
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Before using concrete for a particular purpose, its strength must be determined because its physical properties vary depending on the type of supplementary cementitious material (SCM). Initially, researchers anticipated it with statistical processes; more recently, they started implementing deep learning (DL) and machine learning (ML) models. This research employed ensemble machine learning (EML) approaches to predict the compressive strength (CS) of concrete that was developed for ground-granulated blast furnace slag (GGBS) along with Alccofine 1203 (AF). Boosting regressions of Gradient Boosting Regression (GBR), Extreme Gradient Boosting Regression (XGBR) and Light Gradient Boosting Regression (LGBR) were considered for model prediction using the Jupyter Notebook. The models were created based on the outcome of the compressive strength under the 120 experimental conditions. Moreover, a comparative study was performed among GBR, XGBR and LGBR to benchmark the proposed model against a given combination of features (parameters/factors) and compressive strength. By using CPC-X Neural Power software, the experimental conditions were optimized using the Particle Swam Optimization (PSO) algorithm after the model was created by the Artificial Neural Network (ANN). Of the three boosting algorithms, the smallest errors along with the largest coefficient of determination were observed in the GBR algorithm and the optimized values of CS is 77.4 MPa and its optimized process factors (Alccofine, GGBS, Cement, C.A, F.A, SP dosage and days) were 24.77 kg/m3, 24.63 kg/m3, 534.92 kg/m3, 1100.08 kg/m3, 628.64 kg/m3, 4.20 lit/m3 and 29.03 days respectively.
1. Introduction
Pozzolans such fly ash (FA) and silica fume (SF) are the most commonly used mineral admixtures in high-strength concrete (HSC). When these ingredients are combined with Portland Cement Hydration Products, they generate an additional C-S-H gel, which is the strength-producing component of the paste, as stated by Golewski (Citation2022). As a result, concrete gains strength. It would be difficult to prepare concrete mixtures with high strength without the inclusion of chemical admixtures. A combination of a water-reducing retarder and a superplasticizer is commonly used. Superplasticizers that enable adequate workability at low water-to-cement ratios lead to stronger concrete. The water-reducing retarder slows down the hydration of the cement, giving laborers more time to pour the concrete (Author, Citationn.d). Ternary concrete, which is created using Portland clinkers and two different admixtures, maybe more desirable than binary cement in the building sector because it offers various advantages in terms of material utilization and cost reduction, as proposed by Harilal et al. (Citation2023). It has become easier to make these so-called market-oriented or tailor-made cements with the advancement of separate grinding and mixing technologies in the cement industry. Arora et al. (Citation2016) stated that the combination of Portland cement, limestone, and slag can help create an innovative cement-based material that is superior to binary-blended cement. Compared to cement made from slag or limestone cement, there is a clear benefit in that slag enhances long-term strength, while limestone adds to early strength. This results in an adequate increase in strength.
Environmental problems arise from the increase in cement usage caused by the building industry’s increased need for high-strength concrete (HSC). According to recent research, cement volume can be successfully decreased in concrete by using cementitious materials. The compatibility of cement paste with a poly-carboxylate ether [PCE]-based superplasticizer was examined by Robinson and Srisanthi (Citation2022) utilizing ternary blended combinations created with cement that were partially replaced by silica fume and fly ash. Sowjanya and Adiseshu (Citation2022) conducteda statistical analysis to forecast the Compressive Strength (CS) using ground pond ash and to assess the relationship between the physical qualities of concrete and durability criteria, such as porosity and water absorption. To estimate the CS of ternary blended concrete, Nagaraju et al. (Citation2023) examined binary and ternary blended concrete mixes using silica fume, ceramic powder, bagasse ash, and alccofine and investigated linear regression, K Nearest Neighbours (KNN), and Bayesian-optimized extreme gradient boosting (BO-XGBoost). The prediction results were further evaluated using the coefficient of determination (R2), mean absolute error (MAE), and mean square error (MSE). Salami et al. (Citation2021) predicted the capabilities and effective use of the least squares support vector machine (LSSVM), an ML model for estimating the CS of concrete with ternary blends. The LSSVM model was optimized using a coupled simulated annealing (CSA) approach. Choi et al. (Citation2023) combined deep neural network (DNN) techniques to develop a non-linear regression model that forecasts on-site concrete CS using a variety of input data. The performance was enhanced through hyperparameter tuning to optimize the related deep learning model and an ideal network structure. Alhakeem et al. (Citation2022) implemented a hybrid model of a Gradient Boosting Regression Tree (GBRT) with a grid search cross-validation (Grid Search CV) optimization approach to predict CS and improve the accuracy of the predicted models. The data was collected from 164 observations on sustainable concrete CS using different datasets. Phoeuk and Kwon (Citation2023) examined the predictability of recycled aggregate concrete’s compressive strength employing the CatBoost regressor, light gradient-boosting machine regressor (LGBM), random forest regressor (RFR), and extreme gradient-boosting regressor (XGBoost).
Mustapha et al. (Citation2022) proposed a prediction model utilizing the XGBoost algorithm to assess the physical and mechanical characteristics of pervious concretes. This approach predicts the CS, tensile strength, density, and porosity using four models that were assessed using various statistical variables. To compare individual machine learning regression approaches with Decision Tree Regression (DTR), Random Forest Regression (RFR), Lasso Regression (LR), Ridge Regression (RR), and multiple linear regression (MLR) for HPC, Kamath et al. (Citation2022) constructed regression models. An experimental study was conductedby Mahajan and Bhagat (Citation2022), and supervised ML techniques have been examined to predict the CS of fly ash-based concrete employing decision trees (DT), artificial neural networks (ANN), and gene expression programming (GEP) proved among the results of prediction were investigated. Huang et al. (Citation2022) suggested a hybrid ML method incorporating the firefly algorithm (FA) and random forest (RF) for forecasting the concrete’s CS. This method includesthe input parameters for the concrete and one output variable. To predict the CS of concrete specimens, Almahameed and Sobuz (Citation2023) created a novel combination of the random forests (RF) model with the bagging method using a hybrid ML model described as RF-Bagging and Support Vector Regression (SVR). XGBoost, AdaBoost, GBDT, and RFR were the ML models used in this study to investigate the ideal dataset split ratio of 8:2. Li and Song (Citation2022) determined the sensitivity of the variables used with fly ash, silica fume, and polypropylene fiber using the model. Bui et al. (Citation2018) established a specialized framework based on the ANN model in connection with a modified firefly algorithm (MFA) developed from empirical data to optimize a set of initial weights and biases of the ANN and improve the accuracy of the AI approach. Based on 810 data from experiments, Nguyen and Phan (Citation2024) presented two methods, notably adaptive gradient boosting (AGB) and random forest (RF), with prediction of the CS of ultra-high-performance concrete (UHPC) and evaluated and contrasted the anticipated outcomes using R2, MAE, and RMSE based on the RF and AGB. Chao et al. (Citation2024) conducted an investigation to verify the practical use of the suggested technique by combining ANN, AdaBoost, and the Logic Development Algorithm (LDA). Using this model to estimate the CS of CSA concrete was attempted with a unique approach that incorporates five standard ML algorithms.
As applications of machine learning are gaining more importance in solving complex problems, in this study, three regressions using three different boosting algorithms were used to predict the CS of Alccofine(AF) and GGBS-based prepared concrete. Moreover, because the optimized parameters are useful for society, PSO-based optimization was planned for an ANN model.
2. Machine learning predictions using boosting algorithms
ML is a subset of AI that uses algorithms to self-learn and continues improvement based on past performances or datasets. ML algorithms will develop and improve over time with minimal input from humans (Author 1, Citationn.d). Machine learning is widely applied in engineering to solve a variety of issues, including fatigue life prediction, component failure prognosis, angular velocity estimation, and outage prediction. Previously, structural engineering problems were addressed in civil engineering using AI and ML (Thai, Citation2022). In addition to improving data evaluation and concrete property predictions, machine learning has been employed in structural building design and performance assessment, improving the Finite Element Method of structures. CS predictions were made for a variety of concrete types, including CC, HPC, UHPC, and green concrete, with SCMs such as FA, GGBS, and recycled aggregates. ML/DL may be employed to predict the mechanical and chemical characteristics of concrete, including CS, STS, Flexural Strength (FS), thermal conductivity, and chloride concentration. ANN has been frequently implemented for DL models in previous investigations. Their widespread usage and frequency in research domains such as biomedical, visual identification, natural language processing, robotics, and structural health monitoring have led to this choice.
2.1. Gradient Boosting algorithm
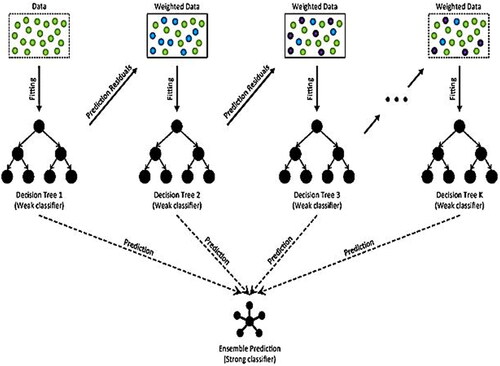
One of the most widely used forward learning ensemble techniques in ML is the gradient boosting machine (GBM) which is an effective method for developing forecasting models for tasks that involve both classification and regression. Using a group of weaker prediction models, such as decision trees, the GBM enables the creation of a model that can be predicted. Gradient-boosted trees are the name of the algorithm that results when a DT exhibits weak learning capability. A powerful boosting algorithm called gradient boosting shifts many weak to strong learners. The objective of training each new model is to minimize the loss function, which can be obtained from the cross-entropy of the old model to its mean squared error (MSE). The algorithm generates a new weak model in every iteration to minimize the gradient of the loss function in connection with actual ensemble predictions. When the stopping criterion was satisfied, the process was iterated with the predictions of the newly constructed model included in the ensemble. The Classification and Regression Trees (CART) are the base learner for a method known as gradient-boosted trees, where the training process for regression issues is represented in the following diagram. In contrast to AdaBoost, every predictor is trained using the residual errors of the prior model as labels whenever the weights of the training examples are modified. Unlike AdaBoost, when the weights of the training instances are adjusted, each predictor is trained with the residual errors of the previous model as labels. This allows us to integrate the forecasts from multiple learner models and construct a final predictive model with the accurate forecast.The algorithmic approach (Deng et al., Citation2021) to GBM is shown in .
Figure 1. Gradient boost algorithm’s architecture.
2.2. XGBoost algorithm
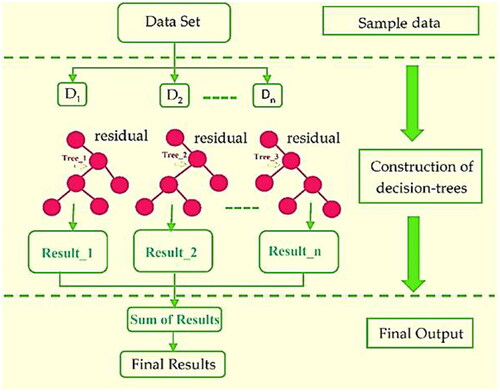
‘Extreme Gradient Boosting’ or XGBoost is an effective supervised learning method that aims at accurately predicting a target variable. The process of improving the ML algorithm in XGB to increase performance is referred to as optimization. This involves altering variables, such as regularization strength, tree depth, and learning rate, to obtain the most effective model for a particular collection of data. Caching- awareness, parallelization, cache block tree pruning, and out-of-score computations that XGB offers to assist in significantly optimizing the model. Regularization helps the model become less over-fit and more widely applicable. The regularization parameters offered by XGBoost, including L1 and L2 regularization, can be tweaked to achieve an ideal trade-off between generalization and the performance of the model. It has been demonstrated to be more precise and quicker than previous algorithms, as well as being able to handle enormous datasets easily. Regularization, cross-validation, early stopping, and other tools to customize the model are among the capabilities that it delivers. It can operate on any kind of system and supports both distribution and parallel computation. outlines the algorithmic approach for XGBoost regression (Ahmed et al., Citation2023).
Figure 2. General architecture of XGBoost algorithm.
2.3. Light gradient boosting machine algorithm
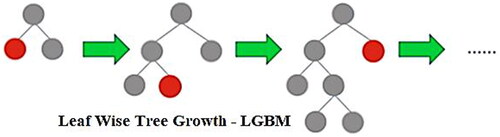
The light gradient boosted machine facilitates the quick and simple application of the GB algorithm. The LGBM is an extension of the GB algorithm that prioritizes boosting pictures in larger gradients and includes an automated feature selection procedure. This may result in a notable improvement in the accuracy of the predictions and the training speed. LGBM is faster than popular GB frameworks such as XGBoost and CatBoost. It happens due to nature that it divides trees using a gradient-based, one-sided sampling technique that increases accuracy where preserving memory. Because it uses leaf-wise growth rather than level-wise growth, it also grows faster than traditional depth-wise growth techniques. Large datasets comprising thousands of features and millions or billions of observations can be handled by the LGBM. It is also capable of handling different types of data such as text, numeric, and category. LGBM has a reputation for being extremely accurate and robust in the face of datasets that are imbalanced. It uses several strategies, including data balancing, regularization, and gradient-based one-sided sampling. Many options are available for optimizing and customizing models using LGBM. Its integrated capabilities for cross-validation, tuning of hyperparameters, and data preprocessing facilitate user model optimization. illustrates the LGBM (Author 2, Citationn.d) implementation.
Figure 3. Implementation of LGBM.
3. Features and data set of experimentation
The dataset consists of 120 experimental conditions with seven features and one response. The blended high-strength concretes were prepared according to the IS 10262:2019 standard (IS: 10262-2019,2019, Citation2019) and tested as per IS 516:1959 (IS 516, 516, Citation1959) to evaluate their CS. The main raw materials used were AF, GGBS, cement, C.A., and F.A; were taken as kilogram/cubic meter and the SP dosage as liters/cubic meter. The limits of the values used for each feature are listed in . confirms the work plan to produce concrete, followed by the attainment of CS for 120 concrete compositions. It also shows the phase of model prediction using machine learning, followed by optimization using PSO for the ANN model.
Figure 4. Experimental plan.

Table 1. Limits of each feature used to prepare the concrete.
Alccofine, GGBS, Cement, C.A, F.A, SP dosage, and days are the features of the ML models. CS (MPa) represents the predicted parameter. shows the correlation between the given features/variables (Beskopylny et al., Citation2022). The responses and each independent input feature were positively and negatively correlated. When one feature is increased, the responses increase linearly when the value is positive, whereas when one feature is increased, the responses decline linearly when the value is negative. displays the statistical characteristics of the experimental dataset.
Figure 5. Correlation matrix.
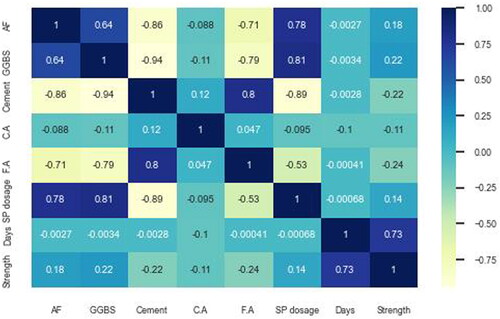
Table 2. Statistical characteristics of experimental dataset.
4. Machine learning models and analysis
4.1. Model building for GBR, XGBR and LGBR
The machine learning model development approach used for this investigation is shown in , where the dataset was imported, and the training and test data were separated on an 80:20 basis to develop this machine learning model (Kioumarsi et al., Citation2023). The model was built using the training data. The test data were later used to assess the model. Three boosting machine learning models GBR, XGBR, and LGBR were developed and evaluated in this study. The CS values of the observed and anticipated values of the testing samples for GBR, XGBR and LGBR are plotted (Li et al., Citation2023) in . The plot shows that GBR has fewer errors than the other two algorithms.
Figure 6. Methodology for development of ML model.
Figure 7. Testing samples’ compressive strength of observed and predicted for (a) Gradient Boosting (b) Extreme Gradient Boosting (c) Light Gradient Boosting.
4.2. Evaluation measures for models
When analyzing models based on regression, it is critical to employ a variety of evaluation metrics to evaluate the model’s performance. The present research employed five indicators: MAE, MAPE, MSE, RMSE, and R2. The following are represented in the prescribed metrics (Turkey et al., Citation2022):
(i)
(i)
(ii)
(ii)
(iii)
(iii)
(iv)
(iv)
(v)
(v)
In equations (i-v) (Beskopylny et al., Citation2022; Turkey et al., Citation2022; Ahmad et al., Citation2021), n is the total number of test conditions and yi and are the measured and predicted values, respectively. The MAE, MAPE, MSE, and RMSE values were employed to evaluate the modeling errors. The preferred value is the one where the variation between the experimental and predicted values is lower.R2, a value that can range from 0 to 1. The closer the numerical value is to 1, the better the model’s optimized fit.
4.3. Results & discussions of regression models
4.3.1. Comparison of training and testing measures
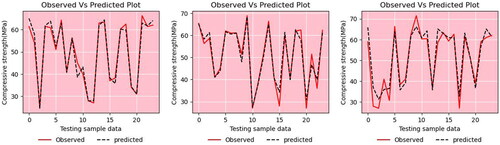
The following metrics; MAE, MAPE, MSE, RMSE, and R2 were used to evaluate the model performance of GBR, XGBR and LGBR. The results are presented in . The CS values of these models were identified separately for the training and testing datasets. Overall, the test data errors indicate the capacity of the developed algorithm for generalization, whereas the training dataset errors indicate the adequacy of the model. More than 90% of R2 was observed in all three models of GBR, XGBR, and LGBR when training and testing the data (Farooq et al., Citation2021).
Table 3. Training and testing measures of regression models.
The GBR model, which achieved 0.99 while training and 0.97 in testing, achieved the best prediction accuracy according to the model’s characteristics; the XGBR model, on the other hand, obtained 0.98 during training and 0.96 during testing and for the LGBR model 0.94 during training and 0.92 during testing. The GBR model also exhibited the lowest training prediction errors with MAE = 0.77, MAPE = 0.01, MSE = 1.04, and RMSE = 0.87. Meanwhile, the errors of XGBR and LBGR were slightly higher than those of the GBR model. Hyperparameter tuning was not attempted for all the models in this investigation, considering that the basic models had a greater prediction accuracy (GBR; R2 = 0.99; XGBR; R2 = 0.98; LGBR; R2 = 0.94). The performance measures of the two models (Beskopylny et al., Citation2022; Rathakrishnan et al., Citation2022) are compared in .
Figure 8. Comparison of evaluation measures of (a) Training (b) Testing for GBR, XGBR, and LGBR.
4.3.2. Comparison of prediction plots
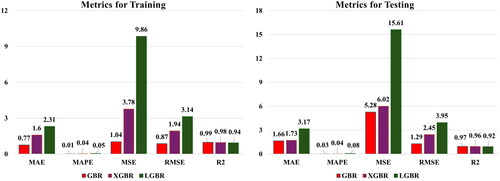
displays the test data’s R2 value of the actual compressive strength of each experiment (yi) on the x axis, while over the y axis, the predicted compressive strength (y and ) by the model is shown (Pereira et al., Citation2020). The best-fit line indicating the prediction in the model was also compared to an identity line at a 45° angle. A degree of variation was observed in this plot. As most of the points are close to identity, this means that the residual of the model’s prediction, to some extent, is close to zero in the GBR and XGBR models. However, certain points are away from identity in the LGBR model, as it has a higher MAE value. This is confirmed by as well.
Figure 9. Comparison of prediction error plots for (a) Gradient Boosting (b) Extreme Gradient Boosting (c) Light Gradient Boosting.
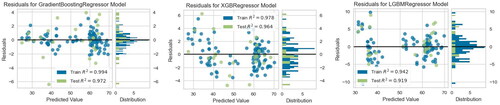
4.3.3. Comparison of residual plots
shows the residuals plotted on the y-axis and the projected values for training and testing on the x-axis. also displays the residual distributions for GBR, XGBR and LGBR. Plotting shows that the residuals are proportionally distributed along the zero axis, indicating the absence of heteroscedasticity (Pereira et al., Citation2020). In addition, there were very few outliers and no clear patterns. The residual (point) locations on the plot can be used to determine the errors. In comparison with the error prediction plots, GBR has less error and XGBR and LGBR have comparatively more error, since almost all of the points are very close to the horizontal black line or point zero on the y-axis. Additionally, it is confirmed that the model uses a linear regression approach residual histograms, which show a normal distribution in the shape of a bell in all three regressions.
Figure 10. Comparison of residual plots for (a) Gradient Boosting (b) Extreme Gradient Boosting (c) Light Gradient Boosting.
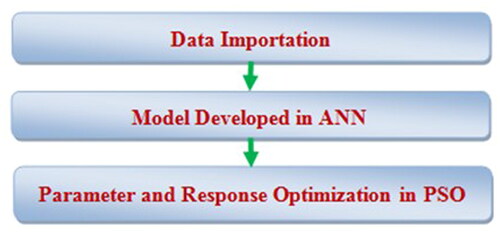
5. Optimization using ANN and PSO
This study employed the Particle Swarm Optimization (PSO) to optimize the model that was created by the ANN. The following addresses the roles of ANN and PSO in modeling and optimization. The combined use of the ANN and PSO is shown in . PSOwas employed to optimize the parameters by applying the same model as the fitness function after the model was established by the ANN. To execute PSO, the fitness function was applied once the population was initialized. The termination criterion was later confirmed. The program terminates and displays the output when the condition is achieved. If not, the phases of selection, crossover, and mutation are explored to create a new population, which is then sent to a criterion check. This process was repeated until the termination criterion was fulfilled.
Figure 11. Integration of ANN and PSO.
5.1. Artificial neural network
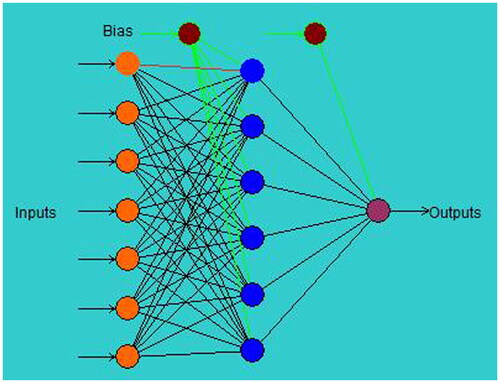
Compared with other models, such as linear and exponential regression, the ANN approach provides a more accurate prediction. Because of their outstanding ability to match input and output correlations and learn algorithms, especially for non-linear and complex systems, artificial neural networks (ANN) have been widely used as prediction tools by academics (Alavala, Citation2008; Pilkington et al., Citation2014). Ebrahimpour et al. (Citation2008) stated that while ANN can recognize the relationships underlying complicated processes, it has enormous modeling potential. To train the data, ANNs use a variety of learning algorithms, including Levenberg-Marquadt, batch back propagation, incremental back propagation, and quick propagation. A variety of non-linear transfer functions are also included, including sigmoid, bipolar, Gaussian, Tanh, linear, threshold, and linear functions (Neural Power User Guide, Citation2003). The software employed in this study comprises two distinct connection types: ‘multilayer full feed-forward’ and ‘multilayer normal feed-forward. Training was terminated based on the divergence of the RMSE’ (Awolusi et al., Citation2019). shows the ANN architecture between the input and response for the compressive strength.
Figure 12. ANN architecture between input and response.
5.2. Particle swarm optimization
Eberhart et al. (Citation2001) proposed PSO algorithm to optimize continuous non-linear functions. This algorithm draws inspiration from the social and collective behavior observed in groups of fish and flocks of birds migrating in the quest for food or survival. The PSO algorithm draws inspiration from the most skilled members of the population while drawing from their own experiences. According to the metaphor, a group of solutions moves through a search space to find the most suitable spot or response. In PSO, each particle is regarded as an individual in the population in the dimensional solution space. Each particle was initiated with the position and velocity randomly and the first position of each particle was evaluated based on the target functions (Bharathi Raja & Baskar, Citation2011). Then gbest is identified amongthe results yielded by the all particles in the populations. Based on this gbest, the pbest particles were fixed. The next velocity is added to the pbest particle, and a new population is created that defines the new(second) positions of all particles. Subsequently, gbest is identified among the results yielded by the newly created population based on the recent pbest particle. This process continues until the stop criteria take action on the algorithm for either the number of iterations or no changes in the gbest value.
5.3. Results of ANN and PSO
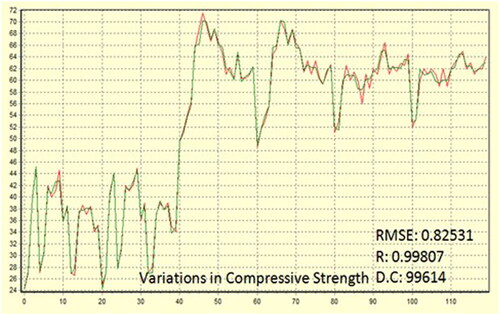
To construct the model and optimize this problem, CPC-X Neural Power was implemented. Within the ANN, the learning algorithms with connection types employed were the levenberg-marquardt (LM) algorithm and multilayer normal feed-forward propagation. A sigmoid transfer function was employed for the output and hidden layers. According to Muthupriya et al. (Citation2011), the sigmoid function is typically utilized over the other functions. There is one hidden layer overall, with six nodes within it. Finally, the model had an RMSE of 0.82531 and a determination coefficient of 0.99614 for the CS. shows the results of the model created by the ANN for the CS of concrete.
Figure 13. ANN model for compressive strength.
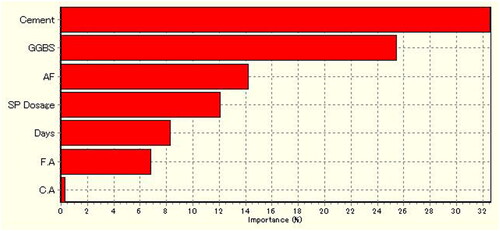
The optimization was carried out in PSO using the following parameters: population size, inertia weight, and learning factors such as cognitive factor (C1) and social factor (C2) of 10, 0.1, 2 and 2 respectively. Finally, the optimized value of CSis77.4 MPa and its optimized process factors (Alccofine, GSBS, Cement, C.A, F.A, SP dosage and Days) were 24.77 kg/m3, 24.63 kg/m3, 534.92 kg/m3, 1100.08 kg/m3, 628.64 kg/m3, 4.20 lit/m3, and 29.03 days respectively. shows the importance of the process parameters (%) on the compressive strength. The percentage importance of cement, GGBS, Alccofine, Sp Dosage, Days, F.A and C.A on the compressive strength were 32.61, 25.49, 14.24, 12.12, 8.34, 6.86 and 0.35 respectively.
Figure 14. Factors importance (%) on CS.
6. Conclusions
Based on the present research, the following conclusions have been drawn.
To predict the CS of concrete, Three EML models; Gradient Boosting Regression (GBR), Extreme Gradient Boosting Regression (XGBR), and Light Gradient Boosting (LGBR), were developed using 120 experiments.
Of the three EML algorithms, the smallest errors along with the largest coefficient of determination were observed in the GBR algorithm. The errors (MAE, MAPE, MSE, RMSE, and R2) were 0.77, 0.01, 1.04, 0.87 and 0.99 respectively. However, XGBR and LGBR have slightly more errors than GBR; however, the models are acceptable as theirsR2are above 0.90.
To optimize this problem by using PSO, a model was constructed involving the input factors and response using an ANN. For CS, the model was found that the root mean square
error (RMSE) is as low as 0.82531 and the determination coefficient (R2) is 0.99614.
The optimized values of CS is 77.4 MPa and its optimized process factors were as follows: Alccofine, GSBS, cement, C.A, F.A, SP dosage and days were 24.77 kg/m3, 24.63 kg/m3, 534.92 kg/m3, 1100.08 kg/m3, 628.64 kg/m3, 4.20 lit/m3 and 29.03 days respectively.
The percentage importance of Cement, GGBS, Alccofine, SP dosage, Days, F.A and C.A on the compressive strength were 32.61, 25.49, 14.24, 12.12, 8.34, 6.86 and 0.35 respectively.
The developed model can be effectively utilized to predict and optimize the CS of concrete, because it can minimize errors and increase the coefficient of determination (R2).
Credit author statement
The corresponding author, Veeraballi Mallikarjuna Reddy, was responsible for ensuring that the descriptions are accurate and agreed by all authors.
The First author, ‘Veeraballi Mallikarjuna Reddy, was responsible for conducting experiments related to materials characterization and analysing the parameters of Alccofine and GGBS Based Concrete for strengthening the concrete with the replacement with Cement.
The Second author ‘LomadaRamaprasad Reddy’ was responsible for assisting and supporting for conducting experiments to the manuscript and helping in improvisation of the technical point of this study.
The Third author, ‘Vivek Kumar C’, and Fourth author ‘R.Karthikeyan’ both employed ensemble machine learning (EML) approaches for predicting the compressive strength (CS) of concrete that was developed with GGBS along with Alccofine. He has written the original draft of the manuscript and responsible for making the final revisions and getting approval from co-authors. The Third author ‘Vivek Kumar C’ was helped in the Methodology and Design of study and revising the manuscript analytically for valuable intellectual content for guiding to complete this manuscript.
The fourth author ‘R Karthikeyan’ written the original draft of the manuscript with all related to the technical data and responsible for making the final revisions related to the ensemble machine learning algorithms.
The fifth author ‘Solovev S. A’ was responsible for assisting and supporting for the manuscript and helping in improvisation of the technical point of this study.
The sixth author ‘Nikolai Ivanovich, Vatin’ partially funded from the Ministry of Science and Higher Education of the Russian Federation as part of the World-class Research Center program: Advanced Digital Technologies (contract No. 075-15-2022-311 dated 20.04.2022).
The seven author ‘Abhishek Joshi’ helped in the corrections of grammar and flow of the manuscript content.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author, [Veeraballi Mallikarjuna Reddy], upon reasonable request.
Additional information
Funding
References
- Ahmad, A., Ahmad, W., Chaiyasarn, K., Ostrowski, K. A., Aslam, F., Zajdel, P., & Joyklad, P. (2021). Prediction of geopolymer concrete compressive strength using novel machine learning algorithms. Polymers, 13(19), 3389. https://doi.org/10.3390/polym13193389
- Ahmed, S., Raza, B., Hussain, L., Aldweesh, A., Omar, A., Khan, M. S., Eldin, E. T., & Nadim, M. A. (2023). The deep learning ResNet101 and ensemble XGBoost algorithm with hyperparameters optimization accurately predict the lung cancer. Applied Artificial Intelligence, 37(1), 2166222. https://doi.org/10.1080/08839514.2023.2166222
- Alavala, C. R. (2008). Fuzzy logic and neural networks: basic concepts and applications. New Age International.
- Alhakeem, Z. M., Jebur, Y. M., Henedy, S. N., Imran, H., Bernardo, L. F. A., & Hussein, H. M. (2022). Prediction of ecofriendly concrete compressive strength using gradient boosting regression tree combined with GridSearchCVHyperparameter-optimization techniques. Materials (Basel, Switzerland), 15(21), 7432. https://doi.org/10.3390/ma15217432
- Almahameed, B. A. A., & Sobuz, H. R. (2023). The role of hybrid machine learning for predicting strength behavior of sustainable concrete. Civil Engineering and Architecture, 11(4), 2012–2032. https://doi.org/10.13189/cea.2023.110425
- Arora, A., Sant, G., & Neithalath, N. (2016). Ternary blends containing slag and interground/blended limestone: Hydration, strength, and pore structure. Construction and Building Materials, 102(1), 113–124. https://doi.org/10.1016/j.conbuildmat.2015.10.179
- Author. n.d. https://www.engr.psu.edu/ce/courses/ce584/concrete/library/materials/Admixture/AdmixturesMain.htm
- Author 1. n.d. https://www.techtarget.com/searchenterpriseai/definition/machine-learning-ML
- Author 2. n.d. https://medium.com/data-reply-it-datatech/lightgbm-for-timeseries-forecasting-408971289a12.
- Awolusi, T. F., Oke, O. L., Akinkurolere, O. O., Sojobi, A. O., & Aluko, O. G. (2019). Performance comparison of neural network training algorithms in the modeling properties of steel fiber reinforced concrete. Heliyon, 5(1), e01115. 2019)https://doi.org/10.1016/j.heliyon.2018.e01115
- Beskopylny, A. N., Stel’makh, S. A., Shcherban’, E. M., Mailyan, L. R., Meskhi, B., Razveeva, I., Chernil’nik, A., & Beskopylny, N. (2022). Concrete strength prediction using machine learning methods catboost, k-nearest neighbors, support vector regression. Applied Sciences, 12(21), 10864. https://doi.org/10.3390/app122110864
- Bharathi Raja, S., & Baskar, N. (2011). Particle swarm optimization technique for determining optimal machining parameters of different work piece materials in turning operation. The International Journal of Advanced Manufacturing Technology, 54(5-8), 445–463. https://doi.org/10.1007/s00170-010-2958-y
- Bui, D.-K., Nguyen, T., Chou, J.-S., Nguyen-Xuan, H., & Ngo, T. D. (2018). A modified firefly algorithm-artificial neural network expert system for predicting compressive and tensile strength of high-performance concrete. Construction and Building Materials, 180, 320–333. https://doi.org/10.1016/j.conbuildmat.2018.05.201
- Chao, Z., Li, Z., Dong, Y., Shi, D., & Zheng, J. (2024). Estimating compressive strength of coral sand aggregate concrete in marine environment by combining physical experiments and machine learning-based techniques. Ocean Engineering, 308 https://doi.org/10.1016/j.oceaneng.2024.118320
- Choi, J.-H., Kim, D., Ko, M.-S., Lee, D.-E., Wi, K., & Lee, H.-S. (2023). Compressive strength prediction of ternary-blended concrete using deep neural network with tuned hyperparameters. Journal of Building Engineering, 75, 107004. https://doi.org/10.1016/j.jobe.2023.107004
- Deng, H., Zhou, Y., Wang, L., & Zhang, C. (2021). Ensemble learning for the early prediction of neonatal jaundice with genetic features. BMC Medical Informatics and Decision Making, 21(1), 338. https://doi.org/10.1186/s12911-021-01701-9
- Eberhart, R. C., Shi, Y., & Kennedy, J. (2001). Swarm intelligence, the Morgan Kaufmann series in evolutionary computation (1st ed.). Morgan Kaufmann.
- Ebrahimpour, A., Abd Rahman, R. N. Z. R., Ean Ch’ng, D. H., Basri, M., & Salleh, A. B. (2008). A modeling study by response surface methodology and artificial neural network on culture parameters optimization for thermostable lipase production from a newly isolated thermophilicGeobacillus sp. strain ARM. BMC Biotechnology, 8(1), 96. https://doi.org/10.1186/1472-6750-8-960
- Farooq, F., Ahmed, W., Akbar, A., Aslam, F., & Alyousef, R. (2021). Predictive modeling for sustainable high-performance concrete from industrial wastes: A comparison and optimization of models using ensemble learners. Journal of Cleaner Production, 292, 126032. https://doi.org/10.1016/j.jclepro.2021.126032
- Golewski, G. L. (2022). The role of pozzolanic activity of siliceous fly ash in the formation of the structure of sustainable cementitious composites. Sustainable Chemistry, 3(4), 520–534. https://doi.org/10.3390/suschem3040032
- Harilal, M., Anandkumar, B., George, R. P., Albert, S. K., & Philip, J. (2023). High-performance eco-friendly ternary blended green concrete in seawater environment. Hybrid Advances, 3, 100037. https://doi.org/10.1016/j.hybadv.2023.100037
- Huang, J., Sabri, M. M. S., Ulrikh, D. V., Ahmad, M., & Alsaffar, K. A. M. (2022). Predicting the compressive strength of the cement-fly ash-slag ternary concrete using the firefly algorithm (FA) and random forest (RF) hybrid machine-learning method. Materials (Basel, Switzerland), 15(12), 4193. https://doi.org/10.3390/ma15124193
- IS 516. (1959). Method of tests for strength of concrete. BIS.
- IS: 10262-2019. 2019. Concrete mix proportioning guidelines (2nd Revision). Bureau of Indian Standards.
- Kamath, M. V., Prashanth, S., Kumar, M., & Tantri, A. (2022). Machine-learning-algorithm to predict the high-performance concrete compressive strength using multiple data. Journal of Engineering, Design and Technology, 22(2), 532–560. https://doi.org/10.1108/JEDT-11-2021-0637
- Kioumarsi, M., Dabiri, H., Kandiri, A., & Farhangi, V. (2023). Compressive strength of concrete containing furnace blast slag; optimized machine learning-based models. Cleaner Engineering and Technology, 13, 100604. https://doi.org/10.1016/j.clet.2023.100604
- Li, D., Tang, Z., Kang, Q., Zhang, X., & Li, Y. (2023). Machine learning-based method for predicting compressive strength of concrete. Processes, 11(2), 390. https://doi.org/10.3390/pr11020390
- Li, Q.-F., & Song, Z.-M. (2022). High-performance concrete strength prediction based on ensemble learning. Construction and Building Materials, 324, 126694. https://doi.org/10.1016/j.conbuildmat.2022.126694
- Mahajan, L., & Bhagat, S. (2022). Machine learning approaches for predicting compressive strength of concrete with fly ash admixture. Research on Engineering Structures and Materials, 9(2), 431–456. https://doi.org/10.17515/resm2022.534ma0927
- Mustapha, I. B., Abdulkareem, Z. J., Abdulkareem, M., & Ganiyu, A. A. (2022). Predictive modeling of physical and mechanical properties of pervious concrete using XGBoost. ArXiv, abs/2206.00003.
- Muthupriya, P., Subramanian, K., & Vishnuram, B. G. (2011). Prediction of compressive strength anddurability of high performance concrete by artificial neural networks. International Journal of Optimization in Civil Engineering, 1, 189–e209.
- Nagaraju, T. V., Mantena, S., Azab, M., Alisha, S. S., El Hachem, C., Adamu, M., & Rama Murthy, P. S. (2023). Prediction of high strength ternary blended concrete containing different silica proportions using machine learning approaches. Results in Engineering, 17, 100973. https://doi.org/10.1016/j.rineng.2023.100973
- Neural Power User Guide. (2003). Retrieved October 10, 2019, from http://www.geocities.com/neural power, https://www2.southeastern.edu/Academics/Faculty/pmcdowell/matlab_nnet_help.pdf
- Nguyen, D. L., & Phan, T. D. (2024). Predicting the compressive strength of ultra-high-performance concrete: An ensemble machine learning approach and actual application. Asian Journal of Civil Engineering, 25(4), 3363–3377. https://doi.org/10.1007/s42107-023-00984-9
- Pereira, F. D., Fonseca, S. C., Oliveira, E. H. T., Oliveira, D. B. F., Cristea, A. I., & Carvalho, L. S. G. (2020). Deep learning for early performance prediction of introductory programming students: A comparative and explanatory study. Revista Brasileira de Informática na Educação, 28, 723–748. http://br-ie.org/pub/index.php/rbie. https://doi.org/10.5753/rbie.2020.28.0.723
- Phoeuk, M., & Kwon, M. (2023). Accuracy prediction of compressive strength of concrete incorporating recycled aggregate using ensemble learning algorithms: Multinational dataset. Advances in Civil Engineering, 2023, 1–23. https://doi.org/10.1155/2023/5076429
- Pilkington, J. L., Preston, C., & Gomes, R. L. (2014). Comparison of response surface methodology(RSM) and artificial neural networks (ANN) towards efficient extraction of artemisinin from Artemisia annual. Industrial Crops and Products, 58, e15–e24. https://doi.org/10.1016/j.indcrop.2014.03.016
- Rathakrishnan, V., Bt Beddu, S., & Ahmed, A. N. (2022). Predicting compressive strength of high-performance concrete with high volume ground granulated blast-furnace slag replacement using boosting machine learning algorithms. Scientific Reports, 12(1), 9539. https://doi.org/10.1038/s41598-022-12890-2
- Robinson, J., & Srisanthi, V. G. (2022). Statistical analysis on mechanical behaviour of ternary blended high strength concrete. Cement Wapno Beton, 27(6), 386–402. https://doi.org/10.32047/CWB.2022.27.6.2
- Salami, B. A., Olayiwola, T., Oyehan, T. A., & Raji, I. A. (2021). Data-driven model for ternary-blend concrete compressive strength prediction using machine learning approach. Construction and Building Materials, 301, 124152. https://doi.org/10.1016/j.conbuildmat.2021.124152
- Sowjanya, S., & Adiseshu, S. (2022). Statistical analysis of the physical properties of ternary blended concrete. Innovative Infrastructure Solutions, 7(1), 10. https://doi.org/10.1007/s41062-021-00610-0
- Thai, H.-T. (2022). Machine learning for structural engineering: A state-of-the-art review. Structures, 38, 448–491. https://doi.org/10.1016/j.istruc.2022.02.003
- Turkey, F. A., Beddu, S. B., Ahmed, A. N., & Al-Hubboubi, S. (2022). Concrete compressive strength prediction using machine learning algorithms. Research Square. https://doi.org/10.21203/rs.3.rs-1665395/v1