
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The current ERP study investigates the role of non-linguistic context in incremental semantic comprehension. Using picture-sentence verification, we examined the neurophysiological correlates of contextual adaptation effects. We manipulated experiment-inherent frequency and tested whether a relatively high ratio of experimental to filler sentences constrains the contextual restriction of the German quantifier alle (“all”). While previous results indicate that the truth evaluation may be postponed when the experimental setting is completely ambiguous with respect to a potentially following restriction, the current study used a higher ratio of non-restricted vs. restricted sentences than the previous one (4:1 vs. 1:1) and thereby tested whether a low restriction probability increases the likelihood of an immediate truth evaluation. Our results show that experiment-inherent frequency distributions immediately modulate the N400 amplitude, analogous to previous studies on speaker reliability.
1. Introduction
Language understanding involves rapidly combining information types from various sources. A case in point is sentence comprehension, where structure building and meaning assignment may be determined by linguistic and non-linguistic contextual cues. In linguistic theory, contextual information is essential to what is called utterance meaning (e.g. Searle, Citation1978; Weigand, Citation1993): the context may include information about the preceding discourse or the utterance situation and often determines the interpretation of deictic (e.g. you, then or there), referential (e.g. definite descriptions like the waitress) or anaphoric expressions (e.g. pronouns like he, she or they that refer back to previously introduced discourse referents). Besides such discourse-related effects, contextual cues may also contain information that is more indirectly related to linguistic theory and the linguistic processing proper, for example, world knowledge, plausibility, and also completely non-linguistic information, such as information about the speaker or about the environment and the frequency with which particular constructions are encountered (Fine et al., Citation2013; Hagoort & Van Berkum, Citation2007; Van Berkum et al., Citation2008). The current study examines the nature of such non-linguistic frequency effects on compositional-semantic processing.
One way in which contextual cues quite generally affect the interpretation of an utterance is by determining what its parts can denote: In certain contexts, the possible denotations of an expression may be more restricted than in others. As an illustration, consider a situation at the counter of a fast food restaurant in which you are asked: Would you like something to drink? In that kind of situation, the set of options to choose from is usually rather limited. The knowledge about restrictions like these comes from world knowledge, e.g. in the present case, by considering the fact that there is usually not so much choice concerning the drinks in fast food locations, and it is rather implausible to find drinks like homemade lemonade in fast food places. A strikingly different situation would arise when being asked the same question in the hippest burger place in town. The set of potential options would presumably be much less restricted, and you might want to acquire further information, if it is not provided right away, e.g.: …from our selection of local craft beers and homemade lemonades.
Though it is intuitively plausible that contextual cues generally affect the way we understand sentences, there has been a long debate about whether they may affect sentence comprehension incrementally, i.e. with each newly incoming word, or whether they are, in fact, considered only at later processing stages. While classical psycholinguistic studies on sentence comprehension predominately examined the role of contextual cues in syntactic ambiguity resolution (e.g. Altmann & Steedman, Citation1988; Tanenhaus et al., Citation1995, among many others), more recent approaches also focus on incremental context effects with regard to semantic and pragmatic processing (Augurzky et al., Citation2017, Citation2019; Augurzky, Hohaus, et al., Citation2020; Bott, Citation2017; Haase et al., Citation2019; Hunt et al., Citation2013; Koornneef, Citation2008; Nieuwland & Kuperberg, Citation2008; Nieuwland & Van Berkum, Citation2006; Politzer-Ahles et al., Citation2013; Tian et al., Citation2010; Urbach et al., Citation2015; Van Berkum et al., Citation2007).
While a majority of these recent studies indicate that immediate effects of contextual cues on the processing of semantic and pragmatic information are principally possible, relatively little is known about the effects of non-linguistic context information. The current ERP study aims to add to these recent approaches by examining non-linguistic context effects on the on-line compositional-semantic interpretation of sentences containing the quantifier alle (“all”) in German. Quantifiers like all, none, some, etc., express quantitative relations between properties and relations mentioned in a sentence. One theoretically challenging characteristic of quantifiers is that their semantic interpretation is heavily context-dependent (e.g. Geurts & Van der Sandt, Citation1999). For instance, in the fast food context introduced above, the phrase all lemonades would be contextually restricted to the available options in the specific restaurant where they are offered. Whereas previous studies have shown that linguistically-related contextual cues may indeed affect the online processing of quantified sentences (see Augurzky et al., Citation2017; Freunberger & Nieuwland, Citation2016; Hunt et al., Citation2013; Nieuwland, Citation2016; Politzer-Ahles et al., Citation2013; Spychalska et al., Citation2016; but see also Augurzky, Schlotterbeck, et al., Citation2020; Urbach et al., Citation2015, for mixed evidence), the present study examines how non-linguistic context effects during online comprehension interact with such restrictive processes associated with the universal quantifier alle (“all”). Specifically, we tested whether the probability of a potential meaning shift that may be induced by delayed restrictive cues occurring at a later position in a sentence affects the incremental interpretation of the universal quantifier.
Therefore, our main aim is to test whether expectations affect compositional semantic processes. More specifically, we investigate whether non-linguistic information modulates the expectation of whether an incomplete utterance will be continued or not. For this reason, the distinction between linguistic and non-linguistic context effects is crucial for defining our present purpose. There are context effects that are quite uncontroversially considered to be linguistic in nature like, e.g. effects due to met vs. unmet presuppositions (Tiemann et al., Citation2011). Similarly, there are other effects that are clearly non-linguistic, e.g. effects of background noise on processing difficulty (Wendt et al., Citation2016). However, further examples of context effects are less obviously classifiable as linguistic or non-linguistic. One way of dealing with these latter cases could be to consider specific properties of the context and determine whether their effects are in some way encoded in the linguistic representation derived from the linguistic input during processing. A similar stance has been taken by Chambers et al. (Citation2004), who distinguished between linguistic and non-linguistic context effects in a visual world eye-tracking study. In particular, they argue that context effects on language understanding that are mediated through lexical representations that encode certain selectional restrictions (i.e. restrictions on properties of suitable arguments of verbs) can be viewed as linguistic. By contrast, contextual effects are viewed as non-linguistic if the relevant contextual properties are not encoded in the linguistic representation. For instance, a verb like pour selects for arguments that denote liquid entities, whereas a verb like put imposes only weak restriction on its arguments. As a consequence, the selection of possible referents has to be restricted by contextual properties that are not encoded in the lexical restrictions of a particular verb. When distinguishing between possible referents that are available in a context, both lexically mediated and purely contextual restrictions are accessed, but, according to Chambers et al. (Citation2004), the underlying representation may be different, namely linguistic vs. non-linguistic. In the case of pour, the decision if a boiled or an unboiled (liquid) egg is considered to be a possible referent is linguistically-driven, as the information about the aggregate state is encoded in the selectional restrictions of the verb. By contrast, the effect associated with put is considered as non-linguistic as the relation between the verb and the possible contextually specified referents is much more arbitrary and therefore not specified in selectional restrictions. Similar distinctions between linguistic and non-linguistic context effects may affect other representational levels, such as representations of complex expressions (e.g. sentence meaning or phrase structure) that are derived through compositional interpretation or related combinatorial processes.
As a matter of fact, we consider the frequency of certain constructions in the context of an experiment (i.e. our present manipulation) as non-linguistic in exactly this way: The linguistic representations that are commonly assumed in syntactic parsing and compositional interpretation do not contain a record of recent encounters with different utterance types. This is also in line with influential computational cognitive models in which it is assumed that aspects like frequency of encounter with some piece of information or its salience are only implicitly encoded in memory representations via their increased activity but usually not themselves part of the stored representations (e.g. spreading activation models or CitationAnderson's, Citation1990, memory model, implemented in the ACT-R architecture, and its psycholinguistic applications, e.g. Lewis & Vasishth, Citation2005). By contrast, we would, for example, classify effects of Questions Under Discussion (QUDs; Roberts, Citation1996, Citation2012) on quantifier processing like reported by Politzer-Ahles and Gwilliams (Citation2015) as being potentially mediated linguistically, because QUDs are part of commonly assumed representations of the discourse context (see Roberts, Citation1996, Citation2012).
One method that is particularly well-suited to demonstrate that contextual cues not only can guide syntactic ambiguity resolution but can also contribute to the on-line, incremental compositional-semantic meaning assignment during the comprehension process is the ERP method. ERPs have been shown to exhibit a high temporal resolution for capturing semantic and pragmatic effects. In particular, one well-studied ERP component, namely the N400 (Kutas & Hillyard, Citation1984), has been repeatedly associated with context effects on on-line sentence comprehension. The N400 is a negative potential with a centro-parietal maximum between 200 and 600 ms post stimulus onset. A wide range of different phenomena has been shown to constitute such context effects on the N400 amplitude, amongst them cloze probability (e.g. Nieuwland, Citation2016), world knowledge, plausibility, speaker identity, and pragmatic inferencing (Filik & Leuthold, Citation2008; Grey & van Hell, Citation2017; Hagoort & Van Berkum, Citation2007; Kutas & Federmeier, Citation2011; Nieuwland et al., Citation2010; Van Berkum et al., Citation2005).
Traditionally, reductions in the N400 amplitude have been attributed to contextual fit, with a facilitating effect of linguistic and non-linguistic contextual information types on lexical-semantic integration (Filik & Leuthold, Citation2008; Hagoort et al., Citation2004; Kutas & Federmeier, Citation2011; Kutas & Hillyard, Citation1984; Kutas et al., Citation2006; Nieuwland & Kuperberg, Citation2008; Van Berkum et al., Citation2005). Moreover, the amplitude of the N400 has sometimes been shown to be associated with the semantic commitment by the parser towards true utterances, with a reduced amplitude for true vs. false sentences (Augurzky et al., Citation2017; Hunt et al., Citation2013; Nieuwland & Kuperberg, Citation2008; Noveck & Posada, Citation2003; Politzer-Ahles et al., Citation2013; Spychalska et al., Citation2016; but see also Fischler et al., Citation1983; Nieuwland & Kuperberg, Citation2008; Nieuwland & Van Berkum, Citation2006.)
Most recently, the N400 amplitude has also been shown to vary as a function of contextual predictions regarding the lexical-semantic properties of the upcoming input, or even about specific words (DeLong et al., Citation2005; Ito et al., Citation2016; Otten et al., Citation2007; Urbach et al., Citation2015; and see Ito et al., Citation2017; Nieuwland et al., Citation2018, for criticism of form-based approaches; for a recent discussion on the different interpretations regarding the N400 and language-related negativities more generally, see Bornkessel-Schlesewsky & Schlesewsky, Citation2019; see also recent studies that link the N400 amplitude with the predictability of upcoming words in probabilistic language models, e.g. Aurnhammer & Frank, Citation2019; Frank & Willems, Citation2017; Rabovsky et al., Citation2018).
With regard to non-linguistic context effects, such as effects of frequency, initial evidence suggests that even factors that are not related to the linguistic processing proper at all, like, for instance, the properties of an experiment itself may affect on-line sentence interpretation. Such properties may include details of the experimental setting, paradigm or procedure as well as the composition of the whole set of stimuli that are presented during the course of the experiment. One way these kinds of contextual properties can be viewed is as a kind of microcosm that can be actively controlled to simulate or modulate statistical regularities and pragmatic properties of the environment in which a sentence is processed. For example, it is common practice to include filler trials into psycholinguistic experiments in order to counterbalance necessary imbalances in the experimental design or to distract participants from the properties of the experimental items and the experimental manipulation. Recent studies suggest that fillers affect the experimental results in significant and theoretically relevant ways (e.g. Brothers et al., Citation2019; Fernandes et al., Citation2018; Fine et al., Citation2013; Grodner et al., Citation2010). These studies show that comprehenders adapt rapidly to changing frequencies in the language input, even during the course of an experiment, to facilitate expectation-based language processing. Consequently, such adaptations (or lack thereof) can affect the interpretation of the experimental results and they should thus be taken into account explicitly.
So far, only few sentence-level ERP studies have investigated the neurophysiological correlates of such adaptation processes. For instance, Brothers et al. (Citation2019), examined whether statistical regularities in an experiment may have an effect on predictive sentence comprehension and may thus constrain the amplitude of the N400. In particular, by manipulating speaker reliability, the authors investigated cue validity effects on predictive sentence comprehension. To this end, participants were listening to sentences that were spoken by either a male or a female voice. Experimental sentences differed with respect to the predictability of specific target words (e.g. Eric sued the taxi driver and took him to court vs. Eric picked up his friend and took him to court) as determined by a cloze probability task. Both of the speakers produced an equal amount of predictable and unpredictable experimental target sentences. Crucially, the experiment also involved filler sentences. For one of the speakers, the reliable speaker, these fillers only involved highly predictable continuations, whereas for the other speaker, the unreliable speaker, the fillers only involved highly unpredictable continuations. By hypothesis, the authors expected a larger N400 predictability effect when sentences were uttered by a reliable speaker if statistical regularities are considered a valid cue for constraining predictive strategies. These expectancies were borne out by the data. For both speakers, unexpected lexical items elicited the larger N400, but, as revealed by difference waves, the amplitude difference between expected and unexpected items was significantly decreased in the unreliable speaker condition. This experiment thus shows that statistical regularities in an experimental context may lead to quick adaptation effects. According to the authors, the results can be taken as evidence for an active prediction account, according to which the amount of anticipatory processing a comprehender engages in depends on the reliability of contextual cues. These results thus indicate that predictions are not triggered automatically by the preceding sentence context. Instead, participants strategically adapt their use of predictive processing to the experimental context. If the validity of predictive cues is low in the experimental context, predictive processing is used to a lesser degree. Finally, comparable adaptation effects were also found in a reading time study by Brothers et al. (Citation2017). Taken together, these findings offer an initial evidence that non-linguistic statistical cues may cause immediate adaptation towards the statistical regularities in the environment.
Further evidence for immediate adaptation effects comes from three visual-world eye-tracking studies that consider the effects of alternatives in the processing of scalar implicatures. Grodner et al. (Citation2010) recorded participants' eye movements while they were listening to sentences like Click on the girl with summa the socks in a context showing multiple potential referents. These sentences contain a prosodically reduced form (i.e. summa) of the scalar expression some of, whose lexical meaning (i.e. some and possibly all) is often enriched to some but not all. This enrichment is often assumed to involve an extra computational step that is associated with increased processing cost. CitationGrodner et al. challenged previous findings by Huang and Snedeker (Citation2009), who used filler items that contained small exact numerals like two or three. These numerals constitute salient lexical alternatives to some, and may thus have led to delays in the interpretation of some because pragmatic enrichment of scalar words like some is assumed to be fundamentally rooted in implicit comparison to lexical alternatives. In contrast to the results of Huang and Snedeker (Citation2009), Grodner et al. (Citation2010) found no delay in implicature calculation when fillers containing numerals were removed from the experiment. However, the studies by Grodner et al. (Citation2010) and Huang and Snedeker (Citation2009) differed across two dimensions: first, the use of numerals, and second, the use of prosodically reduced (CitationGrodner et al.) vs. full (CitationHuang & Snedeker) versions of some. A follow-up study by Huang and Snedeker (Citation2018), therefore, investigated which of these factors was responsible for the more immediate effects in the CitationGrodner et al. study and showed that it was indeed the presence vs. absence of numeral fillers that had caused the difference. Huang and Snedeker (Citation2018) propose what they call the “lexical encoding hypothesis” to explain these findings in terms of the predictability of the critical lexical item some as a description of “subsets” (e.g. scenarios in which a girl has two of four socks shown in the display): When only quantifiers like some or all were presented in an experiment, the description of a referent (e.g. the girl with two of the four socks) was highly predictable and, as a result, this referent was identified faster than in an experiment where alternative lexical forms like the numeral two compete with some for referent description. Thus, when only a few alternatives are present, top-down predictions allow listeners to anticipate how the various referents will be described and to use these expectations to identify referents faster once they have processed the quantifier. In their view, such top-down processes may coincide with simultaneous bottom-up processing during online comprehension. In fact, Huang and Snedeker (Citation2018) consider it possible that the frequency of encounter with competing expressions in the context may also affect bottom-up pragmatic inferencing in addition to top-down predictions. The reason is that informativity is often considered one main driver of such inferencing (e.g. Frank & Goodman, Citation2012) and expressions that are more predictable than others as descriptions of some context tend to also be more informative about that context.
In terms of the distinction between linguistic and non-linguistic context effects, one could, arguably, consider effects of sentential filler items as still linguistic in nature. However, determining the set of alternatives that underlie pragmatic enrichment processes and their relative salience has also been shown to involve non-linguistic properties of the context, e.g. purely perceptual ones (see Frank & Goodman, Citation2012; Qing & Franke, Citation2015; van Tiel et al., Citation2021 for discussion and for data-driven approaches to determining salience of alternatives). In contrast, we focus on the question of whether the recent frequency of encounter with certain utterance types, e.g. in the context of an experiment, affects the time course of semantic commitments regarding quantificational restriction the parser is willing to make during online comprehension of quantified sentences.
By investigating frequency effects, our studies are also closely related to studies investigating adaptation effects in syntactic ambiguity resolution. Initial support for rapid adaptation to frequencies in the stimulus set was obtained by Fine et al. (Citation2013), who investigated the online resolution of syntactic ambiguities during the processing of garden-path sentences. Their results indicate that rapid adaptation to the frequency with which certain syntactic structures are presented during the course of an experiment may affect how similar structures are processed in subsequent trials and may thus also affect the conclusions that are drawn from the experimental results. Whether this initial indication of adaption effects in syntactic parsing does withstand further experimental scrutiny is, however, still undecided. In a recent study, Harrington Stack et al. (Citation2018) failed to replicate the adaptation effects of Fine et al. (Citation2013) in experiments using slightly modified designs. Whether, or to which degree, the data of Harrington Stack et al. (Citation2018) challenge conclusions presented by Fine et al. (Citation2013) is currently debated (see the preprint in Jaeger et al., Citation2019).
Finally, Fernandes et al. (Citation2018) studied the resolution of anaphoric reference and modulated the frequencies of different kinds of antecedents. By comparing two closely related languages, they showed how prior statistical knowledge is integrated with statistical knowledge obtained during the course of the experiment.
In sum, previous studies have shown that contextual adaptations may proceed rapidly, and that, as a consequence, non-linguistic contextual cues may have an effect on on-line sentence comprehension. The current experiment examines whether such effects, namely adaptation to frequency, may also interact with on-line compositional-semantic processing, as evidenced by the processing of quantifier domain restriction related to the German quantifier alle (“all”). Moreover, as data about the neurolinguistic correlates of adaptation effects is still scarce, we carried out an ERP study testing whether such effects immediately constrain the sentences truth evaluation, as evidenced by the amplitude of the N400 component.
2. Experiment: adaptive revision sensitivity?
The present ERP study investigates the effects of non-linguistic contextual information on on-line compositional-semantic processing. We examined experiment-inherent adaptation effects on the processing of quantifier restriction in German. To this end, we conducted a follow-up study to a previous experiment (Augurzky et al., Citation2017). In the current experiment, we changed the frequency in which particular constructions were presented relative to this earlier study. Specifically, we tested whether an increased proportion of experimental items (i.e. short sentences without extra restrictive cues) to filler items (i.e. long sentences with restrictive cues in the form of extraposed relative clauses) could be a salient contextual cue for eliciting incremental effects in sentences that have been shown to be processed in a delayed fashion in Augurzky et al. (Citation2017). In the previous experiment, frequency effects were counterbalanced by presenting a 1:1 ratio of experimental items to fillers, and in the current study, we induced a bias against restriction by means of a 4:1 ratio between the two sentence types.Footnote1 Thus, by comparing the results from the present study with the original experiment, we examined whether the on-line comprehension of sentences involving the quantifier all is affected by statistical regularities in the experimental context.
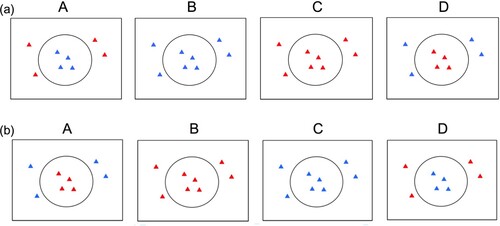
In Augurzky et al. (Citation2017), the processing of questions like (1) was investigated that were presented in the context of a picture showing coloured objects, e.g. triangles, placed inside or outside a container shape, e.g. a circle. At the beginning of each trial, one of four visual contexts () was presented, which was followed by a question containing the quantifier alle (“all”). Half of the sentences were followed by an extraposed restrictive relative clause. The other half ended earlier in the sentence, i.e. on the colour adjective.
Figure 1. Example of visual contexts preceding the target questions in Augurzky et al. (Citation2017) and the present study. A: complex, match inside; B: simple, true; C: simple, false; D: complex, match outside. (a) Example picture presented with adjective blue and (b) example picture presented with adjective red.
(1) Sind alle Dreiecke blau (, die außerhalb des Kreises sind) ?
Are all triangles blue (that outside of the circle are) ?
Are all triangles (that are outside of the circle) blue?
In that kind of setting, a truth-value judgment is, in principle, possible on the colour adjective blue, but it may have to be revised later on if a further restriction is given in the form of a restrictive relative clause. Augurzky et al. (Citation2017) found evidence for incremental truth evaluation on the colour adjective in the form of a reduced N400 for true vs. false sentences (i.e. questions involving true vs. false answers)Footnote2. However, this effect was sensitive to the risk of a potential revision, i.e. a change in truth-value: Whenever an extraposed relative clause could lead to a change in truth-value (e.g. when all and only the triangles outside the container shape were blue), the N400 amplitude was in between unambiguously true and false sentences (i.e. questions involving unambiguously true vs. false answers), suggesting a non-incremental truth evaluation for the ambiguous conditions. Augurzky et al. (Citation2017) interpreted this pattern of results as an indication of revision-sensitive incrementality: The processor plans ahead and only commits to an interpretation if there is no substantial risk to revise that interpretation later on.
Our specific motivation for the present study was thus to test whether the N400 effects observed by Augurzky et al. (Citation2017) are sensitive to the overall frequency of restrictive relative clauses presented during the course of the experiment. To test this, we replicated their experiment with a reduced proportion of extraposed relative clauses. In particular, the only difference between the two experimental designs was the number of restricted vs. non-restricted sentences. The present experiment only differed from the original experiment in the relative frequency of sentences with and without extraposed restrictive relatives.Footnote3
In our current study, we again presented one of the four visual contexts in , and then a question containing the quantifier alle (“all”). In each picture, geometrical objects, e.g. triangles, were presented inside and outside of a shape containing these objects (e.g. a circle). As in Augurzky et al. (Citation2017), the visual contexts were either simple (B, C), or complex (A, D). In the simple pictures, all geometrical objects were of identical colour, and in the complex pictures, objects inside and outside of the container shape differed in colour and either matched or did not match the colour mentioned in the sentence. Specifically, while the contexts in (a) were always presented with the colour adjective blue as in Alle Dreiecke sind blau (“All triangles are blue”), we also included a second item set ((b)), in which the sentences were presented with the colour adjective red as in Alle Dreiecke sind rot (“All triangles are red”). Contrary to Augurzky et al. (Citation2017), 80% of all questions ended directly on the colour adjective, and only 20% involved a further restriction. As we were particularly interested in the effects of our frequency manipulation on the processing of the colour adjective across studies, we averaged ERPs from the onset of the colour adjective (e.g. blue) in the current experiment and compared these results with the previous results reported in Augurzky et al. (Citation2017). In , the complete sentence materials used in the current study are summarised and compared to the reference study of Augurzky et al. (Citation2017).
Table 1. Summary of the design and materials of the present experiment and the reference study of Augurzky et al. (Citation2017).
The comparison between the current study and the previous one by CitationAugurzky et al. allows us to compare the predictions of two theoretical accounts of frequency-driven adaptation effects. First, under a truly revision-sensitive account, one would expect an increasing likelihood of incremental effects in conditions involving a potential change in truth value if the risk of a revision is reduced. In the experiment reported below, we tested this prediction by comparing the current results with those reported in Augurzky et al. (Citation2017). Second, we also considered the predictions derived from an alternative account that is based on predictive processing. In this second alternative, the N400 is not taken as an indication of the commitment to a semantic interpretation but rather of expectations about upcoming lexical items, as was already sketched above.
2.1. Hypotheses and predictions
The purpose of the present experiment was to contrast two hypotheses. The first hypothesis, which we call Strict Revision Sensitivity, is derived from Augurzky et al. (Citation2017). According to this hypothesis, the processor only commits to a semantic interpretation (i.e. a truth value or answer in the context of the present experiment) if it does not run the risk of a later revision to that interpretation. For example, consider the position of the colour adjective in (1). If sentence (1) is processed in the context of a picture that shows only red triangles (e.g. context C: the simple, false condition), the truth value is unambiguously false. Thus, a semantic commitment (i.e. a commitment to a truth value or answer) is safe and can be made without the risk of a later revision. In contrast, revising the interpretation of the sentence may be necessary if the sentence is processed in the context of a picture like context D (complex, match outside) that shows red triangles within a circle but blue ones outside of it. In that case, the local truth value on the colour adjective would again be false. However, if the sentence is continued as shown in (1) where the interpretation of the quantifier is restricted to the triangles outside of the circle, the local truth value would have to be revised from false to true on the colour adjective. Note that Strict Revision Sensitivity depends on the meaning of the quantifier, the utterance context and also on the possibilities a language offers for delayed restriction (e.g. in the form of an extraposed restrictive relative clause in German), but it is completely independent of frequency information about how likely a later revision in interpretation actually is in a particular context.
By contrast, our second hypothesis, which we call Frequency-Driven Adaptivity takes frequency information into account and states that incremental processing is sensitive to how likely revisions in interpretation actually are in the specific context in which a sentence is processed. For instance, according to this view, comprehension processes associated with the processing of the adjective in (1) in visual contexts C (simple, false) vs. A (complex, match inside) and D (complex, match outside) are hardly distinguishable from each other if the probability of encountering further restriction, e.g. in the form of a relative clause, is very low. There are various possible ways of spelling out Frequency-Driven Adaptivity. In the following, we will focus on two of these possible refinements. First, we could think of interpretation processes in terms of probabilistic (in contrast to deterministic) semantic commitments and assume that a lower risk of revision would lead to a higher probability of a local semantic commitment to a truth value at the position of the adjective. We call this first version Frequency-Driven Adaptivity in Judgments. Second, we could spell out Frequency-Driven Adaptivity in terms of expectation-based pragmatic processing. In particular, we could draw on the uncontroversial assumption that during language comprehension, expectations for upcoming words are constantly updated based on prior knowledge and the current linguistic input. But how does the meaning of the current linguistic input determine such expectations? One common and straightforward assumption would be that listeners expect true utterances. This assumption can be motivated by basic pragmatic principles (e.g. the Gricean, Citation1975, maxim of quality or a tendency to communicate about salient aspects of the environment, e.g. Frank & Goodman, Citation2012). If we do in fact assume that true utterances are expected, or in the case of yes-no questions, questions asking about propositions about the world that are actually the case, we arrive at another version of Frequency-Driven Adaptivity. In that version, words are the more expected, the more ‘true’ sentence continuations they still allow. We call this second version Frequency-Driven Adaptivity in Expectations. These alternative versions of Frequency-Driven Adaptivity are elaborated and related to the results of the current experiment in the discussion section below. To preview one aspect of this discussion, we would like to highlight that the assumption of an expectation for ‘true’ utterances is somewhat challenging to relate to the processing of questions. This is because questions are, by themselves, not true or false in a given context but rather, usually, ask for information about that context that is unknown but relevant to the speaker. Nevertheless, we would like to maintain that, if we consider listeners' expectations about continuations of questions, continuations that are in some sense related to the context are plausible candidates and that this relatedness between a question and the context is, in turn, in a general sense rooted in propositions that are true of the context.Footnote4 In the discussion section and in Appendix C, we compare several alternatives of how this relatedness between question and context could be spelled-out under Frequency-Driven Adaptivity in Expectations. These alternatives range from expectations due to superficial lexical matching or salience (e.g. blue is expected if blue objects are shown in the context picture) to strictly truth-value based expectations (i.e. continuations are expected that trigger a “yes, true” response) and we discuss how well these various options explain our experimental results. Taking the importance of truth in deriving expectations about continuations of questions for granted for the moment, the shared prediction of Frequency-Driven Adaptivity in Judgments and Frequency-Driven Adaptivity in Expectations is that comprehension processes should be sensitive to how likely revisions in semantic interpretation are in the specific context in which a sentence is processed.
In sum, comprehension processes should be unaffected by frequency information under Strict Revision Sensitivity. As a matter of fact, the basic pattern of results of Augurzky et al. (Citation2017), in particular the intermediate N400 amplitude of the complex in comparison to the simple contexts, should replicate in the setting of the present experiment even though the probability of encountering a restrictive relative clause is substantially reduced. By contrast, Frequency-Driven Adaptivity lets us expect that comprehension processes quickly adapt to changing frequencies in the language input. As a consequence, processes associated with reading the colour adjective in sentences like (1) should diverge less strongly between contexts like C (simple, false) and contexts like A (complex, match inside) or D (complex, match outside) in the current as compared to the reference study because continuation that would still lead to a “yes, true” response are less likely in the present experiment. Thus, Frequency-Driven Adaptivity lets us expect that the difference in N400 amplitude between the simple, false and complex conditions should be reduced in the present as compared to the reference study by Augurzky et al. (Citation2017).
2.2. Methods
2.2.1. Participants
Twenty-four right-handed students from the University of Tübingen took part in the study. They were native speakers of German with normal or corrected-to-normal vision and were paid for their participation. Two of the participants were excluded from the final analyses due to excessive ocular or muscular artefacts, so that 22 participants entered the final analyses (mean age: 23.4; SD = 3.1, years, 9 male).
2.2.2. Materials
A one-factorial within-subjects design was used with the factor context (levels: A (complex, match inside), B (simple, true), C (simple, false) and D (complex, match outside)). Pictures were generated as quadruplets via MS PowerPoint. Each picture contained geometrical objects like triangles and a container shape like a circle. Geometrical objects were both inside and outside of this shape. For each quadruplet, the geometrical forms were identical but differed in colour. A total set of 40 quadruplets were generated. Per condition, 40 experimental picture-question pairs were presented, resulting in 160 experimental sentences. Of these experimental sentences, eight sentences per condition were presented with a further restriction, as shown in . Four of these sentences were presented with the preposition innerhalb (“inside-of”), and four with the preposition außerhalb (“outside-of”). These long sentences were treated as filler items. As a result, 32 short sentences per condition entered the final EEG analyses, resulting in a total of 128 experimental sentences in which ERPs were aggregated. Conditions were evenly spread over 4 blocks. To control for positional effects, two experimental versions were generated. The first block of the first version corresponded to the final block of the second version, the second block of version 1 corresponded to the third block of version 2 and so on.
2.2.3. Procedure
Prior to the experiment, participants received written instructions informing them about the experimental task. According to these instructions, participants had to perform a truth evaluation, i.e. they had to decide whether the preceding sentence truly or falsely reflected the content of the picture. After processing the written instructions, participants were seated in a dimly-lit, sound-shielded booth in front of a 17” computer screen. Stimuli appeared in a pseudo-randomised fashion. The experimental session was divided into four blocks (40 trials per block), with breaks between each of the blocks. At the beginning of a trial, the context picture appeared in the centre of the screen for 1500 ms. After the context picture was removed from the screen, the question was shown in a word-by-word manner via RSVP (500 ms per word). The following question mark or comma was presented as a separate segment (also 500 ms) in order to avoid the predictability of a further restriction. After each sentence, participants performed their truth evaluation: After the final word had disappeared, three question marks were shown, indicating that participants now should answer with “wahr” (true) or “falsch” (false) by pressing one of two buttons (“F” or “J”) on the keyboard. The keys for true and false answers were counterbalanced across participants. Participants were encouraged to make their truth evaluations as quickly as possible. The initial above timeout was 1200 ms and was adapted to the participants' response speed by employing an exponentially weighted moving average (Leonhard et al., Citation2011). When participants' reaction times exceeded the current timeout, they received visual feedback (Schneller!, “faster”) on the screen. Following each judgment, a blank screen appeared for 500 ms and three exclamation marks in yellow (1200 ms) signalled that participants now could blink until the next picture was presented. A practice session consisting of eight trials preceded the experimental session. Practice trials were designed analogously to the target items in the experiment but contained different geometrical shapes. Moreover, they contained an equal number of yes and no answers and of short and long sentences. Including electrode application, the experimental session lasted between 1 and 1.5 hours.
2.2.4. EEG recording
The EEG was continuously recorded using a BIOSEMI Active-Two amplifier system. Thirty-two Ag/AgCl electrodes were recorded: FP1, FP2, AF3, AF4, F7, F3, Fz, F4, F8, FC5, FC1, FC2, FC6, T7, C3, Cz, C4, T8, CP5, CP1, CP2, CP6, P7, P3, Pz, P4, P8, PO3, PO4, O1, Oz, O2. Six further electrodes were registered: The electrooculogram (EOG, 4 electrodes) was registered by means of electrodes placed at the outer canthus of each eye (horizontal EOG) and above and below the participant's left eye (vertical EOG). In addition, two electrodes were put on the left and right mastoid for off-line referencing. EEG and EOG recordings were sampled at 1024 Hz during recording and downsampled to 256 Hz for data analysis. Off-line, electrode sites were referenced to averaged mastoids. Before entering the ERP analysis, individual participant data were automatically and manually screened for each trial in order to exclude trials with eye movement and muscular artefacts. Data below or above a threshold of 40 microvolts were automatically excluded from the analyses, and muscular and other artefacts that were not covered by this exclusion were manually rejected. The averages were aligned to a 100 ms pre-stimulus baseline. Data per participant and per condition were aggregated from the onset of the colour adjective to 1000 ms post onset. Afterwards, grand averages were calculated over all participants.
2.2.5. Data analysis
To analyse reaction times (RT), a repeated measures analysis of variance (ANOVA) with the within-subject factor context (levels: A (complex, match inside), B (simple, true), C (simple, false) and D (complex, match outside)) was computed. To analyse the truth-value judgments, logit mixed-effects models with the same factor as fixed effect and random intercepts for participants and items as well as random slopes for items were sed.Footnote5 ERPs were aggregated from the onset of the colour adjective. EEG data were analysed statistically by carrying out repeated-measures ANOVAs for mean amplitude values per condition within a 300–400 ms time window which was chosen based on previous studies on truth evaluation tasks related to quantifier processing (e.g Augurzky et al., Citation2017; Augurzky, Schlotterbeck, et al., Citation2020). For the Grand ANOVA, four regions of interest (rois) were introduced: left anterior (Roi 1: F3, F7, FC1, FC5), right anterior (Roi 2: F4, F8, FC2, FC6), left posterior (Roi 3: CP1, CP5, C3, P3) and right posterior (Roi 4: CP2, CP6, C4, P4). From the onset of the colour adjective, we carried out ANOVAs with the factor context (levels: A (complex, match inside), B (simple, true), C (simple, false), D (complex, match outside)) × roi (left anterior, right anterior, left posterior, right posterior).
Individual conditions are only reported if the omnibus ANOVA revealed significant interactions or in case of significant main effects of the factor context. The detailed results of all ANOVAs are provided in the Appendix A. In the text, we will focus on the most relevant results. Only significant interactions (p<.05) were resolved. Corrected p-values (Huynh & Feldt, 1970) were chosen when the analysis involved more than one degree of freedom in the numerator. P-values were Bonferroni adjusted for the planned comparisons between the four levels of the factor context.
2.3. Results
2.3.1. Behavioural data
Mean RT and accuracy for the verification task are given in (a,b), respectively (within-subjects standard errors were computed using the R function summarySEwithin from the Rmisc package; Hope, Citation2013). Mean error rates in the truth evaluation task were 6.8%, reflecting overall good task performance. The logit mixed-effects model analysis revealed a significant effect of context (). This effect was computed on the basis of a model comparison with a simpler model that did not contain the fixed effect. Bonferroni-corrected pairwise comparisons revealed significant differences between all conditions (all corrected p<.05). While comparisons between binary judgment data that are so close to ceiling may be difficult to interpret, we take the difference between the true simple (B) and all the false (A, C and D) conditions as an indication of an overall bias to respond “false”. Such a bias may have been induced by the fact that “false” was the correct response in
of the trials. That participants indeed showed a bias to respond “false” in the current experiment was corroborated in an analysis of indices from Signal Detection Theory (SDT; see Wickens, Citation2001, for an introduction and Huang & Ferreira, Citation2020 for a recent psycholinguistic application).Footnote6 We also computed
as an index of sensitivity and
(see e.g. Wickens, Citation2001, p. 27; same index called c by Huang & Ferreira, Citation2020) as an index of bias. These two indices were computed separately for the short sentences, the long sentences in combination with complex contexts and the long sentences in combination with simple contexts (see (d)). The reason for collapsing conditions into groups in this way was that expected responses differed between them correspondingly (see ). As indicated by
values between 2 and 3, sensitivity was good across all three groups of conditions. The long sentences, in combination with simple contexts, led to the lowest sensitivity. In comparison, a simple linear mixed-effects model analysis revealed that the long sentences in combination with complex contexts led to significantly higher and the short sentences to marginally higher sensitivity (t = 3.05; p = .003 and t = 1.93; p = .061, respectively). Concerning bias, positive values of
indicate a bias to say “no” (in our setting “no” corresponds to the judgment “false”). The long sentences in combination with complex contexts showed no bias towards either response at all, whereas the short sentences and long sentences with simple contexts showed the “false” bias we had conjectured and both differed significantly form the former conditions (t = 7.23; p<.001 and t = 3.01; p = .004, respectively). Coming back to the accuracy data in (b), the difference between the simple (B, C) and complex (A, D) conditions can be explained if we assume that participants in some trials misremembered the colours shown in the pictures. For the short sentences, which we analysed here, mixing up colours (e.g. blue vs. red) would lead to an incorrect response in the simple but not the complex conditions. RT did not differ reliably between conditions (
). RT are, however, difficult to interpret in our task because responses could be prepared even before the end of a trial and the onset of RT measurement.
Table 2. Behavioural results.
2.3.2. Colour adjective
shows ERPs from the onset of the colour adjective. Conditions differed within the early (300–400 ms) N400 time window (cf. Augurzky et al., Citation2017, Citation2019; Augurzky, Hohaus, et al., Citation2020; Augurzky, Schlotterbeck, et al., Citation2020).Footnote7 The detailed results of the ANOVA are provided in Appendix A.
Figure 2. Grand average ERPs from the onset of colour adjective. As before and throughout, context label A stands for complex, match inside; B stands for simple, true; C for simple, false; and D for complex, match outside.
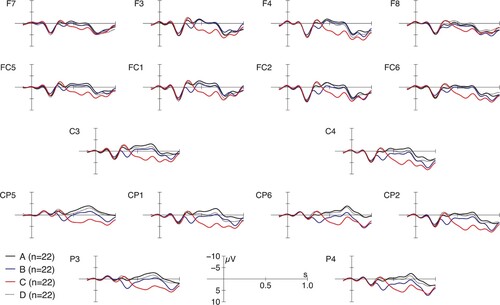
Statistical analyses revealed a significant main effect of context (). Complex conditions (A, D) did not differ from each other (p = 1) and from the simple, false condition (C; both p = 1), each of these conditions differed from the simple, true condition B (A vs. B:
; B vs. D:
). Moreover, the simple, true and the simple, false conditions also differed from each other (B vs. C:
). Additionally, an interaction between roi and context was found (
), showing that the observed main effects were most pronounced in the posterior Rois 3 and 4 (see Appendix A, for the complete statistical analyses).Footnote8
2.3.3. Comparison to Augurzky et al. (Citation2017)
To enable direct comparison with the results from the reference study by Augurzky et al. (Citation2017), we included a plot showing ERPs from the onset of the colour adjective in that study (). In the N400 time window, Augurzky et al. (Citation2017) found significant differences between the two complex conditions (contexts A and D) and the simple false condition (context C), on the one hand, as well as the simple true condition (context B), on the other.Footnote9
Figure 3. Grand average ERPs from the onset of colour adjective in the original experiment (based on the data set by Augurzky et al., Citation2017, baseline-corrected). As before and throughout, context label A stands for complex, match inside; B stands for simple, true; C for simple, false; and D for complex, match outside.
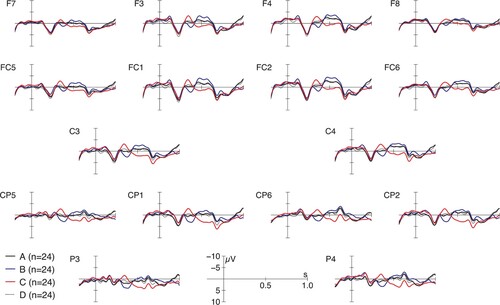
Frequency-Driven Adaptivity predicted a decreased difference in N400 amplitude between simple false (C) and complex (A & D) conditions in the current experiment as compared to the reference study. This comparison is thus most directly relevant to our present research question. The absence of a significant difference in the present but not the previous experiment that we observed is compatible with Frequency-Driven Adaptivity. However, comparison between p-values obtained from two hypothesis tests conducted on two separate data sets is known to be problematic (cf. Wagenmakers, 2007) and does, in itself, not constitute a direct statistical test. For this reason, we carried out a direct statistical test of Frequency-Driven Adaptivity in an analysis comparing effects between the two experiments.Footnote10
To test for the predicted interaction between the factors experiment and context, we conducted a linear mixed-effects model analysis on the basis of participants' mean voltage in the N400 time window. In this model, fixed effects of context and roi were included as within-participants effects and a fixed effect of the experiment was included as a between-participants effect. The main prediction that followed from Frequency-Driven Adaptivity was that the difference between the simple, false context (C) and the two complex contexts (A & D) would be smaller in the present experiment than in the original study of Augurzky et al. (Citation2017). We tested this prediction using orthogonal custom contrasts: In the first step, we simplified the global model, including all simple effects and interactions, as long as such simplification did not worsen model fit significantly. In the second step, we performed a hypothesis test for the specific interaction between the experiment and a contrast encoding the comparison between the simple, false (C) and complex (A & D) conditions (see Appendix B). Crucially, this interaction was highly significant in the final model (t = 7.18, p<.001) because, as predicted by Frequency-Driven Adaptivity, the difference between the simple, false context (C) and the two complex contexts (A & D) was smaller in the present experiment than in the reference study. Thus, the main prediction of Frequency-Driven Adaptivity is borne out, rendering an alternative explanation of the present findings, e.g. in terms of insufficient statistical power, implausible.
3. Discussion
The current ERP study examined the neurophysiological correlates of contextual adaptation effects in the on-line comprehension of quantified sentences following visual contexts. On a general level, our main finding is that non-linguistic experiment-inherent frequency distributions can immediately modulate the amplitude of the N400, analogous to previous studies on speaker reliability (Brothers et al., Citation2019). Our study adds to these previous findings by focusing on compositional-semantic processing. Based on previous experiments, we tested whether experiment-inherent frequency distributions may exert an immediate effect on processes related to determining the restriction (i.e. the domain of quantification) of sentences containing the German universal quantifier alle (“all”). In contrast to previous studies, we directly compared the current results to another experiment (Augurzky et al., Citation2017) that was completely identical except for the frequency manipulation. Our results indicate that non-linguistic contextual cues from beyond the sentence boundary immediately affect restrictive processes in quantifier interpretation. The time course of these processes appears to depend on how often further restriction is provided in the experimental context, e.g. in the form of extraposed restrictive relative clauses. Only if this happens relatively infrequently, is the comprehender ready to commit to a semantic interpretation immediately, as reflected in the observed modulation of the N400 amplitude.
In principle, our results seem compatible with recent considerations on the online processing of scalar implicatures. Based on visual-world eye-tracking, Huang and Snedeker (Citation2018) argued that, depending on the context, top-down and bottom-up processes differentially contribute to the interpretation of sentences containing the scalar quantifier some. When filler items like the numeral two are included in an experiment, they may constitute highly salient and even more informative alternatives for referent description than scalar some. As a consequence, the expectancy for two as a description for “subsets” is stronger than for its competitor some in such cases. This results in a local slow-down in the processing of the scalar, and in particular a slow-down in reference resolution, because the scalar cannot simply be matched to the anticipated referent description. By contrast, in the absence of numerals, some is anticipated as a “subset” description already before the position of the quantifier, and no such slow-down is observed. There are, however, a number of differences between the current study and the study of Huang and Snedeker (Citation2018). Most importantly, we did not investigate lexical alternatives but the effects of larger constituents (namely extraposed restrictive relative clauses) and their frequency. Despite this difference, one could argue that the probability of encountering a particular construction might have affected the relative contribution of top-down vs. bottom-up processing from early on in the sentence. For instance, one could assume that in the current experiment, top-down predictions of an early sentence closure were particularly strong.
The more specific purpose of our study was to decide between two hypotheses that could explain the previous results from Augurzky et al. (Citation2017). In that study, the same picture-sentence pairs as in the current one, albeit with a different proportion of sentences containing restrictive relative clauses, were used to investigate whether and how the truth evaluation of quantified sentences affects the N400. In contrast to the present study, extraposed relatives providing extra restrictive cues appeared in half of the trials. At the position of the colour adjective, a reduced N400 for true vs. false sentences was observed for the simple conditions, where an additional restriction could not trigger a meaning shift in the locally assigned truth value. By contrast, the amplitude for the adjective in complex conditions, which involved such a potential meaning shift, was in between the true and the false simple conditions. The authors interpreted this result as being indicative of a non-incremental truth evaluation for ambiguous conditions and proposed that it can be explained by an account based on revision-sensitive interpretation.
While Augurzky et al. (Citation2017) investigated whether there is a general tendency towards revision-sensitivity, the current study addresses a refinement of this question by examining whether revision-sensitivity can be affected by how large the risk of a potential revision actually is in a specific context. In order to address this open question, we manipulated experiment-inherent frequencies, and we contrasted two hypotheses (see Section 2.1) regarding ERPs on the colour adjective in the present study.
Our first hypothesis, Strict Revision Sensitivity (see Section 2.1), is derived from Augurzky et al. (Citation2017) and states that the processor only commits to a semantic interpretation (i.e. it performs a truth-value judgment) if it does not run any risk of a later revision to that interpretation. However, while CitationAugurzky et al. applied this hypothesis to an experimental setting in which frequencies of all the possible continuations were counter-balanced, the current study manipulated the ratio of sentences that ended on the colour adjective and sentences that continued with a restrictive relative clause. We reduced the number of relative clause continuations to test whether the parser more often commits to a risky interpretation if the chance of a following meaning shift is reduced. While Strict Revision Sensitivity offered an explanation of the effects in CitationAugurzky et al., it does not account for the present pattern of results without refinement. Though the experimental context in the present study was set up in such a way that the probability of potentially revision-inducing restrictive relative clauses was reduced relative to the experiment of CitationAugurzky et al., it was still non-zero and extraposed restrictive relative clauses still occurred in 20% of the trials. As a consequence, the risk of a meaning revision was also reduced but still not removed completely. As Strict Revision Sensitivity only takes into account whether a revision is possible at all, its predictions for the current experiment were the same as for CitationAugurzky et al.. In contrast to these predictions, the present results differ from those from CitationAugurzky et al.: In the current study, the N400 amplitude was indistinguishable between the complex conditions and the simple, false condition. Comparing the two experiments leads us to assume that the comprehension processes, as reflected by the N400, were affected by the extra-linguistic context, in particular by how large the risk of a later meaning revision actually was in the specific context. More specifically, the effects observed locally on the colour adjective indicate that comprehension processes are sensitive to how probable various sentence continuations and the associated global semantic interpretations actually are in a specific context.
The second hypothesis introduced above, Frequency-Driven Adaptivity, is consistent with the obtained results. The general idea behind this hypothesis is that incremental processing quickly adapts to various aspects of the linguistic and non-linguistic contexts, including frequency information about various types of potential sentence continuations. This makes the processor sensitive to how likely a revision in interpretation actually is in the specific context in which a sentence is processed. In the context of the present study, Frequency-Driven Adaptivity can be related to the concept of speaker reliability (cf. Brothers et al., Citation2019). Instead of adjusting to the surface frequencies of potential sentence continuations, we could also think of comprehenders as being adaptive to speaker reliability. In particular, there are two ways in which the (imagined) speaker in the present experiment could be considered unreliable. The first is by producing sentences that are not related in a straightforward way to the visual contexts, e.g. sentences that ask about aspects of the world that are not reflected in the visual contexts (more on this below). The second way in which the speaker can be unreliable is by producing sentences that contain shifts in meaning, i.e. questions in which the correct answer changes during incremental processing. Due to the semantic properties of the sentence materials we used, these two types of unreliablity are opposed to each other in the present experiment. We highlight connections between Frequency-Driven Adaptivity and the speaker reliability where they are relevant.
In Section 2, we briefly introduced two versions of Frequency-Driven Adaptivity, namely Frequency-Driven Adaptivity in Judgments and Frequency-Driven Adaptivity in Expectations. In the following, we discuss these hypotheses in light of our experimental results. The first version, Frequency-Driven Adaptivity in Judgments is based on the distribution of sentence-final truth-value judgments across the experiment and, more specifically, on expectations about what the final truth-value judgment will be in a given trial. According to that account, judging a sentence locally as true at a given sentence position during incremental processing will lead to a decreased N400 amplitude as compared to a local “false”-judgment.Footnote11 In addition, the decision about whether a commitment to a semantic interpretation is made, and thus about whether a truth-value judgment is performed, at a given sentence position, generally depends on what the sentence-final truth-value judgment is expected to be. In the present design, the final truth-value judgment is “false” in the majority of the trials. Under the assumption that the parser predicts this final truth-value at each sentential position, the experiment-inherent frequency distribution provides a strong contextual cue, which is expected to already affect the pattern observed mid-sentence, i.e. on the colour adjective. Therefore, the finding that the N400 amplitude in the complex conditions does not differ from the amplitude elicited by the simple false conditions could simply be explained in terms of a bias for “false”-judgments that leads to a higher proportion of local truth-value judgements. If it is true that frequency manipulations in the present study function in a similar manner as speaker reliability, the current results could reflect a scenario in which the comprehender adapts to a speaker who is unreliable in terms of producing a high proportion of false sentences, or rather questions that lead to the answer “false”. In the results section (Section 2.3), it was already established, using indices from SDT, that there was bias for “false”-judgments in the present experiment. A post hoc comparison to the same bias parameter c for the short sentences in Augurzky et al. (Citation2017) further revealed a significantly higher bias in the present vs. the previous study (means (and sds): .150 (.269) vs. .289 (.109); t = 2.244; p = .030). Thus, we observed an adaptation in response bias that could plausibly also have led to an increased probability of committing to local “false”-judgments already when encountering the colour adjective during online comprehension.
Similarly, the observed effects could also be explained by taking into account how high the risk of a meaning revision is, irrespective of whether the final truth-value judgment will be “true” or “false”. Such an explanation would be based on a type of adaptivity that is driven by meaning shifts: Comprehenders in the present experiment could adapt to a speaker that produces a relatively small proportion of sentences containing meaning shifts. If we relate this type of adaptivity to speaker reliability, comprehenders would adapt to a speaker that is actually more reliable than in Augurzky et al. (Citation2017), in the sense that meaning shifts are avoided. Readers may be cautious in making early commitments if a later semantic revision is highly likely. But if revisions are unlikely in a given context, they may be more inclined to commit to an interpretation early on as this is likely to match the final interpretation. Interestingly, a speaker who is reliable in terms of a large proportion of sentence-final “true”-judgments is, in the context of the present experiment, at the same time unreliable in terms of mid-sentence meaning shifts. As our current design does not allow us to differentiate between these two types of reliability, both alternatives remain viable explanations that may, in fact, both simultaneously play a role in incremental semantic processing.
At any rate, the prediction of a truth-value-based version of Frequency-Driven Adaptivity would be an increased number of local “false”-judgments in the complex conditions of the present experiment since locally, on the colour adjective, the complex conditions are false. This type of account not only explains the results of the present experiment but is compatible with the entire set of results from Augurzky et al. (Citation2017) and from the present experiment: For the simple conditions, which did not involve any risk of a later revision, readers were expected to commit to an interpretation early on. In both studies, this was reflected in a decreased N400 amplitude for true vs. false conditions. By contrast, in the complex conditions, the likelihood of local commitments depends on expectations about sentence-final truth-value judgments, which we manipulated by controlling the frequency of extraposed restrictive relative clauses across experiments. In CitationAugurzky et al., extraposed relative clauses appeared with a probability of 50%. As a consequence, the risk of a semantic revision was relatively high and the probability of sentences that induce global “false”-judgments was relatively low. This may have led to a decreased likelihood of local semantic commitments in the complex conditions, explaining why the N400 amplitude for the simple conditions was in between the N400 elicited by the simple true and simple false conditions. In the present experiment, in which relative clauses appeared only with a probability of 20%, local semantic commitments to “false”-judgments were, by contrast, expected to occur more frequently and thus N400 amplitude in the complex conditions were expected to fall closer together with the amplitudes in the simple false conditions.
The second version of Frequency-Driven Adaptivity, i.e. Frequency-Driven Adaptivity in Expectations, provides a conceptually different explanation of the observed effects in terms of expectation-based pragmatic processing. In particular, it is assumed that the N400 amplitude reflects the probability of encountering a specific sentence continuation in context, and an N400 effect is expected if there is a sufficiently large difference in the probabilities assigned to two potential sentence continuations (e.g. Augurzky et al., Citation2019). In order to assign probabilities to sentence continuations, we distinguish between (i) prior probabilities, i.e. expectations that are based solely on statistical regularities in the language but do not take into account contextual information, and (ii) posterior probabilities which are updated according to contextual cues (cf. Kuperberg & Jaeger, Citation2016, and references therein). Contextual cues include linguistic cues like the local sentence context as well as non-linguistic cues like the visual context and also the context of an entire experiment, including frequency information about the distribution of different types of sentence continuations in the experiment. In the following paragraphs, we sketch how the observed effects can be explained along these lines (details are given in Appendix C).
We start with a rather simple model in which the set of potential sentence continuations is restricted to those that actually occurred in the experiments (cf. Augurzky et al., Citation2019). We assume that a relatively low prior probability, , is assigned to sentence continuations, sc, with extraposed relative clauses (cf. Figure C1 in the appendix). Moreover, since relative clause continuations did, in fact, occur with a relatively low frequency in the present experiment, we assume that these prior probabilities are not modulated strongly, such that the prior probabilities
are roughly identical to the probabilities of the various sentence continuations in the present experiment,
. In Augurzky et al. (Citation2017) we assume a larger divergence between
and
, such that extraposed restrictive relative clauses are assigned a relatively high probability.
Next, we assume that the posterior probabilities over possible sentence continuations in visual context c are derived from the probabilities according to the following formula, where
is equal to 1 if the complete sentence s is true (resp. the answer to the question is “yes”) in context c and 0 otherwise.
Deriving expectations about sentence continuations in this way is not uncommon (e.g. Augurzky et al., Citation2019, for further motivation see Appendix C), but it is not sufficient to account for the differences between our current findings and Augurzky et al. (Citation2017). The reason is that only continuations that were actually presented in the experiment are considered and among these only those that lead to “yes”-answers remain viable options. As a consequence, the only possible continuations after having processed the sentence beginning Are all the triangles… following the complex context A would be either blue that are inside of the circle or red that are outside of the circle. Both of these continuations are assigned a probability of 0.5, irrespective of how probable the extraposed relative clauses would have been in the absence of a visual context.
We would like to discuss two ways in which this simple expectation-based model can be extended in order to capture the observed differences between (Augurzky et al., Citation2017) and the present experiment. The first is by integrating adaptations to speaker reliability and the second is by incorporating sentence continuations that never actually occurred in the experiments.
Adaptations to speaker reliability can be integrated into the model by modulating how strongly depends on sentence meaning (see the appendix for details). We could assume that comprehenders in the present experiment adjust to a speaker who is unreliable in the sense of producing relatively many non-matching sentences (i.e. the first type of reliability from above). For illustration, consider context C (i.e. the simple false condition). If readers pay little attention to sentence meaning, then, in that context, a relatively high probability would still be assigned to sentence continuations starting with the colour adjective blue. This would lead to a decreased N400 amplitude in that condition and, in turn, decrease the difference in N400 amplitudes between condition C and the complex conditions A/D, as was actually observed in the present experiment.
Alternatively, our results could also be explained by incorporating continuations into the model that never actually occurred in the experiments. An example of such a continuation following the sentence beginning Are all the triangles… would be of comparable size. If an increasing probability is assigned to continuations of this kind, readers' expectations of colour adjectives in the complex contexts vanish. The reason is that among our sentence continuations (all starting with colour adjectives) only those containing relative clauses match the visual contexts and relative clauses are by themselves relatively improbable continuations. Under these assumptions, it does indeed make a difference how probable continuations with relative clauses actually are in the context of the experiment. The more probable they are the more expected are the colour adjectives. Thus, differences between N400 amplitudes in the simple false and in the complex conditions depend on the frequency of relative clauses and the observed effects are explained.
At this point, we would like to point out one noteworthy consequence of the just described version of Frequency-Driven Adaptivity. Recall that, in the introduction, the experimental context was considered a microcosm that can be controlled by the experimenter to simulate adaptation effects in language processing. Note, however, that the situation would be a bit more complicated, if the just described version of Frequency-Driven Adaptivity in Expectations is on the right track: How likely sentence continuations that never actually occur in an experiment are expected to be and, more importantly, how these expectations are affected by experiment internal frequency distributions are something that are difficult or maybe even impossible to control in an experiment.
Our current findings also highlight the relation between frequencies in more naturalistic settings, e.g. in corpora, and frequencies within an experiment. Taking for granted, as the current results indicate, that experiment-inherent frequencies affect processes during online language comprehension, the question arises of what role such frequency distributions should play in experimental design (see also Brothers & Kuperberg, Citation2020, for related discussion). On the one hand, one could aim for distributions that mimic natural frequencies, much like we did in the present study. This does, however, often lead to imbalances in experimental design, e.g. in terms of frequencies of different sentence types, word lengths, response biases or biases in interpretation. On the other hand, one may aim for balanced experimental designs. In that case, deviation from natural frequencies may, however, affect comprehension processes in undesirable ways, calling into question the generalisability of the experimental results. As long as explicit models of adaptation effects as reported above have not yet been established, we recommend to compare results obtained using both types of designs whenever possible.
Before moving on to our conclusions, we would like to address one potential concern regarding the validity of the present results and their interpretation, namely the possibility that participants had used an artificial lexical match-to-sample strategy rather than incrementally processing the sentences in a natural and compositional fashion. This point of criticism was already addressed in Augurzky et al. (Citation2017), who carried out a second ERP study to test this assumption. Crucially, the second study involved probe detection instead of a verification task. As a consequence, attention was guided to different positions across the entire sentence, and for successful task fulfilment, readers needed to process the sentence as a whole, as they could not know in advance which of the sentence positions would be probed. Crucially, the N400 effects in this study were replicated, suggesting that they could not have been the result of simple lexical processing strategy (see Augurzky et al., Citation2017, for further details). The possibility of lexical priming has also been extensively discussed in further previous studies, and we refer the reader to this literature, which involves highly comparable experimental designs and procedures. As a whole, the arguments discussed in these studies were based on considerations about potential quasi-compositional meaning representations that would be required to solve the experimental task (Augurzky et al., Citation2019; Augurzky, Hohaus, et al., Citation2020; Augurzky, Schlotterbeck, et al., Citation2020).
For the sake of the present discussion, we would like to additionally point out that the comparison between the current experiment and Augurzky et al. (Citation2017) in itself actually provides one of the strongest arguments against a non-compositional processing strategy. In particular, the mere finding that restriction frequency modulated the N400 amplitude on the colour adjective cannot be straightforwardly explained by referring to a simple lexical match-to-sample strategy. Moreover, if we do assume that participants in the Augurzky et al. (Citation2017) study waited for further information to combine it with the linguistic representation assembled thus far, at least some degree of compositionality is needed to explain the results we obtained. To see this, consider how the two properties expressed by the colour adjective and the preposition could be combined in principle. The simplest way to combine them is presumably their conjunction (e.g. ). If the processor would have integrated this conjunction into the sentence representation in a way that does not necessarily obey standard rules of compositional interpretation, representations like, e.g.
would have been possible. Such representations would, however, have yielded completely unexpected truth-value judgments that would not match our observations. In particular, such representations would have led participants to respond “false” in all conditions with restrictive relative clauses, amounting to an error rate of 100% in these conditions. By contrast, the type of representation that obeys standard rules of compositional interpretation, e.g.
, does explain the truth-value judgments we observed. Taken together, our results thus indicate that participants were more likely to delay their interpretation in order to wait for additional restrictive cues in the experiment of Augurzky et al. (Citation2017) as compared to the present one, and in case additional restriction was in fact provided, they integrated it into the sentence representation in a way that obeys the rules of compositional interpretation.
In conclusion, our present findings show that experiment inherent frequency distributions affect compositional semantic processes during online comprehension. We propose that, in the broadest sense, these effects are driven by expectations about upcoming linguistic material and the associated interpretations. We conclude that such expectations can actually be modulated by controlling the frequencies with which various types of sentences occur in an experiment. This type of sensitivity to frequencies may actually be an essential aspect of adaptations to different types of speakers or different kinds of contexts that comprehenders routinely perform during natural language processing. We have presented four possible accounts of these observations (two versions of Frequency-Driven Adaptivity in Judgments and two versions of Frequency-Driven Adaptivity in Expectations of lexical items in sentence continuations). Which of these accounts, if any, is correct cannot be decided on the basis of the data presented here and thus has to be left open for future research.
Supplemental Material
Download PDF (9.3 MB)Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data that support the findings of this study are openly available in the Tübingen Archive of Language Resources at https://hdl.handle.net/11022/0000-0007-EC4A-D.
Additional information
Funding
Notes
1 Augurzky et al. (Citation2017) had labelled the longer sentences with restrictive cues as “experimental items”, whereas their “filler items” did not contain restrictive relatives. The reason was that Augurzky et al. (Citation2017) were also interested in effects on the prepositions later in the sentence in addition to effects on the colour adjectives. In the present study, an analysis of the prepositions was, however, not feasible due to the lower number of sentences with restrictive relative clauses. For the analysis of ERPs on the colour adjectives, it does not make any difference whether short or long sentences are analysed because sentences did not differ up to the adjectives and the RSVP made any kind of preview of upcoming segments impossible.
2 Note that strictly speaking, and based on formal-semantic theory, the denotations of questions are more complex than those of declarative sentences. In fact, questions are often treated as sets of possible answers, which are “yes” and “no” for the simple polar questions used in the current experiment. We are aware of that fact, and we will use the expressions “true” and “false” throughout the manuscript as a cover term for “questions involving “yes” answers” and “questions involving “no” answers”.
3 An alternative explanation to the observed N400 pattern would be expectation-based. According to such a view, the simple, unicoloured contexts elicit a strong expectancy of a particular target word that is compatible with a “yes” answer. By contrast, predictions are weaker in the case of complex, bicoloured pictures. We will discuss this approach under the notion of “frequency-driven adaptivity in expectations” in the hypotheses and discussion sections below.
4 One motivation for this assumption is that listeners may try to prepare or anticipate their answers, e.g. yes, all triangles outside the circle are blue (cf. Bott et al., Citation2017) and that there are virtually no constraints on possible “no”-answers, rendering continuations leading to a “yes”-answer more expected than any individual continuation leading to a “no”-answer.
5 Including random slopes for participants led to “singular fit” (i.e. the estimated variances were close to zero) and did not improve model fit.
6 We would like to thank an anonymous reviewer for suggesting this post-hoc analysis to us.
7 We also carried out an additional analysis in a late time window (450–800 ms), analogous to the original study by Augurzky et al. (Citation2017). As amplitude differences in the later time window are likely to be task-related effects (see the discussion in Augurzky et al., Citation2017), we refrain from interpreting these results in the current study but provide them in the following footnote and Appendix A for the sake of comparison.
8 In the late time window, an effect of context () was found as well. Complex conditions did not differ from each other (p = 1), and neither did the simple, true condition B differ from condition D (complex, match outside; p = 1), or condition A (complex, match inside) from B (simple, true; p = .1). Each of the conditions, however, differed from condition C (simple, false; all: p<.001). Again, effect sizes differed in the single rois (roi× context interaction:
). In the posterior rois, the difference between condition A (complex, match inside) and B (simple, true) approached significance (p = .06 in Roi 3 and p<.05 in Roi 4).
9 Note that contrary to Augurzky et al. (Citation2017), where a high-pass filter was applied to the raw data without baseline correction, we used a ms baseline in the current study to correct for pre-stimulus activity. For the sake of a better comparison across studies, we re-analysed the data of CitationAugurzky et al.. with the same pre-stimulus baseline as in the current experiment. Due to this process, we excluded four participants from the original CitationAugurzky et al. study, as we had to manually re-analyse the data to exclude trials with extreme slow drifts. ERPs yielded by that analysis led to the same effects as in the results reported in Augurzky et al. (Citation2017) (see ).
10 We would like to thank an anonymous reviewer for pointing out to us that the absence of a significant effect in the present study is by itself hard to interpret. It does not imply the non-existence of the effect but could, instead, also be due to a lack of statistical power. We would like to add to this that Frequency-Driven Adaptivity actually does not predict the absence but rather a decreased magnitude of the effect in the present as compared to the previous experiment. This is one reason, besides others that are discussed in Froman and Shneyderman (Citation2004), Levine and Ensom (Citation2001) and Miller (Citation2009), we refrain from computing a power analysis but decided to carry out a direct statistical test, instead.
11 Asymmetries in processing true vs. false sentences could be explained based on fundamental ideas in logic, in particular computational logic, distinguishing between positive and negative judgments. Such asymmetries can be linked to the closed world assumption (see e.g. Lifschitz, Citation1985, Citation1996), which equates the negation of a proposition with the failure to derive that proposition from a given knowledge base. Interpreting negation in this way is central to efficient logic programming and has also been used successfully in modelling human reasoning and language understanding (Stenning & van Lambalgen, Citation2008; van Lambalgen & Hamm, Citation2005; and see also Baggio, Citation2018 for related research). It leads to an asymmetry between positive and negative judgments absent from classical logic and may thus provide a theoretical explanation for difficulties in processing false sentences that is based on the negative judgments themselves.
References
- Altmann, G., & Steedman, M. (1988). Interaction with context during human sentence processing. Cognition, 30(3), 191–238. https://doi.org/10.1016/0010-0277(88)90020-0
- Anderson, J. R. (1990). The adaptive character of thought. Erlbaum.
- Augurzky, P., Bott, O., Sternefeld, W., & Ulrich, R. (2017). Are all the triangles blue?–ERP evidence for the incremental processing of German quantifier restriction. Language and Cognition, 9(4), 603–636. https://doi.org/10.1016/j.cognition.2017.05.023
- Augurzky, P., Franke, M., & Ulrich, R. (2019). Gricean expectations in online sentence comprehension: An ERP study on the processing of scalar inferences. Cognitive Science, 43(8), e12776. https://doi.org/10.1111/cogs.12776.
- Augurzky, P., Hohaus, V., & Ulrich, R. (2020). Context and complexity in incremental sentence interpretation: An ERP study on temporal quantification. Cognitive Science, 44(11), e12913. https://doi.org/10.1111/cogs.12913.
- Augurzky, P., Schlotterbeck, F., & Ulrich, R. (2020). Most (but not all) quantifiers are interpreted immediately in visual context. Language, Cognition and Neuroscience, 35(9), 1203–1222. https://doi.org/10.1080/23273798.2020.1722846
- Aurnhammer, C., & Frank, S. L. (2019). Evaluating information-theoretic measures of word prediction in naturalistic sentence reading. Neuropsychologia, 134, Article 107198. https://doi.org/10.1016/j.neuropsychologia.2019.107198
- Baggio, G. (2018). Meaning in the Brain. The MIT Press. https://doi.org/10.7551/mitpress/11265.001.0001
- Bornkessel-Schlesewsky, I., & Schlesewsky, M. (2019). Toward a neurobiologically plausible model of language-related, negative event-related potentials. Frontiers in Psychology, 10(298). https://doi.org/10.3389/fpsyg.2019.00298.
- Bott, O. (2017). Context reduces coercion costs – evidence from eyetracking during reading. In Proceedings of the 39th Annual Meeting of the Cognitive Science Society. Cognitive Science Society.
- Bott, O., Augurzky, P., Sternefeld, W., & Ulrich, R. (2017). Incremental generation of answers during the comprehension of questions with quantifiers. Cognition, 166, 328–343. https://doi.org/10.1016/j.cognition.2017.05.023
- Brothers, T., Hoversten, L., Dave, S., Traxler, M., & Swaab, T. (2019). Flexible predictions during listening comprehension: Speaker reliability affects anticipatory processes. Neuropsychologia, 135, Article 107225. https://doi.org/10.1016/j.neuropsychologia.2019.107225
- Brothers, T., & Kuperberg, G. (2020). Word predictability effects are linear, not logarithmic: Implications for probabilistic models of sentence comprehension. Journal of Memory and Language, 116. https://doi.org/10.1016/j.jml.2020.104174
- Brothers, T., Swaab, T., & Traxler, M. (2017). Goals and strategies influence lexical prediction during sentence comprehension. Journal of Memory and Language, 93, 203–216. https://doi.org/10.1016/j.jml.2016.10.002
- Chambers, C. G., Tanenhaus, M. K., & Magnuson, J. S. (2004). Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30(3), 687–696. https://doi.org/10.1037/0278-7393.30.3.687
- DeLong, K. A., Urbach, T. P., & Kutas, M. (2005). Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8(8), 1117–1121. https://doi.org/10.1038/nn1504
- Fernandes, E. G., Luegi, P., Correa Soares, E., & Hemforth, B. (2018). Adaptation in pronoun resolution: Evidence from Brazilian and European Portuguese. Journal of Experimental Psychology: Learning, Memory, and Cognition, 44(12), 1986–2008. https://doi.org/10.1037/xlm0000569
- Filik, R., & Leuthold, H. (2008). Processing local pragmatic anomalies in fictional contexts: Evidence from the N400. Psychophysiology, 45(4), 554–558. https://doi.org/10.1111/j.1469-8986.2008.00656.x
- Fine, A. B., Jaeger, T. F., Farmer, T. A., & Qian, T. (2013). Rapid expectation adaptation during syntactic comprehension. PloS One, 8(10), 1–18. https://doi.org/10.1371/journal.pone.0077661
- Fischler, I., Bloom, P. A., Childers, D. G., Roucos, S. E., & N. W. Perry, Jr. (1983). Brain potentials related to stages of sentence verification. Psychophysiology, 20(4), 400–409. https://doi.org/10.1111/j.1469-8986.1983.tb00920.x
- Frank, M. C., & Goodman, N. D. (2012). Predicting pragmatic reasoning in language games. Science, 336(6084), 998–998. https://doi.org/10.1126/science.1218633
- Frank, S. L., & Willems, R. M. (2017). Word predictability and semantic similarity show distinct patterns of brain activity during language comprehension. Language, Cognition and Neuroscience, 32(9), 1192–1203. https://doi.org/10.1080/23273798.2017.1323109
- Freunberger, D., & Nieuwland, M. S. (2016). Incremental comprehension of spoken quantifier sentences: Evidence from brain potentials. Brain Research, 1646, 475–481. https://doi.org/10.1016/j.brainres.2016.06.035
- Froman, T., & Shneyderman, A. (2004). Replicability reconsidered: An excessive range of possibilities. Understanding Statistics, 3(4), 365–373. https://doi.org/10.1207/s15328031us0304_9
- Geurts, B., & Van der Sandt, R. (1999). Domain restriction. In P. Bosch & R. Van der Sandt (Eds.), Focus: Linguistic, Cognitive, and Computational Perspectives. Cambridge University Press.
- Grey, S., & van Hell, J. (2017). Foreign-accented speaker identity affects neural correlates of language comprehension. Journal of Neurolinguistics, 42, 93–108. https://doi.org/10.1016/j.jneuroling.2016.12.001
- Grice, H. P. (1975). Logic and conversation. In P. Cole & J.L. Morgan (Eds.), Syntax and Semantics (Speech Acts Vol. 3, pp. 41–58). Academic Press.
- Grodner, D. J., Klein, N. M., Carbary, K. M., & Tanenhaus, M. K. (2010). “Some,” and possibly all, scalar inferences are not delayed: Evidence for immediate pragmatic enrichment. Cognition, 116(1), 42–55. https://doi.org/10.1016/j.cognition.2010.03.014
- Haase, V., Spychalska, M., & Werning, M. (2019). Investigating the comprehension of negated sentences employing world knowledge: An event-related potential study. Frontiers in Psychology, 10(2184). https://doi.org/10.3389/fpsyg.2019.02184.
- Hagoort, P., Hald, L., Bastiaansen, M., & Petersson, K. M. (2004). Integration of word meaning and world knowledge in language comprehension. Science (New York, N.Y.), 304(5669), 438–441. https://doi.org/10.1126/science.1095455
- Hagoort, P., & Van Berkum, J. (2007). Beyond the sentence given. Philosophical Transactions of the Royal Society B: Biological Sciences, 362(1481), 801–811. https://doi.org/10.1098/rstb.2007.2089
- Harrington Stack, C., James, A., & Watson, D. (2018). A failure to replicate rapid syntactic adaptation in comprehension. Memory and Cognition, 46(6), 864–877. https://doi.org/10.3758/s13421-018-0808-6
- Hope, R. M. (2013). Rmisc: Rmisc: Ryan miscellaneous (R package version 1.5) [Computer software manual]. Retrieved from https://CRAN.R-project.org/package=Rmisc.
- Huang, Y., & Ferreira, F. (2020). The application of signal detection theory to acceptability judgments. Frontiers in Psychology, 11(73). https://doi.org/10.3389/fpsyg.2020.00073.
- Huang, Y. T., & Snedeker, J. (2009). Online interpretation of scalar quantifiers: Insight into the semantics–pragmatics interface. Cognitive Psychology, 58(3), 376–415. https://doi.org/10.1016/j.cogpsych.2008.09.001
- Huang, Y. T., & Snedeker, J. (2018). Some inferences still take time: Prosody, predictability, and the speed of scalar implicatures. Cognitive Psychology, 102, 105–126. https://doi.org/10.1016/j.cogpsych.2018.01.004
- Hunt, L., Politzer-Ahles, S., Gibson, L., Minai, U., & Fiorentino, R. (2013). Pragmatic inferences modulate N400 during sentence comprehension: Evidence from picture-sentence verification. Neuroscience Letters, 534, 246–251. https://doi.org/10.1016/j.neulet.2012.11.044
- Ito, A., Corley, M., M. J. Pickering, Martin, A. E., & Nieuwland, M. S. (2016). Predicting form and meaning: Evidence from brain potentials. Journal of Memory and Language, 86, 151–171. https://doi.org/10.1016/j.jml.2015.10.007
- Ito, A., Martin, A. E., & Nieuwland, M. S. (2017). How robust are prediction effects in language comprehension? Failure to replicate article-elicited N400 effects. Language, Cognition and Neuroscience, 32(8), 954–965. https://doi.org/10.1080/23273798.2016.1242761
- Jaeger, T., Bushong, W., & Burchill, Z. (2019). Strong evidence for expectation adaptation during language understanding, not a replication failure. a reply to harrington stack, james, and watson (2018). Unversity of Rochester. Retrieved from https://wbushong.github.io/publications/pub_files/Jaeger_etal_response.pdf.
- Koornneef, A. W. (2008). Eye-catching anaphora [Ph.D. thesis, Utrecht University]. Retrieved from https://www.lotpublications.nl/eye-catching-anaphora-eye-catching-anaphora
- Kuperberg, G., & Jaeger, T. F. (2016). What do we mean by prediction in language comprehension?. Language, Cognition and Neuroscience, 31(1), 1–28. https://doi.org/10.1080/23273798.2015.1102299.
- Kutas, M., & Federmeier, K. D. (2011). Thirty years and counting: Finding meaning in the N400 component of the event-related brain potential (ERP). Annual Review of Psychology, 62(1), 621–647. https://doi.org/10.1146/annurev.psych.093008.131123
- Kutas, M., & Hillyard, S. A. (1984). Brain potentials during reading reflect word expectancy and semantic association. Nature, 307, 161–163. https://doi.org/10.1038/307161a0
- Kutas, M., Van Petten, C. K., & Kluender, R.. (2006) ). Psycholinguistics electrified II (1994–2005). In M.J. Traxler & M.A. Gernsbacher (Eds.), Handbook of Psycholinguistics (pp. 659–724). Academic Press.https://doi.org/10.1016/B978-012369374-7/50018-3.
- Leonhard, T., Ruiz Fernández, S., Ulrich, R., & Miller, J. (2011). Dual-task processing when task 1 is hard and task 2 is easy: Reversed central processing order?. Journal of Experimental Psychology. Human Perception and Performance, 37(1), 115–136. https://doi.org/10.1037/a0019238
- Levine, M., & Ensom, M. H. H. (2001). Post hoc power analysis: An idea whose time has passed?. Pharmacotherapy, 21(4), 405–409. https://doi.org/10.1592/phco.21.5.405.34503
- Lewis, R. L., & Vasishth, S. (2005). An activation-based model of sentence processing as skilled memory retrieval. Cognitive Science, 29(3), 375–419. https://doi.org/10.1207/s15516709cog0000_25
- Lifschitz, V. (1985). Closed-world databases and circumscription. Artificial Intelligence, 27(2), 229–235 .https://doi.org/10.1016/0004-3702(85)90055-4.
- Lifschitz, V. (1996). Foundations of logic programming. In G. Brewka (Ed.), Principles of Knowledge Representation (pp. 69–128). CSLI Publications.
- Miller, J. (2009). What is the probability of replicating a statistically significant effect?. Psychonomic Bulletin & Review, 16(4), 617–640. https://doi.org/10.3758/PBR.16.4.617
- Nieuwland, M. S. (2016). Quantification, prediction, and the online impact of sentence truth-value: Evidence from event-related potentials. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(2), 316–334. https://doi.org/10.1037/xlm0000173
- Nieuwland, M. S., Dittman, T., & Kuperberg, G. R. (2010). On the incrementality of pragmatic processing: An ERP investigation of informativeness and pragmatic abilities. Journal of Memory and Language, 63(3), 324–346. https://doi.org/10.1016/j.jml.2010.06.005
- Nieuwland, M. S., & Kuperberg, G. R. (2008). When the truth is not too hard to handle: An event-related potential study on the pragmatics of negation. Psychological Science, 19(12), 1213–1218. https://doi.org/10.1111/j.1467-9280.2008.02226.x
- Nieuwland, M. S., Politzer-Ahles, S., Heyselaar, E., Segaert, K., Darley, E., Kazanina, N., Zu Wolfsthurn, S. V. G., Bartolozzi, F., Kogan, V., Ito, A., Mézière, D., Barr, D. J., Rousselet, G. A., Ferguson, H. J., Busch-Moreno, S., Fu, X., Tuomainen, J., Kulakova, E., Husband, E. M., …Huettig, F. (2018). Large-scale replication study reveals a limit on probabilistic prediction in language comprehension. eLife, 7, Article e33468. https://doi.org/10.7554/eLife.33468
- Nieuwland, M. S., & Van Berkum, J. J. (2006). When peanuts fall in love: N400 evidence for the power of discourse. Journal of Cognitive Neuroscience, 18(7), 1098–1111. https://doi.org/10.1162/jocn.2006.18.7.1098
- Noveck, I., & Posada, A. (2003, May). Characterizing the time course of an implicature: An evoked potentials study. Brain and Language, 85(2), 203–210. https://doi.org/10.1016/S0093-934X(03)00053-1
- Otten, M., Nieuwland, M. S., & Van Berkum, J. J. (2007). Great expectations: Specific lexical anticipation influences the processing of spoken language. BMC Neuroscience, 8(89). https://doi.org/10.1186/1471-2202-8-89
- Politzer-Ahles, S., Fiorentino, R., Jiang, X., & Zhou, X. (2013). Distinct neural correlates for pragmatic and semantic meaning processing: An event-related potential investigation of scalar implicature processing using picture-sentence verification. Brain Research, 1490, 134–152. https://doi.org/10.1016/j.brainres.2012.10.042
- Politzer-Ahles, S., & Gwilliams, L. (2015). Involvement of prefrontal cortex in scalar implicatures: Evidence from magnetoencephalography. Language, Cognition and Neuroscience, 30(7), 853–866. https://doi.org/10.1080/23273798.2015.1027235
- Qing, C., & Franke, M. (2015). Variations on a Bayesian theme: Comparing Bayesian models of referential reasoning. In H. C. Schmitz and H. Zeevat (Eds.), Bayesian natural language semantics and pragmatics (pp. 201–220). Springer.
- Rabovsky, M., Hansen, S. S., & McClelland, J. L. (2018). Modelling the N400 brain potential as change in a probabilistic representation of meaning. Nature Human Behaviour, 2(9), 693–705. https://doi.org/10.1038/s41562-018-0406-4
- Roberts, C. (1996). Information structure in discourse: Towards an inte- grated formal theory of pragmatics. In J. H. Yoon and A. Kathol (Eds.), Papers in semantics (Vol. 49, pp. 6–67). The Ohio State University. http://linguistics.osu.edu/files/linguistics/workingpapers/osu_wpl_49.pdf.
- Roberts, C. (2012). Information structure in discourse: Towards an integrated formal theory of pragmatics. Semantics and Pragmatics, 5(6), 1–69. https://doi.org/10.3765/sp.5.6
- Searle, J. (1978). Literal meaning. Erkenntnis, 13(1), 207–224. https://doi.org/10.1007/BF00160894
- Spychalska, M., Kontinen, J., & Werning, M. (2016). Investigating scalar implicatures in a truth-value judgement task: Evidence from event-related brain potentials. Language, Cognition and Neuroscience, 31(6), 817–840. https://doi.org/10.1080/23273798.2016.1161806
- Stenning, K., & van Lambalgen, M. (2008). Human reasoning and cognitive science. MIT Press.
- Tanenhaus, M., Spivey, M., Eberhard, K., & Sedivy, J. (1995). Integration of visual and linguistic information in spoken language comprehension. Science (New York, N.Y.), 268(5217), 1632–1634. https://doi.org/10.1126/science.7777863
- Tian, Y., H. J. Ferguson, & Breheny, R. (2010). Why we simulate negated information: A dynamic pragmatic account. Quarterly Journal of Experimental Psychology, 63(12), 2305–2312. https://doi.org/10.1080/17470218.2010.525712
- Tiemann, S., Schmid, M., Bade, N., Rolke, B., Hertrich, I., Ackermann, H., Knapp, J., & Beck, S.. (2011). Psycholinguistic evidence for presuppositions: On-line and off-line data. In I. Reich, E. Horch, & D. Pauly (Eds.), Proceedings of Sinn und Bedeutung (Vol. 15, pp. 581–596). https://ojs.ub.uni-konstanz.de/sub/index.php/sub/article/view/401.
- Urbach, T. P., DeLong, K. A., & Kutas, M. (2015). Quantifiers are incrementally interpreted in context, more than less. Journal of Memory and Language, 83, 79–96. https://doi.org/10.1016/j.jml.2015.03.010
- Van Berkum, J. J., Brown, C. M., Zwitserlood, P., Kooijman, V., & Hagoort, P. (2005). Anticipating upcoming words in discourse: Evidence from ERPs and reading times. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(3), 443–467. https://doi.org/10.1037/0278-7393.31.3.443
- Van Berkum, J. J., Koornneef, A. W., Otten, M., & Nieuwland, M. S. (2007). Establishing reference in language comprehension: An electrophysiological perspective. Brain Research, 1146, 158–171. https://doi.org/10.1016/j.brainres.2006.06.091
- Van Berkum, J. J., Van den Brink, D., Tesink, C., Kos, M., & Hagoort, P. (2008). The neural integration of speaker and message. Journal of Cognitive Neuroscience, 20(4), 580–591. https://doi.org/10.1162/jocn.2008.20054
- van Lambalgen, M., & Hamm, F. (2005). The proper treatment of events. Blackwell.
- van Tiel, B., Franke, M., & Sauerland, U. (2021). Probabilistic pragmatics explains gradience and focality in natural language quantification. Proceedings of the National Academy of Sciences, 118(9), e2005453118. https://doi.org/10.1073/pnas.2005453118.
- Weigand, E. (1993). Word meaning and utterance meaning. Journal of Pragmatics, 20(3), 253–268. https://doi.org/10.1016/0378-2166(93)90049-U
- Wendt, D., Dau, T., & Hjortkjær, J. (2016). Impact of background noise and sentence complexity on processing demands during sentence comprehension. Frontiers in Psychology, 7. https://doi.org/10.3389/fpsyg.2016.00345
- Wickens, T. (2001). Elementary signal detection theory. Oxford University Press.