ABSTRACT
Factor analysis which studies correlation matrices is an effective means of data reduction whose inference on the correlation matrix typically requires the number of random variables, p, to be relatively small and the sample size, n, to be approaching infinity. In contemporary data collection for biomedical studies, disease surveillance and genetics, p > n limits the use of existing factor analysis methods to study the correlation matrix. The motivation for the research here comes from studying the correlation matrix of log annual cancer mortality rate change for p = 59 cancer types from 1969 to 2008 (n = 39) in the U.S.A. We formalise a test statistic to perform inference on the structure of the correlation matrix when p > n. We develop an approach based on group sequential theory to estimate the number of relevant factors to be extracted. To facilitate interpretation of the extracted factors, we propose a BIC (Bayesian Information Criterion)-type criterion to produce a sparse factor loading representation. The proposed methodology outperforms competing ad hoc methodologies in simulation analyses, and identifies three significant underlying factors responsible for the observed correlation between cancer mortality rate changes.
1. Introduction
Due to its flexibility in characterising multivariate data, high-dimensional factor analysis is becoming popular in many scientific disciplines including genetic (Zhou, Wang, Wang, Zhu, & Song, Citation2017), biomedical (Shimizu et al., Citation2016) and economic studies (Fan, Lv, & Qi, Citation2011). The objectives of exploratory factor analysis are twofold: (1) identify the number of factors that influence a set of random variables; (2) measure the strength of the relationship between the extracted factors and each random variable.
In many studies where the random variables of interest are highly variable (e.g., cancer mortality rates), it is common to standardise the random variables and analyse the correlation matrix. Standardisation ensures that results from factor analysis will not be driven by random variables with large variances, which is a challenge when performing factor analysis on covariance matrices. Additionally, in the cases where the number of random variables exceeds the sample size, a couple of statistical challenges arise in the analysis of correlation matrices via factor models. First, existing inference methods rely on the number of random variables, p, to be relatively small and fixed, and the sample size, n, to be approaching infinity (Anderson, Citation1963; Johnson & Wichern, Citation1998). Another complication is that factor analysis is not invariant to change on the scale of variables. Methods that infer structure from covariance matrices (Bickel & Levina, Citation2008; Carvalho et al., Citation2008; Fan, Fan, & Lv, Citation2008; Ghosh & Dunson, Citation2009; Huang, Liu, Pourahmadi, & Liu, Citation2006; Patterson, Price, & Reich, Citation2006; West, Citation2003; Wong, Carter, & Kohn, Citation2003) will not always perform similarly on correlation matrices. There appears to be a lack of methodology for performing inference on correlation matrices using factor analysis when p > n. Furthermore, traditional methods for estimating the number of factors to be extracted and their interpretation are insufficient and need further development for correlation matrices when p > n.
We make several contributions with this paper. First, we formalise a test statistic to perform inference of the structure of the correlation matrix using the limiting distribution of eigenvalues. This test statistic from Johnstone (Citation2001) but was not delineated as fully as we do in this paper. Second, we extend the work of Johnstone (Citation2001) to identify the true number of underlying factors present in a factor model, while controlling the type I error. Finally, we propose a BIC (Bayesian Information Criterion)-type criterion to produce sparse factor loadings to ease interpretation of extracted factors.
The format of this paper is as follows. In Section 2, we present a test for inference on the structure of the population correlation matrix, which we term the Tracy–Widom test. In Section 3, we develop a sequential-rescaling procedure to test for the number of significant factors in a given factor model. Section 4 describes a sparse factor model that aids in interpreting the factors detected from the proposed test. Section 5 presents some designed simulation studies based on the proposed methodology. Section 6 applies the developed methodology to study the correlation matrix of cancer mortality ARC data, followed by our concluding remarks in Section 7.
2. Methods
2.1. Factor model formulation
Consider a random vector X = (X1,… , Xp)T where each component Xj follows a standard normal distribution. Because different cancers have varying degrees of volatility, normalisation will ensure that the analysis will not be dominated by a few cancer types. The primary aim of this project is to study the correlation matrix of X.
A factor model postulates that X is linearly dependent on a few underlying, but unobservable, random quantities F1,… , Fm called common factors and p additional sources of variation ε1,… , εp called white noise or specific factors, such that
(1)
where
is a vector of m common factors,
is a p × m matrix of factor loadings with ℓl = (ℓl1,… , ℓlp)T for l = 1,… , m and
is an identity matrix of dimension m. We denote the residual as
where
is a p × p diagonal matrix with the lth diagonal element being ψl = 1 − ℓ21l − ⋅⋅⋅ − ℓ2ml to ensure that Var(Xj) = 1.
If we assume that and
are independent in Equation (Equation1
(1) ), then it follows that the correlation matrix for X is
. Using an eigenvalue decomposition,
with m orthonormal eigenvectors
for l = 1,… , m such that λ1 ≥ λ2 ≥ · · · ≥ λm ≥ 0 and
, which equals 1 if l = k and 0 otherwise. Hence,
and results in
(2)
where λ1, λ2,… , λm correspond to the m largest eigenvalues of
.
2.2. Testing complete independence of the correlation matrix
One of the first objectives of studying the correlation matrix of a set of random variables is to determine if factor analysis is a reasonable method of analysis. This is equivalent to performing inference on the structure of the correlation matrix with test of versus the alternative
. We base our test for
on the largest eigenvalue of the sample correlation matrix of X. A result of random matrix theory (RMT) suggests that we can build a theoretical distribution for the largest eigenvalue of random matrices under the null hypothesis of complete independence (Johnstone, Citation2001). A test of complete independence about the p random variables compares the observed sample eigenvalue
to the theoretical distribution of λ1 under RMT prediction. This test will reveal one of two possibilities: the first being that
will be determined to not significantly differentiate from RMT prediction. This suggests that
cannot be rejected and therefore that factor analysis will not prove to be useful because specific noise factors play a more dominant role in the observed correlation than common underlying factors. The second possibility for a test of the largest eigenvalue is that it will determine
to significantly deviate from RMT prediction (i.e.,
is rejected in favour of the alternative). This scenario suggests that one (or possibly more) underlying factor(s) could be responsible for the observed correlation between the random variables.
To proceed, we describe the test statistic for testing . Suppose that data matrix
has entries that are independent and identically distributed as standard normal. Let
denote the sample eigenvalues of a Wishart Matrix,
. We can test the significance of
, the largest eigenvalue of
, with test statistic
(3)
where
and
Johnstone (Citation2001) has shown that under H0, and n, p → ∞ such that n/p → γ for γ some constant and the test statistic , where W1 is called the Tracy–Widom distribution (Tracy & Widom, Citation2000). We term (Equation3
(3) ) the Tracy–Widom test and will reject the null hypothesis of
when Tnp > W1, 1 − α where W1, 1 − α is the (1 − α) × 100 percentile of the Tracy–Widom distribution. One of the strengths of this test is that it can be applied in the classical setting where n > p as well as in high-dimensional settings where p > n.
2.3. Correlation correction of Tracy–Widom test
A technical note suggests that the Tracy–Widom test applies to the study of covariance matrices and does not directly apply to correlation matrices, which is problematic for distribution theory (Anderson, Citation1963). To be able to apply the Tracy–Widom test to study correlation matrices, we expand on the procedure that was briefly mentioned in Johnstone (Citation2001) but has not been fully studied. To this end, suppose we draw n i.i.d. row vector samples from to produce data matrix
. Under the null hypothesis, the column vectors
are i.i.d on the unit sphere Sn − 1. As a result, we can multiply each
by an independent chi-distributed length to synthesise a Gaussian matrix, call it
such that
where
and ψ2j ∼ χ2(n − 1). We can then construct a sample pseudo-covariance matrix
which approximately follows a Wishart distribution with n − 1 degrees of freedom. Under the null, this data augmentation allows us to apply the Tracy–Widom test on the largest eigenvalue of
to test
.
3. Identifying additional factors
If is rejected, then at least one latent factor is useful in describing the observed correlation among the p random variables. One of the most crucial steps of factor analysis is to estimate the true number of underlying factors, m, as misspecification of the number of factors retained can lead to poor factor-loading pattern reproduction and interpretation (Hayton, Allen, & Scarpello, Citation2004). Furthermore, estimation of the number of factors can affect the factor model results more than other decisions, such as the factor rotation method used (Zwick & Velicer, Citation1986). In this section, we extend the work of Johnstone (Citation2001) to identify the number of relevant factors to be used in a factor model.
Previous work on estimating the number of factors have focused on factor analysis for covariance matrices (Bai, Citation2003; Bai & Ng, Citation2002; Leek, Citation2011; Onatski, Citation2009). Johnstone (Citation2001) and Baik and Silverstein (Citation2006) have considered the asymptotic behaviour of , the (r + 1)th largest eigenvalue of a covariance matrix, when the true population covariance follows a spiked model with
, where τ1 ≥ · · · ≥ τr > 1. As factor analysis is not invariant to changes in the scale of the variables, it is often recommended that factor analysis be performed for standardised variables. Standardisation converts a covariance matrix problem into a correlation problem and it is unclear how these methods would be applied to the study of sample correlation matrices.
Common ad hoc methods of determining the number factors to extract from correlation matrices include the scree plots, Guttman–Kaiser criterion and parallel analysis. The number of extracted factors based on the scree plot is highly subjective as the estimate is visually selected as point that resembles an elbow. The Guttman–Kaiser criterion (Guttman, Citation1954; Kaiser, Citation1960) selects the number of factors to be equal to the number of sample eigenvalues of the correlation matrix that are greater than one. Parallel analysis (Horn, Citation1965) is a simulation-based approach that compares the eigenvalues of the sample correlation matrix to eigenvalues from a matrix of random values of the same dimensionality. The estimated number of factors retained are the number of observed sample eigenvalues greater than the 95th percentile of the distribution of eigenvalues derived from the random data.
3.1. Sequential-rescaling testing procedure
We propose to view the testing procedure of extracting relevant underlying factors as a sequential procedure. Given that the Tracy–Widom test is used to test the largest eigenvalue, we propose a sequential method that removes the effect of the first factor (if significant) and produces a new data matrix from which we can construct a new correlation matrix and apply once again the Tracy–Widom test on the new largest eigenvalue. In general, we will test for the significance of λk only after verifying that λk − 1 are significantly different than RMT prediction and after eliminating the effect of the first k − 1 factors. We remove the effect of the first k − 1 factors because of the phenomenon where the largest eigenvalue has the potential to pull other sample eigenvalues away from unity. The resulting procedure is termed a sequential-rescaling procedure. The advantage of the procedure that follows is that it controls the type I error through the use of an alpha spending function, and it is not a conservative technique based on what has been proposed in Patterson et al. (Citation2006).
Suppose we have declared the first k − 1 eigenvalues to be significantly different than RMT prediction. The following procedure tests the subsequent eigenvalue λk. The procedure assumes the Tracy–Widom test has already identified λ1, λ2,… , λk − 1 to be significant. Associated with eigenvalue λℓ is its corresponding eigenvector . We proceed to test λk through the following two-step procedure:
Construct a data matrix
such that
It can be shown that the sample correlation matrix for the rescaled
We note that caution should be taken when testing subsequent sample eigenvalues. To circumvent the multiple testing issues that are present in this procedure, we apply methodology from the group sequential analysis literature to control the type I error. Lan and DeMets (Citation1983) proposed an alpha spending technique in which the nominal significance level needed to reject the null hypothesis at each analysis is less than α and increases as the study progresses. If an overall type I error (α) is desired, we propose to use the following alpha spending function:
(6)
where α*(k) is the significance level for the kth hypothesis test. This is opposed to Lan and DeMets (Citation1983), as alpha spending function (Equation6
(6) ) does not depend on the overall number of tests being conducted. Therefore, one need not specify the maximum number of eigenvalues being tested, which is ideal for unsupervised learning.
We define type I error as the probability of incorrectly choosing a model that has extracted more factors than the true model. Compared to Lan and DeMets (Citation1983) who suggest that the alpha spending function should be non-decreasing, our spending function is non-increasing (α*(1) > α*(2) > · · · > α*(K)); because finding a parsimonious model is preferred, we need strong evidence for choosing a more complicated model with more significant eigenvalues over a simpler one. We have shown in supplementary material that the overall type I error rate using the proposed spending function (Equation6(6) ) will not exceed α.
4. Interpretation of factors
After an estimation is made for the number of factors to be used, the next objective in factor analysis is to provide an interpretation for each underlying factor. In principle, the factor loadings provide the basis for interpreting the factors underlying the data. The size and direction of the extracted factor loadings denote the strength and direction of the correlation between the random variables and the extracted factors. Traditionally, the task of interpreting factors has been subjective and unsatisfactory.
Because the original factor loadings may not be easily interpretable, it has become common to rotate the loadings (e.g., varimax, oblique, etc.) to increase or decrease the size of factor loadings to ease of interpretation. Unfortunately, regardless of the factor rotation used, it is rare for factor loadings to be set exactly to zero which would ease in the interpretation of the underlying factor.
With the recent developments of regularised regression in mind, we propose to implement a regularisation technique to detect a set of sparse factor loadings for easier interpretation of identified factors. The resulting sparse factor loading vector sets the loadings of negligible random variables to zero, assuring that they will not contribute to the interpretation of the underlying factor, making the interpretation of the factors more straightforward. Additionally, because negligible random variables are removed, the variance explained by the sparse factor loadings will not suffer much from their removal.
Eigenvalue decomposition (Equation2(2) ) provides the factoring of the correlation matrix of
. The factor loading matrix
is given by
where
are the eigenvalue–eigenvector pairs of
. Producing sparse factor loadings is equivalent to setting components of
to zero. It can be shown that apart from the scale value
, the factor loading column
are the coefficients of the principal components of the population. This observation allows us to implement well-studied sparse principal components methods to produce sparse factor loadings.
We propose to regularise for l = 1,… , m using the sparse principal components analysis (SPCA) method proposed by Zou, Hastie, and Tibshirani (Citation2006). SPCA essentially takes the problem of setting PCA loadings to zero and transforms it into a regression-type problem that uses an elastic net regularisation technique to detect sparse loadings even when p > n. Details of SPCA methodology can be found in Zou et al. (Citation2006), but we provide a brief description in the following.
4.1. SPCA for sparse factor loadings
We consider the problem of producing sparse factor loadings for the m estimated factors. Let ,
and
be the n × p data matrix as before and
denote the ith row vector of
. The problem of producing sparse factor loadings can be transformed into the following regression-type criterion with an elastic net penalty:
(7)
for any γ > 0. The last term in Equation (Equation7
(7) ) uses the L1 penalty to produce sparse factor loadings because the estimated sparse factor loadings, defined as
for l = 1,… , m, are a function of the sparse βl vector.
4.2. Selection of tuning parameter
The optimisation problem in Equation (Equation7(7) ) contains two tuning parameters that must be selected. The first tuning parameter, γ, is the same for all the m factors. It has been shown (Zou et al., Citation2006) that when p > n, a positive γ is required to produce exact loadings when the second tuning parameter is set to zero. The tuning parameter γ has been studied and is well understood. Empirical evidence has shown that for the case when n > p, γ can be set to zero. When p > n, γ can be set to a small positive number to overcome collinearity between the columns of
.
The second tuning parameter γ1, l is a factor-specific tuning parameter and requires more development. Zou et al. (Citation2006) did not provide clear guidance on selecting γ1, j, other than choosing γ1, j such that it provides a good compromise between explained variance and sparsity. Other methods exist for selecting the tuning parameters, such as cross validation (Shen & Huang, Citation2008) which could be computationally extensive and requires a large sample size. We add to the current literature on producing sparse factor loadings by proposing a BIC-type criterion for selecting the factor specific tuning parameters (γ1, 1,… , γ1, m).
For a fixed γ, we propose to use the following BIC-type criterion for selection of tuning parameters (γ1, 1,… , γ1, m):
(8)
where
,
is the factor loading matrix and
where
. We define the degrees of freedom,
, to be the number of non-zero loadings in the loading matrix
. Zou, Hastie, and Tibshirani (Citation2007) showed that the number of of non-zero coefficients in lasso regression provides an unbiased estimate for the degrees of freedom and suggests that BIC can be used to determine the optimal number of nonzero factor loadings.
5. Analysis of simulated data
To assess the performance of the proposed method, we simulate data from factor models where the p observable random variables are constructed from zero, one, two or three underlying factors. The zero factor model is given by Xj = εj where εj ∼ N(0, 1) for j = 1,… , p. The one factor model is given by
where U1 ∼ Unif(0, 1) and F1 ∼ N(0, 1). The two factor model is simulated from
where U2 ∼ Unif(0.5, 1.5) and
. Finally, the three-factor model is simulated from the following model:
where U3 ∼ Unif(1, 1.5) and
.
We consider configurations of the data by taking n samples from each of the factor models and we vary p to be less than, equal to or more than n. The following parameter configurations are considered: (p = 100, n = 500), (p = 500, n = 500), (p = 500, n = 100). We also consider the special case when p = 59, n = 39, which is the number of distinct cancer types and the sample size of the SEER cancer mortality data. In this special case, the number of random variables loading on F1 is 25, the number of random variables loading on F2 is 15 and 10 on F3.
5.1. Simulation results for estimating the number of factors
In this section, we use the simulated data-sets to demonstrate the behaviour of the sequential-rescaling procedure when used to estimate the number of factors in a model with zero, one, two or three underlying factors. We compare the proposed procedure to the Guttman–Kaiser criterion and parallel analysis.
We present simulation results in for 1500 simulated data-sets derived from zero-, one-, two- or three-factor models. The results in shows that the proposed method performs well, and in almost all cases outperforms the Guttman–Kaiser criterion and parallel analysis. The Guttman–Kaiser criterion consistently overestimates the number of factors to be retained, compared to other methods (even when n > p). We note that when p is vastly larger than n, the Guttman–Kaiser criterion always estimates the number of factors to be the rank of .
Table 1. Simulation results based on 1500 simulated data-sets for selecting the true number of factors comparing Guttman criterion (Gu), parallel analysis (Pa) and the proposed methodology (Pr). Presented is the discrete probability of the estimated number of factors and its corresponding mean and standard deviation for one-, two- and three-factor models. The number of random variables (p) and sample size (n) are varied.
The parallel analysis method of estimating the number of factors is relatively accurate across the range of factor models when n > p. When p becomes comparable to n, the parallel analysis estimator overestimates m compared to the proposed methodology. As p becomes significantly larger than n, the parallel analysis estimator breaks down and significantly overestimates m.
5.2. Simulation results of BIC criterion
For each of the simulated data-sets, there are numerous random variables that have zero loadings on the underlying factors. We perform SPCA on each of the simulated extracted factor loadings to obtain vectors of factor loadings with zero loadings that can help in interpreting the underlying factors. We choose the factor-specific tuning parameters (γ1, 1,… , γ1, m) based on the BIC criterion described in Section 4.2. We consider 200 simulated data-sets for one-, two- and three-factors models with varying (p, n) as described earlier.
We present the estimated number of non-zero factor loadings, the false positive rate and false negative rate for each factor based on sparse PCA using the proposed BIC criterion in . Across all factor models, the BIC tuning parameter selection method selects the true non-zero loadings with good consistency when n is large and when n is larger or comparable to p. When p > n, the BIC tends to select larger models for factor 2 and factor 3 and the false positive rate and false negative rate are no longer negligible.
Table 2. Simulation results based on 200 simulated data-sets for the proposed BIC-type criterion tuning parameter selection. The |ℓm| denotes the true number of random variables that load on each corresponding factor and denotes the mean number of non-zero factor loadings for each factor across the simulated data-sets. FP and FN denote the false positive rate and false negative rate, respectively. The number of random variables (p) and sample size (n) are varied.
6. Data analysis
The motivation for the proposed statistical methodology is derived from work on identifying change patterns in cancer mortality trends. Cancer mortality data for the United States come from the National Cancer Institute's Surveillance, Epidemiology and End Results (SEER) Program. We analyse age-adjusted cancer mortality change patterns separately for males and females. For the sake of brevity and to avoid redundancy, we only present the results for males.
In the study of cancer mortality change pattern trends, it is common to use the log transformed annual rate change (ARC) instead of the actual mortality rate. The ARC of cancer type j in year i denoted by ARCij is defined as ARCij = log rij − log ri − 1, j, where rij denotes the cancer mortality rate of cancer type j in year i, and the log transformation is applied to normalise the data and the difference to construct independent components (Kim, Fay, Feuer, & Midthune, Citation2000). Because the different cancer types have varying levels of volatility, we will centre and standardise ARCij such that it has mean 0 and variance 1. We denote the standardised rate change as Xij. We obtain an estimate of the correlation matrix, where
is the data matrix with Xij as its (i, j)th entry. Cancer mortality rates were obtained for p = 59 distinct male cancer types over n = 39 years (1969–2008).
6.1. Application of proposed methodology to SEER data
To visualise the correlation matrix of cancer ARC, we construct a correlation matrix using ellipse-shared glyphs for each entry in . Overall, displays how the correlation matrix is dominated by low correlations between the cancer types. It is feasible that the population correlation matrix of ARC could be equal to the identity matrix and that the few moderate observed correlations are simply noisy estimates.
Figure 1. Visualisation of the standardised log-annual cancer mortality rate change correlation matrix of the 59 unique male cancer types. Ellipse-shared glyphs for each entry represent the level curve of a bivariate normal density with the matching correlation. Darker Ellipses denote a positive correlation greater than 0.4 and lighter ellipses denote a negative correlation of more than −0.4. Ellipses with no color denote correlation between −0.4 and 0.4. The cancer type can be matched to the number on the figure and in .

We begin our investigation of the correlation matrix of ARC by testing the null hypothesis versus the alternative
. To test this hypothesis, we study the largest eigenvalue of
which was estimated to be 7.12. After performing the correlation correction of the Tracy–Widom test described in Section 2.3, the estimated largest eigenvalue of the pseudo-covariance matrix is 268.90. Applying the Tracy–Widom test on this value, we calculate the test statistic Tnp = 8.63 where
and
. Compared to the Tracy–Widom distribution of order 1, the test statistic results in a p value <0.0001. We reject the null hypothesis of complete independence in ARC between cancer types which suggests that at least one factor is sufficient to describe the observed correlation among the cancer types.
Next, we determine the number of factors to be used in the analysis using the sequential rescaling procedure described in Section 3.1 and present those results in . suggests that three underlying factors are important in characterising the correlation matrix of cancer mortality ARC.
Table 3. Sequential-rescaling procedure: largest four estimated eigenvalues of the pseudo-covariance matrix () are denoted in the second column. The p value for the corresponding Tracy–Widom test and alpha spending function, α*(k), are in the third and fourth column, respectively. The last column denotes the decision to retain or not retain the factor.
Next, for the three extracted factors we performed sparse principle components analysis described in Section 4 to regularise the factor loadings. Only cancer types with meaningful associations to each underlying factor will have a non-zero factor loading, and we consider these to be important for the interpretation of the factors. We set γ = 1.0 × 104 in our SPCA analysis because the number of cancer types exceeded the number of data points available. To determine the degree of sparsity for each factor, we selected (γ1, 1, γ1, 2, γ1, 3) to be the values that minimised the BIC criterion in Equation (Equation8(8) ).
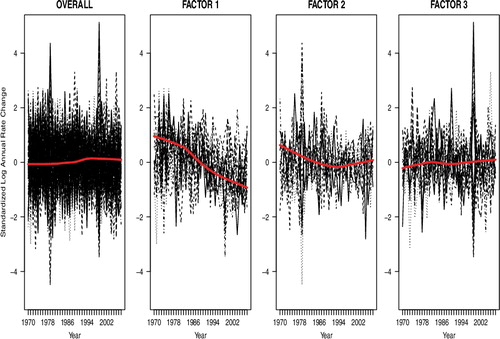
We present in , the 59 unique cancer types and their corresponding sparse factor loadings for the extracted factors. Of all the 59 cancers, 28 cancer types had zero loadings on all three factors. We note that lung and bronchus, prostate and colon cancer sites load heavily on the first factor but has exactly zero loadings for factors 2 and 3. Factor 1 might provide more support to the hypothesis that, as for colorectal cancer, early detection through screening and advances in treatment for prostate cancer are important factors that underlie the change in mortality rate. Factor 2 appears to contrast soft tissue cancers and leukemia, however, it is not clearly evident what is driving to their observed correlation. The interpretation of factor 3 appears to be highly related to miscellaneous cancer types (miscellaneous malignant cancer, other myeloid/monocytic leukemia, other digestive organs, etc.). Figure A1 provides additional information on each factor and their ARC change over time.
Table 4. Specific male cancer types and their corresponding sparse factor loadings. Sparse loadings are estimated by SPCA.
7. Discussion
We have described a methodology based on RMT that uses factor analysis to make inference on correlation matrices for settings where p > n. The methods described herein are applicable to a wide range of data, because it can be applied to cases where p > n as well as to traditional cases where n > p. We observed that current methods for selecting the number of factors (Guttman–Kaiser criterion and parallel analysis) do not perform well when p > n. Thus, we developed a sequential-rescaling procedure to determine the number of significant factors in a factor model using the Tracy–Widom test. This procedure is based on group sequential theory to control for the overall type I error. We described a practical approach to interpret the significant factor loadings using SPCA and a novel BIC-type criterion which regularises the noisy estimates of the factor loadings. Simulation studies demonstrate great performance for the proposed methodology in selecting the number of factors to be extracted and for identifying the important random variables that load on the underlying factors.
A number of open problems present themselves. The methods herein were constructed under the normality assumption. It is unclear how to determine complete randomness against any deviation from normality. For future work, it would be ideal to study the robustness of this methodology and the Tracy–Widom test against different distributional assumptions. Another limitation is that we have not explored any methods that test whether the change patterns of any two specific cancer types are correlated over time. Factor analysis identifies groups of cancers that are linearly dependent upon a few unobservable latent random variables, but cannot make specific statements about pairwise correlations. Identifying specific pairs of cancers that share similar change patterns could be extremely useful for cancer researchers. One avenue to explore related to the identification of significant pairwise change patterns would be to regularise the elements of the correlations themselves, which have been extensively studied for covariance matrices (Cai & Liu, Citation2011; Fan, Liao, & Liu, Citation2016; Rothman, Levina, & Zhu, Citation2009). Finally, although our focus was on the study of the correlation matrix when p > n, future studies should compare the performance of the Tracy–Widom test and sequential-rescaling procedure on covariance matrices to compare the performance and generalisability of these methods.
Acknowledgments
The authors thank Armin Schwartzman for his insightful comments and Amanda Delzer Hill for her editing work that greatly improved the manuscript.
Disclosure statement
The authors have no conflict of interests to declare.
Additional information
Funding
Notes on contributors
Miguel Marino
Miguel Marino is an assistant professor of biostatistics in the Department of Family Medicine at Oregon Health & Science University, with a joint appointment in the School of Public Health.
Yi Li
Yi Li is professor of biostatistics and director of the Kidney Epidemiology and Cost Center at the University of Michigan.
References
- Anderson, T. (1963). Asymptotic theory for principal component analysis. The Annals of Mathematical Statistics, 34(1), 122–148.
- Bai, J. (2003). Inferential theory for factor models of large dimensions. Econometrica, 71(1), 135–171.
- Bai, J., & Ng, S. (2002). Determining the number of factors in approximate factor models. Econometrica, 70(1), 191–221.
- Baik, J., & Silverstein, J. (2006). Eigenvalues of large sample covariance matrices of spiked population models. Journal of Multivariate Analysis, 97(6), 1382–1408.
- Bickel, P., & Levina, E. (2008). Regularized estimation of large covariance matrices. The Annals of Statistics, 36(1), 199–227.
- Cai, T., & Liu, W. (2011). Adaptive thresholding for sparse covariance matrix estimation. Journal of the American Statistical Association, 106(494), 672–684.
- Carvalho, C., Chang, J., Lucas, J., Nevins, J., Wang, Q., & West, M. (2008). High-dimensional sparse factor modeling: Applications in gene expression genomics. Journal of the American Statistical Association, 103(484), 1438–1456.
- Fan, J., Fan, Y., & Lv, J. (2008). High dimensional covariance matrix estimation using a factor model. Journal of Econometrics, 147(1), 186–197.
- Fan, J., Liao, Y., & Liu, H. (2016). An overview of the estimation of large covariance and precision matrices. The Econometrics Journal, 19(1), C1–C32.
- Fan, J., Lv, J., & Qi, L. (2011). Sparse high-dimensional models in economics. Annual Review of Economics, 3, 291–317.
- Ghosh, J., & Dunson, D. B. (2009). Bayesian model selection in factor analytic models. In D. Dunson (Ed.), Random effect and latent variable model selection (pp. 151–163). Hoboken, NJ: Wiley.
- Guttman, L. (1954). Some necessary conditions for common-factor analysis. Psychometrika, 19(2), 149–161.
- Hayton, J., Allen, D., & Scarpello, V. (2004). Factor retention decisions in exploratory factor analysis: A tutorial on parallel analysis. Organizational Research Methods, 7(2), 191–205.
- Horn, J. (1965). A rationale and test for the number of factors in factor analysis. Psychometrika, 30(2), 179–185.
- Huang, J., Liu, N., Pourahmadi, M., & Liu, L. (2006). Covariance matrix selection and estimation via penalised normal likelihood. Biometrika, 93(1), 85–98.
- Johnson, R., & Wichern, D. (1998). Applied multivariate statistical analysis. Englewood Cliffs, NJ: Prentice Hall.
- Johnstone, I. (2001). On the distribution of the largest eigenvalue in principal components analysis. The Annals of Statistics, 29, 295–327.
- Kaiser, H. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20(1), 141–151.
- Kim, H., Fay, M., Feuer, E., & Midthune, D. (2000). Permutation tests for joinpoint regression with applications to cancer rates. Statistics in Medicine, 19(3), 335–351.
- Lan, G., & DeMets, D. (1983). Discrete sequential boundaries for clinical trials. Biometrika, 70(3), 659–663.
- Leek, J. (2011). Asymptotic conditional singular value decomposition for high-dimensional genomic data. Biometrics, 67(2), 344–352.
- Onatski, A. (2009). Testing hypotheses about the number of factors in large factor models. Econometrica, 77(5), 1447–1479.
- Patterson, N., Price, A., & Reich, D. (2006). Population structure and eigenanalysis. PLoS Genetics, 2(12), 2074–2093.
- Rothman, A., Levina, E., & Zhu, J. (2009). Generalized thresholding of large covariance matrices. Journal of the American Statistical Association, 104(485), 177–186.
- Shen, H., & Huang, J. (2008). Sparse principal component analysis via regularized low rank matrix approximation. Journal of Multivariate Analysis, 99(6), 1015–1034.
- Shimizu, H., Arimura, Y., Onodera, K., Takahashi, H., Okahara, S., Kodaira, J., … Hosokawa, M. (2016). Malignant potential of gastrointestinal cancers assessed by structural equation modeling. PloS One, 11(2), e0149327.
- Tracy, C., & Widom, H. (2000). The distribution of the largest eigenvalue in the Gaussian ensembles. Calogero-Moser-Sutherland Models, 4, 461–472.
- West, M. (2003). Bayesian factor regression models in the large p, small n paradigm. Bayesian Statistics, 7, 723–732.
- Wong, F., Carter, C., & Kohn, R. (2003). Efficient estimation of covariance selection models. Biometrika, 90(4), 809–830.
- Zhou, Y., Wang, P., Wang, X., Zhu, J., & Song, P. X. K. (2017). Sparse multivariate factor analysis regression models and its applications to integrative genomics analysis. Genetic Epidemiology, 41(1), 70–80.
- Zou, H., Hastie, T., & Tibshirani, R. (2006). Sparse principal component analysis. Journal of Computational and Graphical Statistics, 15(2), 265–286.
- Zou, H., Hastie, T., & Tibshirani, R. (2007). On the degrees of freedom of the lasso. The Annals of Statistics, 35(5), 2173–2192.
- Zwick, W., & Velicer, W. (1986). Comparison of five rules for determining the number of components to retain. Psychological Bulletin, 99(3), 432–442.
Appendix
In this section, we show that the proposed alpha spending function
to test the number of significant factors will not exceed α, by calculating three probabilities.
| (1) | Probability that a model with one or more factors is chosen given a true zero-factor model. Let Lm be the event that the true model has m significant factors and | ||||
| (2) | Probability that a model is selected with k factors given a true zero-factor model for any k ≥ 1.
| ||||
| (3) | Probability that a model is selected with more than k factors given a true factor model with k factors.
| ||||
Thus, the type I error does not exceed alpha in any of the settings.
In , we plot the cancer mortality standardised log ARC over time for for all 59 cancer types and also three separate plots for the cancer types that have non-zero loadings for each factor. To visualise the pattern over time, we fit a Lowess smoothing line across time. Overall, when we consider the change patterns of ARC for all 59 cancer types simultaneously, we do not observe much change in ARC over time. The factor analysis performed identifies three distinct cancer mortality patterns of ARC over time. Factor 1 is a collection of cancer types (primarily influenced by colon, prostate and lung cancers) that have exhibited a decrease in ARC cancer mortality across time. The cancer types in factor 2 have decreasing ARC that levels off after the year 1990. Finally, factor 3 (miscellaneous) cancer types show no change in ARC over time.
Figure A1. Line plots of standardised log annual cancer mortality rate change over time. Left panel includes all cancer types and the last three panels plot the standardised log ARC for the cancer types that have non-zero loadings on factors 1, 2 and 3, respectively. The solid thick gray line denotes Lowess smoothing curves.