
Abstract
Eating Behavioral Disorders (EBDs) affect an increasing number of consumers. Improving the ability of businesses to target EBDs may contribute to this issue by making people aware of treatments. The vast literature on the identification of EBDs in the medical area is based on the association between a disease and single demographics and is not sufficient for a marketing strategy that minimizes the cost of wrong identifications. Through a complex survey, we studied the discriminant power of several sets of variables, investigated the proper number of clusters in an effective segmentation strategy and described the profiles of target segments.
1. Introduction
Eating Behavioral Disorders (EBDs), also referred to as Eating Disorders, represent an increasingly relevant issue for public health. They are becoming very common in many countries, particularly in the most developed ones. According to a Deloitte report, the estimated number of people affected by an EBD in the USA is 28.8 million in 2020, around 9% of the population (Deloitte, Citation2020). The same report estimates the economic cost of eating disorders in the USA to be $ 64.7 billion in 2018–19. Costs pertain to the health system (e.g., emergency visits, residential and pharmaceutical), productivity (e.g., absenteeism), caregivers, and efficiency losses (e.g., government assistance). Similar figures are common in many other countries. In 2009, the prevalence of EBDs in six European countries ranged from 1.28% in Germany to 4.15% in France (Preti et al., Citation2009). In Italy, for instance, the estimated number of people affected by EBDs is 3.5 million (more than 5% of the population), and EBDs are one of the most common causes of death among young people (Carlorecchio, Citation2020). Although some causes remain elusive, deaths related to EBDs are often associated with complications of the patient’s conditions (such as cardiac failures due to malnutrition) or suicide (Fichter & Quadflieg, Citation2016; Mehler et al., Citation2022).
Reaching and effectively communicating with people potentially affected by EBDs is important to make them aware of the available solutions to their problems. EBDs have been typically tackled from a public health perspective, but they may be seen from a business perspective too. Businesses may contribute to public policies through a win–win strategy. On the one hand, improving the ability of companies to target customers with potential EBDs would partially relieve public officials from the effort of communicating and delivering information, and the whole community would benefit from this. On the other hand, effectively targeting consumers with eating disorders may be important for companies in the industries related to food and drugs because EBDs represent a growing, valuable segment. To this aim, companies should segment the market using observable variables like demographics and lifestyles and target the segments with the highest probability of including EDBs with the appropriate marketing mix. Examples include promoting products through the right communication channel (e.g., billboards at colleges for students, ads on the products that people with EBDs frequently use, such as laxatives or juices) and using the right messages (e.g., by differentiating the messages aimed at people who struggle to lose weight from those aimed at people who do not want to lose weight).
However, identifying people with potential EBD is a hard issue. Diagnoses can only come from a relatively complex investigation of very intimate details of people’s eating and social behavior while companies can only rely upon observable variables. Many studies in medicine-related research areas have explored the associations between observable variables and EBDs. Several types of information, especially demographics, have been scrutinized in search of associations with EBDs. Only a few of them, such as gender and age, are frequently observed to show this kind of correlations. However, gender and age may be insufficient for segmentation and targeting from a company perspective because they would identify too large and heterogeneous market segments. This would lead to weak targeting and, in turn, would cause the development of too generic offers and the increase of costs caused by misdirected communication. In other terms, the few variables showing high correlations with EBDs in epidemiological studies are effective in identifying true positives (people actually affected by EBDs) but they also identify many false positives (many healthy subjects with no risk of developing EBDs).
What can research suggest to marketers who want to target EBDs? The typical issues for marketers are deciding what variables to use, setting the number of segments, knowing the profiles of target segments. Through a complex survey and several statistical analyses, we looked for answers to these issues. First, we studied the discriminant power (i.e., the ability of discriminating between EBDs and healthy people) of several sets of variables, including anthropometrics, awareness, demographics, psychographics, lifestyles and eating habits. Then, we assessed which variables allow a marketer to perform an effective segmentation and what the appropriate number of segments should be. Finally, we described the profiles of target segments.
A relevant difference between our research and the epidemiologic studies is that we assessed the effectiveness of these strategies by measuring the True Positive Rate (TPR, the percentage of actual EBDs correctly identified) and the False Positive Rate (FPR, the percentage of healthy consumers wrongly identified as EBDs). These measures are important from a company’s perspective because an effective strategy has to maximize the TPR and minimize the FPR.
2. Prior literature
EBDs are an emerging issue in the areas of medicine and psychology, and there is a high and growing number of studies in these areas. Given the scope and aim of this paper, we only focused on those studies treating the problem of identifying the subjects with EBDs. We excluded the many studies that investigated the prevalence of EBDs without looking at the characteristics of subjects with EBDs, as well as those explaining EBDs, associating them to other diseases, and so on.
Most studies focus on specific segments, behaviors, characteristics and situations. As examples of this literature, some studies examine single broad segments of population, such as preadolescents (van Eeden et al., Citation2021), adolescents (Troncone et al., Citation2022), elderly women (Conceição et al., Citation2017). Other studies focus on more specific segments of population, such as gender minorities (Murray et al., Citation2021), athletes (Flatt et al., Citation2020), transgender adults (Ferrucci et al., Citation2022), veterans (Vaught et al., Citation2021). Other studies focus on specific behaviors, such as illicit drug use (Ganson et al., Citation2021). Recently, this kind of studies have been conducted in particular contexts, such as during the pandemic (Simone et al., Citation2021).
For a company’s perspective it is more appropriate to look at the studies that analyze large samples and multiple variables. These analyses are relatively scarce for several reasons. First, EBD research is smaller and new compared to research on other disorders. Second, the recruitment and assessment of a large sample of population is complex and expensive. Third, often these studies come from clinical samples, therefore only a peculiar group of people is represented, while many EBDs do not receive treatments and do not get included in clinical samples (Mitchison & Hay, Citation2014).
Gender is certainly the subject characteristic most commonly associated with EBDs. Striegel-Moore et al. (Citation2009) found significant gender differences. However, they noticed that the emphasis on the statistical significance of relatively small differences may have contributed to an under appreciation of the extent of EBDs in men. Hilbert et al. (Citation2012) also found that EBDs are often higher in women than in men. The authors found that EBDs decreased with age in women and were higher in obese individuals. A broader set of characteristics was studied by Mitchison and Hay (Citation2014). They found that female gender, younger age, sexual and physical abuse, participation in esthetic or weight-oriented sports, and heritability are mostly associated with higher EBDs prevalence and incidence. Other social characteristics, such as ethnicity, socioeconomic status, education and urbanicity, do not show strong association. Through a broad literature review Galmiche et al. (Citation2019) found that the prevalence of EBDs in women is higher in general than in men, but this finding varies with the type of EBD. Moreover, the gender ratio tends to evolve in time. EBDs are more prevalent in adolescents. The authors found a general increase of EBDs from 2000 to 2018.
To our knowledge, no study presents a segmentation and targeting approach. One of the reasons is that the problem has never been taken from a marketing perspective but only from a medical one. The results of studies in the medical area may turn out to be insufficient for a company’s strategy. Targeting a very large group of consumers such as young women would probably identify many consumers affected by EBDs, but it would also lead to reach many healthy consumers making the effectiveness of communication very small. Moreover, many other consumers affected by EBDs would remain unidentified.
Taking a company’s perspective does not mean just finding EBDs, as most studies correctly do by following an epidemiological perspective, but rather finding EBDs in consumers segments, i.e., identifying segments of consumers where the probability of finding EBDs is relatively high. The idea guiding this research is to perform a segmentation that allows a marketer to identify clusters (ideally more than one) including consumers affected by EBDs and separating these clusters from those where no EBD would be found. This strategy would lead to identify several groups of target consumers (instead of one large group), each with peculiar characteristics. This would, in turn, allow marketers to develop several different communication campaigns, each targeted to the right target segment leveraging the right characteristics of the EBDs included in that segment. Moreover, the segmentation should maximize the number of true positives and minimize that of false positives.
This research addresses the issues that a marketer has to face in the segmentation and targeting process. First, which variables best target EBDs. Second, what variables should be used in segmentation and how many segments should be used to target EBDs. Third, what the profiles are of the target segments (those including potential EBDs).
3. Methodology
We developed a complex survey including two sections. In the first section, subjects were asked to answer several questions including their anthropometric measures, demographic information, eating behavior, lifestyle and so on. The full list of variables is reported in Appendix 1. The second section was a screening test to assess whether the subject is a potential EBD or not. We then applied statistical models where the variables taken from the first section represent the independent variables. The information taken from the second section was used either as dependent variables or as a performance measure.
We kept a list of variables as large as possible to include all pieces of information that can help identify EBDs. The first section of the survey includes 62 variables overall, grouped in the following categories: Anthropometrics (5), Awareness (4), Demographics (7), Eating habits (25), Lifestyles (13), Psychometrics (8). A total of 17 variables are nominal, 7 are scale, 10 are binary and 28 are ordinal. Each nominal variable was turned into a set of binary variables depending on the number of nominal values. For the sake of space, the Appendix does not report all the response options for the nominal variables. The nominal values are reported in parenthesis when needed in the “Results” section. The final dataset includes 126 variables (scale, ordinal and binary).
The second section of the survey includes the 26 items in the EAT-26 test. This test is one of the most commonly used to assess whether a subject is either an EBD or shows a high likelihood to develop an EBD (Jacobi et al., Citation2004). The EAT-26 test result is expressed by a binary variable indicating whether a subject is a potential EBD or not. The subjects who score more than 20 are classified as EBDs (Garner et al., Citation1981). The accuracy (TPR) of the test is 83.9% in the original study (Garner et al., Citation1981), 88.9% in a recent study (Jacobi et al., Citation2004).
Respondents were recruited among the customers of professionals in medicine and nutrition. Subjects were asked whether they agreed to respond to a survey, which would be used to conduct scientific research on the methods to identify potential EBDs and would include some personal questions. All respondents volunteered to participate in the survey. All of them signed a declaration of informed consent.Footnote1 We collected 200 qualified responses. In the final dataset, each subject is represented by a vector of 126 values (the variables in the survey’s first section) plus the binary variable representing the EAT-26 test result (the survey’s second section).
In order to answer to these research issues, we performed several discriminant analyses and clustering analyses. They are described in the next subsections.
3.1. What variables best target EBDs. Discriminant analysis
We investigated which types of variables, among those collected, best discriminate between subjects with EBDs and healthy consumers. We ran a set of discriminant analyses by using the variables in each type (anthropometrics, awareness, demographics, eating behavior, lifestyle, psychometrics) as independent variables and the EAT-26 test results as dependent variables. We used the stepwise method in order to identify the best discriminating variables in each subset. We eventually collected all the best discriminating variables identified in each type and included them in a mixed subset. We tested the discriminating power of this subset by running an additional analysis. Overall, we ran seven discriminant analyses (the six variable types plus the mixed subset).
The discriminating power is measured by computing the classification matrix and, particularly, the True Positive Rate (TPR) and False Positive Rate (FPR). The TPR is the ratio between the number of subjects who are correctly predicted as EBDs and the total number of actual EBDs (identified by the EAT-26 test). The FPR is the ratio between the number of subjects wrongly predicted as EBDs and the number of healthy subjects (identified as healthy by the EAT-26 test). A good classification has to maximize the TPR and minimize the FPR.
3.2. What variables should be used and how many segments. clustering analysis
Segmentation is crucial from a company’s perspective because a discriminant analysis, such as that described in the previous subsection, may be run only when the actual conditions of consumers (EBD or healthy) is known, which is never the case in a real business context. We explored two basic issues of segmentation: the choice of segmentation variables and the number of segments.
The choice of the variables to deploy in segmentation is a hard issue. Research typically suggests marketers to avoid using noisy variables (unnecessary variables, which divert the attention of the algorithm away from information critical to the extraction of optimal market segments) by asking all necessary and unique questions while resisting the temptation to include unnecessary or redundant questions (Dolnicar et al., Citation2018). Examples of noisy variables include several demographic variables, which often prove to be good segmentation variables but are not always necessary. In our study, only four of them will turn out to be effective, and only one will be included in the final subset. Some complex methods to select necessary variables in high-dimensional datasets have also been developed (see Celeux et al., Citation2019, for a brief review).
In order to bridge the gap between theory and practice, we studied whether segmenting the market using the set of best discriminating variables is more effective than using all the variables. We ran two sets of clustering analyses using a partitioning clustering algorithm. In the first set, we used a small subset of variables taken from the survey, those showing the best discriminating power (the result of the previous analyses). In the second set, we used the whole set of variables as segmentation variables. We ran the clustering algorithm by setting different numbers of segments, namely 2, 3, 4, 5, 6, 8, 10, 12, 15 and 20. Twenty segmentation solutions were then tested overall. We compared these solutions in three ways.
First, we compared the Silhouette Measure of the segmentation solutions, which is a way to assess the distances of each consumer to all segment representatives (Dolnicar et al., Citation2018). We used the metric computed by IBM-SPSS version 28.
Second, since our focus is on the costs of misclassifying target customers, we used again the discriminant analysis to measure the TPR and FPR of each solution. In this case, for each solution, we used the cluster memberships as independent variables and the EAT-26 test result as dependent variable. The idea underlying this method is to assess whether the cluster membership is enough to predict that a consumer has an EBD. Third, for each solution, we calculated the average Between-Group Variance (BGV) and the average Within-Group Variance (WGV). We then plotted the BGV/WGV ratio against the number of clusters (Malhotra et al., Citation2010). The number that maximizes this ratio corresponds to the solution where clusters are best separated and, at the same time, have the highest homogeneity.
3.3. The description of target segments. Profile analysis
Finally, we profiled the segments by using a visualization approach that also incorporates elements of statistical hypothesis and testing. The approach consists in plotting a graph of the mean and dispersion of each variable for each segment (Dolnicar et al., Citation2018). This allows the analyst to assess which segmentation variable actually characterizes a segment by making it different from the sample population as a whole.
The variables that best characterize a segment are called “marker variables” and are defined as variables, which deviate by more than a markup from the overall mean (Dolnicar et al., Citation2018). We set the 95% confidence interval as a markup. For each variable, we drew a plot where the x-axis represents the clusters and the y-axis is the mean value of the variable in each cluster plus the confidence interval (represented by a vertical line). Ideally, a marker variable has a mean value very different from the sample mean, and its confidence interval is small. In principle, these differences can be systematically checked by running statistical tests. However, when the number of subjects in each cluster is small, as in our case, the tests can lead to unreliable results or cannot be performed. For good measurement, we performed the tests where possible and reported the results.
4. Results and discussion
The survey received 200 qualified responses. The sample includes 9 EBDs (4.5%) and 191 healthy consumers (95.5%), 42 men (21.0%) and 157 women (78.5%) with one missing value (the subject preferred not to answer), 71 subjects younger than 30 (35.5%), 70 subjects between 40 and 60 (35.0%), and 59 subjects older than 60 (29.5%). All subjects are white. Moreover, 56 subjects (28.0%) have got a university level degree, 104 (52.0%) a high school degree, 31 (15.5%) a middle school degree, 8 (4.0%) an elementary school degree. Jobs were classified into eight categories (i.e., entrepreneur, autonomous, executive, white collar, blue collar, retired, unemployed, student, housewife), percentage vary from 5.5% (executives) to 30.0% (blue collars). The average yearly income is around 20.000 and 40.000 Euros. Appendix 2 reports mean and standard deviations for scale and ordinal variables.
4.1. What variables best target EBDs. Discriminant analysis
Table reports the results of the discriminant analyses run to test the discriminating power of each type of variable. Each box pertains to each type of variable listed in the Appendix. For ordinal and scale variables, Table reports the item description (as in the Appendix). Since nominal variables were turned into as many binary variables as the number of possible response options, the option is reported in parenthesis when needed.
Table 1. Results of stepwise discriminant analysis for each type of variables
For each type of variables, the stepwise analysis identifies the set of variables with the highest discriminating power. For these variables, the left part of the table reports the unstandardized coefficients in the discriminating function, the F statistic, the statistical significance, the Wilk’s Lambda and Chi-Square. The right part of the box reports the classification results: how many consumers are predicted as EBDs (Y), and how many are predicted to be healthy (N) by the discriminating function, versus the actual EBDs (Y) and actual healthy consumers (N). We can compare every type of variable by looking at the classification performance metrics (TPR and FPR).
Among the anthropometric variables in our survey, the Waist/hip ratio has the highest discriminating power. This variable alone would be sufficient to identify EBDs in our survey, whereas the other variables would not contribute. The positive coefficient means that potential EBDs have a higher Waist/hip ratio (signaling obesity). Looking at the classification results, using this variable would lead to correctly identify seven EBDs out of nine with a TPR of 77.8%, and to wrongly identify 59 healthy consumers (wrongly classified as EBDs) out of 191 with an FPR of 30.9%. In fact, many EBDs are not obese but slim with problems to accept their body image. Looking at the awareness type makes the trade-off between TPR and FPR clear. Asking the question “Who advised you about a diet?” is sufficient to identify all the EBDs (TPR = 100%, the best performance), because all of them were suggested a diet by a doctor. However, this would lead to wrongly take many healthy people as EBDs (FPR = 52.9%, the worst performance). Identifying EBDs by the only demographic variables requires using four variables (age, job, number of people in a family, yearly income). In this case, the TPR would be lower (66.7%) but the misidentification would be very low (FPR = 8.4%). Looking at the coefficients, a potential EBD is a young consumer (the coefficient is negative), student, with a small family (negative coefficient) and a relatively high income. The variables in the eating behavior type show a good classification performance, as the TPR is 66.7% and the FPR is 7.3% (lower than for the demographics). The Lifestyle variables show a similar TPR (66.7%) but a slightly worse FPR (12%). The Psychometric variable has the worst TPR (only 55.6% actual EBDs are identified and a good FPR (7.9%). Finally, the last box in the table shows the results of a stepwise discriminant analysis when all the variables in the previous boxes are used. The nine variables with the highest discriminating power show a very high TPR (77.8% is second best) and a very low FPR (5.8% is the best result).
In order to get a better picture of the comparison, we plotted the FPR against the TPR for each type of variable. Figure shows that a subset of the nine best discriminating variables gets the best FPR and the second best TPR. The nine variables included in the subset are listed at the bottom of Table .
Figure 1. Plot of TPR and FPR for all the types of discriminating variables.

It is important to observe that if we exclude the point labeled as “Subset” in Figure , we see that no variable type outperforms another in terms of both TPR and FPR. Psychometric shows the best (lowest) FPR but the worst TPR. Eating behavior, Demographic and Lifestyle have a better TPR but a worse FPR than Psychometric. Anthropometric improves the TPR but again at the expense of the FPR. Finally, awareness shows the best TPR but the worst FPR. The subset of nine variables identified by our analysis outperforms all the other types except one (awareness) which is largely outperformed by one metric (FPR).
4.2. What variables should be used in segmentation and how many segments. Clustering analysis
We performed a clustering analysis by using two sets of segmentation variables, namely, the subset of the nine best discriminating variables and all the variables, and we varied the number of clusters. In order to find the best solution, we compared the Silhouette Measure, the TPR and FPR obtained by discriminant analysis, the WGV and BGV.
The average Silhouette Measure for the 10 solutions (from 2 to 20 clusters) using all the variables is 0.1 while the same measure for the solutions using the subset of nine best variables is 0.4 for the solutions with 2–12 cluster, 0.5 for the solutions with 15 and 20 clusters. Using the subset of the best variables provides better results.
We then ran another discriminant analysis to predict EBDs from the cluster memberships and measured the TPR and FPR for each segmentation solution. Figure reports the results. According to our expectation, clustering with the subset of nine best discriminating variables (Figure ) often outperforms the benchmark method using all variables (Figure ). This is true especially when a lower number of clusters is used, namely from 2 to 6 clusters.
Figure 2. Performance of different segmentation solutions.
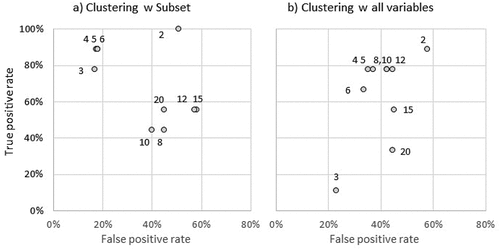
Figure provides a clearer picture of the comparison, as the two graphs are overlapped and the Paretian frontier of each method (corresponding to the solutions that dominate the others) are highlighted. The Paretian frontier of the first method (clustering with the subset, represented by a continuous line) outperforms the one of the benchmark methods (clustering with all variables, represented by a dotted line), because never a point of the dotted line shows a better performance in terms of high TPR and low FPR.
Figure 3. Comparison of Paretian frontiers of different segmentation solutions.
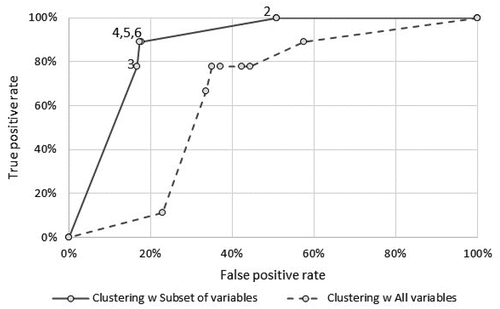
The continuous line also shows that using a relatively low number of clusters (2 to 6) provides better performance compared to using a higher number of segments (8 to 20). For instance, using only 2 segments provides the highest possible TPR but an FPR around 50%, meaning that a company would identify all the EBDs in the population but would also mistakenly target many healthy consumers (around 50%). Using 4 to 6 segments provide a better compromise: a TPR around 90% (the company would miss 10% of the potential EBDs) but an FPR smaller than 20%. The continuous line represents the ROC (Receiver Operating Characteristic) which is a classical performance measure in classification. We computed the Area Under the Curve (AUC) score, which is equal to 0.878. As reported by the literature on Medical Tests (Malhotra et al., Citation2010), an AUC of 0.5 suggests no discrimination, a score from 0.7 to 0.8 is considered acceptable, 0.8 to 0.9 is considered excellent.
In general, a good classifier should also minimize the false negatives. From a marketing perspective, minimizing the false negatives means minimizing the missed income related to consumers who are positives (therefore belong to the target) but are predicted to be negative (the company do not target them). The false negative rate (FNR) is defined as the proportion of positives who are predicted to be negative, FNR = 1 - TPR. Except for the case of two clusters, which had no false negatives, the solutions with 4, 5 and 6 clusters had a minimum FNR (11.1%), followed by the 3 cluster solution (FNR = 22.2%), while the 8 and 10 solutions provided an FNR of 55.6% and the 12, 15 and 20 clusters solutions had an FNR of 44.4%.
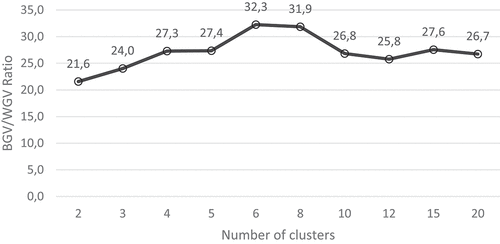
Finally, we computed the Between-Group Variance and the Within-Group Variance for each solution obtained with the subset of nine best discriminating variables and plotted the BGV/WGV ratio against the number of clusters (Figure ). The picture shows that using the solution with six clusters provides, on average, the highest separation between segments (highest BGV) and the best homogeneity (lowest WGV). We eventually picked this solution, computed the number of target consumers in each segment and profiled the six segments.
Figure 4. Ratio between BGV and WGV for different number of clusters.
4.3. The description of target segments. Profile analysis
Before profiling the six segments, it is useful to look at their structure. The first four columns of Table report the cluster number (#), the Size of each segment (number of consumers), the Number of EBDs in the segment, and the percentage of EBDs, which roughly represents the probability to find EBDs in the segments. The segments are ordered by the latter measure. The three small segments show a relatively high probability of including EBDs (from 12.5% to 27.3%). In the other three larger segments, the probability is zero or very low (1.5%, corresponding to only 1 EBD out of 65 consumers).
Table 2. Structure and profiles of the six segments ordered by percentage of EBDs
Figure reports, for each variable and for each one of the six segments, the mean values (horizontal line) and confidence interval at 95% (vertical line). Mean and confidence interval for the whole sample are also shown (Tot.). The marker variables are those for which the mean value differs most from the whole sample. Remember that segments 1, 2 and 3 are those including most EBDs, segment 5 includes only 1, while segments 4 and 6 do not include any EBD but only healthy consumers.
Figure 5. Visualization of mean and dispersion for each variable and segment.
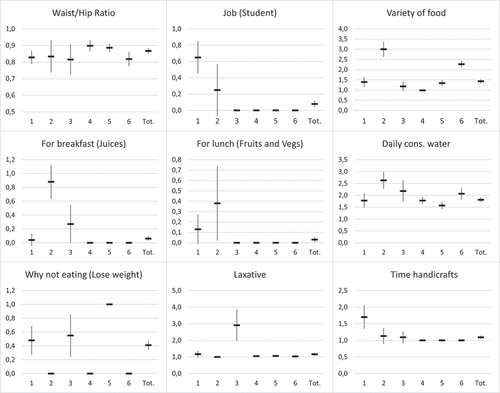
The Waist/Hip Ratio in segment 1 is slightly smaller than the whole sample. The mean values are smaller for segments 2 and 3 too, but with high dispersion (indicating that the difference with the sample may be due to chance). The values in Segment 5 and Segment 4 are not very different from the sample. The value is slightly smaller for Segment 6. Looking at Job, being a student characterizes only Segment 1. The Variety of food is greater for Segment 2, slightly smaller for Segment 3, smaller for Segment 4 and higher for Segment 6. Having Juices for breakfast characterizes Segment 2. Having Fruits and Vegetables for lunch hardly characterizes any segment: the mean values are higher for segments 1 and 2 but with high dispersion. The daily consumption of water is greater for Segment 2, slightly lower for Segment 5. Looking at the reason for not eating, the consumers in Segment 5 state that if they do not eat the reason is losing weight, while those in segments 2, 4 and 6 state that if they do not eat the reason is not losing weight. The use of Laxatives is greater in Segment 3. The time spent for handicraft works is greater for Segment 1.
As a result, we can describe the consumers’ profile in each segment as in Table . We tried to capture the very nature of the profile of segments with EBDs in the Short name. The last column shows what type of variables identify the segment. The symbols refer to the statistical significance found through a t-test (for W/H Ratio) or Chi-Square tests.
Interestingly, the four segments including EBDs (target consumers) are characterized by different types of variables. A psychometric variable characterizes Segment 3, the one with the highest probability of being a target segment. Segment 1 is characterized by a demographic information, lifestyle and an anthropometric measure. Segments 2 and 5 are characterized by the eating behavior of consumers.
4.4. Comparison with previous research
By comparing our research with the studies that have analyzed the epidemiology of EBS, we can highlight two remarkable differences. The first lays in methodology, as we mentioned in the “prior literature” section. No prior research has used a segmentation and targeting approach. Previous studies have used crosstabulation and logistic regression to characterize individuals with potential EBDs (for instance, Preti et al., Citation2009) or literature reviews to disclose the most frequent characteristics associated to EBDs (Galmiche et al., Citation2019; Mitchison & Hay, Citation2014). The second difference is a direct consequence of the methodology. No study identifies clusters of population characterized by sets of distinctive characteristics. Rather, epidemiological studies show the correlations between each single variable used to describe a population and the occurrence of an EBD. Although these results are important for both researchers and institutions, they do not help much identified groups of people that can be reached by appropriate messages to help them deal with their issue. These differences are important from both the theoretical and the managerial viewpoint, as we explain below, because they highlight that using a segmentation and targeting approach, in addition to the typical epidemiological methods, can lead to further and significantly different results, making the ability to help people with EBDs more effective.
5. Conclusions
Eating Behavioral Disorders (EBDs) have considerably increased in many countries and have become a public health issue. We believe that adopting a marketing perspective can contribute to solving it. The extant methods to identify EBDs are based on epidemiologic studies that do not provide indications of what segments of consumers should be targeted and how to minimize the errors of misclassification. To face the problem of targeting EBDs from a company’s perspective, we collected a sample of data by a complex survey including several types of questions and a screening test. We studied the discriminant power of these variable types, ran several clustering models and compared the results. We used several performance metrics including the True positive rate and False positive rates.
5.1. Theoretical implications
Our results show the importance of using a segmentation and targeting approach in addition to other methods typically used in epidemiological studies, particularly those aimed at describing EBDs. The reason is that studying the discriminant power of the characteristics highlighted by epidemiological studies and analyzing and grouping a population by clustering methods allows a researcher to identify groups of individuals, each one characterized by a set of distinctive variables that, taken together, can signal potential EBDs. This strongly increases the ability of communicating with EBDs because each group is reached by an appropriate message. Moreover, our study demonstrates that using only one type of variables, such as demographics (the most commonly associated with EBDs by extant studies), may not be sufficient. Doing so typically leads to maximize the TPR but at the cost of a high FPR, with the consequence of decreasing the ability to identify and reach the individuals at risk of developing EBDs.
5.2. Managerial implications
The first practical implication of our study is that using only one type of variables to target EBDs (typically demographics) is not sufficient because, our study shows, the aim of this method is to provide a high TPR, but it also causes a high FPR. This means wasting the communication effort reaching many healthy consumers. Using a mixed set of variables coming from different types provides much better results in terms of TPR and FPR. In our study, this subset includes variables picked from five of the six types (one from Anthropometric, five from Eating behavior, one from Psychometric, one from Demographic, one from Lifestyle).
Second, this subset of variables is a good set of segmentation variables. Our study shows that the segmentation solutions obtained in this way often outperform the solutions obtained by using all the variables in terms of statistical performance metrics (silhouette and BGV/WGV ratio) and business metrics (TPR and FPR).
The third implication refers to the number of segments. In our study, the best clustering solution includes six segments. Using more segments would decrease the statistical and business performances while using fewer segments would lead to blurry profiles.
Fourth, companies have to target more than one segment. In our study, there is not only one target segment (as one may think only looking at the association between demographics and the occurrence of EBD). We found three segments out of six with a high probability to find EBDs, and one with moderate probability (the other two segments does not include EBDs). These segments are characterized by very different marker variables. The profile of the first target segment includes a psychometric measure, the one of the second segment includes demographic, lifestyle and anthropometric information, and the profile of the other two segments include information related to eating behavior. Targeting three or four segments with different profiles makes the communication effort of companies much better tailored to consumers and more effective compared to one generic marketing mix related to a description of consumers with EBDs based on just few demographics.
We think these findings may contribute to decrease the gap between theory and practice in marketing for companies operating in food and medicine-related industries.
5.3. Limitations and future research
This research shows some limitations that future research should bridge over. The main one lies in the sample size, which is relatively small for the kind of market that we explored. The reason is that identifying EBDs requires either medical diagnoses or screening tests. This makes recruiting consumers available for this kind of investigation rather hard. Another limitation lies in the choice of subjects that were recruited among patients of professionals. This makes the presence of bias possible while a more various sample of consumers would be helpful in making results more generalizable. Another issue is the collection of variables. In our research, we kept it as large as possible to include the many variables that can help identify EBDs. A smaller set of selected variables can lead to better results, and we believe that our analyses represent a step to identifying a subset of effective variables and excluding noisy variables. Finally, other methods of analysis can be used to refine the results such as, for instance, clustering algorithms designed to optimize the values of a dependent variable in clusters. We did not use particularly sophisticated methods just to keep the research as close as possible to practice.
Generalizations should always be done with great caution because every sample may include some form of bias. However, these research findings, namely types of variables, segmentation variables, number of segments, and targeting strategies, look general enough to be taken as guidelines for the targeting activities of companies and for future research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
1. The national law of the country where the research was conducted makes the approval by an IRB mandatory only for clinical studies, not for non-interventional studies such as surveys.
References
- Carlorecchio, F. (2020). ‘Never give up’, la onlus italiana che rompe il silenzio sui disturbi alimentari degli adolescenti [‘Never give up’, the Italian no-profit organization that breaks silence on eating disorders of adolescences]. La Repubblica, June 9.
- Celeux, G., Maugis-Rabusseau, C., & Sedki, M. (2019). Variable selection in model-based clustering and discriminant analysis with a regularization approach. Advances in Data Analysis and Classification, 13(1), 259–19. https://doi.org/10.1007/s11634-018-0322-5
- Conceição, E. M., Gomes, F. V. S., Vaz, A. R., Pinto-Bastos, A., & Machado, P. P. P. (2017). Prevalence of eating disorders and picking/nibbling in elderly women. The International Journal of Eating Disorders, 50(7), 793–800. https://doi.org/10.1002/eat.22700
- Deloitte. (2020). The social and economic cost of eating disorders in the United States of America. https://www.hsph.harvard.edu/striped/report-economic-costs-of-eating-disorders/.
- Dolnicar, S., Grün, B., & Leisch, F. (2018). Market segmentation analysis: Understanding It, Doing It, and Making It Useful. Springer Open.
- Ferrucci, K. A., Lapane, K. L., & Jesdale, B. M. (2022). Prevalence of diagnosed eating disorders in US transgender adults and youth in insurance claims. The International Journal of Eating Disorders, 55(6), 801–809. https://doi.org/10.1002/eat.23729
- Fichter, M. M., & Quadflieg, M. (2016). Mortality in eating disorders - results of a large prospective clinical longitudinal study. The International Journal of Eating Disorders, 49(4), 391–401. https://doi.org/10.1002/eat.22501
- Flatt, R. E., Thornton, L. M., Fitzsimmons-Craft, E. E., Balantekin, K. N., Smolar, L., Mysko, C., Wilfley, D. E., Barr Taylor, C., DeFreese, J. D., Bardone-Cone, A. M., & Bulik, C. M. (2020). Comparing eating disorder characteristics and treatment in self-identified competitive athletes and non-athletes from the national eating disorders association online screening tool. The International Journal of Eating Disorders, 54(3), 365–375. https://doi.org/10.1002/eat.23415
- Galmiche, M., Déchelotte, P., Lambert, G., & Tavolacci, M. P. (2019). Prevalence of eating disorders over the 2000–2018 period: A systematic literature review. The American Journal of Clinical Nutrition, 109(5), 1402–1413. https://doi.org/10.1093/ajcn/nqy342
- Ganson, K. T., Murray, S. B., & Nagata, J. M. (2021). Associations between eating disorders and illicit drug use among college students. The International Journal of Eating Disorders, 54(7), 1127–1134. https://doi.org/10.1002/eat.23493
- Garner, D. M., Olmsted, M. P., Bohr, Y., & Garfinkel, P. E. (1981). The eating attitudes test: Psychometric features and clinical correlates. Psychological Medicine, 12(4), 871–878. https://doi.org/10.1017/S0033291700049163
- Hilbert, A., de Zwaan, M., Braehler, E., & Tomé, D. (2012). How frequent are eating disturbances in the population? Norms of the eating disorder examination-questionnaire. PLos One, 7(1), e29125. https://doi.org/10.1371/journal.pone.0029125
- Jacobi, C., Abascal, L., & Taylor, C. B. (2004). Screening for eating disorders and high-risk behavior: Caution. The International Journal of Eating Disorders, 36(3), 280–295. https://doi.org/10.1002/eat.20048
- Malhotra, N. K., Birks, D. F., & Wills, P. (2010). Marketing Research. Pearson.
- Mehler, P. S., Watters, A., Joiner, T., & Krantz, M. J. (2022). What accounts for the high mortality of anorexia nervosa? The International Journal of Eating Disorders, 55(5), 633–636. https://doi.org/10.1002/eat.23664
- Mitchison, D., & Hay, P. J. (2014). The epidemiology of eating disorders: Genetic, environmental, and societal factors. Clinical Epidemiology, 6, 89–97. https://doi.org/10.2147/CLEP.S40841
- Murray, M. F., Cox, S. A., Henretty, J. R., & Haedt-Matt, A. A. (2021). Women of diverse sexual identities admit to eating disorder treatment with differential symptom severity but achieve similar clinical outcomes. The International Journal of Eating Disorders, 54(9), 1652–1662. https://doi.org/10.1002/eat.23576
- Preti, A., de Girolamo, G., Vilagut, G., Alonso, J., de Graaf, R., Bruffaerts, R., Demyttenaere, K., Pinto-Meza, A., Haro, J. M., & Morosini, P. (2009). The epidemiology of eating disorders in six European countries: Results of the ESEMeD-WMH project. Journal of Psychiatric Research, 43(14), 1125–1132. https://doi.org/10.1016/j.jpsychires.2009.04.003
- Simone, M., Emery, R. L., Hazzard, V. M., Eisenberg, M. E., Larson, N., & Neumark-Sztainer, D. (2021). Disordered eating in a population-based sample of young adults during the COVID-19 outbreak. The International Journal of Eating Disorders, 54(7), 1189–1201. https://doi.org/10.1002/eat.23505
- Striegel-Moore, R. H., Rosselli, F., Perrin, N., DeBar, L., Wilson, G. T., May, A., & Kraemer, H. C. (2009). Gender difference in the prevalence of eating disorder symptoms. The International Journal of Eating Disorders, 42(5), 471–47. https://doi.org/10.1002/eat.20625
- Troncone, A., Affuso, G., Cascella, C., Chianese, A., Pizzini, B., Zanfardino, A., & Iafusco, D. (2022). Prevalence of disordered eating behaviors in adolescents with type 1 diabetes: Results of multicenter Italian nationwide study. The International Journal of Eating Disorders, 55(8), 1108–1119. https://doi.org/10.1002/eat.23764
- van Eeden, A. E., Oldehinkel, A. J., van Hoeken, D., & Hoek, H. W. (2021). Risk factors in preadolescent boys and girls for the development of eating pathology in young adulthood. The International Journal of Eating Disorders, 54(7), 1147–1159. https://doi.org/10.1002/eat.23496
- Vaught, A. S., Piazza, V., & Raines, A. M. (2021). Prevalence of eating disorders and comorbid psychopathology in a US sample of treatment-seeking veterans. The International Journal of Eating Disorders, 54(11), 2009–2014. https://doi.org/10.1002/eat.23591
Appendix 1.
Full list of variables used in this research
Appendix 2.
Mean and standard deviation for “scale” and “ordinal” variables used in this research