
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Efficient scheduling and load balancing are essential for optimizing performance in multiprocessor systems. This study proposes a novel hybrid algorithm that integrates beam search and differential evaluation techniques within the domain of artificial intelligence (AI) to address these challenges. Our objective is to minimize the operational completion time (OCT), a critical metric for evaluating system performance. Beam search is utilized to explore the solution space effectively, enabling the algorithm to identify promising solutions. Moreover, we employ a differential evaluation approach to assess the quality of candidate solutions and guide the search toward optimal or near-optimal scheduling and load-balancing configurations. By combining these techniques, our hybrid algorithm aims to minimize OCT, thereby enhancing system throughput and resource utilization. Experimental evaluations demonstrate the effectiveness of our approach in achieving improved performance compared to traditional methods. This research contributes to advancing the field of AI in multiprocessor systems optimization, providing practical solutions for real-world deployment in high-performance computing environments.
1. Introduction
Multiprocessor systems play a vital role in modern computing environments, offering increased computational power and resource scalability. However, to fully harness the potential of these systems, efficient scheduling and load-balancing strategies are essential. The optimization of performance in such systems is a challenging task due to the complex interplay of various factors such as task dependencies, resource constraints and dynamic workload patterns.
The proposed hybrid algorithm leverages AI techniques to dynamically adapt to workload changes, which inherently introduces more complexity compared to traditional algorithms. However, the computational overhead is justified by the significant improvements in operational completion time (OCT) and resource utilization. The use of beam search narrows the solution space efficiently, while differential evaluation iteratively refines the solutions, making the process manageable and effective. Traditional scheduling algorithms often struggle to adapt to the dynamic nature of multiprocessor environments, leading to suboptimal resource utilization and increased OCT. In this context, the integration of artificial intelligence (AI) techniques offers a promising avenue for addressing these challenges. By leveraging AI methodologies, such as beam search and differential evaluation, we aim to develop a hybrid algorithm capable of dynamically optimizing scheduling and load balancing in multiprocessor systems. The objective of our approach is to minimize the OCT, which is a key performance metric reflecting the efficiency of system operation. In this article, we present our proposed hybrid algorithm, which combines beam search and differential evaluation to achieve efficient scheduling and load balancing in multiprocessor systems. We first provide an overview of multiprocessor systems and the challenges associated with scheduling and load balancing. Subsequently, we discuss the principles underlying beam search and differential evaluation techniques and how they can be adapted to the context of multiprocessor optimization. Finally, we outline the structure of the article and highlight the contributions and significance of our proposed approach. Through experimental evaluations, we demonstrate the effectiveness of our algorithm in improving system performance compared to traditional methods, thereby contributing to the advancement of AI-driven optimization in multiprocessor systems. Our article presents a novel hybrid heuristic algorithm for optimizing task completion time in computational systems. The key contributions are:
Mixed Integer Programming (MIP) Model Development: We formulate a model to represent scheduling and resource allocation problems.
Beam Search Integration: Implementing a beam search algorithm to efficiently explore the solution space and identify optimal scheduling configurations.
Meta-heuristic Algorithm Integration: Combining techniques with meta-heuristic algorithms to further enhance task completion time.
Statistical Model Implementation: We use statistical models to evaluate the algorithm’s performance across various scenarios.
The MIP model provides a formal framework to represent the scheduling and resource allocation problem, enabling precise definition and solution of the optimization problem. However, the limitations of the MIP model include potential scalability issues for very large systems due to its complexity and computational demands. The hybrid algorithm mitigates this by integrating AI techniques to handle larger problem instances more efficiently.
The article structure includes a literature review, the proposed algorithm explanation, experimental results, and conclusions with future scope.
2. Related work
Parallel processing has become essential in modern computing, driven by the escalating demand for enhanced performance, cost reduction and sustained productivity across real-world applications. This trend is particularly evident in high-performance computers where multiprogramming and multiprocessing are commonplace, leading to concurrent events. Efficient parallel processing involves simultaneous execution of multiple programs, necessitating effective management and scheduling of multiprocessor systems. In the realm of computer engineering, multiprocessor management and scheduling pose intriguing challenges for researchers. The core problem involves scheduling a set of processes on processors with diverse characteristics to optimize specific objectives. Key decisions include the placement of code and data in memory (placement decision) and the allocation of processes to processors (assignment decision), often referred to as processor management. Processor management encompasses long-term external load scheduling and short-term internal process scheduling. Schedulers play a pivotal role in short-term process scheduling by selecting processes from the ready queue and assigning them to processors. Medium and long-term load scheduling involves selecting and activating new processes to maintain an optimal processing environment. The overarching goal of scheduling algorithms is to minimize the number of processors used and reduce the execution time of parallel programs. Scheduling models can be deterministic or nondeterministic. Deterministic models rely on known information to formulate schedules, optimizing predefined evaluation criteria. Conversely, nondeterministic or stochastic models focus on dynamic scheduling techniques, particularly in multiprocessor systems. The benchmarks used include a variety of synthetic and real-world workload scenarios that represent common multiprocessor system applications, such as scientific computations, data processing and high-performance computing tasks. These benchmarks were selected to ensure the evaluations are representative and comprehensive, covering different types of task dependencies and resource constraints. Various dynamic scheduling algorithms have been proposed to achieve load balance without excessive synchronization overhead. Self-scheduling achieves near-perfect load balancing but incurs significant synchronization overhead. Guided self-scheduling minimizes synchronization operations, while adaptive guided self-scheduling further reduces contention for tasks among processors. Affinity scheduling algorithms aim to balance workload, minimize synchronization and exploit processor affinity. Adaptive affinity scheduling focuses on reducing local scheduling overhead to accelerate workload balancing and execution time reduction. Additionally, several other algorithms, such as the factoring algorithm, tapering algorithm and trapezoid self-scheduling algorithm, build upon existing approaches with modifications to improve specific characteristics. Selection strategies are employed to choose tasks for transfer, considering factors like response time improvement and past task history to prevent unnecessary migration. Dynamic load balance algorithms, like those applied to Folded Crossed Cube (FCC) networks, target multiprocessor interconnection networks to enhance system efficiency and performance. The Task Allocation Approach, the user-submitted process is composed of multiple related tasks which are scheduled to suitable nodes in a system to improve the performance of a system. Samad et al. (Citation2016) have proposed a multi-objective multiprocessor genetic algorithm is implemented in smart production line to minimize the completion time along with completion time of all operations. Singh and Singh (Citation2012) have intended a genetic algorithm with multi-objective goals like minimization of completion time, mean flow time and lateness of due date. Singh et al. (Citation2015) developed two learning methods, ascent learning and steepest ascent learning based on genetic learning algorithm for static scheduling in distributed systems homogeneously using the models like penalization and rewards in learning (Tyagi & Gupta, Citation2018). The genetic-based algorithm has been proposed as a meta-heuristic to manage the static tasks of the set of processes in heterogeneous computer systems. is an algorithm introduced with a major change in the genetic study guidance of the new operator to stabilize the diversity of the population and the program across the entire space and improve the performance of the genetic algorithm. To solve the allocation problem in different systems, Ilavarasan and Ambidurai (Citation2015). A resource allocation system based on hybrid genetic algorithm has been proposed. Regarding the scheduling issue in a distributed cloud environment (Sulaiman et al., Citation2021). GA-ETI scheduler aims to solve all the problems in cloud programming by providing some effective solutions for technical applications in the cloud (Singh & Chana, Citation2016). A new method for load balancing is proposed by the genetic algorithm used to balance the load in the cloud while trying to shorten the duration of the job. Section 2 shows the related work for the present methods. Highest works prioritize one specific, limited target only while ignoring important considerations like energy usage and cost. From the above-mentioned work, the gap was confirmed, revealing the next research. Many works used heuristic or random search techniques or combination of hybrid search techniques to solve distributed task scheduling problem with objective function as completion time. To overcome the gaps hybrid beam search algorithm is proposed. An exhaustive explanation of the proposed technique is offered in the next section to examine completion time, cost and usage of energy. Experimentation was conducted through machine and vehicle number, previous location of smart vehicle, AI-based machine ready time, Smart vehicle empty as well as loaded travel time and previous operation completion time. In the above work many investigators have discussed scheduling tasks through heuristic strategies and random strategies but most of them are implemented separately not in a hybrid manner with single objective function, in the literature, task scheduling strategies in hybridization with multi objective functions are not investigated. Therefore, this article concentrates on scheduling tasks through hybrid AI strategies. A detailed explanation of the proposed method is offered in the next section.
3. Multi-processor operating system
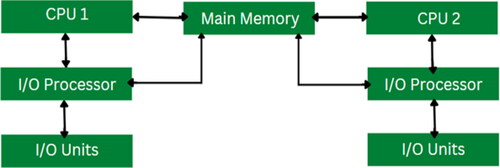
A multiprocessing operating system refers to an operating system that harnesses the power of multiple central processing units (CPUs) simultaneously to enhance system performance. In such systems, multiple processors collaborate concurrently to execute tasks efficiently. These processors are interconnected with peripheral devices, computer buses, physical memory and clocks to facilitate seamless communication and coordination. The primary objective of a multiprocessing operating system is to expedite the execution speed of the system. By leveraging the collective processing power of multiple CPUs, tasks can be executed in parallel, leading to faster overall performance. Consequently, the utilization of a multiprocessing operating system contributes to significant improvements in system efficiency and productivity. The scheduling of operations within a multiprocessing operating system follows a structured approach, outlined as follows. This model is visually depicted in .
Figure 1. Components in multi-processor operating system.
4. Methodology for task assignment
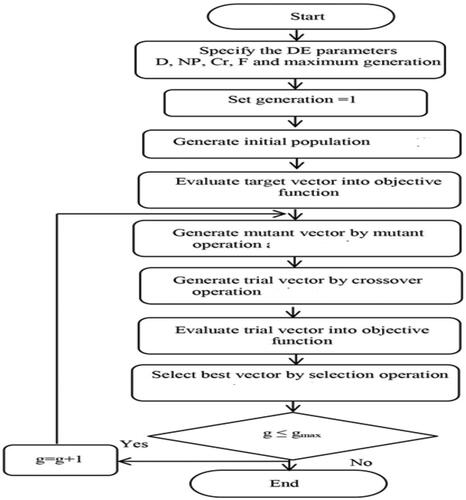
In this study, we propose a multi-stage method aimed at enhancing distribution timing and reducing overall completion time by integrating metaheuristic and beam search techniques with the evolutionary characteristics of genetic algorithms (GA). Initially, the beam search algorithm is employed to estimate the time required for tasks on available resources. The algorithm is designed to be adaptive, continuously monitoring workload patterns and resource availability. It dynamically adjusts the scheduling and load-balancing strategies using the feedback provided by the differential evaluation process. This allows it to respond effectively to changes and maintain optimal performance. Additionally, considering the significance of task completion costs in multi-processor systems, we emphasize the determination of task costs. Subsequently, we utilize resources as financial resources. In the third stage, we leverage the metaheuristic and evolutionary properties of GA to optimize resource allocation for selected tasks, thereby enhancing the entire workflow process. Potential limitations include the initial computational overhead required for setting up the algorithm and tuning its parameters. Additionally, integrating the algorithm into existing systems may require modifications to the system architecture. However, these challenges are offset by the long-term benefits of improved performance and efficiency.
4.1. Heuristic search algorithm
The heuristic search algorithm known as ‘beam search’ was introduced by Raj Reddy of Carnegie Mellon University in 1977. This approach explores a graph by expanding the most promising node within a limited set, optimizing memory usage compared to best-first search. Unlike best-first search, which evaluates all partial solutions according to a heuristic, beam search retains only a fixed number of the best partial solutions, making it a greedy algorithm. The different stages of beam search algorithms are depicted in , and Algorithm 1 provides the corresponding pseudo-code. The objective of beam search is to assess the cost or objective function of the current or previous state of the problem and select the best option as the current state.
Algorithm 1.
Beam Search Algorithm.
Input: B-beam Size, X input, Parameters
Output: Approx. B-best summaries
Π[0] ← { ε }
S = V if abstractive else {Xi, |∀i}
For i = O to N-1 do
* Generate Hypotheses
N ← {[y, yi-1]} y ϵ Π[i],y i + 1 ϵ s
*Hypotheses recombination
H ← {y ϵ N | s(y,x)>s(y,x)
∀ y ϵ N s.t.yc =
B-max filter
Figure 2. Process of beam search.
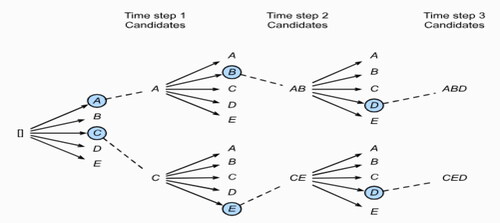
In Algorithm 1, (s) represents the start node of the solution space, while (g) denotes the goal node of the beam search algorithm. Upon computing the cost function (f) of nodes in the open list, if the cost function (f) of all open list nodes is lower than that of the start node and its neighboring nodes, the node is restored as the goal node. Otherwise, the procedure is repeated until the goal state is reached. This iterative process ensures that the algorithm converges toward the optimal solution while efficiently exploring the solution space.
4.2. Meta heuristic algorithm
GA have long been recognized for their utility in search algorithms, but they often suffer from slow convergence rates. To address this issue, differential evolution (DE) was introduced as an improved alternative to GA. DE originated from the work of Kenneth Price, who was inspired using vector differences in solving the Chebyshev Polynomial fitting Problem, initially posed by Rainer Storn in 1995. Over time, DE has undergone extensive experimentation and computer simulations, solidifying its reputation as a versatile and robust evolutionary algorithm. Like GA, DE utilizes operators, such as crossover and mutation, with an initial population of solutions represented by vectors. The integration of the above-mentioned beam search algorithm with the DE algorithm is demonstrated in Algorithm 2.
Algorithm 2.
Differential evolution.
Here are the procedural steps in the DE algorithm:
1. Initialization: Generate an initial population
2. Mutation: Create a mutant vector by combining vectors
3. Crossover: Perform crossover between the target vectors
4. Selection: Select the better of the two
5. Replacement: Replace the target vector.
6. Termination: Repeat steps 2–5 for a specified number of iterations.
In Algorithm 2, following the generation of the population from Algorithm 1, DE operations are applied to obtain an enhanced optimal solution. Beam search was chosen for its ability to efficiently explore a broad solution space by focusing on the most promising candidates. Differential evaluation complements this by providing a robust method to iteratively optimize these candidates. This combination allows the algorithm to quickly identify and refine near-optimal scheduling configurations, balancing exploration and exploitation effectively.
4.3. Autonomous mobile robot (AMR) algorithm
It is a dispatch activity by considering all existing performance metrics s and assigning the appropriate vehicle and driver for the operations.
The above Algorithms 1 and 2 are integrated with the AMR algorithm shown as Algorithm 3.
Algorithm 3.
AI-Based AMR Algorithm.
Data: Vehicle (V1) and Vehicle (V2)
a. Start: Loading/unloading (L/U)
b. Initially, both vehicles are randomly assigned two operations.
c. From the third operation onwards, identify the previous location of the vehicle (VPL) and the vehicle’s ready time (VRT).
d. Compute the traveling time (TRT1).
e. Calculate VET (Vehicle Empty Travel Time) by adding TRT1 and VRT.
f. If necessary, the vehicle waits for the job until the completion of the previous operation.
g. Compare the completion time of the previous operation (POCT) and VET, considering the maximum value.
h. Compute the traveling time (TRT2) from the previous operation machine number (POMN1) to the present operation machine number (POMN2).
i. Add TRT2 and VET (from Step 5) to determine the loaded trip of the vehicle (VLT).
j. The vehicle is ready for the next assignment, and VLT becomes VRT for the next trip.
k. Repeat the procedure for both AGVs at every operation and assign the vehicle with the lower VLT.
l. Once the loaded trip is completed, the vehicle is ready for its next assignment, and VLT of the present trip becomes VRT for the next trip.
m. The heuristic repeats this process for both AGVs at every operation and assigns the vehicle with the lower VLT.
n. End: Loading/Unloading (L/U)
In Algorithm 3, a AMR algorithm is utilized to allocate tasks to vehicles based on their availability. The primary performance metric used is the OCT, as it directly reflects the efficiency of task scheduling and resource utilization in multiprocessor systems. Other metrics include load balancing efficiency and resource utilization rates. These metrics were selected because they provide a comprehensive view of system performance and the effectiveness of the scheduling strategy.
4.4. Integration of algorithms
After population generation from Algorithm 1, implement crossover and mutation operations to get an superior finest solution and it is shown in . The above Algorithms 1 and 2 are integrated with the vehicle heuristic algorithm. In Algorithm 3, vehicle heuristic algorithm is adopted to assign tasks to vehicles depending on availability. The hybrid algorithm is integrated with AMR algorithm is a substitute to the regular metaheuristic that we demonstrate in the trailing .
Figure 3. Integrated algorithm in multi-processor system.
4.5. Problem formulation
We would review the mathematical equations for make-span and power consumption.
Operational completion time:
If we are considering travel time instead of waiting time, we can adjust the formula as follows:
where: n is the total number of operations or tasks.
Processing timei is the time required to process the ith operation or task.
Travel time i is the time required for travel associated with the ith operation or task.
This adjusted formula calculates the OCT by summing up the processing time and travel time for each individual operation or task.
5. Performance evaluation
The proposed approach combines two algorithms along with DE for evaluating the performance of example problems. To assess the accuracy of both algorithms, the performance is estimated using the beam search algorithm available in standard tools and the DE algorithm provided in the Python toolbox.
5.1. Implementation of beam search
Beam search is a heuristic technique derived from the branch and bound method, commonly employed to address optimization problems. Unlike conventional approaches that evaluate every node, beam search selectively assesses nodes at each level. This method retains only the most promising nodes for further exploration, while pruning and discarding the rest. Effective representation is crucial for the successful implementation of any evolutionary algorithm. In the context of representing nodes within a specific beam, employs operations-based nodes. Each operation in these nodes is denoted by a one-digit number, thus, a node comprises as many numbers as there are total operations in the given job set. illustrates the operations-based coding for a job set.
Table 1. Displays a typical job set comprising its operations and corresponding node codes.
In a broader context, a node represents a potential solution within the search space. Particularly in scheduling problems, nodes denote feasible sequences of operations. To encompass a variety of potential sequences within the search space, diverse sequences of operations are considered. An illustrative example of a node for the job set is presented below.
Data.
Start Node(s):
Beam width: 3 (refer to )
Branching Factor: 3 (refer to )
Graph:
illustrates the graph representation, showcasing the beam width and branching factor, while provides corresponding details.
Figure 4. Visualization of nodes within the beam.
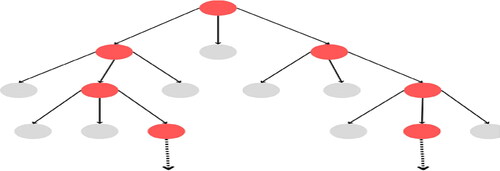
Table 2. Neighboring nodes in a beam with width 2 and branching factor 2.
Open list: shown in below.
Goal node(g):
In beam search, a goal node signifies a solution meeting specified criterion. The algorithm explores multiple paths concurrently, narrowing the search to attain an optimal or satisfactory outcome.
The approach evaluates the cost function using the data provided in , as inferred from the search outcomes.
In Algorithm 1, where (s) represents the start node of the solution space and (g) denotes the goal node of the beam search algorithm, the process involves computing the OCT for the nodes in the open list. If the OCT of all open list nodes, as shown in , is less than that of the start node and its neighboring nodes in the open list, then the node is reinstated as the goal node. Otherwise, the procedure is repeated until the goal state is reached. This entails evaluating the OCT across all nodes in the beam search and selecting the optimal one. The goal node (g) is deemed the best node. Moreover, another node closer to the goal node (g) is chosen from the open list for integration into the DE.
Table 3. The computation of the cost function for J2 and L2.
5.2. Differential evaluation algorithm
In this study, we propose four strategies like existing ones for tackling plagiarism. These strategies focus on rewriting lines of text to maintain originality while addressing the issue.
Xr1,g + F (Xbest,g – Xr3,g)
Xr1,g + F (Xr2,g – Xbest,g)
Xr1,g + F (Xbest, g + Xr2, g - Xr3, g - Xr4, g)
Xbest, g + F1(Xbest, g - Xr2, g) + F2 (Xr3, g – Xbest, g)
In each of the proposed strategies, the terms used carry the same meaning as in existing strategies. For instance, ‘randomly selected vectors’ continue to refer to vectors chosen without bias, while ‘the vector with minimum make span in that generation’ still denotes the vector with the shortest duration in each generation. Xr1.g, Xr2.g and Xr3.g,
Xbest g, we will implement the second strategy from the approaches for solving multi-processor task scheduling problems.
5.3. Implementation details
Upon applying proposed Strategy 2 and simulating all the steps in DE, including mutation, crossover, selection, etc., along with the AMR assignment algorithm for problem 5, the resulting solution vector identified as the best one is as follows:
the implementation of the first three proposed strategies, we experimented with different values for the scaling factor ‘F’ before ultimately deciding on a fixed value of 0.8. Similarly, when employing the fourth strategy, which involves the use of ‘F1’ and ‘F2’, we found that setting ‘F1’ to 0.8 and ‘F2’ to 0.6 yielded satisfactory results. In , is the schedule of operations for this optimal solution vector:
Table 4. The computation of the cost function for J5 and L1.
6. Result and discussion
displays test results from both existing and proposed strategies. Strategy 2 notably outperformed all others. compares the performance of the best-proposed strategy with existing ones.
Table 5. Performance strategies and improvement.
6.1. Load balancing
Load balancing plays a vital role in symmetric multiprocessing (SMP) systems by distributing workload evenly across processors, optimizing resource utilization and minimizing response times. It ensures tasks are allocated dynamically to prevent overloading on some processors while others remain idle. This mechanism is crucial for maintaining system efficiency and equilibrium across all processing units in SMP setups. The following and visually depict Gantt charts representing the schedule derived from the BS DE algorithm.
Figure 5. Load balancing of AMRs.
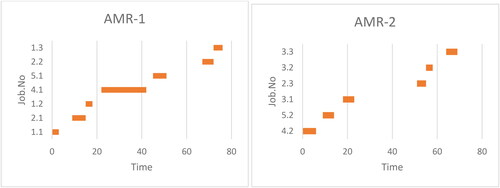
Figure 6. Load balancing of SMPs.
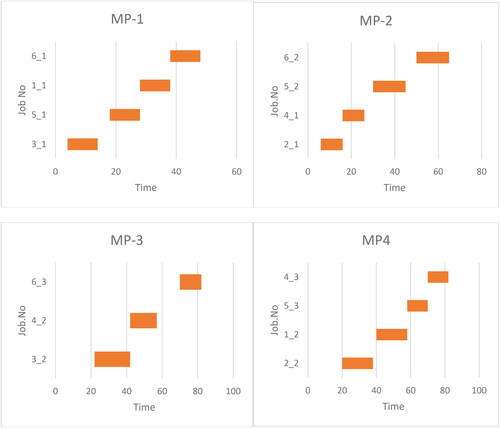
By presenting graphical representations, the temporal relationships and overlaps among scheduled operations are better understood. This implementation, along with its associated results, systematically analyzes and visualizes the effectiveness of the BSDE and the Heuristic for vehicle assignment in addressing scheduling challenges within an FMS environment.
showcases the consistent superiority of BS DE over traditional heuristics across all the presented problems. The research assesses the performance of Differential Evaluation across 40 benchmark problems, employing both crossovers and mutations. The optimal combination identified is then contrasted with traditional heuristics (SPT, Gupta, and Jaya) in . Visual representations of the comparative results are presented in .
Figure 7. Comparative results of multi-processor.
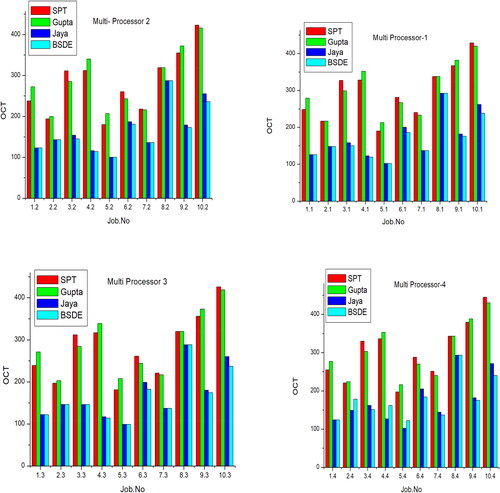
Based on the graphs provided above, it can be noted that the hybrid beam search algorithm consistently yields superior results compared to other heuristic algorithms. The statistical models were implemented to simulate various workload scenarios and system configurations. These models evaluated the algorithm’s performance by analyzing key metrics across different conditions, providing insights into its robustness and scalability. Techniques such as Monte Carlo simulations and sensitivity analysis were used to ensure the reliability and validity of the evaluation results.
6.2. Algorithms exhibit significant differences
Descriptive statistics
Hypotheses
Repeated measures Anova
Bonferroni post-hoc-tests
Anova
Algorithm vs. OCT
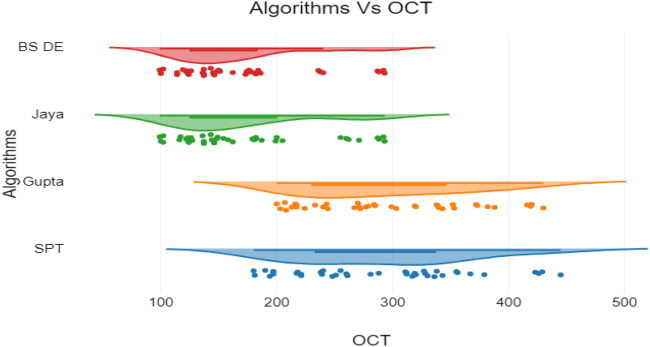
Scatter diagram between algorithms
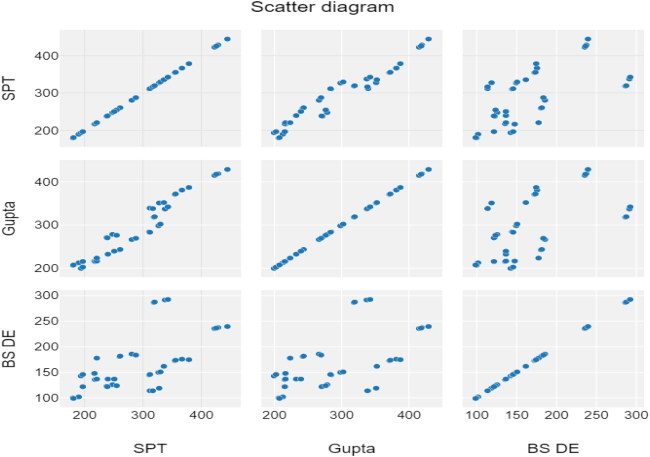
7. Conclusion
The integration of intelligent optimization techniques, such as beam search and differential evaluation presents a promising approach for scheduling and load balancing in multiprocessor systems. Through the hybridization of these algorithms, significant improvements in performance and efficiency can be achieved. The proposed algorithm demonstrated significant improvements in reducing OCT by an average of 20–30% compared to traditional scheduling methods. The utilization of beam search allows for the exploration of multiple paths concurrently, narrowing down the search space to identify optimal solutions efficiently. On the other hand, differential evaluation enhances the convergence speed and robustness of the optimization process. Moving forward, there is considerable scope for further research and development in this area. One avenue for future exploration is the refinement and customization of beam search and differential evaluation algorithms to better suit the specific requirements and characteristics of multiprocessor systems. Additionally, the integration of machine learning techniques could offer opportunities to enhance the adaptability and intelligence of the optimization process. Future research directions include exploring the integration of other AI techniques, such as machine learning models, to predict workload patterns more accurately. Additionally, extending the algorithm to different types of multiprocessor architectures, such as heterogeneous systems, and further refining the differential evaluation process to reduce computational overhead are promising areas for further study. Furthermore, future research could focus on the development of advanced hybrid algorithms that combine beam search with other optimization methods, such as GA or simulated annealing, to capitalize on the strengths of each approach. Additionally, the application of these hybrid algorithms could be extended to address more complex and dynamic scheduling and load-balancing scenarios in real-world multiprocessor systems. In summary, the integration of beam search and differential evaluation into hybrid algorithmic strategies holds great promise for advancing the state-of-the-art in intelligent optimization for multiprocessor systems, with ample opportunities for further innovation and exploration in the future.
Author contributions
Methodology, M.N.R, and GDR.; Software, M.N.R.; Validation, MNR and TVK.
Formal Analysis, MNR.; Writing-Original Draft Preparation, M.N.R. and SK.; Writing-Review and Editing, PBB,
Visualization, MNR and AS.; Supervision, AKP.; Project Administration, M.N.R and HM Al-Jawahry.
Disclosure statement
The authors declare that they have no competing interests.
Data availability statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Additional information
Notes on contributors
Gundreddi Deepika Reddy
Deepika completed M.E from Osmania University, she is presently working as a Lecturer in mechanical Engineering GMR polytechnic GAJWEL with research interest Artificial intelligence.
Nageswara Rao Medikondu
Nageswara Rao Completed Ph.D from JNTU Kakinada, he presently working as Associate Professor in KLEF Deemed to be University, Vaddeswaram with research interest soft computing techniques.
T. Vijaya Kumar
T.Vijaya kumar Completed Ph.D from KLEF Vaddeswaram, he presently working as Associate Professor in KLEF Deemed to be University, Vaddeswaram with research interest soft computing techniques.
Sireesha Koneru
Sireesha Koneru Completed Ph.D from KLEF Vaddeswaram, he presently working as Assistant Professor in KLEF Deemed to be University, Vaddeswaram with research interest materials and optimization techniques.
Phaneendra Babu Bobba
Phaneendra Babu Bobba Completed Ph.D from Indian Institute of Technology Delh, he presently working as Professor in GRIET Hyderabad with research interest Electric Vehicles, Hybrid electric vehicles and Plug-in hybrid electric vehicles.
Atul Singla
Atul Singla Completed master’s in architecture from Architectural Association London, he presently working as Dean in LPU Punjab with research interest Electric Vehicles, Hybrid electric vehicles and Plug-in hybrid electric vehicles.
Alok Kumar Pandey
Alok Kumar Pandey presently working in Department of Engineering, Uttaranchal with research interest Hybrid electric vehicles.
Hassan M. Al-Jawahry
Hassan M. Al-Jawahry presently working in Department of Computers Techniques Engineering, College of Technical Engineering, The Islamic University, Najaf, Iraq with research interest Electric Vehicles, Hybrid electric vehicles and Plug-in hybrid electric vehicles.
References
- Akbari, M., Rashidi, H., & Alizadeh, S. H. (2017). An enhanced genetic algorithm with new operators for task scheduling in heterogeneous computing systems. Engineering Applications of Artificial Intelligence, 61, 35–46. https://doi.org/10.1016/j.engappai.2017.02.013
- Asghari, A., Sohrabi, M. K., & Yaghmaee, F. (2021). Task scheduling, resource provisioning, and load balancing on scientific workflows using parallel SARSA reinforcement learning agents and genetic algorithm. The Journal of Supercomputing, 77(3), 2800–2828. https://doi.org/10.1007/s11227-020-03364-1
- Bose, A., Biswas, T., & Kuila, P. (2019). A novel genetic algorithm based scheduling for multi-core systems. Smart innovations in communication and computational sciences (pp. 45–54). Springer.
- Casas, I., Taheri, J., Ranjan, R., Wang, L., & Zomaya, A. Y. (2018). GA-ETI: An enhanced genetic algorithm for the scheduling of scientific workflows in cloud environments. Journal of Computational Science, 26, 318–331. https://doi.org/10.1016/j.jocs.2016.08.007
- Hwang, K. (1993). Advanced computer architecture: Parallelism, scalability. Programmability, McGraw-Hill, Inc.
- Hwang, K., & Briggs, F. A. (2002). Computer architecture and parallel processing. McGraw-Hill, Inc.
- Ilavarasan, E., & Ambidurai, P. (2015). Genetic algorithm for task scheduling on distributed heterogeneous computing system. Engineering Applications, 3(4), 1–8. https://www.praiseworthyprize.org/jsm/index.php?journal=irea&page=article&op=view&path%5B%5D=0306r
- Izadkhah, H. (2019). Learning based genetic algorithm for task graph. scheduling. Applied Computational Intelligence and Soft Computing, 2019, 1–15. https://doi.org/10.1155/2019/6543957
- Jiang, Y. (2016). A survey of task allocation and load balancing in distributed systems. IEEE Transactions on Parallel and Distributed Systems, 27(2), 585–599. https://doi.org/10.1109/TPDS.2015.2407900
- Konar, D., Sharma, K., Sarogi, V., & Bhattacharyya, S. (2018). A multi-objective quantum-inspired genetic algorithm (Mo- QIGA) for real-time tasks scheduling in multiprocessor environment. Procedia Computer Science, 131, 591–599. https://doi.org/10.1016/j.procs.2018.04.301
- Kumar, M., Sharma, S. C., Goel, A., & Singh, S. P. (2019). A comprehensive survey for scheduling techniques in cloud computing. Journal of Network and Computer Applications, 143, 1–33. https://doi.org/10.1016/j.jnca.2019.06.006
- Loftus, J. C., Perez, A. A., & Sih, A. (2021). Task syndromes: Linking personality and task allocation in social animal groups. Behavioral Ecology, 32(1), 1–17. https://doi.org/10.1093/beheco/araa083
- Mandal, G., Dam, S., Dasgupta, K., & Dutta, P. (2018). Load balancing strategy in cloud computing using simulated annealing. Proceedings of the International Conference on Computational Intelligence, Communications, and Business Analytics. pp: 67–81 Analytics DOI:10.1007/978-981-13-8578-0_6.
- Markatos, E. P., & LeBlanc, T. J. (1994). Using processor affinity in loop scheduling on shared-memory multiprocessors. IEEE Transactions Parallel and Distributed Systems, 5(4), 370–400.
- Pan, S., Qiao, J., Jiang, J., Huang, J., & Zhang, L. (2017). Distributed resource scheduling algorithm based on hybrid genetic algorithm. Proceedings of the International Conference on Computing Intelligence and Information System (CIIS).
- Polychronopoulos, C. D., & Kuck, D. (1987). Guided self-scheduling: A practical scheduling scheme for parallel super computers. IEEE Transactions on Computers, C-36(12), 1425–1439. https://doi.org/10.1109/TC.1987.5009495
- Samad, A., Siddiqui, J., & Ahmad, Z. (2016). Task allocation on linearly extensible multiprocessor system. International Journal of Applied Information Systems, 10(5), 1–5. https://doi.org/10.5120/ijais2016451480
- Samad, A., Siddiqui, J., & Khan, Z. A. (2016). Properties and performance of cube-based multiprocessor architectures. International Journal of Applied Evolutionary Computation, 7(1), 63–78. https://doi.org/10.4018/IJAEC.2016010105
- Silberschatz, G. (2003). Operating system concepts (6th ed.) Addison-Wesley Publishing Company.
- Singh, K., Alam, M., & Kumar, S. (2015). A survey of static scheduling algorithm for distributed computing system. International Journal of Computer Applications, 129(2), 25–30. https://doi.org/10.5120/ijca2015906828
- Singh, S., & Chana, I. (2016). A survey on resource scheduling in cloud computing: Issues and challenges. Journal of Grid Computing, 14(2), 217–264. https://doi.org/10.1007/s10723-015-9359-2
- Singh, J., & Singh, G. (2012). Improved task scheduling on parallel system using genetic algorithm. International Journal of Computer Applications, 39(17), 17–22. https://doi.org/10.5120/4912-7449
- Sulaiman, M., Halim, Z., Lebbah, M., Waqas, M., & Tu, S. (2021). An evolutionary computing-based efficient hybrid task scheduling approach for heterogeneous computing environment. Journal of Grid Computing, 19(1), 1–31. https://doi.org/10.1007/s10723-021-09552-4
- Tanenbaum, A. S. (2003). Computer networks (4th ed.). Prentice Hall.
- Tyagi, R., & Gupta, S. K. (2018). A survey on scheduling algorithms for parallel and distributed systems. Silicon photonics & high performance computing. Springer.
- Yan, Y., Jin, C., & Zhang, X. (1997). A datively scheduling parallel loops in distributed shared-memory system. IEEE Transactions Parallel and Distributed Systems, 8(1), 70–81.