
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper considers the estimation of parameters based on a progressively type-I interval-censored data from a mixed generalized exponential distribution. The maximum likelihood estimation is used but an analytic form cannot be obtained. The EM algorithm is applied to obtain the maximum likelihood estimates. The performance of the estimates is judged by a simulating study and a real data is presented to illustrate the method of estimation developed here.
Public Interest Statement
Progressive type-I interval censoring data in survival analysis and reliability analysis are a kind of interested and popular data type. This work is modeling for this kind of data with a more flexible Mixed Generalized Exponential Distribution including the exponential distribution and Weibull distribution. And the result of this paper can apply to the lifetime analysis in clinical trial, engineering and so on.
1. Introduction
In the life testing, reliability studies and survival analysis, it is extremely common that items are lost or removed from experiments before failure. The most popular censoring schemes are type-I and type-II censoring. Under type-I censoring, the test is continued until a pre-specified time. In type-II censoring, the test is continued up to a pre-specified number of failures. Progressive type-II censoring is an extension of the traditional type-II censoring scheme and it has been studied such as Balakrishnan and Aggarwala (Citation2000), Balakrishnan, Kannan, Lin, and Wu (Citation2004) and so on. Sometimes it is impossible to observe the whole life test process continuously due to time and cost constraint. Only the number of failures is observed in an interval instead of observing the failure time exactly and this is called interval censoring. As the mixture of the interval censoring and progressive censoring, Aggarwala (Citation2001) introduced progressive type-I interval censoring scheme and developed the statistical inference for the exponential distribution based on progressively type-I interval-censored data. Ng and Wang (Citation2009) discussed statistical inference for Weibull distribution under progressive type-I interval censoring. They have compared with different estimation methods for the parameters of Weibull distribution via simulation. Lin, Wu, and Balakrishnan (Citation2009) considered determination of optimum life testing plan with progressively type-I interval-censored data from the log-normal distribution. Chen and Lio (Citation2010) considered parameter estimations for generalized exponential distribution under progressive type-I interval censoring. They have obtained the estimates of unknown parameters using EM algorithm, midpoint approximation method and method of moments. Further, Lio, Chen, and Tsai (Citation2011) presented the parameter estimations of the generalized Rayleigh distribution at the same censoring scheme. Peng and Yan (Citation2011) considered the MLEs and moments estimators of the parameters for gamma distribution based on progressive type-I interval censoring and compared with the biases and mean square errors through simulation. Pradhan and Gijo (Citation2013) considered inference for the unknown parameters of log-normal distribution based on progressively type-I interval-censored data through both frequency and Bayesian approaches.
In most simple life tests, the experimental data come from one population and have only one type of failure. In fact, a mixed distribution can provide a flexible candidate to depict the time to failure. Especially in the analysis of biased life data, the failure hazard in the beginning is quite high and the failure rate is decreased or constant as the age increases. On this occasion, population is not homogeneous but is made up from sub-populations. There are many researches for the mixed distribution, such as McClean (Citation1986), Soliman (Citation2006), Tian, He, and Chen (Citation2008), Tian, Tian and Chen (Citation2012), Tian, Tian, and Zhu (Citation2014), Tian, Zhu and Tian (Citation2013) and so on. Nevertheless, to our best knowledge, no published papers address maximum likelihood estimation of the mixed generalized exponential distribution (MGED) under progressive type-I interval censoring. In this work, we consider the estimation for parameters of the MGED based on progressively type-I interval-censored data. This paper gives the likelihood equations of the unknown parameters. It is observed that there is no closed form of MLEs. Therefore, it is suggested to use the EM algorithm to compute the MLEs and present the performance of the estimates by simulations.
The rest of the paper is organized as follows. The model and data description are provided in Section 2. The maximum likelihood estimators of the unknown parameters are obtained in Section 3. The EM algorithm procedure is given in Section 4. The performance of the estimators is investigated via simulation in Section 5. A data-set is analyzed in Section 6. Section 7 includes some conclusion remarks.
2. The description of the model and data
Consider the MGED with m components with its probability density function, cumulative distribution function and hazard function as follows(2.1)
(2.1)
(2.2)
(2.2)
(2.3)
(2.3)
where ,
,
, 0 < pk < 1, k = 1, …, m − 1,
, αk > 0 are the shape parameters,
are the scale parameters, the number of the parameters is 3m − 1.
Then, progressive type-I interval censoring scheme is as follows. Let n identical items be placed on a test at time t0 = 0 and pre-specify N inspection times t1 < t2 < ⋯ < tN, where tN is the scheduled termination time of the experiment. Suppose Xi is the failure number within the interval of (ti−1, ti], Yi is the survival items numbers at time ti and Ri is the number of items randomly removed from the surviving items at time ti. R1, R2, …, RN can be pre-specified by the percentage of the remaining surviving items. Therefore, for the pre-specified percentage . Alternatively R1, R2, …, Rm can also be pre-specified positive integers. In this case, there must be at least Ri units available for removal. The proportions of surviving units to be removed at the monitoring and censoring points have been given in the simulation. And the progressively type-I interval-censored data are given by {Xi, Ri, ti}, i = 1, 2, …, N, where the sample size
. If Ri = 0, i = 1, 2, …, N – 1, then progressive type-I interval censoring is reduced to the traditional interval-censored data, X1, X2, …, XN, XN+1 = RN.
3. Maximum likelihood estimation
Given a progressively type-I interval-censored data, {Xi, Ri, ti}, i = 1, 2, …, N which sample size is n, from a lifetime distribution with distribution function F(T, θ) and θ is the parameter vector. Then, the likelihood function is (Aggarwala, Citation2001)(3.1)
(3.1)
where t0 = 0. We can obtain the MLEs of the parameters by maximizing the likelihood function in (3.1).
Given the MGED by the Equation (2.2), the above likelihood function can be specified as follows:
And the log-likelihood function is
Taking derivatives of the log-likelihood function with respective to to zero, the following score equations are obtained:
Obviously, the equations are quite complex and there is no closed form for the solutions to the above equations and the EM algorithm introduced as follows to find the MLEs of , k = 1, 2, …, m.
4. EM algorithm
The Expectation Maximization (EM) Algorithm (Dempster, Laird, & Rubin, Citation1977) is a useful tool to estimate the parameters of the distribution based on an incomplete data. Here, some notations are similar to that in the Tian et al. (Citation2014). In order to estimate the MGED models under progressive type-I interval censoring, EM algorithm is applied to estimate the unknown parameters. Suppose τ1, τ2, …, τn are n independent identically distributed (iid) samples from the MGED model and denote
where k = 1, 2, …, m, i = 1, 2, …, n.
Here, the sample τi, i = 1, 2, …, n is divided into two components that consist of τij and . Let τij, j = 1, 2, …, Xi be the lifetimes within interval (ti−1, ti] and
, j′ = 1, 2, …, Ri be the lifetimes for those withdrawn items at ti for i = 1, 2, …, N and the number of the τij and
are
,
, respectively. Introduce an indicator vector Iij = (Iij1, Iij2, …, Iijm) of τij,
of
,
is a binary random variable only taking the value 1 if τij(
) comes the k-th component, and 0 otherwise for k = 1, 2, …, m. Also denote
i = 1, 2, …, N, j = 1, 2, …, Xi, j′ = 1, 2, …, Ri as an indicator matrix composed of n indicator vectors of all life variables τij and
. Evidently random vector Iij = (Iij1, Iij2, …, Iijm) and
follows the multinomial distribution. However, we may not know which component the variate comes from. Namely, I cannot be observed, thus regard it as the missing data in the EM algorithm. In the following paper, denote
,
as the indicator vectors of the data τij and
, respectively.
As to the the lifetimes τij within interval (ti−1, ti], the joint density of τij and is
. Given τij, the conditional density of
is
.
Where, ,
,
,
For the right-censored data , the joint density of
and
is given by
. Given
, the conditional density of
is
. Where
,
In Section 2, denote the progressively type-I interval-censored sample as {Xi, Ri, ti}, i = 1, 2, …, N. In the progressive type-I interval censoring experiments, we can only observe the failure numbers Xi within the intervals (ti−1, ti] and Ri, the number of the censored items withdrawn at the censoring time ti for i = 1, 2, …, N. Then, the observed values can be simply denoted as Y = (t1, t2, …, tN, X1, X2, …, XN, R1, R2, …, RN). However, the true failure time within the interval (ti−1, ti] denoted as τij, i = 1, 2, …, N, j = 1, 2, …, Xi and the true failure time of censored units at ti denoted as , i = 1, 2, …, N, j′ = 1, 2, …, Ri can not be observed in life experiments. Consequently,
can be regarded as missing data. All the missing data can be denoted (τ, I) and all the complete data can be denoted as W = (τ, I, Y). The following procedure will give the MLEs of all unknown parameters via the EM algorithm consisting of two steps: E-step and M-step.
First of all, the likelihood function of the MGED model under the complete data W is given by
The log-likelihood function of the complete data is
Given initial values of the unknown parameter vectors, we can obtain parameter estimates of model (2.1) based on EM algorithm via the following two steps. Of course, estimation performance has a great relationship with the choice of the initial values. Generally, different initial values may be lead to different convergence rate. In the simulation, it is suggest to choose some groups of initial values to compare the estimation results.
E-step: suppose the (h − 1)-th iteration values are , then the Q function of the h-th iteration is obtained by
where,
Then,
where
M-step: we maximize the approximate Q function numerically in E-step with respect to unknown parameters to update estimates which are denoted as
.
In order to obtain the estimates of unknown parameters more conveniently in M-step, use instead of
, respectively. Here,
have the following expressions:
Then the above Q function is:
Then, take the derivatives of unknown parameters and let(4.1)
(4.1)
(4.2)
(4.2)
(4.3)
(4.3)
Solve the Equations (4.1) and (4.2), there are
(4.4)
(4.4)
(4.5)
(4.5)
Solve the Equation (4.3), there is
(4.6)
(4.6)
From Equation (4.6), obtain the h-th iteration values of parameters p1, …, pm−1 which are the solutions of the linear equation group denoted by AP = b, where P, A, b are given respectively as follows
Since , it is easy to testify that the rank of matrix A is m − 1, i.e. A is a invertible matrix. Therefore, the unique solution of parameter vector P of the h-th iteration in the M-step is obtained
(4.7)
(4.7)
From the above Equations (4.4), (4.5) and (4.7), we can update by repeating E-step and M-step till the total error of all estimated parameters approaches the supposed restraint.
5. Simulation study
The purpose of simulation study is to investigate the performance of the estimates for the MGED parameters in modeling progressive type-I interval censoring lifetime data. Here, we use some similar algorithm steps proposed in Aggarwala (Citation2001). The simulation is conducted in R language. To be self-contained, the algorithm is re-produced as follows.
Firstly, generate the numbers, Xi, of failed items in each subinterval (ti−1, ti], i = 1, 2, …, N, from a sample of size n putting on life testing at time ti = 0. A progressively type-I interval-censored data,(Xi, Ri, ti), i = 1, 2, …, N, from MGED which has distribution (2.2) can be generated using the fact that(5.1)
(5.1)
and let X0 = 0 and R0 = 0 for i = 1, 2, …, N,
(5.2)
(5.2)
(5.3)
(5.3)
where floor() returns the largest integer not greater than the argument in R language and 0 = t0 < t1 < ⋯ < tN < ∞ are pre-scheduled times.
In this paper, we just consider the MGED model with two components under the progressive type-I interval censoring scheme. Suppose that the true values of model parameters are , while the initial values are taken as
,
. Each replication of the simulation generates a progressively type-I interval-censored data of size n = 60, 120, 180, 300, 500 with N = 10, pre-specified inspection times t1 = 1, t2 = 2, t3 = 3, t4 = 4, t5 = 5, t6 = 6, t7 = 7, t8 = 8, t9 = 9 and t10 = 10 and t10 = 10 as the time to terminate the experiment.
In this paper, we consider the following progressive interval censoring
Schemes:
Scheme 1:
Scheme 2:
Scheme 3:
Scheme 4:
where censoring in in lighter for the first four intervals and heavier for the next five intervals. The censoring pattern is reversed in
.
is no censoring in the first three interval and then some censoring afterwards.
is the conventional interval censoring where no removals prior to the experiment termination.
Repeat the simulation experiments 1,000 times for the sample sizes n = 60, 120, 180, 300, 500. Denote the h-th estimates as h = 1, …, s, s = 1,000. The final average bias and mean square errors (MSEs) of the estimates are given respectively as
and
, where
is the j-th coordinate of the unknown parameter vector Θ. The computation results for four different censoring schemes are illustrated in Tables –, respectively.
Table 1. Average biases, MSE(s) of estimators for scheme 1 when the sample sizes are n = 60, 120, 180, 300, 500
Table 2. Average biases, MSE(s) of estimators for scheme 2 when the sample sizes are n = 60, 120, 180, 300, 500
Table 3. Average biases, MSE(s) of estimators for scheme 3 when the sample sizes are n = 60, 120, 180, 300, 500
Table 4. Average biases, MSE(s) of estimators for scheme 4 when the sample sizes are n = 60, 120, 180, 300, 500
From Tables –, we can see that the EM algorithm is very effective in dealing with parameter estimation of the MGED for the given four sampling schemes under the progressive type-I interval censoring. The number of the specified inspection is fixed. For the given one scheme, it is obvious that the simulation results are changed as n increases, but the range is very small. It is easy to understand the phenomenon that the estimation of the unknown parameters is biased slightly when the number of the items withdrawn from the experiment is increasing. It is obvious that the simulation results are mainly decided by the sample size n and the censoring proportion. For different censoring schemes, the smaller censoring proportion we design in life testing, the better estimation results we will get. Therefore, the scheme 4 presents the most precise estimation. Further, for fixed N as n increases, on the whole, the biases, the MSEs decrease.
6. Data analysis
In order to illustrate the effectiveness of the model and algorithm, we analyze a real data-set bellow. A data-set which describe the survival times for surgery of a group of 374 patients who underwent operations in connection with a type of malignant disease (Berkson & Gage, Citation1950; Lawless, Citation2003). The data are given in Table .
Table 5. Survival time in interval form for the patients who underwent operations in connection with a type of malignant disease
According to the data above, djs in the first five intervals are significantly different with the last intervals and think that the data may not come from the homogenous population. Thus, consider two components of the MGED (1.1) to analyze this data-set. Through the method discussed above, we can obtain that the parameter estimates are ,
,
,
,
, respectively. And the survival function and the hazard rate function of the model (1.1) are as follow:
(6.1)
(6.1)
(6.2)
(6.2)
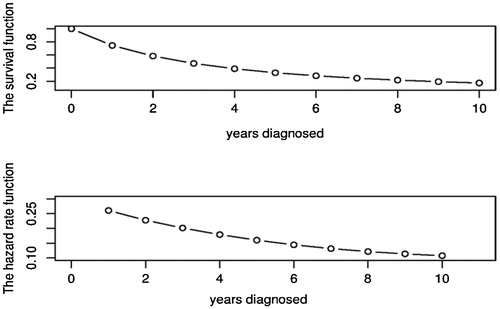
From (6.1) and (6.2), we can get the fitted survival function and hazard rate function of the real data as in Figure . For Figure , the hazard rate function is monotone decreasing function. There is great change in the first few years and then tends to be gentle after eight years. Therefore, for this disease, the risk rate of patients after operation in the short time is higher. In order to avoid the recurrence in the recovery stage after the operation, we suggest to check regularly.
Figure 1. The fitted survival function and hazard rate function of the real data.
In order check the validity of the model, we adopt the Kolmogorov-Smirnov goodness-of-fit test statistic for the fitted distribution . Define the maximum distance in Kolmogorov-Smirnov goodness-of-fit test:
(6.3)
(6.3)
as the distance between the empirical distribution , of the given complete data-set and the fitted distribution function
with
as the MLE of unknown parameter vector θ. When a progressively type-I interval-censored data are given, the empirical distribution is replaced by the following (6.4) in the formula Dn(F).
(6.4)
(6.4)
where
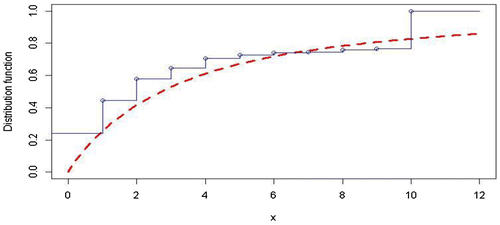
Fit the data-set in Table , we obtain the K-S distance 0.2406. So it is reasonable to say that the MGED provides a good fit for the given data-set in Table . Figure is given to compare the empirical distribution function with the fitted distribution function.
Figure 2. The empirical and fitted distribution function.
7. Conclusion and remarks
This article considers the estimation of parameters based on a progressively type-I interval-censored data from a MGED. Because the data in this paper are not complete, the EM algorithm is used to obtain the maximum likelihood estimates. Then the performance of the estimates is presented by a simulating study in different setups and gets effective results. Lastly, a surgery data of a group of 374 patients who underwent operations in connection with a type of malignant disease are presented to illustrate the method of estimation developed here.
Additional information
Funding
Notes on contributors
Chunjie Wang
Chunjie Wang obtained her PhD degree in Probability and Mathematics Statistics from the School of Mathematics, Jilin University, Changchun, China. She is currently working in Changchun University of Technology (CCUT), Changchun, China, as an associate professor. Her research interests include Survival analysis, Mathematical Statistics.
Shuying Wang
Shuying Wang is currently doing her PhD from Jilin University, Changchun, China. Her research interests include Mathematical Statistics and Survival analysis.
Dehui Wang
Dehui Wang is currently working as professor in the School of Mathematics in Jilin University, Changchun, China. His research interests include Mathematical Statistics, Time Series, and Survival Analysis.
Chunjing Li
Chunjie Li is currently doing her PhD from Jilin University, Changchun, China. Her research interests include Mathematical Statistics and Survival Analysis.
Xiaogang Dong
Xiaogang Dong obtained his PhD degree in Statistics from Jilin University, Changchun, China. He is currently working in Changchun University of Technology (CCUT), Changchun, China, as a professor. His research interests include High frequency data analysis, Survival analysis, Mathematical Statistics, and Applied Statistics.
References
- Aggarwala, R. (2001). Progressive interval censoring: Some mathematical results with applications to inference. Communications in Statistics-Theory and Methods, 30, 1921–1935.10.1081/STA-100105705
- Balakrishnan, N., & Aggarwala, R. (2000). Progressive Censoring. Boston, MA: Birkhauser.10.1007/978-1-4612-1334-5
- Balakrishnan, N., Kannan, N., Lin, C. T., & Wu, S. J. (2004). Inference for the extreme value distribution under progressive Type-II censoring. Journal of Statistical Computation and Simulation, 74, 25–45.10.1080/0094965031000105881
- Berkson, J., & Gage, R. P. (1950). Calculation of survival rates for cancer. Proceedings of the Staff Meetings Mayo Clinic, 25, 270–286.
- Chen, D. G., & Lio, Y. L. (2010). Parameter estimations for generalized exponential distribution under progressive type-I interval censoring. Computational Statistics and Data Analysis, 54, 1581–1591.10.1016/j.csda.2010.01.007
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society. Series B, 39, 1–38.
- Lawless, J. F. (2003). Statistical models and methods for lifetime data (2nd ed.). Hoboken, NJ: John Wiley & Sons.
- Lin, C. T., Wu, S. J. S., & Balakrishnan, N. (2009). Planning life tests with progressively type-I interval censored data from the lognormal distribution. Journal of Statistical Planning and Inference, 139, 54–61.10.1016/j.jspi.2008.05.016
- Lio, Y. Z., Chen, D. G., & Tsai, T. R. (2011). Parameter estimations for generalized Rayleigh distribution under progressively type-I interval censored data. Open Journal of Statistics, 1, 46–57.10.4236/ojs.2011.12006
- McClean, S. (1986). Estimation for the mixed exponential distribution using grouped follow-up data. Journal of the Royal Statistical Society. Series C: Applied Statistics, 35, 31–37.
- Ng, H., & Wang, Z. (2009). Statistical estimation for the parameters of Weibull distribution based on progressively type-I interval censored sample. Journal of Statistical Computation and Simulation, 79, 145–159.10.1080/00949650701648822
- Peng, X., & Yan, Z. (2011). Parameter estimations with gamma distribution based on progressive type- I interval censoring. IEEE International Conference on Computer Science and Automation Engineering, 1, 449–453.
- Pradhan, B., & Gijo, E. V. (2013). Parameter estimation of lognormal distribution under progressive type-I interval censoring (Technical Report No. SQCOR-2013-02).
- Soliman, A. A. (2006). Estimators for the finite mixture of Rayleigh model based on progressively censored data. Communications in Statistics-Theory and Methods, 35, 803–820.10.1080/03610920500501379
- Tian, Y., He, J., & Chen, P. (2008). Mixed generalized exponential with censored data. Journal of Chongqing Institute of Technology (Natural Science), 22, 79–81.
- Tian, Y. Z., Tian, M. Z. I., & Chen, P. (2012). Parameter estimation for a mixture of generalized exponential distribution under grouped and right-censored samples. Chinese Journal of Applied Probability and Statistics, 28, 561–571.
- Tian, Y. Z., Tian, M. Z., & Zhu, Q. Q. (2014). Estimating a finite mixed exponential distribution under progressively type-II censored data. Communications in Statistics-Theory and Methods, 43, 3762–3776.10.1080/03610926.2012.752843
- Tian, Y. Z., Zhu, Q. Q., & Tian, M. Z. (2013). Inference for mixed generalized exponential distribution under progressively type-II censored samples. Journal of Applied Statistics, 41, 660–676.