
Abstract
Herbarium specimens have always played a central role in plant sciences and constitute the cornerstone for systematic and taxonomy. This role is further strengthened with the ongoing digitisation and growing online-availability of collections all over the globe. The increasing usability of specimens demands, however, an improved use and sustainable handling of specimen data not only in new scientific uses correlated with the digitisation, but also by modern workflows applied to the traditional purpose of specimens. A crucial step in the comparative analyses of organisms is the preparation of a character matrix to observe and assess the morphological extent and variability of taxa on the basis of individual specimens. This process and the resulting matrix often are of ephemeral nature since only its results are published in a condensed form. The data relationships are usually not stored, making a re-use impossible and a new analysis inevitable. To overcome the limitations of conventional taxonomy, we here introduce a comprehensive workflow that is currently being implemented on the EDIT Platform for Cybertaxonomy.
Introduction
Specimen usage in systematics
Almost half a billion herbarium specimens are hosted by herbaria worldwide (Thiers Citation2017) and constitute the baseline for all botanical research (Funk et al. Citation2005). Thanks to the continuous collecting over the past centuries, herbaria provide an immense data trove beyond comparison. In the course of the ongoing digitisation, these data-sets successively become accessible online. Consequently, during the last decade, herbarium specimen and in particular their metadata became sources for ecological and distributional data of exceptional value and allowed studies on a global scale. This process is far from being exhausted and several novel ideas and uses are regularly introduced (Soltis Citation2017; Willis et al. Citation2017).
Besides exploring new uses for herbarium specimen, it is also worth to re-evaluate traditional uses by applying new workflows and techniques. Herbarium specimens serve as an archive to substantiate taxonomic and floristic studies (Heberling and Isaac Citation2017), in particular concerning the characterisation of taxa. Herbarium specimens serve two main purposes. First, type specimens fix the application of the taxon name. Second, a (usually larger) set of additional specimens assigned to a taxon determines the morphological range of this taxon. The latter set may vary since it can be subject to changes in the taxonomic concept applied. The characterisation of a taxon is a process of iterative approximation to reality. Every newly collected specimen should ideally be included into this process and redefine the taxon characterisation. Instead, the traditional way of a taxonomic workflow rather is a stepwise and repetitive examination of all or a representative cross section of the specimens available. The data collected from these specimens are usually presented as a condensed taxon description based on pooled raw data. Even if a list of vouchered specimens is provided, full reproducibility is not given since an individual descriptive datum cannot be traced back to the individual specimens it is derived from. This traditional taxonomic workflow hence provides a subjective, heavily summarised snapshot of the morphological circumscription of a taxon, ascertainable at a certain point in time and a certain set of specimen data available to the respective taxonomist. If the complete list of specimens used is not given, the results are not falsifiable. Once new specimens or concepts question the current taxonomy, the whole process of data acquisition must inevitably be repeated, including the specimens already analysed earlier. To achieve the vision of an integrated monographic approach in taxonomy (Borsch et al. Citation2015), taxonomic research practices have to change.
The worldwide provision of huge quantities of specimen in the course of the digitisation and the Internet publication of large collections opens up new opportunities for the classic fields of botany. High resolution scans of herbarium specimens can add valuable data to taxonomic studies that hitherto needed to be gathered in a laborious interplay of loans and travel. This online-availability alone adds value to the individual study, but there is even more that would be feasible. Some of the fundamental principles of science are transparency and reproducibility. In taxonomy, both are difficult to accomplish with the present manner of publishing the outcomes, with the above mentioned non-retraceability of the taxon descriptions to the individual specimens. Data acquired from individual specimens need to be stored and made accessible. The relationship between specimen and data should be persistent, for morphological as well as for molecular data. This would allow not only for the reproducibility of results, but also for the instant use of the current data-set for a possible subsequent splitting or merging of data-sets (Kilian et al. Citation2015). An interesting side effect results from the fact that many botanical specimens are collected in duplicate and distributed to various herbaria, and that these duplicates can normally be identified by means of the data on collection site and event. The duplicates may differ in morphological features, but genetically they should be practically identical, so digitisation and access to the duplicate specimen’s data offers another means of quality control. The necessary technical prerequisites are given – availability of specimen data is constantly increasing and the usage of stable identifiers (Groom, Hyam, and Güntsch Citation2017; Güntsch et al. Citation2017) ensures a permanent and unambiguous assignment of data to the physical entity.
On the basis of the EDIT Platform for Cybertaxonomy (http://www.cybertaxonomy.org, Berendsohn Citation2010), we are developing (a) workflows and user interfaces for specifying morphological vocabularies based on existing ontologies and for publishing these vocabularies via publicly accessible terminology services, (b) user interfaces for efficient capture of morphological measurements based on specimens. Special emphasis is placed on inference mechanisms for the aggregation of the specimen-based measurements toward taxon descriptions and their integration with existing descriptions from literature and other resources. The final system will be configurable for specific taxonomic groups and their relevant morphological vocabularies and freely available as Open Source software.
Background
Character matrices
The idea to dissolve the vagueness of data documentation caused by the traditional taxonomic workflow is not new. Several authors have already pointed at this shortcoming (Deans, Yoder, and Balhoff Citation2012; Kilian et al. Citation2015; Pullan et al. Citation2000, Citation2005) and tried to provide solutions. Based on the principles of encoding assorted characteristics of taxonomically relevant character data in character matrices (Sokal and Sneath Citation1963), a number of applications have been developed using character matrices for subsequent statistic and phylogenetic analyses (Maddison and Maddison Citation2014) and to create taxonomic descriptions and identification keys (Dallwitz Citation1980; Hagedorn and Rambold Citation2000; Lucidcentral Citation1999+; Ung, Causse, and Vignes-Lebbe Citation2010). Standardised exchange formats (e.g. SDD, Hagedorn et al. Citation2005) allow for the exchange of data-sets between different approaches (Berendsohn et al. Citation2011). There are, however, still some areas of concern. For example, the exchange of data between different character matrices remains problematic and finding the optimal structure of modelling characters is challenging (Pullan et al. Citation2005).
Modelling of character concepts
Pullan et al. (Citation2000, Citation2005) intensively discussed the different descriptive models applied. Two principally different approaches have been modelled: the two-part construct also known as EQ-Syntax (Entity-Quality, see Dahdul et al. Citation2010) used by e.g. DELTA (Dallwitz Citation1980) and the three-part representation first suggested by Diederich (Citation1997), later elaborated and used in the Nemisys/Genisys model (for references see Hagedorn Citation2007) and also chosen in the Prometheus Model (Pullan et al. Citation2005). In the former, any feature consists of a “character” (named with an unspecified number of terms) and a “state” (chosen from a predefined set) that expresses the condition of the character present in the object examined (Dallwitz and Paine Citation1992+; Lebbe, Vignes, and Dedet Citation1989; Pankhurst Citation1970, Citation1972). In the latter, the “character” is decomposed into a “structure,” which is a physical component of an organism (e.g. a petal), and a “property” (e.g. colour); the feature thus comprises three parts: a structure (e.g. petal) + a property (e.g. colour) + a state (e.g. red). The two-part approach with its advantage of simplicity appears to be particularly inappropriate when trying to maintain machine processable data-sets with a high degree of granularity, which is essential for the exchange of data between matrices or between different applications. The reason is that parsability and hence machine-readable comparability is only given if a controlled vocabulary with a clearly defined semantics is used. There are, however, no controlled vocabularies, not to mention ontologies that deliver the sufficient amount of terms or groups of terms that explicitly and sufficiently describe characters as such. A controlled term vocabulary compulsorily restricts the usage of terms to maintain both, a predetermined number of terms and the association with the term-definition and its metadata. Conversely, several problems arise when the user tries to define a character as such, using numerous terms that by definition might belong to different categories of vocabulary (Pullan et al. Citation2005). The three-part approach through its decomposition of characters into the dimensions “structures” and “properties” thus essentially reduces the number of necessary term definitions and enables character definitions that are much more standardised. Moreover, it allows the application of classifications (and even hierarchies) with controlled vocabularies for the two dimensions, and therefore helps in achieving manageable and well-structured character sets (Hagedorn Citation2007). Since the decomposition of the character is only an intermediate step and its result the composition of a character, the outcome again complies with the intuitive two-part or entity-quality syntax: the dimensions “structure” (e.g. petal) and “property” (e.g. colour) collectively form a character “petal colour” whose state may be “red.” Assembling a character and its state by three individual terms allows the user to create every character needed as long as the terms are available from the controlled vocabulary used and at the same time enables computational data usage. The trade-off is a restriction in the descriptive naming of a character, leading to a certain stiffness in the list of character names which likely continues to subsequent data products generated thereof (e.g. natural language descriptions).
Controlled vocabularies/glossaries and ontologies
Another fundamental challenge of descriptive biology is the agreement on a comparable, controlled and stable vocabulary. This is all the more important when attempting to build machine readable and (re-)usable character matrices. The web-based establishment of globally available ontologies delivers a solution for this problem (Walls et al. Citation2012). With the PlantOntology (PO, Cooper et al. Citation2013) and related projects, huge vocabularies became available on-line, that deliver not only a controlled and defined terminology but also additional semantic information on the relationships between the terms reflecting those of the morphological equivalent they describe. The PO unites a number of ontologies that describe the morphological and anatomical structures, and the growth and developmental stages of green plants. The spatial, developmental and evolutionary relationships of the different parts of the plant body are represented in the form of “type-of” and “part-of” relations between the respective structures. This provides twofold information: a determination of homologous and non-homologous structures and unambiguous information on the spatial dimensions and relations.
Such collaborative efforts provide valuable structured vocabularies that are the result of a sound agreement process. In particular, the PlantOntology project is already being used intensively and is subject to permanent re-evaluations and extensions by a committee under participation of a global scientific community. Thereby an unprecedented level of agreement has been achieved throughout the scientific disciplines that applied this and similar ontologies for specific terminologies. Sub-ontologies have been developed in addition to these parent ontologies covering terminology of related scientific sectors or provide complementary terms that define attributes of the respective structures. The Phenotypic Quality Ontology (PATO: Mungall et al. Citation2010) or the Plant Trait Ontology (TO: Jaiswal Citation2011) for example, provide property terms with reference to the structures supplied by the PlantOntology. Furthermore, structured vocabularies (e.g. Plant Glossary: Endara et al. Citation2017) have been developed in parallel relating to the ontologies and listing e.g. categorised state terms mined from descriptions and large online glossaries. By referring to the PO as a common denominator, a principle interoperability has become effective not only with subsidiary ontologies and glossaries but also between databases using them. Other morphological or trait databases (e.g. TRY: Kattge et al. Citation2011) can thus reuse and exchange complementary data via exchange standards (see below) since the underlying vocabulary allows a correct mapping.
To gain even wider acceptance, the process reaching consensus needs to be based on a broader scientific fundament. Especially the development of subterminologies (for e.g. certain groups of taxa) needs to be handed over from a committee of a few to a community of as many as possible specialists.
The further development of ontologies includes two types of amendments: extensions and alterations of the vocabulary. Whilst the simple addition of terms to the ontology does not affect resultant data-sets, a change of relations of continuance terms within the ontology has profound effects on already existing data. A continuous development of ontologies parallel to their usage while ensuring the correct semantic relationships between terms and hence their seamless reliable functioning, is an unresolved challenge. The problem needs to be addressed by agreeing on well-defined versioning processes, which have to be followed strictly by both knowledge engineers governing the ontology development process and scientists and software developers processing references to concepts defined by the ontology.
Requirements for character matrices
A character matrix is the table of the different characteristic values determined for certain entities that are to be compared. Taxa are compared by examining, for example, their differential morphological characteristics. Two different purposes prevail: either to characterise and delimit taxa (taxonomic character matrix), or to draw conclusions about phylogeny and relationships of taxa (phylogenetic character matrix). A certain taxon set and character range given, the phylogenetic matrix contains only the (potentially) phylogenetically informative subset of characters of the taxonomic matrix. The latter is necessarily more comprehensive, including all characters that assist in describing and distinguishing a taxon from all morphologically similar taxa, whether related or not. Taxonomic character matrices and the underlying software have to meet growing demands regarding the usability, extensibility and interoperability.
Deans, Yoder, and Balhoff (Citation2012, 81) point out: “Semantic annotations (i.e. phenotype data)… should ultimately be attached to individual specimens rather than taxonomic concepts,” since this would be the only way to allow for automated reasoning about specimen identification and the development of “logically based taxon concepts … via a set of necessary and sufficient trait values.” Hence, the use of character matrices should be more than just the singular base for keys and descriptions. In future, aggregated structured morphological data-sets that have been collected specimen by specimen have to replace static taxon descriptions. To do so, the underlying matrices must be able to deal with different data scenarios for the transitional phase. They must be generic enough to combine atomised written descriptions with specimen-based data. For future usages, they must enable combining and evaluating matrices from different sources into a consensus matrix (see Borsch et al. Citation2015). Besides this merging functionality, the matrix and hence its data content must also be divisible. While every data-set appended adds to the taxonomic circumscription of the taxon, (a) data-set(s) must also be removable from the matrix by reallocating the respective data source (specimen), following e.g. changes in the taxonomic concept or when misidentifications have been revealed. The consensus data-set and potential products of it (automated description) must consequently be automatically modified accordingly (Kilian et al. Citation2015). Improving the functionality of character matrices would make them an important element in the demanded change to describe biodiversity (Deans, Yoder, and Balhoff Citation2012). And the individual organism preserved as a specimen would be given the central role in the taxonomic process.
Deans, Yoder, and Balhoff (Citation2012, 79) add: “Questions of phenotype correlations … could be answered on a large scale if fine-grained, semantic phenotype data were available that were connected to a phylogenetic classification and specimen information for all species.” A fundamental requisite for this is a virtual research environment that enables the storage and management of sample metadata and research data obtained from examined samples (Kilian et al. Citation2015), as already realised in the EDIT Platform for Cybertaxonomy. Starting from a taxonomically homogeneous sample taken (usually) in the field, specimens and every conceivable derivative sample of them (tissue samples, DNA-samples, etc.) can be stored as “units” in a structured hierarchy containing the respective (meta-)data (Berendsohn et al. Citation1999). This can be linked to a taxon that forms a node in a taxonomic backbone pertaining to a specific classification. The Common Data Model (CDM, Anonymous Citation2008; Müller et al. Citation2017) underlying the EDIT Platform software already includes the data structures needed for structured morphological character data of the character/character state type. It is important to note that the EDIT Platform is not intended to replace institutional specimen management databases. Rather, specimen data import and export methods are provided based on internationally agreed community data standards and protocols. For example, the system allows to query the Global Biodiversity Information Facility (GBIF, http://www.gbif.org) as well as individual BioCASE providers (Biological Collection Access Service, http://www.biocase.org) and to import specimen data compatible with the DarwinCore and ABCD Standards. Data export and re-integration into specimen data management platforms are facilitated via DarwinCore-Archive interfaces and BioCASe Provider Software installations.
Still missing in the CDM are the structures and their interrelationships as well as their relation to properties, as needed to fully support the three-part syntax as detailed above. Furthermore, the Platform to a certain extent lacks the functionality that makes it possible to enter, analyse and output structured descriptive data. This is the prerequisite for correlating such data dynamically with the taxon characterisation. An ongoing project funded by the German Research Foundation (DFG) aims at implementing these functions, including new user interfaces essential for an efficient workflow.
Building and using specimen-based character matrices from terminologies
Based on the operating surface of the Taxonomic Editor (Ciardelli et al. Citation2009) and the underlying CDM new GUIs (graphical user interfaces) are developed to realise the workflow that can be outlined as follows: (i) Sets of taxa are chosen that require a morphological examination. (ii) The morphological characters in question are assembled in a character matrix comprising characters and character states created by using an underlying, controlled vocabulary that refers to a generally accepted ontology. (iii) Characters are organised by relating them as properties to a morphological structure; the relationship and the structure also being semantically defined by the underlying vocabularies and ontologies. Since building the matrix and its components (characters and states) as well as assembling the structural relationships (the feature tree) is a laborious process, and since this may be re-used for other (related) taxa, it can be labelled and stored in the system. (iv) Data are taken from the individual specimens, either directly from the physical specimen, or, where appropriate for subsets of characters, from high-resolution specimen images as provided online by the herbaria, or from specific preparations of material from a specimens, such as scanning electron microscopic (SEM) micrographs. Whether the data are gathered manually or, as probably increasingly relevant in future, by computer vision systems, is outside the scope of the current workflow. (v) The individual descriptive data-sets gathered for each specimen are entered into a tabular character matrix (for data gathered by computer vision systems corresponding interfaces could be provided) where they are stored, linked to the respective source unit (an individual specimen or a derivative of it) in the sample hierarchy (see Kilian et al. Citation2015). (vi) The matrix is analysed to survey the morphological variability of the taxon in question and detect possible morphological disparities. (vii) Finally, the taxon character matrix is aggregated from specimen to taxon level and a tabular taxon characterisation based on all data content is produced. This aggregation step offers the possibility to split and merge data-sets (all the way down to the individual specimen) if taxonomic disparity is detected.
Implementation
Taxonomic character matrix and feature tree
Initially, an appropriate morphological character matrix has to be built, with the characters linked to the respective morphological structure, following the three-part syntax detailed above. The morphological structures are organised into a feature tree (see below).
Controlled vocabulary – One essential aspect of the workflow is the development, maintenance and usage of a vocabulary that is published via machine readable services (Figure A) and enhanced/expanded by the community via an editorial committee (Figure B).
Figure 1. Schematic overview of the workflow and the components used, as implemented on the EDIT Platform. A: Terminology service, B: Term Committee, C: CDM Store Database, D: Term Editor, E: Character Editor, F: Working Set, G: Matrix Editor. Modified from Plitzner et al. Citation2017.
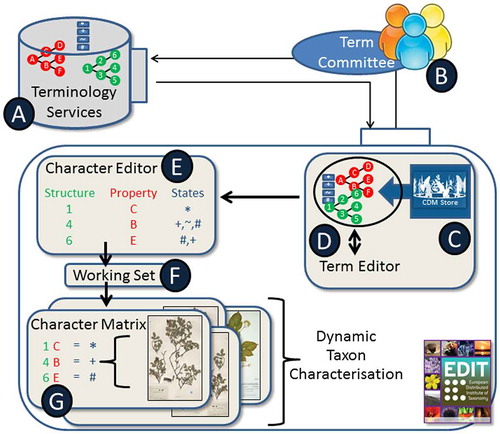
In an initial step, basic vocabularies that provide the baseline for the majority of morphological structures, their properties and their states commonly found throughout angiosperms will be imported from recognised ontologies (see above, in particular Plant Ontology: Cooper et al. Citation2013; Plant Glossary: Endara et al. Citation2017). As an exemplar group of plants that delivers sufficient data and use cases, the huge and morphologically heterogeneous plant order Caryophyllales has been chosen (Borsch et al. Citation2015). The idea is to provide a term ontologies compiled from existing sources for the Caryophyllales community and the means for a web-based community consensus process of editing and enriching this ontology with a focus on characterising the taxa of this order. The vocabulary will be hosted by the terminology services (Karam et al. Citation2016) developed in the context of the German Federation for Biological Data (GFBio, Diepenbroek et al. Citation2014). For using the vocabulary in the EDIT platform, its terms will be imported into the CDM for the matrix building process (Figure C).
Term list/ontology editing – It is to be expected that, in a morphologically diverse group such as the Caryophyllales, the imported basic vocabulary will soon meet its limits, depending on the subgroup under study. For example, a highly specialised vocabulary exists describing the specialised features of Cactaceae. In this case, it is inevitable and explicitly welcome to expand the vocabulary accordingly. To ensure an appropriate extension of the vocabulary, this should be done in a consensual process under participation of as many specialists as possible. The individual user proposes a term and puts it up for discussion by the community and final scrutiny by an authorised committee (Figure B). A web-based collaborative tool such as ThesauForm (Laporte, Mougenot, and Garniera Citation2012) can be used as a community platform to propose new terms and validate their definition, usage and possible integration into existing vocabularies. The management of all these processes (term-related processes detached from taxonomic work) will be bundled in a separate “TermEditor” (Figure D). Here, the user can look for and edit terms that are stored in a simple list, that can be searched and sorted using different criteria. This editor will also provide the interface to the Terminology Services and the interposed committee to expand/alter the sources of the vocabulary used (Figure A + B).
Feature tree assembly – A taxonomic character matrix is a tabular breakdown of characters and the respective states of the entities examined. An indispensable prerequisite for this is a list of characters that is either flat or, if more complex, structured in a useful way. Depending on the respective use case, only a fraction of the whole vocabulary will be used, so a tool to make a preselection is needed. A “FeatureTreeEditor” (not shown in Figure ) will be used to choose a subset of morphological structures needed. This editor will furthermore provide the functionality to organise the respective structures either in an ordered list or in a treelike structure to ease data entry and visibility. The second step is to combine the single structures with property and state terms to characters following the three-part-approach detailed above. Quantitative characters can be complemented by a unit and provide the option to enter an exact value, a range or furthermore a number of optional statistical values such as mean or standard deviation. In a “CharacterEditor,” the user can select the subsets assembled in the “FeatureTreeEditor” and link the terms for each part individually (Figure E). The resulting taxonomic character list can be stored either as a list or, if the subset for “structures” has been organised in some way, in accordance to that structure.
Working set
Analogous to the traditional way of analysing the taxonomy and systematics of a certain group of organisms, the taxa, the specimens investigated and the character set to be included in the analysis have to be selected and build the “working set” (Figure F). The initial taxonomic scope will be selected at the taxon level and will automatically include all sub-taxa belonging to the taxon and their corresponding specimens. Additional (and expandable) filters allow for outlining the “working set” using additional criteria such as geographic limitation or the limitation to certain taxonomic ranks. Potential further filter options might be implemented later if required by the users (e.g. exclusion of single taxa despite the rank filter, etc.). Also part of the working set is the selection of the respective character set intended to be applied in the final taxonomic character matrix. Either an already existing character set can be selected or the process of creating/extending such a set (see above) can be initiated.
Character matrix usage
Once all components have been selected, the taxonomic character matrix containing characters and specimens can be filled with the respective states and values. In the case of numerical characters, the user can make presets to determine how the values are entered and displayed. For example, values can be entered as a range with or without extremes and/or basic statistical values can be used such as mean or median. For the entry, editing and view of the data, the character list will be displayed in a separate tabular view, the “matrix editor,” that conveniently allows a clear representation of the data-sets (Figure G). Following the established style of other widely used applications the user might be accustomed to (e.g. Mesquite, Delta), the characters will be displayed in columns and specimens in rows, respectively. For improved usability and clarity, the table will provide several options to hide, group and order columns and rows. This, for example, allows to avoid displaying a large number of characters that are not relevant for some specimens and thus have no values. If values for a multitude of the same structure (e.g. leaves, stamens) from one specimen shall be treated individually, they can be stored as derivatives of the specimen, to preserve the individual values. An alternative under investigation is the storage in a separate document linked to the aggregated values as a reference (URI).
Automated taxon characterisations
A key product of the current implementation will be taxonomic characterisations generated dynamically from the aggregated character matrices of a certain taxon (Kilian et al. Citation2015). Initial aggregation is done continually in the matrix, as there will be the option to show a row that provides the aggregated values and character states recorded for the current specimen inventory. In this aggregation, categorical characters will be listed and numerical characters will be shown according to the presets (user configurations) made (e.g. range, statistical values, etc.). The character used for aggregation on taxon level can be redefined independently of its original use for specimens. Aggregation of individual character states allows further statistical analyses (average, SD). Furthermore, a quantitative character can be transformed into a categorical character as required for comparative separation e.g. keys or phylogenetic analysis. The values aggregated on taxon level will be displayed in a tabular summary listing the characters and their states. The resulting automated taxon characterisation is organised according to the structure of the underlying taxonomic character list.
Alterations in taxonomy/specimens/data
The individual data belonging to a specimen will always be linked to it and this fundamental connection cannot be changed. In the CDM, specimen data comprise the following components: the specimen itself, its metadata (e.g. accession number, creation date, creator, etc.), its factual/character data and position in the derivative hierarchy. This hierarchy is the result of the different steps of the scientific workflow applied. A derived unit is created for each of these steps and is permanently linked to its parent unit (Kilian et al. Citation2015). However, the assignment of a specimen to a certain taxon and the taxon as such may be subject to changes. Either due to misidentifications (specimen) or changes in the taxonomic concept applied (taxon). As a result, a specimen might have to be reassigned to another taxon and moved accordingly or a taxon is split or merged, a procedure that affects all related data too. In any case, the data stay with the specimen and are mandatorily moved accordingly. The automatically calculated taxon characterisation resulting from the bulk of data entered specimen-wise, will dynamically be adjusted subsequent to these operations. The same adjustment will take place every time a data-set grows by adding new specimen and their data additively.
Finally, an important functionality such a data retention allows, is the aggregation of the data-sets not only in the sense of a merging of similar matrices, but also the aggregation of data sets that have only partial overlap. This will allow for the interoperability of different character matrices beyond inconsistent methodological approaches and across hierarchical limits (Kilian et al. Citation2015). In taxonomy this is of special interest when defining higher taxa using the content of the matrices (i.e. the morphological scope) of its subordinate taxa. With proper algorithms, these aggregations can be performed at every level and may then be used to largely replace static taxon descriptions by adjustable taxon characterisations that automatically attune to the growing (or changing) basis of specimen they are persistently linked to via dynamic character matrices.
All system components are published as open source software based on the Mozilla Public Licence scheme (https://www.mozilla.org/en-US/MPL/). Although local installations of the EDIT Platform are technically possible, a typical setup involves an instance of an EDIT Platform server, at least one installation of the Taxonomic Editor, and publicly accessible setup of the Platform Portal and Web Service Layer. The service layer provides both an open platform independent and machine readable interface for all objects processed by the platform installation and a set of streamlined service endpoints for seamless integration into external information systems and workflows developed by the biodiversity informatics community.
Notes on contributors
Tilo Henning is a postdoctoral researcher in the Research Group Asterales at the Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. He works on the development of tools for cybertaxonomy. His botanical research interests reach from the systematics of Asteraceae and Urticaceae to the evolution and floral biology of Loasaceae.
Patrick Plitzner is a research assistant at the Biodiversity Informatics Research Group at the Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. He worked in several projects based on the EDIT platform. His main fields of work are software engineering, data modelling, data management and interface design.
Anton Güntsch is Head of the Biodiversity Informatics Research Group at the Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. His areas of expertise are Biodiversity Informatics, Information Systems and Knowledge Processing.
Walter G. Berendsohn heads the Dept. of Research and Biodiversity Informatics at the Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. A botanist by training, he has been involved in many projects and initiatives in the areas of taxonomic computing, biodiversity information standards and networking of biological collection information.
Andreas Müller is an information scientist and environmental engineer at Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. His research interest is taxonomic computing with a focus on taxonomic data modelling.
Norbert Kilian is Head of the Research Group Asterales at the Botanic Garden and Botanical Museum Berlin, Freie Universität Berlin. His main research interests are the systematics (phylogenetics and taxonomy) of Asteraceae, in particular of tribe Cichorieae, and the development of cybertaxonomy.
TH prepared the first draft of the manuscript and led the writing process together with NK. TH and PP prepared the figure. All authors participated in completing the manuscript with a special emphasis on those parts regarding their respective focal area.
Disclosure statement
No potential conflict of interest was reported by the authors.
Funding
Funding by the German Research Foundation (DFG, Deutsche Forschungsgemeinschaft, project title: “Achieving additivity of structured taxonomic character data by persistently linking them to preserved individual specimen,” funding code: 1175/2-1) is gratefully acknowledged.
Acknowledgements
The authors thank Naouel Karam and David Fichtmüller (Freie Universität Berlin) for discussing the publication of the additivity ontology via GFBio Terminology Services. The valuable comments made by two anonymous reviewers are gratefully acknowledged.
References
- Anonymous . 2008. Common Data Model. Last Accessed December 6, 2017. http://dev.e-taxonomy.eu/trac/wiki/CommonDataModel.
- Berendsohn, W. G. 2010. “Devising the EDIT Platform for Cybertaxonomy.” In Tools for Identifying Biodiversity: Progress and Problems. Proceedings of the International Congress, Paris, 20–22 September 2010 , edited by Pier Luigi Nimis and Regine Vignes-Lebbe , 1–6. Trieste: EUT Edizioni Università di Trieste.
- Berendsohn, W. G. , A. Anagnostopoulos , G. Hagedorn , J. Jakupovic , P. L. Nimis , B. Valdés , A. Güntsch , R. J. Pankhurst , and R. J. White . 1999. “A Comprehensive Reference Model for Biological Collections and Surveys.” Taxon 48: 511–562.10.2307/1224564
- Berendsohn, W. G. , A. Güntsch , N. Hoffmann , A. Kohlbecker , K. Luther , and A. Müller . 2011. “Biodiversity Information Platforms: From Standards to Interoperability.” ZooKeys 150: 71–87. doi:10.3897/zookeys.150.2166.
- Borsch, T. , P. Hernández-Ledesma , W. G. Berendsohn , H. Flores-Olvera , H. Ochoterena , F. O. Zuloaga , S. von Mering , and N. Kilian . 2015. “An Integrative and Dynamic Approach for Monographing Species-Rich Plant Groups – Building the Global Synthesis of the Angiosperm Order Caryophyllales.” Perspectives in Plant Ecology, Evolution and Systematics 17: 284–300.10.1016/j.ppees.2015.05.003
- Ciardelli, P. , P. Kelbert , A. Kohlbecker , N. Hoffmann , A. Güntsch , and W. G. Berendsohn . 2009. “The EDIT Platform for Cybertaxonomy and the Taxonomic Workflow: Selected Components.” Springer Lecture Notes in Informatics (LNI) 154: 625–638.
- Cooper, L. , R. L. Walls , J. Elser , M. A. Gandolfo , D. W. Stevenson , B. Smith , J. Preece , et al . 2013. “The Plant Ontology as a Tool for Comparative Plant Anatomy and Genomic Analyses.” Plant and Cell Physiology 54 (2): 1–23. doi:10.1093/pcp/pcs163.
- Dahdul, W. M. , J. P. Balhoff , J. Engeman , T. Grande , E. J. Hilton , C. Kothari , et al . 2010. “Evolutionary Characters, Phenotypes and Ontologies: Curating Data from the Systematic Biology Literature.” PLoS ONE 5 (5): e10708. doi:10.1371/journal.pone.0010708.
- Dallwitz, M. J. 1980. “A General System for Coding Taxonomic Descriptions.” Taxon 29: 41–46.10.2307/1219595
- Dallwitz, M.J. , and T.A. Paine . 1992+. Definition of the Delta Format. http://www.delta-intkey.com/www/standard.htm
- Deans, R. A. , M. J. Yoder , and J. P. Balhoff . 2012. “Time to Change How we Describe Biodiversity.” Trends in Ecology and Evolution 27 (2): 78–84. doi:10.1016/j.tree.2011.11.007.
- Diederich, J. 1997. “Basic Properties for Biological Databases: Character Development and Support.” Mathematical and Computer Modelling 25: 109–127.10.1016/S0895-7177(97)00078-2
- Diepenbroek, M. , F. Glöckner , P. Grobe , A. Güntsch , R. Huber , B. König-Ries , I. Kostadinov , et al. 2014. “Towards an Integrated Biodiversity and Ecological Research Data Management and Archiving Platform: The German Federation for the Curation of Biological Data (GFBio).” Lecture Notes in Informatics (LNI) – Proceedings 232: 1711–1724.
- Endara, L. , H. A. Cole , J. G. Burleigh , N. S. Nagalingum , J. A. Macklin , J. Liu , S. Ranade , and H. Cui . 2017. “Building the ‘Plant Glossary’—A Controlled Botanical Vocabulary using Terms Extracted from the Floras of North America and China.” Taxon 66 (4): 953–966 https://doi.org/10.12705/664.9 10.12705/664.9
- Funk, V. , P. Hoch , L. Prather , and W. Wagner . 2005. “The Importance of Vouchers.” Taxon 54: 127–129 https://doi:10.2307/25065309.10.2307/25065309
- Groom, Q. , R. Hyam , and A. Güntsch . 2017. “Data Management: Stable Identifiers for Collection Specimens.” Nature 546: 33. doi:10.1038/546033d.
- Güntsch, A. , R. Hyam , G., Hagedorn , S. Chagnoux , D. Röpert , A. Casino , G. Droege , et al . 2017. Actionable, Long-Term Stable and Semantic Web Compatible Identifiers for Access to Biological Collection Objects. Database 2017 (1): bax003. doi:10.1093/database/bax003.
- Hagedorn, G. 2007. Structuring Descriptive Data of Organisms – Requirement Analysis and Information Models . PhD diss. Universität Bayreuth.
- Hagedorn, G. , and G. Rambold . 2000. “A Method to Establish and Revise Descriptive Datasets over the Internet.” Taxon 49: 517–528.10.2307/1224347
- Hagedorn, G. , K. Thiele , R. Morris , and P. B. Heidorn . 2005. Structured Descriptive Data (SDD) w3c-xml-schema, Version 1.0. Biodiversity Information Standards (TDWG). http://www.tdwg.org/standards/116
- Heberling, J. M. , and B. L. Isaac . 2017. “Herbarium Specimens as Exaptations: New Uses for Old Collections.” American Journal of Botany 104 (7): 963–965.10.3732/ajb.1700125
- Jaiswal, P. 2011. “Gramene Database: A Hub for Comparative Plant Genomics.” In Plant Reverse Genetics , edited by Andy Pereira , 247–275. Totowa, NJ: Humana Press.10.1007/978-1-60761-682-5
- Karam, N. , C. Müller-Birn , M. Gleisberg , D. Fichtmüller , R. Tolksdorf , and A. Güntsch . 2016. “A Terminology Service Supporting Semantic Annotation, Integration, Discovery and Analysis of Interdisciplinary Research Data.” Datenbank-Spektrum 16 (3): 195–205. doi:10.1007/s13222-016-0231-8.
- Kattge, J. , S. Díaz , S. Lavorel , I. C. Prentice , P. Leadley , G. Bönisch , E. Garnier , et al . 2011. “TRY – A Global Database of Plant Traits.” Global Change Biology 17: 2905–2935. doi:10.1111/j.1365-2486.2011.02451.x.
- Kilian, N. , T. Henning , P. Plitzner , A. Müller , A. Güntsch , B. C. Stöver , K. F. Müller , W. G. Berendsohn , and T. Borsch . 2015. “Sample Data Processing in an Additive and Reproducible Taxonomic Workflow by Using Character Data Persistently Linked to Preserved Individual Specimens.” Database 2015: 1–19. doi:10.1093/database/bav094.
- Laporte, M.-A. , I. Mougenot , and E. Garniera . 2012. “ThesauForm – Traits: A Web Based Collaborative Tool to Develop a Thesaurus for Plant Functional Diversity Research.” Ecological Informatics 11: 34–44. doi:10.1016/j.ecoinf.2012.04.004.
- Lebbe, J. , R. Vignes , and J. P. Dedet . 1989. “Computer-Aided Identification of Insect Vectors.” Parasitology Today 5 (9): 301–304.10.1016/0169-4758(89)90025-2
- Lucidcentral . 1999+. Lucidcentral. http://www.lucidcentral.org
- Maddison, W. P. , and D. R. Maddison . 2014. Mesquite: A Modular System for Evolutionary Analysis, version 3.01. Last Accessed January, 2017. http://mesquiteproject.org.
- Müller, A. , W. G. Berendsohn , A. Kohlbecker , A. Güntsch , P. Plitzner , and K. Luther . 2017. “A Comprehensive and Standards-Aware Common Data Model (CDM) for Taxonomic Research.” Biodiversity Information Science and Standards 1: e20367. doi:10.3897/tdwgproceedings.1.20367.
- Mungall, C. J. , G. V. Gkoutos , C. Smith , M. Haendel , S. Lewis , and M. Ashburner . 2010. “Integrating Phenotype Ontologies across Multiple Species.” Genome Biology 11: R2.10.1186/gb-2010-11-1-r2
- Pankhurst, R. J. 1970. “Key Generation by Computers.” Nature 227: 1269–1270.10.1038/2271269a0
- Pankhurst, R. J. 1972. “A Method for Data Capture.” Taxon 21: 549–558.
- Plitzner, P. , T. Henning , A. Müller , A. Güntsch , N. Kilian , and N. Karam . 2017. “Bottom-up Taxon Characterisations with Shared Knowledge: Describing Specimens in a Semantic Context.” Proceedings of the 2nd International Workshop on Semantics for Biodiversity co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 22.
- Pullan, M. R. , M. F. Watson , J. B. Kennedy , C. Raguenaud , and R. Hyam . 2000. “The Prometheus Taxonomic Model: A Practical Approach to Representing Multiple Classifications.” Taxon 49: 55–75.10.2307/1223932
- Pullan, M. R. , K. E. Armstrong , T. Paterson , A. Cannon , J. B. Kennedy , M. F. Watson , S. McDonald , and C. Raguenaud . 2005. “The Prometheus Description Model: An Examination of the Taxonomic Description-Building Process and Its Representation.” Taxon 54: 751–765.10.2307/25065431
- Sokal, R. R. , and P. H. A. Sneath . 1963. Principles of Numerical Taxonomy . San Francisco: Freemon & Co.
- Soltis, P. 2017. “Digitization of Herbaria Enables Novel Research.” American Journal of Botany 104 (9): 1281–1284.10.3732/ajb.1700281
- Thiers, B. 2017. The World’s Herbaria 2016: A Summary Report Based on Data from Index Herbariorum. Accessed March 13, 2017. http://sweetgum.nybg.org/science/ih/
- Ung, V. , F. Causse , and R. Vignes-Lebbe . 2010. “Xper2: Managing Descriptive Data from their Collection to E-Monographs.” In Tools for Identifying Biodiversity: Progress and Problems. Proceedings of the International Congress, Paris, 20–22 September 2010 , edited by Pier Luigi Nimis and Regine Vignes-Lebbe , 113–120. Trieste: EUT Edizioni Università di Trieste.
- Walls, R. L. , B. Athreya , L. Cooper , J. Elser , M. A. Gandolfo , P. Jaiswal , C. J. Mungall , et al . 2012. “Ontologies as Integrative Tools for Plant Science.” American Journal of Botany 99 (8): 1263–1275. doi:10.3732/ajb.1200222.
- Willis, C. G. , E. R. Ellwood , R. B. Primack , C. C. Davis , K. D. Pearson , A. S. Gallinat , J. M. Yostet , et al . 2017. “Old Plants, New Tricks: Phenological Research Using Herbarium Specimens.” Trends in Ecology & Evolution 32 (7): 531–546. doi:10.1016/j.tree.2017.03.015.