
ABSTRACT
Speech perception is heavily influenced by our expectations about what will be said. In this review, we discuss the potential of multivariate analysis as a tool to understand the neural mechanisms underlying predictive processes in speech perception. First, we discuss the advantages of multivariate approaches and what they have added to the understanding of speech processing from the acoustic-phonetic form of speech, over syllable identity and syntax, to its semantic content. Second, we suggest that using multivariate techniques to measure informational content across the hierarchically organised speech-sensitive brain areas might enable us to specify the mechanisms by which prior knowledge and sensory speech signals are combined. Specifically, this approach might allow us to decode how different priors, e.g. about a speaker's voice or about the topic of the current conversation, are represented at different processing stages and how incoming speech is as a result differently represented.
Introduction: aim of this review
The language-processing hierarchy can be broadly organised from bottom to top, i.e. from phonetics, morphology, lexicology, and syntax, to semantics. Errors or misinterpretation of a speech signal can happen all along the hierarchy of speech processing: an unclear phoneme can turn a “cat” into a “bat”, an unclear morpheme can turn the past into the present (“talk-ed” - “talk-s”), and word context can make the difference between life and death (“The chicken is ready to eat.” - leaving ambiguity whether the chicken is going to eat or will be eaten). Especially, under noisy and ambiguous listening conditions, prior experience is a crucial factor in determining the intended meaning and also the specific context in which the sentence is embedded conveys valuable prior cues. One prominent example is the “pop-out” effect (Davis et al., Citation2005): This effect describes the experience that the identical degraded spoken sentence, which is perceived as unintelligible without prior information, does suddenly “pop-out” and becomes clearly comprehensible after lexical information is provided prior to the hearing. Similarly, in a conversation in a noisy environment, we may interpret an utterance either as “It is very important to teach science” or as “It is very important to teach signs”, depending on the context or topic of the conversation, e.g. either epistemology or road safety, respectively. Such prior expectations can be derived from general statistical regularities on multiple levels, such as phonemes, morphemes, words, syntactic structure, or semantic topics and from how these general statistical regularities appear together (Davis & Johnsrude, Citation2007; Donhauser & Baillet, Citation2020; Heilbron et al., Citation2022; Holmes et al., Citation2018; Kuperberg & Jaeger, Citation2016; Levy, Citation2008; Schmitt et al., Citation2021; Stilp, Citation2020).
However, the levels of the linguistic hierarchy are not independent but influence each other mutually under ecologically valid conditions and can hardly be disentangled. If we take the single words “cat” and “bat” as examples for studying phoneme perception, the neural response will inherently be related to differences in semantic processing. Conversely, several probabilistic properties may interfere with other low-level spectrotemporal features such that syntax constrains prepositions to comprise fewer syllables than nouns thereby leading to shorter durations (Miller et al., Citation1958). In addition, neural processing at both higher but also lower processing stages might be changed depending on bottom-up and top-down information, respectively. These interdependencies across different levels of the processing hierarchy require controlled designs to study processing within and across different levels. Predictive information from the specific conversational situation can make these general priors even more powerful, for example using speaker-specific priors (Krumbiegel et al., Citation2022).
Cortical brain regions involved in processing speech and language are hierarchically organised (Davis & Johnsrude, Citation2003; Hickok & Poeppel, Citation2007). Several fMRI studies have shown a gradient of invariance from low-level acoustic towards abstract high-level non-acoustic processes across brain regions: While responses in primary auditory cortex (PAC) are sensitive to the acoustic properties of the speech input, surrounding regions respond to both speech intelligibility as well as the acoustic distortion, and more distant regions within the superior and middle temporal gyri (STG/MTG), and inferior frontal gyrus (IFG) are sensitive to speech intelligibility, but insensitive to the acoustic form (Davis & Johnsrude, Citation2003; Okada et al., Citation2010). Voxelwise modelling based on spectral, articulatory, and semantic features supported hierarchical speech processing further, by revealing spectral features in the core of PAC, mixtures of spectral and articulatory in STG, mixtures of articulatory and semantic in superior temporal sulcus (STS), and semantic in STS and higher-level prefrontal and parietal regions (Heer et al., Citation2017).
While there are many findings in favour of a hierarchical inference process of speech perception, there is contradictory evidence that points towards a parallel and distributed processing stream of speech stimuli (Hamilton et al., Citation2021). Yet, gradually descending sensitivity towards low-level features together with staggered temporal integration windows along the cortical hierarchy encourage us to believe that at least the prevailing organisation seems to be hierarchical (Norman-Haignere et al., Citation2022). With the hierarchical organisation of speech-sensitive regions, the brain is ideally equipped to pass down expectations to improve processing in lower-level brain regions (but see Huettig & Mani, Citation2016).
From univariate analyses of neuroimaging data using different methods, we know that unexpected, surprising speech leads to an increased brain response, whereas expected speech leads to a reduced response (Blank et al., Citation2018; Blank & Davis, Citation2016; Sohoglu et al., Citation2012). While these univariate response reductions clearly indicate that speech processing depends on prior information, they do not determine the underlying neural mechanisms (Alink & Blank, Citation2021; Feuerriegel et al., Citation2021; Todorovic & Lange, Citation2012). Reduced univariate activity for expected speech could be due to either more efficient and less effortful processing of predicted sounds or to suppressed processing of these sounds (i.e. explaining away; Blank & Davis, Citation2016; Kok et al., Citation2012; Murray et al., Citation2004). Both of these proposals can explain reductions in the magnitude of neural responses for speech sounds that are heard and interpreted as being in line with prior expectations and other similar findings from repetition suppression designs (Aitchison & Lengyel, Citation2017; Feuerriegel et al., Citation2021).
In the first part of this review, we discuss the contribution of multivariate methods to deepen our understanding of speech processing, with a focus on non-invasive functional magnetic resonance imaging (fMRI) as a tool with high spatial resolution. In the second part, we discuss the potential of multivariate analysis of brain activity patterns to unravel the neural mechanisms underlying predictive processes in speech perception.
What do multivariate analysis techniques of fMRI data measure?
Traditional univariate analyses of fMRI data evaluate the differences in magnitudes of activation in individual voxels between conditions of interest (Friston et al., Citation1995), while multivariate approaches investigate how distributed spatial patterns of activity encode information (e.g. multivariate pattern analysis, MVPA; Haxby et al., Citation2014). In a typical multivariate fMRI study, the goal is to investigate whether it is possible to decode specific stimulus or task conditions from a collection of voxels in a given brain area. For example, one could ask the question if voxels within a brain region represent a particular dimension of the speech hierarchy (e.g. phonemes) and whether this pattern is driven by the acoustic features only or whether additional higher-level and context-dependent processes may shape the neural activity. The term representation is highly discussed across disciplines such as neuroscience, philosophy, and machine learning research (Baker et al., Citation2022; Jonas & Kording, Citation2017). Here, we use the term representation to refer to any neural pattern that systematically varies with an external (and possibly internal) stimulus through the features it contains and how these features relate to each other. This correlational approach is often used as an attempt to measure mechanistic principles by linking neural representations with representations derived from theoretical frameworks and computational modelling (Haxby et al., Citation2014; Yang et al., Citation2012). With this approach, we use representation in line with the studies we are discussing in this review (Kriegeskorte, Citation2008). Specifically, we provide an outlook on how new methodological advances may allow us to go beyond the simple correlational approach to investigate representations as underpinnings of mechanistic principles of speech processing.
One advantage of multivariate approaches in comparison to univariate approaches is their increased sensitivity arising from combined information across multiple voxels (Hebart & Baker, Citation2018; Pakravan et al., Citation2022). Instead of assuming voxel-independence and considering only a single voxel at a time, multivariate analyses can take the covariance structure of the voxels into account, i.e. the correlation across voxels, so that jointly encoded information is used to gain insights that would otherwise be concealed (Habeck, Citation2010). Moreover, it is inherent to many types of multivariate analyses to move beyond classical best-parameter estimation and use cross-validation procedures to make predictions and draw inferences about the generalisation to population data (Hebart & Baker, Citation2018; Yang et al., Citation2012). For example, semantic generalisation across languages was supported by a simple classification algorithm which was trained on one language and tested on a different one (Correia et al., Citation2014).
Many different classes of multivariate analysis can be applied to neuronal data, of which the most prominent ones in language research are representational similarity analysis (RSA; Kriegeskorte, Citation2008) and classification approaches, such as linear discriminant analysis or support vector machines (SVM; Aglieri et al., Citation2021; Allen et al., Citation2012; Fisher et al., Citation2018; Kilian-Hutten et al., Citation2011). These analyses can be done in whole-brain searchlight analysis, extracting the pattern for every single voxel and its surrounding voxels (Etzel et al., Citation2013) or with a focus on a given region of interest (ROI; Poldrack, Citation2007). Multivariate approaches may allow us to shift the focus from the question about which location in the brain is involved in processing speech (where) to the question about which information is represented (what and possibly how).
What do multivariate analysis techniques of fMRI data not measure?
The previous section illustrates how MVPA can serve as a powerful approach to investigating the neural processes underlying the perception of spoken language. However, only with an elaborate research design, it may be possible to make inferences about the quality of the information (i.e. the information content) present at the neural level (Ritchie et al., Citation2019). Before summarising the contributions of MVPA to our understanding of speech processing, we discuss potential shortcomings of these multivariate approaches. Classification algorithms are information greedy and can pick up on any statistical pattern that is not necessarily related to the intended research question. While decodability indicates that some latent information related to the feature manipulated is processed in a certain brain region, it does not imply that the feature itself is represented there (see Daube et al., Citation2019 for an example), nor that the information is actually decoded or used by subsequent brain regions and finally relevant for behaviour (Baker et al., Citation2022; Ritchie et al., Citation2019). For example, the identity of phonemes could be decoded even though the corresponding percept may have been different (Correia et al., Citation2015; Lee et al., Citation2012). So how could we test whether information, as measured with multivariate analyses, is actually relevant for speech perception? Even if patterns of neural activation and the behavioural response patterns correlate (Kilian-Hutten et al., Citation2011; Preisig et al., Citation2022), this does not necessarily provide evidence about the quality of information contained in the neural representation and whether the neural representation does indeed affect and initiate downstream behaviour (Baker et al., Citation2022; Ritchie et al., Citation2019).
Advantages of similarity-based multivariate analysis techniques
One solution is provided by multivariate approaches based on proximity or distance relationships between conditions, such as RSA. Similarity-based approaches may enable us to make the content of the internal state space more accessible for several reasons (Diedrichsen & Kriegeskorte, Citation2017; Kriegeskorte, Citation2008; Kriegeskorte & Kievit, Citation2013). First, RSA does not only allow us to separate distinct categories based on their (dis)similarity but to assess qualitative features of these categories in terms of their relatedness. Second, RSA can relate continuously parameterised stimuli beyond categorical labels, which is often not the case for classification algorithms in which a class label needs to be discreetly assigned to one category (Kriegeskorte, Citation2008). A third advantage of RSA is the canonical way of testing representations across various data formats, such as electrode recordings and fMRI measures. Hence, the input for RSA can vary across different spatial and temporal dimensions and even across species. In this approach, possible confounds by the structure of the data itself can be introduced (for an example see Dujmović et al., Citation2022), but can possibly be avoided by following best practices like cross-validation procedures. Fourth, the most powerful advantage of RSA is that it allows us to make inferences about the underlying processes in the brain during specific manipulations or conditions. Different theoretical models can be transformed into hypothesis-driven predictions of similarity patterns and fit to the neural and behavioural data. Thereby we can assess whether the mechanism or only the resulting output of two systems is similar (i.e. mimicking behaviour, see Dujmović et al., Citation2022). In summary, results from multivariate approaches provide evidence of varying strength: from the weakest correspondence, i.e. a mere correlation between input and neural response, over a causal role manifest in behaviour, towards a mechanistic approach (Baker et al., Citation2022; Jonas & Kording, Citation2017). Thus, with appropriate research designs and carefully worked-out theoretical and computational hypotheses, multivariate methods have the potential to tell us much more than a simple univariate comparison.
In the following, we will review the state of the art in using multivariate approaches in speech perception and next discuss how we could take advantage of these multivariate approaches to go beyond functional localisation and understand the neural mechanism underlying the integration of priors and incoming speech input. With neural mechanism, we refer to how the brain algorithmically performs the computation related to this integration.
What is possible with decoding multivariate fMRI responses in speech and language?
In the following, we will review previous work showing how multivariate approaches can be used to quantify the amount of information that is carried by the spatial patterns of fMRI activity during speech and language processing ranging from the acoustic and phonetic form of speech, to the semantic content of language ().
Figure 1. Distributed speech and language processing.
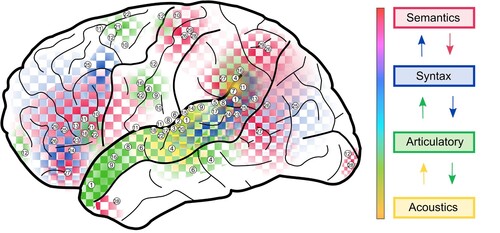
Note. Distributed speech and language processing identified with multivariate pattern analyses along the language-processing hierarchy. The colour coding of brain regions corresponds to the different levels of the speech and language hierarchy (see right). The numbers in the regions correspond to the following studies: 1: Hsieh et al., Citation2012; 2: Joanisse & DeSouza, Citation2014; 3: Okada et al., Citation2010; 4: Evans & Davis, Citation2015; 5: Pasley et al., Citation2012; 6: McGettigan et al., Citation2012; 7: Chang et al., Citation2010; 8: Obleser et al., Citation2010; 9: Arsenault & Buchsbaum, Citation2015; 10: Correia et al., Citation2015; 11: Archila-Meléndez et al., Citation2018; 12: Du et al., Citation2014; 13: Rampinini et al., Citation2017; 14: Formisano et al., Citation2008; 15: Bonte et al., Citation2014; 16: Aglieri et al., Citation2021; 17: Zhang et al., Citation2016; 18: Ogg et al., Citation2019; 19: Kilian-Hutten et al., Citation2011; 20: Levy & Wilson, Citation2020; 21: Lee et al., Citation2012; 22: Preisig et al., Citation2022; 23: Pereira et al., Citation2001; 24: Allen et al., Citation2012; 25: Fedorenko et al., Citation2012; 26: Hoffman & Tamm, Citation2020; 27: Carota et al., Citation2021; 28: Correia et al., Citation2014; 29: Mahon & Caramazza, Citation2010.
Acoustic features
On the one hand, we are highly effective in understanding speech despite degraded acoustic properties (e.g. Davis et al., Citation2005; Evans & Davis, Citation2015; Remez et al., Citation1981). On the other hand, subtle differences in the spectral properties of a sound, i.e. its acoustic features, can be crucial for successful speech perception. For example, small frequency shifts contribute to the categorisation of phonemes and differences as small as 75 Hz are perceptible (Flanagan, Citation2005). The differentiation between up and down sweeps and fast and slow frequency modulations is important for phoneme discrimination, as for example the direction of the frequency modulation at the voice onset distinguishes a /pa/ (rising) from a /ta/ (falling), and the drift rate until voice onset distinguishes /ba/ (fast) from /wa/ (slow). Acoustic features of speech can be successfully decoded with multivariate analyses techniques of fMRI data. For example, fMRI activation patterns from the superior temporal gyrus (STG) and Heschl's gyrus (HG) could be used to classify slow vs fast as well as up and down frequency drifts in complex sound stimuli resembling those of natural sounds, such as speech (Hsieh et al., Citation2012). These differences in acoustic features were not detectable with classical univariate analyses probably due to the spatial interspersedness of the corresponding representations of direction-selective frequency modulations.
This finding was extended by Joanisse and DeSouza (Citation2014) by investigating the neural correlates of rising and falling, fast and slow frequency modulations on a narrower time scale. While the frequency was modulated within 100 ms for fast changes and 400 ms for slow changes by Hsieh et al. (Citation2012) introducing a confound of duration, Joanisse and DeSouza (Citation2014) kept the stimuli at a constant length while the frequency modulation happened either within the first 50 ms or 100 ms. RSA revealed that the auditory cortex excluding HG encoded direction-specific information of the frequency drifts. In contrast, the rate of the frequency modulation was neither significantly detectable across HG, nor across the auditory cortex. The divergence in the results may stem from methodological changes made to the stimuli but also from the regions of interest under investigation. While Hsieh and colleagues (Citation2012) defined HG based on a functional contrast in combination with individual anatomical considerations, Joanisse and DeSouza (Citation2014) based it on an anatomical atlas only.
Different levels of acoustic degradation, i.e. clear, noise-vocoded, spectrally rotated, and spectrally rotated noise-vocoded versions of the same speech could be distinguished based on the multivariate voxel response patterns in the HG (Okada et al., Citation2010). Moreover, in accordance with hierarchical speech processing, primary auditory regions were more sensitive to acoustic variation, whereas anterior and posterior regions in STS responded to higher-level intelligibility features of speech and can be described as acoustically invariant. In this study, the highest acoustic invariance was found in the posterior parts of the STS, while previous univariate and later multivariate studies identified the anterior part of the temporal lobe to care least about the acoustic features but the intelligibility (Evans et al., Citation2014; Scott et al., Citation2000). In addition to the PAC and regions in the STG, supramarginal gyrus (SMG), inferior frontal, and inferior parietal regions were found to be relevant for discerning speech varying in the acoustic clarity which only became apparent through MVPA (Abrams et al., Citation2013; Evans et al., Citation2014; Evans & Davis, Citation2015). By means of RSA, only the SMG as an extra-temporal region was specifically identified to be sensitive to low-level acoustic details, independent of higher-level features such as syllable identity, speaker identity, or intelligibility (Evans & Davis, Citation2015). The neural patterns of surface acoustic form in PAC and in the inferior parietal lobule may indicate multiple lines of processing likely coding for different types of information. Future studies will help to disentangle the specific functions of these brain regions in processing low-level acoustic features and whether they form the basis of a complementary or redundant coding system.
In summary, multivariate analyses repeatedly showed that acoustic features of the speech signal are predominantly processed in the primary auditory regions and adjacent areas along the superior temporal plane.
Articulatory features
Humans are able to produce speech sounds by altering the vocal tract and the air flowing from the lungs, up the larynx to be released from the lips. Specifically, sound production involves moving the vocal folds and the resulting glottal pulse rate is filtered by the shape and length of the vocal tract so that specific formant frequencies are enhanced or suppressed. Vowels are produced without obstruction to the air flow leading to clear formant frequencies, while for consonant production airflow modification is essential, causing them to lie in a higher frequency spectrum. For vowel production, the position of the tongue determines whether certain frequencies get amplified leading to formant frequencies. Therefore, the formants take an indispensable role in vowel characterisation. When the first (F1) and second formant (F2) and their ratio were regressed out of the neural signal, the classification accuracy with which vowels could be identified with MVPA decreased (Markiewicz & Bohland, Citation2016). Also for consonants, the F2 onset frequency and transition magnitude (difference between onset F2 and vowel F2) are linguistically relevant and can integratively map the phonetic distinctions between /b/, /d/ and /g/ (Chang et al., Citation2010). From an articulatory point of view, consonants are produced by a modification of three features: the place of articulation, manner of articulation, and voicing. In general, those features coincide with acoustic properties. For example, place of articulation can determine 1) labial consonants with ascending formant transition towards the vowel formants, 2) alveolar consonants with descending formant transitions, and 3) palatovelar consonants with descending F2 and ascending F3 transition (Nearey, Citation1998). Many of the corresponding articulatory neural patterns could be mapped with multivariate approaches contributing to a greater understanding of speech processing (Aglieri et al., Citation2021; Archila-Meléndez et al., Citation2018; Arsenault & Buchsbaum, Citation2015, Citation2016; Bonte et al., Citation2014; Chang et al., Citation2010; Correia et al., Citation2014; Formisano et al., Citation2008; Gardumi et al., Citation2016; Kilian-Hutten et al., Citation2011; Lee et al., Citation2012; Levy & Wilson, Citation2020; Ley et al., Citation2012; Obleser et al., Citation2010; Preisig et al., Citation2022; Rampinini et al., Citation2017; Zhang et al., Citation2016). In general, vowel representations seem to be more robustly identified with MVPA than consonant representations (Zhang et al., Citation2016), probably because vowels can stand for themselves while consonants unfold their full articulative spectrum only in combination with a vowel and are influenced by coarticulation and therefore more variable. Moreover, it has been shown that consonant and vowel-specific processing relied on distinct sparsely overlapping areas in the STG encoding phonetic features at different levels of abstraction (Chang et al., Citation2010; Obleser et al., Citation2010).
In the following, we will describe how multivariate pattern approaches were used to investigate the perception of consonants and vowels.
Consonants
As explained above, the place of articulation is a crucial feature in consonant discrimination. Chang et al. (Citation2010) found multivariate neural patterns in the pSTG that encoded consonants’ place of articulation characterised by the F2 onset frequency and transition magnitude. A subsequent MVPA study identified brain regions that process specific articulatory features independent of phonemic category and acoustic variation and extended the knowledge through whole-brain coverage which brought about the involvement of frontoparietal regions and the insula. Not only for the place of articulation but for each of the two remaining articulatory features (voicing and manner of articulation) distinct patterns were found. The different articulatory features partly overlapped in anterior temporal lobe and inferior postcentral gyrus, thereby indicating the encoding of common higher-level features (Correia et al., Citation2015). The contribution of the sensorimotor systems (including the postcentral gyrus) and their necessity for speech perception has been a long-standing debate (de Zubicaray et al., Citation2013; Hickok, Citation2014; Kemmerer, Citation2015; Schomers & Pulvermüller, Citation2016). Different hypotheses about the integration between speech perception and speech production have been introduced. Proponents of the motor theory of speech perception postulated that the acoustic signal is decoded as a function of articulatory motor patterns (Liberman et al., Citation1967; Liberman & Mattingly, Citation1985). Moreover, it has been suggested that covert rehearsal of the articulatory features generates a synthesis of perceptual input with procedural motor commands resulting in enhanced intelligibility (Scott & Johnsrude, Citation2003). Others have argued that the connections between the perceptual and procedural systems serve the refinement of speech production during the processing of speech input which is not necessarily mutually exclusive (Rampinini et al., Citation2017). Especially in studies investigating consonant representations, the question around the involvement of sensorimotor areas yielded some controversies. On the one hand, neural patterns from the temporal cortex, but not the motor or premotor cortex, reflected the three distinct articulatory features (Arsenault & Buchsbaum, Citation2015, Citation2016). On the other hand, activity from premotor and motor areas could be used to distinguish between manner of articulation (i.e. stop consonants versus fricatives) and without further training the same classifier generalised to differentiate between places of articulation (Archila-Meléndez et al., Citation2018; Correia et al., Citation2015). Under noise, consonant categorisation based on multivariate fMRI pattern was shown to be more robust in the left ventral premotor cortex and Broca's area than in bilateral temporal regions (Du et al., Citation2014). The enhanced neural activity under noisy conditions could only be differentiated from alternative explanations (i.e. attention, task demands) with RSA indicating that it rather reflects shared phoneme-specific information. A recent review that scrutinised the role of the sensorimotor system in speech perception, proposed that lacking motor involvement is likely due to confounds introduced through excessive scanner noise and prompted motor responses (Schomers & Pulvermüller, Citation2016). This is not entirely in line with a linear relationship between noise and the involvement of premotor regions, but with an inverted U-shape account of noise. An elaborate study design using RSA to reflect different levels of abstraction showed that the left motor cortex is only related to high-level features of speech such as syllable identity and consonant–vowel structure, pointing to a hierarchy-dependent function of sensorimotor integration (Evans & Davis, Citation2015). It is conceivable that predictive mechanisms form the basis for this overarching functional contribution such that for example, the motor system may help in dynamically predicting the signal according to the expected frequencies. Future studies may attend to the challenge and unravel the mechanisms underlying this integrative, possibly predictive, circuitry.
Vowels and voice
Vowel and voice perception both rely on the same acoustic dimensions, i.e. the frequency spectrum of speech sounds. In a seminal study, Formisano and colleagues decoded both distinct speaker as well as distinct vowel identities from multivariate fMRI patterns (Formisano et al., Citation2008), a finding which was later repeatedly replicated (Aglieri et al., Citation2021; Bonte et al., Citation2014; Gardumi et al., Citation2016; Zhang et al., Citation2016). None of these studies found statistically significant contrasts between different speakers and different vowel conditions with conventional univariate analysis. Importantly, even with advanced techniques like ultra-high field fMRI no effect was found (Gardumi et al., Citation2016; Zhang et al., Citation2016). In general, classification of speaker and vowel identity relied on distinct but overlapping regions in the superior temporal sulcus and gyrus (STS/STG; Formisano et al., Citation2008). Also distinct patterns for common articulatory features such as front vowels (/i/ and /e/) in comparison to back vowels (/u/ and /o/) for naturally coarticulated syllables were identified with MVPA, most prominently in aSTG (Obleser et al., Citation2010). While vowel information was represented bilaterally, speaker information was found to be right lateralised (Formisano et al., Citation2008). Interestingly, classification of speakers and vowels based on fMRI response patterns was dependent on the task and hence showed that information obtained from fMRI response patterns depends on top-down enhancement (Bonte et al., Citation2014). Neural classification accuracy which distinguished voices based on the BOLD signal of anterior STG and IFG, correlated with behavioural voice recognition performance across participants, pointing to the importance of extra-temporal higher-level regions in voice recognition (Aglieri et al., Citation2021). For the perception, production, and imagination of vowels, similar brain regions, e.g. IFG and MTG, yet distinct non-overlapping contiguous clusters within these regions were identified to be engaged with multivariate phoneme classification (Rampinini et al., Citation2017). This speaks for distributed patterns representing constant multimodal integration through reciprocal connections facilitating the dynamical neural processing of perception, production and imagery. Yet the exact mechanisms of these connections remain to be studied.
Moreover, it is still an open question whether the auditory processing stream is specifically tuned to human voices like it has been suggested for conspecific vocalisations of animals (Perrodin et al., Citation2011), or whether all acoustic stimuli have the same relative importance. For the decoding of different voices in comparison to instruments, which both vary in their timbre, voxels along the posterior to anterior STG and parts of middle temporal gyrus cloud be exploited by a linear discriminant classifier (Ogg et al., Citation2019). Further multivariate classification analysis showed more privileged processing of human voice sounds, meaning that the neural response to conspecific vocalisations was well-defined and most reliably distinguished from every other living and non-living sound category, in the right middle temporal gyrus (Lee et al., Citation2015). Yet, from this analysis, it remains indistinguishable which features of the voice were relevant for the differentiation and whether it relies rather on low-level acoustic features or on higher-order identity abstraction. Voxels relevant for voice-identity discrimination were only found in a small cluster close to the left PAC indicating that voice-identity classification relies on distinctions in low-level acoustic features (Ogg et al., Citation2019). Despite their intermingled features vowel identity and voice identity could be reliably decoded indicating an abstract representation of those categories. It stands to question how speaker identity and vowel identity are mapped from the variable acoustic signal to abstract category-level representation. We will discuss the neural pattern of this abstraction to discrete behaviourally relevant representations in the next paragraph.
Categorical features
Multivariate approaches were also repeatedly used to test the neural correlates of categorical speech perception, i.e. the observation that listeners perceive speech sounds that vary along a continuum as categorical so that sounds within a category sound more similar than equidistant sounds from different categories (Kilian-Hutten et al., Citation2011; Lee et al., Citation2012; Levy & Wilson, Citation2020; Preisig et al., Citation2022; Zhang et al., Citation2016). Those abstract categorical representations of phonemes were revealed in the STG. Firstly, based on ECoG recordings located in the lateral part of the pSTG, the three phoneme categories /ba/, /da/, and /ga/ were successfully classified and the resulting category boundaries from the neurometric identification function reproduced the corresponding psychometric identification function. When the results were extended to fMRI, consonants could be reliably decoded from voxels across the STG (Obleser et al., Citation2010). In the pSTG however, phoneme classification was not preferentially decodable in comparison to the noise versus speech sound categorisation. Potentially, in contrast to ECoG recordings with high spatial resolution, the coarse BOLD signal in fMRI can detect higher-level, more stable representations of phoneme categories in the higher-level aSTS region. Outside of the temporal lobe, consonant–vowel syllables along a /ba/–/da/ continuum evoked distinct neural activity patterns between the two perceptual categories (/ba/ vs /da/) in Broca's area and the left pre-supplementary motor area (Lee et al., Citation2012). Interestingly, multivariate and univariate analyses revealed different regions for categorical perception when applied to the same data set, though using different contrasts: a multivariate classifier that was trained on the perceptual category boundary between /ba/ and /da/ revealed Broca's area, whereas a univariate adaptation analysis contrasting between-category versus within-category pairs revealed involvement of the SMG (Lee et al., Citation2012; Raizada & Poldrack, Citation2007). Hence the two different analysis approaches seem to identify different functions of Broca's and SMG in speech perception, with phoneme identification versus change detection or discrimination, respectively (Lee et al., Citation2012).
In accordance with the representation of phonetic features at different levels of abstraction, within-category distinction between either two vowels or two consonants based on voxels in the STG generalised to another within-category distinction (i.e. from /ba/ vs /da/ to /ba/ vs /ma/; Zhang et al., Citation2016). The discussion at which level of the speech processing hierarchy the transformation of the veridical sound to the abstract category level representation takes place is still debated. Already at the level of the PAC, an alteration of the veridical speech signal represented information beyond simple acoustic features: multivariate classification of voxels in HG revealed that between-category classification was more accurate than within-category classification even though the difference between the vowel stimuli was perceptually equispaced (Levy & Wilson, Citation2020). Thus, the response patterns did not follow the linear properties of the articulatory features but rather reflected category boundaries. Also, after learning a linguistically-irrelevant, artificial category boundary, which relied on pitch information, perceptual representations of these novel sound categories could be decoded from HG, planum temporale, and regions along the STS - whereas this categorical information was not present when the identical stimuli were classified before learning (Ley et al., Citation2012). Similarly, Kilian-Hutten et al. (Citation2011) found that SVM could exploit the neuronal activation in Heschl's gyrus and sulcus, and the anterior planum temporale to classify the perceptual category of the identical ambiguous phoneme sound (/aba/ versus /ada/). As the acoustic features of the stimuli were physically identical, the spectrotemporal characteristics cannot serve as an explanation for the differences in perception, nor in the BOLD signal. The authors interpreted this finding as an argument against a hierarchical processing organisation of speech sound, because the categorical perception, which supposedly is a more abstract, higher-level feature involving interpretation, was decodable from low-level auditory regions. An alternative interpretation within the framework of predictive processing might be that representations measured in the auditory cortices are influenced by the higher-level predictions, which are conveyed from higher to lower-level auditory regions (for similar reasoning in the domain of face processing see Schwiedrzik & Freiwald, Citation2017). Both of the above studies restricted their analysis to the temporal lobe region or even to the HG. Hence, the investigation of activation in and connectivity to higher-level cortical areas which convey categorical priors to earlier regions would help to resolve these two interpretations.
Evidence for influences on categorical phoneme perception from higher-order cortical regions was provided by a recent study that used MVPA to compare the pattern of unambiguous /da/ and /ga/ stimuli to the pattern of ambiguous stimuli at the individual psychometric boundary (Preisig et al., Citation2022). The ambiguous stimulus was manipulated to be biassed towards one of the two categories by exploiting the mechanism of binaural integration, i.e. presenting the acoustically carved out F3 of either the /da/ (high F3) or /ga/ (low F3) to the left ear and the ambiguous 50% morph of /da/ and /ga to the right ear leading to a biased percept. Critically, there were trials in which the ambiguous stimulus was acoustically warped towards one category, but the opposite category was perceived, which allowed disentangling the intermingled influences of low-level acoustic features (low vs high F3 stimulus) and incongruous top-down higher-level categorical perception (/da/ vs /ga/) of these consonant–vowel speech sounds. While the perceived category in ambiguous conditions could be decoded from distributed clusters, the veridically presented low-level acoustic features could not be distinguished based on their neural response pattern. Remarkably, many higher-order cortical regions seemed to be involved in the categorical perception of consonants. In concordance with previous studies, the classifier trained on the unambiguous stimuli generalised better to the corresponding perceived category than to the acoustically presented stimuli in the auditory parabelt, pars triangularis, and extended motor areas. The authors conclude that it is likely that higher-order cognitive processes impact the neural responses in auditory cortices probably in a predictive manner (Preisig et al., Citation2022). This interpretation is in line with work in the domain of visual perception, showing that multivariate approaches could accurately classify the shape and orientation of an object (i.e. higher-level features) based on the lower-level primary visual cortex (V1), which is considered to be shape- and orientation-invariant (Jehee et al., Citation2011; Williams et al., Citation2008). These low-level activity findings were also explained as reflecting modulations of feedback from higher-level regions. Hence, similar mechanisms of how sensory information is represented based on top-down information such as categories might take place in auditory regions. It remains to be determined whether this effect is indeed driven by a top-down enhancement or an effective categorical representation at the level of PAC.
Many studies have provided evidence of a categorical perception that maps acoustic features nonlinearly to abstract categories. The question at which level of the speech hierarchy this transformation emerges remains elusive. Controlling for alternative factors driving between-pattern variance like low-level sound structures such as loudness, spectral centroid, pitch, or harmonic-to-noise ratio are necessary to disentangle general low-level acoustic processes from category-specific processing (Giordano et al., Citation2013).
Syntactic
One integral part of language is the use of syntactic principles to form more complex expressions consisting of a systematic combination of words or morphemes. While it has been shown that the brain is perfectly equipped to facilitate predictive integration of the linguistic constituent structure through tracking information at different levels of the grammar-based linguistic hierarchy (Ding et al., Citation2016), multivariate analysis provided additional insights into the neural patterns of semantic and syntactic uncertainty that were decodable from activity in IFG, STG and MTG (Pereira et al., Citation2001). Voxels in these areas predicted the response to ambiguous sentences in which ambiguity was resolved in contrast to sentences remaining unambiguous. Further evidence for the syntactic processing in frontal and anterior temporal regions was provided by an MVPA study that disentangled the grammatical pattern of dative and ditransitive sentences, which only differed syntactically in the prepositional phrase while the number of arguments, surface complexity, frequency of occurrence, and the event of the construct remained constant (Allen et al., Citation2012).
Other findings place importance on more posterior regions of the temporal cortex and the IFG for syntactic information processing only (Ding et al., Citation2016; Fedorenko et al., Citation2012). Again solely multivariate, but not univariate, analysis was able to uncover that these regions are involved in syntactic processing. However, no regions in the language network seem to process exclusively syntax-specific information but seem to be concomitantly involved in the representation of lexical information (Fedorenko et al., Citation2012). Also, advanced analysis techniques, such as the identification of neural patterns with neural network language models found syntactic representations only in temporal language regions that were also implicated in other processes (Heilbron et al., Citation2022). The interleaved representations may reflect the interdependence of the different aspects of speech and language processing that rely on the constant integration of dynamic top-down and bottom-up information.
Semantics
The highest level of the speech processing hierarchy that we discuss in this review is the semantic abstraction. To successfully convey a message via auditory communication, the main goal is to relate the acoustic input to meaning. Semantic abstraction can happen already at the level of morphemes, e.g. the prefix “un-'” signifies negation, but is most commonly studied at the level of words or sentences. Homonyms are phonologically similar words that possess two meanings (e.g. bat as the animal or the wooden stick), of which the intended one only becomes apparent through context. They constitute a useful class of words to investigate predictive processes in semantic perception because their acoustic input is identical, hence low-level spectral influences are controlled. Semantic information of single homonyms could be reliably decoded from the IFG, anterior temporal lobe and medial temporal gyrus (Hoffman & Tamm, Citation2020), whereas univariate analysis did not show increased activity in the temporal lobe in response to homonyms.
Different explanations for the emergence of semantic-linguistic meaning have been proposed (Carota et al., Citation2021). On the one hand, distributional theories posit that the semantic meaning of a word is derived from the frequency of its co-occurrence with other words, i.e. the conceptual knowledge through context of language usage (e.g. lake and swim). On the other hand, taxonomic theories advocate that meaning is derived from a hierarchical abstraction of the conceptual properties of words grouped into related categories (e.g. cat and whale). By means of RSA, the left IFG was found to represent semantic meaning in the distributional sense, while pMTG captured the semantic constructs as predicted by the taxonomic account (Carota et al., Citation2021). Additionally, the pattern in the angular gyrus related to semantic concepts irrespective of theory. However, in this study the semantic concepts were only evoked by visual presentation. Multivariate patterns of semantic meaning are mostly investigated with written, not with spoken, language stimuli (Carlson et al., Citation2014; Carota et al., Citation2017; Mitchell et al., Citation2004; Mitchell & Cusack, Citation2016; Pereira et al., Citation2018), probably because this approach does not hold the disadvantages of the confounding scanner noise. However, recent studies using MVPA suggest largely congruent semantic representations between auditory and visually presented language. This is underpinned for example by a semantic model forming accurate predictions irrespective of modality (Deniz et al., Citation2019) and an MEG study showing word-specific neural activity shared between modalities and subjects (Arana et al., Citation2020). Semantic representations evoked by auditory input, which was based on distributional word co-occurrence statistics, yielded an intricate semantic, cortical map persistent across individuals. This semantic map spanned prefrontal, temporal and parietal regions and showed domain specificity that was largely mirrored between hemispheres (Huth et al., Citation2016). In bilingual speakers, it has been shown that semantic representations are highly abstract and generalised across different languages because the meaning of a spoken word could be decoded in one language based on a SVM classifier which was trained on the other language (Correia et al., Citation2014). Univariate contrasts could not capture this abstractness which is mirrored in the vast extent of involved brain regions ranging from the clusters in different regions of the temporal lobe, over clusters in the angular gyrus, to the insula, postcentral gyrus, and occipital cortex. Many of these regions were also reported for semantic processing in visual stimuli, thus further supporting the thesis that, indeed, semantic concepts seem to be robust not only across different languages but also with respect to different sensory modalities.
Conceptual similarity to a preceding word influenced the activity pattern in distributed areas of the brain, primarily in parietal and frontal regions (Mahon & Caramazza, Citation2010). Yet, the relatedness of two words could also be classified based on V1, even though participants were only presented with auditory spoken words, probably due to evoked visual associations. The previous findings highlight the increasing involvement of different distributed systems at the top level of the language hierarchy resulting in a multimodal comprehensive percept. This could be implemented by a distributed set of fragmented supramodal feature nodes that collectively form the semantic concept of an object (Kivisaari et al., Citation2019). The modulation of neural activity as a function of semantic similarity to the preceding context suggests that it is likely that predictive mechanisms of concept similarity influence the perception of speech stimuli. Since successful semantic classification was obtained from neural responses in the left lateral temporal cortex, semantic predictions may even be propagated down the hierarchy to inform peri-auditory regions (Mahon & Caramazza, Citation2010). This is in line with context-dependent semantic processing (Deniz et al., Citation2021). Altogether, MVPA revealed distributed networks of semantic processing that ranged from temporal to frontoparietal regions. Future studies which focus on auditory stimulus presentation may shed light on the predictive nature of semantic speech processing.
How can we use multivariate analysis to tackle open questions (in predictive hierarchical processes) in speech and language?
Information contained in spatiotemporal patterns of neural activity and analyses of representational content (Kriegeskorte & Kievit, Citation2013) might help us to specify the neural mechanisms by which listeners combine prior knowledge and incoming speech signals. Specifically, this approach allows to measure representational content in the speech-sensitive brain areas and to decode whether the expected or the unexpected part of a speech stimulus is represented and how these representations may be linked to perception (Blank et al., Citation2018; Blank & Davis, Citation2016). The key idea here is to distinguish between mechanisms via which prior expectations and acoustic sensory input might be integrated. The commonly observed reduced activity for expected speech might result from a reduced surprise or error signal, as suggested by predictive coding theories, in which neural activity represents the difference between heard and expected signals (prediction error). Alternatively, neural activity might be reduced because it is less noisy and more directly represents the current perceptual experience, i.e. the posterior in Bayesian terms (Aitchison & Lengyel, Citation2017). While both prior knowledge and increased sensory clarity can improve perceptual experience in a similar way and hence result in similar enhanced representations of the posterior, prediction error representations should theoretically be less informative for speech that clearly matches prior expectations (Blank et al., Citation2018; Blank & Davis, Citation2016).
We applied this approach in two previous studies (Blank et al., Citation2018; Blank & Davis, Citation2016), in which we combined informative and uninformative written text with degraded speech while measuring the representational content of STG responses with fMRI. Firstly, we showed that both increased sensory detail and informative priors improved behavioural word report in an additive way, but that corresponding neural representations in the pSTG showed an interaction: There was a greater pattern similarity between clearly articulated, partly-concordant stimulus pairs presented after uninformative text than for those that were degraded. However, if an informative prior was available the pattern similarity between stimulus pairs became weaker for clear than for degraded speech. This shows that there was less shared information between stimulus pairs, hence once prior knowledge is available, expected sensory information can be cancelled out when the stimulus is presented (Blank & Davis, Citation2016). This finding was replicated (Sohoglu & Davis, Citation2020) and rules out both a pure bottom-up account (without influence of prior knowledge, see Norris et al., Citation2000) and sharpening theories of speech perception according to which effects of prior knowledge and sensory quality should be additive (McClelland & Elman, Citation1986). Similarly, misperception, induced by partially deviating prior information as written words preceding degraded spoken words, was explained by multivariate representations of prediction errors (Blank et al., Citation2018). In sum, these two RSA fMRI studies converge in showing representations of prediction error in the STS/STG.
Moreover with a gradual implementation of prior expectations by modulating the transition regularities between events it could be shown with MVPA, that aberrant non-veridical auditory percepts such as auditory hallucinations or tinnitus could result from a dysfunction of overweighting internal priors (Alderson-Day et al., Citation2017; Partyka et al., Citation2019; Partyka et al., Citation2019). By manipulating prior expectations at different levels of the speech hierarchy meaningful insights about (non-)aberrant speech processing may emerge. For example, the long-standing debate about pre-activated predictions imposed by phonological constraints of sentence context (e.g. by the indefinite article a / an) on the following word could benefit from MVPA (DeLong et al., Citation2005; Yan et al., Citation2017). By means of RSA, the neural response after the constraining context could be tested to be either more or less similar to a word overlapping on different levels with the expected word (e.g. “an ace”, acoustic match: ice, syntactic: tree (noun), semantic: trump card (synonym)). Furthermore, it is expected that the similarity between the “matching words” and the anticipated word decreases when the constraining context is modulated to be more uncertain (i.e. presenting a morph between a / an). Additionally, it would be interesting to see whether the neural response after a mismatch depends on the similarity of the neural pre-activation to competing alternatives.
To assess this full range of incrementally unfolding predictions at every level of the nested speech processing hierarchy, methods with high temporal or spatial resolution may enable us to compare the data against predictions from generative models of speech processing that deploy principles of predictive processing (Su et al., Citation2022).
Limitations of MVPA in fMRI
Another consideration is that the different spatial scales, which presumably support hierarchical abstraction, range from small circuits within a specific region to broad macro-networks such as the default mode network (Yeo et al., Citation2011). When considering fMRI analysis, the scale at which neural signals are recorded usually lies more or less around a few cubic millimetres per voxel. MVPA can range from single voxels, local searchlight analysis variable in size, over predefined regions of interest to whole-brain analysis (Jolly & Chang, Citation2021) and each of the approaches balances the trade-off between detecting more local or distributed network patterns. Analyses using a small neighbourhood of voxels in a searchlight analysis detected processes at a smaller spatial scale whereas whole brain analysis revealed processes that generalised well over different task and populations like found for language-invariant semantic representations (Correia et al., Citation2014; Jolly & Chang, Citation2021). Thus, the choice of the spatial scale should depend on the scale of the investigated phenomenon.
Additionally, it has been shown that MVPA is sensitive towards noise correlations across BOLD signals assigning greater importance to vowels with similar noise patterns in classification (Bejjanki et al., Citation2017). With the coarse spatial resolution of fMRI and the slow nonlinear hemodynamic response function, real “second-order multivariate effects” based on the covariance matrix of voxel activity may not be captured. The usage of geometry-aware distance measures such as the Riemannian distance, may more robustly capture multivariate neuronal patterns (Pakravan et al., Citation2022; Shahbazi et al., Citation2021).
Future outlook: using neural networks to decode pattern of language?
Technical advances with ultra-high field fMRI have facilitated neuronal layer-specific analysis which could disentangle predictive bottom-up and top-down processes in the visual and somatosensory domains and has yet to be applied to auditory processing (Kok et al., Citation2016; Muckli et al., Citation2015; Yu et al., Citation2019).
The usage of RSA with a fusion of different data acquisition methods, e.g. MEG combined with fMRI (for an example see Lowe et al., Citation2020), to investigate the informational content in high spatiotemporal may bring the field forward (Cichy et al., Citation2016). With an advanced reconstruction estimate based on a combination of EEG with a hierarchical prior of fMRI data, classification accuracies were comparable to those from ECoG (Yoshimura et al., Citation2016). In the future, a continued combination of multivariate methods of high temporal and spatial resolution may establish fruitful insights into the spectro-temporal hierarchy of predictive speech processing.
In addition, recent work demonstrated how neural networks (NNs) are able to reproduce human auditory behavioural patterns when trained on human sounds and tested on a variety of auditory tasks. This approach can help us to derive testable hypotheses about the mechanisms underlying speech processing and calls for a continued investigation of whether the mechanisms may converge between NNs and human neural representations (Kell et al., Citation2018; Saddler et al., Citation2021). Indeed, it has been found that the better the performance of a NN, the better it mapped onto neuronal data (Schrimpf et al., Citation2021). The representational hierarchy of speech processing was apparent in NNs with intermediate network layers mapping best to neural activity in PAC, while later layers predicted activity in adjacent regions along the temporal plane best (Kell et al., Citation2018). This representational gradient was demonstrated to be independent of the learning modality, i.e. supervised or unsupervised learning in the NN (Wang et al., Citation2019, Citation2022). In line with these findings, the combination of deep neural networks and RSA showed that the informational content of the final network layer represented concepts at the sentence level similar to distributed temporofrontal regions (Acunzo et al., Citation2022).
In another approach, different language models based on word embeddings in combination with MEG were useful to probe the neuronal hierarchy of speech processing (Broderick & Lalor, Citation2020; Heilbron et al., Citation2022). Specifically, MEG recordings revealed a temporal hierarchy of speech features so that acoustic processing was followed by phonemic and syntactic information, which was processed earlier than lexical and semantic predictions (Heilbron et al., Citation2022). In addition, the propagation of high-level predictions towards lower levels and the mutual existence of prediction and prediction error in a predictive coding manner were observed (Broderick & Lalor, Citation2020; Heilbron et al., Citation2022). Moreover, competing next-word predictions from a neural word embedding model could be mapped to neural pre-stimulus activity, which after the onset of the next word was amplified by the amount of the surprise predicted by the network model (Goldstein et al., Citation2021).
Similar approaches based on fMRI data may be beneficial to disentangle the influence of bottom-up prediction error and top-down predictions, such as the successful discrimination of a better-performing hierarchical long-short-term memory model in comparison to a non-hierarchical language model (Schmitt et al., Citation2021). As we have discussed above, a correspondence between NNs and neural activity can arise albeit the mechanistic principles of the underlying systems deviate (Baker et al., Citation2022). How can we take advantage of NNs to go beyond simply observing correspondences with neural activity? To obtain an explanatory mechanism for neural activity from NNs, incrementally varying the training input stimuli in a controlled manner may help to examine the degree of algorithmic equivalence. Best practices for neuroscientific research with NNs such as an expansion of the out-of-sample testing space (to other behavioural tasks) as well as biologically-plausible models can serve as helpful measures (Saxe et al., Citation2021; Schyns et al., Citation2022). However, constraining a NN's biological plausibility might not always be obligatory since idealised models can help to understand the mathematical learning principles and infinite-size networks are paradoxically more interpretable (Ma & Peters, Citation2020; Schyns et al., Citation2022). Tools of explainable AI (XAI) are a promising new approach for filling the gap of interpretability to uncover meaningful patterns in NNs (Samek et al., Citation2021; Thomas et al., Citation2022). Applying these tools (for an example on EEG data see Cui & Weng, Citation2022) together with considering not only the performance of NNs but also their learning trajectories and error landscapes may be beneficial to compare artificial and human mechanisms.
In sum, computational modelling in combination with multivariate analysis techniques of brain data has the potential to improve our understanding of the mechanisms underlying predictive processes in speech processing.
Acknowledgments
This work was funded by the Emmy Noether program of the Deutsche Forschungsgemeinschaft (German Research Foundation; Grant No DFG BL 1736/1-1 to HB).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abrams, D. A., Ryali, S., Chen, T., Balaban, E., Levitin, D. J., & Menon, V. (2013). Multivariate activation and connectivity patterns discriminate speech intelligibility in Wernicke’s, Broca’s, and Geschwind’s areas. Cerebral Cortex, 23(7), 1703–1714. https://doi.org/10.1093/cercor/bhs165
- Acunzo, D. J., Low, D. M., & Fairhall, S. L. (2022). Deep neural networks reveal topic-level representations of sentences in medial prefrontal cortex, lateral anterior temporal lobe, precuneus, and angular gyrus. NeuroImage, 251, 119005. https://doi.org/10.1016/j.neuroimage.2022.119005
- Aglieri, V., Cagna, B., Velly, L., Takerkart, S., & Belin, P. (2021). FMRI-based identity classification accuracy in left temporal and frontal regions predicts speaker recognition performance. Scientific Reports, 11(489). https://doi.org/10.1038/s41598-020-79922-7
- Aitchison, L., & Lengyel, M. (2017). With or without You: Predictive coding and Bayesian inference in the brain. Current Opinion in Neurobiology, 46, 219–227. https://doi.org/10.1016/j.conb.2017.08.010
- Alderson-Day, B., Lima, C. F., Evans, S., Krishnan, S., Shanmugalingam, P., Fernyhough, C., & Scott, S. K. (2017). Distinct processing of ambiguous speech in people with non-clinical auditory verbal hallucinations. Brain, 140(9), 2475–2489. https://doi.org/10.1093/brain/awx206
- Alink, A., & Blank, H. (2021). Can expectation suppression be explained by reduced attention to predictable stimuli? NeuroImage, 231, 117824. https://doi.org/10.1016/j.neuroimage.2021.117824
- Allen, K., Pereira, F., Botvinick, M., & Goldberg, A. E. (2012). Distinguishing grammatical constructions with fMRI pattern analysis. Brain and Language, 123(3), 174–182. https://doi.org/10.1016/j.bandl.2012.08.005
- Arana, S., Marquand, A., Hultén, A., Hagoort, P., & Schoffelen, J.-M. (2020). Sensory-modality independent activation of the brain network for language. Journal of Neuroscience, https://doi.org/10.1523/JNEUROSCI.2271-19.2020
- Archila-Meléndez, M. E., Valente, G., Correia, J. M., Rouhl, R. P. W., Kranen-Mastenbroek, V. H., & Jansma, B. M. (2018). Sensorimotor representation of speech perception. Cross-decoding of place of articulation features during selective attention to syllables in 7T fMRI. Eneuro, 5(2). https://doi.org/10.1523/ENEURO.0252-17.2018
- Arsenault, J. S., & Buchsbaum, B. R. (2015). Distributed neural representations of phonological features during speech perception. Journal of Neuroscience, 35(2), 634–642. https://doi.org/10.1523/Jneurosci.2454-14.2015
- Arsenault, J. S., & Buchsbaum, B. R. (2016). No evidence of somatotopic place of articulation feature mapping in motor cortex during passive speech perception. Psychonomic Bulletin & Review, 23(4), 1231–1240. https://doi.org/10.3758/s13423-015-0988-z
- Baker, B., Lansdell, B., & Kording, K. P. (2022). Three aspects of representation in neuroscience. Trends in Cognitive Sciences, 26(11), 942–958. https://doi.org/10.1016/j.tics.2022.08.014
- Bejjanki, V. R., Silveira, R. A., Cohen, J. D., & Turk-Browne, N. B. (2017). Noise correlations in the human brain and their impact on pattern classification. PLoS Computational Biology, 13(8), e1005674. https://doi.org/10.1371/journal.pcbi.1005674
- Blank, H., & Davis, M. H. (2016). Prediction errors but not sharpened signals simulate multivoxel fMRI patterns during speech perception. PLOS Biology, 14(11). https://doi.org/10.1371/journal.pbio.1002577
- Blank, H., Spangenberg, M., & Davis, M. H. (2018). Neural prediction errors distinguish perception and misperception of speech. The Journal of Neuroscience, 38(27), 6076. https://doi.org/10.1523/JNEUROSCI.3258-17.2018
- Bonte, M., Hausfeld, L., Scharke, W., Valente, G., & Formisano, E. (2014). Task-dependent decoding of speaker and vowel identity from auditory cortical response patterns. Journal of Neuroscience, 34(13), 4548–4557. https://doi.org/10.1523/Jneurosci.4339-13.2014
- Broderick, M. P., & Lalor, E. C. (2020). Co-existence of prediction and error signals in electrophysiological responses to natural speech. bioRxiv. https://doi.org/10.1101/2020.11.20.391227
- Carlson, T. A., Simmons, R. A., Kriegeskorte, N., & Slevc, L. R. (2014). The emergence of semantic meaning in the ventral temporal pathway. Journal of Cognitive Neuroscience, 26(1), 120–131. https://doi.org/10.1162/jocn_a_00458
- Carota, F., Kriegeskorte, N., Nili, H., & Pulvermüller, F. (2017). Representational similarity mapping of distributional semantics in left inferior frontal, middle temporal, and motor cortex. Cerebral Cortex, 27(1), 294–309. https://doi.org/10.1093/cercor/bhw379
- Carota, F., Nili, H., Pulvermüller, F., & Kriegeskorte, N. (2021). Distinct fronto-temporal substrates of distributional and taxonomic similarity among words: Evidence from RSA of BOLD signals. NeuroImage, 224, 117408. https://doi.org/10.1016/j.neuroimage.2020.117408
- Chang, E. F., Rieger, J. W., Johnson, K., Berger, M. S., Barbaro, N. M., & Knight, R. T. (2010). Categorical speech representation in human superior temporal gyrus. Nature Neuroscience, 13(11). https://doi.org/10.1038/nn.2641
- Cichy, R. M., Pantazis, D., & Oliva, A. (2016). Similarity-based fusion of MEG and fMRI reveals spatio-temporal dynamics in human cortex during visual object recognition. Cerebral Cortex, 26(8), 3563–3579. https://doi.org/10.1093/cercor/bhw135
- Correia, J., Formisano, E., Valente, G., Hausfeld, L., Jansma, B., & Bonte, M. (2014). Brain-based translation: FMRI decoding of spoken words in bilinguals reveals language-independent semantic representations in anterior temporal lobe. Journal of Neuroscience, 34(1), 332–338. https://doi.org/10.1523/JNEUROSCI.1302-13.2014
- Correia, J., Jansma, B. M. B., & Bonte, M. (2015). Decoding articulatory features from fMRI responses in dorsal speech regions. Journal of Neuroscience, 35(44), 15015–15025. https://doi.org/10.1523/Jneurosci.0977-15.2015
- Cui, J., & Weng, B. (2022). Towards Best Practice of Interpreting Deep Learning Models for EEG-based Brain Computer Interfaces. https://doi.org/10.48550/arXiv.2202.06948
- Daube, C., Ince, R. A. A., & Gross, J. (2019). Simple acoustic features can explain phoneme-based predictions of cortical responses to speech. Current Biology, 29(12), 1924–1937.e9. https://doi.org/10.1016/j.cub.2019.04.067
- Davis, M. H., & Johnsrude, I. S. (2003). Hierarchical processing in spoken language comprehension. Journal of Neuroscience, 23(8), 3423–3431. https://doi.org/10.1523/JNEUROSCI.23-08-03423.2003
- Davis, M. H., & Johnsrude, I. S. (2007). Hearing speech sounds: Top-down influences on the interface between audition and speech perception. Hearing Research, 229(1), 132–147. https://doi.org/10.1016/j.heares.2007.01.014
- Davis, M. H., Johnsrude, I. S., Hervais-Adelman, A., Taylor, K., & McGettigan, C. (2005). Lexical information drives perceptual learning of distorted speech: Evidence from the comprehension of noise-vocoded sentences. Journal of Experimental Psychology. General, 134(2), 222–241. https://doi.org/10.1037/0096-3445.134.2.222
- DeLong, K. A., Urbach, T. P., & Kutas, M. (2005). Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8(8). https://doi.org/10.1038/nn1504
- Deniz, F., Nunez-Elizalde, A. O., Huth, A. G., & Gallant, J. L. (2019). The representation of semantic information across human cerebral cortex during listening versus Reading Is invariant to stimulus modality. Journal of Neuroscience, 39(39), 7722–7736. https://doi.org/10.1523/JNEUROSCI.0675-19.2019
- Deniz, F., Tseng, C., Wehbe, L., & Gallant, J. L. (2021). Semantic representations during language comprehension are affected by context. bioRxiv. https://doi.org/10.1101/2021.12.15.472839
- de Zubicaray, G., Arciuli, J., & McMahon, K. (2013). Putting an “End” to the motor cortex representations of action words. Journal of Cognitive Neuroscience, 25(11), 1957–1974. https://doi.org/10.1162/jocn_a_00437
- Diedrichsen, J., & Kriegeskorte, N. (2017). Representational models: A common framework for understanding encoding, pattern-component, and representational-similarity analysis. PLoS Computational Biology, 13(4). https://doi.org/10.1371/journal.pcbi.1005508
- Ding, N., Melloni, L., Zhang, H., Tian, X., & Poeppel, D. (2016). Cortical tracking of hierarchical linguistic structures in connected speech. Nature Neuroscience, 19(1). https://doi.org/10.1038/nn.4186
- Donhauser, P. W., & Baillet, S. (2020). Two distinct neural timescales for predictive speech processing. Neuron, 105(2), 385–393.e9. https://doi.org/10.1016/j.neuron.2019.10.019
- Du, Y., Buchsbaum, B. R., Grady, C. L., & Alain, C. (2014). Noise differentially impacts phoneme representations in the auditory and speech motor systems. Proceedings of the National Academy of Sciences, 111(19), 7126–7131. https://doi.org/10.1073/pnas.1318738111
- Dujmović, M., Bowers, J. S., Adolfi, F., & Malhotra, G. (2022). The pitfalls of measuring representational similarity using representational similarity analysis. bioRxiv. https://doi.org/10.1101/2022.04.05.487135
- Etzel, J. A., Zacks, J. M., & Braver, T. S. (2013). Searchlight analysis: Promise, pitfalls, and potential. Neuroimage, 78, 261–269. https://doi.org/10.1016/j.neuroimage.2013.03.041
- Evans, S., & Davis, M. H. (2015). Hierarchical organization of auditory and motor representations in speech perception: Evidence from searchlight similarity analysis. Cerebral Cortex, 25(12), 4772–4788. https://doi.org/10.1093/cercor/bhv136
- Evans, S., Kyong, J. S., Rosen, S., Golestani, N., Warren, J. E., McGettigan, C., Mourao-Miranda, J., Wise, R. J. S., & Scott, S. K. (2014). The pathways for intelligible speech: Multivariate and univariate perspectives. Cerebral Cortex, 24(9), 2350–2361. https://doi.org/10.1093/cercor/bht083
- Fedorenko, E., Nieto-Castañon, A., & Kanwisher, N. (2012). Lexical and syntactic representations in the brain: An fMRI investigation with multi-voxel pattern analyses. Neuropsychologia, 50(4), 499–513. https://doi.org/10.1016/j.neuropsychologia.2011.09.014
- Feuerriegel, D., Vogels, R., & Kovács, G. (2021). Evaluating the evidence for expectation suppression in the visual system. Neuroscience & Biobehavioral Reviews, 126, 368–381. https://doi.org/10.1016/j.neubiorev.2021.04.002
- Fisher, J. M., Dick, F. K., Levy, D. F., & Wilson, S. M. (2018). Neural representation of vowel formants in tonotopic auditory cortex. NeuroImage, 178, 574–582. https://doi.org/10.1016/j.neuroimage.2018.05.072
- Flanagan, J. L. (2005). A difference limen for vowel formant frequency. The Journal of the Acoustical Society of America, 27(3), 613. https://doi.org/10.1121/1.1907979
- Formisano, E., De Martino, F., Bonte, M., & Goebel, R. (2008). ‘Who’ is saying ‘what’? Brain-based decoding of human voice and speech. Science, 322(5903), 970–973. https://doi.org/10.1126/science.1164318
- Friston, K. J., Holmes, A. P., Worsley, K. J., Poline, J.-P., Frith, C. D., & Frackowiak, R. S. J. (1995). Statistical parametric maps in functional imaging: A general linear approach. Human Brain Mapping, 2(4), 189–210. https://doi.org/10.1002/hbm.460020402
- Gardumi, A., Ivanov, D., Hausfeld, L., Valente, G., Formisano, E., & Uludağ, K. (2016). The effect of spatial resolution on decoding accuracy in fMRI multivariate pattern analysis. NeuroImage, 132, 32–42. https://doi.org/10.1016/j.neuroimage.2016.02.033
- Giordano, B. L., McAdams, S., Zatorre, R. J., Kriegeskorte, N., & Belin, P. (2013). Abstract encoding of auditory objects in cortical activity patterns. Cerebral Cortex, 23(9), 2025–2037. https://doi.org/10.1093/cercor/bhs162
- Goldstein, A., Zada, Z., Buchnik, E., Schain, M., Price, A., Aubrey, B., Nastase, S. A., Feder, A., Emanuel, D., Cohen, A., Jansen, A., Gazula, H., Choe, G., Rao, A., Kim, S. C., Casto, C., Fanda, L., Doyle, W., Friedman, D., … Hasson, U. (2021). Thinking ahead: Spontaneous prediction in context as a keystone of language in humans and machines. bioRxiv. https://doi.org/10.1101/2020.12.02.403477
- Habeck, C. G. (2010). Basics of multivariate analysis in neuroimaging data. Journal of Visualized Experiments: JoVE, 41, 1988. https://doi.org/10.3791/1988
- Hamilton, L. S., Oganian, Y., Hall, J., & Chang, E. F. (2021). Parallel and distributed encoding of speech across human auditory cortex. Cell, 184(18), 4626–4639.e13. https://doi.org/10.1016/j.cell.2021.07.019
- Haxby, J. V., Connolly, A. C., & Guntupalli, J. S. (2014). Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience, 37(1), 435–456. https://doi.org/10.1146/annurev-neuro-062012-170325
- Hebart, M. N., & Baker, C. I. (2018). Deconstructing multivariate decoding for the study of brain function. NeuroImage, 180, 4–18. https://doi.org/10.1016/j.neuroimage.2017.08.005
- Heer, W. A., Huth, A. G., Griffiths, T. L., Gallant, J. L., & Theunissen, F. E. (2017). The hierarchical cortical organization of human speech processing. Journal of Neuroscience, 37(27), 6539–6557. https://doi.org/10.1523/JNEUROSCI.3267-16.2017
- Heilbron, M., Armeni, K., Schoffelen, J.-M., Hagoort, P., & de Lange, F. P. (2022). A hierarchy of linguistic predictions during natural language comprehension. Proceedings of the National Academy of Sciences, 119(32), e2201968119. https://doi.org/10.1073/pnas.2201968119
- Hickok, G. (2014). The myth of mirror neurons: The real neuroscience of communication and cognition. W W Norton & Co. p. 292
- Hickok, G., & Poeppel, D. (2007). The cortical organization of speech processing. Nature Reviews. Neuroscience, 8(5), 393–402. https://doi.org/10.1038/nrn2113
- Hoffman, P., & Tamm, A. (2020). Barking up the right tree: Univariate and multivariate fMRI analyses of homonym comprehension. NeuroImage, 219, 117050. https://doi.org/10.1016/j.neuroimage.2020.117050
- Holmes, E., Folkeard, P., Johnsrude, I. S., & Scollie, S. (2018). Semantic context improves speech intelligibility and reduces listening effort for listeners with hearing impairment. International Journal of Audiology, 57(7), 483–492. https://doi.org/10.1080/14992027.2018.1432901
- Hsieh, I.-H., Fillmore, P., Rong, F., Hickok, G., & Saberi, K. (2012). FM-selective Networks in human auditory cortex revealed using fMRI and multivariate pattern classification. Journal of Cognitive Neuroscience, 24(9), 1896–1907. https://doi.org/10.1162/jocn_a_00254
- Huettig, F., & Mani, N. (2016). Is prediction necessary to understand language? Probably not. Language, Cognition and Neuroscience, 31(1), 19–31. https://doi.org/10.1080/23273798.2015.1072223
- Huth, A. G., de Heer, W. A., Griffiths, T. L., Theunissen, F. E., & Gallant, J. L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600). https://doi.org/10.1038/nature17637
- Jehee, J. F. M., Brady, D. K., & Tong, F. (2011). Attention improves encoding of task-relevant features in the human visual cortex. Journal of Neuroscience, 31(22), 8210–8219. https://doi.org/10.1523/JNEUROSCI.6153-09.2011
- Joanisse, M. F., & DeSouza, D. D. (2014). Sensitivity of human auditory cortex to rapid frequency modulation revealed by multivariate representational similarity analysis. Frontiers in Neuroscience, 8, https://doi.org/10.3389/fnins.2014.00306
- Jolly, E., & Chang, L. J. (2021). Multivariate spatial feature selection in fMRI. Social Cognitive and Affective Neuroscience, 16(8), 795–806. https://doi.org/10.1093/scan/nsab010
- Jonas, E., & Kording, K. P. (2017). Could a neuroscientist understand a microprocessor? PLOS Computational Biology, 13(1), e1005268. https://doi.org/10.1371/journal.pcbi.1005268
- Kell, A. J. E., Yamins, D. L. K., Shook, E. N., Norman-Haignere, S. V., & McDermott, J. H. (2018). A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy. Neuron, 98(3), 630–644.e16. https://doi.org/10.1016/j.neuron.2018.03.044
- Kemmerer, D. (2015). Does the motor system contribute to the perception and understanding of actions? Reflections on gregory hickok’s The myth of mirror neurons: The real neuroscience of communication and cognition. Language and Cognition, 7(3), 450–475. https://doi.org/10.1017/langcog.2014.36
- Kilian-Hutten, N., Valente, G., Vroomen, J., & Formisano, E. (2011). Auditory cortex encodes the perceptual interpretation of ambiguous sound. Journal of Neuroscience, 31(5), 1715–1720. https://doi.org/10.1523/Jneurosci.4572-10.2011
- Kivisaari, S. L., van Vliet, M., Hultén, A., Lindh-Knuutila, T., Faisal, A., & Salmelin, R. (2019). Reconstructing meaning from bits of information. Nature Communications, 10(1). https://doi.org/10.1038/s41467-019-08848-0
- Kok, P., Bains, L. J., Mourik, T., Norris, D. G., & Lange, F. P. (2016). Selective activation of the deep layers of the human primary visual cortex by Top-down feedback. Current Biology, 26(3), 371–376. https://doi.org/10.1016/j.cub.2015.12.038
- Kok, P., Jehee, J. F. M., & Lange, F. P. (2012). Less is more: Expectation sharpens representations in the primary visual cortex. Neuron, 75(2), 265–270. https://doi.org/10.1016/j.neuron.2012.04.034
- Kriegeskorte, N. (2008). Representational similarity analysis – connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2. https://doi.org/10.3389/neuro.06.004.2008
- Kriegeskorte, N., & Kievit, R. (2013). Representational geometry: Integrating cognition, computation, and the brain. Trends in Cognitive Sciences, 17(8). https://doi.org/10.1016/j.tics.2013.06.007
- Krumbiegel, J., Ufer, C., & Blank, H. (2022). Influence of voice properties on vowel perception depends on speaker context. The Journal of the Acoustical Society of America, 152(2), 820–834. https://doi.org/10.1121/10.0013363
- Kuperberg, G. R., & Jaeger, T. F. (2016). What do we mean by prediction in language comprehension? Language, Cognition and Neuroscience, 31(1), 32–59. https://doi.org/10.1080/23273798.2015.1102299
- Lee, Y. S., Peelle, J. E., Kraemer, D., Lloyd, S., & Granger, R. (2015). Multivariate sensitivity to voice during auditory categorization. Journal of Neurophysiology, 114(3), 1819–1826. https://doi.org/10.1152/jn.00407.2014
- Lee, Y. S., Turkeltaub, P., Granger, R., & Raizada, R. D. S. (2012). Categorical speech processing in broca’s area: An fMRI study using multivariate pattern-based analysis. Journal of Neuroscience, 32(11), 3942–3948. https://doi.org/10.1523/Jneurosci.3814-11.2012
- Levy, D. F., & Wilson, S. M. (2020). Categorical encoding of vowels in primary auditory cortex. Cerebral Cortex, 30(2), 618–627. https://doi.org/10.1093/cercor/bhz112
- Levy, R. (2008). Expectation-based syntactic comprehension. Cognition, 106(3), 1126–1177. https://doi.org/10.1016/j.cognition.2007.05.006
- Ley, A., Vroomen, J., Hausfeld, L., Valente, G., Weerd, P. D., & Formisano, E. (2012). Learning of new sound categories shapes neural response patterns in human auditory cortex. Journal of Neuroscience, 32(38), 13273–13280. https://doi.org/10.1523/JNEUROSCI.0584-12.2012
- Liberman, A. M., Cooper, F. S., Shankweiler, D. P., & Studdert-Kennedy, M. (1967). Perception of the speech code. Psychological Review, 74(6), 431–461. https://doi.org/10.1037/h0020279
- Liberman, A. M., & Mattingly, I. G. (1985). The motor theory of speech perception revised. Cognition, 21(1), 1–36. https://doi.org/10.1016/0010-0277(85)90021-6
- Lowe, M. X., Mohsenzadeh, Y., Lahner, B., Charest, I., Oliva, A., & Teng, S. (2020). Spatiotemporal dynamics of sound representations reveal a hierarchical progression of category selectivity. bioRxiv. https://doi.org/10.1101/2020.06.12.149120
- Ma, W. J., & Peters, B. (2020). A neural network walks into a lab: Towards using deep nets as models for human behavior. ArXiv. https://doi.org/10.48550/arXiv.2005.02181
- Mahon, B. Z., & Caramazza, A. (2010). Judging semantic similarity: An event-related fMRI study with auditory word stimuli. Neuroscience, 169(1), 279–286. https://doi.org/10.1016/j.neuroscience.2010.04.029
- Markiewicz, C. J., & Bohland, J. W. (2016). Mapping the cortical representation of speech sounds in a syllable repetition task. NeuroImage, 141, 174–190. https://doi.org/10.1016/j.neuroimage.2016.07.023
- McClelland, J. L., & Elman, J. L. (1986). The TRACE model of speech perception. Cognitive Psychology, 18(1), 1–86. https://doi.org/10.1016/0010-0285(86)90015-0
- McGettigan, C., Evans, S., Rosen, S., Agnew, Z. K., Shah, P., & Scott, S. K. (2012). An application of univariate and multivariate approaches in fMRI to quantifying the hemispheric lateralization of acoustic and linguistic processes. Journal of Cognitive Neuroscience, 24(3), 636–652. https://doi.org/10.1162/jocn_a_00161
- Miller, G. A., Newman, E. B., & Friedman, E. A. (1958). Length-frequency statistics for written English. Information and Control, 1(4), 370–389. https://doi.org/10.1016/S0019-9958(58)90229-8
- Mitchell, D. J., & Cusack, R. (2016). Semantic and emotional content of imagined representations in human occipitotemporal cortex. Scientific Reports, 6(1), 20232. https://doi.org/10.1038/srep20232
- Mitchell, T. M., Hutchinson, R., Niculescu, R. S., Pereira, F., Wang, X., Just, M., & Newman, S. (2004). Learning to decode cognitive states from brain images. Machine Learning, 57(1), 145–175. https://doi.org/10.1023/B:MACH.0000035475.85309.1b
- Muckli, L., De Martino, F., Vizioli, L., Petro, L. S., Smith, F. W., Ugurbil, K., Goebel, R., & Yacoub, E. (2015). Contextual feedback to superficial layers of V1. Current Biology, 25(20), 2690–2695. https://doi.org/10.1016/j.cub.2015.08.057
- Murray, S. O., Schrater, P., & Kersten, D. (2004). Perceptual grouping and the interactions between visual cortical areas. Neural Networks, 17(5–6), 695–705. https://doi.org/10.1016/j.neunet.2004.03.010
- Nearey, T. M. (1998). Locus equations and pattern recognition. Behavioral and Brain Sciences, 21(2), 277–277. https://doi.org/10.1017/S0140525X98421174
- Norman-Haignere, S. V., Long, L. K., Devinsky, O., Doyle, W., Irobunda, I., Merricks, E. M., Feldstein, N. A., McKhann, G. M., Schevon, C. A., Flinker, A., & Mesgarani, N. (2022). Multiscale temporal integration organizes hierarchical computation in human auditory cortex. Nature Human Behaviour, 6(3). https://doi.org/10.1038/s41562-021-01261-y
- Norris, D., McQueen, J. M., & Cutler, A. (2000). Merging information in speech recognition: Feedback is never necessary. Behavioral and Brain Sciences, 23(3), 299. https://doi.org/10.1017/S0140525×00003241
- Obleser, J., Leaver, A., VanMeter, J., & Rauschecker, J. (2010). Segregation of vowels and consonants in human auditory cortex: Evidence for distributed hierarchical organization. Frontiers in Psychology, 1. https://doi.org/10.3389/fpsyg.2010.00232
- Ogg, M., Moraczewski, D., Kuchinsky, S. E., & Slevc, L. R. (2019). Separable neural representations of sound sources: Speaker identity and musical timbre. NeuroImage, 191, 116–126. https://doi.org/10.1016/j.neuroimage.2019.01.075
- Okada, K., Rong, F., Venezia, J., Matchin, W., Hsieh, I.-H., Saberi, K., Serences, J. T., & Hickok, G. (2010). Hierarchical organization of human auditory cortex: Evidence from acoustic invariance in the response to intelligible speech. Cerebral Cortex, 20(10), 2486–2495. https://doi.org/10.1093/cercor/bhp318
- Pakravan, M., Abbaszadeh, M., & Ghazizadeh, A. (2022). Coordinated multivoxel coding beyond univariate effects is not likely to be observable in fMRI data. NeuroImage, 247, 118825. https://doi.org/10.1016/j.neuroimage.2021.118825
- Partyka, M., Demarchi, G., Roesch, S., Suess, N., Sedley, W., Schlee, W., & Weisz, N. (2019). Phantom auditory perception (tinnitus) is characterised by stronger anticipatory auditory predictions. bioRxiv. https://doi.org/10.1101/869842
- Partyka, M., Demarchi, G., Sedley, W., Schlee, W., & Weisz, N. (2019). Enhanced anticipatory predictions in the auditory system of individuals with tinnitus. Poster session presented at 49th Annual Meeting of the Society for Neuroscience (SfN), Chicago, Illinois, United States.
- Pasley, B. N., David, S. V., Mesgarani, N., Flinker, A., Shamma, S. A., Crone, N. E., Knight, R. T., & Chang, E. F. (2012). Reconstructing speech from human auditory cortex. PLOS Biology, 10(1), e1001251. https://doi.org/10.1371/journal.pbio.1001251
- Pereira, F., Just, M., & Mitchell, T. (2001). Distinguishing natural language processes on the basis of fMRI-measured brain activation. In L. De Raedt, & A. Siebes (Eds.), Principles of data mining and knowledge discovery (pp. 374–385). Springer. https://doi.org/10.1007/3-540-44794-6_31.
- Pereira, F., Lou, B., Pritchett, B., Ritter, S., Gershman, S. J., Kanwisher, N., Botvinick, M., & Fedorenko, E. (2018). Toward a universal decoder of linguistic meaning from brain activation. Nature Communications, 9(1). https://doi.org/10.1038/s41467-018-03068-4
- Perrodin, C., Kayser, C., Logothetis, N. K., & Petkov, C. I. (2011). Voice cells in the primate temporal lobe. Current Biology, 21(16), 1408–1415. https://doi.org/10.1016/j.cub.2011.07.028
- Poldrack, R. A. (2007). Region of interest analysis for fMRI. Social Cognitive and Affective Neuroscience, 2(1), 67–70. https://doi.org/10.1093/Scan/Nsm006
- Preisig, B., Riecke, L., & Hervais-Adelman, A. (2022). Speech sound categorization: The contribution of non-auditory and auditory cortical regions. NeuroImage, 258, 119375. https://doi.org/10.1016/j.neuroimage.2022.119375
- Raizada, R. D. S., & Poldrack, R. A. (2007). Selective amplification of stimulus differences during categorical processing of speech. Neuron, 56(4), 726–740. https://doi.org/10.1016/j.neuron.2007.11.001
- Rampinini, A. C., Handjaras, G., Leo, A., Cecchetti, L., Ricciardi, E., Marotta, G., & Pietrini, P. (2017). Functional and spatial segregation within the inferior frontal and superior temporal cortices during listening, articulation imagery, and production of vowels. Scientific Reports, 7(1). https://doi.org/10.1038/s41598-017-17314-0
- Remez, R. E., Rubin, P. E., Pisoni, D. B., & Carrell, T. D. (1981). Speech perception without traditional speech cues. Science, 212(4497), 947–950. https://doi.org/10.1126/science.7233191
- Ritchie, J. B., Kaplan, D. M., & Klein, C. (2019). Decoding the brain: Neural representation and the limits of multivariate pattern analysis in cognitive neuroscience. The British Journal for the Philosophy of Science, 70(2), 581–607. https://doi.org/10.1093/bjps/axx023
- Saddler, M. R., Gonzalez, R., & McDermott, J. H. (2021). Deep neural network models reveal interplay of peripheral coding and stimulus statistics in pitch perception. Nature Communications, 12(1). https://doi.org/10.1038/s41467-021-27366-6
- Samek, W., Montavon, G., Lapuschkin, S., Anders, C. J., & Müller, K.-R. (2021). Explaining deep neural networks and beyond: A review of methods and applications. Proceedings of the IEEE, 109(3), 247–278. https://doi.org/10.1109/JPROC.2021.3060483
- Saxe, A., Nelli, S., & Summerfield, C. (2021). If deep learning is the answer, what is the question? Nature Reviews Neuroscience, 22(1). https://doi.org/10.1038/s41583-020-00395-8
- Schmitt, L.-M., Erb, J., Tune, S., Rysop, A. U., Hartwigsen, G., & Obleser, J. (2021). Predicting speech from a cortical hierarchy of event-based time scales. Science Advances, 7(49), eabi6070. https://doi.org/10.1126/sciadv.abi6070
- Schomers, M. R., & Pulvermüller, F. (2016). Is the sensorimotor cortex relevant for speech perception and understanding? An integrative review. Frontiers in Human Neuroscience, 10. https://doi.org/10.3389/fnhum.2016.00435
- Schrimpf, M., Blank, I. A., Tuckute, G., Kauf, C., Hosseini, E. A., Kanwisher, N., Tenenbaum, J. B., & Fedorenko, E. (2021). The neural architecture of language: Integrative modeling converges on predictive processing. Proceedings of the National Academy of Sciences, 118(45), e2105646118. https://doi.org/10.1073/pnas.2105646118
- Schwiedrzik, C. M., & Freiwald, W. A. (2017). High-level prediction signals in a Low-level area of the macaque face-processing hierarchy. Neuron, 96(1), 89–97.e4. https://doi.org/10.1016/j.neuron.2017.09.007
- Schyns, P. G., Snoek, L., & Daube, C. (2022). Degrees of algorithmic equivalence between the brain and its DNN models. Trends in Cognitive Sciences, 26(12). https://doi.org/10.1016/j.tics.2022.09.003
- Scott, S. K., Blank, C. C., Rosen, S., & Wise, R. J. (2000). Identification of a pathway for intelligible speech in the left temporal lobe. Brain: A Journal of Neurology, 123(12), 2400–2406. https://doi.org/10.1093/brain/123.12.2400
- Scott, S. K., & Johnsrude, I. S. (2003). The neuroanatomical and functional organization of speech perception. Trends in Neurosciences, 26(2), 100–107. https://doi.org/10.1016/S0166-2236(02)00037-1
- Shahbazi, M., Shirali, A., Aghajan, H., & Nili, H. (2021). Using distance on the riemannian manifold to compare representations in brain and in models. NeuroImage, 239, 118271. https://doi.org/10.1016/j.neuroimage.2021.118271
- Sohoglu, E., & Davis, M. H. (2020). Rapid computations of spectrotemporal prediction error support perception of degraded speech. ELife, 9, e58077. https://doi.org/10.7554/eLife.58077
- Sohoglu, E., Peelle, J. E., Carlyon, R. P., & Davis, M. H. (2012). Predictive Top-down integration of prior knowledge during speech perception. Journal of Neuroscience, 32(25), 8443–8453. https://doi.org/10.1523/JNEUROSCI.5069-11.2012
- Stilp, C. (2020). Acoustic context effects in speech perception. WIRES Cognitive Science, 11(1), e1517. https://doi.org/10.1002/wcs.1517
- Su, Y., Olasagasti, I., & Giraud, A.-L. (2022). A deep hierarchy of predictions enables assignment of semantic roles in real-time speech comprehension. bioRxiv. https://doi.org/10.1101/2022.04.01.486694
- Thomas, A. W., Ré, C., & Poldrack, R. A. (2022). Interpreting mental state decoding with deep learning models. Trends in Cognitive Sciences, 26(11), 972–986. https://doi.org/10.1016/j.tics.2022.07.003
- Todorovic, A., & Lange, F. P. d. (2012). Repetition suppression and expectation suppression Are dissociable in time in early auditory evoked fields. Journal of Neuroscience, 32(39), 13389–13395. https://doi.org/10.1523/JNEUROSCI.2227-12.2012
- Wang, L., Hu, X., Liu, H., Huang, H., Guo, L., & Liu, T. (2019). Explore the hierarchical auditory information processing Via deep convolutional autoencoder. 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), 1788–1791. https://doi.org/10.1109/ISBI.2019.8759330
- Wang, L., Liu, H., Zhang, X., Zhao, S., Guo, L., Han, J., & Hu, X. (2022). Exploring hierarchical auditory representation via a neural encoding model. Frontiers in Neuroscience, 16. https://doi.org/10.3389/fnins.2022.843988
- Williams, M. A., Baker, C. I., Op de Beeck, H. P., Mok Shim, W., Dang, S., Triantafyllou, C., & Kanwisher, N. (2008). Feedback of visual object information to foveal retinotopic cortex. Nature Neuroscience, 11(12). https://doi.org/10.1038/nn.2218
- Yan, S., Kuperberg, G. R., & Jaeger, T. F. (2017). Prediction (or not) during language processing. A commentary on Nieuwland et al. (2017) and DeLong et al. (2005). bioRxiv. https://doi.org/10.1101/143750
- Yang, Z., Fang, F., & Weng, X. (2012). Recent developments in multivariate pattern analysis for functional MRI. Neuroscience Bulletin, 28, 399–408. https://doi.org/10.1007/s12264-012-1253-3
- Yeo, B. T. T., Krienen, F. M., Sepulcre, J., Sabuncu, M. R., Lashkari, D., Hollinshead, M., Roffman, J. L., Smoller, J. W., Zöllei, L., Polimeni, J. R., Fischl, B., Liu, H., & Buckner, R. L. (2011). The organization of the human cerebral cortex estimated by intrinsic functional connectivity. Journal of Neurophysiology, 106(3), 1125–1165. https://doi.org/10.1152/jn.00338.2011
- Yoshimura, N., Nishimoto, A., Belkacem, A. N., Shin, D., Kambara, H., Hanakawa, T., & Koike, Y. (2016). Decoding of covert vowel articulation using electroencephalography cortical currents. Frontiers in Neuroscience, 10. https://doi.org/10.3389/fnins.2016.00175
- Yu, Y., Huber, L., Yang, J., Jangraw, D. C., Handwerker, D. A., Molfese, P. J., Chen, G., Ejima, Y., Wu, J., & Bandettini, P. A. (2019). Layer-specific activation of sensory input and predictive feedback in the human primary somatosensory cortex. Science Advances, 5(5). https://doi.org/10.1126/sciadv.aav9053
- Zhang, Q., Hu, X., Luo, H., Li, J., Zhang, X., & Zhang, B. (2016). Deciphering phonemes from syllables in blood oxygenation level-dependent signals in human superior temporal gyrus. European Journal of Neuroscience, 43(6), 773–781. https://doi.org/10.1111/ejn.13164