
ABSTRACT
This study investigated morphological decomposition of Tagalog infixed, prefixed, and suffixed words using the masked priming paradigm. We directly compared morphological priming of <in> infixed, ni- prefixed and -in suffixed words to examine whether infixes are processed similarly to other affixes during early and automatic decomposition. We found significant priming effects for infixed, prefixed, and suffixed words, but no semantic or orthographic similarity priming. Magnitudes of priming effects for infixed and prefixed words were not significantly different, suggesting that decomposition of infixed words was not more costly for Tagalog speakers, contrary to phonological readjustment-based accounts of infixation. This is the first psycholinguistic experiment showing that infixed words are decomposed into morphological units during visual word recognition. We provide evidence that the imperfect edge-alignment of the stem within infixed words does not hamper the early morphological decomposition mechanisms, suggesting that edge-alignment might not be critical to trigger activation of morphological units.
Introduction
A large number of visual word recognition studies in the last 40 years have established the involvement of early, form-based decomposition mechanisms in the initial stage of morphological processing (Rastle & Davis, Citation2008; Rastle et al., Citation2004, Citation2000; Badecker & Allen, Citation2002; Drews & Zwitserlood, Citation1995; Grainger et al., Citation1991; Ciaccio et al., Citation2020; Clahsen & Ikemoto, Citation2012; Fiorentino, Naito-Billen, & Minai, Citation2015; Nakano et al., Citation2016; Kim, Wang, & Taft, Citation2015; Boudelaa & Marslen-Wilson, Citation2011, inter multi alia). Such mechanisms appear to be semantically blind, such that we incorrectly decompose words like corner and brother in the first 200 ms of processing, due to the mere presence of orthographic strings like corn, broth and -er (Gold & Rastle, Citation2007; Rastle et al., Citation2004). Although the number of studies that examine early, form-based decomposition has grown exponentially over the past 20 years, it must be noted that many languages and their morphological processes have been ignored in this literature. The overwhelming majority of experimental research investigating morphological decomposition focuses on derivational suffixation (and to a lesser extent prefixation) in Indo-European languages, where affixes can be easily located at the edge of the stem. The current study contributes to closing this gap by examining morphological decomposition of infixed inflected words in Tagalog (Austronesian, Philippines), an affixation process and a language that have not yet been investigated in this literature.
One of the paradigms that has been widely used to examine morphological decomposition for visual word recognition is that of masked priming (Forster, Citation1998). In this paradigm, a morphologically simple target (e.g. CLEAN) is preceded by either a morphologically related prime (e.g. cleaner) or by an unrelated prime (e.g. people) presented for a very brief duration (typically less than 60 ms), too quickly for most people to be consciously aware of. The prime is often further masked by being preceded by a string of symbols (e.g. ######), called a forward mask, and sometimes by a backwards mask of symbols presented after the prime.
The fact that such brief and typically subconscious presentation of a prime is sufficient to facilitate lexical decision times to a morphologically related target indicates that morphological decomposition occurs very rapidly in the initial stages of lexical processing, and the equivalent priming effects for real (e.g. cleaner-CLEAN) and pseudo-related (e.g. corner-CORN) items suggest this decomposition is based on visual word form alone, prior to activation of the stem or whole word’s grammar or semantics (Rastle et al., Citation2000; Rastle, Davis, & New, Citation2004). Lavric et al. (Citation2007), Morris et al. (Citation2007), and Morris et al. (Citation2008), all report similar results for masked morphological priming experiments combined with concurrent EEG recordings, with a consistent finding of reduced negativities between 200–300 ms for both real and pseudo-related prime-target pairs in English.
Masked morphological priming effects have been attested in well-studied languages like English (e.g. Crepaldi et al., Citation2010, Citation2015; Fruchter et al., Citation2013; Morris et al., Citation2007, Citation2011; Morris & Stockall, Citation2012; Morris et al. Citation2013; Rastle & Davis, Citation2008), Dutch (e.g. Drews & Zwitserlood, Citation1995), Spanish (e.g. Badecker & Allen, Citation2002), German (Hasenäcker et al., Citation2016) and French (e.g. Grainger et al., Citation1991). Outside of the Indo-European language family, masked morphological priming effects have also been found in Setswana (Ciaccio et al., Citation2020), Basque (Duñabeitia et al., Citation2009), Japanese (Clahsen & Ikemoto, Citation2012; Fiorentino et al., Citation2015; Nakano et al., Citation2016), Korean (Kim et al., Citation2015), Hebrew (Frost et al., Citation2000; Kastner et al., Citation2018), Arabic (Boudelaa & Marslen-Wilson, Citation2005, Citation2011) and Turkish (Kirkici & Clahsen, Citation2012). The majority of these studies have focused on derivational prefixation and suffixation, where the morphological units can be easily located at the edges of the words.
There are relatively few studies that have looked at inflectional morphology using the masked priming paradigm. So far, robust priming effects have been observed for suffixed inflected words in Turkish (Kirkici & Clahsen, 2013), irregularly inflected word pairs like fell-FALL (e.g. Crepaldi et al., Citation2010) or taught-teach (Morris & Stockall, Citation2012; Fruchter et al., Citation2013) and prefixed derived and inflected words (Ciaccio et al., Citation2020). These studies are consistent with the proposal that inflected words undergo the same decomposition mechanisms as derived words (Marantz, Citation2013; Taft, Citation2004). The present study focuses on infixed, prefixed, and suffixed inflected words to help expand this literature. Understanding how infixed words are processed addresses current debates in both formal linguistics and psycholinguistics. We outline these debates in turn.
Formal accounts of infixation
The Tagalog inflectional infix <in> (e.g. s<in>apak “punched”) marks perfective aspect. Critically, the infix <in>has a prefix allomorph, ni-, appearing with stems that start with l, w, y, j, n, and h, while infix <in> occurs for all other consonants (see Examples 1a and 1b). Tagalog also has the inflectional suffix -in marking patient voice, which has the same phonological form as the infix <in> and is similar to that of the prefix ni- (see 1c).
There have been debates about what the best formal account is for infixation. On the one hand, under a readjustment-based account (e.g. Distributed Morphology), it has been proposed that infixes are underlyingly prefixes that go through phonological readjustment rules (see Halle, Citation2001; Kalin, Citation2022). Under such a proposal, the Tagalog infix <in> is underlyingly a CV prefix ni-. The prefix appears as an infix due to a process of onset metathesis (see 2), triggered by the first consonant of the stem. Such an account, therefore, involves an initial process of prefixation, followed by a separate process of linear adjustment resulting in infixation. On the other hand, under a phonological subcategorization-based account, infixes are a by-product of mismatches between the boundaries of phonological and morphological representations (Yu, Citation2007). Proponents of this account argue that infixes are affixes that are sensitive to the phonological property of their sister (i.e. the pivot). Such phonological sensitivity is encoded in the form of phonological subcategorization by the infix. For example, the infix <in> subcategorises for the initial consonant of the stem as its right sister. When direct infixation to a consonant-initial stem is not possible (i.e. when the consonant initial stem starts with l, w, y, h, and n), the prefixal, ni-, which does not subcategorise for any special phonological environment, is used instead. Note that such subcategorization happens at the phonological level and not at the morphological level. There is therefore no separate additional morphological step needed to account for infixation (Yu, Citation2007).
These two formal accounts make different predictions for morphological processing. The readjustment-based account would suggest that morphological decomposition of infixed words may be different from prefixed or suffixed words. Segmenting infixed words would require an additional step in the decomposition mechanisms that unpack the phonological readjustment rules, thereby making infixed word processing more costly than prefixed word processing. In contrast, the phonological subcategorization-based account does not have a specialised additional mechanism for infixed words. Therefore, it does not predict that parsing of infixed words is more costly than prefixed or suffixed words. The current study can address this debate by directly comparing <in> infixed words and ni- prefixed words in Tagalog and investigating whether or not these two types of morphologically complex words are processed and decomposed differently.
Psycholinguistics accounts of infixation
How morphological decomposition occurs when the affix is placed within the stem and when the form of the stem is disrupted remains under-investigated and under-theorised. Findings from Semitic languages may be relevant. For example in Hebrew, Frost et al. (Citation1997) investigated the morphological process that interleaves a triconsonantal root and a phonological word pattern (e.g. the root ZMR “anything to do with singing” combined with the pattern _a_a_ forms zamar “a male singer”), thereby causing a linear form disruption in the discontinuous root. Robust masked priming effects were found for prime-target pairs that share the same consonantal root (e.g. zmr-TIZMORET “anything to do with singing-ORCHESTRA”), but not for prime-target pairs that share the same word pattern. In Arabic, Boudelaa and Marslen-Wilson (Citation2005) found robust priming effects for prime-target pairs sharing the same consonantal roots at all prime durations (32, 48, 64, 80 ms), whereas prime-target pairs sharing the same word pattern only obtained robust priming effects at longer prime durations (48, 64 ms). These studies showed that priming effects can be obtained despite the morpheme disruption in the consonantal root. However, such findings may not directly extend to Tagalog infixation, as root-pattern morphology in Semitic languages means that roots are always realised as discontinuous. How early and automatic decomposition mechanisms take place for infixed words despite the disruption in a typically continuous stem remains an empirical question.
Some prominent accounts of morphological processing mechanisms, namely the affix stripping model (Taft & Forster, Citation1975) and the single-route, full decomposition model (Stockall & Marantz, Citation2006), generally assume exhaustive segmentation of all types of morphologically complex words. These models would predict that infixed words would be subject to the same early and automatic decomposition mechanisms as prefixed or suffixed words, though infixation is not explicitly considered by either model, hence the processing mechanism for such words is underspecified. The affix stripping model assumes a mechanism that strips any affixes from the stem during visual word recognition, which is followed by stem activation. However, Taft and Forster (Citation1975) did not explicitly state how such affix stripping mechanisms operate. So far, two psycholinguistic models have made explicit claims about how stems and affixes are activated during early morphological processing. For Taft and Nguyen-Hoan’s prelexical decomposition model (Citation2010), stems and affixes are represented as activation units, and such units are activated when they match with the incoming orthographic information. Based on this account, infixed words can only be decomposed if the orthographic matching procedure is flexible, since the initial consonant of the stem in infixed words is separated from the rest of the letter strings, thereby disrupting the orthographic matching. Beyersmann and Grainger’s (Citation2023) word and affix model proposes that the visual system activates embedded stems and affixes that match the incoming orthographic information when they are at the beginning- or end-edge of the letter-strings. Infixation poses a challenge to this model, since the embedded stem and the affix are not perfectly edge-aligned. This model predicts that infixed words are not subject to early and automatic decomposition mechanisms because of the outer-embedded stem (e.g. t<in>awag “called”).
The influence of form disruptions on morphological decomposition
How morpheme disruption affects morphological decomposition mechanisms is unclear from the existing literature. On the one hand, some studies find that masked priming effects are inhibited in some cases where morphemes are disrupted. For example, Christianson et al. (Citation2005) revealed that letter transpositions across a morpheme boundary (e.g. suhnsine) resulted in significantly less facilitation of a constituent target (e.g. shine) compared to a prime with no transposition. However, transposition within one element of a complex prime (e.g. sunhsine) and a prime with no transposition resulted in the same magnitude of masked morphological priming. Christianson et al. (Citation2005)’s finding of a contrast between, within, and across morpheme letter transposition was replicated in Basque (Duñabeitia et al., Citation2007). In Hebrew, Velan and Frost (Citation2007) report that letter transposition generally results in inhibition in masked priming, which they argue is due to the fact that Hebrew orthography typically only writes consonants, and that transposing the consonants in a Hebrew root generally results in a different existing root (e.g. the roots SLX “to send”, XLS “to dominate”, XSL “to toughen” and LXS “to whisper” are all distinct attested roots). Letter transposition in Arabic has also inhibited masked priming effects, suggesting that lexical access during the early stage of morphological processing is sensitive to the Semitic nonlinear morphology (Boudelaa et al., Citation2019). It has also been shown that orthographic changes such as deletion in Setswana (e.g. tshubile-TSHUBA “burned-to burn” involves “a” deletion) and Hebrew (e.g. hpyl-HSPYK involves a deletion of the n in the root npl in the prime /hipil/ “he overthrew”) inhibit masked priming effects (Ciaccio et al., Citation2020 for Setswana; Frost et al., Citation2000 for Hebrew).
On the other hand, there are also studies that have shown that morpheme disruption does not negatively impact morphological processing. For example, significant priming effects were found in English for monomorphemic nonword primes with letter transposition (e.g. wran-WARN) and for letter-transposed primes with real suffixes (e.g. wranish-WARN) (Beyersmann et al., Citation2011). Masked priming effects that are robust to transposition have also been reported in Japanese (Perea & Pérez, Citation2008). Moreover, McCormick et al. (Citation2008) found that various small orthographic discrepancies that commonly arise in English suffixation, such as letter doubling (e.g. slipper rather than sliper), letter deletion (e.g. computer, not computeer), and substitution (e.g. happiness, not happyness) do not disrupt morphological priming, despite somewhat obscuring the precise boundary between morphemes and breaking the perfect stem form identity between a complex word and its simple stem.
In the case of Tagalog infixation, both the linear position of the stem and the finer grained linear sequence within the stem are disrupted as seen in (3). Whether this disruption in the continuous stem negatively impacts Tagalog morphological decomposition is yet to be investigated in the masked priming literature. Overall, Tagalog infixation offers an avenue to explore how much morphological decomposition relies on preserving linear sequencing, alignment, and the form of the stem.
(3) 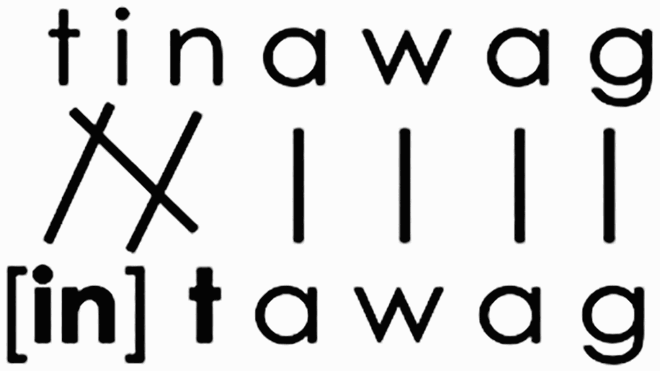
Asymmetry in prefix and suffix morphological priming
Previous morphological processing studies that compared processing of prefixed and suffixed words have found asymmetrical magnitudes of priming effects, thereby suggesting that prefixed and suffixed words are processed differently (e.g. Kim et al., Citation2015; Meunier & Segui, Citation2002). On the one hand, some have argued that suffixed words are accessed via their root morphemes due to a left-to-right parsing procedure, allowing the root of the suffixed word to be accessed faster, while prefixed words’ roots can only be extracted after access to the whole word (Baayen et al., Citation2007; Colé et al., Citation1989). For example in Korean, Kim et al. (Citation2015) found consistent priming effects for suffixed words regardless of the lexicality and interpretability of the primes, while prefixed primes significantly facilitated target responses only when they were real words, and not when they were prefixed pseudowords. They concluded that these findings were consistent with a model in which suffixes are segmented prelexically, whereas prefixed words are only segmented after lexical access has occurred. On the other hand, an account that assumes “beginning-to-end” sequential bias argues otherwise. Since prefixes are encountered earlier than suffixes during processing, prefixes should be more salient and more rapidly detected than suffixes (see Diependaele et al., Citation2009). For example, Meunier and Segui (Citation2002) found prefix priming effects in French regardless of phonological opacity, while suffix priming effects were only obtained if the prime and target were transparently phonologically related. In a similar vein, robust priming effects were also obtained in prefixed words in Setswana, while no such effects were obtained for suffixed words (Ciaccio et al., Citation2020). These findings are in line with the assumption that prefixed words are more easily decomposed than suffixed words due to prefixes’ salient position during processing.
However, prefixed and suffixed words have also exhibited a similar magnitude of priming effects in some studies. For example, Beyersmann et al. (Citation2016) also found equivalently robust priming effects in French prefixed and suffixed words using the masked priming paradigm. These findings are consistent with the idea that both prefixed and suffixed words are processed using the same decomposition mechanisms, as in Taft and Forster’s (Citation1975) and Taft’s (Citation2004) affix stripping model and Stockall and Marantz' (Citation2006) single-route full decomposition model. So far, the overwhelming majority of the masked priming studies comparing prefixed and suffixed word processing have focused on derivational morphology. We exploit the existence of the inflectional suffix -in in Tagalog, which has a similar phonological form to the inflectional prefix ni-, to make a closer comparison between prefixed and suffixed word processing. This adds additional crosslinguistic breadth to our understanding of observed variation in the priming effects for prefixed and suffixed words.
There are thus four ways in which looking at infixation can further inform our understanding of morphological processing: first, some formal accounts of infixation have argued that infixes are underlyingly prefixes that have undergone phonological readjustment rules (Kalin, Citation2022; Halle, Citation2001), while others deny the need for a specialised mechanism that transforms a prefix into an infix (Yu, Citation2007). Directly comparing the processing of words prefixed and infixed with allomorphs of the same morpheme (<in>/ni-) allows us to weigh in on this debate, thereby informing us whether infixed words require a specialised mechanism or not. Second, psycholinguistic models are unclear about how much flexibility the orthographic matching system possesses (Taft & Nguyen-Hoan, Citation2010) and whether edge-alignment is critical during activation of stems and affixes (Beyersmann & Grainger, Citation2023). Investigating the processing of infixed words can shed light into this, as the stem in infixation disrupts the orthographic matching and is not perfectly edge-aligned. Third, infixed words are formed by placing an affix within a continuous stem thereby causing a disruption. Investigating whether such a disruption in the stem hampers the robustness of the morphological parser will shed light into the potential limits of decomposition mechanisms. Fourth, whether linear position of affixes affects morphological decomposition was only explored by comparing prefixed and suffixed words. Looking at infixation allows for a three-way comparison across prefixed, infixed, and suffixed words, thereby extending the scope of investigation about the influence of affix linear position on early and automatic decomposition mechanisms.
Using a single word reading paradigm with concurrent magnetoencephalography (MEG) recording, Wray et al. (Citation2022) compared the processing of reduplicated, infixed and circumfixed words to the processing of morphologically simplex words, and found that the stem:whole word transition probability (Hay, Citation2001) for all three types of complex words reliably correlated with the amplitude of the M170 response component. Such a correlation has been consistently found for real and pseudocomplex affixed words in English (Gwilliams & Marantz, Citation2018; Lewis et al., Citation2011; Solomyak & Marantz, Citation2010), Greek (Neophytou et al., Citation2018) and Japanese (Ohta, Oseki, & Marantz, Citation2019), and thus argues that reduplicated, circumfixed and infixed words are subject to early and automatic decomposition mechanisms. However, the direction of the correlation was opposite for infixed words than for all other complex word types, suggesting infixation may trigger distinct processing mechanisms. The current study directly compares infixation with prefixation and suffixation of phonologically similar affixes to investigate this possibility.
The present study
Tagalog provides an interesting test-case since the infix <in> and the prefix ni- are allomorphs, making it possible to directly compare the processing of infixed words with prefixed words, with minimal variation between the affixes besides position. Although the prefix ni- and the suffix -in are different morphemes, they are both verbal inflection, and the minimal phonological form differences between the two allows for a closer comparison between the processing of prefixed and suffixed words.
This experiment employed the visual lexical decision task with the masked priming paradigm. We had three objectives: [1] to investigate whether infixed, prefixed, and suffixed words in Tagalog are subject to early, form-based decomposition mechanisms as evidenced by morphological priming effects; [2] to compare the magnitudes of priming of prefixed and suffixed words to investigate whether prefixes and suffixes are processed using the same mechanisms; and [3] to directly compare the morphological priming of infixed and prefixed words and infixed and suffixed words to explore whether infixed words are processed differently than prefixed or suffixed words.
We predicted our findings to be consistent with the assumptions of the affix stripping model (Taft & Forster, Citation1975) and single-route full decomposition Model (Stockall & Marantz, Citation2006). Specifically, (a) we expected to find reliable masked priming effects when target words are preceded by morphologically related infixed, prefixed, and suffixed primes, but not when they are preceded by unrelated and purely semantically and orthographically related primes, replicating previous masked priming experiments across different languages (e.g. Ciaccio et al., Citation2020; Clahsen & Ikemoto, Citation2012; Kim et al., Citation2015; Nakano et al., Citation2016; Rastle et al., Citation2004, Citation2008); and (b) we expected to find a similar magnitude of priming effects across all critical conditions, which will contradict the “beginning-to-end” sequential bias account (Diependaele et al., Citation2009; Giraudo & Grainger, Citation2003) and prelexical vs. postlexical decomposition account (Baayen et al., Citation2007; Colé et al., Citation1989).
Finding robust priming effects for the infixed word condition provides solid evidence that the orthographic matching system that activates stems and affixes is more flexible than Taft and Nguyen-Hoan’s original proposal (Citation2010). More importantly, finding evidence that infixed words are decomposed into morphological units contradicts Beyersmann and Grainger’s (Citation2023) model that embedded stems can only be activated if they are edge-aligned.
The comparison between the infix and prefix conditions also allowed us to test the competing predictions between the two formal accounts of infixation: if infixed words are more difficult to decompose than prefixed words due to phonological readjustment rules and stem disruption, then we expected to find a less robust priming effect for the infix condition than the prefix condition, which would support readjustment-based accounts of infixation (Halle, Citation2001; Kalin, Citation2022) and contradict phonological subcategorization-based accounts (Yu, Citation2007). This experiment was pre-registered on the Open Science Framework (https://osf.io/qdsj3).
Method
Participants
Eighty participants with a mean age of 29.85 (SD = 7.474; Range = 19–47) were recruited for the experiment via Prolific.co. All participants were native speakers of Tagalog. We asked them their city of origin in the Philippines and checked whether Tagalog is the dominant language in that area. All participants also reported speaking English. Others additionally spoke another Philippine language (N = 22), Italian (N = 3), Greek (N = 2), Spanish (N = 2), Arabic (N = 1), French (N = 1), Japanese (N = 1), and Korean (N = 1). All participants reported doing their primary and secondary education in the Philippines. The experiment was overseen by the first author’s university human subjects’ ethics review board. All participants gave their informed consent, and they were remunerated £3.13 for a 20-minute experiment.
Design and materials
The entire task was administered on participants’ computers (desktop or laptop) using Gorilla (www.gorilla.sc). We conducted a pilot study to confirm the validity of this fully online experiment presentation platform for testing masked priming online. We found robust priming effects for identical word pairs like tulog-TULOG “sleep” (b = 18.00, SE = 3.65, z = 4.940, p = <.0001), while no priming effects were obtained for word pairs that are only semantically related like isip-UTAK “mind–BRAIN” (b = 0.879, SE = 3.59, z = 0.250, p = 0.803). Our findings successfully replicated identity priming effects previously observed in lab-based masked priming experiments (e.g. Forster et al., Citation1990; Forster & Davis, Citation1984) and in a recent online masked priming experiment using PsychoJS (Angele et al., Citation2022), thereby confirming that Gorilla.sc has sufficiently reliable timing to be used for online masked priming experiments. This pilot study was pre-registered on OSF (https://osf.io/z8ve3).
There are three critical conditions in this experiment, namely the infix (INF) condition, the prefix (PREF) condition, and the suffix (SUF) condition, with 48 trials each. The twenty-four target words in each condition were preceded either by a morphologically related (Morph.Rel) infixed, prefixed, or suffixed prime, or by a morphologically unrelated prime (Morph.Unrel). Two control conditions, the semantic (SEM) condition and orthographic (ORTH) condition, also had 48 trials each. The SEM condition involved a target word preceded by either a semantically related prime (SEM.Rel) or an unrelated prime (SEM.Unrel). The ORTH condition involved a target word preceded by either an orthographically related prime (ORTH.Rel) or an unrelated prime (ORTH.Unrel). Second syllable overlap was chosen as a definition of orthographic relatedness in this study, as the orthographic overlap in the critical conditions is also in the second syllable of the target words. exemplifies related and unrelated trials for all 5 conditions. There were a total of 240 trials (120 related and 120 unrelated) in this experiment. 10 practice trials were also added.
Table 1. Sample item per condition.
Items in the INF, PREF, and SUF conditions were selected from a 198,303,250-word Tagalog corpus from SketchEngine (Kilgarriff et al., Citation2004), an online platform that compiles web-based text corpora from more than 900 languages. First, we generated a large candidate set of morphologically complex words with the infix <in> (e.g. t<in>ago “hidden”, t<in>abi “kept”, s<in>abi “told”), the prefix ni- (e.g. ni-lasing “got drunk”, ni-wasto “corrected”, ni-lustay “spent”), and the suffix -in (e.g. buhat-in “lift”, lasap-in “taste”), respectively. As a second step, only infixed, prefixed, and suffixed words with 6–8 letters and with prime and target whole word frequency above 1 per million were retained in the candidate sets. To generate unrelated primes, 6–8 letter long monomorphemic words with lexical frequencies of above 1 per million were extracted from the corpus. Prime words were hand matched with targets, such that unrelated primes and targets had very minimal orthographic overlap (maximum 3 shared letters) and no perceptible related meaning.
The SEM and ORTH conditions were formed by generating candidate sets of 4–8 letter long monomorphemic words in Tagalog with lexical frequencies above 1 per million using SketchEngine. For the SEM condition, we created a set of word pairs that could be considered semantically related via a strong association (e.g. luha-IYAK “tears-CRY”). We also created a set of semantically unrelated word pairs by assigning an unrelated word counterpart to one of the words in the semantically related word pairs. Word pairs were considered unrelated if they had very minimal orthographic overlap (maximum 2 shared letters) and were not related in meaning. Candidate prime-target pairs were then assessed via a semantic relatedness norming study, in which 10 participants, also on Prolific.co, who were excluded from participating in the masked priming study rated the complete candidate set of semantically related and unrelated prime-target pairs on a scale from 1–7 (7 = highly related). Only word pairs whose mean semantic relatedness ratings were below 2 were included in the unrelated condition, while word pairs whose mean semantic relatedness ratings were above 5 were included in the semantically related condition. Word pairs whose semantic relatedness ratings fell in the mid-range were excluded from the final stimulus list (following Basnight-Brown & Altarriba, Citation2007).
For the ORTH condition, we created a set of word pairs with the same second syllable. We also created a set of unrelated word pairs, which have no semantic and very minimal orthographic overlap between each other. Only word pairs that met the above relatedness and unrelatedness criteria were retained in the candidate set. As a second step, Levenshtein distance (Levenshtein, Citation1965) was used to derive an orthographic overlap score. Only word pairs with a Levenshtein score of 3 and lower were included in the orthographic related condition, while word pairs with a Levenshtein score of above 4 were included in the unrelated condition. For both the SEM and ORTH conditions, the word in each pair with longer character length (2 characters longer than the targets on average) was assigned as the prime, to match the character length difference in the critical conditions.
The targets in the INF, PREF, and SUF conditions were list-wise matched for orthographic length and lexical frequency. Furthermore, the Related and Unrelated primes were pairwise matched for orthographic length and list-wise matched for lexical frequency. The same matching was employed in the SEM and ORTH conditions. All targets and primes in the final stimulus list have frequencies above 1 per million in SketchEngine to ensure they are all familiar words (see ). It is also important to note that the infix <in> is more frequent than the prefix ni-. Based on a 260.9 million word corpus comprised of Wikipedia, newswire, web, and Twitter, <in> has a frequency of 528.41 per million while ni- only has a frequency of 60.69 per million. The suffix -in has a frequency of 254.87 per million.
Table 2. Mean item characteristics (standard deviations, range) for all sets and prime.
We used the Wuggy toolkit augmented with a Tagalog wordlist as training data to generate nonwords (Keuleers & Brysbaert, Citation2010). A total of 240 nonword targets and 120 nonwords primes were selected in the final stimulus list to serve as filler trials. All nonword primes and targets that were selected are pronounceable nonwords ranging between 4–8 characters to match the critical and control trials. The other half of the nonword targets were preceded by real word primes that are 6–8 characters long to avoid cueing participants to the lexical decision they should make. Both nonword and real word primes were list-wise matched for orthographic length. Overall, the entire experiment consisted of 490 trials (see Appendix A for the complete list of materials).
Procedure
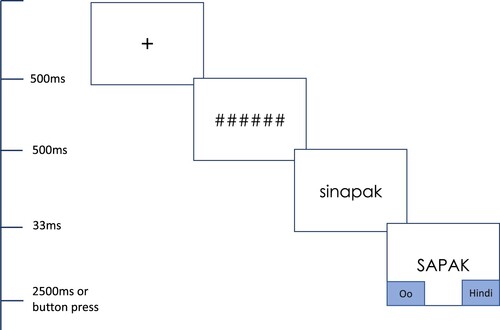
We presented the stimuli in two blocks of 240 trials. Since all participants saw the critical targets in both their related prime and unrelated prime condition, we ensured that the two occurrences of each target were separated into two different blocks, with a short break in between to minimise possible long distance priming effects. The order of items within a block was pseudo-randomized for each participant, and the order of the two blocks was permuted across participants such that each block occurred as the first block for ½ of participants and as the second block for the other half. The task started with a consent form, followed by a brief instruction and a practice session of 10 trials. All visual stimuli were presented in the centre of the screen, in black 50-point size Courier Sans Serif over a white background to provide a contrast. Each trial began with a fixation cross for 500 ms, followed by a 500 ms presentation of a forward mask made up of a row of hash marks (e.g. ######), matching the maximum length of the corresponding prime. Immediately afterwards, the prime was displayed for 33 ms in lowercase letters, followed by the target in uppercase letters. Participants had 2500 ms to judge whether the target word was a real Tagalog word or not by pressing the corresponding arrow key (see ). We also controlled the mapping of “Yes” and “No” to the arrow keys, to ensure results were not dependent on this mapping. For half of the participants, “Oo” (Yes) mapped to the left arrow key and “Hindi” (No) mapped to the right arrow key, while the other half experienced the opposite mapping. This button press counterbalancing is separate from block randomisation. Participants were instructed to respond as quickly and as accurately as possible. The entire experiment took twenty-five minutes to finish.
Figure 1. Sequence of screens within each trial in the experiment. The next trial began upon response, or after the 2500 ms timeout deadline.
After the task, participants were probed about their perception of the primes. No participants reported having noticed the masked primes. They were also asked whether there were real Tagalog words in the experiment that were unfamiliar to them. None of the words in the critical sets were reported to be unfamiliar.
Data pre-processing and analysis
All analyses were performed using R (R Core Team, Citation2015). We first checked for the accuracy of prime presentation to ensure that primes were, in fact, masked. Primes that were presented for >60 ms were removed from the dataset, which led to the exclusion of ten datapoints (0.053%). We then checked for error rates on the responses to target words, and participants with an accuracy rate of <70% were excluded, which led to removal of 10 participants or 12.5% of the data. Seventy participants were retained for further analyses. For the reaction time (RT) analysis, incorrect responses (8.33%) were excluded, as were RTs faster than 200 ms (0.43%) (i.e. minimal trimming). Further outlier trimming was done following Baayen and Milin (Citation2010); we fit a simple mixed model with only random effects and excluded all data points with residuals exceeding 2.5 SD (2.94%). Accuracy rates and cleaned RTs were then analysed using (generalised) linear mixed-effects modelling as implemented in the lme4 package (Bates et al., Citation2015). The models included Relation Type (INF, PREF, SUF, Orth, SEM) and Prime Type (Related, Unrelated) as fixed effects and their interaction. We set “PREF” and “Unrelated” as reference levels in the Relation Type and Prime Type conditions, respectively. Log-likelihood ratio tests were used for significance testing, comparing models with and without the interaction (RelationType * PrimeType vs. RelationType + PrimeType) using the “anova()” function. Multiple comparison correction was done using the emmeans package in R (Lenth et al., Citation2022). We used an alpha level of .05.
All the models fitted included by-participant and by-target random intercepts. For each model, we additionally tested for inclusion of three fixed factors “frequency”, “OS”, and “Browser”, in order to assess whether differences in lexical frequency between conditions, operating systems (Windows, Mac) and browsers (Chrome, Safari) affected priming effects. We checked whether these fixed factors significantly improved the model fit by comparing the model with and without the additional factors using the “anova()” function in R. None of the factors significantly improve the model fit; hence, they are not included in the models reported below. We also tested for inclusion of by-participant and by-target random slopes for the RelationType*PrimeType interaction (Matuschek et al., Citation2017), but convergence issues emerged, prompting us to simplify the model. The final model was coded in R as RT ∼ RelationType * PrimeType + (1|Participant) + (1|Target).
All the data and the scripts to reproduce the analyses are available on OSF (https://osf.io/ujsde/).
Results
presents by-participant mean RTs and accuracy rates for lexical decisions for each condition and prime type.
Table 3. By-subject mean RTs in ms and standard errors, priming effects, and accuracy scores for all conditions and prime types.
As regards the accuracy analysis, there was no substantial increase in accuracy between related and unrelated primes in any of the conditions. Generalised mixed-effects modelling revealed that there was no significant interaction between Prime Type and Relation Type, X2(4) = 0.149, p 0.997. Relation Type, X2(4) = 12.90, p = 0.0117, was associated with a significant effect. Post hoc pairwise comparisons for Relation Type revealed significant accuracy difference between INF and ORTH (b = 0.840, SE = 0.304, 95% CI = [0.830, 0.850], z = 2.763, p = 0.045) and ORTH and SEM (b = −0.833, SE = 0.305, 95% CI = [−0.820, −0.850], z = −2.735, p = 0.049).
With respect to the RT analysis, we found faster RTs to the targets preceded by morphologically related primes in all three critical conditions, with the INF condition showing the largest priming magnitude (24 ms), the SUF condition in the middle (18 ms) and the PREF condition showing the smallest priming magnitude (15 ms). Mixed-effects modelling revealed no significant effect of Relation Type, X2(4) = 3.093, p = 0.542, but there was a significant effect of Prime Type, X2(4) = 21.07, p = <.0001. There was also a significant interaction between Prime Type and Relation Type, X2(4) = 40.99, p = <.0001. Post hoc pairwise comparisons of related and unrelated RT means per condition using Tukey HSD tests confirmed that significant facilitatory priming effects were found only for the critical conditions (INF, b = 26.30, SE = 4.67, z = 5.631, p = <.0001; PREF, b = 15.66, SE = 4.74, z = 3.305, p = 0.0010; SUF, b = 18.20, SE = 4.72, z = 3.857, p = 0.0001), while significant inhibitory effects were found in the ORTH condition, b = −10.20, SE = 4.89, z = −2.084, p = 0.0372. No significant effects were found for the SEM condition, b = −2.73, SE = 4.68, z = −0.584, p = 0.5595. We also found that the numerical differences between PREF and INF (9.54 ms, b = −10.64, SE = 6.653, 95% CI = [−23.68, 2.40], t = −1.559, p = 0.110), INF and SUF (6.63 ms, b = −8.096, SE = 6.639, 95% CI = [−21.11–4.96], t = −1.219, p = 0.223), and PREF and SUF (3.61 ms, b = −2.54, SE = 6.688, 95% CI = [−15.65, 10.56], t = −0.380, p = 0.704) were not significant (see for full output of the model).
Table 4. Reaction time mixed-effects model summary.
All the effect sizes reported above for RT were very small (Cohen, Citation1988). The total model’s explanatory power was substantial (conditional R2 = 0.32, corresponding to a large effect; Cohen, Citation1988). The size of the fixed effects alone (marginal R2) was 0.005 (a small effect; Cohen, Citation1988).
Discussion
The main goal of the present study was to find evidence that Tagalog infixed, prefixed, and suffixed inflected words are segmented into morphological units by the early visual processing system. This goal has been achieved. Specifically, we found that infixed, prefixed, and suffixed inflected word forms yield significant masked priming effects. These facilitatory priming effects are morphological in nature, as we did not find such effects for word pairs that are semantically or orthographically but not morphologically related. This experiment showed that Tagalog infixed, prefixed, and suffixed inflected words are decomposed into constituent morphemes in the initial stage of visual word recognition, which is consistent with previous masked priming experiments with various languages and affixation processes (Ciaccio et al., Citation2020; Crepaldi et al., Citation2010; Kim et al., Citation2015; Rastle & Davis, Citation2008). It is also in line with the assumption that inflected words are subject to the same decomposition mechanisms as derived words (Stockall & Marantz, Citation2006; Taft, Citation2004; Taft & Forster, Citation1975). Moreover, our findings also provide evidence that a disruption in the continuous stem of infixed words does not inhibit the efficiency of the morphological parser, which supports previous masked priming experiments of words with letter transposition (Christianson et al., Citation2005), suffixed words with orthographic changes (McCormick et al., Citation2008), and languages with non-linear morphology like Arabic (Boudelaa & Marslen-Wilson, Citation2005, Citation2011).
The current study makes two novel contributions to the literature concerning this topic: first, it adds typological breadth through the inclusion of the understudied Austronesian language, Tagalog, a language and language family that have not previously been a subject of masked priming experimentation; and second, it demonstrates that words formed via infixation are also decomposed by the visual system. Infixation is a morphological process that has not been investigated using masked priming, despite infixation being widely attested across the Austronesian and Afroasiatic language families. So far, there are only a few Tagalog psycholinguistic experiments and most of them investigate sentence-level processing (e.g. Bondoc & Schafer, Citation2022; Garcia et al., Citation2021; Garcia & Kidd, Citation2020; Pizarro-Guevarra & Wagers, Citation2020). Wray et al. (Citation2022) is the only neurolinguistic work on Tagalog morphological processing as far as we are aware, showing that reduplicated, pseudo-reduplicated, circumfixed, infixed, and pseudo-infixed words are subject to early and automatic decomposition mechanisms. Using a different methodology, we support Wray et al.’s (Citation2022) findings by showing that infixed words are decomposed into morphological units, and contra their results, we find no evidence that infixed words evoke any additional or distinct processes.
Findings from our experiment have also revealed priming effects of similar magnitude for prefixed and suffixed words (15 and 18 ms, respectively), contrary to studies that have found asymmetrical priming effects for prefixation and suffixation, like in the case of Korean (Kim et al., Citation2015), French (Meunier & Segui, Citation2002), and Setswana (Ciaccio et al., Citation2020). The present results are thus unexpected given models like the “beginning-to-end” sequential bias model which holds that prefixed words are more rapidly decomposed than suffixed words due to the salient position of the prefix in the beginning of the letter-string (Diependaele et al., Citation2009; Giraudo & Grainger, Citation2003). Our findings are also not in line with models which assume prelexical vs. postlexical decomposition mechanisms where suffixed words are expected to be more easily decomposable than prefixed words due to the advantageous word-initial position of the root in the former (Baayen et al., Citation2007; Colé et al., Citation1989). The symmetrical priming effects that we found for prefixed and suffixed words add crosslinguistic validity to the results of previous priming studies in English (Marslen-Wilson et al., Citation1994) and French (Beyersmann et al., Citation2016). These are consistent with models in which both prefixes and suffixes are stripped at the initial stage of morphological processing regardless of their linear position and only stems are stored in the mental lexicon (Stockall & Marantz, Citation2006; Taft, Citation2004; Taft & Forster, Citation1975). There is still a paucity of studies that systematically compare prefixed and suffixed word processing in more diverse sets of languages, and there are variations in the design of each of the above studies that make drawing clear conclusions difficult.
As regards the semantic and orthographic control conditions, existing research has shown that semantically related prime-target pairs do not exhibit reliable priming effects under masked priming conditions, at least in the context of a lexical decision task (see Bodner & Masson, Citation2003; De Wit & Kinoshita, Citation2015). This was confirmed for our Tagalog semantic control condition, which did not yield any reliable semantic priming effects, suggesting that the stage of morphological processing that masked priming is tapping into is independent of semantics. Furthermore, previous experiments in languages with alphabetic script systems have provided evidence that pure orthographic overlap does not yield reliable facilitatory priming effects, at least in native speakers (see Nakano et al., Citation2016 for a review), which is also the case in our Tagalog orthographic control condition. In the present study, we found significant inhibitory effects for the orthographic control condition. These inhibitory effects for orthographically related word pairs have been observed in previous masked priming studies (e.g. Davis & Lupker, Citation2006; Frisson et al., Citation2014; Grainger, Citation1990; Grainger & Ferrand, Citation1994; Segui & Grainger, Citation1990). Models of word recognition like the interactive-activation model (IA) explain these inhibitory effects by postulating competition between a word and its orthographic neighbours (McClelland & Rumelhart, Citation1981). When an orthographically related word is primed, the prime word will be a competitor during the recognition of the target word, thereby slowing down responses to the target word (Frisson et al., Citation2014). This reasoning may also apply to our study.
The current study can also weigh in on debates about what the best formal account of infixation is (i.e. readjustment-based accounts vs. phonological subcategorization-based accounts). Tagalog allows us to systematically compare processing of infixed and prefixed words because of the infix <in> and prefix ni- allomorphs. We found a slightly larger priming effect for infixed words than prefixed words, with a non-significant 9 ms difference, suggesting that infixed word processing is not more costly than prefixed word processing for native Tagalog speakers. These findings are unexpected given a readjustment-based account of infixation (Kalin, Citation2022; Halle, Citation2001), which proposes that infixed words are generated by converting a prefixed word into an infixed word, thereby potentially adding an additional step that must be unpacked during processing, making lexical parsing more difficult. It seems that native Tagalog speakers easily detect stems within infixed words with the same ease as detecting stems in prefixed words. These findings suggest that no special mechanism is required to process infixed words, which is in line with the proposal of the phonological subcategorization-based account of infixation (Yu, Citation2007).
However, it needs to be acknowledged that affix frequency might have played a role in our findings. The infix <in> allomorph has a 528.41 per million frequency while the ni- prefix allomorph only has a frequency of 60.69 per million based on a 260.9 million word corpus comprised of Wikipedia, newswire, web, and Twitter. Moreover, the ni- prefix occurs in more restricted phonological environments, surfacing only in stems that start with l, w, y, j, n, and h, while the infix <in> occurs with all other consonants. It is possible that the high frequency of the infix and the wider range phonological environments where it occurs could have cancelled out any difficulty that Tagalog speakers might have experienced during morphological decomposition. It also needs to be noted that the linear position of ni- is variable (Zuraw, Citation2007). For example, in h-initial stems, ni-hinto and h<in>into “stopped” are both possible options in some varieties of Tagalog. Such variability could have affected the Tagalog speakers’ efficiency at detecting and segmenting ni- prefixed words, which then resulted in smaller priming magnitudes for the prefix condition, obscuring any cost for the infix condition (though the equivalent priming effects for the suffix condition make this seem unlikely). This raises an interesting question of how variability in affixation may affect morphological decomposition mechanisms. One way to explore this is to compare two conditions, one with optional ni- prefixed words (e.g. w- and h-initial stems) and one with obligatory ni- prefixed words (e.g. l-initial stems). We leave this for future investigation.
The robust priming effects observed in Tagalog infixed words are generally in line with affix stripping and single-route full decomposition models. Both models would predict robust masked priming effects for all morphologically complex words, regardless of affixation type (Stockall & Marantz, Citation2006; Taft, Citation2004; Taft & Forster, Citation1975), but how processing mechanisms work for infixed words still remains an intriguing question, as none of these models explicitly considered infixation. One possibility is that morphological decomposition mechanisms automatically and rapidly extract or strip the orthographic or phonological sequence “in” when it is preceded by a consonantal onset or a null onset. This allows segmentation of three cases of real infixed words: [1] t<in>awag (which is the focus of this study and the most common case) will be decomposed into morphological units tawag “to call” and <in>; [2] tr<in>abaho (where the infix <in> is preceded by a consonant cluster due to the Spanish loanword) will be segmented into trabaho “to work” and <in>; and [3] ʔ<in>ayos (where <in> visually appears as a prefix due to unwritten ʔ) will be parsed into ʔayos “to fix” and <in>. Moreover, this mechanism would also predict decomposition of pseudo-infixed words like bintang “accusation”, as recently found in Wray et al.’s (Citation2022) study. Ultimately, finding that infixed words are decomposed into morphological units suggests that the matching of orthographic information during the activation of stem is more flexible than Taft and Nguyen-Hoan (Citation2010) had originally proposed. It seems that the visual word recognition system is flexible enough that it allows orthographic matching to be made across non-contiguous letter groupings. In other words, flexibility is built into the orthographic matching system that it allows matching to be made despite the consonantal onset being separated from the rest of the letter strings due to an infix (e.g. t_awag in t<in>awag “called”), thereby allowing the stem to be successfully activated.
Finally, our results pose a challenge to Beyersmann and Grainger’s (Citation2023) word and affix model. They propose that embedded stems and affixes can only be successfully activated if they are edge-aligned. Based on their model, the infixes and stems in infixed words should not have been extracted and activated. The infixes are not aligned to either edge, and the initial consonant of the stem is aligned to the beginning-edge while the rest of the stem is at the end-edge of the letter-strings. The fact that we found evidence showing that infixed words are subject to decomposition suggests that the edge-alignment of embedded stems might not be critical to trigger activation of morphological units. This possibility is further supported by the findings of Wray et al. (Citation2022), where they found neural evidence that Tagalog circumfixed words like ka-gubat-an “forest” are decomposed into morphological units, despite the stem gubat being embedded in the middle of the letter-strings. In other words, the present study and that of Wray et al. (Citation2022) show that the activation of embedded stems might not be constrained by edge-alignment. We call for more psycholinguistic experiments to look at non-edge-aligned embedded stems in other languages (e.g. active in inactivity) to further investigate the influence of edge-alignment in early decomposition mechanisms.
Conclusion
The current study investigated morphological decomposition in Tagalog infixed, prefixed, and suffixed words. Unlike any previous masked morphological priming experiments, this is the first such study investigating infixed words and the first to compare them to prefixed and suffixed words. First, we found that the visual system automatically decomposes infixed, prefixed, and suffixed words in Tagalog during visual word recognition, as evidenced by significant morphological priming effects that are dissociable from semantic and orthographic priming. Second, our findings support models that predict that prefixed and suffixed words are decomposed using similar mechanisms, as we did not find a significant priming effect difference between the prefix and suffix conditions. We provide evidence that segmenting and processing infixed words does not appear to be costly for native Tagalog speakers despite the models which posit a processing cost, as we found robust priming effects for the infix condition that are not significantly different from the prefix or suffix conditions. These results suggest that infixed words may not have gone through phonological readjustment rules and a specialised mechanism is therefore not needed for infixed word processing. Our findings ultimately contribute to the de-exotification of infixation. Finally, we provide evidence that the imperfect edge-alignment of the stem within infixed words does not hamper the early and automatic decomposition mechanisms, contra a recent proposal (Beyersmann & Grainger, Citation2023).
Supplemental Material
Download MS Word (42.9 KB)Acknowledgements
We would like to thank Prof. Pienie Zwitserlood, Prof. Marcus Taft, and one anonymous reviewer for their constructive feedback. We would also like to thank Rowena Garcia, Jed Pizarro-Guevara, and Jonathan Gerona for their help on the stimulus preparation. The support of the Economic and Social Research Council (UK) is gratefully acknowledged.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Angele, B., Baciero, A., Gomez, P., & Perea, M. (2022). Does online masked priming pass the test? The effects of prime exposure duration on masked identity priming. Behavioral Research Methods, 55, 151–167. https://doi.org/10.3758/s13428-021-01742-y.
- Baayen, H., & Milin, P. (2010). Analyzing reaction times. International Journal of Psychological Research, 3(2), 12–28. https://doi.org/10.21500/20112084.807
- Baayen, R., Wurm, L. H., & Aycock, J. (2007). Lexical dynamics for low-frequency complex words: A regression study across tasks and modalities. The Mental Lexicon, 2(3), 419–463. https://doi.org/10.1075/ml.2.3.06baa
- Badecker, W., & Allen, M. (2002). Morphological parsing and the perception of lexical identity: A masked priming study of stem homographs. Journal of Memory and Language, 47(1), 125–144. https://doi.org/10.1006/jmla.2001.2838
- Basnight-Brown, D. M., & Altarriba, J. (2007). Differences in semantic and translation priming across languages: The role of language direction and language dominance. Memory & Cognition, 35(5), 953–965. https://doi.org/10.3758/BF03193468
- Bates, D., M€achler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixedeffects models using LME4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
- Beyersmann, E., Castles, A., & Coltheart, M. (2011). Early morphological decomposition during visual word recognition: Evidence from masked transposed-letter priming. Psychonomic Bulletin & Review, 18(5), 937–942. https://doi.org/10.3758/s13423-011-0120-y
- Beyersmann, E., Cavalli, E., Casalis, S., & Colé, P. (2016). Embedded stem priming effects in prefixed and suffixed Pseudowords. Scientific Studies of Reading, 20(3), 220–230. https://doi.org/10.1080/10888438.2016.1140769
- Beyersmann, E., & Grainger, J. (2023). The role of embedded words and morphemes in Reading. In D. Crepaldi (Ed.), Linguistic morphology in the mind and brain (pp. 26–46). Routledge. https://doi.org/10.4324/9781003159759-3
- Bodner, G., & Masson, M. (2003). Beyond spreading activation: An influence of relatedness proportion on masked semantic priming. Psychonomic Bulletin & Review, 10(3), 645–652. https://doi.org/10.3758/BF03196527
- Bondoc, I. P., & Schafer, A. J. (2022). Differential effects of agency, animacy, and syntactic prominence on production and comprehension: Evidence from a verb-initial language. Canadian Journal of Experimental Psychology, 76(4), 302–326. https://doi.org/10.1037/cep0000280
- Boudelaa, S., & Marslen-Wilson, W. D. (2005). Discontinuous morphology in time: Incremental masked priming in arabic. Language and Cognitive Processes, 20(1–2), 207–260. https://doi.org/10.1080/01690960444000106
- Boudelaa, S., & Marslen-Wilson, W. D. (2011). Productivity and priming: Morphemic decomposition in Arabic. Language and Cognitive Processes, 26(4-6), 624–652. https://doi.org/10.1080/01690965.2010.521022
- Boudelaa, S., Norris, D., Mahfoudhi, A., & Kinoshita, S. (2019). Transposed letter priming effects and allographic variation in arabic: Insights from lexical decision task and same-different task. Journal of Experimental Psychology: Human Perception and Performance, 45(6), 729–757. https://doi.org/10.1037/xhp0000621
- Christianson, K., Johnson, R. L., & Rayner, K. (2005). Letter transpositions within and across morphemes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(6), 1327–1339. https://doi.org/10.1037/0278-7393.31.6.1327
- Ciaccio, L. A., Kgolo, N., & Clahsen, H. (2020). Morphological decomposition in Bantu: A masked priming study on setswana prefixation. Language, Cognition and Neuroscience, 1–15. https://doi.org/10.1080/23273798.2020.1722847
- Clahsen, H., & Ikemoto, Y. (2012). The mental representation of derived words. The Mental Lexicon, 7(2), 147–182. https://doi.org/10.1075/ml.7.2.02cla
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates, Publishers.
- Colé, P., Beauvillain, C., & Segui, J. (1989). On the representation and processing of prefixed and suffixed derived words: A differential frequency effect. Journal of Memory and Language, 28(1), 1–13. https://doi.org/10.1016/0749-596X(89)90025-9
- Crepaldi, D., Hemsworth, L., Davis, C. J., & Rastle, K. (2015). Masked suffix priming and morpheme positional constraints. Quarterly Journal of Experimental Psychology, 69(1), 113–128. https://doi.org/10.1080/17470218.2015.1027713
- Crepaldi, D., Rastle, K., Coltheart, M., & Nickels, L. (2010). ‘Fell’ primes ‘fall’, but does ‘bell’ prime ‘ball’? Masked priming with irregularly-inflected primes. Journal of Memory and Language, 63(1), 83–99. https://doi.org/10.1016/j.jml.2010.03.002
- Davis, C., & Lupker, S. (2006). Masked inhibition priming in English: Evidence for lexical inhibition. Journal of Experimental Psychology: Human Perception & Performance, 32(3), 668–687. https://doi.org/10.1037/0096-1523.32.3.668
- De Wit, B., & Kinoshita, S. (2015). The masked semantic priming effect is task dependent: Reconsidering the automatic spreading activation process. Journal of Experimental Psychology: Learning, Memory, & Cognition, 41(4), 1062–1075. https://doi.org/10.1037/xlm0000074
- Diependaele, K., Sandra, D., & Grainger, J. (2009). Semantic transparency and masked morphological priming: The case of prefixed words. Memory & Cognition, 37(6), 895–908. https://doi.org/10.3758/MC.37.6.895
- Drews, E., & Zwitserlood, P. (1995). Morphological and orthographic similarity in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 21(5), 1098–1116. https://doi.org/10.1037/0096-1523.21.5.1098
- Duñabeitia, J., Laka, I., Perea, M., & Carreiras, M. (2009). Is milkman a superhero like batman? Constituent morphological priming in compound words. European Journal of Cognitive Psychology, 21(4), 615–640. https://doi.org/10.1080/09541440802079835
- Duñabeitia, J. A., Perea, M., & Carreiras, M. (2007). Do transposed-letter similarity effects occur at a morpheme level? Evidence for morpho-orthographic decomposition. Cognition, 105(3), 691–703. https://doi.org/10.1016/j.cognition.2006.12.001
- Fiorentino, R., Naito-Billen, Y., & Minai, U. (2015). Morphological decomposition in Japanese De-adjectival nominals: Masked and overt priming evidence. Journal of Psycholinguistic Research, 45(3), 575–597. https://doi.org/10.1007/s10936-015-9349-3
- Forster, K. (1998). The pros and cons of masked priming. Journal of Psycholinguistic Research, 27(2), https://doi.org/10.1023/A:1023202116609
- Forster, K., Booker, J., Schacter, D. L., & Davis, C. (1990). Masked repetition priming: Lexical activation or novel memory trace? Bulletin of the Psychonomic Society, 28(4), 341–345. https://doi.org/10.3758/BF03334039
- Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10(4), 680–698. https://doi.org/10.1037/0278-7393.10.4.680
- Frisson, S., Koole, H., Hughes, L., Olson, A., & Wheeldon, L. (2014). Competition between orthographically and phonologically similar words during sentence Reading: Evidence from eye movements. Journal of Memory and Language, 73, 148–173. https://doi.org/10.1016/j.jml.2014.03.004
- Frost, R., Deutsch, A., & Forster, K. I. (2000). Decomposing morphologically complex words in a nonlinear morphology. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3), 751–765. https://doi.org/10.1037/0278-7393.26.3.751
- Frost, R., Forster, K. I., & Deutsch, A. (1997). What can we learn from the morphology of hebrew? A masked-priming investigation of morphological representation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(4), 829–856. https://doi.org/10.1037/0278-7393.23.4.829
- Fruchter, J., Stockall, L., & Marantz, A. (2013). MEG masked priming evidence for form-based decomposition of irregular verbs. Frontiers in Human Neuroscience, 7. https://doi.org/10.3389/fnhum.2013.00798
- Garcia, R., & Kidd, E. (2020). The acquisition of the Tagalog symmetrical voice system: Evidence from structural priming. Language Learning and Development, 16(4), 399–425. https://doi.org/10.1080/15475441.2020.1814780
- Garcia, R., Rodriguez, G., & Kidd, E. (2021). Developmental effects in the online use of morphosyntactic cues in sentence processing: Evidence from Tagalog. Cognition, 216. https://doi.org/10.1016/j.cognition.2021.104859
- Giraudo, H., & Grainger, J. (2003). On the role of derivational affixes in recognizing complex words: Evidence from masked priming. In R. H. Baayen, & R. Schreuder (Eds.), Morphological structure in language processing (pp. 209–232). Mouton de Guyter. https://doi.org/10.1515/9783110910186.209
- Gold, B. T., & Rastle, K. (2007). Neural correlates of morphological decomposition during visual word recognition. Journal of Cognitive Neuroscience, 19(12), 1983–1993. https://doi.org/10.1162/jocn.2007.19.12.1983
- Grainger, J. (1990). Word frequency and neighborhood frequency effects in lexical decision and naming. Journal of Memory and Language, 29(2), 228–244. https://doi.org/10.1016/0749-596X(90)90074-A
- Grainger, J., Colé, P., & Segui, J. (1991). Masked morphological priming in visual word recognition. Journal of Memory and Language, 30(3), 370–384. https://doi.org/10.1016/0749-596X(91)90042-I
- Grainger, J., & Ferrand, L. (1994). Phonology and orthography in visual word recognition: Effects of masked homophone primes. Journal of Memory and Language, 33(2), 218–233. https://doi.org/10.1006/jmla.1994.1011
- Gwilliams, L., & Marantz, A. (2018). Morphological representations are extrapolated from morpho-syntactic rules. Neuropsychologia, 114, 77–87. https://doi.org/10.1016/j.neuropsychologia.2018.04.015
- Halle, M. (2001). Infixation versus onset metathesis in Tagalog, Chamorro, and Toba Batak. In M. Kenstowicz (Ed.), Ken Hale: A life in language (pp. 153–168). MIT Press. https://doi.org/10.7551/mitpress/4056.003.0007
- Hasenäcker, J., Beyersmann, E., & Schroeder, S. (2016). Masked morphological priming in German-speaking adults and children: Evidence from response time distributions. Frontiers in Psychology, 7(929), https://doi.org/10.3389/fpsyg.2016.00929
- Hay, J. (2001). Lexical frequency in morphology: Is everything relative? Linguistics, 39(6), https://doi.org/10.1515/ling.2001.041
- Kalin, L. (2022). Infixes really are (underlyingly) prefixes/suffixes: Evidence from allomorphy on the fine timing of infixation. Language, 98(4), 641–682. https://doi.org/10.1353/lan.2022.0017
- Kastner, I., Pylkkanen, L., & Marantz, A. (2018). The form of morphemes: MEG evidence from masked priming of two hebrew templates. Frontiers in Psychology, 9(2163), https://doi.org/10.3389/fpsyg.2018.02163
- Keuleers, E., & Brysbaert, M. (2010). Wuggy: A multilingual pseudoword generator. Behavior Research Methods, 42(3), 627–633. https://doi.org/10.3758/BRM.42.3.627
- Kilgarriff, A., Rychly, P., Smrz, P., & Tugwell, D. (2004). The Sketch Engine. In Williams J. & Vessier S. (Eds.), Euralex 2004 Proceeding (pp. 105–116). Lorient: Université de Bretagne-Sud.
- Kim, S. Y., Wang, M., & Taft, M. (2015). Morphological decomposition in the recognition of prefixed and suffixed words: Evidence from Korean. Scientific Studies of Reading, 19(3), 183–203. https://doi.org/10.1080/10888438.2014.991019
- Kirkici, B., & Clahsen, H. (2012). Inflection and derivation in native and non-native language processing: Masked priming experiments on turkish. Bilingualism: Language and Cognition, 16(4), 776–791. https://doi.org/10.1017/S1366728912000648
- Lavric, A., Clapp, A., & Rastle, K. (2007). ERP evidence of morphological analysis from orthography: A masked priming study. Journal of Cognitive Neuroscience, 19(5), 866–877. https://doi.org/10.1162/jocn.2007.19.5.866
- Lenth, R. V., Buerkner, P., Herve, M., Love, J., Miguez, F., Riebl, H., & Singmann, H. (2022). Emmeans: Estimated marginal means, aka least-squares means. R package version 1.8.2. https://cran.r-project.org/web/ packages/emmeans/index.html
- Levenshtein, V. (1965). Leveinshtein distance. http://en.wikipedia.org/wiki/Levenshtein_distance. Retrieved February 22, 2010
- Lewis, G., Solomyak, O., & Marantz, A. (2011). The neural basis of obligatory decomposition of suffixed words. Brain and Language, 118(3), 118–127. https://doi.org/10.1016/j.bandl.2011.04.004
- Marantz, A. (2013). No escape from morphemes in morphological processing. Language and Cognitive Processes, 28(7), 905–916. https://doi.org/10.1080/01690965.2013.779385
- Marslen-Wilson, W., Tyler, L. K., Waksler, R., & Older, L. (1994). Morphology and meaning in the English mental lexicon. Psychological Review, 101(1), 3–33. https://doi.org/10.1037/0033-295X.101.1.3
- Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing type I error and power in linear mixed models. Journal of Memory and Language, 94, 305–315. https://doi.org/10.1016/j.jml.2017.01.001
- McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88(5), 375–407. https://doi.org/10.1037/0033-295X.88.5.375
- McCormick, S. F., Rastle, K., & Davis, M. H. (2008). Is there a “fete” in “fetish”? effects of orthographic opacity on morpho-orthographic segmentation in visual word recognition. Journal of Memory and Language, 58(2), 307–326. https://doi.org/10.1016/j.jml.2007.05.006
- Meunier, F., & Segui, J. (2002). Cross-modal morphological priming in French. Brain and Language, 81(1–3), 89–102. https://doi.org/10.1006/brln.2001.2509
- Morris, J., Frank, T., Grainger, J., & Holcomb, P. J. (2007). Semantic transparency and masked morphological priming: An ERP investigation. Psychophysiology, 44(4), 506–521. https://doi.org/10.1111/j.1469-8986.2007.00538.x
- Morris, J., Grainger, J., & Holcomb, P. (2008). An eletrophysiological investigation of early effects of masked morphological priming. Language and Cognitive Processes, 23(7-8), 1021–1056. https://doi.org/10.1080/01690960802299386
- Morris, J., Grainger, J., & Holcomb, P. J. (2013). Tracking the consequences of morpho-orthographic decomposition using ERPs. Brain Research, 1529, 92–104. https://doi.org/10.1016/j.brainres.2013.07.016
- Morris, J., Porter, J. H., Grainger, J., & Holcomb, P. J. (2011). Effects of lexical status and morphological complexity in masked priming: An ERP study. Language and Cognitive Processes, 26(4-6), 558–599. https://doi.org/10.1080/01690965.2010.495482
- Morris, J., & Stockall, L. (2012). Early, equivalent ERP masked priming effects for regular and irregular morphology. Brain and Language, 123(2), 81–93. https://doi.org/10.1016/j.bandl.2012.07.001
- Nakano, Y., Ikemoto, Y., Jacob, G., & Clahsen, H. (2016). How orthography modulates morphological priming: Subliminal Kanji activation in Japanese. Frontiers in Psychology, 7. https://doi.org/10.3389/fpsyg.2016.00316
- Neophytou, K., Manouilidou, C., Stockall, L., & Marantz, A. (2018). Syntactic and semantic restrictions on morphological recomposition: MEG evidence from Greek. Brain and Language, 183, 11–20. https://doi.org/10.1016/j.bandl.2018.05.003
- Ohta, S., Oseki, Y., & Marantz, A. (2019, September 6–8). Dissociating the effects of morphemes and letters in visual word recognition: An MEG study of Japanese verbs [Poster presentation]. The 25th Architectures and Mechanisms of Language Processing Conference, Moscow, Russia.
- Perea, M., & Pérez, E. (2008). Beyond alphabetic orthographies: The role of form and phonology in transposition effects in Katakana. Language and Cognitive Processes, 24(1), 67–88. https://doi.org/10.1080/01690960802053924
- Pizarro-Guevarra, J., & Wagers, M. (2020). The predictive value of Tagalog voice morphology in filler-gap dependency. Frontiers in Psychology, 11(517), https://doi.org/10.3389/fpsyg.2020.00517
- Rastle, K., & Davis, M. H. (2008). Morphological decomposition based on the analysis of orthography. Language and Cognitive Processes, 23(7–8), 942–971. https://doi.org/10.1080/01690960802069730
- Rastle, K., Davis, M. H., Marslen-Wilson, W. D., & Tyler, L. K. (2000). Morphological and semantic effects in visual word recognition: A time-course study. Language and Cognitive Processes, 15(4-5), 507–537. https://doi.org/10.1080/01690960050119689
- Rastle, K., Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morpho-orthographic segmentation in visual word recognition. Psychonomic Bulletin & Review, 11(6), 1090–1098. https://doi.org/10.3758/BF03196742
- R Core Team. (2015, December 11). R: A language and environment for Statistical computing. Viena, Austria. Retrieved from https://www.R-project.org
- Segui, J., & Grainger, J. (1990). Priming word recognition with orthographic neighbors: Effects of relative prime-target frequency. Journal of Experimental Psychology: Human Perception and Performance, 16(1), 65–76. https://doi.org/10.1037/0096-1523.16.1.65
- Solomyak, O., & Marantz, A. (2010). Evidence for early morphological decomposition in visual word recognition. Journal of Cognitive Neuroscience, 22(9), 2042–2057. https://doi.org/10.1162/jocn.2009.21296
- Stockall, L., & Marantz, A. (2006). A single route, full decomposition model of morphological complexity: MEG evidence. The Mental Lexicon, 1(1), 85–123. https://doi.org/10.1075/ml.1.1.07sto
- Taft, M. (2004). Morphological decomposition and the reverse base frequency effect. The Quarterly Journal of Experimental Psychology, 57A(4), 745–765. https://doi.org/10.1080/02724980343000477
- Taft, M., & Forster, K. I. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14(6), 638–647. https://doi.org/10.1016/S0022-5371(75)80051-X
- Taft, M., & Nguyen-Hoan, M. (2010). A sticky stick? The locus of morphological representation in the lexicon. Language and Cognitive Processes, 25(2), 277–296. https://doi.org/10.1080/01690960903043261
- Velan, H., & Frost, R. (2007). Cambridge University versus Hebrew University: The impact of letter transposition on Reading English and Hebrew. Psychonomic Bulletin & Review, 14(5), 913–918. https://doi.org/10.3758/BF03194121
- Wray, S., Stockall, L., & Marantz, A. (2022). Early form-based morphological decomposition in Tagalog: MEG evidence from reduplication, infixation, and circumfixation. Neurobiology of Language. Advanced publication. https://doi.org/10.1162/nol_a_00062
- Yu, A. C. L. (2007). A natural history of infixation. Oxford University Press.
- Zuraw, K. (2007). The role of phonetic knowledge in phonological patterning: Corpus and survey evidence from Tagalog infixation. Language, 83(2), 277–316. https://doi.org/10.1353/lan.2007.0105