
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Sunoj et al. [(2009). Characterization of life distributions using conditional expectations of doubly (Intervel)truncated random variables. Communications in Statistics – Theory and Methods, 38(9), 1441–1452] introduced the concept of Shannon doubly truncated entropy in the literature. Quantile functions are equivalent alternatives to distribution functions in modelling and analysis of statistical data. In this paper, we introduce quantile version of Shannon interval entropy for doubly truncated random variable and investigate it for various types of univariate distribution functions. We have characterised certain specific lifetime distributions using the measure proposed. Also we discuss one fascinating practical example based on the quantile data analysis.
1. Introduction
Let X be a non-negative absolutely continuous random variable representing the lifetime of a component with cumulative distribution function (CDF) and survival function
. In modelling and analysis of lifetime data, the average amount of uncertainty associated with a non-negative continuous random variable X is given in the differential entropy function
a continuous counterpart of the Shannon (Citation1948) entropy in the discrete case and
is the probability density function (pdf) of the random variable X. While the concept of entropy has found increased application, little attention has yet been given to the practical problems of estimating entropy. Gong, Yang, Gupta, and Nearing (Citation2014) discussed a method for computing robust and accurate estimates of entropy that accounts for several important characteristics of hydrological data sets. Since this entropy is not applicable to a system which has survived for some unit of time or for used item. The residual lifetime of the system when it is still operating at time t is
which has the probability density
,
. Ebrahimi (Citation1996) proposed the entropy of the residual lifetime
as
(1)
(1) In some practical situations, uncertainty is related to past life time rather than future. In this situation, the random variable
which is known as inactivity time is suitable to describe the time elapsed between the failure of a system and the time when it is found to be ‘down’. Based on this idea, Di Crescenzo and Longobardi (Citation2002, Citation2004) have considered the entropy of the inactivity time
given as
(2)
(2) In many situations, we only have information between two points, and in this case statistical measures are studied under the condition of doubly truncated random variables. The doubly truncated measures are applicable to engineering systems when the observations are measured after it starts operating and before it fails. If the random variable X denotes the lifetime of a unit, then the random variable
is called the doubly truncated (interval) residual lifetime, which in special case
tends to residual lifetime random variable
. Also, we can use the doubly truncated past lifetime random variable
, which in special case
, it tends to past lifetime random variable
. Another extension of Shannon entropy is based on a doubly truncated (interval) random variable, which is as follows,
(3)
(3) Given that a system has survived up to time
and has been found to be down at time
, then
measure the uncertainty about its lifetimes between
and
. Different aspects and properties of
have been studied by Sunoj, Sankaran, and Maya (Citation2009) and Misagh and Yari (Citation2011, Citation2012). For various results on doubly truncated random variable, we refer to Sankaran and Sunoj (Citation2004)), Khorashadizadeh, Rezaei Roknabadi, and Mohtashami Borzadaran (Citation2013), Kayal and Moharana (Citation2016), and Kundu (Citation2017).
All the theoretical investigations and applications using these information measures are based on the distribution function. A probability distribution can be specified either in terms of its distribution function or by the quantile function. Although both convey the same information about the distribution with different interpretations, the concepts and methodologies based on distribution functions are traditional. When traditional approach are either difficult or fails to obtain desired results then quantile-based study were carried out. However, as Gilchrist (Citation2000) discussed, there are many distinct properties for quantile functions that are not shared by the distribution functions, which makes the former attractive in certain practical situations. For inference purposes, quantile-based statistics are often more robust than those based on moments in the distribution function approach. Furthermore, there exist many simple quantile functions, that serve very well in empirical model building, for which distribution function are not in tractable forms, refer to van Staden and Loots (Citation2009), Hankin and Lee (Citation2006) and Nair, Sankaran, and Vinesh Kumar (Citation2012). In many cases, QF is more convenient as it is less influenced by extreme observations and thus provides a straightforward analysis with a limited amount of information. In such cases, conventional tools of analysis using distribution functions are difficult to apply. An alternative approach to the study is to use the quantile functions (QFs), defined by
(4)
(4) When F is continuous, we have from (Equation4
(4)
(4) ),
, where
represents the composite function
. Defining the density quantile function by
and quantile density function by
, where prime denotes the differentiation, we have
refer to Nair, Sankaran, and Balkrishanan (Citation2013). Several researchers have studied information theoretic measures based on quantile function. Sunoj and Sankaran (Citation2012) have considered the quantile version of Shannnon entropy and its residuals form, defined as
(5)
(5) and
(6)
(6) respectively. Sunoj, Sankaran, and Nanda (Citation2013) have considered the quantile past entropy, which is defined as
(8)
(8) Readers can refer to Nanda, Sankaran, and Sunoj (Citation2014), Baratpour and Khammar (Citation2018), Sankaran and Sunoj (Citation2017), Guoxin (Citation2018), and Kumar (Citation2018) for more works on this line.
Motivated with the usefulness of the quantile function and the interval entropy, in the present note, we introduced a quantile version of Shannon interval entropy and derived some new characterisations to certain probability distributions as well as study its important properties. The proposed measure has several advantage. The measure proposed for doubly truncated random variable appears in quasar survey, where an investigator assumes that the apparent magnitude is doubly truncated. Also, the times to progression for patients with certain disease who received chemotherapy, experienced tumour progression and subsequently died, are doubly truncated. Secondly, quantile functions (QFs) have several properties that are not shared by distribution functions. Application of these properties give some new results and better insight into the properties of the measure that are difficult to obtain in the conventional approach. However, the use of QFs in the place of F provides new models, alternative methodology, easier algebraic manipulations, and methods of analysis in certain cases and some new results that are difficult to derive by using distribution function.
The paper is organised as follows. In Section 2, we consider the quantile version of Shannon interval entropy. In Section 3, the quantile interval entropy has been derived in case of some specific distributions. In Section 4, we study characterisation results concerning Quantile Interval Entropy (QIE) and also characterise a few specific lifetime distributions. Finally, conclusions have been given along with comments.
2. Quantile interval entropy
Defining a doubly truncated random variable which represents the lifetime of a unit between
and
, where
. Corresponding to (Equation4
(4)
(4) ), a measure of uncertainty for the doubly truncated random variable in term of quantile function (Equation4
(4)
(4) ) is defined as
(8)
(8) The important quantile measures useful in reliability analysis are hazard quantile function and reversed hazard quantile, defined as
and
, respectively, corresponding to the hazared rate
and reversed hazared rate
of X. In doubly truncation, Ruiz and Navarro (Citation1996) defined the generalised hazard function (GHF) given by
and
, respectively. Thus, generalised quantile hazard functions (GQHF) are defined as
(9)
(9) respectively. Equation (Equation8
(8)
(8) ) can be rewritten as
(10)
(10)
(11)
(11) where (Equation10
(10)
(10) ) and (Equation11
(11)
(11) ) are the expression of quantile entropy in terms of hazard quantile function and reversed hazard quantile function, respectively. Using (Equation6
(6)
(6) ), (Equation7
(8)
(8) ) and (Equation8
(8)
(8) ), the quantile entropy (Equation5
(5)
(5) ) can be decomposed as
(12)
(12) The identity (Equation12
(12)
(12) ) can be interpreted by decomposing the uncertainty about the failure of item into in the following way. into four parts:
The uncertainty about the failure time in
given that the item has failed before
The uncertainty about the failure time in the interval
The uncertainty about the failure time in
The uncertainty of the item that has failed before
Differentiating
When is increasing in
and
, then, (Equation13
(13)
(13) ) and (Equation14
(14)
(14) ) together imply
Nair and Rajesh (Citation2000) gave some applications of geometric vitality function. Sunoj et al. (Citation2009) discussed few properties of this measure and showed that it determines the distribution function uniquely. Next, we define the quantile-based geometric vitality function.
Definition 2.1
Let X be a non-negative random variable then geometric vitality quantile function (GVQF) for a doubly truncated random variable is defined by
(15)
(15)
This gives the geometric mean life of a doubly truncated random variable between the points and
. Relationships between geometric vitality quantile function (Equation15
(15)
(15) ) for doubly truncated random variables and generalised hazard quantile function (Equation9
(9)
(9) ) are given in Table .
Table 1. Relationship between GVQF and GHQF.
2.1. Relationship between and quantile condition measure of uncertainty
Based on residual life distribution, Sankaran and Gupta (Citation1999) have introduced a new measure of uncertainty known as conditional measure of uncertainty, which is defined as The doubly truncated situation was considered in Sunoj et al. (Citation2009) given as follows
Using (Equation4
(4)
(4) ), the quantile-based condition measure of uncertainty for the doubly truncated random variable defined as
(17)
(17) Using (Equation17
(17)
(17) ) in (Equation8
(8)
(8) ), we obtain
(18)
(18) Differentiation of (Equation18
(18)
(18) ) with respect to
and
respectively, provides the relationships with GHQF, which is given as
and
The various relationships between the quantile condition measure of uncertainty (Equation17
(17)
(17) ) and GHQF (Equation9
(9)
(9) ) for some commonly used probability models are given in Table .
Table 2. Relation between and GHQF for various distributions.
3. Quantile interval entropy for various univariate distributions
In reliability theory, while studying the lifetime of a component or a system, a flexible model which is used in the literature is that of a generalised Pareto distribution (GPD) with survival function
It plays an important role in extreme value theory and other branches of statistics. The GPD, as a family of distributions, includes the exponential distribution when
the Pareto type-II distribution or Lomax distribution for
which is used in the investigation of city population, occurrence of natural resources, insurance risk, size of human settlements, reliability modelling and business failure. It has been an important model in many socio-economic studies. The GPD becomes power distribution for
. Next, let us discuss some examples on expression for quantile interval entropy function for some commonly used univariate distribution.
Example 3.1
If X is a random variable following the GPD with quantile function and quantile density function are given, respectively, by and
. Hence quantile interval entropy (Equation8
(8)
(8) ) for GPD is given by
which gives,
(19)
(19) When
and
then (Equation19
(19)
(19) ) reduces to
the quantile residual entropy (Equation6
(6)
(6) ) for GPD. Also when
and
, then (Equation19
(19)
(19) ) reduces to
the quantile past entropy (Equation7
(8)
(8) ) for GPD.
Example 3.2
If random variable X having the Pareto-II distribution with quantile function and quantile density function are given, respectively, by and
. Then quantile interval entropy (Equation8
(8)
(8) ) becomes
Example 3.3
If a random variable X follows the rescaled beta distribution distribution with quantile and quantile density functions are given, respectively, by and
. Then quantile interval entropy for the rescaled beta distribution is given as
which gives,
Example 3.4
If a random variable X having half logistic distribution with quantile and quantile density functions as and
, respectively. Then quantile interval entropy (Equation8
(8)
(8) ) for half logistic distribution is given as
after some algebraic simplifications, we obtain
(20)
(20) Put
and
in (Equation20
(20)
(20) ), we have the quantile residual entropy for the half logistic distribution which is given by
and for
and
then we get quantile past entropy for the half logistic distribution as
Example 3.5
If a random variable X having log logistic distribution with quantile function and quantile density function are respectively given as and
. Then quantile interval entropy for log logistic distribution is given as
which gives,
(21)
(21) Substituting
and
in (Equation21
(21)
(21) ), then we get quantile residual entropy for log logistic distribution given as
whereas the quantile past entropy for log logistic distribution is obtain, when we take
and
is given as
Example 3.6
Let X be a random variable having the exponential geometric distribution with quantile and quantile density functions are given, respectively, by and
. Then quantile interval entropy for the exponential geometric distribution is given as
which gives
(22)
(22) Particularly, if we put
and
in (Equation22
(22)
(22) ), then we get quantile residual entropy for the exponential geometric distribution as
and if we take
and
we get quantile past entropy for the exponential geometric distribution as
Example 3.7
If X is a random variable following the quantile function and quantile density functions of linear hazard rate distribution are given, respectively, by and
. Hence quantile interval entropy
is given as
After some algebraic simplifications, we have
Example 3.8
If X be a random variable following the Davies distribution (2006), that do not have any closed form expressions for distribution and density function, then QFs and quantile density functions are given, respectively, by and
. Hence quantile interval entropy (Equation8
(8)
(8) ) for Davies distribution is given by
We get, after some algebraic calculations,
(23)
(23) If we substitute
and
, then (Equation23
(23)
(23) ) reduces to
the quantile residual entropy (Equation6
(6)
(6) ) for Davies distribution. When we put
and
, then (Equation23
(23)
(23) ) reduces to
the quantile past entropy (Equation7
(8)
(8) ) for Davies Distribution.
Example 3.9
If X be a random variable following the Govindarajulu's distribution that do not have any closed form expressions for distribution and density function, then QFs and quantile density functions are given, respectively, by
Thus quantile-based interval entropy (Equation8
(8)
(8) ) for Govindarajulu's distribution is given as
(24)
(24) which gives
Table provides the relationships between the quantile interval entropy , quantile conditional expectation
(25)
(25) and generalised hazard quantile function
for some commonly used distribution.
Table 3. Relationships between and .
4. Characterisation results
In the literature, the problem of characterising probability distributions has been investigated by many researchers. The standard practice in modelling statistical data is either to derive the appropriate model based on the physical properties of the system or to choose a flexible family of distributions and then find a member of the family that is appropriate to the data. In both the situations, it would be of more use if we find characterisation theorems that explain the distribution using important measures of indices as. In this section, we discussed some characterisation theorems for lifetime distribution taking some important concepts like GHQF, GVQF and quantile-based condition Shannon's measures of uncertainty.
Theorem 4.1
Let X be a random variable defined on having the quantile function
then the relationship
(26)
(26) where k, C are constants holds for all
. If and only if for
C=0, X has exponential distribution with quantile function
Proof.
The if part is straightforward from the Table . To prove the converse, let us assume that (Equation26(26)
(26) ) holds. Using (Equation15
(15)
(15) ), (Equation9
(9)
(9) ) and (Equation16
(16)
(16) ) in (Equation26
(26)
(26) ), we obtain
(27)
(27) Differentiating (Equation27
(27)
(27) ) with respect to
i=1,2 we get, after some algebraic calculations,
or
, which gives the required result.
Theorem 4.2
For a non-negative random variable X, the relation
(28)
(28) holds for all
if and only if X follows exponential distribution with quantile function
.
Proof.
The if part is straightforward from the Table . To prove the converse, let us assume that (Equation28(28)
(28) ) holds. Then using (Equation16
(16)
(16) ) and (Equation25
(25)
(25) ), (Equation28
(28)
(28) ) becomes
(29)
(29) Differentiating (Equation29
(29)
(29) ) with respect to
,
we get, after some algebraic calculations,
or
which characterise the exponential distribution.
Theorem 4.3
If X be a non-negative random variable with quantile function and constants k>0 and c>0. A relationship of the form
(30)
(30) holds for
with
if and only if X follows Pareto-1 distribution with quantile function
;
Proof.
The if part is straightforward. To prove the converse, let us assume that (Equation30(30)
(30) ) holds. Then using (Equation15
(15)
(15) ) and (Equation16
(16)
(16) ), we have
(31)
(31) Differentiating (Equation31
(31)
(31) ) with respect to
,
we get, after some algebraic calculations
or
which gives the required result.
Next, we state the characterisation of power distribution. The proof is similar to that of Theorem 4.3 and hence omitted.
Theorem 4.4
If X is a non-negative random variable with quantile function and
C>1 be constants. A relationship of the form
is holds for
with
if and only if X follows power distribution with quantile function
.
Theorem 4.5
Let X be a random variable defined on with quantile function
. Then X follows one- parameter log exponential distribution if and only if
(32)
(32) where
for all
Proof.
The if part is straightforward from the Table 1. To prove the converse, let us assume that (Equation32(32)
(32) ) holds. Using (Equation15
(15)
(15) ) and (Equation16
(16)
(16) ) in (Equation32
(32)
(32) ), we have
(33)
(33) Differentiating (Equation33
(33)
(33) ) with respect to
we get, after some algebraic calculations,
or
, which gives the required result.
We conclude this section by characterising exponential distribution. The proof is similar to that of Theorem 4.5 and hence omitted.
Theorem 4.6
Let be a random variable having absolutely continuous quantile function
. Then the relationship of the form
where
holds for all
if and only if X follows one-parameter exponential distribution.
4.1. Exploratory data analysis using Q-Q Plot
Quantile-quantile (Q-Q) plot is a diagnostic tool, which is widely used to assess the distributional similarities and differences between two independent univariate samples. It is also a popular device for checking the appropriateness of a specified probability distribution for a given univariate data. The advantages of the Q-Q plot are: The sample sizes do not need to be equal. Many distributional aspects can be simultaneously tested. For example, shifts in location, shifts in scale, changes in symmetry, and the presence of outliers can all be detected from this plot. The Q-Q plot is similar to a probability plot. For a probability plot, the quantiles for one of the data samples are replaced with the quantiles of a theoretical distribution.
Example 4.1
Consider the Rainfall data from seeded clouds and non-seeded clouds are given below: (numbers in paratheses indicate the number of repetitions of the values)
Rainfall from control clouds: 1, 4.9(2), 11.5, 17.3, 21.7, 24.4, 26.1, 26.3, 28.6, 29,36.6,41.1, 47.3, 68.5, 81.2, 87.0, 95, 147.8, 163, 243.3, 321.2, 345.5,372.4, 830.1, 1202.6.
Rainfall from seeded clouds: 4.1, 7.7, 17.5, 31.4, 32.7, 40.6, 92.4, 115.3, 118.3, 119, 129.6, 198.6, 200.7, 242.5, 255.0, 274.7(2),302.8,334.1, 430.0, 489.1, 703.4, 978, 1656, 1697.8, 2745.6. (Source: Simpson, Olsen, & Eden, Citation1975)
The conclusions of our data analysis are as follows:
Compare the location of the data sample (mean, median): Seeded rainfall has greater location parameter than non-seeded rainfall.
Compare scale: The interquartile range indicates the variability of seeded rainfall is greater than non-seeded rainfall.
Side by side box plots: These plot reader can draw using Table ; non-seeded rainfall has a skew distribution,whereas seeded rainfall is symmetric.
Table 4. Numerical summary of rainfall for seeded clouds and non- seeded clouds.
Identification of probability laws: Seeded rainfall and non-seeded data both indicates fit by exponential distribution.
The Q-Q plot is a graphical technique for determining if two data sets come from populations with a common distribution. A Q-Q plot is a plot of the quantiles of the first data set against the quantiles of the second data set. In general for computing a normal probability plot,the standard normal table could be used to approximate the normal quantile. We look up the Z value corresponding to the for
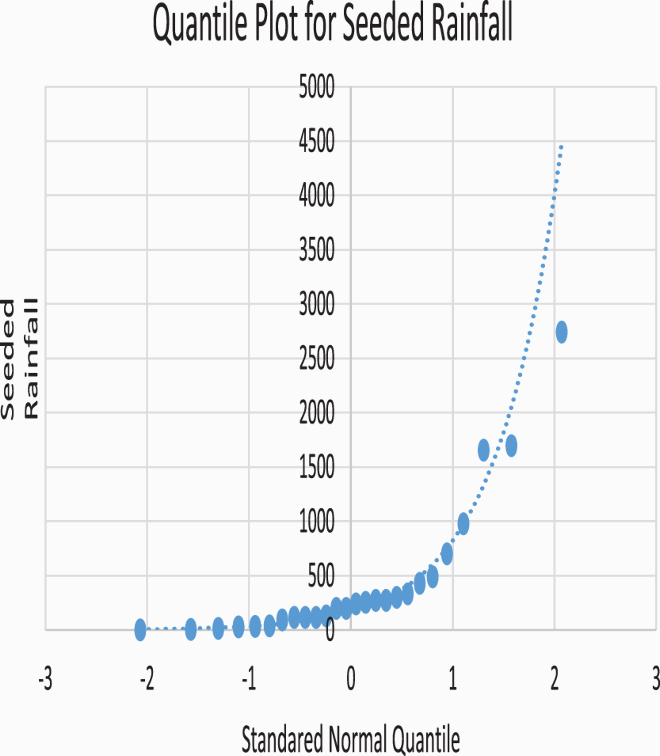
and then plot the ordered data against the corresponding Z value. Table displays the quantiles for rainfall data from seeded clouds as well as the corresponding normal quantile approximated from a standard normal table (Table ).
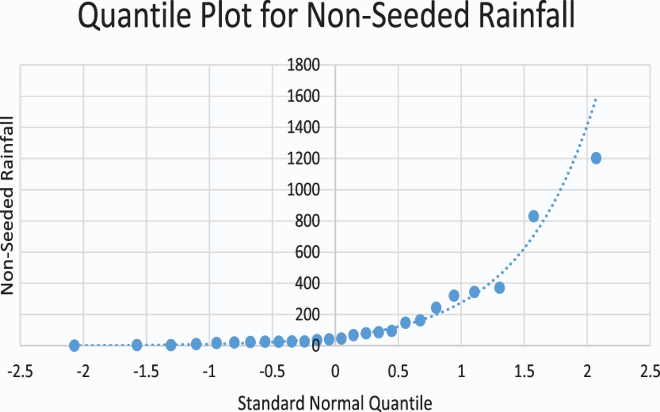
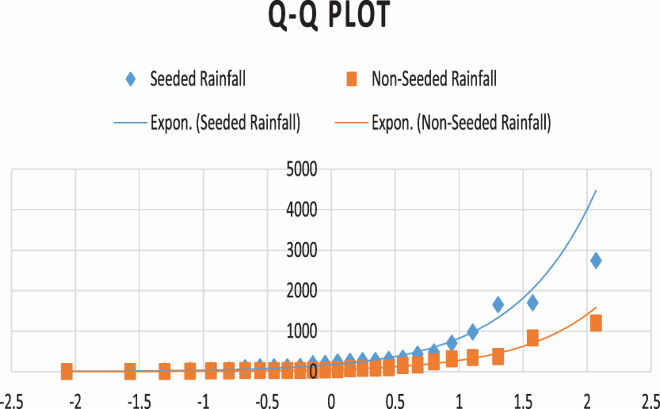
Table 5. Quantile plot table of seeded rainfall.
Table 6. Quantile plot table of non-seeded rainfall.
5. Conclusion
Recently, there has been a great interest in the study of information measures based on quantile functions, namely quantile entropy. When a system has lifetime between two time points the interval entropy plays an important role, in the field of reliability theory and survival analysis. The present work introduced an alternative approach to interval entropy measure using quantile functions. The proposed measures may help information theorists and reliability analysts to study the various characteristics of a system when it fails between two time instants. The results presented here generalise the related existing results in context with quantile entropy for residual and past lifetime random variables.
Acknowledgments
The authors would like to express their gratitude to the reviewers and the editor-in-chief for their valuable comments, which have considerably improved the earlier version of the article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Vikas Kumar
Vikas Kumar has obtained his M.Sc and M.Phil degree in Applied Mathematics from IIT Roorkee and ISM University, Dhanbad in 2005 and 2007 respectively. He received the Ph.D. degree in Mathematics from University of Delhi, Delhi. Currently, he is a Assistant Professor in Mathematics, UIET, M. D. University, Rohtak, India. His research interests are information theory and its applications and mathematical modeling. He has published research articles in reputed international journals of Mathematics and Statistical sciences.
Gulshan Taneja
Dr. Gulshan Taneja is working as Professor in Mathematics at M. D. University, Rohtak. He has vast experience of about 25 years of teaching in mathematics and statistics both at UG and PG levels. Dr. Taneja has published more than sixty research papers in the field of Information Theory & Reliability Theory in journals of international repute and is a member of various national and international societies.
Samsher Chhoker
Samsher Chokker has obtained his M.Sc and M.Phil degree in Mathematics from M. D. University, Rohtak in 2015 and 2017 respectively. He pursuing his Ph.D. degree in Mathematics from M. D. University, Rohtak . Currently, he is a Assistant Professor in Mathematics, Government PG Nehru College Jhajjar, India. His research interests are information theory and and mathematical modeling.
References
- Baratpour, S., & Khammar, A. H. (2018). A quantile-based generalized dynamic cumulative measure of entropy. Communications in Statistics – Theory and Methods, 47(13), 3104–3117. doi: 10.1080/03610926.2017.1348520
- Di Crescenzo, A., & Longobardi, M. (2002). Entropy-based measure of uncertainty in past lifetime distributions. Journal of Applied Probability, 39, 434–440. doi: 10.1239/jap/1025131441
- Di Crescenzo, A., & Longobardi, M. (2004). A measure of discrimination between past lifetime distributions. Statistics & Probability Letters, 67, 173–182. doi: 10.1016/j.spl.2003.11.019
- Ebrahimi, N. (1996). How to measure uncertainty in the residual life distributions. Sankhya Series A, 58, 48–57.
- Gilchrist, W. (2000). Statistical modelling with quantile functions. Boca Raton, FL: Chapman and Hall/CRC.
- Gong, W., Yang, D., Gupta, H. V., & Nearing, G. (2014). Estimating information entropy for hydrological data: One-dimensional case. Water Resources Research, 50, 5003–5018. doi: 10.1002/ 2014WR015874
- Hankin, R. K. S., & Lee, A. (2006). A new family of non-negative distributions. Australian and New Zealand Journal of Statistics, 48, 67–78. doi: 10.1111/j.1467-842X.2006.00426.x
- Kayal, S., & Moharana, R. (2016). Some Results on a doubly truncated generalized discrimination measure. Applications of Mathematics, 61, 585–605. doi: 10.1007/s10492-016-0148-4
- Khorashadizadeh, M., Rezaei Roknabadi, A. H., & Mohtashami Borzadaran, G. R. (2013). Mohtashami Borzadaran Doubly truncated (interval) cumulative residual andpast entropy. Statistics & Probability Letters, 83, 1464–1471. doi: 10.1016/j.spl.2013.01.033
- Kumar, V. R. (2018). A quantile approach of Tsallis entropy for order statistics. Physica A: Statistical Mechanics and its Applications, 503, 916–928. doi: 10.1016/j.physa.2018.03.025
- Kundu, C. (2017). On weighted measure of inaccuracy for doubly truncated random variables. Communications in Statistics – Theory and Methods, 46, 3135–3147. doi: 10.1080/03610926.2015.1056365
- Misagh, F., & Yari, G. (2011). On weighted interval entropy. Statistics & Probability Letters, 29, 167–176.
- Misagh, F., & Yari, G. H. (2012). Interval entropy and Informative Distance. Entropy, 14, 480–490. doi: 10.3390/e14030480
- Nair, K. R. M., & Rajesh, G. (2000). Geometric vitality function and its applications to reliability. IAPQR Transactions, 25, 1–8.
- Nair, N. U., Sankaran, P. G., & Balkrishanan, N. (2013). Quantile based reliability analysis. Statistics for industry and technology. New York, NY: Springer Science+Business Media.
- Nair, N. U., Sankaran, P. G., & Vinesh Kumar, B. (2012). Modeling lifetimes by quantile functions using Parzen's score function. Statistics-A Journal of Theoretical and Applied Statistics, 46(6), 799–811.
- Nanda, A. K., Sankaran, P. G., & Sunoj, S. M. (2014). Renyi's residual entropy: A quantile approach. Statistics & Probability Letters, 85, 114–121. doi: 10.1016/j.spl.2013.11.016
- Qiu, G. (2018). Further results on the residual quantile entropy. Communications in Statistics – Theory and Methods, 47(13), 3092–3103. doi: 10.1080/03610926.2017.1348519
- Ruiz, J. M., & Navarro, J. (1996). Characterizations based on conditional expectations of the doubled truncated distribution. Annals of the Institute of Statistical Mathematics, 48(3), 563–572. doi: 10.1007/BF00050855
- Sankaran, P. G., & Gupta, R. P. (1999). Characterization of lifetime distributions using measure of uncertainty. Calcutta Statistical Association Bulletin, 49, 195–196. doi: 10.1177/0008068319990303
- Sankaran, P. G., & Sunoj, S. M. (2004). Identification of models using failure rate and mean residual life of doubly truncated random variables. Statistical Papers, 45, 97–109. doi: 10.1007/BF02778272
- Sankaran, P. G., & Sunoj, S. M. (2017). Quantile based cumulative entropies. Communications in Statistics – Theory and Methods, 46(2), 805–814. doi: 10.1080/03610926.2015.1006779
- Shannon, C. E. (1948). A mathematical theory of communication. Bell System Technical Journal, 27, 379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x
- Simpson, J., Olsen, A., & Eden, J. (1975). A Baysian analysis of a multiplicative treatment effect in weather modification. Technometrics, 17, 161–166. doi: 10.2307/1268346
- Sunoj, S. M., & Sankaran, P. G. (2012). Quantile based entropy function. Statistics & Probability Letters, 82, 1049–1053. doi: 10.1016/j.spl.2012.02.005
- Sunoj, S. M., Sankaran, P. G., & Maya, S. S. (2009). Chararacterization of life distributions using conditional expectations of doubly (Intervel)truncated random variables. Communications in Statistics – Theory and Methods, 38(9), 1441–1452. doi: 10.1080/03610920802455001
- Sunoj, S. M., Sankaran, P. G., & Nanda, A. K. (2013). Quantile based entropy function in past lifetime. Statistics & Probability Letters, 83, 366–372. doi: 10.1016/j.spl.2012.09.016
- van Staden, P. J., & Loots, M. T. (2009). L-moment estimation for the generalized lambda distribution. Third annual ASEARC conference, New Castle.