
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
There is a significant need to improve the highway safety during roadway planning, design and operations in developing countries like India. To receive appropriate consideration, safety needs to be dealt objectively within the transportation planning and highway design processes. Lack of available tools is a deterrent to quantify safety of a transportation facility during the planning or highway design process. The objective of this paper is to develop safety performance functions considering various elements involved in the planning, design and operation of a section on four-lane National Highway (NH)-58 located in the state of Uttarakhand, India. The mixed traffic on Indian multilane highways comes with a lot of variability within, ranging from different vehicle types to different driver characteristics. This could result in variability in the effect of explanatory variables on crashes across locations. Hence, explanatory variables for highway segment safety analysis considered were geometric characteristics like curvature change rate, slope change rate, transverse slope and traffic characteristics in the form of average daily traffic, light vehicle traffic, light commercial vehicle traffic, heavy vehicle traffic, two-wheelers, non-motorised traffic volume and operating speed were analysed against dependent variable as crash count per 200 m per year. Safety performance functions involving the explanatory variables are calibrated to predict crash frequency using Poisson Weibull technique and crash types are predicted using ordered logit model. Model results suggest that increase in traffic volume leads to higher probability of crash risk and traffic safety is significantly distorted by higher curvature change rate values.
Public Interest Statement
In this study, we develop safety performance functions considering various elements involved in the planning, design and operation of four-lane national highways in India. Explanatory variables for highway segment safety analysis considered were geometric characteristics and traffic characteristics analysed against dependent variable as crash count and collision type. Safety performance functions involving the explanatory variables are calibrated to predict crash frequency using Poisson Weibull technique and crash types are predicted using ordered logit model. Model results suggest that increase in traffic volume leads to higher probability of crash risk and traffic safety is significantly distorted by higher curvature change rate values.
1. Introduction
Over the years due to growth in Indian economy, there has been an unprecedented increase in road transportation and vehicular traffic load on the existing highway network in India, which has led to unsafe conditions on our highways. Casualties due to crashes on these roads are increasing year after year. The road safety is further deteriorated by poor maintenance of vehicle, bad driving practice, lack of enforcement, casual attitude of road users and least concern towards the basic road safety measures by road maintaining agencies.
At present in India, more than 486,476 crashes occur annually. About 137,572 people lose their lives in such crashes. Additionally, nearly 494,893 people get injured in road crashes that lead to lifelong misery for the victims and family (Road Accidents in India, Citation2014). Road Safety Study can ensure that various safety deficiencies in road are reviewed so that these can be taken care at appropriate stage of road design or operation and maintenance of road in a cost-effective way. In recent years, significant effort and investment have been made to enhance highway safety. In the backdrop of resource constraints, the allocation of resources for safety improvement projects must yield maximum possible return on investment. Identifying highway locations that have the potential for crash reduction with the implementation of effective safety counter measures is therefore an important step in achieving the maximum return on safety investment.
Considerable amount of research has been done in recent years for developed countries to establish relationships between crashes and various traffic flow characteristics, geometric characteristics at highway segments and intersections. Understanding of crash-contributing factors on highway system using recent scientific approaches is yet to take off in developing countries.
Miaou and Lum (Citation1993) investigated statistical of four regression models—two conventional linear regression models and two Poisson regression models considering highway geometric design parameters. Study revealed that Poisson regression models overestimate or underestimate the crash frequency. Miaou (Citation1994) evaluated the performance of Poisson, zero-inflated Poisson and negative binomial regression models through maximum likelihood method to predict truck crashes in relation with road geometric parameters. Hauer (Citation1997) describes various conventional approaches for statistical analysis of road safety engineering. Empirical Bayes (EB) approach to the analysis of road accident data is explained extensively. EB approach was adopted to eliminate the bias in estimated accident rates that arise from selection criteria. Persaud, Lord, and Palmisano (Citation2002) studied the transferability of safety performance functions or crash prediction models to other jurisdictions. Study suggested that a single calibration factor is inappropriate and that a disaggregation by traffic volume is preferred.
Miaou and Lord (Citation2003) analysed traffic crashes with respect to traffic flows at intersections. They challenged the assumption of fixed dispersion parameter and worked with various dispersion parameter relationships and functional forms. This study also indicated the advantages of full Bayes versus EB method. Mitra and Washington (Citation2007) developed eight different models with explanatory factors as traffic flow and geometric factors to estimate crashes. Study suggested that model specification may be improved by testing extra variation functions for significance.
Geedipally and Lord (Citation2008) evaluated the safety performance functions using a varying dispersion parameter which precisely estimated crashes with smaller confidence intervals. Geedipally and Lord (Citation2010) investigated crashes as per single- and multi-vehicle crashes separately versus modelling total crash frequency. Cheng, Geedipally, and Lord (Citation2013) evaluated the application of Poisson Weibull (PW) and Poisson Gamma (PG) models and results revealed both the techniques are competitive.
Numerous studies have been performed by many researchers on road safety analysis in India. Landge (Citation2006) reviewed different modelling approaches adopted worldwide. Dinu and Veeraragavan (Citation2011) implemented random parameters count model. The results suggested that the model coefficients for traffic volume, proportion of cars, motorised two-wheelers (TW) and trucks in traffic, and driveway density and horizontal and vertical curvatures are randomly distributed across the locations. Krishnan, Anjana, and Anjaneyulu (Citation2013) applied hierarchical modelling approach to estimate crash frequency and severity of single and dual carriageway roads. Research review illustrated that the safety performance of non-urban four-lane highways was seldom investigated on Indian highways. The review indicated that there is a need to develop models for estimating the safety performance of non-urban highways using recent statistical techniques adopted in developed countries.
The study aims to (1) identify the crash contributing factors and (2) to develop safety performance functions using Bayesian inference to predict crash frequency and different crash types on a section of divided four-lane National Highway-58 in India.
2. Study approach
Real-world crash data that are properly defined can identify the key contributing factors to traffic crashes in terms of crash frequency (number of crashes per segment), crash type (direct impact collision, rear-end collision, sideswipe collision, rollover collision and skid-related collisions) and crash severity (fatal, incapacitating, non-incapacitating, animal-related crashes and property damage only). Hence, for scientific research on crashes, one first needs to have a reliable crash database. In India, there is no organised crash database maintained for in-depth research on crashes. The absence of such nationwide systematic data, seriously impede the scientific research and analysis of road crashes in India. To address this issue and to identify the root cause of crashes in India, it is necessary to fully understand the traffic and crash affecting parameters. Hence, in this study, an attempt is made to create the crash database for scientific research on crashes on four-lane divided national highway.
2.1. Study area description
The National Highway-58 connects Indian capital New Delhi to Mana, near China border in Uttrakhand state. It serves as a lifeline to the hilly part of the state. The road is strategically important being the shortest route from Delhi to international China border. The highway has length of 536 km of which 230-km length in plain and rest in the hilly terrain. The highway connects important religious destinations which attract tourists from all over the country and world throughout the year. The highway has two-lane and four-lane stretches. Traffic on the highway is mixed in nature and comprises heavy and light vehicles. Most of the highway study segment falls in rural areas (approximately 85%).
2.2. Site selection
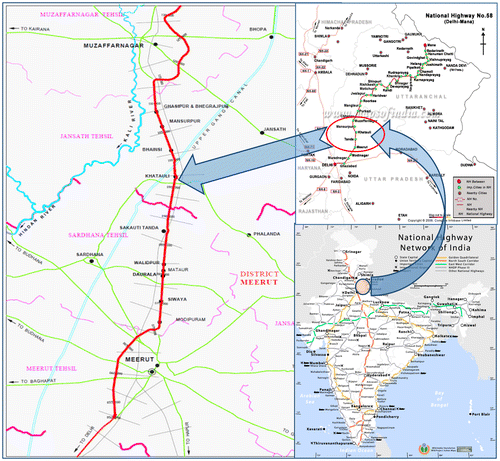
This national highway is maintained and operated by National Highway Authority of India (NHAI) and concessionaire Western Uttar Pradesh Toll Ltd (WUPTL). The study has been done for four-lane road between km 52.00 and 130.00 to identify all safety deficiencies responsible for road crashes. Route map of study section of National Highway-58 is shown in Figure .
Figure 1. Study area route map of National Highway-58.
2.3. Details of road geometrics
Figure shows typical cross-section of the candidate stretch under analysis. Table shows the road infrastructure details for the study area. As per Indian Roads Congress (Citation2000), the ruling design speed for National Highway-58 in plain terrain is 100 kmph.
Figure 2. Typical cross-section for four-lane National Highway-58.
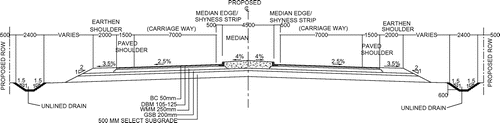
Table 1. Road infrastructures details
2.4. Crash database description
From past studies, it is evident that any crash is a resultant of deficiency in any one of these factors, highway design, driver behaviour and vehicle defect. Hence, there are number of associated parameters for each of these aforementioned three factors leading to the occurrence of crashes and it is practically a challenging job to collect all these parameters. By considering the parameters applied in past crash prediction models and practical availability of data, data were collected for estimating the crash prediction models. Crash records for three years from May 2011 to April 2014 were collected from various police stations along the study section and WUPTL. Highway as-built drawings revealing the plan and profile of the study stretch and average daily traffic (ADT) for the study period was obtained from NHAI.
Classified traffic volume count survey was carried out manually at km 89.00 (near Dadri village) on NH-58 for 24 h on 6 June 2013. Later video graphic traffic volume count for morning and evening peak two hours was conducted at 15 major intersections. Assumption was made that there are no entry and exit of major traffic in between these intersections. Different traffic volumes like major highway traffic, minor road traffic, major road crossing traffic, merging and diverging traffic details were retrieved at each intersection from these video data using a C program.
2.5. Crash pattern and candidate segment
Total crash count (CC) per kilometre for the study period under consideration is as shown in Figure . Crash severity (for both intersection and segment crashes) and collision type (for segment crashes) statistics for the analysis period are revealed in Tables and , respectively. From this, we can visualise that there are more than 20 crashes per kilometre throughout the analysis period along the study stretch. Safety performance functions were developed for crashes occurring on the highway segments only. Crashes occurring within a circle of 76 m (250 feet) were considered as intersection crash (Lord et al., Citation2008) and were excluded from the analysis data. Hence, there were 60 major segments (both directional) which were further divided into 200-m stretches. A minimum segment length of 0.1 mile (≈161 m) (American Association of State Highway and Transportation Officials, Citation2010; Miaou, Citation1994) was considered to avoid low-exposure criteria and large statistical uncertainty of CC per short segment. Segments shorter than 162 m were combined with the neighbouring segments with comparably similar geometrical characteristics.
Figure 3. Total CC per kilometre along the study stretch.
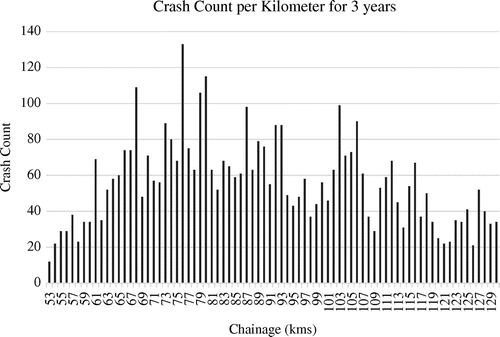
Table 2. Crash severity statistics for the study stretch
Table 3. Collision-type statistics of segment crashes along the study stretch
2.6. Influencing variables
CC per 200 m per year was taken as dependent variable in the crash prediction models. The safety parameters included in study were geometric characteristics like curvature change rate (CCR), slope change rate (SCR), transverse slope (TS) and traffic characteristics as ADT, traffic composition-like car (CAR) [composing cars, three- and four-wheeler autos], SUV, minibus, bus, light commercial vehicles (MTRUCK), heavy traffic volume (HTV) [two-axle trucks, multi-axle trucks, tractor-trailers], two-wheelers (TW) and non-motorised traffic volume (NMTV) [cycles, cycle rickshaws, animal-driven carts] and operating speed, V85 (American Association of State Highway and Transportation Officials, Citation2004; Jacob & Anjaneyulu, Citation2013) of vehicles in the traffic stream. For convenient calculations, natural log of traffic volume, speed, segment length and composition of vehicles was included in the models.
Curvature treated as CCR (Lamm, Wolhuter, Beck, & Rusher, Citation2001) of the segment, calculated as follows:(1)
(1)
where γi is the deflection angle for a contiguous element (curve or tangent) i within a section of length L.
Tables and give the statistical summary of the variables selected to build the safety performance functions for crash frequency and crash-type prediction, respectively. The results in Table revealed that for any subset of the independent variables, the CC exhibits overdispersion.
Table 4. Statistical summaries of NH-58 crash data used in crash prediction models
Table 5. Statistical summaries of NH-58 crash data used in crash severity model
2.7. Model formulation and analysis
Two model forms were considered for analysis as per ease of access to required data, as in most of the situation in India, it is a challenging job to collect crash records, geometric design parameters and other variables for crash analysis.
The following generalized linear model functional form has been used in all Bayesian analyses:
Model A:(2)
(2)
Model B:(3)
(3)
3. Modelling methodology applied
3.1. Poisson–Weibull (PW) model
As the name suggests, PW distribution is a mixture of Poisson and Weibull distribution. PW model is similar to most Poisson-based distributions (e.g. Poisson-gamma and Poisson-lognormal), it is also designed to accommodate the overdispersion. Interested readers are referred to Cheng et al. (Citation2013) for further detailed information. The number of crashes “Yit” for a particular ith site and time period t when conditional on its mean μit is Poisson distributed and independent over all sites and time periods.(4)
(4)
The mean of the Poisson is structured as:(5)
(5)
(6)
(6)
(7)
(7)
where f (·) is a function of the covariates (X); β is a vector of unknown regression coefficients; and εit is the model error independent of all the covariates.
In PW model, it is assumed that εit is independent and Weibull distributed. The Weibull probability density function (p.d.f) is given as follows:(8)
(8)
where λ and v are scale and shape parameters, respectively. The p.d.f. of the Weibull distribution can fit to various shapes similar to that of the gamma, gamma-like, exponential or approximate normal distributions depending on the v values. This characteristic of PW model provides a lot of flexibility to fit different kinds of data.
The mean and variance of the Weibull distribution are:(9)
(9)
(10)
(10)
The PW distribution is defined as the mixture of Poisson and Weibull distributions such that(11)
(11)
The mean or expected value of the PW distribution is given as:(12)
(12)
and the variance is given by:(13)
(13)
3.2. Bayesian-ordered logit model
The ordered logit model is commonly implemented to analyse ordered categorical data (Greene, Citation2007; Xie, Zhang, & Liang, Citation2009; Ye & Lord, Citation2014). The ordered logit model uses a latent variable y*, as shown below to determine the different crash-type outcomes.(14)
(14)
where X is a vector of independent variables for individual crashes; β is a vector of the unknown coefficients for these variables; and ε is a random error term assumed to follow standard normal distribution across observations.
Using Equation 10, the value of the crash-type variable yi is estimated by:(15)
(15)
where are the threshold values for all crash severity levels coded as integers in order; k = 1, … , C (C = 5 in the paper), the five crash types under consideration are: 1 = direct impact collision (DI), 2 = rear-end collision (REC), 3 = sideswipe collision (SSC), 4 = rollover collision (ROC) and 5 = skidding collision (SKC); C is the highest ordered crash-type level.
Given the value of Xi, the probability of a crash category for an individual ith crash belonging to each category is(16)
(16)
3.3. Goodness-of-fit statistics
There are many measures that can be used for estimating how well the model fits the data. There are statistics for indicating the likelihood level of a model, that is, how well the model maximises the likelihood function. Among these statistics are:
3.3.1. Pearson chi-square
Another useful likelihood statistic is the Pearson chi-square and is defined as:(17)
(17)
3.3.2. Deviance information criterion
The deviance information criterion (DIC) (Congdon, Citation2006) calculation in WinBUGS was used as the measure for comparing the different Bayesian hierarchical models; DIC assigns a penalty for the complexity of the model.
The DIC for the jth model is given by:(18)
(18)
where is the deviance
at the posterior mean
of the parameters for model j, called Dhat in WinBUGS,
is the expected deviance
, given by the mean
of the sampled deviances D(t) from Markov Chain Monte Carlo (MCMC) simulations, also called Dbar in WinBUGS, and pDj is the effective number of parameters in the model, computed as the difference between
and
, that is,
.
While comparing between two models, a difference in DIC value greater than 10 will rule out the model giving higher value of DIC (Spiegelhalter, Thomas, Best, & Lunn, Citation2003). Where the difference is less than 10, the models are reasonably similar. Smaller the DIC value indicates a better model fitting.
3.4. Model error estimates
There are statistics for estimating how well the model fit the data and the converse, how much error was in the model. Two error statistics are particularly useful.
3.4.1. Mean absolute deviation
This criterion has been proposed by Oh, Lyon, Washington, Persaud, and Bared (Citation2003) to evaluate the fit of models. The mean absolute deviance (MAD) calculates the absolute difference between the estimated and observed values.(19)
(19)
The model closer to zero value is considered to be best among all the available models.
3.4.2. Mean squared prediction error
The mean squared prediction error (MSPE) is a traditional indicator of error and calculates the difference between the estimated and observed values squared.(20)
(20)
A value closer to 1 means the model fits the data better.
3.4.3. Sum of model deviances
The sum of model deviances (G2) is equal to zero if the model perfectly fits the complete data-set. This is a theoretical lower bound value as the observed values yi are integers and the estimated values are continuous (Washington, Karlaftis, & Mannering, Citation2011).
(21)
(21)
A model with the lowest G2 value is superior to other models fitting to the data-set.
3.4.4. Equivalent measure to R2
Coefficient of determination, R2 cannot be adopted for Poisson regression models due to their nonlinearity of the conditional mean in the data and heteroscedastic characteristic i.e. data variables depict sub-populations with different variabilities from others. Hence, an equivalent measure based on standardised residuals can be adopted. It is the ratio of sum of square errors to total sum of squares subtracted by one (Washington et al., Citation2011).(22)
(22)
The value ranges from 0 to 1 and a value closer to 1 indicates the fitted model explains all variability in the data.
4. Data analysis and results
Bayesian framework was implemented for modelling and inference (Gelman et al., Citation2013). Bayesian hierarchical framework method considers the coefficients for the covariates as random variables rather than fixed values as in classical statistical inference. Hence, the model output will be a sampled posterior distribution for each of the estimated parameter. The parameter estimation and related sampling from the joint posterior probability distribution of multiple variables can be obtained by means of MCMC process using Gibbs sampler as in WinBUGS. As the Bayesian formulation requires priors for all unknown parameters, non-informative normal priors for β’s and Weibull priors for error terms were adopted. For each model, three Markov chains were used in the coefficient estimation process with 20,000 iterations, and 10,000 iterations were used in burn-in process and were discarded.
Convergences of the models were inspected by monitoring the plots in WinBUGS and Gelman Rubin (G–R) diagnostics for the model parameters. If all values were within a zone without strong periodicities or tendencies, the model was considered convergent.
Output analysis and diagnostics for MCMC simulations were carried out on coda files from WinBUGS using coda package in R (R Core Team, Citation2013). The G–R convergence statistic is generally used to verify that the simulation runs converged properly. For model comparison, it was suggested that convergence was achieved when the G–R statistic was less than 1.2 (Mitra & Washington, Citation2007).
4.1. Crash frequency prediction models
4.1.1. General output interpretation for model form ‘A’
This model depicts the effect of important individual independent variable, ADT on crash prediction. As revealed in Table , coefficient of ADT has significantly positive effect on crash occurrence. Both the techniques estimate nearly same coefficient value of ADT. The coefficient sign is comparable with past researchers (Dinu & Veeraragavan, Citation2011). The output of the models can be best evaluated by their goodness-of-fit measures as in Table , PW model reveals χ2 of 2,136, MAD of 4.67, MSPE of 13.07, DIC of 7,166.75 and G2 as 110.38. Equivalent measure to is 0.559 for major segment crash predictions.
Table 6. Parameter estimates and goodness-of-fit for model form A
4.1.2. General output interpretation for model form “B”
The estimated coefficient values for the model form B is as shown in Table . The results indicate that based on the estimates of covariate effects, the CCR, median opening, sport utility vehicles, light commercial vehicles, buses and two-wheelers are the most positively significant variables in explaining crash risk. SCR has minor positive impact on the expectancy of crash. TS, speed, car, minibuses, heavy commercial vehicles and non-motorised traffic have inverse effect on the probability of crash. Parameter coefficient of explanatory variables for both the models is comparable with each other.
Table 7. Parameter estimates and goodness-of-fit for model form B
CCR has positive effect on crash risk supporting the past crash studies (Lamm et al., Citation2001). Higher steep grades on the highway have minor positive effect on probability of crash occurrence. As the TS has negative effect on crash, it depicts negative TS sites are more prone to occurrence of crashes. Speed is having the highest inverse effect on crash revealing crashes occur due to lower operating speeds of traffic. Operating speeds of traffic might be varying due to congestion, bad weather and improper geometric design consistency on the highway stretch. Median openings have direct impact on the probability of crash as the manoeuvring traffic conflict with the opposite traffic stream. Cars have indirect impact on crash frequency as they constitute for the highest share in total traffic volume and are driven cautiously and majority occupants are family members. Sport utility vehicles significantly increase the probability of crash due to their higher speeds and rash driving behaviour as observed practically in the field. Minibuses have indirect impact on crash frequency as they are driven cautiously and majority occupants are tourists. Minitrucks are the light commercial vehicles which have positive effect leading to increase the probability of crash occurrence. Buses also are driven rashly at higher speeds and two-wheelers, the most vulnerable users due to their haphazardous and unpredictable movement in traffic tend to increase the crash frequency. Heavy traffic volume has negative effect on the occurrence of crash. NMTV has slight negative impact on crash risk.
The goodness-of-fit measures are as revealed in Table , χ2 of 2,250, MAD of 4.78 and MSPE of 13.77. DIC of 7,104.12 and G2 as −146.06 are lower than model form A test results revealing a better fit. Equivalent measure to is 0.571, for major segment crash predictions and relatively greater as compared to model form A supporting the fact as the input information is increased, prediction improves.
4.2. Crash severity prediction model
Occurrence of different crash type depends on different parameters like driver behaviour, vehicular type and their characteristics, traffic parameters, geometric condition, weather and pavement conditions. Based on the 4,034 crash records and relevant explanatory parameters as shown in Table , the ordered logit model was fitted using WinBUGS software package. Normal prior distributions were chosen for all parameters (explanatory variables and the thresholds) to be estimated. Mildly informed priors were chosen as the thresholds need to be in order as . Since y values are 1 through C, and priors are set to match this scale, i.e. thresholds should be approximately 1.5, 2.5, … (C−0.5). Hence, a normal prior on each threshold with a standard deviation of about 1 unit. Using MCMC simulation, samples from the posterior distribution of each parameter can be obtained. Out of these samples, an approximate density function can be drawn for each parameter and the posterior mean with standard deviation values is determined.
The parameter estimates for each independent variable, the intercept and the threshold values of the Bayesian-ordered logit model are listed in Table . Model coefficient values and its sign reveal the effect of each independent variable on crash types. A positive sign of an independent variable reflects, an increase in unit value of the variable will increase the probability of occurrence of higher crash category and decrease the probability of least crash category (Washington et al., Citation2011).
Table 8. Parameter estimates and goodness-of-fit for Bayesian ordered logit crash-type model
Direct impact collision includes head-on collisions, direct impact to pedestrians, animals and objects. Other collision types considered are rear-end collision, sideswipe collision, rollover collision and skid-related collisions which occur mainly in collisions involving two-wheelers. Crash-type prediction model considered additional parameters like day-type, hourly time period, daily average high temperature, daily average low temperature and daily precipitation values in addition to crash frequency parameters. Each day was coded numerically starting with Sunday as 1 to Saturday as 7. Hourly time period in 24 h format was also coded numerically with 1:00 am as 1 to midnight 12:00 am as 24.
CCR, TS, median opening, sport utility vehicles, minibuses, and minitrucks, two-wheelers in the traffic stream, time period, average daily higher temperature and precipitation have positive impact revealing their effect to lie in the higher portion of the crash-type scale under consideration. The estimated parameters for SCR, speed, presence of cars, buses, heavy vehicles, non-motorised vehicles in the traffic stream, type of day and average daily lower temperature have significant negative impact on type of crash owing to lower crash-type categories.
Sports utility vehicles, CCR and two-wheelers are the most positive significant parameters revealing the higher probability of crash types lying in the top order like direct impact, rear-end and sideswipe collision. Sports utility vehicles have comparatively higher engine power and come with recent vehicle technologies which make the driver drive rashly as practically observed on the study stretch. Higher change in curvature without any caution to the driver makes him vulnerable to collide with the oncoming object at higher speeds. As the driver cannot judge and react within the limited time. Two-wheelers in the traffic stream have major impact on higher crash levels due to their haphazardous driving behaviour and as the rider loses control of the vehicle as compared to other four-wheelers.
TS has minimal direct effect on crash type revealing higher slope values are prone to lie in the middle of the crash-type scale. The number of median openings per segment is also significantly related to higher crash-type categories of the ordinal scale. This indicates the manoeuvring traffic opposes the oncoming traffic affecting their speed and resulting in mid-to-higher crash levels. Minibuses and minitrucks, mainly tourist vehicles, are having less direct impact on crash type leading from mid-to-higher category crash types. Time period has lower positive effect on crash type depicting mid-category crash type occurs the most during noon period. Higher crash categories have higher probability during evening and until midnight. Lower crash categories occur the most during start of the day. Average higher temperature also have minimal direct effect on crash type revealing their effect to lie in the middle to higher crashes of the ordinal scale. Precipitation too has lower effect illustrating the probability of crash type tends from mid-to-higher level.
SCR has indirect relationship with crash type depicting the category tending from sideswipe to skidding collision. Cars are having significantly negative impact on crash type as they are mostly driven at higher speeds leading to rollover and skidding collision. Buses have minimal indirect effect on crash type revealing crash category to lie in the middle of the crash-type scale. Heavy vehicles and non-motorised vehicles too have minimal inverse effect on crash type revealing their effect to lie in the middle of the severity scale. Daily average lower temperature has negative effect on the crash type leading to lower crash categories on the ordinal scale.
Root mean square error (RMSE) of 2.32 and mean absolute percentage error (MAPE) of 0.0033 were computed by comparing the predicted and observed shares of each crash severity level. Computed goodness-of-fit results and predicted percentage shares of each crash severity categories are presented in Table . Cross-tabulation of the expected outcomes and the predicted probabilities from the ordered logit model is as shown in Table .
Table 9. Measures of fit for Bayesian ordered logit crash severity model
Table 10. Cross-tabulation of outcomes and predicted probabilities
5. Conclusions
This study identifies the contributing factors effecting crash frequency and different crash types on a divided four-lane national highway in India using Bayesian statistical models. Models were developed for three-year crash records on 143.5 km (both directional) of a divided four-lane highway (NH-58). The results of this study can help the policy-makers, decision-makers and road safety stakeholders in optimising allocated funds and planning effective safety countermeasures.
This paper presents two approaches viz. Poisson Weibull technique to analyse road traffic crash frequency and ordered logit model to predict crash type on national highways in India. Model parameters considered for crash analysis were CCR, SCR, TS and traffic characteristics as ADT, light vehicle traffic, light commercial vehicle traffic, Heavy Traffic Volume (HTV), TW and NMTV, operating speed of traffic stream, day-type, hourly time period, daily average high and low temperatures and precipitation. Models were developed using WinBUGS statistical software which facilitate the computation of posterior distributions along with a measure, DIC for model comparisons. Two model forms were analysed as shown in Equations 21 and 22. Hazardous location ranking, development of crash modification factors using the crash prediction models assist the highway professionals to better understand the effect of crash contributing factors and to mitigate the same cost effectively.
Results from the crash frequency analysis accompanied by detailed examination of the road crash model, following variables significantly affect crash frequency.
| (1) | Model results suggest that increase in traffic volume lead to higher probability of crash risk. | ||||
| (2) | Model outputs strongly suggest that traffic safety is significantly distorted by higher CCR values. | ||||
| (3) | Operating speed of traffic stream has indirect impact on the occurrence of crashes. | ||||
| (4) | Cars, minibus and HTV in traffic stream have indirect impact on crashes. | ||||
| (5) | MO, sport utility vehicles, minitruck, bus and two wheeler share are affecting significantly higher on crash occurrence. | ||||
Following are the parameters significantly affecting different crash type:
| (1) | CCR, sport utility vehicles and two-wheelers have higher impact on crash type suggesting probability of higher level category crashes to occur is more. | ||||
| (2) | Operating speed of traffic stream has inverse effect on crash type revealing occurrence of lower collision types of ordinal scale. | ||||
| (3) | Cars, bus, heavy and non-motorised vehicles in traffic stream and average daily lower temperature have indirect impact on crash type. | ||||
| (4) | MO, minibus and minitruck have lower direct impact on crash severity revealing their effect to lie in the middle of the ordinal scale. | ||||
| (5) | Type of day, average daily higher temperature and precipitation have minor negative impact on crash type. | ||||
From the present study, following countermeasures/safety measures emerge from the outputs of safety performance functions in terms of enforcement and engineering terms are to improve safety:
| (1) | Segregation of traffic by providing dedicated lanes to reduce crashes by segregating different vehicle categories in the traffic stream. | ||||
| (2) | To improve curvature change rate by enhancing the deficient curve locations. | ||||
| (3) | Redesigning the critical transverse slope areas. | ||||
| (4) | Closure of illegal median openings and redesigning the unsafe median openings by providing storage lanes and enhancing by proper sign boards and pavement markings. | ||||
| (5) | Increasing police patrolling on the highway to enforce drivers to abide by traffic rules and regulations. | ||||
| (6) | To install electronic sign boards visible during night and bad weather conditions. | ||||
Cover image
Source: Author and WUPTL Data.
Acknowledgements
The inputs received from MORTH Chair Professor sponsored by Ministry of Road Transport & Highways, Government of India is thankfully acknowledged. Naveen Kumar ChikkaKrishna also wishes to express his gratitude to NHAI and WUP Toll Ltd for providing the data used for analysis.
Additional information
Funding
Notes on contributors
Naveen Kumar ChikkaKrishna
Naveen Kumar ChikkaKrishna holds a Master’s degree in Traffic and Transportation Engineering from National Institute of Technology Calicut. He is pursuing his doctoral research in the Department of Civil Engineering, Indian Institute of Technology Roorkee. His research interests include road safety analysis, highway geometric design, traffic impact analysis and transportation planning.
Manoranjan Parida
Manoranjan Parida is a professor in Civil Engineering Department and dean (SRIC) at IIT Roorkee. He is also holding the chair—MoRTH. His areas of specialisation include urban transportation planning, traffic safety, etc. He is recipient of Jawaharlal Nehru Birth Centenary Award, Medals and Prizes of Institution of Engineers (India).
Sukhvir Singh Jain
Sukhvir Singh Jain is a professor in Civil Engineering Department at IIT Roorkee. His main areas of specialisation include pavement management system, transport infrastructure systems, urban transport planning and design, transport environment interaction, intelligent transport system, integrated development of public transport system and road traffic safety.
References
- American Association of State Highway and Transportation Officials. (2004). A policy on geometric design of highways and streets (5th ed.). Washington, DC: Author.
- American Association of State Highway and Transportation Officials. (2010). Highway safety manual (1st ed.). Washington, DC: Author.
- Cheng, L., Geedipally, S. R., & Lord, D. (2013). The Poisson–Weibull generalized linear model for analyzing motor vehicle crash data. Safety Science, 54, 38–42.10.1016/j.ssci.2012.11.002
- Congdon, P. (2006). Bayesian statistical modelling. Chichester: Wiley. 10.1002/9780470035948
- Dinu, R. R., & Veeraragavan, A. (2011). Random parameter models for accident prediction on two-lane undivided highways in India. Journal of Safety Research, 42, 39–42. doi:10.1016/j.jsr.2010.11.007
- Geedipally, S. R., & Lord, D. (2008). Effects of varying dispersion parameter of Poisson–gamma models on estimation of confidence intervals of crash prediction models. Transportation Research Record: Journal of the Transportation Research Board, 2061, 46–54.10.3141/2061-06
- Geedipally, S. R., & Lord, D. (2010). Investigating the effect of modeling single-vehicle and multi-vehicle crashes separately on confidence intervals of Poisson–gamma models. Accident Analysis & Prevention, 42, 1273–1282. doi:10.1016/j.aap.2010.02.004
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian data analysis (3rd ed.). Boca Raton, FL: CRC Press, Taylor & Francis Group.
- Greene, W. H. (2007). Econometric analysis (7th ed.). Boston, MA: Prentice Hall.
- Hauer, E. (1997). Observational before/after studies in road safety estimating the effect of highway and traffic engineering measures on road safety. Oxford: Emerald.
- Indian Roads Congress. (2000). Geometric design standards for rural (non-urban) highways (IRC: 73-1980). New Delhi: Author.
- Jacob, A., & Anjaneyulu, M. V. L. R. (2013). Operating speed of different classes of vehicles at horizontal curves on two-lane rural highways. Journal of Transportation Engineering, 139, 287–294. doi:10.1061/(ASCE)TE.1943-5436.0000503
- Krishnan, M. J., Anjana, S., & Anjaneyulu, M. V. L. R. (2013). Development of hierarchical safety performance functions for urban mid-blocks. Procedia - Social and Behavioral Sciences, 104, 1078–1087. doi:10.1016/j.sbspro.2013.11.203
- Lamm, R., Wolhuter, K. M., Beck, A., & Rusher, T. (2001). Introduction of a new approach to geometric design and road safety. In SATC 2001. Pretoria: CSIR International Convention Centre.
- Landge, V. S. (2006). Development of methodology for road safety for a national highway ( PhD Thesis). Indian Institute of Technology Roorkee, Roorkee.
- Lord, D., Geedipally, S. R., Persaud, B. N., Washington, S. P., van Schalkwyk, I., Ivan, J. N., … Jonsson, T. (2008). Methodology to predict the safety performance of rural multilane highways ( NCHRP Web-Only Document 126). Washington, DC: National Cooperation Highway Research Program.
- Miaou, S.-P. (1994). The relationship between truck accidents and geometric design of road sections: Poisson versus negative binomial regressions. Accident Analysis & Prevention, 26, 471–482.
- Miaou, S. P., & Lord, D. (2003). Modeling traffic crash-flow relationships for intersections: Dispersion parameter, functional form, and Bayes versus empirical Bayes methods. Transportation Research Record, 1840, 31–40.10.3141/1840-04
- Miaou, S. P., & Lum, H. (1993). Modeling vehicle accidents and highway geometric design relationships. Accident Analysis & Prevention, 25, 689–709.
- Mitra, S., & Washington, S. (2007). On the nature of over-dispersion in motor vehicle crash prediction models. Accident Analysis & Prevention, 39, 459–468. doi:10.1016/j.aap.2006.08.002
- Oh, J., Lyon, C., Washington, S., Persaud, B., & Bared, J. (2003). Validation of FHWA crash models for rural intersections: Lessons learned. Transportation Research Record, 1840, 41–49.10.3141/1840-05
- Persaud, B., Lord, D., & Palmisano, J. (2002). Calibration and transferability of accident prediction models for urban intersections. Transportation Research Record, 1784, 57–64.10.3141/1784-08
- R Core Team. (2013). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
- Road Accidents in India. (2014). Government of India. New Delhi: Ministry of Road Transport & Highways, Transport Research Wing.
- Spiegelhalter, D., Thomas, A., Best, N., & Lunn, D. (2003). WinBUGS user manual. Cambridge: MRC Biostatistics Unit.
- Washington, S., Karlaftis, M. G., & Mannering, F. L. (2011). Statistical and econometric methods for transportation data analysis (2nd ed.). Boca Raton, FL: Chapman & Hall, CRC.
- Xie, Y., Zhang, Y., & Liang, F. (2009). Crash injury severity analysis using Bayesian ordered probit models. Journal of Transportation Engineering, 135, 18–25.10.1061/(ASCE)0733-947X(2009)135:1(18)
- Ye, F., & Lord, D. (2014). Comparing three commonly used crash severity models on sample size requirements: Multinomial logit, ordered probit and mixed logit models. Analytic Methods in Accident Research, 1, 72–85. doi:10.1016/j.amar.2013.03.001