netherlands. She received her Bachelor’s degree from Beijing Institute of Technology in China and Master’s degree of Economics from Duke University in the USA. Her current research is a subproject of Supply Chain Control and Compliance (SAtIN) funded by the Netherlands Organization for Scientific Research (NWO). She is interested in fault detection and diagnosis in international supply chains. She also has work experience in data analysis and IT consulting in Accenture. She had been an operating manager in the USA for 2 years after being a research assistant at Duke University.
 Joris Hulstijn is assistant professor in Compliance Management at the Department of Technology, Policy and Management of Delft University of Technology. He has published in international journals on such topics as regulatory compliance, artificial intelligence and law, and information systems. Previously, he worked on compliance reporting and on open norms, i.e. norms that are generic and still have to be made context-specific. His current research focuses on model-based auditing, a computational technique for compliance monitoring and auditing that uses a formal model of the value-cycle, the flow of money and goods in a transaction, to derive hypotheses for cross-verification. This idea is now being applied to new application domains, such as supply chain management. He is a member of the Knowledge Group on Continuous Assurance, Data Analytics and Process Mining at NBA, the Dutch national association for chartered accountants.
Joris Hulstijn is assistant professor in Compliance Management at the Department of Technology, Policy and Management of Delft University of Technology. He has published in international journals on such topics as regulatory compliance, artificial intelligence and law, and information systems. Previously, he worked on compliance reporting and on open norms, i.e. norms that are generic and still have to be made context-specific. His current research focuses on model-based auditing, a computational technique for compliance monitoring and auditing that uses a formal model of the value-cycle, the flow of money and goods in a transaction, to derive hypotheses for cross-verification. This idea is now being applied to new application domains, such as supply chain management. He is a member of the Knowledge Group on Continuous Assurance, Data Analytics and Process Mining at NBA, the Dutch national association for chartered accountants.
 Yao-hua Tan is professor of Information and Communication Technology at the Department of Technology, Policy and Management of Delft University of Technology. He is the programme director of the part-time executive master Customs and Supply Chain Compliance of the Rotterdam School of Management of the Erasmus University Rotterdam. He was Reynolds visiting professor at the Wharton Business School of the University of Pennsylvania. His research interests are IT innovation to make international trade more secure and safe; compliance management for international supply chains; multi-agent modelling to develop automation of business procedures in international trade, ICT-enabled electronic negotiation and contracting. He has published five books and over 220 conference papers and journal articles. He was coordinator and scientific director of various research projects on IT innovation to facilitate international trade; including the EU funded projects ITAIDE (2006–2010), CASSANDRA (2010–2014) and CORE (2014–2018). He was vice-chair of the Committee on Trade of the Trade Division of the United Nations Economic Commission for Europe in Geneva. He also regularly acts as an expert for the European Commission, the Dutch government’s Top Sector Logistics and the Dutch Logistics Information Platform (NLIP).
Yao-hua Tan is professor of Information and Communication Technology at the Department of Technology, Policy and Management of Delft University of Technology. He is the programme director of the part-time executive master Customs and Supply Chain Compliance of the Rotterdam School of Management of the Erasmus University Rotterdam. He was Reynolds visiting professor at the Wharton Business School of the University of Pennsylvania. His research interests are IT innovation to make international trade more secure and safe; compliance management for international supply chains; multi-agent modelling to develop automation of business procedures in international trade, ICT-enabled electronic negotiation and contracting. He has published five books and over 220 conference papers and journal articles. He was coordinator and scientific director of various research projects on IT innovation to facilitate international trade; including the EU funded projects ITAIDE (2006–2010), CASSANDRA (2010–2014) and CORE (2014–2018). He was vice-chair of the Committee on Trade of the Trade Division of the United Nations Economic Commission for Europe in Geneva. He also regularly acts as an expert for the European Commission, the Dutch government’s Top Sector Logistics and the Dutch Logistics Information Platform (NLIP).
Notes
1. Investigation Report 255/12 “Fire and explosion on board the MSC FLAMINIA on 14 July 2012 in the Atlantic and the ensuing events” issued by Federal Bureau of Maritime Casualty Investigation.
2. Referring to a market process in which undesired results occur when buyers and sellers have asymmetric information; the “bad” customers are more likely to apply for the service.
3. The bonded warehouse is under the responsibility of a company, and used to store their goods under customs supervision, requiring a formal licence from customs to operate. Until a customs destination is known, e.g. re-export (transit) or import (free circulation), no import duties are due. (See also https://en.wikipedia.org/wiki/Bonded_warehouse).
4. See more on www.thesupplychaincloud.com and www.opengroup.org: Cloud Computing Open Standards, The Supply Chain Cloud Report.
References
- Hesketh D. Weaknesses in the supply chain: who packed the box? World Customs J. 2010;4(2):3–20.
- de Swart J, Wille J, Majoor B. Het ‘push left’-principe als motor van data analytics in de accountantscontrole [The "push-left"-principle as a driver of data analytics in financial audit]. Maandblad voor Accountancy en Bedrijfseconomie. 2013;87:425–432.
- Eisenhardt KM. Agency theory: an assessment and review. Acad Manag Rev.. 1989;14(1):57–74.
- Romney MB, Steinbart PJ. Accounting information systems, 10e. NJ: Prentice Hall; 2006.
- Geiger JG, editor. Data quality management the most critical initiative you can implement. The Twenty-Ninth Annual SAS® Users Group International Conference; 2004.
- Starreveld RW, de Mare B, Joels E. Bestuurlijke Informatieverzorging (in Dutch) [Administrative information provisioning]. Alphen aan den Rijn: Samsom; 1994.
- Blokdijk JH, Drieënhuizen F, Wallage PH. Reflections on auditing theory, a contribution from the Netherlands. Amsterdam: Limperg Instituut; 1995.
- Wang RY, Kon HB, Madnick SE. Data quality requirements analysis and modeling. Ninth International Conference of Data Engineering; Vienna, Austria, 1993.
- Wang RY, Strong DM. Beyond accuracy: What data quality means to data consumers. J Manag Inform Syst. 1996;12(4):5–33.
- Chapman AD. Principles of data quality. Copenhagen: Global Biodiversity Information Facility; 2005.
- Orr K. Data quality and systems theory. Communications of the ACM. 1998;41(2):66–71.
- Cooper MC, Lambert DM, Pagh JD. Supply chain management: More than a new name for logistics. Int J Logist Manag. 1997;8(1):1–14.
- Gunasekaran A, Ngai EW. Information systems in supply chain integration and management. Eur J Oper Res. 2004;159(2):269–295.
- Lee HL, Padmanabhan V, Whang S. The bullwhip effect in supply chains. Sloan Manag Rev. 1997;38(3):93–102.
- Croom S.., Romano P.., Giannakis M... Supply chain management: an analytical framework for critical literature review. European journal of purchasing & supply management. 2000;6(1):67–83.
- Martin J... Managing the data base environment. Upper Saddle River, NJ, USA: Prentice Hall; 1983.
- Polo M.., Piattini M.., Ruiz F... Reflective persistence (reflective CRUD: Reflective create, read, update and delete). Sixth European Conference on Pattern Languages of Programs (EuroPLOP); 2001.
- Veenstra AW, Hulstijn J, Christiaanse R, et al. Control and monitoring in international logistics. In: Blecker T, Kersten W, Ringle CM, editors. Innovative methods in logistics and supply chain management. Proceedings of the Hamburg International Conference of Logistics. Hamburg: epubli; 2014. P. 18–19.
- Redman TC. Data quality: The field guide. Boston, MA: Digital Press; 2001.