
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Dengue fever modelling in endemic locations is critical to reducing outbreaks and improving vector-borne illness control. Early projections of dengue are a crucial tool for disease control because of the unavailability of treatments and universal vaccination. Neural networks have made significant contributions to public health in a variety of ways. In this paper, we developed a deep learning modelling using random forest (RF) that helps to extract the features of the dengue fever from the text datasets. The proposed modelling involves the data collection, pre-processing of the input texts, and feature extraction. The extracted features are studied to test how well the feature extraction using RF is effective on dengue datasets. The simulation result shows that the proposed method achieves higher degree of accuracy that offers an improvement of more than 12% than the existing methods in extracting the features from the input datasets than the other feature extraction methods that have laid a foundation for Artificial Neural Network (ANN) model efficacy test. Further, the study reduces the errors associated with feature extraction that is 10% lesser than the other existing methods and this shows the efficacy of the model.
PUBLIC INTEREST STATEMENT FOR NON-SPECIALIST READERS
PUBLIC INTEREST STATEMENT FOR NON-SPECIALIST READERS
In 149 tropical and subtropical countries, neglected tropical diseases (NTDs) are thought to impact more than a billion people annually. These parasitic, viral, and bacterial parasites, viruses, and bacteria are what cause these illnesses, which are transmitted by mosquitoes. Since there are presently no widespread dengue immunizations or effective medications, early projections are a crucial tool for disease management. It is necessary to simulate dengue fever in endemic regions to better control vector-borne diseases and reduce dengue outbreaks. In this work, we developed a deep learning model that uses RF augmented ANN to extract dengue fever-related data from text datasets. The simulation results demonstrate that the suggested method performs better than prior feature extraction strategies in accurately extracting features from input datasets. The study shows the model’s utility by reducing feature extraction mistakes by 10% in comparison to other existing methodologies.
1. Introduction
An estimated more than a billion gets affected each year with neglected tropical diseases (NTDs) in 149 countries throughout the tropics and subtropics (Ong et al., Citation2018). These diseases are caused by parasitic, viral, and bacterial parasites, viruses, and bacteria, and are transmitted by mosquitoes. Among the most common NTD types are borne viruses that are regarded as a virus collection that is considered as a naturally transmitted ones between hosts. Despite the fact that the clinical appearance of these disorders is well-known (Arivazhagan et al., Citation2022; Mohana et al., Citation2022), it is difficult to make an appropriate diagnosis of these conditions. In order to make an accurate arboviral diagnosis, a range of factors must be considered, the most prevalent of which are included in the scientific literature. One factor to consider is that arbovirus is typically asymptomatic, meaning that it may be present in a population without creating an outbreak. The second issue is that their illnesses are frequently difficult to distinguish from one another. They all have similar symptoms, which include arthralgia, fever, headache, myalgia, and orbital pain (Gangula et al., Citation2021), among other things. Despite the fact that the symptoms of Dengue, Zika, and Chikungunya are distinct from one another (Garcia-Carretero et al., Citation2022; Hannah et al., Citation2022), all of them, with the exception of Chikungunya, which is associated with joint discomfort, necessitate a high level of clinical competence and understanding in order to be accurately diagnosed.
Because of the vast range of signs and symptoms associated with these illnesses, it may be difficult to diagnose them. Patients who are infected with dengue may not show any symptoms at all, making it difficult to diagnose the virus in these cases. In most cases, a diagnosis of dengue is confirmed 7–10 days after a mosquito bite has occurred (Nishat et al., Citation2021). Some of the individuals tends to experience certain symptoms like headache, fever, muscle and joint soreness, and fatigue. As a result of the disease progression, some individuals who experience organ damage, bleeding, and leakage of plasma (Gumaei et al., Citation2022). It is possible to divide dengue into the feverish and critical stage. The fever symptoms last between 2 and 7 days. Dengue critical phase, which lasts 24–48 hours and begins with defervescence, is the most dangerous phase of the disease. Severe dengue symptoms, such as plasma leakage or fluid accumulation, as well as respiratory problems, serious bleeding, or organ malfunction, can result in death (Shafqat et al., Citation2021). A Chikungunya infection can induce symptoms that are similar to those of dengue fever, but with more severe joint pain and swelling. The development of Chikungunya is divided into three stages.
Rheumatoid arthritis is characterized by a high temperature, a rash, and discomfort in both the small and large joints, among other symptoms (RA). Throughout the subacute phase, the arthralgia gets worse. Despite the low fatality rate associated with the Chikungunya virus, it has the potential to become chronic (Zeng et al., Citation2021). A large number of people suffer from post-Chikungunya rheumatism, which can last for several weeks or even years and has a detrimental influence on their overall quality of life. Among the symptoms of Zika infection, the most serious is congenital Zika syndrome (CZS). When it comes to pregnancy, there is always a risk of infection (Tarasova & Poroikov, Citation2021).
When arbovirus infections are detected early, they have the potential in order of acquiring impacts significantly on the clinical course of patient as well as treatment and care alternatives. Inadequate arbovirus diagnosis is exacerbated by competing demands for finances, as well as for competent and experienced people, due to the presence of multiple disease epidemics at the same time. The development of low-cost, novel and scalable solutions for the epidemiological surveillance of diseases is urgently required. For example, one strategy is the building of computational models using symptoms and clinical data for the purposes of monitoring and diagnostic classification.
Machine Learning (ML)/Deep Learning (DL) models as in Figure are frequently developed in the field of biotechnology for improving the disease prediction and diagnosis. The models include both training and developmental models, where the training models involve artificial intelligence, machine learning, and deep learning. AI is considered as a computer science discipline that makes predictions based on prior experiences by analysing data and analysing patterns. The quality and quantity of data are crucial for the learning process to be successful and, as a result, for the accuracy of model predictions to be guaranteed. Finding the optimal combination of parameters that results in a model that can generalise and perform satisfactorily when confronted with previously unknown new data is the key to designing a machine learning model.
Figure 1. ML/DL model.
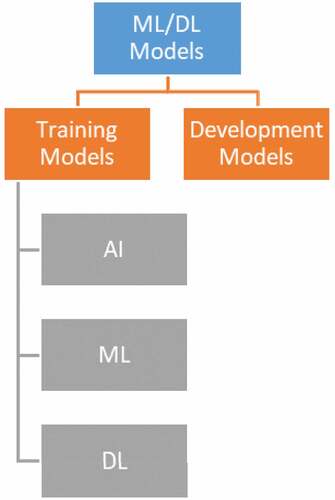
DL is a subfield of machine learning that focuses on learning by layering on successively more meaningful representations and is a subfield of artificial intelligence. DL is a subfield of mathematical logic. When used in this context, the term deep alludes to the concept of piling up representations on top of one another in layers.
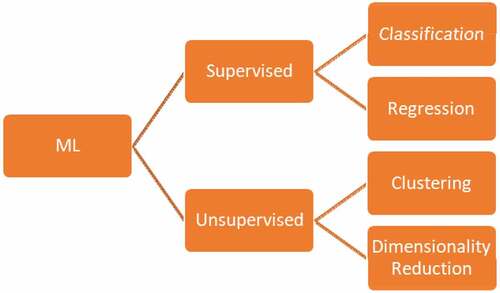
According to the latest research, models based on early neural network (NN) iterations are gradually becoming the most effective machine learning (ML) technique as in Figure due to their capacity to combine feature extraction and categorization at the same time. The ML models in specific involve supervised and unsupervised modelling, where the supervised models operate mainly on classification and regression tasks. The unsupervised models involve clustering and dimensionality reduction techniques. When it comes to the health sector, the fact that most DL models operate as black boxes presents a significant problem because the industry values openness and accountability. As a result, interpretable machine learning models are becoming increasingly common.
Figure 2. Machine learning techniques (Sajana, Navya, Gayathri, Reshma et al., Citation2018).
In this paper, a random forest (RF) deep learning model is utilised to extract dengue illness variables from text datasets using deep learning techniques. The proposed technique for the model includes data collection, input text preprocessing, and feature extraction, all of which are included in the recommended methodology. Dengue datasets are reviewed to see whether or not the RF feature extraction method is effective. Through the use of a simulation, the RF model is tested against a range of datasets. According to the simulation findings, the proposed strategy is more accurate than the other methods at extracting features from the input datasets compared to the other methods.
The paper is categorized into five sections: Section 1 discusses the general knowledge of the subject understudy. Section 2 elaborates similar research topics in the area and pinpoints why this research has taken a different approach. Section 3 discusses about the proposed ANN model resulted from FS, DWT, and ANN combinations to land on the needed classification task. Section 4 widely elaborated the performance of the proposed model and the model efficacy compared to those knowledges discussed in section 2. Finally, section 5 concluded the study and the results obtained and has put forward interesting perspective for future research.
2. Related works
Authors (Tanner et al., Citation2008) developed decision tree models. It was established that 1,200 data points from individuals suffering from acute febrile illness might be utilised to develop the Dengue Diagnostic Model, which was later refined (DDM). The Dengue Severity Prediction Model (DSPM) was developed with data from 161 patients with the goal of classifying the severity of dengue in adults. It was necessary to make comparisons between Naive Bayes and Support Vector Machine (SVM) in order to establish whether that patient is affected with dengue or not. In order to find the ideal hyperparameters of SVM, the gamma parameter and the cost parameter were varied in a grid search. Despite the use of the Grid Search, it was not possible to determine the optimal Naive Bayes configuration. Despite having reduced rate of sensitivity, SVM is found to be the most successful (47%) overall. The Naive Bayes model sensitivity is extremely high, as evidenced by its 18% accuracy rate.
Authors (Sajana, Navya, Gayathri, Reshma et al., Citation2018) presented an MLP, two decision trees, and a Bayesian network as alternative models (C4.5 as well as CART). It was not possible to find documentation for the model configurations (Fathima & Hundewale, Citation2012). Among the models examined, the CART model produced the most accurate results, scoring an error on every metric. The hyperparameter optimization and feature selection are not discussed in detail. One possible explanation for these results is that the ML models are found to be overfitting with small number of records in the dataset (20 records).
Author (Gambhir et al., Citation2018) offered three ML models to determine the condition of patients with dengue or not using Decision Tree model, NN model, and Naive Bayes model. Other models, on the other hand, produced findings that were comparable. In their data set (Gambhir et al., Citation2018), using SVM and decision tree models, researchers were able to determine if the patient is affected with dengue or not, according to the findings of the study (Sanjudevi & Savitha, Citation2019). There was no precision information supplied on the model configurations. Throughout this investigation, WEKA was utilised to carry out the experiments and generate the metrics. Because of the high-performance outcomes, there is a chance of overfitting.
They (Ho et al., Citation2020) used clinical data to develop classification models for dengue, including a logistic regression, decision tree, and CNN model. It was demonstrated that cross-validation tests with a k = 10 sample size were effective in validating and testing the models. For feature selection, the crude odds ratio and modified odds ratio analyses were utilised, respectively. When only four criteria were utilised in all of the investigations, the AUC was close to 84% in all of them. The CNN fared somewhat better than Logistic Regression and Decision Trees when compared to the other two methods. They (Potts et al., Citation2010) developed the decision tree model for the classification of pediatric patients affected with dengue as two classes (severe or non-severe) based on severity. According to Potts et al. (Citation2010), trees 3, 4, and 5 were not included in the study since the study failed to demonstrate significant improvement compared to the control trees. With a misclassification of severe dengue as low risk ranging from 34.9 to 42.6% and a proper categorization of non-severe sickness ranging from 72.1 to 81.5%, all subsequent trees (Trees 3–5) exhibited moderate specificity but limited sensitivity.
They (Phakhounthong et al., Citation2018) developed a model using CART Decision Tree for the severity assessment on Dengue based on laboratory and clinical data collected from patients. They carried out on each attribute for the determination of severity using Logistic Regression its relevance to the overall image. The hematocrit of the patients was found to be the most important predictor of severe dengue. Despite the fact that Logistic Regression was used to select the features, only 65% of the measures evaluated met or exceeded this criterion.
During a study conducted by Faisal et al. (Citation2010), patients were classified as either high risk or low risk, allowing for the development of a binary categorization of dengue risk. To solve the classification problem, an MLP model was provided, and a Grid Search model for optimizing the configuration using the modification of certain parameters that includes neurons, the number of layers, and the number of layers per class (momentum, number of neurons, iterations, and learning rate). Self-Organizing Map (SOM) was used to select seven qualities, and the model was accurate to within 70% of the true value.
The Decision Tree employed by Thitiprayoonwongse et al. (Citation2012) was utilised to categorise patients into four groups: Dengue fever (DF), Dengue Heart Failure (DHF1), DHF2, and DHF3. The features that were utilised to construct a decision tree were provided for each experiment, but the attributes of datasets themselves cannot be provided. Dengue was classified into three groups based on their study of eight different categorization models: dengue fever (DF), dengue heart failure (DHF), and dengue syndrome (DSS). The best results were obtained using the NN model in Scenario (1), where the accuracy, precision, and sensitivity of the model were all 71.3%; in Scenario (2), where these values were 71.5%; and in Scenario (3), where they were all 72%. As indicated by the findings, the selection of features did, in fact, result in considerable improvements in the outcomes
Arafiyah et al. (Citation2018) used Random Forest, Naive Bayes, and SVM classification methods to determine if a sample was DHF or non-DHF. It is a bad thing that the model configurations aren’t documented. All of the research in our collection were focused on the binary categorization of dengue, with only two studies trying multi-class categorization of the disease. Multi-class categorization studies focused on the different dengue subtypes as well as the severity of the sickness. As a result of its simplicity, binary classification has gained universal acceptance. In general, multi-class classification models produce inferior results when compared to simpler models because of the difficulty of performing and evaluating them. However, tree-based learning techniques are frequently utilized for the problems associated with the process of classification with easier implementation, where the datasets of imbalanced type may lead to degraded performance on the ML models.
The method of reducing the shortcomings of the tree splitting criterion is used to determine classification accuracy. It was discovered that a number of studies had been harmed by the overfitting of models. Although each of these investigations used the lowest data sets possible, they were unable to do any additional studies as a result of the lack of detail in their papers.
3. Proposed method
These are the four stages of our method for predicting severe dengue prognosis using machine learning methodologies. The stages are as follows: data acquisition; data preprocessing; feature selection; and classification. The entire procedure is depicted in Figure .
Figure 3. Proposed model.
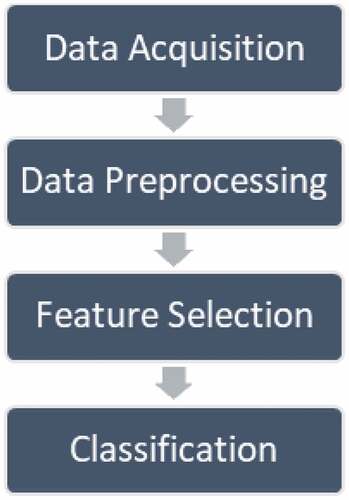
The information on dengue fever cases was acquired through the use of epidemiological questionnaires completed by patients during their treatment after the study. The date, location, gender, and age of notified incidents of feature selection were all compiled into a single database. Geocoding is accomplished by the usage of Python modules in each confirmed case location or area.
3.1. Data collection
The proper identification and evaluation of all relevant factors is essential in order to maintain an effective and accurate healthcare system. Personal, environmental, and health factors have been subdivided as part of the intended Comprehensive Plan of Study (CPS). The data collection module is entrusted with acquiring information about these three variables from the physical world through various means.
3.2. Data preprocessing
The algorithm should be able to quickly comprehend the data’s attributes in order for a model to be accurate and exact in predictions. For improved quality of prediction of the model, the collected epidemiological data from patients were standardized (cleaned, dimension reduction), transformed, and discretized to fit for the proposed method evaluation.
3.3. Random forest
By analysing historical data, Random Forest as in Figure , which is a supervised learning technique, can be used to solve problems and predict recurrence. However, it is mostly used in the resolution of problems. The greater the number of trees in a forest, the denser the forest becomes, and this is true for any random forest. Similar methods allow for the extraction of forecasts from arbitrary forests based on information tests using information tests as a basis. In the end, it all boils down to the voting system. Because it averages the findings, this clustering technique exceeds decision trees in terms of performance.
Figure 4. Random forest model (Sapountzoglou et al., Citation2020).
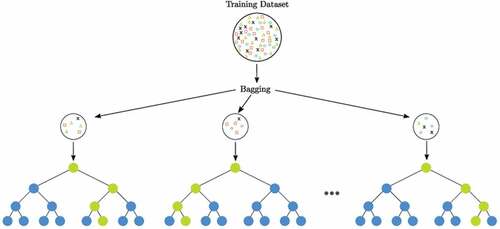
During the training process, Random Forest generates a range of alternative decision trees that can be used to make decisions. When selecting the mean forecast for regression, the forecasts from all trees are taken into consideration, which means that the final expectations are mutual. As a result, it is referred to as an ensemble technique because it draws on a variety of data points to arrive at a single conclusion. The inner workings of the Random Forest computation.
Step 1:The first stage is to select instances from a dataset at random using a computer program.
Step 2:Create an option tree for each situation that you encounter. The projected outcome of each decision tree will then be displayed.
Step 3:In this phase, votes will be cast for each predicted outcome that is presented.
Step 4:The final stage is to choose the forecast that is the most accurate based on the cast ballots. When using the Random Forest Procedure to deal with relapse problems, make sure to apply MSE to each and every hub of your data.
Where;
N—data points
fi—value returned by system
yi—actual value for data i
When utilising Random Forests to group information, you should be aware that the Gini file (the method used to pick the distribution of tree branch hubs) is frequently utilised, so you should be cautious. This equation, which is based on the class and probability, determines the Gini of each node branches and, as a result, which branch is the most likely to occur. The database stores pi as the total incidence of a class and the number c as the total number of modules.
For the purpose of deciding which way the hub should branch, entropy considers the probability of a particular occurrence. This record, in contrast to the Gini record, is significantly more numerically inflated because it is calculated using the logarithmic capacity of the population.
3.4. Classification
As previously indicated, the scikit-learn library was utilised in the development of the ANN. The logistic sigmoid function was used as the activation function, and the weight optimization was carried out using a BFGS with a restricted amount of memory. Searches in bi-dimensional space (layers x neurons) using stratified k-fold cross-validation with k = 10 gave the optimal topology, which had an initial value of 0.001. The best topology was found by using stratified k-fold cross-validation with k = 10.
4. Results and discussions
To assess classification performance, two strategies were used: a test-set technique, which used 25 cases that were unknown to the ANN, and a boosted resubstituting method, which used just 100 training samples. It was never necessary to use the test set when building an ANN classifier; instead, the SVM-RFE technique was employed to discover features, which were then used to train the classifier. In this case, because the test set size is small, the boosted error estimator can be used to verify the results of the test set.
Accuracy can be calculated, which displays the number of correctly labelled positive class samples. Precision, on the other hand, is used to determine the number of correctly labelled positive class samples. Rather than this, positive class-recall is used to predict the total number of accurate samples categorised as belonging to the positive class, which is then divided by the total number of samples to arrive at a prediction. The mathematical formula for recall is provided as follows:
Accuracy = (TP+TN)/(TP+FP+FN+TN) ×100
Precision = TN/(FP+TN) ×100
Recall = TP/(TP+FN) ×100
Error Rate = 100− Accuracy
Where;
TP—true positive,
TN—true negative,
FP—false positive and
FN—false negative.
Dengue outbreak forecasting on a large scale is generally done in order to provide an early warning system. The use of finer granularity in intra-urban prediction seeks to identify places that will be more vulnerable in the near future, allowing for more accurate prevention and management despite the lack of available financing. As a result, in addition to calculating the Pearson correlation coefficient between the anticipated and actual case counts, we developed a hit rate measure to evaluate the forecasting performance from a spatial standpoint, by evaluating the model ability to locate high-risk urban units throughout the town boundaries.
In this scenario, having a higher sensitivity is advantageous because SD is an absolute requirement. According to the accuracy metric, the percentage of projected positive cases that actually occur is calculated as follows: It becomes clear when we compare the proposed technique to the two other methods of error estimation that it has higher precision rates.
As a result of the high precision and recall of the proposed method, it obtained a favorable F1 evaluation. Because the number of SD and DF patients in the data set is not fairly distributed over the population, the estimations of accuracy, precision, and F1-score may be skewed as a result of this. Keeping this in mind will help you when analysing the information. Because of this, there would be no difference in the outcomes of sensitivity (recall) and specificity (precision), which are independent of the data set or population prevalence. Figure depicts the Accuracy Rate.
Figure 5. Accuracy rate.
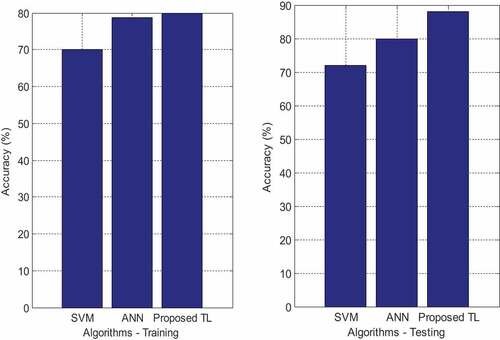
result, the samples are validated using nearest neighbours in ANN, whereas the SVM and NN focused on training samples and consumed a considerable amount of data for disease prediction. As a result, RF is used to select the most advantageous characteristics. The proposed method achieved an accuracy of 88% as a result of RF, SVM achieved an accuracy of 80%, and NN achieved an accuracy of 72%, all of which were superior to the baseline. When comparing the new ANN model augmented with RF method to existing methods, the accuracy of the new method is significantly higher. Because, in this experiment, the DWT technique minimised feature deterioration while SVM and NN did not, the DWT technique is recommended. In addition, the proposed RF strategy efficiently selects the relevant feature for the ANN method, which adaptively learns the data for classification using the selected feature.
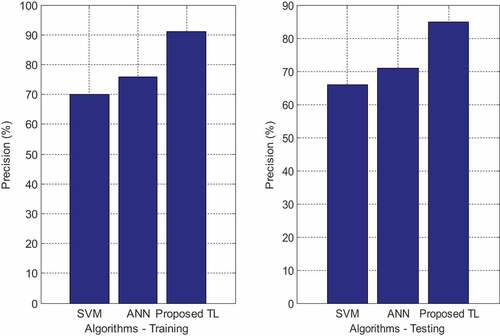
The accuracy of SVM predictions was only 35% of that of ANN and NN predictions, which were not influenced by the FS method, respectively. This is a statistically significant distinction. Despite the fact that SVM performed well on both unstructured and semi-structured data, it performed badly when the target classes were similar in their characteristics. The NN achieved a precision of 65% in the final forecast without the use of the RF algorithm, but this increased by around 3% when the RF approach was utilised. A model requires more than thousands of data points in order to be trained, which is why it is so expensive to build. Because of this, only a small amount of data is used in the research for the prediction of muscular paralysis conditions, artificial neural networks (ANNs) are used, and RF methods were used to achieve 85%.
The ANN approach has several advantages, two of which are instance-based learning and adaptive learning for categorization. However, the greater the number of elements in a system, the less effective the system is at final classification. This has resulted in the development of RF, which has achieved an accuracy rate of 88% when using an ANN. The recall value of the proposed RF using the ANN approach is depicted in Figure .
Figure 6. Precision rate.
The results of the analysis show that the RF approach outperforms the standard classifier in terms of recall value. The ANN achieved only about 75% to 78% of recall values for both the FS and the SVM/ANN techniques, compared to 75% to 77% for the other two approaches. While not employing perfect features for the prediction process of muscular paralysis, the SVM gets 83% recall values when using the FS methodology. However, the same technique reduces its performance to 2% when using the FS methodology. When combined with artificial neural networks, the proposed RF technique extracted the relevant properties from the signal with an 81% recall value. With too many features comes poor performance, so the RF algorithm was used to choose the most suitable characteristics, which when combined with ANN technology, resulted in a recall value of 89%. ANNs have the advantage of being able to learn from data and categorise it in an adaptable fashion, which is a significant advantage. The comparison between the proposed RF with the ANN approach and the NN and SVM methods is shown in Figure .
Figure 7. Recall rate.
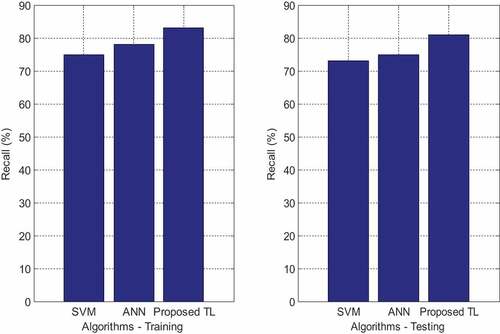
According to our evaluation results, the proposed RF technique using ANN exhibits a lower error rate than neural networks and support vector machines. While all other approaches have lower error rates, NN has the highest, with a 0.28% error rate without FS and a 1% error rate reduction when combined with RF. The high error rate of NN can be attributed to the fact that it requires a considerable amount of training data, despite the fact that only a small number of samples were employed in this experiment. The current SVM has an error rate of 0.18 to 0.19, both with and without FS, and exceeds NN in terms of performance despite these disadvantages. When only the RF feature extraction technique is used, the proposed ANN has an error rate of 0.19, which is quite good. Because of the need for a lower error rate, only the relevant signal features were retrieved by the proposed FE technique in order to achieve that goal.
The system warns key stakeholders of potential health hazards and dispatches medical help as soon as a dengue outbreak is detected, based on a real-time risk assessment based on infection and cardiovascular disease (CVD) risk levels. It is intended that the proposed system, which operates in a cloud environment, will protect user sensitive information from being exposed, as well as identify the critical locations and users who are responsible for virus transmission. All components of diagnosis, monitoring, and risk depiction are organized in the intelligent healthcare system that has been proposed.
The efficiency evaluation of the various components of the proposed system justifies the use of the system under consideration. In addition, the RF-based health risk classification surpasses the alternatives in terms of statistical performance, and this is confirmed by evaluations of the preprocessing and its performance, in addition to the alert generation and RF outbreak risk assessment performed. Although this method is now only applicable to the heart, it has the potential to be expanded to include other vital organs in the future, such as infection and other illnesses that impact these organs.
5. Conclusions
In this paper, the RF for the model includes data collection, input text preprocessing, and feature extraction, all of which are included in the recommended methodology. Using dengue datasets, it is investigated if RF-based feature extraction is effective at extracting features from the datasets. In a simulation, the RF model is evaluated against a variety of different datasets. According to the simulation findings, the proposed strategy is more accurate than the other methods at extracting features from the input datasets compared to the other methods. Although both neural networks and SVM are traditional classifiers, the research shows that the newly presented approach surpasses both of them. When using the RF approach, the ANN achieved 88% accuracy and 89.9% recall, but the NN achieved 72% accuracy, 77% recall, and a 0.27 error rate when used in conjunction with the RF method. However, only 80% of the proposed ANN was found to be accurate, while 75% of the current NN was found to be accurate, and 75% of the current NN was found to be implemented with the Relief-F technique, resulting in an error rate of 0.195. Based on these data, it can be concluded that FS has a major role in the prediction of muscle paralysis in the elderly. Future studies on the methodology will include the use of deep learning multi-scale strategy for the prediction of a wide range of diseases in the future. Further, the methods on neural network can be studied to avoid the problem of overfitting due to the inputs from the previous layers.
Acknowledgements
The authors appreciate the supports from Ambo University, Woliso Campus, Ethiopia. The author thanks Ambo University Woliso Campus School of Technology and Informatics for providing assistance to complete this work.
Data availability statement
The data used to support the findings of this study are included within the article. Further data or information is available from the corresponding author upon request.
Additional information
Funding
References
- Arafiyah, R., Hermin, F., Kartika, I. R., Alimuddin, A., & Saraswati, I. (2018, november). Classification of Dengue Haemorrhagic Fever (DHF) using SVM, naive Bayes and random forest. IOP Conference Series: Materials Science and Engineering, 434(1), 012070. IOP Publishing. https://doi.org/10.1088/1757-899X/434/1/012070
- Arivazhagan, N., Somasundaram, K., Vijendra Babu, D., Gomathy Nayagam, M., Bommi, R. M., Mohammad, G. B., Prabhu Sundramurthy, V., Natarajan, Y., Arulkarthick, V. J., Shanmuganathan, V. K., Srihari, K., Ragul Vignesh, M., & Prabhu Sundramurthy, V. (2022). Cloud-Internet of Health Things (IOHT) task scheduling using hybrid moth flame optimization with deep neural network algorithm for E healthcare systems. Scientific Programming, 2022, 1–14. https://doi.org/10.1155/2022/4100352
- Faisal, T., Ibrahim, F., & Taib, M. N. (2010). A noninvasive intelligent approach for predicting the risk in dengue patients. Expert Systems with Applications, 37(3), 2175–2181. https://doi.org/10.1016/j.eswa.2009.07.060
- Fathima, S. A., & Hundewale, N. (2012, January). Comparitive analysis of machine learning techniques for classification of arbovirus. In Proceedings of 2012 IEEE-EMBS International Conference on Biomedical and Health Informatics (pp. 376–379). IEEE.
- Gambhir, S., Malik, S. K., & Kumar, Y. (2018). The diagnosis of dengue disease: An evaluation of three machine learning approaches. International Journal of Healthcare Information Systems and Informatics (IJHISI), 13(3), 1–19. https://doi.org/10.4018/IJHISI.2018070101
- Gangula, R., Thirupathi, L., Rajashekar Parupati, K., & Sreeveda, S. G. (2021). Ensemble machine learning based prediction of dengue disease with performance and accuracy elevation patterns. Materials Today: Proceedings. https://doi.org/10.1016/j.matpr.2021.07.270
- Garcia-Carretero, R., Roncal-Gomez, J., Rodriguez-Manzano, P., & Vazquez-Gomez, O. (2022). Identification and predictive value of risk factors for mortality due to listeria monocytogenes infection: use of machine learning with a nationwide administrative data set. Bacteria, 1(1), 12–32. https://doi.org/10.3390/bacteria1010003
- Gumaei, A., Ismail, W. N., Hassan, M. R., Hassan, M. M., Mohamed, E., Alelaiwi, A., & Fortino, G. (2022). A decision-level fusion method for COVID-19 patient health prediction. Big Data Research, 27, 100287. https://doi.org/10.1016/j.bdr.2021.100287
- Hannah, S., Deepa, A. J., Chooralil, V. S., BrillySangeetha, S., Yuvaraj, N., Arshath Raja, R., Suresh, C., Rahul Vignesh, Y. K., & Srihari, A. A. (2022). Blockchain-based deep learning to process IoT data acquisition in cognitive data. BioMed Research International, 5038851, 7. https://doi.org/10.1155/2022/5038851
- Ho, T.-S., Weng, T.-C., Wang, J.-D., Han, H.-C., Cheng, H.-C., Yang, -C.-C., Yu, C.-H., Liu, Y.-J., Hu, C. H., Huang, C.-Y., Chen, M.-H., King, -C.-C., Oyang, Y.-J., & Liu, -C.-C. (2020). Comparing machine learning with case-control models to identify confirmed dengue cases. PLoS Neglected Tropical Diseases, 14(11), e0008843. https://doi.org/10.1371/journal.pntd.0008843
- Mohana, J., Bhaskarrao Yakkala, S., Vimalnath, P., Benson Mansingh, M., Yuvaraj, N., Srihari, K., Sasikala, G., Mahalakshmi, V., Yasir Abdullah, R., Prabhu Sundramurthy, V., & Abdulhay, E. (2022). Application of Internet of Things on the healthcare field using convolutional neural network processing. Journal of Healthcare Engineering, 2022(1892123), 7. https://doi.org/10.1155/2022/1892123
- Nishat, M. M., Dip, R. R., Faisal, F., Nasrullah, S. M., Ahsan, R., Shikder, M. F., & Hoque, M. A. (2021). A comprehensive analysis on detecting chronic kidney disease by employing machine learning Algorithms. EAI Endorsed Transactions on Pervasive Health and Technology, 7(29), e1–e1. https://doi.org/10.4108/eai.13-8-2021.170671
- Ong, J., Liu, X., Rajarethinam, J., Kok, S. Y., Liang, S., Tang, C. S., Yap, G., Ng, L. C., & Yap, G. (2018). Mapping dengue risk in Singapore using random forest. PLoS Neglected Tropical Diseases, 12(6), e0006587. https://doi.org/10.1371/journal.pntd.0006587
- Phakhounthong, K., Chaovalit, P., Jittamala, P., Blacksell, S. D., Carter, M. J., Turner, P., Pan-Ngum, W., Sona, S., Kumar, V., Day, N. P. J., White, L. J., & Pan-ngum, W. (2018). Predicting the severity of dengue fever in children on admission based on clinical features and laboratory indicators: Application of classification tree analysis. BMC Pediatrics, 18(1), 1–9. https://doi.org/10.1186/s12887-018-1078-y
- Potts, J. A., Gibbons, R. V., Rothman, A. L., Srikiatkhachorn, A., Thomas, S. J., Supradish, P.-O., Lemon, S., Libraty, D. H., Green, S., & Kalayanarooj, S. (2010). Prediction of dengue disease severity among pediatric Thai patients using early clinical laboratory indicators. PLoS Neglected Tropical Diseases, 4(8), e769. https://doi.org/10.1371/journal.pntd.0000769
- Sajana, T., Navya, M., Gayathri, Y. V., & Reshma, N. (2018). Classification of dengue using machine learning techniques. International Journal of Engineering and Technology (pp. 212–218).
- Sajana, T., Navya, M., Gayathri, Y. V. S. S. V., & Reshma, N. (2018). Classification of dengue using machine learning techniques. International Journal of Engineering & Technology, 7(2.32), 212–218. https://doi.org/10.14419/ijet.v7i2.32.15570
- Sanjudevi, D., & Savitha, D. (2019). Dengue fever prediction using classification techniques. International Research Journal of Engineering and Technology, 6(2), 558–563. https://www.academia.edu/download/59815016/IRJET-V6I210920190621-42492-zzgk5m.pdf
- Sapountzoglou, N., Lago, J., & Raison, B. (2020). Fault diagnosis in low voltage smart distribution grids using gradient boosting trees. Electric Power Systems Research, 182, 106254. https://doi.org/10.1016/j.epsr.2020.106254
- Shafqat, S., Fayyaz, M., Khattak, H. A., Bilal, M., Khan, S., Ishtiaq, O., Chatterjee, P., Shafqat, F., Alnumay, W. S., & Chatterjee, P. (2021). Leveraging deep learning for designing healthcare analytics heuristic for diagnostics. Neural Processing Letters, 1–27 doi:. https://doi.org/10.1007/s11063-021-10425-w
- Tanner, L., Schreiber, M., Low, J. G., Ong, A., Tolfvenstam, T., Lai, Y. L., Ooi, E. E., Leo, Y. S., Thi Puong, L., Vasudevan, S. G., Simmons, C. P., Hibberd, M. L., & Ooi, E. E. (2008). Decision tree algorithms predict the diagnosis and outcome of dengue fever in the early phase of illness. PLoS Neglected Tropical Diseases, 2(3), e196. https://doi.org/10.1371/journal.pntd.0000196
- Tarasova, O., & Poroikov, V. (2021). Machine learning in discovery of new antivirals and optimization of viral infections therapy. Current Medicinal Chemistry, 28(38), 7840–7861. https://doi.org/10.2174/0929867328666210504114351
- Thitiprayoonwongse, D., Suriyaphol, P., & Soonthornphisaj, N. (2012). Data mining of dengue infection using decision tree. Entropy, The 26th Annual Conference of the Japanese Society for Artificial Intelligence, 2012, 2, 2. https://doi.org/10.11517/pjsai.JSAI2012.0_1K2IOS1b7
- Zeng, D., Cao, Z., & Neill, D. B. (2021). Artificial intelligence–enabled public health surveillance—from local detection to global epidemic monitoring and control. Artificial Intelligence in Medicine, Chapter 22 Technical Basis and Clinical Applications, Academic Press, 437–453. https://doi.org/10.1016/B978-0-12-821259-2.00022-3