
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the last decade, agent-based modelling and simulation has emerged as a potential approach to study complex systems in the real world, such as traffic congestion. Complex systems could be modelled as a collection of autonomous agents, who observe the external environment, interact with each other and perform suitable actions. In addition, reinforcement learning, a branch of Machine Learning, that models the learning process of a single agent as a Markov decision process, has recently achieved remarkable results in several domains (e.g. Atari games, Dota 2, Go, Self-driving cars, Protein folding, etc.), especially with the invention of deep reinforcement learning. Multi-agent reinforcement learning, by taking advantage of these two approaches, is a new technique that can be used to further study complex systems. In this article, we present a multi-agent reinforcement learning model for traffic congestion on one-way multi-lane highways and experiment with six reinforcement learning algorithms in this setting.
1. Introduction
Along with the development of modern urban areas, the explosion of individual vehicles makes the public transport infrastructure unable to keep up with society's requirements. As a consequence, traffic congestion, besides air pollution and water pollution, is considered an incurable disease of urbanization in developing countries, such as Vietnam (Le, Citation2018). According to a study, the total damages caused by traffic congestion in Hanoi and Ho-Chi-Minh city are more than 20 trillion dongs/year, including damages in time, fuel, and environment (Le, Citation2018). Traffic jams, during rush hours or on rainy days, can keep people in traffic stuck on the road for hours. It, therefore, causes psychological instability in the residents, harms the health of citizens, and restrains socio-economic development (Le, Citation2018). In addition, traffic congestion might appear, not only in the urban areas but also on highways, where the majority of vehicles are cars, when having an accident, or when a huge number of cars leave/return to cities on/after holidays.
Traffic jams can appear without any centralized cause, but only by the interaction of the vehicles involved (CitationWilensky & Payette, Citationn.d.). When some vehicles are clustered together, they will slow down and cause vehicles behind them to also slow down. As a consequence, a traffic jam forms (CitationWilensky & Payette, Citationn.d.). Even though all vehicles move forward, the traffic jams tend to move backward, because of wave phenomena: the group's behaviour can be very different from the behaviour of the individuals who make up this group (CitationWilensky & Payette, Citationn.d.).
To study complex systems, e.g. traffic congestion, tsunami evacuation, etc., agent-based modelling and simulation (ABMS) is a promising approach and have obtained remarkable results (Le et al., Citation2021). By this approach, complex systems are modelled as a collection of autonomous agents, who can observe the environment's state and then perform suitable actions. The mutual interaction between agents could expose hidden phenomena, that could not be observed by studying the behaviour of a single agent.
In addition, the reinforcement learning (RL) approach, where an agent learns what to do (i.e. how to map situations to actions) to maximize its numerical reward signal (Sutton & Barto, Citation2018), is recently proven efficient in several domains, especially with the contribution of DeepMind company and its invention of deep reinforcement learning (Mnih et al., Citation2013, Citation2015).
The combination of MAS and RL, especially DRL, therefore, is necessary to further study complex systems, that lead to the appearance of multi-agent reinforcement learning (MARL) (Nguyen et al., Citation2020). However, implementing RL algorithms in a multi-agent setting poses a lot of challenges (Nguyen et al., Citation2020), due to the explosion of agent's interactions, the parallel execution of RL algorithms by agents, etc. The first challenge is the non-stationarity problem (Nguyen et al., Citation2020). In a single-agent environment, the agent concerns only with its outcome. However, in a multi-agent environment, each agent observes not only its outcome but also the behaviour of other agents. These agents have to learn concurrently, leading to the requirement of greater computing power. The second challenge is the partial observability problem (Chu et al., Citation2019; Nguyen et al., Citation2020). In a multi-agent environment, agents have only partial observability of the environment, due to limited communication among them. This problem can be modelled using the partially observable Markov decision process (POMDP). In our work, we have modified original RL algorithms, which were proposed for a single-agent environment, to work in a multi-agent environment.
In this article, as an extended version of our conference paper (Le, Citation2022), our research problem is to compare and analyse the RL algorithms. Therefore, we have developed an agent-based traffic model on one-way multi-lane highways and experimented with six RL algorithms on top of this model, including Q-Learning (Watkins & Dayan, Citation1992), SARSA (Sutton & Barto, Citation2018), Deep Q-Learning Footnote1 (Mnih et al., Citation2013), Deep Q-Network (Mnih et al., Citation2015), Naive Actor–Critic and Advantage Actor–Critic without multiple workers (Bhatnagar et al., Citation2009; Sutton & Barto, Citation2018). Then, we analyse the effectiveness of these algorithms according to two metrics: average speed and total reward.
Our contributions are twofold:
| (1) | Extending Traffic-2-Lanes model (CitationWilensky & Payette, Citationn.d.) by taking into account accident situations, where a vehicle could be damaged during its travelling. In the base model, i.e. Traffic-2-Lanes model, there were few input parameters and agents followed a fixed simple rule to move. In our extended model, we have added several RL input parameters. The problem was also modified: not only simulate how traffic jams can appear on highways but also how to deal with traffic jams, by applying RL algorithms. | ||||
| (2) | Implementing six RL algorithms on top of this model and evaluating their effectiveness in terms of average speed and total reward. We have transferred these algorithms from a single-agent environment to a multi-agent environment. | ||||
The remainder of this article is organized as follows. We first present the background of MAS and RL in Section 2. The related works, about the application of MARL for traffic congestion problem, are discussed in Section 3. Section 4 describes our traffic model, with its components and implemented RL algorithms. The simulation results are analysed in Section 5, with some discussions. Finally, a conclusion, including future work, is provided.
2. Preliminary of MAS and RL
2.1. Multi-agent systems
To study complex systems (e.g. transportation, tsunamis, floods, epidemiology, etc.), it is sometimes very difficult, or even impossible, to develop an analytical model, because of their numerous components and the non-linear behaviour (Le et al., Citation2021). Therefore, agent-based modelling and simulation (ABMS) is recently considered as an alternative and bottom-up approach. In this approach, we abstract a complex system as a collection of autonomous agents (Russell & Norvig, Citation2021), who are able to observe the environment and perform reasonable actions. Agents may be reactive, having a simple behaviour, e.g. ants, or may exhibit cognitive and goal-oriented behaviour, e.g. bidder, with high-level interactions, e.g. contract net protocol, Le et al. (Citation2021). Due to the mutual interactions between agents, hidden phenomena, that could not be observed through the behaviour of a single agent, can emerge. For example, while each car is taken into account individually and it follows a set of simple movement rules, traffic congestion can emerge from the collective interactions of these cars.
To support modellers to design their models, several ABMS platforms are developed. Among them, NetLogo (Wilensky & Rand, Citation2015), GAMA (Taillandier et al., Citation2018), or AnyLogic (Grigoryev, Citation2016) are well-known platforms, for general purposes. For the traffic modelling and simulation, SUMO (Lopez et al., Citation2018), VISSIM (Prabuchandran et al., Citation2014), MATSim (Axhausen et al., Citation2016), or CityFlow (Zhang et al., Citation2019) are some good candidates. In addition, Abar et al. (Citation2017) provided a full classification of ABMS platforms, based on the computational strength and model development efforts.
2.2. Reinforcement learning
RL is a learning approach that helps an agent to maximize its long-term return , where
is the discount factor. This approach models the learning process of the agent as a Markov decision process (MDP) (Sutton & Barto, Citation2018). By that, at the time step
, the agent observes the environment's state
(state space), then performs an action
(action space), and receive next reward
(reward space).
In addition, the agent can be classified into two main types, due to its policy:
On-policy: agent learns the value function according to the current action, derived from the policy that is currently in use.
Off-policy: agent learns the value function according to the action derived from another policy.
In our work, we consider six RL algorithms, including Q-Learning (Watkins & Dayan, Citation1992), SARSA (Sutton & Barto, Citation2018), Deep Q-Learning (DQL) (Mnih et al., Citation2013), Deep Q-Network (DQN) (Mnih et al., Citation2015), Naive Actor–Critic (NAC), Advantage Actor–Critic without multiple workers (A2Cwo) (Bhatnagar et al., Citation2009; Sutton & Barto, Citation2018), which are briefly described as follows.
2.2.1. Q-Learning
Q-Learning, an off-policy temporal-difference (TD) algorithm, was invented by Watkins and Dayan (Citation1992). In this algorithm, the Q function would approach the optimal value, , independent of the policy being followed (Sutton & Barto, Citation2018). Q-Learning is described in Algorithm 1.

2.2.2. SARSA
SARSA (State–Action–Reward–State–Action), an on-policy TD control, is a slight variation of the Q-Learning algorithm. In each step, the agent chooses the next action according to its current policy. This algorithm is described in Algorithm 2.

2.2.3. Deep Q-Learning
When the state space and action space are huge, using Q-table is time-consuming and impractical. Therefore, an alternative approach is to approximate Q-function with some parameters θ, i.e. , using neural networks. DQL algorithm, who extends Q-Learning with a neural network, is described in Algorithm 3.

2.2.4. Deep Q-Network
Introduced by DeepMind in 2015, DQN aims to greatly improve and stabilize the training procedure of Q-Learning by two mechanisms: (1) experience replay and (2) update target periodically. This algorithm is described in Algorithm 4.

2.2.5. Actor–Critic methods
Actor–Critic methods, a sub-class of policy-gradient methods, are online approximations of policy iteration (Bhatnagar et al., Citation2009). They aim to reduce the bias and variance of policy-based methods, with two structures: Actor and Critic. While the Actor corresponds to a conventional action-selection policy, mapping states to actions; the Critic evaluates the chosen actions by computing the value function (Bhatnagar et al., Citation2009).
In current work, we have implemented two Actor–Critic algorithms: Naive Actor–Critic (NAC) and Advantage Actor–Critic without multiple workers (A2Cwo), whose main steps are described in Algorithm 5 (Suran, Citation2020). In these implementations, we have used two neural networks, one for the Actor and one for the Critic.

3. Related works
In the literature, MARL techniques have been applied to deal with traffic congestion problem in some research. While most of them considered traffic signal control (TSC) (Bakker et al., Citation2010; Deng et al., Citation2019; Hussain et al., Citation2020; Ma & Wu, Citation2020; Prabuchandran et al., Citation2014), few of them considered autonomous vehicles (AV) (Chen et al., Citation2022; Zhou et al., Citation2022), as agents.
In Bakker et al. (Citation2010), the authors applied MARL techniques to the automatic optimization of traffic light controllers, in order to have higher traffic throughput and reduce traffic congestion. Each traffic junction controller is modelled as an agent, who perceives traffic state information and coordinates with others to optimize the traffic lights, in terms of the average waiting time of cars.
In El-Tantawy and Abdulhai (Citation2012), the authors dealt with traffic congestion in Greater Toronto Area, by applying the MARL technique, with the Q-Learning algorithm, to Adaptive Traffic Signal Control (ATSC). Each controller was modelled as an agent and controlled traffic lights around a traffic junction to minimize the total vehicle delay. The proposed system was tested on top of PARAMICS, a microscopic traffic simulation software.
In Prabuchandran et al. (Citation2014), the authors applied MARL to the TSC problem, using the VISSIM platform. They modelled each traffic signal junction as an agent and used the Q-Learning algorithm, with either ϵ-greedy or UCB-based exploration strategies, to help the agent improve its action. In our work, we have used not only tabular-based algorithms (e.g. Q-Learning, SARSA) but also approximate algorithms (e.g. DQN, Actor–Critic).
In Chu et al. (Citation2019), the authors applied MADRL to large-scale ATSC problem, on top of the SUMO platform. The proposed MA2C (Multi-agent Advantage Actor–Critic) algorithm was proved to outperform other state-of-the-art decentralized MARL algorithms, including independent A2C (IA2C) and independent Q-learning (IQL), in robustness and optimality. In their work, each intersection is modelled as an agent.
In Ma and Wu (Citation2020), on top of the SUMO platform, the authors proposed the FMA2C (Feudal Multi-agent Advantage Critic–Actor) algorithm, an extension of MA2C, to deal with the global coordination problem, in the domain of TSC. They split the traffic network into regions, where each region is controlled by a manager agent and the worker agents would control the traffic lights in this region.
In Hussain et al. (Citation2020), the authors used MADRL and Vehicle-to-Everything (V2X) communication to optimize the duration of traffic signals, using the SUMO simulator. They modelled a traffic light as an agent, who gets information along its lanes within a circular V2X coverage.
In Deng et al. (Citation2019), the authors proposed the MAPPO (Multi-Agent Proximal Policy Optimization) algorithm to solve the ramp metering problem, by improving the operation efficiency of urban freeways. They modelled each ramp metre as an agent. The simulation experiments were performed on top of the SUMO platform and demonstrated that their proposed method is able to automatically smooth traffic flow.
In Chen et al. (Citation2022), the authors applied MARL to solve the on-ramp merging problem on the mixed-traffic highway, where AVs and human-driven vehicles (HDVs) coexist, to maximize the traffic throughput. They modelled each AV as an agent and used the gym-based highway-env simulator (CitationEleurent, Citationn.d.) with three different levels of traffic densities.
In Zhou et al. (Citation2022), also based on the gym-based highway-env simulator, the authors applied MARL to deal with the lane-changing decision, making of AV on the mixed-traffic highway. They proposed a MA2C algorithm, in which each AV is modelled as an agent.
In our work, we applied MARL and MADRL to the traffic model on one-way multi-lane highways, on top of NetLogo platform (Wilensky & Rand, Citation2015). Based on two existing models (Head, Citation2017; CitationWilensky & Payette, Citationn.d.), we have modelled each vehicle as an agent. While the work of CitationWilensky and Payette (Citationn.d.) modelled the traffic system on multi-lane highways as a multi-agent system, without considering accident situations and without RL strategies; the work of Head (Citation2017) implemented only DQN algorithm for vehicles on one-lane highways and with only three actions (i.e. acceleration, deceleration, staying-same).
4. Traffic model for the one-way multi-lane highways
On top of the NetLogo platform, we have developed a traffic model for one-way multi-lane highways. By the time, traffic might slow down and jam might appears. Drivers can accelerate, decelerate, maintain the same speed, or change lanes during the movement.
In our work, we have extended the work of CitationWilensky and Payette (Citationn.d.) with six RL algorithms, including: Q-Learning, SARSA, DQL, DQN, NAC, A2Cwo. We also took into account the accident situations, which are, in our opinion, an important aspect to prove the effectiveness of an algorithm.
4.1. Description of traffic model's interface
The model's interface consists of three areas: (1) input area; (2) output area; and (3) view area.
In the input area, we can calibrate the parameters of our model. We employed several parameters, such as number of cars, number of lanes, acceleration, deceleration, maximum number of patience before a driver decides to change lane, exploration rate, maximum number of damaged cars, exploration decay, learning rate, discount factor and move strategy. In addition, some parameters are reserved for DQL and DQN, such as batch size and memory size.
In the output area, we use several outputs to track different aspects of our model in real-time, for example number of cars per lane, maximum & minimum & average patience, maximum & minimum & average speed, total reward of cars, distribution/percentage of selected actions.
The view area, as shown in , represents a cyclic one-way multi-lane highway. The vehicles travel on this highway at different speeds. When a vehicle is damaged, for some reason, its speed equals 0. The colour of vehicles is corresponding to their selected action, i.e. redred for deceleration, greengreen for acceleration, yellowyellow for staying current speed, and blueblue for changing lanes.
Figure 1. The view area of our model.

4.2. Elements of RL framework for traffic model
The main elements of the RL framework for the traffic congestion problem on highways are described as follows.
4.2.1. State
For SARSA and Q-Learning algorithms, the agent's state is depicted by four factors: (1) vehicle's speed; (2) speed of its blocking vehicle; (3) distance to its blocking vehicle; and (4) number of patience.
For DQL, DQN, NAC, and A2Cwo algorithms, the agent's state, i.e. the input of neural networks, is a tuple, which consists of seven factors: (1) vehicle's speed; (2) distance to the car ahead on the same lane; (3) speed of the car ahead on the same lane; (4) distance to car behind on the same lane; (5) speed of car behind on the same lane; (6) exploration rate; and (7) time step.
4.2.2. Action
When travelling, a vehicle could choose to perform one of four following actions: (1) accelerate, (2) decelerate, (3) stay same, and (4) change lane.
4.2.3. Reward
The agent's reward is defined as a function of the vehicle's speed, as shown in Equation Equation1(1)
(1)
(1)
(1) where sp is the current speed of the vehicle.
4.3. Move strategies for vehicles
In our work, we have experimented with seven move strategies for vehicle agents, including Greedy strategy, and six RL strategies (i.e. Q-Learning, SARSA, DQL, DQN, NAC, A2Cwo).
4.3.1. Greedy strategy
This strategy is already pre-installed in the work of CitationWilensky and Payette (Citationn.d.). When travelling, the cars tentatively speed up. When they detect a blocking car ahead, in their observation distance, they will slow down. In the case that their blocking car is damaged, such as in an accident, they will change lanes.
4.3.2. Q-Learning strategy
This strategy follows Algorithm 1, using ϵ-greedy policy to help vehicles choose their actions. The value of ϵ will decrease over simulation time, using exp-decay parameter. In our implementation, we use a shared matrix Q by all agents, to store the values of state–action pairs. All elements of this matrix are initialized to 0. At time step t, agents will select an action, according to the ϵ-greedy policy. A random number, between 0 and 1, is generated and compared with ϵ. If this number is smaller than or equal to ϵ, agents will choose a random action (i.e. Exploration). Otherwise, they will choose the action that gives the greatest value, in Q-table, to the current state (i.e. Exploitation). Then, agents will perform the selected action and observe the reward. The last step is to update the element in Q-table that corresponds to the state and action at time step t, using the estimation of optimal near-future value.
4.3.3. SARSA strategy
In this strategy, following Algorithm 2, most of the steps are similar to Q-Learning, except for the update function for Q-table. At time step t, agents update the element in Q-table that corresponds to its current state and current action, using the value of the element corresponding to the next state and next action.
4.3.4. DQL strategy
This strategy, that follows Algorithm 3, is based on the work of Head (Citation2017). We have conducted a Q-network with seven input nodes (corresponding to seven factors of the agent's state), three hidden layers (size of 36), and four output nodes (corresponding to four actions). This network and the replay memory are shared among agents. At time step t, agents will select an action, according to the ϵ-greedy policy. Then, they will perform the selected action and observe the reward. We will store the current transition of agents (i.e. current state, current action, current reward, and next state) in the replay memory. After that, we will get a random sample of transitions from replay memory to train Q-network.
4.3.5. DQN strategy
In this strategy, following Algorithm 4, most of the steps are similar to the DQL strategy. We used two shared networks among agents: Q and . Agents will use the value in
-network to train Q-network. And, after some time steps, we will clone
-network from Q-network.
4.3.6. NAC strategy
In this strategy, based on the work of Suran (Citation2020), we have conducted two shared networks: Actor and Critic, with similar architecture as Q-network in DQL. At time step t, agents will select an action, according to the ϵ-greedy policy. Then, they will perform the selected action and observe the reward. After that, we will calculate actor loss and critic loss to train two networks.
4.3.7. A2Cwo strategy
In this strategy, based on the work of Suran (Citation2020), most of the steps are similar to the NAC strategy. However, we update two networks after every n time steps (n>1), instead of each time step, as in NAC strategy.
5. Experiments
In this section, we evaluate seven move strategies in terms of average speed and total reward.
5.1. Experimental settings
The values for input parameters are shown in . In addition, the vehicle speed is normalized between 0.0 and 1.0. Initially, the vehicle's speed is set randomly. We use a random number generator to determine a value between 0.75 and 1.0, with uniform distribution.
Table 1. Value of input parameters.
5.2. Comparing Greedy strategy with RL strategies
Here, we demonstrate the effectiveness of six RL strategies with Greedy strategy, in terms of average speed.
shows the average speed during 50,000 time steps, achieved by seven move strategies.
In comparison with the Greedy strategy, as the baseline one, the Q-Learning and SARSA strategies were less effective in the beginning. However, during the time, when the elements in Q-table approach their optimal values, these strategies will help vehicles to improve the average speed and finally surpass the speed achieved by the Greedy strategy. Moreover, one weakness of the Greedy strategy is that it does not help vehicles to improve their average speed over time.
Figure 2. Comparison of seven move strategies in terms of average speed. The curves are smoothed over 5000 time steps.
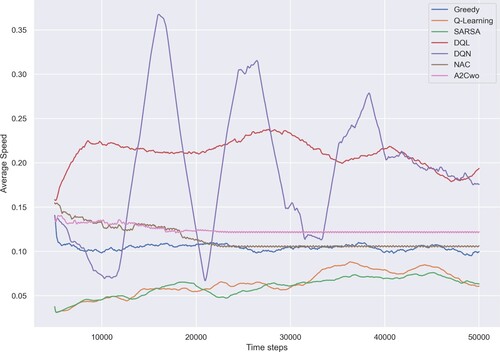
In general, thanks to the approximation approach by using neural networks, the average speeds achieved by DQL, DQN, NAC and A2Cwo strategies are higher than the one achieved by the Greedy strategy.
In addition, the results achieved by DQL and DQN strategies are clearly better than the ones achieved by other strategies. However, the trade-off is more computational resources and time-consuming than Greedy and tabular strategies.
5.3. Comparing RL strategies
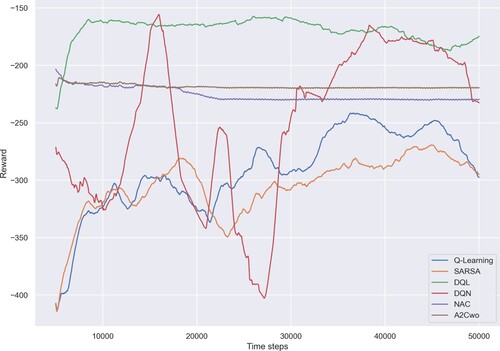
Here, we compare the effectiveness of six RL strategies based on the second criterion: total reward.
shows the total reward of all vehicles during 50,000 time steps, achieved by six RL strategies. As we can see, the results achieved by DQL and DQN strategies are generally better than the ones achieved by Q-Learning, SARSA, NAC, and A2Cwo strategies.
Therefore, in addition to average speed, the total reward aspect, once again, proves that DQL and DQN algorithms are more effective than Q-Learning, SARSA, NAC, A2Cwo, and Greedy algorithms in reducing traffic congestion on highways in accident situations.
Figure 3. Comparison of six RL move strategies in terms of total reward. The curves are smoothed over 5000 time steps.
6. Conclusion
In this article, we presented a case study of applying MARL to traffic congestion problem on one-way multi-lane highways. In the long term, the RL strategies demonstrate their effectiveness, in comparison with the Greedy one, by improving the average speed of vehicles, especially in accident situations. Moreover, DQL and DQN algorithms are proven to be more effective than Q-Learning, SARSA, NAC, A2Cwo algorithms in both two metrics (i.e. average speed, and total reward).
In future work, we will refine our model to be used as a testbed for testing and comparison of RL algorithms. We will improve the reward function, to take into account other aspects (e.g. driving efficiency, comfort, safety, etc.). In addition, more complex maps (e.g. urban areas) will be also considered. For real-world applications, our approach can be applied in autonomous driving systems to train autonomous vehicles in order to reduce traffic congestion.
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Notes on contributors
Nguyen-Tuan-Thanh Le
Nguyen-Tuan-Thanh Le is with Thuyloi University, Hanoi, Vietnam as a lecturer and researcher. He earned a MSc. in Computer Science at IFI, Vietnam and a Ph.D. in Computer Science at Paul Sabatier University, Toulouse, France. His area of research is Multi-agent Systems and Reinforcement Learning.
Notes
1 We temporarily call this algorithm as DQL to distinguish it from the DQN algorithm, which is presented in Mnih et al. (Citation2015). In fact, DQL is a variation of DQN without Target Network.
References
- Abar, S., Theodoropoulos, G. K., Lemarinier, P., & O'Hare, G. M. P. (2017). Agent based modelling and simulation tools: A review of the state-of-art software. Computer Science Review, 24, 13–33. https://doi.org/10.1016/j.cosrev.2017.03.001
- Axhausen, K. W., Horni, A., & Nagel, K. (2016). The multi-agent transport simulation MATSim (p. 618). Ubiquity Press.
- Bakker, B., Whiteson, S., Kester, L., & Groen, F. C. A. (2010). Interactive Collaborative Information Systems (pp. 475–510). Springer Berlin, Heidelberg.
- Bhatnagar, S., Sutton, R. S., Ghavamzadeh, M., & Lee, M. (2009). Natural actor–critic algorithms. Automatica, 45(11), 2471–2482. https://doi.org/10.1016/j.automatica.2009.07.008
- Chen, D., Li, Z., Hajidavalloo, M., Chen, K., Wang, Y., Jiang, L., & Wang, Y. (2022, January 20). Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic. arXiv.org. Retrieved July 29, 2022, from https://arxiv.org/abs/2105.05701.
- Chu, T., Wang, J., Codecà, L., & Li, Z. (2019). Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 21(3), 1086–1095. https://doi.org/10.1109/tits.2019.2901791
- Deng, F., Jin, J., Shen, Y., & Du, Y. (2019). Advanced self-improving ramp metering algorithm based on multi-agent deep reinforcement learning. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE. https://doi.org/10.1109/itsc.2019.8916903
- Eleurent, E. (n.d.). Highway-Env: A minimalist environment for decision-making in autonomous driving. GitHub. Retrieved July 29, 2022, from https://github.com/eleurent/highway-env.
- El-Tantawy, S., & Abdulhai, B. (2012). Multi-agent reinforcement learning for integrated network of adaptive traffic signal controllers (MARLIN-ATSC). In 2012 15th international IEEE conference on intelligent transportation systems (pp. 319–326). IEEE.10.1109/ITSC.2012.6338707
- Grigoryev, I. (2016). Anylogic 7 in three days: A quick course in simulation modeling. Ilya Grigoryev.
- Head, B. (2017). Python-extension/traffic basic – reinforcement.nlogo at main · NetLogo/Python-Extension. GitHub. Retrieved July 29, 2022, from https://github.com/NetLogo/Python-Extension/blob/master/demos/Traffic%20Basic%20-%20Reinforcement.nlogo.
- Hussain, A., Wang, T., & Jiahua, C. (2020, February 23). Optimizing traffic lights with multi-agent deep reinforcement learning and V2X communication. arXiv.org. Retrieved July 29, 2022, from https://arxiv.org/abs/2002.09853.
- Le, N.-T.-T. (2018). Tackling the traffic congestion problem at small bidirectional streets in big cities of vietnam. 7th Conference on Information Technology and Its Application (CITA), Da Nang, Vietnam.
- Le, N.-T.-T. (2022). Experimenting reinforcement learning algorithms in a multi-agent setting: A case study of traffic model for the one-way multi-lane highways. 11th conference on information technology and its application (CITA), Hue, Vietnam.
- Le, N.-T.-T., Nguyen, P.-A.-H.-C., & Hanachi, C. (2021). Agent-based modeling and simulation of citizens sheltering during a tsunami: Application to Da Nang city in Vietnam. Advances in Computational Collective Intelligence, Kallithea, Rhodes, Greecehttps://doi.org/10.1007/978-3-030-88113-9.
- Lopez, P. A., Wiessner, E., Behrisch, M., Bieker-Walz, L., Erdmann, J., Flotterod, Y. -P., Hilbrich, R., Lucken, L., Rummel, J., & Wagner, P. (2018). Microscopic traffic simulation using sumo. In 2018 21st international conference on intelligent transportation systems (ITSC). IEEE. https://doi.org/10.1109/itsc.2018.8569938
- Ma, J., & Wu, F. (2020). Feudal multi-agent deep reinforcement learning for traffic signal control. 19th International conference on autonomous agents and multiagent systems (AAMAS), Auckland, New Zealand.
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013, December 19). Playing Atari with deep reinforcement learning. arXiv.org. Retrieved July 29, 2022, from https://arxiv.org/abs/1312.5602.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533. https://doi.org/10.1038/nature14236
- Nguyen, T. T., Nguyen, N. D., & Nahavandi, S. (2020). Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Transactions on Cybernetics, 50(9), 3826–3839. https://doi.org/10.1109/tcyb.2020.2977374
- Prabuchandran, K. J., Hemanth Kumar, A. N, & Bhatnagar, S. (2014). Multi-agent reinforcement learning for traffic signal control. In 2014 17th international IEEE conference on intelligent transportation Systems (ITSC). IEEE. https://doi.org/10.1109/itsc.2014.6958095
- Russell, S. J., & Norvig, P. (2021). Artificial intelligence: A modern approach. Pearson.
- Suran, A. (2020, August 3). Actor–critic with tensorflow 2.x [part 1 of 2]. Medium. Retrieved July 29, 2022, from https://towardsdatascience.com/actor-critic-with-tensorflow-2-x-part-1-of-2-d1e26a54ce97.
- Suran, A. (2020, August 5). Acto-r-critic with tensorflow 2.x [part 2OF 2]. Medium. Retrieved July 29, 2022, from https://towardsdatascience.com/actor-critic-with-tensorflow-2-x-part-2of-2-b8ceb7e059db.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. The MIT Press.
- Taillandier, P., Gaudou, B., Grignard, A., Huynh, Q.-N., Marilleau, N., Caillou, P., Philippon, D., & Drogoul, A. (2018). Building, composing and experimenting complex spatial models with the gama platform. GeoInformatica, 23(2), 299–322. https://doi.org/10.1007/s10707-018-00339-6
- Watkins, C. J., & Dayan, P. (1992). Q-learning. Machine Learning, 8(3), 279–292. https://doi.org/10.1007/BF00992698
- Wilensky, U., & Payette, N. (n.d.). Traffic 2 lanes. NetLogo Models Library: Traffic 2 Lanes. Retrieved August 2, 2022, from http://ccl.northwestern.edu/netlogo/models/Traffic2Lanes.
- Wilensky, U., & Rand, W. (2015). An introduction to agent-based modeling: Modeling natural, social, and engineered complex systems with NetLogo. The MIT Press.
- Zhang, H., Feng, S., Liu, C., Ding, Y., Zhu, Y., Zhou, Z., Zhang, W., Yu, Y., Jin, H., & Li, Z. (2019). CityFlow: A Multi-Agent Reinforcement Learning Environment for Large Scale City Traffic Scenario. The World Wide Web Conference, San Francisco, CA, USA.
- Zhou, W., Chen, D., Yan, J., Li, Z., Yin, H., & Ge, W. (2022). Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic. Autonomous Intelligent Systems, 2(1), 5. https://doi.org/10.1007/s43684-022-00023-5