
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Cryptography via public key cryptosystems (PKC) has been widely used for providing services such as confality, authentication, integrity and non-repudiation. Other than security, computational efficiency is another major issue of concern. And for PKC, it is largely controlled by either modular exponentiation or scalar multiplication operations such that found in RSA and elliptic curve cryptosystem (ECC), respectively. One approach to address this operational problem is via concept of addition chain (AC), in which the exhaustive single operation involving large integer is reduced into a sequence of operations consisting of simple multiplications or additions. Existing techniques manipulate the representation of integer into binary and m-ary prior performing the series of operations. This paper proposes an iterative variant of sliding window method (SWM) form of m-ary family, for shorter sequence of multiplications corresponding to the modular exponentiation. Thus, it is called an iterative SWM. Moreover, specific for ECC that imposes no extra resource for point negation, the paper proposes an iterative recoded SWM, operating on integers recoded using a modified non-adjacent form (NAF) for speeding up the scalar multiplication. The relative behaviour is also examined, of number of additions in scalar multiplications, with the integers hamming weight. The proposed iterative SWM methods reduce the number of operations by up to 6% than the standard SWM heuristic. They result to even shorter chains of operations than ones returned by many metaheuristic algorithms for the AC.
Public Interest Statement
Data encryptions using public key cryptosystems (PKC) provide higher functionality services such as confidentiality, authentication, integrity and non-repudiation. However, the highly computational cost in the encryption process, involving modular exponentiation or scalar multiplication, made this optimisation strategy relevant. In both cases, very large size of integers (of up to 600 decimal digits) are being utilised as the keys. And, the key size determines that of the exponent or multiplier. One means of reducing the size of the computation is by transforming the process into series of simpler multiplications or additions.
In this paper, we proposed an iterative-based sliding window method (SWM) for improving the computational cost. Our proposed approach searches for optimal parameters for the SWM, corresponding to specific integer utilized as the exponent or multiplier. The experimental results demonstrate that our proposed method improves the solution quality, by reducing the computation size, up to 6
1. Introduction
In public key cryptosystems (PKC) (Diffie & Hellman, Citation1976; El-Gamal, Citation1985; Koblitz, Citation1987; Rivest, Adi, & Adleman, Citation1978), computations involving modular exponentiation and scalar multiplication found in the respective RSA (Rivest et al., Citation1978) and ECC (Koblitz, Citation1987; Miller, Citation1985) are the most expensive operations that determine the efficiencies of the algorithm, and on which the security of the systems also depends. For the applications to be computationally secured the size of the key, which is the exponent or multiplier, respectively, should be of at least 1,024 bits in multiplicative structure such as Diffie–Hellman (Diffie and Hellman, Citation1976) and RSA and 163 bits in additive structure of ECC.
One of the means of optimizing these operations without compromising the security effectiveness is by reducing an exhaustive operation of modular exponentiation to repeated squaring and multiplication and likewise scalar multiplication to repeated doubling and addition via the concept of addition chain (AC). Since modular exponentiation is an additive function of the exponent similar to that of multiplier from scalar multiplication, both operations are adoptable to the idea of AC. In other words, possible shortening of an AC for the exponent/multiplier by reducing the number of doubling and addition corresponds to that of either one of the two operations: thus should be understood as minimizing the number of multiplications in modular exponentiation or of additions in scalar multiplication.
The problem of finding optimal AC for an arbitrary integer, also known as addition chain problem (ACP), exists for long (Dellac, Citation1894; Scholz, Citation1937). Numerous theoretical studies on the problem can be found in Balega (Citation1976), Brauer (Citation1939), Downey, Leong, and Sethi (Citation1981), Mignotte and Tall (Citation2011), Thurber (Citation1993) and Yao (Citation1976). From experimentation perspective, exhaustive approaches have been applied (Clift, Citation2010; Hatem, Citation2011), as well as heuristics (Bos & Coster, Citation1990; Gelgi & Onus, Citation2006; Koç, Citation1995; Park, Park, & Cho, Citation1999; Thurber, Citation1999). Moreover, after Downey et al. (Citation1981) proved that the generic case called addition sequence is an NP-complete problem, various metaheuristics have also been applied (Cruz-cortés, Rodríguez-Henríquez, & Coello, Citation2008; Domínguez-Isidro, Mezura-Montes, & Osorio-Hernández, Citation2015; Jose-Garcia, Romero-Monsivais, Hernandez-Morales, Rivera-Islas, & Torres-Jimenez, Citation2011; León-Javier, Cruz-Cortés, Moreno-Armendáriz, & Orantes-Jiménez, Citation2009, November; Nedjah & de Macedo Mourelle, Citation2006; Osorio-Hernández, Mezura-Montes, Cruz-Cortés, & Rodríguez-Henríquez, Citation2009, May).
For the purpose of simplicity, a generic integer e is used in this paper to represent the exponent or multiplier of either of the operations.
Definition 1.1
Given an integer e, the sequence , is said to be an AC for e if
,
,
. The length of the chain is r.
In the studies of AC by mean of heuristic approach, e is normally represented into an equivalent binary form, from which some form of manipulation is applied in the quest to produce the shortest possible chain.
Definition 1.2
The length of e (denoted as) n(e) is defined as the minimum number of bits to represent e in binary form . n used to indicate the length of an arbitrary n-bit e.
Definition 1.3
The hamming weight (shorten as weight) of e denoted as H(e) is defined as the number of non-zero bits in the binary representation of e.
Using the binary form as found in many heuristic techniques, the total number of operations is counted to the number of doublings (squarings) and additions (multiplication) involved. In fact, the number of squarings is fixed to the bit-length n(e), and thus improvement can only be done on the number of multiplications which is proportionate to weight H(e).
Binary method (Knuth, Citation1998) has been the basic procedure for computing modular exponentiation as well as scalar multiplication. In the modular exponentiation, a sequence of squarings and optional multiplications are performed, depends upon the given digit value of the binary form for e that is 1 or 0, respectively. Similarly, a sequence of doublings and optional additions are performed in the scalar multiplication. For an n-bit e, represented in the binary form as , the method for the exponentiation
follows in Algorithm 1.
In Algorithm 1, number of squarings are performed in step 3, and a multiplication in step 5 corresponding to every non-zero bit encounter, less the most significant bit (MSB):
. Thus, assuming multiplication and squaring are computationally equal, the number of multiplications (operations)
is
(1)
(1)
Since there are n bits in e, each of which is equally likely to be 1 or 0, the asymptotic number of multiplications in Algorithm 1 is . The method is highly efficient in implementation due to its minimal book-keeping in the process (Knuth, Citation1998). However, it performs excessive number of multiplications than is necessary.
An m-ary (also known as or -ary) method is an extension of the binary method. An n-bit e is padded (where necessary) with at most
trail of 0s to form a multiple of k. It is then partitioned into
blocks of fixed k-bit words:
being the most significant word (MSW). Thus,
, and
. Initially, the values
, corresponding to all possible value for
, are pre-computed. The algorithm proceed by scanning the most significant k bits
, raising the corresponding
to the power of
as the partial result. This is followed by subsequent scanning of the remaining
, each time multiplying the partial result by
and raising it to the power of
as:
. That is beginning from
, k-times squaring are performed followed by multiplying the partial result by the next
until the last
is multiplied by. The m-ary method has an average number of multiplications given by Koç (Citation1995).
(2)
(2)
Depending on the k parameter, the method performs less number of multiplications than binary method. However, the pre-computations cost increases exponentially with an increase in the k size.
Note that when (
) the multiplication step is not necessary. Consequently, adaptive window methods are the enhancements of the m-ary that form partitions
of arbitrary length of 0s. In the constant-length non-zero window (CLNW) version, in the partitioning process, the leading zeros in a given k-bit non-zero window (NW) partition
are carved out and concatenated with subsequent zeros encounter to form a zero window (ZW)
partition. The ZW takes any arbitrary length until a non-zero bit is again encountered. Thus, only NWs are restricted to bit-lengths
, and for which list significant bit
. As a result, the pre-computation stage involves computing only
and odd values
at the cost of
multiplications. Whereas, in the variable-length non-zero window (VLNW) version (Koç, Citation1995), the number of ZWs is further maximized by switching NW to ZW partition construction upon encounter of predetermined
consecutive zeros. Transition to the ZW-partition begins with the q zeros. Note, setting
defaults to CLNW. Both methods are also known as SWM (refer to Koç, Citation1995; Park et al., Citation1999, for details).
Given an n-bit e, partitioned into windows of variable lengths such that
, the number of multiplications in
is determined as follows. Beginning from the MSB, let there be
number of NWs in the partition. On deferring until after the partitioning is completed and the largest NW
(henceforth denoted as
) is known, the pre-computation cost reduces to
multiplications. Beginning from MSW
, the exponentiation involves
squaring, and
multiplications corresponding to remaining NWs. The generic procedure is presented as Algorithm 2.
Thus, the number of multiplications is given as follows:(3)
(3)
On the average, are maximized, while their proportionate decimal values (determined by the weight) minimized with increase in the q value towards k; the reverse is the case for relatively smaller value. On the other hand, empirical result from sets of 16 to 2,048-bit es tested shows that delaying the pre-computation reduces the exponentiation cost by an average of three multiplications. Thus, given e, varying k and q while determining the corresponding p,
and
values, until those k and q that minimize Equation (3) are found, amounts to finding the optimal parameters for computing
using SWM: that is it translates to finding the corresponding shortest number of multiplications in the computation. Note that only partitioning is required to determine the optimal parameters. This is the idea of the Iterative SWM.
This paper proposes finite iterative partitioning strategy to determine optimal SWM parameters for any given e, to achieve shortest chain of multiplications in computing modular exponentiation using the SWM. Additionally, the paper proposes an iterative version of the SWM on recoded e utilizing a modified NAF (Eğecioğlu & Koç, Citation1994): in which the increase in the NAF-length is controlled while achieving the same minimum weight. NAF is employed to reduce the cost of additions in scalar multiplication-based ECC. Furthermore the paper examined, utilizing empirical data, the relative increment in the number of additions in scalar multiplications with respect to H(e) in recoded es.
The rest of this paper is organized as follows: Section 2 detailed and analysed the proposed Iterative SWM algorithm; an experiment is then set up and carried out on the algorithm, and the result discussed at the end of the section; proposed recoded version of the iterative SWM is detailed and empirically examined in Section 3. Section 4 concludes the paper.
2. Iterative sliding window method (ISWM)
The proposed ISWM utilizes left-to-right version of the VLNW algorithm (Park et al., Citation1999). But in this case the partition size k is varied from an initial to a predetermined maximum value
. Similarly, the allowable consecutive zeros in a partition q is varied from
to
. At
the algorithm is in CLNW mode (Koç, Citation1995). On every combination of
parameter values, the algorithm partitions e and determines the number of multiplications T(e) according to Equation (3). It keeps track of the parameter values with the shortest T(e), and finally evaluates and returns the corresponding SWM. The ISWM is presented as Algorithm 3.
2.1. Algorithm analysis
Given n-bit e and , in Algorithm 3, the external loop executes at most
times, in each of which the internal loop executes at most k times. Since
, the algorithm is bounded by
number of, mainly, partitioning due to steps 1 and 3. Empirical studies (as detailed shortly) shows that optimal k is bounded by
. Thus, the algorithm is bounded by
partitionings. A complete SWM is executed once in step 11. The partitioning in step 1 is performed in a single pass, depending on the size of k. At worst
and ith-bit
th-bit,
: whereby the n-bit e is partitioned into
number of
, thus it is bounded by O(n).
In fact, for common utilized in PKC, all optimal k value is bounded by
(Koç, Citation1995; Park et al., Citation1999): Thus, at most
partitions are needed in the process.
The memory resource required in running the algorithm is the same as that of the standard left-to-right SWM: as since partitioning is part of the SWM. Estimated as memory units required for the pre-computed and final exponent, it is at worst units.
A preliminary experiment is conducted on the ISWM to estimate the bounds for the k and q, with view to optimizing the number of partitioning. Figure shows the number of multiplications (T) as function of the , corresponding to various sets of n.
Figure 1. ISWM respond with settings. (a) 16–256 bitse and (b) 512–2048 bitse.
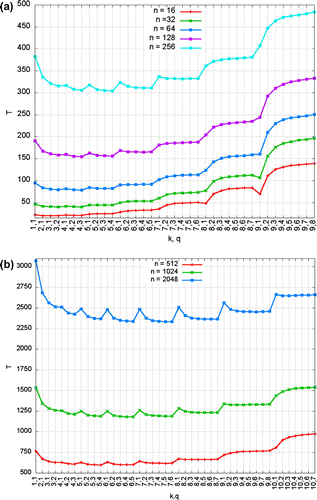
As can be observed in Figure 1(a) and (b), and based on the empirical data collected during the experiment, the optimal T are (by 99.9%) within the parameters ranges as tabulated in Table .
Table 1. parameters ranges for optimal ISWM
2.2. Experimental set-up and result discussions
2.2.1. Experiment setup
Koç (Citation1995) reported theoretical optimal parameters for the standard right-to-left SWM. The same is reviewed by Park et al. (Citation1999). The left-to-right method is more effective in terms of shorter number of multiplications (Park et al., Citation1999). However, there was no exclusive report on its optimal parameters. Therefore, an empirical analysis is carried out on the method to determine the corresponding values, for classes of integers mostly utilized in PKCs. The result is presented in Table .
Table 2. Optimal parameters for SWM
In the subsequent experiment, the number of multiplications T and it relative behaviour with varying weight H(e) are investigated. Thus, random sample integers are generated, to ensure adequate representation for the e range covered, with the details as follows:
| (1) | The integers are classified into 8 classes according to bit-lengths as | ||||
| (2) | Each class is divided into 16 sub-classes: 1 to 16, such that class | ||||
| (3) | 1,000 sample, for each of the sub-class, is generated. And the corresponding numbers of multiplications are concurrently evaluated, applying binary method, SWM and our proposed ISWM, according to parameters in Tables and , respectively; and | ||||
| (4) | The results expressed as the average of the accumulated number of multiplications for the 16,000 ( | ||||
2.3. Result discussions for ISWM
To examine the effectiveness of the ISWM in shortening the number of multiplications, an experiment was conducted using the detailed set-up and the classes of integers in Section . The results are compared with ACs (corresponding to number of multiplications) due to SWM-metaheuristic hybrid methods in Cruz-cortés et al. (Citation2008) and Domínguez-Isidro et al. (Citation2015). This is presented in Table .
Table 3. Average T by various methods
In all the entries in Table , ISWM performs better than the standard SWM. It reduces the length of multiplications on the average by at least 2 (), and up to 12 (
). This reduction is very significant considering that it is on the average basis. On the other hand, AIS-SWM and ACEP-SWM perform better than both SWM and ISWM for 128-bit integers. However, as the integer size increases, the proposed ISWM outperforms both methods: indicating superior advantage of the SWM in handling large-sized integers such as the ones used in PKCs. Based on percentage deviation of ISWM from the standard SWM, the former gains 1% shorter number of multiplications than the latter.
It is interesting to note that SWM effectiveness in computing modular exponentiation with shorter number of multiplications is being underestimated at the expense of its implementation efficiency. In fact with proper choice of windows parameters, even the standard SWM is generally better than other reported heuristic/metaheuristics, for large integers (512–2,048 bits). When approached as proposed, ISWM is comparably better than the reported results in every respect. Therefore, this paper concludes that SWM is still the most effective method for computing modular exponentiation, while it is second to binary method in terms of efficiency.
3. Iterative recoded SWM (IRSWM)
ECC involves repeated point additions of the form for some finite e times: referred to as scalar multiplication, and denoted as eP. The scalar multiplication is structurally similar to modular exponentiation, with the exception that squaring and multiplication are replaced by doubling and addition, respectively. The respective operations are accordingly interchanged in this section. The ECC has the advantage of achieving equivalent level of security with shorter key size than other standard PKCs such as RSA. For example, 233-bit key ECC provides security level equivalent to 2,048-bit key RSA (Dahshan, Kamal, & Rohiem, Citation2015; Win, Mister, Preneel, & Wiener, Citation1998). Additionally, the cost of inversion is negligible: for a point
,
. Therefore, introducing inversion in the computation process is proprietary to ECC with no extra cost.
The effect of the inversion in reducing the number of additions in eP can be demonstrated with n-bit es of the form . They exhibit longest number of additions
on applying binary method to evaluate the corresponding
. But by admitting inversion, the same method reduces the additions to
: consisting of n doublings and an inversion and addition, as
. In general, any k consecutive non-zero bits in binary form of e,
, can be recoded into
-bits as
. Therefore, signed recoding is introduced to reduce the number of additions that follows doubling due to the integer weight H(e). In this regard, balanced ternary
recoding (Knuth, Citation1998) is re-introduced to minimize the weight. Henceforth,
is denoted as
and recoded form for e as
.
Various recoding methods exist, with NAF being canonical having the minimal non-zero bits density of n / 3 (Eğecioğlu & Koç, Citation1994; Reitwiesner, Citation1960; Morain & Olivos, Citation1990). A kNAF is a recoded equivalent of m-ary, capable of reducing the density asymptotically to (Okeya, Schmidt-Samoa, Spahn, & Takagi, Citation2004). Similarly, Laih and Kuo (Citation1997) proposed an m-ary version of modified signed digit (MSD), having the same non-zero bits density as the kNAF. Another method similar to kNAF, but with the advantage of performing the conversion from the MSB, is mutual opposite form (MOF) (Okeya et al., Citation2004). The approach eliminates the need for two parses during the conversion, and an additional n-bit memory required in the process is reduced to 1 (or k-bit for kMOF). Basically, for an n-bit e
(4)
(4)
where all the operations in Equation (4) are bitwise.
Balasubramaniam and Karthikeyan (Citation2007) introduced complementary recoding (CR): 1 + bitwise complement of e is bitwise-subtracted from such that
(5)
(5)
Note that, Equation (5) is equivalent to . However, CR is only effective in reducing the H(e) for an n-bit e, when
: This is because and its (
)-bit CR-recoded
are related as
.
Therefore, CR rather increases the non-zero bit density if . For example, consider
where
.
,
. However,
,
.
NAF optimally reduces H(e), but at tines leads to additional bit to n(e) that could possibly be avoided (Saffar & Said, Citation2015). Integers with binary form have NAF-recoded form as
having
. But an equal non-zero bits density can be realized without the additional 1 bit increase, by suppressing the NAF conversion at the second MSB. For example, consider
having
and
.
, that is
and
. On suppressing the conversion at the second MSB,
is recoded as
with length and weight equal 9 and 5, respectively. As for suitable recoding for SWM heuristic, it is still an open problem (Win et al., Citation1998). Therefore, this paper proposes a modified NAF (mNAF) as a means of avoiding the additional bit increase where possible. The procedure is presented in Algorithm 4.
Table presents average number of additions due to binary method, NAF and mNAF for sets of -bit integers.
Table 4. Effects of integer recoding on number of additions
As can be observed in Table , the NAF and mNAF recoding significantly reduce the number of additions, especially as the integer sizes become larger. On the other hand, the proposed mNAF exhibits shorter additions than the original NAF: this is due to its better performance in containing length while equally reducing the weight
as the NAF.
Iterative recoded SWM (IRSWM) is similar to ISWM (Algorithm 3). Except that e is initially recoded using Algorithm 4; Squaring and multiplications in SWM are replaced with doublings and additions (or subtraction), thus called recoded SWM (RSWM); and, is replaced with the largest absolute value
. The procedure is presented in Algorithm 5.
The experimental set-up in Section is utilized to test the IRSWM. However, considering that the current scalars utilized in ECC are less than 512 bits, the experiment covers 512 bits only. Likewise, little variations where observed in the optimal window parameters for the SWM, when applied on recoded integers. Accordingly, the new values are presented in Table .
Table 5. Optimal parameters for RSWM
Furthermore, preliminary experiment shows that CLNW () on the recoded integers results in shorter number of additions than VLNW. Thus, q is fixed, making Algorithm 5 even faster, as the number of iterations is always less than
.
Additionally, it is observed that level of the weight reduction due to the NAF and various other recoding methods (with the exception of CR) are subject to both the non-zero bits density and their distribution pattern: Two n-bit integers having the same weight exhibit different recoded density, depending on their respective pattern of the 1-bits distribution before recoding. The reduction is highly efficient when the initial 1 bits are clustered. For example, NAF for is
, having
. On the other hand, NAF-recoding
with the same weight results to
, having
. As such empirical results for recoded sets of integers are highly subject to the non-zero bits distribution pattern of the set utilized. And, the resulting number of additions may not tally with theoretically expected ones, for example, asymptotic number of additions due to
, for an n-bit integer. In fact, tests on integers generated by various random generators yield different results, all of which having shorter number of additions than expected theoretical one. Therefore, the results presented in this section are only subjects to the set of random integer sets utilized.
3.1. Variation in number of additions with non-zero bit density
The relative behaviour is examined, of the corresponding number of additions with respect to the non-zero bit density. The test is carried out on NAF, IRSWM and the standard SWM applied on recoded integers, RSWM. A random set of 256-bit integers is utilized. The effect of bit-length is normalized by dividing the number of additions by n. The result is presented in Figure . It also shows relative reduction in the bit-density by the methods examined.
Figure 2. Variation in Number of Additions with H(e) for 256-bit e.
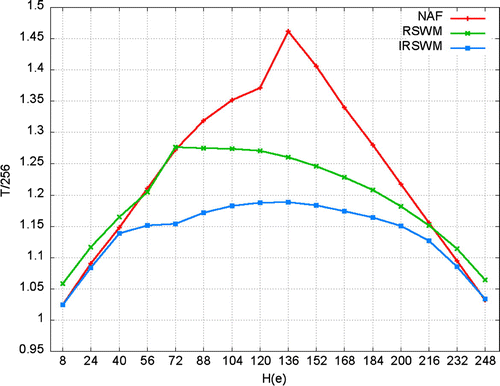
Note that from Figure , initially the number of additions in both NAF and IRSWM increases proportionately with the H(e). Fortunately, peak values are reached shortly after the weight reached n / 2. After which the length continue to decreases. RSWM also exhibits similar trend, except that the peak value is reached when . As for the relative efficiency in containing the density, IRSWM performed best among the three methods. In general, the trend shows that integers with about 1/3–2/3 non-zero bits density exhibit relatively larger number of additions even after recoded; the reverse is the case when the density is very sparse and as well when highly concentric.
3.2. Result discussions for IRSWM
In this section, the experimental results from IRSWM are compared with that of RSWM as well as recoded binary method. The proposed mNAF is utilized in the recoding. The result is presented in Table .
Table 6. Number of additions by various methods on recoded e
The result in Table shows significant improvement on the number of additions returned by IRSWM over that of RSWM. It shows that iteratively searching for the optimal partitioning parameter values reduces the length, on average, by at least 2 () and up to 8 (
). As can be observed from both the Table and Figure , IRSWM also significantly optimizes the length than the other methods examined when the integers bits densities are about half of the bit-length: which is the worst case scenario in terms of the number of additions. Overall estimate using percentage deviation shows that IRSWM improves on RSWM and SWM by 4 and 6%, respectively.
On general note: applying the IRSWM results in the shortest number of additions in ECC scalar multiplications. It is also expected that, for ECC applications in which the scalar can be chosen, the result presented may serve as a tool for much wiser and narrower selection for scalars whose number of additions is a lot lesser.
4. Conclusion and future works
This paper proposes iterative (recoded) SWM to achieve an even shorter number of operations in both modular exponentiation and scalar multiplication that are found in PKC. A modification to classic NAF algorithm is proposed, to contain the increase in integers bit-length after recoding. The relative responds is also explored, of the length of additions in computing scalar multiplications, with respect to hamming weight of the scalar. Empirical results show that the Iterative SWM optimize the number of operations by at least 1% over the SWM, and up to 6% when applied on recoded integer. With respect to relationship between the scalar multiplication and the hamming weight, recoded form of integers with original hamming weights below and above one-third of their corresponding length are more optimal for scalar multiplications than their counterparts. The paper concluded that iteratively finding the optimal window parameters while applying SWM effectively reduces the number of operation in the modular exponentiation and scalar multiplication. An even better performance is realized than the computationally much complex metaheuristic approaches at present.
Even as the proposed iterative SWM shortens the number of operations, there is still room for further optimization. It is expected that introducing simple but effective metaheuristic can further reduce operations towards (nearest) optimal.
Additional information
Funding
Notes on contributors
Adamu Muhammad Noma
Adamu Muhammad Noma received his Bachelor of Technology in Computer Science from Abubakar Tafawa Balewa University Bauchi Nigeria in 2006 and Master of Science in Computer Networking at the Universiti Putra Malaysia in 2014. He is a lecturer with Bauchi State University Gaudau, Nigeria, and is currently pursuing his Doctor of Philosophy in Computing Security at the Universiti Putra Malaysia. His area of research interest includes networks, security in distributed computing systems and optimization. In this research work, they propose a means of speeding up public key cryptosystems in an effort to ensure their seamless implementations in distributed and embedded systems, which are resources-constrained in terms of both computing and memory.
Abdullah Muhammed
Abdullah Muhammed received PhD in computer science from the University of Nottingham in 2014.He is a senior lecturer and HoD of the Department of Communication Technology and Networks, UPM. His research interests include cloud computing, mobile and wireless network, scheduling, heuristic and optimisation.
Zuriati Ahmad Zukarnain
Zuriati Ahmad Zukarnain is an associate professor at the same faculty. She received PhD from the University of Bradford. Her research interests include efficient multiparty QKD protocol for classical network and cloud; wireless and ad hoc networks load balancing; quantum processor unit for quantum computers, authentication time of IEEE 802.15.4 with multiple-key protocol, wireless networks intradomain mobility handling, efficiency and fairness for new AIMD algorithms and kernel model.
Muhammad Afendee Mohamed
Muhammad Afendee Mohamed received PhD in mathematical cryptography from UPM in 2011. Currently, he is a senior lecturer at this university and his research interests are in the domain of information security and mobile and wireless networking.
References
- Balasubramaniam, P., & Karthikeyan, E. (2007). Elliptic curve scalar multiplication algorithm using complementary recoding. Applied Mathematics & Computation, 190, 51–56.
- Balega, E. G. (1976). The additive complexity of a natural number. Soviet Mathematics Doklad, 17, 5–9.
- Bos, J., & Coster, M. (1990). Addition chain heuristics. In Advances in Cryptology – CRYPTO’ 89 Proceedings (pp. 400–407). New York, NY: Springer.
- Brauer, A. (1939). On addition chains. Bulletin of the AMS, 45, 736–740.
- Clift, N. M. (2010). Calculating optimal addition chains. Computing, 91, 265–284.
- Cruz-cortés, N., Rodríguez-Henríquez, F., & Coello, C. A. (2008). An artificial immune system heuristic for generating short addition chains. IEEE Transactions on Evolutionary Computation, 12(1), 1–24.
- Dahshan, H., Kamal, A., & Rohiem, A. (2015). A threshold blind digital signature scheme using elliptic curve dlog-based cryptosystem. In 2015 IEEE 81st Vehicular Technology Conference (VTC Spring) (pp. 1–5). IEEE Press.
- Dellac, H. (1894). Question 49. L’Intermédiaire Math, 1(20).
- Diffie, W., & Hellman, M. E. (1976, June). Multiuser cryptographic techniques. Proceedings of the June 7–10, 1976, National Computer Conference and Exposition - AFIPS’76 (pp. 417–428). ACM.
- Domínguez-Isidro, S., Mezura-Montes, E., & Osorio-Hernández, L.-G. (2015). Evolutionary programming for the length minimization of addition chains. Engineering Applications of Artificial Intelligence, 37, 125–134.
- Downey, P., Leong, B., & Sethi, R. (1981). Computing sequences with addition chains. SIAM Journal on Computing, 10, 638–646.
- Eğecioğlu, O., & Koç, Ç. K. (1994). Exponentiation using canonical recoding. Theoretical Computer Science, 129, 407–417.
- El-Gamal, T. (1985). A public key cryptosystem and a signature Scheme based on discrete logarithms. IEEE Transaction on Information Theory, 31, 469–472.
- Gelgi, F., & Onus, M. (2006). Heuristics for minimum Brauer chain problem. In Computer and Information Sciences – ISCIS 2006 (pp. 47–54). Heidelberg: Springer-Verlang.
- Hatem, B. M. (2011). Star reduction among minimal length addition chains. Computing, 91, 335–352.
- Jose-Garcia, A., Romero-Monsivais, H., Hernandez-Morales, C. G., Rivera-Islas, I., & Torres-Jimenez, J. (2011, October). A simulated annealing algorithm for the problem of minimal addition chains. In Progress in Artificial Intelligence-EPIA11 (pp. 311–325). Verlang Heidelberg: Springer.
- Knuth, D. (1998). Evaluation of powers. D. E. Knuth (Ed.), The Art of Computer Programming (Vol. 2, 3rd ed., chap. 4, pp. 461–485). Stanford, CA: Addison-Wesley.
- Koblitz, N. (1987). Elliptic curve cryptosystems. Mathematics of Computation, 48, 203–209.
- Koç, C.-K. (1995). Analysis of sliding window techniques for exponentiation. Computers & Mathematics with Applications, 30, 17–24.
- Laih, C.-S., & Kuo, W.-C. (1997). Speeding up the computations of elliptic curve cryposystems. Computers & Mathematics with Applications, 33, 29–36.
- León-Javier, A., Cruz-Cortés, N., Moreno-Armendáriz, M. A., & Orantes-Jiménez, S. (2009, November). Finding minimal addition chains with a particle swarm optimization algorithm. In MICAI 2009: Advances in Artificial Intelligence (pp. 680–691). Verlang Heidelberg: Springer.
- Mignotte, M., & Tall, A. (2011). A note on addition chains. International Journal of Algebra, 5, 269–274.
- Miller, V. (1985). Use of elliptic curves in cyptography. Lecture Notes in Computer Science (Vol. 18, pp. 417–428). Springer.
- Morain, F., & Olivos, J. (1990). Speeding up the computations on an elliptic curve using addition-subtraction chains. Theoritical Informatics and Applications, 24, 531–543.
- Nedjah, N., & de Macedo Mourelle, L. (2006). Towards minimal addition chains using ant colony optimisation. Journal of Mathematical Modelling and Algorithms, 5, 525–543.
- Okeya, K., Schmidt-Samoa, K., Spahn, C. & Takagi, T. (2004, August). Signed binary representations revisited. In Advances in Cryptology – CRYPTO 2004 (pp. 123–139). Berlin Heidelberg: Springer.
- Osorio-Hernández, L. G., Mezura-Montes, L., Cruz-Cortés, N., & Rodríguez-Henríquez, F. (2009, May). An improved genetic algorithm able to find minimal length addition chains for small exponents. In Proceedings of the 2009 IEEE Congress on Evolutionary Computation (pp. 1–6). IEEE Press.
- Park, H., Park, K., & Cho, Y. (1999). Analysis of the variable-length non-zero window method for exponentiation. Computers & Mathematics with Applications, 37, 21–29.
- Reitwiesner, G. (1960). Binary arithmetic. Advances in Computers (Vol. 1, pp. 231–308). USA: Elsevier BV.
- Rivest, R. L., Adi, S., & Adleman, L. (1978). A method for obtaining digital signatures and public-key cryptosystems. Communications of the ACM, 21, 120–126.
- Saffar, N. F. H. A., & Said, M. R. M. (2015). Speeding up the elliptic curve scalar multiplication using non adjacent form. Journal of Discrete Mathematical Sciences and Cryptography, 18, 801–821.
- Scholz, A. (1937). Jahresbericht. Deutschen Mathematiker-vereinigung, Auhfgabe, 252, 41.
- Thurber, E. G. (1993). Addition chains - an erratic sequence. Discrete Mathematics, 122, 287–305.
- Thurber, E. G. (1999). Efficient generation of minimal length addition chains. SIAM Journal on Computing, 28, 1247–1263.
- Win, E. D., Mister, S., Preneel, B., & Wiener, M. (1998). On the performance of signature schemes based on elliptic curves. In Lecture Notes in Computer Science (LNCS) 1423 (pp. 252–266). Berlin Heidelberg: Springer.
- Yao, A. C.-C. (1976). On the evaluation of powers. SIAM Journal on Computing, 5, 100–103.