
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article reveals a discontinuity in the mapping from a Lorenz curve to the associated cumulative distribution function. The problem is of a mathematical nature—based on an analysis of the transformation between the distribution function of a bound random variable and its Lorenz curve. It will be proven that the transformation from a normalized income distribution to its Lorenz curve is a continuous bijection with respect to the ([0,1])-metric—for every q ≥ 1. The inverse transformation, however, is not continuous for any q ≥ 1. This implies a more careful attitude when interpreting the value of a Gini coefficient. A further problem is that if you have estimated a Lorenz curve from empirical data,then you cannot trust that the associated distribution is a good estimate of the true income distribution.
PUBLIC INTEREST STATEMENT
This article deals with the relation between the distribution of income and the measurement of economic inequality in a society. The latter is often expressed as the Gini coefficient, G: the expected difference between two randomly drawn household or individual incomes divided by two times the average income. This division was made to be able to compare the magnitude for different societies. Looking at the income distribution, a reasonable degree of equality in the actual society must imply that the difference between the maximal income and the average income is not too large. If we divide this number by the maximal income, we get a quantity, H, comparable between societies. In this article, it will be shown not only that if H is close to zero, then G is close to zero but also that the opposite is not necessarily true. The most direct consequence is that a small G is not enough to ensure relative economic equality in a society.
1. Introduction
Since the 1960s, economists have widely accepted the Lorenz curve as the tool for deriving measures of income inequality in society, among them the Gini coefficient. The traditional method was to group data in a number of intervals and assume all incomes in an interval to be equal to the average income in the actual interval, Morgan (Citation1962). This gives a lower limit of the “true” Gini coefficient.
The ability in our time to collect and centralize precise data about individual income implies that direct methods are now used to compute the Gini coefficient (see, OECD-IDD, Citation2017, p. 8). This actual OECD method does not take its offset in the Lorenz curve of observed data. It is based on the relative mean differences of observed income data.Footnote1
In education in the economic sciences, however, the Lorenz curve keeps its position in illustrating the Gini coefficient. Still, in this century, scholars find new ways to derive the approximations made in the 1950s to 70s (see Golden (Citation2008) and Farris (Citation2010)).
At least since 1970, there has been a critical attitude towards the Gini coefficient as a precise measure of inequality (see Atkinson (Citation1970)). Moreover, different proposals using the Lorenz curve have been advanced to give a more multi-faceted idea of inequality. Most influential in that respect were Kakwani (Citation1980), Donaldson & Weymark (Citation1983), and Yitzhaki (Citation1983) with their generalized or higher-order Gini coefficients. Their formulas turned out to be equivalent. In the last twenty years, a variety of new inequality measures have been developed, among them the generalized entropy family of indices. All the way through, we alternatively could use the ratio of the top to bottom shares (see, e.g., Liu and Gastwirth (Citation2020)).
The voice of critics is thus rather comprehensive. The aim of the present article is to point out 2 potential problems working with the Gini coefficient, problems that remain even when using the class of generalized Gini coefficients proposed by Kakwani and others. This is not just another demonstration of the fact that 2 different distributions could have the same Gini coefficient. Rather, we will discover that a small Gini coefficient does not necessarily imply a noticeable degree of equality. Furthermore, if you try to obtain the populations' income distribution from an estimated Lorenz curve—that is solving an inverse problem—then your result might be far from the true distribution. The cause to the problems is not solely due to observed data. It is a discontinuity in the relationship between 'the distribution function and the Lorenz curve for a bounded random variable, which brings trouble.
Consequently, we will in section 2 establish the connection between a cumulative distribution function for a bound, non-negative random variable and its Lorenz curve. It will be proved that any non-decreasing, convex function mapping [0,1] on [0,1] with a non-vertical left-hand tangent in (1,1) will be the Lorenz curve for some bound distribution. the correspondence is 1–1 up to scale. In section 3, the set of normalized income distributions and its subset, the Lorenz curves will be conceived of as subsets in the linear -spaces. Thus, for any
, a metric is present, and it will be established that the Lorenz curve results from its income cdf through a continuous transformation. Traditional measures of inequality, especially the Gini coefficient, appear as distances in
, and in section 4, we shall see that the inverse transformation, mapping the Lorenz curve to its normalized distribution function, is not continuous. In section 5, we will draw some implications from this fact. The results will be derived in a general manner, which means that there will be no restrictions with respect to the type of bound distribution. This implies that the formal language departs somewhat from prevalent presentation in the economic literature.
2. The transformation mapping a cumulative distribution function to its Lorenz function
A Lorenz curveFootnote2 is formally a curve in the plane with the property, which for every point belonging to it, , will denote a fraction of a population, while
will denote the relative share of some limited resource or goods, which this fraction possesses.
is explicitly the fraction that has the lowest share of the resource. If we assume that
can never be negative, the curve will contain the points (0,0) and (1,1), and it will be non-decreasing. The associated cumulative distribution function, which has this curve as its graph, will in accordance with the current style also be termed the Lorenz curve. In fact, we have implicitly chosen a statistical model that operates with a large or an indefinite number of members of the population, which is treated as a continuous medium. Furthermore, we will only work with bound and non-negative distributions of the good.
As preliminary results, we have that for any real, non-negative and bound random variable , with cumulative distribution function
the expectation exists and could be calculated as
The integral used is the Lebesgue integral, and is the essential supremum of
Note that (1) is valid for any mixture of continuous and atomic distribution functions.
might not exist as a function as it is not required that
is strictly increasing. So, in this text,
simply means the u-fractile of
, formally,
If you are not used to work with in this way, the correctness of the last equality sign in (1) can be justified by Figure . The red curve is the graph of
and the area of the shaded set is both,
and
Figure 1. The graph of a non-continuous cdf. The area of the shaded set is .
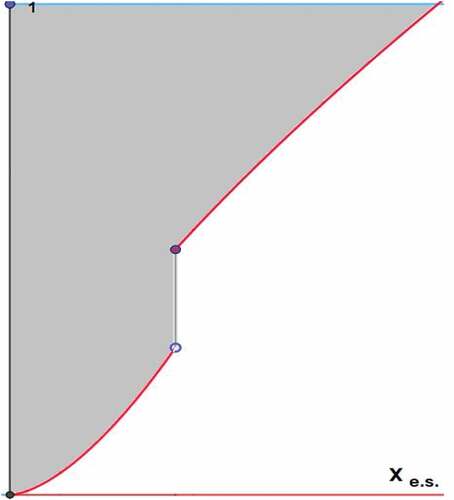
Expression (2) was used by Gastwirth to define the Lorenz curve (see Gastwirth (Citation1971)). Dorfman (Citation1979) in fact generally proves an equivalent result to (2).Footnote3
Note that there is no problem with this definition. As is uniquely determined as a measurable function with up to countably many discontinuities,
is given in [0.1]. That the Lorenz curve might not be differentiable is merely a consequence of the model (half of me earns half of my income, and my income ranked neighbor to the right-hand side might earn the same as me or (considerably) more). If
is an empirical cdf, then one could object to its application if the sample is small (see Yitzhaki and Schechtman (Citation2013) p 28–29). Let us assume that this is not the case.
Formula (2) defines a mapping, , of the class of non-negative, finite distribution functions into itself,
.
Furthermore, (2) ensures that the Lorenz curve, will always be convex.
As the third assumption, familiar to the reader, we have that the distribution function of is given by
We therefore conclude that
EquationEquation (2)(2)
(2) is equivalent to
Here, is the density function corresponding to
, uniquely determined almost everywhere.
Note that is non-decreasing, and because of that, its inverse function will exist in the sense explained above.
In order that is bound,
must be the finite number
Consequently, we have
Theorem 2.1
A non-negative random variable is bound if, and only if, the Lorenz curve associated with it has a non-vertical left-hand tangent in the point (1,1). The slope of this tangent is
EquationEquation (4)(4)
(4) is equivalent to
So, for any fixed and any given
—without a vertical left-hand tangent in (1,1)—
as a cumulative distribution function will be uniquely determined for
We can arrive at the below conclusion:
If the cumulative distribution function for some non-negative, finite random variable
is in the preimage, with respect to the mapping
of a Lorenz function
, the preimage will be exactly
. Thus, we have that
Theorem 2.2
Any finite non-negative distribution function—up to scale—is determined by its Lorenz curve. If the expectation or essential supremum is known, the distribution function is uniquely given.
Formula (4) and Theorem 2.2 were proved by Lambert (Citation1990), p 40–41, in the case of being differentiable and strictly increasing. In the present context, no results depend on the existence of a density function for the actual distribution function.
We realize that, from now on, we only have to look at the normalized random variable,
when we are working with Lorenz functions for finite random variables. We achieve that and that the transformation
is an injection of the class of distribution functions for normalized non-negative random into itself. Remark: Note that for the graph of by Theorem 2.1, the left-hand tangent in (1,1) has a slope of
, where
is the expectation of
Let us illustrate what we found with an example: Suppose that in a given situation,
and that
As
we get
Hence,
It is the unique solution for in this situation.
As a random variable, with this distribution function
has the maximal value of 3, and the normalized random variable is
has the distribution function,
We will denote this class of distribution functions for normalized random variables Normalized Cumulative Distribution Functions.
From the way we constructed it is essential that any member of
fulfills that
We know that is a convex function that maps [0,1] on [0,1]. From Theorem 2.1, we further know that
cannot have an infinite left-hand derivative at
But will any convex function with the domain and range [0,1] be the
-image of some member of
if it only has finite left-hand derivatives?
In the strict sense of convex function, the answer must be no, because the -image will have to be a distribution function. Consider therefore a convex nondecreasing function
mapping [0,1] on [0,1], satisfying that
is a finite number. We denote this class of functions
Convex Cumulative Distribution Functions. Every member of
must be continuous.
If then,
will be a non-decreasing and non-negative function,Footnote4 and hence, and
exist and
So, is differentiable from both the left and the right in any point in [0,1] and
must be differentiable almost everywhere in [0,1] for the following reason: The set of points fulfilling
is at most of numerable cardinality, because if we define
will be non-decreasing in [0,1] and therefore continuous almost everywhere. So, in this way, we found that
on [0,1].
We can identify with
, the inverse function to a member of
multiplied by a constant of value
, which, in fact, equals
, with
being the expectation associated with
Thus, any member of
is the
-image of a member of
.
So far, our investigation has shown the following:
Theorem 2.3
The mapping
is a bijection of the class on the class
Thus, any member of will be the Lorenz curve for some finite cdf.
3. Convergence of sequences in NCDF and CCDF
is a subset of the Banach spaces
Footnote5 for every
with
being the Lebesgue measure.
and
can now be conceived of as metric spaces—the metric of course induced by
. Neither of them is complete, which can be seen in the following example. Let
Then, is a Cauchy sequence in the space
for any of the metrics in
Since
must converge to 1 in the
-metric,
. In the
-metric—the supremum norm—the convergence is obvious. Function 1 on [0,1] is certainly not in
The -image of
is the sequence
It is a Cauchy sequence in the
-metric for any real
because the distance between numbers
and
is less than
, which shrinks to zero with increasing
and
The limit of the sequence will be
Although is a member of
and although it is convex in
, it cannot be in
, because this set contains exclusively continuous functions. In the
-metric, the
-image of
is not even a Cauchy sequence.
We will now examine to which extent convergence of a sequence in implies convergence in
of its
-image.
Lemma 3.1
Given that , if we name the expected values connected with
and
, respectively,
and
, then
Proof:
Now, let be a sequence in
At first, we demand that converges to
belonging to
in the
-metric. Let
and
be the expected values connected with
and
respectively.
Now,
We see that
As a consequence of Lemma 3.1, which means that the first term shrinks to 0 as
increases.
For 2 members of
and
, we consider
But this is exactly identical to as visualized in . As
we conclude
for
Figure 2. The graph of 2 members of named
and
The area of the shaded set is
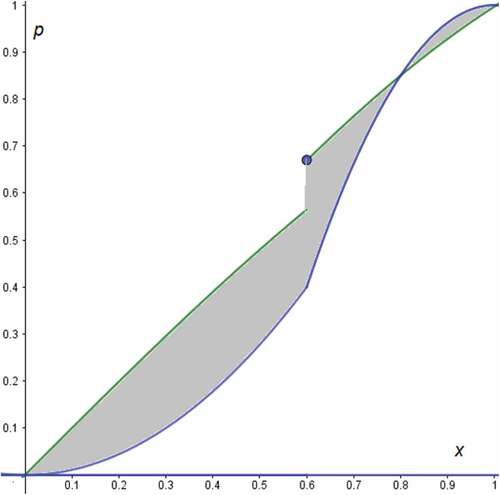
So,
whenever
Next, we let converge to
belonging to
in the
-metric and look at
With an argument similar to the above one, we get that
Again, the first term will shrink to zero as increases. The second term will be equal to or lesser than
where we switched the order of integration. The last expression will be less than
So,
We now face the case where converges to
belonging to
in the
-metric for a
If , then
according to Jensen’s inequality. We just saw that this implies that
As for any
we have that
Furthermore, for every
which means that for every
We can conclude that
This finishes the proof of the following:
Theorem 3.2
For any sequence belonging to
and any
The result could also be stated this way: The transformation that maps any cdf for a normalized random variable 1–1 to its Lorenz curve is continuous with respect to the
-metric for every
4. The  -metric and generalized Gini coefficients
-metric and generalized Gini coefficients
With the -metric in
we have introduced a way of measuring distances between bound distribution functions. If we name the completely equal distribution of the resource under observation
, we have
Given that an will be a measure of the distance between
and a complete equality with respect to the actual resource. We see that
being the expectation associated with
Note that this distance should not be confused with Ebert’s distance between income distributions (Ebert, Citation1984). Every member of Ebert’s class,
is an absolute measure, because the income distributions are meant for absolute income. In contrast, (7) is strictly relative: If you add the same amount to every individual share, the distance will decrease—this also happens for the distance between 2 arbitrary members of
Replacing with
gives
where we have named —as usual—and calculated
to be
the identical mapping.
The value of this integral will be in [0, 0.5], since , as we know, is convex. If we normalize it, i.e., multiply it with 2, we of course get the Gini coefficient for the distribution function
,
This is the most popular way to explain the Gini coefficient, because it is illustrated as the size of an area. If is a quantity near zero, then the Gini coefficient will also be near zero—this is a consequence of theorem 3.2. But the opposite conclusion can generally not be drawn. In other words, we could have a small Gini coefficient in a rather polarized population. E.g., if 96.7 % of the population each earns 37.9% of the maximal income and while 3.3% each earns the maximal income, then
, while
This is a symptom of the following:
Theorem 4.1
The inverse mapping to which maps
the set of Lorenz curves, 1–1 on
the set of distribution functions for normalized random variables, is not continuous with respect to the
-metric for any
Proof:
If we can construct a sequence in with the property that it converges to the identical mapping—and that at the same time its
-image will not converge to
which is the
-image of the identical mapping, then we are through with the proof.
In fact, we are able to choose the sequence in in the following two-parameter-class of linear combination of power functionsFootnote6,
As
we have that
So, if is given by (8), for every
According to theorem 2.1, equals
being the expectation of a normalized random variable with Lorenz curve
can be chosen as any value in
Following formula (8), So, in
, we choose a sequence
of type (8) fulfilling that for every
We regard now,
For , we have
As we conclude that
does not converge to
for any
This finishes the proof.
Note that we also showed that you could have a situation where the Gini coefficient shrinks to zero for a sequence of Lorenz curves, while at the same time, every one of the associated distribution functions has an arbitrarily great difference between the mean and maximal income!
This pattern in fact repeats for every higher-order Gini coefficient for the sequence
Corollary 4.2
For the sequence of Lorenz curves given by (8) and (9), any generalized Gini coefficient will shrink to zero with increasing
Proof:
Using the formula of Kakwani (Citation1980), we have
For is the ordinary Gini coefficient.
We achieve an estimate of using partial integration. Set
which is the th integral of the Lorenz function (8), then
Iterating this process, we get
Inserting the values of and
given by (9), it is easy to see that for every
will shrink to zero as
In principle, the transformation creates a unique connection between any bound, non-negative probability distribution and its Lorenz curve. The mean value is intrinsic when calculating one of the objects from the other. Although the transformation proves to be continuous, the inverse transformation does not possess this feature. The very example that points out the discontinuity shows that the Gini coefficient of a population income can be very small, while in the same population, the income obtained by the majority can be far below the maximal income. This repeats for higher-order Gini coefficients although they were meant to weight poverty higher.
The specific property in our model, which creates this weakness, is the fact that the expected value of the individual share of the good in question determines the slope of the left-hand tangent of the Lorenz curve in the point (1,1).
5. Some conclusions related to the discontinuity of the inverse mapping
The results from section 4 rise at least 2 problems which our examples can illustrate.
First, we already saw that there is an obvious inequality in the non-continuous distribution example mentioned just before theorem 4.1. One can construct a continuous case almost parallel to it with a Lorenz curve of the type (8) choosing and
. This example has
and a Gini coefficient value of 0.04688. In both examples, there is a majority with homogeneous and low income. The minority though is big enough to create a feeling of inequality. Following the advice in Liu and Gastwirth (Citation2020) about supplying the Gini coefficient with other measures, one finds that the series of generalized Gini coefficients gives only slightly different values. The so-called generalized entropy family of indices gives only smaller values. Even Gastwirth’s more promising modified Gini coefficient multiplying the Gini coefficient with the ratio of the mean value to the median gives only a value near 0.05. These measures of inequality are presented in Liu and Gastwirth (Citation2020). In this situation, one should turn to the relative deviation of the income distribution. This means the square root of the variance divided by the double mean value.Footnote7 Yitzhaki and Schechtman (Citation2013, p 22–25) gives thorough analysis and discussion on the relationship between the Gini coefficient and variance. So, if you accept that 5% of a population is not an extremely small part and if the Gini coefficient is suspiciously low, or lower than 0.1, then supply it with a computation of the relative deviation. In our examples, it is about 0.096. You could state it like this: A low Gini coefficient is necessary for relative equality in a society, but it is not sufficient.
Second, the fact that the continuous mapping of a cdf for a normalized random variable to its Lorenz curve has an inverse mapping, which is discontinuous, is in fact just another example of inverse problems in econometry. Horowitz (Citation2014) gives a survey of the problem—all his examples are with respect to the supremum norm—in economics and also some rather different fields. It seems that the phenomenon has a certain prevalence in the empirical sciences. Trying to estimate a distribution following the discontinuous mapping, one is faced with an ill-posed inverse problem. Horowitz shows in his examples how to deal with the problem in some specific cases through regularization.
In our case, one could ask: Is it possible to estimate the income distribution in the society if we have information related to the Lorenz curve? Kleiber and Kotz (Citation2002) point out that a finite, non-negative cdf always could be found exactly as all the moments of it are known. Alternatively knowing the mean of the minimum of independent random variables sharing the cdf for every
gives the same possibility. From there, they conclude that if the sequence
of generalized Gini coefficients is known, then the cdf can be determined. They refined the result somewhat proving that you could do with a subsequence
fulfilling that
Farris (Citation2010) states an idea to make it less labor-intensive: Suppose that you take a sample of incomes. You compute , and
from the empirical distribution function. Then, calculate a Lorenz curve of the type (8) directly from the values of
and
which means that you have estimates of
and
in (8). Finally, you compute the 4th order Gini coefficient from the Lorenz curve you found,
. . If it fits well to
, then you have good model. But if you from this stage conclude that you have a well-estimated income distribution function based on
and
then you are facing an ill-posed inverse problem, and you cannot be sure that your estimated cdf is useful.
6. Epilogue
The widespread idea of illustrating the Gini coefficient as the area between the segment from (0,0) to (1,1) and the Lorenz curve of empirical data or some approximation to them is sound because this area can be conceived of as a distance—in Still, a small Gini coefficient is not enough to ensure a high degree of income equality in a society.
This conclusion is not the same as a removal of the Gini coefficient or its generalizations. Corrado Gini’s own introduction, and especially the moderate rewriting of it made by Dorfman (Citation1979), gives this interpretation: In the population, pick 2 individual shares of the good in question, and
. Let
. Then,
Therefore, if you make a repeated experiment choosing a sample of 2 values, note the first and the least, then in the long run, the ratio between the average of the latter and of the former subtracted from 1 will approximate the Gini coefficient. So, if you take a stroll somewhere in your town and ask a random and honest pedestrian about her income, then on average, the answer would be close to your own income—if the Gini coefficient is low.
Disclosure statement
It is a pleasure to thank the editor and the anonymous reviewers for helping to improve this paper
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Jens Peter Kristensen
Being a math teacher, I often took an interest in courses of teaching in applied mathematics. In the 2 latest decades, this was frequently interdisciplinary courses with social science and economics. After some courses about economic inequality, I wrote an article (in Danish) to the magazine of the Danish Association of Mathematics Teachers, LMFK-bladet 4/2015 p 10 - 15. In a comment, a colleague referred to Farris’ article in AMM 12/2010, leading me to some of the comprehensive economics literature on measuring inequality, Lorenz curve, and Gini coefficient. My prime interest was to analyze the transformation from which you derive the Lorenz curve from a given income distribution. If you demand the distributions to be normalized, this mapping is 1-1 of a set of distributions into itself. The set is contained in a normed space. So, mathematically, you can ask if it is continuous and if the inverse is. Having answered these questions, it remains drawing consequences in economics methodology – which could be further refined. Have among other high schools worked at Hasseris Gymnasium, Denmark.
Notes
1. Furthermore, the current OECD formula weights income higher, the more numerous the household in which the individual lives is.
2. Named after M. O. Lorenz, the American economist who developed the concept in his pioneering research on income inequality. Se Lorenz, M O. (1905) Methods of measuring the concentration of wealth. Journal of American statistical Association. p 209–219.
3. Dorfman does not use the concept of . Furthermore, he uses Stieltjes integrals. Other writers I found only prove the case with a differentiable distribution function. We will at present be content with this, although it is not difficult to prove (2) for any kind of distribution using the Lebesgue measure on [0,1].
4. More details in the proof of these claims about convex functions could be found in Rudin (Citation1974) p 62–63.
5. The term is chosen because here – in accordance with the current literature – is used as argument for Lorenz curves.
6. I found this class of functions in Farris (2010) p 863. He calls them Pareto functions which they obviously not are. They can only be Lorenz curves for finite random variables. One could utter that for b > 2 the associated cdf has a certain resemblance to Pareto distributions.
7. In Liu & Gastwirth’s (Citation2020) terminology this is “one half of the coefficient of variation”.
References
- Atkinson, A. B. (1970). On the measurement of inequality. Journal of Economic Theory, 2(3), 244–16. https://doi.org/10.1016/0022-0531(70)90039-6
- Donaldson, D., & Weymark, J. A. (1983). Ethically flexible gini indices for income distributions in the continuum. Journal of Economic Theory, 29(2), 353–358. https://doi.org/10.1016/0022-0531(83)90053-4
- Dorfman, R. (1979). A formula for the gini coefficient. Review of Economics and Statistics, 61(1), 146–149. https://doi.org/10.2307/1924845
- Ebert, U. (1984). Measures of distance between income distributions. Journal of Economic Theory, 32(2), 266–274. https://doi.org/10.1016/0022-0531(84)90054-1
- Farris, F. A. (2010). The gini index and measures of inequality. American Mathematical Monthly, 12(10), 851–864. https://doi.org/10.4169/000298910x523344
- Gastwirth, J. (1971). A general definition of the Lorenz Curve. Econometrica, 39(6), 1037–1039. https://doi.org/10.2307/1909675
- Golden, J. (2008). A simple geometric approach to approximating the Gini coefficient. Journal of Economic Education, 39(1), 68–77. https://doi.org/10.3200/JECE.39.1.68-77
- Horowitz, J. L. (2014). Ill-posed inverse problems in economics. Annual Review of Economics, 6(1), 21–51. https://doi.org/10.1146/annurev-economics-080213-041213
- Kakwani, N. (1980). On a class of poverty measures. Econometrica, 48(2), 437–446. https://doi.org/10.2307/1911106
- Kleiber, C., & Kotz, S. (2002). A characterization of income distributions in terms of generalized gini coefficients. Social Choice and Welfare, 19(4), 789–794. https://doi.org/10.1007/s003550200154
- Lambert, P. (1990). The distribution and redistribution of income. Basil Blackwell.
- Liu, Y., & Gastwirth, J. (2020). On the capacity of the Gini index to represent income distribution. Metron, 78(1), 61–69. https://doi.org/10.1007/s40300-020-00164-8
- Morgan, J. (1962). The anatomy of income distribution. Review of Economics and Statistics, 44(3), 270–282. https://doi.org/10.2307/1926398
- OECD: Income Distribution Database. (2017). http://www.oecd.org/els/soc/IDD-ToR.pdf
- Rudin, W. (1974). Real and complex analysis. McGraw-Hill.
- Yitzhaki, S. (1983). On an extension of the Gini inequality index. International Economics Review, 24(3), 617–628. https://doi.org/10.2307/2648789
- Yitzhaki, S., & Schechtman, E. (2013). Chapter 2. In The Gini methodology.Springer Series in Statistics 272 (New York: Springer).
