
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Nonparametric stochastic volatility models, although providing great flexibility for modelling the volatility equation, often fail to account for useful shape information. For example, a model may not use the knowledge that the autoregressive component of the volatility equation is monotonically increasing as the lagged volatility increases. We propose a class of additive stochastic volatility models that allow for different shape constraints and can incorporate the leverage effect – asymmetric impact of positive and negative return shocks on volatilities. We develop a Bayesian fitting algorithm and demonstrate model performance on simulated and empirical datasets. Unlike general nonparametric models, our model sacrifices little when the true volatility equation is linear. In nonlinear situations we improve the model fit and the ability to estimate volatilities over general, unconstrained, nonparametric models.
1. Introduction
In financial econometrics, volatility is usually defined as the conditional standard deviation of a discrete-time return series ; namely,
where
is the filtration up to time t−1. Since Engle (Citation1982)'s pioneering autoregressive conditional heteroscedastic (ARCH) model, a plethora of parametric models have been proposed to model financial volatilities. A popular approach is the stochastic volatility (SV) model that originated from Hull and White (Citation1987)'s stochastic differential equation for option pricing. In volatility modelling, two functional relationships are of particular interest – the dependence of volatilities on lagged volatilities, i.e., the autoregressive component, as well as the relationship between volatilities and lagged return shocks, which is also known as the news impact curve in the ARCH literature (see, e.g., Engle & Gonzalez-Rivera, Citation1991; Engle & Ng, Citation1993). The basic discrete-time SV model (Taylor, Citation1994) is essentially a nonlinear state space model with the state variables, the log volatilities, following an autoregressive (AR) process. To capture the asymmetric impact of positive and negative return shocks on volatilities in SV models, researchers have introduced the ‘leverage effect’. A leverage effect is defined as a (usually negative) correlation between the innovations of the volatility process and the lagged innovations of the return process (see Harvey & Shephard, Citation1996; Yu, Citation2005). When the error distributions in the SV models (see Section 2) are normal, the leverage effect can be equivalently expressed as a linear function of the lagged return innovations in the volatility equation (see, e.g., Omori, Chib, Shephard, & Nakajima, Citation2007; Yu, Citation2005, Citation2012).
Although parametric assumptions in traditional SV models, such as the linearity of the autoregressive and leverage components, provide reasonable approximations in some settings, they can also deviate considerably from the truth. Comte (Citation2004) showed the nonlinearity of the autoregressive component in SV models for large cap indices of several major equity markets. Yu (Citation2012) found empirical evidence that the leverage effect for many U.S. large cap equity returns is significantly smaller than zero when the lagged return innovation is negative but not when it is positive, which implies that a linear leverage function is insufficient to capture the news impact curve.
Nonparametric or semiparametric SV models can be used to relax the linearity assumptions in traditional SV models. Such models offer great flexibility for modelling the nonlinear functional relationships in the volatility equation. However, due to the latent structure of the state space model, they can also lead to a very large estimation variance for the volatilities. In this article, we propose to incorporate our knowledge about the shapes (such as monotonicity or piecewise monotonicity) of the functional components in the volatility equation as additional constraints in semiparametric SV models. In particular, we implement the shape constraints in the prior distributions of our Bayesian semiparametric additive model and show that the resulting model is more flexible than the linear parametric model and that the shape-constrained model can achieve lower estimation errors of the log volatilities and higher predictive log likelihood compared to the semiparametric model without shape constraints.
The idea of imposing shape constraints in a semiparametric SV model is warranted by the availability of our knowledge about the functional shapes as well as the proven benefits of imposing shape constraints in linear and generalised linear models. The past two decades have witnessed the accumulation of significant empirical knowledge about the shapes of the autoregressive and leverage components in SV models. For example, the phenomenon of volatility clustering (e.g., Rydberg, Citation2000) suggests that the autoregressive component of the volatility equation should be monotonically increasing as the lagged volatility increases. Additionally, Yu (Citation2012)'s findings show that the leverage function should at least be monotonically decreasing on the negative real line. Additionally, it has long been established that imposing correct shape constraints in function estimation problems has the potential of greatly improving model fit without incurring much additional cost (Ramsay, Citation1988). As a result, shape-constrained function estimation has been widely applied in regression and generalised linear models (for Bayesian implementations, see Brezger & Steiner, Citation2008; Cai & Dunson, Citation2007; Meyer, Hackstadt, & Hoeting, Citation2011; Neelon & Dunson, Citation2004). In state-space models such as SV models, there has been, to the best of our knowledge, no demonstration of the benefits of shape-constrained state smoothing. It is our belief that the aforementioned functional shapes shall be exploited to provide additional regularisation in the semiparametric SV models to ensure better model fit and prediction accuracy.
The remainder of the article is organised as follows. In Section 2, we introduce our shape-constrained semiparametric additive SV model. In Section 3, we develop the Markov chain Monte Carlo procedures for sampling from the posterior distribution and a particle-filter-based procedure for evaluating the predictive log likelihood. We apply our methods to simulated and real-world financial returns in Sections 4 and 5 and demonstrate their advantages over both the linear SV model and the semiparametric model without shape constraints. We close with conclusions and discussions in Section 6.
2. Model specification
2.1. Additive stochastic volatility models
The basic parametric (Gaussian) SV model is
(1)
(1) where
and
are two mutually independent innovation processes. To induce a leverage effect, we assume that
. Since the error distributions are normal, the state equation of the leveraged SV model can be equivalently expressed as
(2)
(2) where
,
and
is independent from
. This alternative form of the leverage effect (Equation2
(2)
(2) ) has been exploited in several papers including (Omori et al., Citation2007; Yu, Citation2005, Citation2012).
In this article, we consider the following semiparametric stochastic volatility model:
(3)
(3) where the innovations
and
are mutually independent. We assume that the autoregressive component, f, and the leverage function, g, are additive. The leveraged SV model (Equation2
(2)
(2) ) is a special case of (Equation3
(3)
(3) ) when both f and g are linear functions. Model (Equation3
(3)
(3) ) includes the models of Comte (Citation2004) and Yu (Citation2012) as special cases: when
, (Equation3
(3)
(3) ) reduces to Comte (Citation2004)'s nonparametric unleveraged SV model; when f is linear and g is piecewise linear, (Equation3
(3)
(3) ) becomes Yu (Citation2012)'s semiparametric leverage effect model. Additionally, when
for all t, model (Equation3
(3)
(3) ) contains the exponential ARCH (EGARCH) model of Nelson (Citation1991).
Additional constraints on the functions f and g are needed for (Equation3(3)
(3) ) to be identifiable. We assume that
and
, where
and
are two fixed numbers within the respective ranges of the processes
and
. Under these conditions, the parameter μ in (Equation3
(3)
(3) ) represents the expected conditional log volatility when
and
. The choice of
and
is discussed in Section 2.2. For the remainder of the article, we will assume that the data have already been de-trended, so
.
2.2. Shape-constrained additive stochastic volatility models
We call model (Equation3(3)
(3) ) the shape-constrained semiparametric additive SV model if f and g are restricted to be of certain shapes. As discussed in Section 1, for equity returns, the autoregressive function f is typically monotonically increasing on the entire real line, while the leverage function g is monotonically decreasing (at least) on the negative real line. The findings in Yu (Citation2012) indicate that
might have some change-point behaviour about zero, but generally, our knowledge of
for positive
is mixed.
To construct a monotone function , we consider the following basis expansion:
(4)
(4) If
's are monotonically increasing in x, then
is monotonically increasing (decreasing) in x if
0 for all
. In particular, given pre-specified knots
, we propose the following basis functions
(5)
(5) where
denotes the ‘center’ of the range of x. As for the choice of M, when the argument of the function, x, represents the previous log volatility,
, we let
. When x represents the lagged return innovation,
, we can always include 0 as the knot
.
The basis functions (Equation5(5)
(5) ) are a shifted version of the basis functions used in Neelon and Dunson (Citation2004), but they considerably improve the computational efficiency for the class of state space models entertained in this article. Note that under (Equation5
(5)
(5) ), the parameter
in (Equation4
(4)
(4) ) represents the ‘center’ of the function through the equation
, while
under the original basis functions of Neelon and Dunson (Citation2004). This makes a difference computationally since the basis functions are nonorthogonal (hence the coefficients are mutually dependent by design) and the estimation variance of
tends to be much smaller than that of
because of the abundance of information contributed by the data from both sides of
. For SV models or other state space models, the benefits of the basis functions (Equation5
(5)
(5) ) are even bigger due the necessity of specifying the knots with a wide enough range to cover all possible values of the latent variables and the resulting scarcity (or lack) of data for estimating
.
Letting and
denote the basis functions for f and g respectively, we can rewrite (Equation3
(3)
(3) ) as
(6)
(6) It is easy to see that model (Equation6
(6)
(6) ) satisfies
and
, which are the additional constraints needed for it to be identifiable. We use the following priors from Neelon and Dunson (Citation2004) on
to ensure their non-negativity:
(7)
(7) The prior for
can be based on prior knowledge of the steepness of the function toward the left tail. However, if such knowledge is not readily available, the flat prior
can be a convenient alternative, which also has a nice property that the posterior distribution does not depend on the starting point, nor on the direction of the latent random walk process
. In other words, the posterior will be exactly the same as by assuming the random walk starts at
with
, for any integer κ from 1 to K.
As for the function , we have empirical evidence showing that it is monotonically decreasing on the negative real line but do not have consistent information about its shape on the positive real line. Accordingly, our priors for
are specified as follows.
(8)
(8)
(9)
(9) In the equation above,
can be specified in the same way as
and ι is an indicator function that depends on the assumption of the shape of g on the positive real line – if
is monotonically decreasing in positive
, then
; if
is monotonically increasing in positive
, then
; finally, if we lack such information or that
is not monotone for positive
, we can simply set
to remove the shape constraint on that part of the leverage function altogether.
The remaining parameters are assumed to be mutually independent. For the priors of the variance parameters and
, we use the conjugate inverse gamma distribution. We assume a
prior for μ and a
prior for the initial state
.
3. Model fitting and comparison
3.1. MCMC procedure
We use the Gibbs sampler to simulate from the joint posterior distribution of model (Equation6(6)
(6) ). The algorithm for a single iteration is described below.
Update
and
Update the variance parameters
Update μ from its normal full conditional distribution.
Update
One challenge of this MCMC algorithm is that both the ‘dependent variable’, , and the ‘independent variables’,
and
, of the state equation change from iteration to iteration. Therefore, in order to update the coefficients
and
, we need to ensure that their respective knot grids cover large enough ranges so that the values of
and
are always within the boundary knots. See the appendix for more details.
Updating the high-dimensional state vector remains a bottleneck for many applications of Bayesian state space models. For the linear unleveraged SV model, (Kim, Shephard, & Chib, Citation1998) developed a popular algorithm by using a mixture of normal distributions to approximate the log chi-squared distribution in the linearised observation equation and then applying the augmented Kalman Filter and simulation smoother to improve the efficiency of the MCMC. This method was later extended to the linear leveraged SV model in Omori et al. (Citation2007) and Nakajima and Omori (Citation2009). However, this approach hinges entirely on the linearity of the state equation, which does not apply in our case. We will briefly discuss other ways to improve our MCMC algorithm in Section 6, but it is not the objective of this article to develop the most efficient algorithm for updating the state vector.
3.2. Model comparison criteria
For simulation studies where the true values of the latent log volatility, , are known, model comparison can be easily accomplished by comparing the estimated and simulated
under the Mean Absolute Error (MAE) or the Mean Squared Error (MSE). Under these two loss functions, it is also desirable that we make comparisons on the log volatility scale rather than the variance or standard deviation scale since the distribution of the former is more symmetric.
For empirical data, a likelihood-based criterion such as the Bayes Factor is a natural choice for model comparison. In this article, we use the predictive log likelihood as our performance measure. Let be an abbreviation for
and let θ denote all model parameters. Then the predictive log likelihood over the test period
can be expressed as
(10)
(10) where
(11)
(11) To compute the predictive log likelihood, we propose to use the ‘Forward Filtering’ stage of the nonlinear Forward-Filtering-Backward-Sampling algorithm of Godsill, Doucet, and West (Citation2004), which allows us to carry out multiple-step-ahead prediction very efficiently. A key step in the multiple-step-ahead prediction approach is to generate samples of
for s>0 (when s=0, the samples of
can be directly obtained from the output of the MCMC algorithm). Given that
(12)
(12) we can apply Gordon, Salmond, and Smith (Citation1993)'s bootstrap filter to get weighted samples from the posterior distribution
without having to re-run the MCMC for each s. When applying the bootstrap filter, we follow the suggestion of Liu and Chen (Citation1998) and resample using the residual resampling scheme only when the effective sample size (ESS) falls below a threshold (see the filtering step iii in the algorithm below). Although the resampling approach alleviates the so-called sample impoverishment problem of particle filters, it is still desirable to re-run the MCMC regularly to obtain new samples. In other words, we need to pick a moderate step size for our multiple-step-ahead prediction in order to limit the impact of the sample impoverishment problem while still allowing fast computation.
In summary, our algorithm is as follows. Let D be the number of the posterior draws after thinning and be the step size of the multiple-step-ahead prediction (i.e., the length of the test data to be evaluated before we re-run the MCMC to refresh the samples). For
, we iterate the following two steps.
The Prediction Step
If
For
Estimate the predictive likelihood for the observation
The Filtering Step
For
Normalize the weights,
If ESS
At the end, after all test data have been evaluated, we calculate the log predictive likelihood using (Equation10(10)
(10) ); that is,
.
4. Simulations
The main objective of our simulation studies is to understand the role of shape constraints in the estimation of log volatilities. We investigate both the unleveraged and the more realistic leveraged SV models with various forms of the volatility function, and compare the fit of our shape-constrained semiparametric additive SV model (denoted by SC-SV) with the fit of two other models: the parametric SV model (AR-SV) as defined by (Equation1(1)
(1) ) and (Equation2
(2)
(2) ), and the semiparametric additive SV model without shape constraints (SP-SV). To allow for different degrees of smoothness, we consider semiparametric models with K=L=10 and 20 knot intervals.
Our simulation results are based on 200 replicate time series of length N=2048 for each experimental condition. We use MAE and MSE to measure our ability to accurately estimate the log volatilities. We assume flat priors for and
, and conjugate multivariate normal priors for
or
in the parametric AR-SV models. The MCMC algorithm for fitting the semiparametric SV models was presented in Section 3.1. The same algorithm also applies to the parametric models (Equation1
(1)
(1) ) and (Equation2
(2)
(2) ), except that the full conditional for the coefficients
or
is now multivariate normal given conjugate priors. We used R (R Core Team, Citation2013) for all computations but accelerated the updating of the log volatilities,
, using C++ through the R package RcppArmadillo (Eddelbuettel & Sanderson, Citation2014). We use the log squared returns as the initial states for
. For the AR-SV and SC-SV models, we sample from the posterior distribution using 21,000 iterations of the MCMC algorithm. To ensure convergence of the Markov chain, we used 31,000 iterations of the MCMC algorithm for the SP-SV model. In both cases, the first 1000 iterations were discarded as burn-in samples and the remaining samples were thinned every 10 iterations.
4.1. Unleveraged SV models
We consider three different forms of the autoregressive component f in the SV model (Equation3(3)
(3) ) without a leverage effect. (Plots of the three f functions are shown as the dashed lines in Figure .) The variance of the error term
of the volatility process is set to be 0.15 for all simulations. Although the scales of the returns and volatilities have no bearing on model performance, we adjust the value of μ in each volatility equation so that the simulated log volatilities are centred around
, which is a typical value for real-world equity returns such as the S&P500 daily returns. The true volatility equations for the three unleveraged SV models are as follows.
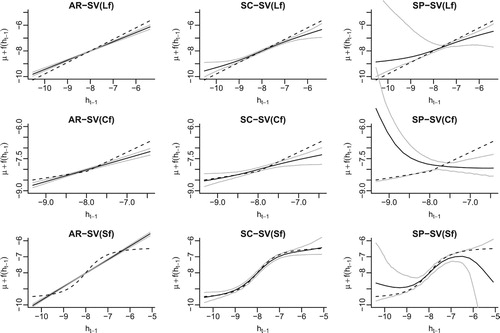
Figure 1. Estimated autoregressive function f for the unleveraged SV models based on a single simulated dataset. The dashed line in each graph shows the true functional form of f and the solid lines represent the posterior average of f as well as the 95% credible bands. For the semiparametric models SC-SV and SP-SV, the 20-knot-interval version is presented.
(Lf) Linear f:
(Cf) Change-point f:
(Sf) Sigmoid f:
Table summarises the estimated MSE and MAE of the posterior means of the log volatilities compared to their simulated values. When the autoregressive function is linear, i.e., when AR-SV is the correct model, the shape-constrained semiparametric model underperforms the AR-SV model by a small margin, while the SP-SV model, without proper shape constraints, is too flexible to pick up the linear form reliably. When the true autoregressive function is nonlinear, the impact of imposing the correct shape constraints on the estimation of the log volatilities becomes evident. For example, with the change-point autoregressive SV model, imposing shape constraints (i.e., the SC-SV model) reduces the MSE over the SP-SV model by 28% (10 knot intervals) and 30% (20 knot intervals) and the reduction in MSE for the sigmoid autoregressive SV model is 26% and 30% respectively. This evidences the gain from including shape constraints in a semiparametric SV model when they are warranted.
Table 1. For the three true unleveraged SV models (Lf , Cf and Sf ), a summary of the MSE and MAE of the log volatilities, , obtained from fitting five different SV models. The averages and standard errors are multiplied by 100, and are based on 200 replicate series.
Our findings from Table can be further confirmed by the fitted autoregressive functions shown in Figure . To simplify our presentation, we only display the 20-knot-interval version of the fitted semiparametric SV models (the 10-knot-interval version was less smooth, but exhibited similar patterns). The true autoregressive functions (denoted by the dark solid lines in each panel of the figure) are estimated by the posterior means of where
is a grid of pre-specified values of
. It is clearly seen in Figure that the estimated autoregressive functions for the semiparametric model without shape constraints (SP-SV) have very large posterior variance, especially toward the tails where the volatility data are scarce. Additionally, the posterior distribution of
can be highly skewed and the posterior averages can deviate substantially from the truth (see the fitted f function for the change-point autoregressive model). Imposing proper shape constraints in the semiparametric model considerably reduces the posterior variance and skewness of the estimated autoregressive function across all values of the past volatilities, and the resulting SC-SV model is still flexible enough to capture the shapes of the different true autoregression functions.
4.2. Leveraged SV models
For the leveraged models, we consider the following three different volatility equations. (Plots of the true autoregressive and leverage functions are shown as the dashed lines in Figure .)
(Lf-Lg) Linear f & Linear g:
(Lf-NLg) Linear f & Nonlinear g:
(NLf-NLg) Nonlinear f & Nonlinear g:
Figure 2. For the three true leveraged SV models (Lf-Lg, Lf-NLg and NLf-NLg), the estimated autoregressive function f (odd rows) and leverage function g (even rows) in different fitted models (columns). The legends are the same as in Figure .
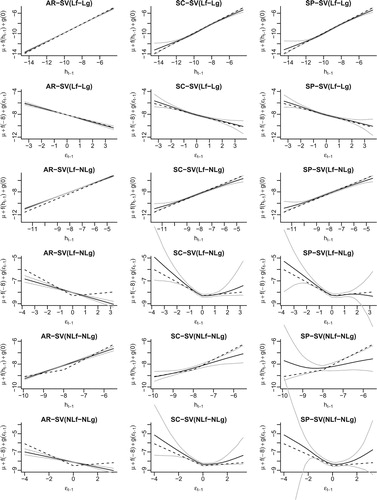
The variances of the terms in the above equations are set to be 0.15. We implement the correct shape constraints in the SC-SV models, which means that for the Lf-Lg case, the leverage function g is assumed to be monotonically decreasing on the entire real line while in the other two cases, it is assumed to be monotonically decreasing on the negative real line and monotonically increasing on the positive real line. The MSE and MAE of the estimated log volatilities compared to the simulated values are shown in Table .
Table 2. For the three true leveraged SV models (Lf-Lg, Lf-NLg and NLf-NLg), a summary of the MSE and MAE of the log volatilities, , obtained from fitting five different SV models. The averages and standard errors are multiplied by 100, and are based on 200 replicate series.
When the autoregressive component f and the leverage function g are both linear, AR-SV is the true model and as expected, it outperforms both semiparametric models. When either f or g is nonlinear, however, the AR-SV model is not flexible enough to pick up the true functional forms, resulting in the larger MSE and MAE as compared to the shape-constrained semiparametric model. For all three forms of the volatility function, the advantage of incorporating shape constraints in the semiparametric models is reflected in the consistently smaller MSE and MAE for the SC-SV model over the SP-SV model. As in Section 4.1, the greatest gain in the MSE and MAE was obtained when the autoregressive function f deviates the most from linearity (the NLf-NLg case).
Figure shows the estimated autoregressive function f (odd rows) and leverage function g (even rows). Whenever the true autoregressive or leverage function is nonlinear, the fitted f or g functions in the semiparametric SV model without shape constraints (SP-SV) can have extremely large posterior variance toward the tails where the data are scarce. Restricting the parameter space through proper shape constraints proves to be essential for more efficient estimation in SV models.
5. Empirical studies
We now assess the advantage of our proposed shape-constrained semiparametric additive SV models for the prediction of volatilities in four real-world equity returns: the S&P500 index, Equity Residential (EQR; a real estate investment trust), Microsoft (MSFT), and Johnson & Johnson (JnJ). The returns are calculated as the change in the logarithm of the daily adjusted closing prices obtained from Yahoo! Finance. For each series, we use the returns from November 1, 2001 to October 29th, 2010 as our training set and the following three years of returns from November 1, 2010 to October 31, 2013 as the test set. For both the training and test return series, we subtract the sample mean from the data so that the returns have zero mean.
As in our simulation studies, we consider the parametric model (AR-SV), the semiparametric additive SV model with shape constraints (SC-SV) and without shape constraints (SP-SV). We fit both a leveraged and an unleveraged version of each model and compare their predictive log likelihoods over the test period. We run the MCMC for 1,02,500 iterations with the first 2500 draws discarded as burn-in samples and the remaining draws thinned every 25 iterations. In terms of the shape constraints in the SC-SV model, exploratory analyses indicated that it is reasonable to assume the autoregressive function f to be monotonically increasing and the leverage function g monotonically decreasing. These assumptions will be assessed later. We use K=20 basis functions for f and L=20 basis functions for g. The predictive log likelihood that we use to compare the models is calculated according to Section 3.2 with the step size for the multiple-step prediction set to be 110.
Table displays the estimated predictive log likelihoods for all six SV models. For each of the four return series, the value in bold denotes the model with the largest predictive log likelihood. The predictive log likelihood of the semiparametric model without shape constraints always lags behind the corresponding shape-constrained model, suggesting that it is desirable to incorporate shape constraints in our semiparametric additive model when the knowledge of the true functional shapes is available. Compared to the AR-SV model, the semiparametric model without shape constraints only outperforms the corresponding AR-SV model in three out of the eight pairs. However, imposing shape constraints increases this ratio to seven out of eight. For Equity Residential, the outperformance of the shape-constrained model compared to AR-SV is substantial. In one case, Johnson & Johnson, the linear parametric AR-SV model seems to be the most suitable model, indicating that a more parsimonious model is preferred for explaining the volatility in this return series.
Table 3. Predictive log likelihood of daily returns from November 1, 2010 to October 31, 2013 using six different SV models. (u) – unleveraged; (l) – leveraged. The results of the best performing model (those with the largest predictive log likelihood) are in bold face.
To assess the appropriateness of our shape assumptions for the four equity returns, we estimate the autoregressive function f and leverage function g in the same way as in the simulation studies. Figure shows the fitted functions (posterior mean) and the associated pointwise 95% credible bands for the leveraged semiparametric SV models (with and without the shape constraints) for each return series.
Figure 3. Fitted autoregressive function f and leverage function g for the daily returns of the S&P500, EQR, MSFT and JnJ. The solid lines show the posterior means and 95% credible bands of the fitted functions in the leveraged semiparametric models with shape constraints while the dashed lines represent the posterior means and 95% credible bands in the leveraged semiparametric models without shape constraints.
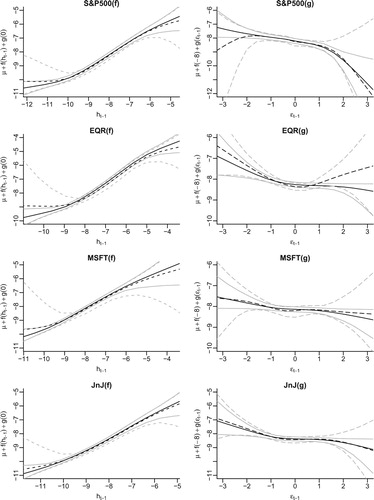
For the S&500 index, both fitted functions are clearly nonlinear, which means that the volatility process and consequently the return series are nonstationary. When the lagged log volatility is small, the lag one autocorrelation for fixed
is diminished as compared to when
is moderate; when
is large, the lag one autocorrelation is also attenuated, but to a lesser degree. In addition, the shapes of the autoregressive and leverage functions estimated from the two semiparametric models (SC-SV and SP-SV) agree with each other for the most part: the function f is monotonically increasing and g monotonically decreasing. This means that our assumptions of the shape constraints are appropriate. Even though the leftmost section of the g function is found to be increasing in the SP-SV model, we find this counterintuitive and also unreliable since our simulation studies showed that the estimated functions towards the boundaries can deviate considerably from the truth if no shape constraints are implemented.
As for the other three return series, it can be seen that our monotonicity assumptions for the autoregressive and leverage functions in the shape-constrained models hold for all except the Equity Residential series (EQR). For EQR, the SP-SV model finds that the posterior mean of the leverage function g is increasing on the positive real line but with a very large degree of uncertainty. As a further investigation, we fit two additional shape-constrained models with the same priors on f and on for
. In the first model, we assumed the leverage function g to be monotonically increasing on the positive real line, but we imposed no shape constraints on
for
in the second one. Their predictive log likelihoods are
and
respectively, both larger than the predictive log likelihoods for the corresponding leveraged AR-SV and SP-SV models. However, neither of these two additional models outperforms the original leveraged SC-SV model with the monotonicity constraint on g. This may be due to the fact that the lagged return innovation
follows the standard normal distribution a priori, which means that it would be rare to observe an extreme
out in the tails. Nevertheless, a monotonically decreasing leverage function seems a reasonable assumption for fitting the shape-constrained semiparametric additive SV models on most equity returns.
6. Conclusion
In this article, we have proposed a class of shape-constrained semiparametric additive stochastic volatility models. We have introduced a parameterisation that allows for more efficient sampling from the posterior distribution, and developed a particle-filter-based model comparison approach. Through simulations and empirical studies, we demonstrated that the shape-constrained semiparametric SV model has the flexibility to capture unknown functional shapes, while not losing too much efficiency compared to a parametric SV model when the true underlying model is best explained by the latter.
We demonstrated the use of specific forms of shape constraints on the autoregressive and leverage function, but we note that within this framework, researchers and practitioners can easily incorporate other shape constraints that they deem appropriate. Furthermore, our methodology of modelling the shape constraints in SV models can also be applied to other nonlinear state space models, such as the stochastic conditional duration (SCD) model (Bauwens & Veredas, Citation2004), to efficiently capture nonlinear features of the state equation. In this article we have fixed the number of basis functions for the nonlinear functions f and g (as denoted by K and L respectively) to be 10 or 20 – more generally we can use the Bayes Factor to select between different numbers of basis functions.
Our shape-constrained SV model can be extended in a number of directions, beyond simply including additional lagged terms. First, the additivity between the autoregressive and leverage function can be relaxed. One option would be to assume that the log volatility satisfies where the function ζ is subject to a two-dimensional shape constraint. The challenge lies in the fact that this function ζ does not have a rectangular support because of the dependence between
and
. Alternatively, we can assume that the additivity holds on a different scale,
, where ς can be a known function other than
– the
scale considered by Comte (Citation2004) would be an example. Second, the idea of incorporating shape constraints in semiparametric SV models can also be applied to additive GARCH-type models for more efficient estimation of the news impact curve. Third, our framework can be adapted to include convexity constraints on the functional components. Under the basis expansion (Equation4
(4)
(4) ) and with the same basis functions (Equation5
(5)
(5) ), convexity constraints can be translated to the ordering of the slope coefficients
. To constrain the function to be convex and monotonically increasing at the same time, the slope coefficients need to satisfy
and the model fitting is straightforward.
There are also several ways to improve our MCMC algorithm, especially the updating of the high-dimensional state vector. First, since the state variables are highly correlated with each other, updating more than one state variable at a time, i.e., using block updating (e.g., Chib & Greenberg, Citation1994, Citation1995), would be more efficient than the one-at-a-time updating. Second, we can improve the proposal distributions for updating the state variables by exploiting the shape of the full-conditional distribution, such as using the Metropolis-adjusted Langevin algorithm (Grenander & Miller, Citation1994; Roberts & Tweedie, Citation1996) and its variations. Finally, particle-filter-based methods, such as the Particle Markov chain Monte Carlo (PMCMC) method (e.g., Andrieu, Doucet, & Holenstein, Citation2010), can be applied as well.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Jiangyong Yin
Jiangyong Yin was a Ph.D. student at The Ohio State University, and is currently working at CapitalG, San Francisco, California.
Peter F. Craigmile
Peter F. Craigmile is Professor at Department of Statistics, The Ohio State University.
Xinyi Xu
Xinyi Xu is an Associate Professor at Department of Statistics, The Ohio State University.
Steven MacEachern
Steven MacEachern is Professor at Department of Statistics, The Ohio State University.
References
- Andrieu, C., Doucet, A., & Holenstein, R. (2010). Particle Markov chain Monte Carlo methods. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 72, 269–342. doi: 10.1111/j.1467-9868.2009.00736.x
- Bauwens, L., & Veredas, D. (2004). The stochastic conditional duration model: A latent variable model for the analysis of financial durations. Journal of Econometrics, 119, 381–412. doi: 10.1016/S0304-4076(03)00201-X
- Brezger, A., & Steiner, W. J. (2008). Monotonic regression based on Bayesian P–splines. Journal of Business & Economic Statistics, 26, 90–104. doi: 10.1198/073500107000000223
- Cai, B., & Dunson, D. (2007). Bayesian multivariate isotonic regression splines. Journal of the American Statistical Association, 102, 1158–1171. doi: 10.1198/016214506000000942
- Chib, S., & Greenberg, E. (1994). Bayes inference in regression models with ARMA(p,q) errors. Journal of Econometrics, 64, 183–206. doi: 10.1016/0304-4076(94)90063-9
- Chib, S., & Greenberg, E. (1995). Understanding the Metropolis-Hastings algorithm. The American Statistician, 49, 327–335.
- Comte, F. (2004). Kernel deconvolution of stochastic volatility models. Journal of Time Series Analysis, 25, 563–582. doi: 10.1111/j.1467-9892.2004.01825.x
- Eddelbuettel, D., & Sanderson, C. (2014). RcppArmadillo: Accelerating R with high-performance C++ linear algebra. Computational Statistics & Data Analysis, 71, 1054–1063. doi: 10.1016/j.csda.2013.02.005
- Engle, R. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50, 987–1007. doi: 10.2307/1912773
- Engle, R., & Gonzalez-Rivera, G. (1991). Semiparametric ARCH models. Journal of Business & Economic Statistics, 9, 345–359.
- Engle, R., & Ng, V. (1993). Measuring and testing the impact of news on volatility. The Journal of Finance, 48, 1749–1778. doi: 10.1111/j.1540-6261.1993.tb05127.x
- Godsill, S. J., Doucet, A., & West, M. (2004). Monte Carlo smoothing for nonlinear time series. Journal of the American Statistical Association, 99, 156–168. doi: 10.1198/016214504000000151
- Gordon, N. J., Salmond, D. J., & Smith, A. F. (1993). Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEEE Proceedings F (Radar and Signal Processing), 140, 107–113. doi: 10.1049/ip-f-2.1993.0015
- Grenander, U., & Miller, M. I. (1994). Representations of knowledge in complex systems. Journal of the Royal Statistical Society. Series B (Methodological), 56, 549–603. doi: 10.1111/j.2517-6161.1994.tb02000.x
- Harvey, A. C., & Shephard, N. (1996). Estimation of an asymmetric stochastic volatility model for asset returns. Journal of Business & Economic Statistics, 14, 429–434.
- Hull, J., & White, A. (1987). The pricing of options on assets with stochastic volatilities. The Journal of Finance, 42, 281–300. doi: 10.1111/j.1540-6261.1987.tb02568.x
- Kim, S., Shephard, N., & Chib, S. (1998). Stochastic volatility: Likelihood inference and comparison with ARCH models. The Review of Economic Studies, 65, 361–393. doi: 10.1111/1467-937X.00050
- Liu, J. S., & Chen, R. (1998). Sequential Monte Carlo methods for dynamic systems. Journal of the American Statistical Association, 93, 1032–1044. doi: 10.1080/01621459.1998.10473765
- Meyer, M. C., Hackstadt, A. J., & Hoeting, J. A. (2011). Bayesian estimation and inference for generalised partial linear models using shape-restricted splines. Journal of Nonparametric Statistics, 23, 867–884. doi: 10.1080/10485252.2011.597852
- Nakajima, J., & Omori, Y. (2009). Leverage, heavy-tails and correlated jumps in stochastic volatility models. Computational Statistics & Data Analysis, 53, 2335–2353. doi: 10.1016/j.csda.2008.03.015
- Neelon, B., & Dunson, D. (2004). Bayesian isotonic regression and trend analysis. Biometrics, 60, 398–406. doi: 10.1111/j.0006-341X.2004.00184.x
- Nelson, D. (1991). Conditional heteroskedasticity in asset returns: A new approach. Econometrica, 59, 347–370. doi: 10.2307/2938260
- Omori, Y., Chib, S., Shephard, N., & Nakajima, J. (2007). Stochastic volatility with leverage: Fast and efficient likelihood inference. Journal of Econometrics, 140, 425–449. doi: 10.1016/j.jeconom.2006.07.008
- R Core Team (2013). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. URL http://www.R-project.org/.
- Ramsay, J. (1988). Monotone regression splines in action. Statistical Science, 3, 425–441. doi: 10.1214/ss/1177012761
- Roberts, G. O., & Tweedie, R. L. (1996). Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli, 2, 341–363. doi: 10.2307/3318418
- Rydberg, T. (2000). Realistic statistical modelling of financial data. International Statistical Review, 68, 233–258. doi: 10.1111/j.1751-5823.2000.tb00329.x
- Taylor, S. (1994). Modeling stochastic volatility: A review and comparative study. Mathematical Finance, 4, 183–204. doi: 10.1111/j.1467-9965.1994.tb00057.x
- Yu, J. (2005). On leverage in a stochastic volatility model. Journal of Econometrics, 127, 165–178. doi: 10.1016/j.jeconom.2004.08.002
- Yu, J. (2012). A semiparametric stochastic volatility model. Journal of Econometrics, 167, 473–482. doi: 10.1016/j.jeconom.2011.09.029
Appendix
Updating and
in the semiparametric SV model (6): Without sign constraints on
(i.e., no shape constraints on the autoregressive function f), we draw
from its normal full conditional distribution whose mean and variance are given as
In the above equations,
and
are the conditional prior mean and variance of
, whereas
and
reflect the new information about
in the data. If we use a flat prior for the initial state of the random walk prior of
, we have
From the likelihood, we can obtain that
and
where
. We can see that for
and
to exist, the corresponding basis function evaluated at
,
, needs to be non-zero for at least some
. However, this is not always guaranteed since by the definition of the basis functions (Equation5
(5)
(5) ), when
,
for
and when k<M,
for
. In other words,
would be zero for all
if all values of
simulated in one MCMC iteration are below
for
or above
for k<M. When this happens, we draw
from its conditional prior distribution
.
If is constrained to be positive a priori, i.e.,
, Neelon and Dunson (Citation2004) shows that the full conditional of
can be expressed as a mixture of two truncated normal distributions. Let
be the cumulative distribution function of a N(m, v) random variable,
be the corresponding density function and tN
;
denote the truncated Normal distribution with support
. Then a MCMC draw for
is simply a draw from a tN
,
;
distribution with probability proportional to
and from a tN
,
;
distribution with probability proportional to
.
Updating and
in the semiparametric SV model (6): The difference between updating
and
lies in the fact that both positive and negative sign constraints for
are considered in (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ). Without sign constraints on
(i.e., without shape constraints on the leverage function g), the full conditional distribution of
is similar to that of
. When
is constrained to be positive, the full conditional distribution of
is again similar to that of
for positive
. However, when
is constrained to be negative, the full conditional distribution of
is a mixture of two truncated normal distributions whose positive part now depends on the conditional prior mean and variance and the negative part on the data.