
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Theories about word production differ in whether they assume that lexical selection involves modality-specific representations or modality-neutral ones, called lemmas. The observation that semantic errors in aphasia may be restricted to either speaking or writing has long been taken to challenge lemma models (Hillis et al., 1999; Kemmerer, 2015, 2019). Whereas patients RGB, HW, and RR make semantic errors in speaking but not in writing, patient RCM exhibits the opposite dissociation. Here, using WEAVER++ simulations and a simple mathematical analysis, a model with lemmas is shown to account for the double dissociation observed in patients. In particular, the model captures the patterns of performance of the patients on vocal picture naming, written picture naming, auditory word comprehension, and writing to dictation, explaining 98% of the variance. The challenge is now for modality-specific models to account for the findings that the lemma model was designed to explain in the first place.
Introduction
In conceptually driven word production in speaking and writing, like in naming a picture, meaning is mapped onto articulatory or manual movements, respectively. Investigators have found no agreement about whether lexical selection in word production involves modality-specific representations (e.g. Caramazza & Hillis, Citation1990) or modality-neutral ones, called lemmas (Levelt et al., Citation1999; Roelofs, Citation1992). According to several investigators, the view of modality-neutral lemmas is challenged by the observation that semantic errors in aphasia may be restricted to either speaking or writing (Caramazza & Miozzo, Citation1997; Hillis et al., Citation1999; Kemmerer, Citation2015, Citation2019), as observed for patients RGB, HW, and RR with errors limited to speaking and for RCM with errors limited to writing. For example, in naming a picture of a clam, RGB erroneously said “octopus” but correctly wrote “clam” (Caramazza & Hillis), whereas in naming a picture of an eagle, RCM correctly said “eagle” but incorrectly wrote “owl” (Hillis et al.). Hillis et al. stated:
“In fact, the production of semantic substitutions restricted to one modality of output (either speaking or writing) poses a serious challenge to models of lexical access that interpose a modality neutral lexical node (lemma) between the semantic system and the modality-specific lexical systems (see Caramazza, Citation1997, for detailed discussion).” (p. 348).
“Advocates of the Lemma Model could try to accommodate the data by postulating separate components for modality-specific phonological and orthographic lemmas, and arguing that difficulties with just spoken or just written word production arise from dysfunctions involving just one pathway (Roelofs et al., Citation1998). But this would be tantamount to abandoning one of the key claims of the theory, namely that lemmas are modality-neutral.” (p. 1105)
“In our view, however, substitution errors need not result from failures in lemma selection but may also result from failures of mapping lemmas onto modality-specific morphemic representations. Occasionally, access to the spoken form of a word from a lemma may be impossible while access to its written form is intact, or vice versa, access to the spoken form may be intact, while access to the written form is impossible. If form access fails, the speaker’s wish to communicate verbally may lead to a random selection of an alternative lemma from the semantic cohort established by the message concept and to subsequent access of the corresponding form (Levelt et al., Citation1991; Roelofs, Citation1992). Thus, substitution errors may differ between modalities and between trials, as empirically observed.” (p. 224)
The aim of the present article is to show, using computer simulation and mathematical analysis, that a model with lemmas accounts for the double dissociation between semantic errors in speaking and writing observed in patients. In the remainder of the introduction, I outline the lemma model account of the double dissociation and its simulation, and describe the patient data in somewhat more detail. Next, using a simple mathematical analysis, I demonstrate that the lemma model accounts for the data, contrary to what has been held in the literature (Hillis et al., Citation1999; Kemmerer, Citation2015, Citation2019). Finally, I outline some of the challenges for the modality-specific view on lexical selection in speaking and writing, which concern findings that the lemma model was designed to explain in the first place.
Accounting for the double dissociation
illustrates the lemma model account of the double dissociation, using the functional architecture of the WEAVER++ model of word production (e.g. Levelt et al., Citation1999; Roelofs, Citation1992). This model was originally designed to explain spoken word production. Thus, to account for the double dissociation, additional assumptions had to be made about written word production, as Roelofs et al. (Citation1998) did. I refer to Kemmerer (Citation2015) for a review of the cognitive neuroscience literature on writing. For an integration of vocal, manual, and executive processing in WEAVER++, I refer to Roelofs (Citation2007, Citation2008a).
Figure 1. Illustration of the lemma model account of lexical selection in speaking and writing using the theoretical framework of the WEAVER++ computational model (Levelt et al., Citation1999; Roelofs, Citation1992).
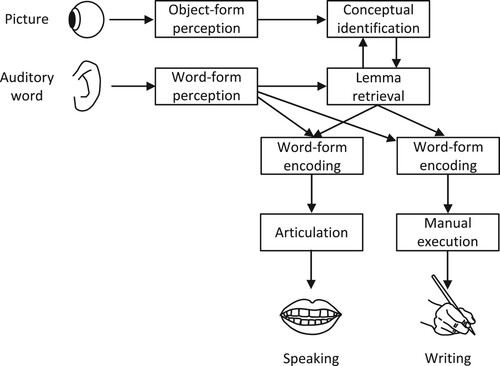
According to the lemma model, in picture naming (e.g. of a clam), the picture is first perceived and conceptually identified, followed by the selection of a lemma for the concept. If encoding of the corresponding word form fails, a semantically related lemma might be selected instead and the corresponding form may be encoded, yielding a semantic error (e.g. octopus). If this happens in vocal naming but not in written naming, semantic errors are observed in speaking but not in writing, as observed for RGB and HW (Caramazza & Hillis, Citation1990) and RR (Kemmerer et al., Citation2005). Conversely, if this happens in written naming but not in vocal naming, semantic errors are observed in writing but not in speaking, as observed for RCM (Hillis et al., Citation1999).
The WEAVER++ model assumes that picture naming engages an associate network in declarative memory and condition-action rules in procedural memory (for a review of the evidence for distinct declarative and procedural memory systems in the brain, see Eichenbaum, Citation2012). The associative network is accessed by spreading activation while condition-action rules select nodes among the activated ones to attain the task goal specified in working memory (here, to name a picture). The network representation of the word cat consists of a lexical concept (CAT), a lemma (cat), a lexical output form or morpheme (<cat>), output phonemes (/k/, /æ/, and /t/), and a syllable motor program ([kæt]). The lexical concept nodes of semantically related concepts, like CAT and DOG, are connected. Lemmas specify the grammatical properties of words, crucial for the production of phrases and sentences. For example, the lemma of cat specifies that the word is a noun (for languages such as Dutch, lemmas also specify grammatical gender). Lemmas also allow for the specification of morphosyntactic parameters, such as number (singular, plural) for nouns, so that the appropriate lexical output form may be retrieved (e.g. singular <cat>). Based on neuroimaging and patient evidence (e.g. Kemmerer, Citation2015, Citation2019) and a meta-analysis of the neuroimaging literature (Indefrey & Levelt, Citation2004; Indefrey, Citation2011), lexical concepts are thought to be represented in anterior-ventral temporal cortex, lemmas in the middle section of the left middle temporal gyrus (mMTG), lexical output forms in left posterior superior and middle temporal gyrus (Wernicke’s area), output phonemes in left posterior inferior frontal gyrus (Broca’s area), and syllable motor program in left ventral precentral gyrus. The condition-action rules are thought to be realized by the basal ganglia, thalamus, frontal cortex (including Broca’s area), and cerebellum (e.g. Roelofs, Citation2014, Citation2022; Roelofs & Ferreira, Citation2019). The rules not only subserve word planning (i.e. selecting a lemma for a concept and encoding a word form) but also executive control (e.g. making sure that the goal of naming a picture is achieved, even when this involves a circumlocution or production of a semantically close alternative).
Levelt et al. (Citation1999) assumed that only the word form corresponding to a selected lemma becomes activated. For example, in naming a cat, the lemmas of both cat and dog are activated (at a lower level for dog), mediated by the conceptual connections, but only the word form of cat is activated after selection of the cat lemma. However, in response to empirical challenges, including neuropsychological data (e.g. Rapp & Goldrick, Citation2000), this serial–discrete assumption has been omitted from the model since Roelofs (Citation2008b), and a parallel–continuous (“cascade”) assumption has been adopted instead. Consequently, in naming a cat, not only the lemmas of cat and dog are activated (lower for dog), but also both corresponding word forms (again, lower for dog). illustrates the lemma model account of the double dissociation using activation curves for naming a cat in simulations with WEAVER++, generated using the cascaded version of the model (i.e. Roelofs, Citation2014, Citation2022). However, the account for the double dissociation holds both under the serial–discrete and parallel–continuous versions of the model, as further discussed later.
Figure 2. Activation curves for lemmas and forms (i.e. syllable motor programs) in WEAVER++ simulations (Roelofs, Citation2014) assuming a lack of activation of some word forms (here, the form of cat). By selecting an alternative lemma (dog) and encoding the corresponding word form, a response is produced rather than omitted. ms = milliseconds; a.u. = arbitrary units.
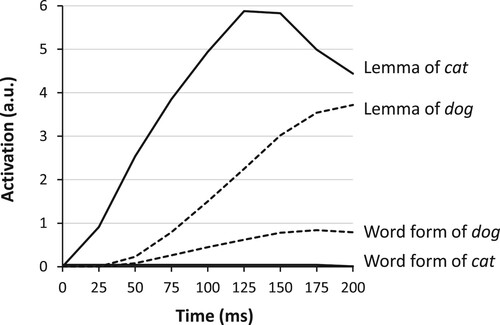
In naming a cat, the lemma of the word cat becomes activated and also somewhat less the lemma of the semantically related word dog via connections between their concepts. Activation spreads from both lemmas to the corresponding word forms. Semantically unrelated words such as house will not be activated. If the word form of cat is not sufficiently activated as a result of brain damage, then the picture name cannot be produced. However, if the word form of a semantically related word like dog is spared, then the patient may demonstrate knowledge by selecting the lemma of dog and encoding the corresponding word form for output. Lemmas of unrelated words like house will not be selected, because they are not activated by the picture. Thus, when an alternative lemma is selected, it will be of a semantically related word (e.g. dog) but not of an unrelated word (e.g. house), yielding a semantic error. If damage concerns spoken but not written word forms, then semantic errors occur in speaking but not in writing, as observed for RGB and HW (Caramazza & Hillis, Citation1990) and RR (Kemmerer et al., Citation2005). Conversely, if damage concerns written but not spoken word forms, then semantic errors happen in writing but not in speaking, as observed for RCM (Hillis et al., Citation1999). How many word forms are inaccessible for speaking or writing is a patient-specific parameter that may be estimated from the real data.
Role of executive control
Patients are usually cooperative and are encouraged, or explicitly prompted, to provide any information that they can access about the picture name (Kemmerer et al., Citation2005). Thus, by producing a semantic alternative word (like the response “owl” to an eagle), the patient demonstrates access of words that are close to the inaccessible target word. In the studies of Caramazza and Hillis (Citation1990) and Hillis et al. (Citation1999), the patients often produced definitions or circumlocutions as response, which were counted as semantic errors. For example, half the semantic errors of RGB consisted of definitions or descriptions (e.g. pajamas → “what you wear at night”). Only rarely, the patients omitted responses, which are uninformative with respect to the knowledge they can retrieve.
Several investigators have argued that picture naming not only taps automatic word planning processes but also involves a degree of executive or semantic control (e.g. Jefferies et al., Citation2007; Roelofs, Citation2003, Citation2014, Citation2018; Schnur et al., Citation2009). The control is required to guarantee that the appropriate conceptual selections are made, such as selecting the concept for the basic-level term cat rather than the superordinate concept for the name animal in response to a picture of a cat (cf. Roelofs, Citation1992). Clearly, the production of definitions or circumlocutions is not the behavioral impairment itself, but it reflects a control strategy of the patient to demonstrate knowledge. In a voxel-based lesion-symptom mapping of semantic errors in vocal picture naming, Schwartz et al. (Citation2009) restricted their count of semantic errors to substituted nouns that were synonyms, category coordinates, superordinates, subordinates, or strongly associated responses. However, Walker et al. (Citation2011) also included other responses like definitions and circumlocutions, which doubled the number of errors while replicating the finding of Schwartz et al. that semantic error rate is mostly strongly correlated with damage to the left MTG. This suggests that the lesion locus that gives rise to single-word errors and the production of definitions and circumlocutions is the same. Moreover, it suggests that single word errors may not always be the automatic consequence of the damage, but instead may also reflect the influence of executive control, as the production of definitions and circumlocutions does.
To summarize, linguistic and executive functions are hypothesized to interact in producing semantic errors restricted to either speaking or writing. A modality-specific semantic error is assumed to occur when access to a modality-specific word form fails and a semantically related lemma is selected instead, instigated by an executive control process. If this happens in vocal naming but not in written naming, semantic errors are observed in speaking but not in writing. Conversely, if this happens in written naming but not in vocal naming, semantic errors are observed in writing but not in speaking. Next, using a simple mathematical analysis, I demonstrate that the lemma model accounts for the data, contrary to what has been held in the literature (Hillis et al., Citation1999; Kemmerer, Citation2015, Citation2019). I first describe the methods and then the results.
Methods
Patients RGB, HW, and RCM were tested by Caramazza and Hillis (Citation1990) and Hillis et al. (Citation1999) on a variety of single-word tasks. The most important ones for present purposes are vocal picture naming (e.g. say “clam” in response to a picture of a clam), written picture naming (write “clam” in response to a picture of a clam), auditory word comprehension (auditory word–picture matching; e.g. upon hearing “clam”, select the picture of a clam from among a set of pictures), and writing to dictation (i.e. write “clam” in response to the auditorily presented word clam). Good performance on auditory word comprehension indicates that semantic errors in naming are not due to disrupted conceptual level processes. Performance on written picture naming and writing to dictation assesses writing for different input modalities. Responses consisting of semantically related words (e.g. “octopus” in response to a picture of a clam) or definitions (e.g. “A bill. … a hundred cents” in response to a picture of a dollar) were counted as semantic errors by Caramazza, Hillis, and colleagues.
Kemmerer et al. (Citation2005) report performance scores of RR for vocal and written naming tasks, but not for auditory word–picture matching and writing to dictation. This is presumably because “aural comprehension” of RR was very poor (i.e. below the first percentile), which precludes application of tests that involve spoken word recognition.
According to the lemma model (see ), naming involves picture perception, conceptual identification, lemma retrieval, and word-form encoding separately for speaking and writing, followed by the execution of the articulatory of manual gestures. In auditory word comprehension, the form of the spoken word is perceived, followed by the retrieval of the corresponding lemma, and identification of the concept. In writing to dictation, the form of the spoken word is perceived, followed by either the retrieval of the corresponding lemma and the encoding of the corresponding written form, or the perceived spoken word is mapped onto the written form through phoneme-to-grapheme conversion.
The accuracy of responding in a task depends on the correctness of the different processing stages that are involved. On the simplest account, the probability of a correct response equals the product of the probabilities that each stage is correct (cf. Schweickert, Citation1985):
(1)
(1)
Here, i ranges over the processing stages involved in a task, like picture perception, conceptual identification, lemma retrieval, word-form encoding, and response execution in picture naming. The probability of failed word-form encoding was estimated from the real data based on the proportions of word forms for speaking and writing that seemed inaccessible for RGB, HW, RR, and RCM, which constituted a single free parameter for each patient. If form access for a word fails, then an alternative lemma is assumed to be selected and its form is encoded, as illustrated in . All other stages were assumed to be performed correctly. Using EquationEquation 1(1)
(1) and the functional routes of speaking and writing in the lemma model (), the accuracies of performance in vocal naming, written naming, auditory word comprehension, and writing to dictation were derived for each patient.
Results
Semantic errors limited to speaking
Patient RGB examined by Caramazza and Hillis (Citation1990) made 32% errors in the vocal naming of pictures, most of which were semantic errors. Of these semantic errors, 52% were definitions or descriptions (e.g. pajamas → “what you wear at night”), 39% were semantic coordinate errors (e.g. celery → “lettuce”), and 11% were associates (e.g. waist → “belt”). RGB made no semantic errors in written picture naming or writing to dictation, but only misspellings (e.g. “squah” for squash). Auditory word comprehension was perfect.
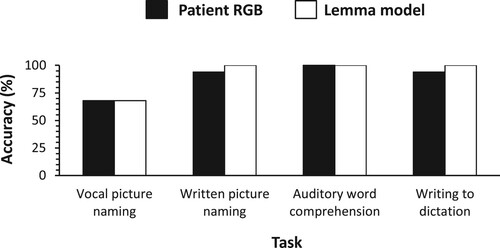
Based on the vocal picture-naming performance of RGB, the probability of successful form access in speaking was estimated to be .68. shows the predictions by the lemma model along with the real data on RGB observed by Caramazza and Hillis (Citation1990). The figure indicates that the model captures the real data.
Figure 3. Accuracy of single-word task performance: Real data on patient RGB (Caramazza & Hillis, Citation1990) and predictions of the lemma model.
Patient HW examined by Caramazza and Hillis (Citation1990) made 26% errors in the vocal naming of pictures, most of which were semantic errors. The pattern of errors was said to be “strikingly similar to that of RGB” (p. 107). HW made no semantic errors in written picture naming or writing to dictation. Auditory word comprehension was perfect. shows the predictions by the lemma model along with the real data on HW observed by Caramazza and Hillis (Citation1990). The figure indicates that the model captures the real data.
Figure 4. Accuracy of single-word task performance: Real data on patient HW (Caramazza & Hillis, Citation1990) and predictions of the lemma model.

The performance of patient RR examined by Kemmerer et al. (Citation2005) was similar to that of patients RGB and HW of Caramazza and Hillis (Citation1990). However, different from RGB and HW, auditory word comprehension of RR was severely impaired. RR made 56% errors in the vocal naming of pictures, but only 8% errors in written picture naming. The majority of errors in vocal picture naming were semantic in nature (62%), although phonological errors (23%) and omission errors (15%) were also made. The accuracy of performance in vocal picture naming and written picture naming is predicted by the lemma model to be 44% and 100% (real: 44% and 92%), respectively.
Semantic errors limited to writing
Whereas the semantic errors of patients RGB and HW (Caramazza & Hillis, Citation1990) and RR (Kemmerer et al., Citation2005) occurred in vocal but not in written picture naming, the opposite was true for patient RCM (Hillis et al., Citation1999). The double dissociation between semantic errors in vocal and written naming has been taken to challenge the assumption of lemmas. I now discuss the results for RCM, the critical second half of the double dissociation.
Patient RCM examined by Hillis et al. (Citation1999) made 47% errors in the written naming of pictures. Of these errors, 81% were semantic errors (barn → “lunch box”), 6% were semantically and orthographically or phonologically related (watch → “watchful”), and 6% nonwords (zebra → “jephrys”). RCM made no errors in vocal picture naming and auditory word comprehension. However, 53% errors were made in writing to dictation. Of these errors, 33% were semantic errors, 33% were orthographically or phonologically related, and 33% were nonwords. RCM could not write nonwords to dictation (0% correct), indicating that it was not an option to map a perceived auditory word onto the written form through phoneme-to-grapheme conversion.
Based on the written picture naming and writing-words-to-dictation performance of RCM, the probability of successful word-form access in writing was estimated to be .50. shows the predictions of the lemma model along with the real data on RCM of Hillis et al. (Citation1999). The figure indicates that the model captures the real data. The errors in written picture naming are predicted to be mostly semantic errors, as empirically observed. However, given that in writing to dictation, the response is derived from an auditory word, the errors are expected to consist of a mixture of semantically related and form-related responses, as empirically observed.
Figure 5. Accuracy of single-word task performance: Real data on patient RCM (Hillis et al., Citation1999) and predictions of the lemma model.

Formally assessing the goodness of fit
Whereas patients RGB, HW, and RR make semantic errors in speaking but not in writing, patient RCM exhibits the opposite dissociation, which is captured by the lemma model, as shown by . To formally assess the goodness of fit, a Pearson correlation was computed. The correlation between model and data on RGB, HW, RR, and RCM is r = .99, p < .001. This means that the model explains 98% of the variance in the patient data.
Discussion
The observation that semantic errors may be restricted to either speaking or writing in aphasia has been taken by Hillis et al. (Citation1999) and Kemmerer (Citation2015, Citation2019) to challenge the view that lexical selection in word production involves modality-neutral lemmas, as proposed by Levelt et al. (Citation1999) and Roelofs (Citation1992). Above, I showed, however, that a model with lemmas accounts for the double dissociation observed in patients. In what follows, I first discuss the account further. Next, I argue that the lemma model account of the double dissociation agrees with the limited evidence on the lesion locus of RGB, HW, RR, and RCM. Finally, I briefly describe a few findings that the lemma model was designed to explain in the first place, and argue that a challenge is now for modality-specific selection models to account for these findings.
The lemma account of the double dissociation
As indicated, several of the theoretical developments of the WEAVER++ model have occurred in response to challenges that neuropsychological studies have provided (e.g. Rapp & Goldrick, Citation2000; Roelofs, Citation2004). Caramazza (Citation1997, p. 193) took “the most compelling argument against” lemmas to be that they are not necessary to explain the double dissociation between semantic errors in oral and written naming. It should be noted, however, that the lemma model was designed to account for spoken word production, not for the double dissociation. Still, the dissociation invited an extension of the model to writing (as detailed in Roelofs et al., Citation1998).
In discussing the lemma model in light of the double dissociation between semantic errors in speaking and writing, Kemmerer (Citation2019) stated:
“Might RGB and RCM have deficits at the level of lemmas? This interpretation fails because it predicts that both spoken and written word production would be impaired. As an alternative approach, suppose the patients were still able to access amodal lemmas, but were no longer able to access modality-specific lexical representations—phonological codes for RGB, and orthographic codes for RCM. This type of deficit analysis also fails because it cannot account for the fact that the errors in the impaired output modality are semantic in nature.” (p. 1105)
Serial–discrete versus parallel–continuous stages
Based on findings of Levelt et al. (Citation1991) about reaction times in picture naming, Roelofs et al. (Citation1998) assumed that only the word form corresponding to a selected lemma is activated. Lemma retrieval and word-form encoding were assumed to be serial stages with a discrete information transmission (cf. Meyer et al., Citation1988), an assumption that was later implemented in the WEAVER++ model (Levelt et al., Citation1999). In the model, word-form encoding started only after lemma retrieval was done (i.e. serial processing) and only the word form corresponding to the selected lemma was encoded (i.e. discrete output). The assumptions of seriality and discreteness entail that when access to a word form in memory fails, there is no other activated word form to select, but an alternative lemma can be selected. For example, different from what is illustrated in , the word form of dog would not be activated. Thus, when in naming a cat, access to the form of the word cat fails, there is no other option for the patient than to provide a definition or description, or to select the lemma of a semantic alternative (e.g. dog), to prevent an omission and to demonstrate knowledge.
To accommodate new accumulating empirical evidence for cascading in lexical access (e.g. Morsella & Miozzo, Citation2002; Rapp & Goldrick, Citation2000), the assumption that only a selected lemma activates its word form has been dropped in subsequent versions of WEAVER++ and was replaced by an assumption of weak cascading (e.g. Roelofs, Citation2008b, Citation2014, Citation2022). In the model, even before a lemma is selected for the picture (i.e. parallel processing), activation spreads from the activated lemmas to the corresponding words forms (i.e. continuous output). Although lemmas that are not selected activate their word forms, as illustrated for dog in , the amount of activation is assumed to be limited (Roelofs, Citation2003, Citation2008b). This opens the possibility that an alternative modality-specific word form rather than an alternative lemma is selected if access to the word form of the target lemma fails. Note that word forms of semantically related lemmas will be more highly activated than the forms corresponding to unrelated lemmas. Therefore, if an alternative word form is selected, a semantic error is likely to occur. Still, given that there is only limited activation of the word form of semantic alternatives, knowledge can best be demonstrated (and an omission will be prevented) by providing a definition or description, or to select the lemma of a semantic alternative (e.g. dog).
Lesion locus of the patients
As Kemmerer (Citation2019) argued, if lexical selection involves modality-neutral lemmas and lemma access is impaired, then semantic errors should occur in both speaking and writing, different from what has been observed for patients RGB, HW, RR, and RCM. Whereas patients RGB, HW, and RR made semantic errors in speaking but not in writing, patient RCM exhibited the opposite dissociation. Therefore, the lemma account of the double dissociation (Roelofs et al., Citation1998) assumes impaired access to modality-specific forms rather than to modality-neutral lemmas. This explanation of the double dissociation entails that the damage in RGB, HW, RR, and RCM should concern brain areas involved in word-form encoding, while areas involved in lemma retrieval should be spared. This implication is supported by the limited evidence on the lesion locus of RGB, HW, RR, and RCM. Note that the view of modality-specific lexical selection (Hillis et al., Citation1999) also assumes damage to brain areas involved in word-form encoding.
Caramazza and Hillis (Citation1990) stated that CT scans “revealed a large, left fronto-parietal infarct” (p. 98) for RGB and “several areas of occipital and parietal infarcts” (p. 99) for HW. According to Kemmerer et al. (Citation2005), the lesion of RR involved “the supramarginal and angular gyri, and the posterior part of the superior temporal gyrus—i.e. nearly all of what is usually demarcated as Wernicke’s area” and “an additional, smaller area of damage in the left prefrontal region, in the pars opercularis” (p. 8). Hillis et al. (Citation1999) stated about RCM: “A head CT scan 6 days post-onset showed a subacute infarct in the left frontal cortex, including the operculum. A brain MRI one month later showed the left frontal infarct with a small amount of hemorrhagic conversion” (p. 339). Thus, the damage in the patients concerned frontal, parietal, and superior temporal regions.
In a meta-analysis of 82 neuroimaging studies on spoken word production in healthy speakers by Indefrey and Levelt (Citation2004), lemma retrieval was localized to the left mMTG (MNI y = −6 to −39 mm) and word-form encoding to left posterior superior and middle temporal gyrus and left inferior frontal gyrus. As indicated, according to the lemma model, damage to the left mMTG should yield semantic errors, which is supported by patient evidence. Factoring out verbal and nonverbal comprehension, Schwartz et al. (Citation2009) observed that semantic error rate in picture naming by stroke patients (N = 64) was most highly associated with damage to the mMTG (centered at MNI y = −18 mm), and the same was observed by Walker et al. (Citation2011). Moreover, in an awake-surgery study (N = 29) using direct electrical stimulation of the brain during vocal picture naming, Gobbo et al. (Citation2021) observed that the probability of making a semantic error increased during stimulation when patients presented with a tumor in mMTG (MNI y = −22). Similarly, when stimulating left temporal cortex in patients with epilepsy (N = 68), Miozzo et al. (Citation2017) observed that semantic errors in picture naming were most strongly associated with mMTG. Thus, converging evidence indicates that semantic errors arise during lemma retrieval underpinned by the mMTG, which is not where the stroke-induced lesions in RGB, HW, RR, and RCM were reported to be. Instead, the frontal, parietal, and superior temporal lesions observed for the patients make it more likely that word-form encoding was impaired, as maintained by the lemma-to-form mapping account of modality-specific semantic errors assumed by the lemma model. According to the account, the patient selected an alternative lemma (or word form) or produced a description or definition when word-form encoding for the picture name failed, yielding the semantic error.
Although the production of definitions and circumlocutions suggests intact executive control, it may be argued that the damage to frontal and parietal cortex may not have fully spared it (e.g. Jefferies et al., Citation2007), which may also have contributed to the semantic errors. Indeed, in addition to the left MTG, Schwartz et al. (Citation2009) and Walker et al. (Citation2011) observed that semantic error rate correlated with damage to the IFG and a few small clusters in parietal cortex. However, after controlling for total lesion volume, these correlations disappeared. Moreover, impairment of executive control is an unlikely explanation for the double dissociation for two reasons. First, evidence suggests that impaired executive control would affect both production and comprehension (e.g. Jefferies et al.), which does not hold for RGB, HW, and RCM. Second, it cannot readily explain why the naming impairment is observed in one output modality only.
To be able to explain why only speaking or writing is impaired, it needs to be assumed that word-form encoding may be selectively damaged in one output modality rather than another. In WEAVER++, word-form encoding for speaking involves morphological encoding, phonological encoding, and phonetic encoding. Impaired access to word forms may concern each of these stages, like selecting one or more morphemes for a lemma and its morphosyntactic specification (e.g. cat plus singular) in morphological encoding. To be able to explain the double dissociation, it must be assumed that the damage observed in frontal, parietal, and superior temporal regions for RGB, HW, RR, and RGM has selectively impaired word-form encoding for speaking in RGB, HW, and RR, and word-form encoding for writing in RCM. Note that impaired access to modality-specific forms is also assumed by the modality-specific account of lexical selection proposed by Caramazza (Citation1997) and Hillis et al. (Citation1999). Thus, to the extent that this assumption of impaired access to modality-specific forms is supported by the available lesion evidence on RGB, HW, RR, and RCM, it supports both accounts.
Challenges for the modality-specific account
Given the demonstration that the lemma model may account for modality-specific semantic errors, a challenge is now for modality-specific selection models to account for the other findings that the lemma model was designed to explain. One of the original motivations for the distinction between lemmas and lexical forms was the observation of two types of stem exchange errors in speaking (Dell, Citation1986; Garrett, Citation1980, Citation1988). The distributional properties of one type of stem exchanges are similar to those of whole-word errors, whereas those of the other type of stem exchanges are similar to those of phoneme errors. For example, the exchanged stems apple and pie in “how many pies does it take to make an apple?” (from Garrett, Citation1988) belong to the same syntactic category (i.e. noun) and come from distinct phrases, which also holds for the exchanged words roof and list in “we completely forgot to add the list to the roof” (from Garrett, Citation1980). In contrast, the exchanged stems thin and slice in “slicely thinned” (from Stemberger, Citation1985) belong to different syntactic categories (adjective and verb) and come from the same phrase, which also holds for phoneme exchanges, such as “she is a real rack pat” for “pack rat” (from Garrett, Citation1988). The difference in distributional properties of the stem exchange errors supports a distinction between a lemma level with abstract morphosyntactic parameters and a morphological level with concrete lexical form representations, as assumed by the lemma model. However, if lexical selection would involve concrete lexical forms, as assumed by the modality-specific view, then the two types of stem exchange errors remain unexplained.
There are several other findings from behavioral, neuroimaging, and aphasia studies that are better explained by a model that assumes modality-neutral lemmas mediating between meaning and form than by a model without lemmas. A discussion of these findings is outside the present article, but for reviews, I refer to Roelofs (Citation2014, Citation2022), Roelofs et al. (Citation1998), and Roelofs and Ferreira (Citation2019), among others.
Conclusion
I have shown that, contrary to what has long been held, the observation that semantic errors may be confined to either speaking or writing in aphasia does not challenge the assumption of lemmas. Rather, a model with lemmas can account for the double dissociation observed in patients, explaining most of the variance in the patient data. The challenge is now for modality-specific selection models to account for the other findings that the lemma model was designed to explain in the first place.
Disclosure statement
No potential conflict of interest was reported by the author.
References
- Caramazza, A. (1997). How many levels of processing are there in lexical access? Cognitive Neuropsychology, 14(1), 177–208. https://doi.org/10.1080/026432997381664
- Caramazza, A., & Hillis, A. E. (1990). Where do semantic errors come from? Cortex, 26(1), 95–122. https://doi.org/10.1016/S0010-9452(13)80077-9
- Caramazza, A., & Miozzo, M. (1997). The relation between syntactic and phonological knowledge in lexical access: Evidence from the `tip-of-the-tongue' phenomenon. Cognition, 64(3), 309–343. https://doi.org/10.1016/S0010-0277(97)00031-0
- Dell, G. S. (1986). A spreading-activation theory of retrieval in sentence production. Psychological Review, 93(3), 283–321. https://doi.org/10.1037/0033-295X.93.3.283
- Eichenbaum, H. (2012). The cognitive neuroscience of memory: An introduction (2nd ed.). Oxford University Press.
- Garrett, M. F. (1980). Levels of processing in sentence production. In B. Butterworth (Ed.), Language production (Vol. 1) (pp. 177–220). Academic Press.
- Garrett, M. F. (1988). Processes in language production. In F. J. Newmeyer (Ed.), Linguistics: The Cambridge survey (Vol. 3) (pp. 69–96). Harvard University Press.
- Gobbo, M., De Pellegrin, S., Bonaudo, C., Semenza, C., Della Puppa, A., & Salillas, E. (2021). Two dissociable semantic mechanisms predict naming errors and their responsive brain sites in awake surgery. DO80 revisited. Neuropsychologia, 151, 107727. https://doi.org/10.1016/j.neuropsychologia.2020.107727
- Hillis, A. E., Rapp, B. C., & Caramazza, A. (1999). When a rose is a rose in speech but a tulip in writing. Cortex, 35(3), 337–356. https://doi.org/10.1016/S0010-9452(08)70804-9
- Indefrey, P. (2011). The spatial and temporal signatures of word production components: A critical update. Frontiers in Psychology, 2, Article 255. https://doi.org/10.3389/fpsyg.2011.00255
- Indefrey, P., & Levelt, W. J. M. (2004). The spatial and temporal signatures of word production components. Cognition, 92(1–2), 101–144. https://doi.org/10.1016/j.cognition.2002.06.001
- Jefferies, E., Baker, S. S., Doran, M., & Lambon Ralph, M. A. (2007). Refractory effects in stroke aphasia: A consequence of poor semantic control. Neuropsychologia, 45(5), 1065–1079. https://doi.org/10.1016/j.neuropsychologia.2006.09.009
- Kemmerer, D. (2015). Cognitive neuroscience of language. Psychology Press.
- Kemmerer, D. (2019). From blueprints to brain maps: The status of the Lemma Model in cognitive neuroscience. Language, Cognition and Neuroscience, 34(9), 1085–1116. https://doi.org/10.1080/23273798.2018.1537498
- Kemmerer, D., Tranel, D., & Manzel, K. (2005). An exaggerated effect for proper nouns in a case of superior written over spoken word production. Cognitive Neuropsychology, 22(1), 3–27. https://doi.org/10.1080/02643290442000013
- Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences, 22(1), 1–38. https://doi.org/10.1017/S0140525X99001776
- Levelt, W. J. M., Schriefers, H., Vorberg, D., Meyer, A. S., Pechmann, T., & Havinga, J. (1991). The time course of lexical access in speech production: A study of picture naming. Psychological Review, 98(1), 122–142. https://doi.org/10.1037/0033-295X.98.1.122
- Meyer, D. E., Osman, A. M., Irwin, D. E., & Yantis, S. (1988). Modern mental chronometry. Biological Psychology, 26(1–3), 3–67. https://doi.org/10.1016/0301-0511(88)90013-0
- Miozzo, M., Williams, A. C., McKhann, G. M., & Hamberger, M. J. (2017). Topographical gradients of semantics and phonology revealed by temporal lobe stimulation. Human Brain Mapping, 38(2), 688–703. https://doi.org/10.1002/hbm.23409
- Morsella, E., & Miozzo, M. (2002). Evidence for a cascade model of lexical access in speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(3), 555–563. https://doi.org/10.1037/0278-7393.28.3.555
- Rapp, B., & Goldrick, M. (2000). Discreteness and interactivity in spoken word production. Psychological Review, 107(3), 460–499. https://doi.org/10.1037/0033-295X.107.3.460
- Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42(1–3), 107–142. https://doi.org/10.1016/0010-0277(92)90041-F
- Roelofs, A. (2003). Goal-referenced selection of verbal action: Modeling attentional control in the Stroop task. Psychological Review, 110(1), 88–125. https://doi.org/10.1037/0033-295X.110.1.88
- Roelofs, A. (2004). Error biases in spoken word planning and monitoring by aphasic and nonaphasic speakers: Comment on Rapp and Goldrick (2000). Psychological Review, 111(2), 561–572. https://doi.org/10.1037/0033-295X.111.2.561
- Roelofs, A. (2007). Attention and gaze control in picture naming, word reading, and word categorizing. Journal of Memory and Language, 57(2), 232–251. https://doi.org/10.1016/j.jml.2006.10.001
- Roelofs, A. (2008a). Attention, gaze shifting, and dual-task interference from phonological encoding in spoken word planning. Journal of Experimental Psychology: Human Perception and Performance, 34(6), 1580–1598. https://doi.org/10.1037/a0012476
- Roelofs, A. (2008b). Tracing attention and the activation flow in spoken word planning using eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34(2), 353–368. https://doi.org/10.1037/0278-7393.34.2.353
- Roelofs, A. (2014). A dorsal-pathway account of aphasic language production: The WEAVER++/ARC model. Cortex, 59, 33–48. https://doi.org/10.1016/j.cortex.2014.07.001
- Roelofs, A. (2018). A unified computational account of cumulative semantic, semantic blocking, and semantic distractor effects in picture naming. Cognition, 172, 59–72. https://doi.org/10.1016/j.cognition.2017.12.007
- Roelofs, A. (2022). A neurocognitive computational account of word production, comprehension, and repetition in primary progressive aphasia. Brain and Language, 227, 105094. https://doi.org/10.1016/j.bandl.2022.105094
- Roelofs, A., & Ferreira, V. S. (2019). The architecture of speaking. In P. Hagoort (Ed.), Human language: From genes and brains to behavior (pp. 35–50). MIT Press.
- Roelofs, A., Meyer, A. S., & Levelt, W. J. (1998). A case for the lemma/lexeme distinction in models of speaking: Comment on Caramazza and Miozzo (1997). Cognition, 69(2), 219–230. https://doi.org/10.1016/S0010-0277(98)00056-0
- Schnur, T. T., Schwartz, M. F., Kimberg, D. Y., Hirshorn, E., Coslett, H. B., & Thompson-Schill, S. L. (2009). Localizing interference during naming: Convergent neuroimaging and neuropsychological evidence for the function of Broca's area. Proceedings of the National Academy of Sciences, 106(1), 322–327. https://doi.org/10.1073/pnas.0805874106
- Schwartz, M. F., Kimberg, D. Y., Walker, G. M., Faseyitan, O., Brecher, A., Dell, G. S., & Coslett, H. B. (2009). Anterior temporal involvement in semantic word retrieval: Voxel-based lesion-symptom mapping evidence from aphasia. Brain, 132(12), 3411–3427. https://doi.org/10.1093/brain/awp284
- Schweickert, R. (1985). Separable effects of factors on speed and accuracy: Memory scanning, lexical decision, and choice tasks. Psychological Bulletin, 97(3), 530–546. https://doi.org/10.1037/0033-2909.97.3.530
- Stemberger, J. P. (1985). An interactive activation model of language production. In A. Ellis (Ed.), Progress in the psychology of language (Vol. 1) (pp. 143–186). Erlbaum.
- Walker, G. M., Schwartz, M. F., Kimberg, D. Y., Faseyitan, O., Brecher, A., Dell, G. S., & Coslett, H. B. (2011). Support for anterior temporal involvement in semantic error production in aphasia: New evidence from VLSM. Brain and Language, 117(3), 110–122. https://doi.org/10.1016/j.bandl.2010.09.008