
ABSTRACT
Morpho-phonological patterns and semantic density influence the processing of spoken complex words and contribute to the dissociation between regularly and irregularly inflected forms. However, it is unclear whether all listeners rely on morpho-phonological and semantic cues to the same degree. The present paper examines whether a listener’s cognitive profile, indicated by processing efficiency, affects the processing strategy employed when listening to morphologically complex words. Two auditory judgement experiments demonstrate that slower responders rely more strongly on semantic processing than faster responders, but all listeners show morpho-phonological effects regardless of processing speed and form effects. This demonstrates that morpho-phonological processing is automatic for all listeners, but processing efficiency determines whether additional semantic cues are engaged. The results highlight the importance of integrating cognitive variability into current models of complex word processing.
Introduction
During auditory word comprehension, listeners have to integrate a multitude of linguistic cues rapidly and efficiently (including phonetic, phonological, morphological, and semantic cues). One type of cues, the morphological properties of inflected words, has received particular attention since the grammatical function of inflections can be used as a tool to understand the different neural computations at play during word recognition (Amenta & Crepaldi, Citation2012; Rastle & Davis, Citation2008).
Many studies have shown processing differences between regularly and irregularly inflected English words (Bacovcin et al., Citation2017; Wilder et al., Citation2018). While regularly inflected words in English consist of predictable patterns that can be segmented into word stems and affixes (hand + s), irregular words are unpredictable idiosyncratic forms that cannot be divided into a clear stem + inflection (children). However, authors have attributed processing differences between regular and irregular complex words to different causes, notably morpho-phonological structure (Marslen-Wilson & Tyler, Citation2007; Post et al., Citation2008), semantic differences (Baayen et al., Citation2019; Baayen & Moscoso del Prado Martin, Citation2005), and differences inherent to the inflectional paradigm such as entropy (Moscoso del Prado Martín et al., Citation2004b). It remains unclear how exactly these different cues interact and whether all listeners rely on them to the same extent.
Individual differences among neurotypical populations have received little attention in models of morphological processing, especially in the auditory modality, following the assumption that language processing is the same for all neurotypical native-speaking adults. However, individuals differ in many respects, including the efficiency (i.e. the speed) with which they retrieve lexical representations (Huettig & Janse, Citation2016; Lewellen et al., Citation1993). It has been shown that processing speed is a core part of the cognitive system (Kail & Salthouse, Citation1994). Indeed, multifarious individual differences have been revealed as a function of processing speed, including general cognitive functions such as reasoning and memory (Kail & Salthouse, Citation1994), as well as language-specific effects such as semantic (Hargreaves et al., Citation2012; Rodd, Citation2004), morphological (Schwarz et al., Citation2020), and morpho-semantic processing during reading (Medeiros & Duñabeitia, Citation2016).
However, the role of processing speed on retrieving morphological and semantic information has yet to be addressed in auditory word recognition. Therefore, in the present study, we investigate auditory processing of morphologically complex words not as a static function, but as the integration of multiple linguistic cues shaped by the cognitive profile of the individual.
Morpho-phonological and semantic cues in inflectional processing
In English, the specific morpho-phonological properties of regular inflections have been found to influence the processing of complex nouns and verbs. This reflects the observation that regular noun and verb inflections in English are formed by a word-final coronal consonant (sounds produced with the tip or blade of the tongue raised towards the alveolar ridge or teeth, such as /d, t, s, z/) which agrees in voicing with its preceding segment (e.g. day/z/, cat/s/). This morpho-phonological pattern has been named the Inflectional Rhyme Pattern (IRP, cf. Marslen-Wilson & Tyler, Citation2007; Post et al., Citation2008; Tyler et al., Citation2002a) and comprises the allomorphic variations of the plural –s and the past tense –ed inflections.
Several auditory experiments focused on the IRP in English verbs. Tyler et al. (Citation2002b) tested four patients with a deficit in regular processing and a control group. Subjects responded to minimally different pairs of regular (hugged-hug) and irregular verbs (taught-teach) and had to indicate if the two words were different. Results showed that both patients and control subjects processed regular verbs differently from irregular verbs. Patients’ performance was not correlated with the level of their phonological deficit, which was interpreted as reflecting automatic decomposition of regular inflections, driven by the presence of the IRP. Post et al. (Citation2008) further investigated the IRP, testing 20 unimpaired English speakers with a similar judgement task as Tyler et al. (Citation2002b). In this experiment, they included responses to pairs of the same word (filled-filled), contrasting regularly inflected items with items that do not feature the IRP. The results showed that any stimulus featuring the IRP – real, pseudo-inflected, and non-words – is responded to more slowly on average than a monomorphemic word, again suggesting that the presence of the IRP triggers automatic decomposition (cf. also Cilibrasi et al., Citation2019). These studies were taken as evidence against a single mechanism for accessing regular and irregular English words (Plaut et al., Citation1996; Seidenberg & McClelland, Citation1989). Instead, a dual-mechanism account was proposed which leads to decomposition of regularly inflected words (rule-based access), while irregular forms are retrieved as whole forms (stored memory representations, e.g. Pinker, Citation1991, Citation1999; Taft & Forster, Citation1975).
Building on decomposition accounts, current research in auditory morphological processing attributes morphological effects of inflected words to the activation of a shared word stem representation, following decomposition of concatenated morphemes (Bacovcin et al., Citation2017; Wilder et al., Citation2018). However, factors independent of the morpho-phonological structure of words have also been found to influence the processing of complex words, including inflectional entropy (Moscoso del Prado Martín et al., Citation2004b), morphological family size (e.g. in English: Baayen et al., Citation1997; Dutch: Schreuder & Baayen, Citation1997; Finnish and Hebrew: Moscoso Del Prado Martín et al., Citation2004a; and German: Lüdeling & De Jong, Citation2002), (base) frequency (e.g. in English: Taft, Citation1979; Chinese: Myers et al., Citation2006; Dutch: Baayen et al., Citation1997, Finnish: Kuperman et al., Citation2008; French: Colé et al., Citation1989), and, most notably, semantic density (e.g. in English, German, & Dutch: Baayen & Moscoso del Prado Martin, Citation2005; Basnight-Brown et al., Citation2007). Baayen and Moscoso del Prado Martin (Citation2005), for example, demonstrated that irregular verbs tend to have denser semantic networks compared to verbs with regular inflectional paradigms, i.e. they are more highly connected in meaning to other words (associations), have a larger number of lexicon entries (as a rough estimate of distinct meanings), and have more semantic neighbours (co-occuring words that are adjacent to the target word or separated by only a few intervening words in a large corpus). This finding has led to the hypothesis that semantic differences – not morpho-phonological structure – could be the primary source of the processing distinction between regular and irregular complex words (Baayen et al., Citation2019).
Whether morpho-phonological structure (e.g. Stockall et al., Citation2019) or semantic-distributional properties (e.g. Baayen et al., Citation2019) best capture the processing differences between regular and irregular words has been a prominent debate in morphological processing (Amenta & Crepaldi, Citation2012). The current literature is inconclusive on the relative significance of these variables, in particular whether and how semantic density interacts with the processing of morpho-phonological cues in the auditory modality. Some of this conflicting evidence, however, could be explained by a factor so far unexplored in auditory morphological processing: individual differences between listeners as to which type of cue – morpho-phonological or semantic – they rely on the most.
Individual differences and their implications for models of complex word processing
Individual differences have received comparatively little attention in models of auditory complex word processing, despite some promising findings from the visual modality suggesting that there is significant variation in the types of (sub-)lexical cues employed by individual language users (Andrews & Lo, Citation2013; Beyersmann et al., Citation2015; Ciaccio & Veríssimo, Citation2022; Medeiros & Duñabeitia, Citation2016). For instance, in visual word processing, reading speed has been found to modulate the size of semantic effects. Several behavioural studies show that faster, i.e. more efficient word recognition reduces the reliance on semantic information (Hargreaves et al., Citation2012; Rodd, Citation2004). Hargreaves et al. (Citation2012) presented a lexical decision task to readers with varying lexical and orthographic knowledge. They found that highly skilled readers (Scrabble players with an extensive vocabulary and strong orthographic skills) responded significantly faster than poor readers and, importantly, relied less on semantic information (captured by concreteness effects) when identifying real words. This aligns with earlier experiments by Rodd (Citation2004) who showed that semantic effects during reading aloud are enhanced for slower readers.
Following this line of research, it has been hypothesized that response speed could also affect morphological processing. Seeing that morphological cues are related to both form and meaning, Duñabeitia et al. (Citation2014) suggested that fast readers predominantly rely on morpho-orthographic information, while slower readers rely on morpho-semantic cues. Medeiros and Duñabeitia (Citation2016) confirmed this prediction using visual derivational suffix priming. Only slower readers (i.e. those with response times above the group median on a lexical decision task) displayed a (morpho-)semantic priming effect, while fast readers used a (morpho-)orthographic route. These results from visual word recognition raise the question whether individual differences in processing (sub-)lexical cues exist in auditory word processing, too. An auditory paradigm also allows us to test the role of processing efficiency independent of knowledge specific to visual word processing (such as print exposure) and as such can reveal whether morpho-phonological and semantic cues contribute to different degrees to complex word processing depending on the cognitive profile of the individual.
The current study
The present paper explores whether slow and fast responders differ in how they engage phonetic, morpho-phonological, and semantic cues when listening to morphologically complex words. More specifically, we investigate the processing of regular and irregular inflections in the context of different allomorphic suffix and stem variations and compare these morpho-phonological effects to semantic and phonetic variables. To this end, listeners were asked to judge whether two auditorily presented words are the same or different. This task avoids a potential confound of varying word recognition points, which is often introduced in priming paradigms. This is the case because the uniqueness point differs between regular (students-student) and irregular word pairs (mice-mouse), with mice differing from mouse at a much earlier point than students from student. Differentiating mice from mouse should therefore be much quicker than differentiating students from student, simply based on their form differences. The current paradigm avoids this confound by modelling only the responses to same-item pairs (students-students; mice-mice).
Investigating the processing of allomorphic suffix and stem variations has interesting theoretical potential because combinatorial approaches to language processing such as decomposition theories predict allomorphs of a regularly inflected word to map onto a shared morphological representation independent of whole-word semantics (Bozic et al., Citation2010; Marslen-Wilson & Tyler, Citation1998, Citation2007; Pinker, Citation1991, Citation1999; Pinker & Ullman, Citation2002). Moreover, an automatic morpho-phonological effect should not require the analysis of the word surface form and as such it would be expected to be independent of purely phonetic effects on response times as well as word stem regularity.
To assess individual differences, we first conduct a quantile regression analysis and, in addition, adapt Medeiros and Duñabeitia’s (Citation2016) method and conduct a median-split analysis on fast and slow responders separately. If auditory morphological processing is subject to processing efficiency, differences between slower and faster responders may emerge. In line with visual morphological processing, individuals who process words more slowly may rely more strongly on semantic networks. However, if processing the morpho-phonological pattern of the IRP is indeed automatic (Marslen-Wilson & Tyler, Citation2007; Post et al., Citation2008), we expect that the effect applies to all listeners, fast and slow, and to all items carrying the IRP, even in the absence of a regular stem (sell-sold) and in the absence of lexicality (i.e. in pseudowords).
Experiment 1
Experiment 1 examined whether listeners’ processing speed (i.e. the efficiency with which they retrieve lexical representations) dissociates their reliance on morpho-phonological vs. semantic cues when processing regular and irregular plural nouns. To this end, the effect of semantic neighbourhood density (as defined by a semantic model that derives how words are connected in meaning from lexical co-occurrence, cf. Shaoul & Westbury, Citation2010) is compared to the morpho-phonological effect of the presence of the Inflectional Rhyme Pattern (IRP; Marslen-Wilson & Tyler, Citation2007; Post et al., Citation2008; Tyler et al., Citation2002a) while listeners perform a same-different judgement task. To model morpho-phonological processing, we exploit the allomorphic properties of the –s plural inflection in English (e.g. books, dogs, days), which goes beyond treating regular and irregular (e.g. children) as a binary distinction by including morpho-phonological variation. All allomorphic variants are expected to be processed in a similar fashion provided that they map onto a single morphological representation as predicted by many theories of morphological decomposition (Pinker, Citation1991, Citation1999; Taft & Forster, Citation1975).
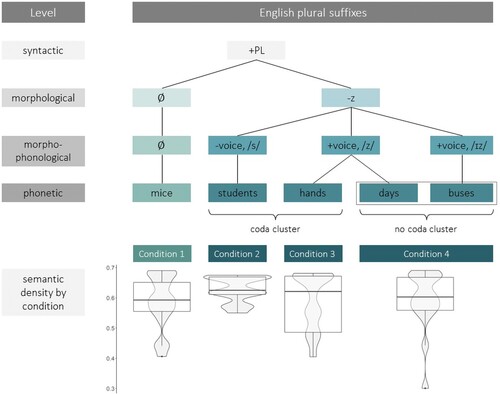
summarises the suffix variation found among regular English plural nouns at the syntactic, morphological, morpho-phonological, and phonetic level, as well as the distribution of semantic neighbourhood density across the four real word conditions. Importantly, semantic density varies between the individual items in the experiment, but is matched across the four conditions. Therefore, differences in processing times between irregular plurals (Condition 1) and regular plurals (Conditions 2–4) cannot be explained by semantic density alone, allowing us to separate allomorphic effects from the effect of semantic density. Under the assumption that all regular allomorphic variants of the IRP are based on a shared morpho-phonological cue to lexical access, processing times between irregular and regular plurals are expected to differ, while processing times for all regular inflectional allomorphs are expected to be the same.
Figure 1. Experiment 1. Visualised properties of plural suffixes at different levels of linguistic analysis.
In addition to real words, we also examined morpho-phonological effects in pseudowords. If the processing effects of regular and irregular words is driven by semantic and distributional properties (e.g. Baayen et al., Citation2019), morpho-phonological decomposition is unlikely to extend to pseudowords.
Materials & Methods
Participants
Fifty four participants were tested, three of which were excluded because they were diagnosed with dyslexia, one because they exceeded the age limit, and one because of high error rates (16.4%, M = 1.6). The remaining 49 participants were native speakers of English without any hearing, writing or speaking difficulties, and without motor problems, between 18 and 30 years of age (M = 22.9, f = 23). Ethical approval was obtained from the University of Cambridge MMLL Research Ethics Committee.
Materials
There were four conditions in Experiment 1 (). Condition 1 consisted of pairs of irregular plural nouns (mice-mice). Irregulars included nouns with a stem vowel change (mouse → mice), identical singular and plural (sheep → sheep), and substitution (person → people). Conditions 2–4 consisted of regular plural nouns which all featured the IRP, but differed with respect to coda consonant cluster and voicing (± consonant cluster; ± voiced inflection): in Condition 2 they were voiceless with coda consonant cluster (books-books); in Condition 3 they were voiced with the cluster (friends-friends), and in Condition 4 they were voiced, but without the consonant coda cluster (guys-guys). Each condition also had an equal number of rhymed matching pseudoword pairs, which were of comparable length to real words and phonotactically legal (e.g. Condition 1: bice-bice; Condition 2: priends-priends; etc.). Stimuli can be found in the supplementary materials.
Table 1. Conditions in Experiment 1.
There were 16 real words and 16 matched pseudowords in each condition (128 items in total). Items across conditions were matched on CV-shape, syllable number, and stress. Word duration could not be matched since irregular plurals tend to have a shorter duration than regular plurals overall. We account for this in the analysis by subtracting word duration from reaction times. For each word item, we obtained their surface form frequency (log transformed token frequency) and semantic neighbourhood density from the English Lexicon Project (Balota et al., Citation2007; ). Semantic neighbourhood density (Shaoul & Westbury, Citation2010) captures semantic relationships derived from lexical co-occurrence, thus measuring the density of the words in the semantic neighbourhood of a given word. In contrast to former work on semantic distributions across regular and irregular words (e.g. Baayen & Moscoso del Prado Martin, Citation2005), shows that the absence/presence of a plural inflection in our stimuli set is not confounded with semantic density, i.e. both semantic density (F(3, 55) = [.607], p = .613) and frequency (F(3, 60) = [.492], p = .689) were matched across conditions.
In addition to the 128 identical word and pseudoword pairs, participants were also presented with 128 filler items of minimally different pairs (teams-team; weams-weam). The fillers also included Latinate words such as data-data to reduce the probability of words ending in –s. Stimuli were recorded by two native English speakers with a Southern British accent (first word female, second word male) so as to ensure that judgements were not made based on low-level phonetic differences. Sound files were processed with Praat (Boersma & Weenink, Citation2015).
Procedure
The experiment was run in E-Prime 2.0 (Schneider et al., Citation2002). Participants sat in front of a computer display with a response box in a sound-proof booth. They heard two stimuli (e.g. mice-mice) in succession over headphones and were asked to press the response button if the words were the same, using the index finger of their dominant hand.
The experiment started with 24 practice items, followed by four blocks of 64 pairs each (pseudo-randomised). Real word pairs (mice-mice) and their matched pseudoword pairs (bice-bice) did not appear in the same block. Each test block was preceded by a short break, a reminder of the instructions, and four dummy stimuli. The second stimulus in each test pair appeared 1000 ms after the onset of the first stimulus. The next pair started 1500 ms after the onset of stimulus 2 of the previous pair, thereby limiting the response time. After each stimulus pair the participant received feedback on their accuracy and the percentage of total correct answers. Reaction times were measured from the onset of the second stimulus and word duration was later subtracted from these in preparation for the statistical analyses. The experiment took ca. 25 min.
Analysis
Errors were removed from the main data analysis (102/6272 responses; 1.6%). Response latencies were calculated by subtracting word duration from response times to account for the variation in word duration and outliers of three standard deviations from the mean were removed (121/6170 responses, 1.9%). Responses were near-normally distributed.
The remaining 6049 responses were analysed in R (version 2021.9.2.382; RStudio Team, Citation2021) with linear mixed-effects models (lme4 package, version 1.1.27.1; Bates et al., Citation2015). Random effects were optimised following Bates et al. (Citation2018). We also modelled responses to IRP-inflected words only to investigate whether there were any significant differences between the allomorph conditions. P-values were calculated with the Satterthwaite approximation for degrees of freedom provided by the anova function of the lmerTest package (version 2.0–11; Kuznetsova et al., Citation2015). Significant p-values are reported at p < .05. Categorical predictors were sum-to-zero contrast coded. Data and analysis scripts can be found in the online repository.
We first fitted a model to the real word items after removing five items for which no semantic neighbourhood density metric existed (remaining N = 2799). The model was fitted with the fixed effects of the IRP (present/absent), log-transformed Word Frequency (token), Semantic Neighbourhood Density, and an interaction between IRP and Semantic Density. We also included random intercepts for Subject and Item, random slopes for Semantic Neighbourhood Density and IRP by Subject, and a random slope for log-transformed Word Frequency (token) by Item. The real word model and subsequent models for pseudowords, allomorphs, and individual differences were optimised by stepwise comparison of AIC scores.
Main effects of the optimised mixed-effects models were further assessed with linear quantile regression. This method estimates the effects within specified quantiles of the RT distribution and thus provides an alternative measure of the locus of estimated means without the need to apply processing speed as an independent measure (Yap et al., Citation2009). Four quantile bands across RTs of all participants were calculated (package quantreg, version 5.94, Koenker, Citation2005) and compared with a Wald test.
To investigate participant-specific effects and compare fast and slow responders directly, we calculated the mean RT for each participant and then divided the whole sample by the group median. We then ran a real word model identical to the first mixed-effects model described above, but with an additional fixed factor of Group, and an interaction between Group and Semantic Density. Finally, median-split models were fitted to fast vs. slow responders to further explore how response speed may influence listeners’ engagement of semantic vs. morpho-phonological cues.
Results
Linear mixed-effects models
The first model established significant main effects for real words across the whole sample. The optimised model included the IRP, Semantic Density, and Word Frequency as fixed factors, random intercepts for Subject and Item, and random slopes for Semantic Density by Subject, and IRP by Subject (Marginal R2 = 4.1%; Conditional R2 = 38.5%). The results confirmed that across the whole sample, main effects of IRP (b = 23.36, 95% CI = [14.54, 32.17], p < .001), semantic density (b = −146.89, 95% CI = [−279.09, −14.69], p < .029) and word frequency (b = 13.74, 95% CI = [2.78, 24.70] p < .014) significantly predicted RTs.
Based on the clear morpho-phonological effect in real words, we expected an IRP effect in pseudowords, too, which was the case (b = 35.35, 95% CI = [25.98, 44.71], p < .001). shows response latencies to real words and pseudowords across conditions.
Figure 2. Experiment 1. Reaction times to real words and pseudowords corrected for word duration.
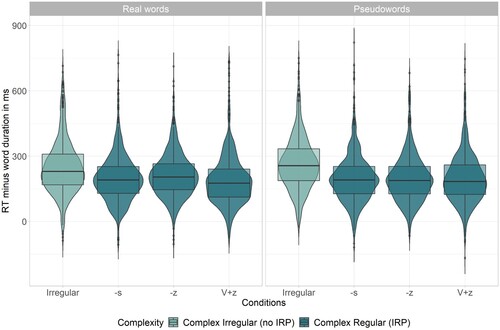
In addition, we compared the three allomorphic variants to each other by fitting a model only to items featuring the IRP (N = 4606), with the fixed factors Allomorphs (three variants, sum-to-zero contrast coded; cf. Conditions 2–4, ), Lexicality (real words vs. pseudowords), their interaction (Allomorphs:Lexicality), and random intercepts for Subject and Item. Since the interaction and Lexicality did not improve the model fit, the model was evaluated with the Allomorph predictor only. No significant differences between allomorphic variations were found (all contrasts p > .1).
Quantile regression analysis
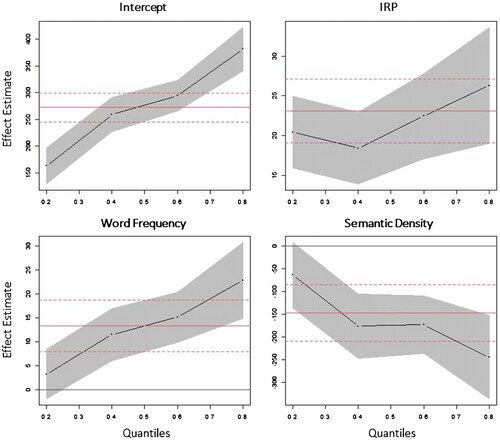
To establish the locus of the observed effects, a quantile regression analysis of the lexical decision response latencies to words and pseudowords with four quantiles was performed. Only main effects that were significant in the linear mixed-effects models were included (i.e. IRP, Semantic Density, Word Frequency for real words, and IRP for pseudowords). With respect to real words, quartiles differed significantly from one another (F(9, 11187) = [2.794], p = .003; ). The effect estimates for semantic neighbourhood density and word frequency significantly increased with response times [F(3, 11193) = [3.928], p = .008 and F(3, 11193) = [5.624], p < .001, respectively], with only the longer RTs (i.e. those in the higher quartiles) significantly affected by these variables. In contrast, the morpho-phonological effect of the IRP did not significantly differ between quartiles (F(3, 11193) = [1.498], p = .213). Similarly, the IRP effect did not differ significantly between the quartiles of pseudowords (F(3, 12021) = [2.103], p = .098). These findings suggest that the IRP influenced the processing of all listeners, while processing speed determined additional lexico-semantic engagement.
Figure 3. Experiment 1. Quantile regression plots of real word response latencies for the effects of Inflectional Rhyme Pattern (IRP), Word Frequency, and Semantic (Neighbourhood) Density. Each dot represents the slope coefficient (y-axis) for the quantile indicated on the x-axis. The red lines indicate the least squares estimate and its confidence interval.
Median-split analysis
Following on from the quantile regression results, which indicated differential lexico-semantic engagement as a function of processing speed, the next set of analyses aimed to compare fast and slow responders directly. To this end, we first ran a model identical to the linear mixed-effects model described above, but with an additional fixed factor of Group, and its interaction with Semantic Density. The optimised real word model showed significant fixed effects for the IRP (b = 23.37, 95% CI = [14.57, 32.18], p < .001), log-transformed Word Frequency (b = 13.73, 95% CI = [2.78, 24.68], p = .014), Semantic Neighbourhood Density (b = −148.34, 95% CI = [−280.42, −16.27], p = .028), Group (b = −76.57, 95% CI = [−106.25, −46.88], p < .001), and an interaction between Semantic Density and Group (b = 55.19, 95% CI = [4.00, 106.38], p = .035). The model also had random intercepts for Subject and Item, and random slopes for Semantic Density by Subject, and IRP by Subject (Marginal R2 = 18.5%; Conditional R2 = 37.6%). The critical interaction between semantic density and slower/faster responders indicated individual differences in semantic engagement, and motivated the subsequent median-split models.
For the median-split models, the same full structure as for the full data model (except the Group predictor) was used and optimised for participants with a mean raw reaction time above the sample median (>= 819 ms, i.e. slow responders: N = 2944, M = 862.0, SD = 130.5) and those below the median (<819 ms, i.e. fast responders: N = 3105, M = 768.7, SD = 119.3). In the optimised real word models, the IRP significantly improved the model fit in both fast responders (b = 17.18, 95% CI = [8.41, 25.95], p < .001), and slow responders (b = 29.52, 95% CI = [19.92, 39.13], p < .001). However, Frequency and Semantic Neighbourhood Density were significant predictors only in the group of slow responders (Frequency: b = 15.95, 95% CI = [3.07, 28.83], p = .015); (Semantic Density: b = −200.23, 95% CI = [−349.08, −51.37], p = .008). However, the differential word frequency effect between faster and slower responders should be interpreted with caution because the difference between the two groups is comparatively small (fast responders b = 11.56, 95% CI [−0.25, 23.38], p = .055; slow responders b = 15.95, 95% CI = [3.07, 28.83], p = .015). For easier comparison, presents the slow and fast responders based on all three variables: IRP, Frequency, and Semantic Density. In line with the real words, the IRP was a significant predictor in pseudowords for both fast responders (b = 35.14, 95% CI = [25.33, 44.95], p < .001) and slow responders (b = 34.10, 95% CI = [23.59, 44.61], p < .001).
Table 2. Experiment 1. Optimised linear mixed-effects models for real words with reaction times as response.
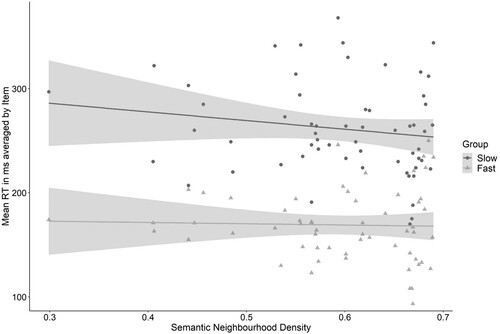
These findings align with the results of the quantile regression analysis and suggest that the IRP influences the processing of all listeners, independent of lexicality, while processing speed determined additional lexico-semantic engagement. shows this differential effect of Semantic Neighbourhood Density between faster and slower responders. Items with a denser semantic neighbourhood led to faster responses for slower responders only.
Figure 4. Experiment 1. Effect of semantic neighbourhood density on reaction times (in ms, corrected for word duration) averaged by item for fast and slow responders.
In summary, the results from Experiment 1 indicate that morpho-phonological patterns and semantic density are independent predictors of reaction times for spoken inflected words. Comparing slow and fast responders, the morpho-phonological effect of the IRP was shown to apply regardless of individual processing speed and in both real words and pseudowords. Moreover, the allomorphic variants of the IRP were processed with a similar speed. Semantic engagement (in real words), in contrast, was modulated by processing speed, replicating similar findings from the visual modality.
Experiment 2
Experiment 1 showed that the IRP effect can be distinguished from semantic processing effects. However, Experiment 1 did not test whether the IRP is a truly morpho-phonological effect, i.e. independent of factors relying purely on the form of inflections in English, such as voicing, consonant clusters, and place of articulation. It is also unclear whether the detection of the inflectional cue necessitates form analysis of the stem-affix structure, as predicted by models of morphological decomposition (e.g. Taft & Forster, Citation1975). Experiment 2 addresses these points by modelling responses not only to fully regular (e.g. call-called) and fully irregular words (e.g. buy-bought), but also semi-regular items which feature irregular stems combined with regular inflectional suffixes (e.g. sell-sold).
Materials and methods
Participants
Forty nine native English speakers (different to those in Experiment 1) without hearing impairment, language deficit, or motor problems (M = 25.0, f = 25) were tested.
Materials
Experiment 2 had six different conditions including nouns and verbs (): Conditions 1 and 2 were morphologically simple words. The coda in Condition 1 consisted of a single consonant (bag; talk), whereas Condition 2 had a word-final coda cluster (bulb; fetch). Conditions 3 and 4 were morphologically complex words featuring the IRP. Condition 3 consisted of items with a regular stem (i.e. a stem which is identical to its uninflected word form) + IRP (bells; called), while the items in Condition 4 were semi-regular and featured an irregular stem + IRP (thieves; kept).Footnote1 Conditions 5 and 6 were irregular morphologically complex words without the IRP. Items in Conditions 5 featured a vowel change (mice; bought), and Condition 6 consisted of words with identical simple and complex form (cod; beat). Word Frequencies (log-transformed token) for all items were taken from the English Lexicon Project as in Experiment 1 and matched across conditions (F(5, 90) = [.168], p = .974).
Table 3. Conditions in Experiment 2.
In total, 96 test pairs (identical word pairs) and 96 filler pairs (minimally different pairs created from the same words; e.g. geese-gee) were presented. Two verbs in Condition 2 were erroneously classified as having a coda cluster (climb, hang) and were therefore re-assigned to Condition 1 (stems without cluster). Stimuli can be found in the supplementary materials.
Two different recordings were made for the first and second items (men-men) by a native English speaker with a Southern British accent in a sound-proof recording booth. The minimally different filler items were created by removing the coda from the second item in each test pair. This reduced the number of items ending in an inflection. It also reduced any bias towards only listening to the word stem and made it impossible for the listener to make a decision before the end of the second word in a pair.
Procedure
The experiment was prepared in E-Prime 2.0 (Schneider et al., Citation2002) and testing took approximately 15 min. The experiment started with 24 practice pairs. The test and filler stimuli were divided into four equal blocks, each preceded by a short break, a reminder of the instructions, and three practice pairs. The order of blocks was pseudo-randomised and items within each block were fully randomised. The task was the same as in Experiment 1 (a single button response on hearing the same word twice). The onset of stimulus 2 followed 1100 ms after the onset of stimulus 1. Participants had a maximum of 1500 ms from the onset of stimulus 2 to respond.
Analysis
The outcome variable was calculated by subtracting word duration from response times. Errors (40/4704, <1%) and outliers of three standard deviations from the mean per participant (79 responses, 1.7%) were removed. Mixed-effects models with random intercepts for Subject and Item and selected random slopes were optimised in R following the procedure described in Experiment 1. First a model was fitted to the full data and then models to fast vs. slow responders in line with Experiment 1.
The model to the full dataset (N = 4585) tested the fixed effects Morphological Complexity (Simple/Complex), the Inflectional Rhyme Pattern (no IRP/IRP), Coronality (place of articulation: word-final consonant is non-coronal vs. coronal), Coda Cluster (absent/present in the coda), Voicing of the final consonant (voiceless/voiced), and Word Frequency (log-transformed token surface frequency from the Subtlex-UK corpus). We also tested Subject and Item random effects, a random slope for IRP by Subject, and a random slope of Frequency by Item. Subsequent mixed-effects models and quantile regressions were fitted to test effects of individual differences and stem regularity.
Results
Linear mixed-effects models
The optimised model across all real word items and participants showed the significant fixed effects IRP (b = 17.29, 95% CI = [9.70, 24.89], p < .001), Coda Cluster (b = 11.26, 95% CI = [3.91, 18.60], p = .003), and Word Frequency (b = 8.48, 95% CI = [1.69, 15.28], p = .014), as well as random intercepts for Subject and Item (Marginal R2 = 4.1%; Conditional R2 = 48.3%). This confirmed that the IRP was a significant predictor over and above purely phonetic effects ().
Figure 5. Experiment 2. Reaction times corrected for word duration by Condition.
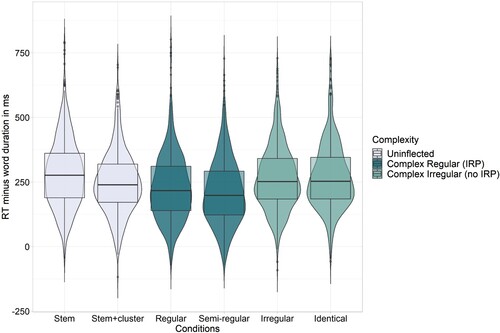
We also tested whether access to a regular stem was necessary for the IRP to take effect as predicted by dual-route models. A model was fitted to all morphologically complex words only (N = 3069) with the binary predictors IRP and stem regularity (without optimising or random slopes). This included the conditions without a change of the stem vowel compared to the uninflected form (regular stem + IRP: call-called; regular stem + no IRP: beat-beat) and those with a changed stem vowel (irregular stem + IRP: keep-kept; irregular stem + no IRP: buy-bought). Only the IRP was a significant predictor (b = 24.15, 95% CI = [16.75, 31.55], p < .001), but not stem regularity (b = 5.76, 95% CI = [−1.64, 13.16], p = .127).
Quantile regression
The quantile regression of the lexical decision response latencies showed significant differences between quartiles (F(9, 18331) = [2.105], p = .026), driven by the effect of word frequency, which reduced significantly across quartiles (F(3, 18337) = [4.215], p = .005), with no effect in the fourth quartile (b = 3.48, t = 1.03, p = .302). The effects of the IRP and Coda Cluster did not differ significantly between quartiles (F(3, 18337) = [1.568], p = .195; F(3, 18337) = [1.092], p = .351).
Median-split analysis
Following the procedure used in Experiment 1, separate models were fitted for participants responding faster than the group median (<=739 ms, N = 2429, M = 668.0, SD = 109.0) and those responding slower than the median (>739 ms, N = 2156, M = 801.6, SD = 124.0), starting with the same maximal fixed structure and random intercepts. The optimised models are summarised in . The expected effect of the IRP was found for both fast responders (b = 18.82, 95% CI = [11.08, 26.57], p < .001) and slow responders (b = 15.48, 95% CI = [6.22, 24.74], p = .001), replicating this finding from Experiment 1, as well as a form effect of Coda Clusters (fast: b = 9.81, 95% CI = [2.33, 17.30], p = .010; slow: b = 13.87, 95% CI = [5.06, 22.67], p = .002). Fast responders also showed a significant effect of Word Frequency (b = 10.90, 95% CI = [3.97, 17.84], p = .002). These results mirror the findings of the quantile regression analysis.
Table 4. Experiment 2. Optimised linear mixed-effects models with reaction times as response.
Discussion
Summary of findings
The present study shows that individual differences modulate the processing of morphologically complex words in the auditory domain. We compared two of the most prominent distributional differences found between regular and irregular English nouns and verbs: predictable morpho-phonological patterns and semantic neighbourhood density. Experiment 1 showed a robust effect of morpho-phonological cues for all listeners, regardless of their processing efficiency, which was independent of affix allomorphy. However, processing efficiency determined the additional engagement of semantic cues, with less efficient mapping of auditory input to lexical representations (higher RT quantiles and listeners responding above the median speed) associated with a greater reliance on semantic neighbourhood information. Experiment 2 replicated the IRP effect among both fast and slow responders and showed that this effect is independent of the regularity of the word stem and form-based coda cluster effects.
Our results suggest that, depending on a listener’s processing efficiency, (sub-)lexical cues differentially contribute to accurate word mapping between auditory input and lexical representation. In line with a substantial body of research in visual word processing, complex word mapping – at least in part – relies on automatic morpho-phonological parsing (Amenta & Crepaldi, Citation2012). Semantic engagement, in addition, supports word mapping when direct access through morpho-phonological processing alone is insufficient. These findings provide a promising new angle on the discussion of what computational mechanisms are at play during lexical access for complex words, and raise important points for theories of morphological processing.
Evidence for distinct processing of morpho-phonological and semantic information
The manipulation of affix and stem allomorphy in the present study provides new information on the underlying nature of morpho-phonological patterns. All inflectional allomorphs in our study were processed with a similar speed. If only phonetic cues and semantic density determined reaction times in our experiments, this would not have been the case. Furthermore, distinct processing of regular affixes (the IRP) did not require a regular stem (as seen in semi-regular items in Experiment 2). This indicates that the morphological effect of regular inflections is independent from the stems to which they are attached.
However, it has been argued that semantic effects are interdependent with effects of form and morphological structure (Feldman & Moscoso del Prado Martin, Citation2022). Therefore, amorphous models of lexical access, such as naïve discriminative learning (Baayen et al., Citation2011) and linear discriminative learning (Baayen et al., Citation2019), do not incorporate a distinct role for morphological representations. Indeed, it has been firmly established that semantic similarity is an important predictor in word recognition tasks, as for example evidenced by overt visual priming (e.g. Feldman et al., Citation2002; Feldman & Soltano, Citation1999; Gonnerman et al., Citation2007; Marslen-Wilson et al., Citation1994; Meunier & Longtin, Citation2007; Rueckl & Aicher, Citation2008) and recently also by auditory priming of semantically transparent and opaque words (Creemers et al., Citation2020). Moreover, Chuang et al. (Citation2021) have modelled the “semantics” of pseudowords through numeric vectors with linear discriminative learning. From this point of view, the morpho-phonological effects of pseudowords in the present study could also be the result of mapping the inflectional exponent onto “an area in semantic space where real words with the exponent are located” (Chuang et al., Citation2021, p. 946).
However, the results of the present study showed that semantic density effects could be dissociated from those of morpho-phonological processing. Semantic density was only observed as a significant predictor of response times in a subset of listeners, namely those with less efficient lexical mapping (i.e. slower responses). These individual differences indicate that computations for morpho-phonological patterns and word meaning are at least partially distinct in auditory word recognition. Enhanced semantic engagement for slower auditory processing is in line with findings from visual word access showing that semantic effects are weaker for faster readers (Hargreaves et al., Citation2012; Rodd, Citation2004). Moreover, Medeiros and Duñabeitia (Citation2016) showed that only slow readers exhibit significant morpho-semantic priming in visual lexical decision. Similarly, our results showed that slower auditory processing leads to stronger semantic engagement. In addition, Medeiros and Duñabeitia (Citation2016) found that fast readers relied more strongly on morpho-orthographic processing. This mirrors the present findings, where all listeners processed the IRP in a similar fashion. Overall, the automatic and rapid sensitivity to morphological cues of affixes aligns well with a large body of research in both modalities (e.g. Post et al., Citation2008; Stockall et al., Citation2019).
While it is possible that the auditory judgement task used in the present study emphasised sensitivity to the IRP to some extent (though still allowing semantic effects to emerge in slower responders), our results clearly suggest that the observed effects are morpho-phonological in nature and that they can be separated from form processing. This is the case because we specifically modelled phonetic features in comparison to the morpho-phonological effect of the IRP, and found that purely form-based effects (Coda Cluster) were distinct from the IRP effect (Experiment 2). If a form-based strategy was driving the IRP effects, separate effects for Coda Cluster and IRP should not have emerged. Moreover, we reduced the number of target items featuring the IRP in Experiment 2 (less than 17%) and found the same morpho-phonological engagement across the board as in Experiment 1. A comparable pattern of automatic IRP decomposition – regardless of the properties of the word stem – has been observed across different tasks in previous work (Bozic et al., Citation2010; Cilibrasi et al., Citation2019).
Nevertheless, the auditory judgement paradigm we used may have evoked semantic engagement to a lesser extent than some other psycholinguistic tasks (e.g. semantic categorisation). This might also explain why a lexicality effect, which taps into lexico-semantic discrimination, was absent when comparing the allomorphic variants of the IRP (Experiment 1; cf. lexicality effects found by Fiorentino & Poeppel, Citation2007; Laszlo & Federmeier, Citation2009). An interesting extension of the work presented here could therefore be the presentation of tasks with different demands to the same set of participants. Moreover, comparing morpho-phonological and lexico-semantic effects in a variety of different languages will be equally important since the frequency and distribution of morphemes varies cross-linguistically (e.g. Medeiros et al., Citation2014). English is a weakly inflected language, where the presence of an IRP marking is likely to be highly informative as it consistently indicates the presence of a grammatical morpheme, thus triggering automatic decomposition independent of items’ lexical status in both behavioural and neuroimaging studies (Post et al., Citation2008; Tyler et al., Citation2002a, Citation2002b). In contrast, this processing strategy might differ to some extent in more richly inflected languages such as Brazilian Portuguese (Medeiros et al., Citation2014) or Polish (Szlachta et al., Citation2012). This is consistent with the “ecological view” that the challenges and demands of a specific language ultimately shape the exact way that processing mechanisms unfold, and guards against strong conclusions made on the basis of results from one language only.
Implications for models of morphological access
The present findings pose several challenges to existing models of complex word processing. On the one hand, the consistently found IRP effect indicates an important role for morphological structure as predicted by decomposition models. More specifically, within the decomposition framework, allomorphic variations of a regularly inflected word would be expected to map onto a common morphological representation independent of semantic factors (i.e. the regular suffix variations in experiment 1; cf. Bozic et al., Citation2010; Marslen-Wilson, Citation2007; Marslen-Wilson & Tyler, Citation1998; Pinker & Ullman, Citation2002; Pinker, Citation1991, Citation1999). This aligns well with our finding that all allomorphs of the -s and -ed inflections were processed with a similar speed. On the other hand, however, the results also indicate that the IRP effect is independent of accessing a real or pseudoword stem. This contradicts many decomposition models which predict that affixes are stripped from the whole word in order to access a regular stem (Grainger & Ziegler, Citation2011; Taft, Citation1994; Taft & Forster, Citation1975). The semi-regular words in Experiment 2 (sell-sold), however, have an irregular stem. Within the dual-route framework, semi-regular items would normally be treated as idiosyncratic forms that have to be stored via associative memory rather than decomposed. However, the results show that the IRP effect applies to semi-regular words, too. These results are in line with morphological effects found in semi-regular words in other languages such as German (Smolka et al., Citation2007, Citation2013), French (Meunier & Marslen-Wilson, Citation2004), and Italian (Orsolini & Marslen-Wilson, Citation1997).
In addition, any neurobiologically motivated model must account for the accumulating evidence that individual differences shape the processing of morphologically complex words (e.g. Medeiros & Duñabeitia, Citation2016; Schwarz et al., Citation2020). Both decompositional and distributed models presume that the same processes guide adult native speakers and therefore have not specified how individual cognitive differences modulate the mechanisms at play. Furthermore, some models such as linear discriminative learning do not feature distinct mechanisms for morpho-phonological and semantic processing (Baayen et al., Citation2019). However, if morpho-phonological effects were a by-product of semantic distributions, we would have expected that morpho-phonological effects consistently co-occur with semantic effects in the present study. This was not the case. Instead, the individual differences in semantic engagement suggest that distinct operations underlie morpho-phonological and semantic effects in auditory lexical access, and that both contribute distinctly to the processing of morphologically complex words. As such, our results stand in contrast to the argument that semantic effects are interdependent with effects of form and morphological structure (Feldman & Moscoso del Prado Martin, Citation2022). Most importantly, however, given the evidence that semantic information processing may vary as a function of individual differences, our data suggest that individual differences should be considered in this context.
Taken together, the results of the present study suggest that morpho-phonological processing of inflections is automatic, independent of the (pseudo)word stem, and distinct from semantic and purely form-based processing. Importantly, the relative contribution of semantic information to complex word processing varies among individuals. These effects can be interpreted within accounts that treat morphological processing as continuous and probabilistic in nature (Stevens & Plaut, Citation2022). Connectionist models, for example, provide a framework that can incorporate a variety of morphological effects “through learned sensitivity to statistical structure among word forms and their meanings” (Stevens & Plaut, Citation2022, p. 2). Provided that the architecture has separate elements for form and meaning (e.g. Plaut & Gonnerman, Citation2000; Raveh, Citation2002; Rueckl & Raveh, Citation1999), the weights of semantic and (morpho-)phonological cues could be adjusted according to processing efficiency to model individual differences. However, as Stevens and Plaut (Citation2022) point out in a recent review of visual morphological models, specifying a learning procedure for how such variable representations are recognised, weighted, and reformed is still a challenge for computational models. Alternatively, the results could be explained by multiple-route models that allow parallel processing of lexical (semantic) and sub-lexical (morpho-phonological) information (Kuperman et al., Citation2009). Individual differences within this framework would be a function of how strongly one relies on each route. Independent of the specific model, the present results are clear in that morpho-phonological and semantic information play distinct roles in auditory word recognition.
At present, incorporating individual differences into models of complex word processing is still problematic because most models have been developed without cognitive variability in mind and for the visual modality only (e.g. Crepaldi et al., Citation2010; Grainger & Ziegler, Citation2011; Rastle & Davis, Citation2008; Taft, Citation1994). Empirical and computational work on the auditory recognition of morphologically complex words remains sparse. However, the present study has demonstrated the theoretical potential of investigating morpho-phonological patterns, semantic neighbourhood density, and individual differences in the auditory modality as a tool to dissociate the different processing mechanisms at play. More empirical work in the auditory modality is needed to successfully incorporate these individual differences into models of lexical access.
Supplemental Material
Download PDF (153.7 KB)Data availability statement
The data and supplementary materials that support the findings of this study are openly available at Open Science Framework (OSF), “Individual Differences in Auditory Word Recognition”, http://doi.org/10.17605/OSF.IO/GHP89
.Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 The semi-regular nouns in Experiment 2 are formed by an -s plural suffix that agrees in voicing with the preceding phoneme (all voiced), and in addition, the stem's coda consonant becomes voiced in the plural form (thief-thieves); the semi-regular verbs are formed by a stop suffix (/d/ or /t/) which agrees in voicing with the preceding sound (voiced or voiceless), and in addition, the stem vowel changes in the past tense form (sell-sold).
References
- Amenta, S., & Crepaldi, D. (2012). Morphological processing as we know it: An analytical review of morphological effects in visual word identification. Frontiers in Psychology, 3, 232. https://doi.org/10.3389/fpsyg.2012.00232
- Andrews, S., & Lo, S. (2013). Is morphological priming stronger for transparent than opaque words? It depends on individual differences in spelling and vocabulary. Journal of Memory and Language, 68(3), 279–296. https://doi.org/10.1016/j.jml.2012.12.001
- Baayen, R. H., Chuang, Y.-Y., Shafaei-Bajestan, E., & Blevins, J. P. (2019). The discriminative lexicon: A unified computational model for the lexicon and lexical processing in comprehension and production grounded not in (de)composition but in linear discriminative learning. Complexity, 2019(1), 1–39. https://doi.org/10.1155/2019/4895891
- Baayen, R. H., Dijkstra, T., & Schreuder, R. (1997). Singulars and plurals in Dutch: Evidence for a parallel dual-route model. Journal of Memory and Language, 37(1), 94–117. https://doi.org/10.1006/jmla.1997.2509
- Baayen, R. H., Milin, P., Revic, D. F., Hendrix, P., & Marelli, M. (2011). An amorphous model for morphological processing in visual comprehension based on naive discriminative learning. Psychological Review, 118(3), 438–481. https://doi.org/10.1037/a0023851
- Baayen, R. H., & Moscoso del Prado Martin, F. (2005). Semantic density and past-tense formation in three Germanic languages. Language, 81(3), 666–698. https://doi.org/10.1353/lan.2005.0112
- Bacovcin, H. A., Goodwin Davies, A., Wilder, R. J., & Embick, D. (2017). Auditory morphological processing: Evidence from phonological priming. Cognition, 164, 102–106. https://doi.org/10.1016/j.cognition.2017.03.011
- Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., & Treiman, R. (2007). The English lexicon project. Behavior Research Methods, 39(3), 445–459. https://doi.org/10.3758/BF03193014
- Basnight-Brown, D. M., Chen, L., Hua, S., Kostić, A., & Feldman, L. B. (2007). Monolingual and bilingual recognition of regular and irregular English verbs: Sensitivity to form similarity varies with first language experience. Journal of Memory and Language, 57(1), 65–80. https://doi.org/10.1016/j.jml.2007.03.001
- Bates, D., Kliegl, R., Vasishth, S., & Baayen, R. H. (2018). Parsimonious mixed models. ArXiv preprint. https://doi.org/10.48550/arXiv.1506.04967
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), https://doi.org/10.18637/jss.v067.i01
- Beyersmann, E., Casalis, S., Ziegler, J. C., & Grainger, J. (2015). Language proficiency and morpho-orthographic segmentation. Psychonomic Bulletin & Review, 22(4), 1054–1061. https://doi.org/10.3758/s13423-014-0752-9
- Boersma, P., & Weenink, D. (2015). Praat: Doing phonetics by computer (Version 5.4.19) [Computer program].
- Bozic, M., Tyler, L. K., Ives, D. T., Randall, B., & Marslen-Wilson, W. D. (2010). Bihemispheric foundations for human speech comprehension. Proceedings of the National Academy of Sciences, 107(40), 17439–17444. https://doi.org/10.1073/pnas.1000531107
- Chuang, Y. Y., Vollmer, M. L., Shafaei-Bajestan, E., Gahl, S., Hendrix, P., & Baayen, R. H. (2021). The processing of pseudoword form and meaning in production and comprehension: A computational modeling approach using linear discriminative learning. Behavior Research Methods, 53(3), 945–976. https://doi.org/10.3758/s13428-020-01356-w
- Ciaccio, L. A., & Veríssimo, J. (2022). Investigating variability in morphological processing with Bayesian distributional models. Psychonomic Bulletin & Review. Advance online publication. https://doi.org/10.3758/s13423-022-02109-w
- Cilibrasi, L., Stojanovik, V., Riddell, P., & Saddy, D. (2019). Sensitivity to inflectional morphemes in the absence of meaning: Evidence from a novel task. Journal of Psycholinguistic Research, 48(3), 747–767. https://doi.org/10.1007/s10936-019-09629-y
- Colé, P., Beauvillain, C., & Segui, J. (1989). On the representation and processing of prefixed and suffixed derived words: A differential frequency effect. Journal of Memory and Language, 28(1), 1–13. https://doi.org/10.1016/0749-596X(89)90025-9
- Creemers, A., Goodwin Davies, A., Wilder, R. J., Tamminga, M., & Embick, D. (2020). Opacity, transparency, and morphological priming: A study of prefixed verbs in Dutch. Journal of Memory and Language, 110, 104055. https://doi.org/10.1016/j.jml.2019.104055
- Crepaldi, D., Rastle, K., Coltheart, M., & Nickels, L. (2010). ‘Fell’ primes ‘fall’, but does ‘bell’ prime ‘ball’? Masked priming with irregularly-inflected primes. Journal of Memory and Language, 63(1), 83–99. https://doi.org/10.1016/j.jml.2010.03.002
- Duñabeitia, J. A., Perea, M., & Carreiras, M. (2014). Revisiting letter transpositions within and across morphemic boundaries. Psychonomic Bulletin & Review, 21(6), 1557–1575. https://doi.org/10.3758/s13423-014-0609-2
- Feldman, L. B., Barac-Cikoja, D., & Kostic, A. (2002). Semantic aspects of morphological processing: Transparency effects in Serbian. Memory & Cognition, 30(4), 629–636. https://doi.org/10.3758/BF03194964
- Feldman, L. B., & Moscoso del Prado Martin, F. (2022). Tuning language processing mechanisms to a language’s morphology without decomposition: the case of semantic transparency. In A. D. Sims, A. Ussishkin, J. Parker, & S. Wray (Eds.), Morphological diversity and linguistic cognition (pp. 31–55). Cambridge University Press. https://doi.org/10.1017/9781108807951.003
- Feldman, L. B., & Soltano, E. G. (1999). Morphological priming: The role of prime duration, semantic transparency, and affix position. Brain and Language, 68(1–2), 33–39. https://doi.org/10.1006/brln.1999.2077
- Fiorentino, R., & Poeppel, D. (2007). Compound words and structure in the lexicon. Language and Cognitive Processes, 22(7), 953–1000. https://doi.org/10.1080/01690960701190215
- Gonnerman, L. M., Seidenberg, M. S., & Andersen, E. S. (2007). Graded semantic and phonological similarity effects in priming: Evidence for a distributed connectionist approach to morphology. Journal of Experimental Psychology: General, 136(2), 323–345. https://doi.org/10.1037/0096-3445.136.2.323
- Grainger, J., & Ziegler, J. (2011). A dual-route approach to orthographic processing. Frontiers in Psychology, 2, 1–13. https://doi.org/10.3389/fpsyg.2011.00054
- Hargreaves, I. S., Pexman, P. M., Zdrazilova, L., & Sargious, P. (2012). How a hobby can shape cognition: Visual word recognition in competitive Scrabble players. Memory & Cognition, 40(1), 1–7. https://doi.org/10.3758/s13421-011-0137-5
- Huettig, F., & Janse, E. (2016). Individual differences in working memory and processing speed predict anticipatory spoken language processing in the visual world. Language, Cognition and Neuroscience, 31(1), 80–93. https://doi.org/10.1080/23273798.2015.1047459
- Kail, R., & Salthouse, T. A. (1994). Processing speed as a mental capacity. Acta Psychologica, 86(2–3), 199–225. https://doi.org/10.1016/0001-6918(94)90003-5
- Koenker, R. (2005). Quantile regression in R: A vignette. CRAN. http://cran.r-project.org.
- Kuperman, V., Bertram, R., & Baayen, R. H. (2008). Morphological dynamics in compound processing. Language and Cognitive Processes, 23(7–8), 1089–1132. https://doi.org/10.1080/01690960802193688
- Kuperman, V., Schreuder, R., Bertram, R., & Baayen, R. H. (2009). Reading polymorphemic Dutch compounds: Toward a multiple route model of lexical processing. Journal of Experimental Psychology: Human Perception and Performance, 35(3), 876–895. https://doi.org/10.1037/a0013484
- Kuznetsova, A., Brockhoff, P., & Christensen, R. (2015). lmerTest: Tests in linear mixed effects models (Version 2.0-25). R package. http://CRAN.R-project.org/package=lmerTest
- Laszlo, S., & Federmeier, K. D. (2009). A beautiful day in the neighborhood: An event-related potential study of lexical relationships and prediction in context. Journal of Memory and Language, 61(3), 326–338. https://doi.org/10.1016/j.jml.2009.06.004
- Lewellen, M. J., Goldinger, S. D., Pisoni, D. B., & Greene, B. G. (1993). Lexical familiarity and processing efficiency: Individual differences in naming, lexical decision, and semantic categorization. Journal of Experimental Psychology: General, 122(3), 316–330. https://doi.org/10.1037/0096-3445.122.3.316
- Lüdeling, A., & De Jong, N. (2002). German particle verbs and word-formation. Verb-Particle Explorations, 315–333. https://doi.org/10.1515/9783110902341.315.
- Marslen-Wilson, W. (2007). Morphological processes in language comprehension. In M. Gaskell (Ed.), The Oxford handbook of psycholinguistics. Oxford University Press. https://doi.org/10.1093/oxfordhb/9780198568971.013.0011
- Marslen-Wilson, W. D., & Tyler, L. K. (1998). Rules, representations, and the English past tense. Trends in Cognitive Sciences, 2(11), 428–435. https://doi.org/10.1016/S1364-6613(98)01239-X
- Marslen-Wilson, W. D., & Tyler, L. K. (2007). Morphology, language and the brain: The decompositional substrate for language comprehension. Philosophical Transactions of the Royal Society B: Biological Sciences, 362(1481), 823–836. https://doi.org/10.1098/rstb.2007.2091
- Marslen-Wilson, W. D., Tyler, L. K., Waksler, R., & Older, L. (1994). Morphology and meaning in the English mental lexicon. Psychological Review, 101(1), 3–33. https://doi.org/10.1037/0033-295X.101.1.3
- Medeiros, J., & Duñabeitia, J. A. (2016). Not everybody sees the ness in the darkness: Individual differences in masked suffix priming. Frontiers in Psychology, 7(1585), 1–10. https://doi.org/10.3389/fpsyg.2016.01585
- Medeiros, J., Weissheimer, J., França, A. I., & Ribeiro, S. (2014). Acesso lexical: uma rota dupla para o português brasileiro. Fórum Linguístico, 11(3), 278–292. https://doi.org/10.5007/1984-8412.2014v11n3p278
- Meunier, F., & Longtin, C. M. (2007). Morphological decomposition and semantic integration in word processing. Journal of Memory and Language, 56(4), 457–471. https://doi.org/10.1016/j.jml.2006.11.005
- Meunier, F., & Marslen-Wilson, W. D. (2004). Regularity and irregularity in French verbal inflection. Language and Cognitive Processes, 19(4), 561–580. https://doi.org/10.1080/01690960344000279
- Moscoso Del Prado Martín, F., Bertram, R., Häikiö, T., Schreuder, R., & Baayen, R. H. (2004a). Morphological family size in a morphologically rich language: The case of Finnish compared with Dutch and Hebrew. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30(6), 1271–1278. https://doi.org/10.1037/0278-7393.30.6.1271
- Moscoso del Prado Martín, F. M., Kostić, A., & Baayen, R. H. (2004b). Putting the bits together: An information theoretical perspective on morphological processing. Cognition, 94(1), 1–18. https://doi.org/10.1016/j.cognition.2003.10.015
- Myers, J., Huang, Y. C., & Wang, W. (2006). Frequency effects in the processing of Chinese inflection. Journal of Memory and Language, 54(3), 300–323. https://doi.org/10.1016/j.jml.2005.11.005
- Orsolini, M., & Marslen-Wilson, W. D. (1997). Universals in morphological representation: Evidence from Italian. Language and Cognitive Processes, 12(1), 1–47. https://doi.org/10.1080/016909697386899
- Pinker, S. (1991). Rules of language. Science, 253(5019), 530–535. https://doi.org/10.1126/science.1857983
- Pinker, S. (1999). Words and rules. Harper Perennial.
- Pinker, S., & Ullman, M. (2002). The past and future of the past tense. Trends in Cognitive Sciences, 6(11), 456–463. https://doi.org/10.1016/S1364-6613(02)01990-3
- Plaut, D. C., & Gonnerman, L. M. (2000). Are non-semantic morphological effects incompatible with a distributed connectionist approach to lexical processing? Language and Cognitive Processes, 15(4–5), 445–485. https://doi.org/10.1080/01690960050119661
- Plaut, D. C., McClelland, J. L., Seidenberg, M. S., & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103(1), 56–115. https://doi.org/10.1037/0033-295X.103.1.56
- Post, B., Marslen-Wilson, W. D., Randall, B., & Tyler, L. K. (2008). The processing of English regular inflections: Phonological cues to morphological structure. Cognition, 109(1), 1–17. https://doi.org/10.1016/j.cognition.2008.06.011
- Rastle, K., & Davis, M. H. (2008). Morphological decomposition based on the analysis of orthography. Language and Cognitive Processes, 23(7–8), 942–971. https://doi.org/10.1080/01690960802069730
- Raveh, M. (2002). The contribution of frequency and semantic similarity to morphological processing. Brain and Language, 81(1–3), 312–325. https://doi.org/10.1006/brln.2001.2527
- Rodd, J. M. (2004). The effect of semantic ambiguity on reading aloud: A twist in the tale. Psychonomic Bulletin & Review, 11(3), 440–445. https://doi.org/10.3758/BF03196592
- RStudio Team. (2021). Rstudio: Integrated development for R. RStudio, PBC.
- Rueckl, J. G., & Aicher, K. A. (2008). Are CORNER and BROTHER morphologically complex? Not in the long term. Language and Cognitive Processes, 23(7–8), 972–1001. https://doi.org/10.1080/01690960802211027
- Rueckl, J. G., & Raveh, M. (1999). The influence of morphological regularities on the dynamics of a connectionist network. Brain and Language, 68(1–2), 110–117. https://doi.org/10.1006/brln.1999.2106
- Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime user’s guide. Psychology Software Tools Inc.
- Schreuder, R., & Baayen, R. H. (1997). How complex simplex words can be. Journal of Memory and Language, 37(1), 118–139. https://doi.org/10.1006/jmla.1997.2510
- Schwarz, J., Bozic, M., & Post, B. (2020). Individual differences in processing pseudo-inflected nonwords. ExLing. https://doi.org/10.36505/ExLing-2020/11
- Seidenberg, M. S., & McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychological Review, 96(4), 523–568. https://doi.org/10.1037/0033-295X.96.4.523
- Shaoul, C., & Westbury, C. (2010). Exploring lexical co-occurrence space using HiDEx. Behavior Research Methods, 42(2), 393–413. https://doi.org/10.3758/BRM.42.2.393
- Smolka, E., Khader, P. H., Wiese, R., Zwitserlood, P., & Rösler, F. (2013). Electrophysiological evidence for the continuous processing of linguistic categories of regular and irregular verb inflection in German. Journal of Cognitive Neuroscience, 25(8), 1284–1304. https://doi.org/10.1162/jocn_a_00384
- Smolka, E., Zwitserlood, P., & Rösler, F. (2007). Stem access in regular and irregular inflection: Evidence from German participles. Journal of Memory and Language, 57(3), 325–347. https://doi.org/10.1016/j.jml.2007.04.005
- Stevens, P., & Plaut, D. C. (2022). From decomposition to distributed theories of morphological processing in reading. Psychonomic Bulletin & Review. Advance online publication. https://doi.org/10.3758/s13423-022-02086-0
- Stockall, L., Manouilidou, C., Gwilliams, L., Neophytou, K., & Marantz, A. (2019). Prefix stripping re-re-revisited: Meg investigations of morphological decomposition and recomposition. Frontiers in Psychology, 10, 1964. https://doi.org/10.3389/fpsyg.2019.01964
- Szlachta, Z., Bozic, M., Jelowicka, A., & Marslen-Wilson, W. D. (2012). Neurocognitive dimensions of lexical complexity in Polish. Brain and Language, 121(3), 219–225. https://doi.org/10.1016/j.bandl.2012.02.007
- Taft, M. (1979). Recognition of affixed words and the word frequency effect. Memory & Cognition, 7(4), 263–272. https://doi.org/10.3758/BF03197599
- Taft, M. (1994). Interactive-activation as a framework for understanding morphological processing. Language and Cognitive Processes, 9(3), 271–294. https://doi.org/10.1080/01690969408402120
- Taft, M., & Forster, K. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14(6), 638–647. https://doi.org/10.1016/S0022-5371(75)80051-X
- Tyler, L., Randall, B., & Marslen-Wilson, W. D. (2002b). Phonology and neuropsychology of the English past tense. Neuropsychologia, 40(8), 1154–1166. https://doi.org/10.1016/S0028-3932(01)00232-9
- Tyler, L. K., de Mornay Davies, P., Anokhina, R., Longworth, C., Randall, B., & Marslen Wilson, W. D. (2002a). Dissociations in processing past tense morphology: Neuropathology and behavioral studies. Journal of Cognitive Neuroscience, 14(1), 79–95. https://doi.org/10.1162/089892902317205348
- Wilder, R. J., Goodwin Davies, A., & Embick, D. (2018). Differences between morphological and repetition priming in auditory lexical decision: Implications for decompositional models. Cortex; A Journal Devoted to the Study of the Nervous System and Behavior, 116, 122–142. https://doi.org/10.1016/j.cortex.2018.10.007
- Yap, M. J., Tse, C.-S., & Balota, D. A. (2009). Individual differences in the joint effects of semantic priming and word frequency revealed by RT distributional analyses: The role of lexical integrity. Journal of Memory and Language, 61(3), 303–325. https://doi.org/10.1016/j.jml.2009.07.001