
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In clinical studies, the period before an event occurs is frequently considered as an outcome. The general term used for this analytical method in clinical studies is “survival time analysis”. The method employs Cox regression to compare hazards between groups. In this paper, we propose an index defined in the Bayesian framework to compare hazards. This index compares the sizes of the hazards directly. Further, we propose two methods to calculate the sizes of the hazards. One is an approximate method, by which we can easily calculate the size, and the other is an exact method. In addition, we apply the proposed index to two actual clinical studies to assess its usability.
Public Interest Statement
In clinical studies, the period before an event occurs is frequently considered as an outcome. The general term used for this analytical method in clinical studies is “survival time analysis”. The method employs Cox regression to compare hazards between groups. In this paper, we propose an index defined in the Bayesian framework to compare hazards. We apply the proposed index to two actual clinical studies to assess its usability.
1. Introduction
Events such as death and survival at the end of the studies are important outcomes in clinical studies. Survival time analysis is generally employed to compare groups when analyzing these outcomes.
It is not an exaggeration to say that in the frequentist framework, the basic methodology of survival time analysis has almost been settled (Colett, Citation2003; Hosmer, Lemeshow, & May, Citation2008). Besides, recently the method of direct comparison of hazards was proposed (Heller & Mo, Citation2015).
In the Bayesian framework, on the other hand, a methodology has not yet been established. In this paper, Bayes introduced the idea of inverse probability, which, following the work of Laplace and others, came to be known as Bayes’ Theorem. The Bayesian approach to statistical inference is useful for several reasons. Perhaps foremost among them is the formal manner in which Bayesian methods incorporate prior information, whether it be expert opinion or historical data. The sequential learning nature of the method, with prior knowledge being updated to yield posterior distributions, forms the basis for adaptive methods, in which models are continually updated with new information. Other advantages of the method include the ease of predictive model building and the avoidance of large-sample approximations in some cases. Furthermore, Bayesian analysis provides straightforward probabilistic statements about parameters of interest and inferential questions. The Bayesian influence can be found in a broad array of fields such as statistics, medicine, epidemiology, computer science, economics, engineering, physics, and philosophy of science. A number of papers on biomedical applications have suggested the use of Bayesian methods in healthcare evaluation (Spiegelhalter, Citation2004; Zhao, Feng, Chen, & Taylor, Citation2015), the pharmaceutical industry (Grieve, Citation2007; Racine, Grieve, Fluhler, & Smith, Citation1986), and clinical trials (Berry, Citation2006; Cornfield, Citation1976; Lee & Chu, Citation2012; Spiegelhalter, Freedman, & Parmar, Citation1993, Citation1994).
As mentioned above, Bayesian statistics are employed in clinical trials to evaluate outcomes, but no one has so far proposed an index for the easy interpretation of results. In Bayesian model selection, the most widely used tools are Bayes factors (BFs) (Kass & Raftery, Citation1995). However, these are unscaled when improper priors are used. In order to overcome this problem and approximate the underlying BFs, fractional and intrinsic BFs (Berger & Pericchi, Citation1996; O’Hagan, Citation1995) have been proposed in the literature. Thus, BFs are useful in Bayesian model selection. However, we cannot directly compare parameters of posterior distributions using BFs. Moreover, it is often difficult to interpret BFs for several reasons; one reason is that the coefficients of BFs do not have intuitive meaning.
Zaslavsky (Citation2010, Citation2013) and Kawasaki and Miyaoka (Citation2012b) were the first to propose a new type of index, called the “Bayesian index”, for the comparison of binomial proportions and to apply it to clinical trial results. These indexes can compare parameters directly, and since the results are evaluated as a probability, it is easy to understand them intuitively. In this paper, we propose the index η = P(h1 < h2 |), which is developed from the index proposed by Kawasaki and Miyaoka (Citation2012a, Citation2012b), for comparison of hazards, where hi indicates the hazard of group i, with the exponential distribution assumed for the survival function. We further assume that the prior distribution is a gamma distribution with parameters αi and βi.
denotes the total observation duration of group i. This index indicates the probability that the hazard of group 1 is less than that of group 2.
The remainder of the paper is organized as follows. We propose a method for the exact calculation of the index η as well as a method for an approximate calculation, with which we can easily calculate the probability of the index, in Section 2. We compare the approximate probability with the exact probability and present the results of actual clinical trials to show the utility of η in Section 3. Finally, we conclude with a brief summary in Section 4.
2. Methods
2.1. Notation
Let Cij and Yij be independent. For patient number j in group i, let Yij be the random variable representing the time to event occurrence, Cij be the random variable representing the time to censoring (where i = 1, 2 and j = 1, 2, …, ni), and Tij = min(Yij,Cij) be the variable representing the observation duration. Additionally, to judge the executing or censoring event for patient number j in group i, we define the event index as
where the realized value of Tij is tij. Furthermore, let the hazard function of patient number j in group i be constant as follows
The probability density function and survival time function can be denoted, respectively, as
2.2. Posterior distribution
We give the likelihood function for group i as
Assuming gamma distributions with parameters αi and βi as prior distributions, and i = 1, 2, we have
From Bayes’ Theorem, the posterior distribution for i is
The posterior distribution follows a gamma distribution with parameters and
.
2.3. Exact expression
Theorem
The exact expression for the posterior hazard of group 1 to be smaller than that of group 2 is(1)
(1)
where denotes the hypergeometric series,
denotes the regularized incomplete beta function and Beta(a, b) denotes the beta function.
Proof
The posterior probability is given by
Hence, its joint probability density function is
From the definition, η can be given as
From Theorem 1 in Kawasaki and Miyaoka (Citation2012a),
Furthermore, from Formulas 26.5.23 and 26.5.2 of Abramowitz and Stegun (Citation2010), i.e.
and
η can be given as
□
We can calculate the exact probability by Equation (1) and using expressions containing various hypergeometric series. In this paper, we use one such expression. Kawasaki and Miyaoka (Citation2012b) give a more detailed proof in a similar problem. For the SAS programming code used for calculating the probability of η, see Appendix 1.
2.4. Approximate expression
We can easily formulate an approximate expression using the expected value of the posterior distribution and the variance. The expected value and the variance of the difference between the posterior distributions are, respectively,
where hi,post denote the posterior hazard, and i = 1, 2. Therefore, we can rewrite Equation (2) as
where Φ(·) is the cumulative distribution function of the standard normal distribution. Thus, η can easily be calculated if we know the cumulative distribution function of the standard normal distribution.
3. Results
3.1. Simulation
Our aim of simulation in Section 3.1 is to verify the condition under which the differences of the probability, indicated by the approximated method and that by the exact method, become greater. Hence, we compare the exact method and the approximation method using simulated data in this section. The simulation method is as follows. Assume the data occur randomly from the exponential distribution when the hazard ratio is between 0.40 and 1.50 in steps of 0.10, and that they occur randomly with binomial proportions when the censoring ratio is 10 or 40%. Further, let the sample sizes for the groups be either balanced or unbalanced. For the balanced cases, we set n1 = n2 = 10, n1 = n2 = 20, n1 = n2 = 50, or n1 = n2 = 100, and for the unbalanced cases, we set n1 = 15 and n2 = 5, or n1 = 75 and n2 = 25. In this simulation, we use the non-informative prior, that is, αi = βi = 0.001 and i = 1, 2.
At the beginning, we verify the difference between the probability by the approximated method and that by the exact method with small sample size. Figure compares the results under the censoring ratios 10 and 40% when n1 = n2 = 10 and n1 = n2 = 20. The box plots show the difference between the exact probability and the approximate probability, with the vertical axis representing the difference between the exact probability and the approximate probability, and the horizontal axis representing the hazard ratio. We make the following observations from Figure :
| • | When the censoring ratio is 10%, the difference between the exact probability and the approximate probability is about 4% at maximum. | ||||
| • | The difference is about 12% at maximum when the censoring ratio is 40% and the hazard ratio is 0.40. | ||||
| • | The difference shows a variance of around 0% when the hazard ratio is 1. | ||||
Figure 1. Comparison of the results under the censoring ratios 10 and 40% when n1 = n2 = 10 and n1 = n2 = 20.
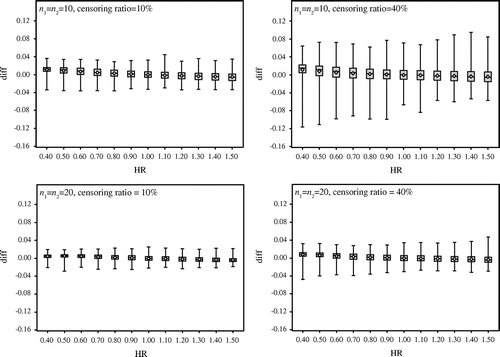
Next, we verify that with large sample size. Figure compares the results under the censoring ratios 10 and 40% when n1 = n2 = 50 and n1 = n2 = 100. Figure shows the following:
| • | The results are not affected by censoring, and the difference between the exact probability and the approximate probability goes up to about 2.5%. | ||||
| • | The interquartile range is very narrow. | ||||
Figure 2. Comparison of the results under the censoring ratios 10 and 40% when n1 = n2 = 50 and n1 = n2 = 100.
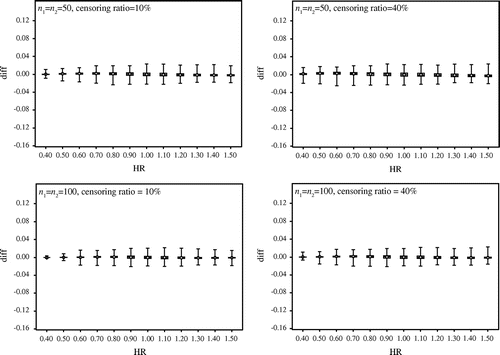
At the end, we verify that with unbalanced sample size. Figure compares the results under the censoring ratios 10 and 40% for the combinations n1 = 15, n2 = 5 and n1 = 75, n2 = 25. Figure shows the following:
| • | Boxes are wide, and the difference between the exact probability and the approximate probability is large. | ||||
| • | The difference is even larger relative to the case where both groups have the same sample size in total. | ||||
Figure 3. Comparison of the results under the censoring ratios 10 and 40% when n1 = 15, n2 = 5 and n1 = 75, n2 = 25.
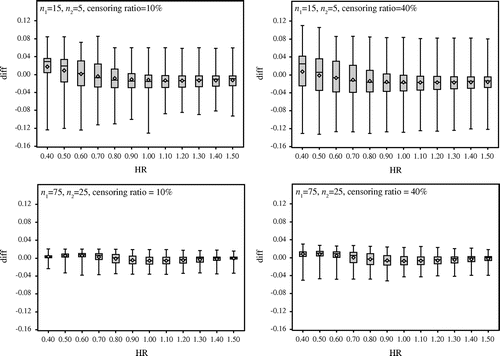
3.2. Examples
3.2.1. Chronic active hepatitis cases
In this section, we apply the proposed index to clinical trial data used in Kirk, Jain, Pocock, Thomas, and Sherlock (Citation1980). In this trial, 44 chronic active hepatitis cases were assigned randomly to either the prednisolone group (treatment group) or the control group with no treatment (control group). From the treatment group’s 22 cases, 11 were observed and the remaining 11 were censored, and from the control group’s 22 cases, 16 were observed and the remaining 6 were censored. The most interesting outcome in the trial was the survival time of patients after the trial commenced.
The p-value was 0.0309 by the log-rank test and 0.0105 by the Wilcoxon test. This indicates a longer survival time for the treatment group at the significance level of 5%. The proposed index indicates 98.35% as the approximate probability and 99.01% as the exact probability, with the hazard of the treatment group lower than that of the control group. We assume the prior distribution to be non-informative for both groups.
3.2.2. Lung cancer data analysis
In this section, we apply the proposed index to clinical trial data used in Chen et al. (Citation2007).
We obtained the non-small-cell lung cancer data used in Chen et al. (Citation2007) from http://www.ncbi.nlm.nih.gov/projects/geo/ with accession number GSE4882. The data contained 672 gene profiles of 125 lung cancer patients. From among them, 38 patients died, and the remainder were censored.
The median follow-up of 101 patients was 20 months. The patients with a high-risk gene signature showed a shorter median overall survival than those with a low-risk gene signature. The p-value was 0.001 by the log-rank test; the proposed index gave 99.99% probability as calculated approximately as well as exactly. A high-risk gene signature was associated with a median relapse-free survival period of 13 months, whereas a low-risk gene signature was associated with a median relapse-free survival period of 29 months. Here, the p-value was 0.002 by the log-rank test, and the proposed index gave 99.53% as the approximate probability and 99.72% as the exact probability.
4. Discussion and conclusions
In this paper, we have proposed an index to compare the hazards defined in the Bayesian framework. Further, we have presented two probability functions: the approximation function, which provides for easy calculation, and the exact function.
Our simulation experiment shows a difference between the exact probability and the approximate probability. Specifically, when we censor more, the difference becomes larger. By contrast, we found that the difference becomes smaller with larger sample sizes; the effect of censoring too becomes less. With unbalanced sample sizes for the groups, the difference becomes larger. Thus, we recommend using the exact probability calculation for cases with small samples, unbalanced sample sizes, or numerous censorings.
We applied the proposed index to actual clinical trial data and confirmed that it shows the difference between groups very clearly. Because, we indicated it in example 1 that the hazard of the treatment group becomes lower than that of the control group with about 99% probability. Thus, as this index provides comparison of the hazards with probability, the result can be indicated within the range of 0–100%. So, the index can be very easy to understand intuitively.
Thus, the index proposed in this paper to compare hazards is easy to understand and intuitive and should be beneficial for use in research studies.
Acknowledgements
The authors also wish to thank the anonymous reviewers for their suggestions that helped to improve the manuscript.
Additional information
Funding
Notes on contributors
Yohei Kawasaki
Yohei Kawasaki received the BS degree in mathematics in 2005 and the MS and PhD degrees in mathematical science from Tokyo University of Science, Japan in 2007 and 2012, respectively. He joined the Mitsubishi Tanabe Pharma Corporation, the National Center for Global Health and Medicine, Tokyo University of Science, in 2005, 2013, and 2014, respectively.
He has published over 70 research articles in reputed international journals. His research interests include the classical analysis, Bayesian analysis, Biostatistics and mathematical education. He is currently a lecturer in the Department of Drug Evaluation and Informatics, School of Pharmaceutical Sciences, University of Shizuoka, Japan.
He also is a guest researcher of National Center for Global Health and Medicine and Shizuoka General Hospital as Biostatistician.
References
- Abramowitz, M., & Stegun, I. A. (2010). Handbook of mathematical functions: With formulas, graphs, and mathematical tables. United States: Dover Publications.
- Berger, J. O., & Pericchi, L. R. (1996). The intrinsic Bayes factor for model selection and prediction. Journal of the American Statistical Association, 91, 109–122.
- Berry, D. A. (2006). Bayesian clinical trials. Nature Reviews Drug Discovery, 5, 27–36.10.1038/nrd1927
- Chen, H.-Y., Yu, S.-L., Chen, C.-H., Chang, G.-C., Chen, C.-Y., Yuan, A., ... Yang, P.-C. (2007). A five-gene signature and clinical outcome in non–small-cell lung cancer. New England Journal of Medicine, 356, 11–20.10.1056/NEJMoa060096
- Colett, D. (2003). Modeling survival data in medical research (2nd ed.). UK: Chapman and Hall/CRC.
- Cornfield, J. (1976). Recent methodological contributions to clinical trials. American Journal of Epidemiology, 104, 408–421.
- Grieve, A. P. (2007). 25 years of Bayesian methods in the pharmaceutical industry: A personal, statistical bummel. Pharmaceutical Statistics, 6, 261–281.10.1002/(ISSN)1539-1612
- Heller, G., & Mo, Q. (2015). Estimating the concordance probability in a survival analysis with a discrete number of risk groups. Lifetime Data Analysis, 2, 1–17.
- Hosmer, D. W., Lemeshow, S., & May, S. (2008). Applied survival analysis: Regression modeling of time-to-event data (2nd ed.). United States: Wiley-Interscience.10.1002/9780470258019
- Kass, R., & Raftery, A. (1995). Bayes factors. Journal of the American Statistical Association, 90, 773–795.
- Kawasaki, Y., & Miyaoka, E. (2012a). A Bayesian inference of P(λ1<λ2) for two Poisson parameters. Journal of Applied Statistics, 39, 2141–2152.10.1080/02664763.2012.702264
- Kawasaki, Y., & Miyaoka, E. (2012b). A Bayesian inference of P (π1 > π2) for two proportions. Journal of Biopharmaceutical Statistics, 22, 425–437.10.1080/10543406.2010.544438
- Kirk, A. P., Jain, S., Pocock, S., Thomas, H. C., & Sherlock, S. (1980). Late results of the Royal Free Hospital prospective controlled trial of prednisolone therapy in hepatitis B surface antigen negative chronic active hepatitis. Gut, 21, 78–83.10.1136/gut.21.1.78
- Lee, J. J., & Chu, C. T. (2012). Bayesian clinical trials in action. Statistics in Medicine, 31, 2955–2972.
- O’Hagan, A. (1995). Fractional Bayes factors for model comparison. Journal of the Royal Statistical Society. Series B (Method-ological), 57, 99–138.
- Racine, A., Grieve, A. P., Fluhler, H., & Smith, A. F. (1986). Bayesian methods in practices: Experiences in the pharmaceutical industry (with discussion). Applied Statistics, 35, 93–150.10.2307/2347264
- Spiegelhalter, D. J. (2004). Incorporating bayesian ideas into health-care evaluation. Statistical Science, 19, 156–174.10.1214/088342304000000080
- Spiegelhalter, D. J., Freedman, L. S., & Parmar, M. K. (1993). Applying Bayesian ideas in drug development and clinical trials. Statistics in Medicine, 12, 1501–1511.10.1002/(ISSN)1097-0258
- Spiegelhalter, D. J., Freedman, L. S., & Parmar, M. K. (1994). Bayesian approaches to randomised trials (with discussion). Journal of the Royal Statistical Society. Series A (Statistics in Society), 157, 357–416.10.2307/2983527
- Zaslavsky, B. G. (2010). Bayesian versus frequentist hypotheses testing in clinical trials with dichotomous and countable outcomes. Journal of Biopharmaceutical Statistics, 20, 985–997.10.1080/10543401003619023
- Zaslavsky, B. G. (2013). Bayesian hypothesis testing in two-arm trials with dichotomous outcomes. Biometrics, 69, 157–163.10.1111/j.1541-0420.2012.01806.x
- Zhao, L., Feng, D., Chen, G., & Taylor, J. M. (2015). A unified Bayesian semiparametric approach to assess discrimination ability in survival analysis. Biometrics, 554–562. doi:10.1111/biom.12453
Appendix 1
SAS programming code
The following SAS macro can be used to calculate η = P(h1 < h2 |).
The parameters are defined as follows: N1 = sample size of group 1; N2 = sample size of group 2; X1 = total survival time of group 1; X2 = total survival time of group 2; e1 = total event count for group 1; e2 = total event count for group 2; alpha1 and beta1 = hyperparameters for group 1; alpha2 and beta2 = hyperparameters for group 2.
Subject: Calculation of η = P(h1 < h2 |)
Output variables: Prob_E (Exact method) and Prob_A (Approximate method)
%MACRO PROBMK(N1=,N2=,X1=,X2=,e1=,e2=,alpha1=,beta1=,alpha2=,beta2=);
data BASE01;
/* sample sizes */
n1 = &N1; n2 = &N2;
/* all survival times */
x1 = &X1; x2 = &X2;
/* all event counts */
e1 = &e1; e2 = &e2;
XT1 = X1/N1; XT2 = X2/N2;
/* Input variables */
/* Hyperparameters */
al1 = &alpha1; be1 = &beta1;
al2 = &alpha2; be2 = &beta2;
a1 = e1 + al1; b1=(n1*XT1)+be1;
a2 = e2 + al2; b2=(n2*XT2)+be2;
run;
%let N = 1000;
/* Hypergeometric work */
data work01;
set BASE01;
o = a2; p = 1-a1;
q = 1 + a2;
u = b2/(b1 + b2);
retain K1 - K&N 1;
array K(&N);
do i = 1 to &N;
do j = 1 to i;
o1 = o + j-1;
p1 = p + j-1;
q1 = q + j-1;
K(j)=(o1*p1)/(q1);
end;
%macro kkk;
SS + %do i = 1%to %eval(&N-1);
K&i*
%end;
K&N*(u**i)/FACT(i);
%mend kkk;
%kkk
end;
F = sum(1,SS);
/* Output variables */
/* Exact */
Prob_E = 1-round(1/(a2*Beta(a1,a2))*((b2/(b1 + b2))**a2)*F,0.0001);
/* Approximate */
FFF1=((-a1/b1)+(a2/b2));
FFF2 = Sqrt(a1/b1**2 + a2/b2**2);
FFF = FFF1/FFF2;
Prob_A = round(CDF(‘Normal’,FFF),0.0001);
keep n1 n2 x1 x2 a1 b1 a2 b2 FFF1 FFF2 Prob_E Prob_A;
run;
proc print data = work01; var Prob_E Prob_A; run;
%MEND PROBMK;
* Program End;