
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Professors Bayarri, Berger, Jang, Ray, Pericchi, and Visser deserve a special congratulation for their great work on Bayesian model and variable selection and a pioneering idea of prior-based Bayesian information criterion (PBIC). This work opens the door for contemporary advances in the difficult problem of model and variable selection.
There exist three types of commonly used Bayesian approaches. The first type works on information criterion, such as the well-known BIC. The newly proposed PBIC belongs to this category. The second type includes the indicator model selection (see, e.g., Brown, Vannucci, & Fearn, Citation1998; Dellaportas, Forster, & Ntzoufras, Citation1997; George & McCulloch, Citation1993; Kuo & Mallick, Citation1998; Yuan & Lin, Citation2005), the stochastic search method (e.g., O'Hara & Sillanpää, Citation2009), and the model space method by Green (Citation1995). The third type, which is considered in this discussion, is to apply priors on the regression coefficients that promotes the shrinkage of coefficients towards 0. This last type of approaches is intrinsically connected with frequentist methods in the sense that, first of all, such priors play the same role as the assumption that the coefficients are sparse for the frequentist approach and secondly, in some sense, the Bayesian solution is equivalent to the corresponding frequentist counterpart with a certain penalty parameter. Typical research papers for this type include Griffin and Brown (Citation2009), Park and Casella (Citation2008), and Kyung, Gilly, Ghosh, and Casella (Citation2010).
The shrinkage prior approach may not provide sparse estimates of regression coefficients in general, which could not only complicate the interpretation but also inflate statistical error in analysis. Even without a well-defined variable selection approach, a Bayesian analysis based on a subset of covariates with size considerably less than the original dimensionality, which is referred to as sparse Bayesian analysis, could produce better results than the Bayesian analysis based on all covariates. Several attempts have been made to obtain sparse Bayesian estimates based on shrinkage priors. For instance, Hoti and Sillanpää (Citation2006) proposed a method based on thresholding; however, the method is based on certain approximations, and the choice of the threshold is ad hoc. Another example is the sparse Bayesian learning by Tipping (Citation2001), but it involves complicated nonconvex optimisation and assumes that the variance of the error term is known.
Under the framework of shrinkage priors, we consider a Bayesian variable selection method via a benchmark variable. The benchmark variable serves as a standard to measure the importance of each variable based on the posterior distribution of the corresponding coefficient.
As the first attempt, we focus on linear regression models with normally distributed errors. Let be an n-dimensional vector of response and, without loss of generality, let
be p centralised n-dimensional vectors of predictors or covariates. Conditional on
,
is assumed to be multivariate normally distributed as
, where
is a p-dimensional column vector whose jth component is
,
are p+1 unknown parameters, σ is an unknown positive parameter,
is a
dimensional vector with all components 1 and
is the identity matrix of order n.
Consider the following prior density on conditioned on
,
(1)
(1) where
and
are hyper-parameters. When
, this is the Laplace prior which was considered by Park and Casella (Citation2008) for their Bayesian Lasso. When
, the prior in (Equation1
(1)
(1) ) is a multivariate normal density and produces the posterior mode of
equivalent to the ridge regression estimate. As the Laplace prior is ‘sharper’ than the Gaussian one, it is expected to yield more sparse predictive models with the potentiality of easier interpretation, which is especially desirable for high-dimensional data with a considerably large amount of noisy variables. However, the posterior inferences associated with Laplace prior involves relatively intensive computation.
For and
that are not involved with variable selection, we consider noninformative priors so that the overall prior for all parameters is
If the posterior distribution of
is nearly the same as that from a noise variable centred at 0, then it is natural to eliminate
as an unimportant covariate. However, the question is how to quantify whether a posterior distribution to be close to that of a noise.
To illustrate our idea, let us first consider an artificial case where a covariate exists and is known to have no effect on
. For example,
is distributed as
with
. Although we know
is redundant, we still put a prior on
such that
and
are independently identically distributed conditioning on
. Under this setting,
could be treated as an unimportant variable if the posterior of
is similar to the posterior of
. In other words, the variable
serves as a benchmark in measuring the importance of
's.
A benchmark variable should have a posterior distribution centred at 0 and should not affect the Bayesian analysis concerning . The question is, how do we find a benchmark variable when we do not have a redundant variable at hand?
We now show that there is a universal solution. Since is column-wisely centralised, the density of
given
is
where
is the average of components of
,
is the average of components of
,
,
, and
is the transpose of
. Under the previously described prior, the joint conditional posterior distribution
can be obtained. Since the intercept
is not of interest, we integrate it out from
and obtain the conditional posterior density of
given
as follows:
(2)
(2) Note that marginalisation over
is equivalent to centralising the response
. After the integration, it could be regarded that the posterior inferences are drawn from the centralised response
instead of the original
. The reason that we introduce
in the model and then integrate it out, instead of eliminating it at the very beginning and directly building a linear regression model as
, is mainly for the mathematical rigorousness, as
is not of full rank and has a degenerate distribution.
The conditional posterior density in (Equation2(2)
(2) ) implies that given
,
and
are independent if and only if
. In other words,
does not affect the posterior of
if and only if
is orthogonal to all
's,
. Meanwhile, the posterior of
is centred at 0 if and only if
. Is there a
orthogonal to
? Clearly,
, the column vector of ones, is a direct solution and could be used as a benchmark to assess the importance of
's. When
, the posterior density of
remains the same as its prior, and the posterior density of
is simplified to
(3)
(3) The benchmark serves as a measure to assess the importance of each covariate, and therefore provide guidance on variable selection. How to carry out variable selection using posterior (Equation3
(3)
(3) ) or extend the ideal to more general settings requires more research. In the rest of this discussion, we consider a real data example.
The prostate cancer data originally came from a research conducted by Stamey et al. (Citation1989), and it was studied by Tibshirani (Citation1996) and Zou and Hastie (Citation2005). The goal of the research was to explore the relation between the level of prostate specific antigen and several clinical measures in men before their hospitalisation for radical prostatectomy. The data frame contains 97 observations and 9 variables. The response is the logarithm of prostate-specific antigen (lpsa), while the 8 covariates are the logarithm of cancer volume (lcavol), logarithm of prostate weight (lweight), age, the logarithm of the amount of benign prostatic hyperplasia (lbph), seminal vesicle invasion (svi), the logarithm of capsular penetration (lcp), Gleason score (gleason) and percentage Gleason score 4 or 5 (pgg45).
Figure visualises the posteriors with Laplace prior (). Results with normal prior (
) are similar and omitted. In Figure , the leftmost boxplot is based on the posterior samples of the coefficient for the benchmark
. It is distributed almost symmetrically around 0 as expected. Other box plots represent the posterior distributions of the coefficients associated with 8 covariates. It can be seen that the three posteriors plotted in the far right of Figure are clearly different from the posterior of the benchmark and, hence, we conclude that the corresponding three covariates, svi, lweight, and lcavol, are useful for the response. On the other hand, the posteriors of three covariates next to the benchmark in Figure are not different from the benchmark posterior and, hence, the covariates pgg45, lcp, and gleason are not useful. The posteriors of lbph and age are just marginally different from that of the benchmark, and we still consider them to be not useful covariates.
Figure 1. Posterior plots on the prostate cancer data.
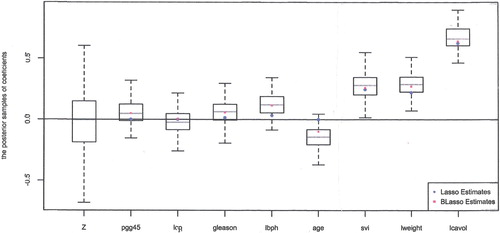
Figure also includes Lasso and Bayesian Lasso estimates of each coefficients, marked as circles and squares in the figure. The Lasso estimates are zero for pgg45, lcp, and age, nonzero for the other 5 covariates. Thus, the Lasso approach agrees with our approach for covariates pgg45, lcp, age, svi, lweight, and lcavol, but does not agree on gleason and lbph. Since the magnitudes of Lasso estimates for gleason and lbph are small, another thresholding added to Lasso will result in the same conclusion with ours. Meanwhile, the Bayesian Lasso evaluates all the coefficients to be nonzero as it doesn't select variables to promote model sparsity.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Brown, P. J., Vannucci, M., & Fearn, T. (1998). Multivariate Bayesian variable selection and prediction. Journal of the Royal Statistical Society, Series B, 60, 627–641. doi: 10.1111/1467-9868.00144
- Dellaportas, P., Forster, J. J., & I., Ntzoufras (1997). On Bayesian model and variable selection using MCMC (Technical Report). Athens: Department of Statistics, Athens University of Economics and Business.
- George, E. I., & McCulloch, R. E. (1993). Variable selection via Gibbs sampling. Journal of the American Statistical Association, 85, 398–409.
- Green, P. J. (1995). Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika, 82, 711–732. doi: 10.1093/biomet/82.4.711
- Griffin, J. E., & Brown, P. J. (2009). Inference with Normal-Gamma prior distributions in regression problems (Technical Report). Institute of Mathematics, Statistics and Actuarial Science, University of Kent.
- Hoti, F., & Sillanpää, M. J. (2006). Bayesian mapping of genotype x expression interactions in quantitative and qualitative traits. Heredity, 97, 4–18. doi: 10.1038/sj.hdy.6800817
- Kuo, L., & Mallick, B. (1998). Variable selection for regression models. Sankhya Series B, 60, 65–81.
- Kyung, M., Gilly, J., Ghosh, M., & Casella, G. (2010). Penalized regression, standard errors, and Bayesian Lassos. Bayesian Analysis, 5, 369–412. doi: 10.1214/10-BA607
- O'Hara, R. B., & Sillanpää, M. J. (2009). Review of Bayesian variable selection methods: What, how and which. Bayesian Analysis, 4, 85–118. doi: 10.1214/09-BA403
- Park, T., & Casella, G. (2008). The Bayesian Lasso. Journal of the American Statistical Association, 103, 681–686. doi: 10.1198/016214508000000337
- Stamey, T., Kabalin, J., McNeal, J., Johnstone, I., Freiha, F., Redwine, E., & Yang, N. (1989). Prostate specific antigen in the diagnosis and treatment of adenocarcinoma of the prostate. II. Radical prostatectomy treated patients. Journal of Urology, 141, 1076–1083. doi: 10.1016/S0022-5347(17)41175-X
- Tibshirani, R. (1996). Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society, Series B, 58, 267–288.
- Tipping, M. (2001). Sparse Bayesian learning and the relevance vector machine. Journal of Machine Learning, 1, 211–244.
- Yuan, M., & Lin, Y. (2005). Efficient empirical Bayes variable selection and estimation in linear models. Journal of the American Statistical Association, 100, 1215–1225. doi: 10.1198/016214505000000367
- Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B, 67, 301–320. doi: 10.1111/j.1467-9868.2005.00503.x