
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
How should we evaluate the effect of a policy on the likelihood of an undesirable event, such as conflict? The significance test has three limitations. First, relying on statistical significance misses the fact that uncertainty is a continuous scale. Second, focusing on a standard point estimate overlooks the variation in plausible effect sizes. Third, the criterion of substantive significance is rarely explained or justified. A new Bayesian decision-theoretic model, “causal binary loss function model,” overcomes these issues. It compares the expected loss under a policy intervention with the one under no intervention. These losses are computed based on a particular range of the effect sizes of a policy, the probability mass of this effect size range, the cost of the policy, and the cost of the undesirable event the policy intends to address. The model is more applicable than common statistical decision-theoretic models using the standard loss functions or capturing costs in terms of false positives and false negatives. I exemplify the model’s use through three applications and provide an R package. Supplementary materials for this article are available online.
1 Introduction
How should we evaluate the effect of a policy on the likelihood of an undesirable event, such as conflict? The significance test (broadly defined) examines the statistical and substantive significance of statistical estimates (Gross Citation2015; Kruschke Citation2018). It looks at whether the measure of statistical uncertainty passes a certain threshold (usually a p-value smaller than 5% or a 95% confidence/credible interval excluding zero), and whether the effect size is practically relevant. For example, Quinn, Mason, and Gurses (Citation2007) report that peacekeeper deployment with a peace agreement, and economic development in the aftermath of civil war, have statistically significant effects and make civil war “substantially” less likely to recur. The study suggests these two factors are important policy options for the international community to sustain peace.
The significance test has three limitations. First, the binary criterion of statistical significance dismisses the fact that uncertainty is a continuous scale. A statistically insignificant effect can be practically significant if its uncertainty is low enough for practical reasons, if not as low as what the conventional threshold of statistical significance demands. The misunderstanding is widespread that statistical insignificance means no effect (McShane and Gal Citation2016, Citation2017). Reliance on statistical significance results in p-hacking and publication bias (Simonsohn, Nelson, and Simmons Citation2014); then, statistically insignificant but practically significant effects are likely to be overlooked or unreported, a lost opportunity.
Second, the effect size chosen to discuss substantive significance is usually the mean even when an interval estimate is reported. The variation in plausible effect sizes is, therefore, overlooked. In terms of statistical uncertainty, some effect sizes other than the mean are also probable. In terms of policy implications, while the mean is by definition computed based on all probable effect sizes and their associated probabilities, some effect sizes might be practically null values (Gross Citation2015; Kruschke Citation2018).
Third, the criterion of substantive significance is rarely explained or justified. While some suggest the importance of defining practically null values (Gross Citation2015; Kruschke Citation2018), they only suggest a context-specific utility/loss function should be developed and do not offer advice on how to do it. Researchers often claim the effect size is significant in an ad hoc way. Referring to preset criteria such as Cohen’s (Cohen Citation1988) would not be desirable either, as it ignores contexts (Duncan and Magnuson Citation2007; Harris Citation2009). For example, a one percentage point decrease in the likelihood of some undesirable event has different degrees of significance depending on what the event is (e.g., a national rail strike vs. civil war).
Decision theory can offer a solution to these problems by linking statistical estimates with a loss function (Berger Citation1985; Mudge et al. Citation2012; Esarey and Danneman Citation2015; Manski Citation2019; for another solution, see Suzuki Citation2022). For example, McNeil and Pauker (Citation1984) discuss the role of decision trees for public health policy, while Baio, Berardi, and Heath (Citation2017) introduce a Bayesian cost-effective analysis for this topic. Cecchetti (Citation2000) and Warjiyo and Juhro (Citation2019) present loss functions that guide macroeconomic policy. Yet, there is insufficient provision of a general decision-theoretic model whose loss function researchers can use “off the shelf,” to interpret the substantive significance of the statistically estimated causal effects of policy interventions for many different topics. Exceptions include Esarey and Danneman (Citation2015), Manski (Citation2019), Mudge et al. (Citation2012) and Tetenov (Citation2012).
To advance this literature, I develop a new general Bayesian decision-theoretic model: the causal binary loss function model (for Bayesian decision theory, see Berger Citation1985; Robert Citation2007; Baio, Berardi, and Heath Citation2017). In summary, the model compares the expected loss under a policy intervention with the one under no intervention. These losses are computed based on a particular range of the effect sizes of a policy, the probability mass of this effect size range, the cost of the policy, and the cost of the undesirable event the policy intends to address. The causal binary loss function model is more applicable for the current purpose, than those using the standard loss functions (see Berger Citation1985, pp. 60–64) or the existing general models capturing costs in terms of false positives (i.e., inferring a non-null effect when the policy actually has no effect or an adverse one) and false negatives (i.e., inferring the null effect when the policy actually has a desired effect) (Mudge et al. Citation2012; Tetenov 2012; Esarey and Danneman Citation2015; Manski Citation2019). The standard loss functions are too restrictive to evaluate the effect of a policy. Modeling costs in terms of false positives and false negatives is more complicated than directly using the costs of a policy and an undesirable event.
The causal binary loss function model is better suited to evaluate the effect of a policy than the significance test, for two reasons. First, the model uses the posterior distribution of a causal effect estimated by Bayesian statistics. This enables the model to incorporate (a) a range of effect sizes other than a standard point estimate and (b) its associated probability mass as a continuous measure of uncertainty. These points address the first two limitations of the significance test.
Second, the model computes approximately up to what ratio of the cost of a policy to the cost of an undesirable event an expected loss remains smaller if the policy is implemented than if it is not. The policy is considered substantively significant up to the cost ratio where an expected loss is smaller if the policy is implemented. This point addresses the third limitation of the significance test.
It is often difficult to measure the costs of a specific policy and outcome. Yet, by definition, the cost of a policy should be smaller than the cost of an outcome, for the policy to be worth implementing. Therefore, the ratio of the former cost to the latter cost should be less than one. Thus, we can compute an expected loss given each of all possible ratios (e.g., 0.01, 0.02, , 0.99) and simulate up to what ratio the expected loss is smaller under a policy intervention. For example, we might state: “The policy is expected to produce a better outcome than that resulting from no policy intervention, if the ratio of the cost of the policy to the cost of the undesirable outcome is approximately up to 0.43.”
Although this may not be as informative to actual policymaking as computing an expected loss based on measured costs, it is an improvement compared to the significance test. The significance test overlooks the cost aspects when evaluating the effect of a policy intervention. Claiming that a causal factor is worth implementing as a policy, without consideration of its relative cost, would equal assuming that the policy is always cost-effective. The purpose of this article is not to use the causal binary loss function model for one specific case of policymaking, but to propose it as a better generic way than the significance test to assess the effects of policy interventions. Certainly, a model is a simplification of reality and, therefore, the causal binary loss function model should be taken as such rather than as the absolute standard for scientific reasoning and policymaking (see, e.g., Laber and Shedden Citation2017). Nonetheless, as I explain in this article, the causal binary loss function model enables richer inference than the significance test (which also uses a model).
If a decision-theoretic model computes an expected loss given the estimate of a causal effect, causal identification is essential for such a model to produce a reliable result. Bayesian decision theory is not a solution to the causal identification problem. However, dismissing a decision-theoretic perspective is not a solution either; causal identification is essential for any model to discuss the effect of a policy intervention. Issues regarding causal identification are beyond the scope of this article (for useful discussion, see, e.g., Morgan and Winship Citation2015; Pearl, Glymour, and Jewell Citation2016; Hernán and Robins Citation2020). The causal binary loss function model is applicable regardless of the types of causal effect estimate (population average, sample average, conditional average, individual, etc).Footnote1
I exemplify the causal binary loss function model through three applications in conflict research: one on the effect of peacekeeper deployment on the likelihood of local conflict continuation (Ruggeri, Dorussen, and Gizelis Citation2017), another on the effect of a negative aid shock on the likelihood of armed conflict onsets (Nielsen et al. Citation2011), and the third on the effect of different peace agreement designs on the likelihood of the agreement being supported by the public (Tellez Citation2019). The first two are observational studies, while the last one is a conjoint survey experiment. The purpose of the applications is neither to scrutinize the original studies nor to provide any substantive policy analysis or recommendation. It is only to illustrate how the model works in applied settings.
The structure of the article is as follows. First, I review the literature on decision theory and illustrate how a decision-theoretic model works in general. Then, I introduce the causal binary loss function model. Afterwards, I present the results of the application to Ruggeri, Dorussen, and Gizelis (Citation2017); the results of the other two applications are available in the supplementary materials. Finally, concluding remarks are stated with implications for future research. To facilitate the use of the causal binary loss function model, I provide an R package and a step-by-step vignette (see the section “supplementary materials”).Footnote2
2 Decision Theory
Decision theory is formal modeling of decision-making. It can be categorized into descriptive versus normative (Rapoport Citation1998, chap. 1), and theoretical versus statistical (e.g., Berger Citation1985; Gilboa Citation2009). Descriptive decision theory explains how people make decisions; normative decision theory examines how people should make decisions. To model uncertainty, theoretical decision theory makes distributional assumptions without incorporated empirical analysis, whereas statistical decision theory statistically incorporates empirics.Footnote3 The causal binary loss function model is a Bayesian normative statistical decision theory. An example of descriptive statistical decision theory is Signorino (Citation1999), who incorporates the implications of game theory into statistical modeling. Examples of frequentist normative statistical decision theory are Manski (Citation2019), Mudge et al. (Citation2012), and Tetenov (2012), which I discuss later.
Decision problems are framed either as a loss or as a gain. In a loss function, a loss is a positive value and the goal is to minimize it, while in a utility function, a gain is a positive value and the goal is to maximize it. The difference lies only in the framing, and it is possible to form a loss function and a utility function in a mathematically equivalent way.Footnote4 This article uses the loss framing.
The basic form of a loss function is(1)
(1) where l is a loss caused by action a,
denotes a loss function, and θ is a parameter (or a set of parameters). Typically, θ is unknown and estimated as a posterior distribution computed by Bayesian statistics (Gelman et al. Citation2013; Gill Citation2015). If an action a minimizes the loss, it is considered as the optimal decision. For example, if a posterior distribution over the chance of rain next week implies Saturday has the highest probability of sunny weather, an outdoor event should be organized for that Saturday to minimize the (expected) loss (here, disappointment caused by bad weather) and not for any other day. However, because it is only an estimate with some probability (though the largest probability among all days), it is still possible that Saturday will be rainy.
Standard loss functions include the absolute error loss, ; the squared error loss,
; and the 0–1 loss,
if
and 1 if
(Berger Citation1985, pp. 60–64; Bååth Citation2015). In other words, as an action deviates from a parameter value, the penalty of the absolute error increases linearly (e.g., a deviation of 2 results in a loss of 2, a deviation of 4 results in a loss of 4, and so on), while the penalty of the squared error loss increases quadratically (e.g., a deviation of 2 results in a loss of 4, a deviation of 4 results in a loss of 16, and so on). The 0–1 loss is an extreme case: no penalty if a decision is correct and full penalty if not, such as cutting a correct cable to defuse a bomb (Bååth Citation2015). These standard loss functions are usually used to evaluate the performance of statistical estimators. The quadratic loss function has also been used to model decision-making for macroeconomic policies, because of its tractability (Horowitz Citation1987; Mayer Citation2003). An example given by the literature is (with slight differences across authors):
, where v is output,
is desired output, z is an inflation rate,
is a desired inflation rate, and w1 and w2 are weights (Cecchetti Citation2000, p. 51; Mayer Citation2003; Warjiyo and Juhro Citation2019, p. 162).
However, none of these standard loss functions is flexible enough to interpret the implications of the statistically estimated causal effects of policy interventions. As for the squared error and absolute error losses, it is unclear what it means to minimize the difference between a, a decision to do a policy intervention, and θ, the effect size of the policy intervention. The 0–1 loss is too simplistic; the costs should take more values than the two integers in policymaking contexts.
Loss functions for causal effects usually model costs in terms of false positives and false negatives. Manski (Citation2019) and Tetenov (2012) offer a frequentist approach to determine the treatment allocation that minimizes the maximum regret. For example, when there are two treatment options—the status quo and an innovation, regret is the mean loss in terms of the population, given a certain portion of individuals is assigned an inferior treatment (Manski Citation2019, p. 302). An allocation is said to minimize the maximum regret if it produces the loss smaller than any other allocations in all possible states of the unknown world (Manski Citation2013, pp. 123–124).
Esarey and Danneman (Citation2015) and Mudge et al. (Citation2012) propose Bayesian and frequentist models, respectively, where the loss function suggests whether a policy should be implemented, given the statistical estimates of its effect size and uncertainty, a decision maker’s desired effect size, and the (expected) costs to the decision maker of a false positive and a false negative. For example, Esarey and Danneman (Citation2015) apply the model to the effect of democracy on the likelihood of civil war. The practical implication of the model is that if the presence of democracy produces greater utility given all the aforementioned factors, democracy should be promoted to prevent civil war.
The causal binary loss function model is different from these models, in that it directly uses the costs of a policy intervention and an undesirable event. It is not necessarily straightforward to map the costs of a policy intervention and an undesirable event onto the (expected) costs of a false positive and a false negative, as explained in the supplementary materials. The causal binary loss function model is not a substitute for the existing statistical decision-theoretic models, as the concept of false positives and false negatives is also important. This model is another addition to researchers’ toolkit.
3 Causal Binary Loss Function Model
3.1 Loss Function
Let denote the posterior distribution of the effect sizes, where θ is a parameter for effect sizes and D denotes data.Footnote5 Also, let Cp
be the cost of implementing a policy and Ce
be the cost of an undesirable event. Ce
is realized only if the undesirable event takes place.
is the cost of the event times the baseline likelihood of it taking place (i.e., without the policy being implemented), where
is the inverse logit function mapping log odds onto probability, and π is the baseline log odds. To avoid confusion, I use “likelihood” to refer to the probability of an event and “probability” to refer to the probability that θ takes a certain range of values.
The causal binary loss function is(2)
(2) where
denotes an expected loss;
is the mean value of the range of the intended effect sizes of a causal factor, that is, the effect sizes each of which reduces the likelihood of an undesirable event by a certain amount (thus,
by definition); p is the probability mass of this range under the entire posterior
;
is the mean value of the range of the unintended effect sizes of the causal factor, that is, the effect sizes each of which increases the likelihood of an undesirable event by a certain amount or by a zero amount (thus,
by definition)Footnote6; q is the probability mass of this range under
; I(i) is an indicator function taking a value of one if the causal factor is implemented as a policy and a value of zero if not. How to specify
and
is explained in greater detail in the next section. While
and
are derived from
, for simplicity I omit the conditional statement
.
If a policy is not implemented (I(i) = 0), the expected loss is the cost of the event weighted by the baseline likelihood, , for example, the cost of civil war weighted by its baseline likelihood. If a policy is implemented (I(i) = 1), the expected loss is the cost of implementing the policy plus the cost of the event weighted by the revised likelihood,
. For example, if
and
, the revised likelihood of the undesirable event is
.
Both and
are necessary ex ante in the loss function, because if the posterior has both negative and positive values, it means the causal factor could decrease or increase the likelihood of the undesirable event. In the special case where the posterior of θ has only negative values, q = 0 and
disappears from the loss function. Similarly, in the special case where the posterior of θ has only positive values, p = 0 and
disappears from the loss function. It might be asked why the loss function does not use the mean of the whole posterior rather than dividing it into the negative and positive values. In fact, the mean is a special case of specifying
and
, as I explain in the following section.
3.2 How to Specify  and
and
As for , we use the mean over the range
:
, where
is some minimum desired effect size by which the likelihood of an undesirable event is reduced (therefore,
by definition). p is the probability mass of this range in terms of
. Formally:
.
As for , we use the mean over the range
:
, where
is some minimum undesired effect size by which the likelihood of an undesirable event is increased or not changed (therefore,
by definition). q is the probability mass of this range in terms of
. Formally:
.
If (where ϵ is an infinitesimal value and
) and/or
, the non-null values between
and
are the region of practically null values (Gross Citation2015; Kruschke Citation2018). The mean of the entire posterior is a special case, where there is no region of practically null values, that is,
and
, so that
.
We do not preset the values of and
, unless we are applying the model to a particular policymaking context and know the values of
and
. Otherwise, the preset values would be as arbitrary as the statistical significance of
. This is why the causal binary loss function has
and
separately, rather than the mean of the posterior only, which would preset
and
. We can vary
and
to see how the results change with respect to the comparison between the expected loss under a policy intervention and the one under no intervention.
exemplifies what and
capture. The density plot is made of 10,000 draws from a normal distribution with the mean of –0.5 and the standard deviation of 0.5. Let us assume the distribution is posterior samples. In the left panel, I set
and
for exposition. For
, the mean over the range of the effect size being smaller than zero is indicated by the solid vertical line, and its probability mass by the gray-shaded area. Formally,
. For
, the mean over the range of the effect size being equal to or greater than zero is indicated by the dashed vertical line, and its probability mass by the white-shaded area. Formally,
.
Fig. 1 Graphical example of and
. In the left panel, the gray-shaded area is where the parameter value < 0; the white-shaded area is where the parameter value
. In the right panel, the gray-shaded area is where the parameter value
; the black-shaded area is the region of the presumed practically null values; the white-shaded area is where the parameter value
. The solid vertical line is the mean within the gray-shaded area; the dashed vertical line is the mean within the white-shaded area.
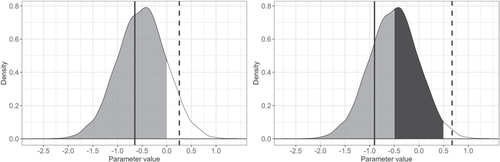
In the right panel, I set and
, again for exposition. For
, the mean over the range of the effect size being equal to or smaller than –0.5 is indicated by the solid vertical line, and its probability mass by the gray-shaded area. Formally,
. For
, the mean over the range of the effect size being equal to or greater than 0.5 is indicated by the dashed vertical line, and its probability mass by the white-shaded area. Formally,
. The black-shaded area is the region of the presumed practically null values.
3.3 How to Define Cp and Ce
As costs in policymaking contexts are often multidimensional and unobservable, so are the cost of a policy intervention, Cp , and the cost of an undesirable outcome, Ce . For example, the cost of a policy may be different for a policymaker and for the general public; the cost may be not only financial but also political, social, and psychological. Nonetheless, even when we do not have the actual values of the costs, ignoring them as in the significance test is not ideal. Claiming that a causal factor is worth implementing as a policy, without consideration of its relative cost, would equal assuming that the policy is always cost-effective. Such an assumption may not always be true. The causal binary loss function model allows for a thought experiment: What if the ratio of Cp to Ce were 0.1, 0.2, 0.3, and so on?
We can compute expected losses given the ratio of Cp to Ce , for example, from 0.01 up to 0.99, by holding Cp at 1 while varying the value of Ce from 1.01 to 100 and assuming that these costs are measured on the same scale.Footnote7 Then, we can make an argument such as: “The policy is expected to produce a better outcome than that resulting from no policy intervention, if the ratio of the cost of the policy to the cost of the undesirable outcome is approximately up to 0.43.”
Varying Ce
rather than Cp
may often allow for more informative interpretation, if it is harder to measure the cost of an undesirable event (such as war) than the cost of a policy intervention (such as sending peacekeepers), as in the case of a rare but extreme event (Taleb Citation2007). It would be unnecessary to consider the case where the ratio of the two costs is one, because such a case would make no difference between a policy intervention and no such intervention, even if the policy reduced the likelihood of an undesirable event to zero. Thus, the meaningful ratio is up to .
There are caveats in defining or interpreting Cp
and Ce
. The value of Cp
does not, and should not, include the benefit a specific policy would bring about; the benefit is captured by another term in the loss function, . The value of Ce
is not, and should not be, the one weighted by the likelihood of an undesirable event; the weighted value is
.
3.4 Statistical Setup
There are four points to consider in setting up a statistical model to estimate π, , and
. First, π,
, and
should be measured on the log odds (ratio) scale, because they are inside the inverse logit function. Bayesian logistic regression estimates the posteriors of log odds ratio coefficients, which can directly be used for the loss function.Footnote8 When the effect size is interpreted, the log odds ratio might be converted to the odds ratio (by exponentiating it), or to the difference on the probability scale (by computing the difference between the predicted likelihood under a policy intervention and the one under no intervention), for ease of interpretation.
Second, the value of 1 in the binary outcome variable must mean something undesirable, so that a reduction in the baseline likelihood, , reduces Ce
. For example, if the outcome of interest is the termination of civil war, the dependent variable should be coded 1 for no termination and 0 for termination, so that the baseline likelihood of civil war going on is reduced from
to
, provided that
, of course.
Third, a unit change in the causal variable of interest must mean a policy intervention that intends to reduce the likelihood of an undesirable event. For example, in Nielsen et al. (Citation2011), the outcome of interest is the onset of armed conflict, and the causal variable of interest is the binary indicator of a large sudden drop in foreign aid that is theoretically expected to increase the likelihood of the onset. Then, a policy intervention to reduce this likelihood is to keep the flow of foreign aid stable (e.g., despite a budget constraint due to a financial crisis). If the binary causal variable is coded such that it takes a value of 1 for a large sudden drop in foreign aid and a value of 0 for its absence as done in Nielsen et al. (Citation2011), and
must be derived from the posterior of the log odds ratio coefficient of the variable times –1, a negative unit change of the variable (from 1 to 0); accordingly, the baseline log odds, π, must capture the case where the causal variable takes a value of 1. If the variable is recoded to take a value of 0 for the presence of a large sudden drop in foreign aid and a value of 1 for its absence,
, and
can be derived directly from the posterior of the log odds ratio coefficient (because it equals being multiplied by 1, a positive unit change of the variable from 0 to 1). The application of the causal binary loss function model to Nielsen et al. (Citation2011) in the supplementary materials exemplifies the latter approach. The same logic applies to a continuous causal variable. θ should be defined as the log odds ratio coefficient times the size of the unit change of interest (e.g., a one million U.S. dollar increase in foreign aid) that captures a policy intervention intended to reduce the likelihood of an undesirable event; π should be defined according to what the baseline value of the continuous causal variable is.
Finally, if there is more than one explanatory variable in a statistical model, we must decide the log odds ratio coefficient of which variable to use to specify and
, while leaving those of the other variables absorbed to π. It is the same logic as when we estimate the fitted values of an outcome variable: we manipulate the value of the treatment variable of interest while leaving the remaining covariates at some fixed values. If we estimated conditional average treatment effects or individual treatment effects and were interested in whether a policy intervention produces a smaller expected loss for a specific case, the covariates could be held at the values that represent that case. If we estimated the sample average treatment effect and were interested in whether a policy intervention on average produces a smaller expected loss, we could compute an inverse logit value for every observation of the data used for the statistical analysis, and take the average of these inverse logit values. Formally,
, where n is the total number of observations used for statistical analysis, j indexes each observation, and πj
here becomes the baseline log odds plus the dot product of the vector of the covariates for j and that of their log odds ratio coefficients. It follows that the sample average treatment effect is what makes the difference between the expected loss under the policy intervention and the one under no intervention. All applications in this article take this latter approach.
3.5 Summary and Caveats
The causal binary loss function model computes approximately up to what ratio of the cost of a policy intervention, Cp
, to the cost of an undesirable event, Ce
, an expected loss remains smaller when the policy intervention is done than when it is not. It uses a Bayesian statistical model that estimates the posterior distribution of the effect sizes of a policy. The model can vary the minimum desired and undesired effect sizes of a policy intervention ( and
) to define a practically relevant range of the effect size. The continuous nature of the uncertainty of a policy’s effect is captured by p and q. p is the probability of the policy realizing at least the minimum desired effect size, that is, the probability mass of the effect size range
under the entire posterior
. q is the probability of the policy realizing at least the minimum undesired effect size, that is, the probability mass of the effect size range
under the entire posterior.
The output of the causal binary loss function model is only an approximation for two theoretical reasons. First, the model relies on the results of a statistical model, and a statistical model itself is an approximation. Second, since a Bayesian statistical model usually estimates parameters by a Markov-chain Monte Carlo (MCMC) method, the stochastic nature of the method may well make exact results differ slightly, depending on computational settings and environments. These points affect the exactness of up to what ratio of the cost of a policy intervention to the cost of an undesirable outcome an expected loss remains smaller when the policy intervention is done than when it is not. This is why I say approximately. The implication is that the more similar the expected losses are between when the policy is implemented and when it is not, the more sensitive the conclusion on which decision is better than the other is to the statistical model and the stochastic nature of an MCMC method. Finally, the practical reason to say “approximately” is that there are usually many decimal points in the results and, for communication purposes, they need to be rounded to fewer digits.
4 Application
Ruggeri, Dorussen, and Gizelis (Citation2017) examine the effect of peacekeeper deployment in a particular locality on the likelihood of local conflict. One of their findings is that, on average, peacekeeper deployment reduces the likelihood of local conflict continuation in its locality. I apply the causal binary loss function model to this analysis. The purpose is neither to scrutinize the original study nor to provide any substantive policy analysis or recommendation. The application is only for illustrative purposes; I take the original empirical model and causal identification strategy for granted.
4.1 Statistical Model
The research design of the original study is as follows (Ruggeri, Dorussen, and Gizelis Citation2017, pp. 169–173). The unit of analysis is grid cells (approximately 55 km × 55 km) per year where violent conflict was observed in a previous year, from 1989 to 2006 in sub-Saharan Africa. The dependent variable is binary, coded 1 if a grid cell observed the continuation of local violent conflict in a year; 0 otherwise. The treatment variable is the presence of peacekeepers in a grid cell in a year, coded 1 if they were present and 0 otherwise. Thus, the policy decision is whether to deploy peacekeepers in a locality where there is ongoing violent conflict.
The original study uses weighted logistic regression adjusting for cell-specific pretreatment covariates, on data matched on these covariates by coarsened exact matching (Iacus, King, and Porro Citation2012). These covariates are the average traveling time to the nearest major city, the distance from the capital, the distance from the international borders, the infant mortality rate, the population, the average roughness of terrains, and the average rain precipitation. For greater detail, see (Ruggeri, Dorussen, and Gizelis Citation2017, pp. 170–172). The weights are those generated by the matching algorithm to account for different numbers of control and treated units across strata (Iacus, King, and Porro Citation2012, p. 5).
I use the following Bayesian logistic regression model with the same set of variables as in Model 2 in the original study:(3)
(3) where the subscript j, t indicates every grid cell-year observation used;
is the dependent variable; β0 is the constant; β1 is the log odds ratio coefficient for
, the treatment variable; and
is the dot product of the vector of the covariates
and that of the corresponding log odds ratio coefficients
.Footnote9 This setup means the effect of peacekeeper deployment is the one averaged within the data.
The posteriors are estimated by the MCMC method via Stan (Stan Development Team Citation2019), implemented via the rstanarm package version 2.21.1 (Goodrich et al. Citation2020). I use four chains, each of which has 20,000 iterations; the first 1,000 iterations are discarded. I use the weights function in the rstanarm package to incorporate the weights generated by the matching algorithm, so that the Bayesian model becomes as close to the original frequentist model as possible.
I use a weakly informative prior of for the log odds ratio coefficients of all explanatory variables. The scales of these priors are then automatically adjusted based on the measurement scale of each variable by the rstanarm package (Goodrich et al. Citation2020). I use a weakly informative prior of
for the constant; the mean of zero makes sense, as the rstanarm package automatically centers all predictors during the estimation process—the returned results are on the original scales (Goodrich et al. Citation2020). The weakly informative priors lead to more data-driven but also regularized Bayesian estimation. I use these priors here for reference purposes only.
4.2 Applying the Loss Function
As the binary treatment indicator is coded such that a value of 1 means peacekeeper deployment (a policy intervention to reduce the likelihood of local conflict continuation), β1 can be directly plugged into the causal binary loss function. It will be denoted as in the context of the loss function (where
stands for peacekeepers).
Let the cost of deploying peacekeepers be and the cost of local conflict continuation be
. Applying the causal binary loss function, we have:
(4)
(4) where I(i) is an indicator function taking a value of 1 if peacekeepers are deployed and a value of 0 if not; n is the total number of observations used in the regression model; nj
is the number of cross-section units (grid cells);
is the number of time units (years) for cross-section unit j.
is the posterior mean of the constant β0 plus the dot product of the vector of the covariates
and that of the posterior means of their corresponding log odds ratio coefficients
.
is the mean of the range of the intended effect sizes of peacekeepers, that is, the effect sizes each of which reduces the likelihood of local conflict continuation by a certain amount; p is the probability mass of this range under the entire posterior
.
is the mean of the range of the unintended effect sizes of peacekeepers, that is, the effect sizes each of which increases the likelihood of local conflict continuation by a certain amount or by a zero amount; q is the probability mass of this range under
. The mean of the inverse logit values across all observations is taken, so that the average treatment effect on the probability scale is what makes the difference between the expected loss under peacekeeper deployment and the one under no deployment.
4.3 Results
The was approximately 1.00 for each parameter, suggesting the Bayesian regression did not fail to converge. The effective sample size exceeded at least 30,000 for each parameter. According to the significance test, the 95% credible interval of the log odds ratio would lead us to conclude that the effect of peacekeeper deployment is statistically significant, as the 95% credible interval excludes zero (see ). Yet, from the perspective of the causal binary loss function, there is no imperative to use the threshold of the 95% probability.
Table 1 Mean and 95% credible interval of the log odds ratio of peacekeeper deployment.
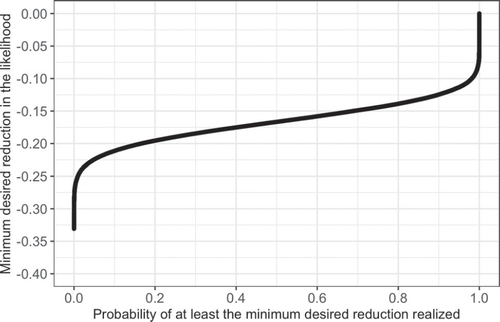
Before computing the expected losses, let us focus on the relationship between the effect size range of interest and its probability mass. In , the y-axis shows different minimum desired effect sizes on the probability scale. The x-axis represents the probabilities that peacekeeper deployment realizes such effects. For example, if one wants to expect that peacekeeper development reduces the likelihood of local conflict continuation at least by 10 percentage points, the probability of peacekeeper deployment realizing that is approximately 98%. If one wants to expect that peacekeeper development reduces the likelihood of local conflict continuation at least by 20 percentage points, the probability of peacekeeper deployment realizing that is approximately 17%. In other words, the probability that peacekeeper deployment is expected to have a desirable effect depends on how much reduction is desired.
Fig. 2 Minimum desired reduction in the likelihood of local conflict continuation and the probability that peacekeeper deployment realizes such an effect. Baseline likelihood of local conflict continuation: 85%.
Now, let us compute the expected losses. First, as for , I change the value of
by assuming that either a 10 percentage point or 20 percentage point reduction in the likelihood of local conflict continuation is the minimum desired effect size. These effect sizes correspond approximately to
and
on the log odds scale in the model. Thus, in the loss function, I define
either as
or as
. p, the probability mass of the range of the desired effect sizes under
, changes accordingly. The choice of these minimum desired effect sizes is arbitrary, as the purpose here is to illustrate how different minimum desired effect sizes change up to what cost ratio an expected loss remains smaller under a policy intervention. Second, as for
, I define
by assuming that no reduction in the likelihood of local conflict continuation is the minimum undesired effect size. In other words,
. It follows that q is the probability mass of this effect size range in terms of
. Third, I change the ratio of
to
from 0.01 to 0.25, holding
at 1 while varying the value of
from 4 to 100. This range of the ratio is large enough to show the crossover point where the expected loss under the policy intervention becomes greater than the one under no intervention, and helps clearer visualization.
The results are displayed in . The x-axis is the ratio of to
. The y-axis is the expected loss. The green dots are the expected losses given I(i) = 1, that is, when peacekeepers are presumed to be deployed; the red dots are those given I(i) = 0, that is, when peacekeepers are presumed not to be deployed.
Fig. 3 Expected losses over different cost ratios. The green dots are the expected losses when peacekeepers are deployed; the red dots are the expected losses when they are not. The vertical blue dashed line indicates the cost ratio up to which the expected loss is smaller when peacekeepers are deployed than when they are not.
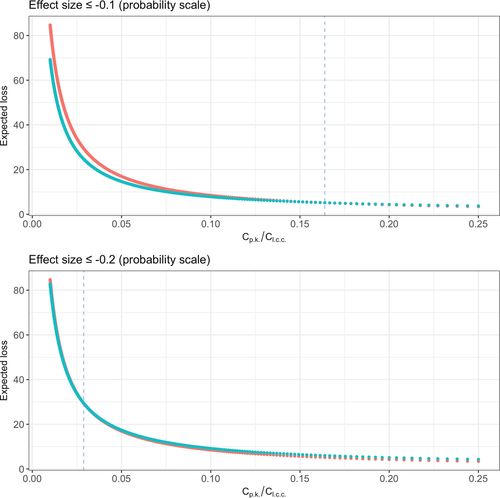
In the top panel of , where the 10 percentage point reduction is the minimum desired effect size, the expected losses are smaller when peacekeepers are deployed than when they are not, approximately up to the cost ratio of 0.1639 (indicated by the vertical blue dashed line). If the 20 percentage point reduction is the minimum desired effect size, as in the bottom panel of the figure, the crossover point is at a smaller value of the cost ratio, approximately at the ratio of 0.0288 (again, indicated by the vertical blue dashed line).
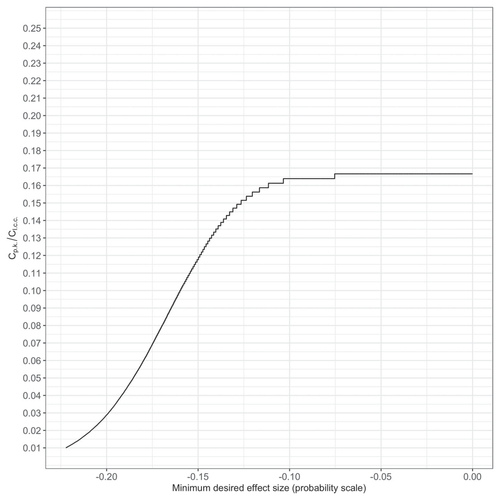
We can generalize these results, by computing the cost ratio up to which the expected loss is smaller when peacekeepers are deployed than when they are not, for every plausible value of the minimum desired effect sizes (by “plausible,” I mean the values available from the posterior samples of the causal parameter). visualizes this relationship.
Fig. 4 Relationship between the cost ratio up to which the expected loss is smaller when peacekeepers are deployed than when they are not, and the plausible minimum desired effect sizes.
To sum up, whether deploying peacekeepers produces a smaller expected loss depends on (a) the minimum desired size of reduction in the likelihood of local conflict continuation, (b) the probability that deploying peacekeepers has at least this minimum desired effect size, and (c) the relative value of to
. Using the causal binary loss function, we can see approximately up to what ratio of
to
peacekeeper deployment produces a smaller expected loss given different minimum desired effect sizes. This is richer inference over the practical implications of the effect of a policy intervention, than the significance test.
While the above discussion is about the general implications of the effect of a policy intervention, one could also consider its implications for a specific policymaking context if information about relevant actors’ preference were available. Here, I discuss two points to be considered. First, a minimum desired effect size may be endogenous to the ratio of the cost of a policy to the cost of an undesirable outcome. In the current example, if the cost of deploying peacekeepers were small, policymakers might think a 10 percentage point reduction is enough, whereas if the cost of deploying peacekeepers were large, they might think a 20 percentage point reduction is necessary to justify the high cost. The process of defining the effect size of interest given the costs is outside the statistical model (French and Argyris Citation2018). Thus, the endogeneity between the effect size of interest and the costs does not affect the statistical estimation.
Second, the costs may well differ across actors. In the current example, some countries may have better capacity to send peacekeepers efficiently than others. The cost of deploying peacekeepers is then lower to the former than to the latter. Similarly, policymakers in some countries may be more concerned with violent conflict in a particular locality than those in other countries, for example, neighboring countries versus distant countries. The cost of local conflict continuation is then perceived to be greater by the former than by the latter.
Whether one refers to a specific policymaking context or not, the main conclusion from the causal binary loss function model holds. Whether a policy (deploying peacekeepers in the current example) produces a smaller expected loss depends on the minimum desired level of reduction in the likelihood of an undesirable event (local conflict continuation in the example), the probability of the policy realizing at least this level of reduction, and the ratio of the cost of the policy to the cost of the undesirable event.
5 Conclusion
This article has introduced the causal binary loss function model, a general Bayesian decision-theoretic model for binary outcomes, to evaluate the practical implications of the effect of a policy on an undesirable event. The model indicates that whether a causal factor should be implemented as a policy to reduce the likelihood of an undesirable event, depends on the effect size range of interest, its probability mass, the cost of the policy, and the cost of the event. It provides richer information about the practical implications of the statistically estimated causal effects of policy interventions, than the significance test using only a standard point estimate and (categorical) uncertainty measures such as the dichotomy of statistical significance versus insignificance.
While the causal binary loss function model focuses on research on policy interventions, it also has implications for nonpolicy research. It might be argued that nonpolicy research should use criteria common in the academic community, such as statistical significance and Cohen’s effect size measure (Cohen Citation1988), to detect an academically meaningful effect, and should be agnostic about a utility/loss function for policymaking. There are two issues to be considered, however. First, it is well-known that the use of statistical significance has led to a skewed distribution of knowledge—the publication bias (Gerber and Malhotra Citation2008; Simonsohn, Nelson, and Simmons Citation2014; Esarey, and Wu Citation2016). Second, there is no consensus over what an academically meaningful effect size is. It is unclear how one can define a meaningful effect size without reference to practical contexts. One solution to these two issues is to use a general decision-theoretic model, such as mine, which treats the continuous nature of statistical uncertainty as such and evaluates effect sizes based on a loss function.
The article has several implications for future research. First, if more than one statistical model is conceivable (which is usually the case), there is uncertainty over the crossover point where an expected loss is smaller if the policy is implemented than if it is not. Such uncertainty could be mitigated by incorporating into the loss function the results aggregated from all conceivable statistical models, e.g., via Bayesian model averaging (Montgomery and Brendan Citation2010).
Second, the causal binary loss function may be extended to be used for (ordered or nonordered) categorical outcome variables. This could be done by computing the expected loss given the cost of each category of the outcome (e.g., a peace agreement, a ceasefire agreement, a stalemate, and ongoing conflict) and the effect of a policy intervention on each outcome category.
Third, the causal binary loss function may also be extended to analyze the effect of more than one policy on an undesirable event. This is simplest when multiple policies are causally independent from one another in the data used. We use the variables to capture these policies in one logistic regression, compute and
for each policy, and plug all of them into the loss function. The cost of policy implementation should be that of implementing all these policies. Meanwhile, if some of the multiple policies cause, or are caused by, each other in the data used, more careful statistical causal modeling (e.g., mediation analysis; see Imai, Keele, and Yamamoto Citation2010) will be necessary to estimate the independent effect of each policy before using their posteriors in the loss function.
Fourth, a policy may influence more than one outcome. In the example used here, the model considers only the (average) effect of peacekeepers on the likelihood of local conflict continuation. But peacekeeping, and many other policies, can affect multiple aspects of society. There can be more benefits of peacekeeper deployment than a reduction in the likelihood of local conflict continuation, for example, greater educational attainment (Reeder and Polizzi Citation2021) or better environmental quality (Bakaki, and Böhmelt Citation2021). Peacekeeper deployment might also have an adverse effect on some other aspects, for example, sexual violence by peacekeepers (Nordås and Rustad Citation2013). To incorporate the effect of a policy intervention on multiple outcomes, a statistical model and the causal binary loss function could be applied to each outcome, and then the expected losses could be aggregated over all models.
Fifth, a framework for multi-phase decision analysis could be developed. If a policy were implemented, a follow-up analysis could use the actual consequence of the policy as new data and the last posterior estimate as a new prior, thereby updating the posterior and therefore, the estimate of the expected loss.
Finally, should the causal binary loss function model serve actual policymaking, for example, to compare the relative cost-effectiveness of several policy options under a certain budget constraint, the question would be how to measure costs, which are usually unobservable and difficult to quantify. A Bayesian statistical model could be developed to estimate costs as latent variables, and their posterior predicted values could be plugged into the loss function.
Supplementary Materials
The supplementary materials are available at https://akisatosuzuki.github.io/papers.html, as well as at the journal’s website. A step-by-step vignette to install the R package “bayesdtm” and implement the causal binary loss function model is available at https://akisatosuzuki.github.io/bayesdtm.html. The preprint of the article was made available at arXiv as Suzuki (Citation2020).
Supplemental Material
Download Zip (812.5 KB)Acknowledgments
I am grateful for their helpful comments to the editors and the anonymous reviewers, Johan A. Elkink, Nial Friel, Zbigniew Truchlewski, Martijn Schoonvelde, James Cross, and participants in the 2019 GPSA-SPSA Methodology conference, the 2019 Bayesian Nonparametrics conference, the 2019 Max Weber June Conference, the 2019 PSAI Annual Conference, and in seminars at Dublin City University, University College Dublin, and the University of Strathclyde. The views expressed are my own unless otherwise stated, and do not necessarily represent those of the institutes/organizations to which I am/have been related.
Disclosure Statement
The author declares no conflict of interest.
Notes
Additional information
Funding
Notes
1 The model can be modified depending on the purpose of causal inference. For example, if one were interested in an average treatment effect and optimal treatment diversification for risk-averse decision makers (Manski Citation2013), the difference between the posterior of losses under a policy intervention and the one under no intervention could be used to compute the optimal proportion of cases to be treated.
2 All statistical analyses for this article were done on RStudio (RStudio Team Citation2020) running R version 4.1.2 (R Core Team Citation2021). The data visualization was done by the ggplot2 package (Wickham Citation2016).
3 The theoretical literature reserves the term “uncertainty” for the circumstance where there is no knowledge of the state of the world, while using the term “risk” for the circumstance where there is partial knowledge (Rapoport Citation1998, p. 50). Risk analysis often uses “risk” to capture both probability and severity of outcomes (Walpole and Wilson Citation2020, p. 136). This article follows the statistical terminology, where decision under uncertainty includes decision with partial knowledge.
4 Prospect theory suggests it changes decision-making whether we frame an issue at stake as a gain or as a loss even when the issue is mathematically equivalent (Kahneman and Tversky Citation1979). This is not a problem in the causal binary loss function model, because what matters is not how much expected loss a decision produces, but which decision produces a smaller expected loss.
5 There is usually the implicit assumption that a posterior is also conditional on the specifications of a statistical model such as a prior choice, causal identification strategy, a functional form, etc.
6 If the policy had the null effect, it would still be undesirable because of the cost of the policy being wasted.
7 is possible especially when Cp
is defined in a narrow, financial sense (e.g., a new policy uses less money than the status-quo policy). This article does not focus on such cases, as it usually costs more to address problems by a policy intervention than doing nothing.
8 The loss function could be modified to accommodate other Bayesian models for binary outcomes. For example, if a Bayesian linear probability model were used, the inverse logit function could be replaced with the identity function.
9 The covariates are those already mentioned plus the cubic polynomials of conflict duration (Carter and Signorino Citation2010).
Related Research Data
References
- Bååth, R. (2015), “Probable Points and Credible Intervals, Part 2: Decision Theory,” Publishable Stuff: Rasmus Bååth’s Research Blog. Accessed May 27, 2019. Available at http://www.sumsar.net/blog/2015/01/probable-points-and-credible-intervals-parttwo/.
- Baio, G., Berardi, A., and Heath, A. (2017), Bayesian Cost-Effectiveness Analysis with the R Package BCEA, Cham: Springer.
- Bakaki, Z., and Böhmelt, T. (2021), “Can UN Peacekeeping Promote Environmental Quality?” International Studies Quarterly, 65, 881–890. DOI: 10.1093/isq/sqab051.
- Berger, J. O. (1985), Statistical Decision Theory and Bayesian Analysis (2nd ed.), New York, NY: Springer.
- Carter, D. B., and Signorino, C. S. (2010), “Back to the Future: Modeling Time Dependence in Binary Data,” Political Analysis, 18, 271–292. DOI: 10.1093/pan/mpq013.
- Cecchetti, S. G. (2000), “Making Monetary Policy: Objectives and Rules,” Oxford Review of Economic Policy, 16, 43–59. DOI: 10.1093/oxrep/16.4.43.
- Cohen, J. (1988), Statistical Power Analysis for the Behavioral Sciences (2nd ed.), Hillsdale, NJ: Lawrence Erlbaum Associates.
- Duncan, G. J., and Magnuson, K. 2007, “Penny Wise and Effect Size Foolish,” Child Development Perspectives, 1, 46–51.
- Esarey, J., and Danneman, N. (2015), “A Quantitative Method for Substantive Robustness Assessment,” Political Science Research and Methods, 3, 95–111. DOI: 10.1017/psrm.2014.14.
- Esarey, J., and Wu, A. (2016), “Measuring the Effects of Publication Bias in Political Science,” Research and Politics, 3, 1–9.
- French, S., and Argyris, N. (2018), “Decision Analysis and Political Processes,” Decision Analysis, 15, 208–222. DOI: 10.1287/deca.2018.0374.
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B, Vehtari, A., and Rubin, D. B. (2013), Bayesian Data Analysis (3rd ed.), Boca Raton, FL: CRC Press.
- Gerber, A., and Malhotra, N. (2008), “Do Statistical Reporting Standards Affect What Is Published? Publication Bias in Two Leading Political Science Journals,” Quarterly Journal of Political Science, 3, 313–326. DOI: 10.1561/100.00008024.
- Gilboa, I. (2009), Theory of Decision under Uncertainty, Cambridge: Cambridge University Press.
- Gill, J. (2015), Bayesian Methods: A Social and Behavioral Sciences Approach (3rd ed.), Boca Raton, FL: CRC Press.
- Goodrich, B., Gabry, J., Ali, I., and Brilleman, S. (2020), “rstanarm: Bayesian Applied Regression Modeling via Stan,” R package version 2.21.1. https://mcstan.org/rstanarm.
- Gross, J. H. (2015), “Testing What Matters (If You Must Test at All): A Context-Driven Approach to Substantive and Statistical Significance,” American Journal of Political Science, 59, 775–788. DOI: 10.1111/ajps.12149.
- Harris, D. N. (2009), “Toward Policy-Relevant Benchmarks for Interpreting Effect Sizes: Combining Effects with Costs,” Educational Evaluation and Policy Analysis, 31, 3–29. DOI: 10.3102/0162373708327524.
- Hernán, M. A., and Robins, J. M. (2020), Causal Inference: What If, Boca Raton, FL: Chapman and Hall/CRC.
- Horowitz, A. R. (1987), “Loss Functions and Public Policy,” Journal of Macroeconomics, 9, 489–504. DOI: 10.1016/0164-0704(87)90016-4.
- Iacus, S. M., King, G., and Porro, G. (2012), “Causal Inference without Balance Checking: Coarsened Exact Matching,” Political Analysis, 20, 1–24. DOI: 10.1093/pan/mpr013.
- Imai, K., Keele, L., and Yamamoto, T. (2010), “Identification, Inference and Sensitivity Analysis for Causal Mediation Effects,” Statistical Science, 25, 51–71. DOI: 10.1214/10-STS321.
- Kahneman, D., and Tversky, A. (1979), “Prospect Theory: An Analysis of Decision under Risk,” Econometrica, 47, 263–292. DOI: 10.2307/1914185.
- Kruschke, J. K. (2018), “Rejecting or Accepting Parameter Values in Bayesian Estimation,” Advances in Methods and Practices in Psychological Science, 1, 270–280. DOI: 10.1177/2515245918771304.
- Laber, E. B., and Shedden, K. (2017), “Statistical Significance and the Dichotomization of Evidence: The Relevance of the ASA Statement on Statistical Significance and p-Values for Statisticians,” Journal of the American Statistical Association, 112, 902–904. DOI: 10.1080/01621459.2017.1311265.
- Manski, C. F. (2013), Public Policy in an Uncertain World: Analysis and Decisions, Cambridge, MA: Harvard University Press.
- Manski, C. F. (2019), “Treatment Choice With Trial Data: Statistical Decision Theory Should Supplant Hypothesis Testing,” The American Statistician, 73, 296–304.
- Mayer, T. (2003), “The Macroeconomic Loss Function: A Critical Note,” Applied Economics Letters, 10, 347–349. DOI: 10.1080/1350485032000056891.
- McNeil, B. J., and Pauker, S. G. (1984), “Decision Analysis for Public Health: Principles and Illustrations,” Annual Review of Public Health, 5, 135–61. DOI: 10.1146/annurev.pu.05.050184.001031.
- McShane, B. B., and Gal, D. (2016), “Blinding Us to the Obvious? The Effect of Statistical Training on the Evaluation of Evidence,” Management Science, 62, 1707–1718. DOI: 10.1287/mnsc.2015.2212.
- McShane, B. B., and Gal, D. (2017), “Statistical Significance and the Dichotomization of Evidence,” Journal of the American Statistical Association, 112, 885–895.
- Montgomery, J. M., and Nyhan, B. (2010), “Bayesian Model Averaging: Theoretical Developments and Practical Applications,” Political Analysis, 18, 245–270. DOI: 10.1093/pan/mpq001.
- Morgan, S. L., and Winship, C. (2015), Counterfactuals and Causal Inference: Methods and Principles for Social Research (2nd ed.), Cambridge: Cambridge University Press.
- Mudge, J. F., Baker, L. F., Edge, C. B., and Houlahan, J. E. (2012), “Setting an Optimal α That Minimizes Errors in Null Hypothesis Significance Tests,” PloS One, 7, 1–7. DOI: 10.1371/journal.pone.0032734.
- Nielsen, R. A., Findley, M. G., Davis, Z. S., Candland, T., and Nielson, D. L. (2011), “Foreign Aid Shocks as a Cause of Violent Armed Conflict,” American Journal of Political Science, 55, 219–232. DOI: 10.1111/j.1540-5907.2010.00492.x.
- Nordås, R., and Rustad, S. C. A. (2013), “Sexual Exploitation and Abuse by Peacekeepers: Understanding Variation,” International Interactions, 39, 511–534. DOI: 10.1080/03050629.2013.805128.
- Pearl, J., Glymour, M., and Jewell, N. P. (2016), Causal Inference in Statistics: A Primer, Chichester: Wiley.
- Quinn, J. M., Mason, T. D., and Gurses, M. (2007), “Sustaining the Peace: Determinants of Civil War Recurrence,” International Interactions, 33, 167–193. DOI: 10.1080/03050620701277673.
- R Core Team. (2021), R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. Available at https://www.R-project.org.
- Rapoport, A. (1998), Decision Theory and Decision Behaviour (2nd ed.), Hampshire: Macmillan Press Ltd.
- Reeder, B. W., and Polizzi, M. S. (2021), “Transforming Zones of Exclusion to Zones of Inclusion? Local-Level UN Peacekeeping Deployments and Educational Attainment,” International Studies Quarterly, 65, 867–880. DOI: 10.1093/isq/sqab018.
- Robert, C. P. (2007), The Bayesian Choice: From Decision-Theoretic Foundations to Computational Implementation (2nd ed.), New York, NY: Springer.
- RStudio Team. (2020), RStudio: Integrated Development for R, Boston, MA: RStudio, PBC. Available at http://www.rstudio.com/.
- Ruggeri, A., Dorussen, H., and Gizelis, T.-I. (2017), “Winning the Peace Locally: UN Peacekeeping and Local Conflict,” International Organization, 71, 163–185. DOI: 10.1017/S0020818316000333.
- Signorino, C. S. (1999), “Strategic Interaction and the Statistical Analysis of International Conflict,” American Political Science Review, 93, 279–297. DOI: 10.2307/2585396.
- Simonsohn, U., Nelson, l. D., and Simmons, J. P. (2014), “P-Curve: A Key to the File-Drawer,” Journal of Experimental Psychology: General, 143, 534–547. DOI: 10.1037/a0033242.
- Stan Development Team. (2019), Stan Reference Manual, Version 2.27. https://mc-stan.org/docs/2 27/reference-manual/index.html.
- Suzuki, A. (2020), “Policy Implications of Statistical Estimates: A General Bayesian Decision-Theoretic Model for Binary Outcomes,” arXiv: 2008.10903 [stat.ME]. https://arxiv.org/abs/2008.10903.
- Suzuki, A. (2022), “Presenting the Probabilities of Different Effect Sizes: Towards a Better Understanding and Communication of Statistical Uncertainty,” arXiv: 2008.07478v3 [stat.AP]. https://arxiv.org/abs/2008.07478.
- Taleb, N. N. (2007), The Black Swan: The Impact of the Highly Improbable, New York, NY: Random House.
- Tellez, J. F. (2019), “Peace Agreement Design and Public Support for Peace: Evidence from Colombia,” Journal of Peace Research, 56, 827–844. DOI: 10.1177/0022343319853603.
- Tetenov, A. (2012), “Statistical Treatment Choice Based on Asymmetric Minimax Regret Criteria,” Journal of Econometrics, 166, 157–165. DOI: 10.1016/j.jeconom.2011.06.013.
- Walpole, H. D., and Wilson, R. S. (2020), “Extending a Broadly Applicable Measure of Risk Perception: The Case for Susceptibility,” Journal of Risk Research, 24, 135–147. DOI: 10.1080/13669877.2020.1749874.
- Warjiyo, P., and Juhro, S. M. (2019), Central Bank Policy: Theory and Practice, Bingley: Emerald Publishing Limited.
- Wickham, H. (2016), ggplot2: Elegant Graphics for Data Analysis (2nd ed.), Cham: Springer.