
ABSTRACT
The current study summarizes the literature on quantum-based structural sequencing methods and their predicted roles in the discovery of new DNA-binding protein domains. Although there is no literature yet showing the role of quantum structural sequencing for the discovery of new domains for DNA-binding proteins, the current study shows that the development of new quantum-based and far-from-equilibrium biological systems can be achieved by 3D-curved room-temperature superconductivity materials. The technology is useful for protein engineering and 3D sequencing of the ratio DNA/RNA secondary structures (DSS)/Physiological Modifications (PM) and will overcome the use of nanopore and ChiP sequencing. This approach is very useful for the protein engineering of recombinant enzymes for the unnatural replication of proteins and glycans for new biochemical activities, treatment of HIV and cancers, new genome editing machinery, artificial replication and translation, first sequencing of DSS/physiological modification/telomere with a correlation to cancer genesis and therapy, The key DSS in this study are: quadruplex, hairpin loop, triplexes and duplexes, i-motif, Holliday junction; and the PM investigated: 6 mA, 6fmA, 5mC, 5fC, 8-oxo-guanine. The DSS/PM ratio is critical for proto-oncogene activation and cancer genesis.
Introduction
DNA sequencing is a technology used to determine the DNA sequences. The sequencing of these bases, including adenine, guanine, cytosine, and thymine, is an important tool that has influenced the depth of biological and medical research worldwide [Citation1]. The importance of DNA sequencing in various fields of basic and applied sciences including medical diagnosis, biotechnology, forensic biology, virology and biological systematics have made sequencing an important tool that have re-shaped the understanding of basic and applied sciences [Citation2]. The techniques tend to aid in the diagnosis of different diseases with ease, thereby increasing the efficiency of the medical management of symptoms and best treatment methods [Citation3]. The sequencing techniques also provide information regarding drugs efficiency, thus preventing adverse effects associated with the drug uses. Genomic sequencing increases the ability to prevent the outbreak of disease because genomic sequencing tends to provide genetic variant information that can lead to disease or can increase the risk of disease development [Citation4]. DNA sequencing data is highly accurate because the procedure and data analysis are done to the highest standards of perfection and precision. The increase in the different techniques used in DNA sequencing has led to tremendous advancements in the DNA sequencing of complete DNA sequences or genomes of different species of organisms, including the human genome [Citation5]. Currently, the methods used for DNA sequencing are costly and time-consuming; developing a low-cost, rapid DNA sequencing method will enable the maximum utilization of DNA sequencing in medicine and applied sciences [Citation6].
In 2003, roughly US$3 billion was spent on DNA sequencing reagents and enzymes, as well as analyzer equipments and softwares for automated sequence determination. The Capillary electrophoresis (CE) method was used to determine the majority of the DNA sequencing output. Over the last ten years, this technology has been proportionately used to develop a faster technique. CE provides high resolution and throughput, automatic operation and data collection, and also online dye detection on DNA extension products. As the run advances operational advances like pulsed-field and graduated electric fields, as well as automated thermal ramping programs, result in higher base resolution and longer sequence reads. Advanced base-calling algorithms and DNA marker additives that use known fragment sizing landmarks can increase fragment base-calling by 20–30%, boosting call accuracy and read durations. Despite CE sequencers’ high efficiency, the complete delineation of the human genome and its implications for genome-wide analysis for personalized medicine are driving the development of devices and chemicals capable of massively increased sequence throughput. Miniaturization of CE into chip-based devices gives all of the above benefits, as well as a significant boost in analysis speed and automation. New array-based sequencing devices promise a quantum increase in efficiency [Citation7].
Whole genomes are currently sequenced in an unstructured set of reads with partial overlap. However, assembling DNA, aligning and combining reads in order to reconstruct the original genome, which is a crucial step for most applications, remains challenging [Citation8,Citation9]. Existing methods for sequencing read analysis rely on de novo assembly or mapping to an established reference [Citation10]. The overlap layout consensus (OLC) technique was used in the early generation of assembly tools [Citation11].
Quantum computers are a new generation of devices that perform computational tasks by utilizing quantum phenomena such as superposition and entanglement [Citation12]. Quantum computers are thought to have a high potential to outperform present technologies in a variety of tasks [Citation13], including modeling complicated systems [Citation14], machine learning [Citation15], and optimization [Citation16]. The subject of how quantum computers could be employed for computational biology and bioinformatics is still being intensively in search [Citation17]. Grover’s search, which may be used as a subroutine for sub-sequence alignment with a quadratic speedup [Citation18], is one of the techniques that can be achieved utilizing quantum computers. In the computational biology domain, there has been an upsurge in activity at the intersection of machine learning and quantum computing [Citation19]. The proposed quantum algorithms [Citation20], which are of great interest in terms of obtaining polynomial and exponential computational speedups, necessitate a large number of qubits and extremely low error rates, which are both beyond the capabilities of current noisy intermediate-scale quantum (NISQ) devices. Many different quantum computing implementations and models have been developed. But no literature report has shown how this sequencing method can aid in the discovery of new domain for DNA-binding proteins despite the promising of quantum microscopy and nanopore sequencing. The current study is aimed at reviewing the available literature on the quantum sequencing method and predicting the role of the quantum sequencing method in the discovery of new domain for DNA-binding proteins.
Data collection
A systematic review of the literature was carried out to determine the current state of knowledge on Quantum Technology as a tool for sequencing the ratio of DSS/DNA Modifications in order to develop new DNA-binding Proteins. The search timeframe was set to 2000–2021 in order to capture all potentially relevant publications. The Web of science, Scopus, and Google data bases were used in the search. A literature review was carried out to determine the focus of published studies. This was then employed in the categorization and analysis of data gathered from relevant studies during the study period. The following English language keywords were searched DNA sequencing, DSS/mutations, DNA-binding Proteins, Quantum Theory, Cancer cells to determine the published articles.
DNA binding proteins
DNA–binding proteins are proteins that possess DNA-binding domains. This domain is the reason why specialized proteins have specific or general affinity toward DNA single or double strand [Citation21]. The DNA-binding sites of the protein tend to interact with the groove of B-DNA due to the presence of more functional groups available for pairing to the bases [Citation22]. Examples of DNA-binding proteins include transcription factors, polymerases, nucleases and histones (). DNA-binding domains include zinc fingers, helix-turn-helix and leucine zippers (). By binding to a certain DNA sequence, transcription factor (TF) modulates the rate of transcription of genetic information from DNA to RNA messengers [Citation23]. TFs regulate genes by turning them on and off to ensure that they are expressed in the proper cell at the right time and in the right amount throughout the cell’s and organism’s lives [Citation24]. TFs’s work serve to control cell division, growth, and death throughout life; cell migration and organization (body plan) during embryonic development; and occasionally in reaction to signals from outside the cell, such as hormones [Citation25]. The human genome contains up to 1600 transcription factors which are both proteome and regulome members [Citation26]. Transcription factors bind to enhancer or promoter regions of DNA in close proximity to the genes they control. The transcription of the neighboring gene is either up- or down-regulated depending on the transcription factor [Citation27]. The enzyme that synthesizes long chains of nucleic acids polymers is referred as a polymerase. DNA polymerase and RNA polymerase copy a DNA template strand utilizing base-pairing interactions or half-ladder replication to construct DNA and RNA molecules, respectively [Citation28]. The nuclease is another enzyme found in the nucleic acid and functions in the cleavage of the phosphodiester links between nucleotides [Citation29]. Single and double stranded breaks in their target molecules are affected differently by nucleases [Citation30]. They are crucial machinery for many aspects of DNA repair in living organisms. Genetic instability or immunodeficiency can be caused by nuclease defects [Citation31]. A zinc finger (ZnF) is a finger-like structural motif that is characterized by the coordination of more than one zinc ion. The finger-like protrusion makes contact with the target molecule easy. This domain tends to bind DNA, RNA, protein, and lipid depending on the amino acid sequence. The number of fingers and linkers between fingers play a role in the binding of biomolecules [Citation32]. The helix-turn-helix (HTH) is a major domain that has two α-helix structures that are linked by a strand of amino acid. One of the α-helix occupied the N-terminal end of the motif while the other occupied the C-terminal. The α-helix occupying the C-terminal is often referred as the recognition helix because it contributes to DNA recognition. The recognition helix is linked to the DNA groove by hydrogen bonds and the van der Waals interactions with the exposed bases. The α-helix at the N- plays a stabilizing role in the interaction between DNA and proteins [Citation33]. The leucine zipper have dimeric organization, in which the C-terminal -helical segments of each monomer are organized in parallel and assume a coiled-coil conformation [Citation34]. The helices’ sequences are distinguished by a heptad repetition with nonpolar residues in the first positions and leucine amino acids in the fourth positions [Citation35]. They have a positively charged basic area that is mostly unstructured in the absence of DNA but becomes helical when it comes into contact with DNA. On opposite sides of the DNA double helix, the helices of the two monomers enter the main groove and hold it like a pincer. Depending on the environment and conditions, many leucine zipper proteins can form both homo- and heterodimers. The DNA-binding affinity, specificity, and function are frequently determined by the dimerization partner (e.g. activator or repressor) [Citation36].
Figure 1. Examples of DNA-binding proteins.
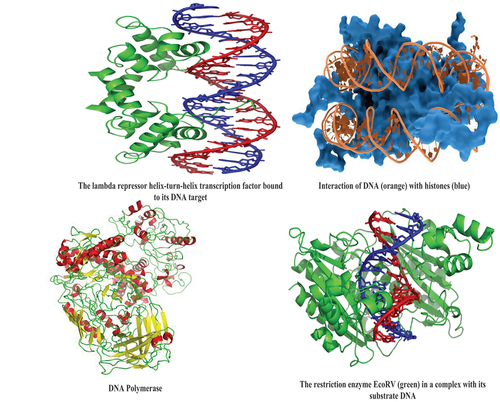
Figure 2. (a,b) Main families of DNA-binding protein domains. The proteins are represented as colored ribbons and the DNA as brown sticks. Zinc ions [Citation37].
![Figure 2. (a,b) Main families of DNA-binding protein domains. The proteins are represented as colored ribbons and the DNA as brown sticks. Zinc ions [Citation37].](/cms/asset/370803d3-1898-46c8-8b50-05c0957de358/teba_a_2082133_f0002_oc.jpg)
Sequencing of DNA/RNA secondary structures, telomere repelling and physiological modifications
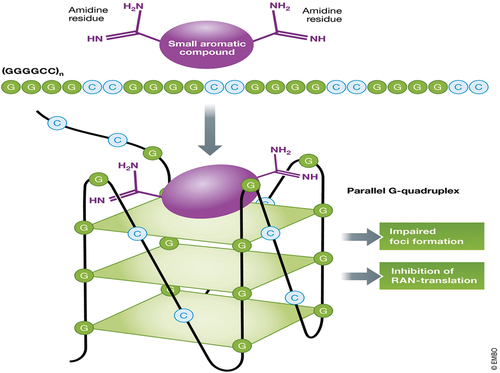
Biologically relevant DNA secondary structures include G-quadruplex, i-motif, triplex/duplex, hairpin bulge, multi-ranched loop and holliday junction. G-quadruplex secondary structures (G4) are produced by guanine-rich sequences () [Citation38]. They have a helical shape and contain guanine tetrads, which can be made up of one, two, or four strands [Citation39]. In microbes and vertebrates, including oncogenes in humans, unimolecular forms are frequently found near the ends of chromosomes, sometimes known as telomeric regions, and in transcriptional regulatory areas of numerous genes [Citation40]. A guanine tetrad (G-tetrad or G-quartet) is a square planar structure formed by four guanine bases linked together by Hoogsteen hydrogen bondings, and two or more guanine tetrads (from G-tracts, continuous sequences of guanine) can be stacked on top of each other to produce a G-quadruplex. The formation of G-quadruplexes is not random, and they serve extremely unusual functional purposes [Citation41]. The presence of a cation, particularly potassium, in a central channel between each pair of tetrads helps to stabilize the quadruplex structure [Citation42]. They can be intramolecular, bimolecular, or tetramolecular, and are made up of DNA, RNA, LNA, and PNA [Citation43]. Structures can be defined as parallel or antiparallel depending on the direction of the strands or sections of a strand that create the tetrads. G-quadruplex structures can be predicted computationally from DNA or RNA sequence motifs, but their actual structures vary greatly within and between the motifs, which can number in the millions per genome. In telomere, gene regulation, and functional genomics research, their activities in basic genetic processes are active area of research [Citation44]. Because of the important function it plays in DNA repair of apurinic/apyrimidinic sites, also known as AP sites, several genome regulatory events have been connected to the development of G-quadruplex structures [Citation45]. AP-seq is a new technique for mapping AP sites that uses a biotin-labeled aldehyde-reactive probe (ARP) to pinpoint certain regions of the genome where AP site damage has been found to be common [Citation46]. Damage in AP sites and the enzyme responsible for its repair, AP endonuclease 1, were both mapped using another genome-wide mapping sequencing technology known as ChIP-sequencing (APE1). Both ChIP-sequencing and ARP, two genome-wide mapping sequencing approaches, have shown that AP site damage is not random. Damage to AP sites was also more common in regions of the genome that contain active promoter and enhancer markers, some of which were associated to lung adenocarcinoma and colon cancer regions [Citation47]. Damage to AP sites was shown to be more prevalent in PQS areas of the genome, where the DNA repair mechanism, base excision repair, regulates and promotes the development of G-quadruplex structures (BER) [Citation47]. Base excision repair activities in cells have been shown to be diminished with aging when mitochondrial components begin to decline, which can lead to the formation of a variety of diseases, including Alzheimer’s disease (AD) [Citation48]. Superhelicity, which favors the unwinding of DNA’s double helical structure and, in turn, loops the strands to form G-quadruplex structures in guanine rich regions, is thought to form these G-quadruplex structures in the promoter regions of DNA [Citation49]. When oxidative DNA base damage is detected, the BER pathway is activated, and structures such as 8-Oxoguanine-DNA glycosylase 1 (OGG1), APE1, and the G-quadruplex play an important part in its repair. These enzymes are involved in BER, which is used to repair specific DNA damages such as 7,8-dihydro-8-oxoguanine (8-oxoG), which converts to guanine bases when exposed to oxidative stress. [5such as 7,8-dihydro-8-oxoguanine (8-oxoG), which converts to guanine bases under oxidative stress [Citation50]. Telomeric repeats from a range of organisms have been shown to produce these quadruplex structures, which have since been confirmed in vivo [Citation51]. The human telomeric repeat (which is the same for all vertebrates) is made up of many repeats of the sequenced (GGTTAG), and the quadruplexes formed by this structure can be bead-like structures ranging in size from 5 nm to 8 nm and their structure has been well studied by using NMR, TEM, and X-ray crystal structure determination [Citation52]. The formation of these quadruplexes in telomeres has been found to reduce the activity of the enzyme telomerase, which is responsible for maintaining the telomere length and is linked to 85% of cancers [Citation53].
Figure 3. Showing structural lock of G-quadruplex.
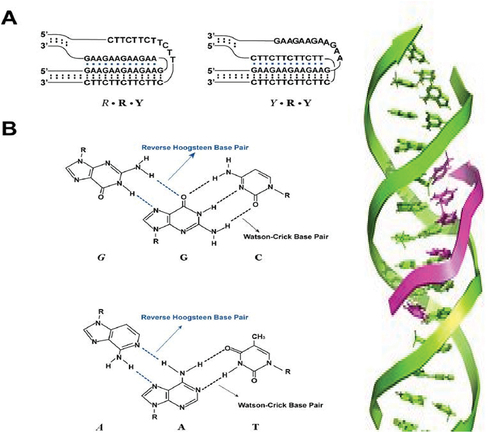
When pyrimidine or purine bases occupy the major groove of the DNA double helix, they lead to the formation of Hoogsteen pairs with purines from the Watson-Crick base pairs, generating a DNA triplex. Triplex forming oligonucleotides (TFO) and target sequences on duplex DNA generate intermolecular triplexes () [Citation54]. Triplex Forming Oligonucleotides (TFO) and Peptide Nucleic Acids (PNA) can be used to create triple-stranded DNA regions (PNAs). Transcription, replication, and protein binding to DNA have all been found to be inhibited by TFO binding in the past [Citation55]. TFOs and mutagens have also been found to induce mutagenesis and enhance DNA damage [Citation56]. Despite the fact that TFO is known to inhibit DNA transcription and replication, current research has revealed that it can be used to regulate site-specifically genes in vitro and in vivo [Citation55]. Another recent study found that TFOs can be utilized to inhibit the proliferation of cancer cells by suppressing oncogenes and proto-oncogenes. TFOs, for example, were utilized in a recent study to prevent cellular mortality in hepatoma cells by lowering MET expression.
Figure 4. Duplex: A, B and Z forms. Triplex.
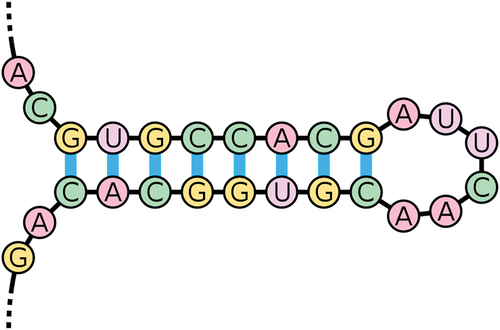
PNA TFOs have the ability to increase recombination frequencies, allowing for focused and precise gene editing. The cell’s own DNA repair mechanism can recognize the PNA-DNA-PNA triplex helix, making the surrounding DNA more susceptible to homologous recombination. A bis-PNA structure can be paired with a 40nt DNA fragment that is homologous to an adjacent region on the target gene in order for a site-specific PNA structure to promote recombination inside a DNA sequence [Citation57]. Recombination of the targeted gene and the neighboring gene target region has been observed when a TFO is linked to a donor DNA strand [Citation58]. The nucleotide excision repair (NER) pathway, which plays a role in detecting and repairing triplex structures, has been related to this type of recombination and repair [Citation57]. Multiple studies demonstrate that the NER factors xeroderma pigmentosum group A (XPA) and replication protein A (RPA) can bind selectively to cross-linked triplex structures as a complex. This mechanism, along with others, is known to play a role in identifying and fixing triplex structures [Citation59]. TFO delivery in vivo has been a key obstacle in the use of TFOs for gene modification [Citation60]. One research on in-vivo targeting of hematopoietic stem cells proposed a novel method of conjugating PNA molecules with cell penetrating peptides (CPPs) and poly(lactic-co-glycolic acid) (PLGA) nanoparticles to allow 6 bp changes in the CCR5 gene. [40] HIV-1 resistance has been linked to editing of the CCR5 gene [Citation61]. CPPs are proteins that can successfully transport ‘cargo’ into cells, such as tiny proteins or molecules. The PGLAs are biodegradable polymers that incorporate PNA molecules as nanoparticles for genome modifications at specific locations [Citation58]. The study show that PNA-DNA PGLA nanoparticles could efficiently edit hematopoietic stem cells with minimal toxicity and virus-free, and that conjugation with CPP allowed for direct targeting of genes for site-specific mutagenesis in stem cells [Citation62]. Three tail-clamp peptide nucleic acids (PNAs) were engineered to be delivered by nanoparticles to correct F508 del mutations on the cystic fibrosis transmembrane conductance regulator (CFTR) in human bronchial epithelial cells in vivo and in vitro in a novel study of cystic fibrosis (CF) gene therapy [Citation63]. The F508 del mutation is the most prevalent mutation that causes cystic fibrosis (CF). The F508 mutation causes the CFTR inhibition, a plasma membrane chloride channel controlled by a cyclic-adenosine monophosphate (cAMP). They were able to develop a novel therapy approach for CF by using nanoparticles to repair the F508 del CFTR mutation in human bronchial epithelial (HBE) cells in vitro and in vivo in a CF mice model, resulting in the development of CFTR-dependent chloride transport [Citation63]. When two portions of the same strand which are generally complementary in nucleotide sequence when read in opposing directions, base-pair to form a double helix that terminates in an unpaired loop known as a double helix. The resultant structure is a crucial component of a range of RNA secondary structures. It can direct RNA folding, protect messenger RNA (mRNA) structural integrity, provide recognition sites for RNA binding proteins, and function as a substrate for enzymatic processes as a RNA secondary structure () [Citation64]. A mutation occurs when the sequence of DNA changes. Mutations can occur as a result of DNA copying errors during cell division, exposure to ionizing radiation, exposure to chemicals known as mutagens, or virus infection. Somatic mutations occur in body cells and are not passed on to offspring, but germ line mutations occur in eggs and sperm and can be passed on to offspring [Citation31].
Figure 5. An example of an RNA stem-loop.
Mutations involved in cancer genesis
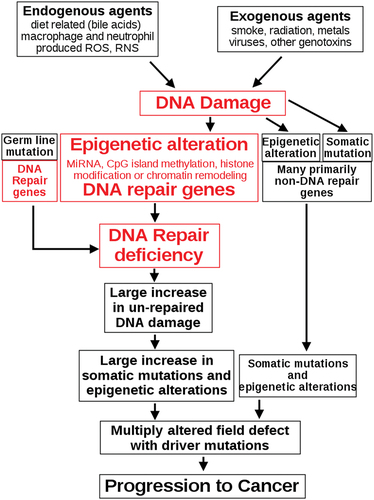
The different genetic alterations that may lead to the formation of cancer cells are classified in a variety of ways. Mutations, or alterations in the nucleotide sequence of genomic DNA, account for many of these alterations [Citation65]. There are numerous epigenetic modifications that affect whether or not genes are expressed. Aneuploidy, or the existence of an abnormal number of chromosomes, is a non-mutational genomic change that can involve the gain or loss of one or more chromosomes due to mitotic errors [Citation66]. A large-scale mutation occurs when a part of a chromosome is deleted or duplicated. When a cell gains several copies (typically 20 or more) of a small chromosomal area, usually including one or more oncogenes and nearby genetic material, genomic amplification occurs [Citation67]. When two different chromosomal regions fuse incorrectly at a specific site, this is known as translocation [Citation68]. The Philadelphia chromosome, or translocation of chromosomes 9 and 22, is a well-known example of this, as it occurs in chronic myelogenous leukemia and results in the development of the BCR-abl fusion protein, an oncogenic tyrosine kinase [Citation69]. Point mutations, deletions, and insertions, which may occur in the promoter of a gene and impact its expression, or in the gene’s coding sequence and alter the function or stability of its protein output, are examples of small-scale alterations [Citation70]. Integration of genomic material from a DNA virus or retrovirus can disrupt a single gene, and such an event can result in the production of viral oncogenes in the damaged cell and its offspring [Citation71]. Cancer is thought to be caused mostly by DNA damage [Citation72]. Endogenous cellular processes cause more than 60,000 new instances of naturally occurring DNA damage per human cell per day on average. Exogenous substances have the potential to cause further DNA damage. Tobacco smoke is an exogenous carcinogen that produces increased DNA damage, which is thought to be the cause of the rise in lung cancer as a result of smoking [Citation73]. UV light from sun radiation, for example, induces DNA damage that is crucial in melanoma. High amounts of reactive oxygen species produced by Helicobacter pylori infection damage DNA and lead to stomach cancer, while the Aspergillus flavus metabolite aflatoxin is a DNA damaging agent that causes liver cancer [Citation74]. Substances produced by the body can also cause DNA damage. Reactive oxygen species produced by macrophages and neutrophils in an inflamed colonic epithelium cause DNA damage that initiates colonic tumorigenesis, and bile acids, which are found in high concentrations in the colons of people who eat a high-fat diet, also cause DNA damage and contribute to colon cancer [Citation75]. The boxes at the top of the illustrate such external and endogenous sources of DNA damage. At the second level of the diagram, the important role of DNA damage in cancer growth is depicted. In the path to cancer, the central aspects of DNA damage, epigenetic changes, and poor DNA repair are shown in red. A lack of DNA repair would result in more DNA damage accumulating, raising the risk of cancer. Individuals with a hereditary problem in any of 34 DNA repair genes are at an increased risk of cancer, with some deficiencies causing a lifetime risk of cancer of up to 100%. (e.g. p53 mutations) [Citation76]. The contribution of such germline mutations to DNA repair deficit is indicated in a box to the left of the illustration in . However, only approximately 1% of cancers are caused by germline mutations (which create highly penetrant cancer syndromes) [Citation77]. The majority of malignancies are classified as ‘sporadic’ or ‘non-hereditary’. About 30% of sporadic cancers have an unidentified hereditary component, while 70% of sporadic cancers have no genetic component [Citation78]. In sporadic cancers, a defect in DNA repair is occasionally caused by a mutation in a DNA repair gene; much more frequently, epigenetic modifications that lower or silence gene expression cause reduced or missing expression of DNA repair genes. This is shown in the third level from the top of the illustration in . Only four colorectal tumors out of 113 had a missense mutation in the DNA repair gene MGMT, while the majority had reduced MGMT expression due to methylation of the MGMT promoter region (an epigenetic alteration) [Citation79]. A DNA repair shortage occurs when the expression of DNA repair genes is decreased. At the fourth level from the top, this is depicted in the diagram. DNA damage persists at a greater than normal level in cells with a DNA repair deficiency (5th level from top in ); this excess damage generates an increased frequency of mutation and/or epimutation (6th level from top of ) [Citation80]. Mutation rates increase significantly in cells that are deficient in DNA mismatch repair or homologous recombinational repair (HRR). HRR-defective cells also have more chromosomal rearrangements and aneuploidy. Incompletely cleared repair sites can produce epigenetic gene silencing during the repair of DNA double-strand breaks or other DNA damage [Citation81]. Field defects aggregate somatic mutations and epigenetic changes caused by DNA damage and DNA repair inadequacies. Field defects are normal-appearing tissues with various changes that are common precursors to the establishment of a cancer’s disorder and over-proliferating clones. Many mutations and epigenetic modifications may be present in such field problems [Citation82]. For the majority of cancers, determining the primary etiology is impossible. In a few situations, there is only one cause: for example, all Kaposi’s sarcomas are caused by the virus HHV-8. However, using cancer epidemiology techniques and data, it is possible to make an estimate of a likely cause in a variety of conditions [Citation83]. Lung cancer, for example, can be caused by a variety of factors, including tobacco use and radon gas exposure. Men who currently smoke tobacco develop lung cancer at a rate 14 times higher than men who have never smoked tobacco: lung cancer in a current smoker is about 93% likely to be caused by smoking; there is a 7% chance that the smoker’s lung cancer was caused by radon gas or another non-tobacco cause [Citation84].
Figure 6. The central role of DNA damage and epigenetic defects in DNA repair genes in carcinogenesis.
The role of quantum sequencing in the discovery new domain for DNA-binding proteins
Quantum technology is a new field of physics and engineering that is based on quantum physics principles. Quantum computing, quantum sensors, quantum cryptography, quantum simulation, quantum metrology, and quantum imaging are all examples of quantum technologies that use quantum mechanics properties, particularly quantum entanglement, quantum superposition, and quantum tunneling [Citation85]. Any science concerned with systems that display noticeable quantum-mechanical effects, where waves have particle qualities and particles behave like waves, is referred to as quantum physics. Quantum mechanics has applications in both explaining natural events and developing technology that rely on quantum effects, such as integrated circuits and lasers [Citation86]. Quantum mechanics is also crucial for understanding how covalent bonds connect individual atoms to form molecules. Quantum chemistry is the application of quantum mechanics to chemistry. Quantum mechanics may also demonstrate which molecules are energetically favorable to which others and the magnitudes of the energy involved in ionic and covalent bonding processes [Citation86]. The algebraic determination of the hydrogen spectrum by [Citation87] and the treatment of diatomic molecules by [Citation88] were the earliest applications of quantum mechanics to physical systems. Modern technology operates on a scale where quantum effects are significant in many ways. Quantum chemistry, quantum optics, quantum computing, superconducting magnets, light-emitting diodes, the optical amplifier and laser, the transistor and semiconductors such as the microprocessor, and medical and research imaging such as magnetic resonance imaging and electron microscopy are all important applications of quantum theory. Many biological and physical phenomena, most notably the macromolecule DNA, have explanations based on the nature of chemical bonds. Multiple governments have established quantum technology exploration programs since 2010, including the UK National Quantum Technologies Programme [Citation89], which created four quantum ‘hubs’, the Singapore Center for Quantum Technologies, and QuTech, a Dutch center to develop a topological quantum computer [Citation90]. The European Union launched the Quantum Technology Flagship in 2016, a €1 billion, ten-year megaproject comparable to the European Future and Emerging Technologies Flagship initiatives. The National Quantum Initiative Act, passed in December 2018, allocates a $1 billion annual budget for quantum research in the United States. Large corporations have made multiple investments in quantum technology in the private sector. Google’s collaboration with the John Martinis group at UCSB, various relationships with D-wave Systems, a Canadian quantum computing business, and investment by many UK corporations in the UK quantum technologies initiative are just a few examples [Citation91].
Although there is no literature yet showing the role of quantum sequencing in the discovery of new domains for DNA-binding proteins, The current study shows that the development of new quantum-based and far-from-equilibrium biological systems can be achieved by 3D-curved quantum materials. These features will be apply as near-red infrared activated materials, new quantum materials for quantum teleportation, entanglement, superposition, control at far-from-equilibrium of Shannon and Von-Neumann entropy, quantum biology. This technology will be useful in controlling new epigenetic and genetic regulations. This technology is also useful in the development of small molecules for tuning cancer signaling and the development of new vaccines, in multi-combinatorial therapies, rewiring the biochemical network, structure-based ligands targeting (DNA/RNA secondary structures: wobble RNA, G-quadruplexes, hairpin loops, i-motif, holliday junctions), small molecules targeting (cancer signaling), late stage modification of complex (natural products), free cell synthesis and directed evolution of enzymes. The technology is useful in protein engineering and 3D sequencing of the ratio DNA/RNA secondary structures (DSS)/base modifications (DM). It will be useful in the protein engineering of recombinant enzymes for the unnatural replication of proteins and glycans for new biochemical activities, treatment of HIV and cancers, new genome editing machinery, artificial replication and translation, first sequencing of DSS/Modifications/telomere with a correlation to cancer genesis, DSS studies: quadruplex, hairpin loop, triplexes and duplexes, i-motif, Holliday junction, based DNA modifications investigated: 6 mA, 6fmA, 5mC, 5fC, 5caC, 8-oxo-guanine, and The DSS/DM ratio is critical for proto-oncogene activation and cancer genesis.
Conclusion
The current study shows the role of quantum technology in the detection of relevant DNA/RNA secondary structures, mutations and based modifications: the development of fluorescent and/or fluorogenic probes targeting and mapping each DNA/RNA secondary structures, DNA modifications for the site-specific structural sequencing of each types of cancer lines, will be the first complete structural sequencing of all key base modifications (5mC, 5fC, 6 mA, 8-oxo-guanine)/structural sequencing of mutations/Nucleic acid Secondary Structures (Quadruplex, triplexes, Duplexes, i-motif, hairpin loops, bulge loops, crossing)/Telomeres/+proteomes (enzymes/binding proteins) and this purpose can be fulfilled by combining: A/ processive enzyme readers/erasers, B/ ChiP Sequencing, C/ Nanopore sequencing, quantum microscopy (MOKe microscopy), D/ Real-time cell single molecule structural sequencing using microfluidic devices, for the study of their impact on cancer signaling of gene expression, control of the gene expression and development of anti-cancer and anti-aging molecules based on these detailed sequencing
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Heather JM, Chain B. The sequence of sequencers: the history of sequencing DNA. Genomics. 2016;107(1):1–8.
- Minchin S, Lodge J. Understanding biochemistry: structure and function of nucleic acids. Essays Biochem. 2019;63(4):433–456.
- Godbey WT. Chapter 15 - DNA fingerprinting. In: Godbey WT, editor. Biotechnology and its applications. Second ed. Cambridge, Massachusetts: Academic Press; 2022. p. 357–367.
- Keni R, Alexander A, Nayak PG, et al. COVID-19: emergence, spread, possible treatments, and global burden. Frontiers in Public Health. 2020;8. DOI:10.3389/fpubh.2020.00216
- Lander ES, Rubenfield M, et al. Initial sequencing and analysis of the human genome. Nature. 2001;409(1):860–921.
- Nadeem MA, Nawaz MA, Shahid MQ, et al. DNA molecular markers in plant breeding: current status and recent advancements in genomic selection and genome editing. Biotechnol Biotechnol Equip. 2018;32(2):261–285.
- Mitchelson KR. DNA SEQUENCING. In: Worsfold P, Townshend A, Poole C, editors. Encyclopedia of analytical science. Second ed. Oxford: Elsevier; 2005. p. 286–293.
- Liao X, Li M, Zou Y, et al. Current challenges and solutions of de novo assembly. Quantitative Biology. 2019;7(2):90–109.
- Park ST, Kim J. Trends in next-generation sequencing and a new era for whole genome sequencing. Int Neurourol J. 2016;20(Suppl 2):S76–83.
- Chaisson MJ, Wilson RK, Eichler EE. Genetic variation and the de novo assembly of human genomes. Nat Rev Genet. 2015;16(11):627–640.
- Myers EW. The fragment assembly string graph. Bioinformatics. 2005;21(Suppl 2):79–85.
- Ladd TD, Jelezko F, Laflamme R, et al. Quantum computers. Nature. 2010;464(7285):45–53.
- Harrow AW, Montanaro A. Quantum computational supremacy. Nature. 2017;549(7671):203–209.
- Lloyd S. Universal quantum simulators. Science. 1996;273(5278):1073–1078.
- Biamonte J, Wittek P, Pancotti N, et al. Quantum machine learning. Nature. 2017;549(7671):195–202.
- Boev AS, Rakitko AS, Usmanov SR, et al. Genome assembly using quantum and quantum-inspired annealing. Sci Rep. 2021b;11(1):13183.
- Emani PS, Warrell J, Anticevic A, et al. Quantum computing at the frontiers of biological sciences. Nat Methods. 2021;18(7):701–709.
- Boev AS, Rakitko AS, Usmanov SR, et al. Genome assembly using quantum and quantum-inspired annealing. Sci Rep. 2021a;11(1):13183.
- Prousalis K, Konofaos N. Α quantum pattern recognition method for improving pairwise sequence alignment. Sci Rep. 2019;9(1):7226.
- Fedorov AK, Gelfand MS. Towards practical applications in quantum computational biology. Nature Computational Science. 2021;1(2):114–119.
- Lin M, Guo J-T. New insights into protein-DNA binding specificity from hydrogen bond based comparative study. Nucleic Acids Res. 2019;47(21):11103–11113.
- Rosano GL, Ceccarelli EA. Recombinant protein expression in Escherichia coli: advances and challenges Front. Microbiol. 5 (2014).
- Latchman DS. Transcription factors: an overview. Int J Biochem Cell Biol. 1997;29(12):1305–1312.
- Vaquerizas JM, Kummerfeld SK, Teichmann SA, et al. A census of human transcription factors: function, expression and evolution. Nat Rev Genet. 2009;10(4):252–263.
- Cawley S, Bekiranov S, Ng HH, et al. Unbiased mapping of transcription factor binding sites along human chromosomes 21 and 22 points to widespread regulation of noncoding RNAs. Cell. 2004;116(4):499–509.
- McGuire AL, Gabriel S, Tishkoff SA, et al. The road ahead in genetics and genomics. Nat Rev Genet. 2020;21(10):581–596.
- Arnold PR, Wells AD, Li XC. Diversity and emerging roles of enhancer RNA in regulation of gene expression and cell fate. Frontiers in Cell and Developmental Biology. 2020;7. DOI:10.3389/fcell.2019.00377
- Gardner AF, Jackson KM, Boyle MM, et al. Therminator DNA polymerase: modified nucleotides and unnatural substrates Front. Mol. Biosci. 6 (2019).
- Yang W. Nucleases: diversity of structure, function and mechanism. Q Rev Biophys. 2011;44(1):1–93.
- Nishino T, Morikawa K. Structure and function of nucleases in DNA repair: shape, grip and blade of the DNA scissors. Oncogene. 2002;21(58):9022–9032.
- Chatterjee N, Walker GC. Mechanisms of DNA damage, repair, and mutagenesis. Environ Mol Mutagen. 2017;58(5):235–263.
- Krishna SS, Majumdar I, Grishin NV. Structural classification of zinc fingers: survey and summary. Nucleic Acids Res. 2003;31(2):532–550.
- Grishin NV. Two tricks in one bundle: helix-turn-helix gains enzymatic activity. Nucleic Acids Res. 2000;28(11):2229–2233.
- Pu WT, Struhl K. Dimerization of leucine zippers analyzed by random selection. Nucleic Acids Res. 1993;21(18):4348–4355.
- Vinson C, Myakishev M, Acharya A, et al. Classification of human B-ZIP proteins based on dimerization properties. Mol Cell Biol. 2002;22(18):6321–6335.
- Pogenberg V, Ogmundsdóttir MH, Bergsteinsdóttir K, et al. Restricted leucine zipper dimerization and specificity of DNA recognition of the melanocyte master regulator MITF. Genes Dev. 2012;26(23):2647–2658.
- Rooman M, René W. Protein–DNA Interactions. In: eLS. John Wiley & Sons, Ltd: Chichester. DOI:10.1002/9780470015902.a0001348.pub3
- Au - Routh ED, Au - Creacy SD, Au - Beerbower PE, et al. A G-quadruplex DNA-affinity approach for purification of enzymatically active G4 resolvase1. JoVE. 2017;18(121):55496.
- Burge S, Parkinson GN, Hazel P, et al. Quadruplex DNA: sequence, topology and structure. Nucleic Acids Res. 2006;34(19):5402–5415.
- Patel DJ, Phan AT, Kuryavyi V. Human telomere, oncogenic promoter and 5’-UTR G-quadruplexes: diverse higher order DNA and RNA targets for cancer therapeutics. Nucleic Acids Res. 2007;35(22):7429–7455.
- Weisz K. A world beyond double-helical nucleic acids: the structural diversity of tetra-stranded G-quadruplexes. ChemTexts. 2021;7(4):25.
- Bhattacharyya D, Mirihana Arachchilage G, Basu S. Metal cations in G-quadruplex folding and stability Front. Chem. 4 (2016).
- Sagi J. G-quadruplexes incorporating modified constituents: a review. J Biomol Struct Dyn. 2014;32(3):477–511.
- Wang Z, Chen R, Hou L, et al. Molecular dynamics and principal components of potassium binding with human telomeric intra-molecular G-quadruplex. Protein Cell. 2015;6(6):423–433.
- Hänsel-Hertsch R, Beraldi D, Lensing SV, et al. G-quadruplex structures mark human regulatory chromatin. Nat Genet. 2016;48(10):1267–1272.
- Poetsch AR. AP-Seq: a method to measure apurinic sites and small base adducts genome-wide. In: Hancock R, editor. The nucleus. New York NY: Springer US; 2020. p. 95–108.
- Roychoudhury S, Pramanik S, Harris HL, et al 2020. Endogenous oxidized DNA bases and APE1 regulate the formation of G-quadruplex structures in the genome. Proceedings of the National Academy of Sciences USA 117:11409.
- Canugovi C, Shamanna RA, Croteau DL, et al. Base excision DNA repair levels in mitochondrial lysates of Alzheimer’s disease. Neurobiol Aging. 2014;35(6):1293–1300.
- Sun D, Hurley LH. The importance of negative superhelicity in inducing the formation of G-quadruplex and i-motif structures in the c-Myc promoter: implications for drug targeting and control of gene expression. J Med Chem. 2009;52(9):2863–2874.
- Ba X, Boldogh I. 8-Oxoguanine DNA glycosylase 1: beyond repair of the oxidatively modified base lesions. Redox Biol. 2018;14:669–678.
- Schaffitzel C, Berger I, Postberg J, et al. 2001. In vitro generated antibodies specific for telomeric guanine-quadruplex DNA react with Stylonychia lemnae macronuclei. Proceedings of the National Academy of Sciences USA 98:8572.
- Kar A, Jones N, Arat NÖ, et al. Long repeating (TTAGGG)n single-stranded DNA self-condenses into compact beaded filaments stabilized by G-quadruplex formation. J Biol Chem. 2018;293(24):9473–9485.
- Jafri MA, Ansari SA, Alqahtani MH, et al. Roles of telomeres and telomerase in cancer, and advances in telomerase-targeted therapies. Genome Med. 2016;8(1):69.
- Frank-Kamenetskii MD, Mirkin SM. Triplex DNA structures. Annu Rev Biochem. 1995;64(1):65–95.
- Ricciardi AS, McNeer NA, Anandalingam KK, et al. Targeted genome modification via triple helix formation. In: Wajapeyee N, ed. Cancer genomics and proteomics: methods and protocols. New York: Springer New York; 2014. p. 89–106.
- Jain A, Wang G, Vasquez KM. DNA triple helices: biological consequences and therapeutic potential. Biochimie. 2008;90(8):1117–1130.
- Rogers FA, Vasquez KM, Egholm M, et al. 2002. Site-directed recombination via bifunctional PNA–DNA conjugates. Proceedings of the National Academy of Sciences USA 99:16695.
- McNeer NA, Schleifman EB, Cuthbert A, et al. Systemic delivery of triplex-forming PNA and donor DNA by nanoparticles mediates site-specific genome editing of human hematopoietic cells in vivo. Gene Ther. 2013;20(6):658–669.
- Vasquez KM, Christensen J, Li L, et al. 2002. Human XPA and RPA DNA repair proteins participate in specific recognition of triplex-induced helical distortions. Proceedings of the National Academy of Sciences of the United States of America USA 99:5848–5853.
- Hnedzko D, Cheruiyot SK, Rozners E. Using triple-helix-forming peptide nucleic acids for sequence-selective recognition of double-stranded RNA. Curr Protoc Nucleic Acid Chem. 2014;58(1):4.60.61–64.60.23.
- Schleifman Erica B, Bindra R, Leif J, et al. Targeted disruption of the CCR5 gene in human hematopoietic stem cells stimulated by Peptide nucleic acids. Chem Biol. 2011;18(9):1189–1198.
- Gupta A, Bahal R, Gupta M, et al. Nanotechnology for delivery of peptide nucleic acids (PNAs). J Control Release. 2016;240:302–311.
- McNeer NA, Anandalingam K, Fields RJ, et al. Nanoparticles that deliver triplex-forming peptide nucleic acid molecules correct F508del CFTR in airway epithelium. Nat Commun. 2015;6(1):6952.
- Svoboda P, Di Cara A. Hairpin RNA: a secondary structure of primary importance. Cell Mol Life Sci. 2006;63(7–8):901–908.
- Stratton MR, Campbell PJ, Futreal PA. The cancer genome. Nature. 2009;458(7239):719–724.
- Armaghany T, Wilson JD, Chu Q, et al. Genetic alterations in colorectal cancer. Gastrointest Cancer Res GCR. 2012;5(1):19–27.
- Takeshima H, Ushijima T. Accumulation of genetic and epigenetic alterations in normal cells and cancer risk. NPJ Precis Oncol. 2019;3(1):7.
- Yadav V, Sun S, Coelho MA, et al. 2020. Centromere scission drives chromosome shuffling and reproductive isolation. Proceedings of the National Academy of Sciences USA 117:7917.
- Kang Z-J, Liu Y-F, Xu L-Z, et al. The Philadelphia chromosome in leukemogenesis. Chin J Cancer. 2016;35(1):48.
- Quintás-Cardama A, Cortes J. Molecular biology of bcr-abl1-positive chronic myeloid leukemia. Blood. 2009;113(8):1619–1630.
- Goswami R, Subramanian G, Silayeva L, et al. Gene therapy leaves a vicious cycle Front. Oncol. 9 (2019).
- Kastan MB. DNA damage responses: mechanisms and roles in human disease. Mol Cancer Res. 2008;6(4):517.
- Cunningham FH, Fiebelkorn S, Johnson M, et al. A novel application of the margin of exposure approach: segregation of tobacco smoke toxicants. Food Chem Toxicol. 2011;49(11):2921–2933.
- Anna B, Blazej Z, Jacqueline G, et al. Mechanism of UV-related carcinogenesis and its contribution to nevi/melanoma. Exp Rev Dermatol. 2007;2(4):451–469.
- Bhattacharyya A, Chattopadhyay R, Mitra S, et al. Oxidative stress: an essential factor in the pathogenesis of gastrointestinal mucosal diseases. Physiol Rev. 2014;94(2):329–354.
- Maynard S, Schurman SH, Harboe C, et al. Base excision repair of oxidative DNA damage and association with cancer and aging. Carcinogenesis. 2009;30(1):2–10.
- Hodgson S. Mechanisms of inherited cancer susceptibility. J Zhejiang Univ Sci B. 2008;9(1):1–4.
- Jasperson KW, Tuohy TM, Neklason DW, et al. Hereditary and familial colon cancer. Gastroenterology. 2010;138(6):2044–2058.
- Lahtz C, Pfeifer GP. Epigenetic changes of DNA repair genes in cancer. J Mol Cell Biol. 2011;3(1):51–58.
- Fayyad N, Kobaisi F, Beal D, et al. Xeroderma pigmentosum C (XPC) mutations in primary fibroblasts impair base excision repair pathway and increase oxidative DNA damage. Frontiers in Genetics. 2020;11. DOI:10.3389/fgene.2020.561687.
- Forrester HB, Li J, Hovan D, et al. DNA repair genes: alternative transcription and gene expression at the exon level in response to the DNA damaging agent, ionizing radiation. PloS one. 2012;7(12):e53358.
- Bernstein C, Nfonsam V, Prasad AR, et al. Epigenetic field defects in progression to cancer. World J Gastrointest Oncol. 2013;5(3):43–49.
- Guo M, Peng Y, Gao A, et al. Epigenetic heterogeneity in cancer. Biomark Res. 2019;7:23.
- Han M, Jia L, Lv W, et al. Epigenetic enzyme mutations: role in tumorigenesis and molecular inhibitors Front. Oncol. 9 (2019).
- Zhang Q, Xu F, Li L, et al. Quantum information research in China. Quantum Sci Technol. 2019;4(4):040503.
- Saleem M. The failure of classical physics and the advent of quantum mechanics. Quantum Mechanics: IOP Publishing; 2015. p. 1-1-1–34.
- Pauli W. Über das Wasserstoffspektrum vom standpunkt der neuen quantenmechanik. Zeitschrift für Physik A Hadrons Nuclei. 1926;36(5):336–363.
- Mensing L. Die Rotations-Schwingungsbanden nach der Quantenmechanik. Zeitschrift für Physik. 1926;36(11–12):814–823.
- Knight P, Walmsley I. UK national quantum technology programme. Quantum Sci Technol. 2019;4(4):040502.
- Riedel MF, Binosi D, Thew R, et al. The European quantum technologies flagship programme. Quantum Sci Technol. 2017;2(3):030501.
- Riedel M, Kovacs M, Zoller P, et al. Europe’s Quantum Flagship initiative. Quantum Sci Technol. 2019;4(2):020501.