
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this article, we propose a new process capability index called which is based on asymmetric loss function (linear exponential) and tolerance cost function for a normal process which provides a tailored way of incorporating the loss and tolerance cost in capability analysis. Next, we estimate the proposed PCI
when the process follows the normal distribution using six classical methods of estimation and we compare the performance of the considered methods of estimation in terms of their mean squared errors through simulation study. Besides, five bootstrap methods are employed for constructing the confidence intervals for the index
. The performance of the bootstrap confidence intervals (BCIs) are compared in terms of average width and coverage probabilities using Monte Carlo simulation. Finally, for illustrating the effectiveness of the proposed index and methods of estimation and BCIs, two real data sets from electronic industries are re-analyzed.
1 Introduction
In almost all manufacturing industries, processes are frequently assessed by adopting process capability indices (PCIs) which provide a numerical measure on whether a monitored process is capable of achieving the quality requirement pre-set by the customers. This statistical tool has received great attention in the quality control and statistical literature as it has been found very useful in decision making and enhancing efforts in process performance. For greater insight into classical capability indices, readers may refer to the works of: Juran (Citation1974), Kane (Citation1986), Chan, Cheng, and Spiring (Citation1988), and Pearn, Kotz, and Johnson (Citation1992). It is noteworthy that classical capability indices were developed by taking into account the assumption of normal probability model with process mean ε and process standard deviation Ϛ.
It dates back to 1974 when Juran (Citation1974) first introduced the PCI denoted by Cp
and is defined as
(1.1)
(1.1)
where
and
are the upper and the lower specification limits. However, there are some limitations of
. One such limitation is that it does not consider process mean. The second limitation is its inability to capture the variation when the process is not centered at the target value. In order to overcome these limitations, several indices were developed wherein variations from the target value are considered while measuring the capability of a particular process. One such index was developed by Hsiang and Taguchi (Citation1985) which was named as
. This index was later modified by Chan, Cheng, and Spiring (Citation1988) by altering the denominator of the index
which is defined as
(1.2)
(1.2)
where ε is the process mean and
is the target value. When
coincides with
. The index
is based on the squared error loss function and is often called the Taguchi index. Several modified versions of Taguchi’s loss based index have been proposed in literature (see, Kackar Citation1986; Pearn, Kotz, and Johnson Citation1992; Stevens and Baker Citation1994). Usually, it has been observed that capability indices are evaluated without considering any loss and tolerance cost functions. However, loss and tolerance cost functions have many uses in varied fields such as industrial engineering, quality engineering, capability analysis, etc; See Jeang et al. (Citation2008), Abdolshah et al. (Citation2011), and Erfanian and Gildeh (Citation2021). For instance, Jeang et al. (Citation2008) pointed out that a low quality loss (good quality) implies a high production cost (tight tolerance), while a high quality loss (poor quality) indicates a low production cost (loose tolerance) in the product life cycle when quality values vary under different circumstances. Therefore, it is important to consider the cost tolerance in evaluating PCIs. Further, Shu, Wang, and Hsu (Citation2005), Hsieh and Tong (Citation2006), Pan (Citation2007), Kethley (Citation2008) and Naidu (Citation2008) pointed out that loss functions can not only be used for predicting the losses but also can be employed for various purposes such as risks evaluation, decision-making, quality engineering, tolerances design, capability analysis etc. We are aware that two types of expenses namely, tolerance cost and quality loss arise in the course of a product’s life cycle. Tolerance Costs includes expenses incurred on a product prior to its sale, while quality loss covers all expenses incurred after the sale of a product. To evaluate the tolerance cost, we adopt the following tolerance cost function suggested by Jeang et al. (Citation2008) which is given by
, where
are the coefficients for the tolerance cost function, and t is the process tolerance.
In this paper, we consider linear exponential (LINEX) loss function (see, Varian Citation1975) and tolerance cost function (see, Jeang et al. Citation2008). The LINEX loss function is in the form
where γ is a constant. The degree of asymmetry of L1 is determined by parameter γ. For small values of γ (e.g.,
), the loss function is almost symmetric and not far from a squared error loss function,
(see, Erfanian and Gildeh Citation2021).
Although, it has been observed that in most studies loss function adopted for evaluating PCI is squared error loss function but in this article, we replace the squared error loss function by linear exponential (LINEX) loss function and add the tolerance cost function in i.e., the denominator of
in EquationEq. (1.2)
(1.2)
(1.2) is replaced by
Thus, the loss and cost based PCI, say, can be written as:
(1.3)
(1.3)
The term includes two types of variation: (i) variation relative to the process mean, and (ii) process mean departure from the goal value. It is easy to see from the definition of
that if the process variance grows (decreases), the denominator of EquationEq. (1.3)
(1.3)
(1.3) will increase (reduce), and
will decrease (increase). Additionally, if the process mean goes away from (towards) the target value, the denominator increases (decreases), and
decreases (increased). Off-target behavior is evidently penalized further by
.
In literature, we come across several studies on various methods of estimation in order to estimate the parameters of a model. However, the maximum likelihood (ML) method is often used as a first tool to estimate the parameters of a model and PCIs. In the premise of this, in this paper, we consider five estimators besides ML estimators for estimating the PCI, under normal distribution, namely least squares estimators (LSE), weighted least squares estimators (WLSE), maximum product spacing estimators (MPSE), percentile estimators (PCE)and Cramér-von Mises estimators(CME). The efficiency of the estimators are assessed with respect to their respective mean squared errors (MSEs) through the Monte-Carlo simulation study. However, due to deviations in the estimators, point estimation may not provide reliable estimates of the PCIs. Thus, for assessing variability or deviation in the estimates, the interval estimation methods of PCIs are employed. In recent times, several techniques like bootstrap method have been developed for constructing confidence intervals (CIs). In this regard, readers may refer to the works of Leiva et al. (Citation2014), Pearn et al. (Citation2014), Pearn, Tai, andWang (Citation2016),Kashif et al. (Citation2017), Rao,Aslam, and Kantam (Citation2016), Dey et al. (Citation2018), Dey and Saha (Citation2018, Citation2019), Saha, Dey, and Maiti (Citation2018, Citation2019a), Saha et al. (Citation2019b), Saha et al. (Citation2020, Citation2021), Saha, Dey, and Nadarajah (Citation2022), Saha, Dey, andWang (Citation2022), Alomani et al. (Citation2020), to name a few. Thus, we consider five bootstrap confidence intervals (BCIs), namely, standard bootstrap (
), percentile bootstrap (
), student’s t bootstrap (
) bias-corrected percentile bootstrap (
) and bias-corrected accelerated bootstrap (
) of
based on the above-cited six classical methods of estimation. The performance of the BCIs are assessed with respect to their estimated coverage probabilities (CPs) and average width (AW).
The motivation of this paper is to obtain five BCIs using based on six considered methods of estimation for normal distribution and to develop a guideline for choosing the best estimation method that gives better estimates and CI for
, which would be of great interest to applied statisticians and quality control engineers, when the quality characteristics of the processes follow normal distribution. As far as our knowledge goes, there are no reports for measuring PCI,
where five BCIs based on above cited six classical estimation methods for the normal distribution is considered. We aim to fill up this gap through this work.
The rest of the paper is organized as follows: in Sec. 2, considered methods of estimation of based on them are derived. In Sec. 3, BCIs for
based on proposed estimators are constructed. In Sec. 4, a simulation study is reported which elucidates the performance of the proposed PCI
based on considered methods of estimation. In the same Section, we assess the performances of different BCIs for the index
under the considered methods of estimation in terms of coverage probabilities (CPs) and average width (AW). Two real data sets from electronic industries are re-analyzed for illustrative purposes in Sec. 5; and a conclusions is given in Sec. 6.
2 Estimation of  for normal distribution
for normal distribution
In this section, we use six methods of estimation mentioned in the Sec. 1 to estimate the PCI using normal distribution. A random variable
has N
, then its probability density function (PDF), cumulative distribution function (CDF) and the p-th quantile function (QF) are, respectively, given by
(2.4)
(2.4)
(2.5)
(2.5)
and
(2.6)
(2.6)
where ε, Ϛ are the mean and standard deviation of the normal distribution and
is the CDF of the standard normal variate.
2.1 Maximum likelihood estimator
Let represents n observed values from
, defined in EquationEq. (2.4)
(2.4)
(2.4) . Then, the likelihood function of the parameters ε and Ϛ is given as
(2.7)
(2.7)
The maximum likelihood estimates (MLEs) of ε and Ϛ are ,
, respectively. Hence, the MLE of
can be expressed as
(2.8)
(2.8)
2.2 Least square and weighted least square estimators
The LS and the WLS estimation procedure were introduced by Swain, Venkatraman, and Wilson (Citation1988) for estimating the parameters of a model. Suppose are ordered observations from the normal distribution with CDF
. The LS estimates are obtained by minimizing the following function:
(2.9)
(2.9)
with respect to the parameters ε and Ϛ. The LSEs
and
of the parameters ε and Ϛ can also be obtained by solving the following nonlinear equations:
(2.10)
(2.10)
and
(2.11)
(2.11)
where
(2.12)
(2.12)
(2.13)
(2.13)
where
is the PDF of standard normal variate. Solving the above Eqns. (11) and (12) for ε and Ϛ, we obtain the LSEs of ε and Ϛ. However, the above equations fail to yield an explicit solution and we resort to nonlinear minimization (NLM) (see, Dennis and Schnabel Citation1983) technique to obtain an LSEs of ε and Ϛ. Hence, the LSEs of
can be expressed as
(2.14)
(2.14)
The WLSEs of the parameters ε and Ϛ can be obtained by minimizing the following function with respect to ε and Ϛ
(2.15)
(2.15)
or equivalently, the WLSEs of ε and Ϛ can be obtained as the solution of the following nonlinear equations:
(2.16)
(2.16)
(2.17)
(2.17)
The weights wi
are equal to and
,
are defined in EquationEqs. (2.12)
(2.12)
(2.12) and Equation(2.13)
(2.13)
(2.13) , respectively. Hence, the WLSEs of
can be expressed as
(2.18)
(2.18)
2.3 Percentile estimator
This method was introduced by Kao (Citation1958) for estimating the parameters of a model. Suppose is an unbiased estimator of
. The PCEs of ε and Ϛ are obtained by minimizing
(2.19)
(2.19)
with respect to ε and Ϛ. Hence, the estimator of
based on PCEs is given by
(2.20)
(2.20)
2.4 Cramèr-von-Mises estimator
The Cramèr-von-Mises estimation method is considered to have less bias than other minimum distance estimators (MacDonald Citation1971). The CMEs of ε and Ϛ are obtained by minimizing
(2.21)
(2.21)
with respect to ε and Ϛ. The CMEs of ε and Ϛ can be obtained as the solution of the following nonlinear equations:
where
and
are defined in EquationEqs. (2.12)
(2.12)
(2.12) and Equation(2.13)
(2.13)
(2.13) , respectively. Hence, the estimator of
based on CMEs is given by
(2.22)
(2.22)
2.5 Maximum product of spacings estimator
MPS technique was developed as an alternative method to the maximum likelihood approach using the Kullback-Leibler information measure; See, Cheng and Amin (Citation1979, Citation1983) and Ranneby (Citation1984). Suppose the uniform spacing
(2.23)
(2.23)
where
and
Thus,
The MPSEs of the parameters ε and Ϛ are obtained by maximizing the following function with respect to ε and Ϛ.
(2.24)
(2.24)
Taking logarithm on both sides of EquationEq. (2.24)(2.24)
(2.24) , we get
(2.25)
(2.25)
The MPSEs can also be obtained by solving the nonlinear equations:
and
where
and
are defined in EquationEqs. (2.12)
(2.12)
(2.12) and Equation(2.13)
(2.13)
(2.13) and for i = 0,
, the derivatives are
Hence, the MPSE of can be written as
(2.26)
(2.26)
3 Confidence intervals of for normal distribution
As far as our knowledge goes, there are no theories developed to obtain the confidence intervals for the parameters as well as PCIs based on considered frequentist methods of estimation except for the method of MLE and which are based on the theory of asymptotic distributions. However, for the construction of CIs based on MPS method, readers may consult Basu, Singh, and Singh (Citation2018). For this reason, we propose to obtain five parametric bootstrap confidence intervals for the PCI . The five different parametric BCIs are: standard bootstrap (
), percentile bootstrap (
), student’s t bootstrap (
) bias-corrected percentile bootstrap (
) and bias-corrected accelerated bootstrap (
). Below, we discuss the algorithm for the bootstrap methods based on the method of ML. A similar procedure has been adopted to obtain the other bootstrap estimate of
using other considered methods (LSE, WLSE, CME, PCE, MPSE) of estimation.
Step 1: Let (
Step 2: Compute the MLEs (
Step 3: There are total number of nn re-samples. From these re-samples, calculate
The arrangement of the entire collection from smallest to largest would constitute an empirical bootstrap distribution: , i.e.,
.
-boot
Let and
be the sample mean and standard deviation of
, i.e.,
and
respectively. A
-boot CI of
is given by
(3.27)
(3.27)
where
is obtained by using upper
-th point of the standard normal variate.
-boot
Let be the ξ percentile of
, i.e.,
is such that
where
is an indicator function. Then, a
-boot CI of
is
(3.28)
(3.28)
-boot
Let be the ξ percentile of
i.e.,
is such that
where
is defined above. A
-boot confidence interval of
is given by
(3.29)
(3.29)
-boot
The idea of this method lies in correcting the potential bias. At first, locate the observed in the order statistics
. Next, compute the probability
Now, calculate and ψl
and ψu
are defined as
Then,
-boot CI of
is
(3.30)
(3.30)
-boot
Calculate
where is the bias-correction and also calculate
where
is called the acceleration factor and
is the MLE of
based on
observations after excluding the
-th observation.
Then, a
-boot confidence interval of
is given as
(3.31)
(3.31)
where
and
, respectively.
4 Comparison via Monte-Carlo simulation study
In this section, the performance of the considered estimation methods of the PCI are examined in terms of their MSEs via Monte Carlo Simulations. Also, the performances of the five BCIs, namely,
-boot,
-boot,
-boot,
-boot, and
-boot are assessed with respect to their AW and CPs. Monte Carlo simulations are conducted under different sample sizes
. We have used different set of parameter values as
and
with lower, target value and upper specification limits as
,
, t = 0.50, respectively. For each design,
bootstrap samples with each of size n are drawn from the original sample and replicated
times.
To investigate the performance of point estimators, we carried out the Monte Carlo simulation with replication 10,000. The average point estimates along with their MSEs of based on the considered methods of estimation are reported in . In addition, in the same table, we report the true values of
and
for comparison purposes. It is observed from that all the estimators reveal the property of consistency i.e., the MSE decreases when the sample size increases for all estimation methods. Furthermore, in terms of performance of the methods of estimation, we found that the MLEs and MPSEs are more or less same in terms of their MSEs and in some of the considered cases MLE performs better than their counterparts. We also visualize the results in = 10) and 2 (n = 20). We observe that as γ increases, true value of
increases when γ is roughly greater than 3. In summary, based on and , the performance of the estimators from best to worst for all parameters combinations is MLE < MPSE < CME < WLSE
PCE < LSE. As afore-mentioned, we can also observe in the figures that the MSE and Bias decrease as the sample size increases.
Fig. 1 (a) MSE of MLE, LSE, WLSE, PCE, CME, MPSE with respect to γ (, and n = 10). (b) their corresponding Bias. (c) Boxplot of MSE values. (d) Boxplot of Bias values.
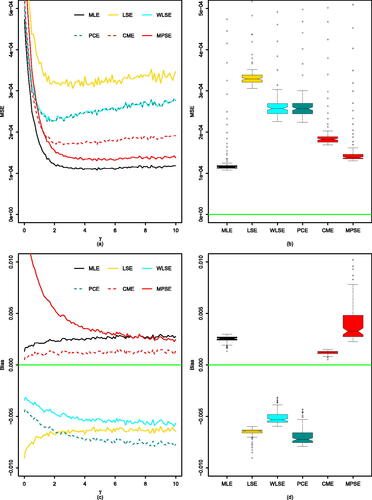
Fig. 2 (a) MSE of MLE, LSE, WLSE, PCE, CME, MPSE with respect to γ (, and n = 20). (b) their corresponding Bias. (c) Boxplot of MSE values. (d) Boxplot of Bias values.
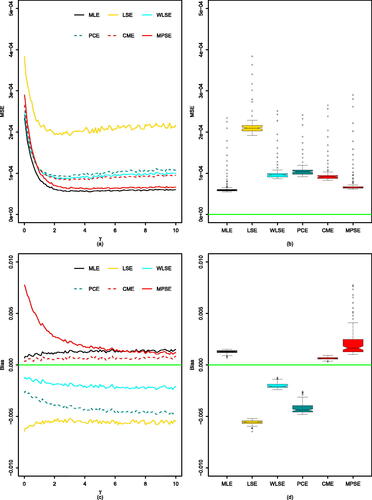
Table 1 True values of and
along with average estimates based on MLE, LSE, WLSE, PCE, CME, MPSE along with their MSEs [
].
Further, the AW and CPs of BCIs based on and
using considered methods of estimation for
are reported in , respectively. The simulation results show that
-boot provides smaller AW than their counterparts for almost all sample sizes and the considered methods of estimation and the order of performance of BCI is
. In addition, we observe that
CIs provide higher CP than their counterparts for all the considered methods of estimation and for almost all sample sizes.
Table 2 AW and CPs of BCIs of using MLEs of the parameters [
] along with true values of
.
Table 3 AW and CPs of BCIs of using LSEs of the parameters [
] along with true values of
.
Table 4 AW and CPs of BCIs of using WLSEs of the parameters [
] along with true values of
.
Table 5 AW and CPs of BCIs of using PCEs of the parameters [
] along with true values of
.
Table 6 AW and CPs of BCIs of using CMEs of the parameters [
] along with true values of
.
Table 7 AW and CPs of BCIs of using MPSEs of the parameters [
] along with true values of
.
5 Applications in electronic industries data
In the last 50 years or so, we have witnessed how technology played a vital role in all spheres of knowledge and how technologies have eased our work by increasing productivity and generating quality products that cater to the needs of the customers. We are aware that the manufacturing industries are susceptible to failures in their manufacturing stages and at the end of the process the generated products may not meet the specifications. Due to this, both the manufacturer and customers may face losses. Motivated by the above, proposed methodology is applied to verify whether the product of a specific company meets the desired specifications and for this purpose, in this section, we re-analyze three real data sets which are taken from electronic industries to demonstrate the performance of the point estimates of and
(see, Saha, Dey, and Wang Citation2022) using considered methods of estimation. Further, the width of BCIs (
,
and
) using considered methods of estimation for the PCIs
and
are obtained and reported in , respectively.
Table 8 Estimates of and
along with width of BCIs based on data set I [
].
Table 9 Estimates of and
along with width of BCIs based on data set II [
].
Data Set I: Thickness of the membrane of color STN display process.
This data set is taken from Chen and Chen (Citation2004) and consists of the thickness of the membrane of color STN display. The specification limits were (where
), that is, the upper and the lower specification limits were set as
and the target value was set to
. If the thickness of the membrane does not fall within the tolerance limits
, color STN display will suffer chromatic aberration. For the ready reference for the researchers, the data set is given below:
12093, 12130, 12105, 12088, 12115, 12086, 12099, 12084, 12114, 12125, 12102, 12092, 12120, 12062, 12087, 12092, 12095, 12078, 12133, 12090, 12114, 12114, 12114, 12080, 12097, 12105, 12094, 12086, 12108, 12138, 12103, 12094, 12120, 12090, 12083, 12068, 12106, 12056, 12108, 12107, 12100, 12133, 12094, 12067, 12108, 12114, 12101, 12082, 12094, 12076, 12099, 12107, 12109, 12101, 12093, 12038, 12086, 12084, 12128, 12122.
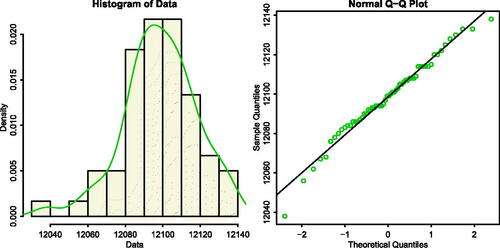
To examine the validity of the normal distribution, several goodness-of-fit statistics and information theoretic criteria are considered, namely: Shapiro and Wilk (Citation1965) normality test, Kolmogorov-Smirnov (KS) with its P-value, AIC and BIC. By computation using shapiro.test built-in package and fitdistrplus library of the R open source software [see, Ihaka and Gentleman (Citation1996)], we have calculated the MLEs of the parameters, which are and
, where the Shapiro-Wilk test statistic is 0.98032 with P-value being 0.4421, log-likelihood=–262.5265, AIC = 529.0530, BIC = 533.2417, the KS statistic and its P values are 0.0618 and 0.9757, respectively, which suggests that the normal model could fit this data set well. Also, also supports the normality of the data set.
Fig. 3 Histogram and Q-Q plot of the data set from thickness of membrane of color STN display process.
Data Set II: Voltage of aluminum foil of an electronic company.
This data set is taken from Tong and Chen (Citation2003) and consists of 50 observations of voltage of aluminum foil of an electronic company. The production specifications of the voltage were . If the voltage falls outside this interval, the aluminum foil will break, and thus will be rejected. The data are:
519.9, 519.5, 520.1, 517.0, 521.1, 517.1, 518.7, 520.1, 521.2, 521.7, 520.4, 517.9, 522.9, 517.7, 517.2, 520.7, 521.0, 519.1, 518.4, 518.9, 517.9, 518.4, 520.8, 519.3, 520.6, 516.6, 519.0, 520.6, 517.9, 519.6, 519.6, 522.6, 518.3, 522.1, 523.1, 519.9, 519.8, 520.7, 516.5, 521.5, 519.2, 521.2, 518.9, 517.8, 521.3, 521.3, 517.4, 519.5, 522.0, 523.8
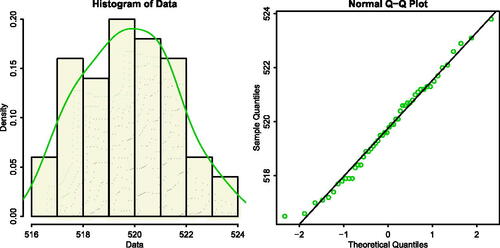
To examine the validity of the normal distribution, several goodness-of-fit statistics and information theoretic criteria are considered, namely: Shapiro and Wilk (Citation1965) normality test, Kolmogorov-Smirnov (KS) with its P-value, AIC and BIC. By computation using shapiro.test built-in package and fitdistrplus library of the R open source software (see, Ihaka and Gentleman Citation1996), we have calculated the MLEs of the parameters, which are and
, where the Shapiro-Wilk test statistic is 0.98462 with p-value being 0.7551, log-likelihood =–99.37723, AIC= 202.7545, BIC = 206.5785, the KS statistic and its p values are 0.0733 and 0.9505, respectively, which suggests that the voltage data of the aluminum foil fits well for normal model. Also, supports the normality of the data set.
Fig. 4 Histogram and Q-Q plot of the data set from voltage of aluminum foil of an electronic company.
In summary, from and , it is observed that the CME performs marginally better than all other considered methods of estimation for both and
. Further, it is observed that
performs better than their counterparts for Data set I. In addition, it is observed that the width of CI of
method is smaller than its counterparts among all BCIs. Besides, the MPSE has smaller AW than its counterparts among all classical methods of estimation in terms of the width of BCIs. Besides, the width of
performs better than
in case of MPS method. In addition, we notice that the value of both
and
turns out to be greater than 1 and the process is capable for Data set I.
6 Concluding remarks
In this present study, five BCIs (,
and
) of the proposed loss and tolerance cost based PCI
by using six discussed estimation methods for the normal distribution have been considered. Further, we have obtained point estimates of the
using considered methods of estimation. It is to be noted that it would be a tedious task to compare all these considered methods theoretically, hence we have conducted an extensive simulation study to compare these methods with different sample sizes and different combinations of the unknown parameters. In addition, the PCI
is also taken into consideration in real data analysis for comparison purposes. The performances of BCIs for the index
are compared in respect of AW and CPs. Results from the simulation study indicate that
-boot CIs perform better than their counterparts in respect of AW and CPs for all estimation methods considered in this paper. Also, MLE performs marginally better than considered methods of estimation. The data analysis shows a similar pattern of results that we have observed in the simulation study. As a future research, the proposed PCI,
can be extended in the development of inspection plans and control charts. It can also extended to multivariate versions for the PCI. We hope our results and methods of estimation and BCIs may help companies in using better methods of obtaining the PCIs and their estimations.
Authors’ contributions
The author read and agreed to the published version of the manuscript.
Acknowledgments
The authors truly appreciate the valuable comments from two anonymous Referee which led to an improvement of our work.
Data availability statement
All data analyzed during this study are included in this published articles: Chen and Chen (Citation2004) and Tong and Chen (Citation2003). The link of the data sets used in this study are included within the article, and data sets are also provided in the article.
Disclosure Statement
The author declare that he has no conflict of interest.
Additional information
Funding
References
- Abdolshah, M., R. M. Yusuff, T. S. Hong, and M. Y. B. Ismail. 2011. “Loss-based Process Capability Indices: A Review.” International Journal of Productivity and Quality Management 7(1):1–21. https://doi.org/10.1504/IJPQM.2011.037729
- Alomani, G., R. Alotaibi, S. Dey, and M. Saha. 2020. “Classical Estimation of the Index Spmk and its Confidence Intervals for Power Lindley Distributed Quality Characteristics.” Mathematical Problems in Engineering 2020:1–17. Article ID 8974349. https://doi.org/10.1155/2020/8974349
- Basu, S., S. K. Singh, and U. Singh. 2018. “Bayesian Inference Using Product of Spacings Function for Progressive Hybrid Type-i Censoring Scheme.” Statistics 52 (2):345–63. https://doi.org/10.1080/02331888.2017.1405419
- Chan, L. K., S. W. Cheng, and F. A. Spiring. 1988. “A New Measure of Process Capability.” Journal of Quality Technology 20:162–75. https://doi.org/10.1080/00224065.1988.11979102
- Chen, J., and K. S. Chen. 2004. “Comparison of Two Process Capabilities by Using Indices Cpm: An Application to a Color STN Display.” International Journal of Quality & Reliability Management 21 (1):90–101. https://doi.org/10.1108/02656710410511713
- Cheng, R. C. H., and N. A. K. Amin. 1979. “Maximum Product-of-Spacings Estimation with Applications to the Log-Normal Distribution.” Math Report 79-1, University of Wales IST.
- Cheng, R. C. H., and N. A. K. Amin. 1983. “Estimating Parameters in Continuous Univariate Distributions with a Shifted Origin.” Journal of the Royal Statistical Society B 45:394–403. https://doi.org/10.1111/j.2517-6161.1983.tb01268.x
- Dennis, Jr., J. E., and R. B. Schnabel. 1983. Numerical Methods for Unconstrained Optimization and Nonlinear Equations. Englewood Cliffs, NJ: Prentice Hall, Inc.
- Dey, S., and M. Saha. 2018. “Bootstrap Confidence Intervals of the Difference between Two Generalized Process Capability Indices for Inverse Lindley Distribution.” Life Cycle Reliability and Safety Engineering 7:89–96. https://doi.org/10.1007/s41872-018-0045-9
- Dey, S., and M. Saha. 2019. “Bootstrap Confidence Intervals of Generalized Process Capability Index Cpyk Using Different Methods of Estimation.” Journal of Applied Statistics 46:1843–1869. https://doi.org/10.1080/02664763.2019.1572721
- Dey, S., M. Saha, S. S. Maiti, and C.-H. Jun. 2018. “Bootstrap Confidence Intervals of Generalized Process Capability Cpyk for Lindley and Power Lindley Distributions.” Communications in Statistics - Simulation and Computation 47:249–62. https://doi.org/10.1080/03610918.2017.1280166
- Erfanian, M., and B. S. Gildeh. 2021. “A New Capability Index for Non-normal Distributions based on Linex Loss Function.” Quality Engineering 33:76–84. https://doi.org/10.1080/08982112.2020.1761026
- Hsiang, T. C., and G. Taguchi. 1985. “A Tutorial on Quality Control and Assurance.” Annual Meeting on the American Statistical Association, Las Vegas, NV.
- Hsieh, K.-L., and L.-I. Tong. 2006. “Incorporating Process Capability Index and Quality Loss Function into Analyzing the Process Capability for Qualitative Data.” International Journal of Advanced Manufacturing Technology 27:1217–22. https://doi.org/10.1007/s00170-004-2314-1
- Ihaka, R., and R. Gentleman. 1996. “R: A Language for Data Analysis and Graphics.” Journal of Computational and Graphical Statistics 5:299–314. https://doi.org/10.2307/1390807
- Jeang, A., C.-P. Chung, H.-C. Li, and M.-H. Sung. 2008. “Process Capability Index for Off-Line Application of Product Life Cycle.” In Proceedings of the World Congress on Engineering 2008 Vol II, WCE 2008, July 2–4, London, U.K.
- Juran, J. M. 1974. Juran’s Quality Control Handbook, 3rd ed. New York: McGraw-Hill.
- Kackar, R. N. 1986. “Taguchi’s Quality Philosophy: Analysis and Commentary.” Quality Progress 19:21–30.
- Kane, V. E. 1986. “Process Capability Indices.” Journal of Quality Technology 18:41–52. https://doi.org/10.1080/00224065.1986.11978984
- Kao, J. H. K. 1958. “Computer Methods for Estimating Weibull Parameters in Reliability Studies.” IRE Transactions on Reliability and Quality Control, PGRQC-13:15–22. https://doi.org/10.1109/IRE-PGRQC.1958.5007164
- Kashif, M., M. Aslam, G. S. Rao, A. H. Al-Marshadi, and C. H. Jun. 2017. “Bootstrap Confidence Intervals of the Modified Process Capability Index for Weibull Distribution.” Arabian Journal of Science and Engineering 42:4565–573. https://doi.org/10.1007/s13369-017-2562-7
- Kethley, R. B. 2008. “Using Taguchi Loss Functions to Develop a Single Objective Function in a Multi-Criteria Context: A Scheduling Example.” International Journal of Information Management 19:589–600.
- Leiva, V., C. Marchant, H. Saulo, M. Aslam, and F. Rojas. 2014. “Capability Indices for Birnbaum-Saunders Processes Applied to Electronic and Food Industries.” Journal of Applied Statistics 41:1881–1902. https://doi.org/10.1080/02664763.2014.897690
- MacDonald, P. D. M. 1971. “Comment on “An Estimation Procedure for Mixtures of Distributions” by Choi and Bulgren.” Journal of the Royal Statistical Society. Series B (Methodological) 33 (2):326–29. https://doi.org/10.1111/j.2517-6161.1971.tb00884.x
- Naidu, N. V. R. 2008. “Mathematical Model for Quality Cost Optimization.” Robotics and Computer Integrated Manufacturing 24:811–15. https://doi.org/10.1016/j.rcim.2008.03.018
- Pan, J. N. 2007. “A New Loss Function-based Approach for Evaluating Manufacturing and Environmental Risks.” International Journal of Quality and Reliability Management 24:861–87. https://doi.org/10.1108/02656710710817135
- Pearn, W. L., S. Kotz, and N. L. Johnson. 1992. “Distributional and Inferential Properties of Process Capability Indices.” Journal of Quality Technology 24:216–31. https://doi.org/10.1080/00224065.1992.11979403
- Pearn, W. L., Y. T. Tai, I. F. Hsiao, and Y. P. Ao. 2014. “Approximately Unbiased Estimator for Non-normal Process Capability Index CNpk.” Journal of Testing and Evaluation 42:1408–17. https://doi.org/10.1520/JTE20130125
- Pearn, W. L., Y. T. Tai, and H. T. Wang. 2016. “Estimation of a Modified Capability Index for Non-normal Distributions.” Journal of Testing and Evaluation 44:1998–2009. https://doi.org/10.1520/JTE20150357
- Ranneby, B. 1984. “The Maximum Spacing Method. An Estimation Method Related to the Maximum Likelihood Method.” Scandinavian Journal of Statistics 11 (2):93–112.
- Rao, G. S., M. Aslam, and R. R. L. Kantam. 2016. “Bootstrap Confidence Intervals of CNpk for Inverse Rayleigh and Log-Logistic Distributions.” Journal of Statistical Computation and Simulation 86:862–73. https://doi.org/10.1080/00949655.2015.1040799
- Saha, M., S. Dey, and S. S. Maiti. 2018. “Parametric and Non-parametric Bootstrap Confidence Intervals of CNpk for Exponential Power Distribution.” Journal of Industrial and Production Engineering 35:160–69. https://doi.org/10.1080/21681015.2018.1437793
- Saha, M., S. Dey, and S. S. Maiti. 2019a. “Bootstrap Confidence Intervals of CpTk for Two Parameter Logistic-Exponential Distribution with Applications.” International Journal of System Assurance Engineering and Management 10 (8):623–31. https://doi.org/10.1007/s13198-019-00789-7
- Saha, M., S. Dey, and S. Nadarajah. 2022. “Parametric Inference of the Process Capability Index for Exponentiated Exponential Distribution.” Journal of Applied Statistics. 49 (16):4097–4121. https://doi.org/10.1080/02664763.2021.1971632
- Saha, M., S. Dey, and L. Wang. 2022. “Parametric Inference of the Loss based Index Cpm for Normal Distribution.” Quality and Reliability Engineering International 38 (1):405–31. https://doi.org/10.1002/qre.2987
- Saha, M., S. Dey, A. S. Yadav, and S. Ali. 2021. “Confidence Intervals of the Index Cpk for Normally Distributed Quality Characteristics Using Classical and Bayesian Methods of Estimation.” Brazilian Journal of Probability and Statistics 35:138–57. https://doi.org/10.1214/20-BJPS469
- Saha, M., S. Dey, A. S. Yadav, and S. Kumar. 2019b. “Classical and Bayesian Inference of Cpm for Generalized Lindley Distributed Quality Characteristic.” Quality and Reliability Engineering International 35 (8):2593–11. https://doi.org/10.1002/qre.2544
- Saha, M., S. Kumar, S. S. Maiti, A. S. Yadav, and S. Dey. 2020. “Asymptotic and Bootstrap Confidence Intervals for the Process Capability Index Cpy based on Lindley Distributed Quality Characteristic.” American Journal of Mathematical and Management Sciences, 39:75–89. https://doi.org/10.1080/01966324.2019.1580644
- Shapiro, S. S., and M. B. Wilk. 1965. “An Analysis of Variance Test for Normality (Complete Samples).” Biometrika 52:591–611. https://doi.org/10.2307/2333709
- Shu, M. H., C.-H. Wang, and B. M. Hsu. 2005. “A Review and Extensions of Sample Size Determination for Estimating Process Precision and Loss with a Designated Accuracy Ratio. International Journal of Advanced Manufacturing Technology 27:1038–46. https://doi.org/10.1007/s00170-004-2268-3
- Stevens, D., and R. Baker. 1994. “A Generalized Loss Function for Process Optimization.” Decision Sciences 25: 41–56. https://doi.org/10.1111/j.1540-5915.1994.tb00515.x
- Swain, J. J., S. Venkatraman, and J. R. Wilson. 1988. “Least-Squares Estimation of Distribution Functions in Johnson’s Translation System.” Journal of Statistical Computation and Simulation 29 (4):271–97. https://doi.org/10.1080/00949658808811068
- Tong, L., and J. Chen. 2003. “Bootstrap Confidence Interval of the Difference between Two Process Capability Indices.” International Journal of Advanced Manufacturing Technology 21:249–56. https://doi.org/10.1007/s001700300029
- Varian, H. R. 1975. “A Bayesian Approach to Real Estate Assessment.” In Studies in Bayesian Econometric and Statistics in Honor of Leonard J. Savage, edited by L. J. Savage, S. E. Feinberg, and A. Zellner, 195–208. New York: North-Holland.