
ABSTRACT
Most studies of series system assume the causes of failure are independent, which may not hold in practice. In this paper, dependent causes of failure are considered by using a Marshall–Olkin bivariate Weibull distribution. We derived four reference priors based on several grouping orders. Gibbs sampling combined with the rejection sampling algorithm and Metropolis–Hastings algorithm is developed to obtain the estimates of the unknown parameters. The proposed approach is compared with the maximum-likelihood method via simulation. We find that the root-mean-squared errors of the Bayesian estimates are much smaller for the case of small sample size, and that the coverage probabilities of the Bayesian estimates are much closer to the nominal levels. Finally, a real data-set is analysed for illustration.
1. Introduction
In reliability and survival analysis, it is quite common that a series system or an individual might fail because of one of several causes of failure (or competing risks). A researcher is interested in a specific cause in the presence of other causes. In the statistical literature, this problem is known as the competing risks model, and the series system is a typical competing risk model. Data for a competing risks model may consist of failure times and other variables indicating the causes of failure, which may be dependent or independent. Most of the literature assumes the causes of failure are independent. See, for example, Kozumi (Citation2004), Kundu, Kannan, and Balakrishnan (Citation2003), Pareek, Kundu, and Kumar (Citation2009), Mazucheli and Achcar (Citation2011), Cramer and Schmiedt (Citation2011), Xu and Tang (Citation2011), Xu, Basu, and Tang (Citation2014) and AL-Hussaini, Abdel-Hamid, and Hashem (Citation2015).
However, the independence assumption among the causes of failure is often unrealistic. For instance, in a tug of war, failure of a player causes additional pressure on the team and poses an increased risk of failure to the remaining members. In other words, a positive dependence between failure times is imposed. Thus, the causes of failure being dependent are more practical. Wang and Ghosh (Citation2003) studied dependent competing risks model with absolutely continuous bivariate exponential lifetime distribution under two non-informative priors (Laplace prior and Jeffreys prior). Lindqvist and Skogsrud (Citation2009) have focused on modelling dependent competing risks in reliability by considering first the passage times of Wiener processes. Dijoux and Gaudoin (Citation2009) proposed an alert-delay model which is a new model of dependent competing risks for maintenance and reliability analysis. Dimitrova, Haberman, and Kaishev (Citation2013) demonstrated how copula functions can be applied in modelling dependence between lifetime random variables in the context of competing risks and studied the impact of removing one or more causes of death on the overall survival. When there is a positive probability of simultaneous failure, the most widely used model is the Marshall–Olkin bivariate lifetime model. The Marshall–Olkin bivariate exponential (MOBE) model, proposed by Marshall and Olkin (Citation1967), has been used extensively to analyse two dependent causes of failure. Guan, Tang, and Xu (Citation2013) considered the objective Bayesian analysis of dependent competing risks model using MOBE distribution. However, the MOBE distribution is very limited, because the hazard function is constant or the marginal function is strictly decreasing. Then the Marshall–Olkin bivariate Weibull (MOBW) distribution which was raised by Marshall and Olkin (Citation1967) can make up this deficiency, and has been long enjoyed popularity in reliability (see Kundu & Dey, Citation2009; Kundu & Gupta, Citation2013; and the references therein). Feizjavadian and Hashemi (Citation2015) developed the maximum-likelihood estimators (MLEs) and approximated MLEs of the unknown parameters when the lifetime of the two causes of failure follows MOBW distribution.
In this paper, Bayesian method will be used to analyse dependent competing risks model when the MOBW distribution is assumed. Both subjective Bayesian analysis and objective Bayesian analysis are popular in practice. Subjective Bayesian analysis is based on informative priors, i.e. conjugate prior. In such a case, the prior information is used to specify the hyperparameters in the prior distribution. However, prior distribution is not easy to elicit, especially in complex models. Then objective Bayesian analysis by using non-informative priors is preferred. The three most used non-informative priors are Laplace prior (Laplace, Citation1812), Jeffreys prior (Jeffreys, Citation1961) and reference prior (Bernardo, Citation1979). Laplace prior uses a constant prior distribution for the unknown parameters, which is quite easy to specify. However, it is not invariant under reparameterisation, and usually leads to an improper posterior distribution. Jeffreys prior, which is proportional to the square root of the determinant of the Fisher information matrix, has been proved to be successful in single-parameter problems. However, Jeffreys prior is often seriously deficient in multi-parameter problems. To overcome the deficiencies of the Jeffreys prior, Bernardo (Citation1979) proposed the reference prior which works well in multi-parameter problems. It is invariant under reparameterisation and typically produces proper posteriors. The reference prior is the Jeffreys prior in usual single-parameter problems. This approach is very successful in various practical problems (see Xu & Tang, Citation2010; Xu, Tang, & Sun, Citation2015). Thus, we will consider noninformative priors for the unknown parameters in the proposed model. To the best of our knowledge, we are the first to develop Bayesian approach, especially objective Bayesian method, to analyse dependent competing risks model using the MOBW distribution. In particular, the reference priors are formally derived, and the properties of these reference priors are studied.
The paper is organised as follows. In Section 2, we describe the MOBW model. The Fisher information matrices under the original and transformed parameters are presented in Section 3. Section 4 is devoted to derive four reference priors under different grouping orders. In Section 5, the propriety of the posterior distribution under different reference priors are proved, and the Gibbs sampling procedures are given to obtain the Bayesian estimates. In Section 6, a simulation is given for illustration. A real data-set is analysed in Section 7. Finally, some concluding remarks are made in Section 8.
2. Marshall–Olkin bivariate Weibull distribution
The MOBW model can be described as follows. It is assumed that U0, U1 and U2 are three independent random variables, and
where ∼ means following in distribution and WE(α, λ) denotes a Weibull distribution with the parameters α > 0 and λ > 0. For a WE(α, λ) distribution, the probability density function (PDF), the cumulative distribution function (CDF) and the survival function (SF) for x > 0 are
respectively.
Let X1 = min {U0, U1} and X2 = min {U0, U2}, then (X1, X2) has the MOBW distribution with the parameters (α, λ0, λ1, λ2), and it will be denoted as MOBW (α, λ0, λ1, λ2). Thus, the joint SF of MOBW (α, λ0, λ1, λ2) can be written as
(2.1)
Therefore, the joint PDF of X1 and X2 can be written as
(2.2)
where
From the above equations, we note that the MOBW distribution has both an absolute continuous part ( f1(x1, x2) and f2(x1, x2)) and a singular part ( f0(x)). For more details about the MOBW distribution, we can refer to Bemis, Bain, and Higgins (Citation1972) and Kundu and Dey (Citation2009).
3. Data and Fisher information matrix
3.1. Data and likelihood function
Suppose that a series system (or a disease) has two causes of failure. The lifetime of the jth cause of failure is Xj (j = 1, 2), and (X1, X2) ∼ MOBW (α, λ0, λ1, λ2). Then the distribution of the lifetime of the series system T = min (X1, X2) is WE(α, λ0 + λ1 + λ2). Assume that there are n series systems in a lifetime experiment. Let (X1i, X2i) be the lifetime of the two causes of failure in the ith system. Therefore, the observed data are (Ti, δ1i, δ2i), i = 1, 2,… , n, where Ti = min (X1i, X2i), δ1i = I(X1i < X2i), δ2i = I(X1i > X2i), I(A) denotes the indicator function of event A. Let λ = λ0 + λ1 + λ2, we can obtain the following facts easily.
Lemma 3.1:
For i = 1,… , n, we have
| (1) | X1i ∼ WE(α, λ0 + λ1), X2i ∼ WE(α, λ0 + λ2), | ||||
| (2) | Ti and (δ1i, δ2i) are independent, | ||||
| (3) | |||||
Denote and
given the observed data (Ti, δ1i, δ2i), i = 1, 2,… , n, the likelihood function
is
(3.1)
Then the log-likelihood function can be written as
3.2. Fisher information matrix
The second-order partial derivatives of the log-likelihood function are as follows:
where q = 0, 1, 2, ρ = 0, 1, 2, q ≠ ρ. Denote Yi = λTαi, i = 1, 2, …, n, then Yi follows the exponential distribution with hazard rate 1. For ν ≥ 1, let rν = ∫∞0(ln y)νe− ydy, which is the νth moment of ln Yi. Then,
After some algebraic calculations, we get
where k(x) = 1 + 2r1 + r2 − 2(r1 + 1)ln x + (ln x)2, q = 0, 1, 2, ρ = 0, 1, 2, q ≠ ρ. Thus, the Fisher information matrix of (α, λ0, λ1, λ2) has the following form:
3.3. Reparameterisation
In practice, the engineers may be interested in the hazard rate function of the series system, which is αλtα − 1. λ affects the scale of the hazard rate function, and α will determine whether the hazard rate function is decreasing (0 < α < 1), constant (α = 1) or increasing (α > 1). Thus, we take the following transformation:
where θ2 and θ3 are the probabilities that the failure of series system is due to the first and second causes of failure, respectively. The transformation from (α, λ0, λ1, λ2) to (α, θ1, θ2, θ3) is one-to-one with the inverse transformation
After reparameterisation, the likelihood function (Equation3.1
(3.1) ) becomes
(3.2)
The Jacobian matrix of the transformation is
where 0 < θ1 < ∞, 0 < θ2 + θ3 < 1.
Lemma 3.2:
The Fisher information matrix of (α, θ1, θ2, θ3) has the following form:
Due to the practical meanings of (α, θ1, θ2, θ3), all the derivations will be based on the new parameters in the following sections. If one is interested in the original parameters, the proposed method in this paper is also suitable.
4. Reference priors
Berger and Bernardo (Citation1992) developed a general algorithm to derive the reference prior. The algorithm needs to divide the parameters into several groups according to the importance of interest. Jeffreys prior treats all the parameters equally, and is shown to yield a decidedly inferior posterior distribution in multivariate-parameter problems (Yang & Berger, Citation1994). Sometimes, Jeffreys prior will result in an inconsistent estimator of the parameters. The benefit of grouping the parameters is that the prior can be obtained in terms of inferential importance of parameters, and usually results in a proper posterior distribution. Thus, before deriving the reference priors, we should divide the parameters {α, θ1, θ2, θ3} according to the inferential importance. For example, the notation {α, (θ1, θ2, θ3)} will be used to represent the case that the parameters are divided into two groups, with α being the most important and θ1, θ2, θ3 being of equal importance. Similarly, {α, θ1, (θ2, θ3)} represents that the parameters are separated into three groups, with α being the most important and (θ2, θ3) being the least important. Ghosh and Mukerjee (Citation1991) and Berger and Bernardo (Citation1992) suggested that switching the role of the parameters of interest and nuisance parameters sometimes gives a reasonable reference prior. We will consider the grouping orders {(α, θ1), (θ2, θ3)}, {(θ2, θ3), (α, θ1)}, {α, (θ1, θ2, θ3)}, {(θ2, θ3), α, θ1}, {α, θ1, θ2, θ3}, {θ3, θ2, θ1, α}, {θ1, (α, θ2, θ3)}, {(θ2, θ3), θ1, α}.
Theorem 4.1:
The possible grouping ordering reference priors of (α, θ1, θ2, θ3) are listed in , and
Table 1. Possible reference prior of (α, θ1, θ2, θ3).
See the proof in the Appendix 1.
Remark 4.1:
From , it can be noted that there are four different reference priors for the eight grouping orders. Actually, the number of grouping orders is much greater than eight. We choose the eight grouping orders because they have some practical meanings. For example, the grouping order {(θ2, θ3), (α, θ1)} can reflect our interest of the failure probabilities of series system due to the first and second causes of failure. While the grouping order {α, (θ1, θ2, θ3)} indicates that more attention is paid to the shape parameter of the MOBW distribution. Of course, someone could choose some other grouping orders. However, the closed form of the reference prior may not be obtained. For instance, when the grouping order is {θ1, θ2, θ3, α}, the reference prior does not have closed form. If all the parameters are interested, the overall objective priors (Berger, Bernardo, & Sun, Citation2015) may be considered. However, the derivation of the overall objective priors is much different from the reference priors. and it is not the scope of our paper. In the following sections, we will study the properties of the four reference priors in detail.
5. Posterior analysis
5.1. Propriety of the posteriors
Since the reference priors listed in are improper, we need to check the propriety of the posteriors before doing the Bayesian analysis.
Theorem 5.1:
When n > 1, the posterior distributions of (α, θ1, θ2, θ3) based on the priors ω1(α, θ1, θ2, θ3), ω2(α, θ1, θ2, θ3), ω3(α, θ1, θ2, θ3), ω4(α, θ1, θ2, θ3) are all proper.
See the proof in the Appendix 2. Theorem 5.1 shows the conditions that the reference priors can be used when at least two failures are observed in the experiment.
5.2. Bayesian estimation
For the sake of convenience, we write the reference priors in a general way:
(5.1)
where c1, c2 and c3 take the particular values when one of the reference priors is used. For example, when ω1(α, θ1, θ2, θ3) is used, c1 = c2 = c3 = 0. Based on (Equation3.2
(3.2) ) and (Equation5.1
(5.1) ), the joint posterior density of (α, θ1, θ2, θ3) is
(5.2)
From (Equation5.2
(5.2) ), we see that (α, θ1) and (θ2, θ3) are independent, which will make posterior sampling efficient. To obtain the Bayesian estimation of the parameters, the Gibbs sampling procedure can be implemented with the full conditional posterior distributions as follows.
| (1) | The conditional posterior density function of α, p(α|θ1, Data), is proportional to
| ||||||||||||||||||||||
| (2) | The conditional posterior density function of θ1, p(θ1|α, Data), is proportional to
| ||||||||||||||||||||||
| (3) | The joint marginal posterior distribution of (θ2, θ3) is proportional to
| ||||||||||||||||||||||
After running the above Gibbs sampling procedure M times and discarding the initial B burn-in iterations, then we have (M − B) iterations kept. Since the generated samples are not independent, we need to monitor the auto-correlations of the generated values and select a sampling lag L > 1 after which the corresponding auto-correlation is low, that is, the length of the thinning interval is L. Considering the length of the thinning interval, the final number of iterations kept is , and these independent samples will be used for posterior analysis. Then we can use the means of the posterior samples to estimate the parameters, and construct 100(1 − γ)% credible intervals of the parameters via the quantiles of posterior samples, where 0 < γ < 1.
6. Simulation study
In this section, we conduct some simulation studies to compare the Bayesian estimators and the MLEs for different parameter values and different sample sizes. We take the shape parameter α = 0.5, 1, 1.5, the sample size n = 15, 30, 50, and (λ0, λ1, λ2) = (0.7, 1, 1.5). The relative bias (RB), the root-mean-squared error (RMSE) and also the coverage percentages (CPs) based on 95% credible (or confidence) intervals are calculated based on 1000 replications. The RB is defined as follows:
where ξ denotes the true value, and
denotes its estimator of the ith iteration. The results are listed in –, where ‘ωu’ denotes that the estimates are obtained under the reference prior ωu(α, θ1, θ2, θ3), u = 1, 2, 3, 4.
Table 2. The RB(%), CPs and RMSEs of the parameters when (α, λ0, λ1, λ2) = (0.5, 0.7, 1, 1.5).
Table 3. The RB(%), CPs and SRMSEs of the parameters when (α, λ0, λ1, λ2) = (1, 0.7, 1, 1.5).
Table 4. The RB(%), CPs and RMSEs of the parameters when (α, λ0, λ1, λ2) = (2, 0.7, 1, 1.5).
Some of the points are quite clear from the simulation study. In all the cases, the estimates are slightly biased, mainly for small sample sizes, but the RBs and RMSEs decrease as the sample size increases. The CPs based on the maximum-likelihood method are a little far from the nominal level, especially when the sample size is small; this is because the asymptotic normality results are used to construct confidence intervals. While all the CPs based on the Bayesian method are close to the nominal level. However, for the case of large sample size, i.e. n = 50, the estimates based on both two methods are similar in terms of RBs and RMSEs. Among the four priors, it is hard to tell which one is better. When estimating α and θ1, the reference priors ω3 and ω4 perform better. When estimating the parameters θ2 and θ3, ω1, ω3 and ω4 are superior to ω2, because the RBs of θ2 and θ3 based on ω2 are the largest even the sample size is 50. As we have indicated before, the reference prior can be selected according to our inferential importance of the parameters. For example, when the parameter θ3 is of interest, the reference prior ω3 is preferred. As is shown in –, the CPs of θ3 based on ω3 are most close to the nominal level 0.95 for all the cases, although the RBs and RMSEs of θ3 are close to those based on the maximum-likelihood method and other priors.
7. Real data analysis
The data come from the Diabetic Retinopathy Study (DRS) conducted by the National Eye Institute to estimate the effect of laser treatment in delaying the onset of blindness in patients with diabetic retinopathy. There are 71 patients involved in the study. At the beginning of the study, for each patient, one eye was randomly selected for laser treatment by one of three methods (argon laser, xenon arc or a combined treatment), while the other eye was given no treatment. Let X1 represent the times to blindness of one eye under laser treatment, and X2 represent the times to blindness of the other eye under no treatment. The observed data of (X1, X2) can be found in Csorgo and Welsh (Citation1989). In , we list the minimum time to blindness (T = min {X1, X2}) and the index (δ*) for specifying the causes of failure for each patient, where
From , we note that some realisations of δ* are 0, which indicates that blindness of two eyes happens simultaneously.
Table 5. Minimum time to blindness in days and its causes for 71 patients with diabetic retinopathy.
Before using the MOBW distribution to analyse the data, we will check the distribution of X1, X2 and min(X1, X2), respectively. In the following analysis, the original data are divided by 365 and computed in terms of year. The function wblplot in MATLAB software is used to graphically assess whether the data come from a Weibull distribution. If the data are from Weibull distribution, the plotted line will be linear. Other distributions might introduce curvature in the plot. From , we can intuitively tell that X1, X2 and min(X1, X2) fit Weibull distribution. The Kolmogorov–Smirnov distances between the empirical CDF and the hypothesised CDF for X1, X2 and min(X1, X2) are 0.0744, 0.0912 and 0.0563, and the corresponding p values are 0.8124, 0.7671 and 0.9745, respectively. Thus, based on the p-values Weibull distribution cannot be rejected for the marginal and for the minimum also. In fact, the MLEs of the shape and scale parameters of the respective Weibull distribution for X1, X2 and min(X1, X2) are (1.6456, 0.2511), (1.6382, 0.2955) and (1.5582, 0.4691), and the confidence intervals of the shape parameter for X1 and X2 are [1.3699, 1.9768] and [1.3715, 1.9568], respectively, which means the hypothesis of the same-shape parameter of the Weibull distribution for X1 and X2 cannot be rejected.
Figure 1. The Weibull probability plot.
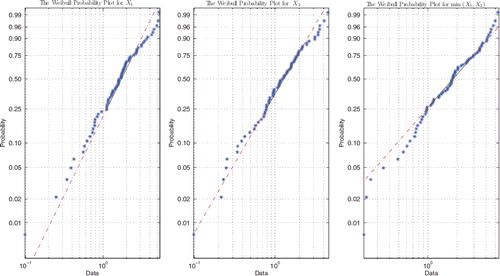
Naturally, we can choose the MOBW distribution to analyse the data. The estimates and 95% confidence (credible) intervals for the parameters are summarised in . From , it can be seen that the estimates of parameters are close to each other. also shows that the shape parameter α > 1 which means the hazard rate function of the lifetime of the two eyes is increasing. Moreover, the failure probability of the laser-treated eye is much smaller than the untreated one, which indicates that the laser treatment has positive effect on delaying the onset of blindness in patients with diabetic retinopathy.
Table 6. The estimates of the parameters for the DRS data.
8. Conclusion
In this paper, we have considered the dependent competing risks model by using an MOBW distribution. The objective Bayesian method is proposed to estimate the parameters. Based on different grouping orders, four reference priors are derived. Then the Bayesian approaches are compared with the maximum-likelihood method in terms of RMSE, RB and CP via a simulation study. The simulation results show that the Bayesian estimates perform better in terms of the CPs and RMSEs, and that we can choose a suitable reference prior to estimate the parameters according to the inferential importance.
Acknowledgments
The authors thank the editor-in-chief Dongchu Sun and the referee for their constructive suggestions that greatly improved the article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Ancha Xu
Ancha Xu received the B.E. degree from the College of Mathematics and Statistics, Central China Normal University, Wuhan, China, and the Ph.D. degree from East China Normal University, Shanghai, China, in 2006 and 2011, respectively. He is currently an Associate Professor in the School of Mathematics and Information Science, Wenzhou University, Zhejiang, China. His research interests include Bayesian statistics, degradation modeling, and accelerated life testing.
Shirong Zhou
Shirong Zhou is currently working toward the Master degree in tSchool of Mathematics and Information Science, Wenzhou University, Zhejiang, China. His research interests include failure data analysis, accelerated life testing, and Bayesian inference.
Related Research Data
References
- AL-Hussaini, E. K., Abdel-Hamid, A. H., & Hashem, A. F. (2015). Bayesian prediction intervals of order statistics based on progressively type-II censored competing risks data from the half-logistic distribution. Journal of the Egyptian Mathematical Society, 23, 190–196.
- Bemis, B., Bain, L. J., & Higgins, J. J. (1972). Estimation and hypothesis testing for the parameters of a bivariate exponential distribution. Journal of the American Statistical Association, 67, 927–929.
- Berger, J. O., & Bernardo, J. M. (1992). On the development of reference priors (with discussion). In J. M. Bernardo, J. O. Berger, A. P. Dawid, & A. F. M. Smith (Eds.), Bayesian statistics (Vol. 4, pp. 35–60). Oxford: Clarendon Press.
- Berger, J. O., Bernardo, J. M., & Sun, D. (2015). Overall objective priors (with discussion). Bayesian Analysis, 10, 189–221.
- Bernardo, J. M. (1979). Reference posterior distributions for Bayesian inference (with discussion). Journal of the Royal Statistical Society B, 41, 113–147.
- Cramer, E., & Schmiedt, A. B. (2011). Progressively type-II censored competing risks data from Lomax distributions. Computational Statistics and Data Analysis, 55, 1285–1303.
- Csorgo, S., & Welsh, A. H. (1989). Testing for exponential and Marshall-Olkin distribution. Journal of Statistical Planning and Inference, 23, 287–300.
- Dijoux, Y. D., & Gaudoin, O. (2009). The alert-delay competing risks model for maintenance analysis. Journal of Statistical Planning and Inference, 139, 1587–1603.
- Dimitrova, D. S., Haberman, S., & Kaishev, V. K. (2013). Dependent competing risks: Cause elimination and its impact on survival. Insurance: Mathematics and Economics, 53, 464–477.
- Feizjavadian, S. H., & Hashemi, R. (2015). Analysis of dependent competing risks in the presence of progressive hybrid censoring using Marshall-Olkin bivariate Weibull distribution. Computational Statistics and Data Analysis, 82, 19–34.
- Ghosh, J. K., & Mukerjee, R. (1991). Characterization of priors under which Bayesian and frequentist bartlett corrections are equivalent in the multiparameter case. Journal of Multivariate Analysis, 38, 385–393.
- Gilks, W. R., & Wild, P. (1992). Adaptive rejection sampling for Gibbs sampling. Applied Statistics, 41, 337–348.
- Guan, Q., Tang, Y. C., & Xu, A. C. (2013). Objective Bayesian analysis for bivariate Marshall-Olkin exponential distribution. Computational Statistics and Data Analysis, 64, 299–313.
- Jeffreys, H. (1961). Theory of probability. London: Oxford University Press.
- Kozumi, H. (2004). Posterior analysis of latent competing risk models by parallel tempering. Computational Statistics and Data Analysis, 46, 441–458.
- Kundu, D., & Dey, A. K. (2009). Estimating the parameters of the Marshall-Olkin bivariate Weibull distribution by EM algorithm. Computational Statistics and Data Analysis, 53, 956–965.
- Kundu, D., & Gupta, A. K. (2013). Bayes estimation for the Marshall-Olkin bivariate Weibull distribution. Computational Statistics and Data Analysis, 57, 271–281.
- Kundu, D., Kannan, N., & Balakrishnan, N. (2003). Analysis of progressively censored competing risks data. In N. Balakrishnan & C. R. Rao (Eds.), Handbook of statistics on survival analysis (Vol. 23, pp. 331–348). New York: Elsevier Publications.
- Laplace, P. (1812). Analytical theory of probability. Paris: Courcier Press.
- Lindqvist, B. H., & Skogsrud, G. (2009). Modeling of dependent competing risks by first passage times of Wiener processes. IIE Transactions, 41(1), 72–80.
- Marshall, A. W., & Olkin, I. (1967). A multivariate exponential distribution. Journal of the American Statistical Association, 62, 30–44.
- Mazucheli, J., & Achcar, J. A. (2011). The Lindley distribution applied to competing risks lifetime data. Computer Methods and Programs in Biomedicine, 104, 188–192.
- Pareek, B., Kundu, D., & Kumar, S. (2009). On progressively censored competing risks data for Weibull distributions. Computational Statistics and Data Analysis, 53, 4083–4094.
- Wang, C. P., & Ghosh, M. (2003). Bayesian analysis of bivariate competing risks models with covariates. Journal of Statistical Planning and Inference, 115, 441–459.
- Xu, A. C., Basu, S, & Tang, Y. C. (2014). A full Bayesian approach for masked data in step-stress accelerated life testing. IEEE Transactions on Reliability, 63, 798–806.
- Xu, A. C, & Tang, Y. C (2010). Reference analysis for Birnbaum-Saunders distribution. Computational Statistics & Data Analysis, 54, 185–192.
- Xu, A. C., & Tang, Y. C. (2011). Objective Bayesian analysis of accelerated competing failure models under type-I censoring. Computational Statistics & Data Analysis, 55, 2830–2839.
- Xu, A. C, Tang, Y. C, & Sun, D. C. (2015). Objective Bayesian analysis for masked data under symmetric assumption. Statistics and its Interface, 8, 227–237.
- Yang, R., & Berger, J. O. (1994). Estimation of a covariance matrix using the reference prior. The Annals of Statistics, 22, 1195–2111.
Appendices
Appendix 1
A1. The reference prior of the MOBW distribution
Following the notions of Berger and Bernardo (Citation1992), according to the inferential importance, we order a multi-dimensional parameter τ = (τ1,… , τl) and separate it into m groups of sizes n1, n2,… , nm, and these groups are given by
where
. Define
then τ[ ∼ 0] = τ and τ[0] is vacuous.
The same as Berger and Bernardo (Citation1992), the notation I(τ) is the Fisher information matrix and S(τ) = (I(τ))−1. We will substitute I and S for I(τ) and S(τ) in the following sections.
Write S as
so that Aij is a ni × nj matrix, and define Sj = upper left (Nj × Nj) corner of S, with Sm = S, and Hj = S− 1j. Then the matrices
play an importance role in deriving the reference priors. In particular, h1 = H1 = A− 111 and, if S is a block diagonal matrix (i.e. Aij = 0 for all i ≠ j), then hj = A− 1jj, j = 1, …, m.
Lemma A.1:
If |hj(τ)| depending only on τ[j] holds, for j = 1,… , m, then the reference prior
where
|hj(τ)| is the determinant of hj(τ), τ* is any fixed point in Θ, and Θ is a compact subset.
One can refer to Berger and Bernardo (Citation1992) for the proof. By using this lemma, the derivation of the m-group reference prior is greatly simplified.
There are four parameters in the MOBW distribution, in the following, we consider three cases, where the parameters are separated into two, three and four groups. We take {α, (θ1, θ2, θ3)}, {(θ2, θ3), α, θ1)} and {α, θ1, θ2, θ3} as an example.
| (I) | The reference prior of {α, (θ1, θ2, θ3)} is ω1(α, θ1, θ2, θ3). | ||||
Proof:
Based on the Fisher information matrix Σ, we can easily derive
According to Sj = upper left (Nj × Nj) corner of S, Hj = S− 1j, we can obtain
Due to hj = lowerright (nj × nj) cornerof Hj, j = 1, 2, then
Choose Θk = Θ1k × Θ234k = {α|a1k < α < b1k} × {(θ1, θ2, θ3)|a2k < θ1 < b2k, a3k < θ2, a4k < θ3, θ2 + θ3 < dk}, such that . Note that h1 and h2 satisfy Lemma A.1, then after some calculations, the reference prior for {α, (θ1, θ2, θ3)} is
| (II) | The reference prior of {(θ2, θ3), α, θ1} is ω1(α, θ1, θ2, θ3). | ||||
Proof:
The Fisher information matrix of {(θ2, θ3), α, θ1} is
Thus
According to Hj = S− 1j, and hj = lower right (nj × nj) corner of Hj, j = 1, 2, 3, we can obtained that
,
, H3 = Σ1. Then h1 = H1,
,
.
Choose Θk = {((θ2, θ3), α, θ1)|a1k < α < b1k, a2k < θ1 < b2k, a3k < θ2, a4k < θ3, θ2 + θ3 < dk}, such that . According to Lemma A.1, it is not difficult to obtain that the reference prior for {(θ2, θ3), α, θ1} is also
| (III) | The reference prior of {α, θ1, θ2, θ3} is ω2(α, θ1, θ2, θ3). | ||||
Proof:
Due to S = Σ−1, we can obtain
Thus
Then
,
,
,
.
Choose Θk = {(α, θ1, θ2, θ3)|a1k < α < b1k, a2k < θ1 < b2k, a3k < θ2, a4k < θ3, θ2 + θ3 < dk}, such that . According to Lemma A.1, we can obtain the reference prior for {α, θ1, θ2, θ3} is
The reference prior for πu(α, λ0, λ1, λ2) can be obtained from ωu(α, θ1, θ2, θ3), u = 1, 2, 3, 4, according to the one-to-one transformation from (α, λ0, λ1, λ2) to (α, θ1, θ2, θ3).
Appendix 2
Proving Theorem 5.1 needs the following two results (Guan et al., Citation2013):
(B.1)
(B.2)
where B( ·, ·) is a beta function.
(I) The likelihood function under parameters (α, θ1, θ2, θ3) is
then the joint posterior distribution of (α, θ1, θ2, θ3) under the prior ω1 can be written as
(B.3)
Denote the right side of (EquationB.3
(B.3) ) as R, using (EquationB.1
(B.1) ), we have
Denote
then c is a constant. For any 0 < ϵ < 1, we have
Obviously,
where T(n) is the largest order statistic of Ti, i = 1, 2,… , n, then R3 < ∞. Thus
Therefore, the posterior distribution of (α, θ1, θ2, θ3) under the prior ω1 is proper. Similarly, using (EquationB.2
(B.2) ), we can prove that the posterior distribution under the prior ω2 is also proper.
(II) The posterior distribution of (α, θ1, θ2, θ3) under the prior ω3 iss
(B.4)
We denote the right side of (EquationB.4
(B.4) ) as P, using (EquationB.2
(B.2) ), we have
denote
then Q is a constant. For any θ1 > 0, there exists a constant M0 satisfying
. Then
according to (I),
Therefore,
Thus the posterior distribution of (α, θ1, θ2, θ3) under the prior ω3 is proper. Similarly, we can prove that the posterior distribution under the prior ω4 is also proper.