
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We give qualitative and quantitative improvements to theorems which enable significance testing in Markov chains, with a particular eye toward the goal of enabling strong, interpretable, and statistically rigorous claims of political gerrymandering. Our results can be used to demonstrate at a desired significance level that a given Markov chain state (e.g., a districting) is extremely unusual (rather than just atypical) with respect to the fragility of its characteristics in the chain. We also provide theorems specialized to leverage quantitative improvements when there is a product structure in the underlying probability space, as can occur due to geographical constraints on districtings.
Keywords:
This note discusses improvements on a number of theorems for significance testing in Markov chains. The improvements to the theorem statements are both qualitative and quantitative to enable strong, easily interpretable statistical claims, and include extensions to settings where more structural assumptions lead to dramatic improvements in the bounds. This class of theorems is of particular interest because they do not assume that the chain has converged to equilibrium, which is of practical importance since the mixing time of Markov chains used in applications is frequently unknown.
The development of this class of algorithms and these particular extensions have been directly motivated by a question of significant contemporary interest; detecting and quantifying gerrymandering. The definiteness and correctness provided by these theorems affords decision makers (e.g., in a legal setting) with an uncommonly rigorous approach to understanding whether a political districting is carefully crafted for partisan advantage. These methods (and theorems) have been used successfully by one of the authors in Gerrymandering court cases in Pennsylvania and North Carolina.
The first technical part of this article gives new results along these lines, extending the work in Chikina, Frieze, and Pegden (Citation2017) to allow separation of effect size from the quantification of statistical significance. The second part, in Section 8, develops versions of some of these results in a special setting with a particular structure on the probability space motivated by recent legal proceedings. In particular, in balancing the federal one-person-one-vote mandate with the “keep counties whole” prevision of the North Carolina Constitution, the North Carolina courts ruled in Stephenson v. Bartlett that a particular algorithm should be used to “cluster” the counties into independent county groups which are districted separately. This gives a product structure to the underlying probability space which can be exploited in theorems designed to take advantage of it.
In Section 1, we consider the technical background and past results necessary to frame the new results of this article; in Section 2, we discuss the practical challenges which motivate the new theoretical framework we develop in this article. The new results are stated and discussed in Section 3. Later sections prove the new theorems.
1 Background and Previous Results
Consider a reversible Markov chain whose state-space Σ is endowed with some labeling
, and for which π is a stationary distribution.
, π, ω, and a fixed integer k determine a vector
where for each i,
is the probability that for a k-step π-stationary trajectory
, the minimum ω value occurs at Xi
. In other words,
is the probability that if we choose X
0 randomly from the stationary distribution π and take k steps in
to obtain the trajectory
, that we observe that
is the minimum among
. Note that if we adopted the convention that we break ties among the values
randomly, we would have that
, for any
and k.
In the context of districting, is generally a random walk on the space of possible districtings of a state; for example, from one districting, we can randomly choose a voting precinct on the boundary of two districts, and switch its district membership if doing so does not violate constraints on contiguity, population deviation, etc. (see for an example of such a move). This transition rule defines a reversible Markov chain on the state space consisting of all valid districtings of the state. The label function ω could be, for example, the partisanship of any given districting—which could be defined, for example, from simulated election results using historical voting data. In this context,
is the probability that if began from a random districting of a state, and carried out a sequence of k random transitions, that the initial districting in the sequence would be the most partisan districting observed in the sequence.
Fig. 1 An example of a Markov chain transition for the legislative districting of Wisconsin.
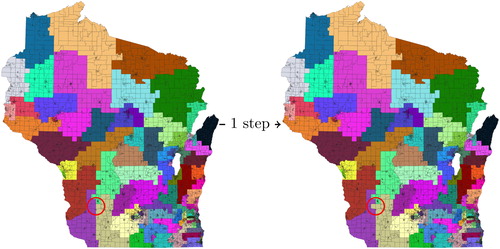
At first glance, it might be natural to assume that we must have something like for all
. This would mean, for example, that if we generated a sequence of 10,000 districtings, and the initial districting was the most partisan, that it would be valid to conclude that the initial districting was not randomly chosen from the stationary distribution, at a p-value of p = 0.0001. But this is actually quite far from the truth; Chikina, Frieze, and Pegden (Citation2017) showed that for some
, we can have
as large as essentially
.
As shown in Chikina, Frieze, and Pegden (Citation2017), this is essentially the worst possible behavior for . In particular, we can generalize the vector
defined above as possible: let us define, given
, k, and
, the vector
where each
is the probability that
is among the smallest ε fraction of values in the list
. Then in Chikina, Frieze, and Pegden (Citation2017) we proved:
Theorem 1.1.
Given a reversible Markov chain with stationary distribution π, an
, and with
defined as above, we have that
In particular, in the case of the first districting which is most partisan on a sequence of 10,000, this supports a p-value of . Note that the example from Chikina, Frieze, and Pegden (Citation2017) realizing
shows that this theorem is best possible, up to constant factors.
As indicated by the example of making a sequence of random changes to a districting, one important application of Theorem 1.1 is that it characterizes the statistical significance associated to the result of the following natural test for gerrymandering of political districtings:
Local outlier test
Beginning from the districting being evaluated,
Make a sequence of random changes to the districting, while preserving some set of constraints imposed on the districtings.
Evaluate the partisan properties of each districting encountered (e.g., by simulating elections using past voting data).
Call the original districting “carefully crafted” or “gerrymandered” if the overwhelming majority of districtings produced by making small random changes are less partisan than the original districting.
Naturally, the test described above can be implemented so that it precisely satisfies the hypotheses of Theorem 1.1. For this purpose, a (very large) set of comparison districtings are defined, to which the districting being evaluated belongs. For example, the comparison districtings may be the districtings built out of Census blocks (or some other unit) which are contiguous, equal in population up to some specified deviation, or include other constraints. A Markov chain is defined on this set of districtings, where transitions in the chain correspond to changes in districtings. (E.g., a transition may correspond to randomly changing the district assignment of a randomly chosen Census block which currently borders more than one district, subject to the constraints imposed on the comparison set.) The “random changes” from Step 2 will then be precisely governed by the transition probabilities of the Markov chain
. By designing
so that the uniform distribution π on the set of comparison districtings Σ is a stationary distribution for
, Theorem 1.1 gives an upper bound on the false-positive rate (in other words, global statistical significance) for the “gerrymandered” declaration when it is made in Step 4.
Remark 1.1. N
ote that while a local outlier test can be used to give a statistical significant finding of gerrymandering, it cannot be used alone to demonstrate rigorously that a districting is not gerrymandered. In particular, when a districting does not seem gerrymandered to a local outlier test, it is quite possible that the chain is simply not mixing well enough to explore the space of alternatives. The theorems discussed in this article give one-way guarantees: for example, observing outlier status confers a statistically significant finding of gerrymandering, but failing to observe it is inconclusive, absent other evidence.
Apart from its application to gerrymandering, Theorem 1.1 has a simple informal interpretation for the general behavior of reversible Markov chains, namely: typical (i.e., stationary) states are unlikely to change in a consistent way under a sequence of chain transitions, with a best-possible quantification of this fact (up to constant factors).
Also, in the general setting of a reversible Markov chain, the theorem leads to a simple quantitative procedure for asserting rigorously that σ
0 is atypical with respect to π without knowing the mixing time of : simply observe a random trajectory
from σ
0 for any fixed k. If
is an ε-outlier among
, then this is statistically significant at
against the null hypothesis that
.
This quantitative test is potentially useful because converges quickly enough to 0 as
; in particular, it is possible to obtain good statistical significance from observations which can be made with reasonable computational resources. Of course, faster convergence to 0 would be even better, but, as already noted,
is roughly a best possible upper bound.
On the other hand, it is possible to achieve better dependence on ε by changing the parameters of the test. For example, we will prove the following theorem as a stepping-stone to the main results of the present manuscript:
Theorem 1.2.
Consider two independent trajectories and
in the reversible Markov chain
(whose states have real-valued labels) from a common starting point
. If we choose σ
0 from a stationary distribution π of
, then for any k we have that
Note that due to the reversibility of the chain, Theorem 1.2 is equivalent to the statement that the probabilities always satisfy
(1)
(1)
Remark 1.2. A
s in the case of Theorem 1.1, it seems like an interesting question to investigate the tightness of the constant 2; we will see in Section 8 that there are settings where the impact of this constant is inflated to have outsize-importance. We point out here that at least for the case of k = 1, can be at least as large as
, showing that the constant 2 in (1) cannot be replaced by a constant less than
, in general. To see this, consider, for example, a bipartite complete graph
, where the labels of the vertices of one side are
and the other are
. For the Markov chain given by the random walk on this undirected graph, we have that
. Note that for this example, it is still the case that
as
, leaving open the possibility that the 2 in (1) can be replaced with an expression asymptotically equivalent to 1.
The informal interpretation of Theorem 1.2 is thus: typical (i.e., stationary) states are unlikely to change in a consistent way under two sequences of chain transitions.
Unknown to the authors at the time of the publication of Chikina, Frieze, and Pegden (Citation2017), Besag and Clifford (Citation1989) described a test related to that based on Theorem 1.2, which has essentially a one-line proof, which we discuss in Section 5:
Theorem 1.3
(Besag and Clifford serial test). Fix any number k and suppose that σ
0 is chosen from a stationary distribution π, and that ξ is chosen uniformly in . Consider two independent trajectories
and
in the reversible Markov chain
(whose states have real-valued labels) from
. If we choose σ
0 from a stationary distribution π of
, then for any k we have that
Here, a real number a
0 is an ε-outlier among if
In particular, the striking thing about Theorem 1.3 is that it achieves a best-possible dependence on the parameter ε. (Notice that ε would be the correct value of the probability if, for example, the Markov chain is simply a collection of independent random samples.) The sacrifice is in Theorem 1.3’s slightly more complicated intuitive interpretation, which would be: typical (i.e., stationary) states are unlikely to change in a consistent way under two sequences of chain transitions of random complementary lengths. Note that the pattern in these theorems is that the simplicity of the intuitive interpretation of the theorem is sacrificed for the quantitative bounds offered; one goal of the present article is prove theorems which avoid this trade off.
2 The Need for New Statistical Approaches
In late 2018, the nonprofit Common Cause filed a lawsuit in North Carolina superior court challenging the state-level districting plans (for the North Carolina state House and Senate districts). The third and fourth authors of this article served as expert witnesses in this case, which ultimately found the challenged districtings to be unconstitutional partisan gerrymanders. In this section, we use some of the findings from the fourth author’s expert report Pegden (Citation2019) in that case as motivation for the need for the new theoretical results we advance in this article.
One interesting feature of districting in North Carolina is the requirement (from the state supreme court case Stephenson v. Bartlett) that districtings of that state must respect particular groupings—county clusters—determined, essentially deterministically, by a prescribed set of rules.
A complete districting of the state of North Carolina is thus composed of completely separate, noninteracting districting problems in each county cluster. One practical question of interest in Common Cause v. Lewis—separate from the question of whether the challenged districtings were partisan gerrymanders—was the question of which specific county clusters were gerrymandered in each (House and Senate) districting.
The basic approach of the analysis used in Pegden (Citation2019) begins with an experiment in which random changes are made to the actual, enacted districting of the state being evaluated. For example, (taken from Pegden (Citation2019)) shows the results of 16 such experiments run on the North Carolina House districting:
Table 1 Results of the analysis from Pegden (Citation2019) for the House districting of North Carolina.
Each number shows, as a percentage, the fraction of districtings encountered in the sequence of random changes which were more Republican-favorable than the enacted plan. The particular choices of partisan metrics and voting data can be found in Pegden (Citation2019). ( shows the initial map as well as three examples of maps encountered in the first experiment.)
Fig. 2 First: The challenged State House districting of North Carolina, and three examples of maps encountered by a sequence of random changes.
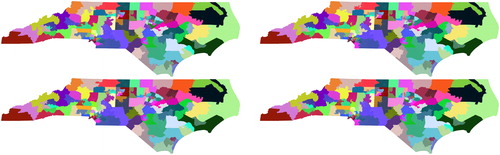
The percentages recorded in show that the enacted House plan is an extreme outlier among the plans generated by making small random changes to the enacted plan. This already gives strong intuitive evidence that the enacted plan is extremely carefully drawn to maximize partisan advantage: as soon as the lines of the map are subjected to small random changes, the overwhelming fraction of encountered maps are less advantageous to Republicans than the enacted plan.
But the next step of the analysis in Pegden (Citation2019) is the application of rigorous theorems to establish statistical significance for the findings in . This is slightly subtle, since, as we will see when setting up the technical details later, we do not make the heuristic assumption that the randomly generated plans are uniform samples from some set of possible maps; instead, we wish to make rigorous statistical claims with respect to the actual experiment, a Markovian process of making a sequence of random changes to the initial map.
The previous paper (Chikina, Frieze, and Pegden Citation2017) also took this approach in an analysis of the Congressional districting of Pennsylvania (which later formed the basis of expert testimony in the League of Women Voters v. Pennsylvania case which challenged the Congressional districting there). The theorem from Chikina, Frieze, and Pegden (Citation2017) allows one to establish statistical significance of when one finds that a
fraction of maps are less advantageous to (say) the Republicans than the enacted map. For example, for Run 1 in ,
and so p = 0.0003 is quite statistically significant, against the null hypothesis of a randomly chosen districting.
But an important question in the Common Cause v. Lewis lawsuit was not simply whether unconstitutional gerrymandering took place in the drawing of the North Carolina plans, but in which county clusters it took place (so that districtings in those clusters could be ordered redrawn). As an example we will consider the county cluster consisting of Forsyth and Yadkin counties; the challenged map and 3 examples of maps encountered by the sequence of random changes are shown in , while the table of results for this cluster are shown in . While shows that the overwhelming fraction of maps encountered by making random changes were less favorable to Republicans, ε values of around 0.002 in this case are not small enough that would be statistically significant. In particular, even if we applied a test like that given by Theorem 1.2 or Theorem 1.3, our level of statistical confidence would be limited by the degree to which the districting in this county cluster is an outlier.
Fig. 3 First: The challenged State House districting within the Forsyth-Yadkin county cluster, and three examples of maps encountered by a sequence of random changes to this districting.
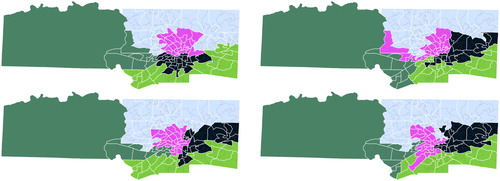
Table 2 Results of the analysis from Pegden (Citation2019) for the House districting of North Carolina in the Forsyth-Yadkin cluster.
Instead, we wish to decouple the statistical significance of our finding from the level of outlier status we can report for the districting in this cluster; this is a major goal of the approach we take in this note.
3 New Results
One common feature of the tests based on Theorems 1.1 and 1.3 is the use of randomness. In particular, the probability space at play in these theorems includes both the random choice of σ 0 assumed by the null hypothesis and the random steps taken by the Markov chain from σ 0. Thus, the measures of “how (globally) unusual” σ 0 is with respect to its performance in the local outlier test and “how sure” we are that σ 0 is unusual in this respect are intertwined in the final p-value. In particular, the effect size and the statistical significance are not explicitly separated.
To further the goal of simplifying the interpretation of the results of these tests, our approach in this note will also show that tests like these can be efficiently used in a way which separates the measure of statistical significance from the question of the magnitude of the effect. For example, our new results would allow one to capture the outlier status of a cluster like Forsyth-Yadkin discussed in the previous section, at a p-value which can be made arbitrarily small, independent of the observed ε values.
To begin, let us recall the probabilities defined previously, let us define the ε-failure probability
to be the probability that on a trajectory
is among the smallest ε fraction of the list
. Now we make the following definition:
Definition 3.1.
With respect to k, the state σ
0 is an -outlier in
if, among all states in
is in the largest α fraction of the values of
over all states
, weighted according to π.
In particular, being an -outlier measures the likelihood of σ
0 to fail the local outlier test, ranked against all other states
of the chain
. For example, fix
. If σ
0 is a
-outlier in
and π is the uniform distribution, this means that among all states
, σ
0 is more likely than all but a
fraction of states to have an ω-value in the bottom
values
. Note that the probability space underlying the “more likely” claim here just concerns the choice of the random trajectory
from
.
Note that whether σ
0 is a -outlier is a deterministic question about the properties of
and ω. Thus, it is a deterministic measure (defined in terms of certain probabilities) of the extent to which σ
0 is unusual (globally, in all of
) with respect to its local fragility in the chain.
The following theorem enables one to assert statistical significance for the property of being an -outlier. In particular, while tests based on Theorems 1.1 and 1.3 take as their null hypothesis that
, the following theorem takes as its null hypothesis merely that σ
0 is not an
-outlier.
Theorem 3.1.
Consider m independent trajectoriesof length k in the reversible Markov chain
(whose states have real-valued labels) from a common starting point
. Define the random variable ρ to be the number of trajectories
on which σ
0 is an ε-outlier.
If σ
0 is not an -outlier, then
(2)
(2)
In particular, apart from separating measures of statistical significance from the quantification of a local outlier, Theorem 3.1 connects the intuitive local outlier test tied to Theorem 1.1 (which motivates the definition of a -outlier) to the better quantitative dependence on ε in Theorem 1.3.
To compare the quantitative performance of Theorem 3.1 to Theorems 1.1 and 1.3, consider the case of a state σ
0 for which a random trajectory is likely (say with some constant probability
) to find σ
0 an
-outlier. For Theorem 1.1, significance at
would be obtained1, while using Theorem 1.3, one would hope to obtain significance of
. Applying Theorem 3.1, we would expect to see ρ around
. In particular, we could demonstrate that σ
0 is an
outlier for
(a linear dependence on ε) at a p-value which can be made arbitrarily small (at an exponential rate) as we increase the number of observed trajectories m. As we will see in Section 6, the exponential tail in (2) can be replaced by a binomial tail. In particular, the following special case applies:
Theorem 3.2.
With as in Theorem 3.1, we have that if
is not an
outlier, then
Theorem 3.2 also has advantages from the standpoint of avoiding the need to correct for multiple hypothesis testing, as we discuss in Section 4.
Example 3.1.
Based on the output in , we can apply Theorem 3.2 to report that the enacted districting of the Forsyth-Yadkin cluster is an -outlier for
and
, at a statistical significance of p = 0.002. In other words, among all possible districtings defined by the constraints imposed (not just those encountered in the 32 runs), the enacted plan has a greater ε-failure probability than 99.1% of districtings of the cluster, a finding we are confident in at a statistical significance of p = 0.002.
In the article where Theorem 1.3 is proved, Besag and Clifford also describe a parallel test, which we will discuss in Section 7. In particular, in Section 7, we will describe a test which generalizes Besag and Clifford’s serial and parallel tests in a way which could be useful in certain parallel regimes.
Finally, we consider an interesting case in the analysis of districtings that arises when the districting problem can be decomposed into several noninteracting districting problems, as is the case in North Carolina because of the county clusters. In this case, the probability space of random districtings is really a product space, and this structure can be exploited in a strong way for the statistical tests developed in this manuscript. We develop results for this setting in Section 8.
The remaining sections of the article are devoted to the proofs of the new results.
4 Multiple Hypothesis Considerations
When applying Theorem 3.1 directly, one cannot simply run m trajectories, observe the list where each
is the minimum
for which σ
0 is an
-outlier on
, and then, post-hoc, freely choose the parameters α and ε in Theorem 3.1 to achieve some desired trade-off between α and the significance p.
The problem, of course, is that in this case one is testing multiple hypotheses (infinitely many in fact; one for each possible pair ε and α) which would require a multiple hypothesis correction.
One way to avoid this problem is to essentially do a form of cross-validation, were a few trajectories are run for the purposes of selecting suitable ε and α, and then discarded from the set of trajectories from which we obtain significance.
A simpler approach, however, is to simply set the parameter as the tth-smallest element of the list
for some fixed value t. The case t = m, for example, corresponds to taking ε as the maximum value, leading to the application of Theorem 3.2.
The reasons this avoids the need for a multiple hypothesis correction is that we can order our hypothesis events by containment. In particular, when we apply this test with some value of t, we will always have . Thus, the significance obtained will depend just on the parameter
returned by taking the tth smallest
and on our choice of α (as opposed to say, the particular values of the other
’s which are not the t-th smallest). In particular, regardless of how we wish to trade-off the values of α and p we can assert from our test, our optimum choice of α (for our fixed choice of t) will depend just on the value
. In particular, we can view α as a function
, so that we when applying Theorem 3.1 with
, we are evaluating the single-parameter infinite family of hypotheses
, and we do not require multiple hypothesis correction since the hypotheses are nested; that is, since
(3)
(3)
Indeed, (3) implies thatwhich ensures that when applying Theorem 3.1 in this scenario, the probability of returning a p-value
for any fixed value p
0 will indeed be at most p
0.
5 Proof Background
We begin this section by giving the proof of Theorem 1.2. In doing so we will introduce some notation that will be useful throughout the rest of this note. To make things as accessible as possible, we give every detail of the proof.
In this article, a Markov chain on Σ is specified by the transition probabilities
of a chain. A trajectory of
is a sequence of random variables
required to have the property that for each i and
, we have
(4)
(4)
In particular, the Markov property of the trajectory is that the conditioning on is irrelevant once we condition on the value of
. Recall that π is a stationary distribution if
implies that
and thus also that
for all
; in this case we that the trajectory
is
-stationary. The Markov chain
is reversible if any π-stationary trajectory
is equivalent in distribution to its reverse
.
We say that aj
is -small among
if there are at most
indices
among
such that
. The following simple definition is at the heart of the proofs of Theorems 1.1–1.3.
Definition 5.1.
Given a Markov chain with labels
and stationary distribution π, we define for each
a real number
, which is the probability that for a π-stationary trajectory
, we have that
is
-small among
.
Observe that (4) implies that all π-stationary trajectories of a fixed length are all identical in distribution, and in particular, that the ’s are well-defined.
Next observe that if the sequence of random variables is a π-stationary trajectory for
, then so is any interval of it. For example,
is another stationary trajectory, and thus the probability that
is
-small among
is equal to
. In particular, since
follows from
for all , we have that
(5)
(5)
We also have that . Indeed, by linearity of expectation, this sum is the expected number of indices
such that
is
-small among
. Thus, averaging the left and right sides of (5) over j from 0 to k, we obtain
(6)
(6)
Line (6) already gives the theorem, once we make the following trivial observation:
Observation 5.1.
Under the hypotheses of Theorem 1.2, we have thatis a π-stationary trajectory.
This is an elementary consequence of the definitions, but since we will generalize this statement in Section 7, we give all the details here:
Proof
of Observation 5.1. Our hypothesis is that and
are independent trajectories from a common state
chosen from the stationary distribution π. Stationarity implies that
Similarly, stationarity and reversibility imply that
Finally, our assumption that and
are independent trajectories from σ
0 is equivalent to the condition that, for any
, we have for all
that
(7)
(7)
Of course, since is a Markov chain, this second probability is simply
In particular, by induction on ,
and in particular(8)
(8)
Pared down to its bare minimum, this proof of Theorem 1.2 works by using that is a lower bound on each
, and then applying the simple inequality
(9)
(9)
The proof of Theorem 1.3 of Besag and Clifford is in some sense even simpler, using only (9), despite the fact that Theorem 1.3 has better dependence on ε (on the other hand, it is not directly applicable to -outliers in the way that we will use Theorem 1.2). Recall from Definition 5.1 that the
’s are fixed real numbers associated to a stationary Markov chain. If
are fixed and ξ is chosen randomly from 0 to k, then the resulting
is a random variable uniformly distributed on the set of real numbers
In particular, Theorem 1.3 is proved by writing that the probability that
is
-small among
is given by
where the inequality is from (9). Note that we are using an analog of Observation 5.1 to know that for any j,
is a π-stationary trajectory.
6 Global Significance for Local Outliers
We now prove Theorem 3.1 from Theorem 1.2.
Proof
of Theorem 3.1. For a π-stationary trajectory , let us define
to be the probability that
is in the bottom ε fraction of the values
, conditioned on the event that
.
In particular, to prove Theorem 3.1, we will prove the following claim:
Claim: If σ
0 is not an -outlier, then
(10)
(10)
Let us first see why the claim implies the theorem. Recall the random variable ρ is the number of trajectories from σ
0 on which σ
0 is observed to be an ε-outlier with respect to the labeling ω. The random variable ρ is thus a sum of m independent Bernoulli random variables, which each take value 1 with probability
by the claim. In particular, by Chernoff’s bound, we have
(11)
(11) giving the theorem. (Note the key point of the claim is that α is inside the square root in (10), while a straightforward application of Theorem 1.1 would give an expression with α outside the square root.)
To prove (10), consider a π-stationary trajectory and condition on the event that
for some arbitrary
. Since
is reversible, we can view this trajectory as two independent trajectories
and
both beginning from σ. In particular, letting A and B be the events that
is an ε-outlier among the lists
and
, respectively, we have that
(12)
(12)
Now, the assumption that the given is not an
-outlier gives that for a random
, we have that
(13)
(13)
Line (12) gives that , and Theorem 1.2 gives that
. Thus taking expectations with respect to a random
, we obtain that
On the other hand, we can use (13) to write
so that we have
The following theorem is the analog of Theorem 3.1 obtained when one uses an analog of Besag and Clifford’s Theorem 1.3 in place of 1.2 in the proof. This version pays the price of using a random k instead of a fixed k for the notion of an -outlier, but has the advantage that the constant 2 is eliminated from the bound. (Note that as in Theorem 3.1, the notion of
-outlier used here is still just defined with respect to a single path, although Theorem 1.3 depends on using two independent trajectories.)
Theorem 6.1.
Consider m independent trajectoriesin the reversible Markov chain
(whose states have real-valued labels) from a common starting point
, where each of the lengths ki
are independently drawn random numbers from a geometric distribution. Define the random variable ρ to be the number of trajectories
on which σ
0 is an ε-outlier.
If σ
0 is not an -outlier with respect to k drawn from the geometric distribution, then
(14)
(14)
Again, there is an analogous version to Theorem 3.2, where is replaced by ε.
Proof
of Theorem 6.1. For a π-stationary trajectory and a real number μ, let us define
to be the probability that
is in the bottom ε fraction of the values
, conditioned on the event that
, where the length k is chosen from a geometric distribution with mean μ supported on 0,1,2,…; that is, k = t with probability
.
To prove Theorem 6.1, it suffices to prove that if σ
0 is not an -outlier with respect to k drawn from the geometric distribution with mean μ, then
(15)
(15)
To prove (15), suppose that k
1 and k
2 are independent random variables which are geometrically distributed with mean μ, and consider a π-stationary trajectoryof random length
, and condition on the event that
for some arbitrary
. Since
is reversible, we can view this trajectory as two independent trajectories
and
both beginning from
, of random lengths k
2 and k
1, respectively. In particular, letting A and B be the events that
is an ε-outlier among the lists
and
, respectively, we have that
(16)
(16)
where, in this last expression, k
1 and k
2 are random variables. Now, the assumption that the given
is not an
-outlier gives that for a random
, we have that
(17)
(17)
Thus, we write(18)
(18) where the last inequality follows from line (16).
On the other hand, considering the right-hand side of Line (18), we have that conditioning on any value for the length of the trajectory, k
1 is uniformly distributed in the range
This is ensured by the geometric distribution, simply because for any
and any
, we have that the probability
is independent of x. In particular, conditioning on any particular value for the length
, we have that the probability that
is an ε-outlier on the trajectory is at most ε, since
is a uniformly randomly chosen element of the trajectory
; note that this part of the proof is exactly the same as the proof of Theorem 1.3. In particular, for the righthand-side of line (18), we are writing
(19)
(19)
This gives line (15) and completes the proof. □
We close this section by noting that in implementations where m is not enormous, it may be sensible to use the exact binomial tail in place of the Chernoff bound in (11). In particular, this gives the following versions:
Theorem 6.2.
With ρ as in Theorem 3.1, we have that if is not an
outlier, then
(20)
(20)
Theorem 6.3.
With ρ as in Theorem 6.1, we have that if is not an
outlier, then
(21)
(21)
7 Generalizing the Besag and Clifford Tests
Theorem 3.1 is attractive because it succeeds at separating statistical significance from effect size, and at demonstrating statistical significance for an intuitively-interpretable deterministic property of state in the Markov chain. This is especially important when public-policy decisions must be made by nonexperts on the basis of such tests.
In some cases, however, these may not be important goals. In particular, one may simply desire a statistical test which is as effective as possible at disproving the null hypothesis . This is a task at which Besag and Clifford’s Theorem 1.3 excels.
In their paper, Besag and Clifford also proved the following result, to enable a test designed to take efficient advantage of parallelism:
Theorem 7.1 (Besag and Clifford parallel test). Fix numbers k and m. Suppose that σ
0 is chosen from a stationary distribution π of the reversible Markov chain , and suppose we sample a trajectory
from
, and then branch to sample m – 1 trajectories
all from the state
. Then we have that
Proof.
For this theorem, it suffices to observe that are exchangeable random variables—that is, all permutations of the sequence
are identical in distribution. This is because if
is chosen from π and then the
’s are chosen as above, the result is equivalent in distribution to the case where Xk
is chosen from π and then each
is chosen (independently) as the end of a trajectory
, and
is chosen (independently) as the end of a trajectory
. Here, we are using that reversibility implies that
is identical in distribution to
. □
With an eye toward finding a common generalization of Besag and Clifford’s serial and parallel tests, we define a Markov outlier test as a significance test with the following general features:
The test begins from a state σ 0 of the Markov chain which, under the null hypothesis, is assumed to be stationary;
random steps in the Markov chain are sampled from the initial state and/or from subsequent states exposed by the test;
the ranking of the initial state’s label is compared among the labels of some (possibly all) of the visited states; it is an ε-outlier if it’s label is among the bottom ε of the comparison labels. Some function
assigns valid statistical significance to the test results, as in the above theorems.
In particular, such a test may consist of single or multiple trajectories, may branch once or multiple times, etc. In this section, we prove the validity of a parallelizable Markov outlier test with best possible function , but for which it is natural to expect the ε-power of the test—that is, its tendency to return small values of ε when σ
0 truly is an outlier—surpasses that of Theorems 1.3 and 7.1. In particular, we prove the following theorem:
Theorem 7.2
(Star-split test). Fix numbers m and k. Suppose that is chosen from a stationary distribution π of the reversible Markov chain
, and suppose that ξ is chosen randomly in
. Now sample trajectories
and
from
, and then branch and sample m – 1 trajectories
all from the state
. Then we have that
In particular, note that the set of comparison random variables used consists of all random variables exposed by the test except .
To compare Theorem 7.2 with Theorems 7.1 and 1.3, let us note that it is natural to expect the ε-power of a Markov chain significance test to depend on:
How many comparisons are generated by the test, and
how far typical comparison states are from the state being tested, where we measure distance to a comparison state by the number of Markov chain transitions which the test used to generate the comparison.
If unlimited parallelism is available, then the Besag/Clifford parallel test is essentially optimal from these parameters, as it draws an unlimited number of samples, whose distance from the initial state is whatever serial running time is used. Conversely, in a purely serial setting, the Besag/Clifford test is essentially optimal with respect to these parameters.
But it is natural to expect that even when parallelism is available, the number n of samples we desire will often be significantly greater than the parallelism factor available. In this case, the Besag/Clifford parallel test will use n comparisons at distance
, where t is the serial time used by the test. In particular, the typical distance to a comparison can be considerably less than t when
compares unfavorably with n.
On the other hand, Besag/Clifford serial test generates comparisons whose typical distance is roughly , but cannot make use of parallelism beyond
. For an apples-to-apples comparison, it is natural to consider the case of carrying out their serial test using only every dth state encountered as a comparison state for some d. This is equivalent to applying the test to the dth-power of the Markov chain, instead of applying it directly. (In practical applications, this is a sensible choice when comparing the labels of states is expensive relative to the time required to carry out transitions of the chain.) Now if
is a small constant, we see that with
steps, the BC parallel test can generate roughly n comparisons all at distance d from the state being tested, the serial test could generate comparisons at distances
(measured in terms of transitions in
), where these distances occur with multiplicity at most 2, and
. In particular, the serial test generates a similar number of comparisons in this way but at much greater distances from the state we are evaluating, making it more likely that we are able to detect that the input state is an outlier.
Consider now the star-split test. Again, to facilitate comparison, we suppose the test is being applied to the dth power of . If serial time
is to be used, then we will branch into
trajectories after
chain, where ξ is randomly chosen from
. Thus, comparisons used lie at a set of distances
similar to the case of the Besag/Clifford serial test above. But now the distances
will have multiplicities at most 2 in the set of comparison distances, while the distances
all have multiplicity at least
. In particular, the test allows us to make more comparisons to more distance states, essentially by a factor of the parallelism factor being used. In particular, it is natural to expect performance to improve as
increases. Moreover, the star-split test is equivalent to the Besag/Clifford serial test for
, and essentially equivalent to their parallel test in the large
limit. (To make this latter correspondence exact, once can apply Theorem 7.2 to the dth power of a Markov chain
, and take k = 1.)
We now turn to the task of proving Theorem 7.2. Unlike Theorems 1.1–1.3, the comparison states used in Theorems 7.1 and 7.2 cannot be viewed as a single trajectory in . This motivates the natural generalization of the notion of a π-stationary trajectory as follows:
Definition 7.1.
Given a reversible Markov chain with stationary distribution π and an undirected tree T, a π-stationary T-projection is a collection of random variables
such that:
for all
for any edge {u, v} in T, if we let Tu denote the vertex-set of the connected component of u in
In analogy to the case of π-stationary trajectories, Definition 7.1 easily gives the following, by induction:
Observation 7.1. For fixed π and T, if and
are both π-stationary T-projections, then the two collections
and
are equivalent in distribution. □
This enables the following natural analog of Definition 5.1:
Definition 7.2.
Given a Markov chain with labels
and stationary distribution π, we define for each
, each undirected tree T, each vertex subset
and each vertex
a real number
, which is the probability that for a π-stationary T-projection
, we have that
is
-small among
.
Observe that as in (9) we have for any tree T and any vertex subset S of T, we have that(22)
(22)
The following observation, applied recursively, gives the natural analog of Observation 5.1. Again the proof is an easy exercise in the definitions.
Observation 7.2.
Suppose that T is an undirected tree, v is a leaf of T, , and
is a π-stationary
-projection. Suppose further that Xv
is a random variable such that for all
we have that
(23)
(23)
where u is the neighbor of v in T. Then is a π-stationary T-projection. □
We can rephrase the proof of Theorem 7.1 in this language. Let T be the tree consisting of m paths of length k sharing a common endpoint and no other vertices, and let S be the leaves of T. By symmetry, we have that is constant over
. On the other hand, Observation 7.2 gives that under the hypotheses of Theorem 7.1,
, and the
’s are a π-stationary T-projection, with obvious assignments (e.g.,
corresponds to a leaf of T; Xk
corresponds to the center). In particular, (23) implies that
, which gives the theorem.
On the other hand, the definitions make the following proof easy as well, using the same simple idea as Besag and Clifford’s Theorem 1.3.
Proof
of Theorem 7.2. Define T to be the undirected tree with vertex set , with edges
for each
and
for each
. Now we let S consist of all vertices of T except the center v
0, and let Sj
denote the set of m vertices in S at distance j from v
0. By symmetry, we have that
is constant in each Sj
; in particular, we have that
and together with (22) this gives that
(24)
(24)
Now if we letthen
is a π-stationary T-projection under the hypotheses of Theorem 7.2, by recursively applying Observation 7.2. Moreover, as ξ is chosen randomly among
, the probability that
is
-small among
is given by
where the inequality is from (25), giving the theorem. □
8 The Product Space Setting
The appeal of the theorems developed thus far in this article is that they can be applied to any reversible Markov chain without any knowledge of its structure. However, there are some important cases where additional information about the structure of the stationary distribution of a chain is available, and can be exploited to enable more powerful statistical claims.
In this section, we consider the problem of evaluating claims of gerrymandering with a Markov chain where the probability distribution on districtings is known to have a product structure imposed by geographical constraints. For example, the North Carolina Supreme Court has ruled in Stephenson v. Bartlett that districtings of that state must respect groupings of counties determined by a prescribed algorithm. In particular, a set of explicit rules (nearly) determine a partition of the counties of North Carolina into county groupings whose populations are each close to an integer multiple of an ideal district size (see Carter et al. Citation2020 for recent results on these rules), and then the districting of the state is comprised of independent districtings of each of the county groupings.
In this way, the probability space of uniformly random districtings is a product space, with a random districting of the whole state equivalent to collection of random independent districtings of each of the separate county groupings. We wish to exploit this structure for greater statistical power. In particular, running trajectories of length k in each of d clusters generates a total of kd
comparison maps with only total Markov chain steps. To take advantage of the potential power of this enormous comparison set, we need theorems which allow us to compare a given map not just to a trajectory of maps in a Markov chain (since the kd
maps do not form a trajectory) but to the product of trajectories. This is what we show in this section.
Formally, in the product space setting, we have a collection of d Markov chains
, each
on state space Σ
i
(each corresponding to one county grouping in North Carolina, for example). We are given a label function
, where here
. In the first theorem in this section, which is a direct analog of the Besag and Clifford test, we consider a
distributed as
, where here
indicates the product space of stationary distributions πi
of the
. (In the gerrymandering case,
is a random map chosen by randomly selecting a map for each separate county cluster.) In the tests discussed earlier in this article, a state
is evaluated by comparing a state σ
0 to other states on a trajectory containing σ
0. In the product setting, we compare
against a product of one trajectory from each
.
In particular, given the collection , a state
, and
, we define the trajectory product
which is obtained by considering, for each i, a trajectory
in
conditioned on
.
is simply the set of all d-tuples consisting of one element from each such trajectory.
We define the stationary trajectory product , analogously, except that the trajectories used are all stationary, instead of conditioning on
.
Theorem 8.1.
Given reversible Markov chains , fix any number k and suppose that
are chosen from stationary distributions
of
, and that
are chosen uniformly and independently in
. For each
, consider two independent trajectories
and
in the reversible Markov chain
from
. Let
be a label function on the product space, write
, and denote by
the (random) set of all vectors
such that for each i,
. Then we have that
(25)
(25)
Proof.
Like the proof of Theorem 1.3, this proof is very simple; it is just a matter of digesting notation. First observe that is simply a trajectory product
, where
and
is the random variable
.
In particular, under the hypothesis that for all i,
is in fact a stationary trajectory product
, In particular, by the random, independent choice of the ξi
’s, the probability in (26) is equivalent to the probability that the label of a random element of the a stationary trajectory product is among ε smallest labels in the stationary trajectory product; this probability is at most ε. □
The following is an analog of Theorem 1.2 for the product space setting.
Theorem 8.2.
Given reversible Markov chains , fix any number k and suppose that
are chosen from stationary distributions
of
. For each
, consider two independent trajectories
and
in the reversible Markov chain
from
. Let
be a label function on the product space, write
, and denote by
the (random) set of all vectors
such that for each i,
. Then we have that
(26)
(26)
Proof.
First consider d independent stationary trajectories for each
, and define
to be the collection of all
d-tuples
where, for each i,
.
In analogy to Definition 5.1, we define for
to be the probability that for
, we have that
is
-small among the ω-labels of all elements of
.
Observe that for , we have in analogy to EquationEquation (5)
(5)
(5) that
(27)
(27) for any
. And of course we have that
Thus, averaging both sides of (27) gives that(28)
(28)
Now observe that the statement that
equivalent to the statement thatfor
; thus (28) gives the theorem, since
is precisely the probability that this second statement holds. □
The presence of the in (26) is now potentially more annoying than the constant 2 in (1.2), and it is natural to ask whether it can be avoided. However, using the example from Remark 1.2, it is easy to see that an exponential factor
may really be necessary, at least if k = 1. Whether such a factor can be avoided for larger values of k is an interesting question. However, as we discuss below, this seemingly large exponential penalty is actually likely dwarfed by the quantitative benefits of the product setting, in many real-world cases.
8.1 Illustrative Product Examples
The fact the estimate in Theorem 8.1 looks like original Theorem 1.3, hides the power in the product version. More misleading is the fact that Theorem 8.2 has a which seems to make the theorem degrade with increasing d.
Let us begin by considering the simplest example we are looking for the single extreme outlier across the entire product space. Let us further assume that this global extreme is obtained by choosing each of the extreme element in each part of the product space. An example of this comes for the Gerrymandering application where one is naturally interested in the seat count. Each of the product coordinates represents the seats from a particular geographic region. In some states such as North Carolina judicial rulings break the problem up into the product measure required by Theorems 8.1 and 8.2 by stipulating that particular geographic regions must be redistricted independently.
For illustrative purposes, let assume that there are L different outcomes in each of the d different factors of the product space. Hence, the chance of getting the minimum in any of the d different components is . However, getting the minimum in the whole product space requires getting the minimum in each of the components and so is
. Hence is this setting one can take
in Theorems 8.1 and 8.2. Thus even in Theorem 8.2 as long as L > 2, one has a significant improvement as d grows.
Now let’s consider a second slightly more complicated example which builds on the proceeding one. Let us equip each with a function ωi
and decide that we are interested in the event
(29)
(29)
Then one can takein Theorem 8.2 and
times this in Theorem 8.2, where
is simply the number of elements in the set
. This can lead to a significant improvement in the power of the test in the product case over the general case when
grows slower than Ld
.
There remains the task of calculating . In the gerrymandering examples we have in mind, this can be done efficiently. When counting seat counts, the map ωi
is a many-to-one map with a range consisting of a few discrete values. This means that one can tabulate exactly the number of samples which produce a given value of ωi
. Since we are typically interested extreme values of
there are often only a few partitions of each value of ω made from possible values of ωi
. When this true, the size of
can be calculated exactly efficiently.
For example, let us assume there are d geographical regions which each needs to be divided into 4 districts. Furthermore each party always wins at least one seat in each geographical region; hence, the only possible outcomes are 1, 2, or 3 seats in each region for a given party. If ωi
counts the number of seats for the party of interest in geographic region i, let us suppose for concreteness that we want are interested in . To calculate
, we need to only keep track of the number of times 1, 2, or 3 seats is produced in each geographic region. We can then combine these numbers by summing over all of the ways the numbers 1, 2, and 3 can add numbers between d and 2d. (The smallest
can be given our assumptions is d.) This is a straightforward calculation for which there exist fast algorithms which leverage the hierarchical structure. Namely, group each region with another and calculate the combined possible seat counts and their frequencies. Continuing up the tree recursively one can calculate
in only logarithmically many levels.
It is worth remarking, that not all statistics of interest fall as neatly into this framework which enables simple and efficient computation. For instance, calculating the ranked marginals used in Herschlag et al. (Citation2018) requires choosing some representation of the histogram, such as a fixed binning, and would yield only approximate results.
8.2 Toward an -Outlier Theorem for Product Spaces
In general, the cost of making a straightforward translation of Theorems 3.1 or 6.1 to the product-space setting are surprisingly large: in both cases, the square root is replaced by a th root, according to the natural generalization of the proofs of those theorems.
Accordingly, in this section, we point out simply that by using a more complicated definition of -outliers for the product space setting, an analog of Theorem 6.1 is then easy. In particular, let us define
(30)
(30) where
is chosen randomly with respect to the uniform distributions
(here
).
Now we define a state to be an
-outlier with respect to a distribution
if among all states in
, we have that
is in the largest α fraction of the values of
over all states
, weighted according to π.
Theorem 8.3.
We are given Markov chains . Suppose that
is not an
-outlier with respect to
. Then
Proof.
This follows immediately from the definitions. From the definition of -outlier given above for the product setting, we have that if σ
0 is not an
-outlier, then for a random
,
Thus, we can write
And of course this expectation is just the probability that a random element of is an ε-outlier on
, which is at most ε. □
Of course this kind of trivial proof would be possible in the general non-product space setting also, but the sacrifice is that -outliers cannot be defined with respect to the endpoints of trajectories, which appears most natural. Whether analogous to Theorems 3.1 and 6.1 are possible in the product space setting without an explosive dependence on the dimension d seems like a very interesting question.
Notes
1 Multiple tests have limited utility here or with Theorem 1.3 since there is no independence (the null hypothesis is not being resampled). In particular, multiple runs might be done merely until a trajectory is seen on which σ
0 is indeed an
outlier (requiring
runs, on average), in conjunction with multiple hypothesis testing.
Additional information
Funding
References
- Besag, J. , and Clifford, P. (1989), “Generalized Monte Carlo Significance Tests,” Biometrika , 76, 633–642. DOI: 10.1093/biomet/76.4.633.
- Carter, D. , Hunter, Z. , Teague, D. , Herschlag, G. , and Mattingly, J. (2020), “Optimal Legislative County Clustering in North Carolina,” Statistics and Public Policy , 7, 19–29. DOI: 10.1080/2330443X.2020.1748552.
- Chikina, M. , Frieze, A. , and Pegden, W. (2017), “Assessing Significance in a Markov Chain Without Mixing,” Proceedings of the National Academy of Sciences of the United States of America , 114, 2860–2864. DOI: 10.1073/pnas.1617540114.
- Herschlag, G. , Kang, H. S. , Luo, J. , Graves, C. V. , Bangia, S. , Ravier, R. , and Mattingly, J. C. (2018), “Quantifying Gerrymandering in North Carolina,” arXiv no. 1801.03783.
- Pegden, W. (2019), “Expert Report,” Common Cause v. Lewis .