
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Poverty is a major problem Tanzania is facing, which depends on agriculture as the main economic activity. Different stakeholders have involved themselves in boosting agricultural productivity, especially in semiarid regions, where their main focus is on drought tolerant crops such as sorghum and millet. If this support is not linked with market opportunities, commodity prices may be depressed and discourage farmers. This paper determines prospect for increasing utilization of animal feed as the market opportunity for farmer by forecast consumption of livestock product such as eggs, milk, chicken and cow meat. Autoregressive integrated moving average models were used for forecasting with the data from FAOSTAT. The result shows that consumption of all livestock products will increase, hence expected demand for animal feed. This paper calls for more research works in analyzing factors that may affect consumption of livestock products such as population increase and change of consumption behavior toward livestock products.
PUBLIC INTEREST STATEMENT
Poverty is a major problem Tanzania is facing, which depends on agriculture as the main economic activity for more than 75% of the population. Different stakeholders have involved themselves in boosting agricultural production especially in regions with less rain. Their main focus is in crops that need less rainfall such as sorghum and millet. If this support is successful, production will increase; however, if this increase in production is not linked with the market, prices may drop and discourage farmers. This paper determines the possibility of future increasing in usage of livestock product as the market opportunity for farmer in regions with less rainfall. The result shows that consumption of all livestock products will increase in the next five years. This means that there is an opportunity of farmers in regions of less rainfall to cultivate crops such as sorghum and millet and sell them in animal feed.
Competing interests
The author declares no competing interests.
1. Introduction
Poverty is a major problem many African countries are facing, especially in the south of Sahara desert. Tanzania is one of the countries, with a population of about 45 million people (Tanzania, Citation2014). The main economic activity is agriculture which employs about 75% of the total population. Even though agriculture is the main activity, its structure is dominated by smallholder farmers who cultivate average farm size of .9–3 ha each with the use of very low technology. It is estimated that 70% of crop area is cultivated by hand hoe, 20% by ox plough and 10% by tractors (Chauvin, Mulangu, & Porto, Citation2012; Chauvin et al., Citation2012; Group, Citation2011; Majid, Citation2008). Due to poor technology and rainfall dependence system, the agricultural sector has shown poor performance and hence promotes more poverty to those who depend on it.
Both the government of Tanzania and other stakeholders have involved themselves in different projects to promote the generation and adoption of technologies that are capable of boosting agricultural productivity. In semiarid region, initiatives have been mainly focusing on drought-tolerant crops such as sorghum and millet rather than tropical crops such as maize, which requires a more even distribution of rainfall (Blum & Sullivan, Citation1986). This support of government and donors to crops like sorghum and millet is important in increasing agricultural productivity in semiarid regions. But these projects could depress commodity prices and farmers’ incomes if they are not linked to market opportunities for farmers, especially with the presence of preferred substitute crops such as maize (Amani, Citation2005).
Feed industry is a potential market for sorghum and millet to substitute maize in the market (Rohrbach and Kiriwaggulu, Citation2001). According to Abdulkadir, Na-Allah and Bala (Citation2013) and Issa, Jarial, Brah, Harouna and Soumana (Citation2015), sorghum can absolutely or partially replace maize in animal feed especially in poultry industry. As maize is preferred than sorghum and millet due to availability and price stability, linking farmers in feed industry is important. Substituting maize with sorghum and millet will be advantageous as it will eliminate competition between animals and humans in the consumption of maize. This paper estimates prospects for increasing utilization in feed concentrate market by forecast production of livestock product such as eggs, milk, chicken and cow meat.
2. Methodology
Autoregressive integrated moving average (ARIMA) models were used to forecast production of livestock products. These models were used because they consider only one variable under each observation. Scholars in different discipline such as Jose and Sojan (Citation2013), Yeboah, Ohene and Wereko (Citation2012), Wang and Yang (2017), Manoj and Madhu (2014), Mandal (Citation2005) and Raymond (Citation1997) used these models for forecasting. The main assumption of these models is that in time series analysis, there is an aspect of past patterns, which continue to remain in the future (Ramasubramanian, Citation2001; Heng, Zhang, & Yang, 2017). These models capture the pattern and use it to forecast future expected values.
2.1. Data collection
Data for all forecasted animal consumptions were collected from the Food and Agricultural Organization database (FAOSTAT, Citation2014). The range of the data is from 1961 to 2013. According to Box and Jenkins who were the pioneers of time series modeling, at least 50 observations are necessary to perform time series analysis.
2.2. Model description
An ARIMA model is divided into three components depending on the type of data. The first component is the autoregressive (AR) time series model which consists of past observations of the dependent variable (i.e. the variable of interest) in the forecast of future observations. The first-order autoregression model (AR (1)) is represented by the Independent Pricing and Regulatory Tribunal of NSW as follows:
where yt is the dependent variable, a is a parameter, yt−1 is a lagged dependent variable and εt is the random or white noise term which represents a shock which cannot be explained.
The second component is the moving average (MA) models which include past observations of the white noise process (i.e. past forecast errors) in the forecast of future observations of the dependent variable. The first-order MA model (MA (1)) is represented as follows:
where b is the parameter and εt and εt−1 are forecast error and the lagged forecast error, respectively.
The combination of the two models MA and AR gives ARMA model, which is stationary. In case the data used are nonstationary, a third component is used to convert the data to achieve stationarity by differencing (integrating (I)) original series, which according to Rohrbach and Kiriwaggulu (Citation2001), and Nau (Citation2018) is represented as
where y′t is the future consumption, yt and yt−1 are original series and lagged original series, respectively (stationary data are defined below).
The combination of the three first-order models gives models which can be used to estimate future consumptions of livestock product.
2.3. Stages in ARIMA model building
The Box–Jenkins methodology for analyzing and modeling time series (Box, Jenkins, & Reinsel, Citation1994) is characterized by three steps: model identification, parameter estimation and model validation.
2.3.1. Model identification
In building time series models, data used are suppose to be stationary. If nonstationary data are used in a model, the results may indicate a relationship that is misleading (Baumohl & Lyocsa, 2009). So before identifying the model, time series data have to be tested for stationarity. Stationary data are the ones whose statistical properties do not change over time (Studenmund, Citation2016). More formally, a time series is stationary if it is characterized with constant mean and variance, and an autocovariance that does not depend on time (Ramasubramanian, Citation2001; Studenmund, Citation2016). If any of these characteristics are not met, the data are declared nonstationary. The autocorrelation function (ACF) will be applied in the data to determine this problem. If ACF plot is positive and shows a very slow linear decay pattern, then the data are nonstationary (Nau, Citation2018). This problem of nonstationarity can be corrected through appropriate differencing of the data if caused by mean or model transformation if caused by variance (Nau, Citation2018; Ramasubramanian, Citation2001).
The next step is to find the initial values for the orders of seasonality and nonseasonality (p and q). In this step, the ACF and partial ACF (PACF) are fundamental analytical tools used. To calculate an autocorrelation of lag k mentioned as one characteristic of stationary data, we compute correlation between Yt and Yt−k over the n–k pairs in the data set
where Yt is the original series, Yt−k is a lagged version of original series and µ is the mean of the data (Studenmund, Citation2016).
The PACF is defined as the linear correlation between Yt and Yt−k, controlling for possible effects of linear relationships among values at intermediate lags. The first-order partial is equal to first-order autocorrelation but the second order can be calculated as follows:
The ACF gives the order of AR (p) and PACF gives the order of MA (q).
2.3.2. Parameter estimation
After identifying suitable order for ARIMA(p,d,q), we attempt to find precise estimates of parameters of the model using least squares as described by Box and Jenkins. The parameters are obtained by maximum likelihood which is asymptotically correct for time series. Estimators are usually sufficient, efficient and consistent for Gaussian distributions and are asymptotically normal and efficient for several non-Gaussian distribution families (Mandal, Citation2005; Nyoni & Bonga, 2019). In this study, the parameters are estimated using SPSS.
2.3.3. Model validation
Models chosen in the last stage are validated using two methods which include Bayesian information criteria (BIC) and plots of ACF residuals.
2.3.3.1. BIC
The BIC is an index used in Bayesian statistics to compare which model is a best fit between two or more models. It is also known as the Schwarz-Bayesian criterion or the Schwarz information criterion. BIC is defined as
where k is the number of parameters which the model estimates, N is the number of observations, θ is the set of all parameters and L(θ) is the likelihood of the model tested in a given data, when evaluated at maximum likelihood values of θ (Neath & Cavanaugh, Citation2012).
When using BIC, the model with the lowest BIC value is considered best fit. BIC is closely related to Akaike information criterion.
2.3.3.2. Plot of ACF residuals
Another method is by plotting the ACF of residuals to examine the goodness of fit. If most of the sample autocorrelation coefficients of the residuals are within the limits of ±1.96/√N where N is the number of observation in which the model is build, then the model is a good fit (Ramasubramanian, Citation2001; Wang-Chuan et al., 2017). For this study, the number of observation is 52; hence, the limit is ±.2718.
3. Results and discussion
3.1. Model building
As stated above, three procedures were followed to build ARIMA models for consumption of animal products.
3.2. Model for consumption of eggs
3.2.1. Model identification
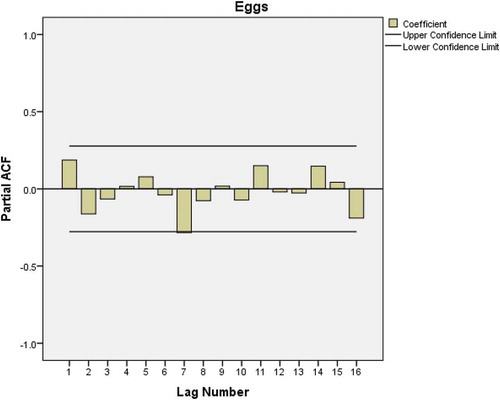
In identifying the model, the ACF is applied in egg consumption data to check if data are stationary. Figure shows a very slow linear decay pattern which is a sign of nonstationary time series. This problem can be corrected by a first-degree order of differentiation. After applying autocorrelation, both ACF (Figure ) and PACF plots (Figure ) show significant spike only at lag 1 meaning that higher order autocorrelations are explained by the lag 1 autocorrelation. This implies that there is no need of adding AR (p) or MA (q).
Figure 1. Autocorrelation plot of eggs consumption data used to test for stationarity.
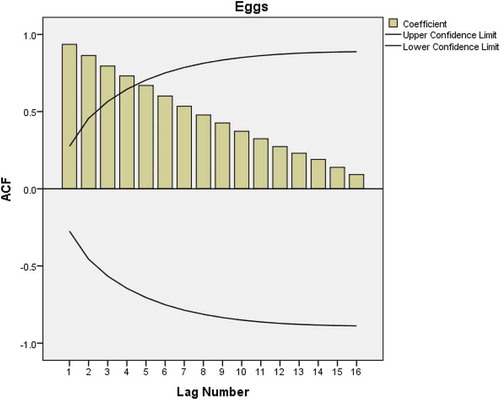
Figure 2. ACF plot after first-order differencing of the eggs consumption data.
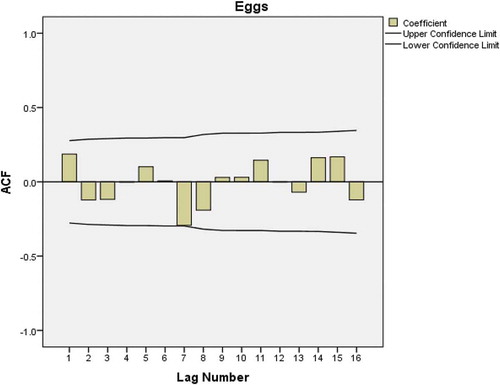
Figure 3. PACF plot after first-order differencing of eggs consumption data.
3.2.2. Parameter estimation and validation
After trial and error, four models are chosen and tested to find a model with low normal BIC. These models include ARIMA(1,1,1), ARIMA(0,1,1), ARIMA(1,1,0) and ARIMA(0,1,0). SPSS is used to estimate each model parameter using ARIMA tab in expert modelers. ACF plots for all the models are within the limit of .2718 (see Figures –), but ARIMA(0,1,0) is observed to have the lowest normal BIC and is chosen as a better model to forecast the consumption of eggs (see Table ).
Table 1. Results from SPSS after modeling sample models using eggs consumption data
Figure 4. Residual plots for ACF and PACF after estimating ARIMA(0,1,0) for eggs consumption.
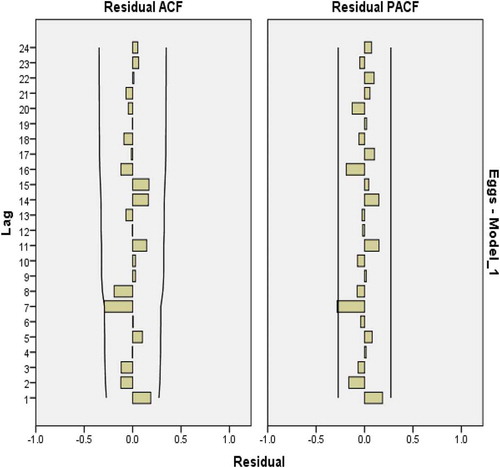
Figure 5. Residual plots for ACF and PACF after estimating ARIMA(1,1,0) for eggs consumption.
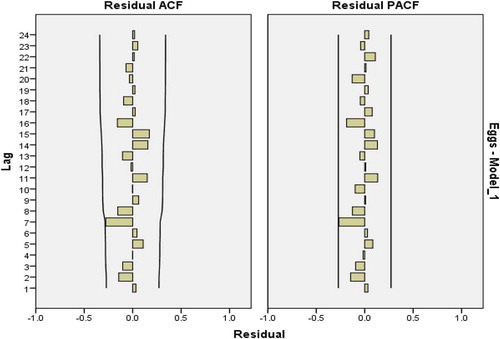
Figure 6. Residual plots for ACF and PACF after estimating ARIMA(0,1,1) for eggs consumption.
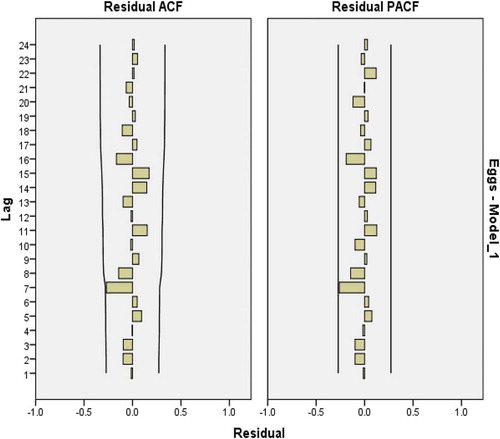
Figure 7. Residual plots for ACF and PACF after estimating ARIMA(1,1,1) for eggs consumption.
ARIMA(0,1,0) model is represented as
where yt is the current production, yt−1 is the lagged value and εt is the error term or the current shock.
From Table , the model is presented as
Table 2. Model statistics
Table 3. Model parameter
Model statistics and parameters for ARIMA(0,1,0) are shown in Tables and . The forecast data for egg consumption are presented in Table .
Table 4. Forecasted data on consumption of eggs
3.3. Model for consumption of cattle meat
3.3.1. Model identification
The procedure for building a consumption of meat model is the same as in the eggs model. The ACF is applied in cattle meat consumption data and again a very slow linear decay pattern is observed (see Figure ). This is a sign of a nonstationarity problem which can be corrected by a first-degree order of differentiation. After applying autocorrelation, both ACF (Figure ) and PACF plots (Figure ) show significant spike only at lag 1 as in egg consumption data. This implies that there is no need of adding AR (p) or MA (q).
Figure 8. Autocorrelation plot of cattle meat consumption data used to test for stationarity.
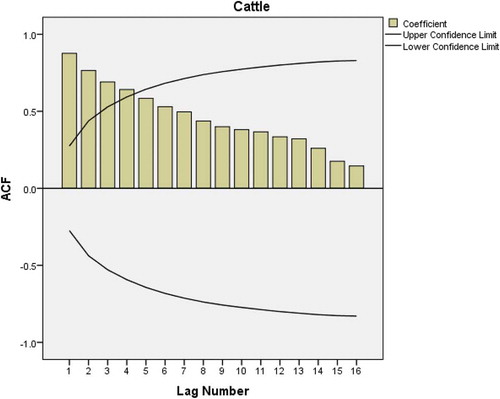
Figure 9. ACF plot after first-order differencing of cattle meat consumption data.
Figure 10. PACF plot after first-order differencing of the cattle meat consumption data.
3.3.2. Parameter estimation and validation
Four models are chosen and tested to find a model with good fit. These models include ARIMA(1,1,1), ARIMA(0,1,1), ARIMA(1,1,0) and ARIMA(0,1,0). The ACF plots of these models are shown in Figures –1. All models are within the limit which indicates good fit. Results from SPSS presented in Table are in favor of ARIMA(0,1,0) which has the lowest normal BIC and is chosen as a better model to forecast consumption of cattle meat.
Table 5. Results from SPSS after modeling sample models using cattle meat consumption data
Figure 11. Residual plots for ACF and PACF after estimating ARIMA(0,1,0) for cattle meat consumption.
Figure 12. Residual plots for ACF and PACF after estimating ARIMA(1,1,0) for cattle meat for cattle consumption.
Figure 13. Residual plots for ACF and PACF after estimating ARIMA(0,1,1) for cattle meat consumption.
Figure 14. Residual plots for ACF and PACF after estimating ARIMA(1,1,1) for cattle meat consumption.
From Table , the model is presented as
Table 6. Model statistics
Table 7. Model parameters
Model statistics and parameters for ARIMA(0,1,0) are shown in Tables and . Forecast data for the cow meat consumption are presented in Table .
Table 8. Forecasted data on consumption of cattle meat
3.4. Model for consumption of cow milk
3.4.1. Model identification
To identify the model, the first step is to plot the ACF of the data. The plotted figure shows a very slow linear decay pattern which is a sign of nonstationary time series (Figure ). This problem can be corrected by a first-degree order of differentiation. Figure shows that autocorrelations are significant for large number of lags. This is because of the propagation of the autocorrelation at lag 1 and can be confirmed in Figure which shows a significant spike only at lag 1 meaning that higher order autocorrelation is explained by the lag 1 autocorrelation. It implies that autocorrelation can be explained more easily by adding AR (p) than MA (q).
Figure 15. Autocorrelation plot of cow milk consumption data used to test for stationarity.
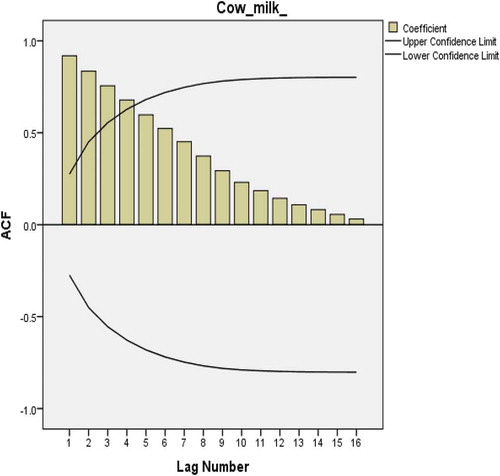
Figure 16. ACF plot after first-order differencing of cow milk consumption data.
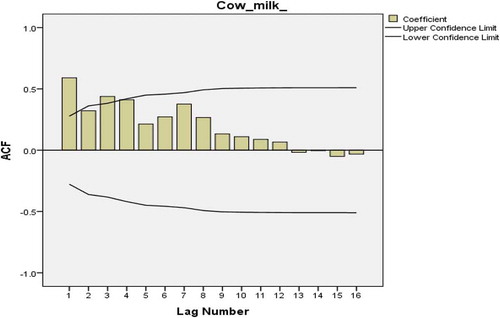
Figure 17. PACF plot after first-order differencing of cow milk consumption data.
Figure 18. Residual plots for ACF and PACF after estimating ARIMA(1,1,0) for cow milk consumption.
Figure 19. Residual plots for ACF and PACF after estimating ARIMA(3,1,0) for cow milk consumption.
Figure 20. Residual plots for ACF and PACF after estimating ARIMA(3,1,1) for cow milk consumption.
Figure 21. Residual plots for ACFand PACF after estimating ARIMA(2,1,1) for cow milk consumption.
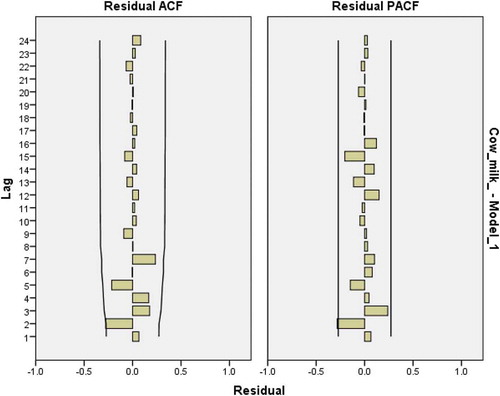
3.4.2. Parameter estimation and validation
Four models are chosen and tested to find a model with a good fit. These models include ARIMA(1,1,0), ARIMA(2,1,0), ARIMA(3,1,0) and ARIMA(3,1,1). The ACF plots in Figures – show that in the models, the correlation coefficients are within a limit. But the results from SPSS in Table are in favor of ARIMA (3,1,0) which has the lowest normal BIC.
Table 9. Results after modeling sample models from SPSS using cow milk consumption data
ARIMA(3,1,0) is represented as follows:
where y't is the dependent variable; a1, a2 and a3 are the parameters; y't−1, y't−2 and y't−3 are lagged differentiated dependent variables and εt is the random error or white noise term (forecast error).
FromTable , estimated model is illustrated which can be presented as
Table 10. Model statistics
Table 11. Model parameters results from SPSS for ARIMA(3,1,0) estimated from cow milk consumption data
Model statistics and parameters for this model are shown in Tables and 1. Forecast data for the cow meat consumption are presented in Table .
Table 12. Forecasted data on consumption of cow milk
3.5. Model for consumption of chicken meat
3.5.1. Model identification
The plot of ACF is created from the data. The plotted figure shows again a sign of nonstationary time series (Figure ). This problem can be corrected by a first-degree order of differentiation. Figures and 2 show a single spike at lag 1 which is a sign of MA(q) term. Also we can add a second-order differentiation but with no constant (Nau, Citation2018).
Figure 22. Autocorrelation plot of chicken meat consumption data used to test for stationarity.
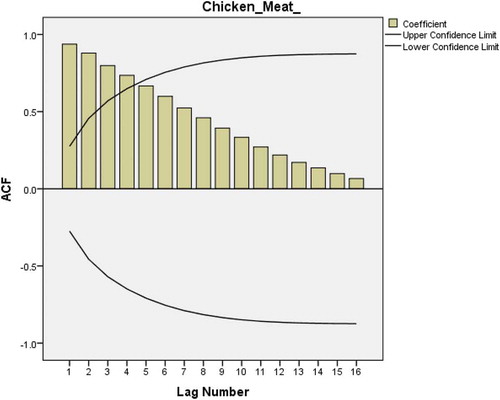
Figure 23. ACF plot after first-order differencing of the chicken meat consumption data.
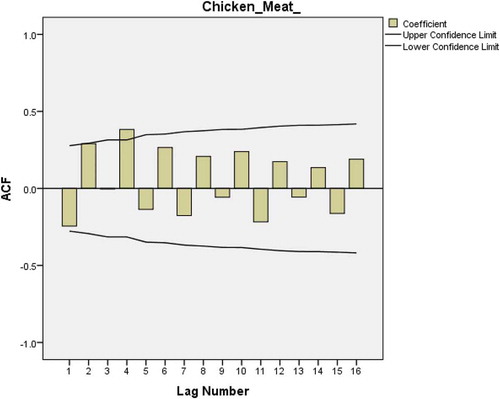
Figure 24. PACF plot after first-order differencing of the chicken meat consumption data.
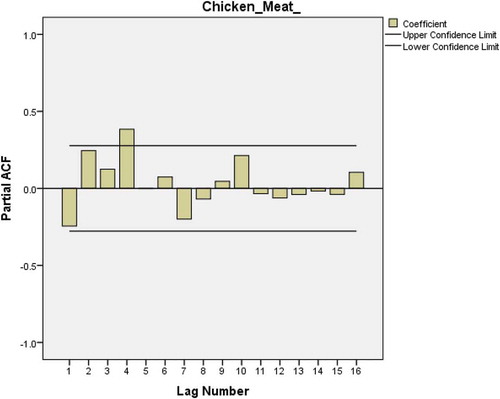
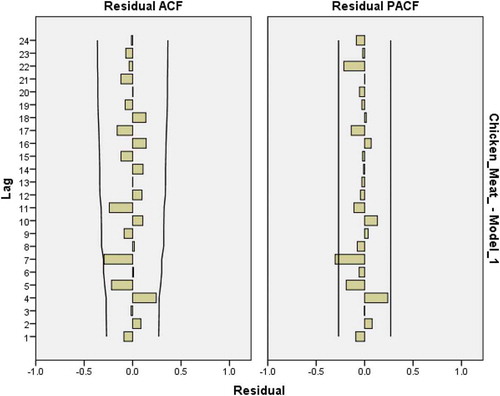
Figure 25. Residual plots for ACF and PACF after estimating ARIMA(0,1,1) for chicken meat consumption.
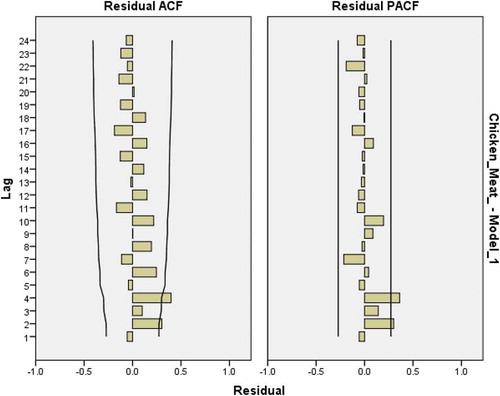
Figure 26. Residual plots for ACF and PACF after estimating ARIMA(0,2,1) for chicken meat consumption.
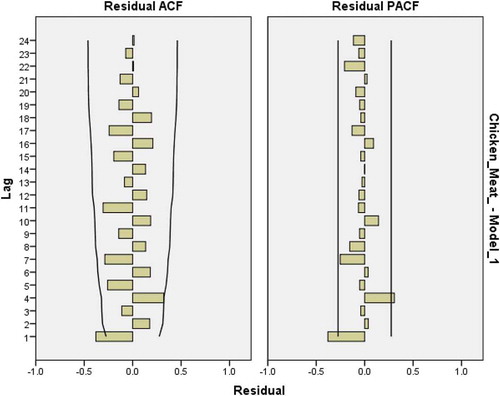
Figure 27. Residual plots for ACF and PACF after estimating ARIMA*(0,2,1) for chicken meat consumption.
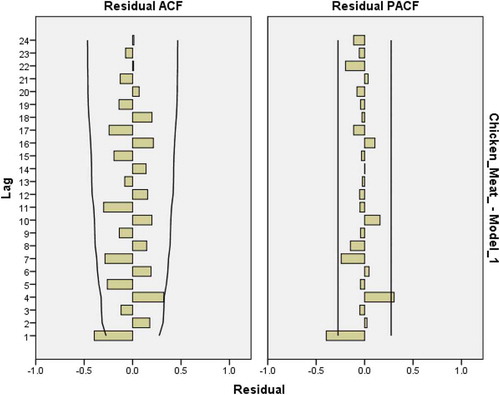
Figure 28. Residual plots for ACF and PACF after estimating BROWN (model) for chicken meatconsumption.
3.5.2. Parameter estimation and validation
Four models are chosen to be tested after trial and error which include ARIMA(0,1,1), ARIMA*(0,2,1),Footnote1 ARIMA(0,2,1) and BROWN models. The Brown model is tested because it is equivalent to ARIMA(0,2,1) and if there is an element of liner trend in the data, smoothing models may be better in forecasting (Alwashali, Fares, & Mohamed, Citation2015; Nau, Citation2018). The ACF's of the four models are plotted and the results are shown in Figures –2. The results show that all ARIMA models have some coefficients that have passed over the limit of .2718. Only BROWN model has all coefficients within the limit. Again Table shows the results of the four models in which BROWN model is observed to have lower normal BIC.
Table 13. Results from SPSS after modeling sample models using chicken meat consumption data
The model is represented as follows:
where ŷt+1 is the forecast value (weighted moving average of all past observation), α is the series weight for each observation and yi−k are the lagged observations (Ostertagová & Osterta, Citation2011). After inclusion of the data from Table , the model is presented as
Table 14. SPSS result from BROWN model using chicken meat consumption data
Table 15. Model parameters
Model statistics and parameters for this model are shown in Tables and 1. Forecast data for the cow meat consumption are presented in Table .
Table 16. Forecasted data on consumption of chicken meat
Overall results from all four estimated models show that production of all livestock products will increase (Table ). Cow milk is going to be consumed most in the future, followed by chicken and cattle meat. This is expected to increase demand for animal feed and is an opportunity for sorghum and millet farmers to capture new markets in animal feed if they can produce enough to keep up with the increase in demand.
Table 17. ARIMA Model, forecasts and annual rates of growth for livestock products from 2016 to 2020, Tanzania
4. Conclusion
The animal feed industry is one of the potential opportunities for sorghum and millet market. As population and income grow, the demand for livestock products (such as meat, milk and eggs) is expected to grow. As a consequence, the demand for animal feed is expected to increase also.
At the moment, efforts should be done to encourage the use of sorghum and millet in animal feed which will help to reduce humans and livestock competition over maize. As long as there is market for sorghum and millet in feed industries, smallholder farmers in semiarid region will be encouraged to abandon traditional crops which are rain dependent. This will improve their livelihood and reduce poverty in these areas.
Forecast done in this study does not consider some other factors that may influence consumption of livestock product. For instance, in recent years, population growth rate has been very high which will also have positive effect on the consumption of livestock. Another factor which may have an impact is a change of eating behavior. In recent years, people have learnt much about eating healthy which may have effect on the consumption of livestock products which are argued to be unhealthy, especially red meat. Hence, more research works are needed to understand by how much both of these two factors may affect the consumption of livestock products so as to measure real opportunity for sorghum and millet farmers to capture market in feed industry.
Cover image
Source: Author.

Additional information
Funding
Notes on contributors

Joseph Frank Mgaya
Joseph Frank Mgaya is an assistant lecturer at the department of Accounting and Finance in the University of Dodoma. For the past nine years, he has been teaching different courses in the department related to accounting and finance. His research interest is mainly in rural development, especially in rural finance, agricultural improvement and agribusiness. Recently, he has gain interest in different econometric models such as forecasting models which are crucial in policy planning and development.
This paper has reported an opportunity in the feed industry which can be utilized by farmers in semiarid regions to involve themselves in drought resistance crops such as sorghum and millet. As maize is preferred than sorghum and millet, linking farmers in feed industry is important. Substituting maize with sorghum and millet will be advantageous to the society as it will eliminate competition between animals and humans in the consumption of maize.
Notes
1. ARIMA*(p,d,q) is an ARIMA model which does not include a constant term.
References
- Abdulkadir, D. I., Na-Allah, Y., & Bala, A. G. (2013). A review - The use of sorghum as a substitute to maize in poultry feed production. Drylands, Katsina State Agricultural and Rural Development Authority, Katsina, Nigeria.
- Alwashali, E., Fares, M., & Mohamed, F. (2015). Prediction of cholera incidence by using the comparison of four models: Autoregressive integrated moving average model, Holt model, Brown model and simple regression model. International Journal of Tropical Disease & Health, 9, 1–29. doi:10.9734/IJTDH/2015/18115
- Amani, H. (2005). Making agriculture impact on poverty in Tanzania: The case on non traditional export crops. Policy dialogue for accelerating growth and poverty reduction in Tanzania. Dar es Salaam: Economic and Social Research Fund.
- Blum, A., & Sullivan, C. Y. (1986). The comparative drought resistance of landraces of and sorghum millet from dry and humid regions. Annals of Botany, 57, 835–846. doi:10.1093/oxfordjournals.aob.a087168
- Box, G. E. P., Jenkins, G. M., & Reinsel, G. C. (1994). Time series analysis; Forecasting and control. 3rd edition, Prentice Hall, Englewood Cliff, New Jersey.
- Chauvin, N. D., Mulangu, F., & Porto, G. (2012). Food production and consumption trends in Sub-Saharan Africa: Prospects for the transformation of the agricultural sector, African center for economic transformation. New York, NY: UNDP Regional Bureau for Africa.
- FAOSTAT. (2014). Livestock consumption data. Rome: Food and Agriculture Organization of the United Nations.
- Group, C.-D. S. (2011). Effective support for agricultural development in Tanzania. China: International Poverty Reduction Center.
- Issa, S., Jarial, S., Brah, N., Harouna, L., & Soumana, I. (2015). Use of sorghum on stepwise substitution of maize in broiler feeds in Niger. Inran/Icrisat, 27(10), 1–6.
- Jose, J., & Sojan, P. (2013). Application of ARIMA(1,1,0) model for predicting time delay of search engine crawlers. Informatica Economică. Bucharest, Department of Computer Applications, BPC College Piravom, Kerala, India. doi:10.12948/issn14531305/17.4.2013.03
- Majid, K. D. (2008). Tanzania’s creative solutions in response to global food crisis. Tanzania: Sokoine University of Agriculture.
- Mandal, B. N. (2005). Forecasting sugarcane productions in India with ARIMA model. New Delhi: IASRI.
- Nau, R. (2018). ARIMA models for time series forecasting. Retrieved from https://people.duke.edu/~rnau/411arim.htm
- Neath, A., & Cavanaugh, J. (2012). The Bayesian information criterion: Background, derivation, and applications. Wiley Interdisciplinary Reviews: Computational Statistics, 4(2), 199–203. doi:10.1002/wics.199
- Ostertagová, E., & Osterta, O. (2011). The simple exponential smoothing model. The 4th International Conference of Mechanical Engineering, Technical University of Kosice, Slovakia.
- Ramasubramanian, V. (2001). Time Series Analysis. New Delhi: I.S.R.I.
- Raymond, Y. C. (1997). An application of the ARIMA model to real-estate prices in Hong Kong. Journal of Property Finance, 8(2), 152–163.
- Rohrbach, D., & Kiriwaggulu, J. A. (2001). Commercialization prospects for sorghum and pearl millet in Tanzania. Working Paper Series no, 7, Bulawayo Zimbabwe/Socioeconomic and Policy Programme, ICRISAT.
- Studenmund, A. H. (2016). Using econometrics: A practical guide (4th ed.). Pearson, USA. ISBN 10: 013418274-X.
- Government of Tanzania (2014). 2012 population and housing census. National Bureau of Statistics & Office of Chief government statician, Tanzania.
- Yeboah, S. A., Ohene, M., & Wereko, T. B. (2012). Forecasting aggregate and disaggregate energy consumption using Arima models: A literature survey. Journal of Statistical and Econometric Methods, 1(2), 71–79. ISSN: 2241 (print), 2241-0376 (online) Scienpress Ltd., 2012.