
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper proposes an improvement in the form of modeling the demand in models of stochastic inventories. For these purposes, it is proposed to occupy the Kernel estimation method to the demand per unit of time and demand during the lead time to generate input scenarios for a stochastic programming in two-stage, in a model of continuous review with shortage. An application of this methodology considers the obtaining of this scenarios from the modeling of actual data of demand of inputs of food service. The possibility of working directly with the densities and accumulated probabilities of demand in an empirical and more realistic way with regard to the data available, improve the task for the decision makers of the operations management.
Public Interest Statement
This paper deals with an application in inventory models to perform sourcing, which considers the Kernel estimation method to obtain the probability density of the demand per unit time of products. We propose its use in a continuous review inventory model under a two stage stochastic programming framework.
The advantage of the use of this proposal is that the Kernel estimation is not limited by distributional assumptions about the demand per unit time of products, allowing a modeling closer to the empirical data of this variable, which causes a reduction of purchase lots, determination of reorder points, expected shortages and more accurate total costs. The proposal also includes a way of working when the supplier’s lead time is random.
1. Introduction
Supply system and the inventories policy reduce the vulnerability of the supply chain management in enterprises, which is achieved by optimizing inventory levels to meet the demand of products of the companies satisfying customers. This optimization is realize considering the variance of the demand data (Hillier & Lieberman, Citation2005). In this context, stochastic inventory models consider the demand for products as a random variable (RV) described by a continuous or discrete distribution. These models optimize total costs (TC) of inventory, which have three components: (a) a cost that is independent of the lot size, (b) a cost that depends on the quantity of products in the lot, and (c) a cost of shortage due to unsatisfied demand (Gjerdrum, Samsatli, Shah, & Papageorgiou, Citation2005). Once the inventory model indicators have been defined and distributional assumptions for demand per unit time (DPUT) and for demand during lead-time (LT), in short LTD, have been established, the expected value of the objective function based on the TC of the inventory must be optimized (Namit & Chen, Citation1999).
The probabilistic treatment of LTD is facilitated when the LT is constant. Otherwise, different distributions have been assumed directly for this RV or the sum of DPUT that conforms it (Rojas & Leiva, Citation2016).
Kernel density estimation is a non-parametric method for estimating a density function from a random sample of data (Pillonetto, Dinuzzo, Chen, De Nicolao, & Ljung, Citation2014). According to Wang, Wang, and Chung (Citation2014), the Kernel estimation method has the advantage of being applicable to large databases, obtaining an approximation to the true PDF of the random data of excellent quality, which allows to obtain a more precise forecast for the RV . This feature makes it very useful for use in inventory models and modelling of the supply chain (Zhu, Ma, & Zhang, Citation2014). Then by this method it is possible obtain an descriptive structure that can must be inserted in the mentioned objective cost function of a inventory model, to find optimal cost by stochastic programming (SP) (Rojas & Leiva, Citation2016; Wanke & Leiva, Citation2015). The way to insert a RV into a objective function or constraints of a SP is by generating scenarios that best represent a finite number of this variable (Shapiro, Dentcheva, & Ruszczynski, Citation2014). Classically it is possible to segment the SP into two stages, where a first decision is made prior to the realization of the RV, and other second stage decisions can be made once the realization of the RVs is revealed (Birge & Louveaux, Citation2011).
The objective of this paper is to propose a way to improve the accuracy of a continuous review inventory models with shortage with a single supplier, by use of Kernel density estimation to randon DPUT and LTD in SP in two-stage. The paper is organized as follows: Section 2 reviews a background built on SP of inventory models of continuous review, Section 3 illustrates the proposal with a actual data and Section 4 provides a discussion and conclusions of the results obtained in this research, as well as their limitations and future research.
2. Background
2.1. Stochastic programming of inventory models of continuous review
As its name suggests, SP is a mathematical programming problem (linear, nonlinear, integer, between others) which contains in its formulation some stochastic element that is unknown, but that can be estimated from its probability distribution (Shapiro et al., Citation2014). The types of models appearing on SP are motivated primarily by problems with decisions kind here and now, or previous decisions under uncertain future, where decisions can be based on a priori information, existing or perceived, on future situations (Birges & Louveaux, Citation2011). This leads to the main idea that the decisions of a stochastic problem can be separated into two stages, where first stage decision is made before the uncertainty is revealed; and two stage decision is made after the uncertainty is revealed (Shapiro et al., Citation2014). This decisions of the first stage does not depend on the scenario that occurs really in the future.
In SP the decisions of first stage are those that determine the quality of the solution of the problem (Escudero, Garín, Merino, & Pérez, Citation2009).
To enter the randomness in stochastic optimization problems the generation of various scenarios is required. In real-life application this scenarios is considered finite. The scenarios represent a realization of RVs and are diagramed in a tree. Each scenario has a weight, that represents the likelihood assigned to this scenarios by the decisor. A common approach to generate scenarios is based on estimating an unknown distribution and matching its moments with moments of a discrete scenario model. By having actual data for the realization of an RV it is possible to estimate the probability density using a non-parametric estimation of Kernel (Rao, Citation2014). Once the empirical distribution is estimated, it is possible to simulate this distribution at each stage in parallel. The problem of finding valuable scenario approximations can be viewed as the problem of optimally approximating a given distribution with some distance function such as a cluster analysis (Gülpinar, Rustem, & Settergren, Citation2004).
A problem of multiple products commonly occurring in inventory policies is to decide what optimal quantities of products must be ordered simultaneously from a same supplier (Hillier & Lieberman, Citation2005). Continuous review policies provide solutions to problems of inventory management in many real-world situations. Inventory models of continuous review are known as models, which are often used for inventory supply planning. This model is based on the economic order quantity or lot size and reorder point, denoted by Q and r, respectively (Rojas, Leiva, Wanke, & Marchant, Citation2015). Indicators Q and r must be determined to minimize the TC of the inventory management. Such a TC is function of the holding, ordering and shortage costs (Hillier & Lieberman, Citation2005). When calculating the reorder point for a fixed service level, the LTD distribution and its corresponding probability density function (PDF) must be used. When the LTD distribution is unknown, this PDF can be approximated by any suitable approach. We employ a simultaneous approach to optimize Q and r (Silver, Pyke, & Peterson, Citation1998; Wanke, Ebwank, Leiva, & Rojas, Citation2016). Then, as has been suggested for two-stage SP can be consider minimize the expected value of the objective function based on the TC of inventory of a continuous review policy, generating scenarios for the DPUT not IID on the time, by means of a density Kernel estimation. SP can be used to solve this optimization problem using the differential evolution (DE) algorithm, which belongs to the family of genetic algorithms, emulating the natural process of choice in evolutionary way (Price, Storn, & Lampinen, Citation2006; Rojas & Leiva, Citation2016; Thangaraj, Pant, Bouvry, & Abraham, Citation2010; Wanke & Leiva, Citation2015).
2.1.1. Continuous review model with inventory shortage in two stage
2.1.1.1. Modeling of demand during lead-time
Let be the observed demand in period
with
and variance
. Let S be the LTD for the product, which is the random sum given by
(1)
(1)
where L be lead time over which the estimation are desired, which has mean and variance
. Our goal is to estimate the entire distribution of the sum of the demands over the lead time, called LTD, furthermore, L is independent from each element of the sequence of independent identically distributed RVs
, which have mean
and variance
. Assume that orders do not cross (Hayya, Bagchi, Kim, & Sun, Citation2008).
Based on actual sequence of DPUT, we can define a Kernel estimate of the unknown PDF by
(2)
(2)
where is a kernel function satisfying
, h a smoothing parameter (or bandwidth) and y the point at which the PDF is estimated. The Gaussian kernel with support in
is often assumed for
given in 2.
When LT denoted by L is a RV, it is necessary to consider a probabilistic distribution of easy estimation to model the LTD PDF as a sum of the DPUT during the LT. In this regard, Wanke et al. (Citation2016) considered the triangular distribution (TRI) for the LT, because of the ease of interpretation of its parameters for decision makers. This justification is also valid in our case. In the case of variable LT, we can consider triangular (TRI) distribution for LT and Kernel distribution for DPUT. In this case, we can make a Kernel estimation for the PDF of the LTD, which generally does not have a closed form in these conditions.
Then, let L be a continuous RV following a TRI distribution with parameters , where a and b are the minimum and maximum values of L, respectively, and c is the mode of the distribution. This is denoted by
. Then, the PDF, cumulated distribution function (CDF) and QF of L are, respectively, given by
The mean and variance of are, respectively, given by
By fixing minimum, maximum and mode values for the RVs LT with TRI distributions, DPUT with Kernel distribution given in 3 and the expression given in (1), we are able to compute a sequence of n LTD observations (data). Then, based on this sequence, we can define a kernel estimate of the unknown PDF
by
(3)
(3)
where is a kernel function satisfying
, h a smoothing parameter (or bandwidth) and s the point at which the PDF is estimated. The Gaussian kernel with support in
is often assumed for
given in 2. However, we are modeling demand data with support in [a, b]. Thus, instead of the Gaussian kernel, it seems more natural to estimate the unknown PDF with a TRI kernel by using Equation4
(4)
(4)
(4)
(4)
where is a TRI kernel of parameters h (bandwidth) and s (point at which the PDF is estimated); see details in Marchant, Bertin, Leiva, and Saulo (Citation2013).
Let S be the LTD for the item, which is the random sum given by 1 with PDF defined in 4, CDF and quantile function (QF)
, for
obtained only by numeric integration. The expectation and variance of S are, respectively, expressed as
(5)
(5)
and(6)
(6)
Note that, in general, the LT and DPUT can be modeled by any discrete or continuous distribution. However, if LT is constant .
2.1.1.2. Use of DPUT and LTD in inventory management models
The expected annual total cost of inventory assuming shortage is expressed as a sum of (i) the holding cost per product unit per year, denoted by , multiplied by the expected quantity in stock of product units; (ii) the ordering cost, denoted by
, multiplied by the number of orders per year, and (iii) the penalty cost whenever there are stock-outs, denoted by
, i.e. the penalty cost per shortage product unit per year multiplied by the number of orders per year and by the expected quantity of shortage product units per year. We are assuming a business has demand 365 days a year. Thus, for the
model, the expected total cost per year is
(7)
(7)
where and
are defined in (5) (Hadley & Whitin, Citation1963; Johnson & Montgomery, Citation1974; Silver et al., Citation1998). On the one hand, note that
is multiplied by 365, because the total cost given in (7) is defined on an annual basis and
on a daily basis. On the other hand,
is not altered, because its scope is verified within each safety inventory cycle. Q and r are decision variables of quantity to order and reorder point, respectively to the model EOQ with shortage. In addition, in (7), S(r) is the expected shortage per cycle given by
(8)
(8)
where is the maximum value of the LTD and, as also mentioned,
is the LTD PDF. Following to Nahmias (Citation2001), the solve of 7 requires an iterative process where an initial solution of
, then it is possible to obtain the complement of the CDF
or probability of stock break, as
and therefore(9)
(9)
then with this value of r we can obtain S(r) given in 8. Finally, it is possible to obtain,(10)
(10)
Iterating 9 and 10 until reaching values that do not vary with respect to a minimum threshold, it is possible to obtain solutions that minimize 7.
In this proposal the TC to miminize is expressed as a general SP in two-stage. TC is a function of Q as a decision variable of first stage more a weighted sum in each scenario for a decision variable of second stage (often called recourse), computable when of the RV of DPUT is revealed. In this case, the decision variable of second stage is the security factor, denoted by k, which serves to establish a reordering point. Thus, for the
model in two stage, the annual total cost to minimized is expressed as
where
where
matrix
matrix
where can be calculated from selected scenarios
gives parameters of PDF to each time t from model 2, the constraint
, represented a budget constraint such that A is the unitary cost of the item, and B is the maximum annual budget available for the item. For second stage,
matrix
because
matrix
matrix
matrix
where correspond to reorder point that depends on the realization of the LTD in scenario
(
), and finally
matrix
Then is differentiable with respect to Q for
continue or discrete, if recourse structure is complete, that is if the system
and
has a solution for every
. In other words, the positive hull of
is equal to the corresponding vector space. Also second stage problem is not unbounded. Because the second stage is a linear programming problem, its dual problem can be written in the form (Birge & Louveaux, Citation2011):
then if we consider the function , then
. Suppose that for given
and
, the value
is finite. Then
is subdifferentiable at
and
where , is the set of optimal solutions of the dual problem. Therefore,
is differentiable, if the dual problem has a solution. Let
, and
, further, that functions
and
are differentiable, and
then
, for more details see Shapiro et al. (Citation2014 (chap.2)).
To solve this problem of two stages is possible to use the L-Shaped algorithm (see Birge & Louveaux, Citation2011).
2.1.2. Generation of scenarios of SP in two-stage
We deal a procedure based on simulation given a Kernel PDF IID of DPUT and LTD (Gülpinar et al., Citation2004). The input to the cost optimization problem is constructed through a tree of scenarios, where the nodes represent a possible value for the RV with certain levels of probabilities in their ramifications. This construction is can carry out considering randomized clustering of quantiles of PDF. Then one give quantile of Kernel PDF IID of DPUT and LTD is designated as the centroid to establish a node, and their probability of ocurrence is given by their PDF.
3. Application
Below, we show how inventory management of products can be planned within companies by using the background proposed in Section 2 and the computational framework developed for this.
3.1. Computational framework
R is a non-commercial and open source software for statistics and graphs, which can be obtained at no cost from http://www.r-project.org. The statistical software R is being currently very popular in the international scientific community. For a use of this software in inventory models, see Rojas et al. (Citation2015). Some R packages related to statistical distributions that may be useful in inventory models are available at http://CRAN.R-project.org. The expected value and other moments of monthly demand products is calculated by using generalized additive models for localization, scale and shape (GAMLSS) implemented in the R software by the packages gamlss.util() for data analysis. The SP of inventory models is performed by the packaged DEoptim() of the same software.
3.2. The data set
To validate the proposed methodology, we use real-world monthly demand data for an assortment of foods service inputs, which it has extracted an example of one daily demand of input. The inputs are shipped from the warehouse of a food service and delivered to make menus that are available to the public, located at the city of Concon, Chile, for a study of supply policy.
3.3. Data analysis
Table show descriptive statistics of monthly DPUTs of a illustrative product with mean, SD, interquartile range (IQR), percentile 0, 25, 75, 100 and sample size (n).
Table 1. Descriptive statistics of monthly DPUTs of illustrative product
To compare the behavior of the proposed SP considering PDF Kernel estimation of the DPUT and LTD, we compare their performance with other distributions used in inventory models. These correspond to the Normal (NO) and Gamma (GA) distributions for the DPUT, and their sum, used as LTD model distributions, which we called Normal sum (NOsum) and Gamma sum (GAsum). Under a GAMLSS approach to modeling the mean of a probability distribution, and using the fitDist command of the gamlss package, we estimate the parameters of the following distributions to model the DPUT (Table ) and the LTD (Table ), respectively. These estimates allow us to study the adequacy of these distributions in the modeling of DPUT and LTD, as well as to obtain results in the performance of the continuous revision inventory model formulated in 7.
Table 2. Modeling of DPUT
Table 3. Modeling of LTD
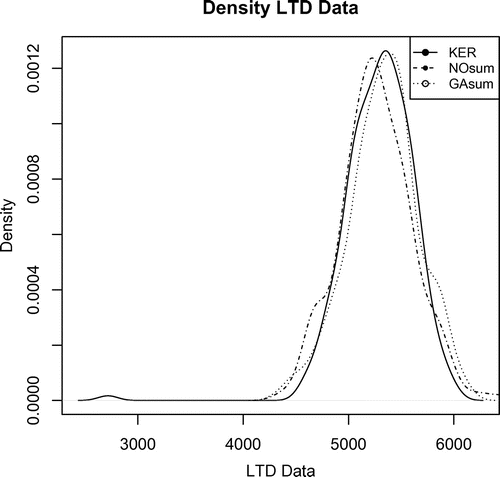
Figures and show the modelling of NO and GA distributions to respect to Kernel estimation to DPUT, and NO sum and GA sum respecto to Kernel estimation to LTD.
Figure 1. Comparison of DPUT density modeling.
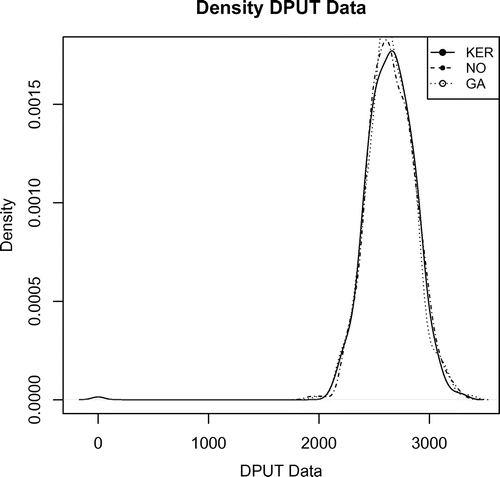
Figure 2. Comparison of LTD density modeling.
The two-stage SP considers find a lot size of purchase (Q) as decision variable of the first stage, before the realization of the DPUT. In the second stage, are considered twelve scenarios () of DPUT with PDF Kernel estimates for a single time, to compare with twelve scenarios NO IID and GA IID to realization of the centiles 95 and 5% of the DPUTs (
and
) and their probabilities are generated by simulation in parallel according to Gülpinar et al. (Citation2004). We compared outcomes of SP to inventory model with continuous review with shortage in two stage in Table . The parameters employed for this programming are TRI mean of lead time of 2 days (
) and TRI standard deviation of lead time of 1.35 days (
), holding cost of 0.42 USD$/year*unit, shortage cost of 0.33 USD$/shortage unit, and order cost of 0.86 USD$/order. In each of the scenarios should find the reorder point (r) that optimizes the TC function. Note that the results of total costs (TCs), quantities to order (Q), reorder point (r) and expected shortage per cycle (S(r)) are more accurate when the PDF of the DPUTs is fits with a PDF Kernel estimation.
Table 4. Effect of modeling of DPUTs with PDF Kernel estimation, NO IID and GA IID on SP of continuous review with shortage in two stages
4. Discussion, conclusions, limitations and future research
The approach of modeling the DPUT and LTD using a PDF Kernel estimation is novel and results in a performance of higher precision inventory models. That is to say, this approach leads to lower total costs, quantities to be requested from the supplier and possible shortages that can be caused by facing a random demand. The use of SP allows to take advantage of a generation of scenarios that acts as a replica of the possible input elements for the demand, where these become more adjusted to the reality when occupying the Kernel estimation of the PDF of DPUT and LTD. At present, the software available for data analysis implements this type of estimation facilitating this task for the decision makers of the area. This allows the possibility of working directly with the accumulated densities and probabilities of demand in an empirical and more realistic way with regard to the data available.
A current limitation of the proposed methodology is found in samples of intermittent demand data, because the PDF Kernel estimation does not consider these values as part of its estimation. In this respect the zero-inflated or zero-adjusted approach could be considered to deal with this type of demand data, where it is possible to construct mix distributions for the PDF Kernel estimation as well as in the empirical CDF of this type of data. This opens a field of investigation of sourcing operations when facing this type of scenarios.
Additional information
Funding
Notes on contributors
Fernando Rojas
Fernando Rojas is Chemical-pharmaceutical of University of Valparaiso, Chile; Master in Management Science at the University Adolfo Iba˜nez, Chile, and PhD of Management Science candidate at the same university. Currently serves as an adjunct professor at the School of Nutrition and Dietetics, that belongs to the Faculty of Pharmacy, University of Valparaiso, Chile, and is research associated to the Micro-Bio Innovation Center from the same school. His research interests is operations research linked to optimal supply decisions, especially in the area of food service.
Related Research Data
References
- Birge, J. R., & Louveaux, F. (2011). Introduction to stochastic programming. New York, NY: Springer.
- Escudero, L., Garín, M., Merino, M., & Pérez, G. (2009). A general algorithm for solving two-stage stochastic mixed 0–1 first-stage problems. Computers and Operations Research, 36, 2590–2600.
- Gjerdrum, J., Samsatli, N., Shah, N., & Papageorgiou, L. (2005). Optimisation of policy parameters in supply chain applications. International Journal of Logistics Research and Application, 8, 15–36.
- Gülpinar, N., Rustem, B., & Settergren, R. (2004). Simulation and optimization approaches to scenario tree generation. Journal of Economic Dynamics and Control, 28, 1291–1315.
- Hadley, G., & Whitin, T. (1963). Analysis of inventory systems. Upper Saddle River, NJ: Prentice-Hall.
- Hayya, J., Bagchi, U., Kim, J., & Sun, D. (2008). On static stochastic order crossover. International Journal of Production Economics, 114, 404–413.
- Hillier, F., & Lieberman, G. (2005). Introduction to operational research. New York, NY: McGraw Hill.
- Johnson, L., & Montgomery, D. (1974). Operations research in production planning, scheduling and inventory control. New York, NY: Wiley.
- Marchant, C., Bertin, K., Leiva, V., & Saulo, H. (2013). Generalized Birnbaum-Saunders kernel density estimators and an analysis of financial data. Computational Statistics and Data Analysis, 63, 1–15.
- Nahmias, S. (2001). Production and operations analysis. New York, NY: McGraw Hill.
- Namit, K., & Chen, J. (1999). Solutions to the inventory model for gamma lead-time demand. International Journal of Physical Distribution and Logistics Management, 29, 138–154.
- Pillonetto, G., Dinuzzo, F., Chen, T., De Nicolao, G., & Ljung, L. (2014). Kernel methods in system identification, machine learning and function estimation: A survey. Automatica, 50, 657–682.
- Price, K. V., Storn, R. M., & Lampinen, J. A. (2006). Differential evolution: A practical approach to global optimization. Berlin: Springer.
- Rao, B. P. (2014). Nonparametric functional estimation. Orlando, FL: Academic Press.
- Rojas, F. & Leiva, V. (2016). Inventory management in food companies with demand statistically dependent. ARLA: Academia Revista Latinoamericana de Administración, 29, 450–485.
- Rojas, F., Leiva, V., Wanke, P., & Marchant, C. (2015). Optimization of contribution margins in food services by modeling independent component demand. Revista Colombiana de Estadística, 38, 1–30.
- Shapiro, A., Dentcheva, D., & Ruszczynski, A. (2014). Lectures on stochastic programming: Modeling and theory (Vol. 16). Philadelphia, PA: SIAM.
- Silver, E., Pyke, D., & Peterson, R. (1998). Inventory management and production planning and scheduling. New York, NY: Wiley.
- Thangaraj, R., Pant, M., Bouvry, P., & Abraham, A. (2010). Solving multi objective stochastic programming problems using differential evolution. In B. Panigrahi, S. Das, P. Suganthan, & S. Dash (Eds.), Swarm, Evolutionary, and Memetic Computing (Vol. 6466, pp. 54–61). Berlin-Heidelberg: Springer.
- Wang, S., Wang, J., & Chung, F.-L. (2014). Kernel density estimation, kernel methods, and fast learning in large data sets. IEEE Transactions on Cybernetics, 44(1), 1–20.
- Wanke, P., Ebwank, H., Leiva, V., & Rojas, F. (2016). Inventory management for new products with triangularly distributed demand and lead-time. Computers and Operations Research, 69, 97–108.
- Wanke, P., & Leiva, V. (2015). Exploring the potential use of the Birnbaum-Saunders distribution in inventory management. Mathematical Problems in Engineering, 1–9. Article ID 827246.
- Zhu, L. Y., Ma, Y. Z., & Zhang, L. Y. (2014). Ensemble model for order priority in make-to-order systems under supply chain environment. In Management Science & Engineering (ICMSE), 2014 International Conference on (pp. 321–328). Helsinki: IEEE.