
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The construction of an internal rating model is the main task for the bank in the framework of the IRB-foundation approach the fact that it is necessary to determine the probability of default by rating class. As a result, several statistical approaches can be used, such as logistic regression and linear discriminant analysis to express the relationship between the default and the financial, managerial and organizational characteristics of the enterprise. In this paper, we will propose a new approach to combine the linear discriminant analysis and the expert opinion by using the Bayesian approach. Indeed, we will build a rating model based on linear discriminant analysis and we will use the bayesian logic to determine the posterior probability of default by rating class. The reliability of experts’ estimates depends on the information collection process. As a result, we have defined an information collection approach that allows to reduce the imprecision of the estimates by using the Delphi method. The empirical study uses a portfolio of SMEs from a Moroccan bank. This permitted the construction of the statistical rating model and the associated Bayesian models; and to compare the capital requirement determined by these models.
PUBLIC INTEREST STATEMENT
Customer rating is an important tool for determining credit pricing. Indeed, the bank must construct a model capable of determining the real profile of the customer. This article proposes a approach to the conception of a rating model that integrates the quantitative and qualitative data of the company can be of great utility for professionals, student credit risk researchers and academics.
It also meets the need for a portfolio manager by combining their opinion with statistical estimation.
The method we have proposed to combine statistical estimation and expert opinion can be used in other risk management areas such as operational and market risk.
1. Introduction
Internal credit risk rating models are based on the modelling of the three risk components, which are probability of default (PD), Loss given default (LGD) and Exposure at default (EAD). As a result, the bank must estimate the three components for each customer exposure.
To model the probability of default (PD), a multitude of techniques can be used, such as linear discriminant analysis (ADL), the intelligence techniques (neural networks and genetic algorithms), bayesian Network and the probabilistic models.
These techniques are based on different logics and have been the subject of a multitude of research and studies conducted by academics and professionals such as:
–Multidimensional linear discriminant analysis
The prediction of default by linear discriminant analysis was developed by Altman (Citation1968), Taffler (Citation1982), Bardos (Citation1998), Bel et al. (Citation1990) and Grice et al.(Citation2001).
–Intelligence techniques
The several studies have applied these techniques to predict the default of the corporates, such as those conducted by Bell, Ribar, and Verchio (Citation1990), Liang and Wu (Citation2003), Bose and Pal (Citation2006) and Back et al. (Citation1996), and Oreski et al. (Citation2012).
–Bayesian Network
The Bayesian classifier (Friedman, Geiger, & Goldszmidt, Citation1997) is based on the calculation of a posterior probability. The opportunities of using probabilistic Bayesian networks in fundamental financial analysis is studied by Gemela (Citation2001); Das, Fan, and Geng (Citation2002) studied the changes in PDs related to changes in ratings, using a modified Bayesian model to calibrate the historical time series of probability of Default changes to historical rating transition matrices; Dwyer (Citation2006) used the Bayesian approach to propose techniques to facilitate probability of default assessment in the absence of sufficient historical default data; Gôssl (Citation2005) introduced a new Bayesian approach to the credit portfolio, and deduced, within a Bayesian framework, the law a posteriori from the probabilities of default and correlation and Tasche (Citation2013) has describes how to implement the uninformed and conservative Bayesian estimators in the dependent one- and multi-period default data cases and compares their estimates with the upper confidence bound estimates.
–Probabilistic models
The several studies have applied these techniques to predict the default of the corporates such as those conducted by Ohlson (Citation1980), Hunter et al. (Hunter & Isachenkova, Citation2002), Hensher, Jones, William, and Greene (Citation2007), Zmijeriski (Citation1984), Grover and Lavin (Citation2001), Bunn and Redwood (Citation2003) and Benbachir and Habachi (Citation2018).
Our study differs from previous research in that we treated the conception of the rating models of the credit portfolio based first on the multidimensional linear discriminant analysis (LDA), which permitted us to determine the probability of default by class. Then, we determined a mathematical passage that allows us to combine the probability of default from the statistical model and that estimated by the experts using Bayesian logic. Then, we developed an information gathering approach based on the Delphi method to ensure the reliability of the estimates. As a result, our approach tends to be more practical than theoretical and may be of interest to professionals in the field of credit risk management. In summary, in this article, we propose a practical approach with a solid theoretical basis to combine the probability of default emanating from the linear discriminant analysis and that emanating from the experts using Bayesian logic and the Delphi method.
The rest of this paper is as follows. Section 2 is devoted to credit risk measurement. We first give a definition of the credit risk situation. We then define the approaches to credit risk measurement and we defined the unexpected and expected credit loss. The third section is reserved to modelling of the probability of default and the construction of the statistical notation model and associated Bayesian models. The fourth section is reserved to the empirical study.
2. Credit risk measurement
The credit risk situation is composed of the following elements:
Probability of default (PD): Probability that a counterpart falls at default in a horizon one year.
Loss given default (
): The share, expressed as a percentage of the amount a bank loses when a borrower falls at default on a credit.
Exposure at default (
Maturity (
2.1. The IRB-foundation approach
The Basel Committee on Banking Supervision(Citation1999, Citation2006, Citation2016) provides for three risk measurement approaches: the standard approach, the foundation internal rating-based foundation approach () and the internal rating-based advanced approach (
). In our study, we will measure the risk according to the internal rating-based foundation (
-A). Under this approach, the bank must model the probability of default while the estimate of loss given default, exposure at default and maturity are provided by the Basel accords.
Indeed, for the loss given default () we use the standard estimate provided under the
approach, which is equal to 45%, while for the exposure at default we proceed as follows:
Let be the amount of the financing authorization granted by the bank to the customer, The exposure at default
is defined as the sum of:
The value accounted for in the balance sheet (
The value of the unused funding commitment, accounted for off-balance sheet (
The mathematical formulation of the is given by the following relationship:
2.2. The expected loss (EL)
The Basel Committee (Citation2015) has established the provision for the expected loss. Indeed, the amount of the expected loss is equal to the multiplication of the three components ,
and
:
2.3. The unexpected loss (UL)
The unexpected loss () and the risk-weighted assets are defined by the Basel Accords as follows:
The parameter () called « Capital requirement» represents the weighting function calculated according to the
,
, correlation
and the effective maturity
.
In this paper, we will calculate the risk-weighted assets of a portfolio of SMEs. Indeed, the Basel Committee defines the parameter relating to this segment by:
Capital requirement (
with
Maturity adjustment (
G(.) =
The correlation
3. The modelling of probability of default
3.1. Constitution and treatment of the database
3.1.1. The constitution of the database (definition of variables)
In our study, we were able to identify 16 quantitative and 19 qualitative variables. The choice of variables is based on current financial analysis practices and the likely impact on business failure.
We present below the selected variables, the explanation and meaning of which are detailed in Appendix 1 (Table A1, Table A2).
–The quantitative variables
The quantitative variables (),
, are divided into six classes, defined in Table .
–The qualitative variables
The variables are grouped by theme
, in Table .
3.1.2. Discretization of qualitative variables and their transformation into a score
For the discretization of the variables we will use the approach proposed in Benbachir and Habachi (Citation2018) which is as follows:
–Discretization of qualitative variables
The qualitative variables ( are discretized into modalities. The number of modalities can be equal at 3 or 5 modalities. The rule of the modalities choice is based on the logical relationship between modalities and default.
–Transformation of quantitative variable into score
Let , be the modalities of the qualitative variable (
and (
) defines the number of modalities (
). For each modality, the score varies between 0 and 100 points with a jump of 50 points per modality for the variables at three modalities and a jump of 25 points for the variables at five-modalities. The score taken by the modalities is:
Variables at three modalities : [0, 50,100]
Example: the modalities relating to the sector default rate are: 1—below average, 2—equal to average, 3—above average. In this case, the scores given are, respectively: 100, 50, 0.
Variables at five modalities : [0, 25, 50, 75,100]
Example: the modalities relating to natural risk are: 1—No risk, 2—Low risk and the adequate crisis plan, 3—High risk and the adequate crisis plan, 4—Low risk without crisis plan, 5—High risk without crisis plan. In this case, the scores are, respectively: 100, 75, 50, 25, 0.
The assessment of the logical relationship between the modalities of each variable and the default is determined on the basis of expert opinion.
3.2. Mathematical modelling of default
The default is modeled by a binary variable defined as follows:
The relationship between the variable to be explained and the explanatory variables
and
is determined by the linear discriminant analysis.
To determine the explanatory variables to be used for modelling, we will use an univariate analysis for each variable in the chosen list. Indeed, the objective of this analysis is to determine the relationship between and each of its quantitative and qualitative variables
et
.
3.3. The linear discriminant analysis
Linear discriminant analysis provides a method for predicting the failure of a enterprise based on quantitative and qualitative discriminant variables.
In the case of the binary modeling given by the formulation (1), the classification function (score function) relating to a vector of characteristic is written:
with:
If the firm is a healthy otherwise the firm is in default. The threshold
) was determined by the model. The classification function
can be written:
From ,
, are the quantitative and qualitative discriminating variables and
are the discriminating coefficients. The linear discriminant analysis is based on the following assumptions:
The discriminating variables should not be overly correlated therebetween.
The discriminating variables derives from a population with Gaussian distribution.
The covariance matrices must be equal for each group.
3.3.1. Choice of variables
The choice of discriminant variables to be used is based on the univariate analysis. Indeed, the discriminant variables must verify the hypothesis of equality of group means is true. The statistical test for equality of group means is in Table .
3.3.2. Testing of the significance of the coefficients
The validation of the multivariate model depends on the following significance tests:
–The Box’s M test (the groups covariance matrices are all equal)
The Box’s M test is used to check whether two or more covariance matrices are equal (Homogeneity of variances). The null hypothesis that “The groups covariance matrices are all equal” and the test statistics are defined by:
with:
The decision of the test depends on the size of the group and the number of discriminating variables because the statistic can be a chi-square law or a Fisher law. Therefore, if the p-value is inferior to 5%,
is rejected.
–Tests relating to the predictive capacity of the classification function (score function)
To test the predictive capacity of the classification function, we use Wilks’ lambda. Indeed, the test statistic is defined in Table .
3.3.3. The confusion matrix
To ensure that the discriminant function provides a good classification of companies into subgroups, we use the confusion matrix defined in the Table .
This matrix permits to determine the capacity of the model to correctly classify the firm. Indeed, it is measured by the ratio: .
This capacity is confirmed by the test defined in Giannelloni and Vernette (Citation2001). The hypothesis
is defined by « the equality of the number of individuals correctly classified by the discriminating function and by hazard ».
The test statistic is: , for
we are
with: is the total number of companies,
is the number of companies correctly classified and
is the number of groups.
The statistic is chi-square law (
) at 1(one) degree of freedom. Indeed, if the p-value is inferior to 5%,
is rejected.
3.3.4. The affectation threshold
The decision to affect a company’s allocation is based on the affectation threshold defined by the functions at group centroids. The separation of groups is defined in Table .
The optimal separation point is the weighted mean of the values of and
(
). However, if both groups are the same size (
the separation point will be the arithmetic mean of
and
(
.
3.3.5. Discriminatory power (power stat)
The discriminatory power represents the model’s ability to predict future situations. We will use the curve to determine the discriminatory power of the model. The determination of the
curve will be done from the classification table of the sample of estimation of the variable
which is presented in Table .
One indicates by sensitivity (), the proportion of the healthy companies classified well:
and by specificity (
), the proportion of the de companies is in default, classified well:
If one varies the “probability threshold” from which it is considered that a company must be regarded as healthy, the sensitivity and specificity varies. The curve of the points () is the
curve.
Definition of the area under the
The area under the
The area under the curve (
) provides an overall measure of model fit (Bewick, Cheek, and Ball (Citation2004). The
varies from 0,5 (predictive capacity absence for the model) to 1 (perfect predictive aptitude for the model).
Accuracy ratio (
The accuracy ratio is defined by the relationship:
The takes values between 0 and 1.
–The determination of explanatory variables
To determine the explanatory variables to be retained for modelling, we will carry out a univariate linear discriminant analysis for each variable in the chosen list.
After selecting the explanatory variables on the basis of the decision rules mentioned above, we will study the correlation between the selected variables. The study of correlations makes it possible to eliminate strongly correlated variables. Indeed, if two or more variables have a correlation coefficient superior to 0,5 then the variable that represents the greatest
will be selected.
–The performance of the multivariate model
The discriminating capacity of the multivariate model is considered acceptable if the is greater than 70%.
3.3.6. The canonical discriminant function
The canonical discriminant function, presented in Klecka (Citation1980), is a linear combination of the discriminant variables. Indeed, it has the following mathematical form:
with are the discriminating variables and
are the canonical coefficients.
The maximum number of canonical functions is equal to the with k is the number of classes and p is the number of discriminating variables.
The canonical coefficients are determined in such a way as to maximize the distance between the group centroids. The canonical discriminant functions can be used to predict the most probable class of membership of an invisible case.
The discriminating canonical analysis is detailed in Palm (Citation1999) and Klecka (Citation1980). Indeed, it is similar to the main component analysis in that it replaces the initial discriminating variables with uncorrelated canonical variables as a linear combination of the initial variables.
3.4. The construction of the rating model
The conception of the rating model is based on the score function because the probability of default () depends on the score attributed by the statistical model. Therefore, the conception process is as follows:
3.4.1. The determination of the score function by linear discriminant analysis
The modeling of default by linear discriminant analysis is done by the simultaneous treatment of quantitative and qualitative variables. Indeed, let be , and
, respectively, the quantitative and qualitative variables retained by the univariate linear discriminant analysis noted, respectively,
and
.
The score function of the linear discriminant analysis is defined by the relationship:
we note the function by
3.4.2. Determination of the rating grid
The determination of the rating grid consists in determining the score interval for each class. Indeed, the standardized score is defined over an interval of 0 to 100 ([0,100]). This interval will be segmented into eight (8) classes to determine the rating classes.
3.4.3. The prediction of healthy firms by the linear discriminant analysis
The prediction of healthy firms by the linear discriminant analysis is based on the function at group centroid defined by Table . Indeed, let and
, be, the characteristics of the firm (
). This firm is considered healthy if:
Table 1. The list of quantitative variables
Table 2. The list of qualitative variables
Table 3. Univariate analysis and choice of discriminant variables
Table 4. Wilks’ lambda
Table 5. The Confusion matrix
Table 6. Functions at group centroids
Table 7. The classification table
Table 8. The rating grid
Table 9. The probability of default by class
Table 10. Rating of the scoring criteria for credit portfolio managers
Table 11. Weighting of credit portfolio managers as a function of the score
Table 12. The portfolio structure in terms of default
Table 13.. () and (
) by rating class
Table 14. Non-discriminatory variables
Table 15. The quantitative and qualitative discriminating variables
Table 16. Analysis of the correlation of quantitative discriminant variables
Table 17. Results of the Box’s M test
Table 18. Wilks’ lambda
Table 19. The Confusion matrix
Table 20. The canonical correlation of variables
Table 21. The functions at group centroids
Table 22. Rating model based on linear discriminant analysis
Table 23. Explicit estimation of the probability of default by class according to experts
Table 24. Estimate of expected losses by class according to experts
Table 25. The probability of default of the experts retained for the modelling
Table 26. Bayesian rating models
Table 27. The unexpected loss according to the model
Table 28. The Bayesian unexpected loss
The firms with a score function between and
, defined by Table , overlap between the sound and default classification. Indeed, the classification in this case is based on the point of separation. Therefore, the firm (
) is considered healthy if:
The classification function of firms can be defined as follows:
3.4.4. The rating grid
The classification of healthy companies is based on the score function. Indeed, this classification gives rise to the rating grid composed of 8 rating classes.
Each company () is classified into a rating class, the classes vary between A and H, and are defined in the Table .
The intervals of score are semi-open on the left to guarantee the independence of the rating classes. Indeed, the lower bound belongs to the “t” class and the upper bound of the interval belongs to the “t +1” class with the exception of class A which has a closed interval.
3.4.5. Calculation of the rating score
The rating score of the firm (
) is defined by:
where is a score fonction of the firm (
).
3.5. Calculation of the probability of default per rating class
The probability of default of the class
is defined by the probability of default of the company (
) knowing that the company (
) belonging to the class
The probability of default can be determined by the probabilistic approach or by empirical calculation:
3.5.1. Theoretical calculation of the default probability of the rating class (K)
In the framework of linear discriminant analysis, the probability of default of the firm (
) is expressed by Gurný et al. (Citation2013) by the following formula:
with is the prior probability of default of the sample and
is expressed by the formula:
where
with is the variance-covariance matrix of the discriminatory variables.
As a result, the probability of default of the class
is determined by the following formula:
3.5.2. Empirical calculation of the probability of default
The probability of default can be calculated from empirical data. Indeed, it represents the proportion of firms at default belonging to the rating class
. As a result, it is calculated by the following formula:
To define this probability of default per rating class, we will distribute the sample of healthy and default companies in Table .
3.6. Bayesian approach to the conception of rating models
The proposed Bayesian rating approach is composed of several steps defined as follows:
3.6.1. Definition of the Bayesian approach
Let be the random variables and
its parameter, According to the Bayesian approach, the parameter
is considered as random variable of density
.
The probability density function of the random vector defined by:
Where:
The Bayes’ theorem says that the posterior density can be calculated as follows:
Where from
is a normalisation constant. π(θ/Y) the posterior distribution can be viewed as a combination of a prior knowledge
with a likelihood function for observed data
. Since
is a normalisation constant, the posterior distribution is often written with the form (15) where ∝ is a symbol for proportionality.
Indeed, the Bayesian estimator for the univariate case is defined as follows:
3.6.2. Calculation of the probability of default by the Bayesian approach
Let be the random variable that models the company’s failure (
) and let be
the random variable that models the parameter of
. Indeed, the variable
is expressed by the relationship:
Let be the probability of
knowing
,
is defined as follows:
Let the number of companies in default in the class
and
the number of companies that belong to the class
,
is expressed by the following formula:
Let be the probability of
knowing
, the variable
is modelled by the binomial distribution. Indeed, the probability
is expressed by the following formula:
3.6.3. Definition of the prior law π(θ) of θ theta
The priori law of of the Binomial distribution is studied in Tasche[31]. Indeed, the priori law for the distribution of
that we will use is the distribution beta with the parameters (
defined by the following formula:
with is the Euler gamma function defined by:
The parameters and
are estimated by the experts, the mathematical expectation and the standard deviation of the Beta law are determined according to
and
as follows:
3.6.4. Determination of the posterior law π(θ/R) of θ theta
The posterior law conjugated at the prior law θ is defined by the formula (15) as follows:
Hence
Knowing that thus:
with is a constant independent of
, thus:
Therefore, is a distribution Beta with the parameters (
,
)
3.6.5. Determination of the bayesian estimator of the parameter θ
The Bayesian estimator of the parameter θ is determined by the formula (16) as follows:
3.6.6. Determination of the bayesian default probability by class K
The formula (19) can be written as follows:
We pose thus
is written:
with:
The formula (20) permits to expressing the posterior probability of default as follows:
The formula (21) shows that the Bayesian probability of default is the weighted mean of the statistical probability of default and the probability of default of the experts.
3.7. The implementation of the Bayesian approach
The implementation of the bayesian approach to determine the probability of default that we propose in this paper is based on the Delphi technique defined in Helmer (Citation1968) and Ayyub (Citation2001). Indeed, the information solicited from experts concerns the probability of default by class and the weighting of the expert opinion
.
3.7.1. Estimation by experts of the probability of default by class PDe,K
The estimation by experts of the probability of default by class is done in two different ways. Indeed, it can be determined implicitly or explicitly:
3.7.1.1. Explicit estimation of the probability of default
The explicit method consists in directly soliciting expert opinion for the default rate of each rating class, on the basis of the classification criteria of the statistical model, the risk profile and the score of each class.
In this case, the expert must furnish a probability of default per score class. Indeed, it must furnish the mean number of defaults for a theoretical sample with sizes equal, respectively, to 100, 1000 and 10,000 companies. The probability of default is equal to the number estimated by the expert divided by each size used.
3.7.1.2. Implicit estimation of the probability of default
In this case, we will implicitly deduce the probability of default of the experts using the expected loss by amounting ( defined by the formula (1). Indeed, the expert must estimate the amount of the expected loss in form of a percentage of the credit volume of each class.
The probability of default is calculated using the estimated of the loss given default (
) fixed by the
approach. For the implicit estimate, the expert must estimate the mean loss per score interval. Indeed, for our study, it must pronounce on the mean loss compared to an exposure of 100 000, 1000 000 and 10 000 000
.
The probability of default will be determined by assuming that the expert will furnish the amount of the expected loss () and using the
estimates for the loss given default(
) fixed at 45% and considering that the exposures relating to a credit conversion factor (
) of 75% are, respectively, equal to 100 000, 1 000 000 and 10 000 000
.
3.7.2. Estimation the weighting of the expert opinion ε epsilon
The weighting of the expert opinion is effected via the participation of the counter-study function of credit dossiers, the permanent control function and the internal audit function. In our study, we used two weighting values that are 25% and 50%. Indeed, the selected experts must verify its two weights.
3.7.3. Definition of the interveners
The implicit and explicit estimation of the probability of default is made by the participation of the following interveners:
Credit portfolio managers (experts)
The portfolio managers must furnish an estimate of the number of defaults and the mean expected loss per rating class.
Internal auditors and permanent controllers (evaluator)
The internal audit and permanent control functions intervenes in weighting the experts’ opinions.
3.7.4. Choice of interveners
3.7.4.1. Choice of experts
For the elaboration of Bayesian models, we will use two values for the weighting of the expert opinion, which are 25% and 50%. Therefore, we need to identify the experts who can be weighted, respectively, at 25% and 50%.
To do this, we drew a list of credit portfolio managers and scoured their profiles; then we retained only those whose estimates can be weighted at 25% and 50%.
The score of the credit portfolio managers is determined with the hierarchical managers and confirmed with the audit function and the permanent control function on the basis of a support composed of the following elements:
Pertinent expertise, university education and professional experience.
The size of the portfolio managed and the rate of companies in difficulty.
Mastery of the process of control, recovery and financial management.
Excellent communication abilities, flexibility, impartiality and capacity to generalize and simplify.
The score must give a value in a grid of . Indeed, each criterion must have a qualification between low, medium and high. To calculate the score, in Table , we assigned the following ratings to these qualifications:
The score is equal to the sum of the ratings assigned to all criteria and the weighting is defined according to the score in Table .
3.7.4.2. Choice of evaluator
The choice of evaluators at the level of permanent control and internal audit is based on expertise in credits. Therefore, we have defined the criteria for selection as follows:
Pertinent expertise, university education and professional experience.
Expertise in credit risk.
The number of control and audit missions of the credit activity.
3.7.5. The conduct of collection of data in experts
Once, we selected the experts and evaluators, we organized evaluation meetings in which the following elements were taken into consideration:
Definition of the objective of the study (modelling of probability of default, rating …)
The presentation of the portfolio of SMEs and their characteristics.
The default rate in the portfolio of SMEs
The need for information: number of defaults and mean loss per rating class.
Data collection from credit portfolio managers and validation with the hierarchy.
Selection and weighting of experts and presentation of criteria for weighting.
Choice of evaluators and presentation of the criteria for choice.
4. Empirical study
4.1. Description of the database
In this study, we used a database of small and medium-sized companies from a Moroccan bank composed of 1447 companies. The quantitative and qualitative information concerns 31-12-2017 and the situation of the companies (healthy or in default) is observed during 2018. In terms of default, the portfolio structure is presented in Table .
The financing authorizations () and balance sheet values (
of this portfolio by rating class are detailed in Table .
4.2. Choice of quantitative and qualitative variables
4.2.1. Univariate discriminant analysis
The univariate linear discriminant analysis of quantitative and qualitative variables permitted to determine the discriminant variables. The choice of quantitative variables is based on the Fisher ratio. Indeed, the non-discriminatory variables are presented in Table .
The Fisher ratio test for the quantitative and qualitative variables presented in the previous table shows that the p-value is superior to 0,05. Therefore, these variables are not discriminating and will not be retained for the multivariate linear discriminant analysis. On contrary, the selected discriminant variables are in Table .
4.2.2. Analysis of the correlation
To eliminate the impact of the correlation of the variables on the prediction of the default, the Table represents the correlation between the quantitative variables:
Analysis of the correlation of the discriminant variables shows that variables and
are highly correlated because the correlation coefficient is equal to 0,6. Therefore, we only retain the variable
for modeling.
The choice to retain the variable is based on the curve of
. Indeed, the
of the variable
is superior to that of the variable
. The results of the performance analysis of the two variables are as follows:
Figure 1. Comparison of the performance of correlated variables and
.
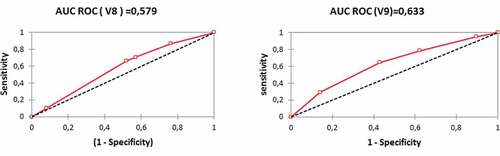
4.2.3. Multivariate analysis and determination of the classification function
Let be the quantitative discriminating variables and
the qualitative discriminating variables with:
(
The multivariate analysis permits the definition of classification functions and
of defaulting enterprises and healthy enterprises, respectively, in the Figure .
4.2.3.1. The classification function of defaulting enterprises Y = 0
The classification function of defaulting enterprises is defined by:
4.2.3.2. The classification function of healthy enterprises Y=1
The classification function of healthy enterprises is defined by:
4.2.4. Testing of the significance
The results of the tests of significance defined in the third section are presented as:
The Box’s M test
The results of the test are presented in the Table .
Since the calculated p-value is lower than the significance level =0,05, the null hypothesis
must be rejected. This means that the model distinguishes between defaulting and healthy enterprises.
Tests relating to the predictive capacity of the score function (Wilks’ lambda)
The results of the test are presented in the Table .
Since the calculated p-value is lower than the significance level =0,05, the null hypothesis
must be rejected. This means that the model has an acceptable capacity to predict companies in default.
The Confusion matrix
The confusion matrix is presented in the Table .
The capacity of the model to classify the company correctly is in the order of 93,7%. This signifies that the model has an excellent capacity to correctly classify enterprises.
Confirmation of this capacity is done using the Q test presented in the third section. The empirical value of the test statistic is:
The critical value of the with 1 degree of freedom is equal to 3,84. Since
is superior to the critical value, the null hypothesis
must be rejected. This confirms that the model has an excellent capacity to correctly classify enterprises and that it offers a better classification compared to the hazard classification.
4.2.5. The performance of the model
The of the model is equal to 0,798 which represents an acceptable performance
. The results are represented by Figure .
Figure 2. Performance of the linear discriminant analysis model.
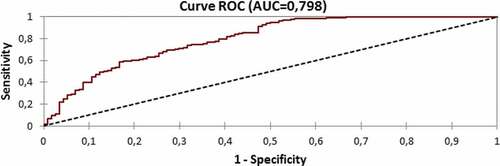
4.3. The canonical discriminant function
4.3.1. The canonical correlation
The canonical correlation of variables is given by the Table .
The canonical correlation of variables is equal to 0,4430. This value does not permit to decide on the discriminating capacity of the model. Indeed, we will support the discriminating capacity of the model on the results of the .
4.3.2. The functions at group centroids
The functions at group centroids are presented in the Table .
4.3.3. The canonical discriminant function
The number of canonical discriminant functions in the case of two groups is limited to a single function. In our study, this function is presented as follows:
The separation point is equal to zero (. Indeed, for the prediction of default, a enterprise is considered healthy if
.
The canonical discriminant function shows that the variables most correlated with the score are the return on equity (=
), the seniority of the principal operational staff (
) and the number of payment incidents in the last 12 months (
).
4.4. Conception of the rating model by linear discriminant analysis
The results of the process of the conception of the rating model are presented in the Table .
The distribution of healthy and defaulting enterprises and the probability of default by rating class are presented in the Figure .
Figure 3. The distribution of healthy and defaulting enterprises and the probability of default by rating class.
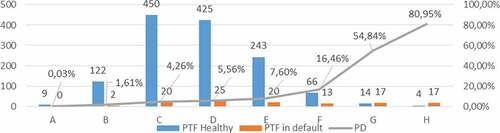
4.5. Conception of the notation model using the bayesian approach
For the conception of Bayesian rating models, we opted for an aggregation of the opinions of the selected experts regardless of their weightings. Indeed, the estimation is made with a working group that contains the two categories of experts. Indeed, the results will be weighted at the same time by 25% and 50% to determine the Bayesian models associated with the model.
4.5.1. The explicit probability of default
The results of the assessment of the explicit default probability by rating class are presented as follows:
4.5.2. The implicit probability of default
The implicit probability of default is defined in the Table .
The results of the assessment of the implicit probability of default by rating class are presented in the Table .
The probability of default by experts ( retained is the mean of the explicit and implicit probability of default with a minimum of 0,03% for class A: The Table summarizes the results as follows:
4.5.3. Determination of bayesian rating models
The Bayesian probability of default is a weighting of the experts’ default probability and the default probability determined by the statistical models:
The Bayesian models according to the weighting of expert opinion are presented in the Table .
4.6. Impact of Bayesian modelling on the calculation of unexpected loss (UL)
In Morocco, the legislator has adjusted the formula (4) to take into consideration the characteristics of Moroccan Footnote3. Indeed, it provides the following correlation formula for each company (i):
For the approach, maturity M for companies is equal to 2,5. As a result, the formula (3) becomes:
The weighted assets for each enterprise () are expressed by:
The unexpected loss incurred with each company ) is expressed as follows:
The weighted assets are determined by rating class for each model. Let be , the size of the class (c), the unexpected loss
of class
is defined as follows:
Knowing that the loss given default () in the framework of the
approach is equal to 45% and that the probability of default (
) of class (c) is the same for all enterprises in this class, the previous formula is written:
We pose thus
The total unexpected loss () is equal to:
4.6.1. The determination of the unexpected loss by LDA
The unexpected loss ( by rating class according to the
model is presented in the Table .
4.6.2. The Bayesian unexpected loss associated with linear discriminant analysis
The bayesian unexpected loss associated with is presented in the Table .
The results show that the Bayesian approach according to the methodology presented above reduces the unexpected loss, respectively, by 4,7% and 10,1%.
5. Conclusion
The measurement of credit risk is a major preoccupation for banks because they have to determine the expected loss to be covered by provisions in the framework of IFRS9 and the unexpected loss that represents the regulatory capital requirement.
The conception of the rating model that classifies counterparties according to their risk profile is the core of the approach. Indeed, several techniques can be used to model the default and determine the different rating classes.
In this paper, we used the linear discriminant analysis to construct a statistical rating model by determining the relationship between the default and the quantitative and qualitative variables of the enterprises.
Then, we proposed a Bayesian approach that permits to integrate the experts’ estimation to calculate the posterior probability of default by rating class. The rating model constructs at the same performance as the statistical model because the adjustment only concerns the probability of default by class.
The proposed approach has several advantages in that it permits the capture of events not taken into account by the statistical model by using the expert opinion such as changes in the economic situation, an increase in the default rate, the various incidents giving rise to the termination of the banking relationship, and changes in the control and decision-making processes.
However, the effectiveness of this approach depends on the rigour of information collection procedures for avoiding an underestimation of default probabilities. Indeed, the Bayesian approach has a major disadvantage related to the quality of information provided by professional experts. As a result, we have presented an approach based on the Delphi technique, proposed the tools for selecting experts and evaluators, and we have determined the steps needed to collect reliable information.
The calculation of the unexpected loss showed that the Bayesian approach reduces the capital requirement. In our empirical study, the lost profit varies between 4,7% and 10,1%.
In summary, the Bayesian approach permits the adjustment of statistical models in order to conform as closely as possible to economic conjuncture and the internal changes in terms of control and decision-making. However, the collection procedures must be very rigorous in order to reduce the risk of the reliability of the information collected from experts.
Additional information
Funding
Notes on contributors
Mohamed Habachi
Mohamed Habachi PhD in management science, banking experience of 20 years.
Specialized in Risk Management and Audit.
Two articles published in the field of operational risk and credit risk
Saâd Benbachir
Saâd Benbachir PhD, Studies and Researches in Management Sciences Laboratoy
Director of the Strategic Studies in Law, Economics and Management Center.
31 articles published in market risk, stochastic volatility, operational risk and credit risk.
Notes
1. The correlation formula for companies and banks is . For exposures to SMEs this formula is adjusted to take into account the size of the entity: 0,04 x (1—(S—5)/45)). S is expressed as total annual sales in millions of euros with values of S falling in the range of equal to or less than €50 million or greater than or equal to €5 million. Reported sales of less than €5 million will be treated as if they were equivalent to €5 million. Paragraph 273 of the Basel Committee on Banking Supervision[7].
2. In the case of two groups, Bartlett’s approximation of the lambda distribution is chi-squared with p degrees of freedom .
3. Bank Al Maghrib’s circular 8/G/2010 considers that SMEs are characterised by a turnover (Sales) that varies between MAD 10 and 175 million . The
whose turnover is less than 10 million
are treated as equivalent to this amount.
Related Research Data
References
- Altman, E. I. (1968, September). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. Journal of Finance, 23(4), 589–34.
- Ayyub, B. (2001). A practical guide on conducting expert-opinion elicitation of probabilities and consequences for corps facilities. U.S. Army Corps of Engineers Institute.
- Back, B., Laitinen, T., Sere, K., & Wezel, M. V. (1996). Choosing bankruptcy predictors using discriminant analysis, Logit analysis and Genetic Algorithms, Turku Center for computer science. Technical Report, 40, 1–18.
- Bardos, M. (1998). Detecting the risk of company failure at the Banque of France. Journal of Banking and Finance, 22, 1405–1419. doi:10.1016/S0378-4266(98)00062-4
- Basel Committee on Banking Supervision. (1999). Credit risk modelling: Current pratices and applications. Bank for International Settlements.
- Basel Committee on Banking Supervision. (2006). International convergence of capital measurement and capital standards. Bank for International Settlements.
- Basel Committee on Banking Supervision. (2015). Guidance on credit risk and accounting for expected credit losses. Bank for International Settlements.
- Basel Committee on Banking Supervision. (2016). Standardised measurement approach for operational risk, consultative document. Bank For International Settlements.
- Bell, T. B., Ribar, G. S., & Verchio, J. R. (1990), Neural nets vs. logistic regression: A comparison of each model’s ability to predict commercial bank failures. Proceedings of the 1990 Deloitte and Touche-University ofKansas Symposium on Auditing Problems, 29–58.
- Benbachir, S., & Habachi, M. (2018). Assessing the impact of modelling on the Expected Credit Loss (ECL) of a portfolio of small and medium-sized enterprises. Universal Journal of Management, 6(10), 409–431. doi:10.13189/ujm.2018.061005
- Bewick, V., Cheek, L., & Ball, L. (2004). Receiver operating characteristic curves. Critical Care, 8(6), 508–512. doi:10.1186/cc3000
- Bose, I., & Pal, R. (2006). Predicting the survival or failure of click-and-mortar corporations: A knowledge discovery approach. European Journal of Operational Research, 174(2), 959–982. doi:10.1016/j.ejor.2005.05.009
- Bunn, P., & Redwood, V. (2003). Company account based modeling of business failures and the implications for financial stability. The Bank of England’s Working Papers Series N°210.
- Das, S. R., Fan, R., & Geng, G. (2002). Bayesian migration in credit ratings based on probabilities of default. Journal of Fixed Income, 12, 17–23. doi:10.3905/jfi.2002.319329
- Dwyer, D. W. (2006). The Distribution of Defaults and Bayesian Model Validation. Moody KMV.
- Friedman, N., Geiger, D., & Goldszmidt, M. (1997). Bayesian Network Classifiers. Machine Learning, 29(2–3), 131–163. doi:10.1023/A:1007465528199
- Gemela, J. (2001). Financial analysis using bayesian networks. Applied Stochastic Models in Business and Industry, 17(1), 57–67. doi:10.1002/(ISSN)1526-4025
- Giannelloni, J. L., & Vernette, E. (2001). Etudes de marché (pp. 420). édition Vuibert. Paris: Librairie Eyrolles.
- Gôssl, C. (2005). Predictions based on certain uncertainties, A Bayesian credit portfolio approach. Working Paper, Hypo Vereinsbank AG. London.
- Grice, J., & Ingram, R. W. (2001). tests of the generalizability of altman's bankruptcy prediction model. Journal of Business Research, Volume 54 Volume 54 54(Issue 1), 53–61. doi:10.1016/S0148-2963(00)00126-0
- Gurný, P., & Gurný, M. (2013). Comparison of credit scoring models on probability of default estimation for US banks. Prague economic papers. 2, 163-181. doi:10.18267/j.pep.446
- Helmer, O., (1968). “Analysis of the future: The Delphi Method”, https://www.rand.org/content/dam/rand/pubs/papers/2008/P3558.pdf
- Hensher, D. A., Jones, S., William, H., & Greene, W. H. (2007). An error component logit analysis of corporate bankruptcy and insolvency risk in Australia. The Economic Record, 83, 86–103. doi:10.1111/j.1475-4932.2007.00378.x
- Hunter, J., & Isachenkova, N. (2002). A panel analysis of UK industrial company failure. ESRC Centre for Business Research Working Paper 228. Cambridge University.
- Klecka, W. (1980). Discriminant analysis (pp. 16). London: Sage Publications.
- Liang, L., & Wu, D. (2003). An application of pattern recognition on scoring Chinese corporations financial conditions based on back propagation neural network. Computers Et Operations Research, 32, 1115–1120. doi:10.1016/j.cor.2003.09.015
- Ohlson, J. A. (1980). Financial ratios and the probabilistic prediction of bankruptcy. Journal of Accounting Research, 18-1, 109–131. doi:10.2307/2490395
- Oreski, S., Oreski, D., & Oreski, G. (2012). “Hybrid system with genetic algorithm and artificial neural networks and its application to retail credit risk assessment”. Expert Systems with Applications, 39, 12605. doi:10.1016/j.eswa.2012.05.023
- Palm, R. (1999). l’analyse discriminante décisionnelle: principe et applications. Notes stat. Inform. (Gembloux) 99/4, 41p.
- Taffler, R. J. (1982). Forecasting company failure in the UK using discriminant analysis and financial ratio data. Journal of the Royal Statistical Society, Series A, General, 145(3), 342–358. doi:10.2307/2981867
- Tasche, D. (2013). “Bayesian estimation of probabilities of default for low default portfolios”. Journal of Risk Management in Financial Institutions, 6(3), 302–326.
- Zmijeriski, M. (1984). Methodological issues related to the estimation of financial distress prediction models. Journal of Accounting Research, 22, 59–82. doi:10.2307/2490859
Appendix
Table A1. Explanation and significance of quantitative variables
Appendix
Table A2. Explanation and significance of qualitative variables