
abstract
New technological advancements combined with powerful computer hardware and high-speed network make big data available. The massive sample size of big data introduces unique computational challenges on scalability and storage of statistical methods. In this paper, we focus on the lack of fit test of parametric regression models under the framework of big data. We develop a computationally feasible testing approach via integrating the divide-and-conquer algorithm into a powerful nonparametric test statistic. Our theory results show that under mild conditions, the asymptotic null distribution of the proposed test is standard normal. Furthermore, the proposed test benefits from the use of data-driven bandwidth procedure and thus possesses certain adaptive property. Simulation studies show that the proposed method has satisfactory performances, and it is illustrated with an analysis of an airline data.
1. Introduction
The advancement and prevalence of computer technology in nearly every realm of science and daily life have enabled the collection of ‘big data’. While access to such wealth of information opens the door towards new discoveries, it also poses challenges to the current statistical and computational theory and methodology. Since it is usually computationally infeasible to make inference directly for big data due to the limitation of computing power and memory space, checking model misspecifications is not an easy task.
We shall now present one motivating example. There is an airline on-time data which consists of flight arrival and departure details for all commercial flights from October 1987 to April 2008 in USA. There are 123,534,969 records and 29 variables. And it occupies 11.2GB space. Due to the highly developed transportation system of airplanes, flight delay problem has become more and more serious. An appropriate model is critical for predicting the delay probability of a flight. Suppose that a parametric model is provided according to historical experience. Naturally, before fitting the new data with the proposed model, we want to make sure whether the proposed model is appropriate or not. However, for such big data, many existing softwares have failed to handle it. Since the ‘big data’ problem is not only the size of the data but also the analysis of it takes a significant amount of time and computer memory. Moreover, since the samples in big datasets are typically aggregated from multiple sources (Fan, Han, & Liu, Citation2014), a computationally feasible and efficient lack-of-fit test is highly desirable for massive datasets.
Let (Y, X) be a random variable in . We have observations (yi, xi)Ni = 1 from the underlying model E(Y|X = x) = m(x). In a parametric regression model, m(x) is assumed to belong to a parametric family of known real functions
on
, where
. We want to test the null hypothesis that the parametric model is correct for a dataset, say
against the alternative hypothesis
A number of nonparametric smoothing-based lack-of-fit tests for small and moderate sample sizes have been proposed during the last 20 years (see González-Manteiga and Crujeiras (Citation2013) for an overview). Among them, some kernel-based tests, such as Zheng (Citation1996) and Hardle and Mammen (Citation1993), are easy to implement when N is not too large. However, the quadratic time complexity and large memory greatly hamper their availability to massive data applications. The main emphasis of this paper is to overcome computational barriers of traditional tests for massive data by using divide-and-conquer (DC) algorithm.
When the data is too large to access the whole dataset once in a processor, one strategy is to divide and conquer. A DC algorithm works by recursively breaking down a big dataset into two or more subsets which are manageable and then analyse these subsets separately and combine the sub-solutions as the final one. Recently, DC strategy has been widely used in analysing massive data concerning parameters estimation of parametric regression (Battey, Fan, Liu, Lu, & Zhu, Citation2015; Chen & Xie, Citation2014; Lin & Xi, Citation2011; Schifano, Wu, Wang, Yan, & Chen, Citation2016), nonparametric regression curve estimation (Cheng & Shang, Citation2015; Zhang, John, & Martin, Citation2013; Zhao, Cheng, & Liu, Citation2016) and bootstrap issue (Kleiner, Talwalkar, Sarkar, & Jordan, Citation2015). However, little attention has been paid to the lack-of-fit test of parametric regression models for massive data. We combine the DC method with the test statistic proposed by Zheng (Citation1996) to solve the computational problem. We separate the data into K subsets evenly with each subset having the same sample size, n. Building test statistic based on each subsample and then averaging these test statistics to obtain the final one, the computational complexity of the test statistic is reduced from N2 to O(Kn2) and the calculation occupies much less memory, which is quite useful for big data.
The choice of smoothing parameter inherent in smoothing-based test plays an essential role, which refers to bandwidth parameter in kernel-based tests. As criteria used for smoothing parameter selection in nonparametric estimation differ from testing, it is inappropriate to apply prevalent smoothing parameter selection approaches for nonparametric estimation in the context of nonparametric hypothesis testing. There has been a growing amount of literatures on smoothing parameter selection in testing (e.g., Eubank, Ching-Shang, & Wang, Citation2005; Gao & Gijbels, Citation2008; Guerre & Lavergne, Citation2005; Hart, Citation1997; Horowitz & Spokoiny, Citation2001; Kulasekera & Wang, Citation1997; Ledwina, Citation1993; Zhang, Citation2003a, Citation2003b). A popular approach is to combine the test statistics obtained from using a series of suitable bandwidth values (Guerre & Lavergne, Citation2005; Horowitz & Spokoiny, Citation2001; Zhang, Citation2003a), resulting in an adaptive test. For instance, Horowitz and Spokoiny (Citation2001)'s test is a maximum test with respect to a set of bandwidth values. They obtained critical values of their test statistic by bootstrap, and thus it is rather time-consuming for big datasets. We suggest to combine the method in Horowitz and Spokoiny (Citation2001) with the DC method to construct an adaptive and computationally feasible nonparametric lack-of-fit test.
The paper is organised as follows. Section 2 describes the test statistics and bandwidth selection procedure. Asymptotic properties are discussed. Simulation studies and a real data analysis are given in Section 3. Section 4 contains some concluding remarks. Technical proofs are provided in the Appendix.
2. Methodology
The nonparametric test proposed by Zheng (Citation1996) combines the kernel method and the conditional moment test. The key idea is to use a kernel-based sample estimator of the conditional moment E{E2(ϑi|xi)f(xi)}, where and f(·) is the density function of xi. The test statistic based on the whole sample is
where
is a p-dimensional kernel function and
, hN is the bandwidth depending on N.
, where
is an estimator of
. Denote the corresponding test based on ZN as ZH test. Clearly, ZN is a computation-intensive when N is large, limiting its usefulness for massive data.
We use the DC strategy to solve the problem by separating the data into K subsets evenly and make each subset have the same sample size n. Denote the test statistic based on the kth subset of data as Vk,
where hn is the bandwidth based on the dataset of size n.
, where
is a DC-based estimator of
(Lin & Xi, Citation2011). The asymptotic null mean and variance of nhp/2nVk are 0 and δ2 according to Zheng (Citation1996) as hn → 0 and nhpn → ∞, where
A consistent estimator of δ2 using the kth subset data is
Since this test is sensitive to the bandwidth selection, a robust test is desired. Following the selection approach proposed in Horowitz and Spokoiny (Citation2001) and Zhang (Citation2003a), for each normalised Vk, we take the maximum of the normalised statistic with respect to a candidate set of hn which is defined as . The maximum and minimum elements in
are denoted as hmax and hmin, respectively. Suppose there are m elements in
and m is finite. This procedure is intended to reduce the dependency of the proposed test on individual h. It makes the test suitable for a broader class of alternatives compared with the original test depending on one h, leading to an adaptive test. Our final test statistic based on K subsets data is
For the sake of simplifying notations, we denote
as Dk(h) and the test based on DN as DM test. {max 1 ⩽ s ⩽ mDk(hs)}Kk = 1 can be treated as K independent identically distributed random variables. On the basis of the above discussion and some mild conditions, we can establish the limiting behaviour of DN. The following are some assumptions needed in our theories.
Assumption 2.1:
The density function f(x) of X is bounded away from 0 and has bounded first-order derivatives.
Assumption 2.2:
g( ·, ·) is uniformly bounded in x and and is twice continuously differentiable with respect to
, with first- and second-order derivatives uniformly bounded in x and
.
Assumption 2.3:
is a bounded and symmetric density function.
Assumption 2.4:
The random variables ϵi are independent with E(ϵi|xi) = 0. We assume that σ2(xi), E(ϵ4i|xi) = σ4(xi) are uniformly bounded in i and have uniformly bounded first-order derivatives for all i.
Assumption 2.5:
Let for any m(·). For any m(·),
is unique and
is the estimator of
such that
. Under H0,
.
The first theorem is similar to Theorem 1 in Zhang (Citation2003a). For notational convenience, we write the index as max 1 ⩽ s ⩽ mDk(hs).
Theorem 2.1:
Suppose Assumptions 2.1–2.5 hold. Under the null hypothesis, for a finite integer m ≥ 1, as hmax → 0, nhpmin → ∞, we have
where (U1,… , Um)T is a mean-zero normal random vector with a covariance matrix Γ = (γst)1≤s,t≤m, with γst = γts = δ2st/δ2,
and lst = hs/ht for 1 ≤ s, t ≤ m.
δ2 can be consistently estimated by and δ2st can be consistently estimated by
,
The mean of max 1 ⩽ s ⩽ mUs can be obtained by Afonja (Citation1972). Then, we use it to approximate the mean of max 1 ⩽ s ⩽ mDk(hs) based on Theorem 2.1 and DasGupta (Citation2008, Theorem 6.2). Therefore, the asymptotic null distribution of DN can be easily got through Lindeberg--Levy central limit theorem and Slutsky's theorem.
Theorem 2.2 (Null hypothesis):
Given Assumptions 1–5, under H0, as K → ∞, nhp → ∞, h → 0, we have that
with
where Rst = {rs,vw,t}, rs,vw,t is the partial correlation between (Us − Uv) and (Us − Uw) given (Us − Ut). Φ(x) denotes the cumulative distribution functions of the standard normal distribution. s2 is the sample variance computed on {max 1 ⩽ s ⩽ mDk(hs)}Kk = 1.
Theorem 2.2 reveals that the asymptotic null distribution of our test is normal under some mild conditions. Based on this theorem, we can calculate the critical value for our test. Another appealing result is that the convergence rate of DN is K−1/2 which can be faster than the nonparametric convergence rate (Nhp/2N)− 1 of ZH test provided that K is large enough. The proposed test can detect against a broad class of alternatives via the above bandwidth selection procedure, and hence it is an adaptive test. And it can also accelerate the calculation of ZH test and effectively reduce the demand for memory.
For the convenience of the presentation of the next result, we denote the variance of max 1 ⩽ s ⩽ mDk(hs) under the null hypothesis as ν2. The next result considers the asymptotic behaviour of DN under the local alternative m(x) = g(x; θ*) + K− 1/4l(x).
Theorem 2.3 (Local alternative):
Suppose Assumptions 1–5 hold. Assume K → ∞, nhp → ∞, h → 0, under the local alternative,
Theorem 2.3 guarantees that the DN test has nontrivial power against contiguous alternative of order K−1/4. Together with Theorem 2.2, Theorem 2.3 reveals that the DN cannot distinguish alternatives of order smaller than K−1/4 from the null.
3. Numerical analysis
3.1. Simulation studies
In this section, we conduct a sample simulation to check the finite samples performance of the proposed DM test based on the size and power. We aim to show the advantages of our test from three perspectives which are computability, time saving and adaptiveness in terms of massive data. And the comparisons are made between ZH test, DM test and GL test, where GL test is an adaptive and asymptotic normal test proposed by Guerre and Lavergne (Citation2005). The data is generated as in Zheng (Citation1996). z1 and z2 are generated from the standard normal distribution. The regressors are given by . Two cases of error term ϵ are considered following the standard normal and a standardised Student with five degrees of freedom distribution. The simulation is based on models which are considered in Zheng (Citation1996) and Fan and Li (Citation2000).
Model 0: Y = 1 + X1 + X2 + ϵ;
Model 1: Y = 1 + X1 + X2 + bX1X2 + ϵ, b ∈ [0, 1];
Model 2: Y = 1 + X1 + X2 + 2sin (bX1)sin (bX2) + ϵ, b ∈ [0, 40].
We treat model 0 as our null hypothesis, which assumes that the real regression model is linear. Model 1 corresponding a fixed alternative is designed to see the power of the test against high-order terms. To investigate the power of the test against a high(low) frequency fixed alternative, we consider model 2. In model 2, small(large) value of b represents low(high) frequency alternative. The kernel function is chosen to be the bivariate standard normal density function
We choose m = 3 for multiple bandwidths and set
. The bandwidth h is chosen to be c0n−1/6 for DM test, where c0 = 0.25 is a constant in order to control the size of the test. h is set to be 0.25N−1/6 for ZH and GL test as these test statistics are constructed based on sample size N. Denote h1 = 0.125N−1/6, h2 = 0.25N−1/6, h3 = 0.5N−1/6. The penalty sequence for GL test is chosen as
, where c = 1, 1.5, 2. The critical values for the three tests are based on the standard normal. For DM test when m = 3,
We approximate μ via estimating δ2 and δ2st by
and
, respectively.
These three tests are compared under the same time budget as time is an important evaluation criterion for massive data analysis. For DM test, we consider two settings of (N, K), which are (20,000, 40), (40,000, 100). Under the same time budget, we choose corresponding N = 7400, 9500 for ZH test, N = 4800, 6200 for GL test. This illustrates the advantage of our test in time. Under the null hypothesis, each experiment is based on 10,000 replications and 1000 under the alternatives. What we can conclude from Tables and is that both ZH and DM test can control type-I error. For DM test, the approximation is more acceptable when N =40,000, K =100 than N =20,000, K = 40. For GL test, there is another tuning parameter c needed to be chosen. c plays a critical role in the approximation under null hypothesis. According to the simulation results, we set c = 2 in the following power comparison experiments.
Table 1. Empirical size, normal errors.
Table 2. Empirical size, Student errors.
The simulation reveals that the performance of ZH test for different models varies with h. ZH(h3) behaves the best under Model 1 and low frequency of Model 2. But it has poor performance for high-frequency model. However, ZH(h1) leads to the opposite results. ZH(h2) is the most robust. It has good performance for both of the proposed alternative models. It is difficult to find out this robust h in practical applications, while our test is capable of robustness. Figures and show that DM test has power closer to GL test, and ZH(h2) for model 1 and low-frequency case of model 2. explains that DM test has power closer to the best case of ZH test, which is obtained via the smaller h1 under high-frequency case of model 2. DM test displays the same adaptive property as GL test. However, it requires less memory than GL test and ZH test under the same time budget. GL test and ZH test are either time-consuming or memory hungry which hinder the scalability to massive datasets.
Figure 1. Comparison of power curves under model 1 of two different error terms at significant level α = 0.05. We set (N, K) = (20,000, 40), (40,000, 100) for DM test. N = 4800, 6200 for GL test. N = 7400, 9500 for ZH test.
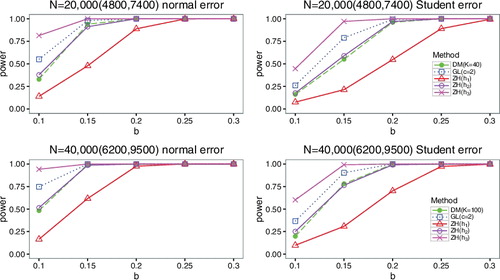
Figure 2. Comparison of power curves under low frequency of model 2 based on two different error terms at significant level α = 0.05.
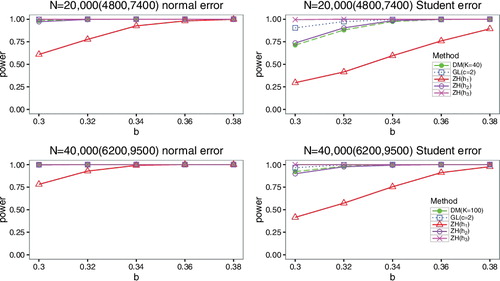
Figure 3. Comparison of power curves under high frequency of model 2 based on two different error terms at significant level α = 0.05.
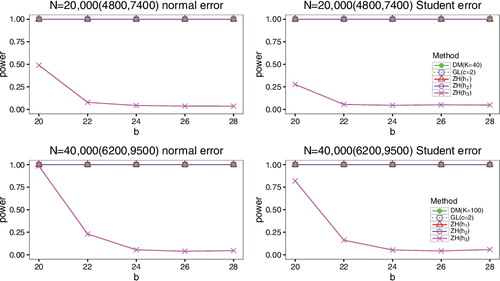
Moreover, we compare DM test with ZH test based on the whole dataset to study the effect of K on the power performance. K is chosen to be {20, 40, 50} and N = 20, 000. The results under model 1 are reported in Tables and . Model 2 follows the same trend and thus is not included. The tables show that the power loss gets more as K gets larger for DM test compared with ZH test.
Table 3. Empirical power of DM test and ZH test based on the whole dataset when the error distribution is normal.
Table 4. Empirical power of DM test and ZH test based on the whole dataset when the error distribution is Student.
3.2. Real data analysis
In this section, we will revisit the airline on-time data for illustrating the proposed test. A flight is considered delayed when it arrived 15 or more minutes later than the schedule. Many researchers use logistic regression to model the probability of late arrival (binary; 1 if late by more than 15 minutes, 0 otherwise; denote as y) as a function of variables may lead to flight delay. We use the logistic regression model to investigate the relationship of scheduled departure time (continuous, x1), scheduled arrival time (continuous, x2), distance (continuous, in thousands of miles, x3) with late arrival. Since GL and ZH tests cannot handle such big data, only the proposed test is implemented to check the goodness of fit of this model. We get N = 120, 748, 239 observations after removing the missing values. K is chosen to be 10,000. The bandwidth set is
The p-value of the proposed test is estimated as 0 which indicates that this model is inadequate to illustrate the late arrival probability. This does not come as a surprise to us, because the weather conditions and mechanical problems are also the causes of flight delay which are not included in the model.
4. Concluding remarks
In this article, we give a test aim to solve the scalability of the traditional nonparametric smoothing-based lack-of-fit test to massive datasets. We focus on two issues which are computability and smoothing parameter selection. The proposed test combines the DC procedure and a simple bandwidth selection method. Theoretically, our test has a manageable asymptotic null distribution. Under the null hypothesis, we use the mean of max 1 ⩽ s ⩽ mUs to approximate max 1 ⩽ s ⩽ mDk(hs)'s mean in each subset, where (U1,… , Um)T is a multivariate normal distribution. To ensure the accuracy of approximation, we need to make sure that the sample size of each subset is large enough. This condition is easy to achieve for massive data. In addition, our test is advantageous to save computational time and memory space. Simulation studies verified the above theoretical properties as well as the adaptiveness.
Acknowledgments
The authors are grateful to the editor and two anonymous referees for their comments that have greatly improved this paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Yanyan Zhao
Yanyan Zhao is a Ph.D. candidate at the Institute of Statistics, Nankai University, Tianjin, China.
Changliang Zou
Changliang Zou is a professor at the Institute of Statistics, Nankai University, Tianjin, China.
Zhaojun Wang
Zhaojun Wang is the corresponding author and professor at the Institute of Statistics, Nankai University, Tianjin, China.
References
- Afonja, B. (1972). The moments of the maximum of correlated normal and t-variates. Journal of the Royal Statistical Society B, 34, 251–262.
- Battey, H., Fan, J., Liu, H., Lu, J., & Zhu, Z. (2015). Distributed estimation and inference with statistical guarantees. arXiv:150905457.
- Chen, X., & Xie, M. (2014). A split-and-conquer approach for analysis of extraordinarily large data. Statistica Sinica, 24, 1655–1684.
- Cheng, G., & Shang, Z. (2015). Computational limits of divide-and-conquer method. arXiv:151209226.
- DasGupta, A. (2008). Asymptotic theory of statistics and probability (1st ed. ). New York, NY: Springer.
- Eubank, R. L., Ching-Shang, L., & Wang, S. (2005). Testing lack of fit of parametric regression models using nonparametric regression techniques. Statistica Sinica, 15, 135–152.
- Fan, Y., & Li, Q. (2000). Consistent model specification tests: Kernel-based tests versus Bierens’ ICM tests. Econometric Theory, 16, 1016–1041.
- Fan, J., Han, F., & Liu, H. (2014). Challenges of big data analysis. National science review, 1(2), 293–314.
- Gao, J., & Gijbels, I. (2008). Bandwidth selection in nonparametric kernel testing. Journal of the American Statistical Association, 484, 1584–1594.
- González-Manteiga, W., & Crujeiras, R. (2013). An updated review of goodness-of-fit tests for regression models. Test, 22, 361–411.
- Guerre, E., & Lavergne, P. (2005). Data-driven rate-optimal specification testing in regression models. Annals of Statistics, 33, 840–870.
- Hall, P. (1984). Central limit theorem for integrated square error of multivariate nonparametric density estimators. Journal of Multivariate Analysis, 14, 1–16.
- Hardle, W., & Mammen, E. (1993). Comparing nonparametric versus parametric regression fits. Annals of Statistics, 21, 1926–1947.
- Hart, J. (1997). Nonparametric smoothing and lack-of-fit tests (1st ed. ). New York, NY: Springer.
- Horowitz, J., & Spokoiny, V. (2001). An adaptive, rate-optimal test of parametric mean-regression model against a nonparametric alternative. Econometrica, 69, 599–631.
- Kleiner, A., Talwalkar, A., Sarkar, P., & Jordan, M. I. (2015). A scalable bootstrap for massive data. Journal of the Royal Statistical Society: Series B, 76(4), 795–816.
- Kulasekera, K., & Wang, J. (1997). Smoothing parameter selection for power optimality in testing of regression curves. Journal of the American Statistical Association, 438, 500–511.
- Ledwina, T. (1993). Data-driven version of Neymans smooth test of fit. Journal of the American Statistical Association, 89, 1000–1005.
- Lin, N., & Xi, R. (2011). Aggregated estimating equation estimation. Statistics and Its Inference, 4, 73–83.
- Powell, J., Stock, J., & Stoker, T. (1989). Semiparametric estimation of index coefficients. Econometrics, 57, 1403–1430.
- Schifano, E., Wu, J., Wang, C., Yan, J., & Chen, M.-H. (2016). Online updating of statistical inference in the big data setting. Technometrics, 58, 393–403.
- Zhang, C. (2003a). Adaptive tests of regression functions via multiscale generalized likelihood ratios. Canadian Journal of Statistics, 31, 151–171.
- Zhang, C. (2003b). Calibrating the degrees of freedom for automatic data smoothing and affective curve checking. Journal of the American Statistical Association, 98, 609–629.
- Zhang, Y., John, D., & Martin, W. (2013). Divide and conquer kernel ridge regression. Journal of Machine Learning Research WCP, 30, 592–617.
- Zhao, T., Cheng, G., & Liu, H. (2016). A partially linear framework for massive heterogeneous data. Annals of Statistics, 44, 1400–1437.
- Zheng, J. (1996). A consistent test of functional form via nonparametric estimation techniques. Journal of Econometrics, 75, 263–289.
Appendix
In the proofs, without loss of generality, we assume q = 1.
Lemma A.1:
Given Assumptions 2.1–2.5. Under the null hypothesis,
as
.
Proof:
Similar to the proof of Lemma 3.3e of Zheng (Citation1996), we can easily get the result of the first part. The second part is as follows:
Sn is a standard U-statistic with
We just need to show that E(‖Hn‖2) = o(n),
Therefore, by Lemma 3.1 of Powell, Stock, and Stoker (Citation1989), we have proved the conclusion.
Proof of Theorem 2.1
Proof:
Under the null hypothesis, as
so we denote Vk = V1k − 2V2k + V3k, where
Then,
Since based on Lemma A.1, we denote D*(hs) = nhp/2sV1kδ− 1. We just need to show
| (a) |
| ||||
| (b) |
| ||||
Then, the main results of Theorem 2.1 can be obtained directly via Slutsky's theorem and Continuous Mapping theorem.
| (a) | Choose m = 2 as an illustration, for every c1hp/21V1k(h1) + c2hp/22V1k(h2) is a U-statistic with kernel Hn = Hn1 + Hn2, where By checking the conditions in Theorem 1 of Hall (Citation1984) via the same way with Zheng (Citation1996), we have
Next, we determine the entries of covariance matrix Γ. Denote (x1 − x2)/h1 = u, l12 = h1/h2, we have
Then, EH2n = EH2n1 + EH2n2 + 2EHn1Hn2 = c21δ2/2 + c22δ2/2 + c1c2δ12 + o(1). So,
Similar result can be derived for m > 2 with lst = hs/ht,
So, by continuous mapping theorem, we have
| ||||
| (b) | Since m is finite, from Lemma 3.3d in Zheng (Citation1996) and Bonferroni inequality, we have the results of (b). | ||||
Proof of Theorem 2.2
Proof:
Since
As
, then the results of Theorem 2.2 follows
.
We elucidate the proof based on Lindeberg--Levy central limit theorem. First, we approximate the mean by asymptotic. Afonja (Citation1972) presents a method for finding the mean of maximum of correlated normal variates. By using their Corollary 2, we can get the mean of
is
with
and rs, v; w, t is the partial correlation between (Us − Uv) and (Us − Uw) given (Us − Ut). Φ(x) denotes the cumulative distribution functions of the standard normal distribution.
For s2 is a consistent estimator of variance of , the theorem results directly follows Lindeberg--Levy central limit theorem and Slutsky's theorem as K → ∞.
Proof of Theorem 2.3
Proof:
Under the local alternative, denote
We proceed with a decomposition of
Through tedious calculation we have, under local alternative, and
As nhp → ∞, h → 0, we have
. Together with Theorem 2.2, we can get the results of Theorem 2.3.