
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Although the existing research on educational robots has exhibited the assistance for EFL learners’ English skills, the evidence which shows robot-assisted systems’ effect on adult learners’ English read-aloud is still rare. Nevertheless, read-aloud is still treated as a useful approach in English classes for speech pronunciations in particular in Asia. This study aims at the design of a system that uses a robot as a tutor equips automatic speech recognition to diagnose learners’ errors while they are reading aloud the English passages. The learner is able to practice and improve pronunciations via the diagnosis. An experiment designed with a pretest, a posttest, and a delayed posttest was conducted to evaluate the proposed robot-tutoring system. 19 university students in Taiwan enrolled in the experiment, and learned with the system for 90 minutes per round, with a total of 2 rounds of self-learning. The results showed the participants’ accuracy of read-aloud in the delayed posttest was significantly better than those of the pretest and immediate posttest. In addition, when looking into the investigation of the participants’ perceptions of the system, most were impressed by the system, and also agreed the system was a useful and helpful tool to help reading English passages aloud. Therefore, this study provides evidence of the effects of robot-tutoring approach on adults’ English read-aloud in Taiwan.
Introduction
Reading aloud, or oral reading, is referred to reading the meaningful text aloud. EFL instructors have found the benefits of using reading aloud for the enhancement of English oral competence, especially in Asia (Huang, Citation2010). EFL instructors often believe that reading aloud is able to help the segmental aspects (i.e. consonant and vowel sounds or phonemes) of pronunciation. However, the objections against reading aloud in L2 classrooms are still found in literatures.
The followings are objections uncovered in literatures against adoption of reading aloud for language learning (Gibson, Citation2008). First, reading aloud may be a boring and perhaps anxiety-provoking activity for certain students who dislike to speak English in public. Reading aloud even demotivates students. Second, EFL students are easy to make incorrect pronunciations while reading aloud. If there is no diagnostic tool for reading aloud, students may not be aware of errors and finally lose correct pronunciations. Third, teachers often agree that reading aloud should be a good tool to identify errors while listening to individual’s oral reading. Nevertheless, listening to students’ oral reading accordingly is a heavy workload to teachers. Fortunately, information technology (IT) is able to overcome or reduce these problems.
IT applications such as web-based learning systems and mobile-assisted language learning (MALL) help learners’ read-aloud (Bashori et al., Citation2022; Kartal, Citation2022; Kruk & Pawlak, Citation2021; Tai, Citation2022). Specific technology like ASR (Automatic Speech Recognition) helps learners record and convert speech into text, so that differences can be identified by comparing learners’ speech rendition with the original transcripts (Bashori et al., Citation2022; Kartal, Citation2022; Tai, Citation2022). Besides personal computers or web-based systems, educational robots are helpful instructional platforms. Robots provide benefits for read-aloud, for example, robots can be assigned the role of peers or tutors to listen to the learners’ speaking, and learners might be willing to speak a second or a foreign language to a robot other than their teacher or peers (Alemi et al., Citation2015; Lin et al., Citation2022; Van den Berghe et al., Citation2019). Moreover, robots can also equip ASR function to detect errors of the learners’ English pronunciation and offer immediate feedback like teachers or tutors to help the learners understand the errors.
Common English pronunciation problems in Taiwan
The existing studies found that segmental features such as vowels and consonants cause Taiwanese learners’ English pronunciation difficulties. For instance, eight difficult consonants,/ʒ, ŋ, θ, z, s, v, tʃ, f/, have been identified in Tzwei (Citation1987). Others such as/e, æ, r, w, l, ʤ,/also trouble Taiwan’s EFL learners in making correct sounds (Chang, Citation2001; Huang, Citation2001). In particular, it is hard for Taiwan’s EFL learners to distinguish between/r/and/l/, and therefore, as an example, they often mispronounce “please” as “prease” (Chien, Citation2014; Huang & Radant, Citation2009).
Besides these difficult consonants, vowel length and final consonants are two identified factors for mispronunciations (Huang & Radant, Citation2009; Lin et al., Citation1995). In terms of vowel length, the mother tongue interference makes it hard for L1 Mandarin-speaking learners to discern the differences between/U/and/u/,/i/and/I/, or/e/and/ɛ/. Furthermore, regarding the problem of final consonants, Mandarin-speaking learners tend to drop the final consonants because there is no CVC (consonant + vowel + consonant) structure in Chinese (Lin et al., Citation1995).
Read-aloud for pronunciation
Gibson (Citation2008) found that the primary reasons from teachers to use read-aloud were for practicing pronunciation. Researchers have demonstrated that the adoption of read-aloud exercises is able to benefit pronunciations. Alshumaimeri (Citation2011) investigated the effect of read-aloud on reading performance. 145 Saudi male 10th-graders in a secondary school were recruited and placed in three groups to rotate 3 reading methods: reading aloud, silent reading, and subvocalizing. Results of this research showed that the subjects’ reading performance using reading aloud was significantly better than those who used other two methods on memorizing words, texts, pronunciation, and comprehension.
In addition, Tost (Citation2013) conducted an investigation to assess whether three Spanish adult students whose English proficiency was level 1 could improve their English pronunciation by blending read-aloud and peer appraisal. The result exhibited that after the weak readers read the passages aloud to the strong readers, the comments from the strong readers could help the correction of wrong pronunciations.
Robots for enhancement of speaking or pronunciation
Two common findings in the studies of applying robots on English speaking can be uncovered. Firstly, the subjects in most of current studies were children rather than adults (Estévez et al., Citation2021; Hong et al., Citation2016; Kanda et al., Citation2004; Lee et al., Citation2011; Wang et al., Citation2013). It was also worthwhile to investigate the effectiveness for adults like university students. Secondly, although these studies aimed at the aspects of speaking skills, the current research which concentrates on adoption of robots in oral reading for the improvement of English pronunciation is rare.
In comparison to the studies that focused on children, the following two studies focused on university students who were adults. Iio et al. (Citation2019) developed a robot-assisted system to enhance English conversations of Japanese adult learners who were university students. The system supported learning methods such as shadowing and role play to improve learners’ performance of English conversations. The evaluation of the system in Iio et al. (Citation2019) was entirely assessed by scales of complexity, accuracy, and fluency. The final result showed that the nine Japanese university students who enrolled in the experiment for approximate 210 minutes in total improved English speaking accuracy, fluency, and pronunciation greatly. In addition, Krisdityawan et al. (Citation2022) adopted an educational robot as a teacher to instruct Japanese adult learners’ English pronunciations and prosody. 29 target English words were utilized to improve the vowel/consonant sounds and two short passages with the patterns of intonation and phrasing were used as well. These learning materials were formed in slides. A NAO robot played the role of an instructor to voice the instructions from its speaker with the slides projected on a screen. The NAO led the learners to speak each target word and instruct them the correct pronunciation and also led the learners to read the passages and guided them to acquire the correct prosody.
Objective of this work
The present research adopted Design science research methodology (DSRM) proposed by Peffers et al. (Citation2007) to develop our robot-tutoring system. Design science research methodology (DSRM) is a systematic approach employed for the development and evaluation of innovative systems, particularly in information systems. The process of DSRM is consisted of six activities: identifying and motivating the problem, establishing solution objectives, designing and developing the system, demonstrating its utility, evaluating the system, and disseminating the findings.
As mentioned above, the problems are identified in Iio et al. (Citation2019) and Krisdityawan et al. (Citation2022). Comparing to the two studies above, our present work aimed at the improvement of EFL learners’ pronunciation, but Iio et al. (Citation2019) concentrated on the improvement of conversation fluency and Krisdityawan et al. (Citation2022) aimed at the opportunity to adopt a robot to serve as a teacher to instruct intentional learning materials for segmental pronunciation and speaking prosody. In addition, the two robot-assisted systems above were not designed for read-aloud task but this instructional approach is still widely applied in English class.
Therefore, the objective of the present research aimed at the development of a robot-tutoring system to improve Taiwanese university students’ English pronunciation in read-aloud task. The idea is to assign an educational robot to serve as a tutor to recognize a student’s speech while he/she was reading aloud a passage displayed by the robot. The accuracy between the recognized text and the text of passages indicates how the robot understood the learners’ speech. Moreover, the system is able to identify the errors to help the learners check the errors indicate what the robot can’t understand and practice the correct pronunciations.
In order to evaluate the utility and effectiveness of our robot-tutoring system, the following measurements were implemented in this research:
Can the university EFL students improve the accuracy of pronunciations while reading aloud to the robot-tutoring system?
What are the differences before and after learning with the proposed system regarding each major type of pronunciation problems?
What are the students’ perceptions of the system?
The development of robot-tutoring system
shows the proposed system structure. It was operated by three modules: educational robot, server, and Google Cloud platform. The educational robot, Zenbo Junior, developed by ASUS was adopted in the system. A learner reads aloud the article displayed by the robot. The server stores and manages all learners’ content. Speech-to-text is performed by Google Cloud platform. The procedure using the proposed system is shown in .
Figure 1. System structure.
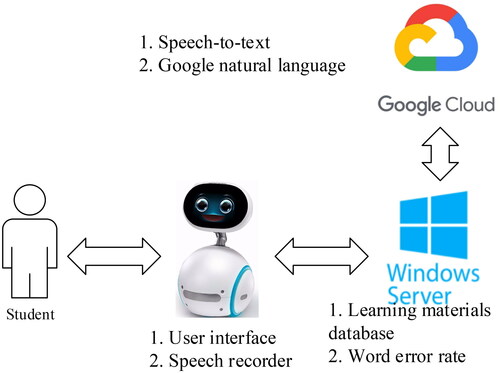
Figure 2. The procedure of diagnosis and correction.
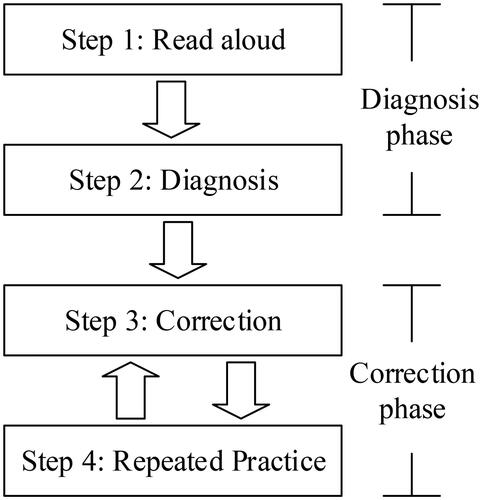
The operational procedure consists of two phases: the diagnosis phase and the correction phase (see ). The diagnosis phase contains two steps. Firstly, the learner performs oral reading and his/her speech is recorded and converted into the audio file (see ). In the second step, the audio file is transferred to Google Cloud platform via the server to proceed ASR and perform Word Error Rate (i.e. WER) measurement which identify the words recognized as incorrect by the robot. WER is determined by EquationEquation (1)(1)
(1) , where S is the number of substitutions, D is the number of deletions, I is the number of insertions, and N is the number of words in the text. The recognized incorrect words indicate that those spoken messages can’t be understood by the robot.
(1)
(1)
Figure 3. Screenshot of the read-aloud function.

The correction phase contains two steps: correction and practice. In the correction step, each sentence that contains error(s) is shown in the individual screen. As shown in , the screen displays the recognized sentence and the original one. The learner is able to find the differences of the represented errors between the two sentences. The learner can use the functions on the bottom panel to practice and record the sentence, and request the robot to diagnose this practice again and again until satisfactory. shows two snapshots of the proposed robot-tutoring system.
Figure 4. Screenshot of “correction and practice”.

Figure 5. The proposed robot-tutoring system.
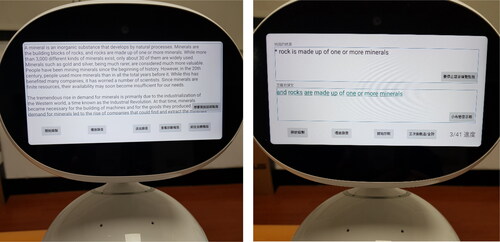
The evaluation of the system
Design
Single group pretest-posttest approach was conducted in our experiment. The change of word accuracy rates among the tests was investigated to measure the effectiveness of the proposed system by adopting a pretest, a posttest, and a delayed posttest.
Participants
A total of 19 university students who majored in computer science in Taiwan voluntarily enrolled in our experiment. Among them, 15 were junior students, including seven males and eight females; in addition, four were sophomores, including three males and one female. Their ages ranged from 21 to 23. All of them are Taiwanese and their native language is Mandarin. At the participants’ university, the General English classes for students are required and levelled based on the students’ English performance of the national college entrance exam. The subjects of this study were from low-advanced and intermediate classes. Before starting the experiment, we interviewed all participants to understand their prior English oral reading proficiency. All responded their oral reading was weak and also replied that although read-aloud activities were general in English classes, their instructors didn’t point out errors of individual students. Therefore, they were not aware of their own read-aloud proficiency.
Procedure
The participants were volunteers to utilize our proposed system to conduct self-learning in a computer laboratory. The intervention from the instructor was few, and the instructor stayed with the participants in the computer laboratory only for repairing the system if any system failures occurred. shows the procedure of the experiment.
Figure 6. Procedure of experiment.
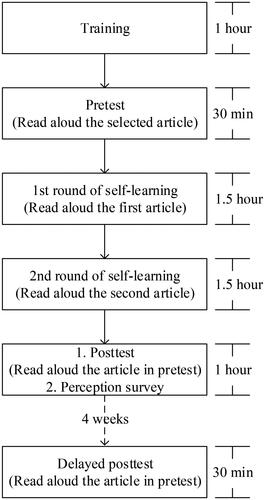
First, all participants received a one-hour training to learn the proposed system in a computer laboratory and to understand the experiment. Next, we explained our research objectives and tutored everyone to operate the system. All participants also signed the consent forms. Second, the participants did a pretest by reading aloud an article selected from the book used in this experiment. The pretest, the posttest as well as the delayed posttest were conducted using the proposed system, so that the accuracy of read-aloud could be determined. The duration of every test was approximate 30 minutes.
Third, after the pretest, the participants had to complete two rounds of self-learning. In each round, the participants had to read aloud one article, and then worked on their self-learning which included diagnosing and correcting the errors. The duration of self-learning was approximate 3 hours per participant. Fourth, the participants sat for an immediate posttest by reading aloud the same article used in the pretest.
After the posttest, the participants filled out a questionnaire, so their perceptions of the system could be surveyed. Finally, a delayed posttest that used the article both in the pretest and the posttest was conducted a month later to measure the residual effectiveness of the proposed system. We have to mention that the article used in the tests weren’t open for self-learning and during the interval between the immediate posttest and the delayed posttest, the participants were not allowed to use the system and practice the articled used in the tests.
Measurement instruments
Learning materials and tests
The three articles adopted in this experiment were from “Reading Voyage: Expert” (McClelland & Walters, Citation2018). This book is designed for EFL students to improve their reading abilities. The articles cover various themes, but we selected “Technology” only because the participants are of science and technology background, and would be more interested in and familiar with this topic. The first article in was adopted for the pretest, the posttest, and the delayed posttest. The other two articles were adopted for the participants’ self-learning in the experiment. Each article contains approximately 350 words. 117 same words appeared in articles 1 and 2, and 128 same words in articles 1 and 3.
Table 1. Articles used in tests and self-learning.
System effectiveness
The measure of the proposed system’s effectiveness was based on the research of Salim et al. (Citation2016). In this research, the reduction in the WER of the learners indicates that the learners’ speech was understood more by the system, and it also meant the system’s effectiveness was higher. In our evaluation, the accuracy of read-aloud determined by WER was adopted in the experiment to measure of the system effectiveness (as shown in EquationEquation (2)(2)
(2) ).
(2)
(2)
The test-retest reliability coefficients were adopted to evaluate the consistency of the same test measured over time. The result shows that the correlations of pretest-posttest was .908 (p = .000), pretest-delayed posttest was .799 (p = .000), and posttest-delayed posttest was .803 (p = .000). Besides the fact that the correlation of pretest-delayed posttests was acceptable, the other two correlations also presented good and excellent reliability.
Analysis of error types
Analysing the rates of major error types occurred in the three tests was helpful to understand what caused the differences in results of three tests. The errors identified by WER are further analysed and categorized using Google Natural Language API. In addition to Deletion and Insertion which are defined in the WER, the Substitution problem defined in the WER was caused by unclear vowel or consonant sounds or phonemes. As discussed in Introduction, some difficult consonants, English vowel length and final consonants often cause pronunciation difficulties to Taiwanese students. Therefore, the Substitution problem was divided into more categories and analysed: Subject-Verb (S + V) Disagreement, Singular/Plural Nouns, Verb Tense, and Misused Words.
The first three categories, Subject-Verb (S + V) Disagreement, Singular/Plural Nouns, and Verb Tense, often occur in EFL students’ speech due to grammatical errors. However, while learning with our system, the learners read aloud the articles displayed by the robot with printed texts which should contain no grammatical mistakes. Coupled with the English teacher-researcher’s experiences and observations in this study, it can be reasonably inferred that the errors of the first three categories happened because of the dropping of final consonants. Furthermore, in EFL learners’ speech and conversations with others, the first three error categories may cause the listeners’ semantic misunderstanding. As a result, it is worth-while to look into these error categories and their frequency of occurrences during the participants’ reading-aloud exercises.
Regarding S + V disagreement, many Taiwanese EFL students are not familiar with clearly pronouncing the verbs which end in “-s”, “-es” and “-ed” such as “works”, “comes”, and “walked”. As a result, S + V disagreements would occur in reading-aloud such as “He/She come” or “He/She work”. The cause of singular/plural nouns and verb tense errors is similar to that of S + V disagreement. The examples are like ‘pieces’ and ‘instances’. Students would usually skip “-s” or “-es”. Moreover, students in Taiwan suffer from the pronunciation of the verbs ending in “-es” and “-ed” as well. They tend to skip it. For instance, “She has work for several hours,” is recognized as a verb tense error by the proposed system.
The misused word error type is referred to ordinary incorrect pronunciation due to unfamiliarity with vowel length, difficult consonants, complex words and retroflexes. It is hard for Mandarin-speaking L1 EFL learners to distinguish vowel length (Huang & Radant, Citation2009; Lin et al., Citation1995). Besides, some sounds, including vowels and consonants, were identified to pose pronunciation difficulties to Taiwanese EFL learners (Chang, Citation2001; Huang, Citation2001). In terms of complex words and retroflexes, for the example of “superior”, EFL students in Taiwan would be confused with the pronunciation because of the word ‘super’. Consequently, ‘superior’ would be pronounced like ‘super-’ and ‘-rior’. Moreover, in read-aloud exercises, the latter, retroflexes, is a more general factor for wrong pronunciations. Many Taiwanese EFL learners pronounce ‘work’ and ‘walk’ almost in the same way because they are unable to pronounce the vowels correctly in the combinations of “vowel + r” and “vowel + consonant(s)”. Another example of read-aloud errors is “won’t” and “want” because EFL students in Taiwan often have trouble in pronouncing the open ‘o’ accurately.
Deletion which occurs in read-aloud activities is referred to the skipped words unknown to learners. These unknown words to Taiwan’s EFL students are perhaps new words, or learned words whose pronunciations they have however forgot. Besides, students would often skip the pronunciations of complicate words such as “characteristic” or “circumstance” while reading a sentence aloud. The last category, Insertion, often happens when an extra sound is added to the intended word. This error, usually a schwa after a consonant, is very common for EFL students in Asia.
Students’ perceptions of the proposed system
A questionnaire which consisted of 14 question items based on the Technology Acceptance Model proposed by Davis (Citation1989) in two dimensions of perceived ease of use and perceived usefulness was adopted to survey the degree of the students’ perceptions of the system. Perceived ease of use refers to “the degree to which a person believes that using a particular system would be free of effort,” and perceived usefulness is an essential factor to measure the success of learning systems. Seven question items were for perceived ease of use, and the other seven were for perceived usefulness. The participants’ responses to the question items were measured with the 5-point Likert scale, from strongly agree to strongly disagree.
Results
System effectiveness (RQ1)
The effectiveness of our system was evaluated by the one-way repeated-measures ANOVA to show the change of read-aloud accuracy among the three tests. shows the descriptive statistics of the three tests, and shows the pairwise comparison by Bonferroni’s method. The findings are listed as follows: First, the comparison of the pretest (Mean = 48.42%, SD = 21.31%) and the posttest (Mean = 52.46%, SD = 18.08%) showed that the accuracy of the posttest results was higher, but there was no significant difference. Second, there was a significant main effect of accuracy on the delayed posttest (F(2, 36) = 8.074, p = .002, ηp2 = .19). After the significant result was found, a post hoc test was used to determine where the differences came from. The Bonferroni post hoc test is a simple way to generate multiple comparisons. It showed that the accuracy of the delayed test results (Mean = 58.00%, SD = 15.18%) was significantly higher than those of the pretest and the posttest (shown in ). This result reveals that the system could significantly improve the participants’ pronunciation in read-aloud such that accuracy was increased, indicating that the robot could understand what the participants spoke more even though they didn’t learn and practice this article between the posttest and the delayed posttest four weeks later apart.
Table 2. Descriptive statistics of the three tests.
Table 3. Pairwise comparisons.
Analysis of major error types (RQ2)
shows the averages of the error rates of all types in the pretest’s records. The top three, S + V disagreement, misused words, and incorrect omission, had averages of 25.67%, 25.99%, and 15.93%, respectively. These three error types were over or approximate 15%. It means they were the main factors to influence the overall participants’ achievement. Therefore, these three categories were worthy of being looked into.
Table 4. Averages of error rates in categories in the pretest.
Error rate of S + V disagreement
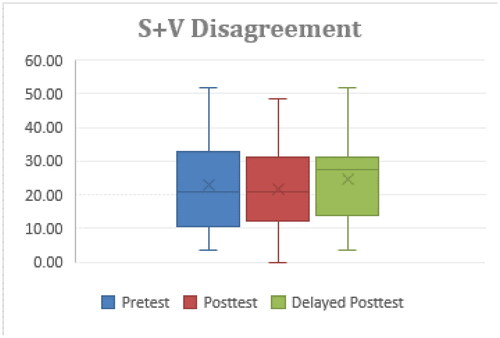
The mean values of rate of S + V disagreement errors in the three tests were 25.67% (SD = 4.13%), 21.46% (SD = 3.10%), and 25.10% (SD = 2.96%) respectively. One-way repeated measures ANOVA showed no significant difference among the three tests. As shown in , the boxplot of the delayed posttest showed that the gap between the median and the third quartile (Q3) was obviously smaller than the gap between the median and the first quartile (Q1), meaning that this is a skewed boxplot and the median (error rate = 27.59%) was very close to the Q3 (error rate = 31.03%). A half of the participants presented error rates higher than 27.59%. This implies that a half of the participants had much higher error rates in the delayed posttest, and reveals that they couldn’t sustain their improvement and almost returned to their previous proficiency.
Figure 7. Rate of S + V disagreement errors.
Error rate of misused words
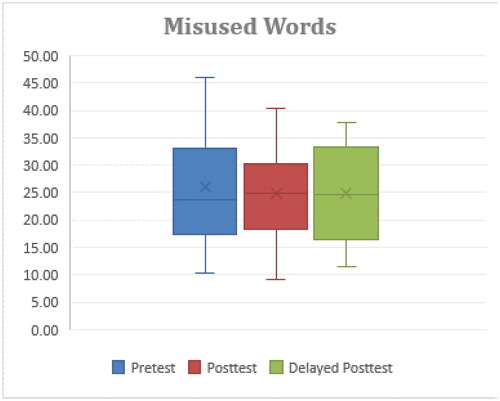
The mean values of rate of misused words errors in the three testes were 25.99% (SD = 9.64%), 24.91% (SD = 9.12%), and 24.76% (SD = 2.96%) respectively. The mean of the delayed posttest was lowest but the analysis by using one-way repeated measures ANOVA showed no significance among the three tests. As shown in , the maximum error rate of the delayed posttest was down to 37.88%, whereas those of the pretest and the posttest were 45.96% and 40.39%. This means the maximum error rate of the delayed posttest was reduced even though the participants did not learn with the robot system for 4 weeks after the posttest.
Figure 8. Rate of misused words errors.
Error rates of deletions
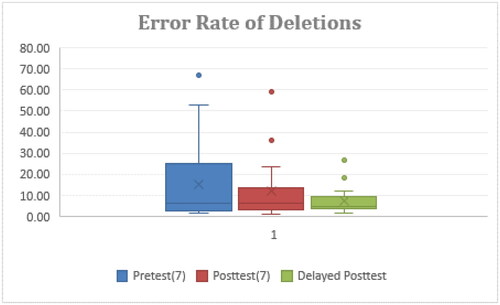
The mean values of rate of deletions errors in the three tests were 15.93% (SD = 19.54), 11.76% (SD = 15.14), and 6.75% (SD = 5.98). The one-way repeated measures ANOVA showed no significance among the three tests. As shown in , except outliers, the maximum error rate of the delayed posttest was the lowest, and the differences to those of the pretest and the posttest were obvious. A similar phenomenon was also found regarding the third quartile (Q3). With regards to the first quartile (Q1), there was nearly no difference among the three tests. In addition, the interquartile range (IRQ) was decreased in the posttest and the delayed posttest, indicating that the error rates of the participants were getting lower. This also implies that the robot system could be more helpful to the participants with low prior read-aloud intelligibility in the pretest on decreasing deletions.
Figure 9. Rate of deletions.
Results of participants’ perceptions of the system (RQ3)
The results of the participants’ perceptions to the system are listed in . The Cronbach’s alpha was .929, indicating that the reliability of the instrument was very high. The mean of all the question items was 4.38 (SD = .83), showing that the participants’ perceptions of our system were positive, and they highly accepted this system for practicing English reading-aloud.
Table 5. Descriptive statistics of learners’ perceptions of the proposed system.
When looking into the results of individual dimensions displayed in , the mean of the participants’ responses to perceived ease of use was 4.47 (SD = .79). It implies the participants highly agreed that it was easy to use the proposed system. The mean values of the responses to all seven question items exceeded 4.1, and item No. 7, “I find the messages displayed by the system is clear and understandable.”, had the highest average–up to 4.68, indicating that the majority of the participants found that it was easy to interact with the proposed system as long as they followed the guideline, messages, and the instruction displayed by the robot. In other words, it was easy to complete the practice of English read-aloud exercises via the aid of the proposed system. Other mean values of the replies to question items such as No. 2, No. 3, and No. 4 were consistent with the finding from No. 7, too.
In terms of perceived usefulness, the mean values of the responses to all seven question items exceeded 4.0, specifying that the participants highly agreed the proposed system was useful for English read-aloud practice. The replies to item No. 13 had the minimum mean (M = 4.00), whereas those to item No. 11 had the maximum mean (M = 4.63). The high mean of item No. 11, “Practicing English reading-aloud by interacting with the system is impressive.” revealed that the participants were impressed by the proposed system since it was their first time to encounter educational humanoid robots that could support personal language training. In addition, the answers to item No. 12 had a high mean, 4.26, which implies that the participants would like to use the system even though the experiment had been ended. This result was consistent with the finding of item No. 14, suggesting that the participants would like to recommend this system to other learners.
Discussion and conclusion
The present study constructed a robot-tutoring system and examined its effectiveness on enhancing the English reading-aloud proficiency of Taiwanese EFL university students. Data collection involved pretest-posttest-delayed posttest, analysis of major error types in read-aloud tasks, and evaluation of participants’ perceptions regarding the implemented system.
The effectiveness of the proposed system
The accuracy of the delayed posttest result was significant, which was better than those in the pretest and the posttest, and the accuracy of the posttest result was also better than that in the pretest. It indicates the participants’ pronunciation was more clearly in read-aloud after using the system. During a month interval, the system effectiveness was still sustained. This finding is congruent with the error rate of deletions in the delayed posttest which was the lowest compared to those of the other two tests since unfamiliarity with vocabulary and pronunciation is a major cause of deletions in read-aloud. Couper (Citation2006) also found that if the learners were exposed to an explicit instruction on the segmental features of English pronunciation, the improvement of New Zealand (NZ) immigrants in this study, largely of Asian origin, could be retained even in the delayed posttest.
The improvement through the aid of the proposed system can also be inferred according to the results in Dizon (Citation2020) and Tai (Citation2022). They claimed that exposing learners to a large amount of oral input to interact with a tangible computer increased more practices in terms of oral input and output. Educational robots are not impatient to listen to learners’ oral reading, and therefore, learners could repeat the practices and the correction of their errors (Moussalli & Cardoso, Citation2016).
Analysis of error types
Regarding S + V disagreement that had the highest error rate, the result revealed no obvious difference in the three tests. It signifies that the participants still suffered from the problems with some verbs ending with ‘-ed’ and ‘-es’. Actually, as an example, the learners could realize ‘he’ or ‘she’ must be paired with ‘wishes’ in present tense or ‘needed’ in past tense, but it was difficult for them to fix this problem, and they still tended to skip the ‘-es’ or ‘-ed’ sound even though they repeated the identical articles three times in the three tests. This result also indicates the problem was hard to be fixed by self-learning with the proposed system. Physical correction therapy through the aid of an expert may be still needed in particular for students in Taiwan.
The type, “misused word”, had the second highest error rate. Three possible causes were described below. First, the results of the three tests show that it was very hard for the learners to pronounce retroflexes. For example, “car” sounded like “ca” and “heart” sounded like “hot”. Second, the participants still suffered from some problems with vowels or consonants like/Ʊ/,/ʌ/,/ɝ/,/θ/,/ð/, etc. The two problems above are hard to be solved for the students by simply listening to correct pronunciations from the computer. In other words, the intervention of the professional English teacher is still necessary. The third cause was the incorrect pronunciations of particular complex words. The students may use incorrect inferences due to their wrong knowledge with some complex words, and consequently make incorrect sounds. For example, “superior” sounded like “super” + “-ior”, or “consequence” sounded like “con” + “sequence”. In order to correctly read these complex words, students may need to practice more articles.
In the pretest, deletion was also the type with a higher error rate. This problem resulted from the participants’ unfamiliarity with some words in the article, so they tended to skip reading these unfamiliar words aloud. This problem was improved with learning and correction with the proposed system because the participants were able to acquire more correct words and pronunciations. Tost (Citation2013) found that the students who read aloud with peer appraisal could aim at the incorrect pronunciations identified by their peers and practiced more. Consequently, the students acquired more correct words as well as pronunciations, and their oral intelligibility and fluency was enhanced. The robot in our research played the role of peers as in Tost’s research, and our result was consistent with his. With acquisition of more correct words and pronunciations, the amount of deletions was obviously reduced, and the outcome in the delayed posttest was positively influenced.
Limitations and future work
Some limitations of the study are identified. First, the accuracy of Google speech recognition cannot reach 100%, and some may argue about it, or that word error rate (WER) is not a perfect evaluation tool. However, WER is still a common metric to evaluate speech recognition tools. Besides, Google reported its speech recognition accuracy could reach approximately 84% in May, 2020. Second, the duration of learning in the recent experiment was short, but pronunciation training needs longer sessions. Third, we did not evaluate the participants’ English speaking fluency. Therefore, in our experiment, no evidence revealed that the proposed system could help improve this skill. Fourth, the sample size was too small to adopt a quasi-experimental method. Consequently, the result exhibited the effectiveness of the proposed system, but could not demonstrate the system was better than other read-aloud training approaches. Hence there is still an opportunity to extend this research.
In terms of future research directions, at present, the system is limited to providing students with repeated practice of words or sentences containing errors detected in their English reading-aloud. However, there is potential to enhance the system by offering tailored correction methods for various types of errors, or by incorporating online resources for correction purposes.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Zeng-Wei Hong
Zeng-Wei Hong received B.S., M.S., and Ph.D. degrees in computer science from the department of Information Engineering and Computer Science, Feng-Chia University, Taichung, Taiwan. He was an Assistant Professor and Associate Professor in Asia University, Taiwan during August 2007 to July 2015. From August 2015, he was an Assistant Professor in Faculty of Information and Communication Technology, UTAR, Kampar, Malaysia until July 2020. Now he is an associate professor at the Department of Information Engineering and Computer Science, Feng Chia University, Taiwan. His current research interests include e-learning and software engineering.
Ming-Hsiu Michelle Tsai
Ming-Hsiu Michelle Tsai is an assistant professor at the Department of Foreign Languages and Literature, Feng Chia University, Taiwan. She received her MA in Chinese-English Translation and Interpretation from the Middlebury Institute of International Studies at Monterey, California, USA. Her research interests include the theory, teaching and techniques of translation and interpretation, ESP, cross-cultural, and interdisciplinary studies such as with the AI and IT industries. She has also been an accredited translator and conference interpreter for over 25 years, specializing in political, economic, cultural and technical areas.
Chin Soon Ku
Chin Soon Ku received the Ph.D. degrees from Universiti Malaya, Malaysia, in 2019. He is currently an Assistant Professor at the Department of Computer Science, Universiti Tunku Abdul Rahman, Malaysia. His research interests include AI techniques (such as genetic algorithm), computer vision, decision support tools, graphical authentication (authentication, picture-based password, graphical password), machine learning, deep learning, speech processing, natural language processing and unmanned logistics fleets.
Wai Khuen Cheng
Wai-Khuen Cheng received his B.Sc. and Ph.D. degrees from Universiti Sains Malaysia in 2004 and 2009, respectively. He is currently serving as the Assistant Professor and Deputy Dean of the Faculty of Information and Communication Technology (FICT) at Universiti Tunku Abdul Rahman (UTAR), Malaysia. His research interests include cloud computing, multi-agent systems, social network services, Internet of things, personalized recommendation, and financial technology.
Jian-Tan Chen
Jian-Tan Chen received his M.S. degree in computer science from the department of Information Engineering and Computer Science, Feng-Chia University, Taichung, Taiwan. His research interests include e-learning systems, educational robots, and mobile apps development.
Jim-Min Lin
Jim-Min Lin received the BS degree in Engineering Science and the MS and PhD degrees in Electrical Engineering, all from National Cheng Kung University, Tainan, Taiwan, in 1985, 1987, and 1992, respectively. From February 1993 to July 2005, he was an associate professor at the Department of Information Engineering and Computer Science, Feng Chia University, Taichung City, Taiwan. Since August 2005, he has been a title of Full Professor at the same department. Since August 2012, he has been serving as the Director of Main Library. Between November 2008 and October 2011, he served as the Secretary General of the Computer Society of the Republic of China (CSROC). His research interests include Operating Systems, Testable Design, Software Integration/Reuse, Embedded Systems and Software Agent Technology.
References
- Alemi, M., Meghdari, A., & Ghazisaedy, M. (2015). The impact of social robotics on L2 learners’ anxiety and attitude in English vocabulary acquisition. International Journal of Social Robotics, 7(4), 523–535. https://doi.org/10.1007/s12369-015-0286-y
- Alshumaimeri, Y. (2011). The effects of reading method on the comprehension performance of Saudi EFL students. International Electronic Journal of Elementary Education, 4(1), 185–195. https://doi.org/10.33503/journey.v1i2.295
- Bashori, M., van Hout, R., Strik, H., & Cucchiarini, C. (2022). ‘Look, I can speak correctly’: Learning vocabulary and pronunciation through websites equipped with automatic speech recognition technology. Computer Assisted Language Learning, 1–29. https://doi.org/10.1080/09588221.2022.2080230
- Chang, Y. (2001). A study of areas of English pronunciation which pose particular difficulties for Taiwanese EFL students based on the first year students from two-year program of Transworld Institute of Technology. Journal of Transworld Institute of Technology, 20, 95–108.
- Chien, C. W. (2014). Non-native pre-service English teachers’ narratives about their pronunciation learning and implications for pronunciation training. International Journal of Applied Linguistics and English Literature, 3(4), 177–190.
- Couper, G. (2006). The short and long-term effects of pronunciation instruction. Prospect, 21(1), 46–66. https://doi.org/10.3316/aeipt.153023
- Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly, 13(3), 319–340. https://doi.org/10.2307/249008
- Dizon, G. (2020). Evaluating intelligent personal assistants for L2 listening and speaking development. Language Learning & Technology, 24(1), 16–26. https://doi.org/10125/44705
- Estévez, D., Terrón-López, M.-J., Velasco-Quintana, P. J., Rodríguez-Jiménez, R.-M., & Álvarez-Manzano, V. (2021). A case study of a robot-assisted speech therapy for children with language disorders. Sustainability, 13(5), 2771. https://doi.org/10.3390/su13052771
- Gibson, S. (2008). Reading aloud: A useful learning tool? ELT Journal, 62(1), 29–36. https://doi.org/10.1093/elt/ccm075
- Hong, Z. W., Huang, Y. M., Hsu, M., & Shen, W. W. (2016). Authoring robot-assisted instructional materials for improving learning performance and motivation in EFL classrooms. Educational Technology & Society, 19(1), 337–349. https://www.jstor.org/stable/jeductechsoci.19.1.337
- Huang, H. L., & Radant, J. (2009). Chinese phonotactic patterns and the pronunciation difficulties of Mandarin-Speaking EFL learners. Asian EFL Journal Quarterly, 11(4), 115–133.
- Huang, L. (2010). Reading aloud in the foreign language teaching. Asian Social Science, 6(4), 148–150. https://doi.org/10.5539/ass.v6n4p148
- Huang, T. L. (2001). Taiwanese and American English segmental phonemes: A contrastive study. Journal of Jin-Wen Institute of Technology, 2, 29–55.
- Iio, T., Maeda, R., Ogawa, K., Yoshikawa, Y., Ishiguro, H., Suzuki, K., Aoki, T., Maesaki, M., & Hama, M. (2019). Improvement of Japanese adults’ English speaking skills via experiences speaking to a robot. Journal of Computer Assisted Learning, 35(2), 228–245. https://doi.org/10.1111/jcal.12325
- Kanda, T., Hirano, T., Eaton, D., & Ishiguro, H. (2004). Interactive robots as social partners and peer tutors for children: A field trial. Human-Computer Interaction, 19(1), 61–84. https://doi.org/10.1207/s15327051hci1901&2_4
- Kartal, G. (2022). Evaluating a mobile instant messaging tool for efficient large-class speaking instruction. Computer Assisted Language Learning, 1–29. https://doi.org/10.1080/09588221.2022.2074463
- Krisdityawan, E., Yokota, S., Matsumoto, A., Chugo, D., Muramatsu, S., & Hashimoto, H. (2022 Effect of embodiment and improving Japanese students’ english pronunciation and prosody with humanoid robot [Paper presentation]. 2022 15th International Conference on Human System Interaction (HSI) (pp. 1–6). IEEE. https://doi.org/10.1109/HSI55341.2022.9869469
- Kruk, M., & Pawlak, M. (2021). Using internet resources in the development of English pronunciation: The case of the past tense-ed ending. Computer Assisted Language Learning, 36(1–2), 205–237. https://doi.org/10.1080/09588221.2021.1907416
- Lee, S., Noh, H., Lee, J., Lee, K., Lee, G., Sagong, S., & Kim, M. (2011). On the effectiveness of robot-assisted language learning. ReCALL, 23(1), 25–58. https://doi.org/10.1017/S0958344010000273
- Lin, H., Fan, C., & Chen, C. (1995). Teaching pronunciation in the learner-centered classroom. ERIC Document Reproduction Service No. ED393292.
- Lin, V., Yeh, H. C., & Chen, N. S. (2022). A systematic review on oral interactions in robot-assisted language learning. Electronics, 11(2), 290. https://doi.org/10.3390/electronics11020290
- McClelland, J. S., & Walters, B. (2018). Reading voyage: Expert. Darakwon.
- Moussalli, S., & Cardoso, W. (2016). Are commercial ‘personal robots’ ready for language learning? Focus on second language speech. In S. Papadima-Sophocleous, L. Bradley & S. Thouësny (Eds.), CALL communities and culture–short papers from EUROCALL (pp. 325–329). Research-Pusliching.Net. https://doi.org/10.14705/rpnet.2016.eurocall2016.583
- Peffers, K., Tuunanen, T., Rothenberger, M. A., & Chatterjee, S. (2007). A design science research methodology for information systems research. Journal of Management Information Systems, 24(3), 45–77. https://doi.org/10.2753/MIS0742-1222240302
- Salim, S. S., Mustafa, M. B. B. P., Asemi, A., Ahmad, A., Mohamed, N., & Ghazali, K. B. (2016). A speech pronunciation practice system for speech-impaired children: A study to measure its success. Research in Developmental Disabilities, 56, 41–59. https://doi.org/10.1016/j.ridd.2016.05.013
- Tai, T. Y. (2022). Effects of intelligent personal assistants on EFL learners’ oral proficiency outside the classroom. Computer Assisted Language Learning, 1–30. https://doi.org/10.1080/09588221.2022.2075013
- Tost, G. (2013). Bettering pronunciation through reading aloud and peer appraisal. Bellaterra Journal of Teaching & Learning Language & Literature, 6(1), 35–55. https://doi.org/10.5565/rev/jtl3.495
- Tzwei, C. R. (1987). An error analysis of English consonant pronunciation of Chinese University students. In Huang T. L. (Ed.), Papers from the forth conference on English teaching and learning in the R. O. C. Crane.
- Van den Berghe, R., Verhagen, J., Oudgenoeg-Paz, O., van der Ven, S., & Leseman, P. (2019). Social robots for language learning: A review. Review of Educational Research, 89(2), 259–295. https://doi.org/10.3102/0034654318821286
- Wang, Y.-H., Young, S. S.-C., & Jang, R. J.-S. (2013). Using tangible companions for enhancing learning English conversation. Educational Technology & Society, 16(2), 296–309. https://www.jstor.org/stable/pdf/jeductechsoci.16.2.296.pdf