
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Minimally invasive laparoscopic surgery is associated with small wounds and short recovery time, reducing postoperative infections. Traditional two-dimensional (2D) laparoscopic imaging lacks depth perception and does not provide quantitative depth information, thereby limiting the field of vision and operation during surgery. However, three-dimensional (3D) laparoscopic imaging from 2 D images lets surgeons have a depth perception. However, the depth information is not quantitative and cannot be used for robotic surgery. Therefore, this study aimed to reconstruct the accurate depth map for binocular 3 D laparoscopy. In this study, an unsupervised learning method was proposed to calculate the accurate depth while the ground-truth depth was not available. Experimental results proved that the method not only generated accurate depth maps but also provided real-time computation, and it could be used in minimally invasive robotic surgery.
1. Introduction
Laparoscopic surgery (LS) has many advantages, such as less bleeding and faster recovery, compared with open surgery. LS is now widely used in abdominal surgery, for example, removal of liver tumors, resection of uterine fibroids, and so on. The surface reconstruction of soft-tissue and organs is an important part of minimally invasive surgery. Traditional two-dimensional (2D) laparoscopy has shortcomings in spatial orientation and identification of anatomical structures. Three-dimensional (3D) laparoscopy has greatly improved the shortcomings of 2D laparoscopy. It not only provides surgeons with a visual depth perception but also quantitative depth information for surgical navigation and robotic surgery. In binocular stereoscopic 3D imaging, accurate registration of depth maps and abdominal tissue is an important technical component of minimally invasive robot-assisted surgery. The binocular stereo depth estimation has become a hot research spot in many countries.
At present, the binocular 3D reconstruction method of soft-tissue surface can be roughly divided into three categories: stereo matching, simultaneous localization and mapping (SLAM), and neural network.
Stereo matching mainly uses feature point matching or block matching to perform 3 D reconstruction matching calculation and reconstructs a 3D scene according to image feature points or blocks. Penza et al. [Citation1] used a modified census transform to calculate the similarity to find the matching regions corresponding to the left and right images, and optimized disparity maps using the super-pixel method for 3D reconstruction. Luo et al. [Citation2] compared the similarity of the color and gradient of the two images of the left and right laparoscopies to find the best-matching feature area and used the bilateral filtering method to optimize the disparity map for 3D reconstruction. However, the time complexity of this kind of 3D reconstruction method was high, but the depth map accuracy was not high.
Most SLAM algorithms achieve interframe estimation and closed-loop detection by feature point matching. For example, Mahmoud et al. [Citation3] proposed an improved parallel tracking and mapping method based on the ORB-SLAM to find new key-frame feature points for 3D reconstruction of porcine liver surface. However, its accuracy was not high.
Laparoscopic 3D reconstruction studies based on neural network are few, and most studies focused on natural scenes. Luo et al. [Citation4] transformed natural scene images into matching blocks for 3D reconstruction. Antal [Citation5] used each feature point of the two images of the left and right hepatic body membranes. The intensity values formed a set of 3D coordinates as the inputs, while the depth image was calculated by a supervised learning neural network method. Zhou et al. [Citation6] jointly trained a monocular disparity prediction network using an unsupervised convolutional neural network and camera pose estimation networks, and these two networks were combined to compute an unsupervised depth prediction network. Garg et al. [Citation7] used the Alexnet network structure [Citation8] to predict the monocular depth image and replace the last layer with a convolution layer to reduce the training parameters. The first two methods were deep predictive networks using supervised learning. The latter two methods used deep predictive networks for unsupervised learning.
Unsupervised learning is more suitable for LS in-depth prediction networks because the ground-truth depth map for laparoscopic soft-tissue and organs is difficult to obtain.
2. Methods
The experimental data for this study came from the Hamlyn Center Laparoscopic/Endoscopic Video Datasets [Citation9]. In this study, the residual network was used to predict the depth map of the soft-tissue surface under LS for the first time. This method was an end-to-end approach where the input was a pair of calibrated stereo images and the output was the corresponding depth image. An unsupervised learning-based binocular dense depth estimation network was trained on unlabeled calibrated laparoscopic binocular stereo image sequence data. The predicted depth image was generated directly when the testing calibrated dataset was input to the trained model.
2.1. Binocular depth estimation network
A nonlinear auto-encoder model was trained to estimate the depth map corresponding to a pair of RGB images. The flowchart of the unsupervised binocular depth estimation network is illustrated in . First, given the calibrated stereo image pairs IL and IR to the auto-encoder network, the corresponding disparity maps (inverse depth) DL and DR were calculated. The spatial transformer network (STN) [Citation10] was used for bilinear sampling DL (DR) to generate IL* (IR*). The image reconstruction process is illustrated with straight lines and the loss function establishment with dashed lines in .
Figure 1. Unsupervised binocular depth estimation network.
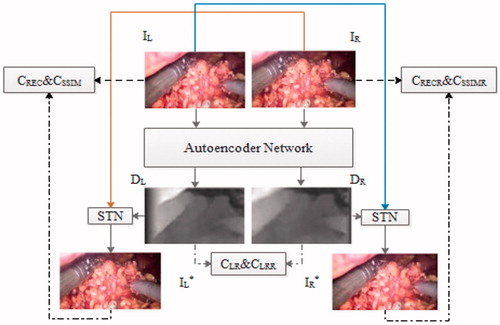
The auto-encoder network comprised two parts: encoder network and decoder network. The encoder network was inspired by the methods described in previous studies [Citation11–13]. The deeper bottleneck architectures [Citation14] were adopted for the Resnet101 encoder network, and the last layer of the fully connected layer was removed to reduce the number of parameters. The encoding network architecture is summarized in . The architecture with multiscale and skip plus [Citation15] was used in the decoder network part. The method discussed in previous studies [Citation6, Citation9] was used in the disparity acquisition layer. The sigmoid activation function was used in the convolution layer to obtain the depth image.
Table 1. Encoder and decoder part.
2.2. Binocular depth estimation loss function
The loss function was minimized to train the unsupervised binocular depth estimation network. The loss function included three parts. The first part was the left–right consistency loss of the error calculated by the L1 metric CLR between the predicted left disparity DL and right disparity DR, where (i, j) is the pixel index of the image:
(1)
(1)
The second part was the structural similarity loss CSSIM (where SSIM is the structural similarity index) of the error between the input image and the reconstruction image (the right counterpart is CSSIMR)
(2)
(2)
The third part was the reconstruction error loss between the input image IL(i,j) and the reconstruction image IL*(i, j) (the right counterpart isCRECR):
(3)
(3)
Four layers of loss function occurred at different scales, and the scale factor was 2. The total loss function was as follows, and α = β = λ = 1.
(4)
(4)
2.3. Training details
An unsupervised binocular depth estimation method was implemented using the TensorFlow framework on Nvidia Tesla P100 GPU (16 GB). An exponential activation function was used in each convolution and deconvolution except for convolution to obtain the disparity map. The Adam optimizer was used. The network had 50 epochs on the training datasets, and the initial learning rate was set to 10-4. The batch sizes were 16, and the total training time was about 8 h. The images were resized to 256 × 128 to reduce the computational time. The number of parameters was about 9.5 × 107.
3. Results
The unsupervised binocular Resnet network depth estimation method was compared with the basic [Citation14] (unsupervised single convolutional neurla network CNN) and Siamese [Citation14] (unsupervised binocular CNN) methods illustrated in . The higher intensity meant that the distance to the camera was closer.
Figure 2. Example results of the three methods. The left two columns are the input images; the third column is the Siamese result; the fourth column is the Basic result; and the last column is the result of this study. Green boxes indicate comparisons of different results under the same organization.
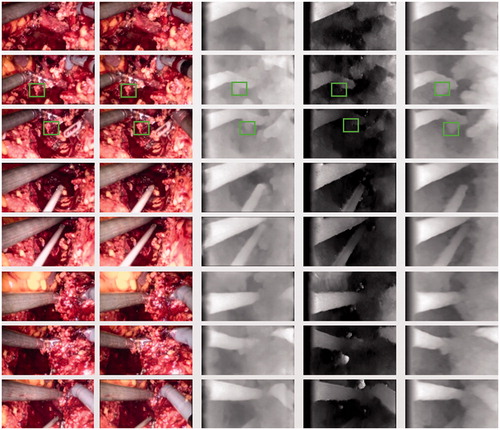
No ground-truth result was available for the dataset. Therefore, the performance was compared with all published results, and the best results were taken as the ground-truth result for evaluation using SSIM and the peak signal-to-noise ratio (PSNR). The average evaluation value of the 7191 pairs of calibrated stereo images in the testing set was evaluated. The results are described in . The time for generating the predicted depth image was about 16 ms.
Table 2. Comparison of evaluation results between the basic and the methods used in this study.
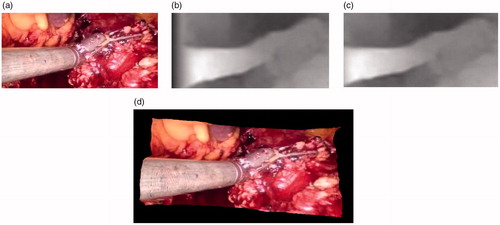
The 3D reconstruction was performed on the left image with the corresponding disparity map and the internal and external parameters of the left camera of the 3D laparoscopy. In the process of 3D reconstruction, an error appeared on the left side of the disparity map due to the occlusion of the laparoscopy, as shown in . We cut the occluded part and the remaining part is shown in Figure 3(c), and the remaining part is reconstructed as shown in Figure 3(d).
Figure 3. An example of 3 D reconstruction. (a) Left image. (b) Disparity map. (c) Post-processing. (d) 3 D reconstruction.
4. Discussion
The results of the present study were found to be better than those obtained using basic methods and similar to those obtained using the Siamese method ( and ). For example, the green boxes in show a whole piece of prominent human tissue. The right half of the tissue is covered with blood, indicating that the tissue was at the same distance from the camera and had same brightness. The result correctly shows the depth map of the covered part.
In the 3D reconstruction in , only pixels were mapped to color in the left image to spatial 3D coordinates, showing the correctness of the estimated depth values and the superiority of the 3D reconstruction results.
5. Conclusions
In this study, a novel end-to-end depth prediction network method was proposed for laparoscopic soft-tissue 3D reconstruction. The residual network was first used in the depth estimation of binocular laparoscopic soft-tissue surface to generate better dense prediction depth maps. The time to generate a map was only 16 ms, which could fulfill the real-time display requirements of real surgical scenes because the calculation of the depth images was the most time-consuming part of the 3D reconstruction.
The future studies would train abdominal soft-tissue surface depth estimation networks through transfer learning and ensemble learning with fine-tuning, enhancing the robustness and accuracy further.
Additional information
Funding
7. References
- Penza V, Ortiz J, Mattos LS, et al. Dense soft tissue 3D reconstruction refined with super-pixel segmentation for robotic abdominal surgery. Int J Cars. 2016;11:197–206.
- Luo XB, Jayarathne UL, Pautler SE, et al. Binocular endoscopic 3-D scene reconstruction using color and gradient-boosted aggregation stereo matching for robotic surgery. In: Zhang Y-J, editor. ICIG 2015, Part I, LNCS 9217: 2015. p. 664–676. Springer, Charm, Switzerland.
- Mahmoud N, Cirauqui I. ORBSLAM-based endoscopic tracking and 3D reconstruction. In: Peters T et al. (Eds.), International workshop on computer-assisted and robotic endoscopy. 2016. p. 72–83. Springer, Charm, Switzerland.
- Antal B. Automatic 3D point set reconstruction from stereo endoscopic images using deep neural networks. In: Ahrens A and Benavente-Peces C (Eds.), Proceedings of the 6th International Joint Conference on Pervasive and Embedded Computing and Communication Systems. 2016. p. 116–121. SciTePress, Setubal, Portugal.
- Luo WJ, Chwing AGS. Efficient deep learning for stereo matching. In: Tuytelars T et al. (Eds.),IEEE, Inc., IEEE Conference on computer Vision and Pattern Recongnition. 2016. p. 5695–5713. Los Alamitos, CA, USA.
- Zhou TH, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video, In: Chellappa R et al. (Eds.) IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017. p. 6612–6619. IEEE, Inc., Los Alamitos, CA, USA.
- Garg R, Vijay Kumar BG, Carneiro G, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue. In: Leibe B et al (Eds.). European Conference on Computer Vision. 2016. p. 740–756. Springer, Charm, Switzerland.
- Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In: Pereira F et al. (Eds.) International Conference on Neural Information Processing Systems. 60(2):1097–1105. 2012. Curran Associates, Inc., Red Hook, NY, USA.
- Ye M, Johns E, Handa A, et al. Self-supervised Siamese learning on stereo image pairs for depth estimation in robotic surgery. In: Yang G-Z (Eds.) Proceedings of the Hamlyn Symposium on Medical Robotics. 2017. p. 27-28. Imperial College London and the Royal Geographical Society, London, UK. 2017. arXiv preprint arXiv:1705.08260.
- Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks. In: Cortes C et al. (Eds.) Advances in Neural Information Processing Systems 28. 2015. p. 2017–2025. Curran Associates, Inc., Red Hook, NY, USA.
- Mayer N, Ilg E, Hausser P, et al. A large dataset to train convolution networks for disparity, optical flow, and scene flow estimation. In: Tuytelaars T et al. (Eds.). IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 4040–4048. IEEE, Inc., Los Alamitos, CA, USA.
- Milletari F, Navab N, Ahmadi SA. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In: Savarese S (Eds.) Fourth International Conference on 3D Vision (3DV). 2016. p. 565–571. IEEE, Inc., Los Alamitos, CA, USA. arXiv preprint arXiv:1704.07813.
- Eigen D, Puhrsch C, Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In: Ghahramani Z et al. (Eds.) Advances in Neural Information Processing Systems 27. 2014. p. 2366–2374. Curran Associates, Inc., Red Hook, NY, USA
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: Bischof H et al. (Eds.) IEEE Conference on computer Vision and Pattern Recognition. 2015. p. 770–778. IEEE, Inc., Los Alamitos, CA, USA.
- Godard C, Aodha OM, Brostow GJ. Unsupervised monocular depth estimation with left-right consistency. In: Chellappa R et al. (Eds.). IEEE Conference on Computer Vision and Pattern Recognition. 2017. p. 6602–6611. IEEE, Inc, Los Alamitos, CA, USA.