
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Production Possibility Set (PPS) is defined as the set of all inputs and outputs of a system in which inputs can produce outputs. In Data Envelopment Analysis (DEA), it is highly important to identify the defining hyperplanes and especially the strong defining hyperplanes of the empirical PPS. Although DEA models can determine the efficiency of a Decision Making Unit (DMU), but they cannot present efficient frontiers of PPS. In this paper, we propose a new method to determine all strong efficient (Pareto-efficient) DMUs and strong defining hyperplanes of the PPS with constant returns to scale including the Pareto-efficient DMUs. Furthermore, we apply the newly proposed method to find the normal vectors or gradient of the strong defining hyperplanes of the PPS including strong efficient DMUs which are under evaluation. Consequently, the equations of these hyperplanes are determined. To illustrate the applicability of the proposed method, some numerical examples are finally provided. Our method can be easily implemented using existing packages for operation research, such as GAMS.
Public interest statement
In this paper, a method to evaluate DMUs and finding all Pareto-efficient DMUs and strong defining hyperplanes of the PPS has been introduced.
Some of the applications of strong defining hyperplanes are: marginal discussions, marginal rates, sensitivity analysis, returns to scale and the efficiency analysis of DMUs.
1. Introduction
Data Envelopment Analysis (DEA) is a non-parametric method which is used for measuring the relative efficiency of a set of Decision Making Units (DMUs). In order to measure the relative efficiency of DMUs, input-oriented or output-oriented CCR or BCC envelopment models can be used (Banker, Charens, & Cooper, Citation1984; Charnes, Cooper, & Rhodes, Citation1978). Of course, there are some other models in DEA by which the relative efficiency of the DMUs can be measured (Cooper, Li, Seiford, & Tone, Citation1999).
The main problem in standard models of DEA is the presence of weak efficient frontiers. These frontiers are identified by adopting zero weights for the input and output factors. Although due to the compensatory structure of these models, there would be many alternative optimal solutions and the zero weights might go unnoticed. Therefore, identification and determination of strong defining hyperplanes, or in other words, the hyperplanes with corresponding strong efficient frontiers become highly significant.
This issue was first raised by Charnes et al. (Citation1978). Yu, Wei, Brockett, and Zhou (Citation1996) analysed the structural properties of PPS efficiency frontiers in a generalized DEA model. By using their method, all DMUs on a hyperplane can be identified, so that an analysis on DEA hyperplanes may be offered (Yu et al., Citation1996). Jahanshahloo, Hosseinzadeh Lotfi, ZhianiRezai and Rezai Balf (Citation2007) presented an algorithm for finding PPS strong defining hyperplanes. Although their method was based on pure mathematics, by using the hyperplanes identified in this method, all members or elements reference set of a DMU can be determined (Jahanshahloo et al., Citation2007). Another different method is introduced by Jahanshahloo, Shirzadi and Mirdehghan (Citation2009). In their paper, a three-stage algorithm is introduced which using the solutions of additive model and multiplier form of BCC model, the strong efficient hyperplanes are identified (Jahanshahloo et al., Citation2009). Amirtaymouri and Korrostami (Citation2012) found all linearly independent strong defining hyperplanes (LISDHs) of the PPS passing through a specific DMU. To do so, they defined corresponding to each efficient unit, a perturbed inefficient unit and by solving at most linear programs, identified the hyperplanes (Amirteimoori & Kordrostami, Citation2012). All of the studies mentioned above were conducted using radial models. There are also some studies which used non-radial models, especially Slack Based Measure (SBM) (Aparicio & Pastor, Citation2013; Hadi Vencheh, Jablonsky, & Esmaeilzadeh, Citation2015; Tone & Tsutsui, Citation2010).
In this paper, for each given DMU of , the corresponding problem in the offered model is formed, and by solving it, the Pareto-efficient or nonPareto-efficient nature of the DMU under evaluation is determined. If the DMU under evaluation is Pareto-efficient, then the production possible set,
, strong defining hyperplanes passing through the origin which including the pareto-efficient DMU under evaluation can be identified. Also, the normal vectors and equations of these defining hyperplanes can be characterized.
2. CCR model and defining hyperplanes
Suppose we have n DMUs, where each , produces the same s outputs
, and using the same m inputs
(i=1,...,m). The PPS corresponding to these DMUs are defined as follows:
(1)
(1)
In fact, linear combinations of inputs and outputs form the frontier of PPS. These combinations are indeed the supporting (or defining) hyperplanes of the PPS. CCR model which first proposed by Charnes et al. (Citation1978) is developed by Tc in the following format:(2)
(2)
where (i=1, ...,m) and
(r=1, ...,s) are the inputs and outputs of the unit under evaluation, respectively. This model is called the envelopment form of the CCR model. The corresponding dual model of (Equation2
(2)
(2) ) is as follows:
(3)
(3)
Optimal solutions of model (3) are corresponding to the coefficient of the supporting hyperplanes of the PPS. These hyperplanes are identified by the following equations:(4)
(4)
where (i=1,..., m) and
(r=1,..., s) are the optimal solutions of model (3). Suppose that
and
. If
and the values for all coefficients are non-zero, then
is called Strong Efficient or Pareto Efficient and a part of the strong efficiency frontier is made with these coefficients. These hyperplanes are called strong defining hyperplanes. If
and in some optimal solutions (3) some variables to be zero, then
is called Weak Efficient or nonpareto Efficient. Weak efficiency occurs when the optimal objective of (3) is one and at least one coefficient of each optimal solution is zero. These weights identify the weakly efficient hyperplanes of the PPS. The efficient frontier is the set of all points (actual or virtual) with efficiency score equal to unity.
3. A model for determining defining hyperplanes
As mentioned in the previous section, the PPS corresponding to the CCR model is a set in the form of . This set is a set with
dimension. The defining hyperplanes of
are the sets with a dimension of
. Therefore, if a DMU is lies on a face with
dimension, then this DMU will be lie on one of the hyperplanes forming the frontier of the PPS. Equations for these hyperplanes can be obtained through solving model (3) and via (4). However, since Model (3) has alternative optimal solutions, without determining all optimal solutions, it is not possible to ensure that the hyperplane on which the DMU under evaluation is located is strong efficient.
Since the defining hyperplanes of are
dimensional sets, we can find
linearly independent vector of
in such a way that every one of these vectors becomes orthogonal to normal vector of these hyperplanes. Suppose these vectors are in the form of
in which
is m-vector,
is s-vector and
is
-vector. If we consider the normal vector defining hyperplanes of
as
which is obtained from solving model (3), then we must have :
Suppose a DMU is located on a number defining hyperplanes of . We know that on each of the defining hyperplanes, there are infinite numbers of vectors. From these infinite numbers of vectors, we select the vectors that along with the other selected vectors on the other hyperplanes binding to the DMU under evaluation form
linearly independent vectors.
The aim of selecting the above-mentioned vectors is to find a direction for movement from the DMU under evaluation to these defining hyperplane in such a way that it is possible to stay on . In order to locate such directions, the following model is offered:
(5)
(5)
where a non-Archimedean number and
and
are m-vector and s-vector respectively, with each component equal to one.
is a small number where we move from the DMU under investigation in the direction of vector
with a step length of
.
In model (5), constraints (5-a) and (5-b) ensure that the movement is in . Constraints (5-c) are positioned in such a way that vectors
are orthogonal to the normal vector of the hyperplane on which the
under evaluation is located. In fact, constraints (5-c) can be as many as the number of the vectors on the mentioned hyperplane, but we will show later that these vectors have a special structure, and only
linearly independent vectors are enough for solving model (5) as shown below:
Suppose that
Then according to constraints (5-c), it is easily possible to select -component vectors
in the following manner:
(6)
(6)
where number 1 is the a-th row and
is the
-th
row of
vector, and the value of the other components are zero. With this choice, the total of the possible cases for vector
will be equal to
.
Now, it is enough from the constructed vectors
, we choose
linearly independent vectors and set them in model (5). By solving it, the strong defining hyperplanes corresponding to
is achieved.
By determining and
vectors in the form of
in (6) and choosing
linear independent vectors of it and by inserting the selected linear independent vectors in model (5), the constraint (5-c) will be a redundant constraint. Therefore, by inserting
selected linearly independent vectors in model (5), the constraints (5-c) can be omitted and instead it constraints
contracted and solved the obtained model.
Theorem 1
From vectors with
-components defined as (6), one can choose
linearly independent vectors.
Proof
By using vectors with
-components obtained from (6), matrix D where is an
matrix, we form as follows :
(7)
(7)
By inserting(8)
(8)
matrix D can be written in the following manner:(9)
(9)
Now it is enough to show that:(10)
(10)
In order to prove (10), the following cases are considered.
Case 1: If and
, then matrix D is a
matrix, and in this case, the accuracy of statement (10) is obvious.
Case 2: If ( and
) or (
and
) since in this case
as well as the number of rows in the resulting matrix D is equal to the number of columns plus one, then by omitting any row of matrix D, the determinant of the remaining matrix which is equal to
would not be equal to zero, and, as a result, Rank(D)=
, and so the statement (10) will be correct in this case as well.
Case 3: If and
, then Rank(D)=
, since if the i-th row of this matrix is considered to be
, then we will have:
(11)
(11)
Therefore, the correctness of statement (10) is obvious.
Case 4: If and
, then since in this case
and
and(12)
(12)
Therefore, it is obvious that , and as a result the rank of matrix D can be at last
. In order to prove Rank(D)=
, we construct a matrix
such as
from matrix D in the following manner.
First consider the following matrix:
and by omitting row from the above-mentioned matrix, the obtained matrix which is an
matrix is selected as matrix
. It is now enough to show that
.
We have:
It is obvious that . (since, according to model (5),
,
), and it completes the proof.
Note that in proving the above-mentioned theorem, the choice of matrix from matrix D is not unique, and some other cases can be considered as well.
It should be mentioned that, we can choose linearly independent vectors out of the available
component vectors of
which are defined in the following manner:
(13)
(13)
where 1 is placed in the -th
row and
is placed the a-th
row of the vector
, and all of the other components are zero.
By considering possible cases in choosing linearly independent vectors and putting them in the model (5), it can be normal vectors and equations all of PPS strong defining hyperplanes with constant returns to scale which including the strong efficient DMUs under evaluation, are determined.
4. Numerical examples
Example 4.1
Consider a system of seven DMUs as shown in Figure . Data is given in Table (see Cooper, Selford, & Tone, Citation2002).
Table 1. Data set for the numerical Example 4.1
Figure 1. Numerical Example 4.1.
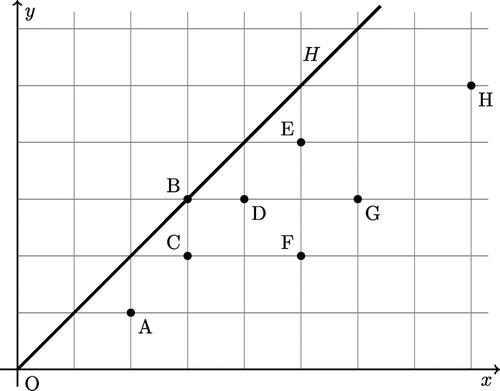
The resulting strong defining hyperplane by Cooper et al. (Citation2002) is as follows.
Since and
, So
. The linearly independent vector,
, is selected using (13) in the following manner:
(14)
(14)
or supposing , we have:
(15)
(15)
By inserting in model (5), each of the DMUs in Table is evaluated supposing
and
. The obtained results are shown up to seven decimal digits in Table .
Table 2. The obtained results based on model (5): Data set for the numerical Example 4.1
The obtained results in Table show that is Pareto-efficient and located on PPS strong defining hyperplane with constant returns to scales obtained from the seven DMUs of A, B, C, D, E, F, G and H. By examining at column
in Table , we see that the obtained normal vector
is the normal vector of defining hyperplane including and origin. Due to the obtained normal vector and considering (4), the equation of the strong defining hyperplane including Pareto efficient
is in access. We have:
and therefore the equation strong defining hyperplane can be written in the following manner: (The same strong defining hyperplane H is in Figure ).
According to the obtained results in columns DMUs A, C, D, E, F, G and H, we observe that DMUs A, C, D, E, F, G and H are not Pareto-efficient or strong efficient.
As can be seen, the results of the proposed model is same as the Cooper et al. (Citation2002).
Example 4.2
Consider a system of four DMUs as shown in Figure . Data is given in Table (see Jahanshahloo et al., Citation2007).
Table 3. Data set for the numerical Example 4.2
Figure 2. Numerical Example 4.2.
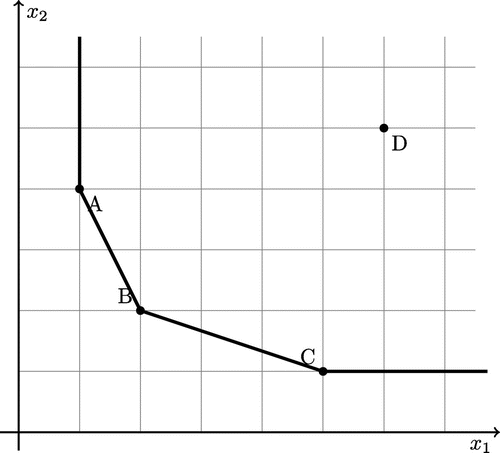
Solution: Since and
, then
. The two linearly independent vectors of
and
are selected using (6) in the following manner:
(16)
(16)
or supposing ,
, we have:
(17)
(17)
By inserting vectors and
in model (5), each of the DMUs in Table are evaluated supposing
and
. The obtained results up to seven decimal digits are shown in Table .
Table 4. The obtained results based on model (5): Data set for the numerical Example 4.2
The obtained results in Table show that ,
and
are pareto-efficient and are located on PPS defining hyperplanes with constant returns to scales obtained from the four DMUs of A, B, C and D. By looking at columns
and
in Table , we observe that the obtained normal vector
is the normal vector of defining hyperplane including ,
and origin. Due to obtained normal vector and considing (4), the equation of the strong defining hyperplane including pareto-efficient DMUs A , B and origin is in access. We have:
and therefore the equation strong defining hyperplane can be written in the following manner:
Similarly, by considering the column , the equation of the strong defining hyperplane includes pareto-efficient DMUs B, C and origin can be obtained as follows:
According to the obtained results in column , we observe that
is not pareto-efficient.
5. Conclusion
This paper proposed a method to evaluate DMUs and find all Pareto-efficient DMUs and strong defining hyperplanes of the PPS with constant returns to scale including the Pareto-efficient DMUs. The proposed model uses the concept of the normal vectors of the hyperplanes instead of determining all optimal solutions for the multiplicative form of the CCR model and specifying positive weights. In the present paper, by only solving one problem for each DMU using model (5), the Pareto-efficient DMUs, as well as the normal vectors and equations strong defining hyperplanes of the PPS with constant returns to scale including the Pareto-efficient DMUs under evaluation, are determined. However, in the documented papers, for example in Jahanshahloo et al. (Citation2009), just the strongly efficient hyperplanes are identified by offering a three-step algorithm and by solving the additive and multiplicative of the BCC form, or in another example such as Amirteimoori and Kordrostami (Citation2012), by solving m + s linear programming problems, only the defining hyperplanes binding in a given DMU are determined.
Note that the model (5) is a non-linear model, and so one may modify it in such a way to be a linear model.
Additional information
Funding
Notes on contributors
Nader Rafati-Maleki
Nader Rafati Maleki is currently a PhD student at Department of Mathematics, Research and Science Branch, Islamic Azad University, Tehran, Iran. His research interests include operation research and data envelopment analysis.
Mohsen Rostamy-Malkhalifeh
Mohsen Rostamy-Malkhalifeh is an associated professor of Department of Mathematics, Science and Research Branch, Islamic Azad University, Tehran, Iran. He has received his PhD in DEA from, Science and Research Branch, Islamic Azad University, Tehran, Iran. His researches includes DEA, decision making in industry and economic, supply chain and its scopes, application of DEA and supply chain in management.
F. Hosseinzadeh Lotfi
F. Hosseinzadeh Lotfi is a full Professor at the Department of Mathematics, Science and Research Branch, Islamic Azad University, Tehran, Iran. His research interests include operation research, data envelopment analysis, MCDM and fuzzy.
References
- Amirteimoori, A., & Kordrostami, S. (2012). Generating strong defining hyperplanes of the production possibility set in data envelopment analysis. Applied Mathematics Letters, 25, 605–609.
- Aparicio, J., & Pastor, J. T. (2013). A well-defined efficiency measure for dealing with closest targets in DEA. Applied Mathematics and Computation, 219, 9142–9154.
- Banker, R. D., Charens, A., & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30, 1078–1092.
- Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2, 429–444.
- Cooper, W. W., Li, S., Seiford, L. M., & Tone, K. (1999). Data envelopment analysis: A comprehensive text with models, applications, References and DEA-solver software. Norwell, MA: Kluwer Academic Publisher.
- Cooper, W. W., Selford, L. M., & Tone, K. (2002). Data envelopment analysis (3th ed.). kluwer Academic Publishers.
- Hadi Vencheh, A., Jablonsky, J., & Esmaeilzadeh, A. (2015). The slack-based measure model based on supporting hyperplanes of production possibility set. Expert Systems with Applications, 42, 6522–6529.
- Jahanshahloo, G. R., Hosseinzadeh Lotfi, F., ZhianiRezai, H., & Rezai Balf, F. (2007). Finding strong defining hyperplanes of production possibility set. European Journal of Operational Research, 177, 42–54.
- Jahanshahloo, G. R., Shirzadi, A., & Mirdehghan, S. M. (2009). Finding strong defining hyperplanes of PPS using multiplier form. European Journal of Operational Research, 194, 933–938.
- Tone, K., & Tsutsui, M. (2010). An epsilon-based measure of efficiency in DEA–--A third pole of technical efficiency. European Journal of Operational Research, 207, 1554–1563.
- Yu, G., Wei, Q., Brockett, P., & Zhou, L. (1996). Construction of all DEA efficient surfaces of the production possibility set under the GDEA. European Journal of Operational Research, 95, 491–510.