
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we introduce a set of critical values for unit root tests that are robust in the presence of conditional heteroscedasticity errors using the normalizing and variance-stabilizing transformation (NoVaS) and examine their properties using Monte Carlo methods. In terms of the size of the test, our analysis reveals that unit root tests with NoVaS-modified critical values have actual sizes close to the nominal size. For the power of the test, we find that unit root tests with NoVaS-modified critical values either have the same power as, or slightly better than, tests using conventional Dickey–Fuller critical values across the sample range considered.
Public Interest Statement
Investors anticipate the future return evolution based on their feeling and they respond according to their expectations. They react aggressively or diminish their trading depending on whether they anticipate an increase or a decrease in future returns. Anticipations depend both on over and underconfidence sentiment of investor and on their optimism/pessimism states. This study try to verify whether there’s an asymmetric relationship between investor sentiment and stock market liquidity when investors are more or less over (under) confident and when they are upper-optimistic or upper-pessimistic. Empirical findings confirm the asymmetric response of the stock market liquidity to both overconfidence and optimism–pessimism indicators in the long term. At short term, a rapid asymmetric reaction to over (under) confidence is noticed.
1. Introduction
Recently, there has been great interest by researchers and practitioners in the simultaneous presence of high-persistence and conditional heteroscedasticity. The main reason is their occurrence in many economic time series, including stock index and exchange rate series, both a common subject for unit root tests. Alongside burgeoning interest in the second moment (or variance), the first difference of economic variables—here, stock index returns and exchange rate changes—has also been the subject of a sizeable modelling literature in finance and related disciplines, with the most representative approach being the autoregressive conditional heteroscedasticity (ARCH) and generalized ARCH (GARCH) family of models.
Subsequent to the seminal work on ARCH/GARCH by Engle (Citation1982) and Bollerslev (Citation1986), the introduction of new models has continued apace, a common feature being that they estimate and allow for time-varying volatility. A number of suitable surveys of GARCH models is available, with Giraitis, Leipus, and Surgailis (Citation2006) providing a useful reference of existing work across the various models that have predictive ability for squared returns (or variance). Of this body of work, Pantula (Citation1989) is one of the first studies investigating non-stationary univariate autoregressive models with a regular unit root and a first-order ARCH error, deriving the asymptotic distribution of the least squares estimator (LSE) of the unit root, the same as that given by Dickey and Fuller (Citation1979).
Subsequently, Kim and Schmidt (Citation1993) employed Monte Carlo simulation to show that the Dickey–Fuller (DF) tests tended to over-reject in the presence of GARCH errors. However, they also found that the problem was not very serious, the exception being near-integration of the GARCH process errors where the volatility parameter was not small. Ling and Li (Citation1998a) later investigated an autoregressive-integrated moving average (ARIMA) model with GARCH (p, q) errors and derived the asymptotic distribution of the maximum likelihood estimation (MLE). They found that the asymptotic distribution of the MLE of various unit roots involves a series of bivariate Brownian motions and that the MLE of unit roots is more efficient than the corresponding LSE when GARCH innovations are present. Using these asymptotic distributions, Ling and Li (Citation1998b) later constructed some new unit root tests and showed that these tests could provide better performance than DF tests in Monte Carlo simulations.
While there are differences across these and other studies, they all suggest that unit root tests require a set of robust critical values that apply in the presence of GARCH errors. For this purpose, this paper provides a simple and easy-to-apply algorithm using the normalizing and variance-stabilizing transformation (NoVaS) in Politis (Citation2007) to produce robust critical values for ensuring DF tests have appropriate size and adequate power in the presence of conditional heteroscedasticity. However, because the subject of unit root tests is large, we limit the analysis here to investigating and demonstrating our procedure as it applies to unit root tests in the absence of serial correlation.
The remainder of the paper is organized as follows: Section 2 presents the simple NoVaS and the unit root test applying in the absence of serial correlation. In Section 3, we present our simulations and use these to establish the size and power properties of the tests. Section 4 provides a brief summary and the main conclusions.
2. NoVaS transformation and the unit root test
2.1. Simple NoVaS transformation
Politis (Citation2007) first defined and analysed the properties of the NoVaS transformation. Let us consider the NoVaS more closely and thereby observe the motivation for our study.
Let {εt} be a sequence of random variables following the ARCH(q) model(1.1)
(1.1)
where ω > 0, ai ≥ 0, 1 ≤ i ≤ q and the innovations et are i.i.d N(0,1).
Note that we use the innovations et as a standard normal because we can interpret the quantity(1.2)
(1.2)
as a “studentized” {εt} sequence. Moreover, this provides an intuitive explanation of the following NoVaS (2.3) quantity.(1.3)
(1.3)
where ,
, γ ≥ 0,
for all
and
.
Equation (1.3) describes the NoVaS transformation proposed by Politis (Citation2007) under which the data series {εt} is mapped to the new series {ut,a}.
The practitioner needs to select the order k(≥0) and the vector of non-negative parameters with the twin goals of normalization/variance-stabilization in mind. With a focus on that primary goal of normalization and variance stabilization, Politis (Citation2007) introduced the so-called simple NoVaS transformation for choosing the order k(≥0) of the parameters ai in (1.3). Mantalos and Karagrigoriou (Citation2012) subsequently modified the algorithm for the simple NoVaS as follows.
Let γ = 0 and then for all 0 ≤ i ≤ k.
Select the order k( > 0) such that the p-value of the Jarque–Bera statistic for the ut,a NoVaS-transformed series is maximized. In our analysis, we undertake this in a loop for k = 1 to 25.
Consider now that is the new NoVaS-transformed innovation. Then the transformed series has the following mean:
(1.4)
(1.4)
It is not difficult to show that, based on the assumption that the innovations et are i.i.d N(0,1) (see Equation (1.1)), that (1.4) becomes zero, that is(1.5)
(1.5)
As shown in Appendix A, the variance of the Simple NoVaS transformed series is(1.6)
(1.6)
The skewness of the innovations et is i.i.d N(0,1) is zero. Lastly, as also shown in Appendix A, the kurtosis is(1.7)
(1.7)
As Equations (1.5) and (1.6) provide zero skewness and kurtosis close to three, the transformed series exhibits the same properties as an i.i.d N(0,1) variable.
2.2. DF unit root tests in the absence of serial correlation
It is well known (Hamilton, Citation1994) that when testing for unit roots, it is important to specify the null and alternative hypotheses appropriately based on the type of the data at hand. For example, if the data do not display any increasing or decreasing trend, then we should not include a time trend in the test regression. Moreover, the inclusion of deterministic terms will also influence the asymptotic distribution of the unit root test statistics. Consequently, given the importance of the correct alternative hypothesis and the trend type, the data will determine the form of the test regression used. For this reason, and also because non-trending financial series, such as interest and exchange rates and spreads, exhibit non-zero means and GARCH errors; the following first model is considered.
2.2.1. Model 1: Constant term in the regression
The test regression is(1.8)
(1.8)
and the hypotheses to be tested are(1.9)
(1.9)
(1.10)
(1.10)
The test statistic we use is that proposed by DF: .
We remind ourselves here that εt follows an unknown ARCH/GARCH process that we could estimate, but which we do not require for the purpose of our test procedure.
The second model we consider is as follows:
2.2.2. Model 2: Time trend and constant term in the regression
The test regression is(1.11)
(1.11)
In this case, we assume that the data under the null hypothesis, with an example being a GDP series, follow a simple random walk with drift. That is(1.12)
(1.12)
whereas under the alternative hypothesis it is an AR(1) model with and trend. However, even here we use the DF test statistic
. Note that this formulation is appropriate for time series such as asset prices, that is, trending time series with several possible kinds of GARCH errors.
2.3. NoVaS critical values for DF unit root tests in the presence of GARCH errors
The underlying idea and method we use in our procedure to produce robust critical values is simple and identical to the manner in which Dickey and Fuller (Citation1979) produced their critical values for the unit root test, that is, using Monte Carlo methods we can approximate the finite-sample distribution of the unit root test.
Model 1:
Consider a sequence of T observations for which we wish to test if there is a unit root in the series. In addition, we assume that our observed data do not display any increasing or decreasing trend while at the same time exhibiting a non-zero mean.
The first step is to estimate the test regression(1.13)
(1.13)
and calculate the DF test statistic .
We perform the simple NoVaS transformation on the estimated residuals from (1.13) , that it is,
.
Based on the simple NoVaS properties (1.5, 1.6, and 1.7), , is a good approximation of the error term in (1.13), where zt, are T i.i.d random numbers from the standard normal distribution.
The next step is to calculate the new series under the null hypothesis .
We then estimate the regression and afterwards the DF test statistic
.
Repeating steps 3–4 a large number of times, NMC (in our Monte Carlo simulations, N = 1,000), we are able to approximate the finite sample distribution of the DF unit root test.
By taking the (1 − α) quintile of the approximate finite-sample distribution of , we obtain the α-level “critical values” (
) and finally reject Ho if
≥
.
A Monte Carlo estimate of the p-value for testing is . We use this to study the size and power of the unit root test (with the assistance of the p-value plot).
Model 2:
In the case of a trend
The first step is to estimate the test regression(1.1.4)
(1.1.4)
and calculate the DF test statistic
We perform the simple NoVaS transformation on the estimated residuals from (1.14), such that(1.15)
(1.15)
That is, .
The next step is to calculate , where zt are as previously T i.i.d random numbers from the standard normal distribution.
The next step is to calculate the new series under the null hypothesis .
We then estimate the regression and afterwards the DF test statistic
.
Steps 6–8 are the same as in Model 1.
Note that in Model 1, the null hypothesis does not contain a drift term, while in Model 2, the null hypothesis contains a drift term, for that reason in the Model 1 is:
and in Model 2:
.
3. Simulations
3.1. Monte Carlo
In this section, we perform a simple Monte Carlo experiment by generating data for the size of the test for Model 1 using(1.16)
(1.16)
For the power test, we generate data using(1.17)
(1.17)
The data-generating process for the size of the test for Model 2 is(1.18)
(1.18)
For the power test, we generate data using(1.19)
(1.19)
We study the performance of the NoVaS critical values with error terms i.i.d N(0,1). We assume white noise and in all other cases, the errors follow a GARCH (1, 1) model with the following data-generating process(1.20)
(1.20)
For each model, we perform 5,000 replications for the calculation of size and 1,000 replications for the power functions. Our results are based on 600, 1,100 and 2,100 replications, where the first 100 time series observations in each replication are discarded to avoid possible initial value effect. We calculate the estimated size of the test by counting how many times we reject the null hypothesis in repeated samples under conditions where the null is true.
3.2. The p-value plots
The conventional way of reporting the results of a Monte Carlo experiment is to tabulate the proportion of times we reject the null hypothesis in repeated samples under conditions where the null is true. Concerning the significance levels used when judging the properties of the tests, different studies have advocated both larger and smaller significance levels. For example, Maddala (Citation1992) suggests significance levels of as much as 25% in diagnostic testing, while MacKinnon (Citation1992) suggests going in the other direction.
To address this problem, in this study we use mainly graphical methods that potentially provide more information about the size and power of the tests. We use the simple graphical methods developed and illustrated in Davidson and MacKinnon (Citation1998) as they are relatively easy to interpret. We employ the p-value plot to assess the size of the tests and size–power curves to evaluate the power of the tests. The graphs of the p-value plots and size–power curves are based on the empirical distribution function (EDF) of the p-values, denoted . For the p-value plots, if the distribution being used to compute the ps terms is correct, each of the ps terms should be distributed uniformly about (0,1). Therefore, the resulting graph should be close to the 45o line. The p-value plots also make it possible and easy to distinguish between tests that systematically over-reject or under-reject the null hypothesis and those tests that reject the null hypothesis near the right amount of time.
To judge the reasonableness of the results, we use a 95% confidence interval for the actual size (π0) given , where N is the number of Monte Carlo replications. We consider any results that lie between these bounds as satisfactory. For example, if we consider 5,000 Monte Carlo replications and a nominal size of 5%, we define a result as reasonable if the estimated size lies between 4.39 and 5.61%.
3.3. White noise case
We begin our study of the behaviour of our test procedure with the simple case of white noise errors, that is, series without GARCH errors. The results for 500 observations given that there is no difference between these and those for 1,000 or 2,000 observations, we find also no difference between these and those for small samples as 75, 100 and 200 observations. As shown in Figure (a), in Model 1, the unit root test behaves well, with both the DF and NoVaS critical values indicating estimated sizes that are inside the confidence interval lines. As we observe the same behaviour for the unit root in Model 2, as shown in Figure (b), we conclude that the NoVaS critical values work as well as we expect for the case of white noise.
Figure 1. Size of the unit root tests of models 1 and 2 for 500 observations with white noise errors: (a) Model 1 and (b) Model 2.
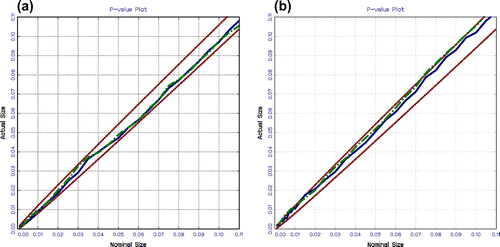
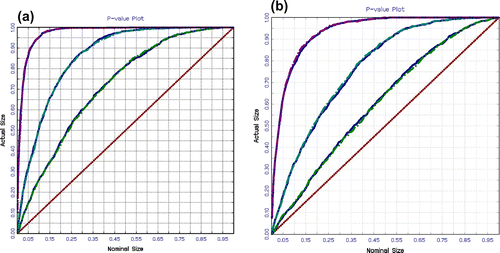
Figure depicts the power of the tests. The first thing we observe is that the unit root tests display the same power when using both the DF and NoVaS critical values. It is also obvious that there is a sample effect (the lowest curves are for 500 observations, followed by 1,000 observations, and the highest curves are for 2,000 observations). In sum, the unit root tests with NoVaS critical values assuming only white noise error work equally as well as the unit root tests with conventional DF critical values.
Figure 2. Power of the unit root tests of Model 1 for 500 observations with white noise: (a) Model 1 and (b) Model 2.
3.4. GARCH case
3.4.1. The size of the tests
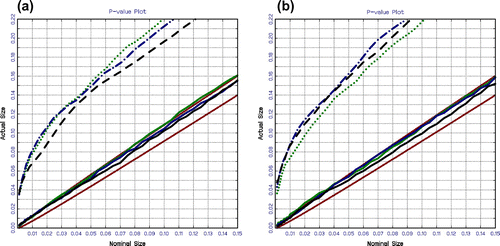
In this subsection, we present the results of our Monte Carlo experiment concerning the size of the unit root test given GARCH errors. As shown in Figure (a) for Model 1 and Figure (b) for Model 2 for 500, 1,000 and 2,000 observations, the p-value plots make it possible to easily distinguish that unit root tests with DF critical values systematically over-reject the null hypothesis, whereas unit root tests with NoVaS critical values reject the null hypothesis at about the right amount of time. Once again, we recall that we use the constant term in the regression for Model 1 and a time trend and constant term in the regression in Model 2. As shown, the unit root test with DF critical values over-rejects by almost three times the nominal size, that is, for a 5% nominal size and Model 1, we estimated sizes of 15.35% for 500 observations, 14.9% for 1,000 observations and for 14.35% for 2,000 observations. We observe a similar picture for the unit root test with DF critical values for Model 2, where for a 5% nominal size we estimated sizes of 14.85% for 500 observations, 16.26% for 1,000 observations, and 15.9% for 2,000 observations. Overall, the unit roots tests with NoVaS critical values unlike those with DF critical values work well in the presence of GARCH errors.
Figure 3 Size of the unit root tests for 500, 1,000 and 2,000 observations with GARCH errors: (a) Model 1 and (b) Model 2.
3.4.2. The power of the tests
In this subsection, we analyse the power of the Wald and bootstrap tests using sample sizes of 500, 1,000, and 2,000 observations. We estimate the power function by calculating the rejection frequencies for 1,000 replications using Equation (1.17) for Model 1 and Equation (1.19) for Model 2. We employ the size–power curves to compare the estimated power functions of the alternative test statistics. We follow the same process to evaluate the EDFs denoted by using the same sequence of random numbers used to estimate the size of the tests.
Figure displays the results using the size–power curves. As shown, the unit root tests with the DF critical values are now superior to the unit root tests with the NoVaS critical values. We also again observe a sample effect, such that the larger the sample, the greater the power of the tests. To ensure a fair comparison of the power of the unit tests with the DF and NoVaS critical values, we apply the size–power curves on a correct size-adjusted basis.
Figure 4. Power of the unit root tests for 500, 1,000, and 2,000 observations with GARCH errors: (a) Model 1 and (b) Model 2.
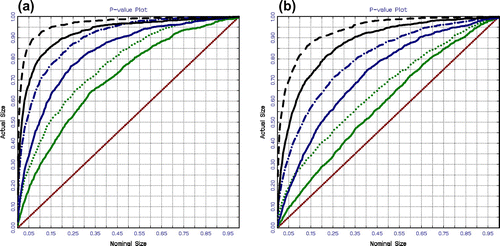
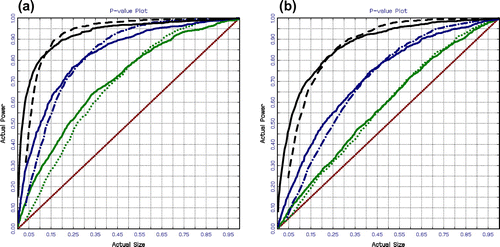
Figure plots the size–power curves and the estimated power functions against the nominal size. By plotting the estimated power functions against the true size, that is against
, we obtain size–power curves on a correct size-adjusted basis. As the unit root tests with DF and NoVaS critical values now share the same power, they are even better for a small nominal size (less than 15%), as shown in Figure . The main finding for our power investigation is that unit root tests with NoVaS critical values generally perform adequately in both the white noise and GARCH error cases.
Figure 5. Size-adjusted power of the unit root tests for 500, 1,000, and 2,000 observations with GARCH errors: (a) Model 1 and (b) Model 2.
4. Brief summary and conclusion
In this section, we summarize the results of our investigation. The purpose of this study has been to study the unit root test in the presence of conditional heteroscedasticity errors with newly proposed critical values modified using the NoVaS method. The main conclusion is that NoVaS-modified critical values are robust, with respect to both white noise and conditional heteroscedasticity errors. Moreover, given the actual size that lies close to their nominal size and adequate power, it makes sense that we would select our NoVaS-modified critical values ahead of the conventional DF critical values, especially in the presence of conditional heteroscedasticity errors.
In summarizing our methodology, we studied the estimated size and power of the unit root test in the presence of conditional heteroscedasticity errors using two sets of critical values: namely, conventional DF values and our newly proposed NoVaS-modified values. In terms of the size of the tests, we used Monte Carlo methods to investigate their properties using 5,000 replications per model, with 500, 1,000, and 2,000 observations. We employed p-value plots to investigate the size of the tests and found that the unit root tests perform better with NoVaS-modified critical values across all of our samples. Importantly, when we consider the power results using the size–power curves, when considered on a correct size-adjusted basis, the unit root tests with NoVaS-modified critical values share the same power as tests using DF critical values or at least the difference is very small across all of our samples.
Additional information
Funding
Notes on contributors
Panagiotis Mantalos
Panagiotis Mantalos, PhD, is an associate professor of statistics and econometrics in Department of Economics and Statistics at Linnaeus University, Sweden. His primary field of research deals with the study and development of statistical methodology for diagnostic testing using bootstrap methods. The bootstrap testing method is always assisting for evaluation and building robust models.
His research includes time series, dynamical models in economics, econometrics and financial data econometrics. He has published numerous articles—both theoretical and applied—which can be used to develop strategies for selecting appropriate models. Moreover, using his bootstrap strategies, we can avoid inadequate models, misleading results and incorrect conclusions.
References
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31, 307–327.10.1016/0304-4076(86)90063-1
- Davidson, R., & MacKinnon, J. G. (1998). Graphical methods for investigating the size and power of hypothesis tests. The Manchester School, 66, 1–26.10.1111/manc.1998.66.issue-1
- Dickey, D. A., & Fuller, W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427–431.
- Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50, 987–1008.10.2307/1912773
- Giraitis, L., Leipus, R., & Surgailis, D. (2006). Recent advances in ARCH modelling. In A. Kirman & G. Teyssiere (Eds.), Long Memory in Economics (pp. 3–38). Berlin: Springer.
- Hamilton, J. (1994). Time series analysis. Princeton: Princeton University Press.
- Kim, K. & Schmidt, P. (1993). Unit root tests with conditional heteroskedasticity. Journal of Econometrics, 59, 287–300.10.1016/0304-4076(93)90027-3
- Ling, S., & Li, W. K. (1998a). Limiting distributions of maximum likelihood estimators for unstable ARMA models with GARCH errors. Annals of Statistics, 26, 84–125.
- Ling, S., & Li, W. K. (1998b). Estimation and testing for unit root processes with GARCH(1,1) errors (Technical report). Department of Statistics, University of Hong Kong.
- MacKinnon, J. G. (1992). Model specification tests and artificial regressions. Journal of Economic Literature, 30, 102–146.
- Maddala, G. S. (1992). Introduction to econometrics (2nd ed.). New York, NY: Maxwell Macmillan.
- Mantalos, P., & Karagrigoriou, A. (2012). Testing for skewness in ARCH models for financial returns series (Working Paper Örebro University) (p. 4). Retrieved from www.oru.se/globalassets/orusv/institutioner/hh/workingpapers/workingpapers2012/wp-4-2012.pdf
- Pantula, S. G. (1989). Estimation of autoregressive models with ARCH errors. Sankhya B, 50, 119–138.
- Politis, D. N. (2007). Model-free versus model-based volatility prediction. Journal of Financial Econometrics, 5, 358–359.10.1093/jjfinec/nbm004
Appendix A
Mean, variance, kurtosis and skewness of NoVaS
Let us consider the model with
, where f is the unknown density function of the εt conditional on the set of past information ψt-1.
The first moment “the mean of NoVaS”
First we remind ourselves that for the simple NoVaS, γ = 0. Now for the simple NoVaS with one lag, that is, , such that we always take account that εt is variance stationary and
, then the mean is
(1.21)
(1.21)
For two lags, the mean is , while for three lags it is
, and finally for the general (k) lags, the mean is
(1.22)
(1.22)
The second moment of NoVaS
For the simple NoVaS model with one lag, we have . By taking the squares of this and then the expectation, we have
(1.23)
(1.23)
If εt is fourth-order stationary with and
, then we have
(1.24)
(1.24)
In the same manner, we can show that the simple NoVaS model with two lags has
(1.25)
(1.25)
for three lags(1.26)
(1.26)
and finally for the general (k) lags(1.27)
(1.27)
Now the variance is .
Consequently, we have(1.28)
(1.28)
(1.29)
(1.29)
Kurtosis
Consider that is the new NoVaS-transformed series. Then the kurtosis of this series is
(1.30)
(1.30)
We can see from (1.22) that the mean of the simple NoVaS is . It is easy to see that for
then (1.22) becomes
(1.31)
(1.31)
Based on this, we have the kurtosis of the new transformed series as(1.32)
(1.32)
Recall that we derived the second moment of the NoVaS for the general (k) lags in (1.27). Now given we expect that is i.i.d normal, and
, then
(1.33)
(1.33)
Consequently, for a simple analysis of (1.33) with the substitution of the , and the right-hand side of (1.27), the kurtosis of the NoVaStransformed series becomes
(1.34)
(1.34)
Moreover, for , (1.34) becomes
(1.35)
(1.35)
The last part of this equation is the kurtosis of the simple NoVaS-transformed series.
