
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The research objectives are as follows: (1) Develop a solid structural model assuming normality and homoscedasticity. (2) Obtain the property estimator of the flexible and robust SFAM structural model. (3) Obtaining hypothesis testing of each relationship built from the flexible and strong SFAM structural model. This research is integrated with a flexible and robust modeling approach based on nonparametric smooth spline regression analysis (RNSS) that can capture the shape and robustness of relationships dependent on empirical data. There are at least three transformation methods namely SRS, MSI and RASCH that will be used in SFAM development. The results obtained are the development of a flexible structural model in the form of relationships between variables and a robust structural model from the two assumptions, then the estimator properties and hypothesis testing of each relationship are built from the two models. The authenticity of this research is very evident in the discovery of a new model, namely SFAM that can accommodate various things, which are the weaknesses of various existing analytical tools such as recursive and recursive models, more than one endogenous variable, flexible and strong models.
1. Introduction
This study will reconstruct the Structural Flexibility and Acceptance Model (SFAM) as the stage of developing a concept/theory/proposal regarding statistical modeling. The meaning of the 4 words in the model are as follows: structural reflects the structural model that has been built, flexibility indicates a flexible model, acceptance implies a strong and hypothesis-free model (Fernandes, Citation2018). reconstruction or statistical model based on stochastic. The novelty of this research can be seen in the discovery of a new model, namely SFAM which can handle several things, which is the weakness of several existing analytical tools such as recursive and recursive models. Frequently used statistical models, such as SEM, PLS, GSCA and WarpPLS, have drawbacks and can be handled using SFAM (Fernandes, Citation2017). This system modeling is a very broad data analysis method, especially in the social, humanistic and educational fields, in research using a quantitative approach.
Quantitative, qualitative and mixed methods research approaches in various fields are developing very rapidly. For example, research in the field of accounting that started using a quantitative approach, is now starting to shift to a qualitative approach, this is after the development of behavioral accounting (Fernandes et al., Citation2014). Likewise in the economic field. Such as the social and humanities fields that have developed earlier, for example sociometry, psychometry and econometrics. Research with a quantitative approach in the social and humanities field is not an interesting thing at first, because researchers often have difficulty in analyzing data. The application of statistics as a data analysis method in general can be difficult for them. However, with the development of computing tools in the form of computer machines, this problem can be overcome. Research in the social humanities generally investigates systems, where one of the characteristics of the system is very complex (Purbawangsa et al., Citation2019). Simplification of the solution can be done through modeling, one of which is modeling using statistics. The main characteristic of statistical modeling is the existence of a relationship between variables and the nature of the relationship is stochastic. In other words, model design always begins with the formulation of research hypotheses.
Theories and results of previous research can be used as a basis for thinking for further research. In designing the relationship between variables in a model based on the construction of hypotheses. The disruption effect, which brings the logic of future thinking to current research, is one of the answers to a current problem. We can follow disruptive innovation when the foundation or perspective of research thinking, namely in structuring the relationship between variables in the model, is developed as follows: (1) Finality norms (scriptures), (2) axioms, (3) theorems/theories/propositions, (4) Results of empirical research, (5) Adoption of theory and/or results of empirical research on the relationship between variables from other fields of science, (6) Non-final norms, such as government regulations, laws, SOPs, and so on, (7) Conditions empirical, (8) Expert judgment, and (9) Intuition/logic. Elements (1), (6) to (9) allow us to build or reconstruct the model through theory (Fernandes et al., Citation2019). New research (new ideas/ideas) can be more easily obtained from local wisdom if the basis or perspective of research thinking can be expanded in such a way so that it can encourage the development of indigenous knowledge.
The nature of research subjects in the social humanities field is changing rapidly and dynamically. System modeling based on innovation which is seen as being able to keep up with rapid and dynamic changes is also capable of capturing future phenomena. Thus, it is hoped that today's researchers, students and lecturers are not limited to existing theories, but can carry out scientific constructions even though they use quantitative research.
This research is an effort to socialize the latest ideas. With disruptive innovation, the main emphasis is on impacting what we produce and on life, both scientific life and people's lives. System modeling analysis that has developed and is often used includes Structural Equation Modeling (SEM). Until now, there have been several SEM analyzes whose applications have developed in Indonesia, including SEM with AMOS/LISREL software, PLS using SmartPLS software, GSCA with GeSCA and WarpPLS software.
Modeling involves latent variables, where the data analyzed are generally obtained by measuring the process using a questionnaire. The questionnaire was applied using a Likert scale model, and produced data in the form of scores. In general, the weakness of all these methods is that they do not include the concept of data transformation in the form of scores into the scale. So it is necessary to develop a model that can include the concept of data transformation in the form of scores into scales. There are at least three transformation methods, namely using SRS, MSI, and RASCH which will be used to complement the modeling method, by developing a Structural Flexibility and Acceptance Model (SFAM).
The Structural Flexibility and Acceptance (SFAM) Reconstruction Model is equipped with the concept of path analysis with categorical data so that it can also be used to analyze categorical data. On the other hand, the development of SFAM is also equipped with a flexible and robust model approach based on nonparametric smoothing spline regression analysis (RNSS) which can capture the form of relationships that depend on empirical data. This study aims to describe the modeling of a flexible and robust structure, the realization of a new model, namely Structural Flexibility and Acceptance (SFAM). This study aims to: (5) Develop a flexible structural model on the relationship between variables. (6) Develop a structural model that is robust against the assumptions of normality and homoscedasticity. (7) obtain a property estimator from a flexible and robust SFAM structural model. (8) Obtaining hypothesis testing of each relationship built from the flexible and robust SFAM structural model.
This research was conducted to reconstruct Structural Flexibility and Acceptance (SFAM), which is a structural model that is strong in handling linearity assumptions, or in other words, a structural model that can accommodate non-linear relationships between variables. and strong on the distribution assumption and the assumption of homoscedasticity. Apart from that, SFAM is also equipped with useful power for analyzing categorical data.
2. Result and discussion
2.1. Development of a flexible structural model in relationship between variables
Regression analysis is a function that relates exogenous variables (X) to endogenous variables (Y) which can be in the form of linear or nonlinear relationships (Fernandes and Taba, Citation2018). Simple linear regression analysis has one exogenous variable and one endogenous variable with the form of a relationship that can be described as a straight line. While simple quadratic regression analysis is a function of one endogenous variable and one exogenous variable that has the highest rank with a value of two, so that the form of the relationship can be described as a parabolic line (Fernandes, Citation2017). Path analysis is an extension of multiple regression analysis, where there is one exogenous variable and two endogenous variables involved, namely the intervening endogenous variable (Y1) and the pure endogenous variable (Y2) which can be described below. path analysis model in .
Figure 1. path analysis diagram.
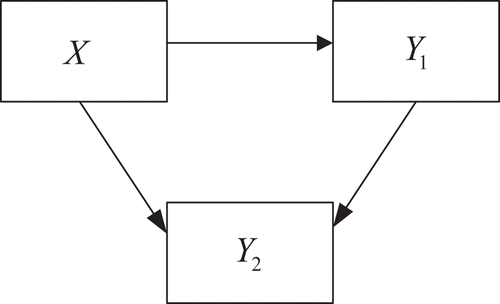
Path analysis can also describe the pattern of relationships between variables that are linear and also nonlinear (Sumardi and Fernandes, Citation2020). Quadratic path analysis involves one exogenous and one intervening variable with endogenous m = 2, and one pure endogenous variable of order m = 1. While complex linear path analysis involves one exogenous variable with q endogenous variables. All variables in complex linear path analysis have an order of m = 1. Thus, a complex quadratic path analysis model can be made with all variables having an order of m = 2. The path analysis model can be further expanded by adding an order of m for each exogenous intervening variable and endogenous so that it can produce a simple m order path analysis model (with 2 endogenous variables) and complex m order path analysis (endogenous variable q-1 and endogenous intervening variable q-1).
Lemma 2.1 Form of simple quadratic path analysis model
If given paired data () with
following the quadratic path analysis model, the quadratic path analysis function is obtained as presented in equation (2.1.1) and the model in (2.1.2)
Matrix form
Proof:
Before obtaining the model in the Simple Quadratic Path Analysis, the first model is obtained from (a) Simple Linear Regression Analysis; (b) Simple Linear Path Analysis; and (c) Quadratic Regression Analysis as follows:
First part: Find out the simple linear regression model with equation (2.1.3) and the model in (2.1.4).
The matrix can be formed:
where:
Endogenous variable of the i-th observation (
);
Exogenous variable of the i-th observation;
The number of observations;
The coefficient of influence of exogenous variables on endogenous (
);
Random error of the i endogenous variable
Part Two: Find a simple linear path analysis model as presented in equation (2.1.5) and the model in (2.1.6).
The following matrix can be formed:
Part Three: After knowing the equations and simple linear regression models, a simple quadratic regression model can be made as presented in equations (2.1.7) and (2.1.8).
The matrix form of the model is:
where:
Endogenous variable of the i-th observation (
);
Exogenous variable of the i-th observation;
Exogenous variable to the power of 2 (squared) of the i-th observation;
The number of observations;
The number of exogenous variables;
The coefficient of influence of exogenous variables on endogenous (
);
Random error of the i endogenous variable
From the equations in the simple linear regression analysis model, simple path analysis, and quadratic regression analysis that has been described, a function that is formed as in equations (2.1.1) and (2.1.2) can be obtained, so that the following matrix is obtained:
Lemma 2.2 Form of complex quadratic path analysis model
If given paired data (),equations and complex quadratic path analysis models can be made as presented in (2.2.1) and (2.2.2).
With the form of a matrix:
Proof:
First part: The equations and models in the simple quadratic path analysis are known as shown in equations (2.2.3) and (2.2.4).
The matrix form of the model is:
Part Two: Equations and models in complex linear path analysis are shown in equations (2.2.5) and (2.2.6).
The matrix form of the model is:
From the results of the description of the model above, an extension of the model obtained in Lemma 3.1 can be made into a complex quadratic path analysis model following equation (2.2.1) and the model in (2.2.2), to obtain the following matrix form:
Lemma 2.3 Form of simple non-linear path analysis model (non-linear m-order)
If paired data () with
follows a simple m-order path analysis model, equations and models can be obtained as presented in equations (2.3.1) and (2.3.2).
The matrix form of the model is:
Proof:
Part One: The results of Lemma 2.1 have been obtained which are a form of the quadratic path analysis function as presented in equation (2.1.1) and the model in (2.1.2) with the following matrix form:
From the results in Lemma 2.1, an expansion can be made by adding the order to m in the exogenous and endogenous intervening variables, so that equations and models are obtained as presented in equations (2.3.1) and (2.3.2) above with the following matrix form:
Lemma 2.4 Model shape non-linear complex path analysis (non-linear m-order)
If given paired data () with
which follows a complex non-linear path analysis model of order m, we can obtain the equations and models presented in equations (2.4.1) and (2.4.2)
The matrix form of the model is:
Proof:
The first part: The equations and models in the complex quadratic path analysis are known as presented in (2.2.1) and (2.2.2) with the following matrix form:
2.2. Development of structural models that are strong with assumptions of normality and homoscedasticity
Theorem 2.2.1 OLS
In a linear model with parameters, the Ordinary Least Square (OLS) method can be used by minimizing the number of squares of the residuals to estimate the path coefficients of the general form of the matrix operation. , Where
The OLS method minimizes the following functions:
The solution to the optimization of equation (2.18) by doing the derivative to
and equated with 0.
Theorem 2.2.2 WLS
In the following section, the prediction process will be carried out using a Weighted Least Square (WLS) optimization, which can accommodate the correlation between errors using a weighted (weighted) in the form of an inverse of the error covariance variance matrix, namely by solving the equation with the value
and
. The equation is as follows:
To solve the optimization in equation (2.9), a partial derivative is performed, as follows:
Note that because the result of both is scalar. The next process is to derive Equationequation (2.4)
(2.4.1)
(2.4.1) for
, which yields Equationequation (2.5)
(2.6)
(2.6) . After that, it is derived for
, then equalized to zero can be seen in Equationequation (2.6)
(2.7)
(2.7) , so that we get estimators
in equation (2.7).
with the variance-covariance matrix Var () =
as follows:
where
and
Theorems 2.1 and 2.2 can be applied to the model, respectively:
1. Lemma 2.1 which has a shape
with
and
Where ;
2. Lemma 2.2 which has a shape
with
and
3. Lemma 2.3 which has a shape
4. Lemma 2.4 which has a shape
3. Linearity testing
The linearity test aims to determine the absence of a linear relationship between two variables. Testing the linearity assumption is done with the help of Software R. One method for testing the linearity of the model is the Ramsey RESET Test (RRT). The following are the steps in the RESET test procedure.
(1) Determine the restricted equation and calculate the coefficient of determination.
Restricted Model:
With the coefficient of determination is as follows.
(2) Determine the unrestricted equation and again calculate the coefficient of determination.
Unrestricted Model:
With the coefficient of determination is as follows.
(3) Test the linearity relationship of the model with the following hypothesis and test statistics.
Hypothesis:
there is at least one
with
Test Statistics:
If the test statistics < tipping point
, then
accepted, which means that the relationship between variables is linear. Otherwise, if the test statistics
> critical point
, then
rejected, which means that the relationship between variables is not linear.
If the results show that the relationship between variables is not linear, then the test is continued using the Modified RRT. This test is carried out in stages starting from testing the quadratic, cubic, quartic, and quantic models.
4. Quadratic model testing
(1) Determine the restricted model and calculate the coefficient of determination.
Restricted Model:
With the coefficient of determination is
(2) Determine the unrestricted model and calculate the coefficient of determination.
Unrestricted Model:
With the coefficient of determination is
(3) Testing the quadratic model relationship with the hypothesis and test statistics as follows.
Hypothesis:
there is at least one
with
Test Statistics:
5. Cubic model testing
(1) Determine the restricted model and calculate the coefficient of determination.
Restricted Model:
With the coefficient of determination is
(2) Determine the unrestricted model and calculate the coefficient of determination.
Unrestricted Model:
With the coefficient of determination is
(3) Testing the relationship of the cubic model with the hypothesis and test statistics as follows.
Hypothesis:
there is at least one
with
Test Statistics:
6. Quartic model testing
(1) Determine the restricted model and calculate the coefficient of determination.
Restricted Model:
With the coefficient of determination is
(2) Determine the unrestricted model and calculate the coefficient of determination.
Unrestricted Model:
With the coefficient of determination is
(3) Test the relationship of the quartic model with the following hypothesis and test statistics.
there is at least one
with
Test Statistics:
If the test statistics <tipping point
, then
accepted, which means that the relationship between variables is quartic. Otherwise, if the test statistics
> critical point
, then
rejected, which means that the relationship between variables is more than quartic.
7. Quartic model testing
(1) Determine the restricted model and calculate the coefficient of determination.
Restricted Model:
With the coefficient of determination is
(2) Determine the unrestricted model and calculate the coefficient of determination.
Unrestricted Model:
With the coefficient of determination is
(3) Testing the quantitative model relationship with the hypothesis and test statistics as follows.
there is at least one
with
Test Statistics:
If the test statistics <tipping point
, then
accepted, which means that the relationship between the variables is quantified. Otherwise, if the test statistics
> critical point
, then
rejected, which means that the relationship between the variables is more than quantitative. However, in this study, if
rejected, the relationship between the models is still considered quantic on the grounds of the Principle of Parsimony.
7.1. The estimator properties of the SFAM structural model are flexible and robust
Some of the estimator properties of the SFAM structural model are unbiased, efficient, and consistent. The first part is estimating the theoretical nature of the model’s unbias.
8. Predictor Properties: unavailable (not biased)
From the results of the unbiased prediction properties:
1. Lemma 2.1 which has a shape
with
and
2. Lemma 2.2 which has a shape
with
and
3. Lemma 2.3 which has a shape
4. Lemma 2.4 which has a shape
9. Predictor nature: efficient
The resampling method comparison is measured based on the relative efficiency value. According to (Wackerly et al., 2008) relative efficiency is calculated by comparing the variance between two parameter estimators. The relative efficiency of the two estimators can be written as follows.
Information:
Table
If the result of the calculation of efficiency is more than 1, estimator more efficient than estimator
. Conversely, if the calculated efficiency is less than 1, estimator
more efficient than estimator
. If the result of the calculation of efficiency is equal to 1, the two estimators are equally efficient.
10. Predictor nature: consistent
Estimator consistency in resampling can be indicated by the bias value, namely the difference (distance) between the estimator and the parameter. The following is a formula for calculating the estimator bias in resampling for the relationship between exogenous variables and endogenous
.
Where:
: bias value
: parameter estimator of the process resampling
: parameter
: parameter estimator of the process resampling
: parameter
Good resampling results will follow a simulation approach that is based on averages.
where is the average parameter estimator obtained from the resampling process. Thus, the bias is based on replicas
is to replace
with
.
Biased value can be used to determine the consistency of estimators obtained from the sample.
11. Data application
Hypothesis testing of flexible and sturdy SFAM structural models
The following section tests the structural model hypothesis with 15 primary data. Applications are made on primary data obtained from 17 fields. The variables used are innovation culture (X1), deviant behavior (Y1), and employee performance (Y2). The research unit is employees from 17 fields. The research instrument used is a questionnaire. The feasibility test of the research instrument was carried out with validity and reliability tests.
Validity and reliability tests were carried out on the test data. The research instrument is said to be valid if the corrected item-total correlation value is positive ≥0.3, while the research instrument is said to be reliable when the Cronbach's Alpha reliability coefficient is ≥0.6. In this study, the trial involved 50 employees. The results of checking the validity and reliability of the research instruments are listed in Table .
Table 1. Validity and reliability examination results
From the results of the validity and reliability test, it shows that all items are valid and reliable. Therefore, it is necessary to evaluate the research instrument. Furthermore, data collection was carried out in 17 fields and applied path analysis to the data obtained. One application of the analysis included in this paper is from PT Bank Rakyat Indonesia (Persero) Tbk
Linearity Test
The test that can be used to determine whether the variables have a linear relationship or not is the Ramsey RESET Test. The results of linearity testing between variables are listed in Table .
Table 2. Test results of linearity assumptions
Based on Table , it can be seen that there are three non-linear relationships. The test was continued by performing the Modified Ramsey RESET Test so that the results in Table were produced.
Table 3. Test results of modified Ramsey reset test
The result of parameter estimation can be seen in Figure .
Figure 2. Path diagram of PT bank republik Indonesia (Persero) Tbk.
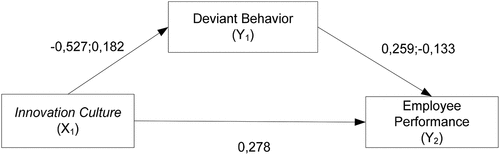
The path analysis model for data from Bank can be written as follows:
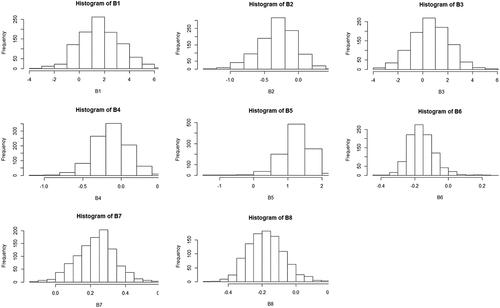
Hypothesis testing is done by resampling Bootstrap. shows that by retrieval of the sample 1000 times, the data estimator approaches the normal distribution, so that a histogram is formed that forms a normal curve.
Figure 3. Parameter estimator histogram with bootstrap.
The results of testing the direct effect hypothesis are shown in Table .
Table 4. Hypothesis testing results direct effect
Based on , it can be seen that the p value <α (0.05) which results in the rejection of H0 and it can be concluded that there is a significant effect on this pathway. The second equation can be interpreted that every increase of one unit of innovation culturewill increase employee performance by 0.278 units.
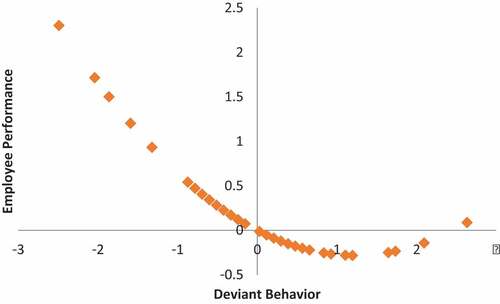
From the first equation, shows that a high innovation culture will reduce employees' desire to behave in a challenging manner. However, at the optimum point of -0.381, the desire for deviant behavior can increase with the assumption that the other variables are constant. also shows that the higher Deviant Behavior, the lower the Employee Performance.
Figure 4. The curve of the relationship between innovation culture and deviant behavior.
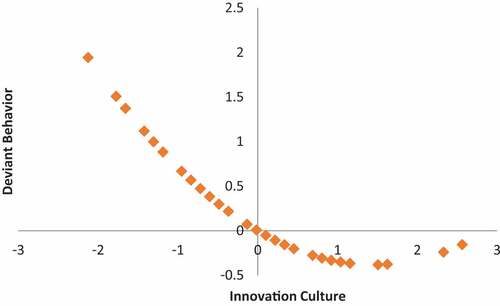
Figure 5. The curve of the relationship between innovation culture and employee performance.
12. Conclusions
The conclusions that can be delivered up to the second year research progress report are as follows:
Obtain a structural model that is robust with the assumptions of normality and homoscedasticity. Among them is the simple structural model theorem of efficient and consistent resampling approach; has produced complex structural model theorem with efficient and consistent resampling approach; has produced a simple structural model theorem with a weighted approach to solving the non-heteroscedasticity case; has produced the theorem of a complex structural model with a weighted approach to solving the non-heteroscedasticity case.
Obtain estimator properties from the flexible and robust SFAM structural model. Among them are the theorems of investigating the unbiased nature of simple structural models; have generated theorems investigating the unbiased nature of complex structural models; investigated the asymptotic nature of the simple structural model function obtained; have investigated the asymptotic nature of the function of the complex structural model obtained.
Obtaining hypothesis testing of each relationship built from the flexible and robust SFAM structural model. From the results of hypothesis testing, it was concluded that of the 18 institutions studied, seven agencies had a non-linear model, while 11 other agencies had a linear model.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Asrun. (2014). Kepemimpinan spiritual: Pengaruhnya Terhadap Spiritualitas di Tempat Kerja, Kepuasan Kerja, dan Perilaku Menyimpang di Tempat Kerja. Disertasi, Universitas Brawijaya).
- Chen, H., & Wang, Y. (2011). A penalized spline approach to functional mixed effects model analysis. Biometrics, 67(1), 861–24. https://doi.org/10.1111/j.1541-0420.2010.01524.x
- Chin, W. W. (2006). Overview of the PLS Method.
- Dillon, W. R., & Goldstein, M. (1984). Multivariate analysis methods and applicationds. John Wiley dan Sons.
- Garson, G. D. (2013). Path analysis. Statistical Associates Publishing.
- Hair, J. F., Jr., Anderson, R. E., Tatham, R. L., & Black, W. C. (2010). Multivariate data analysis with reading. Macmillan Pub. Company.
- Handayanto. (2014) . Pengaruh Budaya Organisasi Terhadap Kepemimpinan, Nilai Personal, dan Perilaku Ihsan di Rumah Sakit Islam Masyitoh Bangil. Disertasi, Universitas Brawijaya).
- Heckman, N., Lockhart, R., & Nielsen, J. D. (2009). Penalized regression, mixed effects models and appropriate modelling. Retrieved, December, 12, 2012. Website: http://www.stat.ubc.ca/~nancy/pubs/lmetechreport.pdf
- Joreskog, K., & Sorbom, D. (1996). LISREL 8: User’s reference guide (Second Edition ed.). Scientific Software International, Inc.
- Fernandes, A. A. R. (2017). Investigation of instrument validity: Investigate the consistency between criterion and unidimensional in instrument validity (case study in management research). International journal of law and management.
- Fernandes, A. A. R. (2017). Moderating effects orientation and innovation strategy on the effect of uncertainty on the performance of business environment. International Journal of Law and Management.
- Fernandes, A. A. R., & Taba, I. M. (2018). Welding technology as the moderation variable in the relationships between government policy and quality of human resources and workforce competitiveness. Journal of Science and Technology Policy Management.
- Fernandes, A. A. R., Budiantara, I. N. I., Otok, B. W., & Suhartono. (2014). Reproducing Kernel Hilbert space for penalized regression multi-predictors: Case in longitudinal data. International Journal of Mathematical Analysis, 8(40), 1951–1961.
- Fernandes, A. A. R., Hutahayan, B., Arisoesilaningsih, E., Yanti, I., Astuti, A. B., & Amaliana, L. (2019, June). Comparison of curve estimation of the smoothing spline nonparametric function path based on PLS and PWLS in various levels of heteroscedasticity. In IOP Conference Series: Materials Science and Engineering (Vol. 546, No. 5, p. 052024). IOP Publishing.
- Fernandes, S., & Rinaldo, A. A. R. A. A. (2018). The mediating effect of service quality and organizational commitment on the effect of management process alignment on higher education performance in Makassar, Indonesia. Journal of Organizational Change Management.
- Purbawangsa, I. B. A., Solimun, S., Fernandes, A. A. R., & Rahayu, S. M. (2019). Corporate governance, corporate profitability toward corporate social responsibility disclosure and corporate value (comparative study in Indonesia, China and India stock exchange in 2013–2016). Social Responsibility Journal, 16(7), 983–999.
- Solimun. (2010). Analisis Multivariat Pemodelan Struktural. Citra.
- Sumardi, S., & Fernandes, A. A. R. (2020). The influence of quality management on organization performance: service quality and product characteristics as a medium. Property Management, 38(3), 383–403.
- Van der Seijs, M. V., de Klerk, D., & Rixen, D. J. (2016). General framework for transfer path analysis: History, theory and classification of techniques. Mechanical Systems and Signal Processing, 68, 217–244. https://doi.org/10.1016/j.ymssp.2015.08.004
- Verbekke, G., Fiews, S., Molenberghs, G., & Davidian, M. (2014). The analysis of multivariate longitudinal data: A review. Statistical Methods in Medical Research, 23(1), 42–59. https://doi.org/10.1177/0962280212445834
- Wiryatmojo, S. (2012). Pengaruh Kompetensi dan Motivasi Terhadap Intuisi dan Kinerja Aparat Reserse. Disertasi, Universitas Brawijaya).
