
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Language comprehension involves coping with ambiguity and recovering from misanalysis. Syntactic ambiguity resolution is associated with increased reading times, a classic finding that has shaped theories of sentence processing. However, reaction times conflate the time it takes a process to complete with the quality of the behavior-related information available to the system. We therefore used the speed-accuracy tradeoff procedure (SAT) to derive orthogonal estimates of processing time and interpretation accuracy, and tested whether stronger retrieval cues (via semantic relatedness: neighed->horse vs. fell->horse) aid interpretation during recovery. On average, ambiguous sentences took 250ms longer (SAT rate) to interpret than unambiguous controls, demonstrating veridical differences in processing time. Retrieval cues more strongly related to the true subject always increased accuracy, regardless of ambiguity. These findings are consistent with a language processing architecture where cue-driven operations give rise to interpretation, and wherein diagnostic cues aid retrieval, regardless of parsing difficulty or structural uncertainty.
Introduction
The defining characteristic of human language is an unbounded combinatorial capacity to form hierarchical sentence structures and compute meaning, even the words and phrases in those structures are separated in time and space, and by other linguistic representations. This capacity minimally requires that words and phrases can be interpreted together, whether they are adjacent or separated. For example, in (1):
The toddler screamed.
In order to form a representation the sentence’s meaning, a linguistic dependency between the noun toddler and the verb screamed must be established. Forming this dependency in (1) might be relatively computationally straightforward because the toddler is adjacent to screamed, and there are no other words in the sentence. But the integration of the toddler as the subject of the verb screamed becomes more complex in structure like (2):
The toddler that the mother loved _endlessly _screamed.
In (2), there is an intervening reduced relative clause, the mother loved endlessly, the processing of which may displace the noun the toddler from the comprehender’s focus of attention. At the verb screamed, a representation of the noun phrase the toddler must be retrieved in order to compute who did what to whom. Whenever comprehension requires retrieval of a previously processed representation from memory, constraints on memory may be a determinant of whether language comprehension is successful or not (see McElree, Citation2006, for a review).
Nonadjacent dependency formation, as in (2) above, cuts the computational problem of online language comprehension at its joints: how is incoming linguistic input recognised, structured, and interpreted accordingly? How might processing be shaped, biased, or even inhibited or facilitated, by recently processed representations?
In a growing body of literature, language processing is cast as a form of skilled memory retrieval (Lewis & Vasishth, Citation2005; Lewis, Vasishth, & Van Dyke, Citation2006; McElree, Foraker, & Dyer, Citation2003) where performance depends upon cues at retrieval, and their links to existing representations in memory, or cue diagnosticity (Martin, Citation2016; Martin & McElree, Citation2011; Martin, Nieuwland, & Carreiras, Citation2012, Citation2014; Nairne, Citation2002).
Under this conception of language processing, a particularly important memory constraint on comprehension is whether a required representation can be immediately retrieved from memory, or whether it must be retrieved via a search. Studies testing memory operations during dependency formation strongly suggest that dependent constituents are retrieved from memory via a direct-access operation (e.g. Foraker & McElree, Citation2007; Martin & McElree, Citation2008, Citation2009, Citation2011; McElree, Citation2000; McElree et al., Citation2003). Direct access occurs because retrieval is cue-based – retrieval cues are assumed to be a subset of the information available at the retrieval site (i.e. one part of the dependency, or the resolution of the open linguistic dependency via argument role filling using the retrieved constituent). Retrieval cues make contact with memory representations that have overlapping content via a unitary process, without recourse to a sequence of searches through irrelevant memories (e.g. Clark & Gronlund, Citation1996; Dosher & McElree, Citation2003; Kohonen, Citation1984). The strength to which the cues uniquely match the required target in memory determines whether retrieval is successful, and, consequently, whether the correct interpretation of a sentence is formed in comprehension. When more representations must be processed within or during the span of the two dependent constituents, the probability that retrieval is successful decreases (e.g. Foraker & McElree, Citation2007; Martin & McElree, Citation2008, Citation2009, Citation2011; Martin et al., Citation2012, Citation2014; McElree, Citation2000; McElree et al., Citation2003; Van Dyke & McElree, Citation2006, Citation2011). This is because the processing of additional representations increases retrieval interference, as the retrieval cues to a given item become less diagnostic or specific to a unique target in memory. If the interpolated representations are similar to the target in terms of their features, or any other representational aspect that may function as a retrieval cue, this state of affairs can result in cue overload, where the cues are insufficient for successful retrieval of a the target item (Nairne, Citation2002; Watkins & Watkins, Citation1975).
But the computational challenges of sentence comprehension do not always occur in perfect or uncertainty-free processing circumstances. In fact, part of the communicative power and representation parity of human language comes from the fact that it can be and often is ambiguous. Words and syntactic structures can often be at least temporarily ambiguous. There is a rich tradition in psycholinguistics to study the effects of ambiguity on sentence processing; the canonical finding being that sentences with ambiguous syntactic structure exhibit slower reaction times compared to sentences that are unambiguous in their structure. Competing theoretical accounts have offered a variety of different explanations for slower response latency. Some of these accounts can be coarsely categorised into those claiming two sources of processing difficulty under ambiguity. The first category of account would claim that ambiguity is costly due to competing lexical or structural representations (so-called representational difference accounts, e.g. (1) Contextual accounts: Altmann, Garnham, & Dennis, Citation1992; Altmann, van Nice, Garnham, & Henstra, Citation1998; (2) Lexicalist or competition accounts: MacDonald, Pearlmutter, & Seidenberg, Citation1994; Trueswell, Tanenhaus, & Garnsey, Citation1994; (3) A “race-based” account: van Gompel, Pickering, & Traxler, Citation2001; (4) A dynamical parsing account: Tabor, Galantucci, & Richardson, Citation2004, (5) A cue-based account: Van Dyke & Lewis, Citation2003). The second category seems to claim that difficulty arises due to the time it takes to reanalyse the ambiguous sentence structure (so-called processing time difference accounts, e.g (1). Minimal Attachment/Late Closure: Frazier & Fodor, Citation1978; Frazier & Rayner, Citation1982; (2) Reanalysis and repair accounts: Ferreira & Henderson, Citation1991; Fodor & Ferreira, Citation1998; (3) A structural change vs. repair account: Sturt, Citation2007; Sturt, Pickering, & Crocker, Citation1999; Sturt, Scheepers, & Pickering, Citation2002; (4) A reprocessing account: Grodner, Gibson, Argaman, & Babyonyshev, Citation2003). However, the key evidence for all these theoretical explanations is slowed or delayed reaction times, usually from self-paced reading or eye-tracking paradigms.
Reaction time is a ubiquitous, useful and informative psychological measurement. But it is an inherent mixture of information about the internal representations and processes we are trying to measure (see Davidson & Martin, Citation2013; Wickelgren, Citation1977 for discussion). Participants (any agent, be it animal or device) can trade processing speed for processing accuracy, and can do so dynamically (Pachella & Pew, Citation1968; Schouten & Bekker, Citation1967; Wickelgren, Citation1977). Speed-accuracy tradeoff occurs because participants can prioritise a fast response over an accurate one simply by lowering their internal criterion, that is, by requiring the accumulation of less information (or lower representation strength or quality) before they reach criterion and make their response (see Macmillan & Creelman, Citation2005; Luce, Citation1986; for definitive guides on interpretation of response time). Participants can also do the opposite – they can prioritise the quality of the information on which they are basing their decision (i.e. their “decision” to move their eyes or press a button or speak) over the time it takes to make the response. Under these circumstances then, how can we discriminate between representational difference and processing time difference accounts, or even conclude that aspects of both accounts may be correct? From reaction time alone, it is entirely possible that any and all of observed syntactic ambiguity resolution effects are due to differences in the quality or strength of the representations that are formed during sentence comprehension, or due to multiple parsing attempts (so-called reanalysis), or due to both. This last possibility, that ambiguity effects arise due to both representational differences and multiple attempts at parsing, is the prediction of a cue-driven account that is hybridised with tenants from both representational difference and processing time difference accounts.
If diagnostic cues determine successful retrieval, and in turn successful comprehension, then they should also play a role in the processing of syntactic ambiguity resolution in as much as that resolution depends upon forming the correct non-adjacent dependency. The processing of temporarily ambiguous structures has functioned as an important paradigm for testing hypotheses about the incremental parsing of incoming linguistic representations. Below is a classic example from Bever (Citation1970):
The horse raced past the barn fell.
Here, the verb raced is ambiguous between being the main verb of the clause the horse raced past the barn and being a past participle verb in a reduced relative clause the horse raced past the barn. Upon encountering the verb fell, the simpler or “default” main verb analysis (MV) of raced has adopted, it must be revised to the reduced relative analysis (RR). A large body of work has focused on the factors that affect the initial interpretation of structural ambiguity (e.g. Altmann & Steedman, Citation1988; Ferreira & Clifton, Citation1986; Frazier & Rayner, Citation1982; Lau & Ferreira, Citation2005; MacDonald et al., Citation1994; Sturt, Citation2007; Sturt et al., Citation2002; Trueswell et al., Citation1994). Less effort has been directed at examining factors that enable the recovery of a structural analysis in which the verb fell rather than raced serves as the main verb in a MV analysis. But it is an empirical question whether this recovery or reanalysis may be in part due to insufficient cues at retrieval. Specifically, is the cost of ambiguity in some sense due to whether the verb fell can provide sufficient cues to retrieve the horse as a potential subject?
Ambiguity, reanalysis, and cue diagnosticity
Given that a comprehender has interpreted the horse raced past the barn as a main clause in which raced is the MV, a reanalysis to the correct interpretation requires two things when encountering the verb fell: First, the comprehender must recognise that raced has a possible past participle analysis, which licenses a RR analysis of raced past the barn, and, second, that fell can be bound to the subject the horse as the MV of the sentence. Recognising that the horse could be the subject for fell requires retrieving the subject when the verb is encountered. The success of that operation may depend on the diagnosticity of retrieval cues at fell, specifically, the ability to retrieve the horse rather than other potential noun phrases in memory.
Indeed, failure to recover from misanalysis of a syntactically ambiguous construction may be due to the lack of diagnosticity of the cues at the point where reanalysis is required. In the case of (3), fell may provide cues that resonate with the barn more than the distant noun phrase the horse, particularly given its recency to the verb. Reanalysis may be blocked by the persistence of a degenerate interpretation in which fell attaches to the barn as a modifier, equivalent to the syntactically well-formed sentence, The horse raced past the barn that fell.
We pursue the hypothesis that failure to recover from a garden path sometimes may be an extreme case of insufficient diagnosticity between the verb and the noun (see also Van Dyke & Lewis, Citation2003). As processing any subject-verb dependency, the cues available at retrieval may fail to elicit the dependent constituent some proportion of the time. Our focus is the contribution of diagnostic retrieval cues to recovery from misanalysis, both the probability that diagnostic cues can aid recovery and affect the timecourse of such a process via number of parsing attempts. While the notion of “reanalysis” stems from observed differences in reaction times (i.e. most commonly, differences in the amount of time a word or phrase is fixated during reading or in the latency of a button-press self-paced reading), as we outlined previously, such reaction time effects can also stem from differences in representation strength or quality, leading to a different internal criterion during the decision process to make the response (Davidson & Martin, Citation2013; Luce, Citation1986; Wickelgren, Citation1977). In this way, differences in representational aspects or states can engender differences that are sometimes interpreted as differences in processing timecourse. In order to compare the relative contributions of representational factors during syntactic ambiguity resolution, as touted by representational difference accounts, with processing time factors, as espoused by processing time difference accounts, we will employ the speed-accuracy tradeoff procedure (SAT). The SAT procedure models processing speed orthogonally from accuracy, thus enabling the detection of differences in representational quality while at the same time veridically estimating processing speed.
Though the nature of retrieval cues used during sentence comprehension is still an open question, some evidence suggests that for subject-verb dependencies in English, the “semantic fit” of the verb to a subject affects retrieval success and parsing choices (Christianson, Hollingworth, Halliwell, & Ferreira, Citation2001; McElree & Griffith, Citation1995; Tabor et al., Citation2004; Taraban & McClelland, Citation1988; Thornton & MacDonald, Citation2003; Trueswell et al., Citation1994; Van Dyke & McElree, Citation2011). For this reason, we ask whether the verb-semantics-based fit or match between a verb and its subject versus other nouns in the sentence, especially more recent nouns given the MV/RR ambiguity, affects the likelihood or incidence of reanalysis. For example, the verb sparkle is associated with the noun jewelry. Moreover, to sparkle is something that both actresses and jewelry can do. Consider the contrast between the sentences The actress sent the jewelry sparkled and The actress sent the jewelry frowned (see and the Appendix). The semantic fit between the local noun jewelry and the verb sparkled is stronger than between jewelry and frowned. In order to quantify this difference in fit, semantic similarity values were calculated for the disambiguating verbs relative to each noun (the true subject and the local noun) using Latent Semantic Analysis (LSA, Landauer & Dumais, Citation1997; available on the Internet at http://lsa.colorado.edu). We attempted to parameterise the match between verb and target relative to local noun by selecting verb-noun combinations that yielded reliable mean differences between nouns by condition using the one-to-many comparison function- we entered each final verb and computed its relation to both nouns in the sentence and then took the difference between these values (see the Methods and Results sections and ). Lastly, we included verbs with thematic requirements the recent noun cannot meet, such as frowned in the case of jewelry.
Table 1. Example of materials.
Table 2. Mean LSA values (standard error) by condition and noun.
One possibility is that diagnostic cues decrease the likelihood that an ambiguous sentence must be reanalysed because on more trials, the correct representation is successfully elicited from memory. If this were the case, then more diagnostic cues might decrease the time it takes to resolve the dependency (NB: retrieval speed is assumed to be constant), as reanalysis occurs less frequently. A second possibility is that less diagnostic cues do not affect the timecourse or number of reanalysis attempts, but do affect the likelihood that the dependency will be successfully resolved at all (i.e. accuracy), therefore only affecting the success of interpretation, but not its timecourse. A third possibility is of course that cue diagnosticity affects both the time it takes to process the dependency and the likelihood that it will be successfully resolved. An analogue of these predictions could also come from the representational difference versus processing time difference categories of accounts, namely, since SAT will measure the degree to which both likelihood of interpretation and processing time are affected by ambiguity. On our interpretation of the literature, Representational difference accounts would claim that reaction time differences arise due to differences in the representations formed under ambiguity or from competition between structural analyses at the point of disambiguation. In SAT, such accounts would then predict that ambiguity should affect asymptotic accuracy, the estimate of the likelihood of successful retrieval and interpretation. Such accounts predict a difference in SAT asymptote parameters – that is, asymptotic differences should be observed with or without a dynamics parameters differences (i.e. estimates of processing speed). In contrast, so-called processing time accounts predict that ambiguous sentences should result in differences in the SAT function’s dynamics parameters (intercept (δ) and rate (β)). However, neither category of account based on reaction time data can make definitive predictions about diagnosticity’s effect either on the likelihood of successful interpretation or on SAT dynamics, because these are necessarily conflated in reaction time measures. Tabor et al. (Citation2004) present a dynamical parsing account that arguably might predict that local match between noun and verb (the Local-match condition), a form of local coherence, would form a parse where jewelry is the subject of sparkled. It is unclear whether such an interpretation would impact a participant’s perception of acceptability or not, nor what the consequences for the timecourse of processing would be. Similarly, while cue-based accounts clearly predict that more diagnostic verbs should increase the likelihood of successful interpretation, they are not explicit about whether reanalysis effects in reaction time data stem from poorer representational quality or insufficient cue strength, or from additional parsing attempts at the point of disambiguation. It is an empirical question as to whether cue diagnosticity interacts with ambiguity resolution when disambiguation occurs. One possibility is that when there is uncertainty about syntactic structure or structural relationships, cue match between semantic features of nouns and verbs influences interpretation more such that diagnosticity effects are larger when ambiguity must be resolved. Another possibility is that ambiguity depresses any contribution of retrieval cues at the point of disambiguation (in this case, semantic features) because the syntactic cues are so uncertain or insufficient, a sort of syntactic bottleneck. In other words, the syntactic retrieval cues are not contributing to retrieval of the subject noun. Both of these outcomes would be expressed in an interaction between diagnosticity and ambiguity as factors.
To test these hypotheses, we employed the multiple response variant of SAT, where participants are probed for an acceptability judgment at multiple points in processing (Foraker & McElree, Citation2007; Martin & McElree, Citation2008, Citation2009, Citation2011; Van Dyke & McElree, Citation2011). The primary benefits of SAT are that speed and accuracy of processing are measured conjointly within a single task and that SAT forces participants to fully resolve ambiguity in order to make the judgment. SAT will allow us to discern whether longer reaction times found in the literature stem from true differences in timecourse or purely representational differences, or both. SAT accomplishes this by probing accuracy of interpretation at multiple times in relation to critical word (CW) onset, starting, crucially, just before (−300 msec) the CW onset. Then, a speed-accuracy function can be derived and fit to the points of empirical performance or accuracy at each lag latency (response tone time or lag + participant’s response time to tone or latency). The crucial point is that the choice to respond is “taken away” from the participant, who must respond (within 200 msec) to the response tones, which have been set at lags that are determined by the experimenter. For each sampled time point (lag + latency), a d′ measure of accuracy is constructed by scaling correct responses to grammatical expressions (hits) against incorrect responses to control expressions with ungrammatical interpretations (false alarms). This scaling provided a measure of the ability of participants to discriminate acceptable from unacceptable interpretations of temporarily ambiguous sentences. SAT functions typically show a period of chance performance (d′ = 0), a period of increasing accuracy, and an asymptotic period where further processing does not improve performance (see ). Each participant’s data were fit with an exponential function, quantifying how interpretation unfolded over time and allowing estimation of processing speed:(1)
(1) The parameter λ, which estimates the asymptote of the function, measures the highest level of discrimination reached with maximal processing time, and hence yields a basic measure of processing accuracy. Here, asymptotes index how successful participants were at retrieving subject for the final verb, interpreting it, and converging upon a grammatical structural interpretation for the whole sentence. Increasing semantic fit with a recent noun may lower accuracy if it decreases diagnosticity between subject and verb in memory, making the subject less likely to be retrieved from memory.
Figure 1. Hypothetical SAT functions illustrating two conditions differing in asymptote (Panel A) or rate (Panel B). The intersection of the horizontal and vertical lines shows the point in time (abscissa) when the functions reach two-thirds of their respective asymptote (ordinate). When dynamics are proportional (Panel A), the functions reach the two-thirds point at the same time.
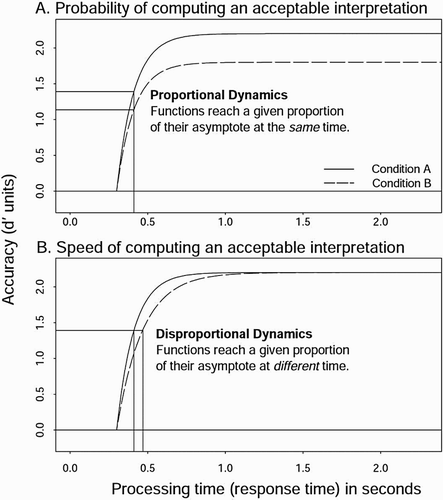
The function’s intercept (δ) and rate (β) provide joint measures of processing speed, indexing how quickly accuracy accrues to its asymptotic level. The parameter δ estimates the intercept, or the point where participants are first sensitive to the information necessary to discriminate acceptable from unacceptable (i.e. d′ departs from 0, chance performance). The parameter β estimates the rate that accuracy grows from chance to asymptote. Decreasing how diagnostic a verb is to a unique subject in memory may slow the dynamics of the SAT function if, on some proportion of trials, the structure of the sentence must be revised or reanalysed more often, and diagnosticity in turn affects the number of reanalysis attempts needed to read an acceptable interpretation. Alternatively, ambiguity alone may slow the dynamics of the SAT function, as more parsing attempts result in increased processing time.
Because the speed-accuracy tradeoff procedure focuses on modelling individual speed-accuracy tradeoff functions and each participant’s response bias via d′, SAT studies require a high number of observations per participant, rather than a low number of observations across many participants as in more common in reaction time measurement studies (e.g. self-paced reading and eye-tracking). Each participant’s data is analyzed separately, and the then parameter estimates across participants are evaluated in order to make inferences about falsification. The number of participants has ranged from 4 in single-response studies where tens of thousands trials per participant were collected (e.g. McElree & Dosher, Citation1989, Citation1993) to between 12 and 22 for multiple-response SAT where thousands of trials are collected per participant with multiple observations at different time points in a single trial (e.g. Foraker & McElree, Citation2007; Martin & McElree, Citation2008, Citation2009, Citation2011; McElree et al., Citation2003; Van Dyke & McElree, Citation2011).
Methods
Participants
Fifteen native speakers of American English (age range 18–26) from the New York University community were paid to participate in eight 60-minute sessions, and a 45-minute practice session.
Materials
Thirty-four sets of 8 sentences as illustrated in featured sentences with the MV/RR ambiguity, unambiguous controls, and crossed with how “diagnostic” a verb is to its subject in relation to other nouns in memory, according to semantic similarity as reflected by LSA on the subject of the dependency. The Local noun-related verb conditions (see for an example) contained a disambiguating verb that was more similar to the local noun, e.g. jewelry than to the matrix subject noun, e.g. actress. This manipulation was meant to decrease the diagnostic match to the true subject actress compared to the local noun, and accomplished this by being both closer in the sentence and more similar to jewelry. The Neutral verb condition consisted of a verb that produced similar LSA values for both nouns (actress and jewelry), and that could combine with both nouns (see ). A repeated measures analysis of variance (rmANOVA) on the LSA values for each noun by Condition showed an interaction between Condition and noun, F2 (2, 66) = 12.39, p < .001). Pairwise comparisons revealed that within the Local noun-related verb condition, the LSA values for each noun given the verb differed reliably from each other such that the Local noun had a higher similarity value given the verb than the Subject noun did (see ). Crucially, this pattern was reversed for the Subject-related verb condition, such that the Subject noun yielded a higher LSA value given the verb than the Local noun did, and in the Neutral verb condition, the nouns’ LSA values did not differ from each other (see ). The Subject-related verb condition used verbs that not only yielded higher LSA values with the true subject actress, but for which the recent noun jewelry would not be a plausible or grammatical subject. That is, actresses and jewelry can both sparkle and arrive, but only actresses can frown. For each triplet of Ambiguous and Unambiguous sentences, we created a matching unacceptable condition, (7) and (8) in , by making the sentence-final verb incompatible with the matrix subject, which created an unacceptable interpretation when the dependency is interpreted (e.g. *the actress clipped). The unacceptable condition was designed to encourage participants to fully process the subject-verb dependency. To discriminate acceptable from unacceptable sentences, participants would have to process the dependency at least to the point where they had retrieved the subject and interpreted it with the local verb. Please see the Appendix for a full list of experimental stimuli and filler items.
Participants saw a total of 2576 sentence stimuli over 8 one-hour sessions, with 17 observations per trial for a total of 4,624 data points per participant. The sentence stimuli were as follows: There were 9 sub-experiments in the 9 sessions (8 experimental sessions with 322 stimuli, 34 from this study and 288 from other studies, plus a 45-minute practice session to familiarise the participants with the button-pressing part of the task). This resulted in ∼33% of the stimuli having a relative clause, where 16.4% was a full relative clause and 16.4% was reduced. There were a total of 1220 unacceptable stimuli, or 47.3% of the total stimuli. Of those violations, 41% stemmed from violation of the requirements of a verb in the sentence. Please see the Appendix for a more detailed description of the sub-experiments which composed the 10 session experiment. We note that our percentage of ∼33% relative clauses (RCs) is similar to or lower than the percentage often presented in the literature (e.g. Ferreira & Henderson, Citation1991 – 50% RCs; Grodner & Gibson, Citation2005– Exp 1: 35% RCs, Exp2: 50% RCs; Hemforth et al., Citation2015– 50% RCs; Traxler et al., Citation2002– Exps: ∼26.67% RCs).
Procedure
In eight experimental sessions, participants read 34 experimental sentences and 288 fillers for a total of 322 trials. There was one practice session to familiarise participants with the task. Participants saw every item in every condition, but at different points across the eight sessions. Participants completed no more than one session per day, on average completing all 9 sessions of the experiment in 10 days. Conditions were counterbalanced across sessions such that participants saw an equal number of items in each condition in each session, though the item used to represent that condition varied. Critical trials, including controls, constituted approximately 10% of each session, and were presented randomly among the remaining 90% fillers (please see Appendix). Sentences were presented phrase-by-phrase, 335 ms per word. Crucially, a 50 ms, 1000 Hz tone cued the first response 300 ms before the CW. This pre-CW response tone served to cue the participant to begin responding before they have perceived or fully processed the CW, in order to render their first response a guess and thus measure the full timecourse of processing. After CW onset, 16 more response signals occurred, 350 ms apart, while the CW remained on the screen, for a total of 17 response signals. In the practice session, participants were trained to synchronise their button presses to the response tone, responding maximally within 200 ms of each tone. They were instructed to simultaneously press both the “yes” and “no” keys as an initial (undecided) response, and then to select, and continue to press, only one of the two keys (with “yes” indicating a judgment that the sentence was acceptable, and “no” indicating that the sentence had been judged unacceptable) as soon as they decided whether they found the sentence acceptable or not.
Data analysis
Accuracy was calculated using a standard d′ measure, d′ = z(hits) – z(false alarms), where a “hit” was an “acceptable” response to an acceptable sentence and a “false alarm” was an “acceptable” response to an unacceptable sentence. The d′ scores provide a measure of the participant’s ability to discriminate acceptable from unacceptable, uncontaminated by response bias. We scaled the acceptable conditions against one unacceptable condition for Ambiguous, and another for Unambiguous.
A hierarchical model-testing scheme was used to determine whether conditions differed in asymptote (λ), rate (β), or intercept (δ) in Equation (1), constrained by reliable differences in empirical d′. Exponential model fits of the data ranged from a null model in which all functions were fit with a single asymptote, rate, and intercept parameter (a 1λ-1β-1δ fit) to a fully saturated (a 6λ-6β-6δ fit) model in which each condition was fit with a unique asymptote, rate, and intercept. For each participant and the averaged data, separate parameters were allotted to the different conditions if they systematically improved the fit of the SAT function to the observed d′ data and the estimates were reliably different from one another over participants. Equation (1) was fit to the data with an iterative hill-climbing algorithm, which minimised the squared deviations of predicted values from observed data. Fit quality was assessed by an evaluation of the consistency of the parameter patterns across the individual participant fits. Model selection occurred via the performance inferential tests of significance computed over individual participants’ d′ data, used to constrain the model selected, and tests on the fitted parameter estimates for each of the candidate models, detailed in the Results section. In , we report 95% confidence intervals (CIs) around the mean difference for paired comparisons of interest. We then confirmed that the best fitting model from the above procedure also had the best adjusted-R2 statistic – the proportion of variance accounted for by the fit, adjusted by the number of free parameters (Judd & McClelland, Citation1989).
Results
presents the average (across participants) d′ values as a function of processing time, along with the best-fitting exponential model described below. presents the Ambiguous and Unambiguous conditions separately for visual illustrative clarity. Parameter values of the best-fitting models can be seen in . Inspection of and illustrates that Ambiguous conditions were less accurately processed than Unambiguous ones, and that less diagnostic cues resulted in lower accuracy than more diagnostic cues.
Figure 2. Average d′ accuracy (symbols) as a function of processing time (lag of the interruption cue plus latency to response) for Ambiguous and Unambiguous conditions from Experiment 1. Smooth curves show the best-fitting exponential fit (see text).
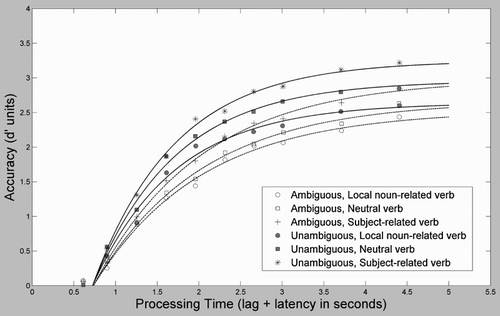
Figure 3. Average d′ accuracy (symbols) as a function of processing time (lag of the interruption cue plus latency to response) for Ambiguous conditions (Top Panel) and Unambiguous conditions (Bottom Panel) from Experiment 1. Smooth curves show the best-fitting exponential fit (see text).
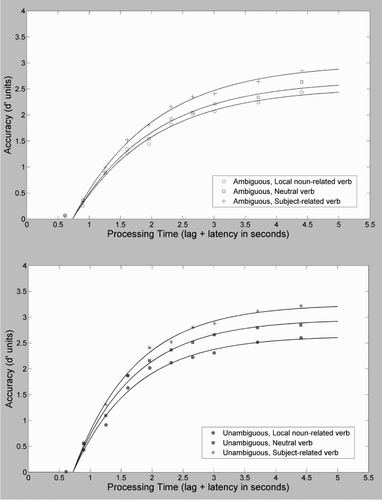
Table 3. Empirical d′ and parameter estimates issuing from best-fitting models.
Empirical d′ results
As an initial means of determining whether there were reliable differences in asymptotic performance as a function of Ambiguity and the relative relation between verb and nouns, or Diagnosticity, we averaged the d′ values for each participant (and, for an item analysis, by each item) in each condition from 4.2 to 5 s post-initial response cue in order to derive an empirical estimate of asymptotic accuracy. An rmANOVA on these values for the conditions revealed a marginal main effect of Ambiguity, F1 (1,14) = 2.96, p < .11, F2 (1, 33) = 31.79, p < .001, and a reliable main effect of Diagnosticity, F1 (2,28) = 23.4, p < .001, F2 (2, 66) = 5.28, p < .01. There was a marginal interaction between Ambiguity and Diagnosticity, F1 (2,28) = 2.96, p < .07, F2 (2, 66) = .78, p < .47.Footnote1
Pairwise comparisons showed that all levels of the Diagnosticity factor differed reliably from each other for both Ambiguous and Unambiguous conditions (see ). This pattern is consistent with the notion that how diagnostic a cue is shapes retrieval regardless of ambiguity; there is a subject-verb dependency that must be formed via retrieving the subject, in all conditions. Subject-related verbs resulted in higher accuracy than Neutral verbs, which in turn resulted in higher accuracy than Local noun-related verbs.
Table 4. Mean differences of interest with pairwise comparisons of empirical d′.
Model fits
Competitive fits of the exponential equation to the empirical data also yielded clear evidence that Ambiguous and Unambiguous conditions differed in processing speed, as well as in asymptotic accuracy: Models that did not allocate separate rate parameters asymptotes for the Ambiguous versus Unambiguous conditions produced poor fits to the empirical SAT data, and they left systematic residuals.
Models: null 1λ-1β-1δ to fully saturated asymptote model 6λ-1β-1δ
In fits of the average data, allocating separate asymptotes to each condition increased the adjusted-R2 from .9722, observed with a null 1λ-1β-1δ model to .9917 with a 6λ-1β-1δ model. This model improved the quality of the fits of the individual participants’ data, systematically increasing the adjusted-R2 values over what was observed with a 1λ-1β-1δ model (ranging from .8316 to .9688 as compared to .7602 to .9557). In fits of the average data, allocating separate rates to Ambiguous and Unambiguous conditions increased the adjusted-R2 from .9917, observed with a null 6λ-1β-1δ model to .9951 with a 6λ-2β-1δ model. This model improved the quality of the fits of the individual participants’ data, systematically increasing the adjusted-R2 values over what was observed with a 6λ-1β-1δ model (ranging from .667 to .961 as compared to .8316 to .9688).
Separate model fits for ambiguous and unambiguous conditions
This pattern was also evident when the Ambiguous and Unambiguous conditions were fit separately, as evidenced by the estimates from the two 3λ-1β-1δ models (see ). Per the results of the pairwise comparisons of empirical d′, we constructed a 4λ-2β-1δ model where Ambiguous and Unambiguous conditions are fit together, but with four asymptotes approximating the reliable differences in empirical d′. In fits of the average data, the adjusted-R2 increased to .9939 as compared to .9710 for a 4λ-1β-1δ model. Over participants, the adjusted-R2 ranged from .8357 to .9658, increased from .7801 to .9590 in a 4λ-1β-1δ model, showing a systematic improvement of the fit over participants. We performed paired t-test on the asymptote parameter estimates for the four levels of d′ to confirm that the estimates differed reliably from each other over participants.
Model fits with variable dynamics parameters
We implemented model of the asymptotes to construct a strong test of the rate difference posited by the 6λ-2β-1δ model. The rate parameters allotted to the Ambiguous and Unambiguous conditions remained reliably different from one another in both cases (paired t-tests on rate (β) estimates from 6λ-2β-1δ, t = 2.65, p = .05; 4λ-2β-1δ t = 2.70, p = .05; between separately fit by Ambiguity 3λ-1β-1δ models t = 2.43, p = .05; see ). In sum, the models we evaluated all yielded better fits of the empirical data when separate rate parameters were allotted to Ambiguous and Unambiguous conditions (2β-1δ models). The most conservative estimate of the difference in processing speed observed is 250 msec from the 6λ-2β-1δ model (see for a comparison of rate (β) over model fits), while the 4λ-2β-1δ model yielded an estimate of 455 msec. The 6λ-2β-1δ model is most conservative because it allows some of the variance to be captured by six different asymptotic parameters, rather than forcing that variance on the rate parameter as in 4λ-2β-1δ.
Discussion
There was a main effect of Diagnosticity on empirical d′ such that lower diagnosticity resulted in lower likelihood of successful interpretation, regardless of Ambiguity. In the best fitting models (separately fit 3λ-1β-1δ’s, 6λ-2β-1δ, 4λ-2β-1δ), the differences in asymptote parameter estimates indicated that subjects of Local noun-related verbs and Neutral verbs were less likely to be successfully retrieved and interpreted than those of Subject-related verbs. Model fits revealed that Ambiguity affected the speed of processing the dependency, with difference in rate (β). Allocating separate rate or intercept parameters to different conditions improved adjusted-R2. Importantly, there were no consistent trends across participants intercept parameters when they were allowed to vary (e.g. models with dynamics parameters such as 1β-2δ, 2β-2δ, and various 1β-4δ and 2β-4δ models) and crucially t-tests on the intercept parameter (δ) estimates were not significant. Hence, there was evidence to suggest that ambiguity affected processing speed and that this effect was expressed on the SAT rate parameter (β) or on the order of a 250–450 msec slowdown in processing time, but, there was no evidence that diagnostic cues affected the SAT function’s dynamics parameters. In trends on empirical d′, the marginal main effect of Ambiguity and the marginal interaction between Ambiguity and Diagnosticity suggested that ambiguity also tended to decrease likelihood of successful interpretation. We will not focus on interpreting these trends further as they are not reliable. We will also refrain from interpreting the lack of evidence for any interaction of variables.
General discussion
Diagnostic cues affected the likelihood that the dependent noun can be recovered from memory, regardless of ambiguity. Higher diagnosticity raised asymptotic accuracy, but did not affect the speed with which the dependent representation was accessed and interpreted. This suggests that lower diagnosticity results in lower likelihood of successful interpretation regardless of ambiguity, but there was no evidence to suggest that the number of reanalysis attempts or the time it takes to reanalyse is affected by diagnosticity. Although we do not interpret the lack of evidence of an effect as evidence of a lack of an effect, we note that a main effect of diagnosticity on accuracy, but not on processing speed, is incompatible with the strongest interpretation of representational difference accounts where representational factors (context, lexical features or statistics, parse frequency or probability) affect processing time. This finding is, however, consistent with the notion that representational differences partly underlie the differences observed in reaction time studies – namely, that cue strength or diagnosticity determines successful interpretation. This conclusion echoes those of Van Dyke and Lewis (Citation2003), wherein cues initiate structural dependencies and any changes to them, and no separate or additional repair or reanalysis mechanism needs to be postulated.
The timecourse profile is consistent with reaction time findings in that Ambiguous sentences took, as a conservative estimate, on average 250 msec longer to process then Unambiguous ones, with the less conservative estimate being 450 msec longer. By itself, this advantage for unambiguous sentences is not surprising – it confirms findings from a myriad of reaction time studies. However, that we find these effects in the rate of the SAT function does offer the first veridical timecourse evidence that reanalysis does indeed require additional processing time, and that the reaction time differences found in the literature do not simply result from differences in representation strength (Davidson & Martin, Citation2013; McElree, Citation2006; Wickelgren, Citation1977). This pattern of results is consistent with the predictions of processing time difference class of accounts, wherein longer latencies during syntactic ambiguity resolution are due to increased processing time (and not only due to representational factors). However, we do not interpret longer processing time as necessarily reflecting either repair to previously processed structures (so-called repair-based reanalysis) or a reanalysis situation with repair (e.g. additional retrieval attempts or starting processing over “from the beginning”). This is because the rate difference itself cannot distinguish between a repair account and other possibilities that would also slow processing time, for example, repeated or multiple cue-based parsing attempts. One advantage of the multiple retrieval attempts interpretation is that it can account for this pattern of results without the postulation of a specialised reanalysis mechanism or process (see Martin, Citation2016; Van Dyke & Lewis, Citation2003 for a unitary process model).
Although it is difficult to discriminate between a case where the retrieval and interpretation in ambiguous sentences takes longer (increase in process duration) and a case where it is attempted more times (increase in process attempts), differences in the rate parameter of the SAT function have been found when more than one gap must be filled and when syntactic structure must be revised (Bornkessel, McElree, Schlesewsky, & Friederici, Citation2004; McElree et al., Citation2003), indicating that additional processes or instances of retrieval attempts affect of the rate of the SAT function. It also seems unlikely that the rate difference observed is due to differences in retrieval speed, given the growing body of evidence for a speed-invariant direct-access retrieval mechanism underlying sentence comprehension (see McElree, Citation2006). The interpretation of this rate difference as ambiguity requiring additional attempts to retrieve a subject and interpret it at the dependency, or reanalysis, is consistent with the processing situations which have led to the few SAT dynamics parameter results in the literature (Bornkessel et al., Citation2004; McElree et al., Citation2003; McElree, Pylkkänen, Pickering, & Traxler, Citation2006). This processing cost is expressed in the veridical estimates of timecourse available via the SAT procedure, and therefore does not seem to stem from representational differences alone, as could have been the case when reasoning from reaction times alone (Davidson & Martin, Citation2013). We interpret our results as offering evidence in support of different aspects of representational difference accounts, including cue-based accounts, as well as aspects of processing time difference accounts. That Diagnosticity raised the likelihood of successful interpretation regardless of ambiguity suggests that relative cue-match or diagnosticity, at least along the dimension of verb semantics, is always facilitatory to processing. But there was no evidence that it was more facilitatory when syntactic cues were ambiguous. The latter finding that veridical estimates of processing speed were slower under ambiguity confirms aspects of processing time difference accounts in as much as it can be taken as evidence for multiple parsing attempts. These hybrid conclusions, and the ability to detect evidence for both representational and processing differences, highlight the potential value of appealing to notions from cue-based retrieval theory, or at least, the value of supposing how constructs supported by convergent evidence from other areas of cognitive psychology might account for or illuminate classic sentence processing phenomena.
PLCP_A_1427877_Supplemental_Materials.zip
Download Zip (27.5 KB)Acknowledgements
We thank Kathy Akey and Lisbeth Dyer for assistance with data collection. We are grateful to Janet Dean Fodor and Mante S. Nieuwland for comments on an earlier version of this work. All errors remain our own. This research was supported by a National Institutes of Health grant [R01-HD056200] awarded to BM. AEM was supported by a National Science Foundation Graduate Research Fellowship [2006025605], a Juan de la Cierva Fellowship from the Spanish Ministry of Science and Innovation [JCI-2011-10228], and a Future Research Leaders grant from the Economic and Social Research Council of the United Kingdom [ES/K009095/1].
Disclosure Statement
No potential conflict of interest was reported by the authors.
ORCID
Andrea E. Martin http://orcid.org/0000-0002-3395-7234
Additional information
Funding
Notes
1. If the conditions are reduced to perform a 2 (Ambiguity: Ambiguous, Unambiguous) × 2(Diagnosticity: Local noun-related verb, Subject-related verb) rmANOVA, we find a marginal main effect of Ambiguity and a main effect of Diagnosticity, F1 (1,14) = 3.18, p < .10, F2 (1, 33) = 22.14, p < .001 for Ambiguity and F1 (2,28) = 50.59, p < .001, F2 (2, 66) = 12.28, p < .01 for Diagnosticity, respectively. The interaction between Ambiguity and Diagnosticity becomes significant by participants, F1 (2,28) = 6.37, p < .05, F2 (2, 66) = 1.20, p < .28.
Related Research Data
References
- Altmann, G. T., Garnham, A., & Dennis, Y. (1992). Avoiding the garden path: Eye movements in context. Journal of Memory and Language, 31(5), 685–712. doi: 10.1016/0749-596X(92)90035-V
- Altmann, G. T. M., & Steedman, M. (1988). Interaction with context during human sentence processing. Cognition, 30, 191–238. doi: 10.1016/0010-0277(88)90020-0
- Altmann, G. T., van Nice, K. Y., Garnham, A., & Henstra, J. A. (1998). Late closure in context. Journal of Memory and Language, 38(4), 459–484. doi: 10.1006/jmla.1997.2562
- Bever, T. G. (1970). The cognitive basis for linguistic structures. In J. R. Hayes (Ed.), Cognition and the development of language (pp. 279–362). New York: Wiley.
- Bornkessel, I., McElree, B., Schlesewsky, M., & Friederici, A. D. (2004). Multi-dimensional contributions to garden path strength: Dissociating phrase structure from case marking. Journal of Memory and Language, 51, 495–522. doi: 10.1016/j.jml.2004.06.011
- Christianson, K., Hollingworth, A., Halliwell, J. F., & Ferreira, F. (2001). Thematic roles assigned along the garden path linger. Cognitive Psychology, 42(4), 368–407. doi: 10.1006/cogp.2001.0752
- Clark, S. E., & Gronlund, S. D. (1996). Global matching models of recognition memory: How the models match the data. Psychonomic Bulletin & Review, 3, 37–60. doi: 10.3758/BF03210740
- Davidson, D. J., & Martin, A. E. (2013). Modeling accuracy as a function of response time with the generalized linear mixed effects model. Acta Psychologica, 144(1), 83–96. doi: 10.1016/j.actpsy.2013.04.016
- Dosher, B. A., & McElree, B. (2003). Memory search: Retrieval processes in short-term and long-term recognition. In J. H. Byrne (Ed.), Learning & memory (pp. 373–379). New York: Gale Group.
- Ferreira, F., & Clifton, C. E. (1986). The independence of syntactic processing. Journal of Memory and Language, 25, 348–368. doi: 10.1016/0749-596X(86)90006-9
- Ferreira, F., & Henderson, J. M. (1991). Recovery from misanalyses of garden-path sentences. Journal of Memory and Language, 30(6), 725–745. doi: 10.1016/0749-596X(91)90034-H
- Fodor, J. D., & Ferreira, F. (1998). Sentence Reanalysis. Dordrecht: Kluwer Academic.
- Foraker, S., & McElree, B. (2007). The role of prominence in pronoun resolution: Active versus passive representations. Journal of Memory and Language, 56, 357–383. doi: 10.1016/j.jml.2006.07.004
- Frazier, L., & Fodor, J. D. (1978). The sausage machine: A new two-stage parsing model. Cognition, 6(4), 291–325. doi: 10.1016/0010-0277(78)90002-1
- Frazier, L., & Rayner, K. (1982). Making and correcting errors during sentence comprehension: Eye movements in the analysis of structurally ambiguous sentences. Cognitive Psychology, 14, 178–210. doi: 10.1016/0010-0285(82)90008-1
- Grodner, D., & Gibson, E. (2005). Consequences of the serial nature of linguistic input for sentenial complexity. Cognitive Science, 29(2), 261–290. doi: 10.1207/s15516709cog0000_7
- Grodner, D., Gibson, E., Argaman, V., & Babyonyshev, M. (2003). Against repair-based reanalysis in sentence comprehension. Journal of Psycholinguistic Research, 32(2), 141–166. doi: 10.1023/A:1022496223965
- Hemforth, B., Fernandez, S., Clifton, C., Frazier, L., Konieczny, L., & Walter, M. (2015). Relative clause attachment in German, English, Spanish and French: Effects of position and length. Lingua, 166, 43–64. doi: 10.1016/j.lingua.2015.08.010
- Judd, C. M., & McClelland, G. H. (1989). Data analysis: A model comparison approach. San Diego: Harcourt Brace Jovanovich.
- Kohonen, T. (1984). Self-Organization and associative memory. Berlin: Springer.
- Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104, 211–240. doi: 10.1037/0033-295X.104.2.211
- Lau, E. F., & Ferreira, F. (2005). Lingering effects of disfluent material on the comprehension of garden path sentences. Language and Cognitive Processes, 20, 633–666. doi: 10.1080/01690960444000142
- Lewis, R. L., & Vasishth, S. (2005). An activation based model of sentence processing as skilled memory retrieval. Cognitive Science, 29(3), 375–419. doi: 10.1207/s15516709cog0000_25
- Lewis, R. L., Vasishth, S., & Van Dyke, J. A. (2006). Computational principles of working memory in sentence comprehension. Trends in Cognitive Sciences, 10(10), 447–454. doi: 10.1016/j.tics.2006.08.007
- Luce, R. D. (1986). Response times: Their role in inferring elementary mental organization (No. 8). New York: Oxford University Press.
- MacDonald, M. C., Pearlmutter, N. J., & Seidenberg, M. S. (1994). The lexical nature of syntactic ambiguity resolution. Psychological Review, 101, 676–703. doi: 10.1037/0033-295X.101.4.676
- Macmillan, N. A., & Creelman, C. D. (2005). Detection theory: A user’s guide. New York: Psychology Press.
- Martin, A. E. (2016). Language processing as cue integration: Grounding the psychology of language in perception and neurophysiology. Frontiers in Psychology: Language Sciences, 7, 120.
- Martin, A. E., & McElree, B. (2008). A content-addressable pointer mechanism underlies comprehension of verb-phrase ellipsis. Journal of Memory and Language, 58, 879–906. doi: 10.1016/j.jml.2007.06.010
- Martin, A. E., & McElree, B. (2009). Memory operations that support language comprehension: Evidence from verb-phrase ellipsis. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 1231–1239.
- Martin, A. E., & McElree, B. (2011). Direct-access retrieval during sentence comprehension: Evidence from sluicing. Journal of Memory and Language, 64, 327–343. doi: 10.1016/j.jml.2010.12.006
- Martin, A. E., Nieuwland, M. S., & Carreiras, M. (2012). Event-related brain potentials index cue-based retrieval interference during sentence comprehension. NeuroImage, 59, 1859–1869. doi: 10.1016/j.neuroimage.2011.08.057
- Martin, A. E., Nieuwland, M. S., & Carreiras, M. (2014). Agreement attraction during comprehension of grammatical sentences: ERP evidence from ellipsis. Brain and Language, 135, 42–51. doi: 10.1016/j.bandl.2014.05.001
- McElree, B. (2000). Sentence comprehension is mediated by content-addressable memory structures. Journal of Psycholinguistic Research, 29, 111–123. doi: 10.1023/A:1005184709695
- McElree, B. (2006). Accessing recent events. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 46, pp. 155–200). San Diego: Academic Press.
- McElree, B., & Dosher, B. A. (1989). Serial position and set size in short-term memory: The time course of recognition. Journal of Experimental Psychology: General, 118(4), 346–373. doi: 10.1037/0096-3445.118.4.346
- McElree, B., & Dosher, B. A. (1993). Serial retrieval processes in the recovery of order information. Journal of Experimental Psychology: General, 122(3), 291. doi: 10.1037/0096-3445.122.3.291
- McElree, B., Foraker, S., & Dyer, L. (2003). Memory structures that subserve sentence comprehension. Journal of Memory and Language, 48, 67–91. doi: 10.1016/S0749-596X(02)00515-6
- McElree, B., & Griffith, T. (1995). Syntactic and thematic processing in sentence comprehension: Evidence for a temporal dissociation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 134–157.
- McElree, B., Pylkkänen, L., Pickering, M. J., & Traxler, M. (2006). A time course analysis of enriched composition. Psychonomic Bulletin & Review, 13, 53–59. doi: 10.3758/BF03193812
- Nairne, J. S. (2002). The myth of the encoding-retrieval match. Memory, 10, 389–395. doi: 10.1080/09658210244000216
- Pachella, R. G., & Pew, R. W. (1968). Speed-Accuracy Tradeoff in Reaction Time: Effect of Discrete Criterion Times. Journal of Experimental Psychology, 76(1p1), 19. doi: 10.1037/h0021275
- Schouten, J. F., & Bekker, J. A. M. (1967). Reaction time and accuracy. Acta Psychologica, 27, 143–153. doi: 10.1016/0001-6918(67)90054-6
- Sturt, P. (2007). Semantic re-interpretation and garden path recovery. Cognition, 105, 477–488. doi: 10.1016/j.cognition.2006.10.009
- Sturt, P., Pickering, M. J., & Crocker, M. W. (1999). Structural change and reanalysis difficulty in language comprehension. Journal of Memory and Language, 40(1), 136–150. doi: 10.1006/jmla.1998.2606
- Sturt, P., Scheepers, C., & Pickering, M. (2002). Syntactic ambiguity resolution after initial misanalysis: The role of recency. Journal of Memory and Language, 46, 371–390. doi: 10.1006/jmla.2001.2807
- Tabor, W., Galantucci, B., & Richardson, D. (2004). Effects of merely local syntactic coherence on sentence processing. Journal of Memory and Language, 50(4), 355–370. doi: 10.1016/j.jml.2004.01.001
- Taraban, R., & McClelland, J. L. (1988). Constituent attachment and thematic role assignment in sentence processing: Influences of content-based expectations. Journal of Memory and Language, 27(6), 597–632. doi: 10.1016/0749-596X(88)90011-3
- Thornton, R., & MacDonald, M. C. (2003). Plausibility and grammatical agreement. Journal of Memory and Language, 48(4), 740–759. doi: 10.1016/S0749-596X(03)00003-2
- Traxler, M. J., Morris, R. K., & Seely, R. E. (2002). Processing subject and object relative clauses: Evidence from eyemovements. Journal of Memory and Language, 47(1), 69–90. doi: 10.1006/jmla.2001.2836
- Trueswell, J. C., Tanenhaus, M. K., & Garnsey, S. M. (1994). Semantic influences on parsing: Use of thematic role information in syntactic ambiguity resolution. Journal of Memory and Language, 33, 285–318. doi: 10.1006/jmla.1994.1014
- Van Dyke, J. A., & Lewis, R. L. (2003). Distinguishing effects of structure and decay on attachment and repair: A cue-based parsing account of recovery from misanalyzed ambiguities. Journal of Memory and Language, 49(3), 285–316. doi: 10.1016/S0749-596X(03)00081-0
- Van Dyke, J. A., & McElree, B. (2006). Retrieval interference in sentence comprehension. Journal of Memory and Language, 55(2), 157–166. doi: 10.1016/j.jml.2006.03.007
- Van Dyke, J. A., & McElree, B. (2011). Cue-dependent interference in comprehension. Journal of Memory and Language, 65, 247–263. doi: 10.1016/j.jml.2011.05.002
- Van Gompel, R. P., Pickering, M. J., & Traxler, M. J. (2001). Reanalysis in sentence processing: Evidence against current constraint-based and two-stage models. Journal of Memory and Language, 45(2), 225–258. doi: 10.1006/jmla.2001.2773
- Watkins, O. C., & Watkins, M. J. (1975). Build-up of proactive inhibition as a cue overload effect. Journal of Experimental Psychology: Human Learning and Memory, 1, 442–452.
- Wickelgren, W. A. (1977). Speed-accuracy tradeoff and information processing dynamics. Acta Psychologica, 41, 67–85. doi: 10.1016/0001-6918(77)90012-9