
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The efficient market hypothesis describes an efficient market as one in which investors cannot consistently predict stock returns because prices instantly reflect all the information flowing into the market. However, return predictability has been documented in many markets. This study tests the predictability of returns using two valuation ratios—the dividend and earnings yields—on the South African market, at both aggregated and sectoral level. Unlike most studies in South Africa, this study employs an apposite present value model, accounts for structural breaks and investigates the non-linearity of the relationship between stock returns and valuation ratios. The results show that returns are predictable at both aggregated and sectoral levels. This finding has implications for market efficiency through enhanced price discovery which, in turn, has implications for investment and portfolio management. However, it should be noted that statistical significance may not translate to economic significance, so there is a need to determine the latter if one intends to use any strategy that relies on this evidence.
PUBLIC INTEREST STATEMENT
This paper investigates whether two valuation ratios – the dividend yield and the earnings yield – can be used to predict returns. We use seven sector indices and the broad market index on the South African market to compute monthly returns over a period spanning 1996 to 2018. The empirical findings show that the valuation ratios can predict returns of both sector indices and the broad market index. These results are contrary to the assertion from which most traditional finance theories depart, the assertion that markets are efficient in processing information such that future price changes and returns cannot be predicted using information that is already available in the market. The findings imply that valuation ratios can be used in trading strategies by investors who seek to earn abnormal returns consistently by predicting price changes.
1. Introduction
1.1. Background
In the efficient market hypothesis, Fama (Citation1970) maintains that stock prices reflect all available information and are, thus, unpredictable. In this hypothesis, Fama (Citation1970) identified three levels of efficiency. In the weak form, the lowest level of efficiency, prices only reflect the information contained in historical prices (Mittal & Thakral, Citation2018). Thus, fundamental and private information can be used to predict price changes. In a semi-strong form, stock prices incorporate only the publicly available information, including past price information. Only private information can be employed to predict prices to earn consistent abnormal returns. Lastly, the strong form efficient market renders stock returns unpredictable since all information is fully incorporated and reflected (Patel et al., Citation2017).
However, there is increasing evidence of return predictability. This evidence goes against the efficient market hypothesis, more so the evidence from markets considered to be at least semi-strong form efficient such as the United States, the United Kingdom and Germany. It is thus possible that markets are adaptive in terms of efficiency (Urquhart & McGroarty, Citation2014). The findings also cast doubt on the validity of the present value model, which suggests that only a discounted stream of dividends can predict stock prices. The ability to predict stock market returns using various variables means that the present value model lacks the pricing efficiency in terms of processing public information (Zaremba & Czapkiewicz, Citation2017). So, there may be a need to use different models.
1.2. Macroeconomic variables and predictability of returns in international markets
Several studies showed that stock returns could be predicted using various macroeconomic variables. For instance, Patelis (Citation1997) found that shifts in the monetary policy could predict US stock returns using vector autoregressions. Rapach et al. (Citation2005) found interest rates and inflation to be significant predictors of US stock returns using predictive regressions. Diether et al. (Citation2009) found that US stock returns were predictable based on short sale strategies. Cremers and Weinbaum (Citation2010) showed that deviations from the put-call parity could predict US stock returns. Shamsuddin and Kim (Citation2010) showed that equity market development indicators could predict equity returns on fifty markets using variance ratio tests.
Lou (Citation2012) found that the flow-driven return effect of mutual funds could partially explain US stock price momentum. Gupta et al. (Citation2014) found that economic policy and equity market uncertainty, consumer sentiment and financial stress do not explain the equity premium on the US market. Narayan and Gupta (Citation2015), found that both positive and negative oil price changes are essential predictors of US stock returns, with negative changes relatively more important. Kostakis et al. (Citation2015) found evidence of short-horizon predictability between 1927 and 2012 on the US market. However, the predictability almost entirely disappeared in the post–1952 period and became weaker as the predictive horizon increased.
Bekiros et al. (Citation2016) found that economic policy and macroeconomic uncertainty indices can predict US stock returns in linear estimations. Devpura et al. (Citation2018) found that on the US market stock return predictability was time-varying and could be explained by shocks emanating from financial variables and market volatility. Phan et al. (Citation2018) found that the ability of economic policy uncertainty to forecast stock returns was country- and sector-dependent through the discount rate rather than the cash flow channel in sixteen countries. Balcilar et al. (Citation2019) found evidence of causality from the economic policy uncertainties for stock return volatility of Malaysia, and both returns and volatility for South Korea.
1.3. Macroeconomic variables and predictability of returns on the South African market
Similar studies have also been done in South Africa. For instance, using weak-form efficiency tests, Magnusson and Wydick (Citation2002), Jefferis and Smith (Citation2005), Simons and Laryea (Citation2006), Smith (Citation2008), and Zhang et al. (Citation2012) found the returns on the South African market to be unpredictable. However, Bonga-Bonga and Makakabule (Citation2010) found that non-linear models with macroeconomic variables can be used to predict returns. Bonga‐Bonga and Mwamba (Citation2011) found evidence of return predictability and showed that non-parametric models performed better than parametric models in return predictability. Kruger (Citation2011), using autoregressive and regime-switching non-linear models, found evidence of linear and non-linear serial dependence in returns, albeit episodic. MacFarlane (Citation2011), using the Johansen cointegration, Granger causality and innovation accounting tests, found weak evidence of predictability of returns based on macroeconomic variables. Gupta and Modise (Citation2013) found that interest rates, world oil production growth and money supply could predict returns.
Van Gysen et al. (Citation2013), using nine macroeconomic variables and non-linear models, found evidence of return predictability in South Africa. Aye et al. (Citation2013) found evidence of structural instability and variability in the predictive ability of the twenty-three variables in different regimes. Wen et al. (Citation2015) found that US and UK market return could predict South African stock returns pre-1996 than post-1996, possibly due to regulatory reforms in the latter period. Smith and Dyakova (Citation2014), analysing the return predictability on eight stock markets including South Africa, found that there were successive periods of predictability and non-predictability, a finding which is consistent with the Adaptive Market Hypothesis of Lo (Citation2004). Balcilar et al. (Citation2015) found that stock returns of the Netherlands and Hong Kong were significant predictors of South African stock returns. Apergis and Gupta (Citation2017) and Olivier (Citation2018) found that unusual weather conditions in New York and South African and US interest rates and exchange rates, respectively, could predict South African returns.
Recently, Vergos and Wanger (Citation2019) investigated the relationship between stock markets and macroeconomic data using VECM in Sub-Saharan African markets for the period between 2008 and 2018. Their findings showed that there were co-movements among sector returns in Sub-Saharan African markets which are a violation of weak-form efficiency. In South Africa, the study showed that there is short-run causality running from the consumer goods sector to the industrials sector which suggested that a shock or innovation in the consumer goods sector influences returns in the industrial sector. Also, Vergos and Wanger (Citation2019) found short-run causality running from gross domestic product to market capitalisation, implying that changes in the economic growth impacted stock market movement in South Africa. Moreover, Rupande et al. (Citation2019) found that market-wide investor sentiment index of macroeconomic proxies is a significant predictor of South African returns using the Generalised Autoregressive Conditional Heteroscedasticity models over a period spanning July 2002 to June 2018
1.4. Valuation ratios and predictability of returns in international markets
There is another band of literature that shows that valuation ratios could predict stock returns. According to Lewellen (Citation2004), these ratios can track time variation in discount rates, so their ability to predict returns is based on the risk premium information they possess that is vital to asset pricing. In this regard, various studies have been conducted to examine the predictive ability of valuation ratios. Fama and French (Citation1988) and Hodrick (Citation1992) showed that dividend yields could predict returns on the US stock market in short horizons. In contrast, Wu and Wang (Citation2000) and Lewellen (Citation2004) evidenced that the predictive ability of dividend yield and earnings-price ratios could be extended over longer horizons, albeit time-varying.
Campbell and Yogo (Citation2006) showed that the earnings-price ratio could predict returns at various frequencies, whereas the dividend-price ratio predicted returns only at an annual frequency. However, this prediction ability weakened in the post-1952 sample. The study also showed that, even if there are predictable components in stock returns, they may be difficult to predict using inefficient statistical tests. Ang and Bekaert (Citation2007) found no evidence of short and long-run predictability in returns using the dividend yield and the earnings yield on the French, Germany, the UK, Japanese and the US stock markets. In contrast, Black et al. (Citation2007) found that dividend yields could predict stock returns in the G7 markets.
Ferreira and Santa-Clara (Citation2011) found that the dividend-price, earnings growth, and price-earnings growth ratios could predict US stock returns using the some-of-the-parts method. Pettenuzzo and Timmermann (Citation2011) found that US stock returns were predictable using the dividend yield. However, the predictive regressions parameters were highly unstable and subject to multiple breaks. Li and Yu (Citation2012) found that overreaction and underreaction were better predictor variables than the dividend yield, stable across subsamples and robust across all the G7 markets. Jordan et al. (Citation2014) showed that dividend yield and earnings-price ratios could explain time-varying variation in stock returns in the US and UK, respectively.
Other studies employed disaggregated data as, per Jung and Shiller (Citation2005), aggregate data might obscure forecasting ability of valuation ratios. Also, present value models are likely to perform better with disaggregated data. McMillan (Citation2010) showed that the dividend yield predicts returns on ten sectoral indices in the UK. However, the predictive ability diminished in the presence of large bubbles. Alexakis et al. (Citation2010) found that valuation ratios, asset utilisation, debt, investment and liquidity ratios could predict stock returns of 47 non-financial firms on the Athens stock market. Güloğlu et al. (Citation2016) showed that financial leverage, dividend yield and market-to-book ratios could predict stock returns of 83 Turkish firms.
Kheradyar et al. (Citation2011) found that dividend yield, earnings yield and book-to-market ratios could predict returns of 960 companies on the Malaysian Stock Exchange. Nargelecekenler (Citation2011) found that the price-earnings ratio could explain the variation of stock returns in 24 sectoral indices on the Turkish market. Bannigidadmath and Narayan (Citation2016) found that the earnings-price, dividend-price, and the book-to-market ratios could forecast sectoral returns on the Indian Stock Exchange. Markus and Sormunen (Citation2018) findings suggested that the dividend yield, price-to-earnings, and price-to-book ratios could predict returns of stocks on the Swedish stock market. Ball et al. (Citation2020) found that the price-earnings ratio subsumes the book-to-market ratio in predicting the cross-section of stock returns on the US market.
1.5. Valuation ratios and predictability of returns in South Africa
Gupta and Modise (Citation2012a) found no evidence of return predictability using price-dividend and price-earnings ratios on the All-Share Index over the period 2001–2009. However, the prediction power improved when predictors, such as interest rates and term spreads, were added. In a follow-up study, Gupta and Modise (Citation2012b) found that the dividend yield and price-earnings ratios could not predict the returns of stocks over the period from 1990 to 2010. However, interest rates, money supply and world oil production were found to be significant predictors over short horizons and the inflation rate over the medium and long horizon. After accounting for data mining, the macroeconomic and financial variables had little to no predictive power in a linear predictive regression framework.
Charteris and Strydom (Citation2016) found that the consumption aggregate wealth ratio can predict returns in South Africa using quarterly data over the period 1990–2013. This predictive power increased when the term spread was added to the model. Pane (Citation2016) compared linear parametric models, non-parametric and Bayesian models on their forecasting of stock return predictability on the JSE for the period spanning 1996 to 2013. To achieve this, Pane (Citation2016) regressed stock return data against the dividend yield, consumer price index, JIBAR, FTSE and S&P 500 returns. Employing the predicted mean square error and mean absolute error, the linear model outperformed the non-parametric model. However, the Bayesian model had better performance than the linear model.
In South Africa, there is a shortage of studies that have employed disaggregated data to investigate the predictability of returns. However, Charteris and Chipunza (Citation2020) tested the predictability of returns using dividends in a present value model that employed a panel of 22 firms over the period between 1999 and 2018. Using Pedroni’s (Citation1999; Citation2004), Kao’s (Citation1999) and Westerlund’s (Citation2007) panel cointegration tests and panel dynamic ordinary least squares and panel fully modified ordinary least squares, they showed that dividends move in tandem with prices. This finding implied that, in South Africa, dividends could be employed to predict the stock returns. However, Charteris and Chipunza (Citation2020) examined the predictive ability of dividends at the firm level and not at the sectoral level.
In the amalgam of empirical evidence on the predictability of returns in South Africa, most studies employed aggregated data in their analyses. Others, however, did not consider structural breaks at a sectoral level. Yet, Hillebrand (Citation2005) posits that, if unaccounted for, structural breaks could have long memory and persistence effects which result in higher-order unconditional moments in financial time series. Further, Andreou and Ghysels (Citation2009) contend that structural breaks could yield erroneous inferences owing to model misspecification. Moreover, structural breaks tend to result in model instability hence ignoring structural breaks could yield biased inferences which could harm the financial risk management and optimal asset allocation (Andreou & Ghysels, Citation2009; Timmermann, Citation2001).
Further, valuation ratios could fail to predict returns at the mean but might have forecasting ability at different parts of the return distribution (Cenesizoglu & Timmermann, Citation2007). Besides, it has been shown that quantile regressions have higher robustness against outliers relative to least squares regressions and relatively better consistent performance under weaker stochastic performance (Hao & Naiman, Citation2007). Nonetheless, this has not been investigated at a sectoral level in South Africa. To this end, this study investigates valuation ratios predictive ability using cointegration techniques accounting for structural breaks and quantile regressions at both sectoral and aggregate level in South Africa. The findings of this study may help improve price discovery as investors employ these ratios in trading strategies. Also, the findings could guide academics on the importance of structural breaks and non-linear models in modelling returns in South Africa.
2. The present value model
A present value model suggested by Campbell and Shiller (Citation1988) is employed in this examination. They derived the dividend yield model as:
where is the log of dividend yield at the start of the period;
is a constant discount factor;
is the future stock return in j period from now; k is a constant term.
is an expectational operator conditional at the beginning of period t; c is a constant term. EquationEquation (1)
(1)
(1) models the log of dividend yield as a present value of all future stock returns and dividend growth
that is discounted at a rate
minus the constant
. Campbell and Shiller (Citation1988) imposed an additional restriction such that an observable ex-post discount rate
will satisfy the condition in EquationEquation (2)
(2)
(2) that there is an ex-post rate whereby the expectation at the beginning of each period plus a constant term is equal to the ex-ante stock returns in period t. If EquationEquation (2)
(2)
(2) is substituted into EquationEquation (1)
(1)
(1) , it yields:
where represents a constant discount factor. Implicitly, the log of dividend yield is equal to an expected discounted value of all future one-period growth-adjusted discounted rates. g denotes a constant growth rate of dividends;
represents dividend per stock at time t;
symbolises the price per share at time t. EquationEquation (3)
(3)
(3) implies that the current dividend yield is a function of expected future returns and growth in dividends such that a lower dividend yield predicts a lower future return or a higher future dividend growth. If the discount and dividend growth rates remain constant and the constant term, c, has the value of zero, then EquationEquation (3)
(3)
(3) can be re-written as EquationEquation (4)
(4)
(4) .
To account for the predictive ability of the earnings yield, EquationEquation (1)(1)
(1) can be extended to model earnings yield-stock return relationship. According to the dividend models, dividend changes are related to unanticipated and permanent changes in the firm’s earnings (Lintner, Citation1956) and firms employ dividend changes to convey earnings information unknown by the market (Miller & Rock, Citation1985). Thus, Wu and Wang (Citation2000) extended Campbell and Shiller (Citation1988) PVM by incorporating earnings yield into the model. The relationship between dividends
and earnings
can be expressed as shown in EquationEquation (5)
(5)
(5) :
where represents the log payout ratio
. Substituting EquationEquation (5)
(5)
(5) into EquationEquation (1)
(1)
(1) yields EquationEquation (7)
(7)
(7) . If the rational expectations assumption similar to EquationEquation (2)
(2)
(2) holds, then EquationEquation (7)
(7)
(7) can be reformulated as follows:
where is a constant, conditional on the information at t. EquationEquation (8)
(8)
(8) can be re-written as (9) if firms follow a constant payout ratio and this suggests that high earnings yields predict high future stock returns or lower future earnings growth, and vice versa.
3. Empirical framework
3.1. Data and sample
Monthly closing prices, dividend and earnings yields for seven sector indices namely, Basic Materials (J510), Industrials (J520), Consumer Goods (J530), Health Care (J540), Consumer Services (J550), Telecommunication (J560) and Financials (J580), and the All-Share Index (J203), were obtained from the IRESS database from 1996:01 to 2018:12. This was necessitated by data availability and the beginning of this period coincides with the period in which major economic and regulatory reforms were instituted in South Africa (Wen et al., Citation2015). The nominal components were deflated by the consumer price index obtained from the South African Reserve Bank. Following Charteris and Strydom (Citation2016), the series were converted into natural logarithm and then normalised using the z-score. The number of lags was determined by the Schwarz Bayesian information criterion (SBIC, Citation1978) and the order of integration was determined by the Augmented Dickey-Fuller (ADF, Citation1979), Zivot and Andrews (ZA, Citation2002) and Kwiatkowski, Phillips, Schmidt, and Shin (KPSS, Citation1992) tests.
3.2. Structural breaks in the cointegrating relationship
To account for structural breaks, the Gregory and Hansen (GH, Citation1996) test, a residual-based test extended from the Engle and Granger (Citation1987) approach, was employed. It tests the null hypothesis of no cointegration at the breakpoint. The authors formulated three models; one with a level shift, one with level shift and a trend and another with regime shift where the intercept and slope change, respectively, as:
In EquationEquation (10)(10)
(10) , a level shift in the cointegrating relationship is modelled as a change in the intercept
and the slope coefficients are held constant.
signifies the intercept before the shift and
denotes the intercept subsequent to the shift. Y is the dependent variable;
denotes the real log dividend yield at time t;
signifies real log earnings yield at time t;
and
signify the cointegrating slope coefficients before the regime shift. The parameters
,
,
and
are time-invariant; t is the time subscript and
is the error term. To model structural change, Gregory and Hansen (Citation1996) introduced a dummy variable
defined as:
if
and
if
where the unknown parameter
denotes the relative timing of the change point and [] signifies integer part.
represents the coefficient of the trend term t.
and
represent the change in slope coefficients. In determining a single endogenous break date in a cointegrating relationship, these models rely on the
,
and
test types. Where the absolute values of these statistics were higher than the critical values, the null hypothesis of no cointegration with structural breaks was rejected. The breakpoint was selected based on the model that had the smallest test statistic as this suggested more significant evidence against the null hypothesis of no cointegration with structural breaks. For robustness, we estimated the long-run relationship between the sectoral returns and valuation ratios using the ARDL model accounting for structural breaks as will be explained subsequently.
3.3. Autoregressive distributed lag model in the presence of structural breaks
To test the long run and short run relationship between valuation ratios and sectoral returns, we employed the ARDL bounds test. This test determines whether there is a cointegrating relationship among the variables using an F-test. The ARDL approach differs from Engle and Granger (Citation1987) and Johansen and Juselius (Citation1990) cointegration techniques in that it tests for cointegration between variables regardless of the order of integration or mutual cointegration. Also, it enables the simultaneous estimation of the long and short-run parameters considering that the dynamic error correction model (ECM) can be derived from the conditional ARDL. Further, it reduces the number of parameters to be estimated since the test is not based on a vector autoregression, but on a single ARDL equation (Narayan, Citation2005).
Using the Pesaran et al. (Citation2001) upper and lower bound critical values, the null hypothesis of no cointegration was rejected when the calculated F-statistic exceeded the upper critical bound. However, there was a failure to reject the null in cases where the F-statistic fell below the lower bound critical values. When the test statistic fell within the upper and lower bounds, the test was considered indecisive. The ARDL model was estimated as:
where lnR, lnDY and lnEY are the returns, dividend and earnings yields, respectively; is the difference operator;
is a structural break dummy which equals 0 before the breakpoint and 1 thereafter;
denotes the error term. The values p, q, r are the selected number of lags for the cointegrating equations based on SBIC. If cointegration was confirmed, an error correction model (ECM) was estimated accounting for structural breaks as:
where is the speed of adjustment;
;
;
are the short-run coefficients.
is the error correction term which measures the adjustment speed towards the long-run equilibrium between the sectoral returns and valuation ratios after a short run deviation from the equilibrium. That said, a larger
was interpreted as a higher speed of adjustment or convergence rate and vice versa. À priori, it was expected that the
will have a statistically significant negative sign to confirm the long-run cointegration.
After estimating the ARDL-ECM in EquationEquation (14)(14)
(14) , several diagnostic tests were conducted. Model stability was tested for using the cumulative sum of recursive residuals (CUSUM) test of Brown et al. (Citation1975). In this test, the null hypothesis is that coefficients in the error correction model are stable is tested and the significance of any departure from the stability is assessed at 5% significance level (Brown et al., Citation1975). The expectation is that the cumulative sum will be within the area of the two critical lines suggesting parameter stability or otherwise if the parameters are unstable. Also, using the residuals of the ARDL-ECM estimated in EquationEquation (14)
(14)
(14) , the Breusch-Godfrey and Durbin-Watson tests were employed to test for serial correlation to avoid biased parameter estimates.
3.4. Quantile regressions
Traditional regression methods focus on the prediction of the mean only. However, the failure of a variable to predict the mean does not necessarily mean that it cannot predict other parts of the return distribution. So, this study employed quantile regressions as they provide more detailed information regarding the return distribution, which could be paramount in portfolio designation and construction (Cenesizoglu & Timmermann, Citation2007). Also, quantile regressions are efficient in addressing outliers, mainly if the data exhibits non-linear distributions as indicated by skewness and leptokurtosis. Thus, inferences drawn from quantile regressions are likely to have less bias since outliers are not accounted for (Koenker & Hallock, Citation2001).
Further, a putative state dependence of the nexus between valuation ratios and sector return could be encapsulated by different quantiles of the conditional distribution: lower (upper) quantiles are associated with bad (good) states (Cenesizoglu & Timmermann, Citation2007; Ma et al., Citation2018). Implicitly, for instance, when a variable is statistically significant in the right tail of the return distribution, it suggests that it has predictive power in the bull state or “upmarket” and vice versa. With that in mind, this study employed quantile regressions, introduced by Koenker and Bassett (Citation1978), to estimate the relationship of the conditional distribution in relation to other predictor variables. The conditional quantile function of at quantile
given explanatory variable
is defined as follows:
where represents the distribution of errors while
and
denote estimated parameters. To estimate the
conditional quantile regression, the following regression is estimated:
where T signifies the sample size and denotes the check function that is defined as
and
(Koenker & Bassett, Citation1978).
4. Results
4.1. Descriptive statistics
The descriptive statistics of the sectoral indices’ returns, dividend yield and earnings yield are shown in Table . The consumer goods sector had the highest average return (0.61%), whereas the health sector had the lowest (−0.56%). The standard deviations of the basic materials, consumer goods, consumer services, financials, health, industrials and telecommunication sector were 7.59%, 6.57%, 6.54%, 6.00%, 14.75%, 5.80% and 8.68%, respectively. These differences suggest that certain sector-specific events influenced volatility in the return series behaviour with the highest standard deviation recorded for the health sector. The risk-return relationship for the health sector suggests high risk as the high standard deviation does not result in higher returns as per finance theory. Thus, based on the standard deviation, the health sector is the riskiest of all the seven sectors.
Table 1. Descriptive statistics
The average real earnings yield ranged between −2.8% and 1.9% (basic materials), −1.89% and 2.09% (consumer goods), −2.05% and 1.56% (consumer services), −2.48% and 1.92% (financials), −1.87% and 1.56% (health), −1.92% and 2.03% (industrials), and −5.10% and 1.61% (telecommunication). The financials sector had the highest average earnings yield, suggesting that it outperformed the other sectors. The sector also had low variability of the earnings yield, as shown by the lowest standard deviation, and the highest average real dividend yield of 6.54%. The telecoms sector had the lowest average real dividend yield of −0.01%. However, it should be noted that although the financials sector had the highest dividend yield, it also recorded the highest variability in the dividend yield. This suggests a higher level of risk, but this is compensated for by the high average dividend yields.
Notably, all the data series of all the sectors are not normally distributed. Instead, they are negatively skewed except for the average real dividend yields for the basic materials, consumer goods and health sectors. Most of the data series of the examined sectors show that there were a few outliers in the data as evidenced by kurtosis values of less than 3 of normal distribution. On the other hand, the stock return series for the consumer services, financials, health and industrials sectors show evidence of fat tails as the kurtosis is greater than 3. This confirms the findings of South African studies such as Gupta and Modise (Citation2012a), who found that stock returns tend to have the fat-tailed effect. Also, the telecoms sector’s earnings yield and the dividend yield had fat tails. This suggests the presence of outliers in the data series; hence interpretation of results ought to have this caveat in mind.
4.2. Stationarity tests
ADF test results in Table show that only the dividend yield of the industrials and telecommunications were stationary in levels. The same applies to the earnings yield with the addition of basic materials. The returns were stationary in levels across all sectors. For the market index, all the variables were stationary in levels. In the Zivot and Andrews (Citation1992) test, which performs the ADF unit root test for every possible observation and selects the structural break date that yields the minimal t-statistic, the null hypothesis of unit roots in levels was rejected at the 1% significance level for the return series across all sectors and aggregated market. However, like the ADF unit root test, the results varied across sectors and valuation ratios as some were I (1) while some were I (0) as shown in Table . From the KPSS test in Table , the dividend and earnings yield series were stationary in first differences in the consumer services, health, financial and telecommunications sectors. Conversely, at the aggregate level, the earnings yield was stationary in first differences. The differences in the order of integration and absence of 1(2) variables necessitated the estimation of the ARDL model to test for cointegration, as suggested by Pesaran et al. (Citation2001).
Table 2. Augmented Dickey-Fuller unit root test
Table 3. Zivot and Andrews unit root test
Table 4. KPSS stationarity test
4.3. Gregory Hansen cointegration test
Following the identification of structural breaks, the GH cointegration test was then employed. The null hypothesis was rejected at the 1% significance level for all sectors and the broad market. Hence, there was strong evidence of stability in the long-run equilibrium relationship among the variables, even in the presence of structural breaks. These results were robust with the inclusion of the intercept shift term, intercept shift and trend term and intercept shift with slope term. Interestingly, Table shows that there are varying breakpoints across all sectors and the broad market, signifying the presence of structural events that uniquely affected the different sectors and the market over the sample period. Apart from the break date heterogeneity across sectors, the identification of the structural break date was sensitive to the test statistics and inclusion of the trend and slope terms.
Table 5. Gregory Hansen cointegration test
4.4. ARDL bounds testing approach
For robustness, a bounds test for cointegration accounting for structural breaks was conducted. The results in Table from the bounds test show that the F-statistics were consistently higher than the upper bound critical values of 3.79 and 4.68 at 5% and 1% significance levels, respectively. Following this, the bounds test concluded that there exists a cointegrating relationship among the variables even in the presence of structural breaks which corroborated results from the GH test.
Table 6. ARDL bounds tests for the existence of a cointegrating relationship
4.5. Error correction model
Considering that a long-run relationship existed in the presence of structural breaks, an ARDL-ECM that accounts for structural breakpoints as specified in EquationEquation (14)(14)
(14) was estimated. The results in Table show that the adjustment coefficient (ECT) in all the models estimated was negative and statistically significant at the 1% level. Considering that the ECT term was close to one, it suggests that disequilibrium is quickly corrected. Turning to the long-run coefficients, the results suggest that an increase in the dividend yield results in a reduction in returns of the basic materials, industrials, and telecommunications sectors. In contrast, an increase in dividend yield could predict an increase in returns in the financial sector in the long run based on the positive slope coefficient, but the magnitude of the slope coefficient suggests that the predicted increase is small. Also, this study found that, in contrast to the dividend yield, an increase in the earnings yield predicted an increase in returns in the basic materials and telecommunications sector as suggested by the positive slope coefficients that were significant at the 5% level.
Table 7. ARDL error correction estimates
On the other hand, an increase in the earnings yield could predict a decline in returns in the financial sector as indicated by a negative slope coefficient which was statistically significant at the 5% level. At the aggregated level, a decline in the dividend yield in the long run predicted a decline in returns. The magnitude was relatively higher than at sectoral level, considering that the dividend yield slope coefficient was negative and significant at the 5% level. However, the earnings yield failed to predict returns at the aggregated market level in the long run since the earnings yield slope coefficient was statistically insignificant at all conventional levels. Also, the results show that the breakpoint dummy coefficient was statistically significant at the 5% level in the basic materials, consumer goods and telecommunications sectors and at 1% level in the financials, industrials, and broad market index. This suggests that the breakpoints had a significant impact on the ARDL-ECM estimated and the presence of the long-run relationship amongst the variables could be explained by the inclusion of structural breaks in the model. However, the breakpoint did not have a significant effect on the ECM estimated for the health and consumer services sectors, suggesting that caution ought to be taken when interpreting these models.
As shown in Table , there was strong evidence that, after accounting for structural breaks, the dividend yield and earnings yield were able to predict returns in the short run across all sectors as the results were statistically significant at the 1% level. However, we found weak evidence that dividend yield could predict returns in for the consumer goods sector since the dividend yield slope coefficient was weakly significant at the 10% level. In fact, all slope coefficients entered with a negative sign suggesting that an increase in the dividend yield and earnings yield in the short run would predict a decline in the returns across all sectors. Similar results were found at the aggregate level where the dividend yield and earnings yield slope coefficients entered at the 1% and 5% level.
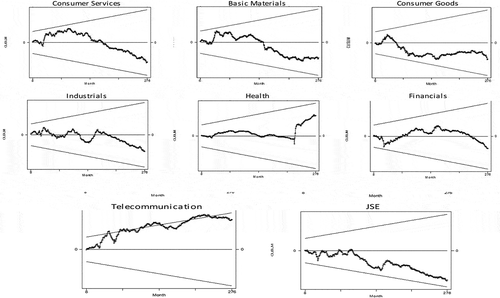
Diagnostic tests on the estimated ECM failed to reject the null hypothesis of no serial correlation at all significance levels according to the Breusch-Godfrey (BG) and Durbin-Watson (DW) tests suggesting that the models were correctly specified (see Table ). Also, after the inclusion of the breakpoints, the CUSUM lied between the upper and lower 5% boundary for all models except the telecommunications model, as shown in Figure . This indicates that the ECMs did not suffer from instability. However, caution ought to be taken when interpreting the telecommunications model whose CUSUM deviated beyond the 5% upper and lower boundary, suggesting that the model was unstable.
Figure 1. CUSUM tests.
4.6. Quantile regressions
An earlier study by Campbell and Yogo (Citation2006) contended that the use of conventional student t-statistic to test the null hypothesis of no predictability of stock returns might be misleading due to the persistence of the commonly used valuation ratios such as the dividend yield and price-to-earnings ratios. This is because the t-statistic can become non-standard when the predictor variables are persistent, which often results in over-rejection of the null hypothesis. Moreover, conventional tests of the predictability of stock returns could be invalid. That is, they reject the null too frequently when the predictor variable is persistent and its innovations are highly correlated with returns (Campbell & Yogo, Citation2006).
Studies by Nelson and Kim (Citation1993), Rapach and Wohar (Citation2006), and Kothari and Shanken (Citation1997) also argued that using the basic t-statistic could be misleading as it is prone to putative size distortions. To mitigate the concerns of over-rejection of the null hypothesis associated with the conventional t-test, this study applied the bootstrap procedure to the t-statistic that corresponds to the slope coefficients in the different quantiles. Following Gupta and Modise (Citation2012b), 1000 replications were employed to compute an empirical distribution for the t-statistic so that the slope coefficient would be devoid of size distortions associated with the conventional t-statistic.
In line with our expectations, from the comparison of the bootstrapped and those without bootstrapped standard errors, the results are very sensitive to robustness tests using bootstrapped standard errors. By drawing a comparison between Tables and , it is evident that in the multivariate quantile regression model, there were significant differences in the slope magnitude and sizes of t-statistic. In fact, the t-statistics became smaller in magnitude after the bootstrapping method was applied, which implies that the conventional t-statistics in Table cannot be relied upon.Footnote1 Therefore, following Gupta and Modise (Citation2012b), we only report the results of the multivariate regression model that used bootstrapped standard errors summarised in Table .
Table 8. Multivariate quantile regressions with earnings yield and dividend yield as regressands (without bootstrapped standard errors)
Table 9. Multivariate quantile regressions with earnings yield and dividend yield as regressands (with bootstrapped standard errors)
The results show that there were differences in the predictive ability of the valuation ratios at different quantiles across the sectors. In the basic materials sector, there is strong evidence suggesting that an increase in the dividend yields would result in a decline in returns in both bad and good market conditions given that the slope coefficients were statistically significant at the 1% level at all quantiles except at the 25th quantile. However, this was more pronounced at 75th quantile as suggested by the relatively more negative slope coefficient. In contrast, the earnings yield was only able to predict returns in the basic materials sector when the market was bearish as suggested by negative slope coefficients in the 25th and 50th quantiles that were statistically significant at the 5% level.
In the consumer goods sector, the dividend and earnings yield were able to predict returns at all quantiles except at the median quantile. However, the slope coefficients were significant at the 1% level only at the 25th quantile, suggesting more robust evidence for dividend yield’s predictive ability for consumer goods sector in the bearish market vis-à-vis bull market. In the consumer service sector, the dividend yield did not have any predictive ability in the bearish market. However, there is evidence that an increase in the dividend yield could predict a decline in consumer service sector returns in the bullish market, albeit weak since the slope coefficients were statistically significant at the 10% level at the 75th and 95th quantiles. By contrast, a surge in earnings yield could predict a decline in returns in the sector in both bullish and bearish markets as indicated by significant negative slope coefficients.
In the financial sector, an increase in the dividend yield could predict a decline in returns only in the bear market as indicated by a negative slope coefficient at the 25th quantile. In comparison, the earnings yield exhibited predictive ability in the financial sector, and this was more pronounced in the bull market as indicated by more negative slope coefficients at the 75th and 95th quantiles. In the health sector, the dividend yield failed to predict returns in the bear market as indicated by statistically insignificant results at the 25th and median quantiles. However, in the bullish market, an increase in the dividend yield could predict a higher decline in returns as indicated by more negative slope coefficients, statistically significant at the 5% level. In contrast, an increase in earnings yield could predict a decline in health sector returns as indicated by a negative slope coefficient that was significant at the 1% level at all quantiles but became less negative at higher quantiles. Implicitly, increases in the earnings yield could predict lower declines in the health sector returns when the market is bullish vis-à-vis bearish.
In the industrial sector, an increase in dividend yield could predict a decline in returns in both market conditions as suggested by a negative slope coefficient at all quantiles except for the 75th quantile. However, at the 95th quantile, the slope coefficient was statistically insignificant at all significance levels. By contrast, there was stronger evidence that an increase in the earnings yield could predict a decline in returns in the industrial sector as indicated by slope coefficients that were significant at the 1% level at all quantiles except for the 95th quantile which was weakly significant at the 10% level. Nonetheless, this provided evidence that the earnings yield could be employed to predict returns in both bad and good market conditions. Comparatively, the earnings yield showed that it could predict a decline in returns, but this decline was more pronounced at the 50th and 75th quantile of the return distribution.
In the telecoms sector, there was strong evidence that an increase in the dividend yield predicts a decline in returns as suggested by negative slope coefficients that were statistically significant at the 1% level. Interestingly, the magnitude of the decline in returns predicted by the dividend yield declined at higher quantiles. Put differently, the magnitude of the predicted decline in returns using the dividend yield was higher in the bearish market. However, the opposite pattern is exhibited using the earnings yield as shown by a lower return decline being predicted at lower quantiles. That is, the earnings yield will predict a higher decline of returns in the bullish market relative to the bearish market. Analogous to the dividend yield, the earnings yield could not predict returns at the 95th quantile. Interestingly, at the aggregate level, the earnings yield loses its predictive power as the slope coefficients at all quantiles were statistically insignificant. In contrast, there was strong evidence that the dividend yield could predict a decline in returns in both bull and bear markets as suggested by slope coefficients that were significant at the 1% level up to the 75th quantile.
Earlier findings by Gupta and Modise (Citation2012a; Citation2012b; Citation2013)) in South Africa suggested that the dividend yield did not have any predictive ability in both the short- and long-run at the market level. However, our study’s findings offer a refutation to this assertion; long-run and short run coefficients in the ECM were statistically significant in most models at a sectoral level, suggesting that both the earnings and dividend yields have some predictive ability in both the short- and long-run. The differences in findings can be attributed to the use of disaggregated data in our study, unlike the aggregated data in Gupta and Modise (Citation2012a; Citation2012b; Citation2013)) studies. That is, their failure to find the predictive ability of these ratios could be attributed to the use of aggregate market data which might obscure forecasting behaviour of valuation ratios (see Jung & Shiller, Citation2005).
It should be noted, however, that our results at the sectoral level confirm the finding of Aye et al. (Citation2013) that accounting for structural breaks could yield more indicative predictive behaviour of valuation ratios even though their finding was at an aggregate level. This is in line with Andreou and Ghysels (Citation2009) argument that, if unaccounted for, structural breaks could yield erroneous inferences owing to model misspecification. Moreover, structural breaks tend to result in model instability which affects the predictability of returns; hence ignoring structural breaks could yield biased inferences (Andreou & Ghysels, Citation2009). Further, this finding reaffirms international studies that valuation ratios can predict returns at the sectoral level (Bannigidadmath & Narayan, Citation2016; McMillan, Citation2010). Also, our results at the aggregate level are contrary to those of Gupta and Modise (Citation2012b) considering that the dividend yield could predict returns at different points of the return distribution. It can be reasoned that their findings were due to reliance on a linear predictive framework and ignoring the possibility that valuation ratios possess predictive power at different parts of the return distribution as argued by Cenesizoglu and Timmermann (Citation2007).
Moreover, the study’s findings confirm return predictability at a sectoral level on the South African market, as demonstrated by Vergos and Wanger (Citation2019). They found in their study that shocks in the consumer goods sector influenced industrial sector returns. However, our study sets itself apart from Vergos and Wanger (Citation2019) by employing valuation ratios as predictor variables of sectoral returns in South Africa. Noteworthy, their analysis was extended to the predictive ability of macroeconomic variables on aggregate stock market returns in South Africa. Albeit the predictive ability of macroeconomic variables on sectoral returns in South Africa was beyond our study’s scope.
5. Conclusion
Departing from the hypothesis that markets are efficient and abnormal returns cannot be consistently earned, this study tested the ability of two valuation ratios—dividend and earnings yields—to predict returns. A present value model that incorporated the earnings yield and the dividend yield was tested in this study. This study differentiates itself from previous ones by accounting for structural breaks, making a comparison between aggregated data at broad market level and disaggregated data at the sector level and by investigating the linearity or the non-linearity of the relationship between stock returns and valuation ratios on the South African stock market.
The Gregory Hansen test provided evidence of a stable long-run equilibrium relationship among the returns, earnings yield and dividend yield in all sectors and the market, even in the presence of structural breaks. These results were confirmed by the autoregressive distributed lag model, which showed that there existed a long-run relationship between the returns and valuation ratios at both sector and broad market level after accounting for structural breaks. The subsequent error correction model showed that any disequilibrium among the variables was corrected quite speedily, providing strong evidence of the ratios’ predictive ability in the short-run across all sectors and aggregate level. Also, though results vary across sectors, findings suggest that the valuation ratios could predict returns at a sectoral level across different parts of the return distribution. However, at the broad market level, earnings yield failed to predict returns at all quantile levels.
These results could be of interest to both investors and academics in numerous ways. As the information in these ratios is publicly available, the findings indicate that the South African stock market is not efficient in processing that information to be reflected in prices. The findings of this study have implications for market efficiency as the predictability of returns will improve price discovery through the actions of investors who continually search for strategies that would enable them to earn higher returns on stock markets. Also, the findings indicated that academics ought to account for structural breaks in modelling for cointegrating relationships between valuation ratios and returns at both market and sectoral level. Further, the results suggest that the conventional present value model might be misspecified on the South African stock market since other financial variables have been shown to predict returns. From investors’ perspective, in light of the quantile regression results, investors ought to consider the predictive ability of earnings yield and dividend yield across the bearish (low quantiles) and bullish (upper quantiles) market regimes.
Considering these results, this study could be extended in numerous ways. Arguably, evidence from this study could be a function of limiting itself to financial ratios. Also, findings could be subject to methodological approaches. As such, future studies could employ in-sample and out-of-sample predictive models following Bannigidadmath and Narayan (Citation2016). Moreover, due to the influence of bubbles on asset pricing, this study could be extended by employing a present value model that is adjusted to the presence of bubbles which warrants the use of a regime-switching model that incorporates bubbles as previously done by McMillan (Citation2010). Lastly, future studies could further disaggregate the data and assess the predictive ability of financial statement information using firm-level panel data as done by Güloğlu et al. (Citation2016) and Alexakis et al. (Citation2010), among others.
Acknowledgements
The authors would like to thank anonymous reviewers for insightful comments which helped in improving the quality of the paper.
Additional information
Funding
Notes on contributors
Kudakwashe Joshua Chipunza
Kudakwashe Joshua Chipunza is a former postgraduate student at the University of KwaZulu-Natal in the School of Accounting, Economics and Finance. His research interests include financial markets, financial inclusion and development finance.
Hilary Tinotenda Muguto
Hilary Tinotenda Muguto is a PhD candidate at the University of KwaZulu-Natal under the HEARD division. His research interests include healthcare equity and finance, financial markets, behavioural finance, investment analysis and development economics.
Lorraine Muguto
Lorraine Muguto is a PhD candidate at the University of KwaZulu-Natal in the School of Accounting, Economics and Finance. Her research interests include financial markets, behavioural finance, financial risk management, investment analysis and development finance.
Paul-Francois Muzindutsi
Paul-Francois Muzindutsi (PhD) is an associate professor of Finance in the School of Accounting, Economics and Finance, University of KwaZulu-Natal. His research interests include financial markets, behavioural finance, financial risk management, time series analysis of macroeconomic variables, investment analysis and development economics.
Notes
1. The univariate estimation results were not significantly different from the multivariate estimation results. These are available upon request.
References
- Alexakis, C., Patra, T., & Poshakwale, S. (2010). Predictability of stock returns using financial statement information: Evidence on semi-strong efficiency of emerging Greek stock market. Applied Financial Economics, 20(16), 1321–27. https://doi.org/https://doi:10.1080/09603107.2010.482517
- Andreou, E., & Ghysels, E. (2009). Structural breaks in financial time series. Handbook of Financial Time Series, 1(1), 839–870. https://doi.org/10.1007/978-3-540-71297-8_37
- Ang, A., & Bekaert, G. (2007). Stock return predictability: Is it there? Review of Financial Studies, 20(3), 651–707. https://doi.org/10.1093/rfs/hhl021
- Apergis, N., & Gupta, R. (2017). Can (unusual) weather conditions in New York predict South African stock returns? Research in International Business & Finance, 41(1), 377–386. https://doi.org/10.1016/j.ribaf.2017.04.052
- Aye, G., Gupta, R., & Modise, M. (2013). Structural breaks and predictive regressions models of the South African equity premium. Frontiers in Finance & Economics, 10(1), 49–86. https://ssrn.com/abstract=2304729
- Balcilar, M., Gupta, R., Kim, W. J., & Kyei, C. (2019). The role of economic policy uncertainties in predicting stock returns and their volatility for Hong Kong, Malaysia and South Korea. International Review of Economics & Finance, 59(1), 150–163. https://doi.org/10.1016/j.iref.2018.08.016
- Balcilar, M., Gupta, R., Modise, M. P., & Mwamba, J. W. M. (2015). Predicting South African equity premium using domestic and global economic policy uncertainty indices: Evidence from a Bayesian graphical model. Working paper. University of Pretoria, South Africa. https://www.up.ac.za/media/shared/61/WP/wp_2015_96
- Ball, R., Gerakos, J., Linnainmaa, J. T., & Nikolaev, V. (2020). Earnings, retained earnings, and book-to-market in the cross-section of expected returns. Journal of Financial Economics, 135(1), 231–254. https://doi.org/10.1016/j.jfineco.2019.05.013
- Bannigidadmath, D., & Narayan, P. K. (2016). Stock return predictability and determinants of predictability and profits. Emerging Markets Review, 26(1), 153–173. https://doi.org/10.1016/j.ememar.2015.12.003
- Bekiros, S., Gupta, R., & Kyei, C. (2016). On economic uncertainty, stock market predictability and non-linear spillover effects. North American Journal of Economics & Finance, 36(1), 184–191. https://doi.org/10.1016/j.najef.2016.01.003
- Black, A. J., Fraser, P., & McMillan, D. G. (2007). Are international value premiums driven by the same set of fundamentals? International Review of Economics & Finance, 16(1), 113–129. https://doi.org/10.1016/j.iref.2005.05.002
- Bonga-Bonga, L., & Makakabule, M. (2010). Modelling stock returns in the South African stock exchange: A non-linear approach. European Journal of Economics, Finance & Administrative Sciences, 19(1), 168–177. https://doi.org/10.19030/iber.v11i9.7183
- Bonga‐Bonga, L., & Mwamba, M. (2011). The predictability of stock market returns in South Africa: Parametric vs non‐parametric methods. South African Journal of Economics, 79(3), 301–311. https://doi.org/10.1111/j.1813-6982.2011.01280.x
- Brown, R. L., Durbin, J., & Evans, J. M. (1975). Techniques for testing the constancy of regression relationships over time. Journal of the Royal Statistical Society, 37(2), 149–163. https://doi.org/10.1111/j.2517-6161.1975.tb01532.x
- Campbell, J. Y., & Shiller, R. J. (1988). The dividend-price ratio and expectations of future dividends and discount factors. Review of Financial Studies, 1(3), 195–228. https://doi.org/10.1093/rfs/1.3.195
- Campbell, J. Y., & Yogo, M. (2006). Efficient tests of stock return predictability. Journal of Financial Economics, 81(1), 27–60. https://doi.org/10.1016/j.jfineco.2005.05.008
- Cenesizoglu, T., & Timmermann, A. (2007). Predictability of stock returns: A quantile regression approach. Working Paper. University of California. https://cirano.qc.ca
- Charteris, A., & Chipunza, K. J. (2020). Stock prices and dividends: A South African perspective. Investment Analysts Journal, 49(1), 1–15. https://doi.org/10.1080/10293523.2019.1682786
- Charteris, A., & Strydom, B. S. (2016). Stock return predictability in South Africa: An alternative approach. Working Paper. Economic Research Southern Africa. https://www.researchgate.net/
- Cremers, M., & Weinbaum, D. (2010). Deviations from put-call parity and stock return predictability. Journal of Financial & Quantitative Analysis, 45(2), 335–367. https://doi.org/10.1017/S002210901000013X
- Devpura, N., Narayan, P. K., & Sharma, S. S. (2018). Is stock return predictability time-varying? Journal of International Financial Markets, Institutions & Money, 52(1), 152–172. https://doi.org/10.1016/j.intfin.2017.06.001
- Dickey, D. A., & Fuller, W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74(366a), 427–431. https://doi.org/10.1080/01621459.1979.10482531
- Diether, K. B., Lee, K. H., & Werner, I. M. (2009). Short-sale strategies and return predictability. Review of Financial Studies, 22(2), 575–607. https://doi.org/10.1093/rfs/hhn047
- Engle, R. F., & Granger, C. W. (1987). Co-integration and error correction: Representation, estimation, and testing. Econometrica, 55(2), 251–276. https://doi.org/10.2307/1913236
- Fama, E. F. (1970). Efficient capital markets: A review of theory and empirical work. Journal of Finance, 25(2), 383–417. https://doi.org/https://doi:10.2307/2325486
- Fama, E. F., & French, K. R. (1988). Dividend yields and expected stock returns. Journal of Financial Economics, 22(1), 3–25. https://doi.org/10.1016/0304-405x(88)90020-7
- Ferreira, M. A., & Santa-Clara, P. (2011). Forecasting stock market returns: The sum of the parts is more than the whole. Journal of Financial Economics, 100(3), 514–537. https://doi.org/https://doi:10.1016/j.jfineco.2011.02.003
- Gregory, A. W., & Hansen, B. E. (1996). Practitioners corner: Tests for cointegration in models with regime and trend shifts. Oxford Bulletin of Economics and Statistics, 5(3), 555–560. https://doi.org/10.1111/j.1468-0084.1996.mp58003008.x
- Gregory, A. W., & Hansen, B. E. (1996). Residual-based tests for cointegration in models with regime shifts. Journal of Econometrics, 70(1),99–126. https://doi.org/10.1016/0304-4076(69)41685-7
- Güloğlu, B., Kangallı Uyar, S. G., & Uyar, U. (2016). Dynamic quantile panel data analysis of stock returns predictability. International Journal of Economics & Finance, 8(2), 115–126. https://doi.org/https://doi:10.5539/ijef.v8n2p115
- Gupta, R., Hammoudeh, S., Modise, M. P., & Nguyen, D. K. (2014). Can economic uncertainty, financial stress and consumer sentiments predict US equity premium? Journal of International Financial Markets, Institutions & Money, 33(1), 367–378. https://doi.org/10.1016/j.intfin.2014.09.004
- Gupta, R., & Modise, M. P. (2012a). South African stock return predictability in the context data mining: The role of financial variables and international stock returns. Economic Modelling, 29(3), 908–916. https://doi.org/10.1016/j.econmod.2011.12.013
- Gupta, R., & Modise, M. P. (2012b). Valuation ratios and stock return predictability in South Africa: Is it there? Emerging Markets Finance & Trade, 48(1), 70–82. https://doi.org/10.2753/REE1540-496X480104
- Gupta, R., & Modise, M. P. (2013). Macroeconomic variables and South African stock return predictability. Economic Modelling, 30(1), 612–622. https://doi.org/10.1016/j.econmod.2012.10.015
- Hao, L., & Naiman, D. Q. (2007). Quantile regression. Sage Publications. http://www.corwin.com/sites/default/files
- Hillebrand, E. (2005). Neglecting parameter changes in GARCH models. Journal of Econometrics, 129(1), 121–138. https://doi.org/10.1016/j.jeconom.2004.09.005
- Hodrick, R. J. (1992). Dividend yields and expected stock returns: Alternative procedures for inference and measurement. Review of Financial Studies, 5(3), 357–386. https://doi.org/10.1093/rfs/5.3.351
- Jefferis, K., & Smith, G. (2005). Capitalisation and weak-form efficiency in the JSE securities exchange. South African Journal of Economics, 72(4), 684–707. https://doi.org/10.1111/j.1813-6982.2004.tb00130.x
- Johansen, S., & Juselius, K. (1990). Maximum likelihood estimation and inference on cointegration- with applications to the demand for money. Oxford Bulletin of Economics and Statistics, 52(2), 169–210. https://doi.org/10.1111/j.1468-0084.1990.mp52002003.x
- Jordan, S. J., Vivian, A. J., & Wohar, M. E. (2014). Forecasting returns: New European evidence. Journal of Empirical Finance, 26(1), 76–95. https://doi.org/10.1016/j.jempfin.2014.02.001
- Jung, J., & Shiller, R. J. (2005). Samuelson’s dictum and the stock market. Economic Inquiry, 43(2), 221–228. https://doi.org/10.1093/ei/cbi015
- Kao, C. (1999). Spurious regression and residual-based tests for cointegration in panel data. Journal of Econometrics, 90(1),1–44. https://doi.org/10.1016/S0304-4076(98)00023-2
- Kheradyar, S., Ibrahim, I., & Nor, F. M. (2011). Stock return predictability with financial ratios. International Journal of Trade, Economics & Finance, 2(5), 391–396. https://doi.org/https://doi:10.7763/ijtef.2011.v2.137
- Koenker, R., & Bassett, J. G. (1978). Regression quantiles. Econometrica: Journal of the Econometric Society, 46(1), 33–50. https://doi.org/10.2307/1913643
- Koenker, R., & Hallock, K. F. (2001). Quantile regression. Journal of Economic Perspectives, 15(4), 143–156. https://doi.org/10.1257/jep.15.4.143
- Kostakis, A., Magdalinos, T., & Stamatogiannis, M. P. (2015). Robust econometric inference for stock return predictability. Review of Financial Studies, 28(5), 1506–1553. https://doi.org/10.1093/rfs/hhu139
- Kothari, S. P., & Shanken, J. (1997). Book-to-market, dividend yield, and expected market returns: A time-series analysis. Journal of Financial Economics, 44(2), 169–203. https://doi.org/10.1016/s0304-405x(97)00002-0
- Kruger, R. (2011). Evidence of return predictability on the Johannesburg stock exchange [Doctoral dissertation] University of Cape Town. http://hdl.handle.net/11427/11473
- Kwiatkowski, D., Phillips, P. C., Schmidt, P., & Shin, Y. (1992). Testing the null hypothesis of stationarity against the alternative of a unit root. Journal of Econometrics, 54(1–3), 159–178. http://dx.doi. org/10.1016/03044076
- Kwaitkowski, D., Phillips, P. C. B., Schmidt, P., & Shin, Y. (1992). Testing the null hypothesis of stationarity against the alternative of a unit root. Journal of Econometrics, 54(1), 159–178. https://doi.org/10.1016/0304-4076(92)90104-y
- Lewellen, J. (2004). Predicting returns with financial ratios. Journal of Financial Economics, 74(2), 209–235. https://doi.org/10.1016/j.jfineco.2002.11.002
- Li, J., & Yu, J. (2012). Investor attention, psychological anchors, and stock return predictability. Journal of Financial Economics, 104(2), 401–419. https://doi.org/10.1016/j.jfineco.2011.04.003
- Lintner, J. (1956). Distribution of incomes of corporations among dividends, retained earnings, and taxes. American Economic Review, 46(2), 97–113. https://www.jstor.org/stable/i332668
- Lo, A. W. (2004). The adaptive markets hypothesis. Journal of Portfolio Management, 30(5),15–29. https://doi.org/10.3905/jpm.2004.442611
- Lou, D. (2012). A flow-based explanation for return predictability. Review of Financial Studies, 25(12), 3457–3489. https://doi.org/10.1093/rfs/hhs103
- Ma, C., Xiao, S., & Ma, Z. (2018). Investor sentiment and the prediction of stock returns: A quantile regression approach. Applied Economics, 50(50), 5401–5415. https://doi.org/https://doi:10.1080/00036846.2018.1486993
- MacFarlane, A. (2011). Do macroeconomic variables explain future stock market movements in South Africa? [Doctoral dissertation]. University of Cape Town. http://hdl.handle.net/11427/12476
- Magnusson, M., & Wydick, B. (2002). How efficient are Africa’s emerging stock markets? Journal of Development Studies, 38(4), 141–156. https://doi.org/10.1080/00220380412331322441
- Markus, D., & Sormunen, J. (2018). A study of value investment strategies based on dividend yield, price-to-earnings, and price-to-book ratios in the Swedish stock market [Masters dissertation]. Jonkoping University. https://www.diva-portal.org/smash/get/diva2:1222141/fulltext01.pdf
- McMillan, D. G. (2010). Present value model, bubbles and returns predictability: Sector‐level evidence. Journal of Business Finance & Accounting, 37(5‐6), 668–686. https://doi.org/https://doi:10.1111/j.1468-5957.2009.02176.x
- Miller, M. H., & Rock, K. (1985). Dividend policy under asymmetric information. Journal of Finance, 40(4), 1031–1051. https://doi.org/10.1111/j.1540-6261.1985.tb02362.x
- Mittal, S. K., & Thakral, M. (2018). Testing the weak form of efficient market hypothesis: Empirical evidence for bullions and base metal segment of the Indian commodity market. Economic Affairs, 63(2), 575–581. https://doi.org/10.30954/0424-2513.2.2018.37
- Narayan, P. K. (2005). The saving and investment nexus for China: Evidence from cointegration tests. Applications Economics, 37(1), 1979–19990. https://doi.org/https://doi:10.1080/00036840500278103
- Narayan, P. K., & Gupta, R. (2015). Has oil price predicted stock returns for over a century? Energy Economics, 48(1), 18–23. https://doi.org/10.1016/j.eneco.2014.11.018
- Nargelecekenler, M. (2011). Stock prices and price/earnings ratio relationship: A sectoral analysis with panel data. Business & Economics Research Journal, 2(2), 165–184. https://repec:ris:buecrj:0048
- Nelson, C. R., & Kim, M. J. (1993). Predictable stock returns: The role of small sample bias. Journal of Finance, 48(2), 641–661. https://doi.org/https://doi:10.1111/j.1540-6261.1993.tb04731.x
- Olivier, A. M. (2018). The effect of South African and international macro-economic variables on the South African Stock Market [Doctoral dissertation]. University of Cape Town. http://hdl.handle.net/11427/29199
- Pane, L. (2016). Addressing the pitfalls of linear regression models in predicting stock returns in South Africa: Bayesian and non-parametric models [Doctoral dissertation]. University of Johannesburg. https://ujcontent.uj.ac.za
- Patel, P., Savani, J., & Poriya, N. (2017). Semi-strong form of market efficiency for dividend and bonus announcements: An empirical study of India stock markets. International Journal of Management, 6(1), 108–121. https://doi.org/https://doi:10.15410/aijm/2017/v6i1/120839
- Patelis, A. D. (1997). Stock return predictability and the role of monetary policy. Journal of Finance, 52(5), 1951–1972. https://doi.org/10.1111/j.1540-6261.1997.tb02747.x
- Pedroni, P. (1999). Critical values for cointegration tests in heterogeneous panels with multiple regressors. Oxford Bulletin of Economics & Statistics, 61(1),653–670. https://doi.org/10.1111/1468-0084.0610s1653
- Pedroni, P. (2004). Panel cointegration: Asymptotic and finite sample properties of pooled time series tests with an application to the PPP hypothesis. Econometric Theory, 20(3),597–625. https://doi.org/10.1017/S0266466604203073
- Pesaran, M. H., Shin, Y., & Smith, R. J. (2001). Bounds testing approaches to the analysis of level relationship. Journal of Applied Economics, 16(1), 289–326. https://doi.org/https://doi:10.1002/jae.616
- Pettenuzzo, D., & Timmermann, A. (2011). Predictability of stock returns and asset allocation under structural breaks. Journal of Econometrics, 164(1), 60–78. https://doi.org/https://doi:10.1016/j.jeconom.2011.02.019
- Phan, D. H. B., Sharma, S. S., & Tran, V. T. (2018). Can economic policy uncertainty predict stock returns? Global evidence. Journal of International Financial Markets, Institutions & Money, 55(1), 134–150. https://doi.org/10.1016/j.intfin.2018.04.004
- Rapach, D. E., & Wohar, M. E. (2006). In-sample vs out-of-sample tests of stock return predictability in the context of data mining. Journal of Empirical Finance, 13(2), 231–247. https://doi.org/10.1016/j.jempfin.2005.08.001
- Rapach, D. E., Wohar, M. E., & Rangvid, J. (2005). Macro variables and international stock return predictability. International Journal of Forecasting, 21(1), 137–166. https://doi.org/10.1016/j.ijforecast.2004.05.004
- Rupande, L., Muguto, H. T., & Muzindutsi, P. F. (2019). Investor sentiment and stock return volatility: Evidence from the Johannesburg stock exchange. Cogent Economics & Finance, 7(1), 1600233. https://doi.org/10.1080/23322039.2019.1600233
- Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics, 6(2),461–464. Doi: 10.1214/aos/1176344136
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. https://doi.org/10.1214/aos/1176344136
- Shamsuddin, A., & Kim, J. H. (2010). Short horizon return predictability in international equity markets. Financial Review, 45(2), 469–484. https://doi.org/10.1111/j.1540-6288.2010.00256.x
- Simons, D. N., & Laryea, S. (2006). Testing the efficiency of African markets. Social Science Research Network Electronic Journal, 1(1), 1–31. https://doi.org/10.2139/ssrn.874808
- Smith, G. (2008). Liquidity and the informational efficiency of African stock markets. South African Journal of Economics, 76(2), 161–175. https://doi.org/10.1111/j.1813-6982.2008.00171.x
- Smith, G., & Dyakova, A. (2014). African stock markets: Efficiency and relative predictability. South African Journal of Economics, 82(2), 258–275. https://doi.org/10.1111/saje.12009
- Timmermann, A. (2001). Structural breaks, incomplete information, and stock prices. Journal of Business and Economic Statistics, 19(3), 299–314. https://doi.org/10.1198/073500101681019954
- Urquhart, A., & McGroarty, F. (2014). Calendar effects, market conditions and the adaptive market hypothesis: Evidence from long-run US data. International Review of Financial Analysis, 35(1), 154–166. https://doi.org/10.1016/j.irfa.2014.08.003
- Van Gysen, M., Huang, C. S., & Kruger, R. (2013). The performance of linear versus non-linear models in forecasting returns on the Johannesburg stock exchange. International Business & Economics Research Journal, 12(8), 985–994. https://doi.org/10.19030/iber.v12i8.7994
- Vergos, K., & Wanger, B. (2019). Evaluating interdependencies in African markets A VECM approach. Bulletin of Applied Economics, 6(1), 65–85. https://ideas.repec.org/a/rmk/rmkbae/v6y2019i1p65-85.html
- Wen, Y. C., Lin, P. T., Li, B., & Roca, E. (2015). Stock return predictability in South Africa: The role of major developed markets. Finance Research Letters, 15(1), 257–265. https://doi.org/10.1016/j.frl.2015.10.014
- Westerlund, J. (2007). Testing for error correction in panel data. Oxford Bulletin of Economics & Statistics, 69(6),709–748. https://doi.org/10.1111/j.1468-0084.2007.00477.x
- Wu, C., & Wang, X. M. (2000). The predictive ability of dividend and earnings yields for long‐term stock returns. Financial Review, 35(2), 97–124. https://doi.org/10.1111/j.1540-6288.2000.tb01416.x
- Zaremba, A., & Czapkiewicz, A. (2017). Digesting anomalies in emerging European markets: A comparison of factor pricing models. Emerging Markets Review, 31(1), 1–15. https://doi.org/10.1016/j.ememar.2016.12.002
- Zhang, D., Wu, T. C., Chang, T., & Lee, C. H. (2012). Revisiting the efficient market hypothesis for African countries: Panel Surkss test with a Fourier function. South African Journal of Economics, 80(3), 287–300. https://doi.org/10.1111/j.1813-6982.2011.01314.x
- Zivot, E. A., & Andrews, D. (1992). Further evidence on the great crash, oil prices shock and the unit root hypothesis. Journal of Business & Economics Statistics, 10(3), 251–270. https://doi.org/10.2307/1391541
- Zivot, E., & Andrews, D. W. K. (2002). Further evidence on the great crash, the oil-price shock, and the unit-root hypothesis. Journal of Business & Economic Statistics, 20(1),25–44. https://doi.org/10.1198/073500102753410372