
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The efficiency and safety of a new treatment is occasionally evaluated using Poisson distributed count data as the criteria in clinical studies. In such scenarios, non-inferiority tests using Poisson distributed count data are often employed and evaluated in frequentist frameworks. However, in our previous work, we proposed and presented an index that demonstrated that the Poisson parameter obtained in the Bayesian statistic framework is superior to that obtained in inference frameworks, and we also proposed a non-inferiority index of the Poisson parameters. In this paper, we expand upon these methods and propose a new index that utilizes the empirical Bayes method. The results of comparisons to approximate values in terms of accuracy as well as application to examples obtained from actual clinical studies indicate that our proposed new index is both effective and easy to understand intuitively, as it delivers probability directly.
Public Interest Statement
We have proposed and presented an index that demonstrated that the Poisson parameter obtained in the Bayesian statistic framework is superior to that obtained in inference frameworks, and we also proposed a non-inferiority index of the Poisson parameters. In this paper, we expand upon these methods and propose a new index that utilizes the empirical Bayes method. The results of comparisons to approximate values in terms of accuracy as well as from application to examples obtained from actual clinical studies indicate that our proposed new index is both effective and easy to understand intuitively, as it delivers probability directly.
1. Introduction
The efficiency and safety of a new treatment is occasionally evaluated using Poisson distributed count data as the criteria in clinical studies. For example, Rudick et al. (Citation2006) used the relapse count per year in multiple sclerosis as a primary endpoint. Tanaka et al. (Citation2010) compared the efficacy of medication comprising a combination of a steroid and mizoribine with that comprising a steroid only in the treatment of patients suffering from systemic lupus erythematosus. Furthermore, Rothman and Greenland (Citation1998), Graham, Mengersen, and Morton (Citation2003), and Ng and Tang (Citation2005) used Poisson distributed count data obtained from a breast cancer study.
The confidence interval and hypothesis test for the non-inferiority of the Poisson parameter have been studied in the past by several researchers in frequentist frameworks. Sato (Citation1990) derived approximate confidence intervals for the difference between two independent Poisson parameters based on efficiency scores. Swift (Citation2009) compared the confidence intervals for the Poisson parameter from twelve different methods. Li, Tang, Poon, and Tang (Citation2011) developed four asymptotic confidence intervals for the difference between two independent Poisson parameters based on a hybrid method.
In a recent study, Patil and Kulkarni (Citation2012) performed a comparative analysis of nineteen Poisson parameter interval estimation methods. Furthermore, Krishnamoorthy and Thomson (Citation2004) proposed an exact conditional test and a test based on estimated p-values for hypotheses formulated in terms of the difference between Poisson parameters. However, the behavior of their proposed exact conditional test is too conservative. Miede and Mueller-Cohrs (Citation2005) presented a method for calculating the sample size and power for three statistical tests: the exact conditional test, the asymptotic likelihood ratio test, and the score test, and presented a Statistical Analysis System (hereafter, SAS) program for these tests. Therefore, whereas many test statistics and confidence intervals for non-inferiority are based on the frequentist framework, research using non-inferiority in the Bayesian framework is limited.
Utilizing the Bayesian inference framework, Kawasaki and Miyaoka (Citation2012) proposed an index , where λi,post denote Poisson parameters following posterior density and Xi is the number of events in a population of ni patients (or over ni units of time), for i = 1, 2. In this study, however, we consider that the lower Poisson parameter is preferred. Furthermore, exact and approximate expressions were provided for calculating θ using the conjugate gamma prior and compared the probabilities obtained using the approximate and exact expressions. Consequently, they suggested that θ might provide useful information in clinical trials. In addition, for non-inferiority tests in Bayesian inference, Kawasaki and Miyaoka (Citation2013) also proposed a new Bayesian index τ = P(π1,post − π2,post < − Δ0|Y1, Y2), where Y1 and Y2 denote binomial random variables for trials n1 and n2 and parameters π1 and π2, respectively, and a non-inferiority margin Δ0 > 0.
In this paper, we propose a new index, where λi,post denote Poisson parameters following posterior density and Xi is the number of events in a population of ni patients (or over ni units of time), for i = 1, 2, and a non-inferiority margin Δ0 > 0. Furthermore, we present exact (using the Markov chain Monte Carlo (MCMC) method) and approximate methods for calculating η using the conjugate gamma prior and compare the probabilities obtained using the approximate and the exact methods presented.
2. Method
2.1. Approximate and exact methods for calculating η
If Xi is the number of events in a population of ni patients (or over ni units of time) and λi is the event rate, then the sampling distribution is
where i = 1, 2. The conjugate prior density of λi is a gamma distribution with parameters αi and βi:
where αi > 0 and βi > 0. The posterior density for λi is given as
where ai = αi + xi, bi = ni + βi and Γ(a) denotes the gamma function. Let denote the Poisson parameter in the posterior density.
2.1.1. Approximate methods for η
η can be calculated via an approximation using the standard normal table, in which we assume that the sample sizes, n1 and n2, are large. We then need to find a Z-test statistic. The expectation of a difference for the posterior density and the variance of this difference can be calculated as follows:
where μi,post = ai/bi denotes the posterior mean of λi. The Zg-test statistic is given by
The Zg-test statistic is approximately distributed according to the standard normal distribution. Therefore, the approximate probability of index η is given as
where is the cumulative distribution function of the standard normal distribution. We can easily calculate the approximate probability. In Section 3, we show the difference between the exact and the approximate probabilities.
2.1.2. MCMC methods for η
Conversely, we can calculate the new index, η, using an exact posterior probability density function (pdf). The exact probability of η is given by
where f (δ) for is an exact posterior pdf. However, computation using an exact posterior pdf is inefficient; as a result, to the best of our knowledge, an exact expression has never been computed in previous studies.
Kawasaki, Shimokawa, and Miyaoka (Citation2013) discovered that the difference in the probability computed using binomial proportions with the exact method to that computed using the MCMC method is minor. Consequently, in this paper we compute using the MCMC method, a means of sampling from a posterior density, as the exact method. We utilize a random-walk Metropolis-Hasting algorithm as our MCMC method and use it to introduce a computational procedure for η. Given that the samples are derived from two independent populations, the posterior joint distribution of λ1 and λ2 is a product of its marginal distributions. Therefore, we can obtain samples from the posterior distribution of by simulating k values from the posterior distribution of λ1 and λ2 using the MCMC procedure of SAS, e.g.
and
, respectively. Then, by computing
, we obtain the simulated values from the posterior distribution of
. The posterior samples obtained via the MCMC method after the burn-in period are
. We take note of the fact that
is equal to
. Thus, η can be expressed as
where
is the empirical distribution function.
3. Results
3.1. Comparative analysis
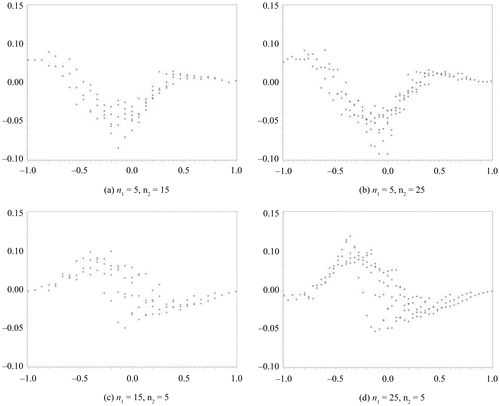
In this section, we compare the exact η defined by the MCMC method to the approximate η. We assume a non-informative prior distribution. In our computation for η via the MCMC method, we set the total number of occurrences at forty-five thousand, the burn-in term at five thousand, and the sampling interval at every ten items. We subsequently confirmed the convergence from the plot of a sample autocorrelation and the plot traced for the overall results. These results are summarized in Figures –. We set the difference in sample rate (X2/n2−X1/n1) on the horizontal axis and plotted the difference between the approximate η and the exact η on the vertical axis. Figures and show the results obtained for the same sample size scenario (n1 = n2 = 10, 20, 30, 50), whereas Figures and show the results for the unbalanced sample size scenario (n1, n2) = (5, 15), (5, 25), (15, 5), (25, 5). In addition, the results depicted in Figures and were obtained with Δ0 = 0.1, whereas those depicted in Figures and were obtained with Δ0 = 0.2.
Figure 1. Δ0 = 0.1.
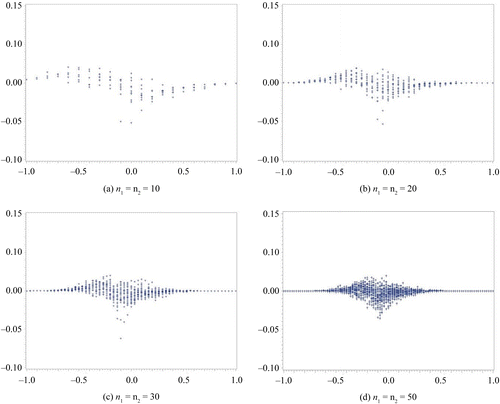
Figure 2. Δ0 = 0.2.
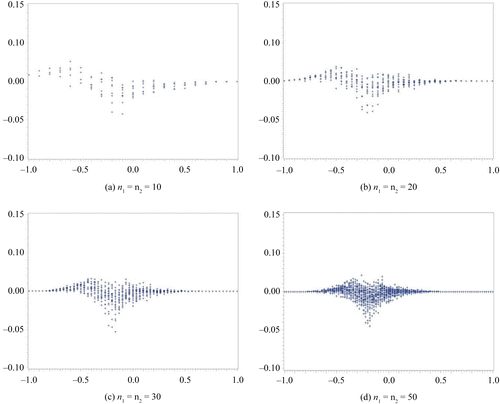
Figure 3. Δ0 = 0.1.
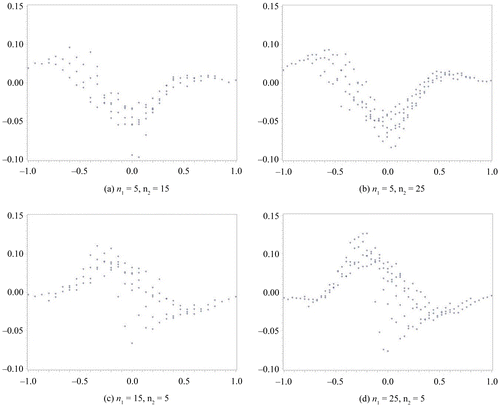
Figure 4. Δ0 = 0.2.
From the results depicted in Figure , it is clear that the difference between the approximate and exact methods is the greatest when the difference in the sample rate is approximately Δ0. There also appears to be a tendency for η to be estimated as being higher by the exact method than the approximate method when the sample rate is negative; that is, when the proportion of X2 is high. Conversely, the approximate method estimates a higher η than the exact method when the sample rate is positive. A difference in η between the approximate and the exact methods closer to zero within the range, which is the large difference of sample rate, is obtained by increasing the sample size.
The results depicted in Figure exhibit the same tendency as those in Figure . The difference between the approximate method and the exact method is the greatest when the difference in the sample rate is approximately Δ0. Although we have not included the corresponding results in this paper, this trend can also be seen when Δ0 is set to a higher value.
From the results depicted in Figure , it can be seen that a larger dispersion of η appears in both the approximate and exact methods when the sample size is unbalanced than when it is equivalent. A tendency for the exact method to estimate a higher η than the approximate method can be observed when the sample rate is negative; a similar tendency is also present when the sample size is equivalent.
The results depicted in Figure exhibit the same tendency as those in Figure . On comparing both sets of results, we discovered that the difference between the η obtained via the approximate method and that obtained via the exact method is only a gap of Δ0; that is, an approximate difference of 0.1. Furthermore, the difference in the η calculated by each method increases when it is approximately Δ0; that is, set as a non-inferiority parameter.
3.2. Example
In this section, we show the utility of η by applying it to the results of clinical trials. Table lists the results of a double-blind, randomized study that compared the efficacy of a combination of a steroid and mizoribine (group CSM) with that of a steroid only (group S) in the treatment of patients with systemic lupus erythematosus (Tanaka et al., Citation2010). The primary objective of the study was to show that the relapse rate of group CSM was lower than that of group S by over 10%. The values obtained for η are listed in the rightmost column of Table . We adopted a non-informative prior. Consequently, both the exact η and the approximate η became similar values, indicating that the relapse rate of group CSM was lower than that of group S by over 10% with a 93.7% probability.
Table 1. Comparison of the efficacy of CSM with that of S
Table lists the results of a double-blind, randomized, phase-3 clinical trial that compared the safety of dienogest (hereafter, the study drug) and buserelin acetate (hereafter, the control drug) in the treatment of patients with endometriosis (from the assessment report of the Pharmaceuticals and Medical Devices Agency, Citation2007). The resulting adverse event rates, that is, one of the safety endpoints, are shown in Table . The primary objective of this study was to show that the occurrence rate of an adverse event for the study drug group was not inferior to that of the control drug group by more than 10%. In other words, the occurrence rate of adverse events for the study drug group was at least 10% lower than that of the control drug group. Using the non-informative prior, the approximate probability of η was obtained as 0.873 whereas the exact probability was obtained as 0.875. Therefore, the occurrence rate of the adverse events of the study drug group was not inferior to that of the control drug group by less than 10% with an 87% probability.
Table 2. Comparison of the safety of study drug with that of control drug
4. Discussion and conclusions
In this paper, we proposed a new index along with two computation methods: an approximate method and an exact method using the MCMC method. The approximate method is very simple to compute, whereas the exact method requires software that can utilize the MCMC method, such as SAS or WinBUGS, to perform computations. Therefore, the exact method is more complex than the approximate method. However, for small sample sizes where there are small differences in sample rate or imbalanced sample sizes in both groups, we found that the difference between the exact probability and the approximate probability only reached a maximum of 10%. Therefore, we recommend employing the exact probability for those cases.
Applying η to examples of actual clinical trials, we discovered that η is easy to understand intuitively because it delivers probability directly. Furthermore, because it uses the empirical Bayes method, we believe that this index can compute probabilities using the results of similar previously conducted clinical trials as well.
In summary, the results presented in this paper indicate that our proposed new index η is both effective and easy to understand intuitively.
Acknowledgments
The authors wish to thank the anonymous reviewers for their suggestions that helped to improve the manuscript.
Additional information
Funding
Notes on contributors
Yohei Kawasaki
Yohei Kawasaki received his BS degree in mathematics in 2005 and his MS and PhD degrees in mathematical science from Tokyo University of Science, Japan in 2007 and 2012, respectively. He joined the Mitsubishi Tanabe Pharma Corporation, the National Center for Global Health and Medicine, and Tokyo University of Science, in 2005, 2013, and 2014, respectively.
He has published over 80 research articles in reputed international journals. His research interests include the classical analysis, Bayesian analysis, biostatistics, and mathematical education.
He is currently a lecturer in the Department of Drug Evaluation and Informatics, School of Pharmaceutical Sciences, University of Shizuoka, Japan. He also is a guest researcher at the Shizuoka General Hospital as a Biostatistician.
Related Research Data
References
- Graham, P. L., Mengersen, K., & Morton, A. P. (2003). Confidence limits for the ratio of two rates based on likelihood scores: Non-iterative method. Statistics in Medicine, 22, 2071–2083.10.1002/(ISSN)1097-0258
- Kawasaki, Y., & Miyaoka, E. (2012). A Bayesian inference of P(λ 1 < λ 2 ) for two Poisson parameters. Journal of Applied Statistics, 39, 2141–2152.10.1080/02664763.2012.702264
- Kawasaki, Y., & Miyaoka, E. (2013). A Bayesian non-inferiority test for two independent binomial proportions. Pharmaceutical Statistics, 12, 201–206.10.1002/pst.1571
- Kawasaki, Y., Shimokawa, A., & Miyaoka, E. (2013). Comparison of three calculation methods for a Bayesian inference of P(π1 > π2). Journal of Modern Applied Statistical Methods, 12, 256–268.
- Krishnamoorthy, K., & Thomson, J. (2004). A more powerful test for comparing two Poisson means. Journal of Statistical Planning and Inference, 119, 23–35.10.1016/S0378-3758(02)00408-1
- Li, H. Q., Tang, M. L., Poon, W. Y., & Tang, N. S. (2011). Confidence intervals for difference between two Poisson rates. Communications in Statistics-Simulation and Computation, 40, 1478–1493.10.1080/03610918.2011.575509
- Miede, C., & Mueller-Cohrs, J. (2005). Power calculation for non-inferiority trials comparing two Poisson distributions. Retrieved April 27, 2015, from http://www.lexjansen.com/phuse/2005/pk/pk01.pdf
- Ng, H. K. T., & Tang, M. L. (2005). Testing the equality of two Poisson means using the rate ratio. Statistics in Medicine, 24, 955–965.10.1002/(ISSN)1097-0258
- Patil, V. V., & Kulkarni, H. V. (2012). Comparison of confidence intervals for the Poisson mean: Some new aspect. REVSTAT—Statistical Journal, 10, 211–227.
- Pharmaceuticals and Medical Devices Agency (PMDA). (2007). Dienogest of assessment report. Tokyo: Author. (in Japanese).
- Sato, T. (1990). Confidence intervals for effect parameters common in cancer epidemiology. Environmental Health Perspectives, 87, 95–101.10.1289/ehp.908795
- Swift, M. B. (2009). Comparison of confidence intervals for a Poisson mean – further considerations. Communications in Statistics—Theory and Methods, 38, 748–759.10.1080/03610920802255856
- Tanaka, Y., Yoshikawa, N., Hattori, S., Sasaki, S., Ando, T., & Ikeda, M. (2010). Combination therapy with steroids and mizoribine in juvenile SLE: A randomized controlled trial. Pediatric Nephrology, 25, 877–882.10.1007/s00467-009-1341-4
- Rothman, K. J., & Greenland, S. (1998). Modern epidemiology. Philadelphia, PA: Lippincott Williams & Wilkins.
- Rudick, R. A., Stuart, W. H., Calabresi, P. A., Confavreux, C., Galetta, S. L., Radue, E. W., … Panzara, M. A. (2006). Natalizumab plus interferon beta-1a for relapsing multiple Sclerosis. New England Journal of Medicine, 354, 911–923.10.1056/NEJMoa044396