
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The paper presents the results of a study done to find the optimal shapes of matrix element partitioning on three abstract heterogeneous processors when performing multiplication operations. An abstract processor model allows applying the research results in systems with different heterogeneous architectures. To determine the optimal partitioning shape, the work uses non-rectangular candidate shapes identified by Ashley DeFlumere in her work as a result of applying the technology of redistribution of matrix elements between the processors «push»: Square Corner, Rectangle Corner, Square Rectangle, Block Rectangle, L-Rectangle, Traditional 1D Rectangular. The optimality of shapes is determined for four classes of matrix multiplication algorithms: Serial Communication with Barrier (SCB), Parallel Communication with Barrier (PCB), Serial Communication with Bulk Overlap (SCO) and Parallel Communication with Overlap (PCO). The Hockney model was used to evaluate the communication complexity of algorithms. Mathematical models of the algorithm execution time were introduced in the paper for each considered candidate shape in all algorithms. Based on the developed mathematical models, software was developed that allows to select the form of elements partitioning between processors, depending on the ratio of their speeds and latency of the transmission medium.
PUBLIC INTEREST STATEMENT
The paper presents the results of a study done to find the optimal shapes of matrix element partitioning on three abstract heterogeneous processors when performing multiplication operations. An abstract processor model allows applying the research results in systems with different heterogeneous architectures. To determine the optimal partitioning shape, the work uses non-rectangular candidate shapes identified by Ashley DeFlumere as a result of applying the technology of redistribution of matrix elements between the processors «push»: Square Corner, Rectangle Corner, Square Rectangle, Block Rectangle, L-Rectangle, Traditional 1D Rectangular. The optimality of shapes is determined for four classes of matrix multiplication algorithms: Serial Communication with Barrier, Parallel Communication with Barrier, Serial Communication with Bulk Overlap and Parallel Communication with Overlap. The Hockney model was used to evaluate the communication complexity of algorithms. Mathematical models of the algorithm execution time were introduced in the paper for each considered candidate shape in all algorithms.
1. Introduction
The amount of processed information and the complexity of computational tasks grow every year. In this regard, the field of parallel data processing research became more and more popular all over the world.
Parallel multiplication of matrices is one of the most popular tasks in various fields of scientific knowledge. In particular, such tasks may include work with connectivity matrices and correspondences in information, engineering and transport networks that control the main information about objects and flows movement continuity and at the same time has significant length and dynamic elements.
According to the state of the Top500 list as of November 2019, the maximum computing speed of 200 petaflops was reached by the Summit supercomputer developed by IBM for Oak Ridge National Laboratory. Summit is used in astrophysics, cancer research and systems biology; it consists of 4,608 servers (crosspoints) and 2 397 824 cores.
If at the initial stage of development of high-performance computing, the top lines of the rating were mainly occupied by supercomputers built on identical elements, now we can trace a steady trend towards greater efficiency of heterogeneous cluster solutions.
While the models and methods of distributing computing resources when multiplying matrices on homogeneous systems are studied well enough, the search for optimal solutions for heterogeneous systems is still being studied.
The partitioning of matrix elements among computational elements when performing linear algebra operations is performed for the purpose of reducing the total computation time.
At the first stages of scientific research in this area, rectangular data partitioning shapes were defined and studied in detail (Beaumont et al., Citation2001; Clarke et al., Citation2012; Lastovetsky, Citation2007). Later works (DeFlumere, Citation2014; DeFlumere & Lastovetsky, Citation2014) showed that non-rectangular shapes of matrix elements partitioning can also be optimal for certain ratios of the computational power of processors. But these works did not take into account the difference in the latency of data transmission networks among computing elements.
The objective of this study is to determine the optimal shapes for matrix partitioning in heterogeneous systems with different latencies between computational elements. A mathematical model is built for four classes of algorithms for parallel matrix multiplication:
Serial Communication with Barrier (SCB);
Parallel Communication with Barrier (PCB);
Serial Communication with Overlap (SCO);
Parallel Communication with Overlap (PCO).
To construct a mathematical model of computation, the notion of an “abstract processor”, considered in work (Zhong et al., Citation2011, Citation2012), is used. Earlier, DeFlumere & Lastovetsky (Citation2014) proved that the model of an abstract processor that is mainly based on the volume of communications and calculations, which accurately forecasts the experimental performance of many processors and even entire clusters for matrix calculations.
The work was done as part of research on the project АР05133699 “Research and development of innovative telecommunication technologies using modern cyber-technical means for the city’s intelligent transport system” of the Institute of ICT of the MES RK.
2. Materials and research methods
For constructing model studies, several assumptions were done:
square source matrices A, B and the resulting matrix Сwith dimension N × N of its elements are used;
matrix multiplication operation is simulated on three abstract heterogeneous processors with fully connected topology;
computing power of abstract processors P, R and S is determined by the ratio Pr:Rr: Sr, where P is the most powerful processor, and Sr = 1. The total processing power of the three-processor system will be equal to T = Pr + Rr + Sr;
matrix elements are divided among the processors in proportion to their computing power;
transmission network latency is
between the processors P and S,
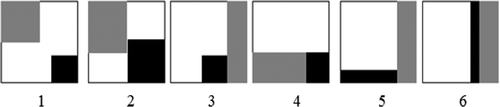
optimality is evaluated for the following candidate shapes Square Corner (SC), Rectangle Corner (RC), Square Rectangle (SR), Block Rectangle (BR), L-Rectangle (LR), Traditional 1D Rectangular (TR) (DeFlumere, Citation2014, p. 77) (Figure ).
The communication complexity of the considered algorithms is estimated using the Hockney model:
where —latency or message delay, measured in seconds;
—bandwidth or time to transmit an element, measured in seconds;
–message size or number of elements to send.
Figure 1. Candidate shapes defined as potentially optimal for three-processor systems.
2.1. Finding of the optimal data partitioning for the serial communication with barrier algorithm
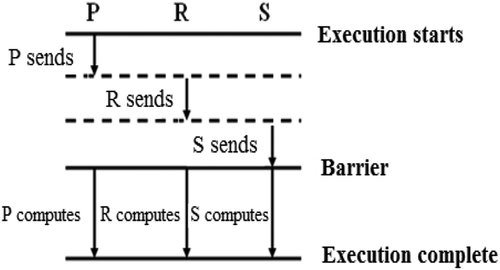
The Serial Communication with Barrier algorithm (SCB) is a simple matrix multiplication algorithm in which all data are sent consistently by the processors, and calculations begin only after all processors have completed data transfer and are running in parallel (Figure ).
The execution time of the algorithm includes the communication time between processors and the time required to perform the calculations:
where —total number of communications;
- the time required by the processor X to calculate the assigned part of the matrix C.
Because the area of the matrix and the number of elements allocated to each processor are proportional to its computing power, the parameter will be the same for all candidate forms considered and may not be taken into account when comparing the execution time of the algorithm.
Figure 2. The serial communication with barrier algorithm for three-processor systems.
The next step is to define the communication time for each considered form according to the formula (2).
Square Corner:
Square Rectangle:
where –side of the square, intended for processor
;
—side of the square, intended for processor
.
Block Rectangle:
L-Rectangle:
Traditional 1D Rectangular:
For the Rectangle Corner shape, the optimal size of R and S will be the combined width of N; that cannot be true, however, based on the classification of candidate forms (DeFlumere & Lastovetsky, Citation2014, p.78). Alternatively, we can establish that . Then,
Rectangle Corner:
where ,
—height and width of the rectangle, intended for processor
;
—height and width of the rectangle, intended for processor
.
To facilitate the analysis of the mathematical model, we get rid of the coefficient , having obtained the ratio of the throughputs between the computational elements
. Thus, we get four variables.
2.2. Finding of optimal data partitioning for parallel communication with the barrier algorithm
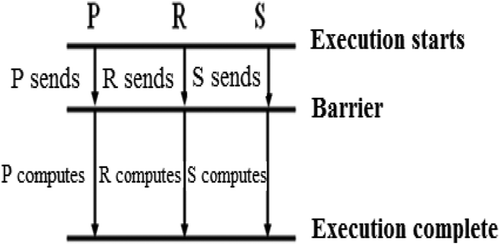
The algorithm of Parallel Communication with Barrier (PCB) assumes that the transfer of data between the processors is carried out in parallel, and that only after the communication is completely completed will the processors begin to perform parallel calculations (Figure ).
Figure 3. The parallel communication with barrier algorithm for three-processor systems.
Evaluation of the execution time of the algorithm is performed using the formula:
where - the amount of data to be transferred by the processor X.
Similar to the SCB algorithm, the parameter may not be taken into account in the formulas; the optimality of the forms will be determined based on the communication time
.
Square Corner:
Square Rectangle:
Block Rectangle:
L-Rectangle:
,
Traditional 1D Rectangular:
,
Rectangle Corner:
2.3. Finding of the optimal data partitioning for the serial communication with overlap algorithm
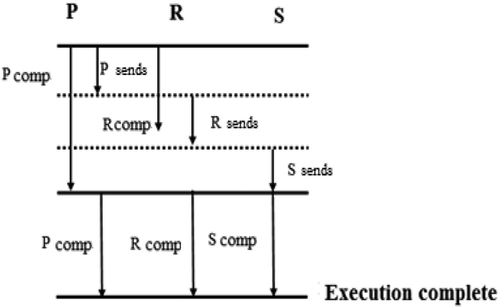
In the algorithm of the Serial Communication with Overlap (SCO), all data are transmitted by processor serially, and in parallelelementsnot engaged in the exchange are calculated.
The rest part of the operations is done only after completion of communication and overlap of computations (Figure ).
The algorithm execution time is calculated by the formula:
where is time spent by processor X for computing elements that do not require communication;
is time spent by processor X for computing the rest elements.
Figure 4. The serial communication with overlap algorithm for three-processor systems.
Let us determine the execution time of the algorithm for each shape considered according to formula (4).
Algorithm execution time for the shape of Square Corner is determined as follows:
Algorithm execution time for the shape of Square Rectangle equals to:
Since matrix elements are distributed among the processors proportionally to their computational power, values will have the same value for all partitioning shapes, and in the rest formulas, it will be indicated as
, respectively.
Algorithm execution time for the shape of Block Rectangle equals to:
Algorithm execution time for the shape of L-Rectangle is determined as:
Algorithm execution time for the shape of Traditional 1D Rectangular is presented as follows:
For the shape of Rectangle Corner, R and S optimal size is a combined width N, which cannot be true based on the classification of candidate shapes (DeFlumere, Citation2014, p.78). As alternative, let us state that . Then,
To simplify the analysis of obtained mathematical model, let us get rid of coefficient having received the ratio of bandwidths between computational elements
. Thus, we get four variables.
2.4. Finding of the optimal data partitioning for the parallel communication with barrier algorithm
Algorithm of Parallel Communication with Overlap (PCO) completes all communications in parallel and simultaneously calculates any sections of the C matrix that do not require interprocessor communication. As soon as the operation data are completed, the rest computations are done (Figure ).
Figure 5. The parallel communication with overlap algorithm for three-processor systems.
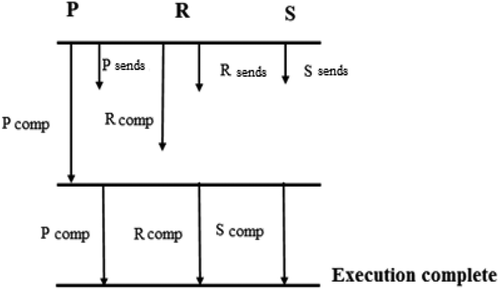
Evaluation of the execution time of the algorithm is performed using the formula:
where is equal to the communication time for the algorithm of the parallel communication with barrier PCB;
is time spent by the processor
for computing the elements that do not require communication;
is time spent by the processor
for computing the rest elements.
Let us construct computation models for each candidate shape according to the formula 5.
Square Corner:
Square Rectangle:
Block Rectangle:
L-Rectangle:
For the shapes of Traditional 1D Rectangular and Rectangle Corner, to evaluate the total duration of execution, only time of communication between the elements is needed.
Traditional 1D Rectangular:
Rectangle Corner:
By analogy with the SCО algorithm let us get rid of the coefficient, having received ratio of bandwidths between computational elements
.
3. Research results
Based on the constructed mathematical model, software was developed in the Java programming language that in text form or via the web interface allows entering the initial parameters (P, R, ,
) and determining the theoretical optimal data partitioning shape (Figures –).
Figure 6. Сlass diagram of “parallel matrix computation on heterogeneous processors” web-application.
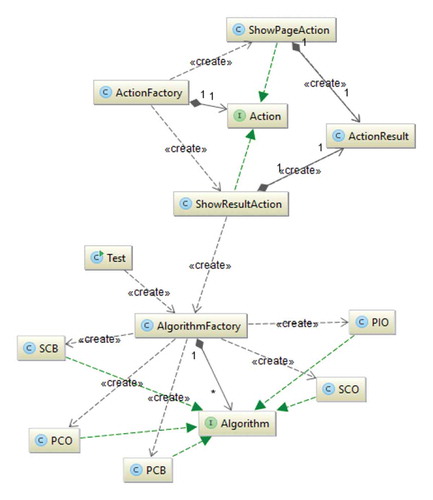
Figure 7. Example of Program Computations for SCB algorithm with different input values of Pr, Rr, ,
.
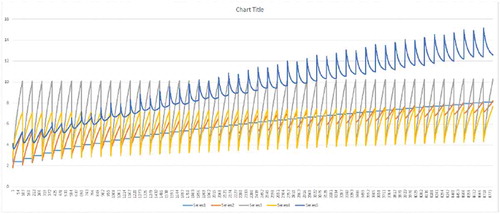
Y axis—execution time; X axis—number of experiments. Series 1—Square Corner; Series 2—Rectangle Corner; Series 3—L Rectangular; Series 4—Block 2D Rectangular; Series 5—Square Rectangle.
Figure 8. Example of program computations for SCB and PCB algorithms with different input values of Pr, Rr, ,
.
Y axis—execution time; X axis—number of experiments. Series shows different types of element partition.
Based on the analysis performed on the basis of calculations obtained according to the constructed mathematical model, the following conclusions were made.
BR, LR, SC and SR partition shapes are optimal for the Serial Communication with Barrier Algorithm. The LR partition shape is optimal at a value of and roughly equal powers of the processors P and R, while significantly exceeding the power of the processor S. The SR form is optimal in cases of small values of the coefficients
and the powers of the processors P and R, significantly exceeding the power of the processor S. In all other cases, the BR and SC forms are optimal.
As in the case of using the SCB algorithm, only BR, LR, SC and SR forms can be optimal for Parallel Communication with the Barrier Algorithm. LR is optimal only for values of the coefficients = 0,1,
and roughly equal the powers of processors P and R while being much larger than S. SR is optimal for
and the computing power values of processors P and R are larger than those in the processor S. In other cases, depending on the selected parameters, the forms BR and SC are optimal.
For the Serial Communication with Overlap Algorithm in the same way as in previous algorithms, optimal matrix partitioning shapes may be BR, LR, SC and SR. SR and SC shapes may beoptimalwiththe P processor power values that significantlyexceedpower of the processors R and S. At the same time, for the SR shape, this statement is true only with the coefficient value of ≥2. The LR shape is optimal with the coefficient value of
and approximately equal power of the processors P and R that significantly exceeds the power of the processor S. In all other cases, optimal shapes are BR.
For the Parallel Communication with Barrier Algorithm, optimal partitioning shapes may be also only BR, LR, SC and SR. The LR shape is only with the coefficient value of 0.6,
and approximately equal power of the processors P and R. The SR shape may be optimalwith
andpower values of processors P and R that significantly exceed the power of the processor S. The SC shape is optimal with the power of the processor P that significantly exceeds the power of the processors R and S and values
,
In other cases, depending on the chosen parameters,optimal shapes are BR.
4. Conclusion
Based on the results of obtained calculation, it can be concluded that, as in the case of three-processor systems with the same bandwidth between computational elements, the Rectangle Corner and Traditional 1D Rectangular data partitioning shapes are optimal for any set of parameters.
In contrast to the results obtained in matrix (DeFlumere, Citation2014, p. 85, 88), the L-Rectangle form is optimal with the powers of the processors P and R greatly exceeding the power of the processor S, and approximately equalling each other in the case of for the SCB algorithm and
= 0,1 for the PCB algorithm. However, in these cases, there is no sense in using a low-power processor S, and the task can be solved on two processors.
The Square Rectangle shape is optimal for small values of the coefficients with the powers of processors P and R significantly exceeding the power of the processor S. With such initial data, the problem can also be solved using two powerful processors.
In other cases, the Square Corner and Block Rectangle forms are optimal in the case of using both algorithms, depending on the values of the coefficients .
L-Rectangle shape may be optimal with approximately equal powers of the processors P and R that significantly exceed the power of the processor S and for the SCО algorithm, and
0.6,
for the PCО algorithm. But in this case, the problem may be solved by two processors, without engaging the processor S.
Square Rectangle shape may be optimal if both caseswithpower values of the processors P and R that significantly exceed the power of the processor S. With such input data, the problem also may be solved using two powerful processors.
In most cases for both algorithm classes, it is preferable to use the Block Rectangle shape.
The developed software can be used to determine the optimal form of partitioning the matrix elements for certain parameters of a real computing system. The results can be used to implement a specific subject area algorithm, for example, for the analysis of large volumes of data presented in the form of matrices, as well as for the analysis of urban structures in modern metropolitan areas, in particular for determining the reachability between the city districts.
Additional information
Funding
Notes on contributors
Ye.G Klyuyeva
Ye.G. Klyuyeva Senior Lecturer, Karaganda State Technical University, Kazakhstan. Research interests: parallel computing, databases, computer networks, software development.
V.V. Yavorskij
V.V. Yavorskij Doctor of Technical Sciences, Professor, Karaganda State Technical University, Kazakhstan. Research interests: mathematical modeling, optimization, intelligent systems.
A.A. Adamov
A.A. Adamov Doctor of Technical Sciences, Professor, Head of the Department of Mathematical and Computer Modeling, L.N. Gumilyov Eurasian National University, Research interests: mathematical modeling, optimization, development of information systems.
I.T. Utepbergenov
I.T. Utepbergenov Doctor of Technical Sciences, Professor, Head of Laboratory of Innovative and Smart Technologies Institute of Information and Computational Technologies CS MES of RK, Kazakhstan. Research interests: ACS, Information technology in education, telecommunications, management, transport.
The research described in the paper was carried out in the framework of the research project grant financing of MES RK AR05133699 “Research and development of innovative telecommunications technologies with the use of modern cyber-technical means for the cities of intelligent transport system”.
References
- Beaumont, O., Boudet, V., Legrand, A., Rastello, F., & Robert, Y. (2001). Heterogeneous matrix-matrix multiplication or partitioning a square into rectangles: Np-completeness and approximation algorithms//Parallel and Distributed processing, 2001. Proceedings Ninth EuromicroWorkshop (pp. 298–13). IEEE.
- Clarke, D., Lastovetsky, A., & Rychkov, V. (2012). Column-based matrix partitioning for parallel matrix multiplication on heterogeneous processors based on functional performance models. Euro-par 2011: parallel processing Workshops (pp. 450–459). Springer.
- DeFlumere, A. (2014). Optimal partitioning for parallel matrix computation on a small number of abstract heterogeneous processors [PhD thesis]. University College Dublin. P. 161.
- DeFlumere, A., & Lastovetsky, A. (2014). Optimal data partitioning shape for matrix multiplication on three fully connected heterogeneous processors, Euro-Par 2014WS, HeteroPar 2014. Twelfth International Workshop on Algorithms, Models and Tools for Parallel Computing on Heterogeneous Platforms (pp. 201–214.
- Lastovetsky, A. L. (2007). On grid-based matrix partitioning for heterogeneous processors//ISPDC.
- Zhong, Z., Rychkov, V., & Lastovetsky, A. (2011). Data partitioning on heterogeneous multicore platforms//Cluster Computing (CLUSTER). 2011 IEEE International Conference (pp. 580–584). IEEE.
- Zhong, Z., Rychkov, V., & Lastovetsky, A. (2012). Data partitioning on heterogeneous multicore and multi-GPU systems using functional performance models of data-parallel applications. Cluster Computing (CLUSTER), 2012 IEEE International Conference (pp. 191–199). IEEE.