
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Several studies have been published which show that it is possible to decode semantic representations directly from brain responses. This has been repeatedly successful when the stimuli used were pictures of objects. However, there is a distinct scarcity of studies decoding responses to orthographic stimuli, particularly those employing time-sensitive imaging methods. We use examples from our own research to highlight the challenges we have faced when attempting to decode semantic representations from MEG responses to written words. We discuss differences in brain responses to pictures and orthographic stimuli to determine the characteristics of the brain responses that allow for successful decoding of semantics. We suspect the limited number of published studies on this topic indicates that these challenges are not unique to our experience. By bringing attention to these issues, we hope to stimulate a new wave of discussion leading to eventual progress.
1. Introduction
Training machine learning models to predict what a person is thinking about from the corresponding brain response patterns (known as neural decoding) stems from the general goal of “mind reading”. One day it may be possible to decode neural activity outside of experimental settings, but the first step towards this is to accurately decode presented stimuli from brain patterns in controlled environments, where the stimuli are known. In particular, we (and many other researchers) are interested in decoding and further understanding the semantic content of the brain responses.
Since the groundbreaking paper by Mitchell et al. (Citation2008), machine learning approaches to understanding concept representations in the brain have become relatively popular, as demonstrated in a recent systematic review on the topic of neural decoding (Rybář & Daly, Citation2022). The majority of studies have used functional magnetic resonance imaging (fMRI) as the neuroimaging method and pictures as stimuli (Rybář & Daly, Citation2022). fMRI provides high spatial resolution imaging, but only yields rough temporal precision, as the blood-oxygen-level-dependent (BOLD) signal is relatively slow to respond (Glover, Citation2011).
It is now well established that decoding semantics from fMRI brain responses using picture stimuli yields highly accurate predictions (e.g. Behroozi & Daliri, Citation2014; Shinkareva et al., Citation2008). Two logical extensions to this line of research involve (a) extending decoding to other stimulus modalities, i.e. written and spoken language (e.g. Akama et al., Citation2012) and (b) addressing the temporal dynamics of semantic processing by using neuroimaging methods with high temporal precision (see Grootswagers et al., Citation2017).
Decoding from fMRI data has been shown to generalise well to written words (Just et al., Citation2010; Kivisaari et al., Citation2019; Mitchell et al., Citation2008) and spoken words (Correia et al., Citation2014). Therefore, along with other researchers (e.g. Clarke et al., Citation2015; Rupp et al., Citation2017; Sudre et al., Citation2012), we have focused on tracking the temporal dynamics using more temporally precise imaging methods (Ghazaryan et al., Citation2022; Hultén et al., Citation2021; Nora et al., Citation2020). In contrast to fMRI, methods such as magneto- or electroencephalography (MEG, EEG) measure electromagnetic neuronal activity directly, thus offering high temporal resolution (Hämäläinen et al., Citation1993). They have shown excellent tracking of cortical processing of pictured items (Clarke, Citation2019; Clarke et al., Citation2015). However, attempts to combine both avenues (a) and (b), i.e. using decoding to track the temporal dynamics of processing written (or spoken) stimuli, have shown limited success, and such studies are relatively rare (Rybář & Daly, Citation2022).
In this article, we present two of our own studies in which we attempt to decode written words from MEG, and the difficulties encountered. We compare results from studies using pictured items as well as fMRI, in the hope to understand why the task remains challenging. We present what was successful, what was not, and directions for future studies. We discuss our observations with respect to representations of concepts in the brain, activation of these representations, and their richness (the level of detail contained within them).
2. Background
Neural decoding is the task of predicting stimuli from neural activity (Rybář & Daly, Citation2022); in other words it is guessing what someone is thinking about based on brain patterns. This is done by training predictive models from brain recordings corresponding to known stimuli. For a trained model to be useful, it should be able to generalise to many possible targets. One way of arriving at models that can generalise is to use a zero-shot learning approach. The basis of zero-shot learning is that a model should be able to correctly predict responses to instances of items that it has not been trained on (Xian et al., Citation2019; Palatucci et al., Citation2009). This is particularly important for language decoding, as it is impossible to train a model on all words or phrases in human language. However, it is more challenging to train models to correctly classify instances of unseen items, than to classify new instances of seen items.
In zero-shot learning, models should not be trained to give direct labels (such as “cat”) to brain responses, instead they should give coordinates in some feature space that can be converted to meaningful labels afterwards. As such, the mapping between brain responses and coordinates in the semantic feature space is learned, rather than the mapping between brain responses and concept labels directly. There are different approaches to model concepts in feature spaces (see Bruffaerts et al., Citation2019, for a review). One prominent approach relies on the idea that semantically similar words appear in semantically similar contexts. The coordinates are then based on co-occurrence statistics in large lexical corpora, so concepts closer in the semantic space are likely to have similar meanings (Harris, Citation1954; Joos, Citation1950; Osgood et al., Citation1978). The word2vec algorithm (Mikolov et al., Citation2013) is a common approach for this, and is what we have used in our studies (Kanerva et al., Citation2014, based on Finnish language corpus).
Decoding models are generally evaluated through prediction accuracy. A common approach for zero-shot learning is leave-two-out pairwise comparisons, in which a model is iteratively trained on all but two items in the set (each item is a brain response-semantic vector pair). The model is then tested on the two left out items. The model predicts vectors for both of the items, and these predictions are compared to the true vectors. If, based on distance metrics, the predictions are more consistent with the correct labelling than the incorrect labelling, decoding is considered successful (see ). Otherwise it is considered unsuccessful. Accuracy can then be quantified as the proportion of pairwise comparisons that result in success, with 0.5 indicating random chance-level performance. Statistical tests (such as permutation tests) can be used to determine if the resulting accuracy values are significantly different from this chance level.
Table 1. Calculation of successful decoding in leave-two-out pairwise comparisons.
Studies on the temporal dynamics generally down-sample high frequency brain recordings before decoding. This is done to improve the signal-to-noise ratio and reduce computational load (Hultén et al., Citation2021). Decoding can then be evaluated on sets of sequential bins (following the procedure described above for each bin), to identify in which time windows decoding performs best. Identifying these time windows allows us to determine when in time semantic processing is occurring and elucidates the temporal dynamics of semantic processing. This can greatly improve understanding of language and semantic systems. Such information could also drastically decrease the amount of data needed to be recorded and processed, and the time required to train or run decoding models, which is important for real-time decoding.
3. State of the field
As highlighted above, decoding brain responses to pictures, including tracking temporal dynamics, has been repeatedly successful. Yet, there have only been a few published studies looking at the temporal dynamics of written word decoding (Rybář & Daly, Citation2022). In this section, we summarise and contrast representative work on pictures and written words, and discuss the decoding approaches and results. We focus on what has been learned and how it relates to our two studies to be presented in the following sections.
Studies tracking picture decoding over time have reported high zero-shot decoding accuracy (above 0.9 in some cases) from around 250 ms after stimulus onset (Bruffaerts et al., Citation2019; Carlson et al., Citation2013; Chen et al., Citation2016; Clarke et al., Citation2015; Rupp et al., Citation2017; Sudre et al., Citation2012). One of the earliest studies to attempt to track decoding of written words as a function of time compared words directly to pictures (Simanova et al., Citation2010). This is a useful starting point, as the same items were presented in both modalities with the same experimental setup and participants, yet decoding was far worse for words than pictures. The authors attempted to decode the category of the stimuli (tools or animals) from EEG recordings, using a binary classifier. They presented eight concepts as pictures, written words and spoken words. Each concept was repeated 80 times in each modality. For pictures, the binary classification of brain responses yielded highly accurate results (mean classification accuracy 0.83) and the decoding of unseen concepts was successful (mean accuracy 0.77). Yet, for written words accuracy was worse (mean classification accuracy 0.62) and for unseen concepts, the category could not be successfully decoded. For pictures, signals could be decoded from 100 ms onwards. For written words, the time window 250–400 ms after stimulus onset was identified as containing semantic information and the decoding accuracy was highest at 240–280 ms. The authors suggested that the nature of the experiment may not have ensured engagement of semantic knowledge, and the high number of repetitions of the same concept (80 times for each modality) could have reduced semantic category effects (Chao et al., Citation2002; Kiefer, Citation2005).
Fyshe et al. (Citation2019) reported successful decoding of adjectives and nouns from MEG brain data in response to written phrases (e.g. “tasty tomato”). There were 30 adjective-noun phrases, which were combinations of 6 adjectives and 8 nouns. Concepts were represented as semantic vectors, and linear ridge regression was used to predict concepts in unseen phrases, using leave-two-out pairwise comparisons (the model was trained on 28 of the phrases and tested on the remaining 2). High decoding accuracy was reported for both nouns and adjectives. However, there was overlap between the training and testing phrases, such that the model was trained on phrases containing the target adjective or noun, but not the unique combination. Nevertheless, the results provide important observations regarding temporal dynamics. Adjectives were best decoded at 200–500 ms after onset, but accuracy was above chance up to 1155 ms after the adjective word had disappeared. Nouns were decodable from 90 ms after they appeared, up to around 800 ms (a shorter window compared to the adjectives). This may indicate that the length of time that knowledge and associations related to the meaning of a particular concept are activated depends on the context (e.g. whether there are relevant words following in a phrase).
More recently, Hultén et al. (Citation2021) indicated that it is possible (albeit difficult) to decode written words from MEG in a true zero-shot learning framework. This study used a much larger set of stimuli than previous studies (118 nouns, either concrete or abstract). The leave-two-out pairwise comparisons yielded a mean decoding accuracy above chance at 290–410 ms after stimulus onset. This successful decoding may have been assisted by the large set of examples for model training.
From the results of these studies, we presume that at least the following factors may influence the decoding success: stimulus presentation modality, semantic context provided by the task, and signal and data quality. In the following sections, we investigate these factors in two studies on written word decoding from MEG.
4. Study 1 – isolated stimuli
4.1. Overview and methods
In this study, we contrasted picture and written word decoding. Participants were presented with concrete nouns in either pictorial or orthographic form (auditory stimuli were also presented, but are not analysed here), and were asked to think about the concept. We used a zero-shot decoding procedure similar to Hultén et al. (Citation2021) and investigated decoding accuracy over time.
MEG measurements were collected using a Vectorview whole-head MEG system (MEGIN (Elekta Oy), Helsinki, Finland). This system has 306 sensors (204 planar gradiometers, 102 magnetometers). Participants' head positions were continuously tracked by five head position indicator coils placed at specific known locations with respect to anatomical landmarks. Eye movements and blinks were captured using two pairs of electrodes (situated above and below the left eye, and in the corner of each eye). Recordings were low-pass filtered at 40 Hz.
MEG recordings were visually inspected to identify noisy channels. External sources of noise were then removed using spatiotemporal signal space separation (Taulu & Simola, Citation2006) using the Elekta Maxfilter software (MEGIN (Elekta Oy), Finland). Independent component analysis (ICA) was performed to reduce contamination related to heartbeats, eye movements and blinks. To minimise the effect of slow drifts on ICA decomposition, we used continuous data high-pass filtered at 1 Hz (Jas et al., Citation2018). Components corresponding to heartbeats, eye movements and blinks were visually identified and excluded from epochs. The signal for each trial was downsampled to create 20 ms bins.
Participants were 20 native speakers of Finnish (mean age: years, range: 20–27, female/male: 10/10). Data from one participant was excluded due to technical issues with the MEG recordings, leaving data from 19 participants in the final analysis. As stimuli, we used 60 concrete Finnish nouns (from 7 categories: animals, body parts, buildings, nature, human characters, tools/artefacts, and vehicles), presented in each stimulus modality. Measurements for each participant took place over three sessions on different days. Overall, there were 18 repetitions of each item per stimulus modality. For pictures, different exemplars were shown for each concept. For written words, repetitions were displayed in different typefaces.
To ensure that participants remained engaged during the experiment, 10% of the trials were followed by a comprehension task in which participants indicated whether or not a written description was characteristic of the previous concept. As this task occurred after a trial it did not interfere with the immediate brain response to the stimulus.
Semantic vector representations of the stimuli were obtained using the word2vec tool with skip-gram architecture and negative sampling algorithm (Mikolov et al., Citation2013). The corpus used was the Finnish Internet Parsebank (Kanerva et al., Citation2014), which is based on a large sample (1.5 billion words) from Finnish-language websites. For further details on data acquisition and pre-processing, see Ghazaryan et al. (Citation2022).
4.2. Results and discussion
We used regularised multivariate ridge regression, as implemented in scikit-learn (Pedregosa et al., Citation2011), to fit models that predict the semantic vector of a target concept based on brain response. As predictors we used the MEG signal captured by the sensors. The signal at each time-point from each sensor was used as a separate predictor. Decoding performance was evaluated using leave-two-out pairwise comparisons. Decoding from the entire 0 to 800 ms signal (using all time-points and sensors in this period as predictors) at the individual level was successful for pictures (0.78–0.94, all higher than chance, p < .05). However, decoding for written words was not (0.38–0.73, only six participants higher than chance, p < .05). Significance testing was done via permutation tests using 1000 iterations (as in e.g. Hultén et al., Citation2021). Decoding at separate windows throughout the time period (using a sliding window with a width of 100 ms) captured different temporal progressions for pictures and words (). Decoding for pictures tended to reach high accuracy before 200 ms and remain at this level. For words, however, there were some indications of increased accuracy around 200–400 ms, which aligns with previous studies (Fyshe et al., Citation2019; Hultén et al., Citation2021; Simanova et al., Citation2010), but the decoding accuracy was not significantly higher than chance.
Figure 1. Decoding accuracy over time for isolated concepts presented as pictures (green) and written words (orange), for each participant. The dashed line indicates the accuracy level required to be significantly different from chance, p < .05, based on a permutation test.
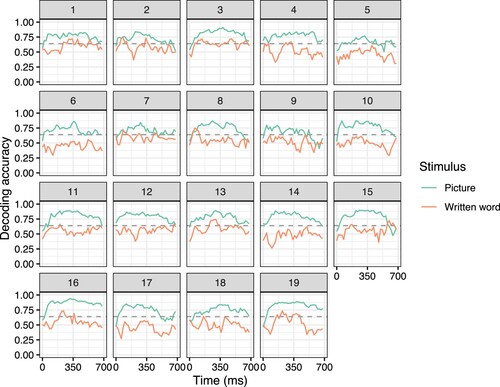
Thus, despite using the same items, same participants and same semantic model for both pictures and written words, the results differed drastically: decoding for pictures was highly successful, whereas decoding for written words had limited success.
It is probable that the obvious difference in imageability between pictures and written words favours decoding of pictures. The visual configurations in pictures already give some semantic information (Bruffaerts et al., Citation2013; Chen et al., Citation2016; Konkle & Alvarez, Citation2022). It is possible that the decoding models predominantly used features related to visual processing (of semantically relevant characteristics) rather than semantic processing. This might be a reason for picture decoding reaching high accuracy relatively early. In contrast, the visual characteristics of written words do not convey semantic meaning and must be processed before any decoding would be successful.
It is possible that pictures (especially photographs) may be more directly related to their semantic content and may activate semantic representations more quickly and easily than written words. These characteristics of pictorial processing may lead to higher decoding accuracy by eliciting richer semantic representations as opposed to incomplete semantic representations that may arise from partial semantic processing of words (Ferreira et al., Citation2002). Incomplete semantic representations are sufficient to support basic comprehension but may lack detailed information about a concept.
Lastly, as in most brain imaging research, the task performed by the participant plays an important role in the type of brain processing that will be elicited, for example silent picture naming or passive viewing tasks are known to elicit reduced activity compared to overt naming (Salmelin et al., Citation1994). This may influence the amount of information encoded in the MEG signal in each time window, thus influencing the decoding accuracy.
Another possibility for the substantial difference in decoding accuracy could be related to signal quality. Pictures are evocative and elicit widespread brain activity without much conscious effort. In contrast, words can be processed at different levels of depth depending on how much attention and cognitive effort is invested, with deeper processing leading to richer semantic representations (Ferreira et al., Citation2002; Sturt et al., Citation2004). Participants responded to the comprehension trials with high accuracy for both modalities (mean for pictures: ; mean for written words:
) implying the representations elicited were “good enough” to serve the immediate needs required by the task (as defined by Ferreira et al., Citation2002). But in the case of written words, representations were not rich enough to elicit clear enough patterns to be decoded from the MEG signal.
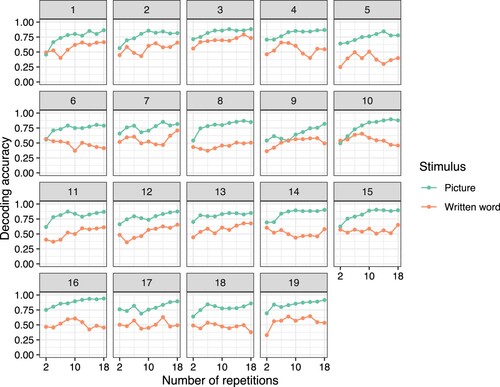
shows how the decoding accuracy depends on the number of repetitions comprising the decoded signal. For this analysis, models were trained and tested on brain data of the entire 0–800 ms time course, using the signal at each time-point from each sensor as a separate predictor. For pictures, it is possible to decode from signal averaged over only two repetitions, and this tends to improve with more repetitions (before reaching plateau). However, for written words, only some participants showed this type of effect. Others showed a relatively constant rate of chance-level decoding accuracy (participants 6, 8, 15, 18 in ), or had the highest accuracy after a subset of repetitions, with decreasing accuracy after further repetitions were included (participants 4, 10, 16 in ). These patterns indicate that the optimal number of repetitions for decoding may vary between individuals. Importantly, it is easier to have repetitions of pictures in a way that may remain engaging for participants. We attempted to do this by presenting different pictorial exemplars of each concept. For written words, repetitions were limited to adjustments to the typefaces.
Figure 2. Decoding accuracy as a function of the number of repetitions included in the averaged brain signal, for each participant. Each point represents decoding accuracy for models using the entire time course (0–800 ms). The MEG signal at each time-point from each sensor was used as a separate predictor.
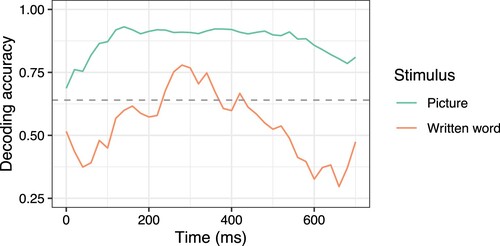
We tried to increase the signal-to-noise ratio by averaging the MEG signal across participants before decoding. This led to improvement and significantly above chance decoding of words between 240 and 420 ms after stimulus onset, with decoding accuracy reaching a maximum of 0.78 (). However, decoding from the entire 0–800 ms block remained unsuccessful. This may indicate that the semantic representations elicited by written words in isolation are transient. Sustained representations are likely to be achieved if words are supported by a greater linguistic context, such that the language surrounding the word gives additional information and clarifies its meaning, as in adjective–noun pairs (Fyshe et al., Citation2019) or other meaningful groups of words (Deniz et al., Citation2023). Furthermore, written words in isolation refer to the prototypical concept, whereas pictures refer to specific varying instances, which serves to reduce priming and may facilitate richer processing of the concept.
Figure 3. Decoding accuracy over time for isolated concepts presented as pictures (green) and written words (orange) using brain data averaged over participants. The dashed line indicates the accuracy level required to be significantly different from chance, p < .05, based on a permutation test.
In order for a model to learn about unseen concepts, there needs to be sufficient information present in the training set. Specifically in our experimental setup, there should be larger differences between concept categories than within concept categories. Effects of category on brain signals were evaluated using non-parametric permutation tests (with 1000 permutations) together with clustering. This addresses the issue of multiple comparisons (Hultén et al., Citation2019; Maris, Citation2012). For pictures, there were significant differences between categories in MEG signals for all participants, p < .05 (). For written words, few participants had significant differences, p < .05 (participants 3, 10, 15, 16 in ). This indicates that the categories were well differentiated by the brain signals for pictures, but not for written words.
Figure 4. Evoked responses to pictures for each semantic category, for each participant. Temporal extent of the cluster which has a significant effect of category is highlighted. Each line represents the global field power (GFP) over the channels for the specified category.
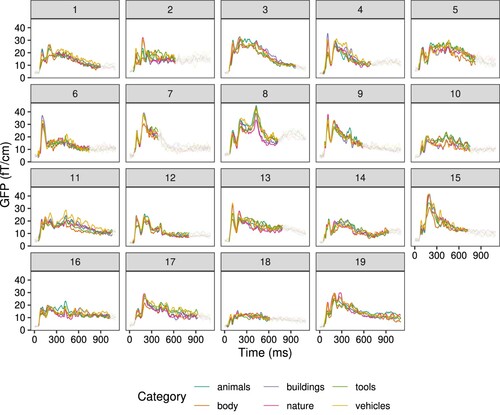
Figure 5. Evoked responses to written words for each semantic category, for each participant. Temporal extent of the cluster in which the category has a significant effect is highlighted. Each line represents the global field power (GFP) over the channels in the cluster for the specified category.
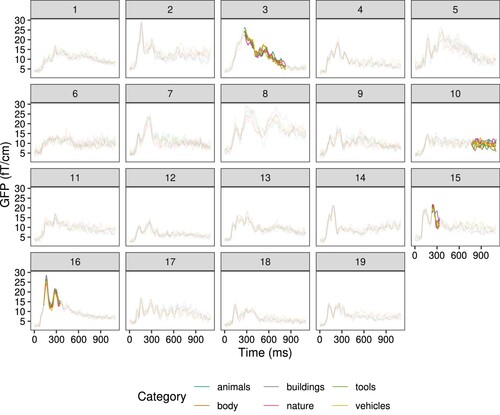
We can conclude from this study that (1) decoding written words may require richer representations than are elicited when reading individual words (which elicit lower amplitude MEG responses than words in sentences; Hultén et al., Citation2019), (2) the number of repetitions is important: we need to balance between too few repetitions and too many in order to arrive at a high, functionally relevant signal-to-noise ratio, and (3) concept categories should be distinct and distant enough from each other in semantic meaning to ensure adequate differences in brain responses for the model to learn.
5. Study 2 – guessing game
5.1. Overview and methods
In this MEG study, we used an experimental paradigm known to work well with fMRI and written stimuli (Kivisaari et al., Citation2019). The experiment is more engaging for participants than the previous one, and with it we attempted to elicit richer representations of the concepts. Instead of direct stimulus presentation, we had participants conjure a concept indirectly, by giving written clues about the concept, rather than the word itself. We used the same MEG measurement setup and preprocessing procedure as in Study 1.
The study included 21 native speakers of Finnish (mean age: years, range: 20–30; female/male: 11/10). Data from 6 participants was excluded due to technical issues with the MEG recordings, leaving data from 15 participants in the final analysis. Measurements for each participant took place over 2 sessions on different days. As in the previous study, we used 60 concrete nouns as target concepts, although now restricting them to 4 categories: animals, fruit/vegetables, tools, and vehicles. Overall, each concept was a target 12 times, with varying clue sets.
The experimental design was adapted from Kivisaari et al. (Citation2019). Each trial started with a fixation cross for 200 ms, after which the clues were presented one after another. Each clue was displayed for 300 ms and was followed by a fixation cross for 1500 ms. After the clues, a string of “#” characters was presented for 2000 ms, prompting the participant to overtly name the target concept. Afterwards, there was a blank screen for 800 ms before the start of the next trial. For example, participants were given the following clues for the target “giraffe”: (1) it can be seen in the zoo, (2) it has patches, (3) it has a long neck. After the third clue they responded verbally.
5.2. Results and discussion
We used the same decoding and evaluation method as in Study 1. Participants had a high accuracy when guessing the target items (mean ). Although somewhat lower than reported by Kivisaari et al. (Citation2019), this indicates that participants were able to conjure the target word in the majority of trials.
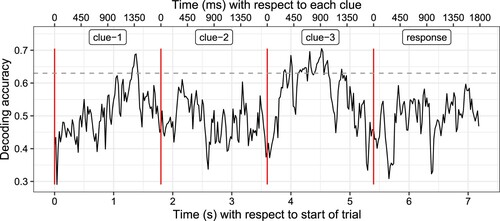
On the individual participant level, decoding was not successful. However, it was possible to decode the target from brain signals averaged over participants after the third clue was presented, with decoding accuracy significantly above chance level, p < .05, based on a permutation test (). This indicates potential signal-to-noise ratio issues for individual-level data. We focused further on responses to the third clue, when we expected the participants to conjure the target representation. In comparison to Study 1, the time window in which accuracy was significantly above chance appeared longer, which may indicate that the conjured representation persisted longer than the representation elicited by reading an isolated word. However, this observation would need further investigation on the individual level, which was not possible as decoding was not successful for individual participants.
Figure 6. Decoding accuracy over time for Study 2 using brain data averaged over all participants. Dotted lines indicate when clues were presented (the first three lines) and when participants responded (the fourth line). Of primary interest is the period following presentation of the third clue, when participants should have guessed the concept. The dashed line indicates the accuracy level required to be significantly different from chance, p < .05, based on a permutation test.
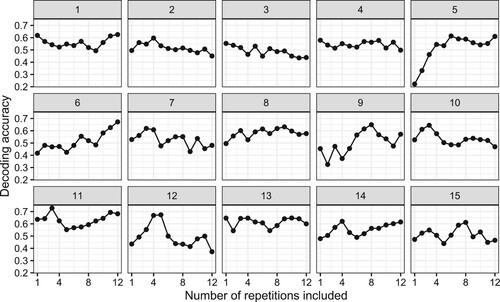
There was no clear trend with regard to the number of repetitions and the decoding accuracy of the third clue response (). For some participants (5, 6, 14) there was a benefit from adding more repetitions. Yet, we also observed that 12 repetitions may have been excessive (participants 7, 11, 12, 15) as decoding accuracy was highest with only using a subset. It is possible that some participants were no longer guessing but rather recalling, which did not elicit rich enough semantic representations to be captured by MEG.
Figure 7. Decoding accuracy for the third clue as a function of the number of repetitions used in the averaged brain signal, for each participant. The signal at each time-point from each sensor was used as a separate predictor.
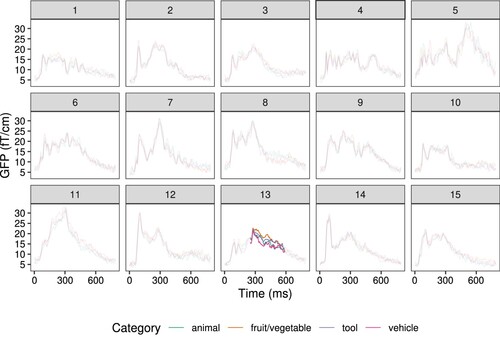
Furthermore, cluster-based permutation tests showed significant effects, p < .05, of category on brain signal only for one participant (participant 13 in ). Again, this indicates that the lack of signal differentiation may be related to low decoding accuracy ().
Figure 8. Evoked responses to the third clue for each semantic category, for each participant. Temporal extent of the cluster which has a significant effect of category is highlighted. Each line represents the global field power (GFP) over the channels for the specified category.
We concluded from this study that written stimuli in context may elicit more sustained representations but there remain issues capturing the representations from MEG signals at the individual level. Further development of this line of research, namely decoding words in contexts, is warranted.
6. Conclusion
Decoding words from MEG remains a challenge. Through our examinations, we have arrived at potential ways forward. We focused on three factors influencing decoding success: stimulus properties, semantic context, and signal quality. However, these three factors are not completely separate and should be considered together. The stimuli and semantic context elicited by the task are crucial for evoking rich enough semantic representations for accurate decoding. Yet, in our studies these did not seem to be the main issues, as the paradigms have been shown by previous work to elicit representations rich enough to be decoded from fMRI data. Instead, the issues appear to be related to signal and data quality, specifically (1) adequately capturing the representations in the MEG signal and (2) providing enough training examples for the decoding model to generalise. We need to have enough repetitions to obtain a clear signal, but the experimental task must also be engaging enough that repetitions continue to elicit rich enough representations. Therefore, rather than repetitions of identical (or very similar) trials, repetitions could incorporate the words in different contexts. For example, a set of sentences or a story can include multiple repetitions of each target word while remaining engaging to participants.
Tracking the temporal dynamics of written word understanding remains a worthwhile challenge. In this paper, we have identified aspects of experimental design which are likely related to low decoding accuracy of written words. We hope that this paper encourages others to explore these aspects of experimental design, and that solutions can be found.
Acknowledgments
We would like to thank Jenna Kanerva and Filip Ginter at the University of Turku for development of the Finnish language word2vec model. Computational resources were provided by the Aalto Science-IT project.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Akama, H., Murphy, B., Na, L., Shimizu, Y., & Poesio, M. (2012). Decoding semantics across fMRI sessions with different stimulus modalities: A practical MVPA study. Frontiers in Neuroinformatics, 6. https://doi.org/10.3389/fninf.2012.00024
- Behroozi, M., & Daliri, M. R. (2014). Predicting brain states associated with object categories from fMRI data. Journal of Integrative Neuroscience, 13(4), 645–667. https://doi.org/10.1142/S0219635214500241
- Bruffaerts, R., De Deyne, S., Meersmans, K., Liuzzi, A. G., Storms, G., & Vandenberghe, R. (2019). Redefining the resolution of semantic knowledge in the brain: Advances made by the introduction of models of semantics in neuroimaging. Neuroscience & Biobehavioral Reviews, 103, 3–13. https://doi.org/10.1016/j.neubiorev.2019.05.015
- Bruffaerts, R., Dupont, P., De Grauwe, S., Peeters, R., De Deyne, S., Storms, G., & Vandenberghe, R. (2013). Right fusiform response patterns reflect visual object identity rather than semantic similarity. NeuroImage, 83, 87–97. https://doi.org/10.1016/j.neuroimage.2013.05.128
- Carlson, T. A., Tovar, D. A., Alink, A., & Kriegeskorte, N. (2013). Representational dynamics of object vision: The first 1000 ms. Journal of Vision, 13(10), 1–1. https://doi.org/10.1167/13.10.1
- Chao, L. L., Weisberg, J., & Martin, A. (2002). Experience-dependent modulation of category-related cortical activity. Cerebral Cortex, 12(5), 545–551. https://doi.org/10.1093/cercor/12.5.545
- Chen, Y., Shimotake, A., Matsumoto, R., Kunieda, T., Kikuchi, T., Miyamoto, S., Fukuyama, H., Takahashi, R., Ikeda, A., & Lambon Ralph, M. A. (2016). The ‘when’ and ‘where’ of semantic coding in the anterior temporal lobe: Temporal representational similarity analysis of electrocorticogram data. Cortex, 79, 1–13. https://doi.org/10.1016/j.cortex.2016.02.015
- Clarke, A. (2019). Neural dynamics of visual and semantic object processing. In Psychology of learning and motivation (Vol. 70, pp. 71–95). Academic Press.
- Clarke, A., Devereux, B. J., Randall, B., & Tyler, L. K. (2015). Predicting the time course of individual objects with MEG. Cerebral Cortex, 25(10), 3602–3612. https://doi.org/10.1093/cercor/bhu203
- Correia, J., Formisano, E., Valente, G., Hausfeld, L., Jansma, B., & Bonte, M. (2014). Brain-based translation: fMRI decoding of spoken words in bilinguals reveals language-independent semantic representations in anterior temporal lobe. Journal of Neuroscience, 34(1), 332–338. https://doi.org/10.1523/JNEUROSCI.1302-13.2014
- Deniz, F., Tseng, C., Wehbe, L., Dupré La Tour, T., & Gallant, J. L. (2023). Semantic representations during language comprehension are affected by context. The Journal of Neuroscience, 43(17), 3144–3158. https://doi.org/10.1523/JNEUROSCI.2459-21.2023
- Ferreira, F., Bailey, K. G., & Ferraro, V. (2002). Good-enough representations in language comprehension. Current Directions in Psychological Science, 11(1), 11–15. https://doi.org/10.1111/1467-8721.00158
- Fyshe, A., Sudre, G., Wehbe, L., Rafidi, N., & Mitchell, T. M. (2019). The lexical semantics of adjective–noun phrases in the human brain. Human Brain Mapping, 40(15), 4457–4469. https://doi.org/10.1002/hbm.24714
- Ghazaryan, G., van Vliet, M., Lammi, L., Lindh-Knuutila, T., Kivisaari, S., Hultén, A., & Salmelin, R. (2022). Cortical time-course of evidence accumulation during semantic processing. bioRxiv. https://doi.org/10.1101/2022.06.24.497472
- Glover, G. H. (2011). Overview of functional magnetic resonance imaging. Neurosurgery Clinics of North America, 22(2), 133–139. https://doi.org/10.1016/j.nec.2010.11.001
- Grootswagers, T., Wardle, S. G., & Carlson, T. A. (2017). Decoding dynamic brain patterns from evoked responses: A tutorial on multivariate pattern analysis applied to time series neuroimaging data. Journal of Cognitive Neuroscience, 29(4), 677–697. https://doi.org/10.1162/jocn_a_01068
- Hämäläinen, M., Hari, R., Ilmoniemi, R. J., Knuutila, J., & Lounasmaa, O. V. (1993). Magnetoencephalography – Theory, instrumentation, and applications to noninvasive studies of the working human brain. Reviews of Modern Physics, 65(2). 413–497. https://doi.org/10.1103/RevModPhys.65.413
- Harris, Z. S. (1954). Distributional structure. WORD, 10(2-3), 146–162. https://doi.org/10.1080/00437956.1954.11659520
- Hultén, A., Schoffelen, J.-M., Uddén, J., Lam, N. H., & Hagoort, P. (2019). How the brain makes sense beyond the processing of single words – an MEG study. NeuroImage, 186, 586–594. https://doi.org/10.1016/j.neuroimage.2018.11.035
- Hultén, A., van Vliet, M., Kivisaari, S. L., Lammi, L., Lindh-Knuutila, T., Faisal, A., & Salmelin, R. (2021). The neural representation of abstract words may arise through grounding word meaning in language itself. Human Brain Mapping, 42(15), 4973–4984. https://doi.org/10.1002/hbm.25593
- Jas, M., Larson, E., Engemann, D. A., Leppäkangas, J., Taulu, S., Hämäläinen, M., & Gramfort, A. (2018). A reproducible MEG/EEG group study with the MNE software: Recommendations, quality assessments, and good practices. Frontiers in Neuroscience, 12. https://doi.org/10.3389/fnins.2018.00530
- Joos, M. (1950). Description of language design. The Journal of the Acoustical Society of America, 22(6), 701–707. https://doi.org/10.1121/1.1906674
- Just, M. A., V. L. Cherkassky, Aryal, S., & Mitchell, T. M. (2010). A neurosemantic theory of concrete noun representation based on the underlying brain codes. PloS One, 5(1), e8622. https://doi.org/10.1371/journal.pone.0008622
- Kanerva, J., Luotolahti, J., Laippala, V., & Ginter, F. (2014). Syntactic N-gram collection from a large-scale corpus of Internet Fnnish. In A. Utka, G. Grigonytė, J. Kapočiūtė-Dzikienė, & J. Vaičenonienė (Eds.), Proceedings of the Sixth International Conference Baltic HLT 2014 (pp. 184–191). IOS Press.
- Kiefer, M. (2005). Repetition-priming modulates category-related effects on event-related potentials: Further evidence for multiple cortical semantic systems. Journal of Cognitive Neuroscience, 17(2), 199–211. https://doi.org/10.1162/0898929053124938
- Kivisaari, S., van Vliet, M., Hultén, A., Lindh-Knuutila, T., Faisal, A., & Salmelin, R. (2019). Reconstructing meaning from bits of information. Nature Communications, 10, 927. https://doi.org/10.1038/s41467-019-08848-0
- Konkle, T., & Alvarez, G. A. (2022). A self-supervised domain-general learning framework for human ventral stream representation. Nature Communications, 13, 491. https://doi.org/10.1038/s41467-022-28091-4
- Maris, E. (2012). Statistical testing in electrophysiological studies. Psychophysiology, 49(4), 549–565. https://doi.org/10.1111/j.1469-8986.2011.01320.x
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, & K. Q. Weinberger (Eds.), Advances in Neural Information Processing Systems 26 (pp. 3111–3119). Curran Associates, Inc.
- Mitchell, T. M., Shinkareva, S. V., Carlson, A., Chang, K. -M., Malave, V. L., R. A. Mason, & Just, M. A. (2008). Predicting human brain activity associated with the meanings of nouns. Science, 320(5880), 1191–1195. https://doi.org/10.1126/science.1152876
- Nora, A., Faisal, A., Seol, J., Renvall, H., Formisano, E., & Salmelin, R. (2020). Dynamic time-locking mechanism in the cortical representation of spoken words. eNeuro, 7(4), ENEURO.0475-19.2020. https://doi.org/10.1523/ENEURO.0475-19.2020
- Osgood, C. E., Suci, G. J., & Tannenbaum, P. H. (1978). The measurement of meaning. University of Illinois Press, Urbana-Champaign.
- Palatucci, M., Pomerleau, D., Hinton, G. E., & Mitchell, T. M. (2009). Zero-shot learning with semantic output codes. In C. Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, & A. Culotta (Eds.), Advances in Neural Information Processing Systems 22 (pp. 1410–1418).
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., & Vanderplas, J. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12(Oct), 2825–2830. https://dl.acm.org/doi/10.5555/1953048.2078195
- Rupp, K., Roos, M., Milsap, G., Caceres, C., Ratto, C., Chevillet, M., Crone, N. E., & Wolmetz, M. (2017). Semantic attributes are encoded in human electrocorticographic signals during visual object recognition. NeuroImage, 148(1), 318–329. https://doi.org/10.1016/j.neuroimage.2016.12.074
- Rybář, M., & Daly, I. (2022). Neural decoding of semantic concepts: A systematic literature review. Journal of Neural Engineering, 19(2), 021002. https://doi.org/10.1088/1741-2552/ac619a
- Salmelin, R., Hari, R., Lounasmaa, O. V., & Sams, M. (1994). Dynamics of brain activation during picture naming. Nature, 368(6470), 463–465. https://doi.org/10.1038/368463a0
- Shinkareva, S. V., Mason, R. A., Malave, V. L., Wang, W., Mitchell, T. M., & Just, M. A. (2008). Using fMRI brain activation to identify cognitive states associated with perception of tools and dwellings. PloS One, 3(1), e1394. https://doi.org/10.1371/journal.pone.0001394
- Simanova, I., van Gerven, M., Oostenveld, R., & Hagoort, P. (2010). Identifying object categories from event-related EEG: Toward decoding of conceptual representations. PLoS One, 5(12). https://doi.org/10.1371/journal.pone.0014465
- Sturt, P., Sanford, A. J., Stewart, A., & Dawydiak, E. (2004). Linguistic focus and good-enough representations: An application of the change-detection paradigm. Psychonomic Bulletin & Review, 11(5), 882–888. https://doi.org/10.3758/BF03196716
- Sudre, G., Pomerleau, D., Palatucci, M., Wehbe, L., Fyshe, A., Salmelin, R., & Mitchell, T. (2012). Tracking neural coding of perceptual and semantic features of concrete nouns. NeuroImage, 62(1), 451–463. https://doi.org/10.1016/j.neuroimage.2012.04.048
- Taulu, S., & Simola, J. (2006). Spatiotemporal signal space separation method for rejecting nearby interference in MEG measurements. Physics in Medicine and Biology, 51(7), 1759–1768. https://doi.org/10.1088/0031-9155/51/7/008
- Xian, Y., Lampert, C. H., Schiele, B., & Akata, Z. (2019). Zero-shot learning - A comprehensive evaluation of the good, the bad and the ugly. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(9), 2251–2265. https://doi.org/10.1109/TPAMI.2018.2857768