
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we propose a tractable Kumaraswamy Bell exponential (KwBE) distribution as a submodel of the Kumaraswamy Bell-G family of distributions. Several well-established properties are obtained for the KwBE distribution, such as the linear functional representation, th moment, incomplete moment, moment generating function using Wright generalized hyper-geometric function, conditional moment and Réyni entropy. Based on the KwBE model, a group acceptance sampling plan (GASP) for the truncated life test is presented using median life as a quality index. Moreover, the essential design parameters are derived by defining the consumer risk and the test termination duration. The comparative study of GASP with ordinary sampling plan (OSP) is performed. A simulation study is performed to highlight the behavior of the estimates. On the inferential side, the associated parameters are estimated using a well-established maximum likelihood estimation method. The detailed model’s comparison analysis, graphical as well as numerical evidence to real-data applications, supports the theoretical work.
1. Introduction with aims
Statistical models are essential in many social and scientific investigations. On the other side, quality control is an important statistical domain that is the collection of statistical tools responsible for ensuring and monitoring the product quantity and quality governed by the models. One of the most popular statistical quality control techniques is the acceptance sampling plan (ASP), which is used to evaluate and decide whether to accept or reject the chosen products based on a sample as well as to check the integrity of products. Generally, ASP is an optimization method to minimize the sample size or a particular cost function for destructive items, while considering a variety of constraints set forth by the supplier and client. The sentencing lot might be either raw materials, modules, or finalized commodities. A lot may be inspected either after fabrication or immediately before being shipped to the supplier. Consumers inspect merchandise once they have received it. Departing inspection is the phrase for a producer’s certification, whereas arriving inspection is the terminology for a customer’s assessment (Khan et al., Citation2022). Because of time and financial constraints, a screening cannot be emphasised in the mass of statistical quality assurance trials (Algarni, Citation2022). Consequently, an ASP serves as a mid-route between
and
inspections (Aslam et al., Citation2011). An ASP is a helpful technique for testing delicate, pricey objects or when the possible legal obligations are higher. Acceptance sampling is a helpful technique for testing delicate, pricey objects or when the possible legal obligations are higher. A favorable lot could be discarded in an acceptance sample, or a defective lot might be approved, both of which are undesired outcomes. Retailer’s risks refer to the first scenario usually denoted as
, in which a quality lot is refused, and customer’s risks refer to the second scenario usually denoted as
, in which a disastrous lot is approved (Khan et al., Citation2022). Furthermore, these ASPs are classified as variable, attributes, accelerated, progressively and group acceptance sampling plans. Nevertheless, the primary goal of these strategies is to protect both the manufacturer and the client while evaluating the sentenced lot using the least sample size. The group acceptance sampling plan (GASP) is the widely used sampling plan and is found superior to any other plan because it is subjected always to optimize cost and time of inspecting the quality of the lot by testing multiple items at once. One may get the optimum sample size along with test duration feasible with the use of a GASP. The underlying premise of the OSP entails that each trial will carry only a single item and hence always results in a hectic time-testing procedure with increased cost. Conversely, in reality, testers who can test many products at once are employed since doing so may cut down testing expenses and time. The result of integrating GASP with curtailed life testing is a GASP based on truncated life tests, which is premised on the presumption that the duration of a product matches a particular probability distribution. The attribute GASP for the truncated life test was developed by (Aslam & Jun, Citation2009a), who assumed that each lifespan of a product followed the Weibull distribution. The economic reliability GASP was developed by (Aslam et al., Citation2010) for the Pareto distribution of the second kind. The repetitive GASP for the Burr XII distribution was developed by (Aslam et al., Citation2013). The skip lot GASP was developed by (Aslam et al., Citation2013) for the Weibull distribution. For specific values of the producer and consumer risks, these sampling plans concurrently determine the frequency of the groups and acceptance numbers. A GASP for the truncated life test, when the lifetime of an item followed the log-logistic inverse Rayleigh distribution, was developed by (Aslam & Jun, Citation2009b). Several other researchers who developed a GASP are Reference (Aslam et al., Citation2011) developed GASP for the generalized exponential model (Rao, Citation2009), for the Marshall-Olkin extended Lomax model (Ameeq et al., Citation2023), for the alpha power transformation model (Naz et al., Citation2023), for the kumaraswamy exponential model (Almarashi et al., Citation2021), for the Marshall-Olkin Kumaraswami exponential model (Tsai & Wu, Citation2006), for the generalized Rayleigh model (Balakrishnan et al., Citation2007), for the Birnbaum-Saunders model (Fayomi et al., Citation2022), for the exponentiated Bell exponential model and (Algarni, Citation2022) for the compounded three-parameter Weibull model.
However, developing enlarged flexible statistical models has become a common practice (Muneeb Hassan et al., Citation2023; Tahir & Cordeiro, Citation2016; Tahir & Nadarajah, Citation2015). The ultimate objective of this entire exercise is to improve the convergent validity of the constructed model and the effective examination of skewness and tail aspects. These expanded models offer practitioners and applied researchers a better understanding of the pattern and evolution of complicated real-world phenomena, ultimately achieving better estimation and optimization (Hassan et al., Citation2023, Citation2023). Generalized classes (G-classes) and compounding are the two main considered generalization techniques that are frequently used and put into practice. Here, we mention a few but not limited, the readers are referred to Marshall-Olkin-G (Marshall & Olkin, Citation1997), exponentiated-G (Gupta et al., Citation1998), beta-G (Eugene et al., Citation2002), Transmuted modified power-G (Naz et al., Citation2023) and McDonald-G (Alexander et al., Citation2012). Based on the genesis of the Kw distribution, Cordeiro and de Castro (Cordeiro & de Castro, Citation2011) presented a highly effective family of generalized distributions, even with censored data. From an arbitrary baseline cumulative distribution function (CDF) and corresponding probability density function (PDF)
, the CDF
and the PDF
, respectively, of the Kw-G family (Cordeiro & de Castro, Citation2011) are given by
and
where and the two parameters
and
that interact with the specific role of incorporating skewness and adjusting the tail weights. The Kw-G family has some similarities to the well-known beta-G family given by Eugene et al. (Eugene et al., Citation2002), the readers are referred to (Cordeiro & de Castro, Citation2011) for the larger extent of the interconnections and advantages of the Kw-G family over the Beta-G family.
An alternative to the commonly used Poisson distribution is a single parameter discrete Bell distribution given by (Castellares et al., Citation2018), which yields somewhat better fits even for over-dispersion data than the Poisson distribution. This distribution involves the features of well-known Bell numbers (Bell, Citation1934) and belongs to the exponential family. Exponentiated Bell-G family, an extended class of Bell distribution recently presented by Fayomi et al. (Fayomi et al., Citation2022), is an analog to exponentiated Poisson-G and demonstrates its usefulness and practical relevance. The genesis of the Bell distribution is used to construct the next family of distributions with the following CDF (Fayomi et al., Citation2022):
The expression of CDF given above has a simple form and tractable feature since it does not involve any special function. Its exponentiated version and mathematical properties, functionalities, and applications are presented by (Fayomi et al., Citation2022) and demonstrate advantageous outcomes. The proposed family of distributions called Kumaraswamy Bell-G (KwBG) is obtained by inserting Eq. (3) into Eq. (1), which is an analogy to Kumaraswamy Poisson-G (KwpG) given by (Chakraborty et al., Citation2022). The CDF of KwBG is as follows:
where and
.
The following are some benefits of using the KwBG family of distributions: that make it interesting.
The proposed family contains the original structure of Bell distribution and features of Bell numbers in connection with Kumaraswamy distribution.
The KwBE submodel yields some flexible HRF shapes, such as increasing, decreasing, upside-down bathtub and reversed bathtub that can be used in a variety of social contexts.
The proposed KwBG family does not involve additional parameters.
The KwBE distribution yields extremely better fits for skewed and heavy-tailed data sets.
The proposed family density can be expressed as a linear combination of exponential densities and allows the extraction of several properties directly from an exponential distribution.
The CDF and HRF have simple closed forms; therefore, they can be utilized to analyze censored data.
Over-dispersion events are common in quality control trials, and the proposed KwBE submodel can produce superior fits in such scenarios.
The rest of the paper is as follows: The KwBE model is presented in Section 2 with some important properties, namely the linear functional representation, th moment, moment generating function (MGF) and Rényi entropy (RE). Section 3 focuses on the estimation of parameters using the maximum likelihood estimation (MLE) approach along with simulation analysis. The construction of a GASP is described in Section 4. In Section 6, we present the real-data applications. Finally, Section 6 ends the study with concluding remarks.
2. KwBE distribution
Because of its simple, beautiful, and closed-form mathematical justifications, the exponential distribution is frequently used in a wide range of real-world applications. In the construction of GASP, we employed exponential as a baseline distribution, with the following CDF and the PDF: and
respectively, where
and
.
Proposition 2.1.
Let for
and
; by replacing
in Eq. (4), then the CDF of the KwBE distribution is given by
The PDF corresponding to Proposition 2.1 is as follows:
The QF of the KwBE distribution is given by
where , denotes the QF of Kumaraswamy distribution (Kw) and
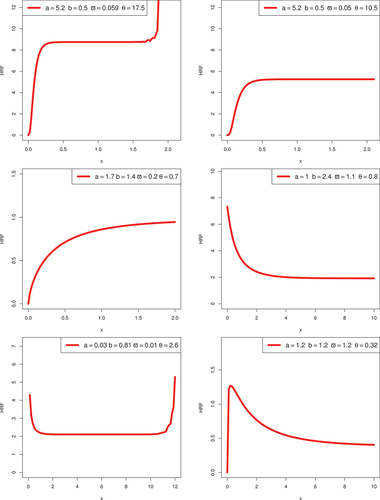
. Some possible HRF and PDF shapes for the KwBE distribution are shown in Figures . These figures illustrate that the KwBE distribution’s PDF can be symmetric, reversed-J-shaped and right-skewed. In general, failure of various engineering systems after a bathtub HRF initially has to decrease, then a relatively static or useful life period and finally, an increasing failure rate. In the context of reliability theory, these three phases are known as burning, random, and wear-out failure zones (Liao et al., Citation2020). The plots of HRF are showing some flexible shapes, including increasing, decreasing, upside-down bathtub-shaped, and reversed bathtub-shaped, which quantifies the lifetime distribution features. It has a long constant failure rate period, which makes it possible to represent the second phase of the bathtub-shaped failure rate. Moreover, it also can effectively deal with the final stage of the bathtub-shaped failure rate. The flexibility in HRF of the proposed KwBE distribution can be used in a variety of social contexts.
Figure 1. Graphical illustration of PDF for some parametric values.
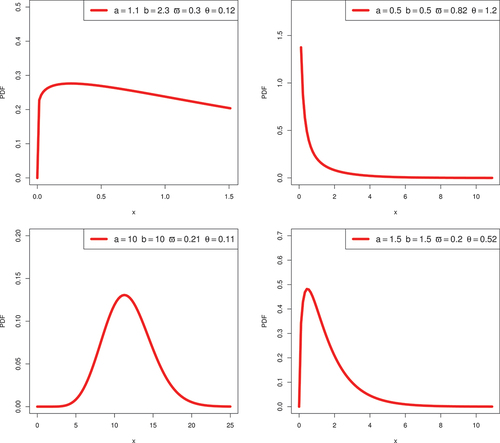
Figure 2. Graphical illustration of HRF for some parametric values.
2.1. Properties
Here, we derive a linear representation of the KwBG family, which is useful for acquiring several important properties of its submodels. Such representation will be used in the submodel of interest, KwBE distribution.
Proposition 2.2.
The linear functional representation of the KwBG family PDF and CDF is given by
and
respectively, where
noting and
are the CDF and PDF, respectively, of the exp-G family with power parameter
.
Here, we use two series binomial expansion and power series for the exponential functions to obtain the linear representation of the KwBG family of distributions as follows:
where represents the generalized binomial coefficients. The formula remains valid for
such that
only and
for any real numbers ,
and
, respectively (Alanzi et al., Citation2023).
Proof.
Let for
and
; then its PDF is given by
By using binomial expansion in (13), we obtained
using power series for exponential function (Alanzi et al., Citation2023; Bourguignon et al., Citation2014)
again using binomial expansion to the last term of EquationEquation (15)(15)
(15) , we get
The desired expression is obtained for . The expression for
is obtained upon integral. This ends the proof of Proposition 2.2.□
Proposition 2.3.
Let for
and
, then a linear representation of the KwBE model by using Eq.(8) is as follows:
where and
is defined in Proposition 2.2.
Proof.
By using Eq.(8) and binomial expansion, we get
The desired result is obtained for . This completes the proof of Proposition 2.3. □
Form Eq.(16), we see that the PDF of the KwBE model can be expressed as an infinite general linear mixture of PDFs of the exponential model. Therefore, several significant properties of the KwBE model can be deduced from the exponential model by using Eq.(16), where is an exp-exponential PDF with parameter
.
2.2. Th moment
The mean and variance of the KwBE distribution can be obtained by using Eq. (18), where that is mean= and variance=
=
Moreover, the first four actual moments can be obtained using the well-established relationship between ordinary and mean moments. The moment-based measure of skewness and kurtosis, respectively, is obtained by using
and
, where
and
. Pearson’s coefficient of skewness and kurtosis can be yielded as
and
, respectively. The
th raw or ordinary moment of the KwBE distribution is given by
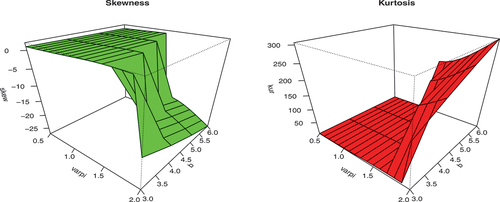
The graphical illustration of mean and variance at varying parameters to underline the effect of parameters is presented in Figures . It is obvious from Figure that as the value of parameter and
increase, the mean and variance tend to decrease for fixed parameter
and scale parameter
. However, from Figure , the skewness and kurtosis of the KwBE distribution tend to rise as the values of parameter
and
increase.
Figure 3. Graphical illustration of mean and variance of the KwBE distribution for ,
,
and
.
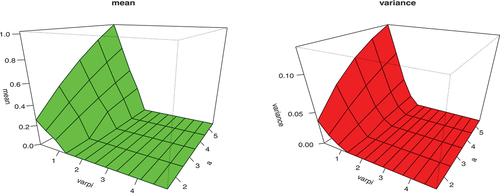
Figure 4. Graphical illustration of mean and variance of the KwBE distribution for ,
,
and
.
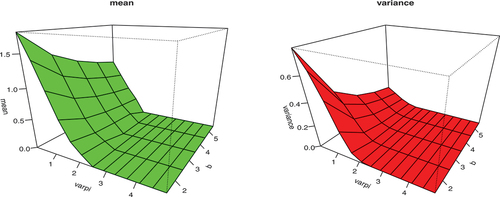
Figure 5. Graphical illustration of skewness and kurtosis of the KwBE distribution for ,
,
and
.
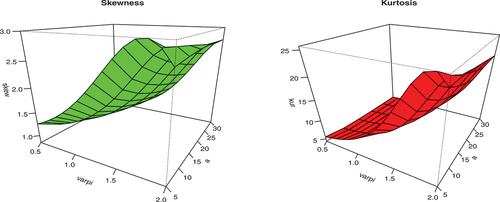
Figure 6. Graphical illustration of skewness and kurtosis of the KwBE distribution for ,
,
and
.
2.3. Moment generating function
The MGF of a real-valued random variable in probability theory and statistics is an effective way to describe its probability distribution. Let T be a random variable with PDF . The MGF is defined by
.
Proposition 2.4.
Let T
for
and
. Then its MGF using Wright generalized hypergeometric function Erdélyi, (Citation1953) by is as follows:
Proof.
The Wright generalized hypergeometric function holds is given by
Using EquationEquation (16)(16)
(16) , and by definition of the MGF and expanding
, we get
after simplification and using Eq. (20) in Eq. (21), we get
This ends the proof of Proposition 2.4.
2.4. Réyni entropy
As a measure of diversity, the Rényi entropy (RE) is significant in ecology and statistics. It is also significant in the field of quantum information because it may be used to quantify entanglement. It was given by Alfréd Rényi, a Hungarian mathematician.
Proposition 2.5.
The functional linear representation of the RE of the KwBG family is given by
where
Let X follows the KwBE model, using the Proposition 2.5, the RE is given by
where and
is defined in EquationEquation (23)
(23)
(23) .
Proof.
By using (22) and considering
after simplification, we get
By replacing EquationEquation (25)(25)
(25) in EquationEquation (22)
(22)
(22) , yields the desired result and completes the proof.□
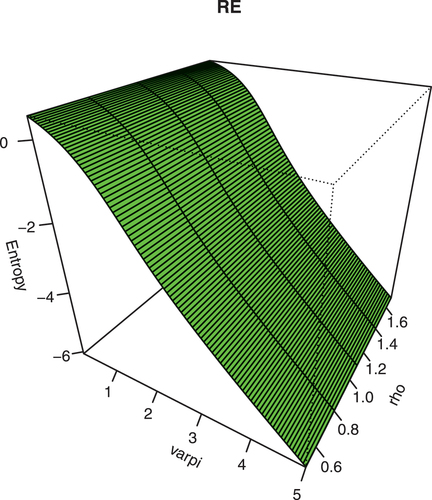
The graphical illustration of RE is presented in Figure , by setting ,
,
,
and
The effect of parameter
and
and RE is negatively associated and indicated that as
and
increases, the RE tends to decrease. Moreover, it shows flexibility under the KwBE model because it yields both positive and negative values.
Figure 7. Plot of RE for some parametric values.
3. Estimation with a simulation study
Let be the observed values of a random sample of size
from the KwBGE model. Then, the log-likelihood function of the parameter vector
is as follows:
By partially differentiating EquationEquation (26)(26)
(26) with respect to
, we obtain the log-likelihood equations of
,
,
and
. Thus, we obtain a system of equations with no explicit solution. Consequently, it needs computer power to use nonlinear numerical approximation methods (quasi Newton-Raphson) to get the maximum likelihood estimators. The partial derivatives of the log-likelihood equations are presented in the appendix.
3.1. Simulation
In this section, a simulation study is carried out to compare the performance of the maximum likelihood estimates of the unknown parameters for the KwBE distribution and analysis outcomes are graphically presented in Figures . The following procedure is adopted to perform a Monte Carlo simulation:
first, choose the starting values for the parameters
and determine the sample size, we consider the initial values as follows
generate a random sample of size
calculate the estimates of the KwBE distribution, mean square errors (MSEs) and biases. The following formulas are used to compute the two accuracy measures (MSEs and biases
respectively (forreplicate the steps (ii) and (iii)
Figure 8. Graphical illustration of biases at varying sample sizes.
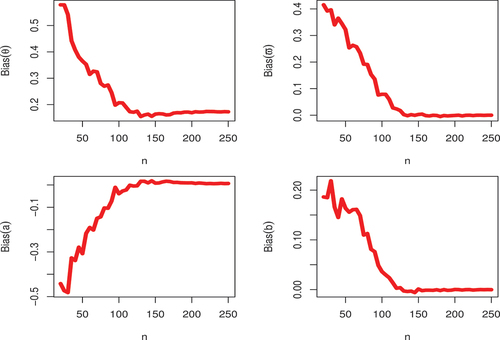
Figure 9. Graphical illustration of MSEs at varying sample sizes.
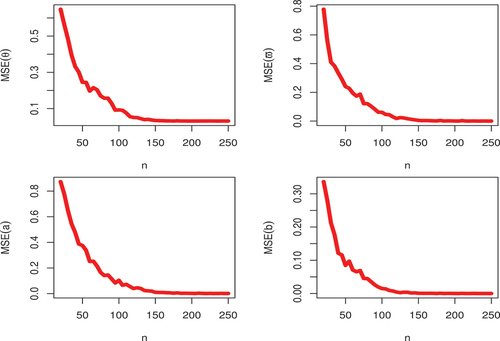
It is obvious form Figures , as increases, both the empirical biases and MSEs tend to zero in all cases for parameter
and
.
4. GASP based on the KwBE model
4.1. Construction
This section emphasizes an optimization of design parameters namely (acceptance number) and
(group size or total number of groups) for truncated life test experiments to accept or reject the lot under investigation. The GASP helps not only minimize the lot inspection duration by considering a variety of items on a single tester but cost-effective. A GASP offers a stricter product inspection than an ordinary ASP because samples are divided among distinct groups. Here, we use the median as a quality index as the QF of the KwBE model that has an elegant closed-form solution. On the other side, it is well established that the median life test for skewed models yields better outputs than mean (Aslam et al., Citation2011). The construction of ASP using multiple items on a single tester is based on the following steps:
First, choose the number of groups g and assign preset r (group size) items to each group. Thus, the size of the lot will be
Second, choose the
Third, run the experiment simultaneously for each of the
Finally, the lot under investigation is accepted if the number of failures does not exceed the acceptance number c.
Assume that for any lot, the median life of the products, say , exceeds the required life, say
. We will accept the lot if there is sufficient evidence that
is at particular levels of producer and consumer risks. Then the lot’s acceptance probability is determined by
where denotes the likelihood that an item in a group would fail before
and it is determined by substituting Eq. (7) in Eq. (5). But first, we need to evaluate the value of parameters
and
. Let assume
where is given in (7), and consider
which implies and
by replacing
,
and
in Eq. (5) and the probability of failure based on the KwBE model can be expressed as follows:
When and
=
are predefined, the probability of failure under the KwBE model,
can be calculated for selected parametric values for
and
. Moreover, the operating characteristic (OC) function
requires that the following two inequalities be satisfied simultaneously to determine the design parameters
and
. While
and
denote the ratio at the consumer’s risk (here, it is considered to be 1) and the ratio at the producer’s risk, respectively
and
The failure probabilities that are associated to both consumer’s () and producer’s (
) risk, denoted by
and
can be evaluated based on the KwBE model using Eq. (32) and Eq. (33), respectively, and can be applied in Eq. (30) and Eq. (31).
and
4.2. Discussion
Tables illustrate the design parameters under GASP based on the KwBE distribution for various values of (1.25 and 1.5). The two-level of
(5, 10) is considered. From Table , it is determined that a decrease in consumer risk (
), results in a rise in the number of groups (
), for instance, when
= 0.25 with true median life
= 4 evaluates
, similarly by reducing
= 0.25 to
= 0.01 yields
= 131. Additionally, the
size rapidly reduces as
rises. Table shows the impact of termination ratio,
= 0.5 and revealed that when
,
= 4,
= 0.5 and
= 5, it requires to put total 200 (
) units on a life test. Similar to this, by increasing
= 10, a considerable decrease in the overall number of units for life testing from 200 to 30 can be seen. As a result, in this case, 10 groups will be preferred because it tends to save enough cost and time. From Table , when the
increases for the GASP under consideration, the size of
drops and the value of operating characteristic (OC) function increases for the KwBE distribution using median lifetime as the quality index, when
= 0.01,
= 1,
= 1.25, and for
= 10.
Table 1. Proposed GASP based on the KwBE model
Table 2. A GASP under the KwBE model, ,
,
Here, we reveal the hypothetical example and assume that the producer believes that the specified value of = 2000 hours, the lifetime of the units follows the KwBE distribution with
= 1.50, the risk to the consumer, and the producer are 0.25 and 0.05, respectively, whereas the group size is
= 5, and the actual value of
is 8000 hours. An experimenter wishes to conduct a life test experiment for 1000 hours and for that, we are interested in formulating GASP for
= 0.5,
= 0.25, and true median life (
) = 4. For the given information and using Table , the design parameters
and
can be obtained as
= 41 and
= 3. As a result, a sample of size 205
should be collected, and each of the 41 groups should get 5 units. If there are no more than three units that fail in any group before 1000 hours, the lot is eventually accepted; if there are more than three, the lot is rejected.
Table 3. A GASP under the KwBE model, ,
,
5. Real-life applications
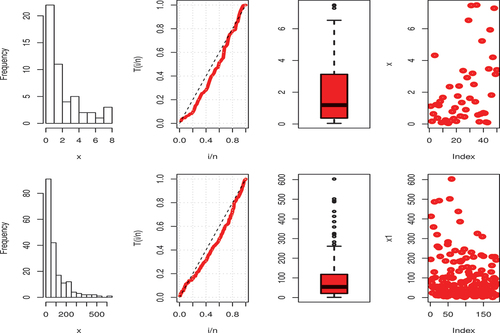
In this section, we use two failure time data sets to underline the usefulness of the proposed KwBE distribution. Recently, Almarashi et al. (Almarashi et al., Citation2021) used the Marshall-Olkin Kumaraswamy Exponential (MOKw-E) distribution and proposed GASP using the breaking stress of carbon fiber (in Gba) data. The following are the data, which consist of 50 observed values for the carbon fiber breaking stress: 1.120, 0.170, 0.640, 4.320, 1.220, 0.370, 1.160, 1.420, 0.090, 1.670, 0.130, 0.250, 0.080, 0.040, 2.350, 0.200, 0.780, 0.340, 1.020, 0.170, 1.760, 2.390, 0.500, 1.350, 3.360, 0.450, 0.900, 2.920, 6.530, 1.620, 7.460, 3.190, 2.490, 1.400, 7.490, 0.570, 0.140, 0.630, 5.230, 0.710, 0.680, 0.120, 0.090, 3.470, 5.930, 1.820, 4.200, 7.290, 3.130 and 3.41. Moreover, Almarashi et al. (Almarashi et al., Citation2021) fitted four-parameter MOKw-E distribution to the above data and the result revealed that the maximum distance between the sample’s empirical distribution function and the reference distribution’s CDF is 0.0681 with a p-value (PV) 0.9743. On the other side, the proposed KwBE distribution outperforms with the least Kolmogorov–Smirnov (KS) statistic 0.04531 and PV exactly 1 (see Table ). The second set of data includes the total number of air conditioning system failures recorded by a fleet of 13 Boeing 720 aircraft (Kumar & Kumar, Citation2019) and the records were kept for how long each aircraft’s air conditioning system failed in succession. The aircraft had a meticulous overhaul after approximately 2000 hours of operation. The data are as follows: 194, 413, 90, 74, 55, 23, 97, 50, 359, 50, 130, 487, 57, 102, 15, 14, 10, 57, 320, 261, 51, 44, 9, 254, 493, 33, 18, 209, 41, 58, 60, 48, 56, 87, 11, 102, 12, 5, 14, 14, 29, 37, 186, 29, 104, 7, 4, 72, 270, 283, 7, 61, 100, 61, 502, 220, 120, 141, 22, 603, 35, 98, 54, 100, 11, 181, 65, 49, 12, 239, 14, 18, 39, 3, 12, 5, 32, 9, 438, 43, 134, 184, 20, 386, 182, 71, 80, 188, 230, 152, 5, 36, 79, 59, 33, 246, 1, 79, 3, 27, 201, 84, 27, 156, 21, 16, 88, 130, 14, 118, 44, 15, 42, 106, 46, 230, 26, 59, 153, 104, 20, 206, 5, 66, 34, 29, 26, 35, 5, 82, 31, 118, 326, 12, 54, 36, 34, 18, 25, 120, 31, 22, 18, 216, 139, 67, 310, 3, 46, 210, 57, 76, 14, 111, 97, 62, 39, 30, 7, 44, 11, 63, 23, 22, 23, 14, 18, 13, 34, 16, 18, 130, 90, 163, 208, 1, 24, 70, 16, 101, 52, 208, 95, 62, 11, 191, 14 and 71. Table presents the descriptive information for both data sets and demonstrates that both are leptokurtic and skew to the right. The Shapiro–Wilk test also confirms that the samples do not come from a normal distribution as W (0.81505 and 0.74743) with PV less than 0.05, for the first and second data, respectively.
Table 4. Descriptive information of both data sets
Figure shows some basic characteristics of data by visually including histograms, TTT, box and index plots of the data sets. Both the data sets are right-skewed and the TTT plot indicates that the HRF of the data sets is increasing-decreasing-increasing.
Figure 10. Graphical illustration of first (top) and second (bottom) data.
Several extended or modified exponential-based distributions are compared with the proposed KwBE distribution, such as the KwPE distribution (Chakraborty et al., Citation2022), the exponentiated exponential (EE) distribution (Nadarajah, Citation2011), the Marshall-Olkin exponential (MOE) distribution (Marshall & Olkin, Citation1997), the exponentiated Weibull (EW) distribution (Mudholkar & Srivastava, Citation1993), the odd Weibull exponential (OWE) distribution (Bourguignon et al., Citation2014), the Kumaraswamy exponential (KE) distribution (Nadarajah et al., Citation2012), the beta exponential (BE) distribution (Jones, Citation2004), the Topp-Leone exponential (TLE) distribution (Al-Shomrani et al., Citation2016), the alpha power exponentiated exponential (APEE) (Afify et al., Citation2020) distribution, the transmuted exponentiated exponential (TEE) distribution (Khan et al., Citation2017), the gamma exponentiated exponential (GEE) distribution (Ristić & Balakrishnan, Citation2012), the exponentiated exponential Poisson (EEP) distribution (Pogány, Citation2015), the Weibull (W) distribution (Weibull, Citation1951) and the Nadarajah and Haghighi (NH) distribution (Nadarajah & Haghighi, Citation2011). Tables show the estimated parameters (Esti.) along with standard error (S.E) of the estimates and goodness-of-fit statistics for both data sets. The proposed KwBE distribution provides better fits compared to several exponential-based extended models. Generally, the model is considered best if earlier statistics and the KS test have the least, but higher PV. For both data sets, the plots of estimated PDF and the CDF based on the KwBE distribution are shown in Figure , which support the goodness-of-fit measures given in Tables .
Figure 11. Graphical illustration of the estimated PDF and the CDF under the KwBE model, first (top) and second (bottom) data.
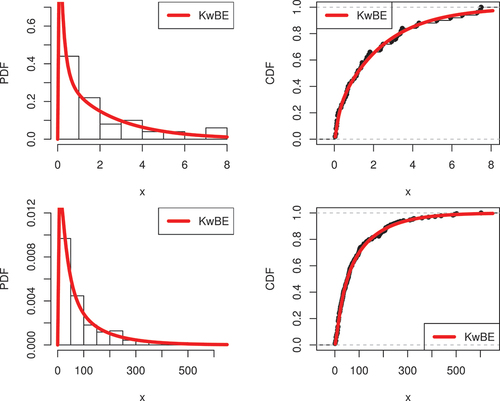
Table 5. The fitted models along with goodness-of-fit statistics, MLEs and S.E, first data
Table 6. The fitted models along with goodness-of-fit statistics, MLEs and S.E, second data
5.1. Comparative study of GASP based on the first data
Recently, Almarashi et al. (Almarashi et al., Citation2021) used the four-parameter exponential-based MOKw-E model to present the GASP in Table using the same first data. The proposed KwBE model also has four parameters and extends the exponential model. Table shows the comparative study of both models based on the first data set. The general findings of the analysis revealed that when ,
and
, the proposed model is efficient, as shown by the fact that the design parameters (
and
), as well as
under the KwBE distribution, are the lowest when compared to the MOKw-E distribution.
Table 7. A GASP based on the KwBE model, ,
,
, first data
Table 8. A GASP under the KwBE model, ,
,
, second data
Table 9. Comparative study of GASP based on the KwBE and MOKw-E distribution, first data
5.2. Comparison of GASP and OSP
In this section, we analyzed the superiority of the GASP over the OSP by making a comparison of the sample sizes of the GASP with the OSP. A procedure termed lot sentencing uses ASP to decide whether arriving or departing batches should be admitted or denied based on a predetermined standard. The duration and sample size of the investigation are the two factors that professional investigators should consider most carefully, and both should be optimized. Although OSPs can help to attain this optimization, it is anticipated in this case that just a single item will be evaluated at a time. In contrast, a GASP may also accomplish the optimal cost and time when numerous objects can be evaluated in a tester by grouping the items. An upgrade of the OSP by taking when
is the advocated GASP. Considering
in
, we analyzed the proposed GASP with the OSP. To accomplish this, we compared the recommended GASP for
and
with the OSP, when
for the KwBE model with
,
, and
, for a given
and
. Analysis of the sample sizes of the GASP and OSP from Table indicated that GASP is the preferred approach when contrasted to OSP because GASP creates groups of objects and tests multiple items at once, whereas OSP determines a sufficiently large sample size and test single item at a time.
Table 10. Sample sizes of GASP and OSP, when ,
,
, second data
6. Concluding remarks
In this paper, we proposed a Kumaraswamy Bell exponential distribution holding the features of well-known Kumaraswamy and Bell numbers. Several commonly used properties of the KwBE distribution are presented such as the linear representation of the KwBE PDF, ordinary, moment-generating function using Wright generalized hyper-geometric function and Réyni entropy. Moreover, GASP for the truncated life test is presented using median life as a quality index. The essential design parameters are derived by defining the consumer risk and the test termination duration. The comparative study showed that GASP outperforms the OSP. The simulation-based empirical findings showed that maximum likelihood estimates are consistent and reliable under different sample size scenarios, revealing that the proposed model can be employed for border inferential analysis. The practical applicability of the proposed KwBE distribution is tested using two real data of quality control. Convincing results are obtained in comparison with several well-known extensions of the exponential distribution.
HRF_1.eps
Download EPS Image (5.8 KB)PDF_44.eps
Download EPS Image (6.2 KB)PDF_11.eps
Download EPS Image (5.9 KB)pp_2.eps
Download EPS Image (43.9 KB)GASP(AutoRecovered)(AutoRecovered)1.xlsx
Download MS Excel (85.4 KB)PDF_22.eps
Download EPS Image (5.9 KB)HRF_5.eps
Download EPS Image (5.9 KB)pdf_new.eps
Download EPS Image (24.1 KB)Article_2.tex
Download Latex File (90.2 KB)SIM_1_MSE.eps
Download EPS Image (10.1 KB)CDF_4.eps
Download EPS Image (10.4 KB)HRF_2.eps
Download EPS Image (5.8 KB)Reyni.eps
Download EPS Image (65.7 KB)PDF_33.eps
Download EPS Image (5.9 KB)HRF_6.eps
Download EPS Image (5.9 KB)PDF_3.eps
Download EPS Image (5.7 KB)VaR.eps
Download EPS Image (4.6 KB)CDF_3.eps
Download EPS Image (8.1 KB)HRF_4.eps
Download EPS Image (6 KB)PP_4.eps
Download EPS Image (26.9 KB)PDF_4.eps
Download EPS Image (5.5 KB)GASP-OSP.xlsx
Download MS Excel (77.2 KB)dot.eps
Download EPS Image (22.2 KB)PP_1.eps
Download EPS Image (20 KB)Article_2.dvi
Download (162.5 KB)SIM_1_BIAS.eps
Download EPS Image (10 KB)CDF_2.eps
Download EPS Image (12.3 KB)CDF_1.eps
Download EPS Image (8.1 KB)PDF_1.eps
Download EPS Image (5.5 KB)HRF_3.eps
Download EPS Image (5.7 KB)HRF.eps
Download EPS Image (16.2 KB)PP_3.eps
Download EPS Image (19.5 KB)Supl File.docx
Download MS Word (12.5 KB)PDF_2.eps
Download EPS Image (5.8 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplementary material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/23311916.2023.2281062
References
- Afify, A. Z., Gemeay, A. M., & Ibrahim, N. A. (2020). The heavy-tailed exponential distribution: Risk measures, estimation, and application to actuarial data. Mathematics, 8(8), 1276. https://doi.org/10.3390/math8081276
- Al-Shomrani, A., Arif, O., Shawky, A., Hanif, S., & Shahbaz, M. Q. (2016). Topp-Leone family of distributions: Some properties and application. Pakistan Journal of Statistics & Operation Research, 12(3), 443–25. https://doi.org/10.18187/pjsor.v12i3.1458
- Alanzi, A. R., Imran, M., Tahir, M. H., Chesneau, C., Jamal, F., Shakoor, S., & Sami, W. (2023). Simulation analysis, properties and applications on a new Burr XII model based on the Bell-X functionalities. AIMS Mathematics, 8(3), 6970–7004. https://doi.org/10.3934/math.2023352
- Alexander, C., Cordeiro, G. M., Ortega, E. M., & Sarabia, J. M. (2012). Generalized beta-generated distributions. Computational Statistics & Data Analysis, 56(6), 1880–1897. https://doi.org/10.1016/j.csda.2011.11.015
- Algarni, A. (2022). Group acceptance sampling plan based on new compounded three-parameter Weibull model. Axioms, 11(9), 438. https://doi.org/10.3390/axioms11090438
- Almarashi, A. M., Khan, K., Chesneau, C., & Jamal, F. (2021). Group acceptance sampling plan using Marshall-Olkin Kumaraswamy exponential (MOKw-E) distribution. Processes, 9(6), 1066. https://doi.org/10.3390/pr9061066
- Ameeq, M., Tahir, M. H., Hassan, M. M., Jamal, F., Shafiq, S., & Mendy, J. T. (2023). A group acceptance sampling plan truncated life test for alpha power transformation inverted perks distribution based on quality control reliability. Cogent Engineering, 10(1), 2224137. https://doi.org/10.1080/23311916.2023.2224137
- Aslam, M., Balamurali, S., Jun, C. H., & Ahmad, M. (2013). Optimal design of skip lot group acceptance sampling plans for the Weibull distribution and the generalized exponential distribution. Quality Engineering, 25(3), 237–246. https://doi.org/10.1080/08982112.2013.769053
- Aslam, M., & Jun, C. H. (2009a). A group acceptance sampling plan for truncated life test having Weibull distribution. Journal of Applied Statistics, 36(9), 1021–1027. https://doi.org/10.1080/02664760802566788
- Aslam, M., & Jun, C. H. (2009b). A group acceptance sampling plans for truncated life tests based on the inverse Rayleigh and log-logistic distributions. Economic Quality Control, 25(2), 107–119. https://doi.org/10.1515/eqc.2010.008
- Aslam, M., Kundu, D., Jun, C. H., & Ahmad, M. (2011). Time truncated group acceptance sampling plans for generalized exponential distribution. Journal of Testing and Evaluation, 39(4), 671–677. https://doi.org/10.1520/JTE102921
- Aslam, M., Lio, Y., & Jun, C.-H. (2013). Repetitive acceptance sampling plans for burr type XII percentiles. The International Journal of Advanced Manufacturing Technology, 68(1–4), 495–507. https://doi.org/10.1007/s00170-013-4747-x
- Aslam, M., Mughal, A. R., Hanif, M., & Ahmad, M. (2010). Economic reliability group acceptance sampling based on truncated life tests using pareto distribution of the second kind. Communications for Statistical Applications and Methods, 17(5), 725–731. https://doi.org/10.5351/CKSS.2010.17.5.725
- Balakrishnan, N., Leiva, V., & Lopez, J. (2007). Acceptance sampling plans from truncated life tests based on the generalized Birnbaum-Saunders distribution. Communications in Statistics-Simulation and Computation, 36(3), 643–656. https://doi.org/10.1080/03610910701207819
- Bell, E. T. (1934). Exponential polynomials. The Annals of Mathematics, 35(2), 258–277. https://doi.org/10.2307/1968431
- Bourguignon, M., Silva, R. B., & Cordeiro, G. M. (2014). The Weibull-G family of probability distributions. Journal of Data Science, 12(1), 53–68. https://doi.org/10.6339/JDS.201401_12(1).0004
- Castellares, F., Ferrari, S. L., & Lemonte, A. J. (2018). On the bell distribution and its associated regression model for count data. Applied Mathematical Modelling, 56, 172–185. https://doi.org/10.1016/j.apm.2017.12.014
- Chakraborty, S., Handique, L., & Jamal, F. (2022). The kumaraswamy poisson-G family of distribution: Its properties and applications. Annals of Data Science, 9(2), 229–247. https://doi.org/10.1007/s40745-020-00262-4
- Cordeiro, G. M., & de Castro, M. (2011). A new family of generalized distributions. Journal of Statistical Computation and Simulation, 81(7), 883–898. https://doi.org/10.1080/00949650903530745
- Erdélyi, A. (Ed.). (1953). Higher transcendental functions. McGraw-Hill.
- Eugene, N., Lee, C., & Famoye, F. (2002). Beta-normal distribution and its applications. Communications in Statistics-Theory and Methods, 31(4), 497–512. https://doi.org/10.1081/STA-120003130
- Fayomi, A., Tahir, M. H., Algarni, A., Imran, M., Jamal, F., & Versaci, M. (2022). A new useful exponential model with applications to quality control and actuarial data. Computational Intelligence and Neuroscience, 2022, 1–27. https://doi.org/10.1155/2022/2489998
- Gupta, R. C., Gupta, P. L., & Gupta, R. D. (1998). Modeling failure time data by Lehman alternatives. Communications in Statistics-Theory and Methods, 27(4), 887–904. https://doi.org/10.1080/03610929808832134
- Hassan, M. M., Ameeq, M., Fatima, L., Naz, S., Sikandar, S. M., Kargbo, A., & Abbas, S. (2023). Assessing socio-ecological factors on caesarean section and vaginal delivery: An extended perspective among women of South-Punjab, Pakistan. Journal of Psychosomatic Obstetrics & Gynecology, 44(1), 2252983. https://doi.org/10.1080/0167482X.2023.2252983
- Hassan, M. M., Tahir, M. H., Ameeq, M., Jamal, F., Mendy, J. T., & Chesneau, C. (2023). Risk factors identification of COVID-19 patients with chronic obstructive pulmonary disease a retrospective study in Punjab Pakistan. Immunity Inflammation & Disease, 11(8), 981. https://doi.org/10.1002/iid3.981
- Jones, M. C. (2004). Families of distributions arising from distributions of order statistics. Test, 13(1), 1–43. https://doi.org/10.1007/BF02602999
- Khan, M. S., King, R., & Hudson, I. L. (2017). Transmuted Weibull distribution: Properties and estimation. Communications in Statistics-Theory and Methods, 46(11), 5394–5418. https://doi.org/10.1080/03610926.2015.1100744
- Khan, M. Z., Khan, M. F., Aslam, M., & Mughal, A. R. (2022). Fuzzy acceptance sampling plan for transmuted Weibull distribution. Complex & Intelligent Systems, 8(6), 4783–4795. https://doi.org/10.1007/s40747-022-00725-6
- Kumar, D., & Kumar, M. (2019). A new generalization of the extended exponential distribution with an application. Annals of Data Science, 6(3), 441–462. https://doi.org/10.1007/s40745-018-0181-0
- Liao, Q., Ahmad, Z., Mahmoudi, E., & Hamedani, G. G. (2020). A new flexible bathtub-shaped modification of the Weibull model: Properties and applications. Mathematical Problems in Engineering, 2020, 1–11. https://doi.org/10.1155/2020/3206257
- Marshall, A. W., & Olkin, I. (1997). A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika, 84(3), 641–652. https://doi.org/10.1093/biomet/84.3.641
- Mudholkar, G. S., & Srivastava, D. K. (1993). Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Transactions on Reliability, 42(2), 299–302. https://doi.org/10.1109/24.229504
- Muneeb Hassan, M., Ameeq, M., Jamal, F., Tahir, M. H., & Mendy, J. T. (2023). Prevalence of COVID-19 among patients with chronic obstructive pulmonary disease and tuberculosis. Annals of Medicine, 55(1), 285–291. https://doi.org/10.1080/07853890.2022.2160491
- Nadarajah, S. (2011). The exponentiated exponential distribution: A survey. AStA Advances in Statistical Analysis, 95(3), 219–251. https://doi.org/10.1007/s10182-011-0154-5
- Nadarajah, S., Cordeiro, G. M., & Ortega, E. M. (2012). General results for the Kumaraswamy-G distribution. Journal of Statistical Computation and Simulation, 82(7), 951–979. https://doi.org/10.1080/00949655.2011.562504
- Nadarajah, S., & Haghighi, F. (2011). An extension of the exponential distribution. Statistics, 45(6), 543–558. https://doi.org/10.1080/02331881003678678
- Naz, S., Al-Essa, L. A., Bakouch, H. S., & Chesneau, C. (2023). A transmuted modified power-generated family of distributions with practice on submodels in insurance and reliability. Symmetry, 15(7), 1458. https://doi.org/10.3390/sym15071458
- Naz, S., Tahir, M. H., Jamal, F., Ameeq, M., Shafiq, S., & Mendy, J. T. (2023). A group acceptance sampling plan based on flexible new Kumaraswamy exponential distribution: An application to quality control reliability. Cogent Engineering, 10(2), 2257945. https://doi.org/10.1080/23311916.2023.2257945
- Pogány, T. K. (2015). The exponentiated exponential Poisson distribution revisited. Statistics, 49(4), 918–929. https://doi.org/10.1080/02331888.2014.932794
- Rao, G. S. (2009). A group acceptance sampling plans based on truncated life tests for Marshall-Olkin extended Lomax distribution. Electronic Journal of Applied Statistical Analysis, 3(1), 18–27. https://doi.org/10.1285/i20705948v3n1p18
- Ristić, M. M., & Balakrishnan, N. (2012). The gamma-exponentiated exponential distribution. Journal of Statistical Computation and Simulation, 82(8), 1191–1206. https://doi.org/10.1080/00949655.2011.574633
- Tahir, M. H., & Cordeiro, G. M. (2016). Compounding of distributions: A survey and new generalized classes. Journal of Statistical Distributions and Applications, 3(1), 1–35. https://doi.org/10.1186/s40488-016-0052-1
- Tahir, M. H., & Nadarajah, S. (2015). Parameter induction in continuous univariate distributions: Well-established G families. Anais da Academia Brasileira de Ciencias, 87(2), 539–568. https://doi.org/10.1590/0001-3765201520140299
- Tsai, T. R., & Wu, S. J. (2006). Acceptance sampling based on truncated life tests for generalized Rayleigh distribution. Journal of Applied Statistics, 33(6), 595–600. https://doi.org/10.1080/02664760600679700
- Weibull, W. (1951). A statistical distribution function of wide applicability. Journal of Applied Mechanics, 18(3), 293–297. https://doi.org/10.1115/1.4010337
1.
Appendix: Partial derivatives of the log-likelihood
The following GASP codes can be run for all Tables after changing
the respective parameters values.
g=seq(1,1000,1);c=c(0,1,2,3,4,5);lp2=double(length(g));
lp1=double(length(g));lp21=double(length(c)); lp22=double(length(c));
lp23=double(length(c));lp24=double(length(c));G1=double(length(c));
G2=double(length(c));G3=double(length(c));G4=double(length(c));
p=function(a,b,p,ratio,lambda,a1){
zeta=log(1-(1-((lambda)^(-1)*(log(log(1-(((1-(1-p)^(1/b))^(1/a))*(1-(exp(-exp(lambda)+1)))))+exp(lambda))))))
G=(1-exp((zeta*((ratio)^-1)*a1)))
y=(1-(1-((1-exp(-exp(lambda)*(1-exp(-lambda*G))))/(1-(exp(-exp(lambda)+1))))^(a))^(b))
return(y)
}
p2=round(p(1,1,0.5,c(2,4,6,8),1.25,0.5),4);p2;p1=round(p(1,1,0.5,1,1.25,0.5),4);p1
for(i in 1:length(c)){
for(j in 1:length(g)){
lp2[j]=(pbinom(c[i],5,p2[2]))^j ##changing the values in p2 from 1 to 4#
## for P2[1] you will not get any values but for p2[2] you will get values###
### see the tables in the paper and match the values ####
## and we need to change the value of a = 5or = 10###
lp1[j]=(pbinom(c[i],5,p1))^j
}
G1[i]=min(which(lp2 ≥ 0.95 & lp1 < 0.25));lp21[i]=round(lp2[G1[i]],4);
G2[i]=min(which(lp2 ≥ 0.95 & lp1 < 0.10));lp22[i]=round(lp2[G2[i]],4);
G3[i]=min(which(lp2 ≥ 0.95 & lp1 < 0.05));lp23[i]=round(lp2[G3[i]],4);
G4[i]=min(which(lp2 ≥ 0.95 & lp1 < 0.01));lp24[i]=round(lp2[G4[i]],4);
}
cbind(c,G1,lp21,G2,lp22,G3,lp23,G4,lp24)