
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Before using concrete for a particular purpose, its strength must be determined because its physical properties vary depending on the type of supplementary cementitious material (SCMs). Initially, researchers anticipated it with statistical processes; more recently, they started implementing deep learning (DL) and machine learning (ML) models. This research employed ensemble machine learning (EML) approaches to predict the compressive strength (CS) of concrete developed for ground-granulated blast furnace slag (GGBFS) along with Alccofine 1203 (AF). Ensemble regressions of Random Forest Regression (RFR) and AdaBoost Regression (ABR) were considered for model prediction using the Jupyter Notebook. The models were created based on the outcome of the compressive strength under the 90 experimental conditions. Moreover, a comparative study was performed between the RFR and ABR to benchmark the proposed model against a given combination of features and CS. The experimental conditions were optimized using a genetic algorithm (GA) after the model was created by ANN. With the two EML algorithms, the smallest errors, along with the largest coefficient of determination, were observed in the RFR algorithm. It was recognized that the optimized value of CS is 48.606 MPa, and their optimized process elements such as cement, alccofine, GGBS, water, and days were 261.506 kg/m3, 0.055 kg/m3, 52.468 kg/m3, 141.007 L, and 27.999 days, respectively.
1. Introduction
Numerous pozzolanic components have been added to concrete, along with cement as its fundamental binding agent, as confirmed by the ternary blended concrete. Blended cement and concrete were the concepts that came before the increasing use of Supplementary Cementitious Materials (SCMs) in concrete manufacturing. To enhance the structural qualities of concrete, the design mix parameters were adjusted to acquire chemical additives, increase cementitious material, lower water content, regulate hydration using SCMs, and control the amount of Ordinary Portland Cement (OPC). Currently, machine learning (ML) approaches are applied to engineering problems, and their models can be helpful for disciplines in sciences that have been examined from multiple perspectives and with successful outcomes. Technologies using artificial intelligence (AI) have been proven to be capable of handling non-linear tasks specifically. With the use of modern computational models that can predict the properties of various concrete mixtures, significant progress has been made in structural engineering. In behavioral models, pattern recognition is helpful and computational intelligence techniques can be applied. Bioinspired models are also useful tools for engineering structural design. Compressive strength (CS) predictions of concrete become easier when AI develops.
Utilizing machine learning (ML) modeling and Python’s Jupyter Notebook, high performance concrete’s (HPC) compressive strength is being predicted (Jiao et al., Citation2023). Individual learning methods, namely decision trees (DT) and multilayer perceptron neuron networks (MLPNN), are applied through bagging and boosting to produce significant connections. For the forecasting techniques, gradient boosting regression (GBR) and RFR, Song et al. (Citation2021) employed 471 data points as the input parameters. Golafshani et al. (Citation2020) examined the purpose of artificial neural networks (ANN) and adaptive neuro-fuzzy inference systems (ANFIS to create prediction models for computing the CS for conventional concrete (CC) in comparison to high-performance concrete (HPC). The Grey Wolf Optimizer (GWO) was later used to hybridize these techniques. Numerous machine learning prediction models, such as the Support Vector Regressor (SVR), Multiple Linear Regressor (MLR), Ada Boost Regressor (ABR), Random Forest Regressor (RFR), XG Boost Regressor (XGBR), and Bagging Regressor (BR), were assessed for accuracy (reliability) by Paudel et al. (Citation2023). The most effective method for anticipating CS has also been identified by researchers (Feng et al., Citation2020; Khashman and Akpinar, Citation2017; Mater et al., Citation2023; Yuan et al., Citation2014). Khademi et al. (Citation2016) and Duan et al. (Citation2013) conducted an investigation to determine the best way to use ANN, ANFIS, and MLR to approximate the 28-day CS of Recycled Aggregate Concrete (RAC). Farooq et al. (Citation2021) used supervised machine-learning techniques, Boosting Regression, GBR, gene expression programming, and DT to determine the CS of concrete by incorporating SCMs. The MAE, MSE, RMSE, and R2 were used to compare and assess the performance of the models. Many R, ANN, and ANFIS models were developed, trained, and tested by Sobhani et al. (Citation2010) using various components of concrete as input variables to predict the 28-day CS of no-slump concrete. For evaluating the CS of silica fume (SF) concrete, Fuzzy logic (FL) and artificial neural network (ANN) analyses were employed to evaluate the CS of SF concrete.
In an investigation of ANNs and FL, Özcan et al. (Citation2009) examined a dataset from an experiment in which a total of 48 concrete mixtures were developed. Naderpour et al. (Citation2018) forecasted recycled aggregate concrete’s(RAC) CS using an ANN by modeling 139 pre-existing sets of data in MATLAB. Decision trees (DT) and AdaBoost ML techniques were used by Shang et al. (Citation2022) to forecast the CS and split tensile strength (STS) of concrete, including RAC, employing 344 data points and nine input parameters. Ahmad et al. (Citation2021) conducted research to anticipate the CS of high-calcium-incorporated fly ash-based geopolymer concrete (GPC) using ANN, boosting, and AdaBoost ML approaches. Sensitivity assessment was used to evaluate the impact level of the input variables. Considering one hidden layer’s back-propagation network (BPN), The ANN structure was developed by considering the BPN of one hidden layer. An ANN was trained and tested using a database that included actual concrete mixture proportions (Lin & Ju, Citation2021). Using Monte Carlo simulations and an ANN-based approach, the CS of concrete incorporating Ground Granulated Blast Furnace Slag (GGBFS) and fly ash (FA) was estimated by Mai et al. (Citation2021). Comparing the GBR model to the other five boosting models, it was found to be the most precise indicator of the CS of HPC with a higher replacement of GGBFS in terms of volume, with an R2 of 0.960 and the lowest model error, with an MAE of 2.73 and RMSE of 3.40, respectively, for the given test dataset (Rathakrishnan et al., Citation2022). Kashem et al. (Citation2024) used hybrid machine learning (HML) techniques including XGB-LGB and XGB-RF, together with ML models utilising light gradient boosting (LGB), extreme gradient boosting (XGB), and random forest (RF), to comprehensively analyzing the factors and evaluate its effect on strength characteristics. Karim et al. (Citation2024) explored that the input factors affected the outcome of the study through 138 data sets for forecasting, statistical analysis, along with parametric analysis. Furthermore, the destructive and non-destructive tests for CS, STS, ultrasonic pulse velocity (UPV), and rebound hammer have been performed with hardened concrete during the study.
As the applications of machine learning are gaining more importance in solving complex problems, in this study, two regressions from Ensemble Machine Learning (EML) algorithms were utilizedto predict the CS of Alccofine- and GGBFS-based prepared concrete. Moreover, optimization was performed by applying a genetic algorithm to the model, which was prepared by ANN, to find the optimized parameters for the experimental condition and the optimized response of the compressive strength.
2. Prediction using machine learning algorithms/regressions
Within the field of artificial intelligence, machine learning (ML) is a subset that employs algorithms to learn from past performances and datasets. ML algorithms will develop and improve over time, with minimal input from humans (https://www.techtarget.com/searchenterpriseai/definition/machine-learning-ML). Machine learning (ML) has become prevalent in engineering to deal with a wide variety of problems, including fatigue life prediction, component failure prognosis, angular velocity estimation, and outage prediction. Previously, structural engineering problems were addressed in civil engineering using AI and ML (Thai, Citation2022). In addition to improving data evaluation and concrete property predictions, machine learning (ML) has been employed in structural building design and performance assessment, improving the Finite Element Method of structures. CS predictions were made for a variety of concrete types, including CC, HPC, UHPC, and green concrete, with SCMs, such as FA, GGBFS, and recycled aggregates. Machine Learning (ML)/Deep Learning (DL) can be applied to predict the mechanical and chemical properties of concrete, including CS, STS, Flexural Strength (FS), thermal conductivity, and chloride concentration. ANN has been frequently implemented for DL models in previous investigations. Their widespread usage and frequency in research domains such as biomedical, visual identification, natural language processing, robotics, and structural health monitoring have led to this choice.
2.1. Random Forest algorithm/regression
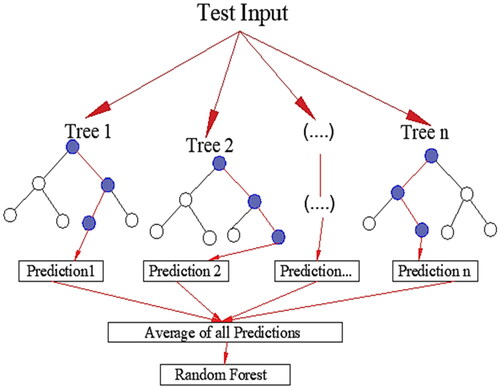
The Random Forest (RF) is an EML algorithm that follows the bagging technique. This is an expansion of the bagging estimator method. Random forests (RF) use decision trees (DT) as the basis estimator. Decision trees are created using the original dataset. Only a random subset of features was considered at each DT node to determine the best possible split. The DT model was fitted to each subset. As a result of the parallel development of trees in random forests (RF), there is no interaction among them as they develop. The optimal prediction was obtained by averaging all the DT predictions. In addition, this method uses the following parameters to create the model: n_estimators, criteria, max_features, max_depth, and min. samples_split: min_samples_leaf, max_leaf_nodes, n_jobs, and random_state. outlines the algorithmic approach to random forest regression (Kwak et al., Citation2022).
Figure 1. Flow diagram for random forest regression.
2.2. AdaBoost algorithm/regression
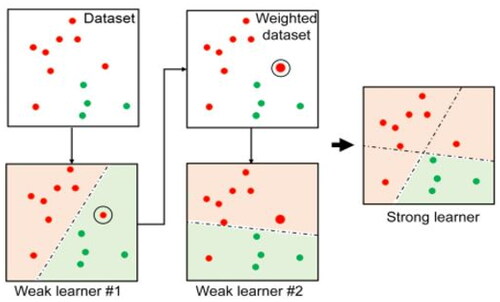
AdaBoost, also known as adaptive boosting, is the most popular basic boosting approach. DTs are frequently employed in modeling. Multiple sequential models were developed, each of which corrected the errors in the preceding model. These subsequent models attempted to accurately predict the outcomes by assigning weights to observations that were not correctly predicted by ABR. This methodis repeated until either the largest number of estimators is reached, or the error function remains constant. The parameters of this method include base_estimators, n_estimators, learning_rate, max_depth, n_jobs, and random_state. The model was optimized by adjusting these parameters. The algorithmic approach (https://www.analyticsvidhya.com/blog/2022/01/introduction-to-adaboost-for-absolute-beginners) for ABR is shown in .
Figure 2. Flow diagram for AdaBoost regression.
3. Feature description and experimental data
The dataset consisted of 90 experimental conditions comprising five features and one response. The blended high-strength concretes were prepared according to the IS 10262:2019 standard (BIS, Citation2019) and tested as per IS 516:1959 (BIS, Citation1959) to evaluate their CS. The main raw materials used were cement, Alccofine, and GGBS, which were taken as kilogram/cubic meter and water in liters. The limits of the values used for each feature are listed in . confirms the work plan to produce concrete, followed by the attainment of CS for 90 various compositions of concrete, and the preparation of the prediction models.
Figure 3. Experimental plan.

Table 1. Limits of each feature used to prepare the concrete.
Cement, Alccofine, GGBS, Water, and Days are features of the ML models. CS (MPa) represents the predicted parameter. shows the correlation between the given features/variables (Beskopylny et al., Citation2022). The responses and each independent input feature were positively and negatively correlated. When one feature is increased, the responses increase linearly when the value is positive, whereas when one feature is increased, the responses decline linearly when the value is negative. lists the statistical characteristics of the experimental dataset.
Figure 4. Correlation matrix.
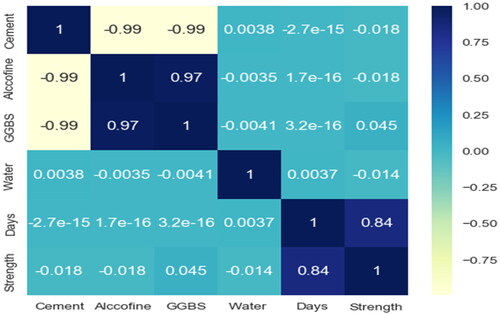
Table 2. Statistical characteristics of experimental data.
4. Machine learning models and analysis
4.1. Model building for Random Forest and AdaBoost regression
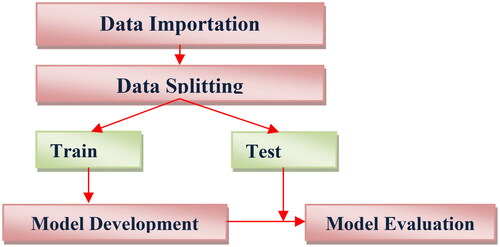
The machine learning (ML) model development approach used in this study is shown in . A dataset was imported and the training and test data were separated on an 80:20 basis to develop a machine learning model (Kioumarsi et al., Citation2023). The model was built using the training data. The test data were later used to assess the model.
Figure 5. Methodology for development of ML model.
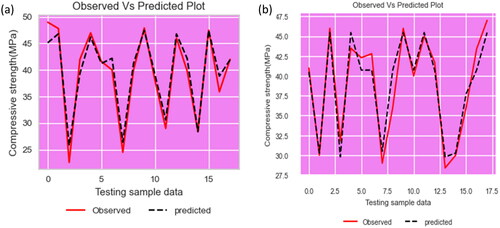
Two machine learning models, Random Forest Regression (RFR) and AdaBoost Regression (ABR), were developed and evaluated in this research. The CS values of the observed and anticipated values of the testing samples for the RFR and ABR are plotted (Li et al., Citation2023) in . The plot suggests that ABR has more errors than RFR because of the difference between the observed and anticipated values of the track linking subsequent values.
Figure 6. Compressive strength of observed and predicted against testing sample of (a) random forest regression and (b) AdaBoost regression.
4.2. Evaluation measures for models
When analyzing models based on regression, it is critical to employ a variety of evaluation metrics to evaluate the model’s performance. The present research employed five indicators: Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and R-Squared (R2). The following are presented in the prescribed metrics (Turkey et al., Citation2022):
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
In the above EquationEquations (1–5) (Ahmad et al., Citation2021; Beskopylny et al., Citation2022; Turkey et al., Citation2022), n is the total number of test conditions and yi and are the measured and predicted values, respectively. The MAE, MAPE, MSE, and RMSE values were employed to evaluate the modeling errors. The preferred value is the one where the variation between the experimental and predicted values is lower. R2 is a value that can range from 0 to 1. The closer the numerical value is to 1, the better the model’s optimized fit.
4.3. Results and discussions of regression models
4.3.1. Comparison of training and testing measures
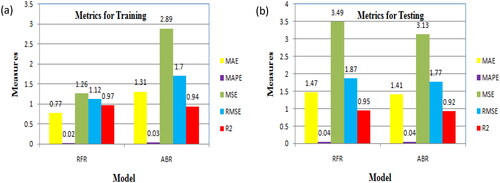
The MAE, MAPE, MSE, RMSE, and R2 were used to evaluate the model performance of the RFR and ABR. The results are presented in . The CS values of these models were identified separately for the training and testing datasets. Overall, the test data errors indicate the capacity of the developed algorithm for generalization, whereas the training dataset errors indicate the adequacy of the model. With an R2 greater than 90%, both the RFR and ABR models showed good agreement when displaying the training data (Farooq et al., Citation2021).
Table 3. Training and testing measures of regression models.
The RFR model, which achieved 0.97 during training and 0.95 during testing, achieved the best prediction accuracy according to the model’s characteristics; the ABR model, on the other hand, obtained 0.94 during training and 0.92 during testing. The RFR model also exhibited the lowest training prediction errors with MAE = 0.77, MAPE = 0.02, MSE = 1.26, and RMSE = 1.12. The error of the ABR model was slightly higher than that of the RFR model. Hyper-parameter tuning was not attempted for either model in this investigation, considering that the basic models had a greater prediction accuracy (RFR: R2 = 0.97; ABR: R2 = 0.94). The performance measures for the two models (Beskopylny et al., Citation2022; Rathakrishnan et al., Citation2022) are compared in .
Figure 7. Comparison of performance metrics of (a) training and (b) testing for random forest regression and AdaBoost regression.
4.3.2. Comparison of prediction plots
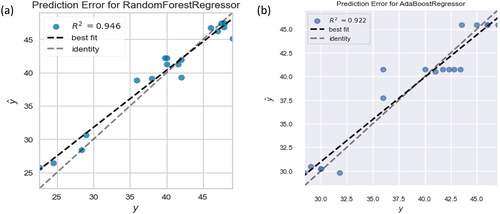
displays the test data’s R2 value of the actual compressive strength of each experiment (yi) on the x axis, while over the y axis, the predicted compressive strength (y ̂) by the model is shown (Pereira et al., Citation2020). The best-fit line indicating the prediction in the model was also compared to an identity line at a 45° angle. A degree of variation was observed in this plot. As almost all points are close to identity, this means that the residual of the model’s prediction is near zero in the RFR regression model. However, certain points are away from identity in the ABR, which could describe a higher MAE value. This is also evident in , where ABR had a higher MAE value than RFR.
Figure 8. Comparison of prediction error plots for (a) random forest regression and (b) AdaBoost regression.
4.3.3. Comparison of residual plots
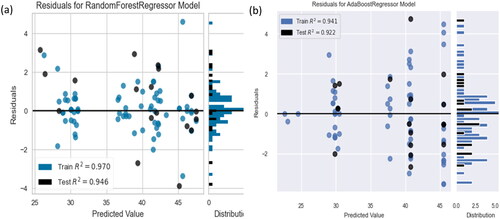
shows the residuals plotted on the y-axis and the projected values for training and testing on the x-axis. also displays the residual distribution for Random Forest and AdaBoost, and regressions. Plotting shows that the residuals are proportionally distributed along the zero axis, indicating the absence of heteroscedasticity (Pereira et al., Citation2020). In addition, there were very few outliers and no clear patterns. The residual (point) locations on the plot can be used to determine the errors. In comparison with the error prediction plots, RFR has less error and ABR has more error because almost all of the points are very close to the horizontal black line, or point zero on the y-axis. Additionally, it is confirmed that the model uses a linear regression approach using residual histograms, which show a normal distribution in the shape of a bell.
Figure 9. Comparison of residual plots for (a) random forest regression and (b) AdaBoost regression.
4.3.4. Comparison of feature importance
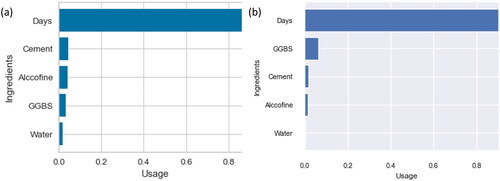
The main objective of feature importance is to assess and compute the influence of a feature on the model’s predictions (Rathakrishnan et al., Citation2022). To update the original dataset, feature values were randomly mixed for each feature. The model assessment metrics for the updated dataset were calculated and compared to the evaluation metrics of the original dataset. Every feature performs repeated iterations to achieve the average and standard deviation associated with the permutation significance scores. To determine how each concrete attribute affects the prediction of the CS of concrete, a feature importance analysis was performed on both ML models in this research. depicts the relative importance of all features incorporated into the CS prediction model. In both ML models, ‘days’ are the most influential feature in the prediction of CS among several features.
Figure 10. Comparison of feature importance for (a) random forest regression and (n) AdaBoost regression.
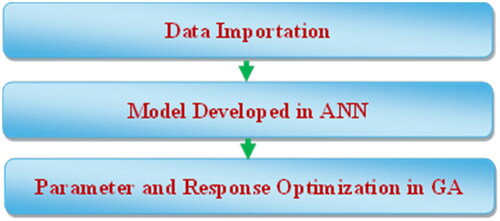
5. Optimization using ANN and genetic algorithm (GA)
In addition to maximizing the CS of concrete, a further objective of the present study was to determine the optimum process parameters after the model had been developed. This study employed the genetic algorithm (GA) to optimize the model created by the ANN. The following addresses the roles of ANN and GA in modeling and optimization. The combined use of the ANN and GA is shown in . GA was employed to optimize the parameters by applying the same model as the fitness function after the model was established by the ANN. To execute the GA, a fitness function was applied once the population was initialized. The termination criteria were later confirmed. The program terminates and displays the output when the condition is achieved. If not, the phases of selection, crossover, and mutation are explored to create a new population, which is then sent to a criterion check. This process is repeated when the termination criterion is fulfilled.
Figure 11. Integration of ANN and GA.
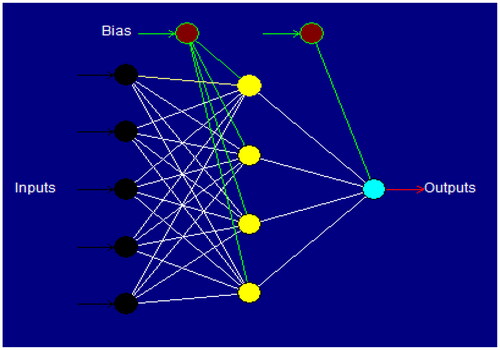
5.1. Artificial neural network
Compared with other models, such as linear and exponential regression, the ANN approach provides a more accurate prediction. Because of their outstanding ability to match input and output correlations and learn algorithms, especially for non-linear and complex systems, artificial neural networks (ANN) have been widely used as prediction tools by academics (Alavala, Citation2008; Pilkington et al., Citation2014). Ebrahimpour et al. (Ebrahimpour et al., Citation2008) stated that while ANN can recognize the relationships underlying complicated processes, it has enormous modeling potential. To train the data, ANNs use a variety of learning algorithms, including Levenberg-Marquadt, batch back propagation, incremental back propagation, and quick propagation. A variety of nonlinear transfer functions are also included, including sigmoid, bipolar, Gaussian, Tanh, linear, threshold, and linear (CPC X software, neural power user guide, Citation2003). The software employed in this research comprises two distinct connection types: ‘multilayer full feed-forward’ and ‘multilayer normal feed-forward’. The training was terminated based on the divergence of the RMSE (Awolusi et al., Citation2019). shows the ANN architecture between the input and response for the compressive strength.
Figure 12. ANN architecture between input and response.
5.2. Genetic algorithm
A Genetic Algorithm has been described as a random search technique that differs from a conventional search. Because of its straightforwardness, minimal requirements, and global perspective, GA is predominantly used to optimize a variety of issues (Panneerselvam et al., Citation2009). A GA essentially consists of multiple modules, including input, initialization, evaluation, selection, crossover, mutation, termination check, and output, to complete the optimization process. The dataset or model was fed into the input module. The initialization module establishes the initial population. The fitness module evaluated the fitness function. The program terminates when the condition is satisfied. Reproduction occurs within the selection module, if it does not. The cross-over module combines two functional chromosomes. Finally, until the program ends and the output is generated, the offspring are formed in the mutation module and sent to the evaluation module.
5.3. Results of ANN and GA
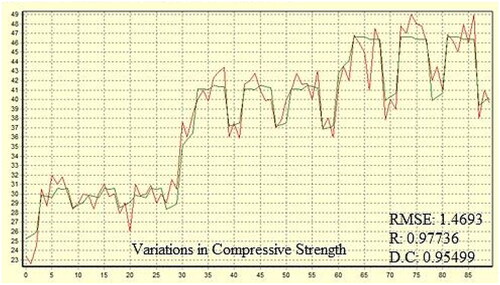
To construct the model and optimize this problem, CPC-X Neural Power was implemented. Within the artificial neural network (ANN), the learning algorithms with connection types employed were the Levenberg-Marquardt (LM) algorithm and multilayer normal feed-forward propagation. A sigmoid transfer function was employed for the output and hidden layers. According to Muthupriya et al. (Citation2011), the sigmoid function is typically utilized over the other functions. There is one hidden layer and four nodes within it. Finally, the model had an RMSE of 1.4693 and a determination coefficient of 0.95499 for the CS. shows the results of the model created by the ANN for the CS of concrete.
Figure 13. ANN model for compressive strength.
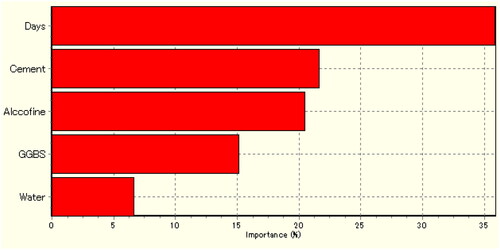
The optimization was carried out in the GA using the following parameters: The population size was 30, crossover rate was 0.8, and mutation rate was 0.1. The output was obtained using tournament selection and single-point crossover. Finally, it was concluded that 48.606 MPa is the optimized strength of CS and its optimized process factors cement (kg/m3), Alccofine (kg/m3), GGBS (kg/m3), water (liters), and days are261.506, 0.055, 52.468, 140.007, and 27.999, respectively. shows the importance of the process parameters (%) on the compressive strength. The percentage importance of Days, Cement(kg/m3), Alccofine (kg/m3), GGBS (kg/m3), and water (liters) on compressive strength were 35.91, 21.68, 20.56, 15.18 and 6.67, respectively.
Figure 14. Factors of importance (%) on CS.
6. Conclusions
Based on the present research, the following conclusions have been drawn.
To predict the CS of concrete, two EML models, Random Forest Regression (RFR) and Adaboost Regression (ABR), were developed using 90 experiments.
Of the two EML algorithms, the smallest errors, along with the largest coefficient of determination, were observed in the RFR algorithm; the errors (MAE, MAPE, MSE, RMSE, and R2) were 0.77, 0.02, 1.26, 1.12, and 0.97, respectively. However, ABR has slightly higher errors than RFR; however, the model is acceptable, as its R2 is 0.94.
To optimize this problem, a model was constructed involving the input factors and response using an ANN. For CS, the model found that the root mean square error (RMSE) is as low as 1.4693 and the determination coefficient (R2) is 0.95499.
It was observed that the optimized value of CS was 48.606 MPa and its optimized process factors Cement, Alccofine, GGBS, Water and Days were 261.506 kg/m3, 0.055kg/m3, 52.468 kg/m3, 141.007 L, and 27.999 days, respectively.
The importance of each feature was analyzed against the compressive strength. In both models, the feature ‘days’ was identified as the most influential among the other features.
The percentage importance of Cement, Alccofine, GGBS, Water and Days on CS was 21.68, 20.56, 15.18, 6.67 and 35.91, respectively.
The developed model can be effectively utilized to predict and optimize the CS of concrete because it can minimize errors and increase the coefficient of determination (R2).
Authors contribution
The corresponding author, Vivek Kumar C, was responsible for ensuring that the descriptions were accurate and agreed upon by all authors. The first author ‘G V V Satyanarayana’ was responsible for assisting and supporting for conducting experiments to the manuscript and helping in the improvisation of the technical point of this study. The second author, ‘Vivek Kumar C’, was responsible for conducting experiments in the Methodology and Design of the study and related to materials characterization and analysing the parameters of Alccofine and GGBFS in Concrete for strengthening the concrete with the replacement with Cement. The third author ‘R M Karthikeyan’ helped revising the manuscript analytically for valuable intellectual content for guiding to complete this manuscript. The second author, ‘Vivek Kumar C’ and the fourth author ‘A Punitha’ both employed ensemble machine learning (EML) approaches for predicting the compressive strength (CS) of concrete that was developed with GGBFS along with Alccofine. He wrote the original draft of the manuscript and responsible for making the final revisions and getting approval from co-authors. The fourth author ‘A Punitha’ also helped in writing the original draft of the manuscript with all related to the technical data and responsible for making the final revisions related to the ensemble machine learning algorithms. The fifth author ‘Nikolai Ivanovich, Vatin’ was responsible for assisting and supporting the manuscript and helping in the improvisation of the technical point of this study. The sixth author ‘Laith Hussein’ is responsible for making the final revisions related to the ensemble machine learning algorithms. The seventh author ‘Abhishek Joshi’ helped in the corrections of grammar and flow of the manuscript content.
Disclosure statement
We declare that we have no significant competing financial, professional, or personal interests that might have influenced the performance or presentation of the work described in this manuscript.
Data availability statement
The data that support the findings of this study are available from the corresponding author, [C Vivek Kumar], upon reasonable request.
Additional information
Notes on contributors
Vivek Kumar C.
C Vivek Kumar working as an Assistant Professor in Department of Civil Engineering, Gokaraju Rangaraju Institute of Engineering and Technology, Bachupally, Hyderabad, Telangana, India. He has 14 years of experience in teaching under graduate and post graduate programmes. He published 24+ papers in various International Journals, presented papers in 10 National and International Conferences. His research areas include Blended Concrete, Seismic Analysis on Distressed Structures, Machine Learning and Optimization techniques in Civil Engineering.
References
- Ahmad, A., Ahmad, W., Chaiyasarn, K., Ostrowski, K. A., Aslam, F., Zajdel, P., & Joyklad, P. (2021). Prediction of geopolymer concrete compressive strength using novel machine learning algorithms. Polymers, 13(19), 3389. https://doi.org/10.3390/polym13193389
- Alavala, C. R. (2008). Fuzzy logic and neural networks: basic concepts and applications. New Age International.
- Awolusi, T. F., Oke, O. L., Akinkurolere, O. O., Sojobi, A. O., & Aluko, O. G. (2019). Performance comparison of neural network training algorithms in the modeling properties of steel fiber reinforced concrete. Heliyon, 5(1), e01115. https://doi.org/10.1016/j.heliyon.2018.e01115
- Beskopylny, A. N., Stel’makh, S. A., Shcherban, E. M., Mailyan, L. R., Meskhi, B., Razveeva, I., Chernil’nik, A., & Beskopylny, N. (2022). Concrete strength prediction using machine learning methods CatBoost, k-nearest neighbors, support vector regression. Applied Sciences, 12(21), 10864. https://doi.org/10.3390/app122110864
- BIS. (1959). IS: 516-1959. Method of tests for strength of concrete. Bureau of Indian Standards.
- BIS. (2019). IS: 10262-2019. Concrete mix proportioning guidelines (second revision). Bureau of Indian Standards.
- CPC X software, neural power user guide. (2003). Available from: http://www.geocities.com/neural power, https://www2.southeastern.edu/, Academics/Faculty/pmcdowell/matlab_nnet_help.pdf.
- Duan, Z. H., Kou, S. C., & Poon, C. S. (2013). Prediction of compressive strength of recycled aggregate concrete using artificial neural networks. Construction and Building Materials, 40, 1200–1206. https://doi.org/10.1016/j.conbuildmat.2012.04.063
- Ebrahimpour, A., Abd Rahman, R. N. Z. R., Ean Ch’ng, D. H., Basri, M., & Salleh, A. B. (2008). A modeling study by response surface methodology and artificial neural network on culture parameters optimization for thermostable lipase production from a newly isolated thermophilic Geobacillus sp. strain ARM. BMC Biotechnology, 8(1), 96. https://doi.org/10.1186/1472-6750-8-960
- Farooq, F., Ahmed, W., Akbar, A., Aslam, F., & Alyousef, R. (2021). Predictive modeling for sustainable high-performance concrete from industrial wastes: A comparison and optimization of models using ensemble learners. Journal of Cleaner Production, 292, 126032. https://doi.org/10.1016/j.jclepro.2021.126032
- Feng, D.-C., Liu, Z.-T., Wang, X.-D., Chen, Y., Chang, J.-Q., Wei, D.-F., & Jiang, Z.-M. (2020). Machine learning-based compressive strength prediction for concrete: An adaptive boosting approach. Construction and Building Materials, 230, 117000. https://doi.org/10.1016/j.conbuildmat.2019.117000
- Golafshani, E. M., Behnood, A., & Arashpour, M. (2020). Predicting the compressive strength of normal and high-performance concretes using ANN and ANFIS hybridized with grey wolf optimizer. Construction and Building Materials, 232, 117266. https://doi.org/10.1016/j.conbuildmat.2019.117266
- Jiao, H., Wang, Y., Li, L., Arif, K., Farooq, F., & Alaskar, A. (2023). A novel approach in forecasting compressive strength of concrete with carbon nanotubes as nanomaterials. Materials Today Communications, 35, 106335. https://doi.org/10.1016/j.mtcomm.2023.106335
- Karim, R., Islam, M. H., Datta, S. D., & Kashem, A. (2024). Synergistic effects of supplementary cementitious materials and compressive strength prediction of concrete using machine learning algorithms with SHAP and PDP analyses. Case Studies in Construction Materials, 20, e02828. https://doi.org/10.1016/j.cscm.2023.e02828
- Kashem, A., Karim, R., Das, P., Datta, S. D., & Alharthai, M. (2024). Compressive strength prediction of sustainable concrete incorporating rice husk ash (RHA) using hybrid machine learning algorithms and parametric analyses. Case Studies in Construction Materials, 20, e03030. https://doi.org/10.1016/j.cscm.2024.e03030
- Khademi, F., Jamal, S. M., Deshpande, N., & Londhe, S. (2016). Predicting strength of recycled aggregate concrete using Artificial neural network, adaptive neuro-fuzzy inference system and multiple linear regression. International Journal of Sustainable Built Environment, 5(2), 355–369. https://doi.org/10.1016/j.ijsbe.2016.09.003
- Khashman, A., & Akpinar, P. (2017). Non-destructive prediction of concrete compressive strength using neural networks. Procedia Computer Science, 108, 2358–2362. https://doi.org/10.1016/j.procs.2017.05.039
- Kioumarsi, M., Dabiri, H., Kandiri, A., & Farhangi, V. (2023). Compressive strength of concrete containing furnace blast slag: Optimized machine learning-based models. Cleaner Engineering and Technology, 13, 100604. https://doi.org/10.1016/j.clet.2023.100604
- Kwak, S., Kim, J., Ding, H., Xu, X., Chen, R., Guo, J., & Fu, H. (2022). Machine learning prediction of the mechanical properties of γ-TiAl alloys produced using random forest regression model. Journal of Materials Research and Technology, 18, 520–530. https://doi.org/10.1016/j.jmrt.2022.02.108
- Li, D., Tang, Z., Kang, Q., Zhang, X., & Li, Y. (2023). Machine learning-based method for predicting compressive strength of concrete. Processes, 11(2), 390. https://doi.org/10.3390/pr11020390
- Lin, C.-J., & Ju, W. N. (2021). An ANN model for predicting the compressive strength of concrete. Applied Sciences, 11(9), 3798. https://doi.org/10.3390/app11093798
- Mai, H.-V. T., Nguyen, T.-A., Ly, H.-B., & Tran, V. Q. (2021). Investigation of ANN model containing one hidden layer for predicting compressive strength of concrete with blast-furnace slag and fly ash. Advances in Materials Science and Engineering, 2021, 1–17. https://doi.org/10.1155/2021/5540853
- Mater, Y., Kamel, M., Karam, A., & Bakhoum, E. (2023). ANN-Python prediction model for the compressive strength of green concrete. Construction Innovation, 23(2), 340–359. https://doi.org/10.1108/CI-08-2021-0145
- Muthupriya, P., Subramanian, K., & Vishnuram, B. G. (2011). Prediction of compressive strength anddurability of high performance concrete by artificial neural networks. International Journal of Optimization in Civil Engineering, 1, 189–e209.
- Naderpour, H., Rafiean, A. H., & Fakharian, P. (2018). Compressive strength prediction of environmentally friendly concrete using artificial neural networks. Journal of Building Engineering, 16, 213–219. https://doi.org/10.1016/j.jobe.2018.01.007
- Özcan, F., Atiş, C. D., Karahan, O., Uncuoğlu, E., & Tanyildizi, H. (2009). Comparison of artificial neural network and fuzzy logic models for prediction of long-term compressive strength of silica fume concrete. Advances in Engineering Software, 40(9), 856–863. https://doi.org/10.1016/j.advengsoft.2009.01.005
- Panneerselvam, K., Aravindan, S., & Noorul Haq, A. (2009). Hybrid of ANN with genetic algorithm for optimization of frictional vibration joining process of plastics. The International Journal of Advanced Manufacturing Technology, 42(7–8), 669–677. https://doi.org/10.1007/s00170-008-1641-z
- Paudel, S., Pudasaini, A., Shrestha, R. K., & Kharel, E. (2023). Compressive strength of concrete material using machine learning techniques. Cleaner Engineering and Technology, 15, 100661. https://doi.org/10.1016/j.clet.2023.100661
- Pereira, F. D., Fonseca, S. C., Oliveira, E. H. T., Oliveira, D. B. F., Cristea, A. I., & Carvalho, L. S. G. (2020). Deep learning for early performance prediction of introductory programming students: a comparative and explanatory study. Revista Brasileira de Informática na Educação, 28, 723–748. http://br-ie.org/pub/index.php/rbie. https://doi.org/10.5753/rbie.2020.28.0.723
- Pilkington, J. L., Preston, C., & Gomes, R. L. (2014). Comparison of response surface methodology (RSM) and artificial neural networks (ANN) towards efficient extraction of artemisinin from Artemisia annual. Industrial Crops and Products, 58, 15–e24. https://doi.org/10.1016/j.indcrop.2014.03.016
- Rathakrishnan, V., Bt. Beddu, S., & Ahmed, A. N. (2022). Predicting compressive strength of high-performance concrete with high volume ground granulated blast-furnace slag replacement using boosting machine learning algorithms. Scientific Reports, 12(1), 9539. https://doi.org/10.1038/s41598-022-12890-2
- Shang, M., Li, H., Ahmad, A., Ahmad, W., Ostrowski, K. A., Aslam, F., Joyklad, P., & Majka, T. M. (2022). Predicting the mechanical properties of RCA-based concrete using supervised machine learning algorithms. Materials, 15(2), 647. https://doi.org/10.3390/ma15020647
- Sobhani, J., Najimi, M., Pourkhorshidi, A. R., & Parhizkar, T. (2010). Prediction of the compressive strength of no-slump concrete: A comparative study of regression, neural network and ANFIS models. Construction and Building Materials, 24(5), 709–718. https://doi.org/10.1016/j.conbuildmat.2009.10.037
- Song, Y., Zhao, J., Ostrowski, K. A., Javed, M. F., Ahmad, A., Khan, M. I., Aslam, F., & Kinasz, R. (2021). Prediction of compressive strength of fly-ash-based concrete using ensemble and non-ensemble supervised machine-learning approaches. Applied Sciences, 12(1), 361. https://doi.org/10.3390/app12010361
- Thai, H.-T. (2022). Machine learning for structural engineering: A state-of-the-art review. Structures, 38, 448–491. https://doi.org/10.1016/j.istruc.2022.02.003
- Turkey, F. A., Beddu, S. B., Ahmed, A. N., & Al-Hubboubi, S. (2022). Concrete compressive strength prediction using machine learning algorithms. Research Square. https://doi.org/10.21203/rs.3.rs-1665395/v1
- Yuan, Z., Wang, L.-N., & Ji, X. (2014). Prediction of concrete compressive strength: Research on hybrid models genetic based algorithms and ANFIS. Advances in Engineering Software, 67, 156–163. https://doi.org/10.1016/j.advengsoft.2013.09.004