
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Accurately detecting human trafficking is particularly challenging due to its covert nature, difficulty in distinguishing trafficking from non-trafficking exploitative conditions, and varying operational definitions. Typically, detecting human trafficking requires resource-intensive efforts from resource-constrained anti-trafficking stakeholders. Such measures may need personnel training or machine learning-based identification technologies that suffer from detection errors. Repeated usage of such measures risks biasing detection efforts and reducing detection effectiveness. Such problems raise the question: “How should imperfect detection resources be allocated to most effectively identify human trafficking?” As an answer, we construct a class of resource allocation models that considers various optimal allocation scenarios. These scenarios range from optimal location selection for monitoring to optimal allocation of a finite set of imperfect resources, given error rates. We illustrate the applicability of these models across both human and technology-facilitated detection contexts at the India–Nepal border and in the global seafood industry. Insights from our models help inform operational strategies for allocating limited anti-human trafficking resources in a way that effectively preserves human rights and dignity.
1. Introduction
Human Trafficking is a complex problem that impacts society, transcends territorial boundaries, and threatens fundamental human rights. It is defined as the commercial exchange and exploitation of individuals for monetary gain or other benefits using force, fraud, or coercion (106th Congress, Citation2000). It occurs in various sectors, including construction, agriculture, fishing, fashion, hospitality, restaurants, entertainment, and commercial sex (International Labour Organization (ILO) and Walk Free Foundation, Citation2017; Dank et al., Citation2021). Human trafficking does not have to include migration; some trafficking groups have trans-continental networks to transfer victims and items created with trafficked labor, while others exploit victims inside their communities.
Effectively and efficiently detecting human trafficking is challenging (see ). Human trafficking operations are covert similar to other criminal supply networks, but they pose additional challenges. For instance, proving the force, fraud, and coercion elements of human trafficking are more complex than verifying whether a substance is an illicit drug. Since exploitation occurs over various working conditions, from “good employment” to long hours with health dangers (International Labour Organization, Citation2013), it can be challenging to distinguish trafficking from other exploitative labor conditions. These difficulties are exacerbated by labor trafficking happening in various labor sectors. Detection technologies or screening questionnaires must be customized to the labor sector, geographical, and cultural setting. However, many organizations executing such detection initiatives are resource-constrained and must allocate limited resources to the most compelling locations.
Table 1. A summary of the major challenges related to Human Trafficking Detection (Okech et al., Citation2018).
Table 2. Summary of sets and parameters for the models described in this section.
Such detection resources can be technological (such as satellites to monitor deep sea fishing vessels) or human (such as nonprofit workers trained to identify signs that someone may be trafficked). Human biases and prejudices can lead to poor detection findings, whereas advanced technologies may have a bias in their detection algorithms (Obermeyer et al., Citation2019). Regional attitudes and biases towards traffickers and their victims substantiate claims of problems in trafficking detection and likely human rights violations (Rojas et al., Citation2020). Thus, although specific resources may be better at detecting trafficking in particular contexts, no resource can perfectly detect human trafficking in all situations.
This article presents a framework for a reliable detection resource allocation mechanism that decreases the risk of false positive and false negative errors. Our approach constructs the problem as a stochastic mixed-integer programming problem to identify where detection resources should be deployed on a graph (nodes or edges). We prove the model’s applicability to several trafficking scenarios (involving differing modes of flows across heterogeneous terrains, such as sea or land) and multiple detection strategies (human- and technology-based). Specifically, we consider two case studies: (i) using Global Fishing Watch satellite data to detect fishing vessels using exploited labor, and (ii) using Love Justice International’s transit monitoring method, which focuses on trained employees to identify potential human trafficking as people pass the India–Nepal border. Our models enable stakeholders to keep improving their (imperfect) detection systems and offer solutions to some of the biggest problems in detecting human trafficking. Further, our resource allocation models address proactive rather than reactive detection strategies, minimizing errors when detecting trafficking among typically legal activities (e.g., migration, fishing).
Overall, our contributions can be summarized as follows:
We formulate and define a novel class of optimum detection resource allocation problems that minimize errors while ensuring a pre-determined amount of trafficking detection. The fundamental focus of these problems is to balance the trade-offs between deploying more and better resources to detect human trafficking and reducing detection errors. Further, we include hard and soft constraints in the problem formulation, so allocation decisions reflect on-ground anti-trafficking realities.
We provide policy recommendations and stakeholder analysis of specific anti-trafficking scenarios. Specifically, we help two large non-governmental organizations combat human trafficking in different geographic regions and make policy decisions. Our insights aim to improve the efficiency of operations (e.g., resources employed for trafficking detection) by these organizations without increasing costs or compromising quality.
The remainder of this article is as follows. In Section 2 we present an overview of the current literature on solving human trafficking problems using Operational Research (OR) techniques and detection error minimization challenges. In Section 3 we present the class of resource allocation models that consider minimizing detection errors. Within each model definition we present evidence of its complexity and explain the utility of its solutions to stakeholders. In Section 4 we apply the established class of models to two specific case studies – Global Fishing Watch and Love Justice International. In Section 5 we discuss insights from our case studies and how our work complements past detection strategies of stakeholders dealing with human trafficking. Finally, in Section 6 we discuss limitations of our approach, extensions, and next steps.
2. Literature review
This article contributes to two areas: OR applied to anti-human trafficking efforts and building enhanced human, and machine-based decision-making systems focused on decreasing detection mistakes.
2.1. OR and human trafficking
Recent work on applying OR to address human trafficking (Caulkins et al., Citation2019; Anzoom et al., Citation2022) has focused on two significant areas: resource allocation and network optimization. Specifically, on the resource allocation front, Maass et al. (Citation2020) considers optimizing the location of shelters for trafficking survivors given locational and budget constraints. Further, Konrad (Citation2019) considers the problem of designing awareness campaigns by using a resource allocation model that determines how to optimize fund allocations so that at-risk people become more aware of human trafficking signs and indications. On the network optimization front, Kosmas et al. (Citation2022) considers a new class of interdiction problems where, after the attacker has made their interdiction decisions, the defender can add new arcs to the network. Their initial findings indicate that judgments taken on a typical max-flow interdiction problem are strongly impacted by post-attack network reorganization. Additionally, Tezcan and Maass (Citation2023) considers a formulation of the typical max-flow problem, wherein the edge-capacity parameter represents the trafficker’s desire to traverse network segments. The anti-human trafficking stakeholder’s purpose is to engage resources in network detection and intervention to decrease the trafficker’s anticipated maximum network utility.
A recent survey by Dimas, Konrad, Lee Maass and Trapp (Citation2022) identified 142 OR and analytics papers published on human trafficking and noted that nearly half of them (69 papers, totaling ) were related to “inferential statistics/detection.” One-hundred-five publications were analytics-related, 15 were thought pieces/position papers, and 22 were OR studies. The analytics articles focus on machine learning classification methods and online commercial sex ads analysis. Our article considers resource allocation to improve human trafficking detection in human-machine-driven systems and answers questions at the intersection of classification algorithms (machine intelligence) and allocation decision-making, such as: How can algorithmic intelligence errors be minimized using past data?
2.2. Human–machine collaboration systems
Technology innovations aim to free up decision-makers’ time to focus on more creative work by automating routine tasks (Mitev et al., Citation2018). This fundamental principle has permeated not only re-imagining typical jobs in the business (e.g., scheduling, shop-floor processes) (Klumpp, Citation2018) but also tackling more complex and error-prone tasks such as detecting hate speech, harmful content, and human trafficking utilizing satellite or drone photography (Kougkoulos et al., Citation2021).
Past work (Haesevoets et al., Citation2021; Zhou and Liu, Citation2021) in this space has focused on how automated systems should be audited to improve their performance. This is important since automation initiatives often start with a collection of characteristics or attributes (Zhou et al., Citation2021). As time passes and the human element (decision-maker) gets experience with the automated system’s surroundings, system objectives and inputs will change (Zhang et al., Citation2022). For the decision-maker, accumulating experience means changing demands and expectations from the automation, adding features, or tuning existing ones to boost performance to desired, updated levels (Kilinc et al., Citation2021). Among these objectives is the necessity to reduce any biases or inaccuracies in initially tuned parameters, due to the decision maker’s innate bias or fixed environmental influences (e.g., institutional structures such as laws, locational constraints such as climate). Recent research (Alahmadi et al., Citation2022) has examined circumstances where biases or errors must be rectified to improve system function.
We concentrate on human-driven human trafficking detection systems. We contribute to tackling the problem of bias and inaccuracy in human trafficking detection, especially when employing technology (e.g., satellites or mobile phones).
3. Resource allocation error minimization models
We represent the network of human trafficking activity as a graph where each node
represents some population unit (e.g., a city, locality, shipping vessel, etc.). The edge set E represents connections between population units (e.g., transportation routes between these nodes), signifying flow (e.g., traffic) across the nodes. The graph-based representation focuses on the structure of human trafficking network relationships and interactions (Newman, Citation2018). Network representation and analysis help measure trafficking network relationships and find structures (e.g., individuals, groups, paths) that assist or obstruct movement (e.g., monetary, information, trafficking) (Konrad et al., Citation2017). Depending on the situation—border area, ships at sea, city safe shelters—the graph is constructed to generate policy analysis and experiments. For instance, cities near an international border may be nodes; consequently, node and edge weights could represent connected roads with city residents and travelers, respectively (Section 4.2 considers a similar case). Complex geographical areas, such as ships docking and traveling at sea, may require more stylized graphs (Section 4.1 considers a similar case). In any case, once a representative graph is appropriately defined based on the scenario under consideration (see Section 4), human trafficking detection resources can be optimally allocated on graph nodes and edges by solving the relevant allocation-optimization problem.
Within G, nodes and edges
are weighted to indicate population
on nodes and traffic flow
on edges. The proportion of trafficking on nodes (
) and edges (
) is uncertain. Let
be the set of all possible combinations of
and
and let
represent an uncertainty scenario. Given
a policymaker considers a distribution on the trafficking proportions
and allocates detection resources on nodes and edges that minimizes the expected detection errors (type-I and II), subject to financial and detection threshold constraints: the minimum threshold of trafficking activity to be identified and an upper limit on incorrectly labeling a non-trafficking activity as a trafficking activity. Using this setting, we provide a base model () with four variants () that minimize detection errors in resource allocation problems.
Table 3. Summary of the proposed human trafficking detection models.
3.1. Base model
We begin by giving an overview of our stochastic programming problem followed by the complexity analysis and solution approach. Human trafficking detection efforts have primarily focused on indicators such as the traffickers’ social circle size, observable social inhibitions, physical conditions, and social interactions (Konrad et al., Citation2017). Human observers or algorithms in deployed detection systems can make such judgments. Any such detection system, however, is known to have a True Positive Rate (TPR), denoted by and a True Negative Rate (TNR), denoted by
Such rates may vary by location. Specifically, environmental constraints (e.g., terrain difficulty, spatial population density) or area-specific factors (e.g., cultural norms, traditions) might increase or decrease the accuracy of the detection mechanisms. Thus, such error rates may be node (i.e.,
) or edge (i.e.,
) specific.
Establishing the TPR or TNR in human trafficking detection is a notably complex task (Farrell and de Vries, Citation2020). These rates are considered to take a range of values based on which the anti-trafficking decision-maker may set a goal of detecting at least K units (e.g., the total number of traffickers and victims) of the trafficking activity in an area. We use ‘trafficking activity’ to mean both traffickers and victims. We later differentiate between traffickers and victims in DTRAP-TV (refer to and Appendix Section E). Further, building on practical scenarios that consider allocating resources to trafficking activity-prone areas, the base model begins by considering the selection of nodes and edges on G to allocate resources with given error rates. Model variants subsequently consider allocation problems of varying complexity (refer ).
Overall, while being strategic, the resource allocation decisions are not straightforward. Detection outcomes can be true-positive (successfully detected trafficking activity), true-negative (successfully detected non-trafficking activity), false-positive (erroneously detected trafficking activity), or false-negative (erroneously detected non-trafficking activity) (Wang, Citation2010). These outcomes affect the performance and design of any detection system (Luque et al., Citation2019). True positives and negatives help decision-making, but false positives and negatives can impact operation effectiveness, and hence, are crucial areas for system improvement. For instance, in the context of our model, given a node or an edge
detection can lead to two types of errors. First, of those who are not traffickers/victims (
or
) some proportion (
or
) are detected as trafficking cases (false-positives); second, of those who are traffickers/victims (
or
) some proportion (
or
) are wrongly detected as non-trafficking (false-negatives). Typically the decision-maker would want to minimize such errors while maximizing successes, given that detection resources on nodes and edges incur costs,
and
respectively. Hence, our proposed optimization framework considers minimizing these errors while achieving a baseline level of success. Thus, we assume a lower (upper) bound on the detected number of trafficking (non-trafficking) activities.
Setting baseline levels of success (i.e., true-positives and negatives) consider the following rationale. Achieving a minimum (maximum) level of true-positives (true-negatives) will inevitably result in false-positives (false-negatives). Error minimization notwithstanding, node populations and edge migrations are poor trafficking indicators. Given the covert and ever-changing nature of trafficking across geographies (Miller and Lyman, Citation2017), it is not straightforward to assume that a low-population node may have low trafficking; similarly, a high migratory flow route is not guaranteed to have high trafficking activity (Broad and Muraszkiewicz, Citation2020). Therefore, bounding the desired true-positives below helps set expectations from an operational efficiency perspective. Further, bounding true-negatives from above helps the resource allocation solutions not only target high-population areas to detect more trafficking.
We, therefore, consider minimizing false-positive and false-negative errors, while detecting the desired level of trafficking activity. Given graph G, the policy-maker has imperfect information regarding trafficking activity (i.e., traffickers and their victims) and has to select nodes and edges to detect such activity, satisfying budget and success rate constraints. As a result, given
estimates, and a set of random realizations of trafficking proportions
the goal is to minimize false-positive and false-negative errors when allocating detection resources to the graph.
Definition 1.
Detection of Trafficking - Resource Allocation Problem - Binary (DTRAP-BIN): Consider the set of realizations for trafficking proportions on nodes and edges,
For this set
the decision-maker, given a budget B, a practice-informed lower threshold of K trafficking activity units (traffickers or victims) and an upper threshold L of non-trafficking activity units, solves:
The objective function considers the expected number of type-I (false positive) and type-II (false negative) errors, given the complete set of node and edge trafficking proportions. The first constraint is related to the budget B; the second constraint is a lower bound on the number of trafficking activity units (traffickers/victims) (K) detected on nodes and edges combined. The final constraint is an upper bound on the level of non-trafficking activity units (L) detected on nodes and edges combined.
We address some important features of DTRAP-BIN related to the practical complexities of human trafficking detection. First, it should be noted that typical operations in detecting trafficking activity consider the proportion of trafficking in an area rather than exact numbers. These proportions are usually informed by local law enforcement, previous victims, and organizations active in anti-human trafficking activities in the area. Our formulation operationalizes the outcomes from such proportions as base thresholds K and L. Proportion-based formulations can be explored and are kept for future work. Second, it can be argued that traffickers’ and victim detection operations can be independent and separate, given the organization’s incentives. We model this aspect of trafficking detection in DTRAP-TV (Section 3.3). Finally, given stochastic realizations of trafficking proportions on nodes or edges, thresholds K and L may not be feasible. We address this issue by presenting the model variant DTRAP-SOFTCON (Section 3.4), which converts these constraints to soft constraints with a penalty for constraint violations included in the objective function.
Proposition 1.
The deterministic equivalent of DTRAP-BIN is NP-Hard.
The proof is in Appendix B. Practical or law-enforcement issues may limit the DTRAP-BIN search space. For instance, local agency data may require monitoring specific nodes and edges notwithstanding budgetary or threshold limits. These limits do not impact the problem’s complexity. Further, binary decision variables imply that a node or edge selected is allocated a resource, with given error rates, capable of detecting trafficking while monitoring the entire population (node) or flow (edge). This assumption of monitoring the entire population is relaxed in model variant DTRAP-DIFFRES in Section 3.2.
Solution Approach: Since the objective function is an expected estimate of errors, given trafficking proportion uncertainty, we use Sample Average Approximation (SAA) (Kleywegt et al., Citation2002; Kim et al., Citation2015). In this approach, DTRAP-BIN’s expected objective function is approximated by an average sample estimate produced from a random sample from The optimization problem is solved using the realization of the stochastic constraints. Consider the following example that illustrates candidate solutions to a simple DTRAP-BIN problem.
Example: Consider a graph G with four vertices (nodes) and three edges () and assume parameter values The node and edge weights are
and
respectively. The estimates of detection error rates are given below, where the order of the nodes and edges are the same as in the node and edge-weight sets:
Figure 1. Simple example showing optimal resource allocations solved using DTRAP-BIN.
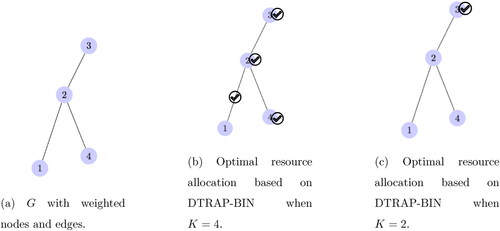
Consider three realizations (indexed by ) of
as follows along with the probabilities
Based on an expected error minimization (SAA objective) the optimization problem for the decision-maker is expressed using Definition 1. Refer to Appendix A for a full enumeration of the objective function along with the constraints. The eventual solution is presented in and when and
Next, we relax some assumptions in DTRAP-BIN to further generalize the model. DTRAP-BIN assumes that each selected edge or node would be monitored entirely, for example, by using remote detection systems (Swartz et al., Citation2021). Now, rather than a binary decision of whether to select an edge or node to monitor, we decide the amount of flow or population to monitor (i.e.,
). Active interventions such as periodic work-site inspections and random checks may be required in more practical scenarios to ascertain traffickers or victims. The associated formulation is referred to as DTRAP-INT and can be found in Appendix Section C.
3.2. Incorporating resource viability levels
Consider the case where detection resources have additional inherent resource-specific limitations, due to which their viability is questionable. For instance, some resources can monitor only a fraction of the population/traffic flow on each edge/node considered for detection, and different resources may be able to monitor different fractions of the flow. Resource level limitations (e.g., deception, corruption) constrain a resource’s capacity to monitor a given node or an edge. The policymaker has to choose from a set of P () such resources to deploy at
inspectors across
locations in a given area. Each inspector has a history of human trafficking detection that signals some viability level,
The policymaker knows these viability levels and has to allocate these inspectors across the given area to minimize detection errors.
The decision-maker’s problem now has a new layer of complexity. Essentially, the problem now resembles the typical assignment problem where the resources selected out of a given set P are each allocated to a node or edge and thus resolve the trade-off between controlling for resource viability and detection errors. Resource viability heterogeneity impacts the overall populations monitored. For instance, for a resource with viability level, monitoring a node i having parameters
and
the effective non-trafficking population monitored is
(the false positive error is
); and the effective trafficking population monitored is
(false negative error is
). Reducing the effective populations monitored reduces detection errors, but at the expense of ignoring trafficking in the unmonitored population. Adding such viability levels complicates the detection challenges faced by stakeholders in the field. More formally, the mathematical formulation of the problem is where the decision-maker has to allocate a set of finite resources with inherent viability levels to nodes and edges (refer to Appendix D for full DTRAP-DIFFRES problem formulation and explanation of computational complexity).
3.3. Distinguishing between traffickers and victims
The formulations proposed in DTRAPs BIN, INT, and DIFFRES consider mixed flows or populations on nodes or edges. Specifically, traffickers, victims, and non-trafficking activity flow across nodes and edges. Given a node or edge, finding traffickers or victims has the same TPR and TNR values for the stakeholder. In other cases, stakeholders may be more concerned with discovering victims than traffickers (Chisolm-Straker et al., Citation2019) or vice versa. Moreover, incentive structures for stakeholders may vary across regions, whereby some may receive funding for aiding victims whereas others may receive funding to aid law enforcement in trafficker interceptions (Twis, Citation2020). We, therefore, modify our previous formulations to distinguish between detecting traffickers and victims. The formulation DTRAP-TV encapsulates these complications succinctly (see Appendix Section E).
3.4. Soft constraints on detection levels
Previous DTRAP formulations assume hard constraints on the number of trafficking and non-trafficking cases detected. For practical purposes, it might be beneficial to define them as soft constraints. A violation of these constraints is allowed along with a well-defined penalty. For example, a high trafficking detection threshold K (or a low value of non-trafficking detection threshold L) might make the problem infeasible. The basic model of DTRAP-BIN can be modified to incorporate soft constraints. This idea bears resemblance to the Lagrangian relaxation proposed by Held and Karp (Citation1970, Citation1971). Note that although we show a reformulation of DTRAP-BIN, both DTRAP-INT and -DIFFRES can be reformulated using soft constraints. We consider those formulations for policy analysis and present the mathematical formulation in terms of DTRAP-BIN in Appendix F.
Note that soft constraints require the decision-maker to provide penalty weights that balance constraint violation and objective function. A high weight places a significant penalty on infeasibility and may nullify soft limitations, while a low value would not adequately penalize infeasible solutions. We perform experiments in Section 4.1 to study the impact of the penalty weights on the allocations found using DTRAP-SOFTCON for the case study on detecting human trafficking in the fishing industry.
4. Case studies
We illustrate the value of the aforementioned models through two case studies: detecting human trafficking in the global fishing industry and migration across international borders.
4.1. Global Fishing Watch
Human trafficking in the fishing industry is garnering increased interest (Mutaqin, Citation2022). Poor regulations and rising worldwide demand for inexpensive seafood, coupled with frequent fishing in international waters outside of any one country’s jurisdiction, has led to pervasive human trafficking in the global seafood industry (Sutton and Siciliano, Citation2016). Stakeholders such as Global Fishing Watch (GFW) have filled a much-needed gap in providing data useful for law-enforcement and commercial stakeholders using monitoring resources in partnership with Oceana and SkyTruth (Yea, Citation2022). The availability of global-scale satellite monitoring data for fishing vessels from GFW has enabled researchers to develop machine learning models for detecting fishing vessels at high risk of using forced labor (McDonald et al., Citation2021). The model of McDonald et al. (Citation2021) used the data made available by GFW to identify features that can help distinguish between high-risk and low-risk vessels. Using dataset features and attributes, we enhance the model of McDonald et al. (Citation2021) predictions and derive optimal allocations under various bias (error rate) scenarios.
We use the McDonald et al. (Citation2021) data on high- and low-risk vessels for human trafficking in two ways: (i) to identify the overall number of vessels at sea that require monitoring allocation decisions; and (ii) to inform estimates of trafficking proportions on these vessels. Since vessel route prediction and tracking is a complex problem conducted using satellite infrastructure (Tafa et al., Citation2019), our focus using DTRAP is to refine monitoring allocation decisions rather than reconstruct a graph with exact vessel locations and routes. We, therefore, consider the vessels as nodes on our graph with no edges. This helps keep the focus on reducing detection errors without adding the complexity of figuring out where a ship will be located. Further, to motivate refining monitoring decisions, we begin with the simple binary selection formulation DTRAP-BIN (along with DTRAP-SOFTCON to deal with infeasible constraints) to demonstrate the value of using our framework.
The GFW data consists of information for fishing vessels from 2012–2018. We formulate separate resource allocation problems for each year. The prediction from the model of McDonald et al. (Citation2021) (henceforth referred to as “ML model”) is used as an estimate for the mean proportion of trafficking cases on a node. Vessel crew size is a proxy for the node’s population/weight
Distance traveled is used to estimate the cost of monitoring
The choice of lower bound on trafficking detected K is one of the most crucial parameters for DTRAP. For our evaluations, we assume that the goal is to detect a fraction
of the instances labeled as having a high risk of trafficking by the ML model. Thus, a suitable K for each year is determined by using
which reflects our confidence in the predictions of the ML model (
is used unless specified otherwise).
The type of vessel (drifting longlines, trawlers, and squid jiggers) coupled with fishing hours, average loitering, and voyage duration are used to determine and
Past detection data and information from local officials and port authorities can bias such efforts based on what has previously been monitored and detected. For example, suppose law enforcement actions identified trafficking on squid jiggers while loitering. In that case, subsequent monitoring may be biased toward similar vessels and focus on loitering. In reality, it may be that trafficking was found on those vessels because they were previously prioritized for inspection. Such biases may complicate future actions since traffickers may avoid loitering and employ alternative vessel types. Unaccounted biases may increase the number of false positive and false negative errors. Thus, we generate policy suggestions assuming different TPR and TNR values.
Using the GFW data, we assume each vessel is considered to have a base and
rate of 0.5 if fishing, loitering, and voyage duration hours are reported as zero (Cases 1-4). Such a rate signifies that for vessels with no hours of activity reported for a given year, the detection mechanism employed by GFW has a
likelihood of a true-positive or true-negative detection. Subsequently, for those vessels that have at least one activity (fishing, loitering, or voyage) reported, we analyze optimal policy recommendations using the scenarios summarized in (for a detailed description, see Appendix Section E). Each case shows a situation with biased TPR and TNR rates given the types of vessels used by traffickers. That is, each of our six scenarios indicates disparities in TPR or TNR rates under which type-I and -II errors need to be minimized. The following section presents results from solving DTRAP-BIN and DTRAP-SOFTCON with GFW data and six bias scenarios.
Table 4. Overview of all bias scenarios considered under GFW Analysis
4.1.1. Results
We solve DTRAP-BIN by assuming that s is a random variable and leaving out r since we do not have edges in our graph. Specifically, we solve DTRAP-BIN using SAA (Kleywegt et al., Citation2002; Kim et al., Citation2015) to minimize the average error over 1000 samples/realizations of the problem. To capture the randomness in s, for each node i, is sampled using a triangular distribution with mode
(obtained using the prediction of the ML model). For our experiments in this Section, we use
compares the results obtained from allocations by DTRAP-BIN, and DTRAP-SOFTCON, with the predictions from the ML model. For the ML model, resources were allocated to
vessels that have the highest predicted probability of trafficking, where
is the number of vessels chosen by the optimal solution of DTRAP-SOFTCON (penalty weights
are used here, see Section F for more details). compares results under different bias scenarios described in . GFW data for 2014 with
and
is used as an illustrative example for the results presented in . For year 2014, the ML model labeled 1480 instances as “positive” for trafficking. Using
we determine
for DTRAP. Results comparing allocations from different years are presented later in the Section. It should be noted that for the HNI bias scenario, the optimization problem is solved to an optimality gap of 0.5% (instead of the standard value of 0.01%) due to the high computational time.
Table 5. Comparing solutions from DTRAP-BIN and DTRAP-SOFTCON with predictions from the ML model for different TPR and TNR bias scenarios using the 2014 GFW data.
Comparing allocations for the LPI bias scenario in , we see that the solutions are very similar under different resource allocation models. However, note that cases HNLP and LNI in are infeasible for DTRAP-BIN, but using soft constraints can provide us with an allocation. Differences emerge in other cases. For example, in all cases except HNI, the DTRAP models identified more cases of trafficking than the ML model. Moreover, the ML model also had higher errors and budget utilization in the HNI case than the DTRAP models. For the HPI, LNI, HPLN, and HNLP cases, the ML model can identify fewer cases of trafficking while also causing more errors. Using the ML model’s predictions directly usually results in a worse allocation. These results show our formulation’s value and potential concerns with using the ML model predictions directly to assign monitoring resources. We observe similar trends for as outlined in in Appendix H.
As described in Section 3.4, DTRAP-SOFTCON provides a way to obtain allocations when DTRAP-BIN becomes infeasible due to a constraint violation. This is achieved by penalizing the constraint violation with an appropriate penalty weight provided by the decision-maker. In , we compare the allocations as the penalty weights and
are changed for the LNI bias scenario. The results show that increasing the penalty weight from 15 to 20 almost doubles the number of monitored vessels. Similarly, increasing the weight from 15 to 25 triples the number of vessels with corresponding increases in errors, budget used, trafficking, and non-trafficking cases monitored. This leaves the decision-maker with the difficult choice of pre-emptively deciding a penalty term, which greatly impacts the obtained allocations. To avert these issues in our analysis, we focus on the solvable bias scenarios under the DTRAP-BIN model.
Table 6. Comparing solutions from DTRAP-SOFTCON under different penalty weights ( and
) for GFW data for the year 2014.
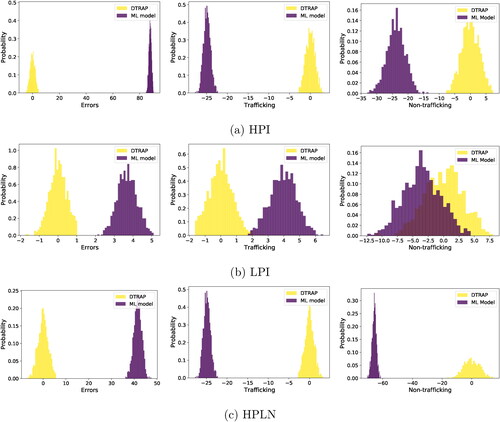
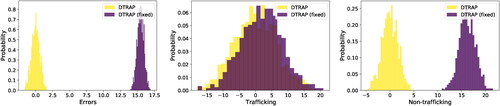
Next, we analyze the distribution of errors, trafficking cases detected, and non-trafficking cases monitored over the 1000 samples of the stochastic optimization problem. Results for bias scenarios HPI, LPI, and HPLN for DTRAP-BIN and the ML model can be seen in . The numbers show the percent deviation from DTRAP-mean BIN’s values. DTRAP-BIN detects more instances of trafficking with fewer errors than ML. These statistics suggest that DTRAP may balance trafficking detection with false positives and negatives.
Figure 2. Distribution of percent deviation from the mean values of errors (left), trafficking cases detected (middle), and non-trafficking cases monitored (right) in GFW for the year 2014. 1000 samples were used, DTRAP-BIN solutions (blue) were compared with allocations obtained from the ML model (orange).
In and , we analyze other aspects of the DTRAP-BIN allocations. plots the distributions of the crew sizes of the monitored vessels under the different cases. We use the GFW data from years 2014 and 2018 for illustration (results for other years can be seen in ) and also show the overall crew size for all the vessels in that year (labeled “data” in the box plot). We find that HPI, LPI, and HPLN tend to allocate resources to vessels with larger crews. Another interesting observation is that vessels with huge crews (outliers in the “data” box plot) are never chosen to be monitored in any of the four cases. In , we see how the gear types of the monitored vessels changes as we use GFW data corresponding to different years for the HPI, LPI, HNI, and HPLN bias scenarios. For comparison, we show the gear type distribution in the data in . Vessels with gear-type drifting longlines were allocated more often during 2012–2017 under the HPI and HPLN bias scenarios, but we observed a change to squid jiggers for 2018.
Figure 3. Highlighting the differences in the crew sizes of the vessels being monitored using DTRAP-BIN under different bias scenarios along with the crew sizes for all the vessels in the corresponding year.
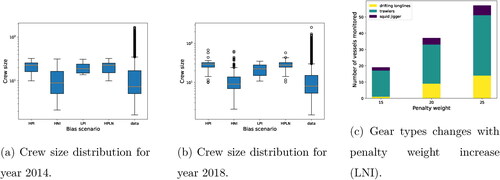
Figure 4. Change in the gear type of the monitored vessels for different bias scenarios over different years.
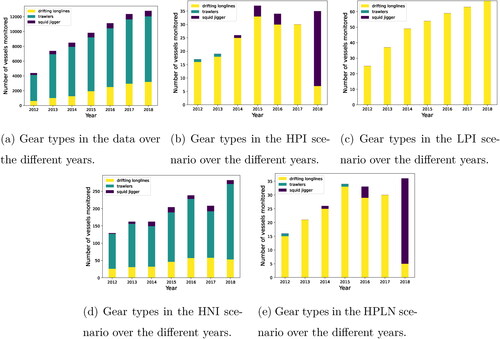
The broader implications from the analysis reflect the trafficking monitoring realities discussed in McDonald et al. (Citation2021). From 2012 to 2017, the number of high-risk longlines and squid jiggers increased; in 2018, longlines declined, and squid jiggers and trawlers increased. Squid jiggers had the highest proportion of high-risk vessels (45% to 94%), followed by longlines (33% to 60%) and trawlers (1% to 4%). Most at-risk trafficking forecasts concerned longlines, whereas squid jiggers and trawlers predictions varied by year and area. In most cases, longline monitoring is required, but our recommendations for squid jiggers and trawlers differ by year. That is, augmenting McDonald et al. (Citation2021) recommendations, our monitoring allocations can also account for trafficking trends in squid-jiggers and trawlers (Sala et al., Citation2018; Welch et al., Citation2022). Profitable longlines promote at-risk trafficking across geographies, whereas trawling and squid-jigging are profitable because of local subsidies and FAO regions. Deep-sea bottom trawlers operate at continental shelf limits and seamounts. Squid jiggers operate in Peru, Argentina, and Japan’s EEZs. Taiwanese squid jigging in the Northwest Pacific is profitable without subsidies (an average of 63,000,000), and South Korean bottom trawling in Atlantic Antarctic waters is profitable (an average of 129,000,000). Hence, trafficking intensity on these vessels can change given the year, geography, or socio-political context (Sala et al., Citation2018). Past TPR and TNR rates may not reflect such variability, hindering resource allocation to such vessels. Further, different vessel types may require more nuanced resource allocation decisions. Our model and scenario-based research indicate how to refine such decisions by varying TPR and TNR ranges.
4.2. LJI
LJI, a non-profit organization that aims to monitor and intercept human trafficking. LJI has developed a system to detect human trafficking in transit and prevent exploitation. At border crossings, bus terminals, train stations, and airports trained LJI workers look for signs of human trafficking and offer interventions for potential victims and traffickers (Hudlow, Citation2015). Personnel and their monitoring operations constitute the so-called Transit Monitoring Stations at various locations across a given area. There are 57 active Transit Monitoring Stations (TMSs) across the world Dimas, Khalkhali, Bender, Maass, Konrad, Blom, Zhu and Trapp (Citation2022). Each TMS is assigned to personnel tasked with detecting trafficking activity (victims and traffickers). As traffic volumes through each TMS are high, one critical issue for LJI has been to find optimal allocations of personnel to each station to detect trafficking. We use DTRAP-INT to model this operational problem.
Our case study covers LJI’s border operations in 2018 and 2019. Nineteen Nepali stations collected data on potential victims and traffickers. Stations are nodes, and routes are edges. We investigate DTRAP node resource allocation due to LJI’s station-only detection policy. For each station, LJI records data on the number of Interception Record Forms (IRFs) completed and for how many of those there was evidence of trafficking. For DTRAP, the proportion of trafficking cases is determined as the fraction of IRFs for which there was evidence of trafficking. In each detailed form completed, LJI volunteers provide a rating between 1 (low) and 5 (high), indicating how sure they were that trafficking was occurring. We estimate
using a weighted sum of these ratings using the following (rating, weight) ordered tuples:
The estimated traffic flow for each station provided by Dimas, Khalkhali, Bender, Maass, Konrad, Blom, Zhu and Trapp (Citation2022) and the IRF people count by LJI are used to estimate the weight
for each station. As no data is collected for individuals not suspected of trafficking,
is set to a constant value. We study the impact of this choice using experiments in the next section. The resource allocation problem for LJI introduces new challenges as the goal is not to determine which stations need to be monitored but how many volunteers should be stationed at each location. To achieve this, we use DTRAP-INT to determine allocations for LJI. We assume that each station needs to be monitored and that the maximum number of volunteers that can be assigned to a station is 10.
4.2.1. Results
To understand the effectiveness of DTRAP in the LJI case study, we consider four experimental settings to study: (i) the impact of changing the TNR on the allocations, (ii) how fixing the allocations for specific stations impacts outcomes, (iii) scenarios when detection efforts distinguish between traffickers and victims using DTRAP-TV (see Section 3.3), and (iv) incorporating resource viability measures when detecting trafficking using DTRAP-DIFFRES (see Section 3.2).
We first analyze the impact of changing the TNR on the distribution of errors, trafficking cases detected, and non-trafficking cases monitored. shows that a 0.05 change in
leads to a 10% change in errors and non-trafficking cases monitored (while maintaining the same level of trafficking detection). Although this is an expected outcome, it raises the question of how the allocations change with the change in
and how an incorrect estimation of
might impact the errors. To test this, we considered instances of DTRAP-INT with TNR rates of 0.5 and 0.7 and compared the obtained allocations on the other instance of the problem. From the results in , we observe that even if the user chooses an slightly incorrect value of
the resulting allocations only lead to a minor increase in the errors. More specifically, in , we plot the change in errors (from the optimal allocations for
) when the allocations for
are used for the problem instance with
and vice versa in . This shows the robustness of DTRAP-INT allocations to a significant change in user-determined parameters.
Figure 5. Comparing DTRAP-INT solutions as the TNR is varied.
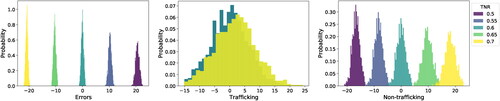
Figure 6. Comparing DTRAP-INT solutions ( and ) as allocations from one problem instance are used for the other. Additionally, comparing allocations (each blue-dot is a differently viable resource) under DTRAP-DIFFRES is shown in .
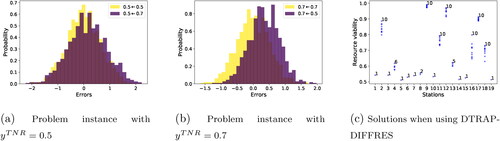
Sometimes, a decision-maker might want to fix the allocations for specific stations. For example, some stations might not have reliable historical data on the proportions of trafficking or volunteers who are only interested in working at particular stations for personal reasons. We identified four stations with high uncertainty in the proportion of trafficking. We solved DTRAP-INT by fixing the allocations for these stations and comparing them with optimal allocations in . We observe a 15% increase in the errors and monitoring of non-trafficking cases while detecting the same amount of trafficking.
Figure 7. Comparing DTRAP-INT solutions with and without any pre-determined allocations.
Next, we consider the scenario where detection resources have limited viability, and LJI has to allocate a finite set of resources at its stations. Resource viability levels are varied between and across 19 stations, resources allocated are between 0 and 10 (please refer ). We see that those stations that are allocated more resources also benefit from resource viability. Nine out of nineteen stations with greater population flows are allocated multiple resources with high viability levels (greater than 0.6), while the rest are allocated with lower viability levels. Our recommendations, therefore, not only improve detection but also recommend personnel allocation strategies that help stakeholders such as LJI improve operational efficiency.
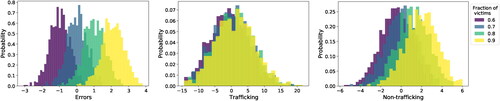
Finally, we consider a scenario where it is possible to distinguish between traffickers and victims in the network and decide on allocations using the DTRAP-TV formulation. Since we do not have data that distinguishes traffickers and victims, we solve DTRAP-TV while varying the number of victims and traffickers in the networks. We assume that it is easier to detect traffickers as compared with victims (Miller and Lyman, Citation2017; Chisolm-Straker et al., Citation2019) (we used for our experiments). Results in show that errors and non-trafficking cases monitored increase by approximately 2% with every 10% reduction in the trafficker population while maintaining the same level of trafficking detection.
Figure 8. Comparing DTRAP-TV solutions as the assumed fraction of victims in the network are changed.
5. Discussion
We discuss DTRAP’s construction and case-based analysis and findings. First, although the models decrease detection errors, they can be expanded to multi-objective optimization. Specifically, the problem formulation can be modified such that, in addition to minimizing detection errors, the constraint related to K can be incorporated into the objective to maximize the number of detection successes. The soft constraint formulation in DTRAP-SOFTCON achieves this to some extent by introducing a trade-off between errors and detection. Any such modifications to the problem mean the decision-maker needs to either pre-define weights for the different objectives or select a solution from the Pareto frontier. In this case, the trade-off for the decision-maker would be selecting those values that achieve a given optimal error and success level, as opposed to the current formulation of satisfying a lower bound on the success level. We hope to extend our work in this area in the future.
Next, note that we do not account for the dynamic nature of trafficking perpetration and prevention. Specifically, field work on trafficking activity prevention (Chisolm-Straker and Chon, Citation2021) has shown that traffickers and victims are constantly trying to evade law enforcement and interdictions by learning from past experiences or sharing experiences with other traffickers and victims. This suggests that the success and error rates of detection resources employed by law enforcement or stakeholders will need constant revision at the very least or a combination of detection methods in the best case. Fortunately, a part of this problem can be tackled through the existing DTRAP setups by varying the rates. This evaluation may overlook edge or node traffic changes. Our models do not include hybrid concepts such as allocating finite resources and determining the optimal number of inspections. Using a mix of measures to stop human trafficking has worked successfully, motivating future work that considers hybrid intervention techniques.
However, our case studies represent the types of problems encountered by non-governmental stakeholders in the field (Baycik et al., Citation2018; Anzoom et al., Citation2022) when using data-intensive ML-based models or human-resource-based detection systems. In particular, GFW shows how ML-based models can be less effective, such as when there are problems with model validation. Swartz et al. (Citation2021) point out that the GFW trafficking prediction analysis in McDonald et al. (Citation2021) suffers from such validation issues. Our DTRAP framework can help alleviate these issues. First, our framework is model-agnostic in that prediction from the McDonald et al. (Citation2021) ML algorithm can be replaced with a better algorithm while keeping the structure of our framework intact. Second, our results in Section 4.1.1 have illustrated that the allocations obtained from DTRAP-BIN and DTRAP-SOFTCON can be completely different from the ML model. Indeed, our framework helps refine predictions from the ML model and, hence, provide stakeholders with improved information for decision-making.
Moreover, DTRAP is flexible enough to help decide on resource allocations for human-resource-based systems that deal with issues such as differentiated resources (viability levels). In particular, LJI shows a situation in which people are used as detection tools for TMSs across an international border. Rai and Rai (Citation2021) point out the complexities (e.g., corruption) when detecting trafficking using humans as observers at TMSs. The DTRAP framework can help improve operational efficiency for such operations. First, our framework is flexible to allow deciding on selecting nodes and edges for allocation (DTRAP-BIN) to deciding on the number of inspections on each node and edge, given detection error and viability levels (DTRAP-INT and DTRAP-DIFFRES). Further, our framework provides a method to set different detection targets for traffickers and victims (DTRAP-TV). Overall, our GFW and LJI results help overcome these issues when utilizing ML-based models or human-machine cooperation systems for detection. Although the geography and circumstances of human trafficking are ever-evolving, we believe our case study analyses can shed light on the trade-offs decision-makers confront when trying to detect trafficking and provide a framework for remedies.
6. Conclusion
We study how to detect human trafficking using limited and imperfect resources. We present a family of resource allocation models that incorporate a range of allocation decisions, such as allocating a finite set of resources to nodes and edges. We also investigate a soft constraint formulation for our class of problems, in which threshold constraints are penalized to minimize errors. Data and context from GFW and LJI help us test our proposed models. In both cases, our models reduce detection errors while maintaining human trafficking detection success. Our results are promising, but future studies are necessary. Our models are single-objective; converting any constraint to an objective function enables multi-objective formulation. Our formulations assume a static network with a set number of nodes and edges. Iteratively solving our models may assist in accounting for the dynamic nature of trafficking networks. However, a fundamental reformulation that allows for stochastic changes in network structure and flow may help extend these models to dynamic optimization. Although we explore ranges of true positive and true negative error rates, a true-positive or true-negative determination in human trafficking detection will always be a challenge. Future research should focus on improving detection approaches and how they interact with refining methods like the one presented in this study.
Supplemental Material
Download PDF (219.5 KB)Reproducibility Report
Download PDF (196.8 KB)Data availability statement
The authors confirm that the data supporting the findings of GFW study are available within McDonald et al. (Citation2021) supplementary materials. The data that support the findings of the LJI study are available upon reasonable request.
Additional information
Notes on contributors
Abhishek Ray
Abhishek Ray is an assistant professor in the Information Systems and Operations Management Area at the School of Business, George Mason University. Dr. Ray holds a PhD (MIS), MS (Industrial Engineering), and MS (Economics) from Purdue University. He worked in IT consulting for five years before entering academia. His research interests include digital platforms and decentralized social networks, game-theoretic policy concerns in online platforms, and big data computational challenges.
Viplove Arora
Viplove Arora is a postdoctoral researcher working on machine learning in Bioinformatics in The Theoretical and Scientific Data Science Group at SISSA. He completed his PhD from the School of Industrial Engineering at Purdue University, where he worked on the generative modeling of networks. His research interests include network science, machine learning, complex systems, algorithm design, and optimization.
Kayse Maass
Kayse Lee Maass is an assistant professor of Industrial Engineering and Director of the Operations Research and Social Justice Lab at Northeastern University. Her research focuses on advancing operations research methodology to address social justice, access, and equity issues within human trafficking, mental health, and housing contexts using a community-based participatory action approach.
Mario Ventresca
Mario Ventresca is an associate professor of Industrial Engineering at Purdue University, prior to which he held postdoctoral positions at The University of Toronto (Mechanical and Industrial Engineering) and Cambridge University (Zoology), which followed his PhD from The University of Waterloo (Systems Design Engineering), MS at Guelph University (Computer Science), and undergraduate degree at Brock University (Computer Science). His research focuses on computational aspects of two primary areas: complex systems and operations research. More specifically, he develops models and algorithms for analyzing, predicting, designing, and controlling such systems in order to discover deeper scientific insight and achieve operational outcomes. He has published ∼80 journal and conference papers in both theoretical and applied contexts, and more than 40 refereed abstracts and posters at leading international conferences. His work has been funded by various government organizations and industry partners.
References
- 106th Congress. (2000) H.R.3244 - 106th Congress (1999-2000): Victims of Trafficking and Violence Protection Act of 2000, U.S. House of Representatives. Available at https://www.congress.gov/bill/106th-congress/house-bill/3244.
- Alahmadi, B.A., Axon, L. and Martinovic, I. (2022) 99% false positives: A qualitative study of soc analysts’ perspectives on security alarms, in Proceedings of the 31st USENIX Security Symposium (USENIX Security), Boston, MA, pp. 10–12.
- Anzoom, R., Nagi, R. and Vogiatzis, C. (2022) A review of research in illicit supply-chain networks and new directions to thwart them. IISE Transactions, 54(2), 134–158.
- Baycik, N.O., Sharkey, T.C. and Rainwater, C.E. (2018) Interdicting layered physical and information flow networks. IISE Transactions, 50(4), 316–331.
- Broad, R. and Muraszkiewicz, J. (2020) The Investigation and Prosecution of Traffickers: Challenges and Opportunities, Cham: Springer International Publishing, pp. 707–723.
- Caulkins, J.P., Kammer-Kerwick, M., Konrad, R., Maass, K.L., Martin, L. and Sharkey, T. (2019) A call to the engineering community to address human trafficking. IC2 Institute, 49(3), 67–73.
- Chisolm-Straker, M. and Chon, K. (2021) The Historical Roots of Human Trafficking: Informing Primary Prevention of Commercialized Violence. Springer Nature, Switzerland.
- Chisolm-Straker, M., Sze, J., Einbond, J., White, J. and Stoklosa, H. (2019) Screening for human trafficking among homeless young adults. Children and Youth Services Review, 98, 72–79.
- Dank, M., Farrell, A., Zhang, S., Huges, A., Abeyta, S., Fanarraga, I., Burke, C.P. and Solis, V.O. (2021) An Exploratory Study of Labor Trafficking Among U.S. Citizen Victims. Technical report, Office of Justice Programs.
- Dimas, G.L., Khalkhali, M.E., Bender, A., Maass, K.L., Konrad, R., Blom, J.S., Zhu, J. and Trapp, A.C. (2022) Estimating effectiveness of identifying human trafficking via data envelopment analysis. arXiv preprint arXiv:2012.07746.
- Dimas, G.L., Konrad, R.A., Lee Maass, K. and Trapp, A.C. (2022, 08) Operations research and analytics to combat human trafficking: A systematic review of academic literature. PLOS ONE, 17(8), 1–24.
- Farrell, A. and de Vries, I. (2020) Measuring the Nature and Prevalence of Human Trafficking, Cham: Springer International Publishing, pp. 147–162.
- Haesevoets, T., De Cremer, D., Dierckx, K. and Van Hiel, A. (2021) Human-machine collaboration in managerial decision making. Computers in Human Behavior, 119, 106730.
- Held, M. and Karp, R.M. (1970) The traveling-salesman problem and minimum spanning trees. Operations Research, 18(6), 1138–1162.
- Held, M. and Karp, R.M. (1971) The traveling-salesman problem and minimum spanning trees: Part ii. Mathematical Programming, 1(1), 6–25.
- Hudlow, J. (2015) Fighting human trafficking through transit monitoring: A data-driven model developed in Nepal. Journal of Human Trafficking, 1(4), 275–295.
- International Labour Organization (2013) Decent Work Indicators: Guidelines for Producers and Users of Statistical AND Legal Framework Indicators. Technical report, ILO, Geneva, Switzerland.
- International Labour Organization (ILO) and Walk Free Foundation. (2017, 9) Global estimates of modern slavery: Forced labour and forced marriage. Technical Report 978-92-2-130132-5, ILO, Geneva, Switzerland. Available at https://www.ilo.org/global/publications/books/WCMS_575479/lang--en/index.htm.
- Kilinc, D., Gel, E.S. and Demirtas, A. (2021) Intelligent teletriage and personalized routing to manage patient access in a neurosurgery clinic. IISE Transactions on Healthcare Systems Engineering, 11(3), 224–239.
- Kim, S., Pasupathy, R. and Henderson, S.G. (2015) A guide to sample average approximation. Handbook of Simulation Optimization, 216, 207–243.
- Kleywegt, A.J., Shapiro, A. and Homem-de Mello, T. (2002) The sample average approximation method for stochastic discrete optimization. SIAM Journal on Optimization, 12(2), 479–502.
- Klumpp, M. (2018) Automation and artificial intelligence in business logistics systems: human reactions and collaboration requirements. International Journal of Logistics Research and Applications, 21(3), 224–242.
- Konrad, R.A. (2019) Designing awareness campaigns to counter human trafficking: An analytic approach. Socio-Economic Planning Sciences, 67, 86–93.
- Konrad, R.A., Trapp, A.C., Palmbach, T.M. and Blom, J.S. (2017) Overcoming human trafficking via operations research and analytics: Opportunities for methods, models, and applications. European Journal of Operational Research, 259(2), 733–745.
- Kosmas, D., Sharkey, T.C., Mitchell, J.E., Maass, K.L. and Martin, L. (2022) Interdicting restructuring networks with applications in illicit trafficking. European Journal of Operational Research, 308(2), 832–851.
- Kougkoulos, I., Cakir, M.S., Kunz, N., Boyd, D.S., Trautrims, A., Hatzinikolaou, K. and Gold, S. (2021) A multi-method approach to prioritize locations of labor exploitation for ground-based interventions. Production and Operations Management, 30(12), 4396–4411.
- Luque, A., Carrasco, A., Martín, A. and de las Heras, A. (2019) The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognition, 91, 216–231.
- Maass, K.L., Trapp, A.C. and Konrad, R. (2020) Optimizing placement of residential shelters for human trafficking survivors. Socio-Economic Planning Sciences, 70, 100730.
- McDonald, G.G., Costello, C., Bone, J., Cabral, R.B., Farabee, V., Hochberg, T., Kroodsma, D., Mangin, T., Meng, K.C. and Zahn, O. (2021) Satellites can reveal global extent of forced labor in the world’s fishing fleet. Proceedings of the National Academy of Sciences, 118(3), 23–37.
- Miller, C.L. and Lyman, M. (2017) Research informing advocacy: An anti-human trafficking tool, in Human Trafficking is a Public Health Issue, Springer, Switzerland, pp. 293–307.
- Mitev, N., Renner, P., Pfeiffer, T. and Staudte, M. (2018) Towards efficient human–machine collaboration: Effects of gaze-driven feedback and engagement on performance. Cognitive Research: Principles and Implications, 3(1), 1–16.
- Mutaqin, Z.Z. (2022) Modern-day slavery at sea: Human trafficking in Thai fishing industry, in ASEAN International Law, Springer, Singapore, pp. 461–480.
- Newman, M. (2018) Networks. Oxford University Press, Oxford, UK.
- Obermeyer, Z., Powers, B., Vogeli, C. and Mullainathan, S. (2019) Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453.
- Okech, D., Choi, Y.J., Elkins, J. and Burns, A.C. (2018) Seventeen years of human trafficking research in social work: A review of the literature. Journal of Evidence-Informed Social Work, 15(2), 103–122.
- Rai, R. and Rai, A.K. (2021) Nature of sex trafficking in India: A geographical perspective. Children and Youth Services Review, 120, 105739.
- Rojas, D.Q., Tapia, R.D. and Rodríguez, R.R. (2020) Human Trafficking Cases in Chile: Challenges for Reducing the “Dark Figure”, in The Palgrave International Handbook of Human Trafficking, Springer, Switzerland, pp. 1151–1164.
- Sala, E., Mayorga, J., Costello, C., Kroodsma, D., Palomares, M.L., Pauly, D., Sumaila, U.R. and Zeller, D. (2018) The economics of fishing the high seas. Science Advances, 4(6), eaat2504.
- Sutton, T. and Siciliano, A. (2016) Seafood slavery: Human trafficking in the international fishing industry. Technical report, Center for American Progress. Retrieved July. Available at https://www.americanprogress.org/article/seafood-slavery/.
- Swartz, W., Cisneros-Montemayor, A.M., Singh, G.G., Boutet, P. and Ota, Y. (2021) Ais-based profiling of fishing vessels falls short as a “proof of concept” for identifying forced labor at sea. Proceedings of the National Academy of Sciences, 118(19), 1–2.
- Tafa, L.N., Su, X., Hong, J. and Choi, C. (2019) Automatic maritime traffic synthetic route: A framework for route prediction, in International Symposium on Pervasive Systems, Algorithms and Networks, Springer, Switzerland, pp. 3–14.
- Tezcan, B. and Maass, K.L. (2023) Human trafficking interdiction with decision dependent success. Socio-Economic Planning Sciences, 15–21.
- Twis, M.K. (2020) Risk factor patterns in domestic minor sex trafficking relationships. Journal of Human Trafficking, 6(3), 309–326.
- Wang, A.H. (2010) Don’t follow me: Spam detection in Twitter, IN 2010 International Conference on Security and Cryptography (SECRYPT), IEEE Press, Piscataway, NJ, pp. 1–10.
- Welch, H., Clavelle, T., White, T.D., Cimino, M.A., Van Osdel, J., Hochberg, T., Kroodsma, D. and Hazen, E.L. (2022) Hot spots of unseen fishing vessels. Science Advances, 8(44), eabq2109.
- Yea, S. (2022) Human trafficking and jurisdictional exceptionalism in the global fishing industry: A case study of Singapore. Geopolitics, 27(1), 238–259.
- Zhang, Y.-j., Huang, N., Radwin, R.G., Wang, Z. and Li, J. (2022) Flow time in a human-robot collaborative assembly process: Performance evaluation, system properties, and a case study. IISE Transactions, 54(3), 238–250.
- Zhou, C., Ma, N., Cao, X., Lee, L.H. and Chew, E.P. (2021) Classification and literature review on the integration of simulation and optimization in maritime logistics studies. IISE Transactions, 53(10), 1157–1176.
- Zhou, T. and Liu, Y. (2021) Long-term person tracking for unmanned aerial vehicle based on human-machine collaboration. IEEE Access, 9, 161181–161193.