
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In many cases robots are directly in touch with humans, this interaction is necessary to design control systems that take into account a human-machine relation. Particularly important is the case when humans share the control with a robot. So, in order to validate control schemes, it is necessary to test them in an environment where the human-machine interaction exists, what could be even dangerous for humans. We present a model of human useful to test controllers, and propose a scheme for human-in-the-loop under shared control. We test the model and the scheme in a lower limb prosthesis that implies naturally a human-machine interaction. Apart from this research, we propose an efficient and low-cost controller for the prosthesis, based on a sensory exoextension and a neuro-decoder consisting of a multilayer perceptrons. The results show the effectiveness of human model to emulate the human interaction.
PUBLIC INTEREST STATEMENT
The proposed method for prosthesis is useful to study the human correction of errors in automatic control. The participation of the human for fine adjustments due to disturbances. The active lower limb prosthesis has the advantage that the amputee can freely change the desired trajectory and does not depend on the healthy leg. It does not require a complex sensory system. Only hip reading status is required for mapping. The study would mainly benefit in the areas of medical robotic, automatic, and computational intelligent.
1. Introduction
Only in Mexico, according to Cruz (Citation2016), there are 128 thousand amputations per year. With what arises the need to restore the motor capacity of amputees, and with it their autonomy. Scientific and technological advances increasingly allow the development of robotic devices with better performance, see, Martinez-Hernandez et al. (Citation2018). However, more work is needed to make these devices not only tools but also able to completely replace missing limbs.
Prostheses can be classified according to the limb they replace in the upper and lower limbs. According to the actuation, the prostheses can be classified into passive and active. Ferreira et al. (Citation2016) mention amputees who use passive limbs generally walk more slowly and expend significantly more energy, about 60% more according to Lawson et al. (Citation2014). Active prostheses can restore locomotion functions and recognize human intention, see, Spanias et al. (Citation2018). But the cost of a smart prosthesis is too high for most people, see, Wen et al. (Citation2018). The reasons for the high cost are sensors and actuators, as well as control.
The most common control strategies are gait mode recognition, in combination with low impedance control and direct electromyography (EMG) control. Echo-control requires high mechanical impedance, it does not feel natural as it does not interact with the amputee, and is only useful for unilateral amputees. The finite state impedance control has the drawback of tuning many parameters as explained by Ferreira et al. (Citation2016), while the EMG-based control is affected by the problem of fatigue, misalignment of electrodes and a low signal-to-signal ratio, see, Ryu et al. (Citation2019); K. Zhang et al. (Citation2019).
The acceptance of prostheses has been complicated by the fact that the control systems are not sufficiently intuitive and the sensory feedback is inadequate, as Yang and Liu (Citation2021) comments in their work on hand prostheses. And as Wu et al. (Citation2021) mentions, due to technological limitations, autonomous systems still cannot fully supply human participation. They suggest the definition of schemes where both elements interact to provide better performance together, creating more intelligent systems Dellermann et al. (Citation2021). The development of this approach has been varied, based on forms of interaction Grønsund and Aanestad (Citation2020); levels of human participation Mabrok et al. (Citation2020); as well as application environments: labor Grønsund and Aanestad (Citation2020), UAVs Feng et al. (Citation2016), autonomous vehicles Li et al. (Citation2020); Wu et al. (Citation2021), economy, machine learning Dellermann et al. (Citation2021), Goecks (Citation2020), Mandel et al. (Citation2017), and Perrusquía et al. (Citation2021), social sciences Dautenhahn (Citation1998), robotic prostheses Welker et al. (Citation2021); Yang and Liu (Citation2021) and rehabilitation Gao (Citation2020).
Some researches have been developed in order to find human-robot interaction dynamics like in Roveda et al. (Citation2020) where using a model-based reinforcement learning approach, they define an Artificial Neural Network to model the dynamics. This approach is not possible to modify directly each of the systems what compound the human. Shi et al. (Citation2021) propose human-centred adaptive control of a lower limb rehabilitation robot based on an HRI dynamic model. An equivalent spring model in three-dimensional space is proposed to express the interaction force between the human and robot. Then, it is just defined one part of the human model, and it is not enough to describe a human in order to be possible to simulate, for example, a general human-machine environment avoiding the real, and most of the times dangerous, human participation, such that there is no a complete human model.
Human-in-the-loop (HITL) simply means a system completely or partially controlled by a human via a control manipulator Mabrok et al. (Citation2020). HITL can be modeled as an input-output system. Mabrok et al. (Citation2020) suggest three challenges in feedback control with HITL:
Understanding the spectrum of driver types with HITL.
Derive models of human behavior
Incorporate human behavior into the formal feedback control methodology.
The importance of these schemes lies in the possibility of a quantitative evaluation of the impact of human behavior in dynamic systems Bae et al. (Citation2019). They contribute to health care or reduction of energy consumption Mabrok et al. (Citation2020). And they are mainly useful when robustness is a priority Yang and Liu (Citation2021). From a control theory perspective.
Various HITL algorithms have been implemented in the area of prosthetics, orthotics, and lower extremity rehabilitation robots mainly for the off-line design of these devices, as well as in the configuration of controller parameters, for example, as in the work of J. Zhang et al. (Citation2017) on optimization of exoskeletons and that of Welker et al. (Citation2021) on optimization of ankle-foot prostheses, who comments on the disadvantages of such an approach. Since this scheme is recently investigated, there is not much research on human in the loop control for prostheses. Examples of these recent investigations are the works of Zhuang et al. (Citation2019) and that of Yang and Liu (Citation2021) where they carry out an implementation of HITL in hand prostheses.
In all these cases, the human has participated actively in the tests, which implies the submission to stress and risks typical of any experiment. Perrusquía et al. (Citation2021) proposes a generalization of reinforcement learning to emulate human behavior. Grønsund and Aanestad (Citation2020) consider humans as supervisors who are responsible for managing performance. Feng et al. (Citation2016) designs human behavior based on cognitive architectures. Bae et al. (Citation2019) regards the human as an intelligent, independent agent to maximize their idiosyncratic utility function. The nature of these schemes leads to the need for a model that mimics human behavior in loop human applications Mabrok et al. (Citation2020).
According to Welker et al. (Citation2021), robotic prostheses have not been sufficiently explored and there is still no definition of the basic principles of how humans and prostheses interact. It is not possible to design controllers based on a mathematical description of human-prosthesis dynamics Gao (Citation2020). Feng et al. (Citation2016) highlights models of human behavior based on cognitive architectures that include memory encoding and organization of elements in mental structures. Work is continuing on the human model, as in the work of Perrusquía et al. (Citation2021), they propose a generalization of reinforcement learning that considers stimuli, skills, knowledge, and previous experiences to emulate human behavior. However, current models of the human are limited Mabrok et al. (Citation2020).
Human behavior has been considered as a random disturbance or as an error compensation mechanism, however humans cannot be considered as irrational decision makers that can be modeled as stochastic disturbances.
HITL under shared control has not yet been implemented in active prostheses.
In order to study human interaction with active lower limb prostheses in efficient and safe ways, we propose a general scheme of HITL for active prostheses, which in turn avoids human involvement during controller testing. The contributions of the paper are
We propose an explicit human model-based system, which allows us to separately modify any part of the system. The model can be implemented for any system adapting the human model.
Theory analysis of the proposed HITL
Application of the proposed HITL to active lower limb prosthesis
1. Human-in-the-loop with shared control
The human-in-the-loop with shared control proposed in this paper is illustrated in . It has the system where the human influenced by the environment controls an exogenous system (a machine) in a shared way with autonomous control (the inner control of the machine).
Figure 1. General scheme of human-in-loop under shared control.
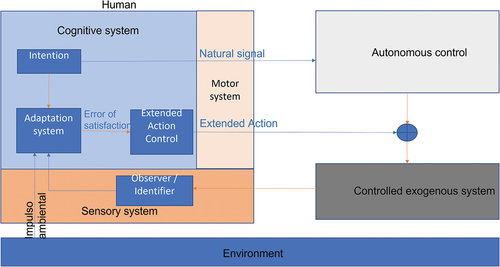
We consider that there exists a system (machine) that is controlled by human and an autonomous controller. That is, there exists a system
if this can be rewritten in the affine form,
where is a nonlinear function that depends on the state,
, and the control
. And
and
are nonlinear functions that depend just in the state,
.
On the other hand, the human can be considered like
That means that human is not considered to be explicitly controlled. That’s the reason why there is no control signal in (3). Human is a system that just react in response to the perceived environment, described by the state, , of the controlled system. Moreover, the state,
, of the human is a function of the control signal,
, what is applied to the controlled system. That simply means that human produces a signal that is considered as a control signal for another system, and that system produces a state,
, that provoke to human to evolve and produce
. That is, in general, the behavior of the system in close loop, for the human-machine interaction.
And if we consider that the machine has an inner controller that produces the control signal, , and at the same time, it receives an outer control signal,
, to add both getting the total control signal,
Then in the close loop, it’s defined an interaction by shared control. That is, the machine is controlled by an inner and outer control, provided by itself and by human.
1.1. Human model
The model of the human we propose consists of
Cognitive system. Within this system, the intention of the human is defined and transmitted to the motor system. Through an adaptation system, the human generates signals based on the perceived exogenous agents, which are transmitted to a control system that produces the extended actions necessary to achieve that the satisfaction error converges to zero. It can be simplified as a controller
where is the control signal produced by human, and
is a function that defines the controller dynamics, which is defined in terms of the satisfaction error
, with
and
the states of the human and the exogenous system.
Motor system. This system acts as a link between humans and exogenous systems. To convey his intention through movements and the imposition of states on the joints. Practically, this is regarded as an usual robot, that is, it can be described as
where the states, corresponds to the human-join states, what could regard the natural and extended actions at the same time, because the actions of the human are produced as a result of the states taken by each of the human-joints. Here, the control,
, is the produced signal by the cognitive system.
Sensory system. It is a system that perceives (identifies and/or observes) exogenous systems or their states. Then, clearly a convenient representation is an observer, the sensors or the signal conditioning stage. Additionally, it can contain an identifier system.
This equation represents an identified system, that describes an estimated dynamics of the exogenous system, where, is the estimated or sensed state for
.
The proposed human model has three signals:
Natural signals. These correspond to the physiological signals of a natural behavior, for example, the bio-mechanical signals that it produces when walking.
Extended Signals. The signals that are produced for the manipulation of external agents, as in the manipulation of tools, are considered.
Intentional signals. They correspond to those associated with human desires.
1.2. Human-robot interaction for active prosthesis
In human-robot interaction, the human defines the desired state of the joints through the residual limb, that is, through the natural actions, but human does not apply extended actions to share the control with the autonomous control of the prosthesis. Moreover, there isn’t exist human feedback to present a human-machine scheme control where human just provides the human intention. In order to compare lately with a scheme where human provides a control signal by closing the loop. See, .
Figure 2. Emulation of human-prosthesis interaction with a 4-DOF robot.
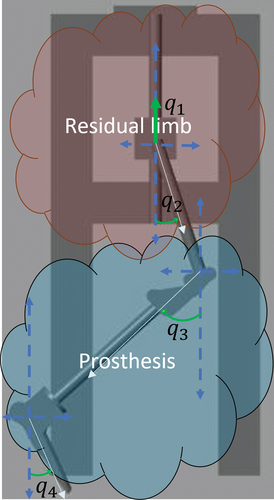
To emulate the control of the prosthesis attached to the residual limb, we design a robot that represents the human-prosthesis system. The complete human-prosthesis system can be regarded as a 4-DOF robot.
The proposed scheme can be used as a test platform that involves the human being in active participation. The scheme allows to emulate human participation without risk to the human. In addition, the model’s ability to learn allows it to be implemented with a real human in the same way that it can be implemented with any other plant, which can improve the performance of the model when learning from another human.
The 4-DOF robot is modeled as
where ,
is the state of the residual limb,
is the state of the lost limb,
The residual limb is controlled by the human who perceives the prosthesis as a perturbation, which is defined
So (8) becomes
where ,
is the control for human hip and thigh
is the control over the prosthesis.
1.3. PD control for human-robot system
Regarding the amputee-prosthesis system as the previously described 4-DOF robot, we base in the perspective of robotics to define a controller for all the complete systems.
Considering, dynamics for the DC motors are almost linear, we can use simple controllers for the joints. We used PD control for the joints (10),
where and
are positive gains,
is the tracking error, it includes the error for residual limb part,
, and for the prosthesis,
,
is the desired trajectory. We use first-order low pass filter to estimate the derivatives. Here, we use first-order low pass filter to estimate the derivatives
In order to obtain good controller, and
, we need to identify the simplified model. For each joint, we use the following second order linear model,
where is the joint position,
is the control,
and
are the parameters to be identified,
is the coupling perturbation. (12) can be written in matrix form,
There are data. We define
The object of the parameter identification is
where The training data are
and
The optimal solution of
is
We can write the error dynamic for each of the joints as
where is the state variable
,
and
. The PD control (10) can be rewritten as
, closed-loop system becomes
In order to assure stability of (17), we chose , such that
is negative definite, i.e., the following polynomial has negative roots,
where the roots are
So we need the controller gains
Here PD gains are based on the estimated parameters.
1.4. PID control for human-robot system
In the human-in-the-loop (HITL) as in Figure , there are two controllers interacting to control the prosthesis. The human signal is given priority over the tracking control signal. We define the human as an intelligent system that acts on a system based on knowledge acquired by interaction. The human applies actions based on the errors obtained by comparing what he wants and what he observes.
So HITL also needs a human model, which considers the following:
Past. The human is based on what he has learned from the system. He accumulates the experience, and takes an action proportional to this accumulated.
Present. He acts to the response of the stimulus, and observes the response with each stimulus, to minimize the error in each application.
Future. The human interacts more with the system, he learns his behavior so that he can anticipate his action.
The above three actions can be modeled as,
It has the form of PID control. We need to specify the parameters of ,
,
, and
.
The human model can be written as
For and
we have
where corresponds to the anthropomorphic femur angle desired with a bounded influence of the environment, what is always bounded. So
and
are bounded states.
and
are variables measured directly by the amputee, they are in
. The active prosthesis estimates the states to produce gait based on
which are the residual signals from the residual limb.
We define the discrete sets
We use mapping to describe an anthropomorphic trajectory followed by the amputee,
Since the model of mapping is not available, we use the following neural network to estimate it,
where ,
,
and
are the output, hidden and input layer weight matrices, respectively, and
,
is based on the data set of Winter (Citation2009) to train the network.
For training, the Backpropagation algorithm was applied using a descending gradient.
uses the same form as (21).
2. Stability analysis of human-in-the-loop with shared control
2.1. Stability analysis of PD
When we apply the controller (10) to each joint (12), we need to assure the closed-loop system be stable. We rewrite (12) with state-space form
where
,
In regulation case, we define
We consider the following Lyapunov candidate function
where From (23)
Using (22)
Because
(26) becomes
where is the upper bound of
We should choose the gain such that
then the closed-loop system is uniformly bounded, convergences to
Here
and
are obtained from (13)
In tracking case we use the same definitions as (23), and define an auxiliary variable
The PD control becomes
So
and
The proposed Lyapunov function is
The derivative of it is ,
where Because
where So
We should choose the gain such that
then the closed-loop system is uniformly bounded, convergences to
From the Lyapunov analysis, we concluded that the PD can stabilize the system. By the identification of the system, we can obtain good control gains.
So, amputee-prosthesis system is stable under previous consideration.
2.2. Stability analysis of PID
As described by (12), the prosthesis can be considered as a 2-DOF robot, subject to a perturbation due to the coupling with the residual limb, described in likewise as a 2-DOF robot subject to the perturbation due to the prosthesis coupling. And more over, each of the joints of the prosthesis can be considered as independent systems perturbed by the interconnections of the other links.
defining ,
. This implies
, and
. Then, the error dynamics can be described as
where the dynamics of the human controller can be written as
So the system in closed loop can be described as
where ,
,
,
,
,
We extend the idea of Thenozhi and Yu (Citation2014) for the PID with derivative filtering. The equilibrium point for the error dynamics must be at ,
and
. From (32)
Defining , so the equilibrium point results
. As the error converge, so
and
are bounded and considering the perturbation,
, bounded too, we can consider constant the control at the equilibrium, so
at equilibrium. Finally, the equilibrium point is defined at
.
In order to analyze the stability of the system, we propose the candidate Lyapunov function
with and
. Assuming positive constants,
and
so
.
Then
substituting the error and control dynamics we get
so
The system is stable if
3. Human-in-the-loop control for active lower limb prosthesis
In order to test the proposed scheme, we define an amputee-prosthesis system.
Here, the human model corresponds to an amputee with a lower residual limb made up of the hip and thigh, and with the ability to control this residual limb according to the desired intention under the influence of the environment.
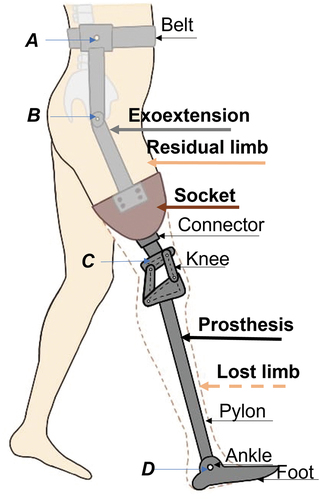
For a complete model, we consider an active transfemoral prosthesis rigidly connected to the stump of the residual limb where humans share control in two ways, 1) by connection of the stump, 2) by extended actions. The complete assemble can be regarded as a model where an active prosthesis includes the dynamics of human system or a human who has attached a prosthesis. See, .
Figure 3. Lower limb prosthesis.
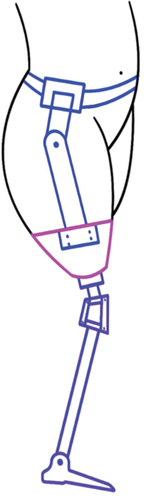
For this implementation, we define:
Natural signals. The human performs the usual movement (through the residual limb) to reach a desired state when walking. These signals,
and
where is the walking frequency and
is as usual the mathematical modulo function, what obtains the remainder when we divide
over
.
Extended. These signal are obtained by the human control, and, in general, is defined as a function,
where
with , the state of the prosthesis.
Signal of intention. It corresponds to the state of the prosthesis desired by the human.
The environment is considered as a system that generates a Boolean signal, as a differentiating means of two environmental conditions.
where is the gain of influence in the system. So assuming interaction with environment and a unitary gain of influence, we have
.
There are exogenous systems that humans can interact with. These systems have a behavior that does not depend at all on the existence of the human being in the system. The exogenous system is an autonomous and independent system. The trajectories of exogenous systems will be defined as exogenous behaviors.
Robotic systems, even other humans, are examples of exogenous systems. The environment is an exogenous system that modifies or motivates the generation of signals. That is, human signals are personal, which means that they differ between human and human, since during his life he is immersed in a unique environment, which provides the particularities of the genesis of his signals. Since each system is considered autonomous, there is a controller for each system that defines a certain behavior.
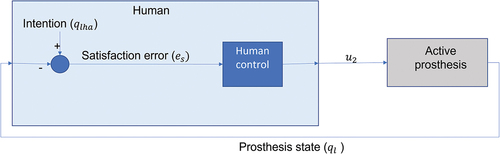
shows the proposed scheme of human-in-the-loop control. Here, the human being influenced by the environment interacts with the prosthesis through the stump and extended actions.
Figure 4. Human-in-the-loop control for prosthesis.
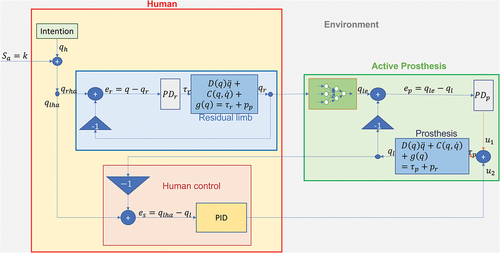
The human intention is defined as
where are the hip, thigh, knee and ankle.
The environment influence is defined as . This signal is added to the desired intention to modify the intention under environment interaction. The intention is
where and
are the desired human hip and thigh.
is the desired state of knee and ankle of the prosthesis.
The closed-loop representation with human control is shown in .
Figure 5. HITL for active lower limb prosthesis.
4. Experimental results
The experimental results was obtained by simulation. The mechanical environment of the human-machine system was developed in SimMechanics over Matlab, exporting designed elements previously designed in Catia based on anthropomorphic dimensions for optimal gait. The control system was implemented in Simulink connected to SimMechanics. The integration method used was ode45, with maximum step size of .
The implementation of prostheses makes human-machine interaction inevitable. In the first test, we consider the case when the human does not have an intervention beyond the imposition of states to the system.
4.1. Open loop HITL control
When the human participates, he does not execute actions additional to the natural ones, and there is not a feedback of the states of the prosthesis influencing its control. We defined it as open loop with the human interaction.
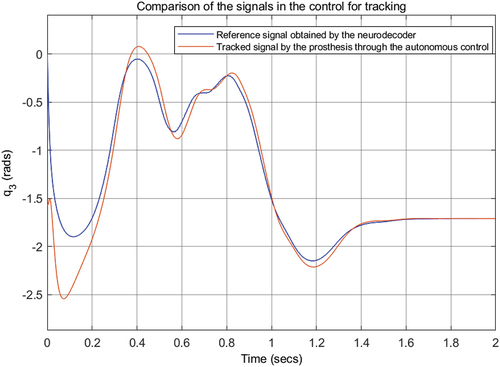
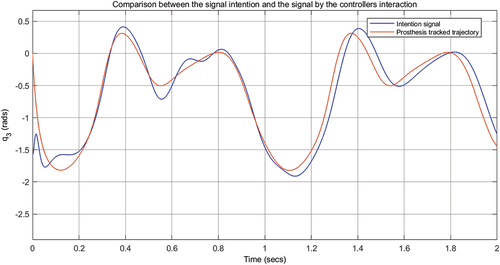
The implementation and simulation of the HITL control are for the knee and the ankle for the prosthesis attached to the human, physically represented by the hip and the thigh as the residual limb such that these provide the more significant information of the desired trajectory for gait. The autonomous control is a PD trajectory tracking control. A comparison of tracking trajectory of the gait pattern obtained by the neuro-decoder is shown in
Figure 6. Comparison of trajectories in tracking control.
The neural decoders receive the signals from the hip and thigh, and return the trajectory of the knee. They apply out-of-range signal to the decoder to emphasize the need for human participation, the behavior shown in . The experiment considered a variation of the range of the signal for which the neural decoder was designed. Instead of having a signal, we defined a
signal, see, . The tracking errors are shown in . Comparison of the human signal and the signal achieved by autonomous control is presented in .
Figure 7. Comparison of the filters to estimate .
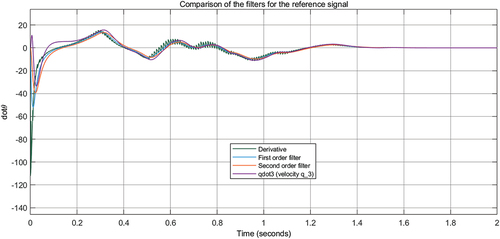
Figure 8. Comparison of the decoded signal.
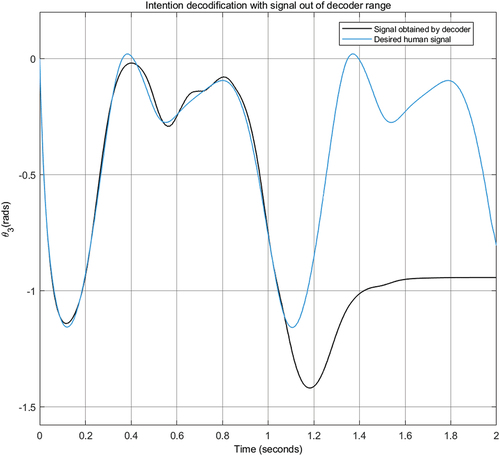
Figure 9. Tracking error of neuro-decoder generated trajectories.
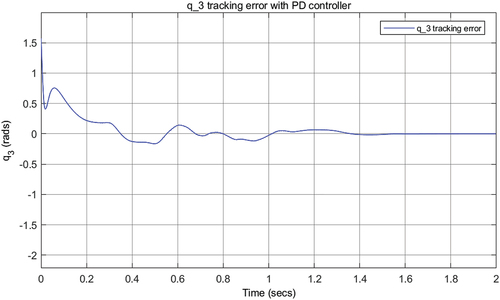
Figure 10. Tracking error in open loop.
Neural networks provide the robustness of the system. Since the value is outside the design parameters of the network, it is very possible that the trajectory achieved is not the one expected by the amputee. However, we consider that there is no such intervention to observe the behavior of the system. The error increases, because the neuro-decoding system cannot adequately identify the intention, when the parameters are outside the design ranges.
4.2. Close-loop HITL control
The system receives intention signal, which is out of range. An environmental signal is included to justify this signal. The human intention signal is taken into account, which is under HITL scheme. The extended human signal is applied to the prosthesis-controller system.
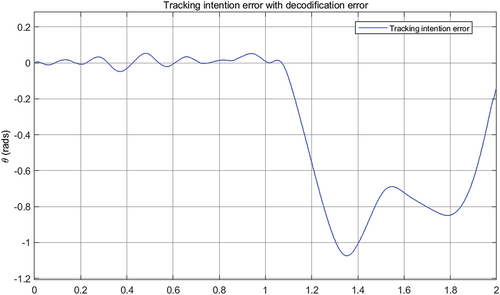
In , the result of the intention tracking based on PID model is shown. Due to the difference in the initial conditions, the participation of the human is small. It only seeks to compensate the signal that was added to the reference. In the second cycle, its participation is greater, because the tracking control fails in the decoding.
Figure 11. PID model in the HITL control.
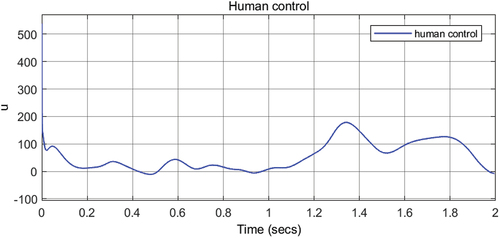
shows the human must influence with greater effort, managing to better track the intention signal but with a lag. This delay comes from human observation to act. It can be solved by adapting an interaction prediction system through intelligent mechanisms.
Figure 12. Human control signal applied in the HITL control.
4.3. Human interaction
The human-robot interaction force is defined in this implementation as the extended actions. The energy used to control the prosthesis is observed through the control signal applied by the human as the force need in the shared control in order to achieve the human desired state. shows the human control needed to correct the state of the prosthesis in order to get the correct desired gait.
So, according to the observations, the human model proposed is useful to study the payload when it shares the control in the proposed scheme. And is clearly than the autonomous tracking control is not the best option to interact with human, so it is not so convenient to do a real-human implementation with this scheme using that control. First to do a real implementation, we could use the proposed human model to design and test better autonomous controller in order to prevent dangerous test for human.
It must be notice, that even when the human signal control, human-robot interaction force, looks high, it is not applied with that magnitude, this is because motors have a previous saturation stage, that is, to prevent overload in motors, the control signal passes through a saturator that limits the signal to to
. That means, human perceive, and actually apply, a higher force than applied to joints. This suggests again that it is better to choose another different control than tracking control, according to literature a possible option to improve this behavior is impedance control.
5. Conclusions
The proposed HITL scheme for prosthesis is useful to study the human correction of errors in autonomous controller dynamics due, for example, to modeling, identification or synchronization errors. As well as the participation of the human for fine adjustments due to disturbances such as environmental ones. In such a way as to guarantee his satisfaction, comfort and safety.
The active lower limb prosthesis has the advantage that the amputee can freely change the desired trajectory and does not depend on the healthy leg, like the eco-control schemes. It does not require a high computational cost treatment like the EMG-based implementation. It does not require a complex sensory system. Only hip reading status is required for mapping.
To improve the model, it is possible to add an adaptive and learning capacity, even psychological. It is still necessary to study stability, and furthermore, an inherently stable model should be considered to make it more suitable to emulate a real human.
In the future, we are going to extend human model in order to incorporate more physical and psychological behavior, and add more DOFs to the motor system, also include hip and thigh as residual limb. This will improve balance of walking process.
Acknowledgement
Authors would like to thank the Department of Automatic Control of CINVESTAV-IPN for providing the experimental devices.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
Additional information
Funding
Notes on contributors
Iván Hernández
Wen Yu received the B.S. degree in automatic control from Tsinghua University, Beijing, China in 1990 and the M.S. and Ph.D. degrees, both in Electrical Engineering, from Northeastern University, Shenyang, China, in 1992 and 1995, respectively. From 1995 to 1996, he served as a lecturer in the Department of Automatic Control at Northeastern University, Shenyang, China. Since 1996, he has been with CINVESTAV-IPN (National Polytechnic Institute), Mexico City, Mexico, where he is currently a professor with the Departamento de Control Automatico. From 2002 to 2003, he held research positions with the Instituto Mexicano del Petroleo. He was a Senior Visiting Research Fellow with Queen’s University Belfast, Belfast, U.K., from 2006 to 2007, and a Visiting Associate Professor with the University of California, Santa Cruz, from 2009 to 2010. He also holds a visiting professorship at Northeastern University in China from 2006. Dr.Wen Yu serves as associate editors of IEEE Transactions on Cybernetics, Neurocomputing, and Journal of Intelligent and Fuzzy Systems. He is a member of the Mexican Academy of Sciences.
Wen Yu
Iván Hernández received the B.S degree in Electronical Engineering from Metropolitan Autonomous University (UAM), CdMx, Mexico in 2014 and the M.S. degree in Electrical Engineering from Center for Research and Advanced Studies of the National Polytechnic Institute (CINVESTAV-IPN), CdMx, Mexico in 2019. He received the medal for university merit from UAM in 2014. He has taught at various institutions since 2005. He is currently working toward the Ph.D. degree in Automatic Control in CINVESTAV-IPN. His main research of interest focuses on biomechatronics, robotics, artificial intelligence, nonlinear control.
References
- Bae, S., Han, S. M., & Moura, S. (2019). Modeling & control of human actuated systems. IFAC-PapersOnLine, 51(34), 40–23. https://doi.org/10.1016/j.ifacol.2019.01.016
- Cruz, Á. (2016). Issste: Se realizan en méxico 128 mil amputaciones de extremidades al año (Tech. Rep.). La Jornada.
- Dautenhahn, K. (1998). The art of designing socially intelligent agents: Science, fiction, and the human in the loop. Applied Artificial Intelligence, 12(7–8), 573–617. https://doi.org/10.1080/088395198117550
- Dellermann, D., Calma, A., Lipusch, N., Weber, T., Weigel, S., & Ebel, P. (2021). The future of human-ai collaboration: A taxonomy of design knowledge for hybrid intelligence systems. arXiv preprint arXiv:2105.03354 .
- Feng, L., Wiltsche, C., Humphrey, L., & Topcu, U. (2016). Synthesis of human-in-the-loop control protocols for autonomous systems. IEEE Transactions on Automation Science and Engineering, 13(2), 450–462. https://doi.org/10.1109/TASE.2016.2530623
- Ferreira, C., Reis, L. P., & Santos, C. P. (2016). Review of control strategies for lower limb prostheses. In Robot 2015: Second Iberian Robotics Conference (pp. 209–220). Lisbon, Portugal , November 19-21, 2015, Springer.
- Gao, X. (2020). Data-efficient reinforcement learning control of robotic lower-limb prosthesis with human in the loop [Unpublished doctoral dissertation]. Arizona State University.
- Goecks, V. G. (2020). Human-in-the-loop methods for data-driven and reinforcement learning systems. arXiv preprint arXiv:2008.13221.
- Grønsund, T., & Aanestad, M. (2020). Augmenting the algorithm: Emerging human-in-the- loop work configurations. The Journal of Strategic Information Systems, 29(2), 101614. https://doi.org/10.1016/j.jsis.2020.101614
- Lawson, B. E., Mitchell, J., Truex, D., Shultz, A., Ledoux, E., & Goldfarb, M. (2014). A robotic leg prosthesis: Design, control, and implementation. IEEE Robotics & Automation Magazine / IEEE Robotics & Automation Society, 21(4), 70–81. https://doi.org/10.1109/MRA.2014.2360303
- Li, S., Zhang, L., & Diao, X. (2020). Deep-learning-based human intention prediction using rgb images and optical flow. Journal of Intelligent & Robotic Systems, 97(1), 95–107. https://doi.org/10.1007/s10846-019-01049-3
- Mabrok, M. A., Mohamed, H. K., Abdel-Aty, A.-H., Alzahrani, A. S., & Farouk, A. (2020). Human models in human-in-the-loop control systems. Journal of Intelligent & Fuzzy Systems, 38(3), 2611–2622. https://doi.org/10.3233/JIFS-179548
- Mandel, T., Liu, Y.-E., Brunskill, E., & Popović, Z. (2017). Where to add actions in human- in-the-loop reinforcement learning. In Thirty-first Aaai Conference on Artificial Intelligence. San Francisco, California, USA, ACM Digital Library.
- Martinez-Hernandez, U., Rubio-Solis, A., & Dehghani-Sanij, A. A. (2018). Recognition of walking activity and prediction of gait periods with a cnn and first-order mc strategy. In 2018 7th Ieee International Conference on Biomedical Robotics and Biomechatronics (Biorob) (pp. 897–902). Enschede, The Netherlands. IEEE Press.
- Perrusquía, A., Yu, W., & Li, X. (2021). Nonlinear control using human behavior learning. Information Sciences, 569, 358–375. https://doi.org/10.1016/j.ins.2021.03.043
- Roveda, L., Maskani, J., Franceschi, P., Abdi, A., Braghin, F., Tosatti, L. M., & Pedrocchi, N. (2020). Model-based reinforcement learning variable impedance control for human-robot collaboration. Journal of Intelligent & Robotic Systems, 100(2), 417–433. https://doi.org/10.1007/s10846-020-01183-3
- Ryu, J., Lee, B.-H., Maeng, J., & Kim, D.-H. (2019). semg-signal and imu sensor-based gait sub-phase detection and prediction using a user-adaptive classifier. Medical Engineering & Physics, 100(69), 50–57. https://doi.org/10.1016/j.medengphy.2019.05.006
- Shi, D., Zhang, W., Zhang, W., Ju, L., & Ding, X. (2021). Human-centred adaptive control of lower limb rehabilitation robot based on human–robot interaction dynamic model. Mechanism and Machine Theory, 162, 104340. https://doi.org/10.1016/j.mechmachtheory.2021.104340
- Spanias, J., Simon, A., Finucane, S., Perreault, E., & Hargrove, L. (2018). Online adaptive neural control of a robotic lower limb prosthesis. Journal of Neural Engineering, 15(1), 016015. https://doi.org/10.1088/1741-2552/aa92a8
- Thenozhi, S., & Yu, W. (2014). Stability analysis of active vibration control of building structures using pd/pid control. Engineering Structures, 81, 208–218. https://doi.org/10.1016/j.engstruct.2014.09.042
- Welker, C. G., Voloshina, A. S., Chiu, V. L., & Collins, S. H. (2021). Shortcomings of human in-the-loop optimization of an ankle-foot prosthesis emulator: A case series. Royal Society Open Science, 8(5), 202020. https://doi.org/10.1098/rsos.202020
- Wen, Y., Gao, X., Si, J., Brandt, A., Li, M., & Huang, H. H. (2018). Robotic knee prosthesis real-time control using reinforcement learning with human in the loop. In International Conference On Cognitive Systems and Signal Processing (pp. 463–473). Zhuhai, China. Springer.
- Winter, D. A. (2009). Biomechanics and motor control of human movement. John Wiley & Sons.
- Wu, J., Huang, Z., Huang, C., Hu, Z., Hang, P., Xing, Y., & Lv, C. (2021). Human-in-the- loop deep reinforcement learning with application to autonomous driving. arXiv preprint arXiv:2104.07246.
- Yang, D., & Liu, H. (2021). Human-machine shared control: New avenue to dexterous prosthetic hand manipulation. Science China Technological Sciences, 64(4), 767–773. https://doi.org/10.1007/s11431-020-1710-y
- Zhang, K., de Silva, C. W., & Fu, C. (2019). Sensor fusion for predictive control of human-prosthesis-environment dynamics in assistive walking: A survey. arXiv preprint arXiv:1903.07674.
- Zhang, J., Fiers, P., Witte, K. A., Jackson, R. W., Poggensee, K. L., Atkeson, C. G., & Collins, S. H. (2017). Human-in-the-loop optimization of exoskeleton assistance during walking. Science, 356(6344), 1280–1284. https://doi.org/10.1126/science.aal5054
- Zhuang, K. Z., Sommer, N., Mendez, V., Aryan, S., Formento, E., D’Anna, E., Artoni, F., Petrini, F., Granata, G., Cannaviello, G., Raffoul, W., Billard, A., Micera, S. (2019). Shared human–robot proportional control of a dexterous myoelectric prosthesis. Nature Machine Intelligence, 1(9), 400–411. https://doi.org/10.1038/s42256-019-0093-5