
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, a hybrid pseudo-spectral (hPS) method is utilized to analyze the uncertainty of the model predictive control (MPC) for nonlinear systems with stochastic parameter uncertainty. The hPS method incorporates Generalized polynomial expansion (gPC) and pseudo-spectral (PS) optimal control in a hybrid format. To quantify the effect of uncertainty on the MPC states and control inputs, we use the gPC method, and for time discretization of the MPC problem, the pseudo-spectral method is employed. The proposed method will be compared with the well-known Monte Carlo (MC) simulation method in terms of computational speed. Two dynamical systems are tested. First, an industrial process, continuous stirred reactor tank, which is a highly nonlinear system, with Gaussian distributed parameter uncertainty and second, a typical second-order dynamical system with uniform and Weibull distributed parameter uncertainty. Simulation results demonstrate that the proposed method can approximate the two first moments of the states and control inputs under MPC much faster and computationally more efficient than MC simulations.
PUBLIC INTEREST STATEMENT
Uncertainty quantification is the science of quantitative characterization of uncertainties in real-world applications. It tries to determine how likely certain outcomes are if some aspects of the system are not exactly known. Most practical systems are exposed to uncertainty and engineers need to know how the uncertainty will affect the system. In this paper, we proposed a hybrid pseudo-spectral algorithm to quantify the effect of uncertainty on nonlinear systems under a model predictive control strategy.
1. Introduction
MPC is one of the most practical methods of advanced process control in the industry. It is an optimal control strategy that is implemented in a receding horizon manner. By implementing the MPC strategy, certain constraints can be imposed on outputs, inputs, and states of the system. Furthermore, it can be implemented on both linear and nonlinear dynamical systems. Many applications of linear MPC have been reported in the literature (Garcia, Prett, & Morari, Citation1989; Muske & Rawlings, Citation1993; Schwickart, Voos, Hadji‐Minaglou, & Darouach, Citation2016; Widd, Liao, Gerdes, Tunestål, & Johansson, Citation2014). For some highly nonlinear systems, the approximated linear model is not sufficient. Therefore, the MPC should be designed directly based on the nonlinear model (Grüne & Pannek, Citation2011; Mayne, Rawlings, Rao, & Scokaert, Citation2000). Several theories have been proposed regarding the stability and feasibility of the MPC, both in linear and nonlinear context. In nonlinear MPC (NMPC), the system or constraints are nonlinear. The efforts to prove the stability of NMPC have led to the well-known four axioms of stability (Mayne et al., Citation2000). Such as nonlinearity, which is the inherent characteristic of real-world systems, parameter uncertainties occur in many practical systems. Uncertainties in the parameters of a system could either be bounded or have a stochastic nature.
When the uncertainty is bounded, the well-known robust MPC strategies are applied. Tube-based MPC is a dominant approach in this field (Mayne, Kerrigan, Van Wyk, & Falugi, Citation2011). For systems with stochastic parameter uncertainty, where the probability distribution of uncertainty is known, the stochastic MPC strategies are employed. In Visintini, Glover, Lygeros, and Maciejowski (Citation2006), the Markov-chain Monte Carlo technique was proposed for solving constrained nonlinear stochastic optimization problems. In Bavdekar and Mesbah (Citation2016), at each sampling time of the MPC, the gPC coefficients were calculated and then the MPC was performed on the gPC coefficients. The Fokker–Planck equation, which described the probability density of the states of the system, was utilized in Annunziato and Borzì (Citation2013) to solve the MPC for the stochastic differential equation. In Annunziato and Borzì (Citation2013), the MPC for the system of stochastic differential equations was transformed into a deterministic MPC with PDE constraint. The stochastic Lyapunov function was considered as an auxiliary constraint in the stochastic MPC framework in Mahmood and Mhaskar (Citation2012) to guarantee the stochastic stability of the SDE under MPC strategy.
Control engineers should always have a general sight of the effects of uncertainty on the system under the MPC strategy. By analyzing the uncertainty effects on the system, one can choose the system hardware and software accordingly. For instance, the effect of the uncertainty on the control actuation can be evaluated and the size of the actuator can be determined. Uncertainty quantification is the science of quantitative characterization of uncertainties in real-world applications. It tries to determine how likely certain outcomes are if some aspects of the system are not exactly known. This paper is the continuation of our previous work (Namadchian & Ramezani, Citation2017) in which we used the pseudo-spectral method for time discretization of the MPC for a CSTR and showed the computational efficiency of the proposed method compared with RK4 time discretization method. In this paper, we have not only used the PS method for time discretization but also applied gPC, for uncertainty quantification and propose a hybrid pseudo-spectral method for uncertainty quantification of nonlinear MPC.
Pseudo-spectral methods referred to a class of spectral techniques which are solved by collocation points (Fornberg, Citation1998). In this paper, for uncertainty propagation in nonlinear MPC, the Generalized Polynomial Chaos (Xiu & Karniadakis, Citation2002) has been utilized. GPC is a very efficient spectral method for uncertainty evaluation. In the sample-based version of the gPC or collocation-based gPC, the uncertainty can be analyzed with much fewer samples than Monte Carlo (MC) simulations.
The proposed hybrid algorithm selects samples from the random space using collocation nodes, after that, inserts those sample values into the differential equations of the system, and then uses a pseudo-spectral based deterministic solver to generate solutions for each of the resulting deterministic problems.
The set of deterministic solutions is then used to construct a polynomial representation of the solution of the stochastic optimal control problem using the gPC method. Since both gPC and PS optimal control can be categorized as PS methods and are incorporated in a hybrid format, we call this approach, the hybrid pseudo-spectral or the hPS method.
PS optimal control is an efficient computational method for solving optimal control problems. The most advanced optimal control softwares such as GPOPS, PSOPT, and RPROPT use PS optimal control to discretize the nonlinear optimal control problem and transform it into a nonlinear programming problem (Becerra, Citation2010; Patterson & Rao, Citation2014.
The hybrid method, involving a combination of the PS optimal control and gPC, has been appeared in few publications. Harmon (Citation2017) utilized the PS optimal control with gPC to quantify the effect of uncertainty on the optimal states of the system. Matsuno, Tsuchiya, Wei, Hwang, and Matayoshi (Citation2015) solved the aircraft conflict resolution by the hPS. The system was a 3D aircraft dynamic under wind uncertainty. The main goal of the optimal control problem was to determine the optimal trajectories in a way that the confliction of the aircraft is avoided. The conflict was modeled as the distance between two aircraft and as a constraint in the optimal control problem, the distance must not exceed a predefined threshold value. Motivated by his previous work, Matsuno developed his approach for aircraft conflict resolution for online applications (Matsuno, Tsuchiya, & Matayoshi, Citation2015). By Polynomial Chaos Kriging method, he constructed a surrogate model for the solution of stochastic optimal control method based on the hPS. Then, the surrogate model was used to circumvent the need for solving a stochastic optimal control problem on-line. Although the mentioned papers utilized both PS optimal control and gPC in a hybrid manner, they did not address the optimal control problem in a receding horizon approach, i.e. MPC framework. What distinguishes our work from these papers is considering the uncertainty quantification of optimal control in a receding horizon manner. The main contribution of our work is to quantify the effect of parameter uncertainty on the states and controls of the nonlinear system under MPC strategy with less computational effort than MC simulations.
The paper is structured as follows: Section 2 gives details on the problem formulation and notations. The PS fundamentals are described in Section 3. The polynomial chaos theory is introduced in Section 4. The hybrid PS-MPC uncertainty propagation algorithm is presented in Section 5. In Section 6, uncertainty evaluation is performed on two examples under MPC strategy and compared with MC simulations.
2. Problem formulation
Consider the following continuous-time system in the state space form:
Since in MPC literature, the control is normally piecewise constant, without loss of generality, we can always express the system (1) with a difference equation by an appropriate sampling time could be expressed as follows:
where is the state of the system at time index
,
is the manipulated input,
is the vector of unknown parameters.
is stochastic uncertainty.
, the component of
are assumed to be independent and identically distributed random variables with pdf
such that
,
is the probability space,
is the sample space,
is the
of the events, and
is the probability measure of events. The first moment or expectation of a random variable
is defined as
.
is the Hilbert space of all random variables
whose
is finite, i.e.
. Also, the second moment of
, called variance, is defined as
, where
is the standard deviation. We assume that
is continuously differentiable with respect to its arguments and the solution of (2) exists uniquely and almost surely.
The MPC formulation for EquationEquation (2)(2)
(2) is as follows:
where is the predicted value of
,
step ahead of
, based on the information available at time
.
and
are prediction and control horizons, respectively.
and
are state and control constraints, respectively, and
is the terminal constraint.
, the cost function, consists of the stage cost
and the terminal cost
.
It is assumed that at each step, the states of the system are measurable. Due to the randomness of
,
and
are stochastic processes. Our goal is to find the mean and variance of the states and control inputs at each time index
to find how the randomness of
will affect the distribution of control inputs and the states of the uncertain system under the MPC strategy.
The terminal constraint (7) imposes an implicit constraint on the control sequence of the form:
where the control constraint set is the set of control sequence
satisfying the state and control constraints:
where is defined by
Therefore, the optimal control problem is defined as:
The following assumptions are considered for the MPC controller:
Assumption 1.
Continuity of the system: for each
, the function
Properties of the constraint set: for each
Theorem.1 (axioms of stability for MPC) (Mayne et al., Citation2000):
If for any , the following assumptions are satisfied, then the states of the system
converge asymptotically to the origin under MPC formulation
:
A1: State constraint satisfied in :
,
closed.
A2: Control constraint satisfied in .
There exists a local controller , such that
.
(
is a local feedback controller on
)
A3: is positively invariant under
A4: is a local Lyapunov function:
Proof:
In the axioms of stability for the MPC, we consider ,
,
such that the axioms are satisfied for each
, so without loss of generality, to prove the theorem, we consider
as a constant and omit it from the equations.
The stability of the MPC will be proved based on using the value function as a decreasing Lyapunov like function. In the first part, we prove that initial feasibility implies recursive feasibility and in the second part, the convergence of the system to the origin will be guaranteed under MPC strategy.
Part 1- recursive feasibility
Suppose has a feasible solution at time
, i.e.
is the optimal control solution that satisfies the control, state, and the terminal constraint. Let
denotes the optimal control trajectories. Implementing
as a feasible control to the system, steers the initial state to the successor state
. For
, we want to find the feasible control sequence. Since
steers
to
, to obtain the feasible control sequence for
, one further element to
need to be added. If we add
to
, since
,
and
the control sequence
is feasible for
, so the initial feasibility gives recursive feasibility.
Part2- Asymptotic stability
The most popular idea in the proof of the stability of the MPC is to show that optimal objective function is a Lyapunov function satisfying
For the optimal control sequence calculated at
, the optimal objective function is:
Also, for sub-optimal control sequence the suboptimal objective function is as follows:
Since is a sub-optimal solution, we have:
and
can be rewritten as follows:
By adding and subtracting to the above expression, we obtain:
It can be seen that the first two terms in the above equation is equal to , thus we can rewrite it as:
From A4 (MPC axioms of stability), for the last tree term in the above expression we have:
Leaving us with the expression:
Since it is assumed that and
is a strictly positive function, we have:
Indicating that the objective function is strictly decreasing along closed-loop trajectories under MPC control, thus the trajectories converge to the origin. ∎
2.1. Design of stable MPC for nonlinear systems
The proper choices of ,
, and
guarantee the asymptotic stability of the MPC.
To design an MPC for the nonlinear system (2), we choose , in which
and
are positive definite. In order to select a proper
and
, the nonlinear system (1) is linearized at the origin to obtain a linear model
In which and
. Also, we assume that
is stabilizable. We choose any controller
can be chosen such that the
is stable. Defining
and solving the Lyapunov equation
, the terminal cost function is chosen to be:
And is the sublevel set
for some suitably chosen constant
. Choosing such a controller, it can be proved that there exists an
such that
.
In order to satisfy the state and control constraints, we choose such that
and
.
It can be demonstrated that by the designed controller, the closed-loop system under the MPC strategy is asymptotically stable (Rawlings & Mayne, Citation2012).
Remark 1: Most of the system variables are functions of . In fact, the whole MPC problem
, the linearized system
and
, the local controller
, the designed terminal constraint
and also the states
and
are all functions of the random variable
. The hard constraints
and
are fixed sets and are not the functions of
.
Remark 2: This paper investigates that how the system variables must have changed under parameter uncertainty to have a stable system under the model predictive controller. Although we can quantify the effect of uncertainty on all of the parameters mentioned in Remark1, in this paper, we just focus on the uncertainty quantification of the states and controls input of the nonlinear system with parameter uncertainty under MPC.
3. Pseudo-spectral fundamentals
There are two approaches to solve a continuous-time optimal control problem, direct methods, and indirect methods (Von Stryk & Bulirsch, Citation1992). Indirect methods use the calculus of variation such as the Pontryagin minimum principle. Indirect methods are usually difficult to solve numerically. Direct methods are known as discretize-then-optimize methods. In direct methods, the state and control functions are approximated by polynomials.
When an optimal control problem solved by the direct method, having fewer discretization points is an advantage. A typical optimal control problem consists of three mathematical equations: (1) integration in the cost function, (2) differential equation governing the system state evolution, and (3) algebraic equations appear as the constraints. PS method is suitable for all three objects. There are a lot of theoretical proofs regarding the convergence, consistency, and optimality of the solution of PS optimal control (Gong, Ross, Kang, & Fahroo, Citation2008; Ross, Citation2005).
The PS approximation was initially developed for solving PDEs. In this method, continuous functions are approximated in a finite set of nodes called collocation nodes. These nodes are selected in a way that guaranty the high accuracy of the approximation. The main exclusivity of the PS method is the smart selection of collocation nodes. Consider the approximation of on
by some interpolants. The simplest choices of nodes are equal distance nodes, but if a special set of nodes such as roots of derivative of Legendre polynomial, known as Legendre-Gauss-Lobatto (LGL) nodes is employed, the higher accuracy with fewer nodes can be achieved. This inequality shows the impressive convergence speed of the PS method (Gong et al., Citation2007).
where is the polynomial interpolation of
.
is a constant.
is the number of collocation points and
is the order of differentiability of
. It can be seen that if
, the polynomial converges at a spectral rate.
In this paper, we chose the Gauss-PS method with Lagrange interpolant. Since the prediction horizon of optimal control problem in the MPC framework is finite, the LGL nodes are adapted for discretization.
Given set of distinct points in
, a standard Lagrange interpolant for control function
and
can be written as:
where and
are a unique polynomial of degree
and
is the N-th order Lagrange polynomial
which satisfies the Kronecker property . This implies that
and
.
The computational domain of Gauss-PS method is , so the time variable should be scaled as follows: for
Any function can be approximated by Lagrange interpolant at the set of LGL nodes :
Also, it can be expressed as matrix multiplication
where and
.
The first derivative of can be written as
where is expressed as:
From these two equations, the derivative of at the LGL node
is approximated by
(14) can be represented in the matrix form:
where is a
matrix defined by:
It is obvious that the approximation of only depends on
. For nodes that are not scaled, i.e.
, the derivative of
at the LGL nodes is as follows:
In the PS method, the integration is approximated by the Gaussian quadrature rule. The rule is as follows:
where in Gauss-PS method are LGL nodes and
are predetermined quadrature weight correspond to LGL nodes. For the arbitrary domain of integration over
, the Gauss quadrature rule can be rewritten as
4. Polynomial chaos uncertainty propagation
gPC is a method for approximation of random variables with finite second-order moments (Cameron & Martin, Citation1947; Wiener, Citation1938). The random variable has the
expansion (Xiu & Karniadakis, Citation2002):
where are expansion coefficient,
are
order multivariate polynomials and
are univariate polynomials of degree
. The optimal form of
is based on the probability distribution of
and is chosen according to the Wiener–Askey scheme (Table ). For instance, for Gaussian distributed
, the Hermit polynomials are the best choice. These polynomials satisfy the orthogonality property
where
is the pdf of
,
is Kronecker delta and
. For practical reason, (22) is truncated, the
term of the series is considered, where
depends on the number of random variables.
and
are selected such that
Table 1. Wiener–Askey scheme (Xiu & Karniadakis, Citation2002)
So the random variable expansion can be reformulated as:
The coefficients are calculated as follows:
To calculate (27), the collocation method is adapted. A proper choice for collocation points is the roots of order polynomial that is chosen based on the Askey scheme. Employing orthogonality property, the first and second moments of the random variable
can be derived by gPC coefficients as follows:
5. Hybrid pseudo-spectral MPC uncertainty propagation
The states and inputs of the system with parameter uncertainty are stochastic processes. and
are the functions of random variable as well as the function of time.
In Section 3, it has been shown that a function of time can be approximated by a polynomial. Just like PS optimal control method which approximates and
, with polynomials, gPC approximates
and
with the same approach. At each sample time
,
and
are random variables. The objective of gPC is to approximate these random variables at each sample time. The main difference between PS optimal control and gPC is that in the PS optimal control, the approximation is performed over the time domain, whereas in gPC the approximation is carried out over the random variable probability space. Therefore, the main goal is to approximate the distribution of
and
.
The procedure of the hybrid algorithm is as follows:
Initial parameters:
Pick
Choose
Choose overall simulation time
For each
In this step, by utilizing PS optimal control, the problem 1 is transformed into the following nonlinear programming (NLP):
In this paper, the sequential quadratic programming is employed to solve the above optimization problem. At this step, and
are calculated during simulation time T at both
and
collocation points.
(3) Calculate the gPC expansion coefficients
For the values of and
at each collocation points
, calculate the coefficients of the gPC using quadrature formula for EquationEquation (27)
(27)
(27)
(4) Derive the statistics of input and state of the system by EquationEquations (28)
6. Numerical examples
In this section, the uncertainty propagation for two dynamical systems under MPC control is analyzed. The first one is an industrial process, continuous stirred reactor tank (CSTR). The CSTR has exposed to Gaussian distributed parameter uncertainty. The second one is a second-order dynamic system with uniform and Weibull distributed parameter uncertainty. All the simulations are performed on a Core i7 laptop with 6G Ram.
Example 1. CSTR
as a highly nonlinear second-order dynamical system is a benchmark process for advanced control strategies. In a CSTR an irreversible first-order exothermic reaction of the form is taking place. The dynamics of a CSTR tank is as follows (Mahmood & Mhaskar, Citation2012):
where is the concentration of species A,
and
are the temperature and volume of the reactor, respectively.
is the amount of heat input to the reactor.
,
, and
are the pre-exponential constant, the activation energy, and enthalpy of the reaction, respectively.
and
denote heat capacity and density of the fluid in the reactor. The states of the system are
and
. The manipulated variables are
and
. The MPC aims to reach to the desired steady-state values of
and
. The uncertainty in the process is considered due to the uncertainty in the two physical parameters
and
. This uncertainty is inevitable because of the experimental measurement complexity of thermal and kinetic phenomena. The values of all the parameters are listed in Table .
Table 2. Parameters of CSTR
As it can be seen from Table , the distributions of the uncertain parameters are Gaussian, so for gPC expansion, the Hermite polynomial is selected based on the Wiener–Askey scheme. The nominal values of uncertain parameters are
and
. Our goal is to steer the state of the system to the equilibrium point
. Without loss of generality, we shifted the equilibrium point to the origin.
The cost function is with
and
. The constraints of the control are
and
. The state constraints are
and
. The initial condition is
. We use Legendre polynomial for PS optimal control and Hermite polynomial for gPC uncertainty propagation. The prediction and control horizons are
and
, respectively. The system is simulated for 3 s. Also, 10 PS optimal control collocation points and
gPC collocation points are considered. As discussed in Section 2.1, (30) was linearized around the equilibrium point to find
,
and
. For the terminal constraint we choose
and for the linearized feedback controller we choose
such that the closed-loop linearized system
has two stable poles at −15 and −5 for each
. Figure shows how the parameter uncertainty affects the terminal constraint
. For different gPC collocation points, the terminal constraints are calculated and sketched in Figure .
Figure 1. Different realizations of terminal constraints for 36 collocation points
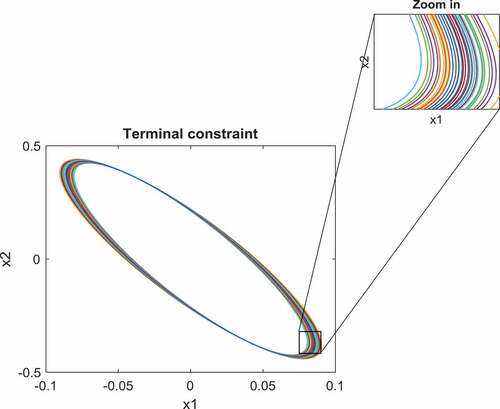
Figure shows how the uncertainty in the parameters of the CSTR affects the optimal control inputs of the system. In other words, it demonstrates how the control input should change to cope with the uncertainty of the parameters in order to have an optimal controller under stable MPC. When the CSTR is exposed to uncertainty, the controls and states will be a stochastic process; thus in Figure , the control first and second moments are indicated. The first moment is the mean of the control sequence which is represented by red lines and the gray interval illustrates the three-sigma area, i.e. which is a representation of the second moment. We choose to show the three-sigma area instead of the standard deviation interval
because it can be visualized better in the figures.
Figure 2. Effect of the parameter uncertainty on the control input for CSTR optimal control problem
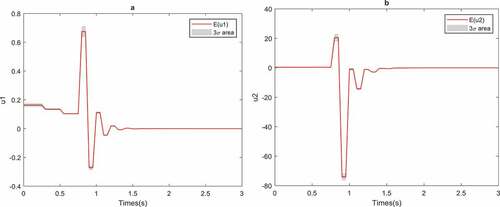
Based on the three-sigma rule for a Gaussian distributed random variable, the probability of values generated by Gaussian pdf lying in the three-sigma area is 0.9974. We cannot claim that for a nonlinear system, with Gaussian uncertainty parameter distribution, the distribution of the states and the controls of the system remains Gaussian for all time. Generally, with the three-sigma rule, we cannot identify the probability of system inputs but it can visualize the two first moments of the system inputs. Also, by the two first moments, we can apply Markov inequality to characterize the probability of the system states and controls in some bounded domain. Fortunately, in contrast to the three-sigma rule, the Markov inequality is not limited to just Gaussian distribution, it can be used for a wide group of the distributions. To highlight the numerical validation of the proposed method, it is compared with MC simulations. In order to be sure that MC simulations are convergent for our system, we already checked the convergence of MC simulations for both mean and variance of the states and the control of the system with parameter uncertainty under MPC. Figures and demonstrate the comparison between mean and the variance of the states of the system for both MC and gPC uncertainty propagation.
Figure 3. Mean of the optimal states of the CSTR with MC and gPC uncertainty propagation
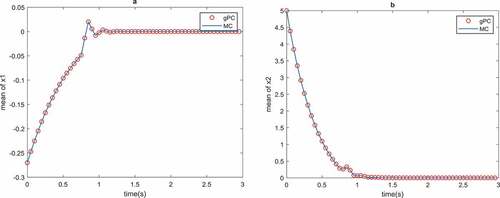
Figure 4. Variance of the optimal states of the CSTR with MC and gPC uncertainty propagation
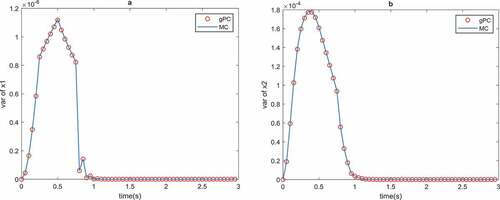
Figures and show that the propose method results are consistent with MC simulations. Also, from Figures and , it can be seen that the MPC objective, i.e. stabilization, is satisfied and the states converge to the origin.
The advantage of gPC method compared to MC simulations is the calculation of the mean and the variance of the system with much fewer samples and less computational time. Table compares the computational time and complexity of the gPC and MC simulations for the CSTR tank.
Table 3. Computational time of gPC and MC uncertainty propagation for CSTR optimal control problem
Table shows that in order to find the effect of the parameter uncertainty for model predictive control of a CSTR system, 30,000 MC simulations must be performed to have a convergent first and second moment for the states and controls of the system. On the other hand, when gPC is used, only 36 samples are needed to determine the first and second moments of the states and the controls of the CSTR tank. The MPC computational time takes 35 h, whereas gPC method only took 11 min of computational time. Thus, it can be found that gPC is a much more efficient method for uncertainty propagation than the MC simulation method.
Example 2.
In Example 1, the validity of the hPS method has been confirmed for uncertainty propagation when the uncertain parameters both have Gaussian distributions. In this example, the ability of the hPS method will be demonstrated when the uncertain parameters of the system have uniform distributions. Consider the following second-order system with parameter uncertainties A and B:
The nonlinear dynamic is under MPC strategy with the cost function with
and
, state constraint
, control constraint
and the initial condition
. The goal of the MPC is to stabilize the system states to the origin.
The parameter A has uniform distribution and parameter B has Weibull distribution
with
and
. According to Wiener–Askey scheme for the uniform distribution, the Legendre polynomial should be selected, but no type of polynomial is determined for Weibull distribution. To use Legendre polynomial, fundamental transformation law of probabilities is utilized to map a random variable with uniform distribution to the B as follows:
Therefore, in the dynamics of the system in the place of B, the term should be inserted. We transfer the Weibull distribution to a uniform random distribution to be able to use a type of polynomial according to standard distribution in Wiener–Askey scheme (Table ). For the terminal constraint we choose
and for the linearized feedback controller,
is chosen such that the closed-loop linearized system
has two stable poles at −2 and −1 for each
. For this example, Legendre polynomial for both PS optimal control and gPC uncertainty propagation is applied. The prediction horizon is
, control horizon is
, and the system is simulated for 11 s. Also, the number of PS collocation points in the time direction considered to be 4 and
gPC collocation points are considered. Figure highlights how the parameter uncertainty affects the optimal control solution of the system. Figures and indicate the consistency of the gPC method with MC simulations in MPC uncertainty propagation. Also, the MPC objective, i.e. stabilization, is satisfied.
Figure 5. Effect of the parameter uncertainty on the control for optimal control problem of Example 2
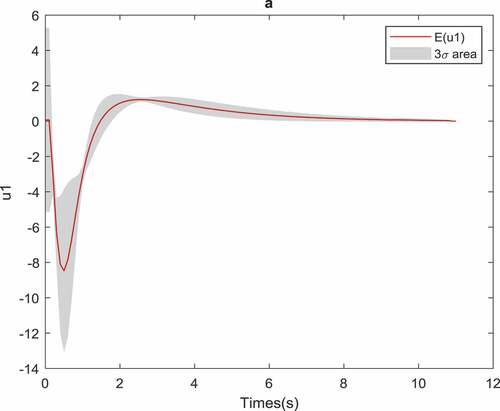
Figure 6. Mean of the optimal states of Example 2 with MC and gPC uncertainty propagation
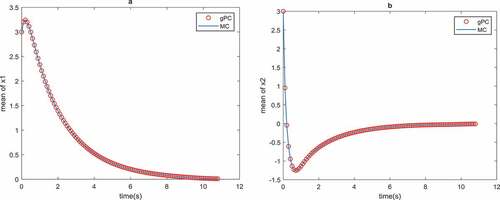
Figure 7. Variance of the optimal states of Example 2 with MC and gPC uncertainty propagation
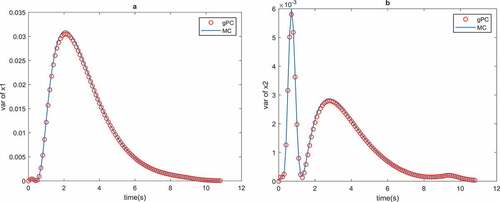
Table compares the computational time and complexity of the gPC and MC simulations for Example 2.
Table 4. Computational time of gPC and MC uncertainty propagation for optimal control problem of Example 2
It shows that gPC uncertainty propagation for Example 2 is much more efficient than MC simulations.
Figures and show that gPC results are in consistent with MC simulation results.
7. Conclusion
In this paper, an efficient method is proposed to evaluate the effect of parameter uncertainty on the inputs and the states of a nonlinear dynamical system under the MPC strategy. The presented method implements a hybrid pseudo-spectral method to increase the speed of the process of uncertainty propagation. Based on the proposed method, the first and second moments of the control sequence of a nonlinear system with uncertain parameters have been found. Two simulation results validate the effectiveness of the proposed method. It is shown that the gPC results are consistent with MC simulations, but gPC method is much superior to MC simulations regarding the computational time. In this paper, the hybrid PS method evaluates the first and second moments of the distributions. For future works, the other moments of the distribution can be evaluated by gPC coefficients to have a better analysis of the non-Gaussian distributions.
Additional information
Funding
Notes on contributors

Ali Namadchian
Ali Namadchian received the M.Sc. degree in control theory and control engineering from the Islamic Azad University of Mashhad, Mashhad, Iran, in 2013; he is currently pursuing the Ph.D. degree with the Department of Electrical and Control Engineering, Tafresh University, Tafresh, Iran. His current research interests include stochastic control, nonlinear control systems and optimal control.
References
- Annunziato, M., & Borzì, A. (2013). A Fokker–Planck control framework for multidimensional stochastic processes. Journal of Computational and Applied Mathematics, 237, 487–18. doi:10.1016/j.cam.2012.06.019
- Bavdekar, V. A., & Mesbah, A. (2016). Stochastic nonlinear model predictive control with joint chance constraints. IFAC-PapersOnLine, 49, 270–275. doi:10.1016/j.ifacol.2016.10.176
- Becerra, V. M. (2010). Solving complex optimal control problems at no cost with PSOPT. In Computer-Aided Control System Design (CACSD), Yokohama, Japan, 2010 IEEE International Symposium on (pp. 1391–1396.
- Cameron, R. H., & Martin, W. T. (1947). The orthogonal development of non-linear functionals in series of Fourier-Hermite functionals. Annals of Mathematics, 385–392. doi:10.2307/1969178
- Fornberg, B. (1998). A practical guide to pseudospectral methods (Vol. 1). Cambridge: Cambridge university press.
- Garcia, C. E., Prett, D. M., & Morari, M. (1989). Model predictive control: Theory and practice—A survey. Automatica, 25, 335–348. doi:10.1016/0005-1098(89)90002-2
- Gong, Q., Kang, W., Bedrossian, N. S., Fahroo, F., Sekhavat, P., & Bollino, K. (2007). Pseudospectral optimal control for military and industrial applications. In Decision and Control, New Orleans, LA, USA, 2007 46th IEEE Conference on (pp. 4128–4142.
- Gong, Q., Ross, I. M., Kang, W., & Fahroo, F. (2008). Connections between the covector mapping theorem and convergence of pseudospectral methods for optimal control. Computational Optimization and Applications, 41, 307–335. doi:10.1007/s10589-007-9102-4
- Grüne, L., & Pannek, J. (2011). Nonlinear model predictive control (pp. 43–66). London: Springer. ed.
- Harmon, F. G. (2017). Hybrid solution of nonlinear stochastic optimal control problems using Legendre Pseudospectral and generalized polynomial chaos algorithms. American Control Conference (ACC), 2017, 2642–2647.
- Mahmood, M., & Mhaskar, P. (2012). Lyapunov-based model predictive control of stochastic nonlinear systems. Automatica, 48, 2271–2276. doi:10.1016/j.automatica.2012.06.033
- Matsuno, Y., Tsuchiya, T., & Matayoshi, N. (2015). Near-optimal control for aircraft conflict resolution in the presence of uncertainty. Journal of Guidance, Control, and Dynamics, 39, 326–338. doi:10.2514/1.G001227
- Matsuno, Y., Tsuchiya, T., Wei, J., Hwang, I., & Matayoshi, N. (2015). Stochastic optimal control for aircraft conflict resolution under wind uncertainty. Aerospace Science and Technology, 43, 77–88. doi:10.1016/j.ast.2015.02.018
- Mayne, D. Q., Kerrigan, E. C., Van Wyk, E., & Falugi, P. (2011). Tube‐based robust nonlinear model predictive control. International Journal of Robust and Nonlinear Control, 21, 1341–1353. doi:10.1002/rnc.v21.11
- Mayne, D. Q., Rawlings, J. B., Rao, C. V., & Scokaert, P. O. (2000). Constrained model predictive control: Stability and optimality. Automatica, 36, 789–814. doi:10.1016/S0005-1098(99)00214-9
- Muske, K. R., & Rawlings, J. B. (1993). Model predictive control with linear models. AIChE Journal, 39, 262–287. doi:10.1002/(ISSN)1547-5905
- Namadchian, A., & Ramezani, M. (2017). Pseudo-spectral model predictive control of continuous stirred-tank reactor. Majlesi Journal of Mechatronic Systems, 6, 23–28.
- Patterson, M. A., & Rao, A. V. (2014). GPOPS-II: A MATLAB software for solving multiple-phase optimal control problems using hp-adaptive Gaussian quadrature collocation methods and sparse nonlinear programming. ACM Transactions on Mathematical Software (TOMS), 41, 1. doi:10.1145/2684421
- Rawlings, J., & Mayne, D. (2012). Postface to model predictive control: Theory and design. Nob Hill Pub, 5, 155–158.
- Ross, I. M. (2005). A historical introduction to the convector mapping principle. Proceedings of Astrodynamics Specialists Conference. Naval Postgraduate School (U.S.)
- Schwickart, T., Voos, H., Hadji‐Minaglou, J. R., & Darouach, M. (2016). A fast model‐predictive speed controller for minimised charge consumption of electric vehicles. Asian Journal of Control, 18, 133–149. doi:10.1002/asjc.1251
- Visintini, A. L., Glover, W., Lygeros, J., & Maciejowski, J. (2006). Monte Carlo optimization for conflict resolution in air traffic control. IEEE Transactions on Intelligent Transportation Systems, 7, 470–482. doi:10.1109/TITS.2006.883108
- Von Stryk, O., & Bulirsch, R. (1992). Direct and indirect methods for trajectory optimization. Annals of Operations Research, 37, 357–373. doi:10.1007/BF02071065
- Widd, A., Liao, H. H., Gerdes, J. C., Tunestål, P., & Johansson, R. (2014). Hybrid model predictive control of exhaust recompression HCCI. Asian Journal of Control, 16, 370–381.
- Wiener, N. (1938). The homogeneous chaos. American Journal of Mathematics, 60, 897–936. doi:10.2307/2371268
- Xiu, D., & Karniadakis, G. E. (2002). The Wiener–Askey polynomial chaos for stochastic differential equations. SIAM Journal on Scientific Computing, 24, 619–644. doi:10.1137/S1064827501387826