
ABSTRACT
This research explores the potential for AUSTLANG – a database of Australian Indigenous languages – to enhance the identification of Australian Indigenous languages in MAchine Readable Cataloguing (MARC) bibliographic records. At present, it is acknowledged in the discipline of Library and Information Sciences (LIS) that material relating to Indigenous peoples are improperly and/or insensitively classified using mainstream library systems such as Dewey Decimal Classification. AUSTLANG was approved as a MARC language source code in November 2018 and has given libraries the ability to identify Australian Indigenous languages with standardised, culturally sensitive identifiers. The following research considers the variety of orthographies, codes and synonyms available for a sample of four Australian Indigenous languages as listed in AUSLANG and contrasts these with the single, authoritative AIATSIS reference names and codes contributed by the database. This research also considers how AUSTLANG can contribute to the classification of Indigenous Knowledge resources. Currently there is only a small body of technical information available on AUSTLANG and little focussed academic research, making it difficult to ascertain the success and characteristics of its implementation. This research represents an exploratory academic contribution and calls for a wider research effort.
1. Introduction
2019 was the United Nations’ International Year for Indigenous Languages (IYIL), a signpost of the increasing global recognition of the value of IndigenousFootnote1 Knowledge and languages (UNESCO, Citation2018). Within the Australian information sector, IYIL 2019 provided impetus for a new approach to the classification of Indigenous Knowledge resources in libraries. During National Aboriginal and Islanders Day Observance Committee (NAIDOC) week 2019, the National Library of Australia (NLA) facilitated a codeathon to add standardised codes to materials containing or pertaining to Australian Indigenous languages (National Library of Australia, Citationn.d.-a). These codes were derived from AUSTLANG, a language database of Australian Indigenous languages maintained by the Australian Institute of Aboriginal and Torres Strait Islander Studies (AIATSIS). At the time of European arrival in 1788, there were around 250 languages and 800 dialects spoken on the Australian continent (Obata, Citation2009). Very few of these languages survive today and the viability of those that do vary between speaking communities (Marmion et al., Citation2014). Prior to the application of AUSTLANG codes in classification, Australian Indigenous languages were identifiable only using a range of non-authoritative codes and orthographies, making it difficult to build coherent collections in and between information organisations.
This research explores AUSTLANG’s contribution to the management of Indigenous Knowledge. It considers the difficulties inherent in classification of Indigenous Knowledge resources using mainstream tools such as Dewey Decimal Classification (DDC) and alternative approaches to classification that have been developed for specialised Indigenous Knowledge collections. It also considers how codes, names and orthographies derived from the AUSTLANG database may be applied to improve the process of the classification of Indigenous Knowledge and the anticipated benefits that stem from this application. AUSTLANG holds great potential to improve the identification and therefore classification of Indigenous Knowledge resources that pertain to Australian Indigenous languages. However, this potential is dependent on its application and integration with classification systems already in place in institutions. Moreover, AUSTLANG’s capacity to improve the management of Indigenous Knowledge more broadly is dependent on deeper types of support such as targeted funding and training within the Library and Information Sciences (LIS) sector.
AUSTLANG’s use as a library tool was approved only recently by the Library of Congress (LOC) in October 2018, and to date, there has been a lack of scholarship on its implementation as a classification tool in Australian libraries. There have been limited, if not any, case studies documenting its implementation – peer-reviewed or otherwise – potentially attributable to the novelty and niche status of this area of study. This paper commences with an overview of alternative systems that were developed for specialised collections to accommodate the characteristics and requirements of Indigenous Knowledge resources. This is followed by a comparison of international standards that are commonly used to classify languages. AUSTLANG’s potential to improve classification of resources in or about Australian Indigenous languages is considered in the Findings section, which compares the single, authoritative heading listed in the database with the range of orthographies, names and codes that may cause inconsistencies and errors in classification. The Discussion section explores the importance of these findings further, stressing that the success of this tool depends on its successful integration with other systems.
2. Literature Review
This review contextualises the classification of material in or about Australian Indigenous languages. It orients this practice within a broader frame of classification of Indigenous Knowledge in Anglo-American libraries and archives and explores tensions that arise from this process. It also introduces the different ways that Australian Indigenous languages may be identified using a sample of language identification standards.
2.1. Classifying Indigenous Knowledge
‘Indigenous Knowledge’ is the knowledge of Indigenous Peoples: complex cultural, political and social systems that were fundamental to Indigenous cultures and nations before European arrival (L. R. Simpson, Citation2004). It pivots on a holistic, perennial view of knowledge that perceives humans in a contextual relationship to their natural, spiritual and geographical surroundings. Indigenous Knowledge represents an alternative epistemology to mainstream ‘Western Knowledge’, the dominant approach to knowing in Anglo-American countries that perceives information as historical, proprietary and taxonomic. These two approaches, despite their differences, are not antithetical; the two can coexist (Nakata et al., Citation2005). Tensions arise from the coexistence of these two epistemologies in information classification, a process that systematically organises and names knowledge based on an overarching system (and philosophy) that defines and delineates this knowledge. Bias emerges as an inevitable outcome of a system that prioritises information based on the values and needs of the organiser (Olson, Citation2001).
This review considers classification systems developed for Indigenous Knowledge collections through nine contemporary case studies documenting the development of alternative systems. In each case, alternatives were developed following a recognition that mainstream systems were not appropriate to classify specific collections containing Indigenous Knowledge. These alternatives were designed to compensate for classification bias in ‘mainstream systems’: classification tools commonly implemented in Anglo-American information organisations, notably Dewey Decimal Classification and Library of Congress Subject Headings (LCSH). The case studies reviewed are summarised in : Summary of alternative classification systems.
Table 1. Summary of alternative classification systems
Decisions to adopt alternative systems were complex and based on a number of factors. Bias towards Indigenous Peoples in classification systems was a unanimous catalyst. Whilst it impacted organisations differently, there were three primary negative outcomes. One, bias stigmatised Indigenous Knowledge: alternative systems were introduced to mitigate bias towards Indigenous Knowledge and people which resulted in the offensive and incorrect description of Indigenous Knowledge concepts. Two, bias marginalised Indigenous Knowledge: resources were classified incorrectly or incoherently, obscuring collections’ value and content, affecting access and browsability as resources were neither adequately described nor arranged coherently. Three, bias devalued Indigenous Knowledge: Indigenous epistemologies that are essential for understanding Indigenous Knowledge were excluded from classification. Other factors were influential but were inconsistently applicable. For example, libraries in Canada (Rigby, Citation2015) and Aotearoa New Zealand (Bardenheier et al., Citation2015) were legislatively required to act in a manner that supported protection and revitalisation of Indigenous languages and cultures. Operational requirements informed the revision of LCSH at the Association of Manitoba Archives (AMA) (Bone & Lougheed, Citation2018) and the amalgamated Brian Deer Classification System (BDCS)/LCSH systems at the Union of British Colombia (UBCIC) library (Cherry & Mukunda, Citation2015). Systems at the Xwi7xwa library (Doyle et al., Citation2015) and the Aanischaaukamikw Cree Cultural Institute (Swanson, Citation2015) were developed to support the requirements of their specialised Indigenous Knowledge collections and in a manner that prioritised Indigenous epistemologies.
Each organisation developed their own solution, recalibrating classification to reflect Indigenous epistemologies suitable for their collection. The most holistic integration of Indigenous epistemologies at Xwi7xwa (Doyle et al., Citation2015), Galiwink’ku (Masterson et al., Citation2019), UBCIC (Cherry & Mukunda, Citation2015) and Aanischaaukamikw Cree Cultural Institute (Swanson, Citation2015) libraries reconsidered the philosophical bases that underpinned their classification of materials, reorienting themselves towards the ‘Indigenization’ (Doyle et al., Citation2015, p. 107) of their collections. Elsewhere, thesauri were updated or created to reflect Indigenous epistemologies and vocabularies (Bone & Lougheed, Citation2018; Littletree & Metoyer, Citation2015). Access for Indigenous languages was included or strengthened with bilingual subject headings and description (Lilley, Citation2015; Rigby, Citation2015) and language-based metadata were added to existing library catalogues (Kleiber et al., Citation2018). None of these responses, however, represent a complete departure from mainstream systems. Nunavut and Sylvia Ashton-Warner libraries declared openly that the continuation of mainstream systems was an important factor for accessibility (Bardenheier et al., Citation2015; Rigby, Citation2015). At AMA, LCSH were updated to improve the classification and description of Indigenous resources within their collection but they mainly did this to support these processes for non-Indigenous resources were not being well described across their branches (Bone & Lougheed, Citation2018). Cutter codes were revised for material at the UBCIC collection to improve coherence between different components of the collection and to facilitate browsing using their implementation of BDCS (Cherry & Mukunda, Citation2015). Existing workflows were augmented to accommodate bilingual classification of Inuit language materials at Nunavut libraries (Rigby, Citation2015). All solutions strengthened mainstream classification through the integration of alternative, supporting systems.
Indigenous languages are intrinsically Indigenous Knowledge and their inclusion in classification systems is crucial to ensure that resources in or pertaining to language are classified correctly, sensitively and in a manner that makes material accessible to users (Rigby, Citation2015); Masterson et al., Citation2019). Despite this centrality, issues surrounding the classification of Indigenous languages were cited as a prime catalyst for the projects at the University of Hawaii’ (Kleiber et al., Citation2018) and Nunavut Libraries Consortium (Rigby, Citation2015). Outside the above two instances, the authors were unable to find a substantial body of recent literature that addresses this facet of Indigenous Knowledge classification specifically. The study of AUSTLANG’s application in MARC bibliographic records is, then, a crucial proposition: not only do we need to understand how this tool works in its new application in a library field but we also need to gain a greater comprehension of the central role that language has for the improvement of Indigenous Knowledge classification within mainstream information institutions. What is more, the classification of Indigenous languages is dependent on international codes, thesauri and standards. These produce their own set of biases and tensions affecting the classification of Indigenous Knowledge that need to be considered and addressed.
2.2. Declaring Language in Classification
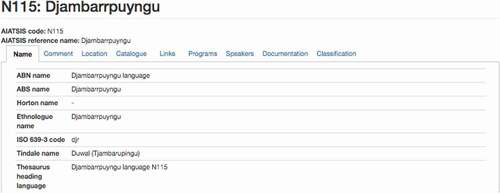
This section considers the practice of language classification and provides a summary of five standards that are used internationally to identify Australian Indigenous languages. They were selected based on their inclusion in the AUSTLANG database and their relevance to library classification. : Summary of standards used for language identification provides an overview of these standards. : Screenshot of MARC record for Tara June Winch’s ‘The Yield’ and : Partial screenshot of the Djambarrpuyngu (N115) entry in AUSTLANG are included to illustrate how these standards appear to the user.
Table 2. Summary of standards used for language identification
Figure 1. Screenshot of MARC record for Tara June Winch’s The Yield (National Library of Australia, Citation2021)

Figure 2. Partial screen shot of the Djambarrpuyngu (N115) entry in AUSTLANG (AIATSIS, Citationn.d.-c)
Modern information systems require the declaration of a resource’s language within its metadata. Declaration is, however, not an objective process and to these ends, a range of standards have been developed for specific user groups (e.g. librarians, engineers) to provide ‘authoritative’ references: orthographies and identifying codes. Often, these standards attempt to classify languages, defining relationships and hierarchies between them (Wright, Citation2015). This is a problematic undertaking as there is no commonly accepted definition of what a language is, particularly how it is distinguished from a dialect (Morey et al., Citation2013). How, even if, a language is treated by a standard can have a real-world impact (Parks, Citation2015). Each standard has its own criteria for inclusion, frequently resulting in the exclusion and misclassification of languages. Officially there is no single authoritative system, yet there is some acknowledgement of the ISO 639 family as the de facto international standard (Kamusella, Citation2012; Parks, Citation2015). For minority languages such as Australian Indigenous languages, the range of available standards can mean that these languages are declared or catalogued incorrectly, inconsistently or not at all. This complicates information discovery as researchers do not know how their target resources have been described and these inconsistencies need to be accommodated in search strategies.
2.2.1. MARC Language Codes
MARC Language Codes are the default standard for language declaration in MARC records (Library of Congress, Citation2007). The standard contains 484 discrete languages, represented by a 3-character lowercase alphabetic string that mostly corresponds to the English name and spelling of each language (e.g. [aus] Australian languages, [eng] English). The standard was developed in a library context as a means of designating language in documents (i.e. written material or literature) (National Information Standards Organization, Citation2001). Languages are included in the standard if they have a ‘significant’ or ‘growing’ body of literature that warrants the creation of a code (Library of Congress, Citation2007, p. 5). MARC codes impose no overt classification criteria, making no distinction between ‘language and dialect’. Codes can refer to individual languages [eng] or groups of languages [aus] (Library of Congress, Citation2007).
2.2.2. Iso 639-3
ISO 639–3 is an international standard that provides an ‘as complete an enumeration of languages as possible’ to support language identification (ISO, Citation2007, s 1). ISO 639–3 lists 500+ languages, making it the largest standard in the ISO 639 family (ISO, Citationn.d., p.v). It was developed with reference to ISO 639–2 (in turn developed using MARC language codes) and with reference to the Ethnologue (ISO, Citationn.d., p.v). ISO 639–3’s registration authority is SIL (SIL International, Citationn.d.). Languages are represented using a three-letter alphabetic code (e.g. [eng] English, [djr] Djambarrpuyngu).
The standard acknowledges the lack of real distinction between languages and dialects but claims to list languages only (ISO, Citationn.d., s. 4.2.2). Inclusion criteria requires that a language be mutually unintelligible to related languages. However, in cases where there is some mutually intelligibility, languages sharing a body of literature are classified together as one language or are classified separately if there is no strong ethnolinguistic diversion between groups of speakers (ISO, Citationn.d., s 4.2.2).
2.2.3. Ethnologue
The Ethnologue (‘Ethnologue’) is a language encyclopaedia that claims to ‘list every recognized language’ in 7,000+ entries (The Ethnologue, Citationn.d.-a). It also provides further information to contextualise each language’s use and geography. Currently in its twenty-third edition, the first volume of Ethnologue was published in 1951 by SIL as a means of sharing information on Bible translations (The Ethnologue, Citationn.d.-b). SIL is the maintenance organisation for both Ethnologue and ISO 639–3: the two share the same inclusion and classification criteria of mutual unintelligibility and use the same three-letter alphabetic codes (The Ethnologue, Citationn.d.-b). There are, however, some divergences in orthography and codes between Ethnologue and ISO 639–3 to accommodate community preference (The Ethnologue, Citationn.d.-c).
2.2.4. Glottolog
Glottolog is a language database developed by the Max Planck Institute, a scientific body funded by the German government. It aims to provide a comprehensive reference for all languages spoken internationally and contains 7,604 entries for prominent languages (Glottolog, Citationn.d.-b). Inclusion criteria is broad: languages must be distinct from other languages; need to have functioned as a means of communication between people and must be documented to a specified extent. Glottolog has their own classification criteria that asserts mutual incomprehensibility between languages, although admits that this is not particularly rigorous (Glottolog, Citationn.d.-b). Glottolog has its own internal reference of codes – Glottocodes – comprised of four alpha-numeric characters and four digits (Glottolog, Citationn.d.-a). For example, English is stan1293 and Djambarrpuyngu is djam1256.
2.2.5. AUSTLANG
AUSTLANG is the most comprehensive referenced database of Australian Indigenous languages (AIATSIS, Citationn.d.-a). It contains 1,204+ records (Lissarrague et al., Citation2019), including all 250 languages and 800+ varieties spoken on the Australian continent in 1788 (Obata, Citation2009). There is no stressed distinction between ‘language’ and ‘dialect’ and all ‘language varieties are included. If it is deemed necessary to understand a relationship between languages, this is indicated with punctuation or through links to related entries (AIATSIS, Citationn.d.-a). AUSTLANG is managed by AIATSIS, an Australian government agency and research body representing the international authority on the histories, cultures and heritages of Indigenous Australia (AIATSIS, Citation2019). The identification of Australian Indigenous languages is difficult due to the inconsistency of information available and the variety of different spellings used. AUSTLANG addresses this difficulty by assigning persistent identifiers to each language in the form of alphanumeric codes which act as an objective reference that can accommodate differences in orthography and cultural preference (AIATSIS, Citationn.d.-a; National Library of Australia, Citation2019). AUSTLANG was originally conceived as a reference for Australian Indigenous languages in the 1990s and was approved for use in libraries as an official MARC language source code in October 2018 (Library of Congress, Citation2018). Prior to this the primary means of indicating language in dedicated language fields in MARC records (namely 041) was through MARC language codes using the collective [aus] code which was problematic as there was no means of identifying individual languages with an authoritative standard. Language (along with other Aboriginal or Torres Strait Islander concepts) were also identifiable using three different AIATSIS thesauri for language, place and subject respectively (Library of Congress, Citation2021). These were used in conjunction with LCSH and were made available through the Subject Heading Cooperative Program (SACO) (Library of Congress, Citationn.d.).
It is currently not possible to assess AUSTLANG’s impact on the classification of resources in or about Australian Indigenous languages and it is difficult to find literature on its implementation as a MARC source language code in libraries. Broadly, there is no substantial body of analysis for the study of standards in general (Krechmer, Citation2014) despite their importance for the metadata requirements of modern systems. Within LIS there is no substantial body of work, but there is some evidence that these standards are causing issues for the identification of Indigenous language such as Kleiber et al.’s (Citation2018) study of Pacific languages in MARC records. The work that does exist in this domain is often interdisciplinary (e.g. Kim & Breuer, Citation2017; Morey et al., Citation2013; Parks, Citation2015). Where analysis does exist, often it is authored by the individuals responsible for creating the standards themselves and, in many cases, these studies are not recent (e.g. Constable & Simons, Citation2002).
This review has considered nine case studies of alternative systems that were developed by information organisations to compensate for the shortcomings of mainstream systems as they relate to the organisation of their collections and the needs of their clients. These new systems are representative of Indigenous epistemologies, respectful of cultural difference and provide a more functional description of collections that has improved access and usability. Aside from Masterson et al.’s (Citation2019) pilot program in Galiwin’ku, there is insufficient literature that addresses the issue in the Australian context. There is also a general lack of recent focused attention on how Indigenous languages are defined and included in mainstream classification processes. Furthermore, there is an insufficient understanding of the impact that language standards have for the representation, inclusion and understanding of Indigenous languages within libraries. AUSTLANG is the first authoritative reference for Indigenous languages to be approved as a MARC source code: documentation and study are imperative to illustrate its implementation and effect. This may serve as a blueprint for the development of similar systems internationally and the value inherent in documenting AUSTLANG’s potential to enhance the classification of Indigenous Knowledge cannot be understated.
3. Methodology
A qualitative methodology was used to gauge AUSTLANG’s impact on the classification of Australian Indigenous languages. Content Analysis was applied using the AUSTLANG database itself, which was freely available through the AIATSIS website. Synonyms, orthographies and codes for a sample of four AUSTLANG entries were counted, coded and these results compared to determine if and how identifiers provided by the AIATSIS codes and reference names simplified the identification of a language. These results are summarised in : Summary of results: language codes and 4: Summary of results: synonyms. Analysis was restricted to external code systems, online language encyclopaedias and lists of known synonyms that were included on the ‘Name’ tab of each individual AUSTLANG entry. References and orthographies derived from ISO 639–3, Ethnologue and Glottolog were included for analysis as these are fields provided in each AUSTLANG entry. Those associated with MARC language codes are not listed in AUSTLANG but were included for analysis due to their widespread use in library classification. This approach was used to gain an understanding of how AUSTLANG classifies Australian Indigenous languages when compared to a small range of common standards.
Table 3. Summary of results language codes
Languages in the sample were selected on the basis of their currency in contemporary Australia as indicated by their inclusion in the second AIATSIS National Indigenous Languages Survey (NILS2) (Marmion et al., Citation2014).Footnote2
3.1. Djambarrpuyngu (N115): A Traditional Language with a Strong Speaking Population Relative to Other Indigenous Languages
DjambarrpuynguFootnote3 (N115) is part of the Yolngu Matha (N230) group of languages spoken in North-East Arnhem land. According to the 2016 census, it has approximately 4,282 active speakers (AIATSIS, Citationn.d.-c) and has been identified as one of 13 Indigenous languages still acquired by children (J. Simpson, Citation2019).
3.2. Dharawal/Tharawal (S59): A Traditional Language that Has Gained Speakers
Dharawal/Tharawal (S59) is spoken in the Illawarra and Shoalhaven regions in NSW. It has approximately 27 speakers according to the 2016 census (AIATSIS, Citationn.d.-e) and has gained speakers in the 0–19 age group since NILS1 in 2005 (Marmion et al., Citation2014, pp. 12–13).
3.3. Wik Mungkan (Y57): A Traditional Language that Is Losing Speakers
Wik Mungkan (Y57) is identified in NILS2 as a language showing signs of decline relative to its status in NILS1 (Marmion et al., Citation2014, p. 10). According to the 2016 census, there are currently 450 speakers (AIATSIS, Citationn.d.-f). Wik Mungkan is spoken in the Cape York peninsula in Northern Queensland.
3.4. Boonwurrung (S35): A Traditional Language with No Active Speaking Population
Boonwurrung (S35) was spoken in the Melbourne area. According to the 2016 census, there are no speakers of Boonwurrung (AIATSIS, Citationn.d.-d). This language was selected from the AUSTLANG database to provide a point of comparison for languages that are not well preserved and studied in Australia.
A quantitative methodology was excluded on the basis that the analysis is largely descriptive and observational: this research explores how a language is identified in terms of its orthography, spelling and synonyms. That said, this does not exclude quantitative methods entirely. One aspect of analysis is quantitative insofar as the number of distinct references to Australian Indigenous languages are counted and compared.
A qualitative methodology was also used to consider the classification of Indigenous Knowledge resources. Nine peer-reviewed case studies that detailed the introduction of alternative classification systems to libraries, archives and museums were analysed. These were selected due to the applicability of their subject matter; their location within Anglo-American countries with a history of British colonialism; their use of mainstream classification tools such as DDC and because they were published recently, between 2015–2020. This sample was representative of different sectors within the information management umbrella: three were drawn from government libraries and archives; three from Indigenous cultural institutions; three from academic libraries. This review was practical in is orientation, considering solutions that addressed functional shortcomings in mainstream classification systems; it did not consider the ethics of classification of Indigenous resources (see for example, Doyle, Citation2006; Olson, Citation2001). Findings from these studies, as well as other academic papers, were used to consider AUSTLANG’s potential to contribute to the classification of these materials as a specialised tool that may be added to mainstream systems.
Material relating to the description of language codes and standards was largely drawn from industry sources as it proved difficult to locate a coherent body of academic literature that addressed this topic, especially for AUSTLANG.
An indicative sample of search terms used for searching academic journals is as follows:
indigenous OR aboriginal OR ‘torres strait’ OR ‘torres strait island*’ OR minority OR ‘first nation*’ OR metis OR maori
language OR dialect
classif* OR catalog* OR marc OR ‘marc record’ OR ‘machine readable catalog*’ OR ‘bibliographic record’ OR ‘library record’ OR ‘subject heading*’ OR ‘authority control’ OR ‘controlled vocabular*’ OR ‘subject access’ OR librar* OR ‘knowledge organi?ation’
‘language code’ OR ‘language tag’ OR ‘ISO 639ʹ OR austlang OR metadata OR glottolog OR Ethnologue
4. Findings
This section analyses the results obtained from the manual count and coding that was performed on the sample of four language entries in AUSTLANG. The variations in names, orthographies and codes between MARC language codes, ISO 639–3, Ethnologue and Glottolog are analysed first, followed by an analysis of synonyms for Australian Indigenous languages. This section aims to establish how the identification of Australian Indigenous languages differs according to the standard employed and to determine if and how AUSTLANG represents a clearer alternative for language identification.
4.1. Standards
Each AUSTLANG entry lists information using an identical structure. Language names provide a heading, under which the associated ‘AIATSIS code (e.g. N115) and the ‘AIATSIS reference name’ (e.g. Djambarrpuyngu) are listed. All remaining information is nested under a series of nine tabs. The ‘Name’ tab comprises 13 fields containing information on how the languages are identified and spelled by different sources. illustrates this arrangement. These fields are presumably non-compulsory, as not all records contain information for all available fields. Three fields refer to language standards: Ethnologue name, ISO 639–3 code and Glottocode. Information held in these three fields was tabled for each of our four sample languages, as summarised in . MARC language codes were added manually with reference to MARC documentation (Library of Congress, Citation2017). These are summarised in : Summary of results: language codes.
Three out of the four sample languages were recognised in these standards: Djambarrpuyngu, Dharawal/Tharawal and Wik Mungkan. There are some consistencies between AUSTLANG and external references and the relationship between the language name and assigned code/spelling are logical. For Djambarrpuyngu and Wik Mungkan, the spellings used in the AUSTLANG reference are also used in the external listings, save for an additional hyphen for Wik Mungkan (Wik-Mungkan). The link between Dharawal/Tharawal’s name and the associated codes is discernible, yet there are inconsistencies. Different spellings are used in each of the three external codes, only one of which (ISO 639–3: [djr]) corresponds to the AUSTLANG reference spelling. Boonwurrung is uniformly unrecognised in external standards and has not been assigned identifiers. None of the sample languages are included in the list of MARC language codes and as such no such codes have been assigned. One language only (Wik Mungkan) is mentioned under the [aus] collective code heading for Indigenous Australian languages in the MARC code list for languages: Part 1 Name Sequence (Library of Congress, Citation2017), but is referred to only as part of the broader umbrella of Australian [aus] languages.
Based on this sample, there is a correlation between a language’s currency and its inclusion in code systems. Djambarrpuyngu, Dharawal/Tharawal and Wik Mungkan, all ‘strong’ languages, are identified to some degree yet there is no overall consistency between the different systems and codes used to these ends. As for Boonwurrung, its complete lack of representation in international systems is unfortunate, if not unsurprising: according to Western perspectives an unused language with zero active speakers does not need to be standardised. The lack of references for individual MARC language codes is, too, unsurprising: due to its intended use for library cataloguing and the historical prevalence of written texts in this domain, a minority language largely associated with the oral storytelling tradition is unlikely to have a sufficient body of literature and in this context would rarely need a MARC code. All of these four languages are subsumed under the [aus] code using MARC language codes. The omission of Boonwurrung and the generalisation of Australian languages under collective codes reflects the primacy of Western thought systems in the formulation of these standards and fails to acknowledge their ongoing value and relevance as individual languages.
4.2. Synonyms
The ‘Name’ tab lists synonymic names for Australian Indigenous languages derived from external references from Australian government agencies (ABS name, ABN name); from anthropologists and linguists (Horton name, Tindale name, Tindale (1974), O’Grady et al. (1966)) and used in AIATSIS thesauri (Thesaurus language heading, thesaurus heading (old)). Additional references are listed in the general fields ‘Other sources’ and ‘Synonyms’, the majority of which are unattributed. These are summarised in Summary of results: synonyms.
Table 4. Summary of results synonyms
All four languages have information included in the large majority of these fields. The only exceptions are Boonwurrung, which has no listing under ‘ABN name’ and ‘ABS name’ and Djambarrpuyngu has no listings under ‘Horton name’ or ‘O’Grady et al. (1966)’. Each field is self-contained and as such there is some repetition of orthographies and names across headings to account for different references that were made for discrete sources. A manual count of different orthographies used for each language show a large degree of variation. Djambarrpuyngu has 43 separate references (24 unique); Dharawal/Tharawal has 57 (29 unique); Wik Mungkan 69 (48 unique) and Boonwurrung has 175 references (91 unique). There is an observable correlation within this sample between the prominence of a language and the number of associated synonyms. That is, the ‘strongest’ language in this sample has the fewest synonyms and theoretically would be easier to identify using the language name alone. Boonwurrung, the weakest language in the sample, has the largest number of synonyms. For Boonwurrung, the cumulative impact of a lack of unique identifiers in international code systems and a large number of associated spellings would make this language particularly difficult to identify consistently.
This analysis of codes and synonyms demonstrates the array of orthographies that exist for Djambarrpuyngu, Dharawal/Tharawal, Wik Mungkan and Boonwurrung. Without the simplicity and accuracy afforded by the AIATSIS code and reference name in AUSTLANG, this choice makes language identification in library classification a difficult undertaking in the absence of a clear, definitive standard that has been approved for use in MARC records. Unambiguously, without AUSTLANG there is a lack of standardisation between references making it impossible to build and identify coherent collections of language materials in and across institutions without a standardised identifier. This de facto system cannot account for the diversity and richness of Traditional languages and permits the use of incorrect (even offensive) exonyms. Steps have been taken to increase respect for Indigenous Australian cultures within AUSTLANG itself. Multiple orthographies are available to accommodate preferences within individual communities for how they wish their language to be identified and spelled (National Library of Australia, Citation2019). The AIATSIS site, in general, contains cultural warnings (AIATSIS, Citation2019). AUSTLANG’s lack of distinction between language and dialect avoids any imposed assumption of relative priority or importance between Australian Indigenous languages. Within the framework of this database, all languages are equally important – and valuable. None of the alternative language standards that were reviewed demonstrated any deep cultural respect for First Nations languages, in Australia or elsewhere.
5. Discussion
The previous section explored the identification of four Australian Indigenous languages, comparing the results from AUSTLANG to other international standards. The main finding from this analysis is that AUSTLANG is a clear, concise resource that standardises spellings and codes, directing users towards common references. Its application to the classification of Indigenous Knowledge resources normalises and legitimises this process. This application carries other potential, discussed below.
5.1. Mitigating Bias Towards Indigenous Knowledge Resources
AUSTLANG has the potential to mitigate bias towards resources in or about Australian Indigenous languages, to address the stigmatisation, marginalisation and devaluation of Indigenous Knowledge resources that arises within mainstream systems. AUSTLANG is the most authoritative and complete resource for Australian Indigenous languages, containing 1,200+ records (Lissarrague et al., Citation2019). It is maintained by the world’s leading research institution for Aboriginal and Torres Strait Island peoples and cultures, it is managed by a specialist linguist in Australian Indigenous languages and is fully referenced to academic standards (AIATSIS, Citationn.d.-a). By contrast, such claims made by systems such as ISO 639–3 are based on their own internal inclusion and classification criteria. They do not offer the same exhaustive coverage of Australian Indigenous languages as AUSTLANG and cannot claim the same level of authority in this domain.
Cataloguing Indigenous Knowledge resources is a challenging, time-consuming process (Lissarrague et al., Citation2019), as is searching for resources that contain Indigenous languages (Lubransky-Moy, Citation2019). Doyle et al. (Citation2015) discussed the ongoing need to educate their Indigenous and non-Indigenous users on how to search for Indigenous Knowledge resources, acknowledging that this process was substantially different to searching for non-Indigenous materials. In isolation, AUSTLANG will not entirely negate these difficulties, but it can ease elements of this process. Its authoritative, standardised references for individual languages carry the potential to unify like-resources together under a single, authoritative heading. Libraries no longer have to develop their own systems to compensate for the lack of specificity in the MARC collective code: for Kleiber et al.’s project (Kleiber et al., Citation2018), a resource similar to AUSTLANG could have removed the need to add ISO 639–3 codes to MARC records. AUSTLANG’s implementation in Trove records has enabled collection building and faceted searching (National Library of Australia, Citationn.d.-b). Systems like AUSTLANG, which are able to identify languages accurately, also carry the potential to unify resources, making information available to a readership of interdisciplinary researchers (Musgrave et al., Citation2013). These benefits are compounded through AUSTLANG’s new status as a MARC source code, which affords it increased visibility and makes it consistently implementable in international libraries (National and State Libraries Australia, Citation2019).
AUSTLANG is a specialised tool for a delimited purpose; it does not attempt universal, generalised classification and, rather, confines itself to the classification and description of a specific subset of languages. Findings from this paper juxtaposed the disorganisation and sheer quantity of information in alternative standards against the simple, concise AIATSIS identifiers. AUSTLANG eschews the complexities inherent in the language vs. dialect debate by making no overt distinction between the two, imposing no real classification hierarchies: on face value, each language carries equal weight in this system. This is in stark contrast to competing systems, such as Glottolog which include languages that meet minimum documentation requirements and classifies these according to a ‘best guess’ in-house system (Glottolog, Citationn.d.-b). AUSTLANG is especially valuable in contemporary libraries where collections are no longer solely focused on books. It compensates for MARC’s focus on written tradition to allow for the inclusion of languages and cultures that retain their histories and information differently to mainstream, Western epistemologies.
5.2. Complementing Mainstream Classification Systems
In their case study of the Galiwin’ku classification system, Masterson et al. (Citation2019) posit that the systems reviewed for their study fell under two distinct types: the development of distinct, alternative First Nations classification systems such as BDCS or the adaptation of mainstream systems like DDC to suit an application to Indigenous Knowledge resources. Whilst it may seem necessary for the successful Indigenization of collection management, a complete departure from mainstream systems is difficult, maybe impossible, to achieve. Individual libraries like Xwi7xwa are often part of greater library networks and are required to adhere to network-wide standards and protocols which will often require organisations to adhere to or maintain mainstream standards. Mainstream standards such as MARC coding are still very much present in Xwi7xwa’s workflows and exist alongside alternative standards like BDCS, despite the strong focus on Indigenous epistemologies at this library. Every knowledge organisation system is a sum of its parts and the strengths and weaknesses of each component contributes to its ability to support the management of a collection. Masterson et al.’s (Citation2019) analysis, then, could be reconsidered as a continuum: on one end, the complete (if not aspirational) Indigenization of a collection; on the other, mainstream generalised systems. Here, the successful management of Indigenous Knowledge rests on compromise between these two extremes that suits the needs and aims of an organisation’s own imperatives, collection, resources and users.
None of the alternative systems developed for Indigenous Knowledge collections within the review represent a true departure from the mainstream. Each system in the review complements select mainstream systems in a manner that compensates for inherent differences between Indigenous and Western knowledge. Processes such as these aim to ensure that the system fits the collection, not the inverse (Swanson, Citation2015) and acknowledge the needs and characteristics of Indigenous Knowledge (Buente et al., Citation2020). In Nakata’s (Citation2007) conception, this process occurs in the ‘cultural interface’: the grey, intermediate area between two cultures, where compromise, understanding and deliberate effort are requisite components for harmonious interaction. It seems logical that at such a site, elements of the two intersecting systems are required for harmonious integration. Applied as a MARC source language code, one of AUSTLANG’s greatest strength resides in its ability to integrate with existing mainstream systems. In isolation, AUSTLANG does not possess the capacity to completely Indigenize a collection, but it is one important component that may contribute to a knowledge organisation system that embraces this principle.
Human-led support is an additional requirement for the development of alternative systems. This was evident throughout the reviewed case studies where human passion, knowledge and determination were fundamental for change. Support systems were put in place surrounding AUSTLANG’s introduction to the Australian library sector during NAIDOC week 2019, which included events and presentations to assist professionals to understand the potential of this new tool (National Library of Australia, Citation2019). As part of its modernisation program, Trove is working to facilitate access to Indigenous Knowledge resources and to make Trove a culturally safe place for all users (Lubransky-Moy, Citation2019). Trove shares 150+ cooperative partnerships with its parent organisation the NLA, sharing resources with 1,000+ institutions across Australia (Lubransky-Moy, Citation2019). The NLA and Trove are influential actors in the Australian library space and their innovations are likely to be seen and adopted by other Australian libraries.
It is important, too, to accept that alternative systems will carry their own biases and imperfections. Despite AUSTLANG’s benefits, there are still shortcomings associated with its conception and implementation. In instances where an identified language is in doubt, cataloguers are instructed not to add codes to their materials (National Library of Australia, Citation2019). AIATSIS acknowledges that the resource is fundamentally incomplete (AIATSIS, Citationn.d.-a); whilst modest, this is an acknowledgement of gaps in knowledge. Moreover, the success of AUSTLANG, and the associated capacity to build coherent Indigenous language collections, depends on its widespread, correct interpretation and implementation. At the time of writing, it has been in use in Australia for less than two years and it is too early to gauge the extent of its impact. Moreover, improving the classification of Indigenous Knowledge is but one small component of a greater struggle of Indigenous peoples to reclaim their knowledge and reform its management. Thorpe (Citation2019) exhorts more drastic change in the LIS industry in Australia that remains fundamentally unchanged and inequitable (if not openly hostile) to Australian Aboriginal and Torres Strait Islander people. AUSTLANG is a sensitive, specialised tool but it does not represent a silver bullet solution to a pernicious problem.
5.3. Further Research and Recommendations
This analysis is limited to findings derived from a sample of AUSTLANG entries for four languages. Whilst the inclusion of languages in categories (speaker numbers) was an effort to represent a range of spoken languages with different contemporary ‘strengths’, they may not necessarily be indicative of the representation of Australian Indigenous languages in all international standards. Future study could include a larger sample of languages to provide a more accurate demonstration of AUSTLANG’s potential as well as guidance for its future study and development.
Due in no small part to its novelty, we lack a coherent body of knowledge and consensus on best practice implementation, making it impossible to estimate how widely and successfully AUSTLANG has been applied. From a practical perspective, documenting AUSTLANG’s implementation may facilitate its continuing diffusion in Australian libraries and may assist its ongoing development and maintenance at AIATSIS and NLA. It is furthermore important to consider that AUSTLANG was not developed as a classification tool and that it was, instead, adapted for application in a library setting. There are surely tensions arising from this application and these require appraisal.
Sufficient documentation is available through AIATSIS and NLA to teach AUSTLANG as a classification tool. This needs to be integrated – meaningfully – into LIS curricula to empower emerging processionals to apply this tool throughout their entire careers and to share this knowledge with their colleagues. AUSTLANG also requires more concerted support from Australian LIS professional organisations to encourage its diffusion and to train established professionals. That the tool is ‘available’ is insufficient: the full weight of the Australian LIS sector is needed for AUSTLANG’s true potential to be realised. There needs to be greater emotional investment in instruments such as AUSTLANG that have the potential to align Australian Indigenous and non-Indigenous interests. Non-Indigenous Australia remains in the throes of accepting how integral Indigenous cultures and knowledge re to our past, present and future. To these ends, information organisations must make a more deliberate contribution as stewards for knowledge that that may assist a greater national reckoning.
Finally, it is necessary to examine AUSTLANG’s influence and use worldwide to determine if it is comprehensible to non-Australian classifiers. By lobbying the LOC to include AUSTLANG as an approved MARC source code, NLA and AIATSIS sought to establish AUSTLANG as an internationally relevant language standard for the library profession. This is pertinent to the Australian Indigenous Knowledge held in overseas institutions and we need to establish if and how AUSTLANG is successfully applied outside the immediate scope of Australia and the influence of AIATSIS and NLA. Findings from this area will be crucial for researchers working with other minority languages that are under- and mis- represented in classification systems.
6. Conclusion
Prior to the introduction of AUSTLANG as a MARC source code, no authoritative standard existed to guide the identification of Australian Indigenous languages for the classification of Indigenous Knowledge resources in libraries, archives and museums. Instead, a variety of orthographies, synonyms and codes compensated for a lack of a specialised, authoritative system. It was difficult, if not impossible, to identify Australian Indigenous languages consistently and to form coherent collections in and between information organisations. This research explored the different ways that Australian Indigenous languages may be identified through the frame of four sample languages, illustrating the lack of consistency and accuracy inherent in this practice. It examined AUSTLANG’s potential to fill this void as an authoritative standard and as a successful addition to the mainstream systems that dominate the practice of information management. Despite AUSTLANG’s potential, more time and documentation are required to examine the full extent of its impact. However, campaigns such as ILYL 2019 accompany a growing awareness of the value of Indigenous Knowledge and languages. There is every reason to hope that this momentum will continue and expand, pulling in its wake the establishment of a harmonious relationship between Indigenous and Western notions of knowledge in mainstream collections.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Amy Miniter
Amy Miniter graduated with a Master’s in Information Management from RMIT University in 2020. She is pursuing further studies in Computer Science at RMIT to complement her Master’s degree. She has recently been appointed to the VALA general committee.
Huan Vo-Tran
Huan Vo-Tran is a senior lecturer in the School of Accounting, Information Sysitems and Supply Chain at RMIT University. He is currently the Postgraduate Program Manager for the Department of Information Systems and Business Analytics, and prior to this he was the Higher Degree by Research Coordinator. Huan Obtained his PhD in 2014 where he explored the information management and sharing practices of architects and builders as they completed a multi-million dollar complex construction project. Currently he has 6 HDR candidates and 4 completions. He currently serves on the Australian Library and Information Association (ALIA) Research Advisory Committee whose focus is to promote the value of research in the profession and to provide advice on ALIA’s role in research in general.
Notes
1. The term ‘Indigenous’ is used in this article to refer, generally, to the First Nations people in present-day states with histories of dispossession following British colonial occupation, subsuming terms such as Aboriginal, Métis and First Peoples. It is acknowledged that the use of this generalised term in research that considers the impact of generalised classification systems may seem incongruous. However, many of the issues discussed do affect Indigenous peoples and the management of Indigenous Knowledge in similar ways worldwide and, primarily for this reason, the term ‘Indigenous’ has been adopted for this paper to convey the generality associated with these outcomes.
2. The Third National Indigenous Languages Survey was released in August 2020, following the completion of this research (Commonwealth of Australia, Citation2020).
3. Orthographies provided as AIATSIS reference names are used to identify languages in this paper.
References
- AIATSIS. (2019). About us. Australian Institute of Aboriginal and Torres Strait Islander Studies. https://aiatsis.gov.au/about-us
- AIATSIS. (n.d.-a). About AUSTLANG [Text]. AIATSIS Collection. https://collection.aiatsis.gov.au/austlang/about
- AIATSIS. (n.d.-b). AUSTLANG dataset 001 [Text]. AIATSIS Collection. https://data.gov.au/data/dataset/70132e6f-259c-4e0f-9f95-4aed1101c053/resource/e9a9ea06-d821-4b53-a05f-877409a1a19c/download/aiatsis_austlang_endpoint_001.csv
- AIATSIS. (n.d.-c). N115: Djambarrpuyngu [Text]. AIATSIS Collection. https://collection.aiatsis.gov.au/austlang/language/n115
- AIATSIS. (n.d.-d). S35: Boonwurrung [Text]. AIATSIS Collection. https://collection.aiatsis.gov.au/austlang/language/s35
- AIATSIS. (n.d.-e). S59: Dharawal/Tharawal [Text]. AIATSIS Collection. https://collection.aiatsis.gov.au/austlang/language/s59
- AIATSIS. (n.d.-f). Y57: Wik Mungkan [Text]. AIATSIS Collection. https://collection.aiatsis.gov.au/austlang/language/y57
- Bardenheier, P., Wilkinson, E. H., & Hēmi Dale, T. A. (2015). Ki te Tika te Hanga, Ka Pakari te Kete: With the right structure we weave a strong basket. Cataloging & Classification Quarterly, 53(5–6), 496–519. https://doi.org/https://doi.org/10.1080/01639374.2015.1008716
- Bone, C. (2016, August). Modifications to the Library of Congress Subject Headings for use by Manitoba archives. Connections. Collaboration. Community. 82nd IFLA General Conference and Assembly. IFLA WLIC 2016, Colombus, USA. http://library.ifla.org/1328/
- Bone, C., & Lougheed, B. (2018). Library of congress subject headings related to Indigenous peoples: Changing LCSH for use in a Canadian archival context. Cataloging & Classification Quarterly, 56(1), 83–95. https://doi.org/https://doi.org/10.1080/01639374.2017.1382641
- Buente, W., Baybayan, C. K., Hajibayova, L., McCorkhill, M., & Panchyshyn, R. (2020). Exploring the renaissance of wayfinding and voyaging through the lens of knowledge representation, organization and discovery systems. Journal of Documentation, 76(6), 1279–1293. https://doi.org/https://doi.org/10.1108/JD-10-2019-0212
- Cherry, A., & Mukunda, K. (2015). A case study in Indigenous classification: Revisiting and reviving the Brian Deer scheme. Cataloging & Classification Quarterly, 53(5–6), 548–567. https://doi.org/https://doi.org/10.1080/01639374.2015.1008717
- Commonwealth of Australia. (2020). National Indigenous languages report [Text]. Department of infrastructure, transport, regional development and communications: office of the arts. https://www.arts.gov.au/what-we-do/indigenous-arts-and-languages/national-indigenous-languages-report
- Constable, P., & Simons, G. (2002). Preparing the way for advancements in language identification standards. (p. 22). SIL International. https://www.sil.org/system/files/reapdata/23/64/66/23646694030523930907147592710071835574/SILEWP2002_004.pdf
- Doyle, A. M. (2006). Naming and reclaiming Indigenous Knowledges in public institutions: Intersections of landscapes and experience. In Knowledge organization for a global learning society: Proceedings of the 9th international conference for knowledge organization. International society for knowledge organization 9th international conference. https://repository.arizona.edu/handle/10150/105581
- Doyle, A. M., Lawson, K., & Dupont, S. (2015). Indigenization of knowledge organization at the Xwi7xwa Library. Journal of Library and Information Studies, 13(2), 107–134. https://doi.org/https://doi.org/10.14288/1.0103204
- Glottolog. (n.d.-a). Welcome to Glottolog 4.2.1. https://glottolog.org/
- Glottolog. (n.d.-b). About langoids. https://glottolog.org/glottolog/glottologinformation#aboutlanguoids
- ISO. (2007). ISO 639-3: Codes for the representation of names of languages—Part 3 Alpha 3 code for comprehensive coverage of language (ISO 639-3:2007(E)). IHS Engineering Workbench
- ISO. (n.d.). ISO 639: Language codes. International Organization for Standardization. https://www.iso.org/iso-639-language-codes.html
- Kamusella, T. (2012). The global regime of language recognition. International Journal of the Sociology of Language, 2012(218), 59–86. https://doi.org/https://doi.org/10.1515/ijsl-2012-0059
- Kim, A., & Breuer, L. M. (2017). On the development of an interdisciplinary annotation and classification system for language varieties: Challenges and solutions. Jazykovedny Casopis; Bratislava, 68(2), 191–207.
- Kleiber, E., Berez-Kroeker, A. L., Chopey, M., Yarbrough, D., & Shelby, R. (2018). Making Pacific languages discoverable: A project to catalog the University of Hawaii’ at Manoa Library Pacific Collection by Indigenous languages. The Contemporary Pacific, 30(1), 110–122. https://doi.org/https://doi.org/10.1353/cp.2018.0005
- Krechmer, K. (2014). Standardization: A primer. Proceedings of the 2014 ITU Kaleidoscope Academic Conference: Living in a converged world - impossible without standards? (pp. 177–184). https://doi.org/https://doi.org/10.1109/Kaleidoscope.2014.6858495
- Library of Congress. (2007). Introduction: MARC code list for languages. https://www.loc.gov/marc/languages/introduction.pdf
- Library of Congress. (2017). MARC code list for languages: Name sequence. MARC Standards. https://www.loc.gov/marc/languages/language_name.html
- Library of Congress. (2018). Technical notice October 26, 2018—Additions to the MARC code lists for relators, sources, description conventions. MARC Standards. https://www.loc.gov/marc/relators/tn181026src.html
- Library of Congress. (2021). Subject heading and term source codes: Source codes for vocabularies, rules, and schemes. https://www.loc.gov/standards/sourcelist/subject.html
- Library of Congress. (n.d.). SACO - Subject authority cooperative program. https://www.loc.gov/aba/pcc/saco/index.html
- Lilley, S. C. (2015). Ka Pō, Ka Ao, Ka Awatea: The Interface between Epistemology and Māori Subject Headings. Cataloging & Classification Quarterly, 53(5–6), 479–495. https://doi.org/https://doi.org/10.1080/01639374.2015.1009671
- Lissarrague, A., McLaughlin, A., & Sweett, C. (2019). In search of Indigenous Australian languages webinar. National Library of Australia. https://www.youtube.com/watch?v=nNFv_qpJzV0&feature=emb_logo
- Littletree, S., & Metoyer, C. A. (2015). Knowledge organization from an Indigenous perspective: The Mashantucket Pequot Thesaurus of American Indian terminology project. Cataloging & Classification Quarterly, 53(5–6), 640–657. https://doi.org/https://doi.org/10.1080/01639374.2015.1010113
- Lubransky-Moy, A. (2019). Trove: Powering Indigenous research for the 21st century. AIATSIS. https://aiatsis.gov.au/publications/presentations/trove-powering-indigenous-research-21st-century
- Marmion, D., Obata, K., & Troy, J. (2014). Community, identity, wellbeing: The report of the Second National Indigenous Languages Survey. (p. 79). AIATSIS. https://aiatsis.gov.au/publications/products/community-identity-wellbeing-report-second-national-indigenous-languages-survey
- Masterson, M., Stableford, C., & Tait, A. (2019). Re-imagining classification systems in remote libraries. Journal of the Australian Library and Information Association, 68(3), 278–289. https://doi.org/https://doi.org/10.1080/24750158.2019.1653611
- Morey, S., Post, M. W., & Friedman, V. A. (2013, January). The language codes of ISO 639: A premature, ultimately unobtainable, and possibly damaging standardization. Research, Records and Responsibility (RRR): Ten Years of the Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC). https://ses.library.usyd.edu.au/handle/2123/9838
- Musgrave, S., Barwick, L., Walsh, M., & Treloar, A. (2013, January). Language identifying codes: Remaining issues, future prospects. Research, Records and Responsibility (RRR): Ten Years of the Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC). https://ses.library.usyd.edu.au/handle/2123/9839
- Nakata, M. (2007). The cultural interface. The Australian Journal of Indigenous Education, 36(S1), 7–14. https://doi.org/https://doi.org/10.1017/S1326011100004646
- Nakata, M., Byrne, A., Nakata, V., & Gardiner, G. (2005). Indigenous knowledge, the library and information service sector, and protocols. Australian Academic & Research Libraries, 36(2), 7–21. https://doi.org/https://doi.org/10.1080/00048623.2005.10721244
- National and State Libraries Australia. (2019). Speaking our language. https://www.nsla.org.au/news/speaking-our-language
- National Information Standards Organization. (2001). ANSI/NISO Z39.53-2001: Codes for the representation of language interchange (Patent No. ANSI/NISO Z39.53-2001). http://xml.coverpages.org/ANSI-NISO-Z39-53.pdf
- National Library of Australia. (2019). Cataloguing notes from AUSTLANG cataloguing webinar. https://www.nla.gov.au/librariesaustralia/sites/nla.gov.au.librariesaustralia/files/cataloguing_notes_from_austlang_cataloguing_webinar.pdf
- National Library of Australia. (2021). NLA catalogue entry for “The Yield” by Tara Winch (website). National Library of Australia. https://catalogue.nla.gov.au/Record/8049239/Details?lookfor=%22The+Yield%22+AND+winch&max=4&offset=2
- National Library of Australia. (n.d.-a). Austlang national codeathon. https://www.nla.gov.au/our-collections/processing-and-describing-the-collections/Austlang-national-codeathon
- National Library of Australia. (n.d.-b). Trove help centre: AUSTLANG codes. https://help.nla.gov.au/trove/for-content-partners/austlang-codes
- Obata, K. (2009). AUSTLANG - online Australian Indigenous languages database. Incite, 30(4), 23. https://search-informit-com-au.ezproxy.lib.rmit.edu.au/documentSummary;dn=704115071899151;res=IELHSS
- Olson, H. A. (2001). The power to name: Representation in library catalogs. Signs: Journal of Women in Culture and Society, 26(3), 639–668. https://doi.org/https://doi.org/10.1086/495624
- Parks, E. (2015). Engaging the discourse of international language recognition through ISO 639-3 signed language change requests. Critical Inquiry in Language Studies, 12(3), 208–230. https://doi.org/https://doi.org/10.1080/15427587.2015.1060559
- Rigby, C. (2015). Nunavut Libraries Online establish Inuit language bibliographic cataloging standards: Promoting indigenous language using a commercial ILS. Cataloging & Classification Quarterly, 53(5–6), 615–639. https://doi.org/https://doi.org/10.1080/01639374.2015.1008165
- SIL International. (n.d.). Information on ISO 639-3. SIL International. https://iso639-3.sil.org/about
- Simpson, J. (2019). The state of Australia’s Indigenous languages – And how we can help people speak them more often. The Conversation. http://theconversation.com/the-state-of-australias-indigenous-languages-and-how-we-can-help-people-speak-them-more-often-109662
- Simpson, L. R. (2004). Anticolonial strategies for the recovery and maintenance of Indigenous Knowledge. The American Indian Quarterly, 28(3/4), 373–384. https://doi.org/https://doi.org/10.1353/aiq.2004.0107
- Swanson, R. (2015). Adapting the Brian Deer classification system for Aanischaaukamikw Cree cultural institute. Cataloging & Classification Quarterly, 53(5–6), 568–579. https://doi.org/https://doi.org/10.1080/01639374.2015.1009669
- The Ethnologue. (n.d.-a). About Ethnologue. The Ethnologue. https://www.ethnologue.com/about
- The Ethnologue. (n.d.-b). History of the Ethnologue. The Ethnologue. https://www.ethnologue.com/about/history-ethnologue
- The Ethnologue. (n.d.-c). Language information. The Ethnologue. https://www.ethnologue.com/about/language-info
- Thorpe, K. (2019). Transformative praxis: Building spaces for Indigenous self-determination in libraries and archives. In the Library with the Lead Pipe. http://www.inthelibrarywiththeleadpipe.org/2019/transformative-praxis/
- UNESCO. (2018). 2019 international year of Indigenous language. 2019 International Year of Indigenous Languages. https://en.iyil2019.org/
- Wright, S. E. (2015). Language codes and language tags. In Routledge encyclopedia of translation technology (pp. 574–587). Routledge. ProQuest Ebook Central. https://ebookcentral.proquest.com/lib/rmit/detail.action?docID=1843560.