
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The Gaussian graphical model (GGM) is a powerful tool to describe the relationship between the nodes via the inverse of the covariance matrix in a complex biological system. But the inference of this matrix is problematic because of its high dimension and sparsity. From previous analyses, it has been shown that the Bernstein and Szasz polynomials can improve the accuracy of the estimate if they are used in advance of the inference as a processing step of the data. Hereby in this study, we consider whether any type of the Bernstein operators such as the Bleiman Butzer Hahn, Meyer-König, and Zeller operators can be performed for the improvement of the accuracy or only the Bernstein and the Szasz polynomials can satisfy this condition. From the findings of the Monte Carlo runs, we detect that the highest accuracies in GGM can be obtained under the Bernstein and Szasz polynomials, rather than all other types of the Bernstein polynomials, from small to high-dimensional biological networks.
Public Interest Statement
The Gaussian graphical model (GGM) is one of the well-known probabilistic modeling approaches for the complex biological systems. Briefly, this model expresses the biological interactions between components of systems, which are genes or proteins, by using the property of the conditional dependency under multivariate normally distributed data. On the other hand, the Bernstein Polynomials are one of the famous Bernstein-type of operators in the approximation theory to smoothen the data via statistical distributions within the range of [0, 1]. From previous studies, it has been shown that these polynomials are successful in getting high accuracy in inference of interactions between genes in the system when they are used as the processing step in advance of GGM. In this study, we consider all Bernstein-type of operators, as the alternatives of the Bernstein polynomials, for the pre-processing step of GGM to discard the bath effects in the original observations.
1. Introduction
The approximation theory is concerned with the study of how well given functions can be proximated by basic functions. In this theory, it is usual to apply the approximating functions in the form of linear positive operators, such as the Bernstein, Szasz–Mirakyan polynomials, the Bleiman Butzer Hahn (BBH) operator, Meyer-König and Zeller (MKZ) operator. From previous works, it is known that the Bernstein and Szasz polynomials can significantly improve the accuracy of estimates from the point of view of their inference via the Gaussian graphical model (GGM) (Purutçuoğlu & Wit, Citation2015). Therefore, here we investigate whether the strong alternatives of the Bernstein polynomials, i.e. the Bleiman and Hahn operator and the Meyer-König and Zeller operator, are as successful as the Bernstein polynomials and can be used alternately.
The Gaussian graphical model is a probabilistic and undirected statistical model for the complex biological networks under the normally distributed random multivariate variables whose dependency structure is represented by a graph (Dempster, Citation1972). In Figure , we represent the structure of the filtered yeast interactome (FYI) network (Han et al., Citation2004) as an example of realistically complex biological systems that GGM can handle with. Hereby, in GGM, we assume that the observations follow a multivariate normal distribution with a mean vector and the variance–covariance matrix
, and the conditional independent structure of the observations can be described via a set of nodes and edges constructing an undirected network by means of the inverse of the covariance matrix, also called the precision
. In
, the non-zero entries indicate the interactions between nodes, i.e. genes, and zero entries imply no interaction between the selected pair of nodes.
Figure 1. The main component of the FYI network (Han et al., Citation2004).

On the other hand, the Bernstein operators which cover the Bernstein and Szasz polynomials are the approximations that are based on the binomial and the Poisson distribution, respectively. But in the literature, different Bernstein-type operators are presented as well. Specifically, the Bleiman–Butzer Hahn (BBH) and the Meyer-König and Zeller (MKZ) operators which are derived from the Bernstein operators are the most well-known ones. The theoretical properties of the BBH operator (Agratini, Citation1996) and MKZ operator (Abel, Citation1995; Becker, Citation1977) have been studied extensively.
In biological networks, the Bernstein polynomials enable us to transform the data in a new range (Lorentz, Citation1953; Bernstein, Citation1912). Accordingly, in this study, we consider to implement the Bernstein polynomials, the BBH operator and the MKZ operator in different dimensional biological systems before estimating the model parameters of GGM.
Accordingly, in the organization of this paper, we introduce GGM and different types of operators in Section 2. In Section 3, we report our outputs based on the Monte Carlo studies. Finally, in Section 4, we summarize our results and discuss our future works.
2. Methods
2.1. Gaussian graphical model
The biological system is an expression between components of the complex biological networks and the interactions between components in this system can be probabilistically represented by the Gaussian graphical model. In this modeling approach, the nodes are indicated as under the assumption that the state vector X has a multivariate Gaussian (normal) distribution via
(1)
(1)
in which is a p-dimensional mean vector and
shows the
variance–covariance matrix for the p-dimensional normal density of the random variable X with n samples per nodes, i.e. genes. Hereby, the p-dimensional normal density of X shown in Equation (1) can be denoted by the following probability density function.
(2)
(2)
In Equation (2), is symmetric and invertible matrix, and its inverse called the precision,
, indicates the dependency structure between two nodes. Accordingly, in GGM, if there exists an edge between two nodes, i.e.
, these two nodes are not conditionally independent given other nodes (Whittaker, Citation1990). In other words, the non-zero entries of the off-diagonal entries of
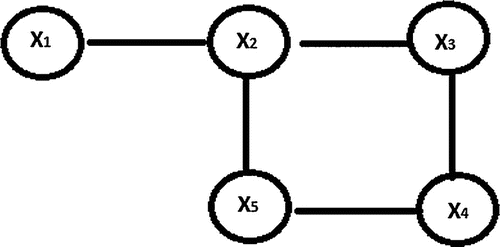
imply a physical or functional interaction between the nodes (Dempster, Citation1972; Wermuth, 1976; Whittaker, 1990). In Figure , we draw a small network having five nodes in which
is conditionally independent on
for given
. Similarly,
is conditionally independent on
for given
and
in the same figure.
Figure 2. Simple representation of the relationship between five nodes in a system.
There are lots of techniques to estimate entries of the precision matrix in GGM. The neighborhood selection method with the lasso regression (Meinshaussen & Bühlmann, Citation2006) is one of the computationally efficient approaches for sparse and high-dimensional graphs. This method belongs to the class of the covariance selection approaches that is based on non-parametric calculation. In this model, given that the set of nodes and the number of nodes in the graph are denoted by and
, respectively, the neighborhood of the node p in
is the smallest subset of the node
. Since each state of the node, i.e. gene, p,
, is defined as conditionally independent on the state of all remaining nodes,
, an optimal prediction of the vector of the regression coefficient of
in the lasso regression (Tibshirani, Citation1996),
, can be found by the following expression.
(3)
(3)
In Equation (3), denotes the set of nodes with n number of observations each,
shows the expectation of the given random variable, and
stands for
. Here, the best predictor for
is detected as a linear function of variables in the set of neighbors of the node (Meinshaussen & Bühlmann, Citation2006).
Furthermore, the graphical lasso, also named as glasso, approach (Friedman, Hastie, & Tibshiran, Citation2008), is another common technique in inference of biological networks. Briefly, this method controls the type I and type II errors by detecting the probability under very low levels when the penalized likelihood expression is defined as below.(4)
(4)
In Equation (4), shows the
-norm, which is the sum of the absolute value of the given element, and
presents the trace. S indicates the sample covariance matrix
. Accordingly, in inference of S in Equation (4) as an unbiased estimator of
in Equation (2), the sample covariance matrix is applied, i.e.
via
(5)
(5)
Here, denotes the ith row and the jth entry of S and n is the total sample size per gene as stated previously. Finally,
stands for the kth sample of the ith gene and
refers to the mean term for the ith gene having totally n observations.
On the other hand, different researchers have also investigated other parametric solutions of this problem. But the main challenge under these calculations is the high dimension of genes (nodes) with respect to the observations per gene, denoted by n, i.e. . This inequality causes a singular covariance matrix, resulting in multiple of solutions if we perform the standard maximum likelihood technique in inference of model parameters. Hereby, in order to unravel this problem, different types of penalized methods are also suggested besides the neighborhood selection and glasso approaches as described above. These methods are based on distinct optimization approaches of the lasso regression in the estimation of
. We can also list grouped lasso (Yuan & Lin, citeyuan), elastic net method (Zou & Hastie, Citation2005), fused lasso (Tibshirani, Saunders, Rosset, Zhu, & Knight, Citation2005), adaptive lasso (Zou, Citation2006), coordinate-wise descent algorithm within the
-penalized lasso (Friedman, Hastie, & Tibshiran, Citation2007), and multivariate methods with scout algorithm (Witten & Tibshirani, witten) approaches as the other most well-known approaches used in GGM. All these methods mainly suggest similar model construction for the penalized maximum likelihood function defined for the lasso regression by either the
norm or
-norm as the penalizing term. On the other side, recently, certain semi-parametric approaches such as the non-paranormal SKEPTIC algorithm (Liu, Han, Yuan, Lafferty, & Wasserman, Citation2012) and fully parametric approaches via Bayesian techniques such as the birth-death Markov chain Monte Carlo (MCMC) (Muhammadi & Wit, Citation2014) approach are proposed in order to estimate
without using any optimization methods. In the literature of GGM, different types of Monte Carlo approaches have been also performed. Atay-Kayis and Massam (Citation2005) apply Monte Carlo methods in the calculation of
when the network graph in GGM is non-decomposable. Dobra, Lenkoski, and Rodriguez (Citation2011) and Wang and Li (Citation2012) introduce the reversible jump MCMC and Dauwels, Yu, Xu, and Wang (Citation2013) implement the Monte Carlo expectation maximization method within copula GGM. Whereas among all these alternatives, the neighborhood selection approach, suggested by Meinshaussen and Bühlmann (2006), is one of the most common techniques due to its simplicity in inference. Hence, in our analyses, we prefer this method and perform it in junction with Monte Carlo simulations in order to evaluate the performance of different estimates.
2.2. Bernstein polynomials
The Bernstein polynomial was introduced by Sergey Natanovich Bernstein as a new proof of the Weierstrass approximation theorem. This polynomial privileges in the approximation theory since it applies the constructive new polynomials to prove the Weierstrass approximation instead of polynomials that are already known as mathematicians.
For the mathematical expression of these polynomials, let N be the set of positive integers for every function . Thus, the Bernstein polynomial for the nth degree is defined by
(6)
(6)
where is called the Bernstein basis polynomial and can shown as
(7)
(7)
for and
binomial coefficient.
If is a continuous function, then the sequence of the Bernstein polynomials
converges uniformly to f on [0, 1],
The Bernstein polynomial (Lorentz, Citation1953) has certain properties such as the positivity, symmetry, and the degree raising. The first characteristic means while
. On the other hand, the second feature presents
and finally, the third one implies that any lower degree Bernstein polynomial is written as a linear combination of the nth Bernstein polynomials.
The generalized version of the Bernstein operator is called the Szas-Mirakyan operator and is defined as(8)
(8)
where and the function f is defined on an infinite interval
.
2.3. Butzer Hahn operator
Bleiman, Butzer and Hahn (BBH) operator (Bleiman, Butzer, & Hahn, Citation1980) which is defined by the Bernstein-type can be represented as below for the nth degree with the k basis polynomials for the value x.(9)
(9)
For Equation (9), the following inequality is satisfied.(10)
(10)
Equation (10) implies that the BBH operator is linear and bounded for when
. Here,
is the class of the real-valued function f defined within the interval
and for all functions of f in this interval,
for each
when
.
Additionally, the property of the uniform approximation of the BBH operator has been studied (Totik, Citation1984) when f belongs to for the continuous function on
. Also Mercer (Mercer (Citation1989)) has independently derived the Voronovskaya-type theorem which gives an asymptotic error term for the Bernstein polynomials for the functions which are twice differentiable as follows.
(11)
(11)
for all with
when
, and
is the second derivative of the function.
Abel (Citation1996) has extended this study by giving the complete asymptotic expansion for the BBH operator as the following form.(12)
(12)
. Here,
represents all the coefficients from
to
.
The Szasz operator is the limiting operator of BBH (Khan, Citation1988) and if f is convex (Khan, Nevai, & Pinkus, Citation1991).
is convex itself if f is a non-increasing convex function.
Jayasri and Sitaraman (Citation1993) have determined that is a pointwise approximation process in which the largest subclass of
for the Bernstein-type of operator.
Then, the following function class is introduced in the study of Hermann, Szbados, and Tandori (Citation1991).(13)
(13)
He has proved that if f belongs to , then for each
, the pointwise convergence is
on
. Moreover, for some
,
, then
. Also the operator
is arisen from the random variable with n observations,
, which has the Bernoulli distribution as below.
(14)
(14)
for the parameters ,
and
.
2.4. Meyer-König and Zeller operator
The operator(15)
(15)
is known as the Meyer-König and Zeller (MKZ) operator when(16)
(16)
for the nth degree and the kth basis polynomial for the value of x as stated previously.
These operators are known as the Bernstein-type of operators. Cheney and Sharma (Citation1996) have defined this operator as a power series of the Bernstein operators.
The MKZ operator can also be obtained from the negative binomial distribution via(17)
(17)
3. Application
In the assessment of the polynomials’ results, we consider four different scenarios. In the first scenario, we estimate the precision matrix from the simulated data-sets under different kinds of the Bernstein polynomials and the Bernstein-type of operators, which are the MKZ operator and the BBH operator. For the analyses of the model, we generate 50, 100, and 500 dimensional data-sets in which each gene has 20 observations. Then, we set all the off-diagonal entries of
to 0.9 arbitrarily and generate scale-free networks by using the huge package in the R programme language. Then, in order to evaluate whether the entry of the off-diagonal terms has any effect in inference, we change it via moderately small and small values too. Hereby, in the second and the third scenarios, the off-diagonal elements of the precision matrix set to 0.7 and 0.5, respectively, when the networks are scale-free. Finally, as the fourth plan, we change the sparsity of the system from the scale-freeness to the hubs property since the former typically indicates a high sparsity level around 90% or above and the latter implies relatively a lower sparsity level at around 80–90%. On the other hand, in our analyses, we have not controlled the performance of methods lower than these sparsities levels as the high sparsity is one of the main features of biological systems (Barabasi & Otiva, Barabasi04).
Accordingly, in all scenarios, we initially generate a data-set for the true network and keep its true path for the best model selection in further steps. Later, we transform this actual data-set via the Bernstein polynomial, the Szasz polynomial, the MKZ operator, and the BBH operator. Finally, all these non-transformed and transformed data are used to estimate the precision matrices by using the neighborhood selection (NB) method. In the application, we choose NB among alternatives due to its computational gain. For the assessment, we calculate the F-measure and the precision for each run as shown below.(18)
(18)
In Equation (18), TP (true positive) indicates the number of correctly classified objects that have positive labels and FN (false negative) shows the number of misclassified objects that have negative labels and finally, Recall is calculated as .
Then, we repeat the calculation of the underlying statistics for 1000 Monte Carlo runs and their means are computed. The results are presented in Table .
Table 1. Comparison of the F-measure and the precision values computed with/without operators in inference of with 0.9 off-diagonal entries under scale-free networks
Table 2. Comparison of the F-measure and the precision values computed with/without operators in inference of with 0.7 off-diagonal entries under scale-free networks
Table 3. Comparison of the F-measure and the precision values computed with/without operators in inference of with 0.5 off-diagonal entries under scale-free networks
Table 4. Comparison of the F-measure and the precision values computed with/without operators in inference of with 0.9 off-diagonal entries under hubs networks
From Table , it is seen that for low dimensions, the Bernstein polynomials give better results than others, in particular, the Szasz polynomials have the highest F-measure. We obtain the same results for the precision values as well. Moreover, we detect that when the dimension of the matrix increases, the F-measure and the precision value decrease. Furthermore, as shown in Tables and , we observe similar findings in the sense the Szasz polynomials typically produce better F-measure and precision even though we decrease the correlation between genes (by off-diagonal entries 0.7 and 0.5). Whereas under these scenarios, it is found that the MKZ operator is as good as the Szasz operator in terms of the accuracy of the estimates under certain conditions. Finally when we evaluate the outputs of Tables –, we see that the results of both the Szasz polynomial and the MKZ operator are very close to each other and overperform with respect to the remaining operators.
On conclusion, all these outputs imply that when the sparsity of networks decreases, all Bernstein-type of operators compute similar results and the Szasz polynomial as well as the MKZ operator are slightly better than others. On the contrary, if the sparsity level raises as mostly observed in biological networks, the operators have different accuracy values and the performance of the Bernstein polynomials, especially, the Szasz polynomial, becomes better.
4. Discussion
In this study, we have compared all well-known Bernstein-type of operators to detect which alternative produces the highest accuracy if it is applied with GGM. For this purpose, we have analyzed the Monte Carlo results of the Bernstein polynomials, BBH and MKZ operators. The results have indicated that the Bernstein polynomials have the highest accuracies if they are performed in advance of the inference of the model parameters of GGM and the MKZ operator can be another good alternative if the sparsity level of the system decreases. But for all choices of operators, we have found that these operators can improve the accuracies of estimates for different dimensional biochemical systems if they are implemented as the pre-processing step before the inference of the precision matrix. As the extension of this study, we consider other approximation methods such as the Fourier transformations in such a way that the distributional feature of the observations can be embedded to the new transformed data in order to smooth the original data-set smartly and get estimates with higher accuracy.
Acknowledgements
The authors would like to thank the anonymous referees, editors, and guest editors of this Special Issue of the journal for their valuable contributions which improve the quality of the paper.
Additional information
Funding
Notes on contributors
Vilda Purutçuoğlu
Vilda Purutçuoğlu is the associate professor in the Department of Statistics at Middle East Technical University (METU) and also affiliated faculty in the Informatics Institute, Institute of Applied Mathematics and Department of Biomedical Engineering at METU. She has completed her BSc and MSc in statistics and minor degree in economics. She received her doctorate at the Lancaster University. Purutçuoğlu’s current researches are in the field of bioinformatics, systems biology and biostatistics. She has a research group with seven doctorates and four master students who have been working on deterministic and stochastic modelings of biological networks and their inferences via Bayesian and frequentist theories. Hereby, the findings in this study are the part of the researches about the improvement of probabilistic inferences of complex networks and these findings can be helpful for eliminating batch effects in their observations before any statistical analyses.
References
- Atay-Kayis, A., & Massam, H. (2005). A Monte Carlo method for computing the marginal likelihood in nondecomposable gaussian graphical models. Biometrika, 92, 317–335.
- Abel, U. (1995). The moments for the Meyer--Knig and Zeller operators. Journal of Approximation Theory, 82, 352–361.
- Abel, U. (1996). On the asymptotic approximation with operators of Bleimann. Butzer and Hahn, Indagationes Mathematicae, 7(1), 1–9.
- Agratini, O. (1996). A class of Bleimann, Butzer and Hahn type operators. Analele Universitătii Din Timişoara, 34, 173–180.
- Barabasi, A. L., & Otiva, Z. N. (2004). Understanding the cell’s functional organization. Nature Reviews Genetics, 5, 101–113.
- Bernstein, N. (1912). Démonstration du th\’{e}or\’{e}me de Weierstrass fond\’{e}e sur le calcul de probabilit\’{e}s. Community of Kharkov Mathematical Society, 13, 1–2.
- Becker, M., Kucharski, D., & Nessel, R. J. (1977). Global approximation theorems for the Szasz--Mirakyanoperators in exponential weight spaces, in linear spaces and approximation. Proceeding of Conference of Oberwolfach, Basel ISNM, 40, 319–333.
- Bleiman, G., Butzer, P. L., & Hahn, L. (1980). A Bernstein-type operator approximating continuous functions on the semi-axis. Indagationes Mathematicae, 42, 255–262.
- Cheney, E. W., & Sharma, A. (1996). Bernstein power series. Canadian Journal of Mathematics, 16, 241–253.
- Dauwels, J., Yu,, H., Xu, S., & Wang, X. (2013). Copula Gaussian graphical model for discrete data. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Vancouver.
- Dempster, A. (1972). Covariance selection. Biometrics, 28, 157–175.
- Dobra, A., Lenkoski, A., & Rodriguez, A. (2011). Bayesian inference for general Gaussian graphical models with application to multivariate lattice data. Journal of the American Statistical Association, 106, 1418–1433.
- Friedman, J. H., Hastie, T., & Tibshiran, R. (2007). Pathwise coordinate optimization. Annals of Applied Statistics, 2, 302–332.
- Friedman, J. H., Hastie, T., & Tibshiran, R. (2008). Sparse inverse covariance estimation with the graphical lasso. Biostatistics, 9, 432–441.
- Han, J.-D., Bertin, N., Hao, T., Goldberg, D. S., Berriz, G. F., Zhang, L. V., ... Vidal, M. (2004). Evidence for dynamically organized modularity in the yeast protein--protein interaction network. Letters to Nature, 430, 88–93.
- Hermann, T., Szbados, J., & Tandori, K. (Eds.). (1991). Approximation Theory, Proceedings Conference Kecskemet/Hung., 1990, On the operator of Bleimann, Butzer and Hahn(58, pp. 355–360). North-Holland.
- Jayasri, C., & Sitaraman, Y. (1993). On a Bernstein-type operator of Bleimann--Butzer and Hahn. Journal of Computational and Applied Mathematics, 47, 267–272.
- Khan, K. A., Nevai, P., & Pinkus, A. (1991). Some properties of a Bernstein type pf operator of Bleimann, Butzer and Hahn. In P. Nevai & A. Pinkus (Eds.), Progress in approximation theory (pp. 497–504). New York, NY: Academic Press.
- Khan, R. A. (1988). A note on a Bernstein-type operator of Bleimann. Butzer and Hahn, Journal of Approximation Theory, 53, 295–303.
- Liu, H., Han, F., Yuan, M., Lafferty, J., & Wasserman, L. (2012). High dimensional semiparametric gaussian copula graphical models. The Annals of Statistics, 40, 2293–2326.
- Lorentz, G. G. (1953). Bernstein polynomials (Mathematical Exposition No. 8). Toronto: University of Toronto.
- Meinshaussen, N., & Bühlmann, P. (2006). High dimensional graphs and variable selection with the lasso. The Annals of Statistics, 34, 1436–1462.
- Mercer, A. (1989). A Bernstein-type operator approximating continuous functions on the half-line. Bulletin of Calcutta Mathematical Societiy, 31, 133–137.
- Muhammadi, A., & Wit, E. C. (2014). Bayesian structure learning in sparse Gaussian graphical models. Bayesian Analysis, 10, 109–138.
- Purut\c{c}uo\u{g}lu, V., A\u{g}raz, M., & Wit, E. (2015). Bernstein approximations in glasso-based estimation of biological networks.
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B, 58, 267–288.
- Tibshirani, R., Saunders, M., Rosset, S., Zhu, J., & Knight, K. (2005). Sparsity and smoothness via the fused lasso. Journal of the Royal Statistical Society, Series B, 67, 99–108.
- Totik, V. (1984). Uniform approximation by Bernstein-type operators. Nederlandse Akademie van Wetenschappen (Indagationes Mathematicae), 50, 87–93.
- Wang, H., & Li, S. Z. (2012). Efficient Gaussian graphical model determination under G-Wishart prior distributions. Electronic Journal of Statistics, 6, 168–198.
- Witten, D. M., Frieman, J. H., & Simon, N. (2011). New insights and faster computations for the graphical lasso. Journal of Computational and Graphical Statistics, 20, 892–900.
- Whittaker, J. (1990). Graphical models in applied multivariate statistics. New York, NY: Wiley.
- Yuan, M., & Lin, Y. (2007). Model selection and estimation in the Gaussian graphical model. Biometrika, 94, 19–35.
- Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101, 1418–1429.
- Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B, 67, 91–108.