
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The demand for analysing sentiment information in social media data is increasing. However, current fine-grained sentiment analysis methods fail to consider both global and local semantic features simultaneously, leading to the oversight of grammatical information in sentences and an inability to address the issue of polysemy. To address these challenges, we propose a microblog fine-grained sentiment analysis model based on multidimensional feature fusion and graph convolutional neural networks (GCN). Built upon the ALBERT model, we utilize BiLSTM and capsule network models to extract global and local semantic features, thereby capturing bidirectional semantic dependencies and textual positional semantic information. Finally, we employ multi-head self-attention and GCN to select key features and sentence information, ensuring the integrity of fine-grained features. The experimental results indicate that the model outperforms several other models on fine-grained sentiment analysis datasets SMP2020-EWECT, NLPCC2013, NLPCC2014, and the binary classification dataset weibo_senti_100k, achieving accuracies of 80.64%, 67.19%, 71.37%, and 98.43%, respectively.
1. Introduction
As a result of the Internet's accelerating technological advancement, individuals are becoming increasingly habituated to expressing highly personal emotional views online. Gradually gaining prominence in the realm of public opinion research, sentiment analysis of microblogs texts has emerged as a significant area of focus on the largest Chinese social media platform globally (Phan et al., Citation2023; Venu Gopalachari et al., Citation2023; Zhang & Cui, Citation2023).
Conventional approaches to sentiment analysis typically divide texts into two distinct categories – positive and negative – or incorporate three additional neutral categories (Khan et al., Citation2022; Tamilselvi et al., Citation2022). However, for microblog texts, which are short, noisy, sparse in contextual semantic information, and heavily symbolized and colloquialized, the simple two- or three-classification coarse-grained sentiment analysis is unable to encompass the rich textual sentiments and may easily lead to information confusion (Bhuvaneshwari et al., Citation2022; Gao et al., Citation2022).
Recently, fine-grained sentiment analysis has gained wide attention, which can replace positive and negative sentiments with more specific ones, such as pleasure, anger, hatred, sadness, etc., according to different requirements, and delineate the sentiment tendency of microblog texts from a more refined dimension (Djaballah et al., Citation2021; Ganganwar & Rajalakshmi, Citation2023). Nowadays, most of the sentiment analysis adopts deep learning, which shows certain superiority compared with traditional methods.
As an instance, Convolutional Neural Network (CNN) employs a multi-layer neural network to extract profound features (Alroobaea, Citation2022; Aslan et al., Citation2023; Thin et al., Citation2023). However, for long texts in Weibo, CNN is limited by its local receptive field, which constrains its ability to capture the global context and long-distance dependencies of Weibo texts. Similarly, Recurrent Neural Network (RNN) is extensively utilized in sentiment classification to acquire contextual semantic information that enhances sentiment classification accuracy (Liu, Citation2023; Swathi et al., Citation2022; Tan et al., Citation2022a). However, RNN encounters the issue of vanishing or exploding gradients when dealing with long sequential data, and the presence of a large amount of noise and unstructured information in the text makes the RNN model susceptible to the influence of such noisy data. Long Short-Term Memory (LSTM) is an enhanced iteration of RNN model that effectively extracts latent features from the paragraph text in order to more precisely determine the sentiment of the text (Chang & Zhu, Citation2023; Naidu et al., Citation2022; Swathi et al., Citation2022; Tan et al., Citation2022b). LSTM performs well in handling long sequential data and capturing long-term dependencies. However, the model's interpretability is poor, and its internal decision-making process is relatively opaque, which can limit the model's generalization performance.
The attention mechanism, which has demonstrated remarkable efficacy in various natural language processing tasks, for instance, machine translation, sentiment analysis, lexical labelling, and more, has experienced tremendous success recently. The application of the attention mechanism to classify the sentiment of text has emerged as a prominent area of research. Certain scholars have implemented this attention mechanism (Liang et al., Citation2022) to extract context-specific information. While previous approaches to sentiment analysis have yielded some positive outcomes, there remain notable challenges. These include the inability to resolve the issue of words having multiple meanings, the complexity of considering both global and local semantic features, the susceptibility to overlooking crucial information, and the tendency to disregard the grammatical structure of sentences.
A microblog fine-grained sentiment analysis method (AB-BCM-GCN) incorporating ALBERT, Bidirectional Long Short-Term Memory (BiLSTM), Capsule Networks, Multi-head self-attention and GCN was suggested to address the existing problems, and its main innovations are as follows:
The ALBERT model with fewer model parameters is invoked to encode the input text, which effectively extracts the contextual semantic information and resolve the issue of words having multiple meanings.
The semantic feature extraction layer uses a combination of local and global feature extraction to acquire extensive semantic information from multiple dimensions. BiLSTM is employed during global feature extraction to store the semantic information of text in both the forward and reverse orientations, thereby enhancing the capture of bidirectional global semantic dependencies. Local feature extraction utilizes the capsule network model, replacing the scalar output in traditional convolutional operations with vector output to better focus on text location semantic information.
To integrate multi-dimensional features into individual nodes and enrich their semantic information, our semantic feature fusion layer adopts a multi-head self-attention mechanism to establish connections among multi-dimensional semantic information. During this process, critical features are dynamically screened, addressing the issue of key information loss encountered by traditional fusion methods.
By utilizing the dependency parsing tree of the text to construct a graph convolutional neural network (GCN), we enable GCN to prioritize the processing of sentence syntax information and fully utilize the rich node information and well-established relationship network. As a result, our model achieves higher accuracy in fine-grained sentiment classification.
2. Related work
Text sentiment analysis approaches currently in existence are primarily categorized into three groups: attentional-based text sentiment analysis approaches, fine-grained-based text sentiment analysis approaches, and GCN-based text sentiment analysis approaches.
2.1. Fine-grained text-based sentiment analysis
Fine-grained text sentiment analysis aims to break down the sentiment analysis task into more specific and detailed sentiment categories or levels. Traditional sentiment analysis typically categorizes text sentiment into basic categories such as positive, negative, or neutral. In contrast, fine-grained methods attempt to understand and categorize sentiment in text at a finer level, subdividing sentiment into more numerous and specific categories. For example, the FGAtten-BiGRU model proposed by Feng and Liu (Citation2019) utilizes a BiGRU neural network and fine-grained attention. Initially, the skip-gram model vectorizes the vocabulary, followed by the generation of a sentiment word list using pre-trained word vectors. To reduce noise interference, the naive Bayesian algorithm is employed. Finally, the model extracts features using BiGRU and fine-grained attention and proposes a fine-grained attention model after extensive evaluation to differentiate features. The efficacy of this model is demonstrated in textual sentiment analysis tasks after validation using sentiment corpora like JD reviews and IMDB, showcasing state-of-the-art performance. However, while the naive Bayesian algorithm can mitigate noise to some extent, it fails to handle the vast amount of unstructured information and specific contexts present in texts. Deng et al. (Citation2022) proposed a microblog sentiment classification model based on ALBERT-FAET, where text embeddings are obtained from a pre-trained ALBERT model and inter-emoji embeddings are learned using an attention-based LSTM network. Additionally, a fine-grained attention mechanism is suggested to capture word-level interactions between plain text and emoji. Subsequently, these concatenated features are fed into a CNN classifier to predict the sentiment labels of tweets. Nevertheless, the highly personalized and diverse nature of language text in microblogs may lead to poor model performance in dealing with their unique language style and expressions. Liao et al. (Citation2021) proposed a two-stage fine-grained text-level sentiment analysis model based on deep semantics and syntactic rule matching. Objects and their corresponding opinions are obtained using syntactic rule matching, and deep semantic networks are utilized for precise identification of objects and opinions. To achieve accurate pairwise matching for extraction outcomes, including multiple objects and opinions requiring matching, an object-opinion matching algorithm is suggested based on the principle of minimum lexical separation distance. Finally, an evaluation across multiple publicly available datasets validates the practicality and efficacy of the proposed algorithm in the text sentiment analysis environment. Although the model combines deep semantics and syntactic rule matching, its syntactic rule matching is insufficient to capture all semantic information in complex semantic environments. For fine-grained sentiment classification, George et al. (Citation2021) proposed a deep learning approach utilizing convolutional neural networks and random forest classifiers (CNN-RF). The model extracts features from input vectors using a convolutional neural network and converts text input into vector form using CBOW. A random forest classifier is implemented within the convolutional neural network instead of a fully connected layer. Following feature extraction, the random forest classifier applies these features to the classification task. Finally, the efficacy of this method is validated across extensive datasets. However, compared to other models, the relatively simple structure of this model fails to fully exploit the semantic information and emotional features in microblog texts.
2.2. Attention-based text sentiment analysis
In traditional text sentiment analysis, models typically represent input text as a fixed-length vector and then perform sentiment classification based on this vector. However, this approach may overlook the varying contributions of different parts of the text to sentiment. To address this issue, attention-based text sentiment analysis enhances the model's focus on sentiment-critical words by introducing an attention mechanism. This allows the model to more effectively gather sentiment-related information from the input text, thereby improving sentiment analysis performance. This approach has demonstrated exceptional efficacy in the field of natural language processing and has been widely applied in various text analysis tasks. Liu et al. (Citation2020) proposed a model for sentiment classification at the aspect level, integrating target-enhanced representation and unbiased attention. To achieve unbiased attention, the method introduced adversarial training techniques and implemented a gating mechanism that preserves embeddings to enhance the importance of targets in word representations. This mechanism dynamically merges target-related features into word representations while retaining the information of the original words. The effectiveness of this model in text sentiment analysis was validated through experiments on real datasets. However, these complex mechanisms may increase the computational complexity of the model, especially for large-scale microblog datasets, leading to inefficient training and inference processes. Sun and Gao (Citation2021) proposed a fine-grained multimodal sentiment analysis method, leveraging gating and attention mechanisms. This method processes text elements at both the word and text levels simultaneously. To extract more detailed sentiment information from characters, convolutional neural networks (CNNs) were employed, along with attention mechanisms to enhance keyword expression. The gating mechanism regulated the transmission of image data within the network, and text and image vectors jointly represented the unprocessed data. Additional learning was achieved through bidirectional LSTM, enhancing information exchange between modalities. Finally, multimodal feature expressions were merged into the classifier. The proposed approach was validated using text and self-constructed image datasets, demonstrating significant improvements in accuracy and F1 score compared to other sentiment classification models. However, platforms like Weibo may contain large amounts of non-textual information, such as emojis, images, and videos, which may limit the model's ability to fully utilize such multimodal information.
2.3. GCN-based analysis of text sentiment
Text sentiment analysis based on Graph Convolutional Networks (GCN) is a method that utilizes GCN to process text data and perform sentiment analysis. In this approach, each word or phrase is considered as a node in a graph, and the graph structure is built based on their associations in the text. The GCN model is then employed to learn the feature representations between nodes in this graph structure, aiming to better understand the semantic and sentiment relationships among words in the text. For instance, Lai et al. (Citation2019) proposed a syntax-based GCN model that integrates dependency parsing trees with GCN, significantly enhancing the classifier's performance and effectively leveraging insights from dependency parsing to improve sentiment detection. However, this method relies on accurate syntactic analysis to construct the graph structure, and the abundance of noise in Weibo text can also lead to decreased performance in sentiment analysis. Additionally, Zhao et al. (Citation2022) introduced a multi-granularity syntax-aware GCN model (MSD-GCN), which redesigns the aspect of the initial representation layer to enhance coarse-grained dependency graphs and constructs fine-grained dependency graphs. Although MSD-GCN demonstrates significant improvements in text sentiment analysis, the presence of a large amount of non-structural information, such as slang and informal language, may affect the accuracy of feature extraction. Yin et al. (Citation2022) proposed an enhanced LSTM model (DPG-LSTM) based on dependency parsing and GCN, combining a hybrid attention mechanism with dependency parsing to extract semantic contextual information. However, the inability to align node feature channels for different structured information limits the performance of GCN.
Compared to the aforementioned methods, our approach focuses more on the quality of nodes in the graph structure, ensuring the quality of node representations before exploring relationships between nodes. To achieve this, we employ the ALBERT model to encode input text, effectively extracting contextual information and addressing the issue of polysemy. Additionally, we augment the original data into four different dimensions of semantic features through various feature extraction layers and aggregate rich semantic information using multi-head attention. Subsequently, we use these features as nodes and construct a topological graph, where each node contains not only local and global features but also the hidden state of global features. This means that the information carried by each node is more comprehensive and diverse, considering more factors that may influence sentiment analysis. In contrast, nodes in traditional methods may only contain a fraction of local or global features, resulting in relatively less information. Moreover, due to the richness and diversity of node information, our approach can more accurately model the relationships between nodes, making these relationships more reasonable and complete, thus improving the performance of GCN in sentiment analysis.
3. Problem definition
In the task of microblog fine-grained sentiment analysis, we assume that the input is the text of web comments. To process the comment text into a format suitable for the model and better capture the emotional information within, it is represented as , where
represents the
word in the comment and n denotes the length of the sentence. We serialize
using the proposed fine-grained sentiment analysis model, extracting main phrases and sentiment keywords to obtain a multi-level sequence text, denoted as
. Here,
represents the
word in the sentence text,
represents the
word in the main phrase, and
represents the
word in the key phrase. Such multi-level sequential text can more comprehensively express the emotional content in the comments, aiding in more accurate sentiment classification. Subsequently, we classify the multi-level sequence text
using a classifier to achieve the goal of sentiment identification.
4. Proposed fine-grained sentiment analysis model
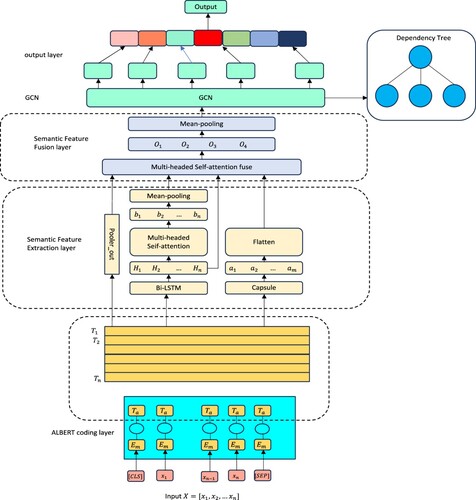
In the proposed AB-BCM-GCN model, the ALBERT is initially employed to extract contextual semantic information in an efficient manner. To gather abundant semantic information from multiple dimensions, a combination of local and global feature extraction is then applied. Multi-head self-attention is ultimately employed to integrate features from various dimensions, while graph convolutional neural network (GCN) attention is directed towards the syntactic information of sentences. This enables the complete extraction of fine-grained text features, thereby facilitating the precise classification of microblog fine-grained sentiment. The Structure of the AB-BCM-GCN model is depicted in .
Figure 1. Structure of the Proposed AB-BCM-GCN Model.
4.1. ALBERT coding layer
Traditional word vector characterization methods such as Word2Vec and Glove appear incapable of coping with the ever-emerging new vocabulary and contextual changes in the Internet era. In order to capture the semantic features of text sequences more comprehensively and accurately, we choose to adopt the ALBERT model for dynamic word vector characterization.
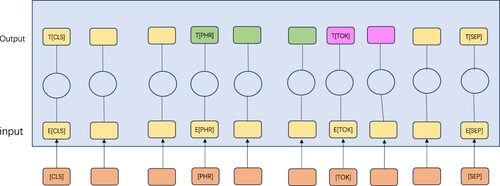
The processing flow first includes cutting Chinese sentences into subwords using a lexer, constructing input sequences, and adding [CLS] symbols before each sequence, as well as inserting [SEP] symbols between two sentences for differentiation. Then, the input sequences are deeply encoded by ALBERT coding layer, and processed by using a multi-layer Transformer, which mainly extracts the hidden features of [CLS] as sentence-level semantics.
In the feature extraction stage, the ALBERT coding layer generates word embedding, segment embedding, and position embedding codes, respectively, which are summed up to acquire the feature representation . Subsequently, the feature representation
is passed into the 12-layer Transformer Encoder to augment the feature vectors of the text sequence. By utilizing the multi-layer Transformer Encoder, each encoder processes the feature vector
. This enables a thorough and precise extraction of the semantic information present in the text and its contextual context. The model is more flexible in response to the evolving contexts of texts in the web age due to this comprehensive approach. The architectural configuration of the ALBERT encoding layer is illustrated in .
Figure 2. The ALBERT Encoding Layer.
4.2. Semantic feature extraction layer
The semantic feature extraction layer is mainly to refine the semantics of the word embeddings extracted from the ALBERT coding layer, and this model mainly adopts the dual-channel semantic feature extraction method that combines global capture and local capture.
4.2.1. Global feature extraction
LSTM is a variant of RNN that is distinguished by its gating mechanism and cell state design, which effectively resolves the gradient disappearance issue that occurs during RNN training. LSTM is also capable of learning the long-distance dependence of text semantics; however, it is unable to encode text information from back to front. By superimposing two LSTM models in opposite directions, the Bi-LSTM model is able to characterize bidirectional semantic dependency more accurately. Global capture obtains contextual text features primarily through the encoding of text context information using a Bi-LSTM network:
(1)
(1)
(2)
(2) where
denotes the current moment input,
denotes the previous moment forward hidden state, and
denotes the previous moment reverse hidden state. In Bi-LSTM, the hidden state
at a certain moment is formed by connecting the hidden state
of the forward LSTM and the hidden state
of the reverse LSTM:
.
To avoid semantic loss, the output of the last step of Bi-LSTM is viewed as the first part of the global semantic feature, and then the multi-head self-attention mechanism is employed to assign weights to the hidden states of each step of Bi-LSTM to obtain
, and then the global semantic feature representation
is obtained by average pooling operation.
4.2.2. Local feature extraction
Local capture mainly utilizes capsule networks to acquire local features of tweet posts. The traditional neural network simulates the human hierarchical classification practice, so as to complete the output of the final goal and has better generalization ability. However, the interpretability is poor, while each capsule in capsule network is a vector, the representation of individual features is richer and has better interpretability. Traditional CNN cannot extract the relative position information in space between low-dimensional features and high-dimensional features, while the direction of the capsule can represent this part of the information. The structure of extracting local features of text post using capsule network is depicted in .
Figure 3. Capsule Flow Chart.
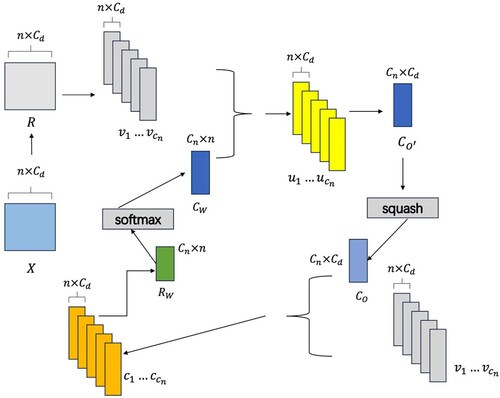
In this paper, the capsule input is a three-dimensional structure, and the word vectors obtained from the ALBERT coding layer cannot be directly passed into the capsule structure, so the first step is to transform the word vectors into the intermediate transition vectors, R, using the one-dimensional convolution.
(3)
(3) where
,
represent the length of the sentence and the input capsule’s number, and
represents the product of the number of output capsules
and the dimension of each capsule
. Next, the capsule structure is adjusted to
,
as the input to the whole capsule network.
(4)
(4)
(5)
(5) Initialize a capsule weight
. And then utilize the dynamic routing algorithm idea as shown in Equations (6)-(10) to determine the final output
.
The first step adjusts the weights to obtain the new capsule weights ,where
.
(6)
(6) In the second step, the weight
is dot-producted with the input capsule
and summed in the dimension where the number of input capsules is located to get the output
,
:
(7)
(7) In the third step, in order not to lose the spatial features, compression is performed by Squash function to ensure that the normalized output results without any change in vector direction.
(8)
(8) In the fourth step the obtained output capsule result
is clicked with the input
and summed over the output capsule dimensions to obtain the new
:
(9)
(9) The fifth step repeats the above four steps and performs Routings to acquire the final output capsule result
. After obtaining the local features of the microblogging statement using the capsule network, they are expanded to obtain the final local semantic representation
with the same dimensions as the rest of the features in order to be able to carry out subsequent fusion operations with the other extracted features, where
.
(10)
(10)
4.3. Semantic feature fusion layer
The paper first obtains the low-level sentence embedding representation , and then extracts local and global features from the sentence embedding: global features represented by the hidden state
and global feature representation
are obtained through the global feature extraction layer, while local feature representation
is obtained through the local feature extraction layer. The principle of the multi-head self-attention mechanism lies in adjusting the weighting parameters to make the model focus on key features while automatically disregarding noise in the encoded information, thereby enhancing the model's ability to capture important features. The paper utilizes the multi-head self-attention mechanism to fuse four different-level multi-feature matrices
,
,
, and
, establishing mutual transmission and connection of information between row vectors in the matrices. This facilitates capturing the global dependency of the text and adaptively focusing on its key features, thereby improving the model's comprehension of microblog text.
The acquired features at each granularity are first stitched together to synthesize the semantic vector , where
.
(11)
(11) The fusion operation is performed using the multi-head self-attention mechanism as illustrated in Equations (12)-(16). Take the operation executed by the
head of the input
of the first channel as an example to illustrate the relevant process of multi-head self-attention fusion: initialize the correlation parameter matrix, perform self-attention operations on each row vector of the semantic matrix
, i.e.
,
,
,
, to establish the correlation connection, obtain the output of the
head, and splice the
heads to obtain the output of
,
.
(12)
(12)
(13)
(13)
(14)
(14)
(15)
(15) where
,
,
represent the linear mapping weight matrices of
,
is the final obtained feature, and
.
The fusion outputs ,
,
of the other features are acquired utilizing the multi-head self-attentive fusion mechanism, where
. The final fusion feature
is obtained using average pooling, where
.
(16)
(16)
4.4. GCN model based on parsing dependency tree
After obtaining the fusion features, focusing the suggested model on sentence syntactic information, a text parsing dependency tree is utilized to construct the GCN, where the parsing dependency tree recognizes subject-verb, adverb, and a variety of other syntactic structures. For each tweet, the GCN model based on parsing dependency tree builds a graph, , where
denotes the vertex set, which consists of all the words that make up the tweet, and
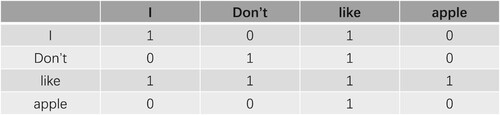
is the set of edges, which represents the word-to-word dependencies. Among the word-to-word dependencies are irrelevant, self-loop, head-to-head dependency and head-to-dependency, which are represented by the numbers ‘0’, ‘1’, ‘1’, and ‘1’, ‘1’, ‘1’, and ‘1’ respectively. For example, I don't like apples, labels the different syntactic structures, and the corresponding neighbourhood matrix can be constructed based on the syntactic dependencies between different words, as shown in . Since each tweet cannot exceed 140 characters in Chinese, the size of each neighbour matrix is set to
. The output of the previous layer is employed as the input of GCN.The computation process of GCN is as follows:
(17)
(17) where
denotes the adjacency matrix,
denotes the degree matrix,
,
denotes the previous layer’s output, and
denotes the weight vector obtained from the network training.
Figure 4. An Example of Parsing a Dependency Tree.
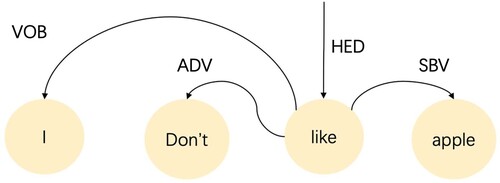
Figure 5. NeighBourhood Matrix Corresponding to a Sentence.
4.5. Percentage pooling
The purpose of pooling layer is to enhance the non-deformation and efficacy of the neural network model, it includes average pooling, maximization pooling and other ways. But there may be some uncontrollable factors in the model, maximization pooling is not stable enough and average pooling is affected by outliers. To solve the problem, a percentage pooling is suggested which takes the lowest value after sorting the elements in ascending order and the pth percentile is considered more reliable than the average due to its lack of sensitivity to outliers. Percentage pooling represents the
percentile of a vector
as a function
, where
ranges from 0 to 100. e.g.
denotes the maximum value and
denotes the median value of
. By using
as a pooling function for percentage pooling, it is known experimentally that the best results are achieved when
.
4.6. Loss function
A regular term is incorporated to the loss function, which consists of the product of the transpose of the weight matrix with itself and the difference of the unit matrix to mitigate the issue of vanishing and exploding gradients, and is calculated as follows:
(18)
(18) where
represents the original loss function,
represents the label,
represents the prediction class,
represents the penalty coefficient,
represents the weight matrix, and
represents the unit matrix.
5. Experiments
5.1. Experimental environment and datasets
In this paper, three datasets are selected for fine-grained sentiment analysis of microblog statements, and one additional dataset is selected for binary sentiment analysis of microblog statements in order to validate the generality of the model. The information of the datasets is illustrated in . The diversity and granularity of sentiment labels in these datasets contribute to training models that can accurately capture and distinguish specific emotions. Additionally, they validate the model's ability to generalize and remain robust in real-world social media environments.
Table 1. Data Set Information.
The three fine-grained multi-classification datasets are SMP2020-EWECT dataset (https://github.com/BrownSweater/BERT_SMP2020-EWECT/tree/main/data/raw), NLPCC2013 Task 2 microblog statement sentiment dataset (http://tcci.ccf.org.cn/conference/2013/pages/page04_tdata.html) and NLPCC2014 Task 1 sentiment dataset (http://tcci.ccf.org.cn/conference/2014/pages/page04_ans.html). The SMP2020-EWECT dataset has 6 types of sentiment labels: Happy, Angry, Sad, Fear, Surprise, and Neural. In the experiments, the two datasets are partitioned into training and testing sets in an 8:2 ratio. The NLPCC2013 Task 2 microblog statement sentiment dataset contains 8 emotion labels: None, Sadness, Like, Anger, Happiness, Disgust, Fear, Surprise, with a total of 14000 microblogs, including 4000 training samples and 10000 test samples. The NLPCC2014 Task 1 sentiment dataset also includes 8 emotion labels: None, Sadness, Like, Anger, Happiness, Disgust, Fear, Surprise, with a total of 20000 microblogs, including 14000 samples for training and 6000 samples for testing.
To address the demands of microblog sentiment analysis at different granularities and to validate the model's capacity to generalize to microblog corpus, the sentiment binary classification of microblog corpus is tested on the weibo_senti_100k dataset (https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k). This dataset contains more than 100,000 microblog texts, of which more than 50,000 are positive and 50,000 are negative. The dataset is separated into a training set, validation set, and test set in a proportion of 8:1:1.
5.2. Experimental setup
In this paper, different parameters are set for different parts of the model, for the ALBERT module, which mainly consists of a bidirectional Transformer encoder and 12 multi-head self-attention modules to train dynamic semantic vectors on the web comment text. The word vector dimension m is initialized to 768, the word list size E is selected to 31128, the hidden layer contains 4096 neurons, and the activation function is configured to GELU. depicts the model parameter settings of model.
depicts the experimental environment of the suggested model.
Evaluation indicators
Table 2. Model Parameter Settings.
Table 3. Experiment Environment.
The accuracy (ACC) and F1 value, which are evaluation metrics for fine-grained sentiment analysis as described in Jiang et al. (Citation2022), are utilized in this experiment to assess the overall performance of the model.
5.3. Model performance comparison
Fine-grained analysis of microblog sentiment is performed on the publicly available dataset SMP2020-EWECT dataset, NLPCC2013 and NLPCC2014 datasets, and sentiment binary classification of microblog corpus is tested on the weibo_senti_100k dataset, and the relevant models are ALBERT-FAET (Deng et al., Citation2022), CNN-RF (George et al., Citation2021), FCLAG (Sun & Gao, Citation2021), and MSD-GCN (Zhao et al., Citation2022).
Performance comparisons of the suggested models in this paper with mainstream models on different publicly available datasets are illustrated in .
Table 4. Comparison of the Performance of Various Models on the SMP2020-EWECT Dataset.
Table 5. Comparison of the Performance of Various Models on the NLPCC2013 Dataset.
Table 6. Comparison of the Performance of Various Models on the NLPCC2014 Dataset.
Table 7. Comparison of the Performance of Various Models on the Weibo_senti_100k Dataset.
Upon examination of the outcomes of the comparison experiments, it becomes evident that the AB-BCM-GCN model outperforms the conventional fine-grained text sentiment analysis models in terms of accuracy and F1 value across all datasets. On the SMP2020-EWECT dataset, the accuracy and F1 value of the AB-BCM-GCN model are enhanced by 1.77% and 2.87%, correspondingly, in contrast to the outcomes of experiments of the best-performing FCLAG; on the NLPCC2013 dataset, by 4.05% and 3.96%, correspondingly; and on the NLPCC2014 dataset, by 0.6% and 2.11%, correspondingly. In addition to the good performance on the microblog sentiment multiclassification dataset, the accuracy and F1 value of the AB-BCM-GCN model on the weibo_senti_100k binary classification dataset are improved by 0.77% and 1.37%, correspondingly, in contrast to the best performing comparison model, which effectively verifies the advancement of the AB-BCM-GCN model in microblog fine-grained sentiment analysis as well as its Effectiveness of the AB-BCM-GCN model in microblog fine-grained sentiment analysis. In summary, the AB-BCM-GCN model demonstrates advantages in various aspects. Firstly, it fully utilizes the multi-head self-attention mechanism in conjunction with the ALBERT model, effectively capturing multidimensional features in the text and thereby improving the quality of feature extraction. Secondly, by leveraging GCN to focus on sentence syntax information and combining it with the multi-head self-attention mechanism for feature fusion, the model enhances its ability to capture important features. In comparison, other models do not perform as well in these aspects. The MSD-GCN model fails to fully utilize the multi-head self-attention mechanism, resulting in limitations in understanding subtle emotions in the text. The ALBERT-FAET model does not employ GCN to focus on syntax information, thereby limiting its ability to capture text syntax structures. The CNN-RF model lacks deep semantic understanding and insufficient attention to emotion-related parts, leading to the neglect of important contextual information during sentiment classification. Furthermore, the FCLAG model overlooks the issues of polysemy and long-distance dependencies between words, making it inferior to the AB-BCM-GCN model in semantic feature extraction.
5.4. Performance comparison of embedding models
The outcomes of a comparison between the ALBERT implemented in the suggested model and the other three embedding models (Glove, FastText, Word2vec) on the NLPCC2014 and weibo_senti_100k datasets are presented in .
Table 8. Comparison of the Performance of Embedded Models.
The ALBERT module used in the suggested model exhibits superior performance when compared to other models in the AUC, F1 metrics. It enhances with the other three word embedding models by 4.04%, 2.58%, and 1.09% under the AUC metrics, and by 2.89%, 1.65%, and 1.09% under the F1 metrics on the NLPCC2014 dataset. 3.08%, 1.95%, 1.16% under AUC metrics; 3.17%, 2.44%, 1.28% under F1 metrics on the weibo_senti_100k dataset, respectively. Analyzing the reasons, it can be inferred that Word2Vec and GloVe primarily rely on local context information to learn word embeddings, whereas ALBERT utilizes the Transformer architecture, enabling better capture of long-range dependencies. While FastText can handle some out-of-vocabulary words through character n-grams, it still relies on local context information. In contrast, ALBERT's deep bidirectional Transformer structure can more effectively capture multi-dimensional features of the text, thereby improving the quality of feature extraction.
5.5. Hyperparametric analysis
5.5.1. Analysis of the number of GCN layers
illustrates the outcomes of the experiments conducted to determine the impact of various configurations of the number of GCN layers on the performance of the model suggested in this paper. The NLPCC2014 dataset was selected to test the effect of those configurations.
Figure 6. Effect of the Number of GCN Layers on the Model.
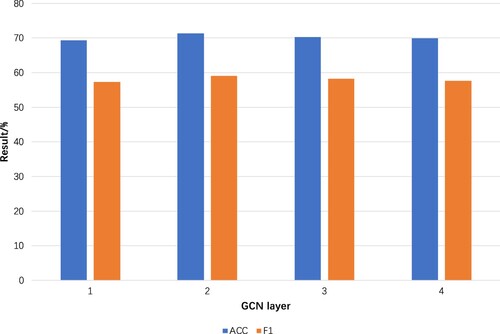
The optimal performance of the suggested AB-BCM-GCN model is achieved with 2 GCN layers, as illustrated in . Therefore, we have established 2 GCN layers in this paper. Appropriate numbers of layers can help the model learn effective relationships between words or phrases in the text, while too many layers may lead to overfitting and node oversmoothing issues.
5.5.2. Analysis of the number of heads of multi-head attention
To assess the impact of the number of heads of multi-head attention on the performance of the model suggested in this paper, various configurations of the number of heads of multi-head attention were implemented on the NLPCC2014 dataset. The outcomes of experiments are illustrated in .
Figure 7. Effect of the Number of Heads of Long Attention on the Model.
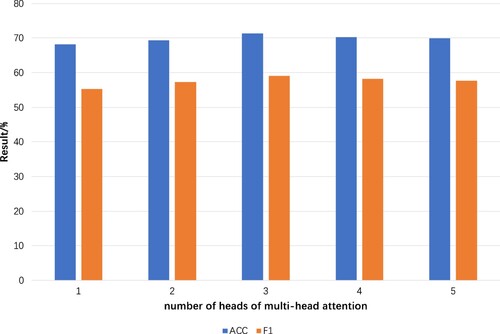
The optimal performance of the suggested AB-BCM-GCN model is achieved with three heads of multi-head attention, as illustrated in . As a result, we establish three heads of multi-head attention in this paper. Different numbers of heads represent the model capturing features of the text from various perspectives, with an excessive number of heads potentially resulting in feature redundancy and weakening the importance of discriminative features.
5.6. Ablation experiment
To validate the efficacy of individual components of the AB-BCM-GCN model for fine-grained sentiment analysis of microblogging utterances, this paper will conduct ablation experiments for relevant validation, removing several key parts of the model to verify their usefulness.
w/o ALBERT: Remove the ALBERT module and directly input the data into the model for feature extraction and fusion operations.
w/o GCN: Remove the GCN layer, directly perform dimension mapping on the fused features, and output sentiment classification results using Softmax.
w/o : based on the suggested AB-BCM-GCN model, the microblog statement embedding feature Pooler_out is removed.
w/o : based on the suggested AB-BCM-GCN model, removing the output feature Hn of BiLSTM with word embedding global capture.
w/o : BiLSTM global fusion feature M based on the suggested AB-BCM-GCN model with word embedding global capture removed.
w/o Flatten: based on the suggested AB-BCM-GCN model, the Flatten feature of capsule network unfolding with word embedding local capture is removed.
To ascertain the efficacy of the model's multi-head self-attention fusion feature approach, the aforementioned operation is substituted with the splicing operation, which is a self-attention fusion operation:
Fuse1: In accordance with the suggested AB-BCM-GCN model, the operation of splicing features is substituted for multi-head self-attention feature fusion.
Fuse2: In accordance with the suggested AB-BCM-GCN model, self-attention fusion feature operation is substituted for multi-head self-attention feature fusion.
The results of the ablation experiments are illustrated in .
Table 9. The Results of the Ablation Experiments.
After removing the ALBERT module, it was observed that both the accuracy and F1 score of the model decreased, clearly demonstrating the crucial role of the ALBERT model in extracting contextual semantic information from text, especially in addressing the issue of polysemy. Similarly, the removal of the GCN layer also indicates the importance of GCN in attending to syntactic information of sentences for mining fine-grained text features, thereby aiding in improving the accuracy of sentiment classification. The types and acquisition methods of multidimensional features are closely related to global semantic features and long-distance dependencies. Therefore, the impact on model performance after removal is significant. Additionally, different fusion methods suggest that computing multi-head self-attention after concatenation is the most efficient approach.
6. Conclusion
A microblog fine-grained sentiment analysis model (AB-BCM-GCN) is suggested in this paper. This model is constructed using multi-head self-attention feature fusion and GCN. Utilizing the full potential of deep learning models such as the ALBERT model, multi-head self-attention, and graph convolutional neural network, the model enhances the accuracy of microblog sentiment classification through the complete extraction of text fine-grained features. A fine-grained analysis of microblog sentiment is conducted using the SMP2020-EWECT, NLPCC2013, and NLPCC2014 datasets. Additionally, the weibo_senti_100k dataset is utilized for the sentiment binary classification evaluation of the microblog corpus. The experimental findings indicate a substantial advancement in comparison to various other sophisticated microblog fine-grained sentiment analysis approaches, potentially bolstering the precision of fine-grained sentiment categorization.
However, the proposed method has some practical and scalability limitations. To enhance its scalability, the suggested AB-BCM-GCN will be implemented in larger social platforms and user groups in the future. The continuous development of novel deep learning network models provides significant opportunities to enhance the performance of the proposed AB-BCM-GCN model in sentiment analysis. Moving forward, we will employ parameter optimization and other techniques to further refine the model's recommendation capabilities. Additionally, to better understand the emotional expression of Weibo users and guide model improvements, we will use statistical tests to explore the key factors and patterns of emotional expression, thereby improving the accuracy and applicability of sentiment analysis.
Data availability statement
The data that support the findings of this study are available from the corresponding author Baisheng Zhong upon reasonable request.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Alroobaea, R. (2022). Sentiment analysis on Amazon product reviews using the recurrent neural network (RNN). International Journal of Advanced Computer Science and Applications, 13(4), 1–12. https://doi.org/10.14569/IJACSA.2022.0130437
- Aslan, S., Kiziloluk, S., & Sert, E. (2023). TSA-CNN-AOA: Twitter sentiment analysis using CNN optimized via arithmetic optimization algorithm. Neural Computing and Applications, 35(14), 10311–10328. https://doi.org/10.1007/s00521-023-08236-2
- Bhuvaneshwari, P., Rao, A. N., Robinson, Y. H., & Thippeswamy, M. N. (2022). Sentiment analysis for user reviews using Bi-LSTM self-attention based CNN model. Multimedia Tools and Applications, 81(9), 12405–12419. https://doi.org/10.1007/s11042-022-12410-4
- Chang, W., & Zhu, M. (2023). Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment. Journal of Intelligent Systems, 32(1), 20230025. https://doi.org/10.1515/jisys-2023-0025
- Deng, Y., Liu, K., Yang, C., Feng, Y., & Li, W. (2022). Emoji-based fine-grained attention network for sentiment analysis in the microblog comments. ArXiv abs/2206.12262, 1-6.
- Djaballah, K. A., Boukhalfa, K., Boussaid, O., & Ramdane, Y. (2021). An improved sentiment analysis approach to detect radical content on twitter. International Journal of Information Technology and Web Engineering, 16(4), 52–73. https://doi.org/10.4018/IJITWE.2021100103
- Feng, X., & Liu, X. (2019). Sentiment classification of reviews based on BiGRU neural network and fine-grained attention. Journal of Physics: Conference Series, 1229, 1–5. doi.10.1088/1742-6596/1229/1/012064
- Ganganwar, V., & Rajalakshmi, R. (2023). Employing synthetic data for addressing the class imbalance in aspect-based sentiment classification. Journal of Information and Telecommunication, 1–22. doi.10.1080/24751839.2270824
- Gao, Z., Li, Z., Luo, J., & Li, X. (2022). Short text aspect-based sentiment analysis based on CNN + BiGRU. Applied Sciences, 12(5), 2707. https://doi.org/10.3390/app12052707
- George, C., Commerce, T. I., & Sumathi, B. M. (2021). A novel deep learning approach of convolutional neural network and random forest classifier for fine-grained sentiment classification. International Journal on Electrical Engineering and Informatics, 1–5. doi.10.15676/ijeei.2020.13.2.13
- Jiang, X., Song, C., Xu, Y., Li, Y., & Peng, Y. (2022). Research on sentiment classification for netizens based on the BERT-BiLSTM-TextCNN model. PeerJ Computer Science, 8, e1005. https://doi.org/10.7717/peerj-cs.1005
- Khan, L., Amjad, A., Afaq, K. M., & Chang, H. (2022). Deep sentiment analysis using CNN-LSTM architecture of English and roman urdu text shared in social media. Applied Sciences, 12(5), 2694. https://doi.org/10.3390/app12052694
- Lai, Y., Zhang, L., Han, D., Zhou, R., & Wang, G. (2019). Fine-grained emotion classification of Chinese microblogs based on graph convolution networks. World Wide Web, 23(5), 2771–2787. https://doi.org/10.1007/s11280-020-00803-0
- Liang, S., Wei, W., Mao, X., Wang, F., & He, Z. (2022). BiSyn-GAT+: Bi-syntax aware graph attention network for aspect-based sentiment analysis. Findings. arXiv:2204.03117.
- Liao, W., Ma, Y., Cao, Y., Ye, G., & Zuo, D. (2021). Two-Stage fine-grained text-level sentiment analysis based on syntactic rule matching and deep semantic. IEICE Transactions on Information and Systems, E104.D(8), 1274–1280. https://doi.org/10.1587/transinf.2020BDP0018
- Liu, J. (2023). Sentiment classification of social network text based on AT-BiLSTM model in a big data environment. International Journal of Information Technologies and Systems Approach (IJITSA), 16, 1–15. doi.10.4018/IJITSA.324808
- Liu, P., Liu, T., Shi, J., Wang, X., Yin, Z., & Zhao, C. (2020). Aspect level sentiment classification with unbiased attention and target enhanced representations. Proceedings of the 35th annual ACM symposium on applied computing, https://doi.org/10.1145/3341105.3373869.
- Naidu, P. A., Yadav, K. D., Meena, B., & Meesala, Y. V. (2022). Sentiment analysis by using modified RNN and a tree LSTM. 2022 international conference on computing. Communication and power technology (IC3P), 6-10. https://doi.org/10.1109/IC3P52835.2022.00012.
- Phan, H. T., Nguyen, N. T., Hwang, D., & Seo, Y. (2023). M2SA: A novel dataset for multi-level and multi-domain sentiment analysis. Journal of Information and Telecommunication, 7(4), 494–512. https://doi.org/10.1080/24751839.2023.2229700
- Sun, Y., & Gao, J. (2021). Fine-grained multimodal sentiment analysis based on gating and attention mechanism. Electronics Science Technology and Application, 7(4), 123–133. https://doi.org/10.18686/esta.v7i4.166
- Swathi, T., Kasiviswanath, N., & Rao, A. A. (2022). An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Applied Intelligence, 52(12), 13675–13688. https://doi.org/10.1007/s10489-022-03175-2
- Tamilselvi, P. R., Balasubramaniam, K., Vidhya, S., Jayapandian, N., Ramya, K., Poongodi, M., Hamdi, M., & Tunze, G. B. (2022). Social network user profiling with multilayer semantic modeling using Ego network. International Journal of Information Technology and Web Engineering, 17(1), 1–14. https://doi.org/10.4018/IJITWE.304049
- Tan, K. L., Lee, C. P., Anbananthen, K. S., & Lim, K. M. (2022a). RoBERTa-LSTM: A hybrid model for sentiment analysis with transformer and recurrent neural network. IEEE Access, 10, 21517–21525. https://doi.org/10.1109/ACCESS.2022.3152828
- Tan, Kian Long, Lee, Chin Poo, Lim, Kian Ming, & Anbananthen, Kalaiarasi Sonai Muthu. (2022b). Sentiment Analysis With Ensemble Hybrid Deep Learning Model. IEEE Access, 10, 103694–103704. https://doi.org/10.1109/ACCESS.2022.3210182
- Thin, D. V., Ngo, H. Q., Hao, D. N., & Nguyen, N. L. (2023). Exploring zero-shot and joint training cross-lingual strategies for aspect-based sentiment analysis based on contextualized multilingual language models. Journal of Information and Telecommunication, 7(2), 121–143. https://doi.org/10.1080/24751839.2023.2173843
- Venu Gopalachari, M., Gupta, S., Rakesh, S., Jayaram, D., & Venkateswara Rao, P. (2023). Aspect-based sentiment analysis on multi-domain reviews through word embedding. Journal of Intelligent Systems, 32(1), 20230001. https://doi.org/10.1515/jisys-2023-0001
- Yin, Z., Shao, J., Hussain, M. J., Hao, Y., Chen, Y., Zhang, X., & Wang, L. (2022). DPG-LSTM: An enhanced LSTM framework for sentiment analysis in social media text based on dependency parsing and GCN. Applied Sciences, 13(1), 354. https://doi.org/10.3390/app13010354
- Zhang, X., & Cui, Y. (2023). Analysis of application and creation skills of story-based MV micro video and big multimedia data in music communication. International Journal of Information Technology and Web Engineering, 18(1), 1–17. https://doi.org/10.4018/IJITWE.325213
- Zhao, Z., Liu, Y., Gao, J., Wu, H., Yue, Z., & Li, J. (2022). Multi-grained syntactic dependency-aware graph convolution for aspect-based sentiment analysis. International Joint Conference on Neural Networks (IJCNN), 1–8. doi:10.1109/IJCNN55064.2022.9892472