
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The service industry, which includes hair salons, currently accounts for almost 70% of Japan’s GDP(Gross Domestic Product). Although hair salons are frequently used, over the years, the industry has decreased in size. However, the number of hair-salon facilities and the number of hairdressers have both continued to increase, thus leading to the overcrowding of salons. Consequently, about 90% of hair salons close within 3 years after they first open; this is a significant issue. Today, various business approaches, such as using coupons, have been positively adopted by the Japanese hair-salon industry. However, some customers use a salon only once, while others use them repeatedly. Consequently, the effectiveness of different business measures can vary greatly, so it is necessary to conduct analyses of the various approaches. Therefore, from a management perspective, it is important to use actual data analysis to determine what types of menu items are most effective. In this study, we have identified soft clusters of customers by using an extension of the recency-frequency-monetary (RFM) analysis that is based on soft clustering. We used a Bayesian network to construct a causal model for each class that was obtained in this way. We also proposed a method that uses sensitivity analysis to determine an optimal menu for business measures.
PUBLIC INTEREST STATEMENT
In the recent years, hair salon industry is one of the biggest service industries in Japan. Many hair salons have been competitive. There is a common problem among the hair salons that some customers use a salon only once, while others use them repeatedly. Consequently, the effectiveness of different business measures varies greatly, so analyses of the various approaches are required. In this study, we have identified soft clusters of customers using an extension of recency-frequency-monetary (RFM) analysis that is based on soft clustering. We can obtain the cluster of customers who are similar in terms of the hair salon usage. Moreover, based on a Bayesian network, the differences of the casual relationship between the using menu for each cluster are clarified. The result obtained by the proposed analysis method helps to determine the effective coupon issuing for the customer growth.
1. Introduction
1.1. Background
Almost 70% of Japan’s GDP comes from the service industry, which makes it one of the nation’s most important industries. One popular type of service provider that is patronized by many people in Japan is the hair salon. In fact, the number of such facilities continues to increase each year. However, owing to a decrease in the population of young people and an increase in new haircut services, the hair-salon industry has entered a period of decline. Consequently, 90% of hair salons tend to close within 3 years of starting operations (Ministry of Health in Japan, Citation2012). Thus, it is important to initiate various efforts in order to maintain hair-salon services. Consequently, many studies have focused on hair salons. One of the early studies in this area was conducted by Soulliere (Citation1997) (Jo-Ting Wei, Chen, & Wu, Citation2013; Soulliere, Citation1997).
One popular strategy is to issue coupons. Many hair salons offer coupons for services such as haircuts, hair dyeing, or permanents as promotional attractions for new customers. An analysis of the effects of issuing coupons, which considers the resulting differences in treatment of hair, is therefore important for ensuring effective hair-salon management. One method for describing the causal structure between the variables is the application of a Bayesian network (Pearl, Citation1988). This model not only reveals the causal relationship between different factors but also enables the functional analysis; that is, it can help to determine the effect ratio of variables when the occurrence ratio of another variable is set to be 100% (Pearl, Citation1988). This paper analyzes the data by using this particular method.
Various types of customers may patronize a hair salon. For example, some customers may stop using a particular hair salon after a few visits, some may continuously utilize the same hair salon, and some others may spend significant amounts of money on their hair treatments. It is thought that many clusters of customers exist, with each cluster having its own structure for hair treatments and coupon use. In this study, we utilized statistical data analysis, which was applied to the marketing research (e.g., Marakkalage et al., Citation2019), to analyze the effect of each coupon menu provided by a hair salon. It should be noted that our proposing method is original. More precisely, we combined a latent class model-based clustering approach to grasp the features of consumers in detail and a Bayesian-network method to understand the effect of the coupon menu on the growth of consumers and hair salons.
To determine the clustering of customers and thus grasp the features of customers in detail, one generally applies a recency-frequency-monetary (RFM) analysis (Dursun & Caber, Citation2016). This method categorizes customers based on three characteristics: (1) recency (i.e., How recently did the customer purchase a given item?), (2) frequency (i.e., How often does the customer purchase a given item?), and (3) money (i.e., How much does the customer spend on the service and the item). Recently, a research study (Zhang, Yamashita, Mikawa, & Goto, Citation2015) proposed a latent-class-analysis model for RFM analysis. This method divides the customers into clusters probabilistically based on a soft-clustering approach, and this method delivers a preferable performance when the customer structure is complex (Zhang et al., Citation2015). Therefore, we employed this soft-clustering approach in the present study.
1.2. Purpose of this study
As mentioned in Subsection 1.1, we analyzed the purchase and treatment data by categorizing the customers through an application of soft clustering based on the RFM approach (Zhang et al., Citation2015); we constructed a Bayesian network for each cluster in order to represent the causal relationship between coupon use and the treatment received. While we expected these models to represent the structure of all the data, two main issues arose while applying these approaches. The first issue was that we determined the distance between each customer’s home and the salon and then applied this information in our analysis. Second, because a Bayesian-network model does not consider the data probabilistically, we could not apply the results of a soft-clustering approach directly to Bayesian Network.
In the present study, we first extended the soft-clustering-based RFM approach to include information about the distances between the customers’ homes and the salons. We termed this extension as “RFMD analysis.” We also proposed the application of a bootstrap (Levich & Thomas, Citation1993) to the Bayesian-network model construction. We then applied the proposed model to real-world data about hair salons obtained from a data-analysis competition sponsored by the Association of Management Science Research, which was held in Japan in 2018. We divided the customers into clusters based on a probabilistic latent semantic analysis (PLSA) approach (Hofmann, Citation1999) and constructed a Bayesian network for each cluster. We then described the results of both models and performed a sensitivity analysis; this enabled us to show the effects of different variables when the probability of one variable was set to unity for each cluster.
Conventionally, many researchers have discussed the approach for running hair salons (e.g., Soulliere, Citation1997; Ward, Galoppo, & Lin, Citation2007), and in more recent times, decision-making with regard to the issuing of coupons (Jo-Ting Wei et al., Citation2013) has also been studied. However, Jo-Ting Wei et al., Citation2013) did not discuss the effect of the menu in quantitative terms; our approach can thus be considered as a study that deals with the quantitative challenge
1.3. Research design
This study’s research design followed Wei’s article (Jo-Ting Wei et al., Citation2013). Wei’s study divided the hair salon users into some groups in terms of the RFM variables and discussed the relevant menu features they chose for each salon. However, that study did not consider the distance from the customer’s home to the salon as a variable; nevertheless, this information was important. Furthermore, sensitivity analysis was useful for utilizing the analysis results in real-world marketing; therefore, we proposed a new method that considers the distance between the consumer’s home and the salon. Sensitivity analysis was thus considered in this study.
This study is organized as follows. We described the basic analysis of this study in Section 2 and introduced the preliminaries in Section 3. In Section 4, we discussed the problems inherent in previous studies and proposed our method. After this, Section 5 provided information about the application to the real-world data, and finally, Section 6 provided the conclusion and future works for this study.
2. Basic analysis
In this section, we will discuss the basic analyses conducted on the supplied data. These data contained the usage histories of the selected hair salons for the period between 1 July 2016 and 30 June 2017; the relevant information of 23,952 customers, without any missing values, was considered for the analysis. Basically, the coupons were distributed only to customers who were using the salon for the first or second time. These coupons provided discounts for haircut, permanent, straight permanent, hair dyeing, hair treatment, blow, or any other treatment. A simple summary of this data is provided as follows.
Figure – show the distributions of recency (R [in days]), frequency (F [in times]), and money (M [in yen]), respectively. Table provides a summary of these statistics. Note that, when a customer uses a gift certificate, the monetary value is denoted as zero.
Figure 1. The distribution of the recency (R) of the customer visits.
Figure 2. The distribution of the frequency (F) of the customer’s visits.
Figure 3. The distribution of the money (M) of the customer monetary.
Table 1. Basic statistical values
Figure – show the distribution of each variable. An ideal customer scores a small value in terms of R and large values in terms of F and M. The ideal distributions for F and M should thus be biased towards the right; however, the actual distributions for F and M were biased towards the left. These figures show that a few customers continued to use the selected hair salon. Naturally, it was found that the number of visits per customer did not increase, and neither did the value of M. This hair salon thus had a serious issue; that is, new customers did not visit it repeatedly, and it was thus difficult for the salon to create loyal customers.
However, the salon was able to retain some loyal customers; for example, one customer visited the hair salon 69 times, and another customer paid a total of 1,130,000 yen. Although the total number of consumers was small, it was clear that some customers did develop into extremely good customers, and loyal customers did exist. By appropriately classifying and analyzing these customers and determining the reasons for loyalty increases in each cluster, we were able to suggest an effective strategy increa for sing the hair salon’s business.
3. Preliminaries
3.1. RFM analysis based on probabilistic latent semantic analysis
A probabilistic latent semantic analysis (PLSA) (Hofmann, Citation1999) is a type of clustering method. When hard clustering methods, such as a k-means approach, (McQueen, Citation1967) are used, we tend to assume that a datum belongs to only one class. Instead, in soft clustering, a datum is clustered probabilistically, and it is thus able to belong to multiple classes probabilistically. Recently, an RFM analysis method that applies the PLSA approach was proposed (Zhang et al., Citation2015). In the relevant study, the researchers proposed a method to apply customer clustering to the purchase-history data of a supermarket.
3.2. Bayesian network (Pearl, Citation1988)
The Bayesian network (BN) graphical model expresses the causal relationships among different variables by using directed acyclic graphs and conditional probabilities. By using a table to clarify the conditional probability, it is possible to examine the relationship between the variables in detail. BN is applied to many marketing data analyses.
One advantage of a BN model is that it enables the application of sensitivity analysis. Such an analysis infers the influence of an explanatory variable on an objective variable (or variables) by conducting stochastic propagation through the graph-like structure of the BN. We can thus determine the values, in terms of the posterior probability, of the objective variable(s) by setting the prior probability of the explanatory variable to unity. One can thus make the following inference: the larger the difference obtained by subtracting the prior probability from the posterior probability, the greater the influence(s) of the explanatory variable on the objective variable(s). In the present research, our goal was to determine an optimal treatment menu for the salon; therefore, we conducted a sensitivity analysis in order to determine an optimal menu for each cluster of customers.
4. Proposed methods
4.1. RFMD analysis based on PLSA
Based on the data provided from competition, we were able to obtain information about the distance (D) between a customer’s home and the selected hair salon. Based on this information, we were also able to determine the loyalty level of the customer with regard to the hair salon. If the customer travels a long distance to visit the hair salon and repeatedly spends a lot of money there, the customer can be said to be highly loyal to the salon. Therefore, based on the PLSA, we added this distance information to the RFM analysis (Zhang et al., Citation2015).
We first defined the variables. The values recency (R), frequency (F), money (M), and distance (D) for each customer —out of a total of
customers—were expressed as
. Here,
was R,
was F,
was M, and
was D. The probability of simultaneous appearance for the four variables, using the latent class
, could then be represented as follows.
Here, it was assumed that the probability density function followed a Gaussian distribution, with parameters meaning
and a variance of
:
For the given data
, the log-likelihood function
was as follows.
Because we could not determine the parameters and
analytically, we employed an expectation-maximization (EM) algorithm (Dempster, Laird, & Rubin, Citation1977), which enabled parameter estimation, including that of latent class variables based on the repetition approach (i.e., e-step and m-step), and it could be formulated as follows.
[e-step]
[m-step]
Each parameter was updated until the log likelihood in (3) converged.
4.2. Bootstrap method
For this study, we proposed a customer classification method that utilized an RFMD analysis based on the PLSA, and we constructed a causal model using a BN for each latent class. A BN was applied in order to clarify and visualize the relationships among the variables, and a wide range of application examples were found to be available (Friedman, Geiger, & Goldzmidt, Citation1997) (Cordeiro, Machás, & Neves, Citation2010) (Levich & Thomas, Citation1993). However, because a BN does not consider the data probabilistically, it was difficult to construct a BN for the probabilistic clusters. Instead, in this study, we generated the data for each class by utilizing an RFMD analysis based on the bootstrap method (Efron & Tibshirani, Citation1986). In this approach, the affiliation probability for customer in the latent class
was represented as follows.
Furthermore, this approach allowed for the random extraction of one history datum for customer , and a dataset reflecting the customer’s feature of each latent class
was then created.
By determining the BN of the dataset for each latent class, we were able to obtain a causal map for each variable, and we were then able to discuss the relationships between the variables. Moreover, conducting a sensitivity analysis enabled us to infer the differences, between the services used by the latent class and those used by the graph structures.
Recently, some studies have proposed Bayesian structural EM algorithm approaches (Friedman, Citation1998) (Peña, Lozano, & Larrañaga, Citation2000), and several data analysis cases that consider the hidden variables in BN have been revealed. In these studies, the hidden variables were considered as the nodes of the BN. However, in this study, our objective was to examine the BNs’ structural differences, as observed among the different featured clusters. Therefore, this study applied a two-step approach based on PLSA and Bayesian networks using the bootstrap simulation.
5. Real data analysis
In this section, we will describe the application of the proposed model to real-world hair salon-related data; this data was taken from a data-analysis competition sponsored by the Association of Management Science Research, which was held in Japan in 2018. We divided the customers into clusters using an RFMD analysis, which was based on the PLSA approach, and we constructed a Bayesian network for each cluster. Next, we will discuss both the causal models and the sensitivity analysis for each cluster.
5.1. Analysis conditions
We analyzed the usage history—involving a period of about 2 years—of a major Japanese hair salon. In order to conduct an RFMD analysis based on the PLSA approach, we set the data for R as the number of days from the last visit date to 1 July 2017; F was set as the number of visits to the salon within this period, M was set as the total amount of money spent within this period, and D was set as the straight-line distance between the customer’s home and the salon. We set the information criterion as AIC (Sakamoto, Ishiguro, & Kitagawa, Citation1986).
We then constructed a BN, where the variables denoted as the treatment items purchased (Yano Research Institute, Citation2018) for each cluster, and we performed a sensitivity analysis of the BN obtained in this way. In the sensitivity analysis, we determined the effects of the treatment options when the probability of using two types of coupons (Coupons 1 and 2) was denoted as unity (That is, we set the coupon as an explanatory variable.). In the sensitivity analysis, we set the objective variables as the treatment options.
5.2. The results of the RFMD analysis based on PLSA
The results of the PLSA-based RFMD analysis are shown in Table . Note that, based on a pre-analysis, the number of latent classes was set as 21 (Soulliere, Citation1997).
Table 2. The results of the RFMD analysis
Now, let us interpret the three characteristic classes. was defined as a class of good customers (good class),
was defined as a class of bad customers (bad class), and
was defined as a class of superior customers, who traveled a long distance (good distance class).
To apply the BN analysis, we generated artificial usage-history data for 10,000 customers by applying the bootstrap method, which we formulated in EquationEquation (7)(7)
(7) , and we also constructed a BN model for each cluster. Furthermore, we applied the AIC information criterion for determining the BN structure.
Note that, a model that incorporated the conditional independence relationships among the RFMD variables and the graphical models could also have been considered. However, in this study, since the data granularities of the RFMD model and the BN were different, we did not consider the conditional independence relationship. As stated in Section 4.2, our objective was to understand the differences in the different featured customers including the good customers and the bad customers. It was necessary to utilize the accumulated usage information of each consumer in order to grasp the relevant consumer features the selected consumers. On the other hand, for issuing coupons, it was necessary to construct BN not by utilizing the accumulated usage data but through the usage data of each time period. Therefore, we adopted a two-step approach: a PLSA-based clustering model and the relational model estimation based on the BN model.
5.3. The results of the BN and sensitivity analyses
In this subsection, we revealed the BNs of the three characteristic clusters in Tables –, respectively. Based on these results, different causal maps could be outlined. This showed that the structure of the relationship between the issued coupons and the menu for each type of customer was different.
Table 3. Effects of coupon 1 on a good cluster
Table 4. Effects of coupon 2 on a good cluster
Table 5. Effects of coupon 1 on a bad cluster
Table 6. Effects of coupon 2 on a bad cluster
Table 7. Effects of coupon 1 on “good customers’ willingness to travel a long distance” cluster
Table 8. Effects of coupon 2 on “good customers’ willingness to travel a long distance” cluster
Next, we will describe the results of the sensitivity analysis. Tables – show the result we obtained for the services used in each latent class. In this subsection, we will describe the results of the sensitivity analysis (See Table –.). The second column in each table, labeled “Probability,” represents the posterior probability; the third column “Difference” represents the difference between the posterior probability and the prior probability; and the fourth column “Lift value” represents the ratio of the posterior probability to the prior probability. If the objective variable was and the explanatory variable was
, the quantities in these tables could be represented as follows.
5.3.1. The results of the good customers
The good customers’ Bayesian network is shown in Figure and sensitivity analysis results were as follows.
Figure 4. Good customers.
We focused on the effect of the treatment coupons. As shown in Tables and , the increased lift values for hair treatments were 5.350 and 19.451, respectively. We found that the coupon provided in the treatment for the good class was effective.
5.3.2. The results of the bad customers
The bad customers’ Bayesian network is shown in Figure and sensitivity analysis results were as follows.
Figure 5. The results of the bad customers.
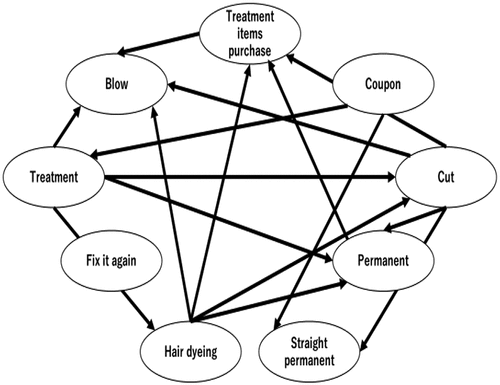
Focusing on the effects of Coupon 1, we found that the treatment was not effective; on the other hand, Coupon 2 was effective as seen in Table and Table .
5.3.3. Good customers travel long distances to reach the salon
The good customers travel long distances to reach the salon is described as Figure . Following the findings of Subsection 5.3.2, we will now focus on the effect of the treatment coupons. Tables and show that the treatment coupons had a positive effect.
Figure 6. Good customers travel long distances to reach the salon.
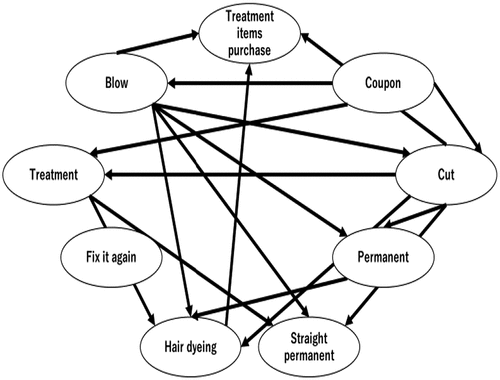
5.3.4. A discussion of the study results and considerations
Here, we will discuss the effect of the coupons. The tables show that treatment had a small effect on the bad class and a large effect on both the good and the good long-distance classes. Similar characteristics could be found with regard to the straight perm for Coupon 1. As these results indicated, issuing a coupon for hair treatment and straight perm was a useful strategy. In contrast, for the effects of Coupon 2, the increased Lift value with regard to hair treatment was significant for all the classes, so issuing a coupon for treatment seemed likely to increase the number of long-distance customers. It should be also noted that hair dyeing had a small effect on the bad class and a large effect on both the good and the good distance classes. Therefore, the issuing of Coupon 2 (for hair dyeing) may not a have been a suitable strategy for increasing the number of good customers’ or ‘encouraging customers to be loyal .
We can thus summarize that the effective menu for Coupon 1 was hair treatment and straight perm and that the effective menu for Coupon 2 was hair dying and hair treatment; overall, treatment was thus a good coupon. Moreover, we found that each coupon had a different effect on customer growth. Therefore, coupons using different strategies, should be applied. This structural difference was found because our proposal enabled BNs that considered the latent classes. It can be said that this analysis was a model case that used real-world data, and it was thus well-suited for our proposal.
Here, we will discuss the adequacy of the proposed method for analyzing the data. Each result was selected based on AIC (Sakamoto et al., Citation1986); for the estimated model, it could be said that the balance of the model fit, and the number of parameters was preferable. However, when we applied the analysis to the real system, we required a detailed verification. A satisfactory verification would allow us to suggest that this method could be incorporated into the system. The system was expected to increase the number of repeat customers, and it increased the number of good customers.
In a previous conventional study (Jo-Ting Wei et al., Citation2013), researchers had similarly suggested the effectiveness of the coupon menu for increasing customer growth; however, the analysis method of that study was based on a self-organization map. They were unable to discuss the effectiveness of the menu by using the prior and posterior probabilities. Therefore, we suggest that our proposal can provide more detailed information compared to the conventional method.
6. Conclusion and future work
6.1. Conclusion
In this study, we proposed a new method for analyzing the relationship between coupon issuing and the growth of the extended soft-clustering-based RFM approach (Zhang et al., Citation2015); the study achieved this objective by adding information about the distance between customers and the salon into the analysis . Furthermore, we have proposed the application of a bootstrap method (Efron & Tibshirani, Citation1986) to a Bayesian-network model construction. This model enabled us to represent the different causal structures of each latent class. In terms of marketing theory, our study should be viewed as a case study for the customization of online advertising,—a subject that is well studied in the marketing field (e.g., Lee, Kim, & Sundar, Citation2015). With regard to the RFMD approach, this study can be considered as a customer evaluation study (e.g., Stein & Ramaseshan, Citation2016).
Moreover, we applied the proposed model to real-world data regarding hair salons and interpreted the results through sensitivity analysis. This interpretation included information regarding the effectiveness of menus for each type of customer, who—in this study—were divided based on the soft clustering approach in terms of four aspects: recency, frequency, monetary, and distance from the salon. The proposed model exhibited the adequacy of using both the causal models and the sensitivity analysis for analyzing the data.
6.2. Theoretical and managerial implications
The theoretical implementation of this study involved introducing the concept of “one-to-one marketing” (Klabjan & Pei, Citation2011) to the BN. Many studies have supported decision-making with regard to personalized coupon issuing based on statistical approaches (e.g., Klabjan et al., 2011; Jo-Ting Wei et al., Citation2013). These approaches did not consider the causal relationships between the factors. Because BN allows for showing the causal relationship between the factors, BN approach can be considered as a preferable option; however, the conventional model was applicable with regard to data from a single population. In the real world, the assumption is strict, and it is necessary to obtain a new BN approach for data from multiple populations. As described above, the consideration of one-to-one marketing in the BN approach is the theoretical implementation.
It should be noted that, for the management and for the issuing of coupons, thus a completely efficient approach has not been developed yet (Jo-Ting Wei et al., Citation2013); each salon and the researches repeat a “trial and error” process (e.g., Soulliere, Citation1997; Ward et al., Citation2007). Therefore, this study can be a support for the decision making for the coupon issuing. However, we have not assembled the method in a real system; it was thus not possible to consider the adequacy.
6.3. Future work
Some limitations and future works remain to be discussed. The first limitation is the validity of the influence of the bootstrap method. Since the results depended on the number of samples, we created samples through boot strap sampling. The simulation study should be derived. Second, the PLSA approach, which is based on the Bayesian estimation, should be considered. We used the maximize likelihood approach when we estimated the parameters of PLSA; however, we should consider the Bayesian approach, since the Bayesian Network is applied by using the results of PLSA analysis. The third one was the proposal of utilizing a BN for probabilistic data. This proposal was expected to solve the setting of the boot strap, since we did not have to create samples through the simulation approach. Furthermore, the theoretical discussion of our method also involved discussions of future work. These future works will enable the realization of a coupon issuing system based on the proposed method. Thus, it is necessary to create a “guideline for use” for practitioners.
Acknowledgements
This paper was written using data obtained from a data-analysis competition, which was sponsored by the Association of Management Science Research Association in 2018 (Management Science Research Committee Union Association).
Additional information
Funding
Notes on contributors
Yuki Horita
Yuki Horita is a student at graduate School of Science and Engineering, Sophia University, Tokyo, Japan. His research interests include data science, marketing, web applications, and machine learning.
Haruka Yamashita is an assistant professor at School of Science and Technology, Sophia University, Japan. She was born in Tokyo, Japan on 30 September 1987. She received the Bachelor’s degree from Tokyo University of Science and Technology in 2010. Moreover, she received the Master’s degree in 2012 and her Ph.D. degree from Keio University in 2015. Her research interests include applied statistics, multivariate analysis, and machine learning. She is a member of the Japanese Society of Applied Statistics, Japanese Industrial Management Association, and Japanese Society of Quality Control.
References
- Cordeiro, C., Machás, A., & Neves, M. M. (2010). A case study of a customer satisfaction problem: Bootstrap and imputation techniques. In Handbook of partial least squares (pp. 279–15). Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society. Series B (methodological), 39(1), 1–38. doi:10.1111/j.2517-6161.1977.tb01600.x
- Dursun, A., & Caber, M. (2016). Using data mining techniques for profiling profitable hotel customers: An application of RFM analysis. Tourism Management Perspectives, 18, 153–160. doi:10.1016/j.tmp.2016.03.001
- Efron, B., & Tibshirani, R. (1986). Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Statistical science, 54–75.
- Friedman, N. (1998). The Bayesian structural EM algorithm,” Proceedings 14th International Conference on Uncertainty in Artificial Intelligence, Madison.
- Friedman, N., Geiger, D., & Goldzmidt, M. (1997). Bayesian network classifiers. Machine Learning, 29(2–3), 131–163. doi:10.1023/A:1007465528199
- Hofmann, T. (1999, July). Probabilistic latent semantic analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence (pp. 289–296). Morgan Kaufmann Publishers Inc.
- Jo-Ting Wei, M., Chen, L. H., & Wu, H. (2013). Customer relationship management in the hairdressing industry: An application of data mining techniques. Expert Systems with Applications, 40(18), 7513–7518. doi:10.1016/j.eswa.2013.07.053
- Klabjan, D., & Pei, J. (2011). In-store one-to-one marketing. Journal of Retailing and Consumer Services, 18(1), 64–73.
- Lee, S., Kim, K. J., & Sundar, S. S. (2015). Customization in location-based advertising: Effects of tailoring source, locational congruity, and product involvement on ad attitudes. Computers in Human Behavior, 51, 336–343. doi:10.1016/j.chb.2015.04.049
- Levich, R. M., & Thomas, L. R. (1993). The significance of technical trading-rule profits in the foreign exchange market: A bootstrap approach. Journal of International Money and Finance, 12(5), 451–474. doi:10.1016/0261-5606(93)90034-9
- Management science research committee union association (written in Japanese). Retrieved from https://jasmac-j.jimdo.com.
- Marakkalage, S. H., Sarica, S., Lau, B. P. L., Viswanath, S. K., Balasubramaniam, T., Yuen, C., … Nayak, R. (2019). Understanding the lifestyle of older population: Mobile crowdsensing approach. IEEE Transactions on Computational Social Systems, 6, 82–95. doi:10.1109/TCSS.2018.2883691
- McQueen, J. (1967). Some methods for classification and analysis of multivariate observations. In Proc. 5th Berkeley Symp. on Math. Statist. Probab. (pp. 281–297). Berkeley.
- Ministry of Health in Japan. (2012). Actual condition of beauty industry and measures to improve management (written in Japanese). Retrieved from http://www.mhlw.go.jp/seisakunitsuite/bunya/kenkou_iryou/kenkou/seikatsu-eisei/seikatsu-eisei22/dl/h22/biyou_housaku.pdf
- Pearl, J. (1988). Probabilistic reasoning in intelligent systems. San Mateo, Ca: Morgan Kaufman.
- Peña, J. M., Lozano, J. A., & Larrañaga, P. (2000). An improved Bayesian structural EM algorithm for learning Bayesian networks for clustering. Pattern Recognition Letters, 21, 779–786. doi:10.1016/S0167-8655(00)00038-6
- Sakamoto, Y., Ishiguro, M., & Kitagawa, G. (1986). Akaike information criterion statistics (pp. 81). Dordrecht, The Netherlands: D. Reidel.
- Soulliere, D. (1997). How hairstyling gets done in the hair salon. Michigan Sociological Review (Vol. 11), 41–63.
- Stein, A., & Ramaseshan, B. (2016). Towards the identification of customer experience touch point elements. Journal of Retailing and Consumer Services, 30, 8–19. doi:10.1016/j.jretconser.2015.12.001
- Ward, K., Galoppo, N., & Lin, M. (2007). Interactive virtual hair salon. Presence: Teleoperators and Virtual Environments, (16), 237–251. doi:10.1162/pres.16.3.237
- Yano Research Institute. (2018). Conducting a survey on hairdressing and beauty market (written in Japanese). Retrieved from https://www.yano.co.jp/press-release/show/press_id/1884
- Zhang, Q., Yamashita, H., Mikawa, K., & Goto, M. (2015). Analysis of purchase history data based on a new latent class model for RFM analysis. Asian Conference of Management Science & Applications, 39(6).